模式识别实验报告
模式识别上机实验报告

实验一、二维随机数的产生1、实验目的(1) 学习采用Matlab 程序产生正态分布的二维随机数 (2) 掌握估计类均值向量和协方差矩阵的方法(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法(4) 熟悉matlab 中运用mvnrnd 函数产生二维随机数等matlab 语言2、实验原理多元正态分布概率密度函数:11()()2/21/21()(2)||T X X d p X eμμπ---∑-=∑其中:μ是d 维均值向量:Td E X μμμμ=={}[,,...,]12Σ是d ×d 维协方差矩阵:TE X X μμ∑=--[()()](1)估计类均值向量和协方差矩阵的估计 各类均值向量1ii X im X N ω∈=∑ 各类协方差矩阵1()()iTi iiX iX X N ωμμ∈∑=--∑(2)类间离散度矩阵、类内离散度矩阵的计算类内离散度矩阵:()()iTi iiX S X m X m ω∈=--∑, i=1,2总的类内离散度矩阵:12W S S S =+类间离散度矩阵:1212()()Tb S m m m m =--3、实验内容及要求产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
1[2,2]μ=--,11001⎡⎤∑=⎢⎥⎣⎦,2[2,2]μ=,21004⎡⎤∑=⎢⎥⎣⎦ (1)画出样本的分布图;(2) 编写程序,估计类均值向量和协方差矩阵;(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵; (4)每类样本数增加到500个,重复(1)-(3)4、实验结果(1)、样本的分布图(2)、类均值向量、类协方差矩阵根据matlab 程序得出的类均值向量为:N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678] N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270] 根据matlab 程序得出的类协方差矩阵为:N=50: ]0628.11354.01354.06428.1[1=∑ ∑--2]5687.40624.00624.08800.0[N=500:∑--1]0344.10162.00162.09187.0[∑2]9038.30211.00211.09939.0[(3)、类间离散度矩阵、类内离散度矩阵根据matlab 程序得出的类间离散度矩阵为:N=50: ]4828.147068.147068.149343.14[=bS N=500: ]3233.179843.169843.166519.16[b =S根据matlab 程序得出的类内离散度矩阵为:N=50:]0703.533088.73088.71052.78[1=S ]7397.2253966.13966.18975.42[2--=S ]8100.2789123.59123.50026.121[=W SN=500: ]5964.5167490.87490.86203.458[1--=S ]8.19438420.78420.70178.496[2=S ]4.24609071.09071.06381.954[--=W S5、结论由mvnrnd 函数产生的结果是一个N*D 的一个矩阵,在本实验中D 是2,N 是50和500.根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。
模式识别实验报告

模式识别实验报告————————————————————————————————作者:————————————————————————————————日期:实验报告实验课程名称:模式识别姓名:王宇班级: 20110813 学号: 2011081325实验名称规范程度原理叙述实验过程实验结果实验成绩图像的贝叶斯分类K均值聚类算法神经网络模式识别平均成绩折合成绩注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2014年 6月实验一、 图像的贝叶斯分类一、实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念:阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
模式识别 实验报告一

402
132
识别正确率
73.36
84.87
99.71
70.31
82.89
86.84
结果分析:
实验中图像3的识别率最高,图像1和图像2的识别率次之。图像1和图像2的分辨率相对图像3更低,同时图像2有折痕影响而图像1则有大量噪声。通过阈值处理能较好的处理掉图像1的噪声和图像2的折痕,从而使得图像1的识别率有所提升,而图像2的识别率变化不大。从而可以得出结论,图像3和图像2识别率不同的原因主要在于图像分辨率,而图像2和图像1识别率的不同则在于噪声干扰。
实验报告
题目
模式识别系列实验——实验一字符识别实验
内容:
1.利用OCR软件对文字图像进行识别,了解图像处理与模式识别的关系。
2.利用OCR软件对文字图像进行识别,理解正确率的概念。
实验要求:
1.利用photoshop等软件对效果不佳的图像进行预处理,以提高OCR识别的正确率。
2.用OCR软件对未经预处理和经过预处理的简体和繁体中文字符图像进行识别并比较正确率。
图像4内容既有简体又有繁体,从识别结果中可了解到错误基本处在繁体字。
遇到的问题及解决方案:
实验中自动旋转几乎没效果,所以都是采用手动旋转;在对图像4进行识别时若采用系统自己的版面分析,则几乎识别不出什么,所以实验中使用手动画框将诗的内容和标题及作者分开识别。
主要实验方法:
1.使用汉王OCR软件对所给简体和繁体测试文件进行识别;
2.理,再次识别;
实验结果:
不经过图像预处理
经过图像预处理
实验图像
图像1
图像2
图像3
图像4
图像1
图像2
字符总数
458
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。
《模式识别》实验报告K-L变换特征提取

《模式识别》实验报告K-L变换特征提取基于K-L 变换的iris 数据分类⼀、实验原理K-L 变换是⼀种基于⽬标统计特性的最佳正交变换。
它具有⼀些优良的性质:即变换后产⽣的新的分量正交或者不相关;以部分新的分量表⽰原⽮量均⽅误差最⼩;变换后的⽮量更趋确定,能量更集中。
这⼀⽅法的⽬的是寻找任意统计分布的数据集合之主要分量的⼦集。
设n 维⽮量12,,,Tn x x x =x ,其均值⽮量E=µx ,协⽅差阵()T x E=--C x u)(x u ,此协⽅差阵为对称正定阵,则经过正交分解克表⽰为x =TC U ΛU ,其中12,,,[]n diag λλλ=Λ,12,,,n u u u =U 为对应特征值的特征向量组成的变换阵,且满⾜1T-=UU。
变换阵TU 为旋转矩阵,再此变换阵下x 变换为()T -=x u y U ,在新的正交基空间中,相应的协⽅差阵12[,,,]xn diag λλλ==x U C U C。
通过略去对应于若⼲较⼩特征值的特征向量来给y 降维然后进⾏处理。
通常情况下特征值幅度差别很⼤,忽略⼀些较⼩的值并不会引起⼤的误差。
对经过K-L 变换后的特征向量按最⼩错误率bayes 决策和BP 神经⽹络⽅法进⾏分类。
⼆、实验步骤(1)计算样本向量的均值E =µx 和协⽅差阵()T xE ??=--C x u)(x u5.8433 3.0573 3.7580 1.1993??=µ,0.68570.0424 1.27430.51630.04240.189980.32970.12161.27430.3297 3.1163 1.29560.51630.12161.29560.5810x----=--C (2)计算协⽅差阵xC 的特征值和特征向量,则4.2282 , 0.24267 , 0.07821 , 0.023835[]diag =Λ-0.3614 -0.6566 0.5820 0.3155 0.0845 -0.7302 -0.5979 -0.3197 -0.8567 0.1734 -0.0762 -0.4798 -0.3583 0.0755 -0.5458 0.7537??=U从上⾯的计算可以看到协⽅差阵特征值0.023835和0.07821相对于0.24267和4.2282很⼩,并经计算个特征值对误差影响所占⽐重分别为92.462%、5.3066%、1.7103%和0.52122%,因此可以去掉k=1~2个最⼩的特征值,得到新的变换阵12,,,newn k u u u -=U。
模式识别与智能信息处理实践实验报告

模式识别与智能信息处理实践实验报告
一、实验目的
本次实验的目的是:实现基于Matlab的模式识别与智能信息处理。
二、实验内容
1.对实验图片进行处理
根据实验要求,我们选取了两张图片,一张是原始图片,一张是锐化处理后的图片。
使用Matlab的imtool命令进行处理,实现对图片锐化、模糊处理、边缘检测、图像增强等功能。
2.基于模式识别算法进行图像分类
通过Matlab的k-means算法和PCA算法对实验图片进行图像分类,实现对图像数据特征提取,并将图像分类结果可视化。
3.使用智能信息处理技术处理实验数据
使用Matlab的BP网络算法,对实验图片进行处理,并实现实验数据的智能信息处理,以获得准确的分类结果。
三、实验结果
1.图片处理结果
2.图像分类结果
3.智能信息处理结果
四、总结
本次实验中,我们利用Matlab进行模式识别与智能信息处理的实践,实现了对图片的处理,图像分类,以及智能信息处理,从而获得准确的分
类结果。
《模式识别》线性分类器设计实验报告
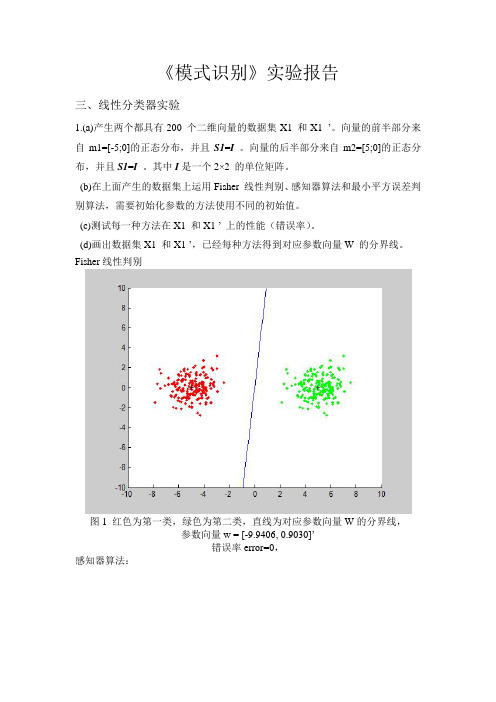
《模式识别》实验报告三、线性分类器实验1.(a)产生两个都具有200 个二维向量的数据集X1 和X1 ’。
向量的前半部分来自m1=[-5;0]的正态分布,并且S1=I 。
向量的后半部分来自m2=[5;0]的正态分布,并且S1=I。
其中I是一个2×2 的单位矩阵。
(b)在上面产生的数据集上运用Fisher 线性判别、感知器算法和最小平方误差判别算法,需要初始化参数的方法使用不同的初始值。
(c)测试每一种方法在X1 和X1 ’ 上的性能(错误率)。
(d)画出数据集X1 和X1 ’,已经每种方法得到对应参数向量W 的分界线。
Fisher线性判别图1 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数向量w = [-9.9406, 0.9030]’错误率error=0,感知器算法:图2 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1;0.1];迭代次数iter=2参数向量w = [-4.8925, 0.0920]’错误率error=0图3 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];迭代次数iter=2参数向量w = [-3.9925, 0.9920]’错误率error=0图4 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[10; 10];迭代次数iter=122参数向量w = [-5.6569, 7.8096]’错误率error=0图5 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 50];迭代次数iter=600参数向量w = [-27.0945, 37.4194]’错误率error=0图6 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 100];迭代次数iter=1190参数向量w = [-54.0048, 74.5875]’错误率error=0最小平方误差判别算法:图7 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1; 0.1];参数向量w = [-0.1908, -0.0001]’错误率error=0图8 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.5; 0.5];参数向量w = [-0.1924, 0.1492]’错误率error=0图9 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 0.5];参数向量w = [-0.1914, 0.0564]’错误率error=0图10 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];参数向量w = [-0.1943, 0.3359]’错误率error= 0.00502.重复1.中的实验内容,数据集为X2 和X2 ’。
模式识别实验报告

模式识别实验报告关键信息项:1、实验目的2、实验方法3、实验数据4、实验结果5、结果分析6、误差分析7、改进措施8、结论1、实验目的11 阐述进行模式识别实验的总体目标和期望达成的结果。
111 明确实验旨在解决的具体问题或挑战。
112 说明实验对于相关领域研究或实际应用的意义。
2、实验方法21 描述所采用的模式识别算法和技术。
211 解释选择这些方法的原因和依据。
212 详细说明实验的设计和流程,包括数据采集、预处理、特征提取、模型训练和测试等环节。
3、实验数据31 介绍实验所使用的数据来源和类型。
311 说明数据的规模和特征。
312 阐述对数据进行的预处理操作,如清洗、归一化等。
4、实验结果41 呈现实验得到的主要结果,包括准确率、召回率、F1 值等性能指标。
411 展示模型在不同数据集或测试条件下的表现。
412 提供可视化的结果,如图表、图像等,以便更直观地理解实验效果。
5、结果分析51 对实验结果进行深入分析和讨论。
511 比较不同实验条件下的结果差异,并解释其原因。
512 分析模型的优点和局限性,探讨可能的改进方向。
6、误差分析61 研究实验中出现的误差和错误分类情况。
611 分析误差产生的原因,如数据噪声、特征不充分、模型复杂度不足等。
612 提出减少误差的方法和建议。
7、改进措施71 根据实验结果和分析,提出针对模型和实验方法的改进措施。
711 描述如何优化特征提取、调整模型参数、增加训练数据等。
712 预测改进后的可能效果和潜在影响。
8、结论81 总结实验的主要发现和成果。
811 强调实验对于模式识别领域的贡献和价值。
812 对未来的研究方向和进一步工作提出展望。
在整个实验报告协议中,应确保各项内容的准确性、完整性和逻辑性,以便为模式识别研究提供有价值的参考和借鉴。
感知准则函数

《模式识别》实验报告1 实验目的1. 学习和掌握关于感知准则函数的知识;2. 应用感知准则函数求解判决面,解决模式识别的分类问题;2 实验内容利用感知准则函数用感知准则函数的方法求解以下数据的判决面,学习率为ρt=0.1,画出每次迭代法向量的变化轨迹,并画出最终的判决曲线。
3 实验原理或步骤初始的线性判别函数为g(x) = w T x + w0为了讨论方便,把向量x 增加一维,但取其值为常数,即定义y = [1,x1,x2,···,x d]T1其中,x1 为样本x 的第i 维分量。
我们称y 为增广的样本向量。
相应地,定义增广的权向量为α = [w0,w1,w2,···,w d]T线性判别函数变为g(y) = αT y决策规则是:如果g(y) > 0,则y ∈ω1;如果g(y) < 0,则y ∈ω2。
设一组样本为y1···,y N,若存在权向量α,使得对于样本集中的任意一个样本y i,i=1,···,N,若y ∈ω1 则αT y i > 0,若y ∈ω2 则αT y i < 0,那么称这组样本或这个样本集是线性可分的。
即在样本的特征空间中,至少存在一个线性分类面能够把两类样本没有错误地分开。
如果定义一个新的变量y′,使对于第一类的样本y′=y,而对第二类样本则y′=−y,即其中i = 1,2,···,N则样本可分性条件就变成了存在α,使这样定义的y′称作规范化增广样本向量。
为了讨论方便,都采用规范化增广样本向量,并且把y′仍然记作y。
对于权向量α,如果某个样本y k 被错误分类,则αT y k ≤ 0。
我们可以用对所有错分样本的求和来表示对错分样本的惩罚这就是Rosenblatt 提出的感知器准则函数。
显然,当且仅当J P(α∗) = minJ P(α) = 0 时α∗是解向量。
模式识别实验【范本模板】

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
模式识别实验报告

实验一Bayes 分类器设计本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
1实验原理最小风险贝叶斯决策可按下列步骤进行:(1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即则k a 就是最小风险贝叶斯决策。
2实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进行分类。
3 实验要求1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。
2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。
模式识别实验报告

二、实验步骤 前提条件: 只考虑第三种情况:如果 di(x) >dj(x) 任意 j≠ i ,则判 x∈ωi 。
○1 、赋初值,分别给 c 个权矢量 wi(1)(i=1,2,…c)赋任意的初
值,选择正常数ρ ,置步数 k=1;
○2 、输入符号未规范化的增广训练模式 xk, xk∈{x1, x2… xN} ,
二、实验步骤
○1 、给出 n 个混合样本,令 I=1,表示迭代运算次数,选取 c
个初始聚合中心 ,j=1,2,…,c;
○2 、 计 算 每 个 样 本 与 聚 合 中 心 的 距 离
,
。
若
, ,则
。
○3 、 计 算 c 个 新 的 聚 合 中 心 :
,
。
○4 、判断:若
,
,则 I=I+1,返回
第二步 b 处,否则结束。 三、程序设计
聚类没有影响。但当 C=2 时,该类别属于正确分类。 而类别数目大于 2 时,初始聚合中心对聚类的影响非常大,仿真
结果多样化,不能作为分类标准。 2、考虑类别数目对聚类的影响: 当类别数目变化时,结果也随之出现变化。 3、总结 综上可知,只有预先分析过样本,确定合适的类别数目,才能对
样本进行正确分类,而初始聚合中心对其没有影响。
8
7
6
5
4
3
2
1
0
0
1
2
3
4
5
6
7
8
9
初始聚合中心为(0,0),(2,2),(5,5),(7,7),(9,9)
K-均 值 聚 类 算 法 : 类 别 数 目 c=5 9
8
7
6
5
4
模式识别实验报告

模式识别实验报告班级:电信08-1班姓名:黄**学号:********课程名称:模式识别导论实验一安装并使用模式识别工具箱一、实验目的:1.掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;2.熟练使用最小错误率贝叶斯决策器对样本分类;3.熟练使用感知准则对样本分类;4.熟练使用最小平方误差准则对样本分类;5.了解近邻法的分类过程,了解参数K值对分类性能的影响(选做);6.了解不同的特征提取方法对分类性能的影响(选做)。
二、实验内容与原理:1.安装模式识别工具箱;2.用最小错误率贝叶斯决策器对呈正态分布的两类样本分类;3.用感知准则对两类可分样本进行分类,并观测迭代次数对分类性能的影响;4.用最小平方误差准则对云状样本分类,并与贝叶斯决策器的分类结果比较;5.用近邻法对双螺旋样本分类,并观测不同的K值对分类性能的影响(选做);6.观测不同的特征提取方法对分类性能的影响(选做)。
三、实验器材(设备、元器件、软件工具、平台):1.PC机-系统最低配置512M 内存、P4 CPU;2.Matlab 仿真软件-7.0 / 7.1 / 2006a等版本的Matlab 软件。
四、实验步骤:1.安装模式识别工具箱。
并调出Classifier主界面。
2.调用XOR.mat文件,用最小错误率贝叶斯决策器对呈正态分布的两类样本分类。
3.调用Seperable.mat文件,用感知准则对两类可分样本进行分类。
4.调用Clouds.mat文件,用最小平方误差准则对两类样本进行分类。
5.调用Spiral.mat文件,用近邻法对双螺旋样本进行分类。
6.调用XOR.mat文件,用特征提取方法对分类效果的影响。
五、实验数据及结果分析:(1)Classifier主界面如下(2)最小错误率贝叶斯决策器对呈正态分布的两类样本进行分类结果如下:(3)感知准则对两类可分样本进行分类当Num of iteration=300时的情况:当Num of iteration=1000时的分类如下:(4)最小平方误差准则对两类样本进行分类结果如下:(5)近邻法对双螺旋样本进行分类,结果如下当Num of nearest neighbor=3时的情况为:当Num of nearest neighbor=12时的分类如下:(6)特征提取方法对分类结果如下当New data dimension=2时,其结果如下当New data dimension=1时,其结果如下六、实验结论:本次实验使我掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;对模式识别有了初步的了解。
模式识别技术实验报告

模式识别技术实验报告本实验旨在探讨模式识别技术在计算机视觉领域的应用与效果。
模式识别技术是一种人工智能技术,通过对数据进行分析、学习和推理,识别其中的模式并进行分类、识别或预测。
在本实验中,我们将利用机器学习算法和图像处理技术,对图像数据进行模式识别实验,以验证该技术的准确度和可靠性。
实验一:图像分类首先,我们将使用卷积神经网络(CNN)模型对手写数字数据集进行分类实验。
该数据集包含大量手写数字图片,我们将训练CNN模型来识别并分类这些数字。
通过调整模型的参数和训练次数,我们可以得到不同准确度的模型,并通过混淆矩阵等评估指标来评估模型的性能和效果。
实验二:人脸识别其次,我们将利用人脸数据集进行人脸识别实验。
通过特征提取和比对算法,我们可以识别不同人脸之间的相似性和差异性。
在实验过程中,我们将测试不同算法在人脸识别任务上的表现,比较它们的准确度和速度,探讨模式识别技术在人脸识别领域的应用潜力。
实验三:异常检测最后,我们将进行异常检测实验,使用模式识别技术来识别图像数据中的异常点或异常模式。
通过训练异常检测模型,我们可以发现数据中的异常情况,从而做出相应的处理和调整。
本实验将验证模式识别技术在异常检测领域的有效性和实用性。
结论通过以上实验,我们对模式识别技术在计算机视觉领域的应用进行了初步探索和验证。
模式识别技术在图像分类、人脸识别和异常检测等任务中展现出了良好的性能和准确度,具有广泛的应用前景和发展空间。
未来,我们将进一步深入研究和实践,探索模式识别技术在更多领域的应用,推动人工智能技术的发展和创新。
【字数:414】。
模式识别实验

姓名:学号:院系:电子与信息工程学院课程名称:模式识别实验名称:神经网络用于模式识别同组人:实验成绩:总成绩:教师评语教师签字:年月日1实验目的1.掌握人工神经网络的基本结构与原理,理解神经网络在模式识别中的应用;2.学会使用多输入多输出结构,构造三层神经网络并对给定的样本进行分类;3.分析学习效率η,惯性系数α,总的迭代次数N,训练控制误差ε,初始化权值以及隐层节点数对网络性能的影响;4.采用批处理BP重复算法进行分类,结果与三层神经网络进行对比。
2原理2.1人工神经网络人工神经网络(Artificial Neural Network,即ANN),是20世纪80年代以来人工智能领域兴起的研究热点。
它从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。
在工程与学术界也常直接简称为神经网络或类神经网络。
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。
每个节点代表一种特定的输出函数,称为激励函数(activation function)。
每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。
网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。
而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
最近十多年来,人工神经网络的研究工作不断深入,已经取得了很大的进展,其在模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等领域已成功地解决了许多现代计算机难以解决的实际问题,表现出了良好的智能特性。
2.1.1人工神经元图 1 生物神经元神经元是大脑处理信息的基本单元,以细胞体为主体,由许多向周围延伸的不规则树枝状纤维构成的神经细胞,其形状很像一棵枯树的枝干。
它主要由细胞体、树突、轴突和突触(Synapse,又称神经键)组成。
胞体:是神经细胞的本体(可看成系统);树突:长度较短,接受自其他神经元的信号(输入); 轴突:它用以输出信号;突触:它是一个神经元与另一个神经元相联系的部位,是一个神经元轴突的端部将信号(兴奋)传递给下一个神经元的树突或胞体;对树突的突触多为兴奋性的,使下一个神经元兴奋;而对胞体的突触多为抑制性,其作用是阻止下一个神经元兴奋。
模式识别实验报告哈工程

一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。
模式识别方PCA实验报告

模式识别作业《模式识别》大作业人脸识别方法一 ---- 基于PCA 和欧几里得距离判据的模板匹配分类器一、 理论知识1、主成分分析主成分分析是把多个特征映射为少数几个综合特征的一种统计分析方法。
在多特征的研究中,往往由于特征个数太多,且彼此之间存在着一定的相关性,因而使得所观测的数据在一定程度上有信息的重叠。
当特征较多时,在高维空间中研究样本的分布规律就更麻烦。
主成分分析采取一种降维的方法,找出几个综合因子来代表原来众多的特征,使这些综合因子尽可能地反映原来变量的信息,而且彼此之间互不相关,从而达到简化的目的。
主成分的表示相当于把原来的特征进行坐标变换(乘以一个变换矩阵),得到相关性较小(严格来说是零)的综合因子。
1.1 问题的提出一般来说,如果N 个样品中的每个样品有n 个特征12,,n x x x ,经过主成分分析,将它们综合成n 综合变量,即11111221221122221122n n n n n n n nn ny c x c x c x y c x c x c x y c x c x c x =+++⎧⎪=+++⎪⎨⎪⎪=+++⎩ij c 由下列原则决定:1、i y 和j y (i j ≠,i,j = 1,2,...n )相互独立;2、y 的排序原则是方差从大到小。
这样的综合指标因子分别是原变量的第1、第2、……、第n 个主分量,它们的方差依次递减。
1.2 主成分的导出我们观察上述方程组,用我们熟知的矩阵表示,设12n x x X x ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦是一个n 维随机向量,12n y y Y y ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦是满足上式的新变量所构成的向量。
于是我们可以写成Y=CX,C 是一个正交矩阵,满足CC ’=I 。
坐标旋转是指新坐标轴相互正交,仍构成一个直角坐标系。
变换后的N 个点在1y 轴上有最大方差,而在n y 轴上有最小方差。
同时,注意上面第一条原则,由此我们要求i y 轴和j y 轴的协方差为零,那么要求T YY =Λ12n λλλ⎡⎤⎢⎥⎢⎥Λ=⎢⎥⎢⎥⎣⎦令TR XX =,则T TRC C =Λ经过上面式子的变换,我们得到以下n 个方程111111212112111221122111121211()0()0()0n n n n n n nn n r c r c r c r c r c r c r c r c r c λλλ-+++=+-++=+++-=1.3 主成分分析的结果我们要求解出C ,即解出上述齐次方程的非零解,要求ij c 的系数行列式为0。
模式识别实验报告

模式识别实验报告实验一、线性分类器的设计与实现1. 实验目的:掌握模式识别的基本概念,理解线性分类器的算法原理。
2. 实验要求:(1)学习和掌握线性分类器的算法原理;(2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类;(3)对实现的线性分类器性能进行简单的评估(例如算法适用条件,算法效率及复杂度等)。
注:三种线性分类器为,单样本感知器算法、批处理感知器算法、最小均方差算法批处理感知器算法算法原理:感知器准则函数为J p a=(−a t y)y∈Y,这里的Y(a)是被a错分的样本集,如果没有样本被分错,Y就是空的,这时我们定义J p a为0.因为当a t y≤0时,J p a是非负的,只有当a是解向量时才为0,也即a在判决边界上。
从几何上可知,J p a是与错分样本到判决边界距离之和成正比的。
由于J p梯度上的第j个分量为∂J p/ða j,也即∇J p=(−y)y∈Y。
梯度下降的迭代公式为a k+1=a k+η(k)yy∈Y k,这里Y k为被a k错分的样本集。
算法伪代码如下:begin initialize a,η(∙),准则θ,k=0do k=k+1a=a+η(k)yy∈Y k|<θuntil | ηk yy∈Y kreturn aend因此寻找解向量的批处理感知器算法可以简单地叙述为:下一个权向量等于被前一个权向量错分的样本的和乘以一个系数。
每次修正权值向量时都需要计算成批的样本。
算法源代码:unction [solution iter] = BatchPerceptron(Y,tau)%% solution = BatchPerceptron(Y,tau) 固定增量批处理感知器算法实现%% 输入:规范化样本矩阵Y,裕量tau% 输出:解向量solution,迭代次数iter[y_k d] = size(Y);a = zeros(1,d);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% k=0;y_temp=zeros(d,1);while k<k_maxc=0;for i=1:1:y_kif Y(i,:)*a'<=tauy_temp=y_temp+Y(i,:)';c=c+1;endendif c==0break;enda=a+y_temp';k=k+1;end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %k = k_max;solution = a;iter = k-1;运行结果及分析:数据1的分类结果如下由以上运行结果可以知道,迭代17次之后,算法得到收敛,解出的权向量序列将样本很好的划分。
模式识别实验报告_3

模式识别实验报告_3第⼀次实验实验⽬的:1.学习使⽤ENVI2.会⽤MATLAB读⼊遥感数据并进⾏处理实验内容:⼀学习使⽤ENVI1.使⽤ENVI打开遥感图像(任选3个波段合成假彩⾊图像,保存写⼊报告)2.会查看图像的头⽂件(保存或者copy⾄报告)3.会看地物的光谱曲线(保存或者copy⾄报告)4.进⾏数据信息统计(保存或者copy⾄报告)5.设置ROI,对每类地物⾃⼰添加标记数据,并保存为ROI⽂件和图像⽂件(CMap贴到报告中)。
6.使⽤⾃⼰设置的ROI进⾏图像分类(ENVI中的两种有监督分类算法)(分类算法名称和分类结果写⼊报告)⼆MATLAB处理遥感数据(提交代码和结果)7.⽤MATLAB读⼊遥感数据(zy3和DC两个数据)8.⽤MATLAB读⼊遥感图像中ROI中的数据(包括数据和标签)9.把图像数据m*n*L(其中m表⽰⾏数,n表⽰列数,L表⽰波段数),重新排列为N*L的⼆维矩阵(其中N=m*n),其中N表⽰所有的数据点数量m*n。
(提⽰,⽤reshape函数,可以help查看这个函数的⽤法)10.计算每⼀类数据的均值(平均光谱),并把所有类别的平均光谱画出来(plot)(类似下⾯的效果)。
11.画出zy3数据中“农作物类别”的数据点(⾃⼰ROI标记的这个类别的点)在每个波段的直⽅图(matlab函数:nbins=50;hist(Xi,nbins),其中Xi表⽰这类数据在第i波段的数值)。
计算出这个类别数据的协⽅差矩阵,并画出(figure,imagesc(C),colorbar)。
1.打开遥感图像如下:2.查看图像头⽂件过程如下:3.地物的光谱曲线如下:4.数据信息统计如下:(注:由于保存的txt⽂件中的数据信息过长,所以采⽤截图的⽅式只显⽰了出⼀部分数据信息)5.设置ROI,对每类地物⾃⼰添加标记数据,CMap如下:6.使⽤⾃⼰设置的ROI进⾏图像分类(使⽤⽀持向量机算法和最⼩距离算法),⽀持向量机算法分类结果如下:最⼩距离算法分类结果如下:对⽐两种算法的分类结果可以看出⽀持分量机算法分类结果⽐最⼩距离算法分类结果好⼀些。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告实验课程名称:模式识别姓名:王宇班级: 20110813 学号: 2011081325注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2014年 6月实验一、 图像的贝叶斯分类一、实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念:阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。
图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。
如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。
如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。
假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。
以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为1122()()()p x P p x P p x =+式中1p 和2p 分别为2121()21()x p x μσ--=2222()22()x p x μσ--=121P P +=1σ、2σ是针对背景和目标两类区域灰度均值1μ与2μ的标准差。
若假定目标的灰度较亮,其灰度均值为2μ,背景的灰度较暗,其灰度均值为1μ,因此有12μμ<现若规定一门限值T 对图像进行分割,势必会产生将目标划分为背景和将背景划分为目标这两类错误。
通过适当选择阈值T ,可令这两类错误概率为最小,则该阈值T 即为最佳阈值。
把目标错分为背景的概率可表示为12()()TE T p x dx -∞=⎰把背景错分为目标的概率可表示为21()()TE T p x dx +∞=⎰总的误差概率为2112()()()E T P E T PE T =+为求得使误差概率最小的阈值T ,可将()E T 对T 求导并令导数为零,可得1122()()P p T P p T =代换后,可得221212222111()()ln 22P T T P σμμσσσ---=-此时,若设12σσσ==,则有2122121ln 2P T P μμσμμ⎛⎫+=+ ⎪-⎝⎭若还有12P P =的条件,则122T μμ+=这时的最优阈值就是两类区域灰度均值1μ与2μ的平均值。
上面的推导是针对图像灰度值服从正态分布时的情况,如果灰度值服从其它分布,依理也可求出最优阈值来。
一般情况下,在不清楚灰度值分布时,通常可假定灰度值服从正态分布。
在实际使用最优阈值进行分割的过程中,需要利用迭代算法来求得最优阈值。
设有一幅数字图像(,)f x y ,混有加性高斯噪声,可表示为(,)(,)(,)g x y f x y n x y =+此处假设图像上各点的噪声相互独立,且具有零均值,如果通过阈值分割将图像分为目标与背景两部分,则每一部分仍然有噪声点随机作用于其上,于是,目标1(,)g x y 和2(,)g x y 可表示为11(,)(,)(,)g x y f x y n x y =+ 22(,)(,)(,)g x y f x y n x y =+迭代过程中,会多次地对1(,)g x y 和2(,)g x y 求均值,则111{(,)}{(,)(,)}{(,)}E g x y E f x y n x y E f x y =+= 222{(,)}{(,)(,)}{(,)}E g x y E f x y n x y E f x y =+=可见,随着迭代次数的增加,目标和背景的平均灰度都趋向于真实值。
因此,用迭代算法求得的最佳阈值不受噪声干扰的影响。
四、实验步骤及程序 1、实验步骤(1)确定一个初始阈值0T ,0T 可取为min max02S S T +=式中,min S 和max S 为图像灰度的最小值和最大值。
(2)利用第k 次迭代得到的阈值将图像分为目标1R 和背景2R 两大区域,其中1{(,)|(,)}k R f x y f x y T =≥ 2{(,)|0(,)}k R f x y f x y T =<<(3)计算区域1R 和2R 的灰度均值1S 和2S 。
(4)计算新的阈值1k T +,其中1212k S S T ++=(5)如果1||k k T T +-小于允许的误差,则结束,否则1k k =+,转步骤(2)。
2、实验源程序I=imread('1.jpg'); Im=rgb2gray(I);subplot(121),imhist(Im);title('Ö±·½Í¼') ZMax=max(max(I)); ZMin=min(min(I)); TK=(ZMax+ZMin)/2; bCal=1; iSize=size(I); while (bCal) iForeground=0; iBackground=0; ForegroundSum=0; BackgroundSum=0; for i=1:iSize(1) for j=1:iSize(2) tmp=I(i,j); if (tmp>=TK)iForeground=iForeground+1;ForegroundSum=ForegroundSum+double(tmp); elseiBackground=iBackground+1;BackgroundSum=BackgroundSum+double(tmp); end end endZO=ForegroundSum/iForeground; ZB=BackgroundSum/iBackground; TKTmp=double((ZO+ZB)/2); if (TKTmp==TK) bCal=0; elseTK=TKTmp;endenddisp(strcat('µü´úºóµÄãÐÖµ£º',num2str(TK))); newI=im2bw(I,double(TK)/255);subplot(121),imshow(I)title('Ô-ͼÏñ')subplot(122),imshow(newI)title('·Ö¸îºóµÄͼÏñ')五、实验结果与分析1、实验结果直方图0100200原图像图1 原图像以及其灰度直方图原图像分割后的图像图2 原图像以及分割后图像2、实验结果分析迭代后的阈值:94.8064实验中将大于阈值的部分设置为目标,小于阈值的部分设置为背景,分割结果大体上满足要求。
实际过程中在利用迭代法求得最优阈值后,仍需进行一些人工调整才能将此阈值用于实验图像的分割,虽然这种方法利用了图像中所有像素点的信息,但当光照不均匀时,图像中部分区域的灰度值可能差距较大,造成计算出的最优阈值分割效果不理想。
具体的改进措施分为以下两方面:一方面,在选取图片时,该图片的两个独立的峰值不够明显,因此在分割后产生误差,应改进选择的图片的背景和物体的对比度,使得分割的效果更好;另一方面,实验程序中未涉及计算最优阈值时的迭代次数,无法直观的检测,应在实验程序中加入此项,便于分析。
实验二、K 均值聚类算法一、实验目的将模式识别方法与图像处理技术相结合,掌握利用K 均值聚类算法进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件 HP D538、MATLAB 、WIT 三、实验原理K 均值聚类法分为三个步骤: 初始化聚类中心1、根据具体问题,凭经验从样本集中选出C 个比较合适的样本作为初始聚类中心。
2、用前C 个样本作为初始聚类中心。
3、将全部样本随机地分成C 类,计算每类的样本均值,将样本均值作为初始聚类中心。
初始聚类1、按就近原则将样本归入各聚类中心所代表的类中。
2、取一样本,将其归入与其最近的聚类中心的那一类中,重新计算样本均值,更新聚类中心。
然后取下一样本,重复操作,直至所有样本归入相应类中。
判断聚类是否合理1、采用误差平方和准则函数判断聚类是否合理,不合理则修改分类。
循环进行判断、修改直至达到算法终止条件。
2、聚类准则函数误差平方和准则函数(最小平方差划分)∑∑=Γ∈-=ci x i im x J 12e∑Γ∈=ix ii x N m 13、单样本改进:每调整一个样本的类别就重新计算一次聚类的中心(){(){}22min 1k m x k m x d l j li j ji -=-=i=1,2,...c 只调整一个样本四、实验步骤及程序 1、实验步骤理解K 均值算法基本原理,编写程序实现对自选图像的分类,并将所得结果与WIT 处理结果进行对比。
K 均值算法步骤:1、给定类别数C 和允许误差m ax E ,1←k2、初始化聚类中心()c i k m i ,...,2,1,=3、修正(){(){}22min 1k m x k m x d i jii jji -=-=0其他i=1,2,......,c;j=1,2,...N4、修正聚类中心()∑∑===+Nj jiNj jjii dx dk m 1115、计算误差()()∑=-+=ci i i k m k m e 121如果max E e 则结束,否则转(3)2、实验源程序clc clear ticRGB= imread ('Water lilies.jpg'); %¶ÁÈëÏñ img=rgb2gray(RGB); [m,n]=size(img);subplot(2,2,1),imshow(img);title(' ͼһ Ô-ͼÏñ')subplot(2,2,2),imhist(img);title(' ͼ¶þ Ô-ͼÏñµÄ»Ò¶ÈÖ±·½Í¼') hold off ; img=double(img); for i=1:200 c1(1)=25; c2(1)=125;c3(1)=200;%Ñ¡ÔñÈý¸ö³õʼ¾ÛÀàÖÐÐÄ r=abs(img-c1(i)); g=abs(img-c2(i));b=abs(img-c3(i));%¼ÆËã¸÷ÏñËػҶÈÓë¾ÛÀàÖÐÐĵľàÀë r_g=r-g;g_b=g-b;r_b=r-b;n_r=find(r_g<=0&r_b<=0);%Ñ°ÕÒ×îСµÄ¾ÛÀàÖÐÐÄn_g=find(r_g>0&g_b<=0);%Ñ°ÕÒÖмäµÄÒ»¸ö¾ÛÀàÖÐÐÄn_b=find(g_b>0&r_b>0);%Ñ°ÕÒ×î´óµÄ¾ÛÀàÖÐÐÄi=i+1;c1(i)=sum(img(n_r))/length(n_r);%½«ËùÓеͻҶÈÇóºÍȡƽ¾ù£¬×÷ΪÏÂÒ»¸öµÍ»Ò¶ÈÖÐÐÄc2(i)=sum(img(n_g))/length(n_g);%½«ËùÓеͻҶÈÇóºÍȡƽ¾ù£¬×÷ΪÏÂÒ»¸öÖмä»Ò¶ÈÖÐÐÄc3(i)=sum(img(n_b))/length(n_b);%½«ËùÓеͻҶÈÇóºÍȡƽ¾ù£¬×÷ΪÏÂÒ»¸ö¸ß»Ò¶ÈÖÐÐÄd1(i)=abs(c1(i)-c1(i-1));d2(i)=abs(c2(i)-c2(i-1));d3(i)=abs(c3(i)-c3(i-1));if d1(i)<=0.001&&d2(i)<=0.001&&d3(i)<=0.001R=c1(i);G=c2(i);B=c3(i);k=i;break;endendRGBimg=uint8(img);img(find(img<R))=0;img(find(img>R&img<G))=128;img(find(img>G))=255;tocsubplot(2,2,3),imshow(img);title(' ͼÈý ¾ÛÀàºóµÄͼÏñ')subplot(2,2,4),imhist(img);title(' ͼËÄ ¾ÛÀàºóµÄͼÏñÖ±·½Í¼')五、实验结果与分析1.WIT结果图3 WIT聚类分析系统分析界面图4 WIT聚类分析系统分析结果聚类类别数 3聚类中心 R=18.8709 G=93.3122 B=190.678迭代次数 256运行时间 60.159ms2、K均值聚类结果图一 原图像2000400060008000 图二 原图像的灰度直方图100200图三 聚类后的图像04 图四 聚类后的图像直方图0100200图5 K 均值聚类分析结果 聚类类别数 3聚类中心 R =19.9483 G =94.4184 B =192.3320 迭代次数 8运行时间 2.278493 seconds小结:K 均值聚类方法和WIT 系统操作后对应的聚类中心误差较小,分别是19.9483 94.4184 192.3320和 18.8709 93.3122 190.678。