MapReduce源码分析完整版
第4章大数据技术教程-MapReduce

第四章分布式计算框架MapReduce4.1初识MapReduceMapReduce是一种面向大规模数据并行处理的编程模型,也一种并行分布式计算框架。
在Hadoop流行之前,分布式框架虽然也有,但是实现比较复杂,基本都是大公司的专利,小公司没有能力和人力来实现分布式系统的开发。
Hadoop的出现,使用MapReduce框架让分布式编程变得简单。
如名称所示,MapReduce主要由两个处理阶段:Map阶段和Reduce 阶段,每个阶段都以键值对作为输入和输出,键值对类型可由用户定义。
程序员只需要实现Map和Reduce两个函数,便可实现分布式计算,而其余的部分,如分布式实现、资源协调、内部通信等,都是由平台底层实现,无需开发者关心。
基于Hadoop开发项目相对简单,小公司也可以轻松的开发分布式处理软件。
4.1.1 MapReduce基本过程MapReduce是一种编程模型,用户在这个模型框架下编写自己的Map函数和Reduce函数来实现分布式数据处理。
MapReduce程序的执行过程主要就是调用Map函数和Reduce函数,Hadoop把MapReduce程序的执行过程分为Map和Reduce两个大的阶段,如果细分可以为Map、Shuffle(洗牌)、Reduce三个阶段。
Map含义是映射,将要操作的每个元素映射成一对键和值,Reduce含义是归约,将要操作的元素按键做合并计算,Shuffle在第三节详细介绍。
下面以一个比较简单的示例,形象直观介绍一下Map、Reduce阶段是如何执行的。
有一组图形,包含三角形、圆形、正方形三种形状图形,要计算每种形状图形的个数,见下图4-1。
图:4-1 map/reduce计算不同形状的过程在Map阶段,将每个图形映射成形状(键Key)和数量(值Value),每个形状图形的数量值是“1”;Shuffle阶段的Combine(合并),相同的形状做归类;在Reduce阶段,对相同形状的值做求和计算。
mapreduce编程实验报告心得

mapreduce编程实验报告心得【实验报告心得】总结:本次mapreduce编程实验通过实际操作,使我对mapreduce编程框架有了更深入的理解。
在实验过程中,我学会了如何编写map和reduce函数,并利用这些函数从大数据集中进行数据提取和聚合分析。
通过这个实验,我还掌握了如何调试和优化mapreduce任务,以提高数据处理效率和性能。
一、实验目的:本次实验的目的是掌握mapreduce编程框架的使用方法,理解其实现原理,并在实际编程中熟练运用map和reduce函数进行数据处理和分析。
二、实验环境和工具:本次实验使用Hadoop分布式计算框架进行mapreduce编程。
使用的工具包括Hadoop集群、HDFS分布式文件系统以及Java编程语言。
三、实验过程:1. 实验准备:在开始实验前,我首先了解了mapreduce的基本概念和特点,以及Hadoop集群的配置和使用方法。
2. 实验设计:根据实验要求,我选择了一个适当的数据集,并根据具体需求设计了相应的map和reduce函数。
在设计过程中,我充分考虑了数据的结构和处理逻辑,以保证mapreduce任务的高效完成。
3. 实验编码:在实验编码过程中,我使用Java编程语言来实现map 和reduce函数。
我按照mapreduce编程模型,利用输入键值对和中间结果键值对来进行数据处理。
在编码过程中,我注意了代码的规范性和可读性,并进行了适当的优化。
4. 实验测试:完成编码后,我在Hadoop集群上部署和运行了我的mapreduce任务。
通过对数据集进行分析和处理,我验证了自己编写的map和reduce函数的正确性和性能。
5. 实验总结:在实验结束后,我对本次实验进行了总结。
我分析了实验中遇到的问题和挑战,并提出了相应的解决方法。
我还对mapreduce编程框架的优缺点进行了评估,并给出了自己的观点和建议。
四、实验结果和观点:通过本次实验,我成功实现了对选定数据集的mapreduce处理。
mapreduce总结

mapreduce总结MapReduce一个由Google出的分布式编程模型,它将大数据处理转化为分布式程序模型,提供了一种简单却强大的方法来处理海量的数据。
MapReduce优点在于提供了一种既可以低成本、高效率地处理大规模数据的数据处理框架,在大数据的处理和管理方面发挥了重要作用。
本文将对MapReduce的相关概念及其实现原理、特点和应用进行综述。
一、MapReduce的概念MapReduceGoogle发明的一种解决海量数据处理的分布式编程模型,它是一种计算框架,可以将一个大型数据集分割成多个小任务,并把任务分发到多台机器上执行,并最终将小任务的结果合并成最终结果。
MapReduce模型由Google在2004年提出,并于2005年在著名论文“MapReduce:A Flexible Data Processing Tool”中被正式发表,其主要贡献者为Google公司的三位研究人员:Jeff Dean、Sanjay Ghemawat Andrew Tomkins。
二、MapReduce的实现原理MapReduce实现原理主要分2个阶段。
1. Map:Map是利用已有的数据,进行数据归类和分块的过程,将大规模的数据量分割成多个中等规模的数据块,每个数据块用一个子任务来处理;2. Reduce阶段:Reduce是从 Map的多个子任务的结果中汇总出最终的结果;MapReduce框架建立在分布式环境之上,将一个大规模的计算任务拆分成小任务,分发到各个节点运行,最后把小任务的结果合并成一个总结果。
三、MapReduce的特点MapReduce模型提供了一种机制,可以实现以下处理大规模数据的特点:1.发处理大数据:MapReduce过将大数据集分成多个小数据集,并由多个节点并行处理,从而提供了大规模数据处理的并发能力,可以提升处理效率;2.错性:MapReduce型支持容错性处理,也即当某台机器出现故障或是宕机,MapReduce架会将任务重新分发到其它机器上执行,从而保证了数据的正确性;3.可伸缩性:MapReduce型具有较高的可伸缩性,即可以根据需求随时增加或减少计算任务的数量,从而改变计算的规模;4.持低延迟的数据处理:MapReduce数据处理过程中,可以有效避免数据倾斜现象,从而减少任务处理的时间。
Hadoop源代码分析(完整版)

关键字: 分布式云计算Google的核心竞争技术是它的计算平台。
Google的大牛们用了下面5篇文章,介绍了它们的计算设施。
GoogleCluster: /archive/googlecluster.htmlChubby:/papers/chubby.htmlGFS:/papers/gfs.htmlBigTable:/papers/bigtable.htmlMapReduce:/papers/mapreduce.html很快,Apache上就出现了一个类似的解决方案,目前它们都属于Apache的Hadoop项目,对应的分别是:Chubby-->ZooKeeperGFS-->HDFSBigTable-->HBaseMapReduce-->Hadoop目前,基于类似思想的Open Source项目还很多,如Facebook用于用户分析的Hive。
HDFS作为一个分布式文件系统,是所有这些项目的基础。
分析好HDFS,有利于了解其他系统。
由于Hadoop的HDFS和MapReduce 是同一个项目,我们就把他们放在一块,进行分析。
下图是MapReduce整个项目的顶层包图和他们的依赖关系。
Hadoop包之间的依赖关系比较复杂,原因是HDFS提供了一个分布式文件系统,该系统提供API,可以屏蔽本地文件系统和分布式文件系统,甚至象Amazon S3这样的在线存储系统。
这就造成了分布式文件系统的实现,或者是分布式文件系统的底层的实现,依赖于某些貌似高层的功能。
功能的相互引用,造成了蜘蛛网型的依赖关系。
一个典型的例子就是包conf,conf用于读取系统配置,它依赖于fs,主要是读取配置文件的时候,需要使用文件系统,而部分的文件系统的功能,在包fs中被抽象了。
Hadoop的关键部分集中于图中蓝色部分,这也是我们考察的重点。
下面给出了Hadoop的包的功能分析。
Hadoop源代码分析(三)由于Hadoop的MapReduce和HDFS都有通信的需求,需要对通信的对象进行序列化。
3-MapReduce编程详解

MapReduce编程一、实验目的1、理解MapReduce编程模型基本知识2、掌握MapReduce开发环境的搭建3、掌握MapReduce基本知识,能够运用MapReduce进行基本的开发二、实验原理MapReduce 是Hadoop两个最基础最重要的核心成员之一。
它是大规模数据(TB 级)计算的利器,Map 和Reduce 是它的主要思想,来源于函数式编程语言。
从编程的角度来说MapReduce分为Map函数和Reduce函数,Map负责将数据打散,Reduce负责对数据进行聚集,用户只需要实现map 和reduce 两个接口,即可完成TB级数据的计算。
Hadoop Map Reduce的实现采用了Master/Slave 结构。
Master 叫做JobTracker,而Slave 叫做TaskTracker。
用户提交的计算叫做Job,每一个Job会被划分成若干个Tasks。
JobTracker负责Job 和Tasks 的调度,而TaskTracker负责执行Tasks。
常见的应用包括:日志分析和数据挖掘等数据分析应用,另外,还可用于科学数据计算,如圆周率PI 的计算等。
MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。
当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。
Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。
按照以上基本的描述,其工作图如下。
从工作流程来讲,MapReduce对应的作业Job首先把输入的数据集切分为若干独立的数据块,并由Map组件以Task的方式并行处理。
处理结果经过排序后,依次输入给Reduce 组件,并且以Task的形式并行处理。
mapreduce编程模型的原理

mapreduce编程模型的原理MapReduce编程模型是一种分布式计算模型,用于处理大规模数据集。
它的原理是将数据集划分成小的数据块,然后并行地在集群的多个节点上执行Map和Reduce操作,最终将结果合并起来形成最终结果。
MapReduce编程模型的主要原理可以归纳为以下几个方面:1. 数据划分MapReduce会将大规模数据集划分为小的数据块,每个数据块通常在64MB到1GB之间。
将数据划分为小的数据块可以方便地并行处理,也可以减少网络传输的数据量。
2. Map操作Map操作是MapReduce中的第一步。
Map操作会对数据块中的每个数据进行处理,其中Map会将每个数据转化为一个中间键-值对(key-value),key表示数据属性,value表示值。
Map操作通常包括以下步骤:(1)输入:从输入数据中读取数据块(2)映射:将输入数据转换为中间键-值对(3)缓存:将处理后的中间键-值对缓存在内存中3. Shuffle操作Shuffle操作是MapReduce中的第二步,Shuffle操作会将Map操作生成的中间键-值对重新组合,并按照key值将它们分组。
Shuffle操作通常包括以下步骤:(1)数据的拷贝:将Map输出的中间键-值对按照key值拷贝到Reduce操作的计算节点上(2)数据的排序:按照key值对中间键-值对进行排序,便于Reduce操作的处理(3)数据的分区:将排序后的中间键-值对分成多个分区,每个分区包含相同key值的中间键-值对4. Reduce操作Reduce操作是MapReduce中的第三步。
在Reduce操作中,Map操作生成的中间键-值对被分成多个分区,每个分区都包含相同key值的键值对。
在Reduce操作中,对每个分区中的中间键-值对进行处理,并生成一个输出结果。
Reduce操作通常包括以下步骤:(1)输入:从Map操作的输出获取中间键-值对分组信息(2)缓存:将Map操作输出的中间键-值对缓存到内存中(3)分组:将缓存中的中间键-值对按照key值分组(4)Reduce:对每个分组中的中间键-值对进行Reduce操作,并将结果输出5. 在Master节点上进行控制和协调MapReduce编程模型中,由Master节点来进行任务的分配、管理和协调。
动态计数器_MapReduce 2.0源码分析与编程实战_[共2页]
![动态计数器_MapReduce 2.0源码分析与编程实战_[共2页]](https://img.taocdn.com/s3/m/46094ffae2bd960591c677b9.png)
第8章 MapReduce 相关特性详解184 if(key.toString().equals("hello")){ //判断计数条件 context.setStatus("BadKey is coming!"); //写入Reduce 状态context.getCounter(ReportTest.ReduceReport).increment(1); //计数增加 }context.write(key, new IntWritable(sum));};}}从以上程序的黑体部分中可以看到,使用了大量的关键字进行计数器的设置,因此可以通过触发条件对计数值进行增加。
图8-4展示了最终结果。
图8-4 程序8-1运行结果计数器视图最上面部分是设置的计数器计数,根据获取条件产生了若干个计数器对结果进行输出。
8.1.3 动态计数器对于设定的计数器,可以通过在初始处设置枚举,使得计数器能够引用枚举中的类型,从而提供计数的功能。
小提示:有些时候,某些问题的产生并不适合在枚举处提供,例如一些产生的错误并不能在一开始定义,因此需要一个动态定义计数器的方法对数据进行定义。
除了前面所述的使用getCounter 方法获取枚举中值的方式外,Context 类中还有一个重载的方法能够对当前计数器进行动态定义,其源码如下所示:public Counter getCounter(String groupName, String counterName) { return reporter.getCounter(groupName, counterName);}此方法通过重新动态定义计数器实现对信息的动态捕获。
代码如程序8-2所示。
大数据实例代码

大数据实例代码大数据在各行各业中的应用越来越广泛,并且通过实例代码的使用,我们可以更好地理解和应用大数据技术。
本文将介绍几个常见的大数据实例代码,以帮助读者更好地掌握和应用这些技术。
一、MapReduce 实现 Word CountMapReduce 是一种用于处理大数据集的编程模型,它将数据分为若干个小块进行并行处理,并最终合并结果。
下面是一个使用MapReduce 实现的 Word Count 实例代码:```javaimport java.io.IOException;import org.apache.hadoop.fs.Path;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");for (String w : words) {word.set(w);context.write(word, one);}}}public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}context.write(key, new IntWritable(sum));}}public static void main(String[] args) throws Exception { Configuration conf = new Configuration();Job job = new Job(conf, "wordcount");job.setJarByClass(WordCount.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);}}```二、Spark 实现数据清洗Spark 是一种快速、通用的大数据处理引擎,支持在大规模数据集上进行高效的数据处理。
mapreduce实验报告总结

mapreduce实验报告总结一、引言MapReduce是一种用于处理和生成大数据集的编程模型和模型化工具,它由Google提出并广泛应用于各种大数据处理场景。
通过MapReduce,我们可以将大规模数据集分解为多个小任务,并分配给多个计算节点并行处理,从而大大提高了数据处理效率。
在本实验中,我们通过实践操作,深入了解了MapReduce的工作原理,并尝试解决了一些实际的大数据处理问题。
二、实验原理MapReduce是一种编程模型,它通过两个核心阶段——Map阶段和Reduce阶段,实现了对大规模数据的处理。
Map阶段负责处理输入数据集中的每个元素,生成一组中间结果;Reduce阶段则对Map阶段的输出进行汇总和聚合,生成最终结果。
通过并行处理和分布式计算,MapReduce可以在大量计算节点上高效地处理大规模数据集。
在本实验中,我们使用了Hadoop平台来实现MapReduce模型。
Hadoop是一个开源的分布式计算框架,它提供了包括MapReduce在内的一系列数据处理功能。
通过Hadoop,我们可以方便地搭建分布式计算环境,实现大规模数据处理。
三、实验操作过程1.数据准备:首先,我们需要准备一个大规模的数据集,可以是结构化数据或非结构化数据。
在本实验中,我们使用了一个包含大量文本数据的CSV文件。
2.编写Map任务:根据数据处理的需求,我们编写了一个Map任务,该任务从输入数据集中读取文本数据,提取出关键词并进行分类。
3.编写Reduce任务:根据Map任务的输出,我们编写了一个Reduce任务,该任务将相同关键词的文本数据进行汇总,生成最终结果。
4.运行MapReduce作业:将Map和Reduce任务编译成可执行脚本,并通过Hadoop作业调度器提交作业,实现并行处理。
5.数据分析:获取处理后的结果,并进行数据分析,以验证数据处理的有效性。
四、实验结果与分析实验结束后,我们得到了处理后的数据结果。
MapReduce案例-流量统计(一)

MapReduce案例-流量统计(⼀)### 需求⼀: 统计求和统计每个⼿机号的上⾏数据包总和,下⾏数据包总和,上⾏总流量之和,下⾏总流量之和分析:以⼿机号码作为key值,上⾏流量,下⾏流量,上⾏总流量,下⾏总流量四个字段作为value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输⼊##### Step 1: ⾃定义map的输出value对象FlowBean```javapublic class FlowBean implements Writable {private Integer upFlow; //上⾏数据包数private Integer downFlow; //下⾏数据包数private Integer upCountFlow; //上⾏流量总和private Integer downCountFlow;//下⾏流量总和public Integer getUpFlow() {return upFlow;}public void setUpFlow(Integer upFlow) {this.upFlow = upFlow;}public Integer getDownFlow() {return downFlow;}public void setDownFlow(Integer downFlow) {this.downFlow = downFlow;}public Integer getUpCountFlow() {return upCountFlow;}public void setUpCountFlow(Integer upCountFlow) {this.upCountFlow = upCountFlow;}public Integer getDownCountFlow() {return downCountFlow;}public void setDownCountFlow(Integer downCountFlow) {this.downCountFlow = downCountFlow;}@Overridepublic String toString() {return upFlow +"\t" + downFlow +"\t" + upCountFlow +"\t" + downCountFlow;}//序列化⽅法@Overridepublic void write(DataOutput out) throws IOException {out.writeInt(upFlow);out.writeInt(downFlow);out.writeInt(upCountFlow);out.writeInt(downCountFlow);}//反序列化@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow = in.readInt();this.downFlow = in.readInt();this.upCountFlow = in.readInt();this.downCountFlow = in.readInt();}}```##### Step 2: 定义FlowMapper类```javapublic class FlowCountMapper extends Mapper<LongWritable,Text,Text,FlowBean> {/*将K1和V1转为K2和V2:K1 V10 1360021750219 128 1177 16852 200------------------------------K2 V2136******** FlowBean(19 128 1177 16852)*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1:拆分⾏⽂本数据,得到⼿机号--->K2String[] split = value.toString().split("\t");String phoneNum = split[1];//2:创建FlowBean对象,并从⾏⽂本数据拆分出流量的四个四段,并将四个流量字段的值赋给FlowBean对象FlowBean flowBean = new FlowBean();flowBean.setUpFlow(Integer.parseInt(split[6]));flowBean.setDownFlow(Integer.parseInt(split[7]));flowBean.setUpCountFlow(Integer.parseInt(split[8]));flowBean.setDownCountFlow(Integer.parseInt(split[9]));//3:将K2和V2写⼊上下⽂中context.write(new Text(phoneNum), flowBean);}}```##### Step 3: 定义FlowReducer类```javapublic class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean> {@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { //1:遍历集合,并将集合中的对应的四个字段累计Integer upFlow = 0; //上⾏数据包数Integer downFlow = 0; //下⾏数据包数Integer upCountFlow = 0; //上⾏流量总和Integer downCountFlow = 0;//下⾏流量总和for (FlowBean value : values) {upFlow += value.getUpFlow();downFlow += value.getDownFlow();upCountFlow += value.getUpCountFlow();downCountFlow += value.getDownCountFlow();}//2:创建FlowBean对象,并给对象赋值 V3FlowBean flowBean = new FlowBean();flowBean.setUpFlow(upFlow);flowBean.setDownFlow(downFlow);flowBean.setUpCountFlow(upCountFlow);flowBean.setDownCountFlow(downCountFlow);//3:将K3和V3下⼊上下⽂中context.write(key, flowBean);}}```##### Step 4: 程序main函数⼊⼝FlowMain```javapublic class JobMain extends Configured implements Tool {//该⽅法⽤于指定⼀个job任务@Overridepublic int run(String[] args) throws Exception {//1:创建⼀个job任务对象Job job = Job.getInstance(super.getConf(), "mapreduce_flowcount");//如果打包运⾏出错,则需要加该配置job.setJarByClass(JobMain.class);//2:配置job任务对象(⼋个步骤)//第⼀步:指定⽂件的读取⽅式和读取路径job.setInputFormatClass(TextInputFormat.class);//TextInputFormat.addInputPath(job, new Path("hdfs://node01:8020/wordcount")); TextInputFormat.addInputPath(job, new Path("file:///D:\\input\\flowcount_input")); //第⼆步:指定Map阶段的处理⽅式和数据类型job.setMapperClass(FlowCountMapper.class);//设置Map阶段K2的类型job.setMapOutputKeyClass(Text.class);//设置Map阶段V2的类型job.setMapOutputValueClass(FlowBean.class);//第三(分区),四(排序)//第五步: 规约(Combiner)//第六步分组//第七步:指定Reduce阶段的处理⽅式和数据类型job.setReducerClass(FlowCountReducer.class);//设置K3的类型job.setOutputKeyClass(Text.class);//设置V3的类型job.setOutputValueClass(FlowBean.class);//第⼋步: 设置输出类型job.setOutputFormatClass(TextOutputFormat.class);//设置输出的路径TextOutputFormat.setOutputPath(job, new Path("file:///D:\\out\\flowcount_out")); //等待任务结束boolean bl = job.waitForCompletion(true);return bl ? 0:1;}public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();//启动job任务int run = ToolRunner.run(configuration, new JobMain(), args);System.exit(run);}}```。
mapreduce编程实例实验总结

mapreduce编程实例实验总结在这个实验总结中,我要讲述的是关于MapReduce编程实例的经验和教训。
在进行MapReduce编程实例实验期间,我们的目标是使用MapReduce框架来解决大规模数据处理的问题。
我们首先需要理解MapReduce的基本概念和原理,以及它的工作流程。
在实验过程中,我首先意识到编写高效的MapReduce程序需要充分理解输入数据的特点和问题的要求。
我学会了通过合理的数据划分和分布,以及适当的数据类型选择和优化,来提高程序性能和可扩展性。
其次,在实验中我开始注重输入数据的预处理和清洗工作。
数据的准确性和一致性对于MapReduce处理过程的正确性至关重要。
我学会了使用适当的数据结构和算法来处理和筛选输入数据,以确保我们得到可靠的结果。
另外,在编写程序时,我熟悉并使用了Map和Reduce函数的操作。
Map函数可以将输入数据转化为键值对的形式,而Reduce函数则根据键值对进行数据的聚合和计算。
合理地设计和实现这些函数对于程序的正确性和效率至关重要。
此外,我还学会了有效地使用MapReduce框架提供的一些工具和函数。
例如,我使用了Combiner函数来实现MapReduce结果的局部聚合,从而减少数据传输和减轻Reduce的负担。
我还使用Counters工具来监控和统计程序中的特定事件和信息。
最后,在实验总结中,我认识到调试和优化MapReduce程序是一个迭代和持续的过程。
通过对程序的性能和输出结果的不断分析和改进,我能够不断提升程序的效率和可靠性。
总的来说,在本次MapReduce编程实例实验中,我收获了对MapReduce框架的深入理解和熟练应用。
通过不断探索和实践,我学会了如何编写高效、稳定的MapReduce程序,并在处理大规模数据时取得了令人满意的结果。
这次实验对于我在大数据处理领域的学习和发展具有重要的意义。
如何在Hadoop中使用MapReduce进行数据分析

如何在Hadoop中使用MapReduce进行数据分析在当今信息爆炸的时代,数据分析已经成为了企业和组织决策的重要工具。
而Hadoop作为一个开源的分布式计算框架,提供了强大的数据处理和分析能力,其中的MapReduce就是其核心组件之一。
本文将介绍如何在Hadoop中使用MapReduce进行数据分析。
首先,我们需要了解MapReduce的基本原理。
MapReduce是一种分布式计算模型,它将大规模的数据集划分成若干个小的数据块,然后通过Map和Reduce两个阶段进行并行处理。
在Map阶段,数据集会被分割成若干个键值对,每个键值对由一个键和一个值组成。
然后,Map函数会对每个键值对进行处理,生成一个新的键值对。
在Reduce阶段,相同键的值会被分组在一起,然后Reduce函数会对每个键的值进行聚合和处理,最终生成最终的结果。
在Hadoop中使用MapReduce进行数据分析的第一步是编写Map和Reduce函数。
在编写Map函数时,我们需要根据具体的数据分析任务来定义键值对的格式和生成方式。
例如,如果我们要统计某个网站的访问量,那么键可以是网站的URL,值可以是1,表示一次访问。
在Reduce函数中,我们需要根据具体的需求来定义对键的值进行聚合和处理的方式。
例如,如果我们要统计每个网站的总访问量,那么Reduce函数可以将所有的值相加得到最终的结果。
编写好Map和Reduce函数后,我们需要将数据加载到Hadoop中进行分析。
在Hadoop中,数据通常以HDFS(Hadoop Distributed File System)的形式存储。
我们可以使用Hadoop提供的命令行工具或者编写Java程序来将数据加载到HDFS 中。
加载完成后,我们就可以使用Hadoop提供的MapReduce框架来进行数据分析了。
在运行MapReduce任务之前,我们需要编写一个驱动程序来配置和提交任务。
在驱动程序中,我们需要指定Map和Reduce函数的类名、输入数据的路径、输出数据的路径等信息。
mapreduce 统计首字母次数 案例

一、背景介绍近年来,随着互联网和大数据技术的迅速发展,大数据分析已经成为各行各业不可或缺的一部分。
而在大数据处理中,MapReduce作为一种经典的并行计算框架,被广泛应用于数据处理和分析任务中。
在实际应用中,经常会遇到需要对大规模数据进行统计分析的需求,比如统计单词、字母出现的频次等。
本文将以统计中文文章中每个词的首字母的出现次数为例,介绍MapReduce在统计任务中的应用。
二、MapReduce介绍MapReduce是一种用于处理大规模数据的编程模型,由Google在2004年提出,并在2006年发表了论文。
它的核心思想是将数据处理任务分解成Map和Reduce两个阶段,使得分布式计算变得简单和高效。
在MapReduce模型中,Map阶段负责对输入数据进行处理和过滤,并生成中间的键值对数据;Reduce阶段则负责对中间数据进行汇总和统计,生成最终的输出数据。
三、统计首字母次数的MapReduce实现在统计中文文章中每个词的首字母的出现次数的案例中,我们可以利用MapReduce模型来实现。
对于输入的中文文章,我们需要对每个词进行分词处理,并提取每个词的首字母;在Map阶段,我们将每个首字母作为键,将出现的频次作为值,生成中间的键值对;在Reduce 阶段,我们对相同首字母的频次进行累加,得到最终的统计结果。
接下来,我们将详细介绍Map和Reduce两个阶段的具体实现。
四、Map阶段:1. 数据输入:将中文文章作为输入数据,以行为单位读取并进行分词处理,得到每个词和其对应的首字母。
2. Map函数:对于每个词,提取其首字母作为键,将出现的频次设为1,生成中间的键值对数据。
3. 数据输出:将生成的中间数据按照键值对的形式输出。
五、Reduce阶段:1. 数据输入:接收Map阶段输出的中间数据,以键为单位进行分组。
2. Reduce函数:对于每个键值对数据,将相同键的频次进行累加,得到每个首字母的总频次。
实验3-MapReduce编程初级实践
实验3 MapReduce编程初级实践1.实验目的1.通过实验掌握基本的MapReduce编程方法;2.掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
2.实验平台已经配置完成的Hadoop伪分布式环境。
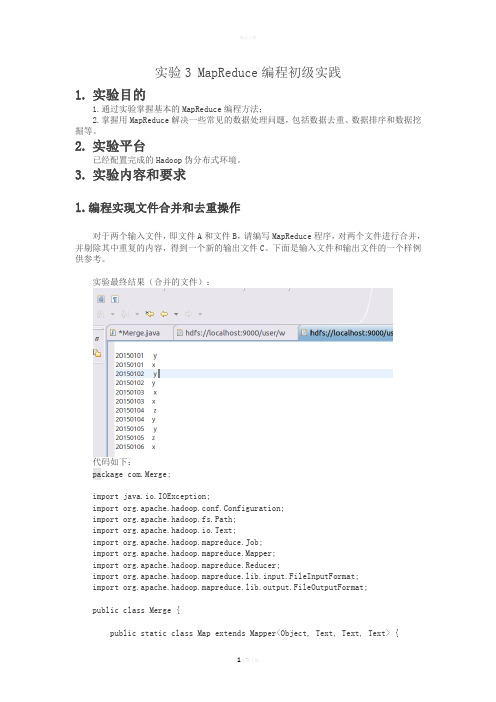
3.实验内容和要求1.编程实现文件合并和去重操作对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。
下面是输入文件和输出文件的一个样例供参考。
实验最终结果(合并的文件):代码如下:package com.Merge;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class Merge {public static class Map extends Mapper<Object, Text, Text, Text> {private static Text text = new Text();public void map(Object key, Text value, Context context)throws IOException, InterruptedException {text = value;context.write(text, new Text(""));}}public static class Reduce extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {context.write(key, new Text(""));}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");String[] otherArgs = new String[] { "input", "output" };if (otherArgs.length != 2) {System.err.println("Usage: Merge and duplicate removal <in><out>");System.exit(2);}Job job = Job.getInstance(conf, "Merge and duplicate removal");job.setJarByClass(Merge.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}2. 编写程序实现对输入文件的排序现在有多个输入文件,每个文件中的每行内容均为一个整数。
实验6:Mapreduce实例——WordCount

实验6:Mapreduce实例——WordCount实验⽬的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会⾃⼰编写WordCount程序进⾏词频统计实验原理MapReduce采⽤的是“分⽽治之”的思想,把对⼤规模数据集的操作,分发给⼀个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
简单来说,MapReduce就是”任务的分解与结果的汇总“。
1.MapReduce的⼯作原理在分布式计算中,MapReduce框架负责处理了并⾏编程⾥分布式存储、⼯作调度,负载均衡、容错处理以及⽹络通信等复杂问题,现在我们把处理过程⾼度抽象为Map与Reduce两个部分来进⾏阐述,其中Map部分负责把任务分解成多个⼦任务,Reduce部分负责把分解后多个⼦任务的处理结果汇总起来,具体设计思路如下。
(1)Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map⽅法。
通过在map⽅法中添加两句把key值和value值输出到控制台的代码,可以发现map⽅法中输⼊的value值存储的是⽂本⽂件中的⼀⾏(以回车符为⾏结束标记),⽽输⼊的key值存储的是该⾏的⾸字母相对于⽂本⽂件的⾸地址的偏移量。
然后⽤StringTokenizer类将每⼀⾏拆分成为⼀个个的字段,把截取出需要的字段(本实验为买家id字段)设置为key,并将其作为map⽅法的结果输出。
(2)Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce⽅法。
Map过程输出的<key,value>键值对先经过shuffle过程把key值相同的所有value值聚集起来形成values,此时values是对应key字段的计数值所组成的列表,然后将<key,values>输⼊到reduce⽅法中,reduce⽅法只要遍历values并求和,即可得到某个单词的总次数。
Mapreduce实例——排序

Mapreduce实例——排序原理Map、Reduce任务中Shuffle和排序的过程图如下:流程分析:1.Map端:(1)每个输⼊分⽚会让⼀个map任务来处理,默认情况下,以HDFS的⼀个块的⼤⼩(默认为64M)为⼀个分⽚,当然我们也可以设置块的⼤⼩。
map输出的结果会暂且放在⼀个环形内存缓冲区中(该缓冲区的⼤⼩默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区⼤⼩的80%,由io.sort.spill.percent属性控制),会在本地⽂件系统中创建⼀个溢出⽂件,将该缓冲区中的数据写⼊这个⽂件。
(2)在写⼊磁盘之前,线程⾸先根据reduce任务的数⽬将数据划分为相同数⽬的分区,也就是⼀个reduce任务对应⼀个分区的数据。
这样做是为了避免有些reduce任务分配到⼤量数据,⽽有些reduce任务却分到很少数据,甚⾄没有分到数据的尴尬局⾯。
其实分区就是对数据进⾏hash的过程。
然后对每个分区中的数据进⾏排序,如果此时设置了Combiner,将排序后的结果进⾏Combia操作,这样做的⽬的是让尽可能少的数据写⼊到磁盘。
(3)当map任务输出最后⼀个记录时,可能会有很多的溢出⽂件,这时需要将这些⽂件合并。
合并的过程中会不断地进⾏排序和combia操作,⽬的有两个:①尽量减少每次写⼊磁盘的数据量。
②尽量减少下⼀复制阶段⽹络传输的数据量。
最后合并成了⼀个已分区且已排序的⽂件。
为了减少⽹络传输的数据量,这⾥可以将数据压缩,只要将press.map.out设置为true就可以了。
(4)将分区中的数据拷贝给相对应的reduce任务。
有⼈可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务⼀直和其⽗TaskTracker保持联系,⽽TaskTracker⼜⼀直和JobTracker保持⼼跳。
所以JobTracker中保存了整个集群中的宏观信息。
只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
大数据技术原理与应用 第七章 MapReduce分析

7.3.2 MapReduce各个执行阶段
节点1
从分布式文件系统中加载文件
节点2
从分布式文件系统中加载文件
InputFormat 文件 文件 Split Split Split Split
InputFormat 文件 Split Split 文件
输入 <key,value>
RR Map
RR Map
Reduce <k2,List(v2)> <k3,v3> 如:<“a”,<1,1,1>> <“a”,3>
7.2 MapReduce的体系结构
MapReduce体系结构主要由四个部分组成,分别是: Client、JobTracker、TaskTracker以及Task
Client
Client
Client
7.4.2 WordCount设计思路
首先,需要检查WordCount程序任务是否可 以采用MapReduce来实现 其次,确定MapReduce程序的设计思路 最后,确定MapReduce程序的执行过程
7.4.3
一个WordCount执行过程的实例
Map输入 Map输出 <Hello,1> <World,1> <Bye,1> <World,1> <Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1> <Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
函数 Map 输入 <k1,v1> 如:
<行号,”a b c”>
mapreduce编程单词计数实验总结

mapreduce编程单词计数实验总结【MapReduce编程单词计数实验总结】MapReduce是一种用于处理大规模数据集的编程模型和算法。
通过将任务拆分为多个子任务,然后分配给不同的计算节点并行处理,MapReduce能够高效地处理海量数据。
在本次实验中,我们使用MapReduce编程模型来实现单词的计数,对实验结果进行了总结与分析。
首先,我们使用Hadoop作为MapReduce编程模型的底层实现。
Hadoop是一个开源的分布式计算框架,提供了MapReduce算法的支持。
为了进行单词计数实验,我们需要安装Hadoop,并进行相关配置。
在配置完成后,我们开始编写MapReduce程序。
MapReduce程序主要包括两个部分:Map函数和Reduce函数。
Map函数负责将输入数据切分为若干个Key-Value对,并进行处理。
在单词计数实验中,我们将输入的文本文件按行拆分,并将每个单词作为Key,初始值设置为1作为Value输出。
Reduce函数负责对Map函数输出的结果进行合并和处理,最终得到最终的计数结果。
在实验过程中,我们遇到了一些问题。
首先是数据的划分和分配。
由于处理的数据量很大,因此需要将数据划分为多个小的数据块,并分配给不同的计算节点进行处理。
这一过程需要通过Hadoop提供的分布式文件系统进行管理和协调。
其次是Map和Reduce函数的编写。
在Map函数中,我们需要根据具体的需求进行数据的提取和处理。
在本次实验中,我们利用正则表达式来提取文本中的单词,并将其作为Key传递给Reduce函数。
Reduce函数则需要对相同的Key 进行合并,并累加计数值。
同时,我们也进行了性能测试和分析。
通过调整计算节点的数量,我们发现并行计算能够大大提高计算速度。
当节点数量较少时,计算过程存在瓶颈,无法充分利用系统资源。
但是当节点数量过多时,网络通信的开销会增加,反而会降低计算效率。
因此,在实际应用中,需要根据具体情况来选择节点数量。
Mapreduce实验报告

Mapreduce实验报告Mapreduce实验报告前⾔和简介MapReduce是Google提出的⼀种编程模型,在这个模型的⽀持下可以实现⼤规模并⾏化计算。
在Mapreduce框架下⼀个计算机群通过统⼀的任务调度将⼀个巨型任务分成许多部分,分别解决然后合并得到最终结果。
Mapreduce可以让程序员以简单的程序来解决实际问题,⽽隐藏了诸如分布、⼯作调度、容错、机器间通信,使得⼤规模任务简单⽽迅速地完成。
⼀.Mapreduce的基本原理1.核⼼思想。
“Divide and Conquer”是Mapreduce的核⼼思想。
⾯对⼀个规模庞⼤的问题,要处理是以TB计的数据,Mapreduce采⽤“输⼊”------“分解”------“解决”------“聚合”------“输出结果”的基本过程。
2.基本原理Map和Reduce是两个核⼼操作,⽤户定义的map函数接收被切割过的原始的key/value对集并且计算出⼀个中间key/value对集。
Mapreduce库函数将所有的具有相同key值的value聚合在⼀起交给⽤户定义的reduce函数处理。
reduce函数将同⼀key值的所有value合并成得到输出⽂件。
在整个过程中,Mapreduce库函数负责原始数据的切割,中间key/value对集的聚合,以及任务的调度,容错、通信控制等基础⼯作。
⽽⽤户定义的map和reduce函数则根据实际问题确定具体操作。
⼆.框架的基本结构和执⾏流程基本结构Mapreduce框架的主要程序分为三种即Master,Map和Reduce。
1.Master:主要功能有两个,任务的分割和任务的调度。
Master把输⼊⽂件切成许多个split,每个split⽂件⼀般为⼏⼗M。
Master同时还要调度任务监视各个map worker和reduce worker的⼯作状态,以做出相应的安排。
Master还要监视各个⼦任务的完成进展情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一MapReduce概述Map/Reduce是一个用于大规模数据处理的分布式计算模型,它最初是由Google工程师设计并实现的,Google已经将它完整的MapReduce论文公开发布了。
其中对它的定义是,Map/Reduce是一个编程模型(programming model),是一个用于处理和生成大规模数据集(processing and generating large data sets)的相关的实现。
用户定义一个map函数来处理一个key/value对以生成一批中间的key/value对,再定义一个reduce函数将所有这些中间的有着相同key的values合并起来。
很多现实世界中的任务都可用这个模型来表达。
二MapReduce工作原理1 Map-ReduceMap-Reduce框架的运作完全基于<key,value>对,即数据的输入是一批<key,value>对,生成的结果也是一批<key,value>对,只是有时候它们的类型不一样而已。
Key和value的类由于需要支持被序列化(serialize)操作,所以它们必须要实现Writable接口,而且key的类还必须实现WritableComparable接口,使得可以让框架对数据集的执行排序操作。
一个Map-Reduce任务的执行过程以及数据输入输出的类型如下所示:Map:<k1,v1> ——> list<k2,v2>Reduce:<k2,list<v2>> ——> <k3,v3>2例子下面通过一个的例子来详细说明这个过程。
WordCount是Hadoop自带的一个例子,目标是统计文本文件中单词的个数。
假设有如下的两个文本文件来运行WorkCount程序:Hello World Bye WorldHello Hadoop GoodBye Hadoop2.1 map数据输入Hadoop针对文本文件缺省使用LineRecordReader类来实现读取,一行一个key/value对,key取偏移量,value为行内容。
如下是map1的输入数据:Key1 Value10 Hello World Bye World如下是map2的输入数据:Key1Value10 Hello Hadoop GoodBye Hadoop2.2 map输出/combine输入如下是map1的输出结果Key2Value2Hello 1World 1Bye 1World 1 如下是map2的输出结果Key2Value2Hello 1Hadoop 1GoodBye 1Hadoop 12.3 combine输出Combiner类实现将相同key的值合并起来,它也是一个Reducer的实现。
如下是combine1的输出Key2Value2Hello 1World 2Bye 1如下是combine2的输出Key2Value2Hello 1Hadoop 2GoodBye 12.4 reduce输出Reducer类实现将相同key的值合并起来。
如下是reduce的输出Key2Value2Hello 2World 2Bye 1Hadoop 2GoodBye 1三MapReduce框架结构1 角色1.1 JobClient每一个job都会在用户端通过JobClient类将应用程序以及配置参数打包成jar文件存储在HDFS,并把路径提交到JobTracker,然后由JobTracker创建每一个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行。
1.2 JobTrackerJobTracker是一个master服务,JobTracker负责调度job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
1.3 TaskTrackerTaskTracker是运行于多个节点上的slaver服务。
TaskTracker则负责直接执行每一个task。
TaskTracker都需要运行在HDFS的DataNode上,2 数据结构2.1 Mapper和Reducer运行于Hadoop的MapReduce应用程序最基本的组成部分包括一个Mapper和一个Reducer类,以及一个创建JobConf的执行程序,在一些应用中还可以包括一个Combiner 类,它实际也是Reducer的实现。
2.2 JobInProgressJobClient提交job后,JobTracker会创建一个JobInProgress来跟踪和调度这个job,并把它添加到job队列里。
JobInProgress会根据提交的job jar中定义的输入数据集(已分解成FileSplit)创建对应的一批TaskInProgress用于监控和调度MapTask,同时在创建指定数目的TaskInProgress用于监控和调度ReduceTask,缺省为1个ReduceTask。
2.3 TaskInProgressJobTracker启动任务时通过每一个TaskInProgress来launchTask,这时会把Task对象(即MapTask和ReduceTask)序列化写入相应的TaskTracker服务中,TaskTracker收到后会创建对应的TaskInProgress(此TaskInProgress实现非JobTracker中使用的TaskInProgress,作用类似,是JobTracker内部类)用于监控和调度该Task。
启动具体的Task进程是通过TaskInProgress管理的TaskRunner对象来运行的。
TaskRunner会自动装载job jar,并设置好环境变量后启动一个独立的java child进程来执行Task,即MapTask或者ReduceTask,但它们不一定运行在同一个TaskTracker中。
2.4 MapTask和ReduceTask一个完整的job会自动依次执行Mapper、Combiner(在JobConf指定了Combiner时执行)和Reducer,其中Mapper和Combiner是由MapTask调用执行,Reducer则由ReduceTask 调用,Combiner实际也是Reducer接口类的实现。
Mapper会根据job jar中定义的输入数据集按<key1,value1>对读入,处理完成生成临时的<key2,value2>对,如果定义了Combiner,MapTask会在Mapper完成调用该Combiner将相同key的值做合并处理,以减少输出结果集。
MapTask的任务全完成即交给ReduceTask进程调用Reducer处理,生成最终结果<key3,value3>对。
这个过程在下一部分再详细介绍。
下图描述了Map/Reduce框架中主要组成和它们之间的关系:3 流程一道MapRedcue作业是通过JobClient.rubJob(job)向master节点的JobTracker提交的, JobTracker接到JobClient的请求后把其加入作业队列中。
JobTracker一直在等待JobClient 通过RPC提交作业,而TaskTracker一直通过RPC向JobTracker发送心跳heartbeat询问有没有任务可做,如果有,让其派发任务给它执行。
如果JobTracker的作业队列不为空, 则TaskTracker发送的心跳将会获得JobTracker给它派发的任务。
这是一道pull过程。
slave节点的TaskTracker接到任务后在其本地发起Task,执行任务。
以下是简略示意图:下面详细介绍一下Map/Reduce处理一个工作的流程。
四JobClient在编写MapReduce程序时通常是上是这样写的:Configuration conf = new Configuration(); // 读取hadoop配置Job job = new Job(conf, "作业名称"); // 实例化一道作业job.setMapperClass(Mapper类型);job.setCombinerClass(Combiner类型);job.setReducerClass(Reducer类型);job.setOutputKeyClass(输出Key的类型);job.setOutputValueClass(输出Value的类型);FileInputFormat.addInputPath(job, new Path(输入hdfs路径));FileOutputFormat.setOutputPath(job, new Path(输出hdfs路径));// 其它初始化配置JobClient.runJob(job);1 配置JobJobConf是用户描述一个job的接口。
下面的信息是MapReduce过程中一些较关键的定制信息:2 JobClient.runJob()运行Job并分解输入数据集一个MapReduce的Job会通过JobClient类根据用户在JobConf类中定义的InputFormat实现类来将输入的数据集分解成一批小的数据集,每一个小数据集会对应创建一个MapTask来处理。
JobClient会使用缺省的FileInputFormat类调用FileInputFormat.getSplits()方法生成小数据集,如果判断数据文件是isSplitable()的话,会将大的文件分解成小的FileSplit,当然只是记录文件在HDFS里的路径及偏移量和Split大小。
这些信息会统一打包到jobFile的jar中。
JobClient然后使用submitJob(job)方法向master提交作业。
submitJob(job)内部是通过submitJobInternal(job)方法完成实质性的作业提交。
submitJobInternal(job)方法首先会向hadoop分布系统文件系统hdfs依次上传三个文件: job.jar, job.split和job.xml。
job.xml: 作业配置,例如Mapper, Combiner, Reducer的类型,输入输出格式的类型等。
job.jar: jar包,里面包含了执行此任务需要的各种类,比如Mapper,Reducer等实现。
job.split: 文件分块的相关信息,比如有数据分多少个块,块的大小(默认64m)等。