jstorm分享
8.JStorm Configuration

topology.enable.classloader: false, classloader is disabled by default. If the jar of the application is conflict with one of jares which JStorm depends on. For example, an application depends on thrift9, but JStorm uses thrift7, then you need to enable this configure item.
# You can get more about cgroup:
# /8s7nexU
supervisor.enable.cgroup: false
### Netty will send multiple messages in one batch
### Setting true will improve throughput, but more latency
# purpose. When it is disabled, the data of timer and histogram metrics
# will not be collected.
# topology.alimonitor.metrics.post: If it is disable, metrics data
# 1. Linux version (>= 2.6.18)
# 2. Have installed cgroup (check the file's existence:/proc/cgroups)
# 3. You should start your supervisor on root
酷狗大数据架构

Layer(DSL)、数据应用层 Data Application Layer(DAL)、数据分析层(Analysis)、 临时提数层(Temp)。 数据缓冲层(DCL):存储业务系统或者客户端上报的,经过解码、清洗、转换后 的原始数据,为数据过滤做准备。
了 kafka 生产者协议。有兴趣同学可以去 Github 上看看,另一同事实现的,现 在在 github 上比较活跃,被一些互联网公司应用于线上环境了。 b.后端日志采集接入: FileCollect,考虑到很多线上环境的环境变量不能改动,为减少侵入式,目前是采 用 Go 语言实现文件采集,年后也准备重构这块。 前端,服务端的数据采集整体架构如下图:
从这张图中,可以了解到大数据处理过程可以分为数据源、数据接入、数据清洗、 数据缓存、存储计算、数据服务、数据消费等环节,每个环节都有具有高可用性、
可扩展性等特性,都为下一个节点更好的服务打下基础。整个数据流过程都被数 据质量监控系统监控,数据异常自动预警、告警。 新一代大数据整体技术架构如图:
将大数据计算分为实时计算与离线计算,在整个集群中,奔着能实时计算的,一 定走实时计算流处理,通过实时计算流来提高数据的时效性及数据价值,同时减 轻集群的资源使用率集中现象。 整体架构从下往上解释下每层的作用: 数据实时采集: 主要用于数据源采集服务,从数据流架构图中,可以知道,数据源分为前端日志, 服务端日志,业务系统数据。下面讲解数据是怎么采集接入的。 a.前端日志采集接入: 前端日志采集要求实时,可靠性,高可用性等特性。技术选型时,对开源的数据 采集工具 flume,scribe,chukwa 测试对比,发现基本满足不了我们的业务场景需 求。所以,选择基于 kafka 开发一套数据采集网关,来完成数据采集需求。数据 采集网关的开发过程中走了一些弯路,最后采用 nginx+lua 开发,基于 lua 实现
JStorm—实时流式计算框架入门介绍
JStorm—实时流式计算框架⼊门介绍JStorm介绍 JStorm是参考storm基于Java语⾔重写的实时流式计算系统框架,做了很多改进。
如解决了之前的Storm nimbus节点的单点问题。
JStorm类似于Hadoop MapReduce系统,⽤户按照指定的接⼝去实现⼀个任务,任务提交给JStorm进⾏运⾏,且这种运⾏是不间断的,因为如果期间有worker发⽣故障,调度器会分配⼀个新的worker去替换这个故障worker。
从应⽤的⾓度来看,JStorm是⼀种分布式应⽤;从系统框架层⾯来看,JStorm⼜是⼀种类似于Hadoop MapReduce的调度系统;从数据层⾯来看,JStorm⼜是⼀种流式的实时计算⽅案。
JStorm优势1. 易开发性: JStomr接⼝简易,只需按照Spout、Bolt及Topology编程规范进⾏应⽤开发即可;2. 扩展性:可以线性的扩展性能,配置并发数即可;3. 容错性:出现故障worker时,调度器会分配⼀个新的worker去代替;4. 数据精准性:JStorm内置ACK机制,确保数据不丢失。
还可以采⽤事务机制确保进⼀步的精准度;5. 实时性:JStorm不间断运⾏任务,且实时计算。
JStorm应⽤场景1. 实时计算:可实时数据统计,实时监控;2. 消息转移:流处理完消息后,可以定向的将结果存储到其他消息中间件中;3. rpc请求:提交任务就是⼀次rpc请求过程;典型的场景:⽤于⽇志分析,rpc请求提交任务,从收集的⽇志中,统计出特定的数据结果,并将统计后的结果持久化到外部存储中,这是⼀种信息流处理⽅式,可聚合,可分析。
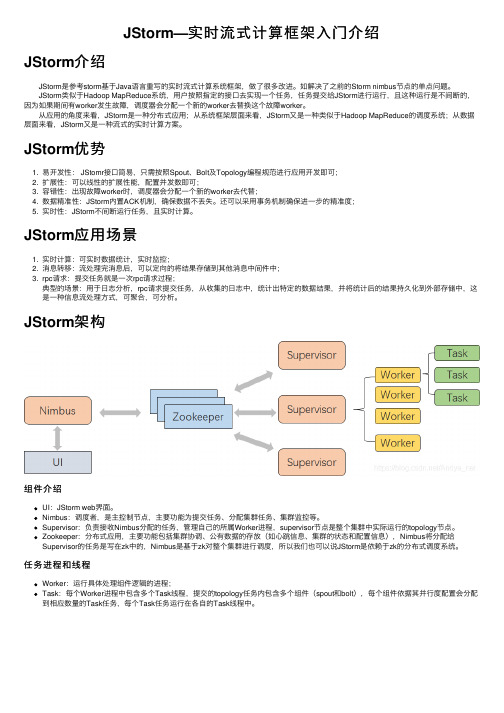
JStorm架构组件介绍UI:JStorm web界⾯。
Nimbus:调度者,是主控制节点,主要功能为提交任务、分配集群任务、集群监控等。
Supervisor:负责接收Nimbus分配的任务,管理⾃⼰的所属Worker进程,supervisor节点是整个集群中实际运⾏的topology节点。
实时云计算平台JStorm简述

实时云计算平台JStorm简述作者:李礼来源:《科学与信息化》2018年第01期摘要 JStorm与Storm比较,阿里巴巴中间件团队用Java重新实现了Storm的Clojure核心,兼容Storm的接口,解决了Strom的雪崩等问题,JStorm是一个强大的企业级流式计算引擎。
关键词 JStorm;云计算;Storm前言JStorm是一个类似于 Hadoop 的MapReduce的计算系统,它是由Alibaba开源的实时计算模型,它使用Java重写了原生的Storm模型,并且再原来的基础上做了许多改进。
用户只需按照指定的接口实现一个任务,然后将这个任务提交给JStorm系统,JStorm在接受了任务指令后,会无间断运行任务,一旦出现异常导致某个Worker发送故障,调度器立刻会分配一个新的Worker去顶替异常的Worker。
1 JStorm基本概念JStorm有点类似于Hadoop的MR(Map-Reduce),但是区别在于,hadoop的MR,提交到hadoop的MR job,执行完就结束了,进程就退出了,而一个JStorm任务,是7*24小时永远在运行的,除非用户主动kill[1]。
1.1 组件在JStorm的topology中,有两种组件:spout和bolt。
spout代表输入的数据源,这个数据源可以是任意的,比如kafka,DB,HBase,甚至是HDFS等,JStorm从这个数据源中不断地读取数据,然后发送到下游的bolt中进行处理。
bolt代表处理逻辑,bolt收到消息之后,对消息做处理(即执行用户的业务逻辑),处理完以后,既可以将处理后的消息继续发送到下游的bolt,这样会形成一个处理流水线[2]。
1.2 架构与Storm架构类似,包括Nimbus(调度器)、Supervisor(Worker的代理角色,负责Kill 掉Worker和运行Worker)、Worker(Task的容器)、Task(任务的执行者)、ZooKeeper (系统的协调者)等[3]。
《Storm框架分享》课件

对Storm框架的未来展望
我们预计Storm框架将与大数据生态系统更深入 地整合,在支持更多编程语言和数据源目标的 同时,提供更强大的实时计算能力。
《Storm框架分享》PPT 课件
欢迎大家参加今天的分享会!在本次课程中,我们将深入探讨Storm框架的各 个方面,包括其特点、基本概念、核心原理、具体应用、优缺点以及未来发 展趋势。
Storm框架简介
什么是Storm框架?
Storm是一个开源的实时计算系统,可用于处理大规模的流数据,提供高并发性和可靠性。
数据的可靠性保障
Storm框架通过在拓扑结构中引入消息可靠性机制,确保数据的传输和处理过程具有高可靠 性。
Storm框架的具体应用
1 实时数据处理
Storm框架适用于对实时流数据进行实时计算和分析,如实时推荐系统、广告投放分析等。
2 流量控制
通过Storm框架,可以对大规模的数据流进行控制和调度,确保数据的顺畅传输和负载均 衡。
Topology
消息处理的拓扑结构,由 多个Spout和Bolt组成,形 成一条处理流水线。
Storm框架的核心原理
数据的流式处理
Storm框架以流的方式进行数据处理,能够实时地对输入数据进行计算和分析。
数据的并行处理
通过将拓扑结构分解为多个任务,Storm框架能够并行处理大规模数据,提高处理效率。
传统数据处理 vs Storm框架
相比传统的批量处理方式,Storm框架能够实现实时流式处理,处理速度更快,反应更及时。
Storm框架的基本概念
Spout
消息的来源,负责从数据 源获取输入数据并发送给 下游的Bolt。
Bolt
消息的处理者,接收Spout 发送的数据并进行计算、 过滤等操作,然后将结果 发送给下一个Bolt。
jprofiler 用法

jprofiler 用法JProfiler 是一款专业的Java 分析工具,可以帮助开发人员深入解析和优化Java 应用程序的性能。
在本文中,我们将一步一步地回答有关JProfiler 的使用方法,帮助您快速上手并利用其强大的功能来优化您的Java 应用程序。
第一步- 下载和安装JProfiler首先,您需要从JProfiler 官方网站上下载JProfiler 的安装包。
安装包包含适用于不同操作系统的安装程序。
下载完毕后,双击安装程序并按照指示进行安装。
安装完成后,您将获得一个JProfiler 的快捷方式,您可以通过点击它来启动JProfiler。
第二步- 连接到您的应用程序在启动JProfiler 后,它将显示一个“Profile Configuration”对话框。
在这里,您需要选择“New Profiling Configuration”并填写与您的应用程序相应的配置信息。
输入配置名称、主机名和端口号,然后选择您的JVM(Java 虚拟机),例如HotSpot、JRockit 或IBM JVM。
完成配置后,JProfiler 将提示您启动应用程序。
您可以选择将其连接到正在运行的应用程序或者将其作为应用程序的一部分启动。
第三步- 运行性能分析一旦连接成功,JProfiler 将显示一个详细的仪表板,其中包含有关Java 应用程序的各个方面的信息。
您可以使用左侧面板上的不同选项卡来访问不同的功能和指标。
其中一个重要的选项卡是“CPU”的选项卡,它显示了应用程序中消耗CPU 时间的方法。
您可以通过检查这些方法来找出耗时的热点,并进行优化。
另一个重要的选项卡是“内存”的选项卡,它显示了应用程序使用的内存情况。
您可以通过检查内存中的对象和其引用来查找内存泄漏并进行优化。
此外,JProfiler 还提供了许多其他选项卡和功能,如线程分析、I/O 监视和数据库分析等,您可以根据需要使用它们。
第四步- 优化性能问题一旦您确定了性能问题所在的区域,您可以使用JProfiler 提供的工具来进行优化。
storm实验后的心得

storm实验后的心得Storm实验后的心得在进行了一系列关于Storm的实验后,我对这个分布式实时计算系统有了更加深刻的理解和认识。
通过实验,我发现Storm具有高性能、可扩展性强、容错性好等优点,适用于处理大规模的实时数据流。
下面我将就我的实验心得进行总结和分享。
我觉得Storm的高性能是它最大的优势之一。
在实验中,我通过构建拓扑结构,将数据流分成多个阶段进行处理。
通过合理的拓扑结构设计和任务划分,我成功地将计算任务分发到不同的计算节点上,实现了并行计算。
这样一来,Storm可以同时处理多个数据流,大大提高了计算效率。
Storm的可扩展性也给我留下了深刻的印象。
在实验中,我可以根据实际需求动态地增加或减少计算节点,而无需停止整个系统。
这种灵活的扩展性使得Storm能够应对不断增长的数据规模和计算需求,保证了系统的稳定性和可靠性。
Storm的容错性也是我在实验中感受到的一大优点。
在实验过程中,我模拟了计算节点的故障情况,并观察了系统的容错能力。
我发现,当一个计算节点发生故障时,Storm会自动将该节点上的任务重新分配给其他正常的节点,确保计算任务的连续性和正确性。
这种容错机制使得Storm具有很高的可靠性,在大规模分布式计算中表现出色。
Storm还具有灵活的数据处理能力。
在实验中,我可以根据实际需求设计不同的数据处理逻辑,包括数据过滤、数据转换、数据聚合等。
通过使用Storm提供的丰富的操作接口和函数库,我能够灵活地处理各种数据类型和数据流,满足不同的业务需求。
在实验过程中,我还发现Storm的学习曲线相对较陡。
由于Storm 的架构和设计思想与传统的批处理系统有很大的差异,初学者可能需要一定的时间来适应和理解Storm的工作原理。
不过,一旦掌握了Storm的基本概念和操作方式,就能够很好地利用它进行实时数据处理和分析。
总结起来,通过对Storm的实验,我深刻地认识到了这个分布式实时计算系统的优势和特点。
JStorm流处理框架

调度更强大(4)
❖在资源平衡算法的前提下
▪ 尽量保证上下游关系的task在同一个worker ▪ 尽量走内部通道,提高性能
调度更强大(5)
❖可以强制某个component的task 运行在不 同的节点上
❖需求:
▪ 聚石塔,海狗项目,某些task提供web service 服务,为了端口不冲突,因此必须强制这些 task运行在不同节点上
❖一条龙服务
▪ 应用开发 ▪ 平台开发 ▪ 系统运维
JStorm 现状
❖Ali 内部
▪ 超过600台 ▪ 日超过1万亿条
JStorm 是什么
❖JStorm 是一个分布式实时计算引擎
▪ 类似Hadoop MR
• 用户按照规定的编程规范实现一个任务,将任务放 到JStorm上,JStorm就将任务7 * 24 小时调度起来
▪ 添加supervisor时, 会触发任务rebalance ▪ Supervisor shutdown时, 触发任务rebalance ▪ 提交新任务时,当worker数不够时,触发其他
任务做rebalance
❖上叙问题不会在JStorm中发生
更稳定(4) – 任务之间影响小
❖新上线的任务不会冲击老的任务
为什么启动JStorm项目
❖现有Storm无法满足一些需求
▪ 现有storm调度太简单粗暴,无法定制化 ▪ Storm 任务分配不平衡 ▪ RPC OOM一直没有解决 ▪ 监控太简单 ▪ 对ZK 访问频繁 ▪ 。。。
更稳定(1) -- nimbus HA
❖Nimbus 实现HA
▪ 当一台nimbus挂了,自动热切到备份nimbus
▪ JStorm 比Storm 更稳定,功能更强大,更快。
jmerter的用法

jmerter的用法JMerter是一个用于生成Markdown格式的思维导图代码的工具。
它可以帮助您将思维导图转换为Markdown格式,从而方便地将其嵌入到文档、笔记或网页中。
以下是JMerter的基本用法:1. 安装JMerter您可以通过下载JMerter的安装程序或使用包管理器来安装JMerter。
安装完成后,您可以在命令行或终端中运行JMerter。
2. 创建思维导图使用JMerter创建思维导图需要以下步骤:* 打开JMerter应用程序,选择“File”菜单中的“New”选项,创建一个新的思维导图。
* 在思维导图编辑器中,使用鼠标或键盘添加节点和子节点。
您可以使用不同的颜色、形状和样式来区分不同的节点。
* 在编辑器中,您还可以添加链接、图片和其他格式的元素。
3. 导出思维导图为Markdown格式在编辑完思维导图后,您可以使用JMerter将其导出为Markdown格式。
以下是导出步骤:* 选择“File”菜单中的“Export”选项。
* 在弹出的对话框中,选择“Markdown”作为导出格式。
* 指定导出文件的名称和位置,然后单击“Save”按钮。
4. 嵌入Markdown格式的思维导图到文档或网页中将Markdown格式的思维导图嵌入到文档或网页中非常简单。
以下是嵌入步骤:* 将导出的Markdown文件插入到您的文档或网页中。
* 您可以使用任何文本编辑器或集成开发环境来编辑Markdown文件。
如果您使用的是Markdown编辑器,它通常会提供一些格式化选项,如标题、列表、代码块等。
* 在文档或网页中,您可以使用HTML标签将Markdown转换为实际格式。
例如,使用<ul>和<li>标签将列表转换为无序列表。
JMerter是一个非常有用的工具,可以帮助您轻松地将思维导图转换为Markdown格式,并将其嵌入到文档、笔记或网页中。
2.JStorm5分钟学习

本文主要讲一下JStorm的基本概念,让你在5分钟内对JStorm有一个大体的了解。
基本概念
首先,JStorm有点类似于Hadoop的MR(Map-Reduce),但是区别在于,hadoop的MR,提交到hadoop的MR job,执行完就结束了,进程就退出了,而一个JStorm任务(JStorm中称为topology),是7*24小时永远在运行的,除非用户主动kill。
通常一个流水线的最后一个bolt,会做一些数据的存储工作,比如将实时计算出来的数据写入DB、HBase等,以供前台业务进行查询和展现。
组件的接口
JStorm框架对spout组件定义了一个接口:nextTuple,顾名思义,就是获取下一条消息。执行时,可以理解成JStorm框架会不停地调这个接口,以从数据源拉取数据并往bolt发送数据。
在一个topology的运行过程中,如果一个进程(worker)挂掉了,JStorm检测到之后,会不断尝试重启这个进程,这就是7*24小时不间断执行的概念。
消息的通信
上面提到,spout的消息会发送给特定的bolt,bolt也可以发送给其他的bolt,那这之间是如何通信的呢?
首先,从spout发送消息的时候,JStorm会计算出消息要发送的目标task id列表,然后看目标task id是在本进程中,还是其他进程中,如果是本进程中,那么就可以直接走进程内部通信(如直接将这个消息放入本进程中目标task的执行队列中);如果是跨进程,那么JStorm会使用netty来将消息发送到目标task中。
JStorm组件
接下来是一张比较经典的Storm的大致的结构图(跟JStorm一样):
JStorm 资源隔离测试(cgroup)

JStorm 资源隔离测试(以下测试中,supervisor.enable.cgroup: true)非root权限启动supervisor测试目标非root情况,supervisor无法启动测试结果Supervisor无法启动,提示需要在root下启动在已挂载CPU子系统的情况下启动supervisor 测试目标正确读取到已挂载的层级,初始化,并在层级下建立rootCgroup运行后:Supervisor启动成功rootCgroup建立成功在未挂载CPU子系统的情况下启动supervisor 测试目标自动挂载CPU子系统到自定义层级上,并建立rootCgroup未挂载cpu启动supervisor:挂载层级成功rootCgroup建立提交一个topology测试目标Worker是否正确地被加入正确的cgroup中Worker成功地被添加到cgroup中,运行正常占用一个cpu slot,cpu weight为1024杀死一个topology 测试目标Cgroup是否被正确删除测试结果Workers的Cgroup被正确删除杀死一个worker测试目标Supervisor能否正确回收被杀死worker的cgroup,并且重新启动worker将worker加入新的cgroup重测试结果死去worker的cgroup被成功删除,新的worker的cgroup被成功创建,worker加入其中提交topology,杀死supervisor,重启supervisor后杀死topology测试目标Supervisor能否正确读取当前状态的cgroup,并且正确的清除当前worker的cgroup测试结果Worker的cgroup被正确地清除了杀死正在运行的worker,然后马上杀死supervisor再重启测试目标重启后的supervisor是否能正确清理cgroup,并且重启worker,放入新的cgroup中测试结果测试成功,旧的cgroup被清理,新的cgroup被创建,新的worker被创建加入其中在spout open过程中sleep超过120s测试目标在worker因为错误没有被正确启动,supervisor会不断尝试重启worker,测试在这种情况下cgroup是否被正确清除.(这里选择的是在open spout时sleep超过120s,supervisor会认为spout启动失败)测试结果超时后旧的cgroup被正确清除,新的cgroup被正确创建。
jstorm简介

jstorm简介最近在研究jstorm,看了很多资料,所以也想分享出来⼀些。
安装部署zeromq简单快速的传输层框架,安装如下:jzmq应该是zmq的java包吧,安装步骤如下:git clone git:///nathanmarz/jzmq.gitcd jzmq./autogen.sh./configuremakemake installzookeeper针对⼤型分布式系统提供配置维护、名字服务、分布式同步、组服务等,可以保证:1. 顺序性:客户端的更新请求都会被顺序处理2. 原⼦性:更新操作要不成功,要不失败3. ⼀致性:客户端不论连接到那个服务端,展现给它的都是同⼀个视图4. 可靠性:更新会被持久化5. 实时性:对于每个客户端他的系统视图都是最新的在zookeeper中有⼏种⾓⾊:1. Leader:发起投票和决议,更新系统状态2. Follower:响应客户端请求,参与投票3. Observer:不参与投票,只同步Leader状态4. Client:发起请求在启动之前需要在conf下编写zoo.cfg配置⽂件,⾥⾯的内容包括:1. tickTime:⼼跳间隔2. initLimit:Follower和Leader之间建⽴连接的最⼤⼼跳数3. syncLimit:Follower和Leader之间通信时限4. dataDir:数据⽬录5. dataLogDir:⽇志⽬录6. minSessionTimeout:最⼩会话时间(默认tickTime * 2)7. maxSessionTimeout:最⼤会话时间(默认tickTime * 20)8. maxClientCnxns:客户端数量9. clientPort:监听客户端连接的端⼝10. server.N=YYYY:A:B:其中N为服务器编号,YYYY是服务器的IP地址,A是Leader和Follower通信端⼝,B为选举端⼝在单机的时候可以直接将zoo_sample.cfg修改为zoo.cfg,然后使⽤启动服务即可(如果报错没有⽬录,⼿动创建即可):sudo ./zkServer.sh start现在⽤netstat -na(或者是./zkCli.sh 127.0.0.1:2181)就能看到在监听指定的端⼝,那么zookeeper现在起来了。
JStorm介绍

JStorm介绍一、简介JStorm是一个分布式实时计算引擎。
JStorm是一个类似于Hadoop MapReduce的系统,用户按照指定的接口实现一个任务,然后将这个任务交给JStorm系统,JStorm将这个任务跑起来,并按7*24小时运行。
如果中间一个worker发生了意外故障,调度器立即分配一个新的worker来替换这个失效的worker。
从应用的角度上看,JStorm是一种遵循某种编程规范的分布式应用;从系统的角度上看,JStorm是一套类似MapReduce的调度系统;从数据角度上看,JStorm是一套基于流水线的消息处理机制。
JStorm通过一系列基本元素实现实时计算的目标,其中包括topology,spout,bolt等。
JStorm在模型上和MapReduce有很多相似的地方。
下表是JStorm组件和MapReduce组件的对比:实时计算任务需要打包成T opology提交,和MapReduce Job相似,不同的是,MapReduce Job在计算完后就结束,而JStorm的Topology任务一旦提交,就永远不会结束,除非显示停止。
二、JStorm系统架构JStorm的系统架构如下所示:JStorm与Hadoop相似,保持了Master/Slaves简洁优雅的架构。
与Hadoop不同的是,JStorm的Master/Salves之间不能直接通过RPC来交换心跳信息,而是借助Zookeeper来实现。
这样的设计虽然引入了第三方依赖,但是简化了Nimbus/Supervisor的设计,同时也极大提高了系统的容错能力。
整个JStorm系统中共存三类不同的daemon进程,分别为Nimbus,Supervisor和Worker。
•Nimbus:JStorm的主控节点,作为调度器的角色。
Nimbus类似于MapReduce的JobTracker,负责接收和验证客户端提交的topology;分配任务;向ZK写入任务相关的元信息。
【分享】一些共享软件 (JEMS etc.)

【分享】一些共享软件(JEMS etc.)看到有同仁求模拟软件如JEMS。
手上正好有去年欧洲电镜会发布的共享软件列表,分享一下。
(不记得有人发过没有??)这里的JEMS 应该是学生共享版,我没有怎么测试因为我有别的软件。
但是我如果没有记错的话是不需要注册也没有限制的。
软件列表:(下载地址对应编号在下边找)CASINO (by D. Drouin) [4]monte CArlo SImulation of electroN trajectory in sOlidsCM Alignment Help (by M. T. Otten) [5]program for step-by-step alignment of Philips CM microscopes(good help function with basics on electronoptics)Crystal (by M. T. Otten) [5]program for performing simple crystallographic calculationsCTF Explorer (by M.V. Sidorov) [6]allows to calculate the Phase Contrast Transfer Function of a TEMDigital Micrograph (by Gatan) [7] advanced program for image and EELS analysisEELS Model (by J. Verbeeck) [8]software to quantify EEL spectra by using modelfittingElectron Direct Methods (by L. Marks & R. Kilaas) [9]set of programs to combine various aspects of image processing andmanipulation of HRTEM images and diffraction patterns as well as direct methodsImageJ (by W. Rasband) [10] open source image processing and analysisJava Electron Crystallography Package (by X.Z. Li) [11] stereographic projection, simulation and analysis of electrondiffraction patternsJEMS Student Edition (by P. Stadelmann) [12]the swiss army knife for simulation of HRTEM images and diffractionpatternsMonte Carlo Simulations of electron-solid interactions (by D. Joy) [13]introduction to Monte Carlo simulation of electron transport in solidsNCEMSS (by R. Kilaas) [9]HRTEM image and diffraction pattern simulation on the basis of themulti-slice algorithmOff-line CBED Thickness (by M. T. Otten) [5]program for calculating specimen thickness from convergent beamelectron diffraction patternsPowder Cell (by W. Kraus, G. Nolze) [14]displays crystal structures and calculates (xray) powder diagrams and d-spacingsProcess Diffraction (by J. Labar) [15]allows to obtain quantitative structural information from selected area electron diffraction patternsSpace Group Explorer (by Calidris) [16]gives equivalent positions in real and reciprocal space, the symmetry of the diffraction pattern,and information about systematic absences and enhancements. It alsogives phase relationships of the Fourier terms, and seminvariant vectorsVESTA (by K. Momma, F. Izumi) [17] program for displaying crystal structures withco-ordination polyhedra etc. (excellent graphics!)XVis (by O. Yefanov) [18]an educational open-source program for demonstration of reciprocal-space construction and diffraction principles 下载地址:4.herbrooke.ca/casino/index.html5. M. T. Otten, private communication6. http://clik.to/ctfexplorer7. /8. http://webh01.ua.ac.be/eelsmod/eelsmodel.htm9. /edm/10. /ij/11. /CMRAcfem/XZLI/programs.htm12.http://cimewww.epfl.ch/people/stadelmann/jemsSE/jemsS Ev3_2710u2008.htm13. /~srcutk/htm/simulati.htm14.http://www.bam.de/de/service/publikationen/powder_cell_a .htm15. http://www.mfa.kfki.hu/~labar/ProcDif.htm16. /archive.html17. http://www.geocities.jp/kmo_mma/crystal/en/vesta.html18. .ua/xvis.html19. http://www.jonelo.de/java/nc/。
阿里中台中间件

阿⾥中台中间件2020-12-16演讲⼈阿⾥中间件⽬录01组件02整体架构01组件流式计算JStormJStorm是Storm的Java版本,使⽤Java重写的同时在其基础上进⾏了⼤幅度的改进与优化.与Hadoop对⼤数据进⾏离线全量处理相对应,JStorm主要做的是对⼤数据的实时增量计算与流式计算分布式缓存TairTair是阿⾥巴巴集团⾃研的弹性缓存/存储平台,在内部有着⼤量的部署和使⽤。
Tair的核⼼组件是⼀个⾼性能、可扩展、⾼可靠的NoSQL存储系统。
⽬前⽀持MDB、LDB、RDB等存储引擎。
其中MDB是类似Memcached的内存存储引擎,LDB是使⽤LSMTree的持久化磁盘KV存储引擎,RDB是⽀持Queue、Set、Maps等数据结构的内存及持久化存储引擎。
分布式数据库TDDLDDL旨为⽤户提供在线数据库服务。
TDDL部分兼容MySQL关系型数据库,并提供数据库在线扩容、性能监测及分析功能。
TDDL⽀持弹性扩容.精卫精卫填海(简称精卫)是⼀个基于MySQL数据库的数据复制组件,远期⽬标是构建⼀个完善可接⼊多种不同类型源数据的实时数据复制框架愚公数据⾃动迁移引擎,海量数据⾃动运维⼯具,可⽤于对⽤户⽆影响的⾃动扩容和缩容,数据平滑迁移,以及异构数据源迁移,⽬前已经完成了214次业务迁移或扩容。
消息Notifynotify是⼀款⾼性能,⾼可靠,可⽆限⽔平扩展,⽀持分布式事务,⽀持复杂消息过滤的与互联⽹时代紧密结合的消息中间件,是⽬前公司内部使⽤最⼴泛的⼀个消息中间件产品之⼀,承担着公司内部90%以上消息服务。
他使⽤推消息的模型,集群可⽔平扩展,但不保证顺序,也不保证重复的消息中间件产品MetaQMetaQ是⼀款分布式、队列模型的消息中间件。
分为Topic与Queue两种模式,Push和Pull两种⽅式消费,⽀持严格的消息顺序,亿级别的堆积能⼒,⽀持消息回溯和多个维度的消息查询分布式服务HSF⾼速服务框架HSF(High-speedServiceFramework),是在阿⾥巴巴⼴泛使⽤的分布式RPC服务框架。
storm 知识点

Storm 知识点Storm 是一款开源的分布式实时计算系统,它能够处理海量的实时数据,并以高效、可靠的方式进行大规模的实时数据处理。
本文将从基础概念、架构、使用场景和案例等方面逐步介绍 Storm 的知识点。
1. Storm 简介Storm 是由 Twitter 公司开发并开源的一款分布式实时计算系统,它提供了高性能的数据流处理能力。
Storm 的设计目标是处理实时数据流,并能够保证数据的低延迟和高可靠性。
2. Storm 架构Storm 的架构中包含以下几个核心组件:2.1 NimbusNimbus 是 Storm 集群的主节点,它负责协调集群中的各个组件,并进行任务的分配和调度。
Nimbus 还负责监控集群的状态,并处理故障恢复等操作。
2.2 SupervisorSupervisor 是 Storm 集群的工作节点,它负责运行实际的计算任务,并按照Nimbus 的指示进行数据的处理和传输。
每个 Supervisor 节点可以运行多个Worker 进程,每个 Worker 进程负责一个具体的计算任务。
2.3 TopologyTopology 是 Storm 中的一个概念,它表示实际的数据处理流程。
Topology 中包含了 Spout 和 Bolt 两种组件,Spout 负责数据的输入,Bolt 负责对输入数据进行处理和转换。
2.4 ZooKeeperZooKeeper 是一个分布式协调服务,Storm 使用 ZooKeeper 来管理集群中的各个组件。
ZooKeeper 负责维护集群的状态信息,并提供分布式锁等功能,用于实现Storm 的高可靠性和容错能力。
3. Storm 使用场景Storm 在实时数据处理领域有着广泛的应用场景,以下是一些常见的使用场景:3.1 实时数据分析Storm 可以对实时数据进行分析和处理,帮助企业快速了解和响应数据的变化。
例如,可以利用 Storm 进行实时的用户行为分析,及时发现用户的偏好和趋势,并根据分析结果做出相应的调整。
JAVA视频资料百度网盘分享

JAVA视频资料百度⽹盘分享1、javascript视频教程链接: /s/1gd57FVH 密码: d9ei2、JPA视频教程链接: /s/1dDCx1fj 密码: fwwd3、马⼠兵hibernate视频教程链接:/s/1dFILSYH 密码:nuwz4、JAVA电⼦书链接: /s/1o6xlV9w 密码: 347e5、ext4.0视频教程链接: /s/1ntvmfKd 密码: n6fi6、hadoop实战链接: /s/1nttQoRJ 密码: r6857、android视频教程链接: /s/1mgpi4TM 密码: tx2e8、photoshop基础教程视频链接:/s/1eRVuN4I 密码:d9yv9、马⼠兵struts2视频教程链接: /s/1qWGeCg8 密码: m53e10、junit视频教程链接: /s/1jGCTjQA 密码: sncp11、Struts2+Spring3+Hibernate4+Maven+EasyUI整合⼊门视频链接: /s/1gfJVC8F 密码: fwmi12、spring mvc视频教程链接: /s/1eSvBih0 密码: 5irb13、ext视频教程链接: /s/1pLAlQRL 密码: j2dk14、UML视频教程链接: /s/1c1AXZP2 密码: h3ng15、⽹页与UI设计从⼊门到精通视频教程链接: /s/1mg7z1bi 密码: w7zw16、JSP视频教程链接: /s/1gdBDuIR 密码: jv2u17、java邮件开发视频教程链接: /s/1o61pEgq 密码: cjm518、EJB视频教程链接: /s/1c05DRe4 密码: 3jdy19、编译原理视频教程链接: /s/1mgxVZBy 密码: s6vc20、韩顺平J2SE视频教程21、银⾏交易系统实现链接: /s/1pJL6yAv 密码: qt3m 22、⿊客攻防技术见招拆招视频教程链接: /s/1hqEZgCO 密码: 1d3f 23、scm_cvs_svn视频教程链接: /s/16xQKA 密码: fmb3 24、dreamweaver教学视频链接: /s/1i3ffpGT 密码: cdy3 25、马⼠兵j2se、j2EE视频教程链接:/s/1dFlBRWX 密码:swsf 26、Unix操作系统(哈⼯⼤)链接: /s/1jIx4Oo2 密码: zgfh 27、Android开发视频教程链接: /s/1bn6vR2n 密码: yasa 28、dwr视频教程链接: /s/1bnmdj47 密码: 98bp 29、jquery视频教程链接: /s/1jGARtqe 密码: f95u 30、马⼠兵spring3视频教程链接: /s/1kVCvSXL 密码: ntia 31、java并发教程链接: /s/1yWqEq 密码: 4mxe 31、巴巴⽹开发实现链接: /s/1c0sgDSc 密码: w7z9 32、张孝详J2SE⾼深讲解链接: /s/1mg1ZLcG 密码: 2dg4 33、Flash动画制作教程视频链接: /s/1mirvfq4 密码: dig7 34、C语⾔基础链接: /s/1dDsK8ZB 密码: b4g6 35、php视频教程链接: /s/1r4M6q 密码: w4ak 36、linux视频教程-韩顺平链接: /s/1qXIHdmO 密码: jk9k 37、spring-mvc视频教程链接: /s/1o7SU7xC 密码: fkcf 38、[吉林⼤学计算机操作系统视频教程]链接: /s/13ad9k 密码: bux4 39、mysql特级课视频教程链接: /s/1o8O1exc 密码: 8v8b 40、NoSQL视频教程41、maven视频教程链接: /s/1dDg9ulb 密码: 1f5k42、JNI视频教程链接: /s/1i3tsv45 密码: edvc43、易语⾔资料与教程链接: /s/1c14S1rE 密码: ht9u44、⿊客新⼿综合书藉链接: /s/1mgD4VJq 密码: p4zd45、tomcat视频教程链接: /s/1qWxhRmG 密码: kpcs46、计算机操作系统原理视频教程链接: /s/1pJ1nEeJ 密码: vke747、oracle视频教程及OCP认证教程链接: /s/1o6IQDya 密码: mx1n48、SEO⽹站优化视频教程-学⽆忧链接: /s/1i36jBcp 密码: 9gae49、设计模式视频教程链接: /s/1kTjKUjX 密码: k7m850、jdbc视频教程链接: /s/1kTJCIYN 密码: hk8b51、php从⼊门到精通链接: /s/1i3rq877 密码: c79252、html+CSS教程[13个视频⽂件+1个rar⽂件-423M+资源⼤⼩]链接: /s/1jHPEVZK 密码: hrgd53、JAVA编程⾼级知识链接: /s/1hqEtm5I 密码: yr3x54、OA+⼯作流视频教程链接: /s/1mgLC9Jy 密码: 7em955、webservice视频教程链接: /s/1sjIe7Wp 密码: eka856、数据结构视频教程链接: /s/1mgElasg 密码: wtus57、计算机⽹络视频教程链接: /s/1mgH8NkG 密码: 75wj58、HTML5开发框架PhoneGap实战(jQuery Mobile开发、API解析、3个经典项⽬实战)链接: /s/1nvyKEz3 密码: 47gn59、SpringMvc+Spring+MyBatis+Maven整合视频链接: /s/1ntEOVwt 密码: 7ibg60、weblogic视频教程链接:/s/1bo8YojX 密码: qmy961、java⽹上在线⽀付实战视频62、23种设计模式视频教程链接: /s/1eQ7BD3k 密码: bhff 63、lucene视频教程链接: /s/1mgH8NlY 密码: 5g41 64、xml视频教程链接: /s/1i5kFFbJ 密码: vn86 65、HTML5⼊门视频教程【秀野堂】链接: /s/1sl4ciFb 密码: s46y 66、微普年薪10W版Android教学视频链接: /s/1gdJKOqn 密码: dp2i 67、ibatis视频教程链接: /s/1o6Mo4h8 密码: jfgv 68、传智播客-韩顺平-php从⼊门到精通链接: /s/1c04XT9A 密码: rhuv 69、国内⾸部Zookeeper从⼊门到精通链接: /s/1dD5BOLb 密码: trv7 70、⿊马ios链接: /s/1ntneBJr 密码: xb3f 71、phonegap HTML5开发视频链接: /s/1boRpe5x 密码: 6ws3 72、Zookeeper⼊门到精通链接: /s/1ntEOV4d 密码: gtj3 73、java⼊门链接: /s/1bn7bLWb 密码: r5kz 74、SSH2+activiti5OA管理系统案例视频链接: /s/1gdjnfdL 密码: a54r 75、word转换链接: /s/1pJ5r14R 密码: pbvv 76、桌⾯UI链接: /s/1sj470UL 密码: h32b 77、ajax链接: /s/1kVLjw8n 密码: 38by 78、axure视频教程链接: /s/1kTD7fq3 密码: dk89 79、兄弟连NoSQL视频教程 redis链接: /s/1pJzlMt1 密码: bjsu 80、Hadoop链接: /s/1mgKqEqG 密码: rea5 81、JS视频教程共150集链接: /s/1o6pe3t4 密码: 3cwz 82、activiti ⼯作流学习专题83、oa链接: /s/1o6laJEE 密码: 5scp 84、前段资料链接: /s/1eSmNDwI 密码: m9uk 85、简单微信[⼩项⽬]链接: /s/1bnqgNSj 密码: qu4j 87、nutch链接: /s/1jGsAxE2 密码: ckjq 88、anocation链接: /s/1i3HES0d 密码: cpym 89、DataGuru视频链接: /s/1kThdcMz 密码: v3sn 90、Nutch相关框架视频教程(压缩超清)链接: /s/1dD2nYoT 密码: 9eb6 91、Mars《Android开发视频教程》链接: /s/1sjswhbv 密码: wdbi 92、Python链接: /s/1hqrY4KG 密码: wf77 93、oa activiti 新版链接: /s/1jGMw8E6 密码: 5y4h 94、maven视频教程链接: /s/1i3g1iD3 密码: 1wik 95、linux视频教程链接: /s/1bn2Yacf 密码: k6df 96、⼩布⽼师Git⼊门链接: /s/1i3sCzS5 密码: fqkb 97、Redis链接: /s/1hq2hVta 密码: t7r5 98、⼯作流相关资料链接: /s/1o6tiskE 密码: 664u 99、EasyUI⼊门视频教程链接: /s/1jGxufxc 密码: 1s8m 100、MongoDB视频教程链接: /s/1pLk30d9 密码: 6jsc 101、thinkphp链接: /s/1sjKg4VF 密码: 1vek。
JSmooth 0.9.9-7使用经验
附带我个人的一些使用经验,错的话请见谅
一,关于图片问题的.如果java gui上用到的有图片的话把图片文件夹和java打包成的jar文件放在同一个目录下面就OK啦.
二,关于连接数据库的jar包问题,为了方便把连接数据库的jar包和生成的jar文件放在一个目录下,然后用jsmooth指定这些jar(mysql是一个包,MSSQL是四个包)包,生成后这些数据库jar文件也不能删除,用jsmooth时指定jar包时只是引用,否则会连不上数据库的.
三.就是运行环境的问题.要想生成的exe在没有JDK的环境下运行,就要把JVM捆绑上去,只要指定到JRE文件就可以啦.
希望个位能够运行顺利,还有一些个人感觉不错的工具有点大,无法上传,个人联系方式kingdom_612@
Java程序生成的jar文件
数据库包,只是引用,既使生成exe后,这些包
也不能删
OK啦。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• execute是bolt实现核心, 完成自己的逻辑,即接受每一
次取消息后,处理完,有可能用collector 将产生的新消息 emit出去
Jstorm例子
• declareOutputFields, 定义bolt发送数据,每个字段的含 义 • getComponentConfiguration 获取本bolt的component 配 置
Jstorm架构及数据模型
– nimnus:主控节点,负责在集群中发布代码,分配工作给机器 ,并且监听状态 – supervisor:一个机器,工作节点,会监听分配给的工作,根据 需要启动和关闭工作进程。 – woker:执行topology的工作进程,用于生成task – task:每个spout和bolt都可以作为task在storm中运行,一个task 对应一个线程
Jstorm架构及数据模型
JStorm在模型上和MapReduce有很多相似的地方,下表 从不同维度对JStorm和MapReduce进行了比较。
Jstorm架构及数据模型
• 对象介绍 – topology:一个拓扑是一个个计算节点组成的图,每个节点包换 处理的逻辑,节点之间的连线表示数据流动的方向 – spout:表示一个流的源头,产生tuple – bolt:处理输入流并产生多个输出流,可以做简单的数据转换计 算,复杂的流处理一般需要经过多个bolt进行处理 – tuple:表示流中一个基本的处理单元,可以包括多个field,每 个filed表示一个属性
Jstorm ACK机制
• C接收到T1并成功处理后: R2=r1 <id0,<taskA,r1^r2^R2>> =<id0,<taskA,r1^r2^r1>> =<id0,<taskA,r2>>
• D接收到T2并成功处理后: R3=r2
<id0,<taskA,r2^R3>> =<id0,<taskA,r2^r2>> =<id0,<taskA,0>> • 当结果为0时Acker可以通知taskA根消息id0的消息树已被成功处理 完成。
Jstorm例子
• 创建topology的生成器
– TopologyBuilder builder = new TopologyBuilder();
• 创建Spout, 其中new CaseSpout() 为真正spout对象,第一个
参数为spout名 第三个参数为任务数(并发线程数)
– builder.setSpout("CaseSpout", new CaseSpout(emitNum), spout_Parallelism_hint);
Jstorm ACK机制
Jstorm ACK机制
• Acker任务保存了数据结构
– Map<MessageID,Map< TaskID, Value>> – MessageID: Acker 知道Spout任务的哪个消息被成功处理完成 – TaskID:Acker 当消息树处理完成后通知的Spout任务 – Value:一个64bit的长整型数字,是树中所有消息的随机 ID的异 或结果。表示了整棵树的的状态,无论这棵树多大,只需要这 个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答 的时候都会有相同的MessageID发送过来做异或。当Acker发现一 棵树的Value值为0的时候,表明这棵树已经被成功处理完成。
次取消息后,处理完,有可能用collector 将产生的新消息 emit出去
Jstorm例子
bolt对象必须是继承Serializable, 因此要求spout内所有 数据结构必须是可序列化的 • prepare是当task起来后执行的初始化动作 • cleanup是当task被shutdown后执行的动作
• Jstorm提供了6种stream group模型
– 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保 证每个任务获得相等数量的tuple。 – 字段分组(Fields grouping):根据指定字段分割数据流,并分 组。例如,根据“user-id”字段,相同“user-id”的元组总是分发 到同一个任务,不同“user-id”的元组可能分发到不同的任务。 – 全部分组(All grouping):tuple被复制到bolt的所有任务。这种 类型需要谨慎使用。
Jstorm架构及数据模型
• JStorm通过一系列基本元素实现实时计算的目标,其 中包括了Topology、Stream、Spout、Bolt等等。 • 计算任务Topology是由不同的Spout和Bolt通过Stream
连接起来的。下面是一个典型Topology的结构示意图:
Jstorm架构及数据模型
Jstorm架构及数据模型
• 实时计算任务需要打包成Topology提交,和MapReduce Job
相似,不同的是,MapReduce Job在计算完成后结束,而
JStorm的Topology任务一旦提交永远不会结束,除非显式
停止。
Jstorm 架构图
Topology 流程图
Jstorm分配策略
Jstorm例子
• IRichBolt为Bolt接口
Jstorm例子
bolt对象必须是继承Serializable, 因此要求spout内所有 数据结构必须是可序列化的 • prepare是当task起来后执行的初始化动作 • cleanup是当task被shutdown后执行的动作
• execute是bolt实现核心, 完成自己的逻辑,即接受每一
– Custom Grouping:用户自定义分组策略,需要实现的接
CustomStreamGrouping是自定义分组策略时用户口。
Jstorm ACK机制
• 为保证无数据丢失,JStorm使用了非常漂亮的可靠性处理
机制,当定义Topology时指定Acker,JStorm除了Topology本身任 务外,还会启动一组称为Acker的特殊任务,负责跟踪Topolgogy DAG中的每个消息。每当发现一个DAG被成功处理完成,Acker 就向创建根消息的Spout任务发送一个Ack信号。Topology中Acker 任务的并行度默认parallelism hint=1,当系统中有大量的消息时 ,应该适当提高Acker任务的并行度。
Jstorm例子
• 创建bolt, CaseBolt 为bolt名字,new CaseBolt() 为bolt对象
,bolt_Parallelism_hint为bolt并发数,并以shuffleGrouping
方式接受CaseSpout的数据
– builder.setBolt("CaseBolt", new
Jstorm分享
索引 Jstorm背景介绍 Jstorm架构及数据模型 Jstorm分配策略
Jstorm Ack机制
Jstorm实例及讨论
背景介绍
• Storm是开源的分布式容错实时计算系统,核心采用 Clojure实现
• Jstorm是阿里巴巴中间件团队用Java重新实现的类Storm, 在网络IO、线程模型、资源调度、可用性及稳定性上做了 持续改进,可被用于“连续计算”,对数据流做连续处理 ,在计算时就将结果以流的形式输出给用户。
Jstorm分配策略
– 全局分组(Global grouping):全部流都分配到bolt的同一个任 务。明确地说,是分配给ID最小的那个task。 – 无分组(None grouping):你不需要关心流是如何分组。目前 ,无分组等效于随机分组。 – 直接分组(Direct grouping):这是一个特别的分组类型。元组 生产者决定tuple由哪个元组处理者任务接收。
Jstorm ACK机制
boltC spoutA boltB boltD
• A发送T0给B后: R0=r0 ----> <id0,<taskA,R0>> • B接收到T0并成功处理后向C发送T1,向D发送T2: R1=R0^r1^r2=r0^r1^r2
• <id0,<taskA,R0^R1>>
• =<id0,<taskA,r0^r0^r1^r2>> =<id0,<taskA,r1^r2>>
Thanks
• activate 是当task被激活时,触发的动作
• deactivate 是task被deactive时,触发的动作
Jstorm例子
• nextTuple 是spout实现核心, nextuple完成自己的逻辑, 即每一次取消息后,用collector 将消息emit出去 • Ack 当spout收到一条ack消息时,触发的动作 • fail, 当spout收到一条fail消息时,触发的动作 • declareOutputFields, 定义spout发送数据,每个字段的 含义 • getComponentConfiguration 获取本spout的component 配置
CaseBolt(emitNum,calNum,addbolt),
bolt_Parallelism_hint).shuffleGrouping("CaseSpout");
Jstorm例子
• IRichSpout为最简单的Spout接口
Jstorm例子
spout对象必须是继承Serializable, 因此要求spout内所有 数据结构必须是可序列化的 • open是当task起来后执行的初始化动作 • close是当task被shutdown后执行的动作