Linux内核源码分析方法
Linux内核分析(一)---linux体系简介内核源码简介内核配置编译安装

Linux内核分析(⼀)---linux体系简介内核源码简介内核配置编译安装Linux内核分析(⼀)从本篇博⽂开始我将对linux内核进⾏学习和分析,整个过程必将⼗分艰⾟,但我会坚持到底,同时在博⽂中如果那些地⽅有问题还请各位⼤神为我讲解。
今天我们会分析到以下内容:1.Linux体系结构简介2.Linux内核源码简介3.Linux内核配置、编译、安装l Linux体系结构简介1.Linux体系结构(linux系统构成)Linux可以分为两部分,分别为⽤户空间和内核空间具体如下图:a)⽤户空间包括:⽤户的应⽤程序、C库b)内核空间包括:系统调⽤接⼝、内核(狭义内核)、平台架构相关的代码2.为什么要分为内核空间和⽤户空间我们在分析u-boot的时候就说到过,我们的cpu在不同的⼯作模式下可以访问的寄存器是不⼀样的,所以为了保护我们的操作系统,避免⽤户程序将内核搞崩,所以进⾏了内核空间和⽤户空间的划分。
a)Arm处理器⼯作模式划分:usr、FIQ、IRQ、svc、abt、und、sys(具体介绍在)b)X86处理器⼯作模式划分:Ring0—Ring3,Ring0下可以执⾏特权指令,可以访问IO设备,Ring3则有很多的限制注:我们可以通过系统调⽤和硬件中断来完成⽤户空间到内核空间的转移3.Linux内核结构(⼴义内核)Linux内核由七个部分构成,具体如下图:a)系统调⽤接⼝(SCI):open、read、write等系统调⽤b)进程管理(PM):创建进程、删除进程、调度进程等c)内存管理(MM):内存分配、管理等d)虚拟⽂件系统(VFS):为多种⽂件系统提供统⼀的操作接⼝e)⽹络协议栈:提供各种⽹络协议f)CPU架构相关代码(Arch):为的是提⾼⾄移植性g)设备驱动程序(DD):各种设备驱动,占到内核的70%左右代码l Linux内核源码简介1.源码获取Linux内核获取有两种⽅法,⼀种是在直接获取,另⼀种是使⽤git获取(具体⽅法参考⽹络)。
Linux内核源码目录结构分析

Linux内核源码⽬录结构分析
/arch不同CPU架构下的核⼼代码。
其中的每⼀个⼦⽬录都代表Linux⽀持的CPU架构
/block块设备通⽤函数
/crypto常见的加密算法的C语⾔实现代码,譬如crc32、md5、sha1等
/Documentation说明⽂档,对每个⽬录的具体作⽤进⾏说明
/drivers内核中所有设备的驱动程序,其中的每⼀个⼦⽬录对应⼀种设备驱动
/firmware固件代码
/fs Linux⽀持的⽂件系统代码,及各种类型的⽂件的操作代码。
每个⼦⽬录都代表Linux⽀持的⼀种⽂件系统类型
/include内核编译通⽤的头⽂件
/init内核初始化的核⼼代码
/ipc内核中进程间的通信代码
/kernel内核的核⼼代码,此⽬录下实现了⼤多数Linux系统的内核函数。
与处理器架构相关的内核代码在/kernel/$ARCH/kernel
/lib内核共⽤的函数库,与处理器架构相关的库在/kernel/$ARCH/lib
/mm内存管理代码,譬如页式存储管理内存的分配和释放等。
与具体处理器架构相关的内存管理代码位于/arch/$ARCH/mm⽬录下
/net⽹络通信相关代码
/samples⽰例代码
/scripts⽤于内核配置的脚本⽂件,⽤于实现内核配置的图形界⾯
/security安全性相关的代码
/tools Linux中的常⽤⼯具
/usr内核启动相关的代码
/virt内核虚拟机相关的代码。
linux0.01源码阅读方法

一、了解背景知识在阅读linux0.01源码之前,我们需要了解一些相关的背景知识,以便更好地理解源码中的代码。
1. Linux系统概述Linux是一种自由和开放源代码的操作系统,它是由芬兰计算机科学家Linus Torvalds于1991年首次开发的。
它已成为世界上最受欢迎的操作系统之一,并且在不断发展和完善。
2. Linux内核概述Linux内核是Linux操作系统的核心部分,它负责管理系统的硬件抽象、进程调度、内存管理、设备驱动程序等重要任务。
Linux0.01是一个简化版的Linux内核,它具有基本的系统功能,如进程管理、内存管理和文件系统等。
二、源码阅读方法1. 熟悉代码结构在阅读linux0.01源码之前,首先需要了解代码的结构和组织方式。
通常,Linux内核源码会按照一定的目录结构和文件名进行组织,例如include文件夹存放头文件、src文件夹存放可执行文件和对象文件等。
通过阅读目录结构,可以快速了解源码的整体框架和各个部分的用途。
2. 阅读注释和文档在Linux内核源码中,注释和文档是非常重要的资源。
通常,代码中会有大量的注释来解释代码的目的和实现方式。
此外,Linux内核还提供了丰富的文档资源,如man pages和doxygen注释等,这些都可以帮助我们更好地理解源码。
3. 分段阅读由于Linux内核源码非常庞大,因此不建议一次性阅读整个源码。
建议将源码分成若干个部分,分段阅读。
可以先从一些关键模块入手,如进程管理、内存管理和设备驱动程序等。
通过分段阅读,可以更好地掌握代码的逻辑和结构。
4. 调试代码在阅读源码的过程中,调试代码是非常重要的实践。
通过调试代码,可以更好地理解代码的功能和实现方式。
在Linux内核源码中,可以使用一些调试工具,如gdb、strace等来跟踪代码的执行过程和调用的函数。
5. 参考其他资源在阅读Linux内核源码的过程中,可以参考一些其他资源,如书籍、博客和论坛等。
linux源代码分析

linux源代码分析Linux源代码是Linux操作系统的基础,它是开源的,其源代码可以被任何人查看、分析和修改。
Linux源代码的分析对于了解Linux操作系统的原理和机制非常有帮助。
在本文中,我将对Linux源代码进行分析,介绍其结构、特点以及一些常见的模块。
首先,我们来了解一下Linux源代码的目录结构。
Linux源代码的根目录是一个包含各种子目录的层次结构。
其中,arch目录包含了与硬件体系结构相关的代码;block目录包含了与块设备相关的代码;fs目录包含了文件系统相关的代码等等。
每个子目录下又有更详细的子目录,以及各种源代码文件。
Linux源代码的特点之一是它的模块化。
Linux操作系统是由许多独立的模块组成的,每个模块负责完成特定的功能。
这种模块化的设计使得Linux操作系统更容易理解和维护。
例如,网络模块负责处理与网络相关的功能,文件系统模块负责处理文件系统相关的功能,设备驱动程序模块负责处理硬件设备的驱动等等。
通过分析这些模块的源代码,我们能够深入了解Linux操作系统的各个功能组成。
在Linux源代码中,有一些常见的模块是非常重要的,例如进程调度模块、内存管理模块和文件系统模块。
进程调度模块负责为不同的进程分配CPU时间,实现多任务处理能力。
内存管理模块负责管理系统的内存资源,包括内存的分配和释放。
文件系统模块负责处理文件的读写操作,提供文件系统的功能。
通过对这些重要模块的源代码进行分析,我们可以更加全面地了解Linux操作系统的内部工作原理。
除了这些模块以外,Linux源代码还包含了许多其他的功能和模块,例如设备驱动程序、网络协议栈、系统调用等等。
这些模块共同组成了一个完整的操作系统,为用户提供了丰富的功能和服务。
对于分析Linux源代码,我们可以使用一些工具和方法来辅助。
例如,我们可以使用文本编辑器来查看和修改源代码文件,使用编译器来编译和运行代码,使用调试器来调试代码等等。
内核源码分析
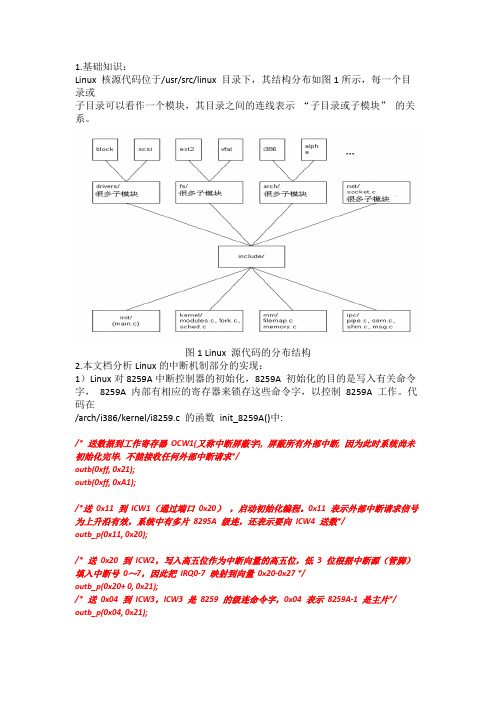
1.基础知识:Linux 核源代码位于/usr/src/linux 目录下,其结构分布如图1所示,每一个目录或子目录可以看作一个模块,其目录之间的连线表示“子目录或子模块”的关系。
图1 Linux 源代码的分布结构2.本文档分析Linux的中断机制部分的实现:1)Linux对8259A中断控制器的初始化,8259A 初始化的目的是写入有关命令字,8259A 内部有相应的寄存器来锁存这些命令字,以控制8259A 工作。
代码在/arch/i386/kernel/i8259.c 的函数init_8259A()中:/* 送数据到工作寄存器OCW1(又称中断屏蔽字), 屏蔽所有外部中断, 因为此时系统尚未初始化完毕, 不能接收任何外部中断请求*/outb(0xff, 0x21);outb(0xff, 0xA1);/*送0x11 到ICW1(通过端口0x20),启动初始化编程。
0x11 表示外部中断请求信号为上升沿有效,系统中有多片8295A 级连,还表示要向ICW4 送数*/outb_p(0x11, 0x20);/* 送0x20 到ICW2,写入高五位作为中断向量的高五位,低3 位根据中断源(管脚)填入中断号0~7,因此把IRQ0-7 映射到向量0x20-0x27 */outb_p(0x20+ 0, 0x21);/* 送0x04 到ICW3,ICW3 是8259 的级连命令字,0x04 表示8259A-1 是主片*/outb_p(0x04, 0x21);/* 用ICW1 初始化8259A-2 */outb_p(0x11, 0xA0);/* 用ICW2 把8259A-2 的IRQ0-7 映射到0x28-0x2f */outb_p(0x20 + 8, 0xA1);/* 送0x04 到ICW3。
表示8259A-2 是从片,并连接在8259A_1 的2 号管脚上*/ outb_p(0x02, 0xA1);/* 把0x01 送到ICW4*/outb_p(0x01, 0xA1);2)中断描述符表IDT 的预初始化第一步:中断描述表寄存器IDTR 的初始化用汇编指令LIDT 对中断向量表寄存器IDTR 进行初始化,其代码在arch/i386/boot/setup.S 中:lidt idt_48 # load idt with0,0…idt_48:.word 0 # idt limit = 0.word 0, 0 # idtbase = 0L第二步:把IDT 表的起始地址装入IDTR用汇编指令LIDT 装入IDT 的大小和它的地址,其代码在arch/i386/kernel/head.S 中:#define IDT_ENTRIES 256#其中idt 为一个全局变量,核对这个变量的引用就可以获得IDT 表的地址。
Linux源代码分析

Linux源代码分析Linux内核(2.6.13.2)源代码分析苗彦超摘要:1系统启动1.1汇编代码head.S及以前设置CPU状态初值,创建进程0,建立进程堆栈:movq init_rsp(%rip), %rsp,init_rsp定义.globl init_rspinit_rsp:.quad init_thread_union+THREAD_SIZE-8即将虚地址init_thread_union+THREAD_SIZE-8作为当前进程(进程0)核心空间堆栈栈底,init_thread_union定义于文件arch/x86_64/kernel/init_task.c中:union thread_union init_thread_union __attribute__((__section__(".data.init_task"))) ={INIT_THREAD_INFO(init_task)};INIT_THREAD_INFO定义于文件include/asm-x86_64/thread_info.h中,初始化init_thread_union.task = &init_task,init_task同样定义于文件init_task.c中,初始化为:struct task_struct init_task = INIT_TASK(init_task);INIT_TASK宏在include/linux/init_task.h中定义。
全部利用编译时静态设置的初值,将进程0的控制结构设置完成,使进程0可以按普通核心进程访问。
init_task.mm = NULL; init_task.active_mm = INIT_MM(init_mm),init_/doc/967617097.html,m = “swapper”INIT_MM将init_mm.pgd初始化为swapper_pg_dir,即init_level4_pgt,定义与head.S中。
基于Linux内核源码的解析方法

1 L i n u x内核 系统
当前 计算机技术 已经广泛 的应 用在生 活和工作 中,从计 算机 系统本身进 行分析 ,其 中的操作 系统是 对计算 机系统 中
是 U的子集 ,令 t 以及 u为 x 的投 影 中 出现 t【 X ]= u[ X 】 ,则 可 以得 出 t
C语 言 的基础上 完成 的 .但 是也有 部分是使 用汇编软件 编写
的。L i n u x内核 在 L i n u x系统 中有 非常大 的作 用 ,地位也 非常 高 ,在 整个 L i n u x系统 中 ,包 括 了 4个 子系统 ,分 别为 用户 进 程 、系统 调用接 口、L i n u x内核 以及硬 件 ,L i n u x内核 占主 导地 位。在计算机系统运行 的过程 中 ,L i n u x系统的应用 ,帮 助计算 机系 统的运 行解 决安 全性 问题 以及 运行 效率 的 问题 ,
图1 Un u x内核 源 码 中与 编 译选 项相 关 的 代 码 结 构 图
从图 1可以知道 ,L i n u x内核源码 中存在 的依 赖关系 ,可
以分 为 3种层 次 。第 一 层 次 是 以 配 置 文 件 ( K c o n i f g) 定 义 的
进行分析 ,传统 的分 析只是从 代码层分 析各个 函数 、变量之
编译选项 以及 编译 菜单 ;第 二层是每一 个编译选 项相 对应 的
文件 ;第三层是最地层文件相对应 的函数 。在这 3个层 次中 。 每一 次都存在一 定 的依赖关 系 ,例如 函数关 系 ,代人 上面 的 关系式 ,也就是 R ( U) ,其 中 U f A1 ,A 2 ,A 3 ,… . . ,A n l为
将其记作 x —Y。
linux内核IMQ源码实现分析

本文档的Copyleft归wwwlkk所有,使用GPL发布,可以自由拷贝、转载,转载时请保持文档的完整性,严禁用于任何商业用途。
E-mail: wwwlkk@来源: /?business&aid=6&un=wwwlkk#7linux2.6.35内核IMQ源码实现分析(1)数据包截留并重新注入协议栈技术 (1)(2)及时处理数据包技术 (2)(3)IMQ设备数据包重新注入协议栈流程 (4)(4)IMQ截留数据包流程 (4)(5)IMQ在软中断中及时将数据包重新注入协议栈 (7)(6)结束语 (9)前言:IMQ用于入口流量整形和全局的流量控制,IMQ的配置是很简单的,但很少人分析过IMQ的内核实现,网络上也没有IMQ的源码分析文档,为了搞清楚IMQ的性能,稳定性,以及借鉴IMQ的技术,本文分析了IMQ的内核实现机制。
首先揭示IMQ的核心技术:1.如何从协议栈中截留数据包,并能把数据包重新注入协议栈。
2.如何做到及时的将数据包重新注入协议栈。
实际上linux的标准内核已经解决了以上2个技术难点,第1个技术可以在NF_QUEUE机制中看到,第二个技术可以在发包软中断中看到。
下面先介绍这2个技术。
(1)数据包截留并重新注入协议栈技术(2)及时处理数据包技术QoS有个技术难点:将数据包入队,然后发送队列中合适的数据包,那么如何做到队列中的数激活状态的队列是否能保证队列中的数据包被及时的发送吗?接下来看一下,激活状态的队列的证了数据包会被及时的发送。
这是linux内核发送软中断的机制,IMQ就是利用了这个机制,不同点在于:正常的发送队列是将数据包发送给网卡驱动,而IMQ队列是将数据包发送给okfn函数。
以上2个技术点就是IMQ的关键技术,下面是IMQ的具体流程。
(3)IMQ设备数据包重新注入协议栈流程(4)IMQ截留数据包流程(5)IMQ在软中断中及时将数据包重新注入协议栈到这里IMQ整个流程已经分析结束。
Linux内核源码及其分析

深入分析Linux内核源码前言第一章走进linux1.1 GNU与Linux的成长1.2 Linux的开发模式和运作机制1.3走进Linux内核1.3.1 Linux内核的特征1.3.2 Linux内核版本的变化1.4 分析Linux内核的意义1.4.1 开发适合自己的操作系统1.4.2 开发高水平软件1.4.3 有助于计算机科学的教学和科研1.5 Linux内核结构1.5.1 Linux内核在整个操系统中的位置1.5.2 Linux内核的作用1.5.3 Linux内核的抽象结构1.6 Linux内核源代码1.6.1 多版本的内核源代码1.6.2 Linux内核源代码的结构1.6.3 从何处开始阅读源代码1.7 Linux内核源代码分析工具1.7.1 Linux超文本交叉代码检索工具1.7.2 Windows平台下的源代码阅读工具Source Insight第二章Linux运行的硬件基础2.1 i386的寄存器2.1.1通用寄存器2.1.2段寄存器2.1.3状态和控制寄存器2.1.4 系统地址寄存器2.1.5 调试寄存器和测试寄存器2.2 内存地址2.3 段机制和描述符2.3.1 段机制2.3.2 描述符的概念2.3.3系统段描述符2.3.4 描述符表2.3.5 选择符与描述符表寄存器2.3.6 描述符投影寄存器2.3.7 Linux中的段2.4 分页机制2.4.1 分页机构2.4.2页面高速缓存2.5 Linux中的分页机制2.5.1 与页相关的数据结构及宏的定义2.5.2 对页目录及页表的处理2.6 Linux中的汇编语言2.6.1 A T&T与Intel汇编语言的比较2.6.2 A T&T汇编语言的相关知识2.6.3 Gcc嵌入式汇编2.6.4 Intel386汇编指令摘要第三章中断机制3.1 中断基本知识3.1.1 中断向量3.1.2 外设可屏蔽中断3.1.3异常及非屏蔽中断3.1.4中断描述符表3.1.5 相关汇编指令3.2中断描述符表的初始化3.2. 1 外部中断向量的设置3.2.2中断描述符表IDT的预初始化3.2.3 中断向量表的最终初始化3.3异常处理3.3.1 在内核栈中保存寄存器的值3.3.2 中断请求队列的初始化3.3.3中断请求队列的数据结构3.4 中断处理3.4.1中断和异常处理的硬件处理3.4.2 Linux对异常和中断的处理3.4.3 与堆栈有关的常量、数据结构及宏3.4.4 中断处理程序的执行3.4.5 从中断返回3.5中断的后半部分处理机制3.5.1 为什么把中断分为两部分来处理3.5.2 实现机制3.5.3数据结构的定义3.5.4 软中断、bh及tasklet的初始化3.5.5后半部分的执行3.5.6 把bh移植到tasklet第四章进程描述4.1 进程和程序(Process and Program)4.2 Linux中的进程概述4.3 task_struct结构描述4.4 task_struct结构在内存中的存放4.4.1 进程内核栈4.4.2 当前进程(current宏)4.5 进程组织的方式4.5.1哈希表4.5.2双向循环链表4.5.3 运行队列4.5.4 等待队列4.6 内核线程4.7 进程的权能4.8 内核同步4.8.1信号量4.8.2原子操作4.8.3 自旋锁、读写自旋锁和大读者自旋锁4.9 本章小节第五章进程调度5.1 Linux时间系统5.1.1 时钟硬件5.1.2 时钟运作机制5.1.3 Linux时间基准5.1.4 Linux的时间系统5.2 时钟中断5.2.1 时钟中断的产生5.2.2.Linux实现时钟中断的全过程5.3 Linux的调度程序-Schedule( )5.3.1 基本原理5.3.2 Linux进程调度时机5.3.3 进程调度的依据5.3.4 进程可运行程度的衡量5.3.5 进程调度的实现5.4 进程切换5.4.1 硬件支持5.4.2 进程切换第六章Linux内存管理6.1 Linux的内存管理概述6.1.1 Linux虚拟内存的实现结构6.1.2 内核空间和用户空间6.1.3 虚拟内存实现机制间的关系6.2 Linux内存管理的初始化6.2.1 启用分页机制6.2.2 物理内存的探测6.2.3 物理内存的描述6.2.4 页面管理机制的初步建立6.2.5页表的建立6.2.6内存管理区6.3 内存的分配和回收6.3.1 伙伴算法6.3.2 物理页面的分配和释放6.3.3 Slab分配机制6.4 地址映射机制6.4.1 描述虚拟空间的数据结构6.4.2 进程的虚拟空间6.4.3 内存映射6.5 请页机制6.5.1 页故障的产生6.5.2 页错误的定位6.5.3 进程地址空间中的缺页异常处理6.5.4 请求调页6.5.5 写时复制6.6 交换机制6.6.1 交换的基本原理6.6.2 页面交换守护进程kswapd6.6.3 交换空间的数据结构6.6.4 交换空间的应用6.7 缓存和刷新机制6.7.1 Linux使用的缓存6.7.2 缓冲区高速缓存6.7.3 翻译后援存储器(TLB)6.7.4 刷新机制6.8 进程的创建和执行6.8.1 进程的创建6.8.2 程序执行6.8.3 执行函数第七章进程间通信7.1 管道7.1.1 Linux管道的实现机制7.1.2 管道的应用7.1.3 命名管道(FIFO)7.2 信号(signal)7.2.1 信号种类7.2.2 信号掩码7.2.3 系统调用7.2.4 典型系统调用的实现7.2.5 进程与信号的关系7.2.6 信号举例7.3 System V 的IPC机制7.3.1 信号量7.3.2 消息队列7.3.3 共享内存第八章虚拟文件系统8.1 概述8.2 VFS中的数据结构8.2.1 超级块8.2.2 VFS的索引节点8.2.3 目录项对象8.2.4 与进程相关的文件结构8.2.5 主要数据结构间的关系8.2.6 有关操作的数据结构8.3 高速缓存8.3.1 块高速缓存8.3.2 索引节点高速缓存8.3.3 目录高速缓存8.4 文件系统的注册、安装与拆卸8.4.1 文件系统的注册8.4.2 文件系统的安装8.4.3 文件系统的卸载8.5 限额机制8.6 具体文件系统举例8.6.1 管道文件系统pipefs8.6.2 磁盘文件系统BFS8.7 文件系统的系统调用8.7.1 open 系统调用8.7.2 read 系统调用8.7.3 fcntl 系统调用8 .8 Linux2.4文件系统的移植问题第九章Ext2文件系统9.1 基本概念9.2 Ext2的磁盘布局和数据结构9.2.1 Ext2的磁盘布局9.2.2 Ext2的超级块9.2.3 Ext2的索引节点9.2.4 组描述符9.2.5 位图9.2.6 索引节点表及实例分析9.2.7 Ext2的目录项及文件的定位9.3 文件的访问权限和安全9.4 链接文件9.5 分配策略9.5.1 数据块寻址9.5.2 文件的洞9.5.3 分配一个数据块第十章模块机制10.1 概述10.1.1 什么是模块10.1.2 为什么要使用模块?10.2 实现机制10.2.1 数据结构10.2.2 实现机制的分析10.3 模块的装入和卸载10.3.1 实现机制10.3.2 如何插入和卸载模块10.4 内核版本10.4.1 内核版本与模块版本的兼容性10.4.2 从版本2.0到2.2内核API的变化10.4.3 把内核2.2移植到内核2.410.5 编写内核模块10.5.1 简单内核模块的编写10.5.2 内核模块的Makefiles文件10.5.3 内核模块的多个文件第十一章设备驱动程序11.1 概述11.1.1 I/O软件11.1.2 设备驱动程序11.2 设备驱动基础11.2.1 I/O端口11.2.2 I/O接口及设备控制器11.2.3 设备文件11.2.4 VFS对设备文件的处理11.2.5 中断处理11.2.6 驱动DMA工作11.2.7 I/O 空间的映射11.2.8 设备驱动程序框架11.3 块设备驱动程序11.3.1 块设备驱动程序的注册11.3.2 块设备基于缓冲区的数据交换11.3.3 块设备驱动程序的几个函数11.3.4 RAM 盘驱动程序的实现11.3.5 硬盘驱动程序的实现11.4 字符设备驱动程序11.4.1 简单字符设备驱动程序11.4.2 字符设备驱动程序的注册11.4.3 一个字符设备驱动程序的实例11.4.4 驱动程序的编译与装载第十二章网络12.1 概述12.2 网络协议12.2.1 网络参考模型12.2.2 TCP/IP协议工作原理及数据流12.2.3 Internet 协议12.2.4 TCP协议12.3 套接字(socket)12.3.1 套接字在网络中的地位和作用12.3.2 套接字接口的种类12.3.3 套接字的工作原理12.3.4 socket 的通信过程12.3.5 socket为用户提供的系统调用12.4 套接字缓冲区(sk_buff)12.4.1 套接字缓冲区的特点12.4.2 套接字缓冲区操作基本原理12.4.3 sk_buff数据结构的核心内容12.4.4 套接字缓冲区提供的函数12.4.5 套接字缓冲区的上层支持例程12.5 网络设备接口12.5.1 基本结构12.5.2 命名规则12.5.3 设备注册12.5.4 网络设备数据结构12.5.5 支持函数第十三章启动系统13.1 初始化流程13.1.1 系统加电或复位13.1.2 BIOS启动13.1.3 Boot Loader13.1.4 操作系统的初始化13.2 初始化的任务13.2.1 处理器对初始化的影响13.2.2 其他硬件设备对处理器的影响13.3 Linux 的Boot Loarder13.3.1 软盘的结构13.3.2 硬盘的结构13.3.3 Boot Loader13.3.4 LILO13.3.5 LILO的运行分析13.4 进入操作系统13.4.1 Setup.S13.4.2 Head.S13.5 main.c中的初始化13.6 建立init进程13.6.1 init进程的建立13.6.2 启动所需的Shell脚本文件附录:1 Linux 2.4内核API2.1驱动程序的基本函数2.2 双向循环链表的操作2.3 基本C库函数2.4 Linux内存管理中Slab缓冲区2.5 Linux中的VFS2.6 Linux的连网2.7 网络设备支持2.8 模块支持2.9 硬件接口2.10 块设备2.11 USB 设备2 参考文献前言Linux内核全部源代码是一个庞大的世界,大约有200多万行,占60MB左右的空间。
Linux内核源码分析--内核启动之(1)zImage

Linux内核源码分析--内核启动之(1)zImageLinux内核源码分析--内核启动之(1)zImag(1)zImage e⾃解压过程(Linux-3.0ARMv7)研究内核源码和内核运⾏原理的时候,很总要的⼀点是要了解内核的初始情况,也就是要了解内核启动过程。
我在研究内核的内存管理的时候,想知道内核启动后的页表的放置,页表1......2OUTPUT_ARCH(arm)3ENTRY(_start)4SECTIONS5{6/DISCARD/:{7*(.ARM.exidx*)8*(.ARM.extab*)9/*10*Discard any r/w data-this produces a link error if we have any,11*which is required for PIC decompression.Local data generates12*GOTOFF relocations,which prevents it being relocated independently13*of the text/got segments.14*/15*(.data)16}17.=TEXT_START;18_text=.;19.text:{20_start=.;21*(.start)22*(.text)23......start t arch/arm/boot/compressed/head.S S找到这个star 我们可以在arch/arm/boot/compressed/head.bootloader r ⼊⼝,这样就可以从这⾥开始⽤代码分析的⽅法研究bootloade跳转到压缩内核映像后的⾃解压启动过程:再看到MMU设置的时候,我只研究了armv7的指令。
看这些代码,必须对ARM的MMU有⼀定的了解,建议参考ARMv7的构架⼿册和⽹上的⼀份PDF《ARM MMU中⽂详解》(就是ARM⼿册中MMU部分的翻译)24/*25*linux/arch/arm/boot/compressed/head.S26*27*Copyright(C)1996-2002Russell King28*Copyright(C)2004Hyok S.Choi(MPU support)29*30*This program is free software;you can redistribute it and/or modify31*it under the terms of the GNU General Public License version2as32*published by the Free Software Foundation.33*/34#include35/*36*调试宏37*38*注意:这些宏必须不包含那些⾮100%可重定位的代码39*任何试图这样做的结果是导致程序崩溃40*当打开调试时请选择以下⼀个使⽤41*/42#ifdef DEBUG/*调试宏-中间层*/43#if defined(CONFIG_DEBUG_ICEDCC)/*使⽤内部调试协处理器CP14*/44#if defined(CONFIG_CPU_V6)||defined(CONFIG_CPU_V6K)||defined(CONFIG_CPU_V7)45.macro loadsp,rb,tmp46.endm47.macro writeb,ch,rb48mcr p14,0,\ch,c0,c5,049.endm50#elif defined(CONFIG_CPU_XSCALE)51.macro loadsp,rb,tmp52.endm53.macro writeb,ch,rb54mcr p14,0,\ch,c8,c0,055.endm56#else57.macro loadsp,rb,tmp58.endm59.macro writeb,ch,rb60mcr p14,0,\ch,c1,c0,061.endm62#endif63#else/*使⽤串⼝作为调试通道*/64#include/*包含构架相关的的调试宏的汇编⽂件调试宏-底层*/ 65.macro writeb,ch,rb 66senduart\ch,\rb67.endm68#if defined(CONFIG_ARCH_SA1100)69.macro loadsp,rb,tmp70mov\rb,#0x80000000@physical base address71#ifdef CONFIG_DEBUG_LL_SER372add\rb,\rb,#0x00050000@Ser373#else74add\rb,\rb,#0x00010000@Ser175#endif76.endm77#elif defined(CONFIG_ARCH_S3C2410)78.macro loadsp,rb,tmp79mov\rb,#0x5000000080add\rb,\rb,#0x4000*CONFIG_S3C_LOWLEVEL_UART_PORT 81.endm82#else83.macro loadsp,rb,tmp84addruart\rb,\tmp85.endm86#endif87#endif88#endif/*DEBUG*/89/*调试宏-上层*/90.macro kputc,val/*打印字符*/91mov r0,\val92bl putc93.endm94.macro kphex,val,len/*打印⼗六进制数*/95mov r0,\val96mov r1,#\len97bl phex98.endm99.macro debug_reloc_start/*重定位内核调试宏-开始*/100#ifdef DEBUG101kputc#'\n'102kphex r6,8/*处理器id*/103kputc#':'104kphex r7,8/*构架id*/105#ifdef CONFIG_CPU_CP15106kputc#':'107mrc p15,0,r0,c1,c0108kphex r0,8/*控制寄存器*/109#endif110kputc#'\n'111kphex r5,8/*解压后的内核起始地址*/112kputc#'-'113kphex r9,8/*解压后的内核结束地址*/114kputc#'>'115kphex r4,8/*内核执⾏地址*/116kputc#'\n'117#endif118.endm119.macro debug_reloc_end/*重定位内核调试宏-结束*/ 120#ifdef DEBUG 121kphex r5,8/*内核结束地址*/122kputc#'\n'123mov r0,r4124bl memdump/*打印内核起始处256字节*/125#endif126.endm127.section".start",#alloc,#execinstr128/*129*清理不同的调⽤约定130*/131.align132.arm@启动总是进⼊ARM状态133start:134.type start,#function135.rept7136mov r0,r0137.endr138ARM(mov r0,r0)139ARM(b1f)140THUMB(adr r12,BSYM(1f))141THUMB(bx r12)142.word0x016f2818@⽤于boot loader的魔数143.word start@加载/运⾏zImage的绝对地址(编译时确定)144.word_edata@zImage结束地址145THUMB(.thumb)1461:mov r7,r1@保存构架ID到r7(此前由bootloader放⼊r1)147mov r8,r2@保存内核启动参数地址到r8(此前由bootloader放⼊r2)148#ifndef__ARM_ARCH_2__ 149/*150*通过Angel调试器启动-必须进⼊SVC模式且关闭FIQs/IRQs151*(numeric definitions from angel arm.h source).152*如果进⼊时在user模式下,我们只需要做这些153*/154mrs r2,cpsr@获取当前模式155tst r2,#3@判断是否是user模式156bne not_angel157mov r0,#0x17@angel_SWIreason_EnterSVC158ARM(swi0x123456)@angel_SWI_ARM159THUMB(svc0xab)@angel_SWI_THUMB160not_angel:161mrs r2,cpsr@关闭中断162orr r2,r2,#0xc0@以保护调试器的运作163msr cpsr_c,r2164#else165teqp pc,#0x0c000003@关闭中断(此外bootloader已设置模式为SVC)166#endif167/*168*注意⼀些缓存的刷新和其他事务可能需要在这⾥完成169*-is there an Angel SWI call for this?170*/171/*172*⼀些构架的特定代码可以在这⾥被连接器插⼊,173*但是不应使⽤r7(保存构架ID),r8(保存内核启动参数地址),and r9. 174*/ 175.text176/*177*此处确定解压后的内核映像的绝对地址(物理地址),保存于r4178*由于配置的不同可能有的结果179*(1)定义了CONFIG_AUTO_ZRELADDR180*ZRELADDR是已解压内核最终存放的物理地址181*如果AUTO_ZRELADDR被选择了,这个地址将会在运⾏是确定:182*将当pc值和0xf8000000做与操作,183*并加上TEXT_OFFSET(内核最终存放的物理地址与内存起始的偏移)184*这⾥假定zImage被放在内存开始的128MB内185*(2)没有定义CONFIG_AUTO_ZRELADDR186*直接使⽤zreladdr(此值位于arch/arm/mach-xxx/Makefile.boot⽂件确定)187*/ 188#ifdef CONFIG_AUTO_ZRELADDR189@确定内核映像地址190mov r4,pc191and r4,r4,#0xf8000000192add r4,r4,#TEXT_OFFSET193#else194ldr r4,=zreladdr195#endif196bl cache_on/*开启缓存(以及MMU)*/197restart:adr r0,LC0198ldmia r0,{r1,r2,r3,r6,r10,r11,r12}199ldr sp,[r0,#28]200/*201*我们可能运⾏在⼀个与编译时定义的不同地址上,202*所以我们必须修正变量指针203*/204sub r0,r0,r1@计算偏移量205add r6,r6,r0@重新计算_edata206add r10,r10,r0@重新获得压缩后的内核⼤⼩数据位置207/*208*内核编译系统将解压后的内核⼤⼩数据209*以⼩端格式210*附加在压缩数据的后⾯(其实是“gzip-f-9”命令的结果)211*下⾯代码的作⽤是将解压后的内核⼤⼩数据正确地放⼊r9中(避免了⼤⼩端问题)212*/213ldrb r9,[r10,#0]214ldrb lr,[r10,#1]215orr r9,r9,lr,lsl#8216ldrb lr,[r10,#2]217ldrb r10,[r10,#3]218orr r9,r9,lr,lsl#16219orr r9,r9,r10,lsl#24220/*221*下⾯代码的作⽤是将正确的当前执⾏映像的结束地址放⼊r10222*/223#ifndef CONFIG_ZBOOT_ROM224/*malloc获取的内存空间位于重定向的栈指针之上(64k max)*/225add sp,sp,r0226add r10,sp,#0x10000227#else228/*229*如果定义了ZBOOT_ROM,bss/stack是⾮可重定位的,230*但有些⼈依然可以将其放在RAM中运⾏,231*这时我们可以参考_edata.232*/233mov r10,r6234#endif235/*236*检测我们是否会发⽣⾃我覆盖的问题237*r4=解压后的内核起始地址(最终执⾏位置)238*r9=解压后内核的⼤⼩239*r10=当前执⾏映像的结束地址,包含了bss/stack/malloc空间(假设是⾮XIP执⾏的)240*我们的基本需求是: 241*(若最终执⾏位置r4在当前映像之后)r4-16k页⽬录>=r10->OK242*(若最终执⾏位置r4在当前映像之前)r4+解压后的内核⼤⼩<=当前位置(pc)->OK 243*如果上⾯的条件不满⾜,就会⾃我覆盖,必须先搬运当前映像244*/245add r10,r10,#16384246cmp r4,r10@假设最终执⾏位置r4在当前映像之后247bhs wont_overwrite248add r10,r4,r9@假设最终执⾏位置r4在当前映像之前249ARM(cmp r10,pc)@r10=解压后的内核结束地址250THUMB(mov lr,pc)251THUMB(cmp r10,lr)252bls wont_overwrite253/*254*将当前的映像重定向到解压后的内核之后(会发⽣⾃我覆盖时才执⾏,否则就被跳过)255*r6=_edata(已校正)256*r10=解压后的内核结束地址257*因为我们要把当前映像向后移动,所以我们必须由后往前复制代码,258*以防原数据和⽬标数据的重叠259*/260/*261*将解压后的内核结束地址r10扩展(reloc_code_end-restart),262*并对齐到下⼀个256B边界。
Linux 源代码分析

Linux内核(2.6.13.2)源代码分析苗彦超摘要:1系统启动1.1汇编代码head.S及以前设置CPU状态初值,创建进程0,建立进程堆栈:movq init_rsp(%rip), %rsp,init_rsp定义.globl init_rspinit_rsp:.quad init_thread_union+THREAD_SIZE-8即将虚地址init_thread_union+THREAD_SIZE-8作为当前进程(进程0)核心空间堆栈栈底,init_thread_union定义于文件arch/x86_64/kernel/init_task.c中:union thread_union init_thread_union __attribute__((__section__(".data.init_task"))) ={INIT_THREAD_INFO(init_task)};INIT_THREAD_INFO定义于文件include/asm-x86_64/thread_info.h中,初始化init_thread_union.task = &init_task,init_task同样定义于文件init_task.c中,初始化为:struct task_struct init_task = INIT_TASK(init_task);INIT_TASK宏在include/linux/init_task.h中定义。
全部利用编译时静态设置的初值,将进程0的控制结构设置完成,使进程0可以按普通核心进程访问。
init_task.mm = NULL; init_task.active_mm = INIT_MM(init_mm), init_m = “swapper”INIT_MM将init_mm.pgd初始化为swapper_pg_dir,即init_level4_pgt,定义与head.S中。
linux 内核源码需要掌握的数据结构和算法

linux 内核源码需要掌握的数据结构和算法在深入理解Linux内核源码的过程中,掌握数据结构和算法是非常重要的。
数据结构和算法是编程和系统编程的基础,也是理解Linux内核源码的关键。
本文将介绍Linux内核源码需要掌握的一些常见数据结构和算法,帮助读者更好地理解内核源码。
一、数据结构1.数组:Linux内核源码中经常使用数组来存储固定大小的元素。
数组在内核源码中主要用于存储数据结构(如链表、树、图等)的元素。
2.链表:链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
在Linux内核源码中,链表常用于实现内存管理、文件系统、网络协议等。
3.树:树是一种由节点和边组成的图形结构,其中每个节点最多只有两个子节点。
在Linux内核源码中,树常用于进程调度、内存管理、文件系统等。
4.二叉树:二叉树是一种特殊的树结构,每个节点最多只有两个子节点,通常称为根、左子节点和右子节点。
在Linux内核源码中,二叉树常用于维护设备树、路由表等。
5.图:图是由节点和边组成的图形结构,其中每个节点可以有多个相邻节点。
在Linux内核源码中,图常用于网络协议、进程间通信等。
6.哈希表:哈希表是一种基于哈希函数的数据结构,它可以快速查找、插入和删除元素。
在Linux内核源码中,哈希表常用于进程调度、内存管理等。
二、算法1.遍历算法:遍历算法是用于遍历数据结构的算法,如深度优先搜索(DFS)、广度优先搜索(BFS)等。
这些算法在Linux内核源码中常用于遍历链表、树、图等数据结构。
2.排序算法:排序算法是用于将数据元素按照一定顺序排列的算法,如冒泡排序、快速排序等。
在Linux内核源码中,排序算法常用于维护内存分配表、设备驱动等。
3.查找算法:查找算法是用于在数据结构中查找特定元素的算法,如线性查找、二分查找等。
在Linux内核源码中,查找算法常用于设备驱动、内存管理等。
4.递归算法:递归算法是一种通过函数自我调用来解决问题的方法。
Linux内核调试机制源代码分析

kimage_entry_t *entry; kimage_entry_t *last_entry; unsigned long destination; unsigned long start; struct page *control_code_page; struct page *swap_page; unsigned long nr_segments; struct kexec_segment segment[KEXEC_SEGMENT_MAX]; /*段数组*/ struct list_head control_pages; struct list_head dest_pages; struct list_head unuseable_pages; /* 分配给崩溃内核的下一个控制页的地址*/ unsigned long control_page; /* 指定特殊处理的标识*/ unsigned int type : 1; #define KEXEC_TYPE_DEFAULT 0 #define KEXEC_TYPE_CRASH 1 unsigned int preserve_context : 1; };
内核 kexec 接口函数说明如下:
extern void machine_kexec(struct kimage *image); /*启动内核映像*/ extern int machine_kexec_prepare(struct kimage *image); /*建立内核映 像所需要的控制页*/ extern void machine_kexec_cleanup(struct kimage *image); extern asmlinkage long sys_kexec_load(unsigned long entry, unsigned long nr_segments, struct kexec_segment __user *segments, unsigned long flags); /*装 载内核的系统调用*/ extern int kernel_kexec(void); /*启动内核*/
linux源码分析(一)

linux源码分析(⼀)前置:这⾥使⽤的linux版本是4.8,x86体系。
其实linux的内核启动的⼊⼝⽂件还是⾮常好找的,init/main.c。
static 和 extern⾸先理解的是static和extern的区别:static int kernel_init(void *);extern void init_IRQ(void);extern void fork_init(void);extern void radix_tree_init(void);这个代码说的是kernel_init函数的定义在这个⽂件中,extern说明init_IRQ函数的定义在其他⽂件中。
这三个extern分别是对中断的初始化,对fork功能的初始化,对基数树的初始化。
不过具体不知道为什么有的函数以init_xxx为风格,有的⼜以xxx_init的风格来做。
宏main的第⼀⾏看到了这么个语句#define DEBUG感觉有点奇怪,原来还有#define <宏名> ⽽没有定义具体的值。
其实这个可以当作已经有定义,且定义了空串来理解。
继续往下⾯看,还会看到bool early_boot_irqs_disabled __read_mostly;这⾥最后的__read_mostly 是⼀个宏,它标记了前⾯这个变量是很经常被读取的。
那么做了标记有什么⽤呢?如果在有缓存的平台上,它就能把这个变量存放到cache中,以保证后续读取的速度。
这个宏定义在 arch/arm/include/asm/cache.h#define __read_mostly __attribute__((__section__(".data..read_mostly")))这⾥的意思是将这个数据结构链接进data.read_mostly段。
EXPORT_SYMBOLEXPORT_SYMBOL(system_state);这个是和extern⼀起使⽤的,表⽰system_state这个⽅法在这个模块中定义了,提供给其他模块使⽤。
Linux内核网络部分源码分析-唐文

Linux内核网络部分实现机制分析(Netfilter、连接跟踪、多连接协议、e1000网卡驱动)唐文~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~前言在内核的参考书中以及互联网上,网络部分尤其netfilter的实现机制的介绍很少,此文档为本人分析内核源码以及参考相关资料所作的学习笔记,一方面为了满足自己对内核的强烈兴趣,另一方面也为了项目的需要。
正是因为对网络部分的了解,才使本人完成软硬件结合识别应用层协议架构的设计。
在分析内核源码时,为了尽可能还原内核设计者的设计思想,本人尽最大努力避免直接的源码注释分析,而是在分析源码的基础上反推其实现的机制,将各个部分联系起来,从而抽象出其实现框架。
介于时间因素,只分析了内核网络部分的一小部分,希望有机会可以对内核的其他部分有更深入的了解。
尽管内核变化较快,尤其是网络部分,但只要掌握了恰当的分析方法,则可以较容易的适应其变化。
在完成对此部分的分析过程中,得益于以下参考书籍以及chinaunix内核版的相关技术讨论帖,本文档的某些部分已经发到CU内核版,同时也被很多其他网站转发,如果需要讨论交流或发现有问题,可以直接到CU内核版去搜索相关帖子,也欢迎直接发邮件给我: tangwen1123@或tangwen1123@。
《Understanding Linux Network Internals》《Understanding the Linux Kernel 3rd》《Linux Device Driver 3rd》《Linux Kernel Development》《Essential Linux Device Drivers》《The Linux Network Architecture – Design and Implementation of Network Protocols in the Linux Kernel》······等等。
【VIP专享】Linux内核源代码分析与移植

Abstractthis paper has mainly developed the software hardware design and realization of the embedded Web server Boa based on ARM. And The core o f the Hardware part is S3C2410X microprocessor produced by Samsung . The final achievement is the embedded webserver which can remote visit. Boa i s a single-tasking Http server. That means that unlike traditional webservers, it does not fork for each incoming connection, nor does it fork many copies of itself t o handle multiple connections. I t internally multiplexes all of the ongoing http connections. And forks only for CGI programs, this is very important to embedded system. At the same time, it also has the function of automatic directory generation、automatic file gunzipping and so on. So Boa is of highly value in the embedded system application.2.1 嵌入式系统简介嵌入式系统被定义为:以应用为中心、以计算机技术为基础、软件硬件可裁剪、适应应用系统对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。
Linux内核源码分析

Linux内核源码分析Linux内核在启动的时候需要一些参数,以获得当前硬件的信息或者启动所需资源在内存中的位置等等。
这些信息可以通过bootloader 传递给内核,比较常见的就是cmdline。
以前我在启动内核的时候习惯性的通过uboot传递一个cmdline给内核,没有具体的分析这个过程。
最近在分析内核启动过程的时候,重新看了一下内核启动参数的传递过程,彻底解决一下在这方面的疑惑。
一、bootloader与内核的通讯协议内核的启动参数其实不仅仅包含在了cmdline中,cmdline不过是bootloader传递给内核的信息中的一部分。
bootloader和内核的通信方式根据构架的不同而异。
对于ARM构架来说,启动相关的信息可以通过内核文档(Documentation/arm/Booting)获得。
其中介绍了bootloader与内核的通信协议,我简单总结如下:(1)数据格式:可以是标签列表(tagged list)或设备树(device tree)。
(2)存放地址:r2寄存器中存放的数据所指向的内存地址。
在我所做过的开发中,都是使用tagged list的,所以下面以标签列表为例来介绍信息从bootloader(U-boot)到内核(Linux-3.0)的传递过程。
内核文档对此的说明,翻译摘要如下:1.4a. 设置内核标签列表2.--------------------------------3.4.bootloader必须创建和初始化内核标签列表。
一个有效的标签列表以ATAG_CORE标签开始,且以ATAG_NONE标签结束。
ATAG_CORE标签可以是空的,也可以是非空。
一个空ATAG_CORE标签其 size 域设置为 '2' (0x00000002)。
ATAG_NONE标签的 size 域必须设置为 '0'。
5.6.在列表中可以保存任意数量的标签。
linux启动内核源码分析

linux启动内核源码分析内核的启动时从main.c这个⽂件⾥⾯的start_kernel函数开始的,这个⽂件在linux源码⾥⾯的init⽂件夹下⾯下⾯我们来看看这个函数这个函数很长,可以看个⼤概过去asmlinkage __visible void __init start_kernel(void){char *command_line;char *after_dashes;set_task_stack_end_magic(&init_task);smp_setup_processor_id();debug_objects_early_init();cgroup_init_early();local_irq_disable();early_boot_irqs_disabled = true;/** Interrupts are still disabled. Do necessary setups, then* enable them.*/boot_cpu_init();page_address_init();pr_notice("%s", linux_banner);setup_arch(&command_line);/** Set up the the initial canary and entropy after arch* and after adding latent and command line entropy.*/add_latent_entropy();add_device_randomness(command_line, strlen(command_line));boot_init_stack_canary();mm_init_cpumask(&init_mm);setup_command_line(command_line);setup_nr_cpu_ids();setup_per_cpu_areas();smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */boot_cpu_hotplug_init();build_all_zonelists(NULL);page_alloc_init();pr_notice("Kernel command line: %s\n", boot_command_line);parse_early_param();after_dashes = parse_args("Booting kernel",static_command_line, __start___param,__stop___param - __start___param,-1, -1, NULL, &unknown_bootoption);if (!IS_ERR_OR_NULL(after_dashes))parse_args("Setting init args", after_dashes, NULL, 0, -1, -1,NULL, set_init_arg);jump_label_init();/** These use large bootmem allocations and must precede* kmem_cache_init()*/setup_log_buf(0);vfs_caches_init_early();sort_main_extable();trap_init();mm_init();ftrace_init();/* trace_printk can be enabled here */early_trace_init();/** Set up the scheduler prior starting any interrupts (such as the* timer interrupt). Full topology setup happens at smp_init()* time - but meanwhile we still have a functioning scheduler.*/sched_init();/** Disable preemption - early bootup scheduling is extremely* fragile until we cpu_idle() for the first time.preempt_disable();if (WARN(!irqs_disabled(),"Interrupts were enabled *very* early, fixing it\n"))local_irq_disable();radix_tree_init();/** Set up housekeeping before setting up workqueues to allow the unbound * workqueue to take non-housekeeping into account.*/housekeeping_init();/** Allow workqueue creation and work item queueing/cancelling* early. Work item execution depends on kthreads and starts after* workqueue_init().*/workqueue_init_early();rcu_init();/* Trace events are available after this */trace_init();if (initcall_debug)initcall_debug_enable();context_tracking_init();/* init some links before init_ISA_irqs() */early_irq_init();init_IRQ();tick_init();rcu_init_nohz();init_timers();hrtimers_init();softirq_init();timekeeping_init();time_init();printk_safe_init();perf_event_init();profile_init();call_function_init();WARN(!irqs_disabled(), "Interrupts were enabled early\n");early_boot_irqs_disabled = false;local_irq_enable();kmem_cache_init_late();/** HACK ALERT! This is early. We're enabling the console before* we've done PCI setups etc, and console_init() must be aware of* this. But we do want output early, in case something goes wrong.*/console_init();if (panic_later)panic("Too many boot %s vars at `%s'", panic_later,panic_param);lockdep_init();/** Need to run this when irqs are enabled, because it wants* to self-test [hard/soft]-irqs on/off lock inversion bugs* too:*/locking_selftest();/** This needs to be called before any devices perform DMA* operations that might use the SWIOTLB bounce buffers. It will* mark the bounce buffers as decrypted so that their usage will* not cause "plain-text" data to be decrypted when accessed.*/mem_encrypt_init();#ifdef CONFIG_BLK_DEV_INITRDif (initrd_start && !initrd_below_start_ok &&page_to_pfn(virt_to_page((void *)initrd_start)) < min_low_pfn) {pr_crit("initrd overwritten (0x%08lx < 0x%08lx) - disabling it.\n",page_to_pfn(virt_to_page((void *)initrd_start)),min_low_pfn);initrd_start = 0;#endifkmemleak_init();setup_per_cpu_pageset();numa_policy_init();acpi_early_init();if (late_time_init)late_time_init();sched_clock_init();calibrate_delay();pid_idr_init();anon_vma_init();#ifdef CONFIG_X86if (efi_enabled(EFI_RUNTIME_SERVICES))efi_enter_virtual_mode();#endifthread_stack_cache_init();cred_init();fork_init();proc_caches_init();uts_ns_init();buffer_init();key_init();security_init();dbg_late_init();vfs_caches_init();pagecache_init();signals_init();seq_file_init();proc_root_init();nsfs_init();cpuset_init();cgroup_init();taskstats_init_early();delayacct_init();check_bugs();acpi_subsystem_init();arch_post_acpi_subsys_init();sfi_init_late();/* Do the rest non-__init'ed, we're now alive */arch_call_rest_init();}这个函数⾥⾯我们会看到有很多的各种init,也就是初始化,我们只说⼏个重点操作⾸先来看下这个函数set_task_stack_end_magic(&init_task);在linux⾥⾯所有的进程都是由⽗进程创建⽽来,所以说在启动内核的时候需要有个祖先进程,这个进程是系统创建的第⼀个进程,我们称为0号进程,它是唯⼀⼀个没有通过fork或者kernel_thread的进程然后就是初始化系统调⽤,对应的函数就是trap_init();这⾥⾯设置了很多中断门,⽤于处理各种中断系统调⽤也是通过发送中断的⽅式进⾏的。
Linux内核源代码分析

Linux内核源代码的组成
核心模块
– 核心模块代码部分布在内核中,部分位 于modules包中。核心代码位于 kernel/modules.c且其数据结构与核心后 台进程kerneld消息位于 include/linux/module.h和 include/linux/kerneld.h目录中。必要时 需查阅inlude/linux/elf.h中的ELF文件格 式。
– 利用自由软件让个人计算机带十几个硬 盘实现阵列技术,及其亚微米超大规模 集成电路CAD系统,可直接输出生产线 控制数据等。
– Linux内核的许多面向通信的底层代码对 开发我国自己的信息安全产品极有参考 价值。
分析Linux内核的意义
开发高水平软件
– 目前Linux的源代码中包含了世界各地几 百名计算机高手的作品,分析这些源代 码对于我们掌握核心技术会起到事半功 倍的作用,尤其是各种驱动程序的编写, 对于我们把软硬件结合起来发展民族信 息产业至关重要。
Linux内核源代码的组成
核心
– 大多数通用代码位于kernel目录下,而处理器相 关代码被放在arch/kernel中,调度管理程序位 于kernel/sched.c ,fork代码位于kernel/fork.c。 底层部分处理及中断处理的代码位于 include/linux/interrupt.h里。在/linux/sched.h中 可以找到task_struct的描述。
– Windows下的一个阅读源代码的工具:Source Insight。该软件可从下载
– Linux下一个阅读源代码的工具是LXR
网络
– 网络代码位于net目录而大多数包含文件位于 include/net中,BSD套接字代码位于socket.c中。 IPv4的INET套接字代码位于net/ipv4/af_inet.c中。 通用协议支撑代码(包括sk_buff处理过程)位 于net/core中,同时TCP/IP网络代码位于 net/ipv4中。网络设备驱动位于drivers/net中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Linux内核源码分析方法一、内核源码之我见Linux内核代码的庞大令不少人“望而生畏”,也正因为如此,使得人们对Linux的了解仅处于泛泛的层次。
如果想透析Linux,深入操作系统的本质,阅读内核源码是最有效的途径。
我们都知道,想成为优秀的程序员,需要大量的实践和代码的编写。
编程固然重要,但是往往只编程的人很容易把自己局限在自己的知识领域内。
如果要扩展自己知识的广度,我们需要多接触其他人编写的代码,尤其是水平比我们更高的人编写的代码。
通过这种途径,我们可以跳出自己知识圈的束缚,进入他人的知识圈,了解更多甚至我们一般短期内无法了解到的信息。
Linux内核由无数开源社区的“大神们”精心维护,这些人都可以称得上一顶一的代码高手。
透过阅读Linux 内核代码的方式,我们学习到的不光是内核相关的知识,在我看来更具价值的是学习和体会它们的编程技巧以及对计算机的理解。
我也是通过一个项目接触了Linux内核源码的分析,从源码的分析工作中,我受益颇多。
除了获取相关的内核知识外,也改变了我对内核代码的过往认知:1.内核源码的分析并非“高不可攀”。
内核源码分析的难度不在于源码本身,而在于如何使用更合适的分析代码的方式和手段。
内核的庞大致使我们不能按照分析一般的demo程序那样从主函数开始按部就班的分析,我们需要一种从中间介入的手段对内核源码“各个击破”。
这种“按需索取”的方式使得我们可以把握源码的主线,而非过度纠结于具体的细节。
2.内核的设计是优美的。
内核的地位的特殊性决定着内核的执行效率必须足够高才可以响应目前计算机应用的实时性要求,为此Linux内核使用C语言和汇编的混合编程。
但是我们都知道软件执行效率和软件的可维护性很多情况下是背道而驰的。
如何在保证内核高效的前提下提高内核的可维护性,这需要依赖于内核中那些“优美”的设计。
3.神奇的编程技巧。
在一般的应用软件设计领域,编码的地位可能不被过度的重视,因为开发者更注重软件的良好设计,而编码仅仅是实现手段问题——就像拿斧子劈柴一样,不用太多的思考。
但是这在内核中并不成立,好的编码设计带来的不光是可维护性的提高,甚至是代码性能的提升。
每个人对内核的了理解都会有所不同,随着我们对内核理解的不断加深,对其设计和实现的思想会有更多的思考和体会。
因此本文更期望于引导更多徘徊在Linux内核大门之外的人进入Linux的世界,去亲自体会内核的神奇与伟大。
而我也并非内核源码方面的专家,这么做也只是希望分享我自己的分析源码的经验和心得,为那些需要的人提供参考和帮助,说的“冠冕堂皇”一点,也算是为计算机这个行业,尤其是在操作系统内核方面贡献自己的一份绵薄之力。
闲话少叙(已经罗嗦了很多了,囧~),下面我就来分享一下自己的Linix内核源码分析方法。
二、内核源码难不难?从本质上讲,分析Linux内核代码和看别人的代码没有什么两样,因为摆在你面前的一般都不是你自己写出来的代码。
我们先举一个简单的例子,一个陌生人随便给你一个程序,并要你看完源码后讲解一下程序的功能的设计,我想很多自我感觉编程能力还可以的人肯定觉得这没什么,只要我耐心的把他的代码从头到尾看完,肯定能找到答案,并且事实确实是如此。
那么现在换一个假设,如果这个人是Linus,给你的就是Linux内核的一个模块的代码,你还会觉得依然那么轻松吗?不少人可能会有所犹豫。
同样是陌生人(Linus要是认识你的话当然不算,呵呵~)给你的代码,为什么给我们的感觉大相径庭呢?我觉得有以下原因:1.Linux内核代码在“外界”看来多少有些神秘感,而且它很庞大,猛地摆在面前可能感觉无法下手。
比如可能来源于一个很细小的原因——找不到main函数。
对于简单的demo程序,我们可以从头至尾的分析代码的含义,但是分析内核代码这招就彻底失效了,因为没有人能把Linux代码从头到尾看上一遍(因为确实没有必要,用到时看就可以了)。
2.不少人也接触过大型软件的代码,但多数属于应用型项目,代码的形式和含义都和自己常接触的业务逻辑相关。
而内核代码不同,它处理的信息多数和计算机底层密切相关。
比如操作系统、编译器、汇编、体系结构等相关的知识的欠缺,也会让阅读内核代码障碍重重。
3.分析内核代码的方法不够合理。
面对大量的并且复杂的内核代码,如果不从全局的角度入手,很容易陷入代码细节的泥淖中。
内核代码虽然庞大,但是它也有它的设计原则和架构,否则维护它对任何人来说都是一个噩梦!如果我们理清代码模块的整体设计思路,再去分析代码的实现,可能分析源码就是一件轻松快乐的事情了。
针对这些问题,我个人是这样理解的。
如果没有接触过大型软件项目,可能分析Linux内核代码是一个很好的积累大型项目经验的机会(确实,Linux代码是我目前接触到的最大的项目了!)。
如果你对计算机底层了解的不够透彻,那么我们可以选择边分析边学习的方式去积累底层的知识。
可能刚开始分析代码的进度会稍显迟缓,但是随着知识的不断积累,我们对Linux内核的“业务逻辑”会逐渐明朗起来。
最后一点,如何从全局的角度把握分析的源码,这也是我想与大家分享的经验。
三、内核源码分析方法第一步:资料搜集从人认识新事物的角度来讲,在探索事物本质之前,必须有一个了解新鲜事物的过程,这个过程是的我们对新鲜事物产生一个初步的概念。
比如我们想学习钢琴,那么我们需要先了解弹奏钢琴需要我们学习基本的乐理、简谱、五线谱等基础知识,然后学习钢琴弹奏的技巧和指法,最后才能真正的开始练习钢琴。
分析内核代码也是如此,首先我们需要定位要分析的代码涉及的内容。
是进程同步和调度的代码,是内存管理的代码,还是设备管理的代码,还是系统启动的代码等等。
内核的庞大决定着我们不能一次性将内核代码全部分析完成,因此我们需要给自己一个合理的分工。
正如算法设计告诉我们的,要解决一个大问题,首先要解决它所涉及的子问题。
定位好要分析的代码范围,我们就可以动用手头的一切资源,尽可能的全面了解该部分代码的整体结构和大致功能。
这里所说的一切资源是指无论是Baidu、Google大型网络搜索引擎,还是操作系统原理教材和专业书籍,亦或是他人提供的经验和资料,甚至是Linux源码提供的文档、注释和源码标识符的名称(不要小看代码中的标识符的命名,有时它们能提供关键的信息)。
总之这里的一切资源指的就是你能想到的一切可用资源。
当然,我们不太可能通过这种形式的信息搜集获得所有的我们想要的信息,我们只求尽可能全面即可。
因为信息搜集的越全面,之后分析代码的过程能使用的信息就更多,分析过程的困难就会越小。
这里举一个简单的例子,假定我们要分析Linux的变频机制实现的代码。
目前为止我们仅仅是知道这个名次而已,透过字面含义我们可以大致猜测它应该和CPU的频率调节相关。
通过信息搜集,我们应该能得到如下的相关的信息:1.CPUFreq机制。
2.performance、powersave、userspace、ondemand、conservative调频策略。
3./driver/cpufreq/。
4./documention/cpufreq。
5.P state和C state。
……分析Linux内核代码如果能搜集到这些信息,应该说是非常“幸运”了。
毕竟有关Linux内核的资料确实不如.NET和JQuery那么丰富,不过这相比于十数年前,没有强大的搜索引擎,没有相关的研究资料的时期应该称得上是“大丰收”时代了!我们通过简单的“搜索”(可能会花费一到两天的时间吧),甚至找到了这部分代码所在的源码文件目录,不得不说这样的信息简直是“价值连城”!第二步:源码定位从资料搜集中,我们“有幸”找到了源码相关的源码目录。
但是这并非意味着我们的确就是分析这个目录下的源代码。
有时我们找到的目录有可能是分散的,也有时我们找到的目录下有很多和具体机器相关的代码,而我们更关心的是待分析代码的主要机制,而非与机器相关的特化代码(这样更有助于我们理解内核的本质)。
因此,我们需要对资料中涉及代码文件的资料进行仔细甄选。
当然,这一步也不太可能一次性完成,谁也不能保证一次就能选择出所有待分析的源码文件而且一个不漏。
但是我们也不必担心,只要我们能抓住大多数模块相关的核心源文件,通过后期对代码的具体分析,就很自然的把它们全部找出来。
回到上述的例子中,我们认真的阅读/documention/cpufreq下的文档说明。
目前的Linux源码会把模块相关的文档说明保存在源码目录的documention的文件夹下,如果待分析的模块没有文档说明,这多少会增加定位关键源码文件的难度,但是不会导致我们找不到我们要分析的源码。
通过阅读文档说明,我们至少能关注到/driver/cpufreq/cpufreq.c这个源文件。
通过这个对源文件的文档说明,结合之前搜罗到的调频策略,我们很容易关注到cpufreq_performance.c、cpufreq_powersave.c、cpufreq_userspace.c、cpufreq_ondemand、cpufreq_conservative.c这五个源文件。
所有涉及的文件都找完了吗?不用担心,从它们开始分析,迟早能找到其他的源文件。
如果在windows下使用sourceinsight阅读内核源码的话,我们通过函数的调用和查找符号引用等功能,结合代码的分析可以很方便的找到另外的文件freq_table.c、cpufreq_stats.c和/include/linux/cpufreq.h。
按照搜索出的信息流动方向,我们完全可以定位到需要分析的源码文件。
源码定位这一步并非十分关键,因为我们不需要找出所有源码文件,我们可以把部分工作推迟到分析代码的过程中。
源码定位也比较关键,找到一部分源码文件是分析源码的基础。
第三步:简单注释在已定位好的源码文件中,分析每个变量、宏、函数、结构体等代码元素的大致含义和功能。
之所以称此为简单注释,并非指这部分的注释工作很简单,而是指这部分的注释可以不必过分细化,只要大致描述出相关代码元素的含义即可。
相反,这里的工作其实是整个分析流程中最困难的一步。
因为这是第一次深入到内核代码的内部,尤其是对于首次分析内核源码的人来说,大量的生疏GNU的C语法和铺天盖地的宏定义会令人很绝望。
此时只要沉下心来,弄清每个关键的难点,才能保证以后碰到类似的难点不会再被困住。
而且,我们对内核相关的其他知识会不断的像树一样扩展开来。
比如在cpufreq.c文件开始就会出现“DEFINE_PER_CPU”宏的使用,我们通过查阅资料可以基本弄清这个宏的含义和功能。
这里使用的手段和之前搜集资料使用的方法基本一致,另外我们也可以使用sourceinsight提供的转到定义等功能查看它的定义,或者使用LKML(Linux Kernel Mail List)查阅,实在不行我们还可以到提问寻求解答(想了解什么是LKML和stackoverflow?搜集资料吧!)。