模式识别实验报告
实验一模式识别范文

实验一模式识别范文
模式识别是计算机科学领域一个研究内容,它的目的是识别永久存在
的模式,以实现有效的数据处理和决策。
它主要集中在分类机制和分类算
法上,并且对特征结构及分类的准确性进行测试以应用到实际需求中。
模式识别是处理大量信息的基础,是一些新的有用信息与其他类别信
息区分的过程。
它可以建模出特殊情况,并有效的对这些类别判断准确性。
模式识别也可以改善监督学习、无监督学习、半监督学习的模式学习和其
他机器学习中的性能。
模式识别有各种应用,比如计算机视觉、声音识别、语言识别、手写
识别、面部识别、自然语言处理等,它们都是基于模式识别技术实现的。
模式识别技术可以大大提升机器人的视觉系统,以实现更准确和更快速的
行为。
在安全管理、公共交通、智能制造和生物医学等领域中,模式识别
技术也有广泛的应用。
模式识别也有其缺点,比如分类算法的运算速度容易延迟,特征选取
也有可能不太准确。
因此要正确使用模式识别,需要为特征选取和算法进
行合理的优化,以保证正确的识别结果。
总之,模式识别是一项广泛应用的技术,它可以提高机器学习的精确度,在计算机视觉等各个领域中有着广泛的应用。
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。
模式识别专业实践报告(2篇)

第1篇一、实践背景与目的随着信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
作为人工智能领域的一个重要分支,模式识别技术对于图像处理、语音识别、生物识别等领域的发展具有重要意义。
为了更好地理解和掌握模式识别技术,提高实际应用能力,我们组织了一次为期一个月的模式识别专业实践。
本次实践旨在通过实际操作,加深对模式识别理论知识的理解,提高解决实际问题的能力。
二、实践内容与过程1. 实践内容本次实践主要包括以下几个方面:(1)图像识别:利用深度学习算法进行图像分类、目标检测等。
(2)语音识别:实现语音信号处理、特征提取和识别。
(3)生物识别:研究指纹识别、人脸识别等生物特征识别技术。
(4)模式分类:运用机器学习算法进行数据分类和聚类。
2. 实践过程(1)理论学习:在实践开始前,我们首先对模式识别的基本理论进行了系统学习,包括图像处理、信号处理、机器学习等相关知识。
(2)项目准备:根据实践内容,我们选取了具有代表性的项目进行实践,如基于深度学习的图像识别、基于HMM的语音识别等。
(3)实验设计与实施:在导师的指导下,我们设计了实验方案,包括数据预处理、模型选择、参数调整等。
随后,我们使用Python、C++等编程语言进行实验编程,并对实验结果进行分析。
(4)问题分析与解决:在实验过程中,我们遇到了许多问题,如数据不足、模型效果不佳等。
通过查阅文献、请教导师和团队成员,我们逐步解决了这些问题。
三、实践成果与分析1. 图像识别我们使用卷积神经网络(CNN)对CIFAR-10数据集进行了图像分类实验。
实验结果表明,经过多次迭代优化,模型在测试集上的准确率达到89.5%,优于传统机器学习方法。
2. 语音识别我们采用HMM(隐马尔可夫模型)对TIMIT语音数据集进行了语音识别实验。
实验结果表明,经过特征提取和模型训练,模型在测试集上的词错误率(WER)为16.3%,达到了较好的识别效果。
3. 生物识别我们研究了指纹识别和人脸识别技术。
模式识别实习报告

一、实习背景随着科技的飞速发展,人工智能、机器学习等技术在各个领域得到了广泛应用。
模式识别作为人工智能的一个重要分支,具有广泛的应用前景。
为了更好地了解模式识别技术,提高自己的实践能力,我在2023年暑假期间参加了某科技有限公司的模式识别实习。
二、实习单位简介某科技有限公司是一家专注于人工智能、大数据、云计算等领域的科技创新型企业。
公司致力于为客户提供智能化的解决方案,业务涵盖智能识别、智能监控、智能分析等多个领域。
此次实习,我将在该公司模式识别部门进行实践学习。
三、实习内容1. 实习前期(1)了解模式识别的基本概念、原理和应用领域;(2)熟悉模式识别的相关算法,如神经网络、支持向量机、决策树等;(3)掌握Python编程语言,学会使用TensorFlow、Keras等深度学习框架。
2. 实习中期(1)参与实际项目,负责模式识别算法的设计与实现;(2)与团队成员协作,完成项目需求分析、算法优化和系统测试;(3)撰写项目报告,总结实习过程中的收获与不足。
3. 实习后期(1)总结实习期间的学习成果,撰写实习报告;(2)针对实习过程中遇到的问题,查找资料、请教同事,提高自己的解决问题的能力;(3)为后续实习工作做好充分准备。
四、实习收获与体会1. 理论与实践相结合通过实习,我深刻体会到理论与实践相结合的重要性。
在实习过程中,我将所学的模式识别理论知识运用到实际项目中,提高了自己的动手能力。
同时,通过解决实际问题,我更加深入地理解了模式识别算法的原理和应用。
2. 团队协作能力实习期间,我学会了与团队成员有效沟通、协作。
在项目中,我们共同面对挑战,分工合作,共同完成项目任务。
这使我认识到团队协作的重要性,为今后的工作打下了基础。
3. 解决问题的能力在实习过程中,我遇到了许多问题。
通过查阅资料、请教同事、独立思考等方式,我逐渐学会了如何分析问题、解决问题。
这种能力对我今后的学习和工作具有重要意义。
4. 深度学习框架的使用实习期间,我学会了使用TensorFlow、Keras等深度学习框架。
模式识别实习报告

实习报告一、实习背景及目的随着科技的飞速发展,模式识别技术在众多领域发挥着越来越重要的作用。
模式识别是指对数据进行分类、识别和解释的过程,其应用范围广泛,包括图像处理、语音识别、机器学习等。
为了更好地了解模式识别技术的原理及其在实际应用中的重要性,我参加了本次模式识别实习。
本次实习的主要目的是:1. 学习模式识别的基本原理和方法;2. 掌握模式识别技术在实际应用中的技巧;3. 提高自己的动手实践能力和团队协作能力。
二、实习内容及过程实习期间,我们团队共完成了四个模式识别项目,分别为:手写数字识别、图像分类、语音识别和机器学习。
下面我将分别介绍这四个项目的具体内容和过程。
1. 手写数字识别:手写数字识别是模式识别领域的一个经典项目。
我们使用了MNIST数据集,这是一个包含大量手写数字图片的数据集。
首先,我们对数据集进行预处理,包括归一化、数据清洗等。
然后,我们采用卷积神经网络(CNN)作为模型进行训练,并使用交叉验证法对模型进行评估。
最终,我们得到了一个识别准确率较高的模型。
2. 图像分类:图像分类是模式识别领域的另一个重要应用。
我们选择了CIFAR-10数据集,这是一个包含大量彩色图像的数据集。
与手写数字识别项目类似,我们先对数据集进行预处理,然后采用CNN进行训练。
在模型训练过程中,我们尝试了不同的优化算法和网络结构,以提高模型的性能。
最终,我们得到了一个识别准确率较高的模型。
3. 语音识别:语音识别是模式识别领域的又一项挑战。
我们使用了TIMIT数据集,这是一个包含大量语音样本的数据集。
首先,我们对语音样本进行预处理,包括特征提取、去噪等。
然后,我们采用循环神经网络(RNN)作为模型进行训练。
在模型训练过程中,我们尝试了不同的优化算法和网络结构。
最后,我们通过对模型进行评估,得到了一个较为可靠的语音识别系统。
4. 机器学习:机器学习是模式识别领域的基础。
我们使用了UCI数据集,这是一个包含多个数据集的数据集。
模式识别与智能信息处理实践实验报告

模式识别与智能信息处理实践实验报告
一、实验目的
本次实验的目的是:实现基于Matlab的模式识别与智能信息处理。
二、实验内容
1.对实验图片进行处理
根据实验要求,我们选取了两张图片,一张是原始图片,一张是锐化处理后的图片。
使用Matlab的imtool命令进行处理,实现对图片锐化、模糊处理、边缘检测、图像增强等功能。
2.基于模式识别算法进行图像分类
通过Matlab的k-means算法和PCA算法对实验图片进行图像分类,实现对图像数据特征提取,并将图像分类结果可视化。
3.使用智能信息处理技术处理实验数据
使用Matlab的BP网络算法,对实验图片进行处理,并实现实验数据的智能信息处理,以获得准确的分类结果。
三、实验结果
1.图片处理结果
2.图像分类结果
3.智能信息处理结果
四、总结
本次实验中,我们利用Matlab进行模式识别与智能信息处理的实践,实现了对图片的处理,图像分类,以及智能信息处理,从而获得准确的分
类结果。
中科大模式识别miniproject实验报告

模式识别miniproject实验报告一、算法介绍:本实验采用了SVM( Support Vector Machines)分类模型。
由于实际问题中很少线性可分,故本实验采用非线性SVM方法。
即通过一个适当的非线性映射ϕ(x) ,将数据由原始特征空间映射到一个新特征空间,然后在新空间中寻求最优(线性)判定面。
本实验选取的的核函数为RBF(径向基函数)中的高斯核函数,即k(x,y) = exp(-0.5*(norm(x-y)/s)^2)。
关于支持向量机的类型,本实验选取为二类分类算法,即svc_c。
算法方面,由于同时求解n个拉格朗日乘子涉及很多次迭代,计算开销太大,所以实验采用Sequential Minimal Optimization(SMO)算法,即每次只更新两个乘子,迭代获得最终解。
计算时,首先根据预先设定的规则,从所有样本中选出两个拉格朗日因子,然后保持其他拉格朗日乘子不变,更新所选样本对应的拉格朗日乘子,循环N次直到满足要求。
二、实验1、评价标准本实验采用正确率来作为评价指标,即。
2、整体试验方法及步骤(1)定义核函数的类型及相关参数;(2)构建两类训练样本:(考虑到实验程序运行时间问题,本实验只选用了testdata的第200至1200项共1000个作为训练样本)(3)训练支持向量机;(4)寻找支持向量;(5)测试输出;(6)计算评价指标,即正确率3、分类器训练算法的参数调整步骤(1)随机生成多个参数向量(解)(2)在目标函数上验证解的质量(3)根据解的质量由好到坏进行排序。
取出其中较好的一部分(例如一半)解,在这些解的每一个元素上加上一个随机数,从而得到一些新解(4)把新解和老解比较,取出最好的一部分,作为下一次迭代的初始解4、实验结果经实验,得到测试输出,将其第十一列,即样本类别与testdata 中的第十三列相比,即可得到正确率。
本实验将以上结果取于EXECL 中进行统计,部分结果截图如下。
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告-贝叶斯分类一、实验目的通过使用贝叶斯分类算法,实现对数据集中的样本进行分类的准确率评估,熟悉并掌握贝叶斯分类算法的实现过程,以及对结果的解释。
二、实验原理1.先验概率先验概率指在不考虑其他变量的情况下,某个事件的概率分布。
在贝叶斯分类中,需要先知道每个类别的先验概率,例如:A类占总样本的40%,B类占总样本的60%。
2.条件概率后验概率指在已知先验概率和条件概率下,某个事件发生的概率分布。
在贝叶斯分类中,需要计算每个样本在各特征值下的后验概率,即属于某个类别的概率。
4.贝叶斯公式贝叶斯公式就是计算后验概率的公式,它是由条件概率和先验概率推导而来的。
5.贝叶斯分类器贝叶斯分类器是一种基于贝叶斯定理实现的分类器,可以用于在多个类别的情况下分类,是一种常用的分类方法。
具体实现过程为:首先,使用训练数据计算各个类别的先验概率和各特征值下的条件概率。
然后,将测试数据的各特征值代入条件概率公式中,计算出各个类别的后验概率。
最后,取后验概率最大的类别作为测试数据的分类结果。
三、实验步骤1.数据集准备本次实验使用的是Iris数据集,数据包含150个Iris鸢尾花的样本,分为三个类别:Setosa、Versicolour和Virginica,每个样本有四个特征值:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
2.数据集划分将数据集按7:3的比例分为训练集和测试集,其中训练集共105个样本,测试集共45个样本。
计算三个类别的先验概率,即Setosa、Versicolour和Virginica类别在训练集中出现的频率。
对于每个特征值,根据训练集中每个类别所占的样本数量,计算每个类别在该特征值下出现的频率,作为条件概率。
5.测试数据分类将测试集中的每个样本的四个特征值代入条件概率公式中,计算出各个类别的后验概率,最后将后验概率最大的类别作为该测试样本的分类结果。
6.分类结果评估将测试集分类结果与实际类别进行比较,计算分类准确率和混淆矩阵。
哈工大模式识别实验报告
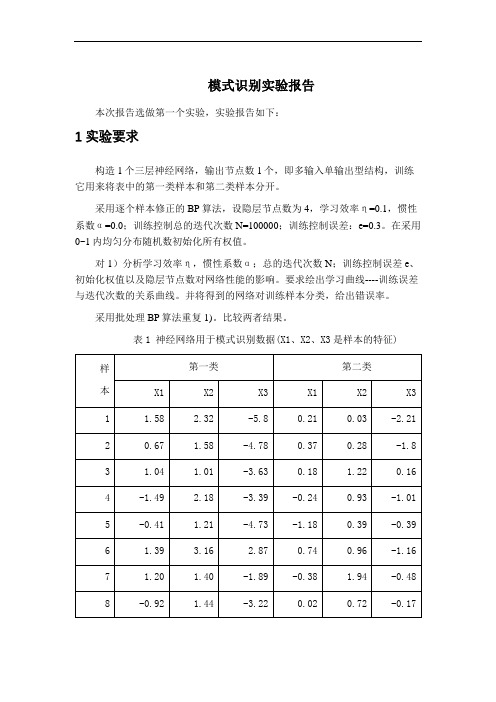
模式识别实验报告本次报告选做第一个实验,实验报告如下:1 实验要求构造1个三层神经网络,输出节点数1个,即多输入单输出型结构,训练它用来将表中的第一类样本和第二类样本分开。
采用逐个样本修正的BP算法,设隐层节点数为4,学习效率η=0.1,惯性系数α=0.0;训练控制总的迭代次数N=100000;训练控制误差:e=0.3。
在采用0~1内均匀分布随机数初始化所有权值。
对1)分析学习效率η,惯性系数α;总的迭代次数N;训练控制误差e、初始化权值以及隐层节点数对网络性能的影响。
要求绘出学习曲线----训练误差与迭代次数的关系曲线。
并将得到的网络对训练样本分类,给出错误率。
采用批处理BP算法重复1)。
比较两者结果。
表1 神经网络用于模式识别数据(X1、X2、X3是样本的特征)2 BP 网络的构建三层前馈神经网络示意图,见图1.图1三层前馈神经网络①网络初始化,用一组随机数对网络赋初始权值,设置学习步长η、允许误差ε、网络结构(即网络层数L 和每层节点数n l );②为网络提供一组学习样本; ③对每个学习样本p 循环a .逐层正向计算网络各节点的输入和输出;b .计算第p 个样本的输出的误差Ep 和网络的总误差E ;c .当E 小于允许误差ε或者达到指定的迭代次数时,学习过程结束,否则,进行误差反向传播。
d .反向逐层计算网络各节点误差)(l jp δ如果l f 取为S 型函数,即xl e x f -+=11)(,则 对于输出层))(1()()()()(l jp jdp l jp l jp l jp O y O O --=δ 对于隐含层∑+-=)1()()()()()1(l kj l jp l jp l jp l jp w O O δδe .修正网络连接权值)1()()()1(-+=+l ip l jp ij ij O k W k W ηδ式中,k 为学习次数,η为学习因子。
η取值越大,每次权值的改变越剧烈,可能导致学习过程振荡,因此,为了使学习因子的取值足够大,又不至产生振荡,通常在权值修正公式中加入一个附加动量法。
模式识别实验报告

模式识别实验报告关键信息项:1、实验目的2、实验方法3、实验数据4、实验结果5、结果分析6、误差分析7、改进措施8、结论1、实验目的11 阐述进行模式识别实验的总体目标和期望达成的结果。
111 明确实验旨在解决的具体问题或挑战。
112 说明实验对于相关领域研究或实际应用的意义。
2、实验方法21 描述所采用的模式识别算法和技术。
211 解释选择这些方法的原因和依据。
212 详细说明实验的设计和流程,包括数据采集、预处理、特征提取、模型训练和测试等环节。
3、实验数据31 介绍实验所使用的数据来源和类型。
311 说明数据的规模和特征。
312 阐述对数据进行的预处理操作,如清洗、归一化等。
4、实验结果41 呈现实验得到的主要结果,包括准确率、召回率、F1 值等性能指标。
411 展示模型在不同数据集或测试条件下的表现。
412 提供可视化的结果,如图表、图像等,以便更直观地理解实验效果。
5、结果分析51 对实验结果进行深入分析和讨论。
511 比较不同实验条件下的结果差异,并解释其原因。
512 分析模型的优点和局限性,探讨可能的改进方向。
6、误差分析61 研究实验中出现的误差和错误分类情况。
611 分析误差产生的原因,如数据噪声、特征不充分、模型复杂度不足等。
612 提出减少误差的方法和建议。
7、改进措施71 根据实验结果和分析,提出针对模型和实验方法的改进措施。
711 描述如何优化特征提取、调整模型参数、增加训练数据等。
712 预测改进后的可能效果和潜在影响。
8、结论81 总结实验的主要发现和成果。
811 强调实验对于模式识别领域的贡献和价值。
812 对未来的研究方向和进一步工作提出展望。
在整个实验报告协议中,应确保各项内容的准确性、完整性和逻辑性,以便为模式识别研究提供有价值的参考和借鉴。
模式识别实验【范本模板】

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
模式识别实验报告

实验一Bayes 分类器设计本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
1实验原理最小风险贝叶斯决策可按下列步骤进行:(1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即则k a 就是最小风险贝叶斯决策。
2实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进行分类。
3 实验要求1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。
2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。
模式识别实验报告

二、实验步骤 前提条件: 只考虑第三种情况:如果 di(x) >dj(x) 任意 j≠ i ,则判 x∈ωi 。
○1 、赋初值,分别给 c 个权矢量 wi(1)(i=1,2,…c)赋任意的初
值,选择正常数ρ ,置步数 k=1;
○2 、输入符号未规范化的增广训练模式 xk, xk∈{x1, x2… xN} ,
二、实验步骤
○1 、给出 n 个混合样本,令 I=1,表示迭代运算次数,选取 c
个初始聚合中心 ,j=1,2,…,c;
○2 、 计 算 每 个 样 本 与 聚 合 中 心 的 距 离
,
。
若
, ,则
。
○3 、 计 算 c 个 新 的 聚 合 中 心 :
,
。
○4 、判断:若
,
,则 I=I+1,返回
第二步 b 处,否则结束。 三、程序设计
聚类没有影响。但当 C=2 时,该类别属于正确分类。 而类别数目大于 2 时,初始聚合中心对聚类的影响非常大,仿真
结果多样化,不能作为分类标准。 2、考虑类别数目对聚类的影响: 当类别数目变化时,结果也随之出现变化。 3、总结 综上可知,只有预先分析过样本,确定合适的类别数目,才能对
样本进行正确分类,而初始聚合中心对其没有影响。
8
7
6
5
4
3
2
1
0
0
1
2
3
4
5
6
7
8
9
初始聚合中心为(0,0),(2,2),(5,5),(7,7),(9,9)
K-均 值 聚 类 算 法 : 类 别 数 目 c=5 9
8
7
6
5
4
模式识别技术实验报告

模式识别技术实验报告本实验旨在探讨模式识别技术在计算机视觉领域的应用与效果。
模式识别技术是一种人工智能技术,通过对数据进行分析、学习和推理,识别其中的模式并进行分类、识别或预测。
在本实验中,我们将利用机器学习算法和图像处理技术,对图像数据进行模式识别实验,以验证该技术的准确度和可靠性。
实验一:图像分类首先,我们将使用卷积神经网络(CNN)模型对手写数字数据集进行分类实验。
该数据集包含大量手写数字图片,我们将训练CNN模型来识别并分类这些数字。
通过调整模型的参数和训练次数,我们可以得到不同准确度的模型,并通过混淆矩阵等评估指标来评估模型的性能和效果。
实验二:人脸识别其次,我们将利用人脸数据集进行人脸识别实验。
通过特征提取和比对算法,我们可以识别不同人脸之间的相似性和差异性。
在实验过程中,我们将测试不同算法在人脸识别任务上的表现,比较它们的准确度和速度,探讨模式识别技术在人脸识别领域的应用潜力。
实验三:异常检测最后,我们将进行异常检测实验,使用模式识别技术来识别图像数据中的异常点或异常模式。
通过训练异常检测模型,我们可以发现数据中的异常情况,从而做出相应的处理和调整。
本实验将验证模式识别技术在异常检测领域的有效性和实用性。
结论通过以上实验,我们对模式识别技术在计算机视觉领域的应用进行了初步探索和验证。
模式识别技术在图像分类、人脸识别和异常检测等任务中展现出了良好的性能和准确度,具有广泛的应用前景和发展空间。
未来,我们将进一步深入研究和实践,探索模式识别技术在更多领域的应用,推动人工智能技术的发展和创新。
【字数:414】。
模式识别实验报告哈工程

一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。
模式识别实验报告2_贝叶斯分类实验_实验报告(例)

end
plot(1:23,t2,'b','LineWidth',3);
%下面是bayesian_fun函数
functionf=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10- (x'*W2*x+w2'*x+w20);
%f=bayesian_fun.m
function f=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10 - (x'*W2*x+w2'*x+w20);
w10=-1/2 * u1'*S1tinv*u1 - 1/2 *log(det(S1t)) + log(pw1);
w20=-1/2 * u2'*S2tinv*u2 - 1/2 *log(det(S2t)) + log(pw2);
t2=[]
fort1=1:23
tt2 = fsolve('bayesian_fun',5,[],t1,W1,W2,w1,w2,w10,w20);
'LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0 1 0],...
'MarkerSize',10)
模式识别实验报告

实验报告实验课程名称:模式识别:王宇班级:20110813 学号:2011081325注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2014年6月实验一、图像的贝叶斯分类一、实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件HP D538、MATLAB三、实验原理概念:阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值围的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。
图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。
如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模式识别与智能信息处理实践实验一聚类分析一、实验目的通过聚类分析实验,加深对聚类分析基本思想、方法的理解和掌握。
二、实验内容了解动态、静态聚类算法的特点;熟练掌握k-均值算法或层次聚类算法;编写能对实际模式样本正确分类的算法程序。
掌握动态聚类算法的基本思想;认识类别数、初始类心的选择对k-均值算法聚类结果的影响;编写能对实际模式样本正确分类的k-均值算法程序。
三、方法手段设类别数为k,选取k个初始聚类中心,按最小距离原则将各模式分配到k类中的某一类,不断地计算类心和调整各模式的类别使每个模式特征矢量到其所属类别中心的距离平方之和最小。
四、k-均值算法(1)从D中随机取k个元素,作为k个簇的各自的中心。
(2)分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
(3)根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。
(4)将D中全部元素按照新的中心重新聚类。
(5)重复第4步,直到聚类结果不再变化。
五、k-均值程序运行结果(1)改变初始类心,观察对聚类结果的影响若选初始类心是[1 2 3]时的结果为其分为1类共39个,分为2类共61个,分为3类共50个,其中被分为第1类的样本为{51 53 78 101 103 104 105 106 108 109 110 111 112 113 116 117 118 119 121 123 125 126 129 130 131 132 133 135 136 137 138 140 141 142 144 145 146 148 149}被分为第2类的样本为{52 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 102 107 114 115 120 122 124 127 128 134 139 143 147 150}被分为第3类的样本为{1 2 3 4 5 6 7 8 9 1011 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50}。
若选初始类心是[2 4 5]时其聚类结果为其分为1类共96个,分为2类共22个,分为3类共个32,其中被分为第1类的样本为{51 52 53 54 55 56 57 59 60 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 95 96 97 98 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150}被分为第2类的样本为{ 2 3 4 7 9 10 13 14 25 26 30 31 35 39 42 43 46 48 58 61 94 99}被分为第3类的样本为{1 5 6 8 11 12 15 16 17 18 19 20 21 22 23 24 27 28 29 32 33 34 36 37 38 40 41 44 45 47 49 50}。
可见,初始类心的选择对于K均值算法的影响较大。
(2)改变类别数k,比较其对类内距离平方和的大小的影响若k=3且选初始类心是[1 2 3]时,其最终各类中心的距离为[1.1657 0.8230 4.0783],若k=4且选初始类心是[1 2 3 4]时,其最终各类中心的距离为[1.3049 0.4917 4.0783 1.3928],可见,改变类别数k,其对类内距离平方和的大小有直接的影响,且k越大,其类内距离平方和距离越小。
六、实验总结影响k-均值算法结果的因素有:初始类心的选择以及k值的选择,且k-均值算法适用于k值已知的情况,即类别号已知的情况。
七、Kmeans程序function y=my_Kmeans(k,mid)k=3;%类数mid=[1 2 3]; %随便给三个聚类中心%从文本文件读入数据放入X中load fisheriris;X=meas;k=3;mid=[1 2 3]; %Iris测试数据集num=size(X,1);%获得X维数大小for i=1:kZ(i,:)=X(mid(i),:);%获取k个聚类中心的初始坐标end%计算新的聚类中心,K-均值算法的核心部分temp=[];while(~isequal(Z,temp)) %聚类中心是否变化,若不变化则停止循环temp=Z;class=cell(k,1);%初始化类样本classvalue=cell(k,1);%初始化类样本的坐标valuefor j=1:numfor t=1:kD(t)=dist(X(j,:),Z(t,:)');%计算每个样本到类中心的距离 [minu,index]=min(D);%求出离聚类中心最小的一个样本endclass{index}=cat(1,class{index},j);%将该样本归于一类value{index}=cat(1,value{index},X(j,:));%存放该类样本的坐标 endfor i=1:kZ(i,:)=mean(value{i});%计算k类样本的均值,更新聚类中心endendcelldisp(class);%显示Kmeans聚类结果D %显示最终类间距离实验二 判别域代数界面方程法一、实验目的通过实验加深对判别域代数界面方程法基本思想、方法的认识,了解线性判别函数的分类能力,熟练掌握感知器算法,或H-K 算法,或累积势函数分类法,以及它们各自的适用条件,加深对有监督训练、线性可分、解空间、权空间等概念的理解,编写能对实际模式样本正确分类的算法程序。
二、实验内容编写能对实际模式样本正确分类的感知器算法,或H-K 算法,或累积势函数分类法的算法程序,能对实际模式样本进行正确分类。
三、方法手段设已知类别模式特征矢量集为{x 1,x 2,…,x N },类别数为c 。
感知器算法是基于一次准则函数的梯度下降法。
从任意初始解矢量w 0出发,利用产生错分的样本对解矢量进行迭代校正:w k =w k-1+ρx i ,i=1,2,…,c,k=0,1,2…,ρ=常数,从而解得线性判决函数d(x )=w ’x 的解矢量w . 四、感知器算法 1、算法思想校正方法实际上是最优化技术中的负梯度下降法。
该算法也是人工神经网络理论中的线性阈值神经元的学习算法。
2、算法原理步骤 设给定一个增广的训练模式集{}N x x x ,,,21,其中每个模式类别已知,它们分属1ω类和2ω类。
(1) 置步数1=k ,令增量=ρ某正的常数,分别赋给增广权矢量初值)1(w的各分量较小的任意值。
(2) 输入训练模式k x 。
(3)计算判别函数值k x k w )('。
(4)调整增广权矢量,规则是① 如果1ω∈k x 和0)(≤'k x k w ,则k x k w k wρ+=+)()1(;(偏小,故加) ② 如果2ω∈k x 和0)(≥'k x k w,则k x k w k w ρ-=+)()1(;(偏大,故减) ③ 如果1ω∈k x 和0)(>'k x k w ,或2ω∈k x 和0)(<'k x k w ,则)()1(k w k w =+。
(分类正确,不校正)(5)令1+=k k 。
如果N k ≤,返至⑵。
如果N k >,检验判别函数x w '对N x x x ,,,21是否都能正确分类。
若是,结束;若不是,令1=k ,返至(2)。
如果训练模式已经符号规范化,即2ω∈k x 已乘以-1(包括增广分量1),则校正权矢量的规则可统一为⎩⎨⎧ρ+=+k x k w k w k w )()()1()(0)()(0)(错误分类若正确分类若≤'>'k k x k w x k w在用全部模式训练完一轮后只要还有模式被判错,则需要进行第二轮迭代,用全部训练模式再训练一次,建立新的权矢量。
如果对训练模式还有错分的,则进行第三轮迭代,余类推,直至对所有训练模式均能正确分类为止,此时的w即为所求的权矢量。
五、感知器算法实验结果(1)改变权矢量初值,观察对算法的影响已知w1:X1=(0 0)’,X2=(1 0)’,X3=(1 1)’,X4=(1 2)’;w2:X5=(1 3)’,X6=(2 3)’,X7=(3 2)’,X8=(3 3)’, 若步长因子ρ=1不变,权初始值取w=[0 0 0],则需迭代eth0=15步,若权初始值取w=[1 1 1],则需迭代eth0=18步,可见,权初始值选取的不同,将直接导致算法的收敛速度不同。
(2)改变步长因子ρ,观察对算法的影响若权初始值取w=[0 0 0]不变,取步长因子ρ=1,则需迭代eth0=15步,若取步长因子ρ=0.1,则需迭代eth0=16步,可见,步长因子ρ选取的不同,也将直接导致算法的收敛速度不同。
(3)算法的适用性若已知w1:X1=(1 3)’,X2=(2 3)’,X3=(1 1)’,X4=(1 2)’;w2:X5=(0 0)’,X6=(1 0)’,X7=(3 2)’,X8=(3 3)’,则导致该程序死循环,可见,感知器算法只适用两类样本线性可分的条件下(图1),若希望在两类样本线性不可分的条件下,构造一判决平面,则可考虑使用势函数。
图1 感知器算法分类结果图2 线性不可分的情况六、实验程序function y=my_preception(W1,W2)%感知器算法,对两类问题生成线性判别函数%注意:前提是两类可线性判别,否则将死循环%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%W1=[0 0;1 0;1 1;1 2];%w1类中的样本W2=[1 3;2 3;3 2;3 3];%w2类中的样本%%%%%%初始化w=[0 0 0]; %任取w初值c=1; %任取校正增量系数c=1;%%%%%%感知器算法部分%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%增广样本w1和w2乘(-1)[m,n]=size(W1);for i=1:mW1(:,n+1)=1;%w1增广end[m,n]=size(W2);for i=1:mW2(:,n+1)=1;%w2增广endW2=-W2;%取反%将增广向量转换成元组,便于处理M=ones(1,m);w1=mat2cell(W1,M,n+1);w2=mat2cell(W2,M,n+1);X=cat(1,w1,w2);%合并两类增广样本%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%eth0=0; %迭代次数%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%感知器算法核心部分[m,n]=size(X);temp1=[];temp2=1;%随意两个赋不等的值while(~isequal(temp1,temp2)) %判断权值是否变换化,若不变化,则终止循环 eth0=eth0+1;temp2=temp1;clear temp1;%不清除此变量不行啊!!for i=1:mtemp1{i,1}=w;if(w*X{i}'<=0) %w乘X{i}的转置w=w+c*X{i}; %若小于0更新权值endendend %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%w %显示线性分类器权值eth0 %显示迭代次数实验三 Bayes 分类器设计一、实验目的通过实验,加深对统计判决与概率密度估计基本思想、方法的认识,了解影响Bayes 分类器性能的因素,掌握基于Bayes 决策理论的随机模式分类的原理和方法。