常用信息代码标准
ASCII编码0~255

ASCII编码0~255
ASCII编码指“美国信息交换标准代码”,是一种用于信息交换的美国标准代码。
7位字符集广泛用于代表标准美国键盘上的字符或符号。
通过将这些字符使用的值标准化,ASCII允许计算机和计算机程序交换信息。
ASCII 字符集是与ANSI字符集中的前面128个(0-127)字符相同。
美国信息交换标准代码ASCII为"美国信息交换标准代码"九个字的缩写,ASCII文件是简单的无格式文本文件,可以由任何计算机所识别,Windows中的记事本及任何文字处理程序都可以阅读及创建ASCII文件。
ASCII文件通常都具有扩展名.TXT(例如README.TXT)
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机比较傻,只有0和1两位数的二进制比较适合于它使用),同样的,象a、b、c、d这样的52个字母(包括大写)、以及0、1、2等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪个数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通讯而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了所谓的ASCII编码,统一规定了上述常用符号用哪个二进制数来表示。
以下整理互联网ASCII0~255编码,前127个常用,128~255不常用。
常用编码方式

常用编码方式
常用的编码方式有:
1. ASCII码:美国信息交换标准代码是一种用于计算机通讯的编码方式,共包含128个字符及其对应的数字码(0-127),常用于英文、数字、标点符号等基本字符的编码。
2. Unicode编码:是一种国际标准的字符集,包含多种语言的字符,并且允许用不同的编码方式来表示,目前最常用的是UTF-8编码方式。
3. UTF编码系列:UTF-8是一种变长字符编码方式,是Unicode的一种实现方式,可表示所有Unicode字符,支持多语言,成为web标准。
另外,UTF-16、UTF-32等也是Unicode的实现方式。
4. ISO-8859编码:国际标准组织定义的不同字符集编码,共有16份,用于支持除英文外的各种字符,如ISO-8859-1是用于西欧语言的编码,ISO-8859-2是用于中欧语言的编码等等。
5. GB2312编码:是中国国家标准的简体中文字符集,包括汉字和非汉字部分,使用两个字节表示一个汉字。
6. Big5编码:是台湾地区使用的繁体中文编码,也是多字节编码,一般使
用两个字节来表示一个汉字。
7. Base64编码:一种将二进制数据转换为ASCII字符的编码方式,经常用于电子邮件、传输文件等场合,它的优点是可以减少存储和传输过程中的数据量。
综上所述,不同编码方式适用于不同的场合,选择合适的编码方式有助于提高数据处理和传输的效率。
常用编码方式

常用编码方式常用编码方式编码是人类通讯的一种基本方式,对于计算机而言,为了能够处理和保存各种类型的数据,也需要有一种统一的编码方式。
以下是常用的几种编码方式:一、ASCII编码ASCII编码是美国信息交换标准代码的缩写,是一种基于拉丁字母的编码方式。
它定义了128个字符,包括数字、字母、标点符号和一些控制字符。
由于只有128个字符,存储效率和传输效率比较高,但是只能表示英文字符,不能表示汉字等其他语言的字符。
二、Unicode编码Unicode编码是国际组织制定的一种万国码,目的就是解决计算机处理多语言的问题。
Unicode编码采用32位编码方式,可以表示2^32个字符,不仅包括了世界上所有的语言文字,还包括了一些图形符号、表情符号等特殊符号。
三、UTF-8编码UTF-8编码是一种对Unicode编码进行转换的编码方式。
UTF-8编码采用变长编码方式,能够同样表示所有Unicode字符,但是在表示英文字符时只需要一个字节,而对于中文等其他常用字符采用3个字节表示,使得存储效率和传输效率都得到了优化。
四、GB2312编码GB2312编码是中国制定的中文编码方式,采用双字节编码,共收录了6763个汉字和682个非汉字字符。
GB2312编码虽然不能够表示所有的中文字符,但是对于一般的中文书写和交流已经够用。
在此基础之上,GB18030编码进行了扩充,可以表示Unicode完整字符集,包括了中文和其他字符。
五、Base64编码Base64编码是一种基于64个可打印字符的编码方式,常用于在数据传输时对二进制数据进行编码,以便于传输。
Base64编码可以将任何类型的数据转换为可打印的ASCII字符,但编码后会把数据长度增加到原来的4/3倍,这会造成一定程度上的数据冗余,在传输速度和存储空间中需要平衡考量。
六、URL编码URL编码是指对URL中的一些特殊字符进行编码,以便于在传输过程中不同的系统能够正确解析。
信息的编码

汉字编码
汉字编码
实践体验: 使用UltraEdit软件,查看16进制形式显示字符的内码。
字符 科 普 知 内码
识
A
B
C
汉字编码
1.ASCII码只占( 1 )个字节,汉字编码占( 2 )个字节。
十六 进制 0 1 2 3 4 5 6 7 8 9 A B C D E F
10010101B=(1001 ,0101)=95H (11010101111101) =(0011,0101,0111,1101) =(357D)
2 2
6 7 8 9
16
10 11 12 13 14 15
数字编码
十六进制 二进制
多媒体信息编码 • 现实世界中各种各样的信息,通常是连续变化的“模 拟量”,计算机如果要存储、处理它们,首先要将它 们数字化,即将它们变成一系列二进制数据形式的 “数字量”。 模拟量怎样才能转换成数字量呢?基本的方法是以 很小的时间间隔不断测得模拟量在这些瞬间的样品 (幅度)值(采样),并以某种数值(量化)形式加 以保存,通过“采样”和“量化”就可以实现模拟量 的数字化,这个过程称为“模数转换(A/D转换)”。 而反之,将数字信号转换成模拟信号的过程称为“数 模转换(D/A转换)”
四、声音、图像和视频信息的数字化
• 声音是振动产生的波,它是一种模拟信息,话筒以及相关电路可以把声波转换成电 压的波形,但这仍然是一种连续平滑变化的模拟信号。只有通过采样和量化,模拟 信号才能转换成数字信号。例如,在录制声音的过程中, 声源的声音是一种模拟量, 话筒是传感器,声卡则对采样和量化所得的声音信号进行编码,最后形成数字化的 声音文件。
常用信息代码标准

性别:
GB/T 2261-1980 代码
0未知性别
1男性
2女性
9未说明性别
性别:执行标准(GB/T 2261.1-2003)
2003-12-01实施,代替GB/T 2261-1980
由于这些标准都是在网上查的,这些已经足够我在做项目选择用了,因为跟国际标准ISO 5218一样而且多了3\4的编码,多了这两个多像中国特色呀,而且项目多这两个不用也无所谓
如果你非要非常准确按国家标准请买个人信息国家标准信息查询。
0 = 未知项,
1 = 男性,
2 = 女性,
3 = 女改男,男性,
4 = 男改女,女性,
9 = 未规定项(未指明)
在维基百科中查到国际标准代码如下:
国际标准化组织的ISO 5218国际标准以一位数定义人类性别表示法。
其目标是在资讯(信息)系统以可靠的方法表示人类性别。
使用的代码是:
0 = 未知项,
1 = 男性,
2 = 女性,
9 = 未规定项(未指明)。
此标准指明先男后女的顺序仅反映发起此标准的国家的习惯。
证件类型代码:
国籍类型代码:
民族代码表:
血型:
婚姻状况代码:
文化程度代码:
单位性质代码:。
国际建设工程项目管理的信息代码分类标准

国际建设工程项目管理的信息代码分类标准国际建设工程项目管理的信息代码分类标准,是指将项目管理中的各种信息按照一定的标准进行分类和编码,以便于信息的组织、存储、检索和交流。
一个完善的信息代码分类标准能够提高项目管理的效率和准确性,促进项目团队之间的沟通和协作。
在国际建设工程项目管理中,信息代码分类标准一般包括以下几个方面:1.项目组织结构码:用于区分项目中的各个组织单元和角色。
例如,P代表项目,CP代表项目经理,CM代表施工经理,D代表设计单位,C代表施工单位等。
2.项目阶段代码:用于标识项目的不同阶段。
例如,P0代表前期研究阶段,P1代表设计阶段,P2代表施工阶段,P3代表验收阶段,P4代表运营阶段等。
3.项目专业代码:用于区分不同的专业领域。
例如,A代表建筑专业,S代表供水与排水专业,E代表电气专业,M代表机械专业等。
4.项目工作任务代码:用于标识项目中的各项工作任务和活动。
例如,WBS(工作分解结构)码,可以将项目的工作任务按照不同的层级进行编码,以便于对项目工作进行组织和管理。
5.项目资源代码:用于标识项目中的各项资源。
例如,R代码可以表示人力资源,M代码可以表示材料资源,E代码可以表示设备资源等。
6.项目成本代码:用于标识项目成本的不同项和分类。
例如,C1代表人工成本,C2代表材料成本,C3代表设备成本,C4代表质量成本,C5代表安全成本等。
7.项目风险代码:用于标识项目中的各项风险和控制措施。
例如,R1代表人员流动风险,R2代表市场风险,R3代表技术风险,R4代表合同风险等。
以上只是国际建设工程项目管理信息代码分类标准的一些示例,实际项目管理中,可以根据项目的具体特点和需求进行适当调整和扩展,以满足项目管理的需要。
通过信息代码分类标准,能够对项目的各种信息进行统一和标准化,提高项目管理的效率和规范性,为项目的顺利实施提供支持和保障。
标准ascii码

标准ascii码ASCII码(American Standard Code for Information Interchange)是一种用于标准化字符编码的字符集。
它使用7位二进制数来表示128个字符,包括数字、字母、标点符号和控制字符。
ASCII码最初是为了在计算机和通信设备之间交换信息而设计的,但现在它已经成为了标准的字符编码方式,被广泛应用于计算机系统和软件中。
ASCII码的编码方式非常简单,每个字符都对应一个唯一的7位二进制数。
例如,大写字母A的ASCII码为65,小写字母a的ASCII码为97,数字0的ASCII码为48。
通过这种编码方式,计算机可以准确地识别和处理不同的字符,从而实现文本的输入、输出和处理。
在ASCII码中,除了可打印字符外,还包括一些控制字符,如换行符、制表符、退格符等。
这些控制字符在文本处理和打印时起着重要的作用,可以控制文本的格式和排版。
此外,ASCII码还包括一些特殊字符,如美元符号、百分号、斜杠等,这些字符在计算机编程和数据处理中经常被使用。
虽然ASCII码只能表示128个字符,但它为后续的字符编码标准奠定了基础。
随着计算机技术的发展,出现了扩展的ASCII码和Unicode等字符编码标准,可以表示更多的字符和符号。
但ASCII 码作为最早的字符编码标准,仍然在计算机系统和软件中得到广泛应用。
在实际的应用中,我们可以通过查表的方式来获取字符的ASCII码。
许多编程语言和软件都提供了内置的函数或方法来实现字符和ASCII码之间的转换。
这些功能使得我们可以方便地处理和操作文本数据,实现各种文本处理和分析的功能。
总的来说,ASCII码作为字符编码标准,在计算机系统和软件中发挥着重要的作用。
它简单、有效地实现了字符的标准化编码,为文本数据的处理和交换提供了基础。
虽然现在出现了更多的字符编码标准,但ASCII码仍然是计算机领域中不可或缺的基础知识。
通过学习和理解ASCII码,我们可以更好地理解计算机系统和软件中的文本处理和编码方式,提高自己的计算机技术水平。
信息编码(ASSCII码表)

控制码在计算机中不作为字符来显示,而是 作为某一特定动作的功能代码。例如,代码7 的功能是使主机中的扬声器鸣声,代码10 (20H)是空格字符,65(41H)是字符 “A”,97(61H)是字符“a”。完整的基本ASCII 码表如下表所示:
1.1.7.2字形编码
计算机显示的字符是从ASCII码转化为字符点阵 来实现的。常用的字符输出有两种手段:屏幕显示 和打印输出。例如,如果要输出字符H,则不应输 出其编码72或对应的二进制数、十六进制数,而 应输出字形H。这种用于输出的、表示字符字形的 数据,称为字形编码。屏幕显示时,字形编码为1 的点则亮,为0的点则不亮;打印机输出时,计算 机控制打印机的打印针,有的打下去,有的不打, 便打出所需的符号和文字。
1、基本ASCII码 在ASCII码中,二进制最高位为0的编码为基本ASCII码,其
编码范围是十进制数0~127(即0000 0000B~01111111B或 00H~7FH),即基本ASCII码有128组编码。可见,基本ASCII码 只需要7位二进制进行编码就可以了,所以又称为7位字符编码。 在实际存储时,由于存储器是按字节作为最小单位来组织的,7 位编码仍然需要占用1个字节的存储空间,必须在编码前补一个 二进制数0,使者成为一个字节。
因而,计算机内部总是存储字符编码,而不存储字
形编码,只在输出时根据字符编码(如ASCII码),在字形 编码库中取出相应的字形码,送到输出设备(屏幕或打印 机)去输出。
1.1.7.3 内码和外码
内码是指电子计算机内部进行存贮、传递和运算所使 用的数字代码。例如,字符“A”的内码是65(41H),外 码是指电子计算机与人进行交换的字形代码,例如,字符 “B”的外码是它的字形编码。
国际建设工程项目管理的信息代码分类标准

国际建设工程项目管理的信息代码分类标准一、引言国际建设工程项目管理的信息代码分类标准是为了规范项目管理中信息的分类和编码,便于项目团队的沟通和信息的交流。
本文将对国际建设工程项目管理的信息代码分类标准进行详细介绍。
二、项目基本信息代码分类1. 项目名称代码:用于标识项目的名称,便于快速识别和查找。
2. 项目编号代码:用于标识项目的唯一编号,便于项目跟踪和管理。
3. 项目类型代码:包括建筑工程、道路工程、桥梁工程等,用于区分不同类型的项目。
4. 项目地点代码:用于标识项目所在地,便于项目团队的定位和管理。
三、项目进展信息代码分类1. 项目计划代码:用于标识项目的计划进度,包括开始时间、结束时间和里程碑节点。
2. 项目进度代码:用于记录项目的实际进度,包括已完成工作量、剩余工作量和完成百分比。
3. 项目风险代码:用于记录项目的风险情况,包括风险等级、风险描述和应对措施。
4. 项目变更代码:用于记录项目的变更情况,包括变更原因、变更内容和影响分析。
四、项目质量信息代码分类1. 质量目标代码:用于设定项目的质量目标,包括产品质量和工程质量。
2. 质量计划代码:用于编制项目的质量计划,包括质量检查和测试计划。
3. 质量控制代码:用于记录项目的质量控制措施,包括过程控制和结果控制。
4. 质量验收代码:用于记录项目的质量验收情况,包括验收标准和验收结果。
五、项目成本信息代码分类1. 预算编制代码:用于编制项目的预算,包括人工成本、材料成本和设备成本。
2. 成本控制代码:用于记录项目的成本控制措施,包括成本偏差分析和成本调整措施。
3. 成本支付代码:用于记录项目的成本支付情况,包括支付时间、支付金额和支付方式。
4. 成本收益代码:用于记录项目的成本收益情况,包括投资回报率和利润率。
六、项目资源信息代码分类1. 人力资源代码:用于记录项目的人力资源情况,包括人员数量、技能要求和分工情况。
2. 物资资源代码:用于记录项目的物资资源情况,包括材料需求、供应商信息和采购计划。
ASCII码对照表&完整版

好用的ASCII 码对照表完整版信息在计算机上是用二进制表示的,这种表示法让人理解就很困难。
因此计算机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式将信息在这些设备上显示出来供人阅读理解。
为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,它的全称是“美国信息交换标准代码”。
ASCII在Web开发时,如下的ASCII码只要加上&#和;就可以变成Web可以辨认的字符了在处理特殊字符的时候特别有用,如:' 单引号在数据库查询的时候是杀手,但是如果转换成'(注意:转换后的机构有:&# +字符的ASCII码值+; 三个部分组成)再来存数据库,就没有什么影响了。
其他的字符与ASCII码的对照如下表ASCII表键盘常用ASCII码ESC键 VK_ESCAPE (27)回车键: VK_RETURN (13)TAB键: VK_TAB (9)Caps Lock键: VK_CAPITAL (20) Shift键: VK_SHIFT ($10)Ctrl键: VK_CONTROL (17)Alt键: VK_MENU (18)空格键: VK_SPACE ($20/32)退格键: VK_BACK (8)左徽标键: VK_LWIN (91)右徽标键: VK_LWIN (92)鼠标右键快捷键:VK_APPS (93)Insert键: VK_INSERT (45) Home键: VK_HOME (36)Page Up: VK_PRIOR (33) PageDown: VK_NEXT (34)End键: VK_END (35)Delete键: VK_DELETE (46)方向键(←): VK_LEFT (37)方向键(↑): VK_UP (38)方向键(→): VK_RIGHT (39)方向键(↓): VK_DOWN (40)F1键: VK_F1 (112)F2键: VK_F2 (113)F3键: VK_F3 (114)F4键: VK_F4 (115)F5键: VK_F5 (116)F6键: VK_F6 (117)F7键: VK_F7 (118)F8键: VK_F8 (119)F9键: VK_F9 (120)F10键: VK_F10 (121)F11键: VK_F11 (122)F12键: VK_F12 (123)Num Lock键: VK_NUMLOCK (144) 小键盘0: VK_NUMPAD0 (96)小键盘1: VK_NUMPAD0 (97)小键盘2: VK_NUMPAD0 (98)小键盘3: VK_NUMPAD0 (99)小键盘4: VK_NUMPAD0 (100)小键盘5: VK_NUMPAD0 (101)小键盘6: VK_NUMPAD0 (102)小键盘7: VK_NUMPAD0 (103)小键盘8: VK_NUMPAD0 (104)小键盘9: VK_NUMPAD0 (105)小键盘.: VK_DECIMAL (110)小键盘*: VK_MULTIPLY (106)小键盘+: VK_MULTIPLY (107)小键盘-: VK_SUBTRACT (109)小键盘/: VK_DIVIDE (111)Pause Break键: VK_PAUSE (19) Scroll Lock键: VK_SCROLL (145)。
浙江省计算机高考复习(第6课)常用信息的编码

(3)汉字字形码
在计算机系统中,要显示或打印任何字符、汉字都 是由点阵式的字模组成。
16*16的点阵的汉字
字形码:
为了使计算机能识别和存储字模,就必须对字模进 行数字化,把字模中的每一个点都用二进制数表示,即 用“1”表示黑点,用“0”表示白点。这种数字化的字 模点阵代码就是字形码。
精品课程
常用信息的编码
计算机内部均采用二进制数来表示各种信息。要想使输 入设备输入的数字、字符、标点符号和文字等信息能被计算 机所识别,必须将其转换为相应的二进制编码。
目前常用的编码有:
BCD码、ASCII码、汉字编码和奇偶校验码等。
BCD码(了解)
用四位二进制数码来表示一个十进制数。 规则:选用0000-1001来表示0-9的十个数符。 如: (365)10=(0011 0110 0101)BCD 11001.11B= (25.75)10 =(0010 0101.0111 0101)BCD
练习3:某计算机系统中采用奇校验,若字符‘A’在
传送到目的地时为“11000010”,传输过程是否出错?
计算机能否发现?
奇偶校验码只能发现一位或者奇数位错误,而且不能纠 正错误。
汉字地址码:
指出汉字模信息在汉字库中存放的逻辑地址的编码。
三、奇偶校验码
校验码:具有发现或纠正传送过程中出现的错误的编码。
最常用、最简单的校验方法就是奇偶校验,一般以 一个字节为单位加奇偶校验位。 奇校验: 确保被传输的数据中‘1’的个数是奇数个。
偶校验:
确保被传输的数据中‘1’的个数是是偶数个。
信息编码(asscii码表)

它输出的则有点阵码和矢量码。点阵码占用的存储空间比较大, 而且在进行字号变化时效果很差,但可以直接送到输出设备进 行输出。矢量码则占用的存储空间较少,进行字号变化时不会 改变字形,效果较好,但需要进行适当处理后才能送到输出设 备进行输出。
1.1.7.7 汉字交换码
汉字交换码是用于不同计算机汉字系统之间进行信息交 换的汉字代码。因为实际汉字系统中使用的汉字内码不尽相同, 必须采用统一的编码才能在不同系统间交流汉字信息。目前国 内使用的汉字交换代码是“中国国家标准信息交换用汉字编码 字符表——基本集”,即GB—2312—80(简称国标码)及若 干辅助集。
高位字节=区码+32+128 (=区码+20H+80H)
低位字节=位码+32+128 (=位码+20H+80H)
在区码和位码上都加上20H是为了避开基本ASCII码的控 制码:加上80H是为了把最高二进制位(即第8位)定为1, 使高位字节和低位字节都为扩充的ASCII码。这样高位字节和 低位字节所表示的内码范围在161~254(A1H~FEH)之间。 这就是汉字字符集为94X94的原因。
汉字的数量大,常用汉字约4000~5000个。由于1个字节有 8位二进制数,因此至多表示256种状态。如果用一个字节来 表示一个汉字,无法区分如此多的汉字。为了能表示汉字,1 个汉字的内码用两个扩充的ASCII码组成,即汉字内码为两个 字节。
要让汉字正确传递和交换,必须建立统一的编码,否则会造 成混乱。我国国家标准局于1981年公布了国标GB2312---80汉 字编码字符集。该标准规定,全部汉字及符号构成94X94的矩 阵。在此矩阵中,每一行称为一个区,每一列称为一个位。这 样便组成了一个有94区(01~94),每区有94位(01~94)的 汉字字符集。区码和位码组合在一起(即两位十进制区码在前,
美国标准信息交换代码(

美国标准信息交换代码( American Standard Code for Information Interchange, ASCII )是由美国国家标准学会(American National Standard Institute , ANSI )制定的,标准的单字节字符编码方案,用于基于文本的数据。
控制字符二进制十进制十六进制缩写解释0000 0000 0 00 NUL 空字符(Null)0000 0001 1 01 SOH 标题开始0000 0010 2 02 STX 正文开始0000 0011 3 03 ETX 正文结束0000 0100 4 04 EOT 传输结束0000 0101 5 05 ENQ 请求0000 0110 6 06 ACK 收到通知0000 0111 7 07 BEL 响铃0000 1000 8 08 BS 退格0000 1001 9 09 HT 水平制表符0000 1010 10 0A LF 换行键0000 1011 11 0B VT 垂直制表符0000 1100 12 0C FF 换页键0000 1101 13 0D CR 回车键0000 1110 14 0E SO 不用切换0000 1111 15 0F SI 启用切换0001 0000 16 10 DLE 数据链路转义0001 0001 17 11 DC1 设备控制10001 0010 18 12 DC2 设备控制20001 0011 19 13 DC3 设备控制30001 0100 20 14 DC4 设备控制40001 0101 21 15 NAK 拒绝接收0001 0110 22 16 SYN 同步空闲0001 0111 23 17 ETB 传输块结束0001 1000 24 18 CAN 取消0001 1001 25 19 EM 介质中断0001 1010 26 1A SUB 替补0001 1011 27 1B ESC 溢出0001 1100 28 1C FS 文件分割符0001 1101 29 1D GS 分组符0001 1110 30 1E RS 记录分离符0001 1111 31 1F US 单元分隔符0111 1111 127 7F DEL 删除可显示字符二进制十进制十六进制字符0010 0000 32 20 空格0010 0001 33 21 !0010 0011 35 23 # 0010 0100 36 24 $ 0010 0101 37 25 % 0010 0110 38 26 & 0010 0111 39 27 '0010 1000 40 28 ( 0010 1001 41 29 ) 0010 1010 42 2A * 0010 1011 43 2B + 0010 1100 44 2C , 0010 1101 45 2D - 0010 1110 46 2E . 0010 1111 47 2F / 0011 0000 48 30 0 0011 0001 49 31 1 0011 0010 50 32 2 0011 0011 51 33 3 0011 0100 52 34 4 0011 0101 53 35 5 0011 0110 54 36 6 0011 0111 55 37 7 0011 1000 56 38 8 0011 1001 57 39 9 0011 1010 58 3A : 0011 1011 59 3B ; 0011 1100 60 3C < 0011 1101 61 3D = 0011 1110 62 3E > 0011 1111 63 3F ? 0100 0000 64 40 @可显示字符二进制十进制十六进制字符0100 0001 65 41 A 0100 0010 66 42 B 0100 0011 67 43 C 0100 0100 68 44 D 0100 0101 69 45 E 0100 0110 70 46 F 0100 0111 71 47 G 0100 1000 72 48 H 0100 1001 73 49 I 0100 1010 74 4A J0100 1100 76 4C L 0100 1101 77 4D M 0100 1110 78 4E N 0100 1111 79 4F O 0101 0000 80 50 P 0101 0001 81 51 Q 0101 0010 82 52 R 0101 0011 83 53 S 0101 0100 84 54 T 0101 0101 85 55 U 0101 0110 86 56 V 0101 0111 87 57 W 0101 1000 88 58 X 0101 1001 89 59 Y 0101 1010 90 5A Z 0101 1011 91 5B [ 0101 1100 92 5C \ 0101 1101 93 5D ] 0101 1110 94 5E ^ 0101 1111 95 5F _ 0110 0000 96 60 `可显示字符二进制十进制十六进制字符0110 0001 97 61 a 0110 0010 98 62 b 0110 0011 99 63 c 0110 0100 100 64 d 0110 0101 101 65 e 0110 0110 102 66 f 0110 0111 103 67 g 0110 1000 104 68 h 0110 1001 105 69 i 0110 1010 106 6A j 0110 1011 107 6B k 0110 1100 108 6C l 0110 1101 109 6D m 0110 1110 110 6E n 0110 1111 111 6F o 0111 0000 112 70 p 0111 0001 113 71 q 0111 0010 114 72 r 0111 0011 115 73 s0111 0101 117 75 u 0111 0110 118 76 v 0111 0111 119 77 w 0111 1000 120 78 x 0111 1001 121 79 y 0111 1010 122 7A z 0111 1011 123 7B { 0111 1100 124 7C | 0111 1101 125 7D } 0111 1110 126 7E ~。
我国字符编码标准

我国字符编码标准我国字符编码标准我国字符编码标准是指在计算机系统中,将字符与二进制代码相互对应的规则。
我国字符编码标准主要有GB2312、GBK、GB18030等。
GB2312是我国最早的字符编码标准,于1980年发布。
它包含了6763个汉字和682个非汉字字符,其中包括了基本汉字、次常用汉字和一些符号。
GB2312采用双字节编码,每个汉字占两个字节,每个非汉字字符占一个字节。
GB2312的出现,使得计算机能够处理中文字符,为中文信息处理提供了基础。
GBK是GB2312的扩展版本,于1995年发布。
GBK包含了21003个汉字和882个非汉字字符,其中包括了GB2312中的所有字符。
GBK同样采用双字节编码,但是它的编码范围更广,能够表示更多的汉字字符。
GBK的出现,使得计算机能够更好地处理中文字符,为中文信息处理提供了更多的可能性。
GB18030是我国最新的字符编码标准,于2000年发布。
GB18030包含了27484个汉字和760个非汉字字符,其中包括了GBK中的所有字符。
GB18030同样采用双字节编码,但是它的编码范围更广,能够表示更多的汉字字符和其他语言字符。
GB18030的出现,使得计算机能够更好地处理多语言字符,为多语言信息处理提供了更多的可能性。
总的来说,我国字符编码标准的发展历程,是从GB2312到GBK再到GB18030的过程。
这一过程中,我国字符编码标准不断完善和扩展,为计算机处理中文和多语言信息提供了更好的支持。
同时,我国字符编码标准的发展,也为中文信息处理和多语言信息处理的发展提供了重要的技术基础。
在实际应用中,我们需要根据具体的需求选择合适的字符编码标准。
如果只需要处理基本的中文字符,可以选择GB2312;如果需要处理更多的中文字符,可以选择GBK;如果需要处理多语言字符,可以选择GB18030。
选择合适的字符编码标准,可以提高计算机处理信息的效率和准确性,为信息处理提供更好的支持。
常用计算机代码

应用层网关防火墙
将应用层的通信建立在可 信的网关上,通过代理服 务来实现对应用层的访问 控制。
混合型防火墙
结合了包过滤防火墙和应 用层网关防火墙的特点, 提供更全面的防护功能。
黑客攻击防御
入侵检测系统(IDS)
实时监测网络流量,发现异常行为或攻击行为,及时报警并采取 相应的安全措施。
服务器性能优化
硬件升级
根据服务器性能需求,升级硬件组件,如 增加内存、SSD硬盘等。
数据库优化
执行数据库性能优化查询,调整数据库配 置参数,提高数据库性能。
操作系统优化
调整操作系统设置,提高服务器性能和响 应速度。
负载均衡
使用负载均衡器分配服务器流量,提高服 务器的处理能力和吞吐量。
RESTful API设计
API架构
采用RESTful架构风格,设计具有良好可扩 展性和可维护性的API接口。
资源标识
使用适当的URL结构和HTTP方法来标识和 访问不同的资源。
数据传输
使用JSON格式传输数据,实现高效的数据 交换和解析。
错误处理
设计适当的错误处理机制,以响应用户请 求失败的情况。
缓存技术
缓存策略
根据应用需求,选择适当的缓存策略,如LRU、LFU等。
常用计算机代码
2023-10-28
contents
目录
• 编程语言类别 • 算法与数据结构 • 数据库相关 • 前端开发相关 • 后端开发相关 • 测试与部署相关 • 信息安全相关
01
编程语言类别
Java
总结词
跨平台、面向对象的编程语言,适用于大型企业级应用 开发、Web后端开发等领域。
常见信息编码
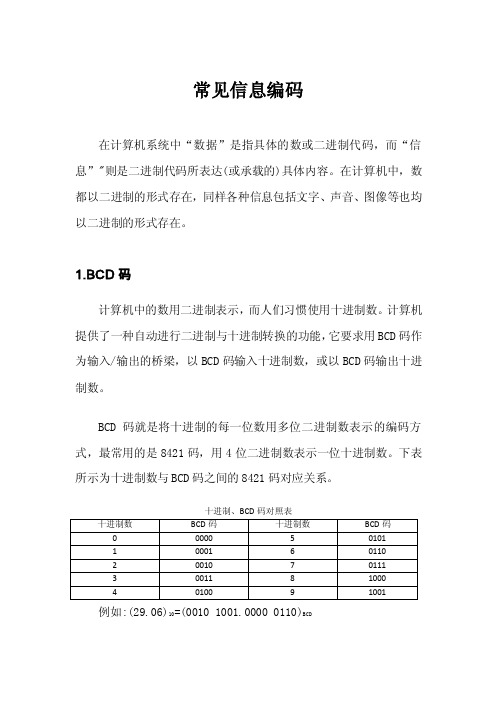
常见信息编码在计算机系统中“数据”是指具体的数或二进制代码,而“信息”"则是二进制代码所表达(或承载的)具体内容。
在计算机中,数都以二进制的形式存在,同样各种信息包括文字、声音、图像等也均以二进制的形式存在。
1.BCD码计算机中的数用二进制表示,而人们习惯使用十进制数。
计算机提供了一种自动进行二进制与十进制转换的功能,它要求用BCD码作为输入/输出的桥梁,以BCD码输入十进制数,或以BCD码输出十进制数。
BCD码就是将十进制的每一位数用多位二进制数表示的编码方式,最常用的是8421码,用4位二进制数表示一位十进制数。
下表所示为十进制数与BCD码之间的8421码对应关系。
十进制、BCD码对照表例如:(29.06)10=(0010 1001.0000 0110)BCD.字符的ASCII计算机中常用的基本字符包括十进制数字符号0~9,大小写英文字母A~Z,a~z,各种运算符号、标点符号以及一些控制符、总数不超过128个,在计算机中它们都被转换成能被计算机识别的二进制编码形式。
目前,在计算机中普遍采用的一种字符编码方式,就是已被国际标准化组织(ISO)采纳的美国标准信息交换码(ASCII),如下表所示。
其中:NUL 空; FF 走纸控制; CAN 作废;SOH 标题开始; CR 回车; EM 纸尽;STX 正文开始; SO 移位输出; SUB 换置;EIX 正文结束; SI 移位输入; ESC 换码;EOT 结束传输; DLE 数据链换码; FS 文字分隔符;ENQ 询问; DC1 设备控制1; GS 组分隔符;ACK 承认; DC2 设备控制2; RS 记录分隔符;BEL 报警; DC3 设备控制3; US 单元分隔符;BS 退格; DC4 设备控制4; SP 空格;HT 横向列表; NAK 否定; DEL 删除;LF 换行; SYN 空转同步;VT 纵向列表; ETB 信息组传送结束;在ASCII中,每个字符用位二进制代码表示。
常见的编码

常见的编码编码是计算机中最基本的操作之一,它是将文字、数字等非机器语言转为机器语言的过程,即将一个文本或符号创造一个等价的数字序列。
编码的作用是给计算机传递信息、实现信息的存储和传输,以及实现各种软件和应用程序的运行。
以下是几种常见的编码及其相关参考内容。
1. ASCII编码ASCII(美国信息交换标准代码)是一种使用7位或8位二进制代码表示文本字符的编码系统。
ASCII编码通常用于计算机和其他电子设备中,它包括从数字0到127的128种字符。
ASCII编码是王者级别的编码,无论是在计算机还是在通信中都广泛使用。
2. Unicode编码Unicode编码是一种国际化的字符编码方案,它将世界上各种语言的符号和文字都列在了一个编码表中,使得不同语言之间也能实现统一的字符处理。
Unicode编码的最初设想是为了解决一些互联网应用中字符集的缺乏和混乱问题。
目前Unicode 编码的版本是13.0版本。
3. UTF-8编码UTF-8编码是一种用来表示Unicode字符的编码方式,它是一种变长的编码方式,在含有英文字母和数字等内容的文本中表现非常高效。
UTF-8编码在网络上的广泛应用,使得人们可以在没有任何支持国际语言的纯英文网址上输入任何国际字母和符号来找到自己要的网页。
4. GBK编码GBK编码是中国的汉字编码标准之一,它是以二进制代码表示汉字和一些其他字符的编码方式,包含了大量的汉字和中文符号,适用于中文电子书、中文网页等各种文本信息。
GBK 编码在计算机界的广泛使用,使得人们可以在网络中、电子系统中使用中文进行传输和交流。
总结起来,编码在计算机中起着至关重要的作用,没有它,计算机上的信息将无法被识别、传输和处理。
以上几种常见的编码均有其特定的应用场景,在不同领域都有广泛的应用。
尽管有多种编码可以使用,但程序员们需要根据需求选择合适的编码方式,以确保系统的正常运行和数据的正确传递。
中文编码字符集标准大全

中文编码字符集标准大全国家标准代码,简称国标码,是中华人民共和国的中文常用汉字编码集,亦为新加坡采用。
现时中华人民共和国官方强制使用GB 18030标准,但较旧的计算机仍然使用GB 2312。
较常见的国家汉字标准代码列表:GB 2312-80信息交换用汉字编码字符集基本集(又称 GB 或 GB0)GB 13000.1-93信息技术通用多八位编码字符集(UCS)第一部分(相当于 ISO 10646-1:1993 中文版)GB 18030-2005信息技术中文编码字符集---GB 2312或GB 2312-80是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集·基本集》,又称为GB0,由中国国家标准总局发布,1981年5 月1日实施。
GB2312编码通行于中国大陆;新加坡等地也采用此编码。
中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
GB 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
--GB 13000,中华人民共和国国家标准的国家标准代码之一,全称 GB 13000.1-93《信息技术通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面》。
此标准等同采用国际标准化组织 ISO/IEC 10646.1:1993《信息技术通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面》。
GB 13000的字符集包含20,902个汉字。
--GBK全名为汉字内码扩展规范,英文名Chinese Internal Code Specification。
常用信息代码标准

性别:
GB/T 2261-1980 代码
0未知性别
1男性
2女性
9未说明性别
性别:执行标准(GB/T 2261.1-2003)
2003-12-01实施,代替GB/T 2261-1980
由于这些标准都是在网上查的,这些已经足够我在做项目选择用了,因为跟国际标准ISO 5218一样而且多了3\4的编码,多了这两个多像中国特色呀,而且项目多这两个不用也无所谓
如果你非要非常准确按国家标准请买个人信息国家标准信息查询。
0 = 未知项,
1 = 男性,
2 = 女性,
3 = 女改男,男性,
4 = 男改女,女性,
9 = 未规定项(未指明)
在维基百科中查到国际标准代码如下:
国际标准化组织的ISO 5218国际标准以一位数定义人类性别表示法。
其目标是在资讯(信息)系统以可靠的方法表示人类性别。
使用的代码是:
0 = 未知项,
1 = 男性,
2 = 女性,
9 = 未规定项(未指明)。
此标准指明先男后女的顺序仅反映发起此标准的国家的习惯。
证件类型代码:
国籍类型代码:
民族代码表:
血型:
文化程度代码:
单位性质代码:。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
性别:
GB/T 2261-1980 代码
0未知性别1男性2女性
9未说明性别
性别:执行标准(GB/T 2261.1-2003)
2003-12-01 实施,代替GB/T 2261-1980
由于这些标准都是在网上查的,这些已经足够我在做项目选择用了,因为跟国际标准
ISO 5218 一样而且多了3\4的编码,多了这两个多像中国特色呀,而且项目多这两个不用也无所谓如果你非要非常准确按国家标准请买个人信息国家标准信息查询。
0 =未知项,
1 =男性,
女性,
女改男,男性,男改女,女性,
未规定项(未指明)在维基百科中查到国际标准代码如下
国际标准化组织的ISO 5218国际标准以一位数定义人类性别表示法。
其目标是在资讯(信息)系统以可靠的方法表示人类性别。
使用的代码是:
0 =未知项,
1=男性,
2=女性,
9 =未规定项(未指明)。
此标准指明先男后女的顺序仅反映发起此标准的国家的习惯。
证件类型代码
国籍类型代码
民族代码表:
血型:
婚姻状况代码:
文化程度代码
单位性质代码。