Stata软件在医学研究中的应用
stata可用数据案例

stata可用数据案例Stata(统计与数据分析软件)是一种流行的统计软件,广泛应用于社会科学、医学、经济学等领域的数据分析和研究中。
下面列举了十个以Stata可用数据案例为题的例子。
1. 经济增长与人均GDP使用Stata分析不同国家的经济增长率与人均GDP之间的关系。
数据包括各国的GDP增长率和人均GDP数据,利用回归分析来探讨经济增长对人均GDP的影响。
2. 教育水平与收入差距使用Stata分析教育水平与个人收入之间的关系。
数据包括个人的教育程度和收入数据,通过计算相关系数和回归分析来研究教育与收入之间的关系。
3. 社会支出与健康状况使用Stata分析各国社会支出与人均健康状况之间的关系。
数据包括各国的社会支出和健康指标数据,通过可视化和回归分析来探讨社会支出对健康状况的影响。
4. 城市化与环境污染使用Stata分析城市化程度与环境污染之间的关系。
数据包括各城市的人口密度和环境指标数据,通过相关性分析和回归分析来研究城市化对环境污染的影响。
5. 金融市场与经济波动使用Stata分析金融市场指数与经济波动之间的关系。
数据包括金融市场指数和宏观经济指标数据,通过时间序列分析和相关系数计算来研究金融市场对经济波动的影响。
6. 健康保险与医疗费用使用Stata分析健康保险覆盖率与个人医疗费用之间的关系。
数据包括个人的健康保险信息和医疗费用数据,通过回归分析和描述统计来研究健康保险对医疗费用的影响。
7. 教育投资与就业率使用Stata分析教育投资与就业率之间的关系。
数据包括各国的教育投资和就业率数据,通过回归分析和可视化来探讨教育投资对就业率的影响。
8. 基础设施建设与经济增长使用Stata分析基础设施建设投资与经济增长之间的关系。
数据包括各国的基础设施建设投资和GDP增长率数据,通过相关性分析和回归分析来研究基础设施建设对经济增长的影响。
9. 政府开支与财政赤字使用Stata分析政府开支与财政赤字之间的关系。
流行病学中的流行病学调查与统计分析软件

流行病学中的流行病学调查与统计分析软件流行病学调查和统计分析是流行病学领域中非常重要的研究方法和工具。
在过去的几十年里,由于计算机技术的不断发展和进步,流行病学调查和统计分析软件的应用得到了广泛推广和普及。
本文将介绍流行病学中常用的调查和统计分析软件以及其在流行病学研究中的应用。
一、调查软件调查软件在流行病学调查中起着至关重要的作用。
它们可以用于设计问卷、收集数据、管理数据,并对调查结果进行分析。
目前,流行病学调查常用的软件有Epi Info、OpenEpi和REDCap等。
1. Epi InfoEpi Info是由美国疾病控制与预防中心(CDC)开发的免费的流行病学调查软件。
它具有简单易用、功能强大的特点,并提供了广泛的数据收集、管理和分析功能。
Epi Info支持多种调查方法,包括横断面调查、队列研究和病例对照研究等。
此外,Epi Info还提供了绘制流行病曲线和制作交叉表等功能,方便研究人员进行流行病学分析。
2. OpenEpiOpenEpi是一款开源的流行病学统计软件,其目的是为研究人员提供易于使用和广泛共享的流行病学工具。
OpenEpi包括了多种统计方法,如描述性统计、推断性统计和生存分析等,以及常见流行病学研究设计。
此外,OpenEpi还提供了在线计算器和统计图形绘制功能,方便用户进行数据分析和结果展示。
3. REDCapREDCap是一种专门用于临床研究数据管理和收集的软件。
它由美国维尔京亚历山大大学开发,广泛应用于流行病学研究。
REDCap具有简单灵活、安全可靠的特点,并提供了强大的数据导入、导出和编辑功能,支持多语言和多中心研究。
此外,REDCap还支持自定义问卷和字典,以及用户权限管理,满足不同研究需求。
二、统计分析软件统计分析是流行病学研究中必不可少的环节。
通过对数据进行统计分析,可以揭示流行病的特点和规律,为疾病预防和控制提供科学依据。
目前,常用的流行病学统计分析软件有SPSS、R和Stata等。
统计学考研掌握常见统计软件的实际应用

统计学考研掌握常见统计软件的实际应用统计学考研是统计学专业研究生的入学考试,是考生进修和深造的重要途径。
在统计学考研中,掌握常见的统计软件已经成为一个不可或缺的要求。
统计软件在现代统计学研究和应用中发挥着至关重要的作用。
本文将介绍统计学考研中常用的统计软件以及它们的实际应用。
## 1. SPSSSPSS(Statistical Package for the Social Sciences,社会科学统计软件)是一款常见且功能强大的统计软件。
它广泛应用于社会科学研究和数据分析领域。
SPSS提供了丰富的统计分析功能,包括描述统计、推断统计、探索性数据分析等。
不论是基本的 t 检验、方差分析,还是复杂的回归分析、因子分析等,SPSS都能帮助学者轻松完成。
## 2. SASSAS(Statistical Analysis System,统计分析系统)是一款广泛应用于统计学、数据挖掘和大数据分析的软件。
SAS提供了强大的数据处理和分析功能,具备高效、灵活和稳定的特点。
对于大规模数据分析、复杂模型拟合和预测,SAS都能胜任。
在统计学考研中,掌握SAS将为你的研究提供有力的支持。
## 3. RR是一种功能强大的开源统计软件和编程语言。
它广泛用于统计学习、数据挖掘和计量经济学等领域。
R拥有丰富的统计分析函数和包,可以通过编写代码实现各种复杂的统计分析和图形展示。
它的开源特性使得R拥有庞大的用户社区,用户可以自由分享和获取各种统计学资源。
## 4. StataStata是一款广泛应用于社会科学和生物医学研究的统计软件。
它提供了丰富的统计分析和数据管理功能,如线性回归、生存分析、面板数据分析等。
Stata的语法简洁易学,而且具备强大的图形展示功能,可以满足研究者对于数据分析和结果呈现的需求。
## 5. ExcelExcel是一款常见而易于使用的电子表格软件,也可作为一种基础的统计工具。
虽然功能和上述专业统计软件相比较有限,但Excel擅长于数据处理和简单的统计分析。
STATA使用教程

STATA使用教程第一章:介绍 StataStata 是一款统计分析软件,广泛应用于经济学、社会科学、健康科学和医学研究等领域。
本章将介绍 Stata 软件的基本特点、适用范围和主要功能。
1.1 Stata 的特点Stata 是一款功能强大、易于使用的统计软件。
不同于其他统计软件,Stata 具有灵活性高、数据处理效率好的优点。
它支持多种数据文件格式,可以处理大规模的数据集,并且具有丰富的数据处理、统计分析和图形展示功能。
1.2 Stata 的适用范围Stata 软件适用于各类研究领域,涵盖了经济学、社会科学、医学、健康科学等多个领域。
它广泛应用于定量分析、回归分析、面板数据分析、时间序列分析等领域,可用于统计推断、数据可视化和模型建立等任务。
1.3 Stata 的主要功能Stata 软件提供了丰富的功能模块,包括数据导入导出、数据清洗、数据管理、描述性统计、推断统计、回归分析、面板数据分析、时间序列分析、图形展示等。
这些功能模块为用户提供了全面且灵活的数据分析工具。
第二章:Stata 数据处理数据处理是统计分析的前置工作,本章将介绍 Stata 软件的数据导入导出、数据清洗和数据管理等功能。
2.1 数据导入导出Stata 支持导入多种文件格式的数据,如文本文件、Excel 文件和 SAS 数据集等。
用户可以使用内置命令或者图形界面进行导入操作,导入后的数据可以存储为 Stata 数据文件(.dta 格式),方便后续的数据处理和分析。
2.2 数据清洗数据清洗是数据处理的重要环节,Stata 提供了多种数据清洗命令,如缺失值处理、异常值处理和数据类型转换等。
用户可以根据实际情况选择合适的数据清洗操作,确保数据的准确性和完整性。
2.3 数据管理数据管理是有效进行数据处理的关键,Stata 提供了许多数据管理命令,如数据排序、数据合并、数据分割和数据标记等。
这些命令可以帮助用户高效地对数据进行管理和组织,提高数据处理效率。
基于STATA的数据分析

基于STATA的数据分析数据分析是一项非常重要的技能,在现代社会大量产生的数据下,数据分析为我们提供了丰富的信息和洞察。
同时,“大数据时代”也为数据分析带来了更加广泛、深入、高效的工具和方法。
其中,STATA作为一款专业的统计软件,被广泛运用于各个领域中。
接下来,让我们一起探讨基于STATA的数据分析。
一、STATA简介STATA是一款专业的统计软件,广泛应用于社会科学、医学、商业等领域。
它具有强大的数据处理和分析能力,可以进行统计分析、回归分析、数据可视化、时间序列分析等多种操作。
STATA的优点主要有三点:数据处理、结果输出、文献写作。
二、STATA的操作流程进行数据分析的初步任务是读入数据,STATA提供了多种数据读入的方式,用户可以根据自己的习惯进行选择。
在数据读入之后,还需要针对数据进行初步的数据清理工作。
这一步我们可以使用STATA中的数据浏览、数据编辑、删除变量、删除观测等操作进行完成。
接着进行数据探索,包括描述性统计、绘图等操作。
STATA提供的方便的数据分析功能,我们可以轻松地进行不同类型的数据分析,如卡方检验、t检验、方差分析、多元回归等分析。
在数据分析的最后,我们还需要探索和验证结果的合理性。
三、STATA的应用场景STATA适用的领域较广泛,特别是在社会科学、医学、商业等领域中应用较广。
其中,社会科学中常需要进行统计分析、趋势分析、时间序列分析、多元线性回归分析等操作。
医学中常用于实验设计、生存分析、分类模型选择等方面。
商业中,我们可以利用STATA进行市场测量、营销模型、预测分析等数据分析。
综上所述,基于STATA的数据分析是一项强大的技术,它可以帮助我们在不同领域中,发现有价值的信息和洞察,更好地促进决策和战略的制定。
当然,在进行数据分析的时候,我们还需要关注数据质量和数据分析方法的准确性等方面。
通过不断的学习和实践,我们可以更好地掌握基于STATA的数据分析技术。
医学统计学(预防医学)

医学统计学具有以下特点
实践性
医学统计学的方法和理论是建立在大量实践经验的基础上的,它提供了解决实际问题的具体方法和技术。
多元性
医学统计学涉及的领域广泛,包括流行病学、临床试验、病因学、预防医学等多个方面。
可靠性
医学统计学的分析结果具有可靠性,因为其分析方法和技术是建立在科学原理和严格数学理论基础上的。
临床试验设计
在临床试验中,医学统计学提供了数据收集、整理、分析和解释的方法和技术,以确保试验结果的准确性和可靠性。
医学统计学的应用领域
医学统计学基本概念
02
VS
在医学统计学中,变量是用于描述和度量个体或群体特征的量度。变量可以是离散的(如性别、血型)或连续的(如体温、血压)。
数据类型
医学统计学中涉及的数据类型包括计数数据(如出生人数、死亡人数)、计量数据(如身高、体重)、等级数据(如疾病严重程度评分)和时间序列数据(如发病率、死亡率随时间的变化)。
医学统计学的定义与特点
03
04
05
起源
医学统计学起源于17世纪,当时欧洲的一些学者开始尝试应用数学方法研究人类生理和病理现象。
医学统计学的历史与发展
发展
自19世纪中叶以来,医学统计学得到了迅速发展,应用范围不断扩大,逐渐成为医学领域中不可或缺的一部分。
现状
目前,医学统计学已经成为一个独立的学科领域,具有较为完善的理论和方法体系。同时,随着计算机技术的不断发展,医学统计学的应用更加广泛和深入。
功能特点
SAS具有强大的数据处理和统计分析能力,同时支持编程方式进行数据处理和分析,可扩展性较强。
应用实例
在医学研究中,SAS可用于复杂的数据处理和高级统计分析,如生存分析、混合效应模型等。
stata pearson相关系数

stata pearson相关系数Stata Pearson相关系数引言Pearson相关系数是一种常用的统计方法,用于衡量两个变量之间的线性关系强度和方向。
在Stata中,我们可以使用correl命令来计算Pearson相关系数。
本文将介绍Pearson相关系数的概念、计算方法以及在Stata中的应用。
概念Pearson相关系数是一个介于-1和1之间的值,可以衡量两个变量之间的线性关系强度和方向。
当相关系数为正时,表示两个变量呈正相关;当相关系数为负时,表示两个变量呈负相关;当相关系数为0时,表示两个变量之间没有线性关系。
计算方法在Stata中,我们可以使用correl命令来计算Pearson相关系数。
具体操作如下:1. 打开Stata软件,并在命令窗口输入correl。
2. 在弹出的对话框中,选择需要计算相关系数的变量,并点击确定。
3. Stata会自动计算并显示Pearson相关系数的结果。
应用Pearson相关系数在实际研究中有着广泛的应用。
以下是一些常见的应用场景:1. 经济学研究:在经济学领域,Pearson相关系数可以用来衡量两个经济变量之间的关系,如GDP与失业率之间的相关性。
2. 社会科学研究:在社会科学领域,Pearson相关系数可以用来研究不同变量之间的关系,如教育水平与收入之间的相关性。
3. 医学研究:在医学研究中,Pearson相关系数可以用来研究两个变量之间的关系,如体重指数与心脏病发病率之间的相关性。
4. 市场研究:在市场研究中,Pearson相关系数可以用来研究市场变量之间的关系,如产品价格与销量之间的相关性。
总结Pearson相关系数是一种衡量两个变量之间线性关系强度和方向的统计方法。
在Stata中,我们可以使用correl命令来计算Pearson 相关系数。
该方法在经济学、社会科学、医学研究以及市场研究中都有广泛的应用。
通过计算Pearson相关系数,我们可以更好地理解变量之间的关系,为实际问题的解决提供有力的统计依据。
现代医学统计方法与Stata应用(第一版)

recode(x,x1,x2,…,xn) =
……
xn-1
如果xn-2<x<=xn-1
xn
如果x>xn-1
缺失值 如果x为缺失值。
10.自动归组函数autocode(x,ng,xmin,xmax) 自动将区间(xmin,xmax)分成ng个等长的小
区间,其结果是包含x值那个小区间的上界值。其作用与归组函数相同。
而index("this","it")的结果是0
8. trim(s)
/*去除字符串前面和后面的空格
9. ltrim(s)
/*去除字符串前面的空格
10. rtrim(s)
/*去除字符串后面的空格
四、 特殊函数
1. 符号函数sign(x) x>0时取1, x<0时取-1, x=0时取0。 2. 取 整 函 数 int(x) 去 掉 x的 小 数 部 分, 得 到 整 数 。 int(x+0.5) 是 对x 四 舍 五 入 取 整 , int(x+sign(x)/2)产生与x最近的一个整数 。 3. 求和函数sum(x) 很常用,获得包括当前记录及以前的所有记录的x 的和。缺失值 (missing value)当0处理。 4. 最大值函数max(x1,x2,...,Xn) 忽略缺失值。
现代医学统计方法与Stata应用 • 1
第一章 Stata 概貌
§1.1 Stata的功能、特点和背景
Stata是 一 个 用 于 分 析 和 管 理 数 据 的 功 能 强 大 又 小 巧 玲 珑 的 实 用 统 计 分 析 软 件, 由美国计 算机资源中心(Computer Resource Center)研制。从1985至1998的十四年时间里,已连续推出 1.1,1.2,1.3,1.4,1.5,……及2.0,2.1,3.0,3.1,4.0,5. 0,6.0等多个版本,通过不断更 新和扩充,内容日趋完善。 它同时具有数据管理软件、统计分析软件、 绘图软件、 矩阵计算软 件和程序语言的特点 ,又在许多方面 别具一格。Stata融汇了上述程序的优点,克服了各自的 缺点,使其功能更加强大, 操作更加灵活、简单, 易学易用, 越来越受到人们的重视和欢迎。
05Stata的绘图功能-《现代医学统计方法与STATA应用》
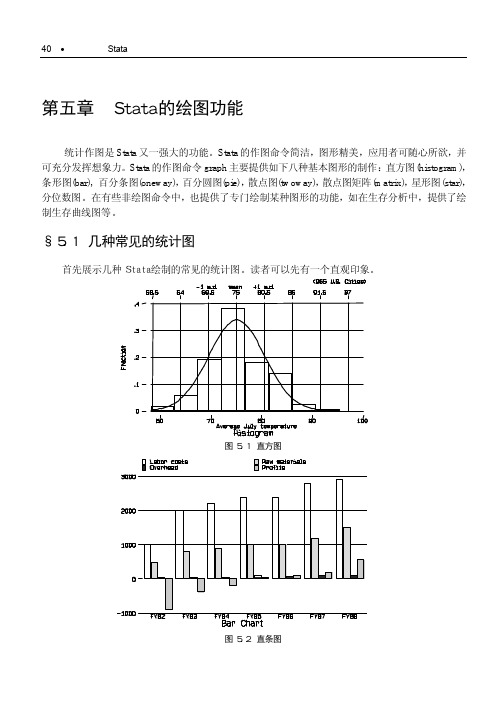
表 5.1 某地二年三种疾病的死亡率(1/10 万)
44 • 第五章 Stata 的绘图功能
图 5.9 例 4.1 资料的直方图
适当选用选择项可以使图形更精细。如:
. gra x, bin(9) freq xlab(108,111,114,117,120,123,126,129,132,135) ylab(0,5,10, 15,20,25,30,35) norm gap(4) b2("height (CM)")
为使图形更具有可读性,还可对变量及其取值给予必要的说明:
. lab var d "Reasons of die" . lab var p52 "Rate of die in 1952" . lab var p72 "Rate of die in 1972" . lab define d 1 "tuberculosis" 2 "heart disease" 3 "tumour" . des Contains data from ex5-1.dta Obs: 3 (max= 4719) Vars: 3 (max= 99) Width: 12 (max= 200) 1. d float %9.0g Reasons of die 2. p52 float %9.0g Rate of die in 1952 3. p72 float %9.0g Rate of die in 1972 Sorted by: . save d:\mydata\ex5-1,replace file ex5-1.dta saved
stata实验报告

stata实验报告Stata实验报告引言:Stata是一种统计分析软件,广泛应用于社会科学、经济学、医学研究等领域。
本实验报告旨在介绍使用Stata进行数据分析的一般步骤,并通过一个实际案例来展示其应用。
一、数据收集与准备在进行Stata数据分析之前,首先需要收集和准备好所需的数据。
数据的来源可以是实地调查、公共数据库或者实验室实验等。
在收集数据时,要确保数据的准确性和完整性,并进行必要的数据清洗和变量定义。
二、数据描述与可视化在开始数据分析之前,我们需要对数据进行描述和可视化。
通过使用Stata提供的统计函数和图表功能,我们可以对数据进行基本统计分析和可视化展示。
例如,我们可以计算数据的平均值、标准差、频数等,并绘制直方图、散点图等图表来展示数据的分布和关系。
三、假设检验与回归分析在确定数据的基本特征后,我们可以进行假设检验和回归分析来探索数据之间的关系。
假设检验可以帮助我们判断某个变量是否对另一个变量产生显著影响,而回归分析可以帮助我们建立模型并预测变量之间的关系。
在Stata中,可以使用t检验、方差分析、卡方检验等方法进行假设检验。
同时,Stata还提供了多种回归分析方法,包括线性回归、逻辑回归、多项式回归等。
通过这些方法,我们可以得到变量之间的显著性水平、回归系数和拟合优度等信息。
四、因果推断与实证研究除了描述和预测数据之外,Stata还可以用于因果推断和实证研究。
通过使用实验、自然实验或者倾向得分匹配等方法,我们可以评估某个政策或干预措施对特定变量的影响。
在Stata中,可以使用处理效应模型、差分差分模型等方法进行因果推断。
这些方法可以帮助我们控制其他可能的干扰因素,并得到准确的因果效应估计。
五、结果解释与报告撰写在完成数据分析后,我们需要对结果进行解释和报告撰写。
在解释结果时,应注意结果的可靠性和有效性,并结合理论和实证研究来进行解释。
在撰写报告时,要注意结构清晰、逻辑严谨,并使用恰当的图表和表格来展示结果。
Stata软件在诊断性研究的meta分析中的命令

Stata软件在诊断性研究的meta分析中的命令在诊断性研究的meta分析中可以计算合并阳性似然比、合并阴性似然比、诊断OR值、ROC值、SROC曲线、HSROC-bivariate meta-analysis等。
Stata进行诊断研究meta分析时的起始命令:*Variable codes: tp=true positives; fp=false positives; tn=true negatives;fn=false negatives*add .5 to all zero cellsgen zero=0replace zero=1 if tp==0|fp==0|fn==0|tn==0replace tp=tp+.5 if zero==1replace fp=fp+.5 if zero==1replace fn=fn+.5 if zero==1replace tn=tn+.5 if zero==1gen tpr= tp/(tp+fn)gen fpr=fp/(fp+tn)gen logittpr=ln(tp/fn)gen logitfpr=ln(fp/tn)gr7 tpr fpr, s(O) noaxis ysize(6) xsize(6) xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1) ylab(0(.1)1) t1(1-Specificity) l1(Sensitivity) b2(1-Specificity) b1(ROC Plot of Sensitivity vs Specificity)gr7 logittpr logitfprspearman logittpr logitfpr1.1 合并阳性似然比命令:metan tp fn fp tn, rr random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary LR+, Random Effects)2.2 合并阴性似然比命令:metan fn tp tn fp, rr random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary LR-, Random Effects)2.3 合并诊断OR值命令:metan tp fn fp tn, or random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary Diagnostic Odds Ratio, Random Effects)2.4 ROC值命令:gr7 tpr fpr, s(O) noaxis ysize(6) xsize(6) xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1) ylab(0(.1)1) t1(1-Specificity) l1(Sensitivity) b2(1-Specificity) b1(ROC Plot of Sensitivity vs Specificity)2.5 SROC曲线命令:gen sum= logittpr+ logitfprgen diff= logittpr- logitfprregress diff sumpredict yhatgr7 diff yhat sum, ylab(3,4,5,6,7,8) xlab(-4,-3,-2,-1,0,1,2) c(.l) s(oi)gen tse=1/(1+(1/(exp(_cons/1-_b)*(fpr/spec)^1+_b/1-_b)))(constant and b are derived from the above regression model)*plot SROC curve (generic)gr7 se tse fpr, ysize(6) xsize(6) noaxis xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1)ylab(0(.1)1) s(Oi) c(.s) l1(Sensitivity) b2(1-Specificity) ti(Summary ROC Curve) key1(" ")key2(" ")2.6 HSROC-bivariate meta-analysis命令:metandi tp fp fn tn, plot (基于SROC命令)2.7 发表偏倚命令:gen or=(tp*tn)/(fp*fn)gen lnor=ln(or)gen selnor=(1/tp)+(1/fp)+(1/fn)+(1/tn)*Begg and Egger test for publication bias with Begg's funnel plot: metabias lnor selnor, graph(begg)*Begg and Egger tests for subgroups (eg. Covariate=1)metabias lnor selnor if covariate==1, graph(begg)。
应用Stata软件的Meta分析完成医学科研定量评价

947 中华中医药学刊应用Stata 软件的Meta 分析完成医学科研定量评价王静,莫传伟,陈群,徐志伟,范晔,柴华,马俊昌(广州中医药大学,广东广州510405) 摘 要:目的:用Stata 统计软件进行Meta 分析,高效完成医学文献系统评价。
方法:采用Stata 中的Meta 分析命令进行医学科研资料实例分析并辅以图例说明。
结果:用metan 命令完成效应量的合并与分析;用Meta 命令对效应量及对数效应量进行合并分析;用metacu m 命令对有时间顺序的资料进行累积M eta 分析,反映研究结果的动态变化趋势;用metareg 命令进行回归模型定量合并,既可控制混杂因素,也可作为探讨数据异质性来源的方法;metainf 、metabias 、metafunnel 、metatri m 等命令,可对发表偏倚识别纠正。
结论:Stata 软件功能强大,好学易用,结果准确、图形精美。
关键词:Stata;Meta 分析;发表偏倚中图分类号:R195.1 文献标识码:A 文章编号:1673-7717(2008)05-0947-03App lica ti o n o fM e ta -a na l ys is i n S ta ta o n M ed ica l R e sea rche s Q uan tita tive A s se s sm e n tWANG J ing,MO Chuang 2wei,CHE N Qun,XU Zhi 2wei,F AN Ye,CHA I Hua,MA Jun 2chang(Guangzhou University of Chinese Medicine,Guangzhou 510405,Guangdong,China )Ab s tra c t:O bjective:To p r ovide an overvie w of M eta -analytical methods in Stata f or medical literature syste matic revie ws .M ethods:Meta -analytical commands and a range of p l ots in Stata,ca me t o be intr oduced by analyzing medical scientific research datasets .R esu lts:Commands based on metan required the user t o supp ly the treat m ent effect esti m ate for each study;Commands based on meta required the user t o supp ly the treat m ent effect esti m ate and its standard err or f or each study;Commands based on metacu m perfor med cu mulative meta -analysis in which the cu mulative evidence at the ti m e each study was published is calculated;Commands based on metareg was used,by the method of regress models,t o contr ol m ixed fact ors and als o t o app r oach the evidence for heter ogeneity bet w een studies .Commands based on metainf,metabias,metafunnel,metatri m were used t o identify and t o adjust publicati on bias in funnel p l ots .Conclusion :Stata is a powerful,versatile,easy t o learn,si m p le t o dra w excellent p l ots,general statistical package .Key wo rd s:Stata;M eta analysis;publicati on bias .收稿日期:2008-01-09基金项目:国家重点基础研究发展计划(973计划)资助项目(2005CB523502);国家自然科学基金资助项目(30472122)作者简介:王静(1982-),女,河南开封人,硕士研究生,研究方向:预防医学与诊断技术在中医诊断学习的应用。
stata应用实验报告

stata应用实验报告Title: Stata应用实验报告摘要:本实验报告使用Stata统计软件进行数据分析和实验设计,通过对实际数据的处理和分析,展示了Stata在统计学和数据分析领域的强大功能和应用价值。
本文将介绍实验设计和数据收集的过程,并使用Stata进行数据清洗、描述性统计、回归分析等操作,最终得出实验结果和结论。
1. 导言Stata是一款专业的统计分析软件,广泛应用于学术研究、市场调研、医学研究等领域。
本实验报告将使用Stata软件进行数据分析和实验设计,展示其在实际应用中的优势和功能。
2. 实验设计和数据收集本实验选取了某公司销售数据作为研究对象,通过问卷调查和实地调研收集了相关数据。
数据包括销售额、产品种类、销售渠道、客户满意度等多个变量,旨在分析销售额与其他因素之间的关系。
3. 数据处理和分析首先,我们使用Stata进行数据清洗和整理,包括缺失值处理、异常值检测等操作。
然后,进行描述性统计分析,包括平均值、标准差、频数分布等。
接着,进行相关性分析,探讨销售额与其他变量之间的相关性。
最后,进行多元回归分析,建立销售额与其他因素的回归模型,并进行显著性检验和模型诊断。
4. 实验结果和结论经过数据分析和回归分析,我们得出了以下结论:销售额受产品种类、销售渠道、客户满意度等因素的影响较大;其中,产品种类对销售额的影响最为显著。
同时,我们还发现了一些新的规律和趋势,为公司的销售策略和营销决策提供了参考和建议。
5. 结语本实验报告通过Stata软件对实际数据进行了深入分析和实验设计,展示了Stata在统计学和数据分析领域的强大功能和应用价值。
希望本文能够为读者提供一些关于Stata应用的启发和帮助,激发更多人对数据分析和统计学的兴趣。
Stata在Meta分析中的应用

Stata在Meta分析中的应用随着现代医学研究的发展,Meta分析作为一种系统性综合研究方法,被广泛应用于医学领域中不同疾病的研究中。
而Stata作为一种统计软件,提供了丰富的工具和功能,可以有效地辅助进行Meta分析的数据处理和结果分析。
本文将探讨,并介绍其主要功能和操作流程。
首先,Stata可以帮助研究者进行Meta分析的数据管理和清洗。
在Meta分析中,需要收集和整理来自不同研究的原始数据,包括样本量、效应量和区间估计等信息。
Stata提供了丰富的数据管理功能,可以帮助研究者快速导入和整理数据。
例如,研究者可以使用Stata中的import命令将原始数据导入到软件中,然后使用merge命令将多个数据文件进行合并,以便进行后续的数据分析。
其次,Stata可以实现Meta分析中的效应量计算和合并。
在Meta分析中,研究者需要计算不同研究间的效应量,并进行合并,以获得总体效应量和其置信区间。
Stata提供了多种计算效应量的方法,包括计算风险比、风险差和标准化均值差等。
例如,研究者可以使用Stata中的metan命令来计算不同研究的效应量,并使用forestplot命令生成效应量的森林图。
通过这些功能,研究者可以直观地了解不同研究效应量之间的差异,并系统地进行合并分析。
此外,Stata还可以进行Meta回归和敏感性分析。
在Meta分析中,研究者经常面临到不同研究之间的异质性和潜在的影响因素。
Stata提供了meta命令,可以进行Meta回归,通过考虑不同研究间的异质性因素来解释研究间的差异。
同时,Stata还可以进行敏感性分析,通过排除某些研究或重新计算效应量来评估Meta分析结果的稳定性和一致性。
除了上述功能之外,Stata还提供了丰富的数据可视化和报告功能,可以帮助研究者直观地展示Meta分析的结果。
研究者可以使用Stata中的graph命令绘制不同研究间的效应量分布图和漏斗图,以及random命令生成不同研究效应量的散点图。
stata卡方检验的命令

stata卡方检验的命令1. 什么是卡方检验卡方检验是一种用于比较观察值与期望值是否存在显著差异的统计方法。
它适用于分析两个或多个分类变量之间的关联性或独立性。
卡方检验的原理是通过计算观察值与期望值之间的差异来判断是否存在显著性差异。
2. 卡方检验的应用场景卡方检验广泛应用于各个领域的研究中,例如医学、社会科学、市场调研等。
下面是一些卡方检验的应用场景:2.1. 疾病与风险因素的关联性分析卡方检验可以用来分析某种疾病与特定风险因素之间的关联性。
例如,研究人员可以使用卡方检验来分析吸烟与肺癌之间的关联性。
2.2. 市场调研中的品牌偏好分析在市场调研中,卡方检验可以用来分析不同人群对于不同品牌的偏好程度是否存在显著差异。
通过卡方检验,可以判断不同人群在品牌偏好上是否存在显著性差异。
2.3. 教育领域的学习成绩分析在教育领域的研究中,卡方检验可以用来分析不同学习方法对学习成绩的影响是否存在显著差异。
通过卡方检验,可以判断不同学习方法在学习成绩上是否存在显著性差异。
3. stata中的卡方检验命令3.1. 命令格式在stata中,进行卡方检验的命令是tabulate。
其基本格式如下:tabulate var1 var2 [if] [in] , chi2其中,var1和var2是要进行卡方检验的两个变量,if和in是可选项,用于指定进行卡方检验的子样本。
3.2. 实例演示下面通过一个实例来演示如何使用stata进行卡方检验。
假设我们有一个数据集data.dta,其中包含了两个变量gender和smoking,分别表示性别和吸烟情况。
我们想要分析性别和吸烟情况之间是否存在关联性。
首先,我们需要加载数据集:use data.dta然后,我们使用tabulate命令进行卡方检验:tabulate gender smoking, chi2运行以上命令后,stata会输出卡方检验的结果,包括卡方统计量、自由度、p值等信息。
Stata软件在Meta分析中异质性检验的应用

investigating heterogeneity in meta—analysis
点击蓝色字体sbe20.1进入:
·728·
主堡煎堑痘堂盘查!!!!生!旦箜!!鲞箜!塑垦!垫』垦£i!!垫i!!!』!!!!!!!!∑!!:!!!塑!:!
package sbe20—1 from http://www.stata.com/stb/stb56
3.H统计量:见以下公式。
[·nH(=H√)]高)厂j{s下HE的[f-n9(5H%)]C=I丢:×ex÷p(;1n;Hi±;z;。gi.ado和galbr.ado软件包。 表1 西酞普兰与阿米替林治疗老年抑郁症随机
对照试验恶心的不良反应情况
式中k表示纳入Meta分析的研究数,统计量H值 为1表示各研究间无异质性。一般情况下,若H> 1.5提示研究间存在异质性,H<1.2则提示可认为 各个研究是同质;若H值在1.2~1.5之间,当H值 的95%CJ包含1,在0.05的检验水准下无法确定是 否存在异质性,若没包含1则可认为存在异质性‘3。。
STB-56 sbe20 1‘‘’‘。‘‘·······。’’’’’。‘‘·····’’’’’’’’’。。+··Update of galbr (help galbr if installed)···…………·····…………。A.Tobias
7/100 P.14;STB Reprints V01.10,P.72
Key words:galbr Search:(1)Official help files,FAQs,Examples,SJS,and STBs
(2)web resources from Stata and from other users
Search of official help files,FAQs,Examples,SJS,and STBs
统计软件在医学统计学中的应用

统计软件在医学统计学中的应用
统计软件在医学统计学中的应用非常广泛。
以下是一些常见的应用领域:
1. 数据收集和管理:统计软件可以用于设计和管理医学研究中的数据收集工具,如问卷调查和电子数据捕获系统。
它们可以帮助研究人员收集和存储大量的医学数据,并确保数据的准确性和完整性。
2. 数据分析:统计软件可以用于对医学数据进行各种统计分析。
例如,它们可以用于描述性统计分析,如计算均值、中位数、标准差等。
它们还可以用于推断统计分析,如假设检验、置信区间估计和回归分析。
这些分析可以帮助研究人员理解医学数据中的模式和关联,并从中得出结论。
3. 数据可视化:统计软件可以用于创建各种图表和图形,以帮助研究人员更好地理解和传达医学数据。
例如,它们可以用于创建直方图、散点图、箱线图等,以展示数据的分布和关系。
这些可视化工具可以帮助研究人员发现数据中的趋势和异常,并提供对数据的直观理解。
4. 生存分析:统计软件可以用于进行生存分析,即对医学数据中的生存时间和事件进行分析。
生存分析可以用于评估治疗效果、预测患者生存时间等。
统计软件可以提供各种生存分析方法,如Kaplan-Meier曲线、Cox比例风险模型等。
5. 质量控制:统计软件可以用于医疗机构和实验室的质量控制。
它们可以帮助
监测和分析医学数据的质量,识别潜在的问题和异常,并采取相应的措施进行改进。
总之,统计软件在医学统计学中的应用可以帮助研究人员更好地收集、管理、分析和解释医学数据,从而为医学研究和临床实践提供有力的支持。
结构方程模型及stata 应用

结构方程模型及stata 应用结构方程模型及Stata应用1. 什么是结构方程模型(Structural Equation Model, SEM)•SEM是一种统计分析方法,用于检验和建立变量之间的因果关系模型。
•它可以将观测到的指标与潜在变量之间的关系捕捉到一个更全面的模型中。
2. SEM的应用领域社会科学研究•在社会科学中,SEM被广泛用于研究各种复杂的关系模型,如影响教育成就的因素、心理健康模型等。
经济学研究•SEM在经济学中的应用非常广泛,可以用于研究市场需求、投资决策、经济增长等问题。
医学研究•在医学研究中,SEM可以用于探索病因学、治疗效果评估等问题。
3. Stata软件在SEM中的应用数据准备和模型设定•使用Stata软件可以方便地对数据进行准备和整理,包括数据清洗、变量命名等操作。
•在Stata中,可以使用语法设置SEM模型,包括指定潜变量、指定观测变量和建立路径模型。
模型拟合和参数估计•Stata提供了多种方法来进行模型的拟合和参数估计,如最小二乘法、最大似然估计等。
•拟合过程中可以通过检查模型拟合指数来评估模型的拟合程度,如拟合优度指数(Comparative Fit Index, CFI)、均方根误差逼近指数(Root Mean Square Error of Approximation, RMSEA)等。
结果解释和图形展示•Stata可以生成模型结果报告,包括各路径的系数、标准误、置信区间等信息。
•可以使用Stata绘制结构方程图和路径图,直观展示模型的结构和路径关系。
4. 总结•结构方程模型及其在Stata中的应用为我们研究复杂的因果关系提供了一种有效的方法。
•Stata软件提供了强大的工具来支持SEM的建模和分析,使得我们能够更加深入地理解数据背后的模式和关系。
•无论是社会科学、经济学还是医学研究,SEM和Stata的结合都能为我们的研究提供有力的支持。
5. SEM在教育研究中的应用•SEM在教育研究中被广泛应用于探索学生学业成就的影响因素。
Stata软件在Meta-分析发表性偏倚识别中的探讨

Stata软件在Meta-分析发表性偏倚识别中的探讨Stata软件在Meta-分析发表性偏倚识别中的探讨随着医学研究的不断发展,Meta-分析成为了获取高质量证据的一种重要方法。
然而,由于人们更倾向于发表具有显著结果的研究,导致论文中存在一种称为发表性偏倚(publication bias)的问题。
发表性偏倚通过排除未发表研究或选择只发表正面结果的研究,从而影响了Meta-分析的结果和结论。
因此,如何识别和纠正发表性偏倚,提高Meta-分析的准确性和可靠性成为了研究者们面临的一个重要挑战。
Stata软件作为一种统计分析软件,提供了多种可用于应对发表性偏倚的方法和工具。
其中,Begg和Mazumdar的秩和相关系数法(rank correlation method)是一种常用的方法。
该方法通过评估研究的样本容量与研究结果的效应大小之间的相关性,从而检测到发表性偏倚的存在。
具体而言,该方法通过计算每个研究的效应估计与其标准误的相关系数来判断是否存在发表性偏倚。
在Stata软件中,可以使用metabias命令来实现Begg和Mazumdar的秩和相关系数法。
使用该命令的关键是提供每个研究的效应估计和标准误。
在Stata中,可以通过调用Meta-分析后的结果或手动输入研究的效应估计和标准误来完成相关计算。
metabias命令会返回一个常规的相关系数,如果该相关系数的p值小于0.05,则可以认为存在发表性偏倚。
此外,metabias命令还会绘制一个漏斗图(funnel plot),用于可视化各个研究的效应大小和相对的标准误,以帮助进一步评估是否存在发表性偏倚。
除了Begg和Mazumdar的方法外,在Stata中还提供了其他方法用于识别和纠正发表性偏倚。
例如,Egger的线性回归法(Egger's regression method)通过在回归模型中引入效应估计的逆标准误来评估发表性偏倚的存在。
而Trim andFill方法则通过估计缺失的研究来校正发表性偏倚。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
作者单位 " ! " # # ! $ 南京医科大学公共卫生学院 流 行 与 卫 生 统 计 学系
万方数据
,6 4 M,
中华预防医学杂志 ! ! # # 6 年 $ 月第 6 ? 卷第 8 期 !D 1 ) *H; 9 = I/ = + % = & = E B = 9! # # 6!J , > 6 ?!K , 5 8 <
万方数据
中华预防医学杂志 ! ! # # 6 年 $ 月第 6 ? 卷第 8 期 !D 1 ) *H; 9 = I/ = + % = & = E B = 9! # # 6!J , > 6 ?!K , 5 8 <
(6 4 ?(
从上述例子可以看到 ! 命令容易 % & ’ & ’是一 个 非 常 友 好 " 掌握 " 结果便于解释的 小 巧 玲 珑 的统计分析软件 # 更详细的 内容可以在U * & = 9 * = &网上$ % & ’ & ’网站 -5 . & ’ & ’ 5 0 , E 和中文网 站% 医学统计之星 1 % & & & & ’ 浏览 # & & ’ . 5 M & , ! 6 5 0 , E E = + . & ’ & . & ’ 9 < < 参
*+ 例 )! 直线回归 % 资料来源 & 文献 ! 例 " #5 "6 %
$ ( 简 % & ’ & ’中的直线 回 归 及 多 元 回 归 是 用 命 令 # 9 = 9 = . . N ) 进行的 % 命令后第 " 个变量是应变量 ! 第 ! 个变 量 记为 9 = N 为自变量 % 用# $ 命 令 进 行 生 存 曲 线 的 比 较! 可以选用 . & .& = . & > , 9 ’ * T和 ) > 0 , * , 3选择项分别进行> , C 9 ’ * T检验和 N N ( ) > 0 , * , 3 检验等 %
!检验 ’
%& 例 &! 文献 ! 例 75 !检验 ’ 资料来源 " 46 ’
命令与结果如下 "
+ , 完成 ’本例 # 将四格表的 7个数据按行输入 # 行间用 + , 隔 & ’ B ) "
! 开 ’逗号后加选择项0 # 分别指定输出 ! 检验结果和 1 )和 = 3 ’ 0 &
确切概率 ’% 划线部分为输入 # 下同) ’ & ’ & ’的命令如下( 输出结果简洁 # 明了 ’
结果中给出 了 直 线 回 归 方 程 及 其 方 差 分 析 " 回归系数 ( ) 及其假设检验和可信区间 " 决定系数 ( ) " 校 D , = O 5 P C . G ’ 9 = + Q 正决定 系 数 ( 等% 求 出 回 归 方 程 后! 可用 : + C % G ’ 9 = +) RP Q # $ 命令计 算 应 变 量 的 估 计 值 ! 用# 命令作散点 9 = + ) 0 & 9 ’ 1$ < N < 图或回归直线等 % 结果中给出了实际的观察数 ( ) 和期望事 = I = * & ., B . = 9 I = + ) " 件数 ( = I = * & .= 3 = 0 & = + > , C 9 ’ * T 的卡 方 0 1 ) !及其相应的概 < N 率( ) % ; 9 1 ) ! #0
心率 ? M " M 6 M M M ? M 4 M $ ? # ? 8 ? $ 4 6 4 M $ 次& ’8 E ) * 收缩 7 # 86 $ 66 $ ?7 # #6 4 #6 4 66.
考
文
献
% & ’ & ’9 = O = 9 = * 0 =/ ’ * G ’ > . = &V , 9?5 #$ I , > G E = ." C 7’ W % & ’ & ’; 9 = . . 5 " $ $ $5 " C M " # W 陈峰主编 5 现代医学 统 计 方 法 与 % 中国统计出 & ’ & ’ 应 用 5北 京 % 版社 ! " $ $ $5 " C 8 # W 杨 树 勤 主 编5 卫 生 统 计 学W 第 6 版W 北 京 % 人 民 卫 生 出 版 社! " $ $ 65 4 6! 6 !! M ?! ? "! $ 4 W 陈峰5 医 用 多 元 统 计 分 析 方 法 5北 京 % 中 国 统 计 出 版 社! ! # # "5 " 6 8 C " 7 7 W
*+ 例 ’! 率的可信区间 % 资料来源 & 文献 ! 例 ?5 86 %
*+ 例 *! 生存分析 % 资料来源 & 文献 7 例 45 !7 %
首先 用 # $ 命令定义时间变量( ) 和截尾变量 . & . = & & ) E = ( ) ’ 用# $ 命令作 S 0 = * . , 9 . & . ’ > ’ * C / = ) = 9生存曲线 % < 命令 # $ 后的两个数字分别是总例数和阳性数 % 0 ) )
同时具有数 & ’ & ’软件是由 美 国 计 算 机 资 源 中 心 研 制 # !!% 据管理 $ 统计分析 $ 统计绘图 $ 矩阵运算和编程等功能 的 统 计
"# !& 分析 软 件 包 % # 适用于 ( $ ) * + , . / ’ 0 ) * & , . 1和 2 * ) 3操作
目前的最新版本是 45 系统 # #’ ( 程 序 容 量 较 小# 对计算机要求 "5 % & ’ & ’软件的 特 点 " ") 不高 # 适用面 广 # 操 作 简 单# 用 户 界 面 友 好 *( 数据管理功 !) 能强大 # 可以非常 方 便 地 在 各 软 件 之 间 交 换 数 据 *( 统计 6) 分析方法齐全 # 能 满 足 日 常 科 研 工 作 的 需 要 *( 计算结果 7) 输出形式简洁 # 与目 前 教 科 书 上 的 表 达 形 式 相 类 似 # 便于实 际工作者理解和在较短时间内掌握 *( 所绘统计图形非常 8) 精美 # 并可直接被图形处理软件 $ 图文并排软件 ( 如( ) 调 , 9 + 用 ’ 因此 # % & ’ & ’软件深受医学院校 学 生 和 临 床 医 生 的 青 睐 # 也是国际临床流行 病 学 网 络 推 荐 使 用 的 统 计 分 析 软 件 ’ 与 即输入一个命 % : %$ % ; % %软 件 不 同# % & ’ & ’软 件 是 命 令 式 的 # 计算机作一次运算 # 完成一项分析任务 ’ 令# !5 % & ’ & ’软件的主要统计分析方法 " % & ’ & ’中包含的统 计
中华预防医学杂志 ! # # # 6 年 $ 月第 6 ? 卷第 8 期 !D 1 ) *H; 9 = I/ = + % = & = E B = 9! # # 6#J , > 6 ?#K , 5 8 <
!6 4 8!
! 医学研究统计方法应用 !
第十七讲 !! " # " #软件在医学研究中的应用
陈峰
" ! 6 7
" 标准差 肝炎患者血清转铁蛋白 含 量 均 数 为 !5 6 8E X! N 为 #5 " " 7E X$ 问 患 者 和 正 常 人 转 铁 蛋 白 含 量 是 否 有 N 差异?差值的 $ 8F 可信区间是多少? 每例均观 ! 医院肿瘤科 6 年来共治疗 乳 腺 癌 患 者 " 6 "例! 其中单纯手 术 治 疗 组 观 察 4 存活8 察满 8 年 ! 7例! ?例! 存活率为 M 联合治疗% 手 术 Y 术 后 化 疗& 组观察 ?5 $F # 存活 6 存活率 为 4 两组存活率有无差 7 ?例! $例! 65 #F ! 别? 次" & 与心脏 6 某医院测定 " ! 名正常成 年 男 子 的 心 率 % E ) * & 的 数 据 见 表 "$ 问 心 率 左心 室 电 机 械 收 缩 时 间 % E . % 次" & 与心脏左心室电机械收缩时间 % & 是否相关! E ) * E . 如何根据心率估计收缩时间? 表 $!" ! 名正常成年男子的心率与左心室电机械收缩时间
*+ 例 (! 事件数的可信区间 % 资料来源 & 文献 ! 例 ?5 86 %
命令 # $ 后的两 个 数 字 分 别 是 观 察 单 位 数 和 事 件 发 生 0 ) ) 数 % 结果中给出 了 暴 露 单 位 数 ( ) " 均数( " 标 = 3 , . G 9 = E = ’ *) < 准 误( ) 及其按 ; % & + 5 A 9 9 5 , ) . . , * 分布计算的确切的 $ 8F# $%
%& 例 $! 四格表的检验 ’ 资料来源 " 文献 ! 例 45 46 ’ ! 列联表 的 ! 检 验# 似然比检验及确切概率可用命令
结果 中 输 出 了 各 组 治 疗 前 $ 治疗后及差值的均数 ( ) $ 标准差( ) $ 标准误( ) 及均数的 E = ’ * % & + 5A 9 9 5 % & + 5A 9 9 5 ’ 给 出 了 配 对 样 本 均 数 的 双 侧! 检 $ 8F 可信区间 ( $ 8F# $) 验和两个方向的单侧检验结果 # 一目了然 ’ 在& 加选择项 G # 表示进行成组比较的 & = . &命令后 # * ’ ) 9 <