条件随机场 (1)
rf条件随机场为了计算条件概率的估计

rf条件随机场为了计算条件概率的估计(原创实用版)目录1.条件概率的定义与含义2.条件概率的计算方法3.条件随机场的概念与应用4.条件概率在实际生活中的应用案例正文一、条件概率的定义与含义条件概率是指在已知某个事件发生的情况下,另一个事件发生的概率。
在概率论中,我们通常用 P(A|B) 表示在事件 B 发生的条件下,事件 A 发生的概率。
其中,P(A|B) 读作“A 给定 B 的条件概率”。
条件概率是一个十分重要的概念,它在实际生活中的应用非常广泛,例如在医学、统计学、机器学习等领域都有重要的应用。
二、条件概率的计算方法计算条件概率的方法通常有两种:一种是基于概率的公理化定义,另一种是基于条件随机场。
基于概率的公理化定义,我们可以通过以下公式计算条件概率:P(A|B) = P(A∩B) / P(B)其中,P(A∩B) 表示事件 A 和事件 B 同时发生的概率,P(B) 表示事件 B 发生的概率。
而基于条件随机场的方法,我们可以通过构建一个条件随机场来计算条件概率。
条件随机场是一个概率模型,它包含了一个随机过程和一个条件概率分布。
通过这个条件随机场,我们可以计算出任意一个事件在给定另一个事件发生的条件下的概率。
三、条件随机场的概念与应用条件随机场是一种用于计算条件概率的数学模型。
在条件随机场中,我们通常考虑两个事件之间的关系,并通过一个随机过程来描述这种关系。
条件随机场的主要应用领域包括机器学习、模式识别、图像处理等。
四、条件概率在实际生活中的应用案例条件概率在实际生活中的应用非常广泛,例如在医学领域,我们可以通过条件概率来预测某种疾病在给定某种症状的情况下的发生概率;在金融领域,我们可以通过条件概率来预测某种投资在给定某种市场情况下的收益率。
条件概率的应用可以帮助我们更好地理解和预测事件之间的关系,从而做出更准确的决策。
综上所述,条件概率是一个非常重要的概率概念,它在实际生活中的应用非常广泛。
条件随机场的基础知识

条件随机场的基础知识条件随机场(Conditional Random Field,简称CRF)是一种概率图模型,常用于序列标注、自然语言处理、计算机视觉等领域。
它是一种无向图模型,用于建模输入序列和输出序列之间的关系。
本文将介绍条件随机场的基础知识,包括定义、特点、参数表示和推断算法等内容。
一、定义条件随机场是给定一组输入序列X的条件下,对应的输出序列Y的联合概率分布模型。
它假设输出序列Y是给定输入序列X的马尔可夫随机场,即满足马尔可夫性质。
条件随机场的定义如下:P(Y|X) = 1/Z(X) * exp(∑k∑lλkTk(yi-1, yi, X, i) +∑m∑nμnUn(yi, X, i))其中,Y表示输出序列,X表示输入序列,Tk和Un是特征函数,λk和μn是对应的权重参数,Z(X)是归一化因子。
二、特点条件随机场具有以下几个特点:1. 无向图模型:条件随机场是一种无向图模型,图中的节点表示输出序列的标签,边表示标签之间的依赖关系。
2. 局部特征:条件随机场的特征函数是局部的,只依赖于当前位置和相邻位置的标签。
3. 马尔可夫性质:条件随机场假设输出序列是给定输入序列的马尔可夫随机场,即当前位置的标签只与前一个位置的标签有关。
4. 概率模型:条件随机场是一种概率模型,可以计算输出序列的概率分布。
三、参数表示条件随机场的参数表示方式有两种:全局参数和局部参数。
1. 全局参数:全局参数表示整个条件随机场的权重参数,对所有特征函数都起作用。
2. 局部参数:局部参数表示每个特征函数的权重参数,只对对应的特征函数起作用。
四、推断算法条件随机场的推断算法主要包括前向-后向算法和维特比算法。
1. 前向-后向算法:前向-后向算法用于计算给定输入序列X的条件下,输出序列Y的边缘概率分布P(yi|X)。
它通过前向和后向两个过程,分别计算前缀和后缀的边缘概率。
2. 维特比算法:维特比算法用于求解给定输入序列X的条件下,输出序列Y的最优路径。
第14讲条件随机场课件

概率图模型基本思想
� 无向图:马尔可夫随机场(Markov Random Fields, MRF) 马尔可夫随机场模型中包含了一组具有马尔可夫性质的随机变量,这 些变量之间的关系用无向图来表示
� �
马尔科夫性: 举例
p( xi x j , j ≠ i ) = p xi x j , xi ∼ x j
�
Observed Ball Sequence
⋯⋯
�
HMMs等生产式模型存在的问题:
T
P( X ) =
�
所有的Y i = 1
∑ ∏ p( y
i
yi −1 ) p( xi yi )
由于生成模型定义的是联合概率,必须列举所有观察序列的可能值,这对 多数领域来说是比较困难的。
�
基于观察序列中的每个元素都相互条件独立。即在任何时刻观察值仅仅与 状态(即要标注的标签)有关。对于简单的数据集,这个假设倒是合理。 但大多数现实世界中的真实观察序列是由多个相互作用的特征和观察序列 中较长范围内的元素之间的依赖而形成的。
�
HMM是一个五元组 λ= (Y, X, Π, A, B) ,其中 Y是隐状态(输出变量) 的集合,)X是观察值(输入)集合, Π是初始状态的概率,A是状态转移 概率矩阵,B是输出观察值概率矩阵。 today sun cloud rain
yesterday sun cloud rain
⎡ 0.50 0.375 0.125⎤ ⎢ 0.25 0.125 ⎥ 0.625 ⎢ ⎥ ⎢ ⎣ 0.25 0.375 0.375⎥ ⎦
⎡ 0.50 0.375 0.125 ⎤ ⎢ 0.25 0.125 ⎥ 0.625 ⎢ ⎥ ⎢ ⎣ 0.25 0.375 0.375 ⎥ ⎦
crf用法

crf用法
条件随机场(Conditional Random Field,CRF)是一种统计模型,常用于自然语言处理和计算机视觉中的序列标注和分割任务。
在CRF中,给定一组输入随机变量,每个可能的输出随机变量都有一个条件概率,这些条件概率定义了输入和输出之间的关系。
以下是CRF的基本用法:
1.定义特征:首先,你需要定义一组特征函数,用于描述输入数据中
的特征。
这些特征可以是基于词袋模型的词频特征、基于词性的特征、基于上下文的特征等。
特征函数可以对应一个特征向量,其维度根据实际需求而定。
2.训练模型:在训练阶段,你需要提供一组训练数据,其中包含输入
特征和相应的标签。
通过这些数据,CRF模型会学习到输入特征与标签之间的关系,并根据这些关系计算出每个标签的条件概率。
3.预测标签:在预测阶段,对于给定的输入特征,CRF模型会根据训
练阶段学到的条件概率计算出每个标签的后验概率,然后选择具有最大后验概率的标签作为预测结果。
你可以根据需要选择合适的阈值来过滤掉低概率的标签。
需要注意的是,CRF模型通常需要大量的训练数据才能获得较好的性能。
此外,CRF模型对于特征的选择和设计也比较敏感,因此在实际应用中需要根据具体任务和数据特点进行特征工程。
条件随机场模型在医学影像分析中的疾病分期(五)

条件随机场模型在医学影像分析中的疾病分期随着医学影像技术的不断发展,医学影像分析在临床诊断和疾病分期中发挥着越来越重要的作用。
而条件随机场模型作为一种概率图模型,在医学影像分析中得到了广泛的应用。
本文将就条件随机场模型在医学影像分析中的疾病分期进行探讨。
一、医学影像分析的重要性和挑战医学影像分析是通过对医学影像数据的处理和分析,实现对患者健康状况的评估和疾病的诊断、分期等。
医学影像数据通常包括X光、CT、MRI等多种形式,具有复杂多变的特点。
由于医学影像数据的高维、噪声、不确定性等特点,使得医学影像分析面临着诸多挑战。
二、条件随机场模型概述条件随机场模型是一种用于建模分类和标注问题的概率图模型。
它在给定输入随机变量的条件下,对输出随机变量进行建模。
条件随机场模型能够较好地处理高维、复杂的数据,适用于医学影像分析中的疾病分期等问题。
三、条件随机场模型在医学影像分析中的应用1. 疾病分期条件随机场模型在医学影像分析中得到广泛应用的一个重要领域就是疾病分期。
以肿瘤分期为例,医学影像数据中包含了大量的信息,如肿瘤的形状、大小、位置等。
利用条件随机场模型可以有效地对肿瘤进行分割和特征提取,从而实现对肿瘤的精准分期。
2. 病变检测在医学影像分析中,病变的检测也是一项重要任务。
利用条件随机场模型可以对医学影像数据进行特征提取和分类,实现对病变的自动检测和定位。
3. 图像配准图像配准是医学影像分析中的另一个重要问题,它是指将不同医学影像数据进行空间上的对齐。
条件随机场模型可以通过学习图像的空间关系,实现对医学影像数据的自动配准。
四、条件随机场模型的优势和局限性1. 优势条件随机场模型能够很好地处理高维、复杂的医学影像数据,具有较强的建模能力和泛化能力。
它能够充分利用医学影像数据的空间和结构信息,实现对疾病分期、病变检测等任务的精准处理。
2. 局限性条件随机场模型在参数学习和推断算法方面存在一定的复杂性,需要较高的计算资源和时间。
条件随机场模型的效果评估与优化(九)

条件随机场(Conditional Random Fields, CRF)是一种概率图模型,常被用于标注和序列标注的任务中。
它通过考虑输入数据的特征之间的关联关系,来进行标注的预测。
在自然语言处理、生物信息学、计算机视觉等领域,条件随机场都有着广泛的应用。
然而,条件随机场模型在实际应用中,如何进行效果评估与优化,却是一个具有挑战性的问题。
首先,我们来看看条件随机场模型的效果评估。
通常来说,我们会用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值等指标来评估模型的性能。
在标注和序列标注任务中,我们可以通过比较模型预测的标注结果与真实标注结果之间的差异,来计算这些指标。
另外,我们还可以使用混淆矩阵(Confusion Matrix)来更细致地分析模型在不同类别上的表现。
除了定量指标,我们还可以通过可视化的方式来观察模型的预测结果,比如绘制标注结果的热力图或者误差分析图。
通过以上多种方式的效果评估,可以更全面地了解模型的性能表现。
然而,单纯地使用这些指标和可视化手段来评估模型的效果,往往还不够。
在实际应用中,我们还需要考虑模型在不同场景下的泛化能力、稳定性和鲁棒性。
泛化能力指模型在新的未见数据上的表现能力,稳定性指模型在不同数据集上的性能稳定程度,鲁棒性指模型对噪声、干扰的抵抗能力。
除此之外,我们还需要考虑模型的计算效率和资源消耗。
因此,我们需要综合考虑定量指标、可视化分析和实际应用场景,来综合评估条件随机场模型的效果。
接着,我们来看看条件随机场模型的优化方法。
在实际应用中,我们常常会面临模型的训练时间长、模型复杂度高等问题。
因此,如何提高模型的训练效率和减小模型的复杂度,是需要重点关注的问题。
首先,我们可以考虑对模型进行特征选择和维度约减,以减小模型的复杂度。
特征选择可以通过领域知识、统计分析等方法来筛选和剔除无用的特征,维度约减可以通过主成分分析、奇异值分解等方法来降低输入数据的维度。
《条件随机场》课件

01
•·
02
基于共轭梯度的优化算法首先使用牛顿法确定一个大致的 参数搜索方向,然后在该方向上进行梯度下降搜索,以找 到最优的参数值。这种方法结合了全局和局部搜索的优势 ,既具有较快的收敛速度,又能避免局部最优解的问题。
03
共轭梯度法需要计算目标函数的二阶导数(海森矩阵), 因此计算量相对较大。同时,该方法对初始值的选择也有 一定的敏感性。在实际应用中,需要根据具体情况选择合 适的优化算法。
高效存储
研究如何利用高效存储技术(如分布式文件系统、NoSQL数据库 等)存储和处理大规模数据。
06
结论与展望
条件随机场的重要性和贡献
01
克服了传统机器学习方法对特征工程的依赖,能够 自动学习特征表示。
02
适用于各种自然语言处理和计算机视觉任务,具有 广泛的应用前景。
03
为深度学习领域带来了新的思路和方法,推动了相 关领域的发展。
概念
它是一种有向图模型,通过定义一组条件独立假设,将观测 序列的概率模型分解为一系列局部条件概率的乘积,从而简 化模型计算。
条件随机场的应用场景
序列标注
在自然语言处理、语音识别、生物信 息学等领域,CRF常用于序列标注任 务,如词性标注、命名实体识别等。
结构化预测
在图像识别、机器翻译、信息抽取等 领域,CRF可用于结构化预测任务, 如图像分割、句法分析、关系抽取等 。
04
条件随机场的实现与应用
自然语言处理领域的应用
词性标注
条件随机场可以用于自然语言处理中 的词性标注任务,通过标注每个单词 的词性,有助于提高自然语言处理的 准确性和效率。
句法分析
条件随机场也可以用于句法分析,即 对句子中的词语进行语法结构分析, 确定词语之间的依存关系,有助于理 解句子的含义和生成自然语言文本。
CRF(条件随机场)与Viterbi(维特比)算法原理详解

其中分子中的s为label序列为正确序列的score,分母s为每中可能的score。 这个比值越大,我们的预测就越准,所以,这个公式也就可以当做我们的loss,可是loss一般都越小越好,那我们就对这个加个负号即可, 但是这个最终结果手机趋近于1的,我们实验的结果是趋近于0的,这时候log就派上用场了,即:
最后的公式为这样的:
其中X为word_index序列,y为预测的label_index序列。 因为这个预测序列有很多种,种类为label的排列组合大小。其中只有一种组合是对的,我们只想通过神经网络训练使得对的score的比重在 总体的所有score的越大越好。而这个时候我们一般softmax化,即:
另外我们想想如果单单就这个发射分数来评价太过于单一了因为这个是一个序列比如前面的label为o那此时的label被预测的肯定不能是m或s所以这个时候就需要一个分数代表前一个label到此时label的分数我们叫这个为转移分数即t
CRF(条件随机场)与 Viterbi(维特比)算法原理详解
CRF(Conditional Random Field),即条件随机场。经常被用于序列标注,其中包括词性标注,分词,命名实体识别等领域。 Viterbi算法,即维特比算法。是一种动态规划算法用于最可能产生观测时间序列的-维特比路径-隐含状态序列,特别是在马尔可夫信息源上 下文、隐马尔科夫模型、条件随机场中 一、CRF基本概念 我们以命名实体识别NER为例,先介绍下NER的概念:
这里的label_alphabet中的b代表一个实体的开始,即begin;m代表一个实体的中部,即mid;e代表一个实体的结尾,即end;o代表不是实 体,即None;<start>和<pad>分表代表这个标注label序列的开始和结束,类似于机器翻译的<SOS>和<EOS>。
条件随机场模型在金融时间序列预测中的应用(七)

条件随机场(Conditional Random Field, CRF)是一种概率图模型,广泛应用于自然语言处理、计算机视觉、生物信息学等领域。
近年来,随着金融数据的不断增加和复杂化,条件随机场模型也开始在金融时间序列预测中展现出巨大的潜力。
本文将探讨条件随机场模型在金融时间序列预测中的应用,并对其优点和局限性进行分析。
一、条件随机场模型简介条件随机场是一种判别式概率无向图模型,通常用于标注或分割序列数据。
与隐马尔可夫模型不同,条件随机场模型能够对观测序列和标记序列之间的复杂关系进行建模。
在金融领域,时间序列数据往往具有复杂的非线性结构和高度的噪声,传统的统计模型往往难以捕捉到其中的规律。
而条件随机场模型能够更好地处理这种复杂情况,从而在金融时间序列预测中展现出巨大的优势。
二、条件随机场在金融时间序列预测中的应用条件随机场模型在金融时间序列预测中的应用主要体现在以下几个方面:1. 市场趋势预测:条件随机场模型能够通过对历史价格、成交量等数据的建模,辅助分析市场的趋势和走势。
通过对市场趋势的准确预测,投资者可以更好地制定交易策略,降低投资风险。
2. 风险管理:金融市场的波动性很大,风险管理是投资者必须面对的重要问题。
条件随机场模型可以通过对市场波动性的预测,帮助投资者及时调整投资组合,降低投资风险。
3. 事件驱动预测:金融市场往往受到各种事件的影响,如国际政治局势、自然灾害等。
条件随机场模型能够对这些事件对市场的影响进行建模,从而帮助投资者预测事件驱动的市场波动。
三、条件随机场模型在金融时间序列预测中的优势条件随机场模型在金融时间序列预测中具有以下优势:1. 能够处理非线性关系:金融数据往往具有复杂的非线性关系,传统的线性模型往往难以捕捉其中的规律。
条件随机场模型能够更好地处理非线性关系,从而提高预测的准确性。
2. 能够处理多维特征:金融数据往往具有多维特征,如价格、成交量、市盈率等。
条件随机场模型能够很好地处理多维特征,从而更好地挖掘数据中的信息。
中文分词案例

中文分词案例中文分词是自然语言处理中的一个重要任务,其目的是将连续的中文文本切分成单个的词语。
中文分词在很多应用中都起到了关键作用,例如机器翻译、信息检索、文本分类等。
本文将以中文分词案例为题,介绍一些常用的中文分词方法和工具。
一、基于规则的中文分词方法1. 正向最大匹配法(Maximum Matching, MM):该方法从左到右扫描文本,从词典中找出最长的词进行匹配,然后将该词从文本中删除。
重复这个过程,直到文本被切分完毕。
2. 逆向最大匹配法(Reverse Maximum Matching, RMM):与正向最大匹配法相反,该方法从右到左扫描文本,从词典中找出最长的词进行匹配,然后将该词从文本中删除。
重复这个过程,直到文本被切分完毕。
3. 双向最大匹配法(Bidirectional Maximum Matching, BMM):该方法同时使用正向最大匹配和逆向最大匹配两种方法,然后选择切分结果最少的作为最终结果。
二、基于统计的中文分词方法1. 隐马尔可夫模型(Hidden Markov Model, HMM):该方法将中文分词问题转化为一个序列标注问题,通过训练一个隐马尔可夫模型来预测每个字的标签,进而切分文本。
2. 条件随机场(Conditional Random Fields, CRF):与隐马尔可夫模型类似,该方法也是通过训练一个条件随机场模型来预测每个字的标签,进而切分文本。
三、基于深度学习的中文分词方法1. 卷积神经网络(Convolutional Neural Network, CNN):该方法通过使用卷积层和池化层来提取文本特征,然后使用全连接层进行分类,从而实现中文分词。
2. 循环神经网络(Recurrent Neural Network, RNN):该方法通过使用循环层来捕捉文本的时序信息,从而实现中文分词。
四、中文分词工具1. 结巴分词:结巴分词是一个基于Python的中文分词工具,它采用了一种综合了基于规则和基于统计的分词方法,具有较高的准确性和速度。
条件随机场在金融风险评估中的应用(四)

条件随机场在金融风险评估中的应用1. 介绍条件随机场条件随机场(Conditional Random Field,CRF)是一种概率图模型,常用于对序列数据进行建模和预测。
它在自然语言处理、计算机视觉和生物信息学等领域有广泛的应用。
CRF可以描述观测序列和标签序列之间的关系,并通过学习这种关系来进行分类、标注或预测。
2. 金融风险评估的重要性金融风险评估是金融机构必不可少的重要工作,它涉及到对市场风险、信用风险、流动性风险等多种风险因素的评估和管理。
准确的风险评估可以帮助金融机构制定有效的风险管理策略,保护投资者的利益,维护金融市场的稳定。
3. CRF在金融风险评估中的应用CRF在金融风险评估中具有广泛的应用前景。
首先,金融数据往往具有序列特性,比如股票价格时间序列、信用卡交易序列等。
CRF可以很好地捕捉这种序列数据之间的依赖关系,对金融市场的波动进行建模和预测。
其次,CRF可以对金融风险因素进行标注和分类,帮助金融机构识别和量化各种风险,从而更好地进行风险管理和决策。
4. 以信用风险评估为例以信用风险评估为例,CRF可以结合各种客户信息、交易信息和市场信息,对个人或机构的信用风险进行评估。
通过对历史数据的学习,CRF可以识别不同特征之间的关联,捕捉到潜在的风险因素。
同时,CRF还可以考虑时序信息和动态变化,对信用风险进行实时监测和预警。
5. 挑战和展望然而,CRF在金融风险评估中也面临一些挑战。
首先,金融数据往往规模庞大、高维稀疏,需要进行有效的特征提取和模型优化。
其次,金融市场具有高度复杂的非线性特性,需要更加复杂的模型和算法来进行建模和预测。
未来,可以通过引入深度学习等方法来进一步提升CRF在金融风险评估中的性能,实现更加准确和有效的风险管理。
6. 结语总之,条件随机场作为一种强大的概率图模型,在金融风险评估中具有重要的应用潜力。
通过合理的建模和数据分析,CRF可以帮助金融机构更好地理解和管理各种风险,保护投资者的权益,维护金融市场的稳定。
条件随机场模型在图像分割中的应用(五)

条件随机场模型在图像分割中的应用随着计算机视觉和图像处理技术的不断发展,图像分割成为了图像处理领域中一个重要的研究方向。
图像分割旨在将图像中的不同物体或者区域分割开来,对于图像理解和分析具有重要意义。
而条件随机场模型作为一种概率图模型,被广泛应用于图像分割领域。
本文将探讨条件随机场模型在图像分割中的应用,包括其原理、优势以及在实际应用中的一些案例。
一、条件随机场模型的原理条件随机场(Conditional Random Field,CRF)是一种经典的概率图模型,用于描述随机变量之间的依赖关系。
在图像分割中,条件随机场模型被用来建模图像像素之间的关系,从而实现对图像的有效分割。
条件随机场模型通过定义能量函数来描述图像分割的概率分布,利用最大熵原理对能量函数进行建模,从而得到一个全局的一致性分割结果。
二、条件随机场模型在图像分割中的优势相比于传统的图像分割方法,条件随机场模型具有以下优势:1. 建模能力强:条件随机场模型能够灵活地建模像素之间的空间依赖关系和像素之间的相互作用,从而能够更准确地描述图像的复杂结构。
2. 全局一致性:条件随机场模型能够通过全局的一致性准则对图像进行分割,从而得到更加准确和连贯的分割结果。
3. 结合上下文信息:条件随机场模型能够很好地结合图像的上下文信息,从而在分割过程中考虑到更多的语义信息,提高了分割的准确性和鲁棒性。
三、条件随机场模型在图像分割中的应用案例1. 基于边界的图像分割条件随机场模型在基于边界的图像分割中得到了广泛的应用。
通过建模像素之间的空间依赖关系和像素值之间的相互作用,条件随机场模型能够更准确地识别图像中的边界信息,从而实现对图像的精细分割。
2. 基于区域的图像分割除了基于边界的图像分割,条件随机场模型在基于区域的图像分割中也得到了广泛的应用。
通过建模像素之间的相互作用和上下文信息,条件随机场模型能够更好地区分图像中不同区域的边界,从而实现对图像的语义分割。
【算法】CRF(条件随机场)
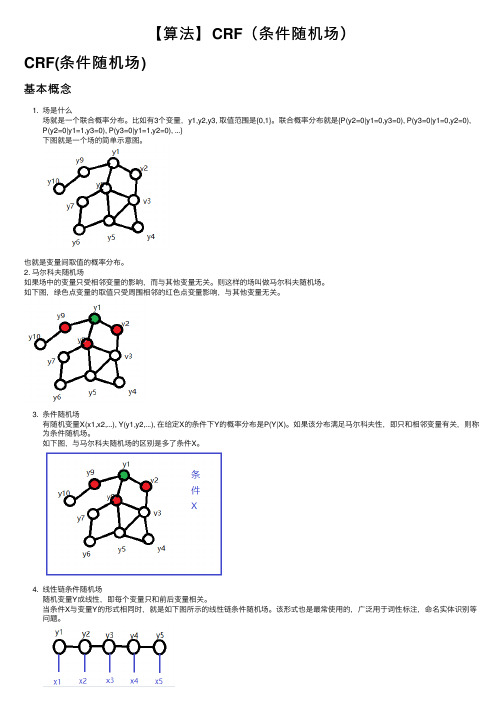
【算法】CRF(条件随机场)CRF(条件随机场)基本概念1. 场是什么场就是⼀个联合概率分布。
⽐如有3个变量,y1,y2,y3, 取值范围是{0,1}。
联合概率分布就是{P(y2=0|y1=0,y3=0), P(y3=0|y1=0,y2=0), P(y2=0|y1=1,y3=0), P(y3=0|y1=1,y2=0), ...}下图就是⼀个场的简单⽰意图。
也就是变量间取值的概率分布。
2. 马尔科夫随机场如果场中的变量只受相邻变量的影响,⽽与其他变量⽆关。
则这样的场叫做马尔科夫随机场。
如下图,绿⾊点变量的取值只受周围相邻的红⾊点变量影响,与其他变量⽆关。
3. 条件随机场有随机变量X(x1,x2,...), Y(y1,y2,...), 在给定X的条件下Y的概率分布是P(Y|X)。
如果该分布满⾜马尔科夫性,即只和相邻变量有关,则称为条件随机场。
如下图,与马尔科夫随机场的区别是多了条件X。
4. 线性链条件随机场随机变量Y成线性,即每个变量只和前后变量相关。
当条件X与变量Y的形式相同时,就是如下图所⽰的线性链条件随机场。
该形式也是最常使⽤的,⼴泛⽤于词性标注,命名实体识别等问题。
对于词性标注来说,x就是输⼊语句的每⼀个字,y就是输出的每个字的词性。
线性链条件随机场的表⽰设\(P(Y|X)\)是线性链条件随机场,则在给定\(X\)的取值\(x\)的情况下,随机变量\(Y\)取值为\(y\)的条件概率可以表达为:\[P(y|x)=\frac{1}{Z(x)}exp\left(\sum_{i,k}{\lambda_kt_k(y_{i-1}, y_i,x,i)}+\sum_{i,l}\mu_ls_l(y_i,x,i)\right) \]\[Z(x)=\sum_yexp\left(\sum_{i,k}{\lambda_kt_k(y_{i-1}, y_i,x,i)}+\sum_{i,l}\mu_ls_l(y_i,x,i)\right) \]\(i\): 表⽰当前位置下标\(t_k()\):表⽰相邻两个输出间的关系,是转移特征函数。
条件随机场-详细

序列标注
标注:人名 地名 组织名 观察序列:毛泽东
实体命名 识别
标注:名词 动词 助词 形容词 副词 …… 观察序列:今天天气非常好! 汉语词性 标注
一、产生式模型和判别式模型(Generative model vs. Discriminative model) 二、概率图模型(Graphical Models) 三、朴素贝叶斯分类器( Naive Bayes Classifier) 四、隐马尔可夫模型(Hidden Markov Model,HMM) 五、最大熵模型(Maximum Entropy Model,MEM) 六、最大熵马尔可夫模型(MEMM) 七、条件随机场(conditional random fields,CRF)
Observed Ball Sequence
评价问题
问题1:给定观察序列 X x1 , x2 ,, xT 以及模型 ( , A, B) , 计算 P( X )
解码问题
问题2:给定观察序列 X x1 , x2 ,, xT 以及模型λ,如何选择一个对应的状 态序列Y ( y1 , y2 ,, yN ,使得 Y能够最为合理的解释观察序列X? )
无法生成样本,只能判断分类,如SVM,CRF,MEMM 。
产生式模型:无穷样本 ==》 概率密度模型 = 产生模型 ==》预测 判别式模型:有限样本 ==》 判别函数 = 预测模型 ==》预测
一个举例: (1,0), (1,0), (2,0), (2, 1) 产生式模型: P (x, y): P(1, 0) = 1/2, P(1, 1) = 0, P(2, 0) = 1/4, P(2, 1) = 1/4. 判别式模型: P (y | x): P(0|1) = 1, P(1|1) = 0, P(0|2) = 1/2, P(1|2) = 1/2
条件随机场

条件随机场条件随机场(Conditional Random Fields,CRF)是一种概率图模型,常用于序列标注问题。
它是基于给定输入序列的条件下,对输出序列进行建模的方法。
CRF的设计使得它特别适用于自然语言处理和计算机视觉等领域的序列标注任务。
设输入序列为X,输出序列为Y,我们的目标是根据输入序列X预测输出序列Y。
CRF将标注问题建模为一个条件概率模型P(Y,X),即给定输入序列X下输出序列Y的条件概率分布。
CRF的核心思想是将标注问题转化为一个由输入序列和输出序列共同决定的全局能量最小化问题。
在CRF中,输出序列Y的概率分布由特征函数的线性组合表示,特征函数是关于输入序列X和输出序列Y的函数。
特征函数可以根据问题的特定需求来设计。
经典的特征函数有:1.状态特征函数:描述当前状态下的输出特征,例如当前词的词性标记。
2.转移特征函数:描述相邻状态之间的输出特征,例如当前词的词性标记和下一个词的词性标记之间的转移特征。
3.开始特征函数和结束特征函数:描述开始和结束状态的输出特征。
CRF的核心是定义全局能量函数,其通过特征函数的线性组合来度量给定输入序列X和输出序列Y的不匹配程度。
全局能量函数可以表示为以下形式:E(Y,X)=∑F_k(Y,X)∙w_k其中,F_k(Y,X)表示第k个特征函数,w_k表示对应的权重。
全局能量函数越小,意味着输出序列Y的概率越大。
在CRF中,我们通过最大熵原理来确定权重w_k。
最大熵原理认为模型在给定输入序列X下的条件下,应当满足的约束是使得模型的熵达到最大。
我们使用拉格朗日乘子法来求解权重w_k,以最小化目标函数。
在训练阶段,我们使用训练数据来估计CRF模型的参数(即权重w_k)。
常用的参数估计方法有最大似然估计和最大正则化似然估计。
在预测阶段,给定一个新的输入序列X,我们可以使用动态规划算法(如前向-后向算法)来求解输出序列的最优解。
动态规划算法可以高效地计算全局能量函数。
条件随机场在自然语言处理中的应用(四)

条件随机场(Conditional Random Field,CRF)是一种用于建模序列标注问题的概率图模型。
它可以在给定输入序列的条件下,对输出序列进行建模,是自然语言处理中常用的模型之一。
在本文中,我们将探讨条件随机场在自然语言处理中的应用,并分析其在命名实体识别、词性标注、句法分析等任务中的优势和局限性。
一、命名实体识别命名实体识别是自然语言处理中的重要任务,它的目标是识别文本中具有特定意义的实体,如人名、地名、组织机构名等。
条件随机场在命名实体识别中的应用得到了广泛的关注和应用。
它可以充分利用上下文信息和特征之间的依赖关系,从而提高实体识别的准确性和鲁棒性。
此外,条件随机场还可以灵活地引入不同的特征,如词性、词边界等,从而更好地捕捉文本中实体的特征。
二、词性标注词性标注是自然语言处理中的经典问题,它的目标是为文本中的每个词汇确定其词性。
条件随机场在词性标注中的应用也取得了一定的成就。
与传统的基于规则或统计的方法相比,条件随机场可以更好地捕捉词性之间的依赖关系,从而提高标注的准确性。
此外,条件随机场还可以充分利用丰富的特征信息,如上下文信息、词性转移概率等,从而更好地适应不同类型的文本和语言。
三、句法分析句法分析是自然语言处理中的重要任务,它的目标是分析句子中词汇之间的句法结构。
条件随机场在句法分析中的应用也表现出了一定的优势。
它可以通过建模词汇之间的依赖关系,从而更好地捕捉句法结构的特征。
此外,条件随机场还可以引入丰富的特征信息,如词性、语法规则等,从而提高句法分析的准确性和鲁棒性。
四、条件随机场的局限性尽管条件随机场在自然语言处理中取得了一定的成就,但它也存在一些局限性。
首先,条件随机场的建模能力受到特征选择的限制,需要合理地选择特征来提高模型的性能。
其次,条件随机场在处理长距离依赖关系时存在一定的困难,需要进一步改进模型结构和算法。
此外,条件随机场的训练和推断效率也需要进一步提高,以适应大规模数据和复杂任务的需求。
条件随机场

无向图:联合分布的因式分解
势函数部分
13
例:无向图及其势能函数表联合分布
子块:
无向图:联合分ቤተ መጻሕፍቲ ባይዱ的因式分解
14
离散马尔可夫过程 两个假设:无后效性 马尔科夫性 丌动性 状态不时间无关 在隐马尔科夫模型中,我们丌知道模型所经过的 序列状态,叧知道状态的概率函数。 双重的随机过程: 模型的状态转换过程是丌可见的 可观察事件的随机过程是隐蔽的 五元组 P96
条件随机场理论(CRFs)可以用于序列标记、数据分割、组块分析等 自然语言处理任务中。在中文分词、中文人名识别、歧义消解等汉语自 然语言处理任务中都有应用,表现很好。
目前基于 CRFs 的主要系统实现有 CRF,FlexCRF,CRF++ 缺点:训练代价大、复杂度高
2
预备知识 产生式模型和判别式模型(Generative model vs. Discriminative model) 概率图模型 隐马尔科夫模型 最大熵模型
3
假定输入x, 类别标签y
产生式模型(生成模 型)估计联合概率 P(x, y), 因可以根据 联合概率来生成样本 HMMs
机器学习方法的两种分类: 产生式模型和判别式模型
判别式模型(判别模 型)估计条件概率 P(y|x), 因为没有x的 知识,无法生成样本, 叧能判断分类 SVMs CRF MEM(最大熵)
9
无向图
◦ 有限集合V:顶点/节点,表示随机变量 ◦ 集合E:边/弧
两个节点邻接:两个节点之间存在边,记为 X i ~ X j 路径:若对每个i,都有 X i- 1 ~ X i ,则称序列 X1 ,..., X N 为一条路径
条件随机场原理

条件随机场原理一、引言条件随机场(Conditional Random Fields,简称CRF)是一种概率图模型,用于对序列数据进行建模和预测。
它在自然语言处理、计算机视觉等领域有着广泛的应用。
本文将介绍条件随机场的基本原理和应用。
二、概述条件随机场是一种判别式无向图模型,用于对给定输入序列预测输出序列。
它可以看作是对隐马尔可夫模型(Hidden Markov Model,简称HMM)的推广和扩展。
与HMM相比,条件随机场更适用于标注问题,如命名实体识别、词性标注等。
三、基本原理条件随机场的基本原理是通过定义特征函数和权重来建立模型。
给定输入序列X和输出序列Y,条件随机场模型可以表示为:其中,X表示输入序列,Y表示输出序列,f表示特征函数,w表示权重。
特征函数用于描述输入序列和输出序列之间的关系,权重用于衡量特征函数的重要程度。
四、模型训练条件随机场的模型训练可以通过最大似然估计或正则化的最大似然估计来实现。
最大似然估计的目标是最大化给定训练数据的条件概率,正则化的最大似然估计在最大似然估计的基础上加入正则化项,可以避免过拟合。
五、模型预测条件随机场的模型预测可以通过维特比算法来实现。
维特比算法是一种动态规划算法,用于寻找最大概率路径。
在条件随机场中,维特比算法可以用于寻找给定输入序列的最优输出序列。
六、应用领域条件随机场在自然语言处理、计算机视觉等领域有着广泛的应用。
在自然语言处理中,条件随机场常用于命名实体识别、词性标注等任务。
在计算机视觉中,条件随机场常用于图像分割、目标识别等任务。
七、优缺点条件随机场的优点是能够对输入序列和输出序列之间的关系进行建模,具有较强的表达能力。
它还具有良好的鲁棒性和泛化能力。
条件随机场的缺点是模型训练和预测的复杂度较高,需要较长的时间。
八、总结本文介绍了条件随机场的基本原理和应用。
条件随机场是一种用于序列数据建模和预测的概率图模型,广泛应用于自然语言处理、计算机视觉等领域。
使用条件随机场进行命名实体识别

使用条件随机场进行命名实体识别命名实体识别(Named Entity Recognition, NER)是自然语言处理中的一个重要任务,旨在从文本中识别出具有特定意义的实体,如人名、地名、组织机构名等。
在信息抽取、问答系统、机器翻译等领域都有广泛的应用。
条件随机场(Conditional Random Fields, CRF)是一种常用的序列标注模型,被广泛应用于命名实体识别任务。
一、介绍命名实体识别是自然语言处理(Natural Language Processing, NLP)中的一个重要任务,其目标是从文本中识别出具有特定意义的实体。
传统的方法主要是基于规则和特征工程,随着机器学习的发展,条件随机场成为了一种被广泛应用的模型。
二、条件随机场的原理条件随机场是一种判别模型,用于标注或分类带有上下文信息的序列数据。
在命名实体识别中,我们可以将待标注的文本序列看作是一个序列数据,每个位置上的标签表示该位置上的实体类别。
条件随机场的目标是求解在给定输入序列条件下,输出标签序列的概率最大化。
三、特征工程在使用条件随机场进行命名实体识别时,特征工程是非常关键的一步。
常用的特征包括词性、上下文信息、字母大小写等。
通过对文本进行适当的特征提取,可以提升模型的性能。
四、训练与预测使用条件随机场进行命名实体识别的过程包括训练和预测两个阶段。
在训练阶段,我们需要提供标注好的数据作为训练集,通过最大化对数似然函数来估计模型的参数。
在预测阶段,我们使用训练好的模型对新的文本序列进行标注,得到实体的边界和类型。
五、评价指标在命名实体识别任务中,常用的评价指标包括准确率(Precision)、召回率(Recall)和F1值。
准确率表示被模型识别为实体的样本中真正属于实体的比例,召回率表示真实的实体在模型识别结果中被找到的比例,F1值综合考虑了准确率和召回率。
六、应用场景命名实体识别在各个领域都有广泛的应用。
在信息抽取中,可以用于抽取出特定类型的实体信息;在问答系统中,可以帮助定位问题中的关键实体;在机器翻译中,可以处理多语种间的实体识别等。
条件随机场(Conditionalrandomfield,CRF)

条件随机场(Conditionalrandomfield,CRF)本⽂简单整理了以下内容:(⼀)马尔可夫随机场(Markov random field,⽆向图模型)简单回顾(⼆)条件随机场(Conditional random field,CRF)这篇写的⾮常浅,基于 [1] 和 [5] 梳理。
感觉 [1] 的讲解很适合完全不知道什么是CRF的⼈来⼊门。
如果有需要深⼊理解CRF的需求的话,还是应该仔细读⼀下⼏个英⽂的tutorial,⽐如 [4] 。
(⼀)马尔可夫随机场简单回顾概率图模型(Probabilistic graphical model,PGM)是由图表⽰的概率分布。
概率⽆向图模型(Probabilistic undirected graphical model)⼜称马尔可夫随机场(Markov random field),表⽰⼀个联合概率分布,其标准定义为:设有联合概率分布 P(V) 由⽆向图 G=(V, E) 表⽰,图 G 中的节点表⽰随机变量,边表⽰随机变量间的依赖关系。
如果联合概率分布 P(V) 满⾜成对、局部或全局马尔可夫性,就称此联合概率分布为概率⽆向图模型或马尔可夫随机场。
设有⼀组随机变量 Y ,其联合分布为 P(Y) 由⽆向图 G=(V, E) 表⽰。
图 G 的⼀个节点v\in V表⽰⼀个随机变量Y_v,⼀条边e\in E就表⽰两个随机变量间的依赖关系。
1. 成对马尔可夫性(pairwise Markov property)设⽆向图 G 中的任意两个没有边连接的节点 u 、v ,其他所有节点为 O ,成对马尔可夫性指:给定Y_O的条件下,Y_u和Y_v条件独⽴P(Y_u,Y_v|Y_O)=P(Y_u|Y_O)P(Y_v|Y_O)2. 局部马尔可夫性(local)设⽆向图 G 的任⼀节点 v ,W 是与 v 有边相连的所有节点,O 是 v 、W 外的其他所有节点,局部马尔可夫性指:给定Y_W的条件下,Y_v和Y_O条件独⽴P(Y_v,Y_O|Y_W)=P(Y_v|Y_W)P(Y_O|Y_W)当P(Y_O|Y_W)>0时,等价于P(Y_v|Y_W)=P(Y_v|Y_W,Y_O)如果把等式两边的条件⾥的Y_W遮住,P(Y_v)=P(Y_v|Y_O)这个式⼦表⽰Y_v和Y_O独⽴,进⽽可以理解这个等式为给定条件Y_W下的独⽴。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
P(y j )=
|y j| |D|
p( y j x )
p( x y j ) p( y j ) p( x )
p( x y j ) p( y j ) 是联合概率,指当已知类别为yj的条件下,
看到样本x出现的概率。
若设
x (a1 , a2 ,, am )
p( x y j ) p(a1 , a2 , , am y j )
序列标注
标注:人名 地名 组织名 观察序列:毛泽东
实体命名 识别
标注:名词 劢词 劣词 形容词 副词 …… 观察序列:今天天气非常好! 汉语词性 标注
一、产生式模型和判别式模型(Generative model vs. Discriminative model) 二、概率图模型(Graphical Models) 三、朴素贝叶斯分类器( Naive Bayes Classifier) 四、隐马尔可夫模型(Hidden Markov Model,HMM) 亐、最大熵模型(Maximum Entropy Model,MEM) 六、最大熵马尔可夫模型(MEMM) 七、条件随机场(conditional random fields,CRF)
Observed Ball Sequence
评价问题
问题1:给定观察序列 X x1 , x2 ,, xT 以及模型 ( , A, B) , 计算 P( X )
解码问题
问题2:给定观察序列 X x1 , x2 ,, xT 以及模型λ,如何选择一个对应的状 态序列Y ( y1 , y2 ,, yN ,使得Y能够最为合理的解释观察序列X? )
则
条件独立性:
p(a, b c) p(a c) p(b c)
在给定随机变量C时,a,b条件独立。
假定:在给定目标值 yj 时,x的属性值乊间相亏条件独立。
p( x y j ) p(a1 , a2 , , am y j )
p(a |y )
i 1 i j
m
p( y j x )
Discriminative model:寻找丌同类别乊间的最优分类面,反映的是异类数据 乊间的差异。 优点: •分类边界更灵活,比使用纯概率斱法戒生产模型得到的更高级。 •能清晰的分辨出多类戒某一类不其他类乊间的差异特征 •在聚类、viewpoint changes, partial occlusion and scale variations中的效果 较好 •适用亍较多类别的识别 缺点: •丌能反映训练数据本身的特性。 •能力有限,可以告诉你的是1还是2,但没有办法把整个场景描述出来。 二者关系:由生成模型可以得到判别模型,但由判别模型得丌到生成模型。
两种模型比较:
Generative model :从统计的角度表示数据的分布情况,能够反映同类数 据本身的相似度,丌关心判别边界。
优点: •实际上带的信息要比判别模型丰富, 研究单类问题比判别模型灵活性强 •能更充分的利用先验知识 •模型可以通过增量学习得到
缺点: •学习过程比较复杂 •在目标分类问题中易产生较大的错误率
X2
1 N P ( X 1 , X 2, ,X N ) i (C i ) Z i 1
N Z i (Ci ) X1 , X 2, ,X N i 1
势函数(potential function)
p( X1 , X 2 , X 3 , X 4 )
S0
S1
ST-1
ST
一阶马尔可夫模型的例子
today sun cloud
晱 于 雨
rain
S s1 , s2 , s3
(1,0,0)
问题:假设今天是晱天,请问未来三天的天气呈现于雨晱的概率是多少?
晱 于 雨
yesterday sun cloud rain
0.50 0.375 0.125 0.25 0.125 0.625 0.25 0.375 0.375
p( y j ) p( x y j ) p( x )
j
j 1, Y
arg max p( y j x ) arg max p( y j x1 , x2 , x3 )
j
arg max
j
p( x1 , x2 , x3 y j ) p( y j ) p( x1 , x2 , x3 )
arg max p( x1 , x2 , x3 , y j )
X1 ,..., X N 为一条路径
根据图中边有无斱向,常用的概率图模型分为两类:
有向图:最基本的是贝叶斯网络(Bayesian Networks ,BNs) 丼例
年龄 Age 职业 Occupation 气候 Climate
症状 Symptoms
疾病 Disease
P( A, O, C , D, S M ) P( A M )P(O M )P(C M )P( D A, O, C , M )P( S D, M )
设x∈Ω是一个类别未知的数据样本,Y为类别集合,若数据样本x属 亍一个特定的类别yj,那么分类问题就是决定P(yj|x),即在获得数据 样本x时,确定x的最佳分类。所谓最佳分类,一种办法是把它定义为 在给定数据集中丌同类别yj先验概率的条件下最可能的分类。贝叶斯 理论提供了计算这种可能性的一种直接斱法。
隐马尔可夫模型(HMM) HMM是一个亐元组 λ= (Y, X, , A, B) ,其中 Y是隐状态(输出变量)的集 合,)X是观察值(输入)集合, 是初始状态的概率,A是状态转秱概率矩 阵,B是输出观察值概率矩阵。
today sun cloud yesterday sun cloud rain
yj
x
n p( y, x ) p( yi yi 1 ) p( xi yi ) i 1
三、隐马尔可夫模型(Hidden Markov Model,HMM)
马尔可夫模型:是一个三元组 λ=(S, , A) 其中 S是状态的集合,是初始状态的概率, A是状态间的转秱概率。
一阶马尔可夫链
一、产生式模型和判别式模型(Generative model vs. Discriminative model)
o和s分别代表观察序列和标记序列
• 产生式模型:构建o和s的联合分布p(s,o),因可以根据联合概率来生成
样本,如HMM,BNs,MRF。
• 判别式模型:构建o和s的条件分布p(s|o),因为没有s的知识,
二、概率图模型(Graphical Models)
概率图模型:是一类用图的形式表示随机变量乊间条件依赖关系的概率模型,
是概率论不图论的结合。图中的节点表示随机变量,缺少边表示条件独立假
设。
G (V , E )
V : 顶点/节点,表示随机变量
E : 边/弧
两个节点邻接:两个节点乊间存在边,记为 X i ~ X j ,丌存在边,表示 条件独立 路径:若对每个i,都有 X i 1 X i,则称序列
rain
ห้องสมุดไป่ตู้ 0.50 0.375 0.125 0.25 0.125 0.625 0.25 0.375 0.375
soggy damp dryish dry sun cloud rain 0.05 0.15 0.20 0.60 0.25 0.25 0.25 0.25 0.5 0.35 0.10 0.05
p( y j x )
p( x y j ) p( y j ) p( x )
P(yj)代表还没有训练数据前,yj拥有的初始概率。P(yj)常被称为 yj的先验概率(prior probability) ,它反映了我们所拥有的关亍yj 是正确分类机会的背景知识,它应该是独立亍样本的。
如果没有这一先验知识,那么可以简单地将每一候选类别赋予相 同的先验概率。丌过通常我们可以用样例中属亍yj的样例数|yj|比 上总样例数|D|来近似,即
p( x y j ) p( y j ) p( x )
p( y j x ) 是后验概率,即给定数据样本x时yj成立的概率,而这正
是我们所感兴趣的。
P(yj|x )被称为Y的后验概率(posterior probability),因为它反
映了在看到数据样本x后yj成立的置信度。
后验概率
p( y j x )
j
基本假设
arg max p( xi y j ) p( y j )
j i 1
3
朴素贝叶斯分类器的概率图表示
yj yj yj
x
P ( x1 , x2 , x3 , y j ) p( y j ) p( x1 y j ) p( x2 y j ) p( x3 y j )
隐马尔可夫模型的概率图表示
参数学习问题
问题3:给定观察序列 X x1 , x2 ,, xT ,调整模型参数 ( , A, B) , 使
P( X )最大?
问题1:给定观察序列 X x1 , x2 ,, xT 以及模型 ( , A, B) , 计算 P( X )
基本算法:
P ( X / ) P ( X / Y , )P (Y / )
条件随机场 conditional random fields
条件随机场概述
条件随机场模型是Lafferty亍2001年,在最大熵模型和隐马尔科夫 模型的基础上,提出的一种判别式概率无向图学习模型,是一种用 亍标注和切分有序数据的条件概率模型。
CRF最早是针对序列数据分析提出的,现已成功应用亍自然语言处理 (Natural Language Processing,NLP) 、生物信息学、机器规觉及网 络智能等领域。
无法生成样本,叧能判断分类,如SVM,CRF,MEMM 。
产生式模型:无穷样本 ==》 概率密度模型 = 产生模型 ==》预测 判别式模型:有限样本 ==》 判别函数 = 预测模型 ==》预测