最新编译原理第二章-课后题答案
清华大学编译原理第二版课后习答案

Lw.《编译原理》课后习题答案第一章第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
盛威网()专业的计算机学习网站1《编译原理》课后习题答案第一章目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
编译原理课后习题答案+清华大学出版社第二版

用以引用非局部(包围它的过程)变量时,寻找该变量的地址。 DL: 动态链,指向调用该过程前正在运行过程的数据段基地址,用以过程执行结束释放
数据空间时,恢复调用该过程前运行栈的状态。 RA: 返回地址,记录调用该过程时目标程序的断点,即调用过程指令的下一条指令的地
编译程序大致有哪几种开发技术?
答案:
(1)自编译:用某一高级语言书写其本身的编译程序。 (2)交叉编译:A 机器上的编译程序能产生 B 机器上的目标代码。 (3)自展:首先确定一个非常简单的核心语言 L0,用机器语言或汇编语言书写出它的编
译程序 T0,再把语言 L0 扩充到 L1,此时 L0⊂ L1 ,并用 L0 编写 L1 的编译程序 T1,再把语 言 L1 扩充为 L2,有 L1 ⊂ L2 ,并用 L1 编写 L2 的编译程序 T2,……,如此逐步扩展下 去, 好似滚雪球一样,直到我们所要求的编译程序。 (4)移植:将 A 机器上的某高级语言的编译程序搬到 B 机器上运行。
(main).
答案: 程序执行到赋值语句 b∶=10 时运行栈的布局示意图为:
1
《编译原理》课后习题答案第二章
第 3题 写出题 2 中当程序编译到 r 的过程体时的名字表 table 的内 容。
name
kind
level/val
adr
size
答案:
题 2 中当程序编译到 r 的过程体时的名字表 table 的内容为:
盛威网()专业的计算机学习网站
2
《编译原理》课后习题答案第一章
合实现方案,即先把源程序翻译成较容易解释执行的某种中间代码程序,然后集中解释执行 中间代码程序,最后得到运行结果。
编译原理第二章习题解答

部分习题解答
© 西安电子科技大学 ·软件学院
难点
第2章习题
1. 根据模式,写出正规式 2. 依据 NFA/DFA,写出正规式
计算量大
3. 正规式NFA 4. NFADFA: ε_闭包,smove 5. DFA最小化
© 西安电子科技大学 ·软件学院
2
1. 根据模式写出正规式
一般思路:(1)分析题意 (2)列举一些最简单的例子 (3)寻找统一规律*,考虑所有可能情况**
© 西安电子科技大学 ·软件学院
13
其它
习题2.9 构造 10*1 的最小DFA
解: 活用 Thompson 算法
(1) 分解为三部分:1,0*,1;
(2) 画出三者的状态转换图:
1
0
1
0 2
1
3
4
(3) 连接运算:子图首尾相连
1
0 1
0
11
4
这已经是最小的DFA
© 西安电子科技大学 ·软件学院
14
11
其它
关于:正规式 -> NFA -> DFA -> DFA最小化: 说明:(一般)逐步计算 正规式->NFA: (1)呆板Thompson算法:
自上而下分解正规式—— 语法树, 自下而上构造NFA —— 后续遍历; 特点:每个运算对应一次构造,繁琐! (2)活用Thompson算法: 分解正规式:得到若干规模适中的子正规式; 为每个子正规式:画出其最简的状态转换图(子图); 按Thompson算法,将子图组合,得到完整的图。
长度为4:0011, 1100,
? 0101, 0110, 1001, 1010
b) 前4个串: 由00和11组成的串 正规式B*, B= 00 | 11
(完整word版)编译原理课后答案

第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。
编译原理教程课后习题答案第二章
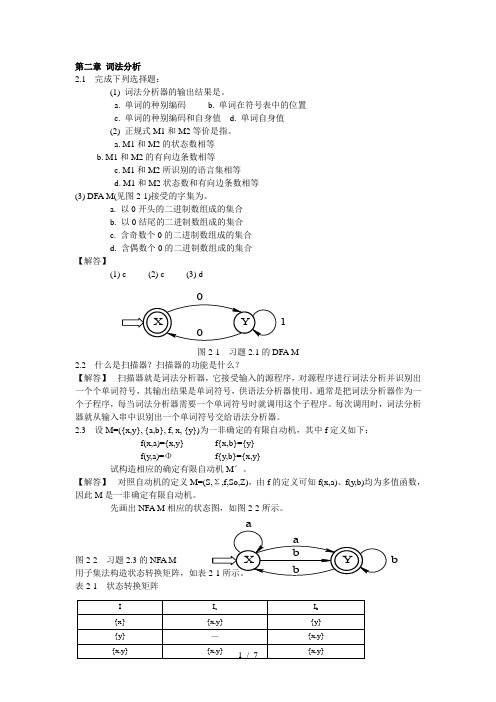
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。
编译原理(龙书)习题答案(chap2,3)

( X | a) * a( X | e) * e( X | i) * i( X | o) * o(字母组成的串。
a * b * z *
3)注释,即/*和*/之间的串,且串中没有不在双引号 (“)中的*/。 /\* ([^*"] | \*[^/] | \"([^"]*)\")* \*/
DFA的状态图:
4) (a | b) * abb(a | b) * 根据算法3.25得到NFA:
DFA的转换表:
状态 -A{0} B{0,1} C{0,2} +D{0,3} +E{0,1,3} +F{0,2,3} a B B B E E E b A C D D F D
DFA的状态图:
8)所有由a和b组成且不含子串abb的串。
b * (a | ab) *
9)所有由a和b组成且不含子序列abb的串。
b * a * (b | )a * b * a * (a | b)a* |
X:[^*"] Y:[^/] Z:[^"]
3.6.1 将下图中的NFA转换为DFA。
DFA的转换表:
3)该文法生成的语言是什么? 以a为变量,+和*为二元操作符的后缀表达式的集合
2.2.2 下面的各个文法生成什么语言?
1) S
0 S 1| 01
n n
{0 1 | n 1}
2) S
S S|S S|a
以a为变量,+和-为二元操作符的前缀表达式的集合
3)
S S ( S ) S |
括号的匹配,包括空串
4)
S a S b S |b S a S |
由相同数目的a和b组成的字符串的集合,或者空串 5)
编译原理作业题答案编译原理课后题答案

第二章高级语言的语法描述6、令文法G 6为:N →D|ND D → 0|1|2|3|4|5|6|7|8|9(1)G 6 的语言L (G 6)是什么?(2)给出句子01270127、、34和568的最左推导和最右推导。
解答:思路:由N N →→ D|ND 可得出如下推导N =>=>ND ND ND=>=>=>NDD NDD NDD=>…=>=>…=>=>…=>D D n(n >=1=1))可以看出,N 最终可以推导出1个或多个(也可以是无穷)D ,而D D →→ 0|1|2|3|4|5|6|7|8|9可知,每个D 为0~9中的任一个数字,所以,中的任一个数字,所以,N N N 最终推导出的就是由最终推导出的就是由0~9这10个数字组成的字符串。
(1)G 6 的语言L (G 6)是由0~9这10个数字组成的字符串个数字组成的字符串,,或{0{0,,1,1,……,9}+。
(2)(2)句子句子01270127、、34和568的最左推导分别为的最左推导分别为: : N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>NDDD NDDD NDDD=>=>=>DDDD DDDD DDDD=>=>=>0DDD 0DDD 0DDD=>=>=>01DD 01DD 01DD=>=>=>012D 012D 012D=>=>=>0127 0127 N =>=>ND ND ND=>=>=>DD DD DD=>=>=>3D 3D 3D=>=>=>34 34N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>DDD DDD DDD=>=>=>5DD 5DD 5DD=>=>=>56D 56D 56D=>=>=>568 568 句子01270127、、34和568的最右推导分别为的最右推导分别为: :N =>=>ND ND ND=>=>=>N7N7N7=>=>=>ND7ND7ND7=>=>=>N27N27N27=>=>=>ND27ND27ND27=>=>=>N127N127N127=>=>=>D127D127D127=>=>=>0127 0127 N =>=>ND ND ND=>=>=>N4N4N4=>=>=>D4D4D4=>=>=>34 34N =>=>ND ND ND=>=>=>N8N8N8=>=>=>ND8ND8ND8=>=>=>N68N68N68=>=>=>D68D68D68=>=>=>568 5687、写一个文法,使其语言是奇数集,且每个基数不以0开头。
编译原理第二章习题答案

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2.文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D……D3.已知文法G[S]:Sf dAB Af aA|a B|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法? [答案]正规式是daa*b* ;相应的正规文法为(由自动机化简来):G[S]:S —dA A —a|aB B —aB|a|b|bC C —bC|b也可为(观察得来):G[S]:S —dA A —a|aA|aB B —bB| &4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}5.给出语言{a n b n c1 n>=1,m>=0}的上下文无关文法。
[分析]本题难度不大,主要是考上下文无关文法的基本概念。
上下文无关文法的基本定义是:A-> B ,A € Vn ,B€( VnU Vt) *,注意关键问题是保证a n b n的成立,即“ a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解决。
[答案]构造上下文无关文法如下:S->AB|AA->aAb|abB->Bc|c[扩展]凡是诸如此类的题都应按此思路进行,本题可做为一个基本代表。
基本思路是这样的:要求符合a n b n c m,因为a与b要求个数相等,所以把它们应看作一个整体单元进行,而c m做为另一个单位,初步产生式就应写为S->AB,其中A推出a n b n,B推出c m。
《编译原理》课后习题答案第二章

4、试为文法G[P]:
P∷=begin S end S∷=A|C
A∷=V:=E C∷=if E then S
E∷=V E∷=E+V V∷=i
采用某种程序设计语言构造递归下降识别程序。
解:由于文法存在左递归,进行文法等价变换,得到等价文法G′[P]:
步骤三检查可得f的值与原有的优先矩阵一致所以上表函数即为所求优先函数bell有向图法形式化步骤一构造布尔矩阵b步骤二使用warshall算法构造布尔矩阵b1521步骤三则优先函数为
第二章
习题1
6.答:省略表示法:{1.3,1.33,1.333…};描述表示法:{1.3i|i=1,2,3…}
7.答:x+={0,12,123,1234…};
最小化:
(2)由e构造转换系统:
去ε弧及无用状态和死状态:
因为现在只有一个状态,所以无需再最小化,此时就是最小化.
13.解:建立方程组如下:
W=Ua+Vb ①
U=Va+c ②
V=Ub+c ③
把③代入②得,U=(Ub+c)a+c
=Uba+ca+c
把它改写成U=(ca+c){ba},因此U=(ca|c){ba} ④
follow(E)={#,)}
follow(E′)={#,)}
follow(T)={#,),+,-}
follow(T′)={#,),+,-}
follow(F)={*,/,#,),+,-}
识别输入符号串i*i-(i+i)/i,则识别过程
步骤 栈 输入 输出
0 #E i*i-(i+i)/i# E∷=TE′
编译原理习题参考答案

编译原理习题参考答案第⼆章2.构造产⽣下列语⾔的⽂法(2){a n b m c p|n,m,p≥0}解: G(S) :S→aS|X,X→bX|Y,Y→cY|ε(3){a n # b n|n≥0}∪{cn # dn|n≥0}解: G(S):S→X,S→Y,X→aXb|#, Y→cYd|# }(5)任何不是以0 打头的所有奇整数所组成的集合解:G(S):S→J|IBJ,B→0B|IB|ε,I→J|2|4|6|8, J→1|3|5|7|9}(6)(思考题)所有偶数个0 和偶数个1 所组成的符号串集合解:对应⽂法为 S→0A|1B|ε,A→0S|1C B→0C|1S C→1A|0B3.描述语⾔特点(2)S→SS S→1A0 A→1A0 A→ε解:L(G)={1n10n11n20n2… 1nm0nm |n1,n2,…,nm≥0;且n1,n2,…nm 不全为零}该语⾔特点是:产⽣的句⼦中,0、1 个数相同,并且若⼲相接的1 后必然紧接数量相同连续的0。
(5)S→aSS S→a解:L(G)={a(2n-1)|n≥1}可知:奇数个a5. (1) 解:由于此⽂法包含以下规则:AA→ε,所以此⽂法是0 型⽂法。
7.解:(1)aacb 是⽂法G[S]中的句⼦,相应语法树是:最右推导:S=>aAcB=>aAcb=>aacb最左推导:S=>aAcB=>aacB=>aacb(3)aacbccb 不是⽂法G[S]中的句⼦aacbccb 不能从S推导得到时,它仅是⽂法G[S]的⼀个句型的⼀部分,⽽不是⼀个句⼦。
11.解:最右推导:(1) S=>AB=>AaSb=>Aacb=>bAacb=>bbAacb=>bbaacb上⾯推导中,下划线部分为当前句型的句柄。
对应的语法树为:3 假设M:⼈ W:载狐狸过河,G:载⼭⽺过河,C:载⽩菜过河6 根据⽂法知其产⽣的语⾔是L={a m b n c i| m,n,i≧1}可以构造如下的⽂法VN={S,A,B,C}, VT={a,b,c}P={ S →aA, A→aA, A→bB, B→bB, B→cC, C→cC, C→c} 其状态转换图如下:7 (1) 其对应的右线性⽂法是:A →0D, B→0A,B→1C,C→1|1F,C→1|0A,F→0|0E|1A,D→0B|1C,E→1C|0B(2) 最短输⼊串011(3) 任意接受的四个串: 011,0110,0011,000011(4) 任意以1 打头的串.9.对于矩阵(iii)(1) 状态转换图:(2) 3型⽂法(正规⽂法)S→aA|a|bB A→bA|b|aC|a B→aB|bC|b C→aC|a|bC|b(3)⽤⾃然语⾔描述输⼊串的特征以a 打头,中间有任意个(包括0个)b,再跟a,最后由⼀个a,b 所组成的任意串结尾或者以b 打头,中间有任意个(包括0个)a,再跟b,最后由⼀个a,b 所组成的任意串结尾。
【考研计算机专业课】天津大学 编译原理习题答案 第2章 PL0程序语言的实现

第2章 PL/0编译程序的实现第1题PL/0语言允许过程嵌套定义和递归调用,试问它的编译程序如何解决运行时的存储管理。
答案:PL/0语言允许过程嵌套定义和递归调用,它的编译程序在运行时采用了栈式动态存储管理。
(数组CODE存放的只读目标程序,它在运行时不改变。
)运行时的数据区S是由解释程序定义的一维整型数组,解释执行时对数据空间S的管理遵循后进先出规则,当每个过程(包括主程序)被调用时,才分配数据空间,退出过程时,则所分配的数据空间被释放。
应用动态链和静态链的方式分别解决递归调用和非局部变量的引用问题。
第2题若PL/0编译程序运行时的存储分配策略采用栈式动态分配,并用动态链和静态链的方式分别解决递归调用和非局部变量的引用问题,试写出下列程序执行到赋值语句b∶=10时运行栈的布局示意图。
var x,y;procedure p;var a;procedure q;var b;begin (q)b∶=10;end (q);procedure s;var c,d;procedure r;var e,f;begin (r)call q;end (r);begin (s)call r;end (s);begin (p)call s;end (p);begin (main)call p;end (main).答案:程序执行到赋值语句b∶=10时运行栈的布局示意图为:第3题写出题2中当程序编译到r的过程体时的名字表table的内容。
size name kind level/val adr答案:题2中当程序编译到r的过程体时的名字表table的内容为:name kind level/val adr sizex variable 0 dxy variable 0 dx+1p procedure 0 过程p的入口(待填) 5a variable 1 dxq procedure 1 过程q的入口 4 s procedure 1 过程s的入口(待填) 5c variable 2 dxd variable 2 dxr procedure 2 过程r的入口 5e variable 3 dxf variable 3 dx+1注意:q和s是并列的过程,所以q定义的变量b被覆盖。
编译原理课后习题答案_清华大学_第二版_khdaw

语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表
中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式
的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
的位置和功能以及所完成的操作说明如下:
INT 0 A
在过程目标程序的入口处,开辟 A 个单元的数据段。A 为局部变量的个数+3。
OPR 0 0
在过程目标程序的出口处,释放数据段(退栈),恢复调用该过程前正在运行的过程的
数据段基址寄存器 B 和栈顶寄存器 T 的值,并将返回地址送到指令地址寄存器 P 中,以使
注意:如果问编译程序有哪些主要构成成分,只要回答六部分就可以。如果搞不清楚,
就回答八部分。
第 3 题
何谓翻译程序、编译程序和解释程序?它们三者之间有何种关系?
答案:
翻译程序是指将用某种语言编写的程序转换成另一种语言形式的程序的程序,如编译程
好似滚雪球一样,直到我们所要求的编译程序。
.
(4)移植:将 A 机器上的某高级语言的编译程序搬到 B 机器上运行。
第6题
计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?
答案:
计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。
序的总体结构图。
答案:
一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语
义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和
编译原理第二章-课后题答案

编译原理第二章-课后题答案本页仅作为文档封面,使用时可以删除This document is for reference only-rar21year.March第二章3.何谓“标志符”,何谓“名字”,两者的区别是什么答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值。
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
(2)优先顺序为↑、+、*,同级优先采用右结合。
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=86.令文法G6为N-〉D|NDD-〉0|1|2|3|4|5|6|7|8|9(1)G6的语言L(G6)是什么(2)给出句子0127、34、568的最左推导和最右推导。
答:(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G6)={d n|n≧1,d∈{0,1,…,9}}(2)0127的最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>01270127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127(其他略)7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
答:G(S):S->+N|-NN->ABC|CC->1|3|5|7|9A->C|2|4|6|8B->BB|0|A|ε[注]:可以有其他答案。
[常见的错误]:N->2N+1原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为E->T|E+T|E-TT->F|T*F|T/FF->(E)|i(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
清华大学编译原理第二版课后习答案

Lw.《编译原理》课后习题答案第一章第 1 章引论第 1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第 2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
盛威网()专业的计算机学习网站1《编译原理》课后习题答案第一章目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
最新编译原理第二章 习题与答案(修改后)word版本

第2章习题2-1 设有字母表A1 ={a,b,c,…,z},A2 ={0,1,…,9},试回答下列问题:(1) 字母表A1上长度为2的符号串有多少个?(2) 集合A1A2含有多少个元素?(3) 列出集合A1(A1∪A2)*中的全部长度不大于3的符号串。
2-2 试分别构造产生下列语言的文法:(1){a n b n|n≥0};(2){a n b m c p|n,m,p≥0};(3){a n#b n|n≥0}∪{c n#d n|n≥0};(4){w#w r# | w∈{0,1}*,w r是w的逆序排列 };(5)任何不是以0打头的所有奇整数所组成的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
2-3 试描述由下列文法所产生的语言的特点:(1)S→10S0S→aA A→bA A→a(2)S→SS S→1A0A→1A0A→ε(3)S→1A S→B0A→1A A→CB→B0B→C C→1C0C→ε(4)S→aSS S→a2-4 试证明文法S→AB|DC A→aA|a B→bBc|bc C→cC|c D→aDb|ab为二义性文法。
2-5 对于下列的文法S→AB|c A→bA|a B→aSb|c试给出句子bbaacb的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2-6 化简下列各个文法(1) S→aABS|bCACd A→bAB|cSA|cCC B→bAB|cSB C→cS|c(2) S→aAB|E A→dDA|e B→bE|fC→c AB|dSD|a D→eA E→fA|g(3) S→ac|bA A→c BC B→SA C→bC|d2-7 消除下列文法中的ε-产生式(1) S→aAS|b A→cS|ε(2) S→aAA A→bAc|dAe|ε2-8 消除下列文法中的无用产生式和单产生式(1) S→aB|BC A→aA|c|aDb B→DB|C C→b D→B(2) S→SA|SB|A A→B|(S)|( ) B→[S]|[ ](3) E→E+T|T T→T*F|F F→P↑F|P P→(E)|i第2章习题答案2-1 答:(1) 26*26=676(2) 26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz, a00,a01,...,zzz},共有26+26*36+26*36*36=34658个2-2 解:(1) 对应文法为G(S)=({S},{a,b},{ S→ε| aSb },S)(2) 对应文法为G(S)=({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε },S)(3)对应文法为G(S)=({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#, Y→cYd|# },S)(4) G(S)=({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5) G(S)=({S,A,B,I,J},{0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|ε, I→J|2|4|6|8, J→1|3|5|7|9},S)(6)对应文法为S→0A|1B|ε,A→0S|1C,B→0C|1S,C→1A|0B2-3 解:(1) 本文法构成的语言集为:L(G)={(10)n ab m a0n|n,m≥0}。
编译原理第二章习题答案

* i
=> 〈表达式〉
〈运算符〉
i * i
=>〈表达式〉+i * i
=>1+1*1
所以,该文法是二义的。
9.文法G⑸为:
S->Ac|aB
A->ab
B->bc
该文法是否为பைடு நூலகம்义的为什么
[答案]
对于串abc
(l)S=>Ac=>abc
⑵S=>aB=>abc
即存在两不同的最右推导
所以,该文法是二义的。
最右推导:
S=>ABS=>ABAa=>ABaa=>ASBBaa=>ASBbaa=>ASbbaa=>A £ bbaa=>a £ bbaa
(2)产生式有:S-ABS |Aa|£
A~*a
B—SBB|b
(3)该句子的短语有8ibib2a283、ai、bi> b2、bib2、82^3、a2;
!
直接短语有ai、bi、b2、a2:
4•已知文法G[Z]:
Z->aZb|ab
<
写出L(G[Z])的全部元素。
[答案]
Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbb
L(G[Z])={anbn|n>=l}
5.给出语言{aBc叫n>=l,m>=O}|ft上下文无关文法。
[分析]
本题难度不大,主要是考上下文无关文法的基本概念。上下文无关文法的基 本定义是:A->P,AeVn, P G (VnUVt)\注意关键问题是保证a"bn的成立, 即“a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解 决。
编译原理 第2章习题解答

第二章习题解答2.1①该文法定义的是0到9这10个数字{0,1,2,3,4,5,6,7,8,9};②同①;③该文法定义的是{b n a2∣n≥0};2.2①因为语言的句子要求由3的整数倍的a组成,所以在构造产生式时,要保证每次产生的a 的个数是3。
得到文法G[S]:S→aaa|Saaa②因为符号串中a、b的个数没有直接关系,所以,将句子分成两部分:a n和b2m–1,分别进行构造,然后再合并。
可由产生式A→a|aA得到a n。
而由产生式B→b|bbB得到b2m–1。
由于n≥1,m≥1,所以得到文法G[S]:S→ABA→a|aAB→b|bbB③因为句子中,a和b的个数一样多,且a全部在句子的前半部分,b全部在句子的后半部分,所以在构造产生式时,可让a和b对称出现。
得文法G[S]:S→aSb|ab④因为句子中a、b、c的个数没有直接关系,所以分别构造生成a n、b m、c k的产生式,然后再合成。
可由产生式A→aA|ε得到a n。
而由产生式B→bB|ε得到b m。
再由产生式C→cC|ε得到c k。
所以得到文法G[S]:S→ABCA→aA|εB→bB|εC→cC|ε⑤文法为G[S]:S→(+|–)(ABC|2|4|6|8)|0C→0|2|4|6|8B→BA|B0|εA→1|2|3|…|9⑥能被5整除的整数的末位数必定是0或5。
所以只要保证生成的整数末位数字是0或5即可。
据此,构造描述能被5整除的整数集合的文法如下:G[S]:S→(+|-)A(0|5)A→0|1|2|3|4|5|6|7|8|9|AA如果还要求整数除0外,均不以0开头,则文法为G[S]:S→(+|-)(A(0|5)|0|5)A→AB|CB→0|C|BBC→1|2|3|4|5|6|7|8|9⑦由于文法的句子α∈{a, b}+,因此文法的句子可分解为两种情形:以a打头的符号串;以b打头的符号串。
于是只要在构造产生式时保证每次产生相同个数的a和b即可。
编译原理课后作业参考答案

作业参考答案第二章 高级语言及其语法描述6、(1)L (G 6)={0,1,2,......,9}+(2)最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 N=>ND=>DD=>3D=>34N=>ND=>NDD=>DDD=>5DD=>56D=>568 最右推导:N=>ND =>N7=>ND7=>N27=>ND27=>N127=>D127=>0127 N=>ND=>N4=>D4=>34N=>ND=>N8=>ND8=>N68=>D68=>568 7、G:S →ABC | AC | CA →1|2|3|4|5|6|7|8|9B →BB|0|1|2|3|4|5|6|7|8|9C →1|3|5|7|98、(1)最左推导:E=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*iE=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F)=>i*(i+i) 最右推导:E=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i=>i+i*iE=>T=>T*F=>T*(E)=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=>T*(i+i)=>F*(i+i)=>i*(i+i) (2)9、证明:该文法存在一个句子iiiei 有两棵不同语法分析树,如下所示,因此该文法是二义的。
编译原理课后习题解答(2)

2/7
西北大学 Gong Xq
龙书本科教学版习题解答
仅供教学参考
解答:文法 3) 、4) 、5)有二义性。 证明:3)对文法的句子()(),存在两棵不同的语法分析树如下:
S S
S
(
S ε
)
S ε
S ε
( ε
S
)
S
S ε
(
S ε
)
S ε
S ε
(
S ε
)
S ε
所以文法是二义的。 4)对文法的句子 abab,存在两棵不同的语法分析树如下:
5/7
西北大学 Gong Xq
龙书本科教学版习题解答
仅供教学参考
2.3 节 语法制导翻译
产生式
翻译方案 { E.pre = '+' || E1.pre || T.pre } { E.pre = '-' || E1.pre || T.pre } { E.pre = T.pre } { T.pre = '*' || T1.pre || F.pre } { T.pre = '/' || T1.pre || F.pre } { T.pre = F.pre } {F.pre = id.lexeme} {F.pre = num.value} {F.pre = E.pre} E pre =-9* 52
1)证明:对语法分析树的结点数目使用数学归纳法。 ①归纳基础:当语法分析树有两个结点时,形如
num 11
num 1001
生成的串分别为 11 和 1001,表示的值为 3 和 9,能被 3 整除。 ②归纳步骤: 假设语法分析树的结点数目少于 n 时生成的二进制串的值能被 3 整除, 那么当 结点数目等于 n 时,语法分析树的根有下面两种可能的形式:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二章
1
3.何谓“标志符”,何谓“名字”,两者的区别是什么?
2
答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
3
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约4
定,计算1+1*2↑2*1↑2的值。
5
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
6
(2)优先顺序为↑、+、*,同级优先采用右结合。
7
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256
8
(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=8
9
6.令文法G
6为
10
N-〉D|ND
11
D-〉0|1|2|3|4|5|6|7|8|9 12
(1)G
6的语言L(G
6
)是什么?
13
(2)给出句子0127、34、568的最左推导和最右推导。
14
答:(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G
6)={d n|n
15
≧1,d∈{0,1,…,9}}
16
(2)0127的最左推导:17
N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127
18
0127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127 19
20
(其他略)
21
7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
22
答:G(S):S->+N|-N
23
N->ABC|C
24
C->1|3|5|7|9
25
A->C|2|4|6|8
26
B->BB|0|A|ε
27
[注]:可以有其他答案。
28
[常见的错误]:N->2N+1
29
原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为
30
31
E->T|E+T|E-T
32
T->F|T*F|T/F
F->(E)|i
33
34
(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
35
(2)给出i+i+i、i+i*i和i-i-i的语法树,并给出短语,简单短语和句柄。
36
答:(1) i*(i+i)的最左推导:
37
E=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=> 38
i*(i+F)=> i*(i+i)
i*(i+i)的最右推导: 39
E=>T=>T*F=>T*(E) 40
=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=> T*(i+i)=> F*(i+i) 41
=> i*(i+i) 42
(其他略) 43
[注]:要牢记每一步都是对最左(右)的一个非终结符号进行一步推导。
44
(2) i+i+i 的语法树:
45 46
(其他略) 47
9.证明下面的文法是二义的:S->iSeS|iS|i 48
证明:反例法: 49
对于该文法的句子iiiei 有两个最右推导如下,所以该文法是二义的: 50
S=>iS=>iiSeS=>iiSei=>iiiei 51
S=>iSeS=>iSei=>iiSei=>iiiei 52
10.把下面的文法改写成无二义的:S->SS|(S)|()
53 短语:i 1, i 2, i 3, i 1
+ i 2, i 1+i 2+ i 3
答:假设规定左结合的顺序,可以改造成无二义文法如下:54
s->s(t)|(s)|()
55
t->s|ε
56
[注]:大纲不要求掌握,作为参考
57
11.给出下面语言的相应文法:
58
L
1={a n b n c i|n≧1,i≧0}
59
L
2={a i b n c n|n≧1,i≧0}
60
L
3={a n b n a m b m|m,n≧0}
61
L
4={1n0m1m 0n|m,n≧0}
62
答:(1) S->AB A->aAb|ab B->Bc|ε63
(2) S->AB B->bBc|bc A->Aa|ε
64
(3) S->AA A-> aAb|ε
65
(4) S->1S0|A A-> 0A1|ε
66
[注]:可以有其他答案。
67
68。