C语言概率算法简介
概率的计算--知识讲解

概率的计算--知识讲解概率是数学中的一个重要概念,用来描述事件发生的可能性大小。
在日常生活中,我们经常会面临需要估计一些事件发生的概率的情况,比如天气预报是否准确、购彩中奖的概率等等。
因此,掌握概率的计算方法对我们进行合理决策和判断具有重要意义。
1.基本概率原理基本概率原理是概率计算的基石,它指出任何事件的概率均在[0,1]这个闭区间内。
具体地说,事件A发生的概率应满足以下两个条件:(1)非负性:P(A)≥0(2)规范性:P(S)=1,其中S表示样本空间。
2.经典概型经典概型是指在有限样本空间中,所有基本事件发生的概率相等的情况。
例如,投掷一枚均匀硬币,正反面都是基本事件,且它们发生的概率相等为1/2、在经典概型中,我们可以通过计数来确定事件发生的概率。
3.条件概率条件概率指的是事件B在事件A已经发生的条件下发生的概率,记为P(B,A)。
条件概率可以通过以下公式计算:P(B,A)=P(A∩B)/P(A)4.独立事件如果事件A和事件B的发生与否互不影响,即事件A的发生与否不会改变事件B发生的概率,那么称事件A和事件B是独立事件。
对于独立事件来说,我们有以下公式:P(A∩B)=P(A)*P(B)5.全概率公式当我们面临多个互不相容的事件时,我们可以使用全概率公式来计算一些事件的概率。
设事件B_1,B_2,...,B_n是一个样本空间的一个划分,即它们两两互斥且并起来等于样本空间。
那么对于任意事件A,我们有:P(A)=P(A∩B_1)+P(A∩B_2)+...+P(A∩B_n)=ΣP(A,B_i)*P(B_i),其中Σ表示求和运算。
6.贝叶斯公式贝叶斯公式是概率论中很重要的推理工具,它将条件概率和全概率公式结合起来,可以用于推理过程中的反向求解。
设B_1,B_2,...,B_n 是一个样本空间的一个划分,且P(A)>0,那么对于任意的i,我们有:P(B_i,A)=P(A,B_i)*P(B_i)/[ΣP(A,B_j)*P(B_j)],其中Σ表示求和运算。
c语言产生4位数的随机函数

c语言产生4位数的随机函数1.引言1.1 概述在此部分,我们将介绍关于C语言中随机函数的概述。
随机函数在计算机编程中起着至关重要的作用,它能够生成一系列随机数,为程序的执行过程增加不确定性和灵活性。
C语言提供了rand()函数来生成随机数。
这个函数能够返回一个伪随机数,它首先需要通过调用srand()函数设置一个种子值。
种子值是生成随机数算法的起始点,不同的种子值将产生不同的随机数序列。
C语言的随机函数虽然不是真正意义上的随机,但在大多数应用中已经足够满足需求。
为了提高随机性,我们可以通过调用time()函数来获取当前时间作为随机数的种子值。
这样,每次运行程序时都会得到一个不同的种子值,从而生成不同的随机数序列。
本文的目的是介绍如何使用C语言中的随机函数来生成一个4位数的随机数。
我们将讨论生成4位数的方法,并通过示例代码展示具体实现过程。
希望读者通过本文的学习能够掌握C语言中随机函数的使用,并能够灵活运用于其他项目中。
接下来,在第二部分中,我们将更详细地介绍C语言中的随机函数和生成4位数的方法。
1.2 文章结构文章结构部分的内容:本文主要分为引言、正文和结论三个部分。
引言部分概述了文章的主题和目的,介绍了本文主要讨论的问题——如何使用C语言编写生成4位数的随机函数。
文章结构清晰,逻辑性强。
正文部分分为两个小节。
首先,2.1小节讲解了C语言中的随机函数的基本概念和使用方法,详细介绍了如何在C语言中调用随机函数生成随机数。
其次,2.2小节阐述了生成4位数的方法,提供了一种具体的实现思路,包括生成一个4位数的步骤,并给出了相关的代码示例。
结论部分分为总结和结果分析两个小节。
在3.1小节中,对整篇文章进行了总结,强调了本文讨论的问题和解决方法。
在3.2小节中,对结果进行了分析,探讨了该方法的可行性和效果,并提出了可能存在的改进空间。
通过上述的文章结构,读者可以清晰地了解本文的内容和组织,便于阅读和理解。
c语言随机数生成器使用方法

c语言随机数生成器使用方法C语言随机数生成器是一种用来生成随机数的工具。
在C语言中,我们可以使用stdlib.h头文件中的rand()函数来生成伪随机数。
本文将介绍如何使用C语言的随机数生成器,并提供一些常见的用例和技巧。
##随机数的概念随机数是指在一定范围内,按照一定规律随机生成的数值。
在计算机领域,我们通常将随机数分为真随机数和伪随机数。
真随机数是完全由随机性产生的数值,这种随机性可以来自于物理过程,例如测量微弱的电磁波干扰、大气噪声、光子计数等。
真随机数具有不可预测性和不确定性,但是它们往往难以获得,并且会消耗大量的计算资源。
因此,在计算机中常用的是伪随机数。
伪随机数是通过确定性的算法生成的数值,它们在一定程度上模拟了真随机数的随机性。
伪随机数的生成算法通常依赖于一个称为随机数生成器的函数,并且可以通过指定一个种子值来控制生成的随机数序列。
在C语言中,rand()函数就是一个伪随机数生成器。
## C语言随机数生成器的使用在C语言中,要使用随机数生成器,首先需要引入stdlib.h头文件:```c#include <stdlib.h>```然后,就可以使用rand()函数来生成随机数。
rand()函数会返回一个范围在0到RAND_MAX之间的伪随机整数值。
RAND_MAX是一个常量,表示伪随机数生成器能够生成的最大随机数。
下面是一个简单的例子,演示如何使用rand()函数生成随机数:```c#include <stdio.h>#include <stdlib.h>int main(){int i;for (i = 0; i < 10; i++){int random_num = rand();printf("%d\n", random_num);}return 0;}```运行该程序,会输出10个随机整数,范围在0到RAND_MAX之间。
概率的计算方法

概率的计算方法概率是描述随机事件发生可能性的数学工具,它在各个领域都有着重要的应用。
在实际生活中,我们经常需要计算概率来做出决策或者预测结果。
本文将介绍概率的计算方法,包括基本概率、条件概率和贝叶斯定理等内容。
首先,我们来看基本概率的计算方法。
对于一个随机事件A,它发生的概率可以用如下公式来表示:P(A) = N(A) / N(S)。
其中,P(A)表示事件A发生的概率,N(A)表示事件A发生的次数,N(S)表示样本空间S中事件发生的总次数。
通过这个公式,我们可以计算出事件A的概率。
接下来,我们介绍条件概率的计算方法。
条件概率是指在另一个事件B已经发生的条件下,事件A发生的概率。
它的计算公式为:P(A|B) = P(A∩B) / P(B)。
其中,P(A|B)表示在事件B发生的条件下,事件A发生的概率,P(A∩B)表示事件A和事件B同时发生的概率,P(B)表示事件B发生的概率。
通过这个公式,我们可以计算出在事件B已经发生的条件下,事件A发生的概率。
最后,我们介绍贝叶斯定理的计算方法。
贝叶斯定理是一种通过已知信息来更新概率的方法。
它的计算公式为:P(A|B) = P(B|A) P(A) / P(B)。
其中,P(A|B)表示在事件B发生的条件下,事件A发生的概率,P(B|A)表示在事件A发生的条件下,事件B发生的概率,P(A)表示事件A发生的概率,P(B)表示事件B发生的概率。
通过这个公式,我们可以根据已知信息来更新事件A的概率。
综上所述,概率的计算方法包括基本概率、条件概率和贝叶斯定理等内容。
通过这些方法,我们可以计算出事件发生的概率,从而在实际生活中做出合理的决策和预测。
希望本文能够帮助读者更好地理解概率的计算方法,并在实际应用中发挥作用。
c语言 高斯曲线拟合

c语言高斯曲线拟合摘要:一、引言二、高斯曲线拟合原理1.高斯曲线的定义2.高斯曲线拟合的方法三、C 语言实现高斯曲线拟合1.数据结构2.函数设计与实现3.示例程序与结果分析四、结论正文:一、引言高斯曲线拟合是一种常用的数学方法,它在许多领域都有广泛的应用,如信号处理、图像处理等。
C 语言是一种通用的编程语言,具有良好的性能和灵活性,适合实现高斯曲线拟合算法。
本文将介绍基于C 语言的高斯曲线拟合原理及其实现方法。
二、高斯曲线拟合原理(一)高斯曲线的定义高斯曲线,又称正态分布曲线,是一种连续概率分布曲线。
它具有一个对称的钟形,其特点是数据分布集中在均值附近,离均值越远的数据越少。
高斯曲线的数学表达式为:f(x) = (1 / (σ * sqrt(2π))) * exp(-((x-μ)) / (2σ))其中,μ为均值,σ为标准差,x 为随机变量。
(二)高斯曲线拟合的方法高斯曲线拟合的方法有多种,如最小二乘法、最大似然估计等。
最小二乘法是一种常用的方法,其基本思想是寻找一条曲线,使得所有数据点到这条曲线的垂直距离之和最小。
三、C 语言实现高斯曲线拟合(一)数据结构在C 语言中,可以使用数组来存储数据点,使用结构体来表示高斯曲线的参数。
(二)函数设计与实现1.读取数据点设计一个函数read_data,用于从文件中读取数据点。
函数的原型为:void read_data(data_point *data, int n)其中,data 为数据点的指针,n 为数据点的个数。
2.计算高斯曲线参数设计一个函数calc_gaussian,用于计算高斯曲线的参数。
函数的原型为:void calc_gaussian(data_point *data, int n, double *mean, double *std_dev)其中,data 为数据点的指针,n 为数据点的个数,mean 为均值的指针,std_dev 为标准差的指针。
二维坐标gmm算法c语言代码 -回复

二维坐标gmm算法c语言代码-回复GMM算法(Gaussian Mixture Model)是一种常用的聚类算法,特别适用于二维坐标数据的聚类分析。
本文将从理解GMM算法的基本原理开始,逐步介绍其C语言代码的实现细节。
一、GMM算法基本原理GMM算法基于统计学中的高斯分布理论,将数据集中的每个样本点看作是由多个高斯分布组合而成。
GMM算法通过最大似然估计确定每个高斯分布的参数,从而实现对数据集的聚类。
具体而言,GMM算法包含以下几个基本步骤:1. 初始化每个高斯分布的参数:高斯分布的参数包括均值、协方差矩阵和权重。
一般而言,可以随机初始化这些参数。
2. E步:根据当前的高斯分布参数,计算每个样本点属于每个高斯分布的后验概率(即给定样本点后,该样本点属于当前高斯分布的概率),这里使用了EM算法的思想。
3. M步:根据E步计算出的后验概率,更新每个高斯分布的参数。
4. 重复执行E步和M步,直到迭代收敛,即高斯分布的参数变化不再显著。
二、C语言代码实现下面是一个简单的实现GMM算法的C语言代码:cinclude <stdio.h>include <stdlib.h>include <math.h>define N 100 样本数量define K 3 高斯分布数量double data[N][2]; 样本数据double mu[K][2], sigma[K][2][2]; 高斯分布参数double weight[K]; 高斯分布权重void init_params() {初始化高斯分布参数和权重for (int i = 0; i < K; i++) {weight[i] = 1.0 / K;mu[i][0] = rand() 10;mu[i][1] = rand() 10;sigma[i][0][0] = 1;sigma[i][0][1] = 0;sigma[i][1][0] = 0;sigma[i][1][1] = 1;}}double gaussian_prob(double x, double mu, double sigma) { 计算高斯分布的概率密度函数值double exp_val = exp(-0.5 * pow((x - mu), 2) / sigma);double prob = exp_val / (sqrt(2 * M_PI * sigma));return prob;}void expectation(double gamma[N][K]) {E步:计算样本点属于每个高斯分布的后验概率for (int i = 0; i < N; i++) {double sum = 0;for (int j = 0; j < K; j++) {gamma[i][j] = weight[j] * gaussian_prob(data[i][0], mu[j][0], sigma[j][0][0]) *gaussian_prob(data[i][1], mu[j][1], sigma[j][1][1]);sum += gamma[i][j];}for (int j = 0; j < K; j++) {gamma[i][j] /= sum;}}}void maximization(double gamma[N][K]) {M步:根据后验概率更新高斯分布参数for (int j = 0; j < K; j++) {double sum_weight = 0;double sum_x = 0, sum_y = 0;double sum_xx = 0, sum_yy = 0, sum_xy = 0;for (int i = 0; i < N; i++) {sum_weight += gamma[i][j];sum_x += gamma[i][j] * data[i][0];sum_y += gamma[i][j] * data[i][1];sum_xx += gamma[i][j] * pow(data[i][0], 2);sum_yy += gamma[i][j] * pow(data[i][1], 2);sum_xy += gamma[i][j] * data[i][0] * data[i][1];}weight[j] = sum_weight / N;mu[j][0] = sum_x / sum_weight;mu[j][1] = sum_y / sum_weight;sigma[j][0][0] = sum_xx / sum_weight - pow(mu[j][0], 2);sigma[j][0][1] = sum_xy / sum_weight - mu[j][0] * mu[j][1];sigma[j][1][0] = sum_xy / sum_weight - mu[j][0] * mu[j][1];sigma[j][1][1] = sum_yy / sum_weight - pow(mu[j][1], 2);}}void gmm() {double gamma[N][K]; 后验概率矩阵,记录样本点属于每个高斯分布的概率for (int iter = 0; iter < 100; iter++) { 设置最大迭代次数expectation(gamma);maximization(gamma);}}int main() {生成样本数据,这里随机生成二维坐标for (int i = 0; i < N; i++) {data[i][0] = rand() 20;data[i][1] = rand() 20;}init_params();gmm();输出聚类结果for (int i = 0; i < N; i++) {for (int j = 0; j < K; j++) {printf("lf\t", gamma[i][j]);}printf("\n");}return 0;}以上是一个简单的二维坐标数据聚类的GMM算法C语言代码实现。
c语言rand函数原理

c语言rand函数原理C语言rand函数原理什么是rand函数?rand函数是C语言中的一个随机数生成函数,它用于产生一个指定范围内的伪随机数。
rand函数的使用非常广泛,在很多程序中都能见到它的身影。
rand函数的使用方法首先,需要在程序中引入头文件。
然后,可以使用rand函数来生成伪随机数。
以下是一个简单的例子:#include <>#include <>int main() {int randomNum = rand();printf("随机数:%d\n", randomNum);return 0;}rand函数生成的随机数具有以下性质:1.多次运行程序时,每次生成的随机数序列是不同的。
2.生成的随机数是均匀分布的,也就是说,每个数的出现概率相等。
rand函数的原理rand函数的原理是通过一个叫做“线性同余生成器”的算法来实现的。
这个算法的基本思路是通过一个递推式不断生成新的随机数。
1.首先,我们需要选择一个合适的初始值,称为“种子”。
一般情况下,我们可以使用系统时间作为种子,确保每次程序运行时种子都是不同的。
2.然后,使用一系列的计算公式对种子进行操作,生成新的随机数。
具体的计算公式如下:next = (a * seed + c) % m;其中,a、c、m是事先选定的常数,seed是当前的种子。
3.最后,将新生成的随机数作为下一次计算的种子,重复上述步骤。
4.当我们需要生成一个指定范围内的随机数时,可以将生成的随机数对范围进行取模运算,得到所需的结果。
尽管rand函数在日常编程中非常有用,但是它也存在一些局限性:1.生成的随机数是伪随机数,而不是真正的随机数。
这是因为生成的随机数是通过算法计算出来的,而不是基于物理过程的随机事件。
2.同一个种子生成的随机数序列是确定性的,也就是说,如果我们使用相同的种子,那么生成的随机数序列是相同的。
3.rand函数生成的随机数不是完全均匀分布的,可能会存在一定的偏差。
概率的计算与分析

概率的计算与分析概率是数学中的一个重要概念,在各个领域中都有广泛应用。
它可以帮助我们预测结果、解决问题以及进行决策。
在本文中,我们将探讨概率的计算与分析方法,以及其在实际生活中的应用。
一、基本概率计算方法1.1 频率概率频率概率是通过观察事件出现的频率来计算概率。
具体而言,我们统计事件发生的次数,并将其除以总试验次数来得到概率值。
例如,假设我们投掷一个均匀骰子,想要计算出现6的概率,我们可以进行多次实验,记录6出现的次数,并将其除以总实验次数。
1.2 古典概率古典概率是基于事件的可能性数量来计算概率。
当事件的所有可能结果是等可能且有限的时候,我们可以使用古典概率来计算。
例如,一枚均匀硬币的正反面概率为1/2。
1.3 条件概率条件概率是指当已知某些条件时,事件发生的概率。
它是通过条件概率公式来计算的,即P(A|B) = P(A∩B) / P(B)。
其中,P(A|B)表示在已知事件B发生的条件下,事件A发生的概率。
二、概率分析方法2.1 加法法则加法法则用于计算两个事件任一发生的概率。
对于两个互斥事件A和B,即A和B不同时发生,我们可以使用加法法则计算它们的概率。
加法法则的公式为:P(A或B) = P(A) + P(B)。
2.2 乘法法则乘法法则用于计算两个事件同时发生的概率。
对于两个独立事件A和B,即A的发生不受B的发生影响,我们可以使用乘法法则计算它们的概率。
乘法法则的公式为:P(A和B) = P(A) * P(B)。
2.3 贝叶斯定理贝叶斯定理是计算条件概率的重要方法,它可以帮助我们用已知信息更新事件发生的概率。
贝叶斯定理的公式为:P(A|B) = P(A) * P(B|A) / P(B)。
其中,P(A|B)表示在已知事件B发生的条件下,事件A发生的概率;P(B|A)表示在已知事件A发生的条件下,事件B发生的概率。
三、概率在实际生活中的应用3.1 风险评估概率可以帮助我们评估和管理风险。
通过对可能事件和其发生概率进行分析,我们可以识别风险,并采取相应的措施来减少风险的发生。
概率的基本概念和计算

概率的基本概念和计算概率是数学中一个重要的概念,在现代科学和社会科学中有着广泛的应用。
概率可以帮助我们预测事件发生的可能性,并且在决策和推理中起着重要的作用。
本文将介绍概率的基本概念和计算方法。
一、概率的概念概率是描述事件发生可能性的数值,通常用0到1之间的实数表示。
当事件的概率接近0时,表示事件极不可能发生;当事件的概率接近1时,表示事件非常可能发生。
在概率论中,我们将样本空间表示为S,事件表示为E,概率表示为P(E)。
二、基本概率规则1. 加法规则:当事件的样本空间不重叠时,两个事件的概率可以通过相加来计算。
即P(A或B) = P(A) + P(B)。
2. 乘法规则:当事件A和B独立时,两个事件同时发生的概率可以通过相乘来计算。
即P(A和B) = P(A) * P(B)。
三、条件概率条件概率是指在已知某一事件发生的条件下,另一事件发生的概率。
用P(A|B)表示事件B发生的条件下,事件A发生的概率。
条件概率可以通过乘法规则计算。
即P(A|B) = P(A和B) / P(B)。
四、独立事件如果两个事件A和B的发生互不影响,即P(A|B) = P(A),则称事件A和B为独立事件。
对于独立事件,乘法规则可以简化为P(A和B) = P(A) * P(B)。
五、贝叶斯定理贝叶斯定理是用来计算条件概率的重要工具。
根据贝叶斯定理,可以通过已知的先验概率和条件概率来计算后验概率。
贝叶斯定理的公式为:P(A|B) = (P(B|A) * P(A)) / P(B)。
六、随机变量与概率分布随机变量是可以取不同值的变量,而这些不同值是在某种概率分布下发生的。
概率分布描述了随机变量的取值和相应概率之间的关系。
常见的概率分布包括离散概率分布和连续概率分布。
七、期望值与方差期望值是随机变量取值的平均值,表示了随机变量在长期观测中的平均表现。
方差衡量了随机变量取值与期望值的偏离程度,是对随机变量的离散程度的度量。
八、大数定律与中心极限定理大数定律指出,随着样本数量的增加,样本平均值会趋近于期望值。
概率的基本原理和计算

概率的基本原理和计算概率是数学中一个重要的分支,它研究随机事件发生的可能性。
在我们日常生活中,概率无处不在。
例如,我们可以计算掷硬币出现正面的概率,或者计算从一副扑克牌中抽到红心的概率等。
本文将介绍概率的基本原理和计算方法。
一、概率的基本原理概率的基本原理是基于频率的。
频率是指重复试验中某个事件发生的次数与总试验次数之比。
当试验次数足够多时,频率会趋近于一个常数,这个常数就是概率。
概率的大小通常用0到1之间的数值表示,其中0表示不可能发生的事件,1表示一定会发生的事件。
例如,掷一次骰子,出现1的概率是1/6,出现2的概率也是1/6,以此类推。
所有可能的结果概率之和必须等于1。
二、概率的计算方法1. 事件的概率计算公式对于一个随机试验E,如果事件A在试验E中发生的次数为n(A),总试验次数为n,那么事件A发生的概率可以用如下公式表示:P(A) = n(A) / n2. 互斥事件的概率计算公式互斥事件指的是两个事件不可能同时发生的情况。
如果事件A和事件B是互斥事件,那么事件A或事件B发生的概率可以用如下公式表示:P(A或B) = P(A) + P(B)3. 独立事件的概率计算公式独立事件指的是一个事件的发生不受其他事件的影响。
如果事件A 和事件B是独立事件,那么事件A和事件B同时发生的概率可以用如下公式表示:P(A和B) = P(A) × P(B)三、概率的应用1. 排列组合与概率排列和组合是概率中常用的计算方法。
排列是指从一组元素中按照一定的顺序选择若干个元素的方式,组合是指从一组元素中按照无序的方式选择若干个元素的方式。
在排列与组合中,我们可以通过计算每种情况的概率来得到总体的概率。
例如,从一组数字中选择3个数字,我们可以计算每种数字的概率,然后将它们相加得到最终的概率。
2. 条件概率条件概率是指在已经发生了某个事件的前提下,另一个事件发生的概率。
条件概率可以用如下公式表示:P(A|B) = P(A和B) / P(B)其中,P(A|B)表示在事件B发生的情况下发生事件A的概率。
概率计算的常见方法总结

概率计算的常见方法总结概率计算是数学中的一个重要分支,研究随机事件发生的可能性和规律。
在实际应用中,概率计算广泛用于统计学、金融、工程等领域。
本文将总结一些常见的概率计算方法,以帮助读者更好地理解和应用概率计算的技巧。
一、基础概率计算方法1. 古典概率计算古典概率计算是最基础的概率计算方法,涉及到等可能事件的计算。
当每个事件发生的可能性相等时,事件A发生的概率P(A)等于事件A包含的有利结果数目除以总结果数目。
其计算公式为:P(A) = 有利结果数目 / 总结果数目。
2. 排列与组合排列与组合是一种常见的概率计算方法,用于确定事件发生的顺序或选择方式。
排列是指从一组元素中按照一定顺序选取若干元素的方式,而组合是指从一组元素中按照任意顺序选取若干元素的方式。
排列计算公式为:P(A) = n! / (n-k)!;组合计算公式为:C(A) = n! / (k!(n-k)!),其中n为元素总数,k为选择个数。
二、条件概率计算方法1. 直接计算法直接计算法是条件概率计算中最简单的方法,直接利用条件概率的定义计算。
条件概率计算公式为:P(A|B) = P(A ∩ B) / P(B),其中P(A|B)表示在事件B发生的条件下事件A发生的概率。
2. 全概率公式全概率公式用于计算复杂情况下的条件概率。
当事件B可以分解为多个相互独立的事件时,可以利用全概率公式计算条件概率。
全概率公式的表达式为:P(A) = Σ P(A|Bi) * P(Bi),其中Bi为所有可能的事件。
三、独立事件的概率计算方法1. 乘法定理乘法定理用于计算多个独立事件同时发生的概率。
当事件A和事件B独立时,两事件同时发生的概率等于事件A发生的概率乘以事件B发生的概率。
乘法定理的计算公式为:P(A ∩ B) = P(A) * P(B)。
2. 加法定理加法定理用于计算两个事件中至少一个发生的概率。
当事件A和事件B互斥时(即两事件不可能同时发生),两事件中至少一个发生的概率等于事件A发生的概率加上事件B发生的概率。
转:随机数产生原理及应用

转:随机数产⽣原理及应⽤摘要:本⽂简述了随机数的产⽣原理,并⽤C语⾔实现了迭代取中法,乘同余法等随机数产⽣⽅法,同时,还给出了在符合某种概率分布的随机变量的产⽣⽅法。
关键词: 伪随机数产⽣,概率分布1前⾔:在⽤计算机编制程序时,经常需要⽤到随机数,尤其在仿真等领域,更对随机数的产⽣提出了较⾼的要求,仅仅使⽤C语⾔类库中的随机函数已难以胜任相应的⼯作。
本⽂简单的介绍随机数产⽣的原理及符合某种分布下的随机变量的产⽣,并⽤C语⾔加以了实现。
当然,在这⾥⽤计算机基于数学原理⽣成的随机数都是伪随机数。
注:这⾥⽣成的随机数所处的分布为0-1区间上的均匀分布。
我们需要的随机数序列应具有⾮退化性,周期长,相关系数⼩等优点。
2.1迭代取中法:这⾥在迭代取中法中介绍平⽅取中法,其迭代式如下:Xn+1=(Xn^2/10^s)(mod 10^2s)Rn+1=Xn+1/10^2s其中,Xn+1是迭代算⼦,⽽Rn+1则是每次需要产⽣的随机数。
第⼀个式⼦表⽰的是将Xn平⽅后右移s位,并截右端的2s位。
⽽第⼆个式⼦则是将截尾后的数字再压缩2s倍,显然:0=<Rn+1<=1.这样的式⼦的构造需要深厚的数学(代数,统计学,信息学)功底,这⾥只是拿来⽤⼀下⽽已,就让我们站在⼤师的肩膀上前⾏吧。
迭代取中法有⼀个不良的性就是它⽐较容易退化成0.平⽅取中法的实现:View Code#include <stdio.h>#include <math.h>#define S 2float Xn=12345;//Seed & Iterfloat Rn;//Return Valvoid InitSeed(float inX0){Xn=inX0;}/*Xn+1=(Xn^2/10^s)(mod 10^2s)Rn+1=Xn+1/10^2s*/float MyRnd(){Xn=(int)fmod((Xn*Xn/pow(10,S)),pow(10,2*S));//here can's use %Rn=Xn/pow(10,2*S);return Rn;}/*测试主程序,注意,这⾥只列举⼀次测试主程序,以下不再重复*/int main(){int i;FILE * debugFile;if((debugFile=fopen("outputData.txt","w"))==NULL){fprintf(stderr,"open file error!");return -1;}printf("\n");for(i=0;i<100;i++){tempRnd=MyRnd();fprintf(stdout,"%f ",tempRnd);fprintf(debugFile,"%f ",tempRnd);}getchar();return0;}前⼀百个测试⽣成的随机数序列:0.399000 0.920100 0.658400 0.349000 0.180100 0.243600 0.934000 0.235600 0.550700 0.327000 0.692900 0.011000 0.012100 0.014600 0.021300 0.045300 0.205200 0.210700 0.439400 0.307200 0.437100 0.105600 0.115100 0.324800 0.549500 0.195000 0.802500 0.400600 0.048000 0.230400 0.308400 0.511000 0.112100 0.256600 0.584300 0.140600 0.976800 0.413800 0.123000 0.512900 0.306600 0.400300 0.024000 0.057600 0.331700 0.002400 0.000500 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000容易看出其易退化成0的缺点.2.2乘同余法:乘同余法的迭代式如下:Xn+1=Lamda*Xn(mod M)Rn+1=Xn/M各参数意义及各步的作⽤可参2.1当然,这⾥的参数的选取是有⼀定的理论基础的,否则所产⽣的随机数的周期将较⼩,相关性会较⼤。
概率公式大全
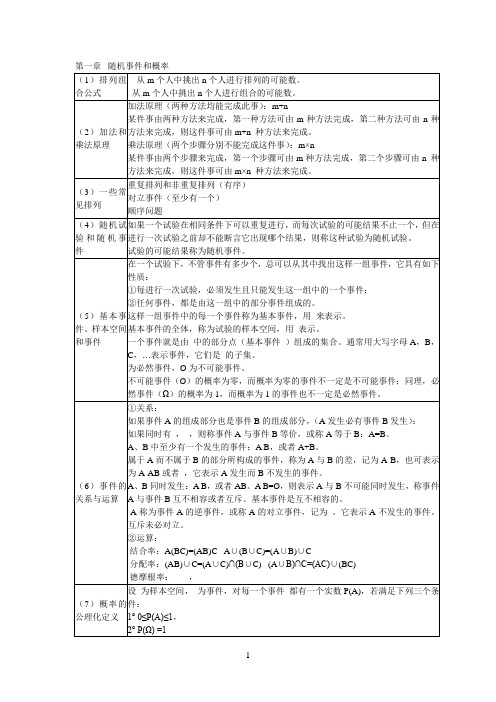
第一章随机事件和概率第二章随机变量及其分布第三章二维随机变量及其分布第四章随机变量的数字特征第七章参数估计单正态总体均值和方差的假设检验公式整理1.随机事件及其概率吸收律:A AB A A A A =⋃=∅⋃Ω=Ω⋃)( AB A A A AA =⋃⋂∅=∅⋂=Ω⋂)()(AB A B A B A -==-反演律:B A B A =⋃ B A AB ⋃=n i in i iA A 11=== ni in i iA A 11===2.概率的定义及其计算)(1)(A P A P -=若B A ⊂ )()()(A P B P A B P -=-⇒对任意两个事件A , B , 有 )()()(AB P B P A B P -=- 加法公式:对任意两个事件A , B , 有)()()()(AB P B P A P B A P -+=⋃ )()()(B P A P B A P +≤⋃)()1()()()()(2111111n n nnk j i kjinj i jini i n i i A A A P A A A P A A P A P A P -≤<<≤≤<≤==-+++-=∑∑∑3.条件概率 ()=A B P )()(A P AB P 乘法公式())0)(()()(>=A P A B P A P AB P()())0)(()()(12112112121>=--n n n n A A A P A A A A P A A P A P A A A P 全概率公式∑==ni i AB P A P 1)()( )()(1i ni i B A P B P ⋅=∑=Bayes 公式)(A B P k )()(A P AB P k =∑==n i i i k k B A P B P B A P B P 1)()()()(4.随机变量及其分布 分布函数计算)()()()()(a F b F a X P b X P b X a P -=≤-≤=≤<5.离散型随机变量 (1) 0 – 1 分布1,0,)1()(1=-==-k p p k X P k k(2) 二项分布 ),(p n B 若P ( A ) = pn k p p C k X P k n kk n ,,1,0,)1()( =-==-*Possion 定理0lim >=∞→λn n np有,2,1,0!)1(l i m ==---∞→k k ep p C kkn n k nkn n λλ(3) Poisson 分布 )(λP,2,1,0,!)(===-k k ek X P kλλ6.连续型随机变量 (1) 均匀分布 ),(b a U⎪⎩⎪⎨⎧<<-=其他,0,1)(b x a ab x f ⎪⎪⎩⎪⎪⎨⎧--=1,,0)(a b a x x F(2) 指数分布 )(λE⎪⎩⎪⎨⎧>=-其他,00,)(x e x f x λλ⎩⎨⎧≥-<=-0,10,0)(x e x x F xλ (3) 正态分布 N (μ , σ 2 )+∞<<∞-=--x e x f x 222)(21)(σμσπ⎰∞---=xt t ex F d 21)(222)(σμσπ*N (0,1) — 标准正态分布+∞<<∞-=-x ex x 2221)(πϕ+∞<<∞-=Φ⎰∞--x t ex xt d 21)(22π7.多维随机变量及其分布二维随机变量( X ,Y )的分布函数⎰⎰∞-∞-=xydvdu v u f y x F ),(),(边缘分布函数与边缘密度函数⎰⎰∞-+∞∞-=xX dvdu v u f x F ),()(⎰+∞∞-=dv v x f x f X ),()(⎰⎰∞-+∞∞-=yY dudv v u f y F ),()(⎰+∞∞-=du y u f y f Y ),()(8. 连续型二维随机变量(1) 区域G 上的均匀分布,U ( G )⎪⎩⎪⎨⎧∈=其他,0),(,1),(Gy x A y x f(2)二维正态分布+∞<<-∞+∞<<∞-⨯-=⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡-+------y x ey x f y y x x ,121),(2222212121212)())((2)()1(21221σμσσμμρσμρρσπσ9. 二维随机变量的 条件分布0)()()(),(>=x f x y f x f y x f X X Y X0)()()(>=y f y x f y f Y Y X Y⎰⎰+∞∞-+∞∞-==dy y f y x f dy y x f x f Y Y X X )()(),()(⎰⎰+∞∞-+∞∞-==dx x f x y f dx y x f y f X X Y Y )()(),()()(y x f Y X )(),(y f y x f Y =)()()(y f x f x y f Y X X Y = )(x y f X Y )(),(x f y x f X =)()()(x f y f y x f X Y Y X = 10.随机变量的数字特征数学期望∑+∞==1)(k k k p x X E⎰+∞∞-=dx x xf X E )()(随机变量函数的数学期望 X 的 k 阶原点矩)(k X E X 的 k 阶绝对原点矩)|(|k X E X 的 k 阶中心矩)))(((k X E X E - X 的 方差)()))(((2X D X E X E =- X ,Y 的 k + l 阶混合原点矩)(l k Y X E X ,Y 的 k + l 阶混合中心矩()l k Y E Y X E X E ))(())((--X ,Y 的 二阶混合原点矩)(XY E X ,Y 的二阶混合中心矩 X ,Y 的协方差()))())(((Y E Y X E X E --X ,Y 的相关系数XY Y D X D Y E Y X E X E ρ=⎪⎪⎭⎫⎝⎛--)()())())((( X 的方差D (X ) =E ((X - E (X ))2))()()(22X E X E X D -=协方差()))())(((),cov(Y E Y X E X E Y X --=)()()(Y E X E XY E -=())()()(21Y D X D Y X D --±±= 相关系数)()(),cov(Y D X D Y X XY =ρ⎰∞---=xt t ex F d 21)(222)(σμσπ*N (0,1) — 标准正态分布+∞<<∞-=-x ex x 2221)(πϕ+∞<<∞-=Φ⎰∞--x t e x xt d 21)(22π7.多维随机变量及其分布二维随机变量( X ,Y )的分布函数⎰⎰∞-∞-=xydvdu v u f y x F ),(),(边缘分布函数与边缘密度函数⎰⎰∞-+∞∞-=xX dvdu v u f x F ),()(⎰+∞∞-=dv v x f x f X ),()(⎰⎰∞-+∞∞-=yY dudv v u f y F ),()(⎰+∞∞-=du y u f y f Y ),()(8. 连续型二维随机变量(1) 区域G 上的均匀分布,U ( G )⎪⎩⎪⎨⎧∈=其他,0),(,1),(Gy x A y x f(2)二维正态分布+∞<<-∞+∞<<∞-⨯-=⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡-+------y x ey x f y y x x ,121),(222221212121)())((2)()1(21221σμσσμμρσμρρσπσ9.二维随机变量的 条件分布0)()()(),(>=x f x y f x f y x f X X Y X0)()()(>=y f y x f y f Y Y X Y⎰⎰+∞∞-+∞∞-==dy y f y x f dy y x f x f Y Y X X )()(),()(⎰⎰+∞∞-+∞∞-==dx x f x y f dx y x f y f X X Y Y )()(),()( )(y x f Y X )(),(y f y x f Y = )()()(y f x f x y f Y X X Y = )(x y f X Y )(),(x f y x f X = )()()(x f y f y x f X Y Y X = 10.随机变量的数字特征数学期望∑+∞==1)(k k k p x X E⎰+∞∞-=dx x xf X E )()(随机变量函数的数学期望X 的 k 阶原点矩)(k X EX 的 k 阶绝对原点矩)|(|k X E X 的 k 阶中心矩)))(((k X E X E - X 的 方差)()))(((2X D X E X E =- X ,Y 的 k + l 阶混合原点矩)(l k Y X E X ,Y 的 k + l 阶混合中心矩()l k Y E Y X E X E ))(())((--X ,Y 的 二阶混合原点矩)(XY EX ,Y 的二阶混合中心矩 X ,Y 的协方差 ()))())(((Y E Y X E X E --X ,Y 的相关系数XY Y D X D Y E Y X E X E ρ=⎪⎪⎭⎫⎝⎛--)()())())((( X 的方差D (X ) =E ((X - E (X ))2))()()(22X E X E X D -=协方差()))())(((),cov(Y E Y X E X E Y X --=)()()(Y E X E XY E -=())()()(21Y D X D Y X D --±±= 相关系数)()(),cov(Y D X D Y X XY =ρ。
第12章 概率算法
蒙特卡罗型概率算法
对于许多问题来说,近似解毫无意义。蒙特 卡罗型(Monte Carlo)概率算法用于求问题 的准确解。 蒙特卡罗型概率算法偶尔会出错,但无论任 何输入实例,总能以很高的概率找到一个正 确解。换言之,蒙特卡罗型概率算法总是给 出解,但是,这个解偶尔可能是不正确的, 一般情况下,也无法有效地判定得到的解是 否正确。蒙特卡罗型概率算法求得正确解的 概率依赖于算法所用的时间,算法所用的时 间越多,得到正确解的概率就越高。
素数测试问题
采用概率算法进行素数测试的理论基础来自 现代数论之父费尔马(Pierre de Fermat), 他在1640年证明了下面的费尔马定理。 费尔马定理 如果n是一个素数,a为正整数且 0<a<n,则an-1 mod n≡1。 例如,7是一个素数,取a=5,则an-1 mod n =56 mod 7=1;67是一个素数,取a=2,则 an-1mod n=266 mod 67=1。
蒙特卡罗型概率算法
设p是一个实数,且1/2<p<1。如果一个蒙 特卡罗型概率算法对于问题的任一输入实例 得到正确解的概率不小于p,则称该蒙特卡 罗型概率算法是p正确的。如果对于同一输 入实例,蒙特卡罗型概率算法不会给出两个 不同的正确解,则称该蒙特卡罗型概率算法 是一致的。如果重复地运行一个一致的p正 确的蒙特卡罗型概率算法,每一次运行都独 立地进行随机选择,就可以使产生不正确解 的概率变得任意小。
舍伍德型(Sherwood)概率算法来消除算法 的时间复杂性与输入实例间的联系。 应用方式: (1)在确定性算法的某些步骤引入随机因素, 将确定性算法改造成舍伍德型概率算法; (2)借助于随机预处理技术,即不改变原有 的确定性算法,仅对其输入实例随机排列(洗 牌),然后再执行确定性算法。
概率c公式计算方法

概率c公式计算方法宝子,今天咱们来唠唠概率里的C公式计算方法哈。
概率C呢,其实就是组合数。
组合数的公式是C_n^k=(n!)/(k!(n - k)!)。
这里面的“n”就表示总数,“k”表示选取的个数。
这个感叹号“!”是阶乘的意思哦。
比如说5的阶乘,就是5!=5×4×3×2×1。
咱举个超有趣的例子吧。
假如你有10个超可爱的小玩偶 ,你想从中选3个出来陪你睡觉 。
那这里n = 10,k = 3。
按照公式来计算,先算10的阶乘,10!=10×9×8×7×6×5×4×3×2×1,3的阶乘呢,3!=3×2×1,7的阶乘(因为n - k = 10 - 3 = 7),7!=7×6×5×4×3×2×1。
然后把这些数往公式里一套,C_10^3=(10!)/(3!(10 -3)!)=(10×9×8×7×6×5×4×3×2×1)/((3×2×1)×(7×6×5×4×3×2×1))。
这里面好多数就可以约掉啦,最后就得到一个具体的数值啦。
再比如说,学校要从20个同学里选5个去参加一个超酷的活动。
那这时候n = 20,k = 5。
就按照这个公式一步一步算就行啦。
先把20的阶乘、5的阶乘和15的阶乘(20 - 5 = 15)算出来,再代入公式里。
宝子,你可别被这个公式吓着哈。
其实多做几道这样的小例子,你就会发现还挺好玩的呢。
你就想象自己在做一些超有趣的选择,像从一堆好吃的里选几个吃,从好多漂亮衣服里选几件穿出去逛街一样。
概率C的计算就是这么个事儿,加油呀,你肯定能轻松掌握的 。
C语言中的概率算法实现

C语言中的概率算法实现概率算法是计算机科学中常用的一种算法,用于处理随机事件的概率分布和概率计算。
在C语言中,我们可以使用各种技术和方法来实现概率算法。
本文将介绍C语言中常用的概率算法实现方式和示例代码。
一、伪随机数生成器在概率算法中,伪随机数生成器(pseudo-random number generator)是一种常用的工具。
它可以生成接近于真正随机数的数列,用于模拟随机事件的概率分布。
C语言中提供了许多生成伪随机数的函数,比如rand()函数,该函数可以生成一个在范围[0, RAND_MAX]之间的整数。
示例代码:```c#include <stdio.h>#include <stdlib.h>#include <time.h>int main() {int i, n;srand(time(0)); // 初始化随机数种子printf("生成10个随机数:");for (i = 0; i < 10; i++) {n = rand();printf("%d ", n);}return 0;}```在上述示例代码中,使用srand()函数初始化随机数种子,使用rand()函数生成随机数。
二、概率分布函数为了实现具体的概率算法,我们通常需要使用概率分布函数(probability distribution function),它描述了随机事件的概率分布情况。
C语言中提供了一些常用的概率分布函数,比如均匀分布、正态分布等。
示例代码:```c#include <stdio.h>#include <stdlib.h>#include <time.h>double uniform_distribution() {return (double)rand() / RAND_MAX; // 生成[0, 1)之间的均匀分布随机数}double normal_distribution(double mean, double stddev) {double u = uniform_distribution();double v = uniform_distribution();double z = sqrt(-2 * log(u)) * cos(2 * M_PI * v);return mean + stddev * z; // 生成均值为mean,标准差为stddev的正态分布随机数}int main() {int i;srand(time(0));printf("生成10个均匀分布随机数:");for (i = 0; i < 10; i++) {double n = uniform_distribution();printf("%lf ", n);}printf("\n生成10个正态分布随机数:");for (i = 0; i < 10; i++) {double n = normal_distribution(0, 1);printf("%lf ", n);}return 0;}```在上述示例代码中,uniform_distribution()函数生成[0, 1)之间的均匀分布随机数,normal_distribution()函数生成均值为mean,标准差为stddev的正态分布随机数。
概率的证明计算公式

概率的证明计算公式概率是描述随机事件发生可能性的一种数学工具,它在现代统计学、金融学、工程学等领域有着广泛的应用。
概率的计算公式是概率论中的基础知识,通过这些公式可以计算出各种随机事件发生的可能性。
在本文中,我们将介绍概率的计算公式,并通过一些例子来说明如何使用这些公式进行概率计算。
概率的计算公式包括了基本概率公式、条件概率公式、全概率公式和贝叶斯公式等。
下面我们将分别介绍这些公式及其证明。
1. 基本概率公式。
基本概率公式是描述一个事件发生的可能性的最基本的公式。
如果事件A发生的可能性为P(A),那么事件A不发生的可能性为1-P(A)。
这可以表示为:P(A) + P(A') = 1。
其中,P(A)表示事件A发生的概率,P(A')表示事件A不发生的概率。
这个公式可以通过逻辑推理进行证明,因为事件A和事件A'是互斥的,它们的概率之和必然等于1。
2. 条件概率公式。
条件概率公式描述了在已知事件B发生的条件下,事件A发生的可能性。
它可以表示为:P(A|B) = P(A∩B) / P(B)。
其中,P(A|B)表示在事件B发生的条件下,事件A发生的概率,P(A∩B)表示事件A和事件B同时发生的概率,P(B)表示事件B发生的概率。
这个公式可以通过概率的定义进行证明,即事件A和事件B同时发生的概率等于事件B发生的概率乘以在事件B发生的条件下,事件A发生的概率。
3. 全概率公式。
全概率公式描述了在一组互斥事件发生的情况下,另一个事件发生的可能性。
假设事件B1、B2、...、Bn构成一个完备事件组,即它们两两互斥且它们的并集为样本空间Ω,那么事件A发生的概率可以表示为:P(A) = Σ P(A|Bi) P(Bi)。
其中,P(A|Bi)表示在事件Bi发生的条件下,事件A发生的概率,P(Bi)表示事件Bi发生的概率。
这个公式可以通过条件概率公式和全概率的定义进行证明,即事件A发生的概率等于在每个事件Bi发生的条件下,事件A发生的概率的加权平均。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
平时我们一般开始考虑的是一个有着很好平均性能的选择算法,但在最坏情况下对某些实例算法效率较低。这时候我们用概率算法,将上述算法改造成一个舍伍德型算法,使得该算法对任何实例均有效。
不过在有些情况下,所给的确定性算法无法直接改造成舍伍德型算法。这时候就可以借助随机预处理技术,不改变原有的确定性算法,仅对其输入进行随机洗牌,同样可以得到舍伍德算法的效果。还是刚才的例子,换一种方法实现:
return pivot;
a[l]=a[j];
a[j]=pivot;
if(j-l+1<k)
{
k=k-j+l-1;
在这里,我们用舍伍德型选择算法随机的选择一个数组元素作为划分标准。这样既能保证算法的线性时间平均性能又避免了计算拟中位数的麻烦。非递归的舍伍德型算法可描述如下:
template<class Type>
Type select(Type a[], int l, int r, int k)
l=j+1;
}
else
r=j-1;
}
}
template <class Type>
Type Select(Type a[], int n, int k)
{
if(k<1||k>n)
throw OutOfBounds();
return select(a, 0, n-1, k);
拉斯维加斯算法不会得到不正确的解,一旦用拉斯维加斯算法找到一个解,那么这个解肯定是正确的。但是有时候用拉斯维加斯算法可能找不到解。与蒙特卡罗算法类似。拉斯维加斯算法得到正确解的概率随着它用的计算时间的增加而提高。对于所求解问题的任一实例,用同一拉斯维加斯算法反复对该实例求解足够多次,可使求解失效的概率任意小。
{
randseed=multiplier*randseed+adder;
return (unsigned short)((randseed>>16)%n);
}
double RandomNumber::fRandom(void)
a0=d
Hale Waihona Puke an=(ban-1+c)mod m n=1,2.......
其中,b>=0, c>=0, d>=m。d称为该随机序列的种子。
下面我们建立一个随机数类RadomNumber,该类包含一个由用户初始化的种子randSeed。给定种子之后,既可产生与之相应的随机数序列。randseed是一个无符号长整型数,既可由用户指定也可由系统时间自动产生。
对于函数fRandom,先用Random(maxshort)产生一个0-(maxshort-1之间的整型随机序列),将每个整型随机数除以maxshort,就得到[0,1)区间中的随机实数。
下面来看看数值概率算法的两个例子:
1.用随机投点法计算π
while(a[--j]>pivot);
if(i>=j)
break;
Swap(a[i], a[j]);
}
if(j-l+1==k)
{
return Random(maxshort)/double(maxshort);
}
函数Random在每次计算时,用线性同余式计算新的种子。它的高16位的随机性较好,将randseed右移16位得到一个0-65535之间的随机整数然后再将此随机整数映射到0-n-1范围内。
double x=dart.fRandom();
double y=dart.fRandom();
if((x*x+y*y)<1)
k++;
}
return 4*k/double(n);
//构造函数,缺省值0表示由系统自动产生种子
RandomNumber(unsigned long s=0);
//产生0-n-1之间的随机整数
unsigned short Random(unsigned long n);
class RandomNumber
{
private:
//当前种子
unsigned long randseed;
public:
Swap(a[i], a[j]);
j=r+1;
Type pivot=a[l];
while(true)
{
while(a[++i]<pivot);
{
static RandomNumber rnd;
while(true){
if(l>=r)
return a[l];
int i=l, j=l=rnd.Random(r-l+1);
舍伍德算法总能求得问题的一个解,且所求得的解总是正确的。当一个确定性算法在最坏情况下的计算复杂性与其在平均情况下的计算复杂性有较大差别时,可以在这个确定算法中引入随机性将它改造成一个舍伍德算法,消除或减少问题的好坏实例间的这种差别。舍伍德算法精髓不是避免算法的最坏情况行为,而是设法消除这种最坏行为与特定实例之间的关联性。
}
再简单举个舍伍德算法的例子。
我们在分析一个算法在平均情况下的计算复杂性时,通常假定算法的输入数据服从某一特定的概率分布。例如,在输入数据是均匀分布时,快速排序算法所需的平均时间是O(n
logn)。但是如果其输入已经基本上排好序时,所用时间就大大增加了。此时,可采用舍伍德算法消除算法所需计算时间与输入实例间的这种联系。
double Darts(int n)
{
static RandomNumber dart;
int k=0;
for(int i=1;i<=n;i++){
数值概率算法常用于数值问题的求解。这类算法所得到的往往是近似解。而且近似解的精度随计算时间的增加不断提高。在许多情况下,要计算出问题的精确解是不可能或没有必要的,因此用数值概率算法可得到相当满意的解。
蒙特卡罗算法用于求问题的准确解。对于许多问题来说,近似解毫无意义。例如,一个判定问题其解为“是”或“否”,二者必居其一,不存在任何近似解答。又如,我们要求一个整数的因子时所给出的解答必须是准确的,一个整数的近似因子没有任何意义。用蒙特卡罗算法能求得问题的一个解,但这个解未必是正确的。求得正确解的概率依赖于算法所用的时间。算法所用的时间越多,得到正确解的概率就越高。蒙特卡罗算法的主要缺点就在于此。一般情况下,无法有效判断得到的解是否肯定正确。
本文简要的介绍一下数值概率算法和舍伍德算法。
首先来谈谈随机数。随机数在概率算法设计中扮演着十分重要的角色。在现实计算机上无法产生真正的随机数,因此在概率算法中使用的随机数都是一定程度上随机的,即伪随机数。
产生随机数最常用的方法是线性同余法。由线性同余法产生的随机序列a1,a2,...,an满足
设有一半径为r的圆及其外切四边形,如图所示。向该正方形随机投掷n个点。设落入圆内的点在正方形上均匀分布,因而所投入点落入圆内的概率为πr^2/4r^2,所以当n足够大时,k与n之比就逼近这一概率,即π/4。由此可得使用随机投点法计算π值的数值概率算法。具体实现时,只需要在第一次象限计算即可。
const unsigned long maxshort=65536L;
const unsigned long multiplier=1194211693L;
const unsigned long adder=12345L;
//产生[0,1)之间的随机实数
double fRandom(void);
};
RandomNumber::RandomNumber(unsigned long s)
{
if(s==0)
randseed=time(0);
else
randseed=s;
}
unsigned short RandomNumber::Random(unsigned long n)
概率算法的一个基本特征是对所求解问题的同一实例用同一概率算法求解两次可能得到完全不同的效果。这两次求解问题所需的时间甚至所得到的结果可能会有相当大的差别。一般情况下,可将概率算法大致分为四类:数值概率算法,蒙特卡罗(Monte
Carlo)算法,拉斯维加斯(Las Vegas)算法和舍伍德(Sherwood)算法。
概率算法简介
很多算法的每一个计算步骤都是固定的,而在下面我们要讨论的概率算法,允许算法在执行的过程中随机选择下一个计算步骤。许多情况下,当算法在执行过程中面临一个选择时,随机性选择常比最优选择省时。因此概率算法可在很大程度上降低算法的复杂度。