数据结构课后习题与解析第四章
数据结构与算法 习题解答 第4章
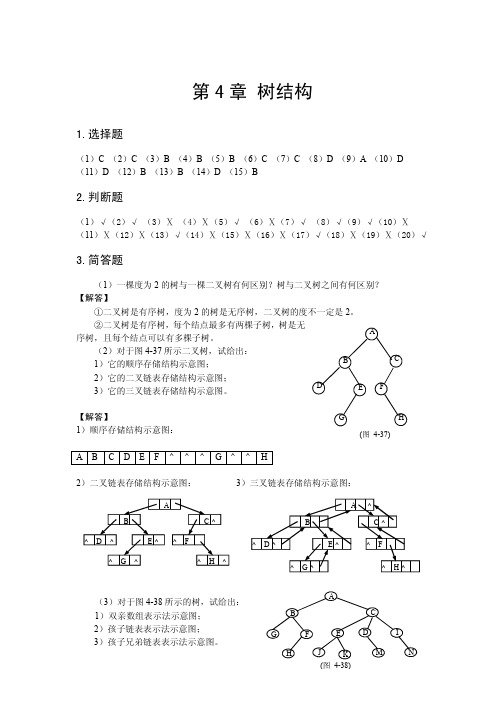
第 4 章 树结构1.选择题(1)C (2)C (3)B (4)B (5)B (6)C (7)C (8)D (9)A (10)D (11)D (12)B (13)B (14)D (15)B2.判断题(1)√(2)√ (3)Ⅹ (4)Ⅹ(5)√ (6)Ⅹ(7)√ (8)√(9)√(10)Ⅹ (11)Ⅹ(12)Ⅹ(13)√(14)Ⅹ(15)Ⅹ(16)Ⅹ(17)√(18)Ⅹ(19)Ⅹ(20)√3.简答题(1)一棵度为 2 的树与一棵二叉树有何区别?树与二叉树之间有何区别?【解答】①二叉树是有序树,度为 2 的树是无序树,二叉树的度不一定是 2。
②二叉树是有序树,每个结点最多有两棵子树,树是无序树,且每个结点可以有多棵子树。
A(2)对于图 4-37 所示二叉树,试给出: 1)它的顺序存储结构示意图;BC2)它的二叉链表存储结构示意图; 3)它的三叉链表存储结构示意图。
DEF【解答】 1)顺序存储结构示意图:AB CDEF ^ ^ ^ G^ ^ HGH(图 4-37)2)二叉链表存储结构示意图:3)三叉链表存储结构示意图:ABC^^D^E^ ^ F^G^^H^A^BC^^ D^E^^F^ G^^ H^(3)对于图 4-38 所示的树,试给出: 1)双亲数组表示法示意图; 2)孩子链表表示法示意图; 3)孩子兄弟链表表示法示意图。
ABCGFEDIHJKMN(图 4-38)【解答】 1)双亲数组表示法示意图:2)孩子链表表示法示意图:0 A -1 1 B0 2 C0 3 D2 4 E2 5F1 6 G1 7 H5 8I 2 9J 4 10 K 4 11 M 3 12 N 83)孩子兄弟链表表示法示意图:0A 1B 2C 3D 4E 5F 6G 7H 8I 9J 10 K 11 M 12 N12^56^348^11 ^ 910 ^7^12 ^ABC^^GFEDI^^ H^^J^ K^ ^ M^ ^ N^(4)画出图 4-39 所示的森林经转换后所对应的二叉树,并指出森林中满足什么条件的 结点在二叉树中是叶子。
数据结构课后习题答案第四章

第四章一、简述下列每对术语的区别:空串和空白串;串常量和串变量;主串和子串;静态分配的顺序串和动态分配的顺序串;目标串和模式串;有效位移和无效位移。
答:●空串是指不包含任何字符的串,它的长度为零。
空白串是指包含一个或多个空格的串,空格也是字符。
●串常量是指在程序中只可引用但不可改变其值的串。
串变量是可以在运行中改变其值的。
●主串和子串是相对的,一个串中任意个连续字符组成的串就是这个串的子串,而包含子串的串就称为主串。
●静态分配的顺序串是指串的存储空间是确定的,即串值空间的大小是静态的,在编译时刻就被确定。
动态分配的顺序串是在编译时不分配串值空间,在运行过程中用malloc和free等函数根据需要动态地分配和释放字符数组的空间(这个空间长度由分配时确定,也是顺序存储空间)。
●目标串和模式串:在串匹配运算过程中,将主串称为目标串,而将需要匹配的子串称为模式串,两者是相对的。
●有效位移和无效位移:在串定位运算中,模式串从目标的首位开始向右位移,每一次合法位移后如果模式串与目标中相应的字符相同,则这次位移就是有效位移(也就是从此位置开始的匹配成功),反之,若有不相同的字符存在,则此次位移就是无效位移(也就是从此位置开始的匹配失败)。
二、假设有如下的串说明:char s1[30]="Stocktom,CA", s2[30]="March 5 1999", s3[30], *p;(1)在执行如下的每个语句后p的值是什么?p=stchr(s1,'t'); p=strchr(s2,'9'); p=strchr(s2,'6');(2)在执行下列语句后,s3的值是什么?strcpy(s3,s1); strcat(s3,","); strcat(s3,s2);(3)调用函数strcmp(s1,s2)的返回值是什么?(4)调用函数strcmp(&s1[5],"ton")的返回值是什么?(5)调用函数stlen(strcat(s1,s2))的返回值是什么?解:(1) stchr(*s,c)函数的功能是查找字符c在串s中的位置,若找到,则返回该位置,否则返回NULL。
数据结构肖启宏课后习题答案第四章

一. 名词解释(1)栈——只允许在一端进行插入或删除操作的线性表称为栈。
其最大的特点是“后进先出”。
(2)顺序栈——采用顺序存储结构的栈称为顺序栈。
(3)链栈——采用链式存储结构的栈称为链栈。
(5)队列——只允许在一端进行插入,另一端进行删除操作的线性表称为队列。
其最大的特点是“先进先出”。
(6)顺序队列——采用顺序存储结构的队列称为顺序队列。
(7)链队列——采用链式存储结构的称队列为链队列。
(8)循环队列——为了解决顺序队列中“假溢出”现象,将队列的存储空间想象为一个首尾相链的环(即把队头元素与对尾元素链结起来),存储在其中的队列称为循环队列。
二.判断题(下列各题,正确的请在前面的括号内打√;错误的打ㄨ)(1)√(2)√(3)ㄨ(4)ㄨ(5)ㄨ(6)ㄨ(7)√(8)√(9)ㄨ(10)√(11)ㄨ(12)ㄨ三. 填空题(1)后进先出(2)栈顶栈底(3)栈空栈满(4)O(1)O(1)(5)必须一致(6)栈(7)栈空(8)p->next=top top=p(9)- - + +(10)LS->next 首(11)先进先出(12)队尾队头(13)队列是否为空队列是否为满(14)可变的(15)-1 NULL(16)O(n) O(1) O(1) O(1)(17)front==rear front==(rear+1)% MAXLEN MAXLEN-front (18)空只含有一个结点(19)front==rear && front <>NULL(20)队尾指针写入四. 选择题(1)C (2)A (3)D (4)B (5)C(6)D (7)B (8)A (9)A (10)D(11)A (12)A (13)C (14)A (15)B (16) A五、简答题答:n个(同类)数据元素的有限序列称为线性表。
线性表的特点是数据元素之间存在“一对一”的关系。
栈和队列都是操作受限制的线性表,它们和线性表一样,数据元素之间都存在“一对一”的关系。
数据结构课后习题第四章

第四章串习题4一、选择题1.串是一种分外的线性表,其分外性体现在()。
A.可以顺序存储B.数据元素是一个字符C.可以连接存储D.数据元素可以是多个字符2.有两个串P和Q,求P在Q中首次出现的位置的运算称为()。
A.模式匹配B.联接C.求子串D.求串长3.设S为一个长度为n的字符串,其中的字符各不相同,则S中的互异的非通俗子串(非空且例外于S本身)的个数为()。
A.n²B.(n²/2)+(n/2)C.(n²/2)+(n/2)-1D.(n²/2)-(n/2)-14.设串s1=“ABCDEFG”,s2=“PQRST”,函数concat(x,y)返回x和y串的连接串,subString(s,i,j)返回串s的从序号i的字符开始的j个字符组成的子串,Strlength(s)返回串s的长度,则concat(subString(s1,2,Strlength(s2)),subString(s1,Strlength(s2),2)))的结果串是()。
A.BCDEFB.BCDEFGC.BCPQRSTD.BCDEFEF5.顺序串中,根据空间分配方式的例外,可分为()。
A.直接分配和间接分配B.静态分配和动态分配C.顺序分配和链式分配D.随机分配和不变分配6.设串S=“abcdefgh”,则S的所有非通俗子串(除空串和S自身的串)的个数是()。
A.8B.37C.36D.357.设主串的长度为n,模式串的长度为m,则串匹配的KMP算法时间复杂度是()。
A.O(m)B.O(n)C.O(m+n)D.O(n*m)8.已知串S=“aaab”,其next数组值为()。
A.0123B.1123C.1231D.1211二丶填空题1.在空串和空格串中,长度不为0的是()。
2.空格串是指(),其长度等于()。
3.按存储结构的例外,串可分为()、()和()。
4.C语言中,以字符()表示串值的终结。
5.在块链串中,为了提高存储密度,应该增大()。
数据结构(第二版)习题答案第4章

gets(s2.str);
s2.length=strlen(s2.str);
m=strcompare(s1,s2);
if(m==1) printf("s1>s2\n");
else if(m==-1) printf("s2>s1\n");
free(S);
free(T1);
free(T2);
}
【参考程序
2】:
#include<stdio.h>
#define MAXSIZE 100
typedef struct{
char str[MAXSIZE];
int length;
}seqstring;
for(k=0;k<t2.length;k++)
s->str[c+k]=t2.str[k];
else if(t1.length<t2.length)
{ for(m=s->length-1;m>i-1;m--)
s->str[t2.length-t1.length+m]=s->str[m]; //后移留空
while (i<t->length && j<p->length)
{
if(j==-1||t->str[i]==p->str[j])
{i++; j++;}
else j=next[j];
}
if (j==p->length) return (i-p->length);
数据结构答案第4章

⑴二维数组A的每个元素是由6个字符组成的串,行下标的范围从0~8,列下标的范围是从0~9,则存放A至少需要()个字节,A的第8列和第5行共占()个字节,若A按行优先方式存储,元素A[8][5]的起始地址与当A按列优先方式存储时的()元素的起始地址一致。
A 90 B 180 C 240 D 540 E 108 F 114 G 54
⑵二维数组A中行下标从10到20,列下标从5到10,按行优先存储,每个元素占4个存储单元,A[10][5]的存储地址是1000,则元素A[15][10]的存储地址是()。
【解答】1140
【分析】数组A中每行共有6个元素,元素A[15][10]的前面共存储了(15-10)×6+5个元素,每个元素占4个存储单元,所以,其存储地址是1000+140=1140。
Head(Tail(Tail(Head(ST))))=奖金
⑵工资表ST的头尾表示法如图4-7所示。7.若在矩阵A中存在一个元素ai,j(0≤i≤n-1,0≤j≤m-1),该元素是第i行元素中最小值且又是第j列元素中最大值,则称此元素为该矩阵的一个马鞍点。假设以二维数组存储矩阵A,试设计一个求该矩阵所有马鞍点的算法,并分析最坏情况下的时间复杂度。
⑵因为k和i, j之间是一一对应的关系,k+1是当前非零元素的个数,整除即为其所在行号,取余表示当前行中第几个非零元素,加上前面零元素所在列数就是当前列号,即:
数据结构第4章作业参考答案

第4章(数组和广义表)作业参考答案一、单项选择题1.将一个A[1..100,1..100]的三对角矩阵,按行优先压缩存储到一维数组B[1‥298]中,A 中元素A[66][65]在B数组中的位置K为(C )。
A. 198B. 197C. 195D. 1962.广义表(a,(b,c),d,e)的表头为( A )。
A. aB. a,(b,c)C. (a,(b,c))D. (a)3.在三对角矩阵中,非零元素的行标i和列标j的关系是( A )。
A. |i-j|≤1B. i>jC. i==jD. i<j4.广义表L=(a,(b,c)),进行Tail(L)操作后的结果为( D )。
A. cB. b,cC.(b,c)D.((b,c))5.设二维数组A[1..m,1..n](即m行n列)按行存储在数组B[1..m*n]中,则二维数组元素A[i,j]在一维数组B中的下标为( D )。
A. j*m+i-1B. (i-1)*n+j-1C. i*(j-1)D. (i-1)*n+j6.广义表(( ),( ),( ))的深度为( C )。
A. 0B. 1C. 2D. 37.假设以行序为主序存储二维数组A[0..99,0..99],设每个数据元素占2个存储单元,基地址为10,则LOC(A[4][4])=( C )。
A. 1020B. 1010C. 818D. 8088.已知广义表A=((a,b),(c,d)),则head(A)等于( A )。
A. (a,b)B. ((a,b))C. a,bD. a9.已知一个稀疏矩阵的三元组表如下:(1,2,3),(1,6,1),(3,1,5),(3,2,-1),(4,5,4),(5,1,-3)则其转置矩阵的三元组表中第3个三元组为( C )。
A. (2,3,-1)B. (3,1,5)C. (2,1,3)D. (3,2,-1)10.广义表((b,c),d,e)的表尾为( C )。
数据结构第四章的习题答案

数据结构第四章的习题答案数据结构第四章的习题答案在学习数据结构的过程中,习题是非常重要的一环。
通过解答习题,我们可以更好地理解和应用所学的知识。
在第四章中,我们学习了树和二叉树的相关概念和操作。
下面我将为大家提供一些第四章习题的答案,希望能帮助大家更好地掌握这一章节的内容。
1. 请给出树和二叉树的定义。
树是由n(n>=0)个结点构成的有限集合,其中有且仅有一个特定的结点称为根结点,其余的结点可以分为若干个互不相交的有限集合,每个集合本身又是一个树,称为根的子树。
二叉树是一种特殊的树结构,其中每个结点最多有两个子结点,分别称为左子结点和右子结点。
二叉树具有递归的定义,即每个结点的左子树和右子树都是二叉树。
2. 请给出树和二叉树的遍历方式。
树的遍历方式包括前序遍历、中序遍历和后序遍历。
前序遍历是先访问根结点,然后依次遍历左子树和右子树。
中序遍历是先遍历左子树,然后访问根结点,最后遍历右子树。
后序遍历是先遍历左子树和右子树,最后访问根结点。
二叉树的遍历方式包括前序遍历、中序遍历和后序遍历。
前序遍历是先访问根结点,然后依次遍历左子树和右子树。
中序遍历是先遍历左子树,然后访问根结点,最后遍历右子树。
后序遍历是先遍历左子树和右子树,最后访问根结点。
3. 给定一个二叉树的前序遍历序列和中序遍历序列,请构建该二叉树。
这个问题可以通过递归的方式解决。
首先,根据前序遍历序列的第一个结点确定根结点。
然后,在中序遍历序列中找到根结点的位置,该位置左边的结点为左子树的中序遍历序列,右边的结点为右子树的中序遍历序列。
接下来,分别对左子树和右子树进行递归构建。
4. 给定一个二叉树的中序遍历序列和后序遍历序列,请构建该二叉树。
和前面的问题类似,这个问题也可以通过递归的方式解决。
首先,根据后序遍历序列的最后一个结点确定根结点。
然后,在中序遍历序列中找到根结点的位置,该位置左边的结点为左子树的中序遍历序列,右边的结点为右子树的中序遍历序列。
《数据结构》第四章习题参考答案

《数据结构》第四章习题一、判断题(在正确说法的题后括号中打“√”,错误说法的题后括号中打“×”)1、KMP算法的特点是在模式匹配时指示主串的指针不会变小。
( √)2、串是一种数据对象和操作都特殊的线性表。
( √)3、只包含空白字符的串称为空串(空白串)。
( ×)4、稀疏矩阵压缩存储后,必会(不会)失去随机存取功能。
( ×)5、使用三元组表示稀疏矩阵的非零元素能节省存储空间。
( √)6、插入与删除操作是数据结构中最基本的两种操作,因此这两种操作在数组中也经常使用。
(×)7、若采用三元组表存储稀疏矩阵,只要把每个元素的行下标和列下标互换(错的),就完成了对该矩阵的转置运算。
(×)二、单项选择题1.下面关于串的的叙述中,哪一个是不正确的?( B )A.串是字符的有限序列B.空串是由空格构成的串(空串是长度为零的串)C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储2.有串S1=’ABCDEFG’,S2 = ’PQRST’,假设函数con(x,y)返回x和y串的连接串,subs(s,i,j)返回串s的从序号i的字符开始的j个字符组成的子串,len(s)返回中s的长度,则con(subs(s1,2,len(s2)),subs(s1,len(s2),2))的结果串是( D )。
A.BCDEF B.BCDEFG C.BCPQRST D.CDEFGFG3、串的长度是指( B )A.串中所含不同字母的个数B.串中所含字符的个数C.串中所含不同字符的个数D.串中所含非空格字符的个数三、填空题1、串是一种特殊的线性表,其特殊性表现在_数据元素为字符,操作集也不同__;串的两种最基本的存储方式是_顺序存储_、__ 链式存储_;两个串相等的充分必要条件是__两串的长度相等且两串中对应位置的字符也相等__。
2、设正文串长度为n,模式串长度为m,则串匹配的KMP算法的时间复杂度为_O(m+n)__。
(完整版) 《数据结构》教材课后习题+答案

第1章绪论习题1.简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
2.试举一个数据结构的例子,叙述其逻辑结构和存储结构两方面的含义和相互关系。
3.简述逻辑结构的四种基本关系并画出它们的关系图。
4.存储结构由哪两种基本的存储方法实现?5.选择题(1)在数据结构中,从逻辑上可以把数据结构分成()。
A.动态结构和静态结构B.紧凑结构和非紧凑结构C.线性结构和非线性结构D.内部结构和外部结构(2)与数据元素本身的形式、内容、相对位置、个数无关的是数据的()。
A.存储结构B.存储实现C.逻辑结构D.运算实现(3)通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着()。
A.数据具有同一特点B.不仅数据元素所包含的数据项的个数要相同,而且对应数据项的类型要一致C.每个数据元素都一样D.数据元素所包含的数据项的个数要相等(4)以下说法正确的是()。
A.数据元素是数据的最小单位B.数据项是数据的基本单位C.数据结构是带有结构的各数据项的集合D.一些表面上很不相同的数据可以有相同的逻辑结构(5)以下与数据的存储结构无关的术语是()。
A.顺序队列 B. 链表 C. 有序表 D. 链栈(6)以下数据结构中,()是非线性数据结构A.树B.字符串C.队D.栈6.试分析下面各程序段的时间复杂度。
(1)x=90; y=100;while(y>0)if(x>100){x=x-10;y--;}else x++;(2)for (i=0; i<n; i++)for (j=0; j<m; j++)a[i][j]=0;(3)s=0;for i=0; i<n; i++)for(j=0; j<n; j++)s+=B[i][j];sum=s;(4)i=1;while(i<=n)i=i*3;(5)x=0;for(i=1; i<n; i++)for (j=1; j<=n-i; j++)x++;(6)x=n; //n>1y=0;while(x≥(y+1)* (y+1))y++;(1)O(1)(2)O(m*n)(3)O(n2)(4)O(log3n)(5)因为x++共执行了n-1+n-2+……+1= n(n-1)/2,所以执行时间为O(n2)(6)O(n)第2章线性表1.选择题(1)一个向量第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是()。
严蔚敏数据结构课后习题及答案解析

第一章绪论一、选择题1.组成数据的基本单位是A数据项B数据类型C数据元素D数据变量2.数据结构是研究数据的以及它们之间的相互关系;A理想结构,物理结构B理想结构,抽象结构C物理结构,逻辑结构D抽象结构,逻辑结构3.在数据结构中,从逻辑上可以把数据结构分成A动态结构和静态结构B紧凑结构和非紧凑结构C线性结构和非线性结构D内部结构和外部结构4.数据结构是一门研究非数值计算的程序设计问题中计算机的①以及它们之间的②和运算等的学科;① A数据元素B计算方法C逻辑存储D数据映像② A结构B关系C运算D算法5.算法分析的目的是;A 找出数据结构的合理性B研究算法中的输入和输出的关系C分析算法的效率以求改进D分析算法的易懂性和文档性6.计算机算法指的是①,它必须具备输入、输出和②等5个特性;① A计算方法B排序方法C解决问题的有限运算序列D调度方法② A可执行性、可移植性和可扩充性B可行性、确定性和有穷性C确定性、有穷性和稳定性D易读性、稳定性和安全性二、判断题1.数据的机内表示称为数据的存储结构;2.算法就是程序;3.数据元素是数据的最小单位;4.算法的五个特性为:有穷性、输入、输出、完成性和确定性;5.算法的时间复杂度取决于问题的规模和待处理数据的初态;三、填空题1.数据逻辑结构包括________、________、_________ 和_________四种类型,其中树形结构和图形结构合称为_____;2.在线性结构中,第一个结点____前驱结点,其余每个结点有且只有______个前驱结点;最后一个结点______后续结点,其余每个结点有且只有_______个后续结点;3.在树形结构中,树根结点没有_______结点,其余每个结点有且只有_______个前驱结点;叶子结点没有________结点,其余每个结点的后续结点可以_________;4.在图形结构中,每个结点的前驱结点数和后续结点数可以_________;5.线性结构中元素之间存在________关系,树形结构中元素之间存在______关系,图形结构中元素之间存在_______关系;6.算法的五个重要特性是_______、_______、______、_______、_______;7.数据结构的三要素是指______、_______和________;8.链式存储结构与顺序存储结构相比较,主要优点是________________________________;9.设有一批数据元素,为了最快的存储某元素,数据结构宜用_________结构,为了方便插入一个元素,数据结构宜用____________结构;四、算法分析题1.求下列算法段的语句频度及时间复杂度参考答案:一、选择题1. C 3. C 4. A、B 5. C 、B二、判断题:1、√2、×3、×4、×5、√三、填空题1、线性、树形、图形、集合;非线性网状2、没有;1;没有;13、前驱;1;后继;任意多个4、任意多个5、一对一;一对多;多对多6、有穷性;确定性;可行性;输入;输出7、数据元素;逻辑结构;存储结构8、插入、删除、合并等操作较方便9、顺序存储;链式存储四、算法分析题fori=1; i<=n; i++forj =1; j <=i ; j++x=x+1;分析:该算法为一个二重循环,执行次数为内、外循环次数相乘,但内循环次数不固定,与外循环有关,因些,时间频度Tn=1+2+3+…+n=nn+1/2有1/4≤Tn/n2≤1,故它的时间复杂度为On2, 即Tn与n2 数量级相同; 2、分析下列算法段的时间频度及时间复杂度for i=1;i<=n;i++for j=1;j<=i;j++for k=1;k<=j;k++x=i+j-k;分析算法规律可知时间频度Tn=1+1+2+1+2+3+...+1+2+3+…+n由于有1/6 ≤ Tn/ n3 ≤1,故时间复杂度为On3第二章线性表一、选择题1.一个线性表第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是A110 B108C100 D1202. 向一个有127个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动个元素;A64B63 C D73.线性表采用链式存储结构时,其地址;A 必须是连续的B 部分地址必须是连续的C 一定是不连续的D 连续与否均可以4. 在一个单链表中,若p所指结点不是最后结点,在p之后插入s所指结点,则执行As->next=p;p->next=s; B s->next=p->next;p->next=s;Cs->next=p->next;p=s; Dp->next=s;s->next=p;5.在一个单链表中,若删除p所指结点的后续结点,则执行Ap->next=p->next->next; Bp=p->next; p->next=p->next->next;Cp->next=p->next; Dp =p->next->next;6.下列有关线性表的叙述中,正确的是A线性表中的元素之间隔是线性关系B线性表中至少有一个元素C线性表中任何一个元素有且仅有一个直接前趋D线性表中任何一个元素有且仅有一个直接后继7.线性表是具有n个的有限序列n≠0A表元素B字符C数据元素D数据项二、判断题1.线性表的链接存储,表中元素的逻辑顺序与物理顺序一定相同;2.如果没有提供指针类型的语言,就无法构造链式结构;3.线性结构的特点是只有一个结点没有前驱,只有一个结点没有后继,其余的结点只有一个前驱和后继;4.语句p=p->next完成了指针赋值并使p指针得到了p指针所指后继结点的数据域值;5.要想删除p指针的后继结点,我们应该执行q=p->next ;p->next=q->next;freeq;三、填空题1.已知P为单链表中的非首尾结点,在P结点后插入S结点的语句为:_______________________ ;2.顺序表中逻辑上相邻的元素物理位置相邻, 单链表中逻辑上相邻的元素物理位置_________相邻;3.线性表L=a1,a2,...,an采用顺序存储,假定在不同的n+1个位置上插入的概率相同,则插入一个新元素平均需要移动的元素个数是________________________4.在非空双向循环链表中,在结点q的前面插入结点p的过程如下:p->prior=q->prior;q->prior->next=p;p->next=q;______________________;5.已知L是无表头结点的单链表,是从下列提供的答案中选择合适的语句序列,分别实现:1表尾插入s结点的语句序列是_______________________________2 表尾插入s结点的语句序列是_______________________________1.p->next=s;2.p=L;3.L=s;4.p->next=s->next;5.s->next=p->next;6.s->next=L;7.s->next=null;8.whilep->next= Q p=p-next;9.whilep->next=null p=p->next;四、算法设计题1.试编写一个求已知单链表的数据域的平均值的函数数据域数据类型为整型;2.已知带有头结点的循环链表中头指针为head,试写出删除并释放数据域值为x的所有结点的c函数;3.某百货公司仓库中有一批电视机,按其价格从低到高的次序构成一个循环链表,每个结点有价格、数量和链指针三个域;现出库销售m台价格为h的电视机,试编写算法修改原链表;4.某百货公司仓库中有一批电视机,按其价格从低到高的次序构成一个循环链表,每个结点有价格、数量和链指针三个域;现新到m台价格为h的电视机,试编写算法修改原链表;5.线性表中的元素值按递增有序排列,针对顺序表和循环链表两种不同的存储方式,分别编写C函数删除线性表中值介于a与ba≤b之间的元素;6.设A=a0,a1,a2,...,an-1,B=b0,b1,b2,...,bm-1是两个给定的线性表,它们的结点个数分别是n和m,且结点值均是整数;若n=m,且ai= bi 0≤i<n ,则A=B;若n<m ,且ai=bi 0≤i<n ,则A<B;若存在一个j, j<m ,j<n ,且ai=bi 0≤i<j , 若aj<bj,则A<B,否则A>B;试编写一个比较A和B的C函数,该函数返回-1或0或1,分别表示A<B或A=B或A>B;7.试编写算法,删除双向循环链表中第k个结点;8.线性表由前后两部分性质不同的元素组成a0,a1,...,an-1,b0,b1,...,bm-1,m和n为两部分元素的个数,若线性表分别采用数组和链表两种方式存储,编写算法将两部分元素换位成b0,b1,...,bm-1,a0,a1,...,an-1,分析两种存储方式下算法的时间和空间复杂度;9.用循环链表作线性表a0,a1,...,an-1和b0,b1,...,bm-1的存储结构,头指针分别为ah和bh,设计C函数,把两个线性表合并成形如a0,b0,a1,b1,…的线性表,要求不开辟新的动态空间,利用原来循环链表的结点完成合并操作,结构仍为循环链表,头指针为head,并分析算法的时间复杂度;10.试写出将一个线性表分解为两个带有头结点的循环链表,并将两个循环链表的长度放在各自的头结点的数据域中的C函数;其中,线性表中序号为偶数的元素分解到第一个循环链表中,序号为奇数的元素分解到第二个循环链表中;11.试写出把线性链表改为循环链表的C函数;12.己知非空线性链表中x结点的直接前驱结点为y,试写出删除x结点的C函数;参考答案:一、选择题1. B 3. D 4. B 5. A 7、C二、判断题:参考答案:1、×2、√3、×4、×5、√三、填空题1、s->next=p->next; p->next=s;2、一定;不一定3、n/24、q->prior=p;5、16 32 2 91 7四、算法设计题1、include ""include ""typedef struct node{int data;struct node link;}NODE;int averNODE head{int i=0,sum=0,ave; NODE p;p=head;whilep=NULL{p=p->link;++i;sum=sum+p->data;}ave=sum/i;return ave;}2、include ""include ""typedef struct node{int data; / 假设数据域为整型/struct node link;}NODE;void del_linkNODE head,int x / 删除数据域为x的结点/ {NODE p,q,s;p=head;q=head->link;whileq=head{ifq->data==x{p->link=q->link;s=q;q=q->link;frees;}else{p=q;q=q->link;}}}3、void delNODE head,float price,int num {NODE p,q,s;p=head;q=head->next;whileq->price<price&&q=head{p=q;q=q->next;}ifq->price==priceq->num=q->num-num; elseprintf"无此产品"; ifq->num==0{p->next=q->next; freeq;}}4、include ""include ""typedef struct node {float price;int num;struct node next;}NODE;void insNODE head,float price,int num {NODE p,q,s;p=head;q=head->next;whileq->price<price&&q=head{p=q;q=q->next;}ifq->price==priceq->num=q->num+num;else{s=NODE mallocsizeofNODE;s->price=price;s->num=num;s->next=p->next;p->next=s;}}5、顺序表:算法思想:从0开始扫描线性表,用k记录下元素值在a与b之间的元素个数,对于不满足该条件的元素,前移k个位置,最后修改线性表的长度;void delelemtype list,int n,elemtype a,elemtype b{int i=0,k=0;whilei<n{iflisti>=a&&listi<=b k++;elselisti-k=listi;i++;}n=n-k; / 修改线性表的长度/}循环链表:void delNODE head,elemtype a,elemtype b{NODE p,q;p= head;q=p->link; / 假设循环链表带有头结点/ whileq=head && q->data<a{p=q;q=q->link;}whileq=head && q->data<b{r=q;q=q->link;freer;}ifp=qp->link=q;}6、define MAXSIZE 100int listAMAXSIZE,listBMAXSIZE; int n,m;int compareint a,int b{int i=0;whileai==bi&&i<n&&i<mi++;ifn==m&&i==n return0;ifn<m&&i==n return-1;ifn>m&&i==m return1;ifi<n&&i<mifai<bi return-1;else ifai>bi return1;}7、void delDUNODE head,int i{DUNODE p;{head=head->next;head->prior=NULL;return0;}Else{forj=0;j<i&&p=NULL;j++p=p->next;ifp==NULL||j>i return1;p->prior->next=p->next;p->next->prior=p->proir;freep;return0;}8.顺序存储:void convertelemtype list,int l,int h / 将数组中第l个到第h个元素逆置/ {elemtype temp;fori=h;i<=l+h/2;i++{temp=listi;listi=listl+h-i;listl+h-i=temp;}}void exchangeelemtype list,int n,int m; {convertlist,0,n+m-1;convertlist,0,m-1;convertlist,m,n+m-1;}该算法的时间复杂度为On+m,空间复杂度为O1 链接存储:不带头结点的单链表typedef struct node{elemtype data;struct node link;}NODE;void convertNODE head,int n,int m{NODE p,q,r;int i;p=head;q=head;fori=0;i<n-1;i++q=q->link; /q指向an-1结点/r=q->link;q->link=NULL;whiler->link=NULLr=r->link; /r指向最后一个bm-1结点/head=q;r->link=p;}该算法的时间复杂度为On+m,但比顺序存储节省时间不需要移动元素,只需改变指针,空间复杂度为O1typedef struct node{elemtype data;struct node link;}NODE;NODE unionNODE ah,NODE bh {NODE a,b,head,r,q;head=ah;a=ah;b=bh;whilea->link=ah&&b->link=bh {r=a->link;q=b->link;a->link=b;b->link=r;a=r;}ifa->link==ah /a的结点个数小于等于b的结点个数/{a->link=b;whileb->link=bhb=b->link;b->link=head;}ifb->link==bh /b的结点个数小于a的结点个数/{r=a->link;a->link=b;b->link=r;}returnhead;}该算法的时间复杂度为On+m,其中n和m为两个循环链表的结点个数.10.typedef struct node{elemtype data;struct node link;}NODE;void analyzeNODE a{NODE rh,qh,r,q,p;int i=0,j=0;/i为序号是奇数的结点个数j为序号是偶数的结点个数/ p=a;rh=NODE mallocsizeofNODE;/rh为序号是奇数的链表头指针/qh=NODE mallocsizeofNODE; /qh为序号是偶数的链表头指针/r=rh;q=qh;whilep=NULL{r->link=p;r=p;i++;p=p->link;ifp=NULL{q->link=p;q=p;j++;p=p->link;}}rh->data=i;r->link=rh;qh->data=j;q->link=qh;}11.typedef struct node {elemtype data;struct node link;}NODE;void changeNODE head {NODE p;p=head;ifhead=NULL{whilep->link=NULLp=p->link;p->link=head;}}12.typedef struct node {elemtype data;struct node link;}NODE;void delNODE x,NODE y{NODE p,q;elemtype d1;p=y;q=x;whileq->next=NULL / 把后一个结点数据域前移到前一个结点/ {p->data=q->data;q=q->link;p=q;p->link=NULL; / 删除最后一个结点/freeq;}第三章栈和队列一、选择题1. 一个栈的入栈序列是a,b,c,d,e,则栈的不可能的输出序列是;A edcbaBdecbaCdceab Dabcde2.栈结构通常采用的两种存储结构是;A 线性存储结构和链表存储结构B散列方式和索引方式C链表存储结构和数组D线性存储结构和非线性存储结构3.判定一个栈ST最多元素为m0为空的条件是;A ST-〉top=0 BST-〉top==0CST-〉top=m0 DST-〉top=m04.判定一个栈ST最多元素为m0为栈满的条件是;AST->top=0 BST->top==0CST->top=m0-1DST->top==m0-15.一个队列的入列序列是1,2,3,4,则队列的输出序列是;A4,3,2,1B1,2,3,4C1,4,3,2D3,2,4,16.循环队列用数组A0,m-1存放其元素值,已知其头尾指针分别是front和rear则当前队列中的元素个数是Arear-front+m%m B rear-front+1 Crear-front-1Drear-front7.栈和队列的共同点是A 都是先进后出B都是先进先出C只允许在端点处插入和删除元素D没有共同点8.表达式ab+c-d的后缀表达式是;Aabcd+-Babc+d- Cabc+d-D-+abcd个元素a1,a2,a3和a4依次通过一个栈,在a4进栈前,栈的状态,则不可能的出栈序是Aa4,a3,a2,a1 Ba3,a2,a4,a1Ca3,a1,a4,a2 Da3,a4,a2,a110.以数组Q0..m-1存放循环队列中的元素,变量rear和qulen分别指示循环队列中队尾元素的实际位置和当前队列中元素的个数,队列第一个元素的实际位置是Arear-qulen Brear-qulen+mCm-qulen D1+rear+m-qulen% m二、填空题1.栈的特点是_______________________,队列的特点是__________________________;2.线性表、栈和队列都是_____________________结构,可以在线性表的______________位置插入和删除元素,对于栈只能在________插入和删除元素,对于队列只能在_______插入元素和_________删除元素;3.一个栈的输入序列是12345,则栈有输出序列12345是____________;正确/错误4.设栈S和队列Q的初始状态皆为空,元素a1,a2,a3,a4,a5和a6依次通过一个栈,一个元素出栈后即进入队列Q,若6个元素出队列的顺序是a3,a5,a4,a6,a2,a1则栈S至少应该容纳_____个元素;三、算法设计题1.假设有两个栈s1和s2共享一个数组stackM,其中一个栈底设在stack0处,另一个栈底设在stackM-1处;试编写对任一栈作进栈和出栈运算的C函数pushx,i和popi,i=l,2;其中i=1表示左边的栈,,i=2表示右边的栈;要求在整个数组元素都被占用时才产生溢出;2.利用两个栈s1,s2模拟一个队列时,如何用栈的运算来实现该队列的运算写出模拟队列的插入和删除的C函数;一个栈s1用于插入元素,另一个栈s2用于删除元素.参考答案:一、选择题1. C 3. B 4. B 5. B 7、C 8、C 9、C 10、D二、填空题1、先进先出;先进后出2、线性;任何;栈顶;队尾;对头3、正确的4、3三、算法设计题1.define M 100elemtype stackM;int top1=0,top2=m-1;int pushelemtype x,int i{iftop1-top2==1 return1; /上溢处理/elseifi==1 stacktop1++=x;ifi==2stacktop2--=x;return0;}int popelemtype px,int iifi==1iftop1==0 return1; else{top1--;px=stacktop1;return0;}elseifi==2iftop2==M-1 return1; else{top2++;px=stacktop2;return0;}}elemtype s1MAXSIZE,s2MAZSIZE; int top1,top2;void enqueueelemtype x{iftop1==MAXSIZE return1;else{pushs1,x;return0;}}void dequeueelemtype px{elemtype x;top2=0;whileemptys1{pops1,&x;pushs2,x;pops2,&x;whileemptys2{pops2,&x;pushs1,x;}}第四章串一、选择题1.下列关于串的叙述中,正确的是A一个串的字符个数即该串的长度B一个串的长度至少是1C空串是由一个空格字符组成的串D两个串S1和S2若长度相同,则这两个串相等2.字符串"abaaabab"的nextval值为A0,1,01,1,0,4,1,0,1 B0,1,0,0,0,0,2,1,0,1C0,1,0,1,0,0,0,1,1 D0,1,0,1,0,1,0,1,13.字符串满足下式,其中head和tail的定义同广义表类似,如head‘xyz’=‘x’,tail‘xyz’= ‘yz’,则s= ; concatheadtails,headtailtails= ‘dc’; Aabcd Bacbd Cacdb Dadcb4.串是一种特殊的线性表,其特殊性表现在A可以顺序存储B数据元素是一个字符C可以链式存储D数据元素可以是多个字符5.设串S1=‘ABCDEFG’,s2=‘PQRST’,函数CONCATX,Y返回X和Y串的连接串,SUBSTRS,I,J 返回串S从序号I开始的J个字符组成的字串,LENGTHS返回串S的长度,则CONCATSUBSTRS1,2,LENGTHS2,SUBSTRS1,LENGTHS2,2的结果串是ABCDEF B BCDEFG CBCPQRST DBCDEFEF二、算法设计1.分别在顺序存储和一般链接存储两种方式下,用C语言写出实现把串s1复制到串s2的串复制函数strcpys1,s2;2.在一般链接存储一个结点存放一个字符方式下,写出采用简单算法实现串的模式匹配的C 语言函数int L_indext,p;参考答案:一、选择题1. A 3. D 4. D 5. D二、算法设计1.顺序存储:include ""define MAXN 100char sMAXN;int S_strlenchar s{int i;fori=0;si='\0';i++;returni;}void S_strcpychar s1,char s2 include "" typedef struct node{char data;struct node link;}NODE;int L_indexNODE t,NODE p{NODE t1,p1,t2;int i;t1=t;i=1;whilet1=NULL{p1=p;t2=t1->link;whilep1->data==t1->data&&p1=NULL{p1=p1->link;t1=t1->link;}ifp1==NULL returni;i++;t1=t2;}return0;}第五章数组和广义表一、选择题1. 常对数组进行的两种基本操作是A建立与删除B索引和修改C查找和修改D查找与索引2.二维数组M的元素是4个字符每个字符占一个存储单元组成的串,行下标i的范围从0到4,列下标j的范围从0到5,M按行存储时元素M35的起始地址与M按列存储时元素的起始地址相同;AM24BM34CM35DM443.数组A810中,每个元素A的长度为3个字节,从首地址SA开始连续存放在存储器内,存放该数组至少需要的单元数是;A80B100C240D2704.数组A810中,每个元素A的长度为3个字节,从首地址SA开始连续存放在存储器内,该数组按行存放时,元素A74的起始地址为;ASA+141BSA+144CSA+222DSA+2255.数组A810中,每个元素A的长度为3个字节,从首地址SA开始连续存放在存储器内,该数组按列存放时,元素A47的起始地址为;ASA+141BSA+180CSA+222DSA+2256.稀疏矩阵一般的压缩存储方法有两种,即;A 二维数组和三维数组B三元组和散列C三元组和十字链表D散列和十字链表7.若采用三元组压缩技术存储稀疏矩阵,只要把每个元素的行下标和列下标互换,就完成了对该矩阵的转置运算,这种观点;A正确B错误8.设矩阵A是一个对称矩阵,为了节省存储,将其下三角部分按行序存放在一维数组B1,nn-1/2中,对下三角部分中任一元素ai,ji<=j,在一组数组B的下标位置k的值是;Aii-1/2+j-1Bii-1/2+jCii+1/2+j-1 Dii+1/2+j二、填空题1.己知二维数组Amn采用行序为主方式存储,每个元素占k个存储单元,并且第一个元素的存储地址是LOCA00,则A00的地址是_____________________;2.二维数组A1020采用列序为主方式存储,每个元素占一个存储单元,并且A00的存储地址是200,则A612的地址是________________;3.有一个10阶对称矩阵A,采用压缩存储方式以行序为主,且A00=1,则A85的地址是__________________;4.设n行n列的下三角矩阵A已压缩到一维数组S1..nn+1/2中,若按行序为主存储,则Aij对应的S中的存储位置是________________;5.若A是按列序为主序进行存储的4×6的二维数组,其每个元素占用3个存储单元,并且A00的存储地址为1000,元素A13的存储地址为___________,该数组共占用_______________个存储单元;三、算法设计1.如果矩阵A中存在这样的一个元素Aij满足条件:Aij是第i行中值最小的元素,且又是第j 列中值最大的元素,则称之为该矩阵的一个马鞍点;编写一个函数计算出1×n的矩阵A的所有马鞍点;只猴子要选大王,选举办法如下:所有猴子按1,2,...,n编号围坐一圈,从1号开始按1、2、...、m报数,凡报m号的退出到圈外,如此循环报数,直到圈内剩下只猴子时,这只猴子就是大王;n 和m由键盘输入,打印出最后剩下的猴子号;编写一程序实现上述函数;3.数组和广义表的算法验证程序编写下列程序:1求广义表表头和表尾的函数head和tail;2计算广义表原子结点个数的函数count_GL;3计算广义表所有原子结点数据域设数据域为整型〉之和的函数sum_GL;参考答案:一、选择题1. C 3. C 4. C 5. B 7、B 8、B二、填空题1、locA00+ni+jk2、3323、424、ii+1/2+j+15、1039;72三、算法设计题1.算法思想:依题意,先求出每行的最小值元素,放入minm之中,再求出每列的最大值元素,放入maxn之中,若某元素既在mini中,又在maxj中,则该元素Aij便是马鞍点,找出所有这样的元素,即找到了所有马鞍点;因此,实现本题功能的程序如下:include <>define m 3define n 4void minmaxint amn{int i1,j,have=0;int minm,maxn;fori1=0;i1<m;i1++/计算出每行的最小值元素,放入minm之中/{mini1=ai10;forj=1;j<n;j++ifai1j<mini1 mini1=ai1j;}forj=0;j<n;j++/计算出每列的最大值元素,放入maxn之中/{maxj=a0j;fori1=1;i1<m;i1++ifai1j>max j maxj=ai1j;}fori1=0;i1<m;i1++forj=0;j<n;j++ifmini1==maxj{printf"%d,%d:%d\n",i1,j,ai1j;have=1;}ifhave printf"没有鞍点\n";}2.算法思想:本题用一个含有n个元素的数组a,初始时ai中存放猴子的编号i,计数器似的值为0;从ai开始循环报数,每报一次,计数器的值加1,凡报到m时便打印出ai值退出圈外的猴子的编号,同时将ai的值改为O以后它不再参加报数,计数器值重新置为0;该函数一直进行到n 只猴子全部退出圈外为止,最后退出的猴子就是大王;因此,现本题功能的程序如下:include ""main{int a100;int count,d,j,m,n; scanf"%d %d",&m,&n;/ n>=m/ forj=0;j<n;j++aj=j+1;count=0;d=0;whiled<nforj=0;j<n;j++ifaj=0{count++;ifcount==m{printf"% d ",aj;aj=0;count=0;}}}3.include ""include ""typedef struct node { int tag;union{struct node sublist; char data;}dd;struct node link;}NODE;NODE creat_GLchar s {NODE h;char ch;s++;ifch='\0'{h=NODEmallocsizeofNODE; ifch==''{h->tag=1;h->=creat_GLs;}Else{h->tag=0;h->=ch;}}elseh=NULL;ch=s;s++;ifh=NULLifch==','h->link =creat_GLs; elseh->link=NULL; returnh;}void prn_GLNODE p {ifp=NULL{ifp->tag==1{printf"";ifp-> ==NULL printf" ";elseprn_GLp-> ;}elseprintf"%c",p->;ifp->tag==1printf"";ifp->link=NULL{printf",";prn_GLp->link;}}}NODE copy_GLNODE p{NODE q;ifp==NULL returnNULL;q=NODE mallocsizeofNODE; q->tag=p->tag;ifp->tagq-> =copy_GLp-> ;elseq-> =p->;q->link=copy_GLp->link;returnq;}NODE headNODE p /求表头函数/{returnp->;}NODE tailNODE p /求表尾函数/{returnp->link;}int sumNODE p /求原子结点的数据域之和函数/ { int m,n;ifp==NULL return0;else{ ifp->tag==0 n=p->;elsen=sump->;ifp->link=NULLm=sump->link;else m=0;returnn+m;}}int depthNODE p /求表的深度函数/ {int h,maxdh;NODE q;ifp->tag==0 return0;elseifp->tag==1&&p->==NULL return 1; else{maxdh=0;whilep=NULL{ifp->tag==0 h=0; else{q=p->;h=depthq;}ifh>maxdhmaxdh=h; p=p->link;}returnmaxdh+1;}}main{NODE hd,hc;char s100,p;p=getss;hd=creat_GL&p; prn_GLheadhd;prn_GLtailhd;hc=copy_GLhd;printf"copy after:";prn_GLhc;printf"sum:%d\n",sumhd;printf"depth:%d\n",depthhd;}第六章树和二叉树一、选择题1.在线索化二叉树中,t所指结点没有左子树的充要条件是At-〉left==NULL Bt-〉ltag==1Ct-〉ltag=1且t-〉left=NULLD以上都不对2.二叉树按某种顺序线索化后,任一结点均有指向其前趋和后继的线索,这种说法A正确B错误C不同情况下答案不确定3.二叉树的前序遍历序列中,任意一个结点均处在其子女结点的前面,这种说法A正确B错误C不同情况下答案不确定4.由于二叉树中每个结点的度最大为2,所以二叉树是一种特殊的树,这种说法A正确B错误C不同情况下答案不确定5.设高度为h的二叉树上只有度为0和度为2的结点,则此类二叉树中所包含的结点数至少为;A2h B2h-1C2h+1Dh+16.已知某二叉树的后序遍历序列是dabec;中序遍历序列是debac,它的前序遍历序列是;Aacbed BdecabCdeabc Dcedba7.如果T2是由有序树T转换而来的二叉树,那么T中结点的前序就是T2中结点的A前序B中序C后序D层次序8.某二叉树的前序遍历结点访问顺序是abdgcefh,中序遍历的结点访问顺序是dgbaechf,则其后序遍历的结点访问顺序是;Abdgcefha Bgdbecfha Cbdgaechf Dgdbehfca9.二叉树为二叉排序树的充分必要条件是其任一结点的值均大于其左孩子的值、小于其右孩子的值;这种说法A正确B错误C不同情况下答案不确定10.按照二叉树的定义,具有3个结点的二叉树有种;A3B4C5D611.在一非空二叉树的中序遍历序列中,根结点的右边A只有右子树上的所有结点B只有右子树上的部分结点C只有左子树上的部分结点D只有左子树上的所有结点12.树最适合用来表示;A有序数据元素B无序数据元素C元素之间具有分支层次关系的数据D元素之间无联系的数据13.任何一棵二叉树的叶结点在先序、中序和后序遍历序列中的相对次序A不发生改变B发生改变C不能确定D.以上都不对14.实现任意二叉树的后序遍历的非递归算法而不使用栈结构,最佳方案是二叉树采用存储结构;A二叉链表B广义表存储结构C三叉链表D顺序存储结构15.对一个满二叉树,m个树叶,n个结点,深度为h,则An=h+m Bh+m=2nCm=h-1Dn=2h-116.如果某二叉树的前序为stuwv,中序为uwtvs,那么该二叉树的后序为Auwvts BvwutsCwuvts Dwutsv17.具有五层结点的二叉平衡树至少有个结点;A10B12C15D17二、判断题1.二叉树中任何一个结点的度都是2;2.由二叉树结点的先根序列和后根序列可以唯一地确定一棵二叉树;3.一棵哈夫曼树中不存在度为1的结点;4.平衡二叉排序树上任何一个结点的左、右子树的高度之差的绝对值不大于2三、填空题1.指出树和二叉树的三个主要差别___________,___________,_______________;2.从概念上讲,树与二叉树是两种不同的数据结构,将树转化为二叉树的基本目的是____________3.若结点A有三个兄弟包括A本身,并且B是A的双亲结点,B的度是_______________4.若一棵具有n个结点的二叉树采用标准链接存储结构,那么该二叉树所有结点共有_______个空指针域;5.已知二叉树的前序序列为ABDEGCFHIJ,中序序列为DBGEAHFIJC,写出后序序列_______________;6.已知二叉树的后序序列为FGDBHECA,中序序列为BFDGAEHC ,并写出前序序列_________________;7.找出满足下列条件的二叉树1先序和中序遍历,得到的结点访问顺序一样;_________________________2后序和中序遍历,得到的结点访问顺序一样;_________________________3先序和后序遍历,得到的结点访问顺序一样;__________________________8.一棵含有n个结点的k叉树,可能达到的最大深度和最小深度各是多少____________________9.一棵二叉树有67个结点,这些结点的度要么是0,要么是2;这棵二叉树中度为2的结点有______________________个;10.含有100个结点的树有_______________________________________条边;四、问答题1.一棵深度为h的满m叉树具有如下性质:第h层上的结点都是叶结点,其余各层上每个结点都有m棵非空子树;若按层次从上到下,每层从左到右的顺序从1开始对全部结点编号,试计算:1第k层结点数1≤k≤h;2整棵树结点数;3编号为i的结点的双亲结点的编号;4编号为i的结点的第j个孩子结点若有的编号;2.证明:一个满k叉树上的叶子结点数n0和非叶子结点数n1之间满足以下关系:n0=k-1n1+13.已知一组元素为50,28,78,65,23,36,13,42,71,请完成以下操作:1画出按元素排列顺序逐点插入所生成的二叉排序树BT;2分别计算在BT中查找各元素所要进行的元素间的比较次数及平均比较次数;3画出在BT中删除23〉后的二叉树;4.有七个带权结点,其权值分别为3,7,8,2,6,10,14,试以它们为叶结点构造一棵哈夫曼树请按照每个结点的左子树根结点的权小于等于右子树根结点的权的次序构造〉,并计算出带权路径长度WPL及该树的结点总数;5.有一电文共使用五种字符a,b,c,d,e,其出现频率依次为4,7,5,2,9;1试画出对应的编码哈夫曼树要求左子树根结点的权小于等于右子树根结点的权;2求出每个字符的晗夫曼编码;3求出传送电文的总长度;4并译出编码系列101的相应电文;五、算法设计已知一棵具有n个结点的完全二叉树被顺序存储在一维数组An中,试编写一个算法输出Ai结点的双亲和所有孩子;参考答案:一、选择题1. B 3. A 4. B 5. B 7、A 8、D 9、B 10、C 11、A 12、C 13、A 14、C 15、D 16、C 17 C。
《数据结构及其应用》笔记含答案 第四章_串、数组和广义表

第4章串、数组和广义表一、填空题1、零个或多个字符组成的有限序列称为串。
二、判断题1、稀疏矩阵压缩存储后,必会失去随机存取功能。
(√)2、数组是线性结构的一种推广,因此与线性表一样,可以对它进行插入,删除等操作。
(╳)3、若采用三元组存储稀疏矩阵,把每个元素的行下标和列下标互换,就完成了对该矩阵的转置运算。
(╳)4、若一个广义表的表头为空表,则此广义表亦为空表。
(╳)5、所谓取广义表的表尾就是返回广义表中最后一个元素。
(╳)三、单项选择题1、串是一种特殊的线性表,其特殊性体现在(B)。
A.可以顺序存储B.数据元素是一个字符C.可以链式存储D.数据元素可以是多个字符若2、串下面关于串的的叙述中,(B)是不正确的?A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储解释:空格常常是串的字符集合中的一个元素,有一个或多个空格组成的串成为空格串,零个字符的串成为空串,其长度为零。
3、串“ababaaababaa”的next数组为(C)。
A.012345678999 B.012121111212 C.011234223456 D.01230123223454、串“ababaabab”的nextval为(A)。
A.010104101B.010102101 C.010100011 D.0101010115、串的长度是指(B)。
A.串中所含不同字母的个数B.串中所含字符的个数C.串中所含不同字符的个数D.串中所含非空格字符的个数解释:串中字符的数目称为串的长度。
6、假设以行序为主序存储二维数组A=array[1..100,1..100],设每个数据元素占2个存储单元,基地址为10,则LOC[5,5]=(B)。
A.808 B.818 C.1010 D.1020解释:以行序为主,则LOC[5,5]=[(5-1)*100+(5-1)]*2+10=818。
数据结构4-7习题答案
队列回顾
第六章队列知识要点:
1、队列类型的定义:(a1,a2,„,an),只在队首进 行删除操作,在队尾进行插入操作,先进先出。 2、队列的存储形式:
链式存储: 顺序存储:循环队列
6.1 循环队列的优点是什么?如何判别它的空和满?
由于队列的顺序存储结构中从队尾入队、从队首出队,可能 会造成存储空间实际未满,但又数据元素无法入队的情况,即 虚溢出现象,而循环队列将整个队列看成一个环,则可以解决 虚溢出问题。 对于循环队列Q,其存储空间大小为MAXQSIZE,则: 队空条件:Q.front==Q.rear 队满条件:(Q.rear+1)%MAXQSIZE==Q.front 6.2 设长度为n的链队列用循环单链表表示,若只设头指针,则 入列操作、出列操作实现的时间开销是多少?若只设尾指针呢?
5.11写一算法识别依次读入的一个以‘#’为结束符的字 符序列是否是形如“序列1@序列2”的字符序列。其中 ,序列1和序列2中都不含有字符‘@’,且序列2是序 列1的逆序列。例如“aab*c^da@ad^c*baa”是满足条 件的字符序列。
int IsReverse() //判断输入的字符串中'@'前和'@'后部 分是否为逆串,是则返回1,否则返回0 {InitStack(s); char e; cin>>e; while(e!='@' and e!=’#’) { push(s,e); cin>>e;} if (e==’#’) return 0; while(e!='#') { cin>>e; if(StackEmpty(s)) return 0; pop(s,c); if(e!=c) return 0; } if(!StackEmpty(s)) return 0; return 1; }//IsReverse
数据结构(C语言版)习题及答案第四章

数据结构(C语言版)习题及答案第四章习题4.1选择题1、空串与空格串是(B)。
A、相同B、不相同C、不能确定2、串是一种特殊的线性表,其特殊性体现在(B)。
A、可以顺序存储B、数据元素是一个字符C、可以链式存储D、数据元素可以是多个字符3、设有两个串p和q,求q在p中首次出现的位置的操作是(B)。
A、连接B、模式匹配C、求子串D、求串长4、设串1=“ABCDEFG”,2=“PQRST”函数trconcat(,t)返回和t串的连接串,trub(,i,j)返回串中从第i个字符开始的、由连续j 个字符组成的子串。
trlength()返回串的长度。
则trconcat(trub(1,2,trlength(2)),trub(1,trlength(2),2))的结果串是(D)。
A、BCDEFB、BCDEFGC、BCPQRSTD、BCDEFEF5、若串=“oftware”,其子串个数是(B)。
A、8B、37C、36D、94.2简答题1、简述空串与空格串、主串与子串、串名与串值每对术语的区别?答:空串是指长度为0的串,即没有任何字符的串。
空格串是指由一个或多个空格组成的串,长度不为0。
子串是指由串中任意个连续字符组成的子序列,包含子串的串称为主串。
串名是串的一个名称,不指组成串的字符序列。
串值是指组成串的若干个字符序列,即双引号中的内容。
2、两个字符串相等的充要条件是什么?答:条件一是两个串的长度必须相等条件二是串中各个对应位置上的字符都相等。
3、串有哪几种存储结构?答:有三种存储结构,分别为:顺序存储、链式存储和索引存储。
4、已知两个串:1=”fgcdbcabcadr”,2=”abc”,试求两个串的长度,判断串2是否是串1的子串,并指出串2在串1中的位置。
答:(1)串1的长度为14,串2的长度为3。
(2)串2是串1的子串,在串2中的位置为9。
5、已知:1=〃I’matudent〃,2=〃tudent〃,3=〃teacher〃,试求下列各操作的结果:trlength(1);答:13trconcat(2,3);答:”tudentteachar”trdelub(1,4,10);答:I’m6、设1=”AB”,2=”ABCD”,3=”EFGHIJK,试画出它们在各种存储结构下的结构图。
数据结构课后习题(第4-5章)

【课后习题】第4章 串 第5章 数组和广义表网络工程2010级( )班 学号: 姓名:题 号 一 二 三 四 总分 得 分一、填空题(每空1分,共30分)1. 串有三种机内表示方法: 、 和 ,其中前两种属于顺序存储结构,第三种属于 。
2. 若n 为主串长度,m 为子串长度,则串的BF (朴素)匹配算法最坏的情况下需要比较字符的总次数为 ,T(n)= 。
3. 是任意串的子串;任意串S 都是S 本身的子串,除S 本身外,S 的其他子串称为S 的 。
4. 设数组a[1…50, 1…60]的基地址为1000,每个元素占2个存储单元,若以行序为主序顺序存储,则元素a[32,58]的存储地址为 。
5. 对于数组,比较适于采用 结构够进行存储。
6. 广义表的深度是指_______。
7. 将一个100100 A 的三对角矩阵,按行优先存入一维数组B[297]中,A 中元素66,66A 在B 数组中的位置k 为 。
8. 注意:a i,j 的k 为 2(i-1)+j-1,(i=1时j=1,2;1<i<=n 时,j=i-1,i,i+1) 。
9. 称为空串; 称为空白串。
10. 求串T 在主串S 中首次出现的位置的操作是 ,其中 称为目标串, 称为模式。
11. 对称矩阵的下三角元素a[i,j],存放在一维数组V 的元素V[k]中(下标都是从0开始), 12. k 与i ,j 的关系是:k= 。
13. 在n 维数组中每个元素都受到 个条件的约束。
14. 同一数组中的各元素的长度 。
15. 三元素组表中的每个结点对应于稀疏矩阵的一个非零元素,它包含有三个数据项,分别表示该元素的 、 和 。
16.稀疏矩阵中有n个非零元素,则其三元组有行。
17.求下列广义表操作的结果:18.(1)GetHead【((a,b),(c,d))】=== ;19.(2)GetHead【GetTail【((a,b),(c,d))】】=== ;20.(3)GetHead【GetTail【GetHead【((a,b),(c,d))】】】=== ;21.(4)GetTail【GetHead【GetTail【((a,b),(c,d))】】】=== ;22.广义表E=(a,(b,E)),则E的长度= ,深度= ;二、判断题(如果正确,在下表对应位置打“√”,否则打“⨯”。
数据结构课后习题答案第四章

第四章串一、单项选择题1.B2. B3.B4.C5. C二、填空题1.空、字符2.由空格字符(ASCII值32)所组成的字符串空格个数3.长度、相等、子、主4.55.011223126.(1)char s[ ] (2) j++ (3) i >= j7.[题目分析]本题算法采用顺序存储结构求串s和串t的最大公共子串。
串s用i指针(1<=i<=s.len)。
t串用j指针(1<=j<=t.len)。
算法思想是对每个i(1<=i<=s.len,即程序中第一个WHILE循环),来求从i开始的连续字符串与从j(1<=j<=t.len,即程序中第二个WHILE循环)开始的连续字符串的最大匹配。
程序中第三个(即最内层)的WHILE循环,是当s中某字符(s[i])与t中某字符(t[j])相等时,求出局部公共子串。
若该子串长度大于已求出的最长公共子串(初始为0),则最长公共子串的长度要修改。
(1) i+k<=s.len && j+k<=t.len && s[i+k]==t[j+k] //所有注释同上(a)(2) con=0 (3) j+=k (4) j++ (5) i++三、应用题1.空格是一个字符,其ASCII码值是32。
空格串是由空格组成的串,其长度等于空格的个数。
空串是不含任何字符的串,即空串的长度是零。
2.(a)A+B “ mule”(b)B+A “mule ”(c)D+C+B “myoldmule”(d)SUBSTR(B,3,2) “le”(e)SUBSTR(C,1,0) “”(f)LENGTH(A) 2(g)LENGTH(D) 2(h)INDEX(B,D) 0(i)INDEX(C,”d”) 3(j)INSERT(D,2,C) “myold”(k)INSERT(B,1,A) “m ule”(l)DELETE(B,2,2) “me”(m)DELETE(B,2,0) “mule”3.朴素的模式匹配(Brute-Force)时间复杂度是O(m*n),KMP算法有一定改进,时间复杂度达到O(m+n)。
数据结构课后习题和解析第四章

第四章习题1. 设s=’I AM A STUDENT’, t=’GOOD’, q=’WORKER’。
给出下列操作的结果:StrLength(s); SubString(sub1,s,1,7); SubString(sub2,s,7,1);StrIndex(s,’A’,4); StrReplace(s,’STUDENT’,q);StrCat(StrCat(sub1,t), StrCat(sub2,q));2. 编写算法,实现串的基本操作StrReplace(S,T,V)。
3. 假设以块链结构表示串,块的大小为1,且附设头结点。
试编写算法,实现串的下列基本操作:StrAsign(S,chars);StrCopy(S,T);StrCompare(S,T);StrLength(S);StrCat(S,T);SubString(Sub,S,pos,len)。
4.叙述以下每对术语的区别:空串和空格串;串变量和串常量;主串和子串;串变量的名字和串变量的值。
5.已知:S=”(xyz)*”,T=”(x+z)*y”。
试利用联接、求子串和置换等操作,将S转换为T.6.S和T是用结点大小为1的单链表存储的两个串,设计一个算法将串S中首次与T匹配的子串逆置。
7.S是用结点大小为4的单链表存储的串,分别编写算法在第k个字符后插入串T,及从第k个字符删除len个字符。
以下算法用定长顺序串:8.编写下列算法:(1)将顺序串r中所有值为ch1的字符换成ch2的字符。
(2)将顺序串r中所有字符按照相反的次序仍存放在r中。
(3)从顺序串r中删除其值等于ch的所有字符。
(4)从顺序串r1中第index 个字符起求出首次与串r2相同的子串的起始位置。
(5)从顺序串r中删除所有与串r1相同的子串。
9.写一个函数将顺序串s1中的第i个字符到第j个字符之间的字符用s2串替换。
10.写算法,实现顺序串的基本操作StrCompare(s,t)。
11.写算法,实现顺序串的基本操作StrReplace(&s,t,v)。
数据结构答案第4章

数据结构答案第4章第4xxxx线性表--- 多维数组和xx表2005-07-14第4章广义线性表一一多维数组和广义表课后习题讲解1. 填空⑴数组通常只有两种运算:()和(),这决定了数组通常采用()结构来实现存储。
【解答】存取,修改,顺序存储【分析】数组是一个具有固定格式和数量的数据集合,在数组上一般不能做插入、删除元素的操作。
除了初始化和销毁之外,在数组中通常只有存取和修改两种操作。
⑵二维数组A中行下标从10到20,列下标从5到10,按行优先存储,每个元素占4个存储单元,A[10][5]的存储地址是1000,则元素A[15][10]的存储地址是()。
【解答】1140【分析】数组A中每行共有6个元素,元素A[15][10]的前面共存储了(1510) X 6椅元素,每个元素占4个存储单元,所以,其存储地址是1000+140=114(!⑶设有一个10阶的对称矩阵A采用压缩存储,A[0][0]为第一个元素,其存储地址为d,每个元素占1个存储单元,则元素A[8][5]的存储地址为()。
【解答】d+41【分析】元素A[8][5]的前面共存储了(1+2+ +8)+5=4价元素。
⑷稀疏矩阵一般压缩存储方法有两种,分别是()和()。
【解答】三元组顺序表,十字链表⑸广义表((a), (((b),c)),(d))勺长度是(),深度是(),表头是(),表尾是【解答】3, 4, (a), ((((b),c)),(d))⑹已知广义表LS=(a (b, c, d), e),用Head和Tail函数取出LS中原子b 的运算是()。
【解答】Head(Head(Tail(LS)))2. 选择题⑴二维数组A的每个元素是由6个字符组成的串,行下标的范围从0~8, 列下标的范围是从0~9,则存放A至少需要()个字节,A的第8列和第5行共占()个字节,若A按行优先方式存储,元素A[8][5]的起始地址与当A按列优先方式存储时的()元素的起始地址一致。
数据结构课后题答案(第4章).
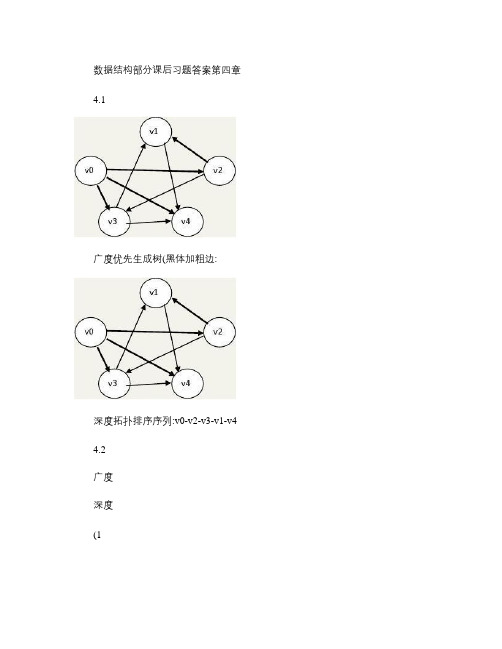
数据结构部分课后习题答案第四章4.1广度优先生成树(黑体加粗边:深度拓扑排序序列:v0-v2-v3-v1-v4 4.2广度深度(1(2加边顺序a-b b-e e-d d-f f-c4.3、如图所示为一个有6个顶点{u1,u2,u3,u4,u5,u6}的带权有向图的邻接矩阵。
根据此邻接矩阵画出相应的带权有向图,利用dijkstra 算法求第一个顶点u1到其余各顶点的最短路径,并给出计算过程。
带权有向图:4.4证明在图中边权为负时Dijkstra算法不能正确运行若允许边上带有负权值,有可能出现当与S(已求得最短路径的顶点集,归入S内的结点的最短路径不再变更内某点(记为a以负边相连的点(记为b确定其最短路径时,它的最短路径长度加上这条负边的权值结果小于a原先确定的最短路径长度,而此时a在Dijkstra算法下是无法更新的。
4.5P.198 图中的权值有负值不会影响prim和kruskal的正确性如图:KRUSKAL求解过程:4.6 Dijkstra算法如何应用到无向图?答:Dijkstra算法通常是运用在带非负权值的有向图中,但是无向图其实就是两点之间两条有向边权值相同的特殊的有向图,这样就能将Dijkstra算法运用到无向图中。
4.7用FLOYD算法求出任意两顶点的最短路径(如图A(6所示。
A(0= A(1= A(2=A(3= A(4=A(5= A(6= V1 到 V2、V3、V4、V5、V6 往返路径长度分别为 5,9,5,9,9,最长为 9,总的往返路程为 37 同理 V2 到 V1、V3、V4、V5、V6 分别为 5,8,4,4,13,最长为 13,总和 34 V3 对应分别为 9,8,12,8,9,最长为 12,总和为 46 V4 对应分别为 5,4,12,4,9,最长为 12,总和为 34 V5 对应分别为9,4,8,4,9,最长为 9,总和为 34 V6 对应分别为 9,13,9,9,9,最长为13,总和为 49 题目要求娱乐中心“距其它各结点的最长往返路程最短” ,结点V1, V5 最长往返路径最短都是 9。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章习题1. 设s=’I AM A STUDENT’, t=’GOOD’, q=’WORKER’。
给出下列操作的结果:StrLength(s); SubString(sub1,s,1,7); SubString(sub2,s,7,1);StrIndex(s,’A’,4); StrReplace(s,’STUDENT’,q);StrCat(StrCat(sub1,t), StrCat(sub2,q));2. 编写算法,实现串的基本操作StrReplace(S,T,V)。
3. 假设以块链结构表示串,块的大小为1,且附设头结点。
试编写算法,实现串的下列基本操作:StrAsign(S,chars);StrCopy(S,T);StrCompare(S,T);StrLength(S);StrCat(S,T);SubString(Sub,S,pos,len)。
4.叙述以下每对术语的区别:空串和空格串;串变量和串常量;主串和子串;串变量的名字和串变量的值。
5.已知:S=”(xyz)*”,T=”(x+z)*y”。
试利用联接、求子串和置换等操作,将S转换为T. 6.S和T是用结点大小为1的单链表存储的两个串,设计一个算法将串S中首次与T匹配的子串逆置。
7.S是用结点大小为4的单链表存储的串,分别编写算法在第k个字符后插入串T,及从第k个字符删除len个字符。
以下算法用定长顺序串:8.编写下列算法:(1)将顺序串r中所有值为ch1的字符换成ch2的字符。
(2)将顺序串r中所有字符按照相反的次序仍存放在r中。
(3)从顺序串r中删除其值等于ch的所有字符。
(4)从顺序串r1中第index 个字符起求出首次与串r2相同的子串的起始位置。
(5)从顺序串r中删除所有与串r1相同的子串。
9.写一个函数将顺序串s1中的第i个字符到第j个字符之间的字符用s2串替换。
10.写算法,实现顺序串的基本操作StrCompare(s,t)。
11.写算法,实现顺序串的基本操作StrReplace(&s,t,v)。
实习题1.已知串S和T,试以以下两种方式编写算法,求得所有包含在S中而不包含在T中的字符构成的新串R,以及新串R中每个字符在串S中第一次出现的位置。
(1)利用CONCAT、LEN、SUB和EQUAL四种基本运算来实现。
(2)以顺序串作为存储结构来实现。
2.编写一个行编辑程序EDLINE,完成以下功能:(1)显示若干行:list [[n1]-[n2]]:显示第n1行到第n2行,n1缺省时,从第一行开始,n2缺省时,到最后一行,(2)删除若干行。
del [[n1]-[n2]]:n1、n2说明同(1)。
(3)编辑第n行。
edit n:显示第n行的内容,另输入一行替换该行。
(4)插入一行。
ins n:在第n行之前插入一行。
(5)字符替换。
replace str1,str2, [[n1]-[n2]]:在n1到n2行之间用str2替换str1。
3.设计一个文学研究辅助程序,统计小说中特定单词出现的频率和位置。
第四章答案4.1 设s=’I AM A STUDENT’,t=’GOOD’,q=’WORKER’。
给出下列操作的结果:【解答】StrLength(s)=14;SubString(sub1,s,1,7) sub1=’I AM A ’;SubString(sub2,s,7,1) sub2=’ ’;StrIndex(s,4,’A’)=6;StrReplace(s,’STUDENT’,q);s=’I AM A WORKER’;StrCat(StrCat(sub1,t),StrCat(sub2,q)) sub1=’I AM A GOOD WORKER’。
4.2编写算法,实现串的基本操作StrReplace(S,T,V)。
【解答】算法如下:int strReplace(SString S,SString T, SString V){/*用串V替换S中的所有子串T */int pos,i;pos=strIndex(S,1,T); /*求S中子串T第一次出现的位置*/if(pos = = 0) return(0);while(pos!=0) /*用串V替换S中的所有子串T */{switch(T.len-V.len){case 0: /*串T的长度等于串V的长度*/for(i=0;i<=V.len;i++) /*用V替换T*/S->ch[pos+i]=V.ch[i];case >0: /*串T的长度大于串V的长度*/ for(i=pos+t.ien;i<S->len;i--) /*将S中子串T后的所有字符S->ch[i-t.len+v.len]=S->ch[i]; 前移T.len-V.len个位置*/for(i=0;i<=V.len;i++) /*用V替换T*/S->ch[pos+i]=V.ch[i];S->len=S->len-T.len+V.len;case <0: /*串T的长度小于串V的长度*/ if(S->len-T.len+V.len)<= MAXLEN /*插入后串长小于MAXLEN*/ { /*将S中子串T后的所有字符后移V.len-T.len个位置*/for(i=S->len-T.len+V.len;i>=pos+T.len;i--)S->ch[i]=S->ch[i-T.len+V.len];for(i=0;i<=V.len;i++) /*用V替换T*/S->ch[pos+i]=V.ch[i];S->len=S->len-T.len+V.len; }else{ /*替换后串长>MAXLEN,但串V可以全部替换*/if(pos+V.len<=MAXLEN){ for(i=MAXLEN-1;i>=pos+T.len; i--)S->ch[i]=s->ch[i-T.len+V.len]for(i=0;i<=V.len;i++) /*用V替换T*/S->ch[pos+i]=V.ch[i];S->len=MAXLEN;}else /*串V的部分字符要舍弃*/{ for(i=0;i<MAXLEN-pos;i++)S->ch[i+pos]=V.ch[i];S->len=MAXLEN;}}/*switch()*/pos=StrIndex(S,pos+V.len,T); /*求S中下一个子串T的位置*/ }/*while()*/return(1);}/*StrReplace()*/附加题:用链式结构实现定位函数。
【解答】typedef struct Node{ char data;struct Node *next;}Node,*Lstring;int strIndex(Lstring S, int pos, Lstring T)/*从串S的pos序号起,串T第一次出现的位置*/{Node *p, *q, *Ppos;int i=0,,j=0;if(T->next= =NULL || S->next = =NULL) return(0);p=S->next;q=T->next;while(p!=NULL && j<pos) /*p指向串S中第pos个字符*/{p=p->next; j++;}if(j!=pos) return(0);while(p!=NULL && q!=NULL){Ppos=p; /*Ppos指向当前匹配的起始字符*/if(p->data = = q->data){p=p->next; q=q->next;}else /*从Ppos指向字符的下一个字符起从新匹配*/{p=Ppos->next;q=T->head->next;i++;}}if(q= =NULL) return(pos+i); /*匹配成功*/else return(0); /*失败*/}第4章串习题1. 设s=’I AM A STUDENT’, t=’GOOD’, q=’WORKER’。
给出下列操作的结果:StrLength(s); SubString(sub1,s,1,7); SubString(sub2,s,7,1);StrIndex(s,’A’,4);StrReplace(s,’STUDENT’,q);StrCat(StrCat(sub1,t), StrCat(sub2,q));[参考答案]StrLength(s)=14; sub1=’I AMA_’; sub2=’_’; StrIndex(s,’A’,4)=6;StrReplace(s,’STUDENT’,q)=’I AM A WORKER’;StrCat(StrCat(sub1,t), StrCat(sub2,q))=’I AM A GOOD WORKER’;2. 编写算法,实现串的基本操作StrReplace(S,T,V)。
3. 假设以块链结构表示串,块的大小为1,且附设头结点。
试编写算法,实现串的下列基本操作:StrAsign(S,chars);StrCopy(S,T);StrCompare(S,T);StrLength(S);StrCat(S,T);SubString(Sub,S,pos,len)。
[说明]:用单链表实现。
4.叙述以下每对术语的区别:空串和空格串;串变量和串常量;主串和子串;串变量的名字和串变量的值。
5.已知:S=”(xyz)*”,T=”(x+z)*y”。
试利用联接、求子串和置换等操作,将S转换为T.6.S和T是用结点大小为1的单链表存储的两个串,设计一个算法将串S中首次与T匹配的子串逆置。
7.S是用结点大小为4的单链表存储的串,分别编写算法在第k个字符后插入串T,及从第k个字符删除len个字符。
以下算法用定长顺序串:8.写下列算法:(1)将顺序串r中所有值为ch1的字符换成ch2的字符。
(2)将顺序串r中所有字符按照相反的次序仍存放在r中。
(3)从顺序串r中删除其值等于ch的所有字符。
(4)从顺序串r1中第index 个字符起求出首次与串r2相同的子串的起始位置。
(5)从顺序串r中删除所有与串r1相同的子串。
9.写一个函数将顺序串s1中的第i个字符到第j个字符之间的字符用s2串替换。
[提示]:(1)用静态顺序串(2)先移位,后复制10.写算法,实现顺序串的基本操作StrCompare(s,t)。
11.写算法,实现顺序串的基本操作StrReplace(&s,t,v)。