应用回归分析试题(二)
回归分析考试试题及答案

回归分析考试试题及答案一、单项选择题(每题2分,共20分)1. 回归分析中,自变量和因变量之间的关系是()。
A. 确定性关系B. 函数关系C. 相关关系D. 因果关系答案:C2. 简单线性回归模型中,回归系数的估计值是通过()方法得到的。
A. 最小二乘法B. 最大似然法C. 贝叶斯方法D. 决策树方法答案:A3. 在多元线性回归分析中,如果自变量之间存在完全相关关系,则会导致()。
A. 多重共线性B. 异方差性C. 自相关D. 非线性答案:A4. 回归分析中,残差平方和(SSE)是用来衡量()的。
A. 模型的拟合优度B. 模型的预测能力C. 模型的解释能力D. 模型的预测误差答案:D5. 回归方程的显著性检验中,F检验的零假设是()。
A. 所有回归系数都等于0B. 所有回归系数都不等于0C. 至少有一个回归系数等于0D. 至少有一个回归系数不等于0答案:A6. 回归分析中,调整后的R平方(Adjusted R-squared)用于()。
A. 调整模型的复杂性B. 调整样本量的大小C. 调整自变量的数量D. 调整因变量的范围答案:C7. 在回归分析中,如果自变量的增加导致因变量的增加,则称自变量和因变量之间存在()。
A. 正相关B. 负相关C. 无相关D. 完全相关答案:A8. 回归分析中,残差的标准差(S)是用来衡量()的。
A. 模型的拟合优度B. 模型的预测能力C. 模型的解释能力D. 模型的预测误差答案:D9. 在多元线性回归中,如果一个自变量的t统计量显著,那么我们可以得出结论()。
A. 该自变量对因变量有显著影响B. 该自变量对因变量没有显著影响C. 该自变量对因变量的影响不明确D. 该自变量对因变量的影响是正的答案:A10. 回归分析中,Durbin-Watson统计量用于检测()。
A. 多重共线性B. 异方差性C. 自相关D. 非线性答案:C二、多项选择题(每题3分,共15分)11. 以下哪些因素可能导致回归模型中的异方差性?()A. 模型中遗漏了重要的解释变量B. 模型中包含了不应该包含的变量C. 模型中的误差项不是独立同分布的D. 模型中的误差项具有非恒定的方差答案:CD12. 在回归分析中,以下哪些方法可以用来处理多重共线性问题?()A. 增加样本量B. 移除相关性高的自变量C. 使用岭回归D. 增加更多的自变量答案:BC13. 以下哪些是回归分析中常用的诊断图?()A. 残差图B. 正态Q-Q图C. 散点图D. 杠杆值图答案:ABD14. 在回归分析中,以下哪些因素可能导致模型的预测能力下降?()A. 模型过拟合B. 模型欠拟合C. 模型中的误差项具有自相关性D. 模型中的误差项具有异方差性答案:ABCD15. 以下哪些是回归分析中常用的模型选择标准?()A. AIC(赤池信息准则)B. BIC(贝叶斯信息准则)C. R平方D. 调整后的R平方答案:ABCD三、简答题(每题10分,共30分)16. 简述简单线性回归模型的基本形式。
应用回归分析+第2章详细答案word资料7页

由⎪⎪⎩⎪⎪⎨⎧=β-β-=β∂∂=β-β-=β∂∂∑∑=β=β=β=βn1i i i 10i ˆ1n 1i i 10i ˆ00x )x ˆˆy (Q 0)x ˆˆy (Q 1100得⎪⎪⎩⎪⎪⎨⎧==-==-∑∑∑∑====n 1i n 1i i i i i i n 1i n1i i i i 0x e x )y ˆy (0e )y ˆy ( 2.4在),0(N ~2i σε的正态分布假定下,10,ββ的最小二乘估计与最大似然估计等价,求对数似然函数的极大值等价于对∑=β+β-n1i 2i 10i )]x (y [求极小值,至此与最小二乘估计原理完全相同2.52.6 2.7 2.8(1)22i2i 2i2i 2i2i2i i2i i xx 1xx 1r 12n r )y y ()y y ˆ(12n r )y y ()y yˆ()y y (2n r )y y ()yˆy (2n r )y ˆy (2n L ˆˆL ˆt --=----=-----=---=--β=σβ=∑∑∑∑∑∑∑∑(2)F )2n /(SSE 1/SSR SSE SSR )2n (SSTSSR 1SST SSR)2n (r 1r )2n (t 222=-=-=--=--= 2.92.11如果一个线性回归方程通过F 检验,只能说明x 与y 之间的线性关系是显著的,不能说明数据拟合得很好,决定系数r 2是一个回归直线与样本观测值拟合优度的相对指标。
2.12如果自变量观测值都乘以2,回归参数的最小二乘估计0ˆβ不变,1ˆβ变为原来的½; 如果自变量观测值都加上2,回归参数的最小二乘估计0ˆβ,1ˆβ都扩大两倍; 2.13不成立,相关系数与样本量n 有关,当n 较小时,相关系数的绝对值容易接近于1;当n 较大时,相关系数绝对值容易偏小。
2.14(1)散点图为(2)x 与y 之间大致呈线性关系(3)设回归方程为 x ˆˆy ˆ10β+β= 模型非标准化系数 标准系数 tSig.B标准 误差试用版1(常量)-1.0006.351-.157.885x7.0001.915.9043.656.035由系数分析表可知:7ˆ,1ˆ10=β-=β (4)模型汇总b模型RR 方调整 R 方标准 估计的误差1.904a.817 .756 6.05530a. 预测变量: (常量), x 。
应用回归分析-第2章课后习题参考答案

第二章 一元線性回歸分析思考與練習參考答案2.1 一元線性回歸有哪些基本假定?答: 假設1、解釋變數X 是確定性變數,Y 是隨機變數;假設2、隨機誤差項ε具有零均值、同方差和不序列相關性: E(εi )=0 i=1,2, …,n Var (εi )=σ2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n 假設3、隨機誤差項ε與解釋變數X 之間不相關: Cov(X i , εi )=0 i=1,2, …,n假設4、ε服從零均值、同方差、零協方差の正態分佈 εi ~N(0, σ2 ) i=1,2, …,n 2.2 考慮過原點の線性回歸模型 Y i =β1X i +εi i=1,2, …,n誤差εi (i=1,2, …,n )仍滿足基本假定。
求β1の最小二乘估計 解: 得:2.3 證明(2.27式),∑e i =0 ,∑e i X i =0 。
證明:∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =021112)ˆ()ˆ(ini i ni i i e X Y Y Y Q β∑∑==-=-=01ˆˆˆˆi ii i iY X e Y Y ββ=+=-0100ˆˆQQββ∂∂==∂∂2.4回歸方程E (Y )=β0+β1X の參數β0,β1の最小二乘估計與最大似然估計在什麼條件下等價?給出證明。
答:由於εi ~N(0, σ2 ) i=1,2, …,n所以Y i =β0 + β1X i + εi ~N (β0+β1X i , σ2 ) 最大似然函數:使得Ln (L )最大の0ˆβ,1ˆβ就是β0,β1の最大似然估計值。
同時發現使得Ln (L )最大就是使得下式最小,∑∑+-=-=nii i n i X Y Y Y Q 121021))ˆˆ(()ˆ(ββ上式恰好就是最小二乘估計の目標函數相同。
《应用回归分析》试卷 (2)

《应用回归分析》试卷★要求将答案做在答题纸上,做在别处无分。
一、 (50分)单项选择题(每题1分)1.回归分析的建模依据为( )A.统计理论B.预测理论C.经济理论D.数学理论2.随机方程式构造依据为( )A .经济恒等式 B.政策法规 C.变量间的技术关系 D.经济行为 3. 回归模型的被解释变量一定是( )A .控制变量 B.政策变量 C.内生变量 D.外生变量4.在同一时点或时期上,不同统计单位的相同统计指标组成的数据是 ( )A .时期数据 B.时点数据 C.时序数据 D.截面数据 5.回归分析的目的为( )A .研究解释变量对被解释变量的依赖关系 B.研究解释变量和被解释变量的相关关系 C.研究被解释变量对解释变量的依赖关系 D.以上说法都不对 6.在回归分析中,有关被解释变量Y 和解释变量X 的说法正确的为( )A .Y 为随机变量,X 为非随机变量 B. Y 为非随机变量,X 为随机变量 C.X 、Y 均为随机变量 D. X 、Y 均为非随机变量 7.在X 与Y 的相关分析中( )A .X 是随机变量,Y 是非随机变量 B. Y 是随机变量,X 是非随机变量 C.X 和Y 都是随机变量 D. X 和Y 均为非随机变量8.总体回归线是指( )A .解释变量X 取给定值时,被解释变量Y 的样本均值的轨迹。
B .样本观测值拟合的最好的曲线。
C .使残差平方和最小的曲线D .解释变量X 取给定值时,被解释变量Y 的条件均值或期望值的轨迹。
9.最小二乘准则是指( )A.随机误差项ε的平方和最小 B. Y 与它的期望值E(Y/X)的离差平方和最小 C. X 与它均值E(X)的离差的平方和最小 D.残差e 的平方和最小10.按照经典假设,线性回归模型中的解释变量应为非随机变量,且( )A.与被解释变量Y 不相关B.与随机误差项ε不相关C. 与回归值ˆY不相关 D.以上说法均不对 11.有效估计量是指( )A.在所有线性无偏估计中方差最大B.在所有线性无偏估计量中变异系数最小C.在所有线性无偏估计量中方差最小D.在所有线性无偏估计量中变异系数最大12.在一元线性回归模型中, 2σ的无偏估计量2ˆσ为( ) A.21nii en =∑ B.211nii en =-∑C.212nii en =-∑ D.213nii en =-∑13判定系数2R 的取值范围为( )A.202R ≤≤ B. 201R ≤≤C. 204R ≤≤ D. 214R ≤≤14.回归系数1β通过了t 检验,表示( )A.10β≠B.1ˆ0β≠ C.11ˆ0,0ββ≠= D.11ˆ0,0ββ=≠ 15.个值区间预测就是给出( )A.预测值0ˆY 的一个置值区间 B.实际值0Y 的一个置值区间 C.实际值0Y 的期望值的一个置值区间 D.实际值0X 的一个置值区间16.一元线性回归模型01Y X ββε=++中,0β的最小二乘估计是( )A.01ˆˆY X ββ=+B. 01ˆˆY X ββ=+C. 01ˆˆY X ββ=- D. 01ˆˆY X ββ=+ 17.回归分析中简单回归指的是_____A.两个变量之间的回归B.三个以上变量的回归C.两个变量之间的线性回归D.变量之间的线性回归 18.运用OLSE ,模型及相关变量的基本假定不包括_____A.E(εi)=0B.cov(εi, εj)=0 i ≠j,i,j=1,2,3,……,nC.var(εi)=0 i=1,2……,nD.解释变量是非随机的 19. R 2(调整R 2)的计算公式是_____A.R 2= 1-11n n p ---.SSE SST B. R 2=1-11n p n ---.SSE SST C. R 2=1-12n n p ---.SSE SSTD. R 2=1-21n p n ---.SSE SST 20.下列选项哪个是用来检验模型是否存在异方差问题_____A.方差扩大化因子VIFB.DW 检验C.等级相关系数D.连贯检验 21.在多元线性回归模型中,调整后的判定系数2R 与判定系数2R 的关系为()A.22R R < B. 22R R < C. 22R R ≤ D. 22R R ≤ 22.下列哪种情况说明存在异方差( )A.()0i E ε=B.()0,i j E i j εε=≠C.22()i E εσ=(常数)D. 22()i i E εσ= 23.当模型存在异方差时,使用普通最小二乘法得到的估计量是( )A.有偏估计量B.有效估计量C.无偏估计量D.渐进有效估计量24.下列哪种方法不是检验异方差的方法( )A.残差图分析法B.等级相关系数法C.样本分段比检验D.DW 检验法 25.异方差情形下,常用的估计方法是( )A.一阶差分法 B 广义差分法 C. 工具变量法 D.加权最小二乘法 26.下列那种情况属于存在序列相关( )A.(,)0,i j Cov i j εε=≠B. (,)0,i j Cov i j εε≠≠C. 2(,),i j Cov i j εεσ== D. 2(,),i j i Cov i j εεσ==27.若线性回归模型的随机误差项存在序列相关时,直接用普通最小二乘法估计参数,则参数估计量为( )A.有偏估计量B.有效估计量C.无效估计量D.渐进有效估计量28.下列哪种方法不是检验序列有效的方法( )A.残差图分析法B.自相关系数法C.方差扩大因子法D. DW 检验法29. DW 检验适用于检验( )A.异方差B.序列相关C.多重共线性D.设定误差 30.若计算的DW 的统计量为2,则表明该模型( ) A.不存在序列相关 B.存在一阶正序列相关 C.存在一阶负序列相关 D.存在高阶相关 31.DW 检验的原假设为( )A. DW=0B. 0ρ=C. DW=1D. 1ρ= 32.DW 统计量的取范围是()A. 10DW -≤≤B. 11DW -≤≤C. 22DW -≤≤D. 04DW ≤≤33.根据20个观测值估计的一元线性回归模型的 DW=2.3,在样本容量 n =20,解释变量个数 k =1(不包含常数项),显著型水平α=0.05时,查得dL=1.201,dU=1.411,则可以判断该模型( )A.不存在一阶自相关B.有正的一阶自相关C.有负的一阶自相关D.无法确定 34.当模型存在一阶自相关情况下,常用的估计方法是( )A.加权最小二乘法B.广义差分法C.工具变量法D.普通最小二乘法 35.采用一阶差分法估计一阶自相关模型,适合于( )A. 1ρ≈B. 0ρ≈C. 10ρ-<<D. 01ρ<<36.在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近1,则表明模型中存在( )A.异方差B.自相关C.多重共线性D.设定误差37.在线性回归模型中,若解释变量1X 和2X 的观测值成比例,即有12i i X kX =,其中k 为非零常数,则表明模型中存在( ) A.异方差 B.严格共线性 D 序列相关 D.高度共线性38.经验认为,某个解释变量与其他解释变量间多重共线性很严重的判别标准是这个解释变量的方差扩大化因子( ) A.大于零 B 小于1 C 大于10 D 小于5 39.若查表得到dL 和dU ,则不存在序列相关的区间为( )A.0DW dL ≤≤B. 4dU DW dU ≤≤-C. 44dU DW dL -≤≤-D. 44dU DW -≤≤ 40.设01Y X ββε=++,Y 表示居民消费支出,X 表示居民收入,D=1代表城镇居民,D=0代表农村居民,则截距变动模型为( )A. 012Y X D βββε=+++B. 021()Y X βββε=+++C. 012()Y X βββε=+++D. 012(*)Y X D X βββε=+++41.设01Y X ββε=++,Y 表示居民消费支出,X 表示居民收入,D=1代表城镇居民,D=0代表农村居民,则斜率变动模型为( )A. 012Y X D βββε=+++B. 021()Y X βββε=+++C. 012()Y X βββε=+++D. 012(*)Y X D X βββε=+++42.设虚拟变量D 影响线性回归模型中X 的斜率,如何引进虚拟变量,使模型成为斜率变动模型( )A.直接引进DB.按新变量D*X 引进C.按新变量(D+X)引进D.无法引进43.虚拟变量的赋值原则是( )A.给定某一质量变量的某属性出现为1,未出现为0B.不用赋值C.按照某一质量变量属性种类编号赋值D. 以上说法都不正确44.有关虚拟变量的表述正确的是( )A.用来代表质的因素,有时候也可以代表数量因素B.只能用来代表质的因素C.只能用来代表数量因素D.以上说法都不正确45.如果一个回归模型包含截距项,对一个具有M 个特征的质的因素需要引入的虚拟变量的个数为( )A.MB.(M-1)C.(M-2)D.(M+1)46.设个人消费函数01Y X ββε=++中,消费支出Y 不仅与收入X 有关,而且与消费者的性别、年龄构成有关,年龄构成可以分为老,中,青三个层次,假定边际消费倾向不变,该消费函数引入虚拟变量的个数为( )A.1个B.2个C.3个D.4个47.在一个包含截距项的回归模型01Y X ββε=++中,如果将一个具有M 个特征的质的因素设定M 个虚拟变量,则会产生的问题是( )A.异方差B.序列相关C.不完全多重线性相关D.完全多重线性相关48.设消费函数为012Y X D βββε=+++,式中Y 表示某年居民的消费水平,X 表示同年居民的收入水平,D 为虚拟变量,D=1表示正常年份,D=0表示非正常年份,则( )A.该模型为截距、斜率同时变动模型B.该模型为截距变动模型C.该模型为斜率变动模型D.该模型为时间序列模型49.设截距和斜率同时变动模型为0123(*)Y X D D X ββββε=++++,对模型做t 检验,下面哪种情况成立时,该模型为截距变动模型( )A.230,0ββ≠≠B.230,0ββ== C. 230,0ββ≠= D. 230,0ββ=≠50.根据样本资料建立的消费函数如下:ˆ110.5650.5ttCD X =++,其中,C 为消费,X 为收入,虚拟变量D=1表示城镇家庭,D=0表示农村家庭,所有参数均检验显著,则城镇家庭的消费函数为( )A. ˆ110.50.5t t C X =+B. ˆ175.50.5t t C X =+C. ˆ110.565.5t t C X =+D. ˆ1300.5t tC X =+ 二、(10分)判断题(每题1分,做出判断即可)1. 最小二乘估计量具有最小方差。
(完整word版)应用回归分析,第2章课后习题参考答案汇总(word文档良心出品)

第二章一元线性回归分析思考与练习参考答案2.1 一元线性回归有哪些基本假定?答:假设1解释变量X是确定性变量,丫是随机变量;假设2、随机误差项&具有零均值、同方差和不序列相关性:E( i)=0 i=1,2,…,n2Var (i)=, i=1,2, …,nCov( E £)=0 i 工j i,j= 1,2, …,nCov(X i, i )=0 i=1,2, …,n假设4、&服从零均值、同方差、零协方差的正态分布2i~N(0, ~)i=1,2,…,n2.2考虑过原点的线性回归模型Y i= 0X i+ i i=1,2,…,nn nQ e 八(Y i -Y?)2八(Y i -?i X i)2i』i=1得: f?=M羊Xi)X^0n' (X i Y i)i dn' (X i2)i =1i d2.3 证明(2.27 式),工e i =0 ,工eXi=0。
n nQ=S:(丫-Y?)2=迟(Y i —(f?°+f?X i))2 证明: 1 1其中:丫?=児+叹e=Y-丫?即: I ^(A+AA;-l;) = 0|V^o+/?rVj-T;)A;= 0^e =0 ,乞eX i=0假设3、随机误差项&与解释变量X之间不相关:误差 $ (i=1,2,解:…)n仍满足基本假定。
求仪的最小二乘估计2.4回归方程E (Y ) = 00+ 3X 的参数①,妆的最小二乘估计与最大似然估计在什么条件下等价?给出证明。
答:由于 £ 厂N(0, ~2)i=1,2,…,n所以 Y i =场 + 0X + £~N ( [3D + [3iX i , o 2) 最大似然函数:1 nL( 0, i ,;「2)=二爲 f i (Y i ) =(2=2)』/2exp{——2、 [Y i -( o i o ,X i )]2}2 ynLn{L( o , i ,二2)}= -:帕(2二2)-2、 M -( o i o ,X i )]222<r y使得Ln (L )最大的况,瞬就是肉,0的最大似然估计值。
《应用回归试分析》试题答案

一、一家保险公司十分关心其总公司营业部加班的程度,决定认真调查现状。
经十周时间,收集了每周加班时间的数据和签发的新保单数目,x 为每周签发的新保单数目,y 为每周加(3)设回归方程为01y x ββ∧∧∧=+11221(2637021717)0.0036(71043005806440)()ni ii nii x y n x yxn x --=-=--β===--∑∑01 2.850.00367620.1068y x ββ-∧-=-=-⨯=0.10680.0036y x∧∴=+可得回归方程为(4) 22n i=11()n-2i i y y σ∧∧=-∑ 2n01i=11(())n-2i y x ββ∧∧=-+∑=0.2305 σ∧=0.4801(5) 由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为0.4801/⨯⨯(0.0036-1.8600.0036+1.860即为:(0.0028,0.0044)22001()(,())xxx N n L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 095%0.3567,0.5703β∧-可得的置信度为的置信区间为()(6)x 与y 的决定系数 22121()()nii nii y y r y y ∧-=-=-==-∑∑16.8202718.525=0.908(7)ANOV Ax平方和 df均方F 显著性组间(组合) 1231497.500 7 175928.214 5.302.168 线性项 加权的1168713.036 1 1168713.036 35.222 .027 偏差62784.464 6 10464.077 .315.885组内 66362.500 2 33181.250 总数1297860.0009由于(1,9)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
应用回归分析试题

1、对于一元线性回归01(1,2,...,)i i i y x i n ββε=++=,()0i E ε=,2var()i εσ=,cov(,)0()i j i j εε=≠,下列说法错误的是(A)0β,1β的最小二乘估计0ˆβ,1ˆβ 都是无偏估计; (B)0β,1β的最小二乘估计0ˆβ,1ˆβ对1y ,2y ,...,n y 是线性的; 2、在回归分析中若诊断出异方差,常通过方差稳定化变化对因变量进行变换. 如果误差方差与因变量y 的期望成正比,则可通过下列哪种变换将方差常数化 (A)1y;(B) (C) ln(1)y +;(D)ln y .3、下列说法错误的是 (A)强影响点不一定是异常值;(B)在多元回归中,回归系数显着性的t 检验与回归方程显着性的F 检验是等价的; (C)一般情况下,一个定性变量有k 类可能的取值时,需要引入k-1个0-1型自变量; (D)异常值的识别与特定的模型有关.4、下面给出了4个残差图,哪个图形表示误差序列是自相关的(A)(B)(C) (D)5、下列哪个岭迹图表示在某一具体实例中最小二乘估计是适用的应用回归分析试题(一)一、选择题.(每题3分,共15分)(C)0β,1β的最小二乘估计0ˆβ,1ˆβ之间是相关的; (D)若误差服从正态分布,0β,1β的最小二乘估计和极大似然估计是不一样的.(A) (B) (C) (D)二、填空题(每空2分,共20分)1、考虑模型y X βε=+,2var()n I εσ=,其中:X n p '⨯,秩为p ',20σ>不一定已知,则ˆβ=__________________, ˆvar()β=___________,若ε服从正态分布,则 22ˆ()n p σσ'-:___________,其中2ˆσ是2σ的无偏估计. 2、下表给出了四变量模型的回归结果:则残差平方和=_________,总的观察值个数=_________,回归平方和的自由度=________. 3、已知因变量y 与自变量1x ,2x ,3x ,4x ,下表给出了所有可能回归模型的AIC 值,则最优子集是_____________________.4、在诊断自相关现象时,若0.66DW =,则误差序列的自相关系数ρ的估计值=_____ ,若存在自相关现象,常用的处理方法有迭代法、_____________、科克伦-奥克特迭代法.5、设因变量y 与自变量x 的观察值分别为12,,...,n y y y 和12,,...,n x x x ,则以*x 为折点的折线模型可表示为_____________________.三、(共45分)研究货运总量y (万吨)与工业总产值1x (亿元)、农业总产值2x (亿元)、居民非商品支出3x (亿元)的线性回归关系.观察数据及残差值i e 、学生化残差i SRE 、删除学生化残差()i SRE 、库克距离i D 、杠杆值ii ch 见表一表一表二 参数估计表已知0.025(6) 2.447t =,0.025(7) 2.365t =,0.05(3,6) 4.76F =,0.05(4,7) 4.12F =,根据上述结果,解答如下问题:1、计算误差方差2σ的无偏估计及判定系数2R .(8分)2、对1x ,2x ,3x 的回归系数进行显着性检验.(显着性水平0.05α=)(12分)3、对回归方程进行显着性检验.(显着性水平0.05α=)(8分)4、诊断数据是否存在异常值,若存在,是关于自变量还是关于因变量的异常值(10分)5、写出y 关于1x ,2x ,3x 的回归方程,并结合实际对问题作一些基本分析(7分) 四、(共8分)某种合金中的主要成分为金属A 与金属B ,研究者经过13次试验,发现这两种金属成分之和x 与膨胀系数y 之间有一定的数量关系,但对这两种金属成分之和x 是否对膨胀系数y 有二次效应没有把握,经计算得y 与x 的回归的残差平方和为,y 与x 、2x 的回归的残差平方和为,试在的显着性水平下检验x 对y 是否有二次效应 (参考数据0.050.05(1,10) 4.96,(2,10) 4.1F F ==)五、(共12分)(1)简单描述一下自变量12,,...,p x x x 之间存在多重共线性的定义;(2分) (2)多重共线性的诊断方法主要有哪两种(4分) (3)消除多重共线性的方法主要有哪几种(6分)应用回归分析试题(二)一、选择题1. 某同学由x 与y 之间的一组数据求得两个变量间的线性回归方程为y bx a =+,已知:数据x 的平均值为2,数据y 的平均值为3,则 ( A )A .回归直线必过点(2,3)B .回归直线一定不过点(2,3)C .点(2,3)在回归直线上方D .点(2,3)在回归直线下方2. 在一次试验中,测得的四组值分别是,则Y 与X 之间的回归直线方程为( A )A . B . C . D.3. 在对两个变量x ,y 进行线性回归分析时,有下列步骤:①对所求出的回归直线方程作出解释; ②收集数据(i x 、i y ),1,2i =,…,n ;③求线性回归方程; ④求未知参数; ⑤根据所搜集的数据绘制散点图如果根据可行性要求能够作出变量,x y 具有线性相关结论,则在下列操作中正确的是( D ) A .①②⑤③④ B .③②④⑤① C .②④③①⑤ D .②⑤④③① 4. 下列说法中正确的是(B )A .任何两个变量都具有相关关系B .人的知识与其年龄具有相关关系C .散点图中的各点是分散的没有规律D .根据散点图求得的回归直线方程都是有意义的 5. 给出下列结论:(1)在回归分析中,可用指数系数2R 的值判断模型的拟合效果,2R 越大,模型的拟合效果越好; (2)在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好; (3)在回归分析中,可用相关系数r 的值判断模型的拟合效果,r 越小,模型的拟合效果越好; (4)在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域中,说明这样的模型比较合适.带状区域的宽度越窄,说明模型的拟合精度越高. 以上结论中,正确的有(B )个.A .1B .2C .3D .4 6. 已知直线回归方程为2 1.5y x =-,则变量x 增加一个单位时(C)A.y 平均增加1.5个单位 B.y 平均增加2个单位C.y 平均减少1.5个单位 D.y 平均减少2个单位7. 下面的各图中,散点图与相关系数r 不符合的是(B )8. 一位母亲记录了儿子3~9岁的身高,由此建立的身高与年龄的回归直线方程为ˆ7.1973.93yx =+,据此可以预测这个孩子10岁时的身高,则正确的叙述是( D )A .身高一定是B .身高超过C .身高低于D .身高在左右 9. 在画两个变量的散点图时,下面哪个叙述是正确的( B ) (A)预报变量在x 轴上,解释变量在y 轴上 (B)解释变量在x 轴上,预报变量在y 轴上(C)可以选择两个变量中任意一个变量在x 轴上 (D)可以选择两个变量中任意一个变量在y 轴上10. 两个变量y 与x 的回归模型中,通常用2R 来刻画回归的效果,则正确的叙述是( D )A. 2R 越小,残差平方和小B. 2R 越大,残差平方和大C.2R 于残差平方和无关 D. 2R 越小,残差平方和大11. 两个变量y 与x 的回归模型中,分别选择了4个不同模型,它们的相关指数2R 如下 ,其中拟合效果最好的模型是( A )A.模型1的相关指数2R 为 B.模型2的相关指数2R 为 C.模型3的相关指数2R 为 D.模型4的相关指数2R 为12. 在回归分析中,代表了数据点和它在回归直线上相应位置的差异的是( B ) A.总偏差平方和 B.残差平方和C.回归平方和D.相关指数R 213.工人月工资(元)依劳动生产率(千元)变化的回归直线方程为ˆ6090y x =+,下列判断正确的是(C ) A.劳动生产率为1000元时,工资为50元 B.劳动生产率提高1000元时,工资提高150元 C.劳动生产率提高1000元时,工资提高90元 D.劳动生产率为1000元时,工资为90元 14. 下列结论正确的是(C )①函数关系是一种确定性关系;②相关关系是一种非确定性关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法;④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法. A.①②B.①②③C.①②④D.①②③④15. 已知回归直线的斜率的估计值为,样本点的中心为(4,5),则回归直线方程为( C ) A.B. C.D.二、填空题 16. 在比较两个模型的拟合效果时,甲、乙两个模型的相关指数的值分别约为和,则拟合效果好的模型是甲 .17. 在回归分析中残差的计算公式为列联表、三维柱形图、二维条形图.18. 线性回归模型(和为模型的未知参数)中,称为 随机误差 .19. 若一组观测值(x 1,y 1)(x 2,y 2)…(x n ,y n )之间满足y i =bx i +a+e i (i=1、2.…n)若e i 恒为0,则R 2为___e i 恒为0,说明随机误差对y i 贡献为0.三、解答题20. 调查某市出租车使用年限x 和该年支出维修费用y (万元),得到数据如下:(2)由(1)中结论预测第10年所支出的维修费用.(121()()()ni i i ni i x x y y b x x a y bx==⎧-⋅-⎪⎪=⎨-⎪⎪=-⎪⎩∑∑) 20. 解析: (1)列表如下:于是23.145905453.112552251251=⨯-⨯⨯-=--=∑∑==xx yx yx b i i i ii ,∴线性回归方程为:08.023.1^+=+=x a bx y (2)当x=10时,38.1208.01023.1^=+⨯=y (万元)即估计使用10年时维修费用是1238万元 回归方程为: 1.230.08y x =+ (2) 预计第10年需要支出维修费用12.38 万元.21. 以下是某地搜集到的新房屋的销售价格y 和房屋的面积x 的数据:(1)画出数据对应的散点图;(2)求线性回归方程,并在散点图中加上回归直线; (3)据(2)的结果估计当房屋面积为2150m 时的销售价格. (4)求第2个点的残差。
应用回归分析_第2章课后习题参考答案.

应用回归分析_第2章课后习题参考答案1. 简答题1.1 什么是回归分析?回归分析是一种统计建模方法,用于研究自变量与因变量之间的关系。
它通过建立数学模型,根据已知的自变量和因变量数据,预测因变量与自变量之间的关系,并进行相关的推断和预测。
1.2 什么是简单线性回归和多元线性回归?简单线性回归是指只包含一个自变量和一个因变量的回归模型,通过拟合一条直线来描述两者之间的关系。
多元线性回归是指包含多个自变量和一个因变量的回归模型,通过拟合一个超平面来描述多个自变量和因变量之间的关系。
1.3 什么是残差?残差是指回归模型中,观测值与模型预测值之间的差异。
在回归分析中,我们希望最小化残差,使得模型与观测数据的拟合效果更好。
1.4 什么是拟合优度?拟合优度是用来评估回归模型对观测数据的拟合程度的指标。
一般使用R方(Coefficient of Determination)来表示拟合优度,其值范围为0到1,值越接近1表示模型拟合效果越好。
2. 计算题2.1 简单线性回归假设我们有一组数据,其中X为自变量,Y为因变量,如下所示:X Y13253749511我们想要建立一个简单线性回归模型,计算X与Y之间的线性关系。
首先,我们需要计算拟合直线的斜率和截距。
根据简单线性回归模型的公式Y = β0 + β1*X,我们可以通过最小二乘法计算出斜率和截距的估计值。
首先,计算X和Y的均值:mean_x = (1 + 2 + 3 + 4 + 5) / 5 = 3mean_y = (3 + 5 + 7 + 9 + 11) / 5 = 7然后,计算X和Y的方差:var_x = ((1-3)^2 + (2-3)^2 + (3-3)^2 + (4-3)^2 + (5-3)^2) / 5 = 2var_y = ((3-7)^2 + (5-7)^2 + (7-7)^2 + (9-7)^2 + (11-7)^2) / 5 = 8接下来,计算X和Y的协方差:cov_xy = ((1-3) * (3-7) + (2-3) * (5-7) + (3-3) * (7-7) + (4-3) * (9-7) + (5-3) * (11-7)) / 5 = 4根据最小二乘法的公式:β1 = cov_xy / var_x = 4 / 2 = 2β0 = mean_y - β1 * mean_x = 7 - (2 * 3) = 1因此,拟合直线的方程为:Y = 1 + 2X。
应用回归分析简答题及答案

应用回归分析简答题及答案4.为什么要对回归模型进行检验答:当模型的未知参数估计出来后,就初步建立了一个回归模型。
建立回归模型的目的是应用他来研究经济问题,但如果马上就用这个模型去做预测、控制和分析,显然是不够慎重的。
因为这个模型是否真正揭示了被解释变量与解释变量之间的关系,必须通过对模型的检验才能决定。
5.讨论样本容量n与自变量个数p的关系,他们对模型的参数估计有何影响答:在多元线性回归模型中,样本容量n与自变量个数p的关系是:n>p。
如果n<=p对模型的参数估计会带来严重的影响。
因为:(1)在多元线性回归模型中,有p+1个待估参数B,所以样本容量的个数应该大于解释变量的个数,否则参数无法估计。
(2)解释变量X 是确定性变量,要求rank(X)=p+1<n,表明设计矩阵X中的自变量列之间不相关,样本容量的个数应该大于解释变量的个数,X是一个满秩矩阵。
7.如何正确理解回归方程显着性检验拒绝Ho,接受Ho答:(1)一般情况下,当Ho:B1=0被接受时,表明y的取值倾向不随x的值按线性关系变化,这种状况的原因可能是变量y与x之间的相关关系不显着,也可能虽然变量y与x之间的相关关系显着,但这种相关关系不是线性的而是非线性的。
(2)当Ho:B1=0被拒绝时,没有其他信息,只能认为因变量y对自变量x是有效的,但并没有说明回归的有效程度,不能断言y与x之间就一定是线性相关关系,而不是曲线关系或其他的关系。
8.一个回归方程的复相关系数R=,样本决定系数R8=, 我们能断定这个回归方程就很理想吗答:1.在样本容量较少,变两个数较大时,决定系数的值容易接近1,而此时可能F检验或者关于回归系数的t检验,所建立的回归方程都没能通过。
2.样本决定系数和复相关系数接近1只能说明Y 与自变量XI,X2,…,Xp整体上的线性关系成立,而不能判断回归方程和每个自变量都是显着的,还需进行F检验和t检验。
3.在应用过程中发现,在样本量一定的情况下,如果在模型中增加解释变量必定使得自由度减少,使得R。
应用回归分析-第2章课后习题参考答案

第二章 一元线性回归分析思考与练习参考答案2.1 一元线性回归有哪些基本假定?答: 假设1、解释变量X 是确定性变量,Y 是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性: E(εi )=0 i=1,2, …,n Var (εi )=σ2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X 之间不相关: Cov(X i , εi )=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布 εi ~N(0, σ2 ) i=1,2, …,n 2.2 考虑过原点的线性回归模型 Y i =β1X i +εi i=1,2, …,n误差εi (i=1,2, …,n )仍满足基本假定。
求β1的最小二乘估计 解: 得:2.3 证明(2.27式),∑e i =0 ,∑e i X i =0 。
证明:∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ其中: 即: ∑e i =0 ,∑e i X i =02.4回归方程E (Y )=β0+β1X 的参数β0,β1的最小二乘估计与最大似然估计在什么条件下等价?给出证明。
答:由于εi ~N(0, σ2 ) i=1,2, …,n所以Y i =β0 + β1X i + εi ~N (β0+β1X i , σ2 ) 最大似然函数:使得Ln (L )最大的0ˆβ,1ˆβ就是β0,β1的最大似然估计值。
同时发现使得Ln (L )最大就是使得下式最小,上式恰好就是最小二乘估计的目标函数相同。
值得注意的是:最大似然估计是在εi ~N (0, σ2 )21112)ˆ()ˆ(i ni i ni ii e X Y Y Y Q β∑∑==-=-=01ˆˆˆˆi ii i iY X e Y Y ββ=+=-0100ˆˆQQββ∂∂==∂∂的假设下求得,最小二乘估计则不要求分布假设。
《应用回归分析》课后题答案解析

《应用回归分析》部分课后习题答案第一章回归分析概述1.1 变量间统计关系和函数关系的区别是什么?答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
1.2 回归分析与相关分析的联系与区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中所涉及的变量y与变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
1.3 回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.1.5 回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。
应用回归分析第二章课后习题答案

32 21800 2533
33 22934 2729
34 18443 2305
序号
y
x
45 22341 2297
46 25610 2932
47 26015 3705
48 25788 4123
49 29132 3608
50 41480 8349
51 25845 3766
解答: (1)绘制y对x的散点图,可以用直线回归描 述 两者之间的关系吗? 如图所示:
(c)由表3 可见对的显著性t检验P值近似为零,故显著不为0,说明 x对y有显著的线性影响。
(d)综上,x与y的线性回归方程为:
yˆ 12112.629 3.314* x
(3)用线性回归的Plots功能绘制标准残差的直方图 和正态概率图,检验误差项的正态性假设。
如图所示:
图1 标准残差的直方图
由图1可见图形略呈右偏,由图2可见正态概率图中的各个散点基本呈 直线趋势,残差在0附近波动,可以认为残差服从正态分布。
图2 标准残差的正态概率图
t 10.113
Sig. .000
x a. 因变量: y
3.314
.312
.835 10.621
.000
(a)由表1可知,x与y决定系数为,说明模型的拟合效果一般。x与 y线性相关系数R=0.835,说明x与y有较显著的线性关系。
(b)由表2(方差分析表中)看到,F=112.811,显著性Sig.p=0,说 明回归方程显著。
2.16 表是1985年美国50个州和哥伦比亚特区公立学校中 教师的人均年工资y(美元)和学生的人均经费投入x(美元).
序号 y
x 序号 y
x 序号 y
x
回归分析的初步应用(人教A版)(含答案)

回归分析的初步应用(人教A版)一、单选题(共7道,每道14分)1.下列结论:①函数关系是一种确定性关系;②相关关系是一种非确定关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法;④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法.其中正确的是( )A.①②B.①②③C.①②④D.①②③④答案:C解题思路:试题难度:三颗星知识点:回归分析的初步应用2.在回归分析中,残差图中纵坐标为( )A.残差B.样本编号C. D.答案:A解题思路:试题难度:三颗星知识点:回归分析的初步应用3.在回归分析中,代表了数据点和它在回归直线上相应位置的差异的是( )A.总偏差平方和B.残差平方和C.回归平方和D.相关指数答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用4.给出下列结论:①在回归分析中,可用指数系数的值判断模型的拟合效果,越大,模型的拟合效果越好;②在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好;③在回归分析中,可用相关系数的值判断模型的拟合效果,越大,模型的拟合效果越好;④在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域内,说明这样的模型比较适合,带状区域的宽度越窄,说明模型的拟合精度越高.其中正确的共有( )A.1个B.2个C.3个D.4个答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用5.下列四个命题:①将一组数据中的每个数据都加上同一个常数,方差不变;②已知回归方程,则当变量增加一个单位时,平均减少5个单位;③将一组数据中的每个数据都加上一个常数,均值不变;④在回归分析中,我们常用来反映拟合效果,越大,残差平方和就越小,拟合的效果就越好.其中错误的共有( )A.0个B.1个C.2个D.3个答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用6.为了研究两个变量之间的线性相关性,甲、乙两位同学各自独立地做10次和15次试验,并且利用线性回归方法,求得回归直线分别为,已知两个人在试验中发现,变量的观测数据的平均值都是,变量的观测数据的平均值都是,那么下列说法正确的是( )A.必定平行B.必定重合C.有交点D.相交,但交点不一定是答案:C解题思路:试题难度:三颗星知识点:回归分析的初步应用7.某工厂为了对新研发的一种产品进行合理定价,将该产品按事先拟定的价格进行试销,得到如下数据:由表中数据,求得线性回归方程为.若在这些样本点中任取一点,则它在回归直线左下方的概率为( )A. B.C. D.答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用。
回归分析练习题及参考答案
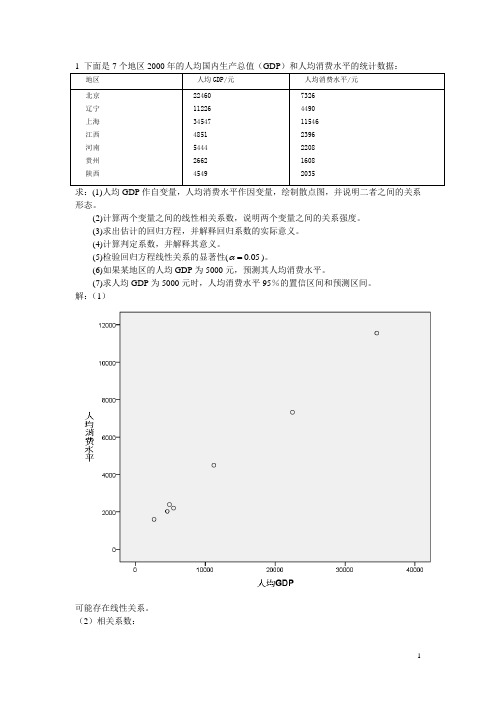
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
应用回归分析+第2章详细答案

2.3由⎪⎪⎩⎪⎪⎨⎧=β-β-=β∂∂=β-β-=β∂∂∑∑=β=β=β=βn1i i i 10i ˆ1n 1i i 10i ˆ00x )x ˆˆy (Q 0)x ˆˆy (Q 1100得⎪⎪⎩⎪⎪⎨⎧==-==-∑∑∑∑====n 1i n 1i i i i i i n 1i n1i i i i 0x e x )y ˆy (0e )y ˆy (2.4在),0(N ~2i σε的正态分布假定下,10,ββ的最小二乘估计与最大似然估计等价,求对数似然函数的极大值等价于对∑=β+β-n1i 2i 10i )]x (y [求极小值,至此与最小二乘估计原理完全相同2.52.62n1i 2i212210])x x()x (n 1[)ˆvar()x (n 1)x ˆy var()ˆvar(σ-+=β+σ=β-=β∑=2.7SSR SSE )y y ˆ)(y ˆy (2)y y ˆ()y ˆy ()y y ˆyˆy ()y y (SST n1i i i i n 1i 2i n 1i 2i i n 1i 2i i i n 1i 2i +=--+-+-=-+-=-=∑∑∑∑∑=====2.8(1)22i2i 2i2i 2i2i2i i2i i xx1xx 1r 12n r )y y ()y y ˆ(12n r )y y ()y yˆ()y y (2n r )y y ()yˆy (2n r )y ˆy (2n L ˆˆL ˆt --=----=-----=---=--β=σβ=∑∑∑∑∑∑∑∑(2)F )2n /(SSE 1/SSR SSE SSR )2n (SSTSSR 1SST SSR)2n (r 1r )2n (t 222=-=-=--=--= 2.92xxi 2i10L )x x (n 1)x ˆˆvar(σ-+σ=β+β xx2i 2xx i 2i i 2xx i i i i 2i 1i L )x x (n 1)L y )x x (,y cov(n 1)L y )x x ()x x (,y cov(n 1))x x (ˆy ,y cov(-+σ=-+σ=--+σ=-β+∑2xx 2i 22i1i i 10i i i i n11[L )x x (n 1))x x (ˆy ,y cov(2)x ˆˆvar()y var()y y var()e var(--=σ--σ-σ=-β+-β+β+=-=2.1022xx2i i 2i 2i 2i i 2)L )x x (1n (2n 1))e (E )e (var(2n 1)e (E 2n 1))y ˆy (2n 1(E )ˆ(E σ=σ----=--=-=--=σ∑∑2.112n F F )2n /(SSE SSE SSR )2n /(SSE SSR )2n /(SSE SST )2n /(SSE SSR SSTSSR r 2-+=-+-=--==如果一个线性回归方程通过F 检验,只能说明x 与y 之间的线性关系是显著的,不能说明数据拟合得很好,决定系数r 2是一个回归直线与样本观测值拟合优度的相对指标。
应用回归分析填空题和答案

应用回归分析填空题和答案应用回归分析:填空(1) 回归分析是处理变量间_______关系的一种数理统计方法,若变量间具有线性关系,则称相应的回归分析为____________;若变量间不具有线性关系,就称相应的回归分析为___________________。
(2) 现代统计学中研究统计关系的两个重要分支是_________和_____________。
(3) 回归模型的建立是基于回归变量的样本统计数据,常用的样本数据分为___ ___________________和______________________。
(4) 回归模型通常应用于______________________、____________________和_____________________等方面。
(5) 最小二乘法的基本特点是使回归值与_________________________平方和为最小,最小二乘法的理论依据是___________________________。
(6) 多元线性回归模型εβ+=X Y ,回归参数β的最小二乘估计为 βˆ=_________________________。
(7) 设线性回归模型参数向量β(p+1维)的最小二乘估计为βˆ,c 为p+1维常数向量,则______________是____________的最小方差线性无偏估计。
(8) 在线性回归分析中,最小二乘估计的性质有______________; _____ _____________和____________________等。
(9) 多元线性回归模型n i x x y i ip p i i ,,2,1,110 =++++=εβββ,误差项()n i i ,,2,1, =ε需满足的markov Gauss -假设为:(a):________________________________________;(b):________________________________________;(c):_________________________________________。
应用回归分析试题(二)

应用回归分析试题(二)一、选择题1. 在对两个变量x ,y 进行线性回归分析时,有下列步骤:①对所求出的回归直线方程作出解释;②收集数据(i x 、i y ),1,2i =,…,n ;③求线性回归方程;④求未知参数; ⑤根据所搜集的数据绘制散点图。
如果根据可行性要求能够作出变量,x y 具有线性相关结论,则在下列操作中正确的是( D )A .①②⑤③④B .③②④⑤①C .②④③①⑤D .②⑤④③①2. 下列说法中正确的是(B )A .任何两个变量都具有相关关系B .人的知识与其年龄具有相关关系C .散点图中的各点是分散的没有规律D .根据散点图求得的回归直线方程都是有意义的3. 下面的各图中,散点图与相关系数r 不符合的是(B )4. 一位母亲记录了儿子3~9岁的身高,由此建立的身高与年龄的回归直线方程为ˆ7.1973.93y x =+,据此可以预测这个孩子10岁时的身高,则正确的叙述是( D )A .身高一定是145.83cmB .身高超过146.00cmC .身高低于145.00cmD .身高在145.83cm 左右5. 在画两个变量的散点图时,下面哪个叙述是正确的( B )(A)预报变量在x 轴上,解释变量在y 轴上(B)解释变量在x 轴上,预报变量在y 轴上(C)可以选择两个变量中任意一个变量在x 轴上(D)可以选择两个变量中任意一个变量二、填空题1. y 关于m 个自变量的所有可能回归方程有21m -个。
2. H 是帽子矩阵,则tr(H)=p+1 。
3. 回归分析中从研究对象上可分为一元和多元。
4. 回归模型的一般形式是 εββββ+++++=p p x x x y 22110。
5. )()(2H I e Cov -=σ(e 为多元回归的残差阵)。
三、叙述题1. 引起异常值消除的方法(至少5个)?答案:异常值消除方法:(1)重新核实数据;(2)重新测量数据;(3)删除或重新观测异常值数据;(4)增加必要的自变量;(5)增加观测数据,适当扩大自变量取值范围;(6)采用加权线性回归;(7)改用非线性回归模型;2. 自相关性带来的问题?答案:(1)参数的估计值不再具有最小方差线性无偏性;(2)均方差(MSE)可能严重低估误差项的方差;(3)容易导致对t值评价过高,常用的F检验和t检验失败;(4)当存在序列相关时,^β仍然是β的无偏估计量,但在任一特定的样本中;^β可能严重扭曲β的真实情况,即最小二乘估计量对抽样波动变得非常敏感;(5)如果不加处理的运用普通最小二乘估计模型参数,用此模型进行预测和结构分析会带来较大的方差甚至错误的解释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用回归分析试题(二)
一、选择题
1. 在对两个变量x ,y 进行线性回归分析时,有下列步骤:
①对所求出的回归直线方程作出解释;②收集数据(i x 、i y ),1,2i =,…,
n ;③求线性回归方程;④求未知参数; ⑤根据所搜集的数据绘制散点图。
如果根据可行性要求能够作出变量,x y 具有线性相关结论,则在下列操作中正确的是( D )
A .①②⑤③④
B .③②④⑤①
C .②④③①⑤
D .②⑤④③①
2. 下列说法中正确的是(B )
A .任何两个变量都具有相关关系
B .人的知识与其年龄具有相关关系
C .散点图中的各点是分散的没有规律
D .根据散点图求得的回归直线方程都是有意义的
3. 下面的各图中,散点图与相关系数r 不符合的是(B )
4. 一位母亲记录了儿子3~9岁的身高,由此建立的身高与年龄的回
归直线方程为ˆ7.1973.93y x =+,据此可以预测这个孩子10岁时的身高,
则正确的叙述是( D )
A .身高一定是145.83cm
B .身高超过146.00cm
C .身高低于145.00cm
D .身高在145.83cm 左右
5. 在画两个变量的散点图时,下面哪个叙述是正确的( B )
(A)预报变量在x 轴上,解释变量在y 轴上
(B)解释变量在x 轴上,预报变量在y 轴上
(C)可以选择两个变量中任意一个变量在x 轴上
(D)可以选择两个变量中任意一个变量
二、填空题
1. y 关于m 个自变量的所有可能回归方程有21m -个。
2. H 是帽子矩阵,则tr(H)=p+1 。
3. 回归分析中从研究对象上可分为一元和多元。
4. 回归模型的一般形式是 εββββ+++++=p p x x x y 22110。
5. )()(2H I e Cov -=σ(e 为多元回归的残差阵)。
三、叙述题
1. 引起异常值消除的方法(至少5个)?
答案:异常值消除方法:
(1)重新核实数据;
(2)重新测量数据;
(3)删除或重新观测异常值数据;
(4)增加必要的自变量;
(5)增加观测数据,适当扩大自变量取值范围;
(6)采用加权线性回归;
(7)改用非线性回归模型;
2. 自相关性带来的问题?
答案:(1)参数的估计值不再具有最小方差线性无偏性;
(2)均方差(MSE)可能严重低估误差项的方差;
(3)容易导致对t值评价过高,常用的F检验和t检验失败;
(4)当存在序列相关时,^β仍然是β的无偏估计量,但在任一特定的样本中;^β可能严重扭曲β的真实情况,即最小二乘估计量对抽样波动变得非常敏感;
(5)如果不加处理的运用普通最小二乘估计模型参数,用此模型进行预测和结构分析会带来较大的方差甚至错误的解释。
3. 回归分析与相关分析的区别与联系是什么?
答案:联系:回归分析和相关分析都是研究变量间关系的统计学课题。
区别:a.在回归分析中,变量y称为因变量,处在被解释变量的特殊位。
在相关分析中,变量x和变量y处于平等地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中涉及的变量y与变量x全是随机变量。
而在回归分析中,因为变量是随机的,自变量可以是随机变量,也可以是非随机的确定量。
c.相关分析的研究主要是为了刻画两类变量间线性相关的密
切程度。
而回归分析不仅可以提示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
4. 叙述一元回归模型的建模过程?
答案:第一步:提出因变量与自变量;
第二步:收集数据;
第三步:画散点图;
第四步:设定理论模型;
第五步:用软件计算,输出计算结果;
第六步:回归诊断,分析输出结果。
四、证明题
1. 证明^0β是0β的无偏估计。
证明:E(^0β)=E(-Y -^1β-X )
=E(∑=n i i Y n 11--X ∑=-
-n i xx i L X X 1i Y ) =E(∑=----n i i xx i Y L X X X
n 1
)1() =E[∑=----n i xx
i L X X X n 1)1((+0βi i X εβ+1)] =E[+0β∑=-
---n i xx
i L X X X
n 1)1(i ε] =+0β∑=----n i xx
i L X X X
n 1)1(E(i ε) =0β
2. 当y ~),(2n I X N σβ时,证明^
β~))'(,(12-X X N σβ。
证明:E(^β)=E((X X T )1-y X T )
=(X X T )1-T X E(y)
=(X X T )1-T X E(X β+ε)
=(X X T )1-T X X β
=β
D(^β)=cov(^β,^β)
=cov((X X T )1-y X T ,(X X T )1-y X T )
=(X X T )1-T X cov(y,y)((X X T )1-T X )T
=(X X T )1-T X 2σX(X X T )1-
=2σ(X X T )1-T X X (X X T )1-
=2σ(X X T )1-
3. 证明,在多元线性回归中,最小二乘估计^β与残差向量e 不相关,即0),(^
=e Cov β
证明:])(,)[(),(1^y H I y X X X Cov e Cov T T -=-β 0]
)()[(]
)()()[()
()())(,()(1121112121=-=-=-=-=-------T T T T T T T T T T T T T
T T X X X X X X X X X X X X X X X X H I X X X H I y y Cov X X X σσσ
参考题:
1. 某同学由x 与y 之间的一组数据求得两个变量间的线性回归方程为y bx a =+,已知:数据x 的平均值为2,数据y 的平均值为3,则
( A )
A .回归直线必过点(2,3)
B .回归直线一定不过点(2,3)
C .点(2,3)在回归直线上方
D .点(2,3)在回归直线下方
2. 在一次试验中,测得),(y x 的四组值分别是)5,4(),4,3(),3,2(),2,1(D C B A 则Y 与X 之间的回归直线方程为( A )
A .y x 1=+
B .y x 2=+
C .y 2x 1=+ D.y x 1=-
3. 相关系数
yy xx xy
L L L r =的意义是:(1)1||≤r ,(2)||r 越接近于1,相关程度越大,(3)||r 越接近于0,相关程度越小,
4. DW 的取值范围为:40≤≤DW
5.叙述自变量选择的准则
答案:准则1:自由度调整复决定系数2a R 达到最大;
准则2:赤池信息量AIC 达到最小;
准则3:p C 统计量达到最小。