第10讲数据的统计分析与描述
第10章 数据的收集、整理与描述【过关测试】(原卷版)七年级数学下册单元复习(人教版)

第10章数据的收集、整理与描述过关测试(时间:90分钟,分值:100分)一、选择题(共12小题,满分36分,每小题3分)1.(3分)为全面掌握小区居民新冠疫苗接种情况,社区工作人员设计了以下几种调查方案:方案一:调查该小区每栋居民楼的10户家庭成员的疫苗接种情况;方案二:随机调查该小区100位居民的疫苗接种情况;方案三:对本小区所有居民的疫苗接种情况逐一调查统计.在上述方案中,能较好且准确地得到该小区居民疫苗接种情况的是()A.方案一B.方案二C.方案三D.以上都不行2.(3分)下列调查方式中,适合用普查方式的是()A.对某市学生课外作业时间的调查B.对神舟十三号载人航天飞船的零部件进行调查C.对某工厂生产的灯泡寿命的调查D.对某市空气质量的调查3.(3分)下列调查中,最适合采用抽样调查的是()A.调查一批防疫口罩的质量B.调查某校初一一班同学的视力C.为保证某种新研发的大型客机试飞成功,对其零部件进行检查D.对乘坐某班次飞机的乘客进行安检4.(3分)某校八年级共有5个班级,每个班的人数在50人左右.为了了解该校八年级学生最喜欢的体育项目,八年级(二)班的四位同学各自设计了如下的调查方案:甲:我准备给八年级每班的学习委员都发一份问卷,由学习委员代表班级填写完成.乙:我准备给八年级所有女生都发一份问卷,填写完成.丙:我准备在八年级每个班随机抽取10名同学各发一份问卷,填写完成.丁:我准备在八年级随机抽取一个班,给这个班所有的学生每人发一份问卷,填写完成.则四位同学的调查方案中,能更好地获得该校学生最喜欢的体育项目的是()A.甲B.乙C.丙D.丁5.(3分)某校为了解本校七年级500名学生的身高情况,随机选择了该年级100名学生进行调查.关于下列说法:①本次调查方式属于抽样调查;②每个学生是个体;③100名学生是总体的一个样本;④总体是该校七年级500名学生的身高.其中正确的说法有()A.1个B.2个C.3个D.4个6.(3分)要想了解九年级1500名学生的心理健康评估报告,从中抽取了300名学生的心理健康评估报告进行统计分析,下列说法正确的是()A.1500名学生是总体B.每名学生的心理健康评估报告是个体C.被抽取的300名学生是总体的一个样本D.300名是样本容量7.(3分)某中学就周一早上学生到校的方式问题,对八年级的所有学生进行了一次调查,并将调查结果制作成了如下表格,则步行到校的学生频率是()八年级学生人数步行人数骑车人数乘公交车人数其他方式人数300751213578 A.0.1B.0.25C.0.3D.0.458.(3分)李阳同学某周中每天背得的单词分别是:16个、19个、15个、18个、22个、30个、26个,为了反映他这一周所背得的单词变化情况,制作最简捷最合适的统计图应该是()A.折线图B.条形图C.扇形图D.直方图9.(3分)为弘扬中华传统文化,某乡镇举行了一场“诗词背诵”比赛,赛后整理所有参赛选手的成绩x(单位:分)如表,则m为()10.(3分)某汽车油箱存油量()Q与汽车工作时间()t的关系如表,下列说法不正确的是()时间t(分)0102030405060⋯存油量Q(升)20191817161514⋯A.油箱中原存油20升B.汽车每分钟耗油0.1升C.汽车工作2小时,油箱中存油8升D.油箱中的油只可供汽车工作3小时11.(3分)某校七年级开展“阳光体育”活动,对爱好排球、足球、篮球、羽毛球的学生人数进行统计,得到如图所示的扇形统计图.爱好排球的人数是21人,爱好足球的人数是爱好羽毛球的人数的4倍,则下列正确的是()A.喜欢篮球的人数为16人B.喜欢足球的人数为28人C.喜欢羽毛球的人数为10人D.被调查的学生人数为80人12.(3分)如图,是九(1)班45名同学每周课外阅读时间的频数分布直方图(每组含前一个边界值,不含后一个边界值),由图可知,每周课外阅读时间不小于6小时的人数是( )A.6人B.8人C.14人D.36人二、填空题(共10小题,满分30分,每小题3分)13.(3分)七年级一班的小明根据本学期“从数据谈节水”的课题学习,知道了统计调查活动要经历5个重要步骤:①收集数据;②设计调查问卷;③用样本估计总体;④整理数据;⑤分析数据.但他对这5个步骤的排序不对,请你帮他正确排序为.(填序号)14.(3分)小红要调查数学书中有无印刷错误,适合采用(填“抽样调查”或“普查”).15.(3分)某市今年共有12万名考生参加中考,为了了解这12万名考生的数学成绩,从中抽取了1500名考生的数学成绩进行统计分析.在这次调查中,被抽取的1500名考生的数学成绩是.(填“总体”,“样本”或“个体”)16.(3分)在一个不透明的袋子中有50个除颜色外均相同的小球,通过多次摸球试验后,发现摸到白球的频率约为36%,估计袋中白球有个.17.(3分)2022年2月22日22点02分是千年难遇的时刻,数“20222222202”充分体现了数学书的对称之美,在这个数的所有数字中“2”出现的频数是.18.(3分)王老师为了解本班学生对新冠病毒防疫知识的掌握情况,对本班45名学生的新冠病毒防疫知识进行了测试,并把测试成绩分为5组,第1~4组的频数分别为12,10,6,8,则第5组的频率是.19.(3分)一个样本有100个数据,拟绘制频数分布直方图.现已知最大数为96,最小数为53,如果设置组距为5,则可分成组.20.(3分)某校开展“庆祝中国共产党成立100周年”征文比赛(每位同学限一篇),每篇作品的成绩记为x分(60100)x,学校从中随机抽取部分学生的成绩进行统计,并将统计结果制成下边的统计表.根据统计表可得,表中m的值为.分数段频数频率90100x220.22x<m0.480907080x<300.3x<80.08607021.(3分)如图是初中七年级某班学生一周课外阅读时间的扇形统计图,已知阅读4小时以下与阅读10小时以上的人数相同,则阅读4小时以下所对应的扇形圆心角为︒.22.(3分)为了做到合理用药,使药物在人体内发挥疗效作用,该药物的血药浓度应介于最低有效浓度与最低中毒浓度之间.某成人患者在单次口服1单位某药后,体内血药浓度及相关信息如图:根据图中提供的信息,下列关于成人患者使用该药物的说法中:①首次服用该药物1单位约10分钟后,药物发挥疗效作用;②每间隔4小时服用该药物1单位,可以使药物持续发挥治疗作用;③每次服用该药物1单位,两次服药间隔小于2.5小时,不会发生药物中毒.所有正确的说法是.三、解答题(共5小题,满分34分)23.(6分)某学校初、高中六个年级共有3000名学生,现采用抽样调查的方法了解其视力情况,各年级学生人数如下表所示:年级七年级八年级九年级高一高二高三合计人数/名56052050050004804403000调查人数/名(1)如果按10%的比例抽样,此次抽样的样本容量是多少?(2)考虑到不同年级学生的视力差异,为了保证样本具有较好的代表性,各年级分别应调查多少人?将结果直接填写在题中所提供的数据表中.24.(6分)某中学进行了一次演讲比赛,分段统计参赛同学的成绩,结果如下(分数为整数,满分为100分)请根据表中提供的信息,解答下列问题:分数段(分)人数(人)91~100781~90671~80861~704(1)参加这次演讲比赛的同学有多少?(2)已知成绩在91~100分的同学为优秀者,那么优胜率为多少?25.(6分)一块400平方米的菜地,四种蔬菜的种植面积分布如图所示.(1)西红柿和辣椒的种植面积分别是多少平方米?(2)如果豆角每平方米的产量是12千克,因不能及时采摘导致损耗,实际共采摘豆角1368千克,求损耗了多少千克?26.(8分)为深入开展青少年毒品预防教育工作,增强学生禁毒意识,某校联合禁毒办组织开展了“2021年青少年禁毒知识竞赛”活动,并随即抽查了部分同学的成绩,整理并制作成图表如下:分数段频数频率x<300.16070x<90n70808090x<0.4x600.290100根据以上图表提供的信息,回答下列问题:(1)抽查的总人数为人,n=;(2)请补全频数分布直方图;(3)若成绩在80分以上(包括80分)为“优秀”,请你估计该校2400名学生中竞赛成绩是“优秀”的有多少名?27.(8分)观察图,回答下列问题.(1)截至12月9日22时,绍兴地区有阳性感染者例.(2)新冠肺炎的传染途径与方式非常复杂,假设阳性感染者第二天就能传染给他人,且1例阳性感染者在不知情的情况下平均每天传播使2个人感染阳性,如果不对阳性感染者进行隔离,那么截至12月12日22时,绍兴地区累计阳性感染者将会达到多少例?(3)事实上,截至12月12日,绍兴地区累计阳性感染者108例,请你说说政府采取了哪些有效的防疫措施?(请写出至少两条)。
第十章《数据的收集、整理与描述》教材分析

七年级数学(人教版)第十章《数据的收集、整理与描述》教材分析西葛中学董介文一、教材的地位:在当今的信息社会里,我们需要用数据解决问题。
统计概率所提供的“运用数据进行推断”的思考方法已成为现代社会一种普遍使用并且强有力的思维方式。
数据的收集、整理与描述与我们的生活息息相关。
例如:日本的福田地震、海啸和核泄漏问题已成为全世界人民关注的焦点,每天都需要收集大量的统计数据,并对这些数据进行精细的分析,并得出结论,从而采取有效措施;全国的人口普查;一个家庭的收入与支出;分析中考学生的数学成绩;统计学生的视力情况、身高、体重等等,都需要收集数据、整理数据、描述数据、得出结论。
这一章的知识充分体现了数学来源于生活,并服务于生活,更注重了数学的时效性。
在人教版的数学课程中,已加强统计概率的份量,已将“统计与概率”列为知识领域之一,成为与“数与代数”“图形与几何”并重的内容,这使得义务教育阶段的数学课程结构更加合理,使学生解决问题的能力得到更全面的培养。
在近几年的中考120分中,与数据的收集、整理与描述相关的这些统计知识和概率知识所占的比重有所加大,占9分左右。
“统计与概率”领域主要学习收集、整理、描述和分析数据等处理数据的基本方法和概率的初步知识,这些内容在三个年级均有安排,教学要求随着年级的升高和学生水平的增长逐渐提高。
本套教材安排了三章。
这三章内容采用统计部分和概率部分分开编排的方式,前两章是统计,最后一章是概率。
统计部分的两章内容按照数据处理基本过程的不同侧重点来安排,分别是7年级下册的第10章“数据的收集、整理与描述”,8年级下册的第20章“数据的分析”;概率部分为9年级上册的第25章“概率初步”。
二、教材安排:第十章是统计部分的第一章,内容包括:1.利用全面调查与抽样调查(以抽样调查为重点)收集和整理数据;2.利用统计图表(以直方图为重点)描述数据;3.展现收集、整理、描述和分析数据得出结论的统计调查的基本过程。
《数据解读与分析》教学设计

讨论目的:通过前面对图表的类型与作用的了解,能够在不同的场合使用最适合的图表。
教师小结操作情况,并对操作好的同学提出表扬和鼓励。
8、布置课外任务:
【课件展示】课后请大家统计出全班同学在上网时最常做的事情是什么聊天游戏还是上网查资料将男生人数与女生人数分开统计。
教学重点
掌握解读图表的方法,对图表进行适当调整。
教学难点
修改图表,对图表进行个性化设置。
学情分析
学生前面通过Word和Excel的学习,对一些基本操作已经掌握得很好,本课虽然是新课,但是因为学生前面在操作上已打好基础,所以学习起来很简单。
主要教法
任务驱动教学法结合讲解、演示
学法指导
讨论、探究、练习
教学流程
探究目的:明确图表与产生该图表的工作表数据之间的关系。
5、探究学习三:
【课件展示】总结出不同图表类型适用的场合。
教师提示:在制作图表的第一步里,选择图表类型时就可以发现我们要的答案。
学生完成后,请个别学生起来回答结果,师生共评。
探究目的:了解图表的类型与作用,能够在不同的场合使用最适合的图表。
6、探究学习四:
学生根据老师的提示先在电脑上练习,并将操作步骤填到课本的表内。在学生上台演示时对其操作进行评价并反思自己的操作。
通过教师小结提高学习效果。
学生在老师的提示下先找出适合的图表类型,然后各自完成操作。
个别同学上台演论做出评价。
学生在课外先统计数据,然后做出图表,进行对比和反思,找出自己的不足之处。
因为不少学生前面的基础不太好,教师在小结的时候,针对部分有难度的操作应该加以演示,反复强调,以便所有学生都能掌握。
描述统计-数据中心的位置

描述统计-数据中⼼的位置平均数,中位数和众数重在分析数据的集中趋势。
都可作为数据⼀般趋势的代表。
数据分析的基本概念:1.平均数(mean):提供数据中⼼位置的度量。
反映⼀组数据的平均⼤⼩。
代表平均⽔平。
平均数和每⼀个数相关,任何⼀个数字的变动都会影响到平均数。
主要缺点是⾮常的容易受到极端数据的影响,如果遇到了极端⼤值,那么整体的平均数都会偏⾼,如果遇到了极端⼩值,那么整体的平均数就会降低。
SQL 语句 AVG(数据集), EXCEL 公式 average(数据集)。
R语⾔ mean(x)2.中位数(median):提供数据中⼼位置的另外⼀种度量。
将所有数据从⼩到⼤排列后,位于中间的数值称为中位数。
当观测值为奇数时,中位数就是位于中间的那个数,当观测值为偶数时,中位数就是中间两个观测值的平均数。
中位数像⼀条分界线,将⼀组数据分成前半部分和后半部分。
代表中等⽔平。
中位数只和数据的位置有关,与平均值不同的是,某些数值变动,不会影响中位数的⼤⼩。
SQL 语句:create table state_midasselect user_id,avg(price)from (select er_id, e.pricefrom producte e, producte dwhere er_id = er_idgroup by er_id, e.pricehaving sum(case when e.price = d.price then 1 else 0 end)>= abs(sum(sign(e.price - d.price))))tgroup by user_idps(当⼀列数列的数量N是奇数的时候。
则中位数的那个数字在数列中的数量>=中位数减去所有数字的结果的符号值(1,0,-1中的⼀个)的和的绝对值。
当⼀列数列的数量N是偶数的时候。
这时候⽤条件筛选出来的就会是最靠近中位数的那两个数字。
则为最靠近中位数的那两个数字在数列中的数量>=那两个数字减去所有数字的结果的符号值(1,0,-1中的⼀个)的和的绝对值。
人教版七年级数学下册第十章《数据的应用:直方图、统计图》知识梳理、考点精讲精练、课堂小测、课后作业第

第26讲数据的应用--直方图、统计图1、频数:一般地,我们称落在不同小组中的数据个数为该组的频数。
也称次数。
在一组依大小顺序排列的测量值中,当按一定的组距将其分组时出现在各组内的测量值的数目,即落在各类别(分组)中的数据个数。
2、频率:频数与数据总数的比为频率。
用文字表示定义为:每个对象出现的次数与总次数的比值是频率。
3、频率:频数与数据总数的比为频率。
在相同的条件下,进行了n次试验,在这n次试验中,事件A发生的次数n(A)称为事件A发生的频数。
比值n(A)/n称为事件A发生的频率,并记为fn(A).用文字表示定义为:每个对象出现的次数与总次数的比值是频率。
1、组数和组距:在统计数据时,把数据按照一定的范围分成若干各组,分成组的个数称为组数;每一组两个端点的差叫做组距。
2、列频数分布表的注意事项运用频数分布直方图进行数据分析的时候,一般先列出它的分布表,其中有几个常用的公式:各组频数之和等于抽样数据总数;各组频率之和等于1;数据总数×各组的频率=相应组的频数。
3、画频数分布直方图的目的,是为了将频数分布表中的结果直观、形象地表示出来,其中组距、组数起关键作用,分组过少,数据就非常集中;分组过多,数据就非常分散,这就掩盖了分布的特征,当数据在100以内时,一般分5~12组。
4、直方图的特点通过长方形的高代表对应组的频数与组距的比(因为比是一个常数,为了画图和看图方便,通常直接用高表示频数),这样的统计图称为频数分布直方图。
特点:①清楚显示各组频数分布情况; ②易于显示各组之间频数的差别。
5、制作频数分布直方图的步骤(1)找出所有数据中的最大值和最小值,并算出它们的差。
(2)决定组距和组数。
(3)确定分点。
(4)列出频数分布表。
(5)画频数分布直方图。
1、表示数据的两种基本方法:一是统计表,通过表格可以找出数据分布的规律;二是统计图,利用统计图表示经过整理的数据,能更直观地反映数据的规律。
必考点解析人教版(五四制)六年级数学下册第十章数据的收集、整理与描述达标测试练习题(无超纲)
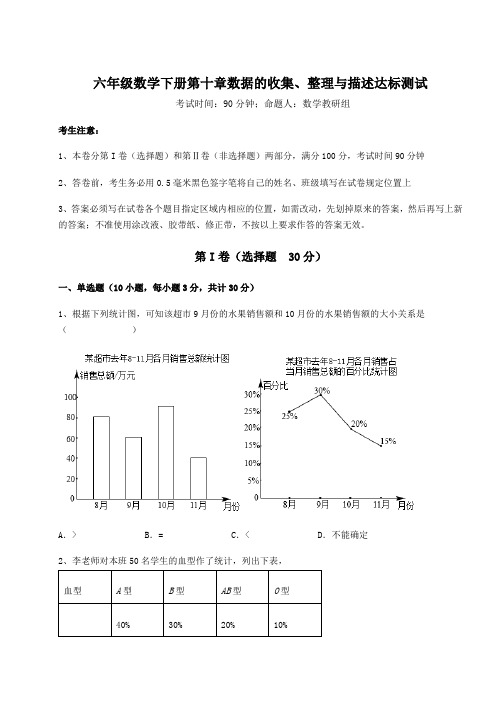
六年级数学下册第十章数据的收集、整理与描述达标测试考试时间:90分钟;命题人:数学教研组考生注意:1、本卷分第I卷(选择题)和第Ⅱ卷(非选择题)两部分,满分100分,考试时间90分钟2、答卷前,考生务必用0.5毫米黑色签字笔将自己的姓名、班级填写在试卷规定位置上3、答案必须写在试卷各个题目指定区域内相应的位置,如需改动,先划掉原来的答案,然后再写上新的答案;不准使用涂改液、胶带纸、修正带,不按以上要求作答的答案无效。
第I卷(选择题 30分)一、单选题(10小题,每小题3分,共计30分)1、根据下列统计图,可知该超市9月份的水果销售额和10月份的水果销售额的大小关系是()A.> B.= C.< D.不能确定2、李老师对本班50名学生的血型作了统计,列出下表,则本班B型血的人数是()A.20人B.15人 C.10人D.5人3、为了解某市七年级学生的一分钟跳绳成绩,从该市七年级学生中随机抽取100名学生进行调查,以下说法正确的是()A.这100名七年级学生是总体的一个样本B.该市七年级学生是总体C.该市每位七年级学生的一分钟跳绳成绩是个体D.100名学生是样本容量4、下列调查中,调查方式选择不合理的是()A.为了了解新型炮弹的杀伤半径,选择抽样调查B.为了了解某河流的水质情况,选择普查C.为了了解神舟飞船的设备零件的质量情况,选择普查D.为了了解一批袋装食品是否含有防腐剂,选择抽样调查5、下列调查中,最适合采用全面调查(普查)的是()A.对投影仪使用寿命的调查B.对我市市民知晓“一盔一带”交通新规情况的调查C.对我市中学生观看电影《中国医生》情况的调查D.对我国“神州十三号”载人飞船发射前各零部件质量情况的调查6、最适合采用全面调查的是()A.调查全国中学生的体重B.调查“神舟十三号”载人飞船的零部件C.调查某市居民日平均用水量D.调查某种品牌电器的使用寿命7、调查下列问题时,适合采用普查的是()A.了解一批圆珠笔芯的使用寿命B.了解我市七年级学生的视力情况C.了解一批西瓜是否甜D.神舟十二号载人飞船发射前对重要零部件的检查8、下面调查中,适合采用普查方式的是()A.今天班上有几名同学打扫教室B.某品牌的大米在市场上的占有率C.某款汽车每百公里的耗油量D.春节晚会的收视率9、某校为了解全校1000名学生的视力情况,抽查了200名学生的视力进行统计分析.在这个问题中,下列说法:①这1000多学生的视力的全体是总体;②每名学生是个体;③200名学生是总体的一个样本;④样本容量是200.其中说法正确的有()A.①②③④B.①②④C.①③④D.①④10、某校为了解九年级学生的视力情况,从九年级的800名学生中随机抽查200名学生进行视力检测,下列说法正确的是()A.800名学生是总体B.200名学生是个体C.200名学生是总体的一个样本D.200是样本容量第Ⅱ卷(非选择题 70分)二、填空题(5小题,每小题4分,共计20分)1、第十二届全国人大四次会议审议通过的《中华人民共和国慈善法》已于今年9月1日正式实施,为了了解居民对慈善法的知晓情况,某街道办从辖区居民中随机选取了900名居民进行调查,并将调查结果制作成了如下不完整的统计图和表:根据以上信息求得“非常清楚”所占扇形的百分比为__%.2、已知某校学生来自A、B、C三个地区,这三个地区的学生人数比是1:3:2,如图所示的扇形图表示上述分布情况,则代表A地区的扇形圆心角是 _____.3、某校七年级二班在订购本班的班服前,按身高型号进行登记,对女生的记录中,身高150cm以下记为S号,150~160cm记为M号,160~170cm记为L号.170cm以上记为XL号.若绘制成统计图描述这些数据,合适的统计图是_____(填“条形”、“折线”、“扇形”中的一个)统计图.4、已知某校学生来自A、B、C三个地区,这三个地区的学生人数比是1:3:2,如图所示的扇形图表示上述分布情况,则代表A地区的扇形圆心角是 _____.5、数学老师布置10道选择题作为课堂练习,学习委员将全班同学的做题情况绘制成条形统计图,则做对的题数大于等于9道的学生有______人.三、解答题(5小题,每小题10分,共计50分)1、某中学六年级共有学生200人,参加课外活动小组情况如图所示(每人只参加一项).(1)参加科技小组的学生有多少人?(2)参加美术小组的比参加体育小组的学生多多少人?2、为了了解长春市冬季的天气变化情况,热爱气象观察的小明记录了2021年11月份30天的天气情况,具体信息如下:请你帮助小明同学把以上数据整理成统计图表.2021年11月份长春市最低气温统计表(1)补全条形统计图;(2)2021年11月份长春市最低气温统计表中a=;b=;m=.3、上海迪士尼乐园调查了部分游客前往乐园的交通方式,并绘制了如下统计图.已知选择“自驾”方式的人数是调查总人数的415,选择“其它”方式的人数是选择“自驾”人数的58,根据图中提供的信息,回答下列问题:(1)本次调查的总人数是多少人?(2)选择“公交”方式的人数占调查总人数的几分之几?4、某中学为了了解学生“大课间操”的活动情况,在七、八、九年级学生中,分别抽取相同数量的学生对“你最喜欢的运动项目”进行调查(每人只能选一项).调查结果的部分数据如图所示的统计图表.其中八年级学生最喜欢排球的人数为12人.七年级学生最喜欢的运动项目人数统计表请根据统计图表解答下列问题:(1)本次调查共抽取了多少名学生?(2)七年级学生“最喜欢踢键子”的学生人数m ________.(3)补全九年级学生最喜欢的运动项目人数统计图.(4)求出所有“最喜欢跳绳”的学生占抽样总人数的百分比.5、为落实我校“着眼终身发展为幸福人生奠基”的办学理念,丰富学生的课余生活,我校组织开设了书法、健美操、乒乓球和朗诵四个社团活动,每个学生选择一项活动参加.为了了解活动开展情况,学校在所有七八九年级学生中随机抽取了部分学生进行调查,将调查结果绘制成条形统计图和扇形统计图;请根据以上的信息,回答下列问题:a______;(1)抽取的学生有______人,n=______,=(2)请列式求样本中朗诵的人数并补全条形统计图;(3)我校有学生2400人.请估计参加乒乓球社团活动的学生人数.-参考答案-一、单选题1、B【解析】【分析】先分别求出该超市9月份的水果销售额和10月份的水果销售额,即可求解.【详解】⨯=万元,解:根据题意得:9月份的水果销售额为6030%18⨯=万元,10月份的水果销售额为9020%18∴该超市9月份的水果销售额和10月份的水果销售额相等.故选:B【点睛】本题主要考查了条形统计图,和折线统计图,明确题意,准确从统计图获取信息是解题的关键.2、B【解析】【分析】用B型血的人数所占百分比乘以总人数50即可求解【详解】B型血的人数:5030%15⨯=人,故选:B.【点睛】本题考查了根据统计表求某项的值,读懂统计表是解题的关键.3、C【解析】【分析】总体是指考查的对象的全体,个体是总体中的每一个考查的对象,样本是总体中所抽取的一部分个体,而样本容量则是指样本中个体的数目.我们在区分总体、个体、样本、样本容量,这四个概念时,首先找出考查的对象.从而找出总体、个体.再根据被收集数据的这一部分对象找出样本,最后再根据样本确定出样本容量.【详解】解:A.这100名七年级学生的一分钟跳绳成绩是总体的一个样本,故该选项不符合题意;B、该市七年级学生的一分钟跳绳成绩是总体,故该选项不符合题意;C、该市每位七年级学生的一分钟跳绳成绩是个体,故该选项符合题意;D、样本容量是100,故该选项不符合题意;故选:C.【点睛】本题考查了总体、个体、样本、样本容量,解题要分清具体问题中的总体、个体与样本,关键是明确考查的对象.总体、个体与样本的考查对象是相同的,所不同的是范围的大小.样本容量是样本中包含的个体的数目,不能带单位.4、B【解析】【分析】根据调查的不同目的来选择全面调查或抽样调查,再判断四个选项即可.【详解】解:A选项,C选项,D选项选择调查方式合理,故A选项,C选项,D选项不符合题意.B选项,为了了解某河流的水质情况,选择普查耗费人力,物力和时间较多,而选择抽样调查更加节约,且和普查的结果相差不大,故B选项符合题意.故选:B.【点睛】本题考查全面调查和抽样调查,对于具有破坏性的调查、无法进行全面调查、全面调查的意义或价值不大时,应选择抽样调查,对于精确度要求高的调查,事关重大的调查往往选用全面调查.5、D【解析】【分析】普查是对总体中每个对象的调查,对各个选项进行一一分析即可.【详解】A. 对投影仪使用寿命的调查,只适合抽样调查,故选项A不合题意;B. 对我市市民知晓“一盔一带”交通新规情况的调查,适合抽样调查,故选项B不合题意;C. 对我市中学生观看电影《中国医生》情况的调查,适合抽样调查,故选项C不合题意;D. 对我国“神州十三号”载人飞船发射前各零部件质量情况的调查,适合普查,载人飞船发射前各零部件质量检查是安全的要求,故选项D符合题意.故选D.【点睛】本题考查普查与抽样调查,掌握普查是对总体的全貌调查,抽样调查是对总体中一部分个体的调查,熟悉它们的区别是解题关键.6、B【解析】【分析】根据全面调查和抽样调查的区别(对于具有破坏性的调查、无法进行普查、普查的意义或价值不大,应选择抽样调查;对于精确度要求高的调查,事关重大的调查选用普查)求解即可得.【详解】解:A、调查全国中学生的体重,适合采用抽样调查,不符合题意;B、调查“神舟十三号”载人飞船的零部件,适合采用全面调查,符合题意;C、调查某市居民日平均用水量,适合采用抽样调查,不符合题意;D、调查某种品牌电器的使用寿命,适合采用抽样调查,不符合题意;故选:B.【点睛】题目主要考查全面调查和抽样调查的区别及适用范围,理解抽样调查和全面调查的适用范围是解题关键.7、D【解析】【分析】根据为一特定目的而对所有考查对象所作的全面调查叫普查,对各选项进行一一分析即可.【详解】解:A. 了解一批圆珠笔芯的使用寿命,适合抽样调查,故选项A不合题意;B. 了解我市七年级学生的视力情况,适合抽样调查,故选项B不合题意;C. 了解一批西瓜是否甜,适合抽样调查,故选项C不合题意;D. 神舟十二号载人飞船发射前对重要零部件的检查,对每个重要部件要一一检查才能使飞船安全,适合普查,故选项D符合题意.故选D.【点睛】本题考查普查与抽样调查的识别,熟练掌握普查与抽样调查的概念与特点是解题关键.8、A【解析】【分析】由全面调查得到的调查结果比较准确,但所费人力、物力和时间较多,而抽样调查得到的调查结果比较近似.逐一判断即可.【详解】解:A.今天班上有几名同学打扫教室,适合全面调查,故选项符合题意;B.某品牌的大米在市场上的占有率,适合抽样调查,故选项不符合题意;C.某款汽车每百公里的耗油量,适合抽样调查,故选项不符合题意;D.春节晚会的收视率,适合抽样调查,故选项不符合题意;故选:A.【点睛】本题考查了抽样调查和全面调查的区别,选择普查还是抽样调查要根据所要考查的对象的特征灵活选用,一般来说,对于具有破坏性的调查、无法进行普查、普查的意义或价值不大,应选择抽样调查,对于精确度要求高的调查,事关重大的调查往往选用普查.9、D【解析】【分析】根据总体、个体、样本和样本容量的定义即可判断.【详解】这1000多学生的视力的全体是总体,故①正确;每名学生的视力是个体;故②错误;200名学生的视力是总体的一个样本,故③错误;样本容量是200,故④正确.故选:D.【点睛】本题考查抽样调查相关的概念,总体:考察对象的全体;个体:组成总体的每一个考察对象;样本:从总体中抽取的一部分个体;样本容量:样本中个体的数目,掌握总体、个体、样本和样本容量的定义是解决问题的关键.10、D【解析】【分析】根据总体,样本,个体,样本容量的定义,即可得出结论.【详解】解:A.800名学生的视力情况是总体,故本选项不合题意;B.每一名学生的视力情况是个体,故本选项不合题意;C.200名学生的视力情况是总体的一个样本,故本选项不合题意;D.样本容量是200,故本选项符合题意.故选:D.【点睛】本题考查了总体、个体、样本、样本容量,解题要分清具体问题中的总体、个体与样本,关键是明确考查的对象.二、填空题1、30【解析】【分析】由“清楚”扇形所对应的圆心角可得其占总体的百分比,再根据各项百分比之和为1可得答案.【详解】解:∵“清楚”的人数占总人数的百分比为90360×100%=25%,∴“非常清楚”扇形所占的百分比为1﹣(30%+15%+25%)=30%,故答案为:30.【点睛】本题主要考查扇形统计图,掌握整个圆表示总数用圆内各个扇形的大小表示各部分数量占总数的百分数是解题的关键.2、60【解析】【分析】根据三个地区的学生人数比求出扇形图上三个地区对应扇形的圆心角度数的比,进而可求出A地区的扇形圆心角.【详解】解:∵A、B、C三个地区的学生人数比是1:3:2.∴A、B、C三个地区对应扇形的圆心角度数的比是1:3:2.∴A地区的扇形圆心角为136060132︒⨯=︒++.故答案为:60︒.【点睛】本题考查扇形统计图的圆心角,熟练掌握该知识点是解题关键.3、条形【解析】【分析】条形统计图能很容易看出数量的多少;折线统计图不仅容易看出数量的多少,而且能反映数量的增减变化情况;扇形统计图能反映部分与整体的关系;由此根据情况选择即可.【详解】解:为了清晰显示四种型号衣服的具体数量,应选用条形统计图,故答案为:条形.【点睛】此题主要考查统计图的选择,应根据条形统计图、折线统计图、扇形统计图各自的特点进行解答.4、60︒【解析】【分析】根据三个地区的学生人数比求出扇形图上三个地区对应扇形的圆心角度数的比,进而可求出A地区的扇形圆心角.【详解】解:∵A、B、C三个地区的学生人数比是1:3:2.∴A、B、C三个地区对应扇形的圆心角度数的比是1:3:2.∴A地区的扇形圆心角为136060132︒⨯=︒++.故答案为:60︒.【点睛】本题考查扇形统计图的圆心角,熟练掌握该知识点是解题关键.5、26【解析】【分析】根据图表可直接得出做对的题数大于等于9道的学生有26人.【详解】解:根据图表得,做对的题数大于等于9道的学生有18826+=人,故答案为:26.【点睛】此题考查了条形统计图,解题的关键是从不同的统计图中得到必要的信息,条形统计图能清楚地表示出每个项目的数据.三、解答题1、 (1)参加科技小组的学生有70人;(2)参加美术小组的比参加体育小组的学生多10人.【解析】【分析】(1)根据“科技小组”所占的百分比,根据频率=频数÷总数即可求出科技小组的人数;(2)求出参加美术小组的比参加体育小组的学生多的所占的百分比即可.(1)解:参加科技小组的学生有200×35%=70(人),答:参加科技小组的学生有70人;(2)解:参加体育小组所占的百分比为1-35%-25%-20%=20%,参加美术小组的比参加体育小组的学生多的人数为200×(25%-20%)=10(人),答:参加美术小组的比参加体育小组的学生多10人.【点睛】本题考查扇形统计图,理解扇形统计图表示数据的特征是解决问题的前提,掌握频率=频数 总数是正确解答的关键.2、 (1)见解析(2)9、6、0.2【解析】【分析】(1)由已知数据知,晴天的有6天,多云的有18天,阴的有5天,小雪的有1天,据此补全图形即可;(2)由已知数据知,大于等于-10℃小于-5℃的天数a=9,-10℃以下的天数b=6,其对应频率m=6÷30=0.2.(1)由已知数据知,晴天的有6天,多云的有18天,阴的有5天,小雪的有1天,补全图形如下:(2)由已知数据知,大于等于-10℃小于-5℃的天数a=9,-10℃以下的天数b=6,其对应频率m=6÷30=0.2,故答案为:9、6、0.2.【点睛】本题主要考查条形统计图,条形统计图是用线段长度表示数据,根据数量的多少画成长短不同的矩形直条,然后按顺序把这些直条排列起来.3、 (1)120;(2)17 30【解析】【分析】(1)用自驾的人数除以所占百分数计算即可;(2)先计算出乘公交的人数=总人数-自驾人数-其它人数,后计算即可.(1)∵ “自驾”方式的人数是32人,且是调查总人数的4 15,∴总人数为:32÷415=120(人).(2)∵选择“其它”方式的人数是选择“自驾”人数的58,“自驾”方式的人数是32人,∴选择“其它”方式的人数是32×58=20(人)∴选择公交的人数是:120-32-20=68(人),∴选择“公交”方式的人数占调查总人数的6817 12030=.【点睛】本题考查了条形统计图,样本估计整体,正确获取解题信息是解题的关键.4、(1)150人;(2)14;(3)作图见解析;(4)22%【解析】【分析】(1)根据扇形统计图的性质,得八年级喜欢排球的学生比例,结合八年级学生最喜欢排球的人数计算,即可得八年级抽取的学生数,结合题意,通过计算即可得到答案;(2)根据(1)的结论,得七年级抽取的学生数为50人,根据题意计算,即可得到答案;(3)根据(1)的结论,得九年级抽取的学生数为50人,根据条形统计图的性质补全,即可得到答案;(4)首先计算得抽取的七、八、九年级学生中喜欢跳绳的人数,根据用样品评估总体的形式分析,即可得到答案.【详解】(1)根据题意,八年级喜欢排球的学生比例为:120%10%30%16%24%----=∵八年级学生最喜欢排球的人数为12人∴八年级抽取的学生数为:1250 24%=人∵在七、八、九年级学生中,分别抽取相同数量的学生对“你最喜欢的运动项目”进行调查∴本次调查共抽取的学生人数为:503150⨯=人(2)根据(1)的结论,得七年级抽取的学生数为50人七年级学生“最喜欢踢键子”的学生人数为:508715614----=人∴14m故答案为:14;(3)根据(1)的结论,得九年级抽取的学生数为50人∴九年级学生最喜欢跳绳的人数为50101213510----=人九年级学生最喜欢的运动项目人数统计图如下:(4)抽取的七、八、九年级学生中,喜欢跳绳的人数为:155016%101581033+⨯+=++=人∴所有“最喜欢跳绳”的学生占抽样总人数的百分比为:33100%22% 150⨯=.【点睛】本题考查了调查统计的知识;解题的关键是熟练掌握扇形统计图、条形统计图、用样品评估总体的性质,从而完成求解.5、 (1)200,54,25(2)40人,图见解析(3)960人【解析】【分析】(1)由参加乒乓球社团活动的学生人数及其所占百分比可得抽取的总人数,用360°乘以参加健美操社团活动的学生人数所占比例即可得n ,根据参加书法社团活动的学生人数和抽取的总人数求出参加书法社团活动的学生所占比例可得a 的值;(2)先根据参加四个社团活动的学生数之和等于总人数,据此求出参加朗诵社团活动的学生人数,再补全条形统计图;(3)用总人数乘以样本中参加乒乓球社团活动的学生人数对应的百分比可得答案.(1)解:抽取的学生有80÷40%=200(人),3036054200︒︒⨯=,∴n =54, 50100%25%200⨯=,∴a =25, 故答案为:200,54,25;(2)参加朗诵社团活动的学生人数为200-(50+30+80)=40(人),补全条形统计图如图:(3)估计参加乒乓球社团活动的学生人数为2400×40%=960(人).答:估计参加书法社团活动的学生人数为960人.【点睛】本题主要考查读条形统计图与扇形统计图的能力和利用统计图获取信息的能力;利用统计图获取信息时,必须认真观察、分析、研究统计图,才能作出正确的判断和解决问题.。
统计学教案统计数据的描述与分析

统计学教案统计数据的描述与分析主题:统计学教案——统计数据的描述与分析引言:统计学是一门研究如何收集、分析和解释数据的学科。
在现代社会中,统计学在各个领域都起着重要作用,帮助我们了解和解释各种现象。
本教案将介绍统计学中数据的描述和分析方法,以及如何运用这些方法进行实际问题的解决。
一、数据的描述在统计学中,我们经常需要描述数据的特征,以便更好地理解和分析数据。
以下是几种常用的描述统计量:1. 平均数:平均数是数据的总和除以观测次数的结果。
它是最直观也是最常用的描述统计量。
2. 中位数:中位数是将数据按照大小顺序排列后,位于中间位置的数值。
3. 众数:众数是数据中出现次数最多的数值。
4. 极差:极差是数据最大值与最小值之间的差异。
5. 方差:方差表示数据的离散程度,是各个观测值与平均数之差的平方的平均值。
6. 标准差:标准差是方差的平方根,用于度量数据分布的广度。
二、数据的分析数据分析是统计学的核心内容,通过分析数据可以得出结论和推断。
以下是几种常用的数据分析方法:1. 频率分析:频率分析是按照某个变量的取值进行分类,然后统计每个分类的频数。
2. 相关分析:相关分析用于判断两个变量之间的关系和相关性。
常用的相关分析方法有皮尔逊相关系数和斯皮尔曼相关系数。
3. 回归分析:回归分析用于研究一个或多个自变量对因变量的影响程度和方向。
4. 置信区间:置信区间是用来估计未知参数真值区间的统计量。
通过计算得出的置信区间可以帮助我们对未知参数进行推断。
小结:统计学作为一门重要的学科,提供了丰富的工具和方法来描述和分析数据。
数据的描述能够帮助我们理解数据的特征,数据的分析则能够帮助我们得出结论和推断。
通过学习统计学,我们可以更好地应用这些知识解决实际问题,提高数据分析的准确性和效率。
参考文献:1. 劳伦斯·S.沃尔斯(2013),《统计学导论》。
2. 陈忠进,王洪敏(2017),《应用统计学》。
注:本教案属于纯粹的学术内容,与任何政治、色情等不相关。
新人教版七年级数学下册第十章数据的收集、整理与描述题测试题(含答案)

人教版七年级下期第10章《数据的收集、整理与描述》(有答案)人教版七年级下期第10章《数据的收集、整理与描述》(有答案)一.选择题(共6小题)1.以下问题,不适合用全面调查的是()A.了解全班同学每周体育锻炼的时间B.旅客上飞机前的安检C.学校招聘教师,对应聘人员面试D.了解全市中小学生每天的零花钱2.下列调查中,适合采用普查方式的是()A.调查市场上婴幼儿奶粉的质量情况B.调查黄浦江水质情况C.调查某个班级对青奥会吉祥物的知晓率D.调查《直播南京》栏目在南京市的收视率3.下列调查中,须用普查的是()A.了解某市学生的视力情况B.了解某市中学生课外阅读的情况C.了解某市百岁以上老人的健康情况D.了解某市老年人参加晨练的情况4.为了检查一批灯管的使用寿命,从中抽取了10只进行检测,以下说法正确的是()A.这一批灯管是总体B.10只灯管是总体的一个样本C.每只灯管是个体D.10只灯管的使用寿命是总体的一个样本5.为了了解某地区12 000名初中毕业生参加中考的数学成绩,从中抽取了500名考生的数学成绩进行统计分析,下列说法正确的是()A.个体是指每个考生B.12000名考生是个体C.500名考生的成绩是总体的一个样本D.样本是指500名考生6.今年我市有近4万名考生参加中考,为了解这些考生的数学成绩,从中抽取1000名考生的数学成绩进行统计分析,以下说法正确的是()A.这1000名考生是总体的一个样本B.近4万名考生是总体C.每位考生的数学成绩是个体D.1000名学生是样本容量二.填空题(共8小题)7.学校为七年级学生订做校服,校服型号有小号、中号、大号、特大号四种.随机抽取了100名学生调查他们的身高,得到身高频数分布表如下,已知该校七年级学生有800名,那么中号校服应订制套.145155x<x<155165x<165175175185x<8.已知一组数据是连续的整数,其中最大值是242,最小数据是198,若把这组数据分成9个小组,则组距是.9.某镇卫生部门2014年4月份对镇所辖学校的中小学生进行体质健康测试,随机抽取了200名学生的测试成绩作为样本,数据整理如下表,其中x的值为.D410.如图是某市20132016-年私人汽车拥有量和年增长率的统计图.该市私人汽车拥有量年净增量最多的是年,私人汽车拥有量年增长率最大的是年.11.图1表示某地区2003年12个月中每个月的平均气温,图2表示该地区某家庭这年12个月中每月的用电量.根据统计图,请你说出该家庭用电量与气温之间的关系(只要求写出一条信息即可):.12.我区有15所中学,其中九年级学生共有3000名.为了了解我区九年级学生的体重情况,请你运用所学的统计知识,将解决上述问题要经历的几个重要步骤进行排序.①收集数据;②设计调查问卷;③用样本估计总体;④整理数据;⑤分析数据.则正确的排序为.(填序号)13.为了解我市某学校“书香校园”的建设情况,检查组在该校随机抽取40名学生,调查了解他们一周阅读课外书籍的时间,并将调查结果绘制成如图的频数直方图(每小组的时间值包含最小值,不包含最大值),根据图中信息估计该校学生一周课外阅读时间不少于4小时的人数占全校人数的百分数约等于.14.对某班组织的一次考试成绩进行统计,已知80.5~90.5分这一组的频数是8,频率是0.2,那么该班级的人数是人.三.解答题(共6小题)15.2013年我国中东部地区先后遭遇多次大范围雾霾天气,其影响范围、持续时间、雾霾强度历史少见,给人们生产生活造成了严重影响.为此“雾霾天气的主要成因”就成为某校环保小组调查研究的课题,他们随机调查了部分市民,并对调查结果进行整理,绘制了如下尚不完整的统计图表.请根据图表中提供的信息解答下列问题;(1)填空:m=,n=,扇形统计图中表示E组的扇形圆心角等于度.(2)若该市人口约有800万人,请你估计其中持D组“观点”的市民人数;(3)治理雾霾天气需要每个人的环保行动和参与,作为一名中学生的你能为“应对雾霾天气,保护环境”做些什么?请你写出来.(只需写出一条措施或建议即可)16.某校有1000名学生.为了解全校学生的上学方式,该校数学兴趣小组在全校随机抽取了100名学生进行抽样调查.整理样本数据,得到下列图表(频数分布表中部分划记被污染渍盖住)(1)本次调查的个体是;(2)求扇形统计图中,乘私家车部分对应的圆心角的度数;(3)请估计该校1000名学生中,选择骑车和步行上学的一共有多少人?17.为了让学生了解环保知识,增强环保意识,某中学举行了一次“环保知识竞赛”,共有900名学生参加了这次竞赛.为了解本次竞赛成绩情况,从中抽取了部分学生的成绩进行统计.请你根据尚未完成的频数分布表和频数分布直方图,解答下列问题:(1)填充频数分布表的空格;(2)补全频数直方图,并绘制频数分布直方图;(3)全体参赛学生中,竞赛成绩落在哪组范围内的人数最多?(4)若成绩在90分以上(不含90分)为优秀,则该校成绩优秀的约为多少人?18.网瘾低龄化问题已引起社会各界的高度关注,有关部门在全国范围内对1235-岁的网瘾人群进行了简单的随机抽样调查,得到了如图所示的两个不完全统计图.请根据图中的信息,解决下列问题:(1)求条形统计图中a的值;(2)求扇形统计图中1823-岁部分的圆心角;(3)据报道,目前我国1235-岁的人数.-岁网瘾人数约为2000万,请估计其中122319.某校为开展每天一小时阳光体育活动,准备组建篮球、排球、羽毛球、乒乓球四个兴趣小组,并规定每名学生只能参加1个小组,且不能不参加.该校对九年级学生报名情况进行了抽样调查,并将所得数据绘制成了如下两幅统计图:根据图中的信息,解答下列问题:(1)本次调查共抽样了名学生;(2)补全条形统计图;(3)若该校九年级共有450名学生,试估计报名参加排球兴趣小组的人数.20.班主任张老师为了了解本班学生课堂发言情况,对前一天本班男、女生的发言次数进行了统计,并绘制成如下频数分布折线图(图1).(1)该班共有名学生;(2)在张老师的鼓励下,该班学生第二天的发言次数比前一天明显增加,图2是全班第二天发言次数变化的人数的扇形统计图人教版七年级数学下册第十章数据的收集、整理与描述单元检测试题(解析版)人教版七年级数学下册第十章数据的收集、整理与描述单元测试题学校:__________ 班级:__________ 姓名:__________ 考号:__________一、选择题(本题共计10 小题,每题3 分,共计30分,)1. 某同学想了解寿春路与阜阳路交叉路口1分钟内各个方向通行的车辆数量,他应采取的收集数据方法为()A.查阅资料B.实验C.问卷调查D.观察2. 下列调查中,适合采用全面调查(普查)方式的是()A.对长江水质情况的调查B.对端午节期间市场上粽子质量情况的调查C.对某类烟花爆竹燃放安全情况的调查D.对神舟飞船的零部件的质量情况的调查3. 下列调查中,适宜采用普查的是()A.调查我县初三学生每天体育锻炼的时间B.调查全校学生每月花费的零花钱C.调查初三1班某次数学考试成绩D.调查初三学生参加这次月考的心理状态4. 某纺织厂从10万件同类产品中随机抽取了100件进行质检,发现其中有5件不合格,那么估计该厂这10万件产品中合格品约为()A.9.5万件B.9万件C.9500件D.5000件5. 下列调查方式合适的是()A.了解炮弹的杀伤力,采用普查的方式B.了解全国中学生的视力状况,采用普查的方式C.了解一批罐头产品的质量,采用抽样调查的方式D.对载人航天器“神舟七号”零部件的检查,采用抽样调查的方式6. 某市有3000名初一学生参加期末考试,为了了解这些学生的数学成绩,从中抽取200名学生的数学成绩进行统计分析.在这个问题中,下列说法:①这3000名初一学生的数学成绩的全体是总体;②每个初一学生是个体;③200名初一学生是总体的一个样本;④样本容量是200.其中说法正确的是()A.4个B.3个C.2个D.1个7. 某市将大、中、小学生的视力进行抽样分析,其中大、中、小学生的人数比为2:3:5,若已知中学生被抽到的人数为150人,则应抽取的样本容量等于()A.1500B.1000C.150D.5008. 为了估计水塘中的鱼数,养鱼者首先从鱼塘中捕获20条鱼,在每条鱼身上做好记号后,把这些鱼放归鱼塘.再从鱼塘中打捞100条鱼,如果在这100条鱼中有5条鱼是有记号的,则估计该鱼塘中的鱼数约为()A.300条B.380条C.400条D.420条9. 实验中学九年级进行了一次数学测试,参加考试人数共540人,为了了解这次数学成绩,下列所抽取的样本中较合理的是()A.抽取前:100名同学的数学成绩B.抽取各班学号为3的倍数的同学的数学成绩C.抽取1、2两班同学的数学成绩D.抽取后100名同学的数学成绩10. 某校七(3)班的同学进行了一次安全知识测试,测试成绩进行整理后分成四个组,并绘制如图所示的频数直方图,则第二组的频数是()A.0.4B.18C.0.6D.27二、填空题(本题共计10 小题,每题3 分,共计30分,)11. 一个样本的50个数据分别落在5个小组内,其中第3组有8个数,那么第3组的频率为________.12. 一个容量为77的样本最大值是153,最小值是60,取组距为10,则可分成________组.13. 为了更好的刻画数据的总体的规律,我们还可以在得到的频数分布直方图上________,________,得到________图.14. 一组数据的最大值为169,最小值为141,在绘制频数分布直方图时要求组据为6,则组数为________.15. 某校对去年毕业的350名学生的毕业去向进行跟踪调查,并绘制出扇形统计图(如图所示),则该校去年毕业生在家待业人数有________人.16. 某校为了了解八年级学生的体能情况,随机选取一部分学生测试一分钟仰卧起坐次数,并绘制了如图所示的直方图,学生仰卧起坐次数在25∼30之间的频率是________.该店决定本周进货时,多进一些尺码为厘米的鞋,影响鞋店决策的统计量是18. 下图是根据某中学为地震灾区玉树捐款的情况而制作的统计图,已知该校在校学生3000人,请根据统计图计算该校共捐款________元.19. 今年5月份有关部门对计划去上海迪士尼乐园的部分市民的前往方式进行调查,图1和图2是收集数据后绘制的两幅不完整统计图.根据图中提供的信息,那么本次调查的对象中选择公交前往的人数是________.20. 某校为了解本校九年级学生足球训练情况,随机抽查该年级若干名学生进行测试,然后把测试结果分为4个等级:A、B、C、D,并将统计结果绘制成两幅不完整的统计图.该年级共有700人,估计该年级足球测试成绩为D等的人数为________人.三、解答题(本题共计6 小题共计60分,)(2)计算各种果树对应的圆心角度数;(3)制作扇形统计图.请根据表中信息,回答下列问题:(1)活动小组共有学生多少人?(2)制作标本数在6个及以上的人数占小组总人数的百分比是多少?(3)根据统计表制作一个形象的统计图.23. 吸烟有害健康:为配合“禁烟”运动,某校组织同学们在某社区开展了“你支持哪种戒烟方式”的问卷调查,征求市民的意见,并将调查结果整理后制成了如图所示统计图:(1)同学们一共随机调查了________人;(2)请你把条形统计图补充完整;(3)如果在该社区随机咨询一位市民,那么该市民支持“强制戒烟”的概率是多少?(4)假定该社区有1万人,请估计该地区支持“警示戒烟”这种方式的大约有多少人?24. 某校七年级数学兴趣小组的同学调查了若干名家长对“初中学生带手机上学”现象的看法,统计整理并制作了如下的条形与扇形统计图.依据图中信息,解答下列问题:(1)接受这次调查的家长人数为多少人?(2)表示“无所谓”的家长人数为多少人?(3)在扇形统计图中,求“不赞同”的家长部分所对应扇形的圆心角大小.25. 如图所示的是一位同学设计的一幅象形统计图,不过这位同学太粗心了,应该给出的题目及一些说明性文字都忘了写,你能看出这幅图是要反应什么内容吗?能把图形中缺少的文字补上吗?(能补上三项文字性的说明即可)26. 下面三幅统计图,反映了某市两个化肥厂三个方面的情况,请看图回答问题.(1)从折线统计图中可以看出,哪个厂的产值增长得快?(2)从条形统计图中可以看出,哪个厂的工人人数多,哪个厂的技术人员多?(3)从扇形统计图中可以看出,哪个厂的外销产品占产品销售总数的百分比大?(4)综合上面的分析,你认为哪个厂的生产搞得好,为什么?参考答案与试题解析七年级数学下册第十章数据的收集、整理与描述单元检测试题一、选择题(本题共计10 小题,每题 3 分,共计30分)1.【答案】D【解析】根据收集数据的基本方法有观察、统计、调查、实验、查阅文献资料或因特网查询等分析判断即可.【解答】解:想了解寿春路与阜阳路交叉路口1分钟内各个方向通行的车辆数量,他应采取的收集数据方法为观察,故选:D.2.【答案】D【解析】根据适合普查的方式一般有以下几种:①范围较小;②容易掌控;③不具有破坏性;④可操作性较强,进而判断即可.【解答】解:A、适合抽样调查,因为普查的难度较大,故此选项错误;B、适合抽样调查,因为调查的破坏性较大,故此选项错误;C、适合抽样调查,因为调查的破坏性较大,故此选项错误;D、适合全面调查,因为神舟飞船零部件要求极高,不能出现任何问题,故此选项正确.故选:D.3.【答案】C【解析】由普查得到的调查结果比较准确,但所费人力、物力和时间较多,而抽样调查得到的调查结果比较近似.【解答】解:A,对全国中学生每天体育锻炼的时间的调查不必全面调查,大概知道因为普查工作量大,适合抽样调查;B,调查全校学生每月花费的零花钱,适合抽样调查;C,调查初三1班某次数学考试成绩,适合普查;D,调查初三学生参加这次月考的心理状态,适合抽样调查.故选:C.4.【答案】A【解析】由于100件中进行质检,发现其中有5件不合格,那么合格率可以计算出来,然后利用样本的不合格率估计总体的不合格率,就可以计算出10万件中的不合格品产品数,进而求得合格品数.【解答】解:∵100件中进行质检,发现其中有5件不合格,∴合格率为(100−5)÷100=95%,∴10万件同类产品中合格品约为100000×95%=95000=9.5万件.故选A.5.【答案】C【解析】调查方式的选择需要将普查的局限性和抽样调查的必要性结合起来,具体问题具体分析,普查结果准确,所以在要求精确、难度相对不大,实验无破坏性的情况下应选择普查方式,当考查的对象很多或考查会给被调查对象带来损伤破坏,以及考查经费和时间都非常有限时,普查就受到限制,这时就应选择抽样调查.【解答】解:A、了解炮弹的杀伤力,有破坏性,故得用抽查方式,故本选项错误;B、了解全国中学生的视力状况,工作量大,得用抽查方式,故本选项错误;C、了解一批罐头产品的质量,工作量大,得用抽查方式,故本选项正确;D、对载人航天器“神舟七号”零部件的检查十分重要,故进行普查检查,故本选项错误.故选C.6.【答案】C【解析】根据总体、个体、样本、样本容量的定义即可判断.【解答】解:①这3000名初一学生的数学成绩的全体是总体正确;②每个初一学生的期末数学成绩是个体,故命题错误;③200名初一学生的期末数学成绩是总体的一个样本,故命题错误;④样本容量是200,正确.故选C.7.【答案】D【解析】根据分层抽样方法,设抽到的大、中、小学生人数分别为2x、3x、5x,由抽到的中学生人数可得x,继而可得样本容量.【解答】解:设抽到的大、中、小学生人数分别为2x、3x、5x,由3x=150可得x=50,∴应抽取的样本容量等于10x=500(人),故选:D.8.【答案】C【解析】首先求出有记号的5条鱼在100条鱼中所占的比例,然后根据用样本中有记号的鱼所占的比例等于鱼塘中有记号的鱼所占的比例,即可求得鱼的总条数.【解答】×100%=5%,解:∵5100∴20÷5%=400(条).故选C9.【答案】B【解析】抽取样本注意事项就是要考虑样本具有广泛性与代表性,所谓代表性,就是抽取的样本必须是随机的,即各个方面,各个层次的对象都要有所体现.【解答】解:A、不具有代表性,故A错误B、抽取各班学号为3的倍数的同学的数学成绩,具有代表性广泛性,故B正确;C、不具有代表性,故C错误;D、不具有代表性,故D错误;故选:B.10.【答案】B【解析】根据频数分布直方图即可求解.【解答】解:根据频数分布直方图可知,第二组的频数是18.故选B.二、填空题(本题共计10 小题,每题 3 分,共计30分)11.【答案】425【解析】根据频率的定义,频率=频数数据总和即可求解.【解答】解:第3组的频率为850=425.故答案是:425.12.【答案】10【解析】先求出该组数据最大值与最小值的差,再用极差除以组距即可得到组数.【解答】解:∵153−60=93,而93÷10=9.3,∴应该分成10组.故答案为:10.13.【答案】取点,连线,频数分布折线【解析】根据画频数分布折线图的方法即可求解.【解答】解:为了更好的刻画数据的总体的规律,我们还可以在得到的频数分布直方图上取点,连线,得到频数分布折线图.故答案为取点,连线,频数分布折线图.14.【答案】5【解析】由于一组数据的最大值为169,最小值为141,那么极差为169−141=28,而在绘制频数直方图时要求组距为6,那么根据它们即可求出组数.【解答】解:∵一组数据的最大值为169,最小值为141,∴最大值与最小值的差是169−143=28,而要求组距为6,∴28÷6=423,∴组数为5.故答案为:5.15.【答案】28【解析】首先求得在家待业的百分比,然后乘以毕业的总人数即可.【解答】解:在家待业的毕业生所占百分比为:1−24%−68%=8%,故该校去年毕业生在家待业人数有350×8%=28人,故答案为:28.16.【答案】0.2【解析】即可求解.根据频率的计算公式:频率=频数总数【解答】=0.2.解:学生仰卧起坐次数在25∼30之间的频率是:630故答案是:0.2.17.【答案】众数【解析】平均数、中位数、众数是描述一组数据集中程度的统计量;方差、标准差是描述一组数据离散程度的统计量.销量大的尺码就是这组数据的众数.【解答】由于众数是数据中出现次数最多的数,故影响鞋店决策的统计量是众数.18.【答案】37770【解析】首先根据扇形统计图求得各年级的人数,再结合条形统计图求得共捐款数.【解答】解:初一人数:3000×32%=960(人);初二人数:3000×33%=990(人);初三人数:3000×35%=1050(人).该校共捐款数:960×15+990×13+1050×10=37770(元).19.【答案】6000【解析】根据自驾车人数除以百分比,可得答案.【解答】由题意,得4800÷40%=12000,公交12000×50%=6000人教版七年级下册第十章数据的收集、整理与描述单元练习题(解析版)人教版七年级数学下册第十章数据的收集、整理与描述单元测试题一、选择题1.为了了解某校初三年级400名学生的体重情况,从中抽查了50名学生的体重进行统计分析,在这个问题中,总体是()A.400名学生的体重B.被抽取的50名学生C.400名学生D.被抽取的50名学生的体重2.下列调查中,调查方式选择合理的是()A.为了了解某一品牌家具的甲醛含量,选择全面调查B.为了了解某公园的游客流量,选择抽样调查C.为了了解神州飞船的设备零件的质量情况,选择抽样调查D.为了了解一批袋装食品是否有防腐剂,选择全面调查调查3.墨墨对他所住小区的100户居民2月份天然气的使用量(单位:m3)进行统计,其结果如图所示,图中36-38段因不小心洒上水而看不清,则2月份天然气的使用量在36-38段的居民有()A.18户B.20户C.22户D.24户4.某班同学参加植树,第一组植树15棵,第二组植树18棵,第三组树数14棵,第四组植树19棵.为了把这个班的植树情况清楚地反映出来,应该制作的统计图为()A.条形统计图B.折线统计图C.扇形统计图D.条形统计图、扇形统计图均可5.PM2.5指数是测控空气污染程度的一个重要指数.在一年中最可靠的一种观测方法是()A.随机选择5天进行观测B.选择某个月进行连续观测C.选择在春节7天期间连续观测D.每个月都随机选中5天进行观测6.水库中放养鲤鱼8 000条,鲢鱼若干.在n次随机捕捞中,共抓到鲤鱼320条,抓到鲢鱼400条,估计塘中原来放养了鲢鱼()A.9 000条B.9 600条C.10 000条D.12 000条7.老师对某班全体学生在电脑培训前后进行了一次水平测试,考分以同一标准划分为“不合格”、“合格”、“优秀”三个等级,成绩见下表.下列说法错误的是()A.培训前“不合格”的学生占80%B.培训前成绩“合格”的学生是“优秀”学生的4倍C.培训后80%的学生成绩达到了“合格”以上D.培训后优秀率提高了30%8.某校对全体学生开展心理健康知识测试,七、八、九三个年级共有800名学生,各年级的合格人数如表所示,则下列说法正确的是()A.七年级的合格率最高B.八年级的学生人数为262名C.八年级的合格率高于全校的合格率D.九年级的合格人数最少二、填空题9.为了考察某区3500名毕业生的数学成绩,从中抽出20本试卷,每本30份,在这个问题中,样本容量是________.10.我国泰山,华山等五座名山的海拔高度如下表.若根据表中的数据作出统计图,以便能更清楚地对几座名山的高度进行比较,则应选用________统计图.11.为了掌握我校初中二年级女同学身高情况,从中抽测了60名女同学的身高,这个问题中的总体是____________________,样本是____________________.12.某市2016年将有九万名考生参加中考,为了了解这九万名考生的视力情况,从中抽取了2 000名考生的视力情况进行统计分析,得出①这种调查采用了抽样抽样调查的方式;②九万名考生是总体;③2 000名考生的视力情况是总体的一个样本;④每一名考生是个体;⑤样本容量为1 000名,则以上5个结论正确的是________.13.为了了解某所初级中学学生对6月5日“世界环境日”是否知道,从该校全体学生1 200名中,随机抽查了80名学生,结果显示有2名学生“不知道”,由此,估计该校全体学生中对“世界环境日”约有________名学生“不知道”.14.下列调查中,适合用抽样调查的为________.(填序号)①了解全班同学的视力情况;②了解某地区中学生课外阅读的情况;③了解某市百岁以上老人的健康情况;④日光灯管厂要检测一批灯管的使用寿命.15.调查市场上某种食品的色素含量是否符合国家标准,这种调查适用________________.(填全面调查或者抽样调查)16.如图是某班50名学生身高(精确到1 cm)的频率分布直方图,从左起第一、二、三、四个小长方形的高的比是1∶3∶5∶1,那么身高是160 cm及160 cm以上的学生有________人.三、解答题17.某市建设森林城市需要大量的树苗,某生态示范园负责对甲、乙、丙、丁四个品种的树苗共500株进行树苗成活率试验,从中选择成活率高的品种进行推广.通过实验得知:丙种树苗的成活率为89.6%,把实验数据绘制成下面两幅统计图(部分信息未给出).(1)实验所用的乙种树苗的数量是________株.(2)求出丙种树苗的成活数,并把图2补充完整.(3)你认为应选哪种树苗进行推广?(4)请通过计算说明理由.18.请指出下列样本是否具有代表性:(1)在全县范围内随意选择十个幼儿园,对其中每个孩子的情况进行调查,以了解该县幼儿园的身体发育等情况;(2)到省城一所中学进行调查,以便了解全省中学生上网的情况;(3)在每个省任意确定两名房地产开发商,让他们每人填写一张内容详尽的调查表,包括他们负责的工程质量,所盖楼房中使用的涂料、门窗、地板是不是合格,以及建房的利润情况等,以了解全国各地的房地产开发商的工作情况.19.2016年3月,某中学以“每天阅读1小时”为主题,对学生最喜爱的书籍类型进行随机抽样调查,收集整理数据后,绘制出以下两幅未完成的统计图,请根据图1和图2提供的信息,解答下列问题:(1)请把折线统计图(图1)补充完整;(2)如果这所中学共有学生900名,那么请你估算最喜爱科普类书籍的学生人数.。
数据的统计与分析

数据的统计与分析数据的统计与分析是研究数据收集、整理、描述和解释的一种方法。
它包括数据的收集、数据的整理、数据的描述和数据的分析四个步骤。
一、数据的收集数据的收集是研究的第一步,可以通过调查、观察、实验等方式进行。
收集数据时要注意数据的真实性、准确性和可靠性。
二、数据的整理数据的整理是将收集到的数据进行归类、排序和处理的过程。
常用的整理方法有表格法、图形法和统计量表示法。
三、数据的描述数据的描述是通过图表、统计量等手段对数据的分布、趋势、规律等进行展示。
常用的描述方法有条形图、折线图、饼图、散点图等。
四、数据的分析数据的分析是对数据进行解释和推理的过程,目的是发现数据背后的规律和趋势。
常用的分析方法有频数分析、百分比分析、平均数、中位数、众数等统计量的计算和比较等。
五、概率与统计概率是研究事件发生可能性的一种数学方法。
常用的概率计算方法有古典概型、几何概型和条件概率等。
统计是研究数据收集、整理、描述和解释的一种方法,它包括数据的收集、数据的整理、数据的描述和数据的分析四个步骤。
六、统计图表统计图表是数据整理和描述的重要工具。
常用的统计图表有条形图、折线图、饼图、散点图等。
七、数据的处理数据的处理是对数据进行加工、转换和分析的过程。
常用的处理方法有数据的清洗、数据的转换、数据的插补等。
八、统计推断统计推断是通过样本数据对总体数据进行推断和预测的一种方法。
常用的统计推断方法有假设检验、置信区间等。
九、回归分析回归分析是研究变量之间相互关系的一种统计方法。
常用的回归分析方法有线性回归、多元回归等。
十、统计软件统计软件是进行数据统计和分析的重要工具。
常用的统计软件有SPSS、SAS、R等。
以上就是数据的统计与分析的相关知识点,希望对你有所帮助。
习题及方法:某学校进行了一次数学测试,共有100名学生参加。
以下是部分学生的成绩:80, 85, 90, 88, 87, 92, 84, 86, 91, 83求这组数据的众数、中位数和平均数。
第十章 统计与概率内容分析与教学研究----统计与概率教学策略

• 6.能设计统计活动,检验某些预测。 • 7.能解释统计结果,根据结果做出简单的判断和预测,并能进行交
流。
• 8.初步体会数据可能产生误导。
(二)第二学段的总目标:
• 经历简单数据统计过程,进一步收 集、整理和描述数据的方法,并根 据数据分析的结果作出判断与预测; 在具体情境中体会事件发生可能性 的含义,并能计算一些简单事件发 生的可能性;较为清晰的表达自己 的看法。
• ④通过丰富的实例,如向学生提供“一名身高1.4 米的学生在一个水深1.2米的游泳池中会不会有危 险?”这样一个现实背景的问题情境来帮助学生 准确把握平均数的意义,继而引导学生求简单平 均数(结果为整数)。
• ⑤组织学生进行调查,如设计让学生从报刊、杂 志、电视等媒体中获取有关数据信息,从而使学 生认识到统计的必要性和广泛性。
解释统计结果试分析数据的一种能力, 也是对数据统计结果进行判断的基础。学生 只有会从不同的角度解释统计结果,才能根 据结果做出判断和预测。
这一学段课程目标要求学生能设计统计 活动,检验某些预测、能理解统计结果,根 据结果做出简单的判断和预测,并能进行交 流。
5、渗透统计与概率知识之间的联系
这部分内容的教学,应为发展和运用 比、分数、百分数、度量、图像等概念提 供活动背景,统计与概率之间的关联在这 一学段有初步表现。例如:让学生调查统 计“白色污染”问题、“统计交通路口车 流量”等等。加深对不同统计量意义的理 解。在活动中运用已学知识,感受丢弃塑 料袋行为对大自然所造成的污染,唤起环 保意识。
• 计 算 器 和 计 算 机 在 提 供、 记录和处理数据方面, 为学生提供了一个良好 的 工 具 。计 算 机 还 可 以 产生足够的模拟结果, 是学生更好地体会事件 发 生 概 率 的 意 义 ,较 为 准确地获得事件发生的 概 率。
小学五年级数学教案:数据的分析和统计

【小学五年级数学教案】数据的分析和统计一、教学目标:1.理解数据分析和统计的基本概念;2.学会使用各种数据整合方法;3.学会通过数据整合得出相关结论。
二、教学重难点:1.了解数据整合的基本方法;2.能够根据数据结论进行统计学思维的训练。
三、教学方法:本节课的教学方法包:提问法、讲解法、示范法、练习法、小组研讨法等。
四、教学过程:1.课前导入:老师问组员关于数据相关的常识:什么是数据?数据可以有哪些类型?为什么需要进行统计?2.案例分析(1)统计数字出场次数第一部分,老师让学生看一段视频,让学生记录一些数字出现的次数,如高楼、汽车、人群等等。
第二部分,老师让学生数一下6~8月份的登月标示同步发射场发射了多少枚火箭,然后将数据整合在一起,得出过去两个月每天的发射量情况。
(2)折线图练习老师在黑板上画一幅横轴表示时间,纵轴表示销售量的折线图,并向学生说明如何使用数据整合方法来制作折线图。
3.练习检测(1)在线折线图将学生分成小组,每组有一台电脑,让他们打开在线制作折线图的工具(推荐Google在线制图)并尝试制作一幅折线图。
(2)猜谜游戏让学生制作一个数字谜语,将值分为四分区并表现出来。
分组,让团队相互猜数,并使用两个分数来比较谜底和猜测数。
五、教学随笔:数据是现代社会中流行的一种国际语言。
数据分析和统计是现代信息社会最受欢迎的技能之一,在小学阶段,让孩子了解数据的意义以及如何整合数据是非常重要的。
我们可以通过一些具体的事例教学,来帮助学生理解数据统计的基本知识。
在实践中获得这些技能,将帮助我们的孩子更好地适应未来数字化社会的发展需求。
六、教学扩展:让孩子观察周围世界中的数字、文案、表格等,并与现实生活中的商业、工业、社会等进行联系,将鼓励他们积极思考,遗播统计学思维。
孩子们可以自己设计一些数据样本来进行实验和分析,并加强他们的数字思维能力。
另外,使用基础软件如Excel打造图表也可以在职业生涯中大有裨益。
数据统计分析方法

数据统计分析方法数据统计分析是指通过收集、整理、描述、分析和解释数据来寻求特定问题的答案或结论的方法。
它是研究、决策和预测的基础,可以用于各种领域,如经济、金融、医学、社会科学等。
在数据统计分析过程中,可以使用各种统计方法和技术来帮助理解数据,并从中发现有意义的模式、关系和结论。
1.描述统计分析:这种方法用于描述数据的基本特征,包括中心趋势(如平均值、中位数、众数)、离散程度(如方差、标准差)和分布形状(如偏度、峰度)。
通过描述统计分析,可以对数据的总体情况有一个整体的了解。
2.相关分析:这种方法用于探索两个或多个变量之间的关系。
通过计算相关系数(如皮尔逊相关系数)来衡量变量之间的线性关系的强度和方向。
相关分析可以帮助确定变量之间的关联性,并发现隐藏的模式和趋势。
3.回归分析:回归分析用于建立变量之间的函数关系,并通过拟合一个数学模型来预测一个变量的值。
线性回归是最常用的回归方法之一,它假设变量之间存在线性关系。
回归分析可以用于预测和解释变量之间的关系。
4.方差分析:方差分析(ANOVA)用于比较两个或多个群体之间的均值是否有显著差异。
它可以帮助确定不同因素对群体均值的影响,并检验这些因素是否统计上显著。
5.t检验与z检验:t检验和z检验是用于比较两个群体均值的方法。
t检验用于小样本(样本量较小)情况,而z检验适用于大样本(样本量较大)情况。
这些检验方法可用于确定两个群体均值之间是否存在显著差异。
6. 非参数统计方法:非参数统计方法在对总体分布形状和参数未知的情况下使用。
它不依赖于特定的总体分布假设,而是基于样本数据进行推断。
例如,Wilcoxon秩和检验和Kruskal-Wallis检验是用于比较两个或多个群体之间中位数的非参数方法。
7.时间序列分析:时间序列分析是研究时间上连续观测值的统计方法。
它可以帮助发现时间上的趋势、季节性和周期性。
时间序列分析可以用于预测未来的值,并做出决策。
以上只是一些常见的数据统计分析方法,还有其他更复杂和高级的方法,如因子分析、聚类分析、多元回归等。
数据的统计描述和分析

数据的统计描述和分析数据是指通过观察、测量或收集而得到的事实或现象,是科学研究和决策制定的基础。
在进行数据分析时,需要对数据进行统计描述和分析,以便更好地了解数据的特征、规律和趋势。
下面将对数据的统计描述和分析方法进行详细介绍。
数据的统计描述主要包括中心趋势和离散程度两个方面。
中心趋势描述了数据的集中程度,常用的统计指标有均值、中位数和众数。
均值是将所有数据相加后除以数据的个数得到的平均值,可以反映数据的总体情况;中位数是将数据按大小顺序排列后的中间值,可以表示数据的中间水平;众数是数据中出现次数最多的数值,可以反映数据的频数分布状况。
离散程度描述了数据的波动程度,常用的统计指标有极差、方差和标准差。
极差是数据的最大值与最小值之间的差异,可以反映数据的范围;方差是各数据与均值之差的平方和的平均值,可以表示数据的离散程度;标准差是方差的平方根,可以反映数据的分布状况。
除了统计描述,数据还可以进行图形描述和分析。
常用的图形描述方法有直方图、饼图、散点图和折线图。
直方图可以展示数据的分布情况,横轴表示数据的取值范围,纵轴表示数据的频数或频率;饼图可以展示数据的占比情况,将数据按照不同类别进行划分;散点图可以表示两个变量之间的关系,横轴和纵轴分别表示两个变量的取值;折线图可以表示数据随时间的变化趋势。
数据的分析可以从不同的角度进行,包括描述性分析、比较分析和相关分析等。
描述性分析主要用于描述数据的特征,通过统计指标和图形展示数据的集中程度和离散程度;比较分析主要用于比较不同组别之间的差异,可以通过集中趋势和离散程度的比较来判断差异的大小;相关分析主要用于研究变量之间的关系,可以通过相关系数来度量变量之间的线性相关程度。
在进行数据的统计描述和分析时,需要注意以下几点。
首先,要选择合适的统计指标和图形描述方法,以便能够准确、全面地描述数据的特征;其次,要进行适当的数据清理和预处理工作,包括处理缺失值、异常值和重复值等;最后,要进行数据的可靠性和有效性检验,包括数据的抽样方法和样本大小的确定。
统计数据的表示与分析

统计数据的表示与分析统计数据的表示与分析是研究数据收集、整理、描述和解释的重要方法。
它包括数据的收集、数据的整理、数据的描述和数据的分析四个方面。
一、数据的收集数据的收集是统计学的基础,可以通过调查、观察、实验等方式进行。
收集数据时,要注意数据的真实性、准确性和全面性。
二、数据的整理数据的整理是对收集到的数据进行清洗、分类、排序等操作,以便于后续的描述和分析。
整理数据时,常用的方法有频数分布表、条形图、饼图等。
三、数据的描述数据的描述是对数据进行概括和总结的过程,常用的描述性统计量有众数、平均数、中位数、方差等。
通过这些统计量可以对数据的一般水平、波动情况等进行了解。
四、数据的分析数据的分析是对数据进行解释和推理的过程,常用的分析方法有假设检验、相关性分析、回归分析等。
通过这些方法可以对数据的背后规律进行探究。
在统计数据的表示与分析过程中,要熟练掌握各种统计方法,能够根据实际问题选择合适的统计量和方法进行分析,从而对数据进行科学合理的解释。
同时,还要注意保持数据的客观性,避免因为个人主观意识对数据进行分析,以确保分析结果的准确性。
习题及方法:1.习题:某班有50名学生,其中有20名男生,30名女生。
请用合适的统计图表示男生和女生的数量。
答案:可以用条形图来表示男生和女生的数量。
横轴表示男生和女生,纵轴表示数量。
男生用一个条形表示,女生用另一个条形表示,条形的高度分别对应男女生的人数。
2.习题:某商品在一个月内卖出了80件,其中有30件是在第一周卖出的,20件是在第二周卖出的,15件是在第三周卖出的,15件是在第四周卖出的。
请用合适的统计图表示每周卖出的商品数量。
答案:可以用条形图来表示每周卖出的商品数量。
横轴表示每周,纵轴表示数量。
每周卖出的商品数量用一个条形表示,条形的高度对应每周卖出的商品数量。
3.习题:某班级的学生身高数据如下:160cm, 165cm, 170cm, 168cm, 162cm, 166cm, 164cm, 163cm, 167cm, 161cm。
七年级数学第10章(数据的收集、整理与描述)单元测试试卷

一、填空题(共14小题,每题2分,共28分)1.在用表格整理数据时,我们通常用_______法来记录数据.2.为了掌握我校初中二年级女同学身高情况,从中抽测了60名女同学的身高,这个问题中的总体是_______,样本是_______.3.调查某县所有学生的课外作业量应选用_______.(调查方式)5.如果让你调查班级同学喜欢哪类运动,那么:(1)你的调查问题是_______;(2)你的调查对象是_______;(3)你要记录的数据是_______;(4)你的调查方法是_______.6.为了对收集到的数据实行整理和分析,我们需要制作统计表或统计图.统计图有、和.7.护士若要统计一病人一昼夜体温情况,应选用_______统计图.8.小亮是位足球爱好者,某次在练习罚点球时,他在10分钟之内罚球20次,共罚进15次,则小亮点球罚进的频数是,频率是.9.第29届奥运会在北京胜利召开,在一场射击比赛中,一个射击选手,连续射靶10次,其中1次射中10环,3次射中9环,5次射中8环,1次射中7环,射中______环的频数最大,其频率是______.10.连续抛一枚硬币1000次,你认为正面朝上大约有次,反面朝上的频率大约是.11.某校对1000名学生实行“个人爱好”调查,调查结果统计如图,则爱第11题好音乐的学生共有人.12.如图,是某报刊“百姓热线”一周内接到的热线电话统计图,其中相关环境保护问题最多,共有70个.请回答下列问题:(1)本周“百姓热线”共接到热线电话个.(2)相关交通问题的电话有个.13.请写出从2050年世界人口预测的条形统计图中获得的2条信息:第12题(1) ; (2) .14.如图,图中折线表示一人骑自行车离家的距离与时间的关系,骑车者九点离开家,十五点到家,根据折线图提供的信息: (1)该人离家最远距离是_____km ; (2)此人总共休息了_______分.二、选择题(共4小题,每题3分,共12分)15.能够反映出每个对象出现的频繁水准的是 ( )A .频数B .频率C .频数和频率D .以上答案都不对 16.某班实行民主选举班干部,要求每位同学将自己心中认为最合适的一位侯选上,投入推荐箱.这个过程是收集数据中的 ( ) A .确定调查对象 B .展开调查 C .选择调查方法 D .得出结论. 17.为反映某种股票的涨跌情况,应选择 ( ) A .扇形统计图 B .条形统计图 C .折线形统计图 D .以上三种都一样 18.小明在选举班委时得了28票,下列说法中错误的是 ( )A .不管小明所在班级有多少学生,所有选票中选小明的选票频率不变B .不管小明所在班级有多少学生,所有选票中选小明的选票频数不变C .小明所在班级的学生人数很多于28人D .小明的选票的频率不能大于1 三、解答题(60分)第13题第14题19.(5分)指出以下各情况哪些适宜用全面调查,哪些适宜作抽样调查?并简要说明理由.(1)某棉布厂了解一批棉花的纤维长度的情况;(2)一个水库养了某种鱼10万条,调查每条鱼的平均重量问题;(3)了解一个跳高训练班的训练成绩是否达到了预定的训练目标.20.(5分)指出下列问题中总体、样本分别是什么?(1)为了了解某商店的日营业额,现抽出某月里的6天的营业额实行统计;(2)为了了解某种酱油的质量合格情况,从几个大商场的柜台上共购买了30瓶该酱油实行化验.21.(5分)为获得某地区中小学视力情况的数据,找出保护视力的措施,小明在调查问卷中,提出了如下问题:(1)在你看书时,眼睛与书本的距离是______;(2)你学习时使用的灯具是______;(3)你喜欢穿的服装颜色是______.你认为他提出的问题恰当吗?如不恰当应怎样改正.22.(5分)李娟同学为考察学校的用水情况,她在4 月份一周内每天同一时刻连续记录了李娟估计学校4月份(按30天计算)的用水量约是______吨.23.(6分)某甲鱼养殖专业户共养甲鱼200条,为了与客户签订购销合同,对自己所养甲鱼的总重量实行估计,随意捕捞了5条,称得重量分别为1.5,1.4,1.6,2,1.8(单位:千克).(1)根据样本估计甲鱼的总重量约是多少千克?(2)若甲鱼的市场价为每千克150元,则该专业户卖出全部甲鱼的收入约为多少元?24.(6分)某班共50名学生实行一次调查,得到:喜欢的体育项足球蓝球乒乓球羽毛球目人数(频数)30 25 40 20 频率回答下列问题:(1)计算喜欢各项体育活动的人数占全班人数的百分比,(2)上述百分比能否用扇形统计图表示?为什么?(3)若想表示上述数据,可选用什么统计图?请画出该统计图.(8分)25.(6分)如下图(1)是我市某中学为地震灾区小伙伴“献爱心”自愿捐款情况制成的条形图,图(2)是该中学学生人数比例分布图,该校共有学生1450人,(1)八年级学生共捐款多少元?(2)该校学生平均每人捐款多少元?图1图226.(6分)据气象局统计,某市一年中每月的降水量分别是5、15、20、20、60、140、185、200、60、35、20、10(单位:毫米)(1)请你设计一张统计表,表达这段文字的信息.(2)再请你设计一个折线图,反映降雨量的变化情况.27.(8分)在学期结束前,某校想知道学生对本学期食堂饭菜的满意水准,特向有学校食堂用膳的1000人作了问卷调查,其结果如下:反馈意见满意很满意不满意很不满意人数550 100 300 50合计650 350(1)计算每一种反馈意见所占总人数的比率,并作出扇形统计图;(2)你认为本调查结果对学校领导改善食堂伙食有影响吗?为什么?其他坐公共汽车 44%28.(8分)某中学准备搬迁新校舍,在迁入新校舍之前,同学们就该校学生如何到校问题实行了一次调查,并将调查结果制成了表格、条形图和扇形统计图,请你根据图表信息完成下列各题:(1)此次共调查了多少位学生?(2)请将表格填充完整;(3)请将条形统计图补充完整.一、填空题(共14小题,每题2分,共28分)1.某校八年级共有学生300人,为了了解这些学生的体重情况,抽查了50•名学生的体重,对所得数据实行整理,在所得的频数分布表中,各小组的频数之和是________,若其中某一小组的频数为8,则这个小组的频率是_______,所有小组的频率之和是__________.2.为了了解社区居民的用水情况,小江调查了80户居民,他发现人均日用水量在基本标准量(50升)范围内的频率是75%,那么他所调查的居民超出了标准量的有_________户.3.已知样本:8,6,10,13,10,8,7, 10,11,12,10,8,9,11,9,12,10,12,11,9.在列频数分布表时,如果取组距为2,那么应分成_________组;9.5~11.5这个组的频率是_______.4.一个扇形图中各个扇形的圆心角的度数是45°、60°、120°、135°,则各扇形占圆的百分比分别是_______、_______、_______、_______.5.在对1200个数据实行整理的频率分布表中,各组的频数之和等于____,各组的频率之和等于_____.6.某校九年级(2)班有50名同学,综合素质评价“运动与健康”方面的等级统计如图所示,则该班“运动与健康”评价等级为A 的人数是 .7.如图,是抽样调查了50名同学获取新闻的途径绘制的扇形统计图,其中A 、B 、C 、D 分别表示通过广播电视、报纸杂志、网络及其他途径获取新闻的人数,则通过报纸杂志获取新闻的人数为________,表示通过网络获取新闻的人数的扇形的圆心角为________.8.学校有师生共1200人,绘制如图所示的扇形统计图.则表示教师人数的扇形的圆心角为__ _,学生有__________人.9.小明将2008年北京奥运会中国男子篮球队队员的年龄情况绘制成了如图所示的条形统计图,则中国篮球队共有___________名队员.10.为了创建绿色家园,从2008年6月1日起,全国统一禁止国内各超市向顾客无偿提供塑料袋.这天本市环保局向永丰花苑小区居民发放了500只环保布袋,以减少使用塑料袋产生的白色污染.为了了解塑料袋白色污染的情况,某校七(2)班的同学对有2500户居民的某小区的25个家庭实行了一天丢弃塑料袋情况的调查,统计结果如下:第9题第6题第7题 第8题以此为样本,估计这个小区一天丢弃塑料袋总数大约是_________个.11.2008年5月12日下午的那一场大地震,让四川汶川县多少孩子失去校园,学习用品也被掩埋在废墟当中.为了让灾区的孩子能早日返回学校读书,本市某班全体同学在“献爱心”活动中,都捐了图书,捐书的情况如下表:每人捐书的册数 5 10 15 20相对应的捐书人17 22 4 2数根据题目中的所给条件回答下列问题:该班学生共有_______名;全班一共捐_______册图书.12.你喜欢足球吗?下面是对某学校七年级学生的调查结果:男同学女同学喜欢的75 24不喜欢的15 36则男同学中喜欢足球的人数占全体同学的百分比是______.13.有一些乒乓球,不知其数,先取6个作了标记,把它们放回袋中,混合均匀后又取了20个,发现含有两个做标记的,能够估计这袋乒乓球有______个.14.“在一次考试中,考生有2万多名,如果为了得到这些考生的数学成绩的平均水平,若将他们的成绩全部相加再除以考生的总数,那将是十分麻烦的,那么怎样才能了解这些考生的数学平均成绩呢?”“通常,在考生很多的情况下,我们是从中抽取部分考生(比如500名)的成绩,用他们的平均成绩去估计所有考生的平均成绩.”在上述文字表述中,提到了调查的两种方式是____ __和___ ___;反映了用样本估计总体的数学思想,其中,总体是___ ___,样本是__ ____,请用较简洁的语言,举一个在实际生活中,使用同种思想解决问题的例子,写在下面:___.二、选择题(共4小题,每题3分,共12分)第16题15.要了解一个城市的气温变化情况,下列观测方法最可靠的一种方法是( )A .一年中随机选中20天实行观测B .一年中随机选中一个月实行连续观测;C .一年四季各随机选中一个月实行连续观测D .一年四季各随机选中一个星期实行连续观测.16.为了了解本校九年级学生的体能情况,随机抽查了其中30名学生,测试了1分钟仰卧起坐的次数,并绘制成如图10-5所示的频数分布直方图,请根据图示计算,仰卧起坐次数在25~30次的频率为( ) A .0.1 B .0.2 C .0.3 D .0.417.天籁音乐行出售三种音乐CD ,即古典音乐、流行音乐、民族音乐,为了表示这三种唱片的销售量占总销售的百分比,应该用( )A .扇形统计图B .折线统计图C .条形统计图D .以上都能够 18.为了了解我市6000名学生参加的初中毕业会考数学考试的成绩情况,从中抽取了200名考生的成绩实行统计,在这个问题中,下列说法:(1)这6000名学生的数学会考成绩的全体是总体;(2)每个考生是个体;(3)200名考生是总体的一个样本;(4)样本容量是200,其中说法准确的有( )A .4个B .3个C .2个D .l 个三、解答题(共60分) 19.(5分)“六一”儿童节期间,为活跃同学们的文化生活,少儿影剧院免费向儿童开放.小红调查了某一天看电影的学生最喜欢四部电影中的哪一部,调查结果如下: A A B C A D A C D B B C A D C B A D A A C D B C A C D A B B B D A C A D B A C D 其中,A 代表《海底总动员》,B 代表《黑客帝国》,C 代表《终结者》,D 代表《极度深寒》.根据上面的情况,制出统计表,并说出该电影院四部电影中最受欢迎的是哪一部.20.(5分)下面记录了某班级男同学一次立定跳远的成绩:(单位:米)1.25 1.40 1.29 1.41 1.27 1.081.21 1.15 1.43 1.32 1.30 1.121.43 1.50 1.36 1.47 1.22 1.241.24 1.52 1.39 1.45 1.31 1.321.19 1.35 1.44 1.29 1.27 1.41(1)根据以上成绩制作统计表;(2)参加立定跳远的男同学一共有______人;(3)成绩超过1.29米的男同学一共有______人,占男同学总数的______%;(4)成绩在______段的男同学人数最多,是______人;(5)这次立定跳远最差成绩是______,最好成绩是______,它们相差______.21.(5分)老张要对某居住小区所聘用的物业管理公司的“服务质量”进行调查,他从不同住宅中随机选取300名入住时间较长的居民进行调查,并将得到的数据制成扇形统计图(如图所示).(1)在这个调查中,对“服务质量”表现“满意”的有人;(2)请估计该社区2000名居民对“服务质量”表现为“基本满意”以上的人数(包含“基本满意”、“满意”、“非常满意”).22.(5分)红星煤矿人事部欲从内部招聘管理人员一名,对甲、乙、丙三名候选人进行专业知识测试,成绩如下表所示;并依录用的程序,组织200名职工对三人进行民主评议投票推荐,三人得票率如图所示.(没有弃权票,每位职工只能投1票,每得1票记作1分)(1)请填出三人的民主评议得分:甲得 分,乙得 分,丙得 分; (2)根据招聘简章,人事部将专业知识、民主评议二项得分按6:4的比例确定各人成绩,成绩优者将被录用.那么 将被录用,他的成绩为 分.23.(6分)如图是李大爷的孙女小丽统计一周内各种雪糕的销售数量,你能根据这张图告诉李大爷明天怎样进货吗?测试项目测试成绩(单位:分)甲 乙 丙专业知识 73 74 67丙 31% 甲35%乙 34% 雪糕的数量A B C D 雪糕的品种E24.(6分)某公司销售部有营销员15人,销售部为了制定销售计划,调查了这15人某日某种商品的日销售额,统计数据见下表:(1)求这15位营销员该日的平均销售量是多少?(2)假设销售部负责人把营销人员的日销售额定为320件,你认为合理吗?为什么?25.其中:≤50时,空气质量为优;50<≤100时,空气质量为良;100<≤150时,空气质量为轻微污染.(1)如果要利用面积分别表示空气质量的优、良及轻微污染,那么这三类空气质量的面积之比为多少?(2)估计该城市一年(以365天计)中有多少天空气质量达到良以上;(3)保护环境人人有责,你能说出几种保护环境的好方法吗?26.(6分)为了估算冬季取暖一个月使用天然气的开支情况,从11月15日起,小刚连续八天每晚记录了天然气表显示的读数如下表(单位:m3).小刚妈妈11月15日买了一张面值500元的天然气使用卡,已知每立方米天然气1.60元,请你估计这张卡够小刚家用一个月(按30天算)吗?27.(8分)为了保护环境,某校环保小组成员小明收集废电池,第一天收集1号电池4节,5号电池5节,总质量为460克,第二天收集1号电池2节,5号电池3节,总质量240克.(1)求1号电池和5号电池每节各重多少克;(2)学校环保小组为了估计四月份收集电池的总质量,他们随机抽取了该月某5天收集废电池的节数如下表:分别计算这5天两种废电池每天平均收集多少节?并由此估计4月份环保小组收集废电池的总质量是多少克?28.(8分)阅读对人成长的影响是巨大的,一本好书往往能改变人的一生.1995年联合国教科文组织把每年4月23日确定为“世界读书日”.如图是某校三个年级学生人数分布扇形统计图,其中八年级人数为408人,下表是该校学生阅读课外书籍情况统计表.请你根据图表中的信息,解答下列问题:(1)求该校八年级的人数占全校总人数的百分率.,的值.(2)求表(1)中A B Array(3)该校学生平均每人读多少本课外书?图书种类频数频率科普常识840 B名人传记816 0.34漫画丛书A0.25其它144 0.06。
人教版数学八年级下册20章《数据的分析》教案

一、教学内容
本节课选自人教版数学八年级下册第20章《数据的分析》。教学内容主要包括以下几部分:
1.平均数、中位数、众数的概念及求法;
2.方差的定义和计算方法;
3.用平均数、中位数、众数和方差描述数据的集中趋势和离散程度;
4.数据的收集、整理、表述及分析;
5.结合实际问题,运用本章所学知识解决数据分析和数据处理问题。
实践活动环节,学生们表现得比较积极,但有些小组在数据分析时还是显得有些吃力。这说明学生们在将理论知识运用到实际问题解决上还存在一定难度。针对这一点,我打算在接下来的教学中,增加一些类似的实践活动,让学生们有更多的机会去实践、去操作,以提高他们的实际应用能力。
在讲解重点难点时,我发现有些学生对方差的计算过程理解不够透彻。这可能是因为我讲解得不够详细,或者学生们对方差的概念还不够熟悉。为了帮助学生更好地理解方差,我计划在下一节课中,再次强调方差的意义和计算方法,并通过更多的实例来进行讲解。
(四)学生小组讨论(用时10分钟)
1.讨论主题:学生将围绕“数据分析在实际生活中的应用”这一主题展开讨论。他们将被鼓励提出自己的观点和想法,并与其他小组成员进行交流。
2.引导与启发:在讨论过程中,我将作为一个引导者,帮助学生发现问题、分析问题并解决问题。我会提出一些开放性的问题来启发他们的思考,如“在什么情况下使用平均数更合适?”
(三)实践活动(用时10分钟)
1.分组讨论:学生们将分成若干小组,每组讨论一个与数据分析相关的实际问题,如“如何比较两个班级的数学成绩”。
2.实验操作:为了加深理解,我们将进行一个简单的实验操作。比如,收集两组数据,计算它们的平均数、中位数、众数和方差,并分析这些统计量的实际意义。
人教版七年级数学下册第10章 数据的收集、整理和描述期末复习题(无答案)

人教版七年级数学下册第10 章数据的收集、整理与描述期末复习题一、选择题1.当前,“低头族”已成为热门话题之一,小颖为了了解路边行人边走路边低头看手机的情况,她应采用的收集数据的方式是()A.对学校的同学发放问卷进行调查B.对在路边行走的学生随机发放问卷进行调查C.对在图书馆里看书的人发放问卷进行调查D.对在路边行走的路人随机发放问卷进行调查2.下面获取数据的方法不正确的是()A.我们班同学的身高用测量方法B.快捷了解历史资料情况用观察方法C.抛硬币看正反面的次数用实验方法D.全班同学最喜爱的体育活动用访问方法3.某同学想了解学校门前10 分钟内通行的车辆数量,他应采取的收集数据方法为()A.查阅资料B.实验C.问卷调查D.观察4.以下问题,不适合采用全面调查方式的是()A.调查全班同学对商丘“京雄商”高铁的了解程度B.“冠状病毒”疫情期间,对所有疑似病例病人进行病毒检测C.为准备开学,对全班同学进行每日温度测量统计D.了解梁园区全体中小学生对“冠状病毒”的知晓程度5.某校为了了解七年级女同学的800 米跑步情况,随机抽取部分女同学进行800 米跑测试,按照成绩分为优秀、良好、合格、不合格四个等级,绘制了如图所示统计图.该校七年级有400 名女生,则估计800 米跑不合格的约有()A.2 人B.16 人C.20 人D.40 人6.下列调查方式,你认为最合适的是()A.为了了解同学们对央视《主持人大赛》栏目的喜爱程度,小华在学校随机采访了10 名七年级学生B.咸阳机场对旅客上飞机进行安检,采用抽样调查方式C.为了了解西安市七年级学生的身高情况,采用全面调查方式D.为了了解我省居民的日平均用电量,采用抽样调查方式7.有下列调查:其中不适合普查而适合抽样调查的是()①了解地里西瓜的成熟程度;②了解某班学生完成 20 道素质测评选择题的通过率;③了解一批导弹的杀伤范围;④了解成都市中学生睡眠情况.A..①②③B..①②④C.①③④D..②③④8.精准扶贫是全面建成小康社会的重要保障,某乡为了解果农的年收入情况,从全乡果农中随机抽取50 户果农进行调查,这50 户果农的年收入是()A.样本B.样本容量C.个体D.总体9.某县为了传承中华优秀传统文化,组织了一次全县600 名学生参加的“中华经典诵读”大赛.为了解本次大赛的选手成绩,随机抽取了其中50 名选手的成绩进行统计分析.在这个问题中,下列说法:①这600 名学生的“中华经典诵读”大赛成绩的全体是总体.②每个学生是个体.③50 名学生是总体的一个样本.④样本容量是50 名.其中说法正确的有()A.1 个B.2 个C.3 个D.4 个10.为了了解某地区6000 名学生参加初中学业水平考试数学成绩情况,从中随机抽取了200 名考生的数学成绩进行统计分析.在这个问题中,下列说法:①这6000 名学生考试的数学成绩的全体是总体;②每个考生是个体;③所抽取的200 名考生是总体的一个样本;④样本容量是200,其中正确说法的个数是()A.4 个B.3 个C.2 个D.1 个11.小文同学统计了某栋居民楼中全体居民每周使用手机支付的次数,并绘制了直方图.根据图中信息,下列说法错误的是()A.这栋居民楼共有居民125 人B.每周使用手机支付次数为28~35 次的人数最多C.有的人每周使用手机支付的次数在35~42 次D.每周使用手机支付不超过21 次的有15 人12.如图是我市某景点6 月份内1~10 日每天的最高温度折线统计图,由图信息可知该景点这10 天中,气温26℃出现的频率是()A.3 B.0.5 C.0.4 D.0.313.如图是某组15 名学生数学测试成绩统计图,则成绩高于或等于60 分的人数是()A.4 人B.8 人C.10 人D.12 人14.为了了解某校九年级学生的体能情况,随机抽查了该校九年级若干名学生,测试了1 分钟仰卧起坐的次数,并绘制成如图所示的直方图,请根据图示计算,仰卧起坐次数在25~30 次的学生人数占被调查学生人数的百分比为()A.40% B.30% C.20% D.10%15.某班级的一次数学考试成绩统计图如图,则下列说法错误的是()A.得分在70~80 分的人数最多B.该班的总人数为40C.人数最少的得分段的频数为2D.得分及格(≥60)的有12 人16.为了了解2019 年北京市乘坐地铁的每个人的月均花费情况,相关部门随机调查了1000 人乘坐地铁的月均花费(单位:元),绘制了如下频数分布直方图,根据图中信息,下面三个推断中,合理的是()①小明乘坐地铁的月均花费是75 元,那么在所调查的1000 人中一定有超过一半的人月均花费超过小明;②估计平均每人乘坐地铁的月均花费的不低于60 元;③如果规定消费达到一定数额可以享受折扣优惠,并且享受折扣优惠的人数控制在20%左右,那么乘坐地铁的月均花费达到120 元的人可享受折扣.A.①②B.①③C.②③D.①②③二、填空题17.为了解游客对江淮文化园、苏中七战七捷纪念馆、中洋河豚庄园和人民广场四个旅游景区的满意率情况,某实践活动小组的同学给出以下几种调查方案:方案①:在多家旅游公司随机调查100 名导游;方案②:在江淮文化园景区随机调查100 名游客;方案③:在人民广场景区随机调查100 名游客;方案④:在上述四个景区各随机调查 100 名游客.在这四种调查方案中,最合理的是“方案”(填序号).18.为了了解某风景区一年中每天的旅游人数,抽取30 天中每天的旅游人数进行统计,那么,这个抽样调查的总体是.19.为了了解我市60000 名学生参加初中毕业升学数学考试的成绩情况,从中抽取了200 名考生的成绩进行统计,在这个问题中,样本容量是.20.某学校食堂为了了解服务质量,随机调查了来食堂就餐的200 名学生,调查的结果如图所示,根据图中给出的信息,这200 名学生中对该食堂的服务质表示不满意的有人.21.如图,某医院护士为一群流感患者测量体温并制成统计图表,在这些病人中,体温超过37°(不包括37°)的流感患者共有人.22.为了解小学生的体能情况,抽取了某小学同年级50 名学生进行1 分钟跳绳测试,将所得数据整理后,画出如图所示的频数分布直方图(各组只含最小值,不含最大值),已知图中从左到右各组的频率分别a,0.3,0.4,0.2,设跳绳次不低于100 次的学生有b 人,则a,b 的值分别是.23.江涛同学统计了他家10 月份的长途电话明细清单,按通话时间画出直方图如图,则他家这个月打了长途电话的次数一共是.24.我市某校在举办的“优秀小作文”评比活动中,共征集到小作文若干篇,对小作文评比的分数(分数均为整数)整理后,画出如图所示的频数分布直方图,已知从左到右5 个小长方形的高的比为1:3:7:6:3,如果分数大于或等于80 分以上的小作文有72 篇,那么这次评比中共征集到的小作文有篇.25.某校学生“汉字听写”大赛成绩的频数直方图(每一组含前一个边界值,不含后一个边界值)如图所示,其中成绩为“优良”(80 分及以上)的学生有人.三、解答题26.调查作业:了解你所在学校学生本学期社会实践活动的情况.小明、小亮和小天三位同学在同一所学校上学.该学校共有三个年级,每个年级都有 6 个班,每个班的人数在30~40 之间.为了了解该校学生本学期社会实践活动的情况,他们各自设计了如下的调查方案:小明:我给每个班学号分别为1、2、11、12、21、22 的同学各发一份问卷,一两天就可以得到结果.小亮:我把要调查的问题放在某两个班的微信群里,这样群里的大部分人就可以完成调查的问题,并很快就可以反馈给我.小天:我给每个班发一份问卷,一两天也就可以得到结果了.根据以上材料回答问题:小明、小亮和小天三人中,哪一位同学的调查方案能较好地获得该校学生本学期社会实践活动的情况,并简要说明其他两位同学调查方案的不足之处.27.某校为了解学生最喜欢的球类运动情况,随机选取该校部分学生进行调查,要求每名学生只写一类最喜欢的球类运动,以下是根据调查结果绘制的统计图的一部分,根据以上信息,解答下列问题:(1)被调查学生的总人数为人.(2)最喜欢篮球的有人,最喜欢足球的学生数占被调查总人数的百分比为%.(3)该校共有1500 名学生,根据调查结果,估计该校最喜欢排球的学生人数有多少?28.为了丰富校园文化生活,某校计划在午间校园广播台播放“百家讲坛”的部分内容为了了解学生的喜好,抽取若干名学生进行问卷调查(每人只选一项内容),整理调查结果,绘制统计图如下:请根据统计图提供的信息回答以下问题:(1)这一调查属于(选填“抽样调查”或“普查”),抽取的学生数为名;(2)估计喜欢收听易中天《品三国》的学生约占全校学生的%(精确到小数点后一位);(3)已知该校女学生共有1800 名,则该校喜欢收听刘心武评《红楼梦》的女学生大约有多少名?29.调查某中学七年级学生身体素质情况,体育老师以七年级(1)班 60 位学生为样本进行一分钟跳绳次数测试,测试结果得出部分频数分布表和部分频数分布直方图,如下组别次数x 频数(人数)第 1 组80≤x<100 16第 2 组100≤x<120 8第 3 组120≤x<140 a第 4 组140≤x<160 16第 5 组160≤x<180 6请结合图表完成下列问题:(1)求表中的a 的值;(2)已知该校七年级共有学生720 人,请你估计一分钟跳绳次数不低于140 次的七年级学生有多少名?30.九(1)班同学为了解2019 年某小区家庭月均用水情况,随机调查了该小区部分家庭,并将调查数据进行如下整理.请解答以下问题:月均用水量x(t)频数(户)频率0<x≤5 60.125<x≤10 0.2410<x≤15 16 0.3215<x≤20 10 0.2020<x≤25 425<x≤30 20.04(1)把上面的频数分布表和频数分布直方图补充完整;(2)求该小区用水量不超过15t 的家庭占被调查家庭总数的百分比;(3)若该小区有1000 户家庭,根据调查数据估计,该小区月均用水量超过20t 的家庭大约有多少户?31.校园手机现象已经受到社会的广泛关注.某校的一个兴趣小组对“是否赞成中学生带手机进校园”的问题,在该校校园内进行了随机调查.并将调查数据作出如下不完整的整理;看法频数频率赞成5无所谓0.1反对40 0.8(1)本次调查共调查了人;(直接填空)(2)请把整理的不完整图表补充完整:(3)若该校有3000 名学生,请您估计该校持“反对”态度的学生人数.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
偏度: g1
1 s3
n
(Xi
i 1
X )3
峰度: g2
1 s4
n
(Xi
i 1
X)4
偏度反映分布的对称性,g1 >0 称为右偏态,此时数据位于均值 右边的比位于左边的多;g1 <0 称为左偏态,情况相反;而 g1 接近 0 则可认为分布是对称的.
峰度是分布形状的另一种度量,正态分布的峰度为 3,若 g2 比 3 大很多,表示分布有沉重的尾巴,说明样本中含有较多远离均值的数
数学建模与数学实验
数据的统计描述和分析
实验目的
1.直观了解统计基本内容. 2.掌握用数学软件包求解统计问题.
实验内容
1.统计的基本理论. 2.用数学软件包求解统计问题. 3.实验作业.
数
据
统计的基本概念
的
统
计
参数估计
描
述
和
假设检验
分
析
一、统计量
1. 表示位置的统计量—平均值和中位数.
平均值(或均值,数学期望): X
总体的某些参数 i (i=1,2,…,k),由于 k 个参数一定可以
表为不超过 k 阶原点矩的函数,很自然就会想到用样本的 r 阶原点矩去估计总体的 r 阶原点矩,用样本的一些原点 矩的函数去估计总体的相应的一些原点矩的函数,再将 k 个 参数反解出来,从而求出各个参数的估计值.这就是矩估计法, 它是最简单的一种参数估计法.
据,因而峰度可用作衡量偏离正态分布的尺度之一.
4.
k 阶原点矩:Vk
1 n
n i 1
X
k i
k 阶中心矩:U k
1 n
n
(Xi
i 1
X )k
二、分布函数的近似求法
1.整理资料: 把样本值 x1,x2,…,xn 进行分组,先将它们依大小次序排列,
得
x1*
x2*
x
* n
.在包含
[
x1*
,
xn*
]
0.15
0.1
0.05
0
-4
-2
0246来自2. 2 分布 2 (n)
若随机变量 X1,X2,…,Xn 相互独立,都 服从标准正态分布 N(0,1),则随机变量
Y=
X
2 1
X
2 2
X
2 n
服从自由度为 n 的 2 分布,记为 Y~ 2 (n).
Y 的均值为 n,方差为 2n.
0.16
0.14
0.12
n
p(x1,1, ,k ) p( x2 ,1, ,k ) p( xn ,1, ,k ) p( xi ,1, ,k ) i 1
2. 区间估计:构造两个函数 i1 ( X1,X2,…,Xn)和 i2 ( X1,X2,…, Xn),把( i1 , i2 )作为参数 i 的区间估计.
一、点估计的求法
(一)矩估计法
假设总体分布中共含有 k 个参数,他们往往是一些原 点矩或一些原点矩的函数,例如,数学期望是一阶原点矩, 方差是二阶原点矩与一阶原点矩平方之差等.因此,要想估计
若 F~ F(n1,n2),则
1 F
~
F (n2 , n1 )
F(10,50)分布的密度函数曲线
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0
0.5
1
1.5
2
2.5
3
返回
无论总体 X 的分布函数 F(x;1, 2 ,, k )的类型已知或未知,我
们总是需要去估计某些未知参数或数字特征,这就是参数估计问题.即参
数估计就是从样本(X1,X2,…,Xn)出发,构造一些统计量ˆi ( X1,X2,…,
Xn)(i=1,2,…,k)去估计总体 X 中的某些参数(或数字特征) i(i=1,
2,…,k).这样的统计量称为估计量.
1. 点估计:构造(X1,X2,…,Xn)的函数ˆi ( X1,X2,…,Xn) 作为参数 i 的点估计量,称统计量ˆi 为总体 X 参数 i 的点估计量.
fi
ni n
.
3.作频率直方图:在直角坐标系的横轴上,标出
x1'
,
x
' 2
,
,
x
' n
各点,分别以
(
xi'
,
x' i 1
]
为底边,作高为
fi xi'
的矩形, xi'
xi'1 xi' , i 1,2,, n 1,即得
频率直方图.
三、几个在统计中常用的概率分布
1.正态分布N (m,s 2 )
密度函数:p(x)
1
( xm )2
e 2s 2 分布函数:F (x)
2p s
其中 m 为均值,s 2 为方差, x .
1
e dy x
( ym)2 2s 2
2ps
标准正态分布:N(0,1)
密度函数
j(x)
1
x2
e2
2p
分布函数
F(x)
1
x
y2
e 2 dy
2p
0.4
0.35
0.3
0.25
0.2
0.1
0.08
0.06
0.04
0.02
0
0
5
10
15
20
3. t 分布 t(n)
若 X~N(0,1),Y~ 2 (n),且相互独
立,则随机变量
T X Y
n
服从自由度为 n 的 t 分布,记为 T~t(n). t(20)分布的密度函数曲线和 N(0,1)的
曲线形状相似.理论上 n 时,T~t(n) N(0,1).
1 n
n i 1
Xi
中位数:将数据由小到大排序后位于中间位置的那个数值.
2. 表示变异程度的统计量—标准差、方差和极差.
标准差: s
[ 1 n 1
n i1
(Xi
1
X )2 ]2
它是各个数据与均值偏离程度的度量.
方差:标准差的平方.
极差:样本中最大值与最小值之差.
3. 表示分布形状的统计量—偏度和峰度
(二)极大似然估计法
极大似然法的想法是: 若抽样的结果得到样本观测值 x1,x2,…,xn, 则我们应当选取参数 i 的
值,使这组样本观测值出现的可能性最大.即构造似然函数:
L(1, 2 ,, k ) P( X1 x1, X 2 x2 ,, X n xn ) P( X1 x1 )P( X 2 x2 )P( X n xn )
0.4
0.35
0.3
0.25
0.2
0.15
0.1
0.05
0
-6
-4
-2
0
2
4
6
4. F 分布 F(n1,n2)
若 X~ 2 (n1),Y~ 2 (n2),且相互独立,则随机变量
X
F n1 Y
n2
服从自由度为(n1,n2)的 F 分布,记作 F~ F(n1,n2).
由 F 分布的定义可以得到 F 分布的 一个重要性质:
的区间[a,b]内插入一些等分点:
a
x1'
x2'
xn'
b,
注意要使每一个区间
(
x
' i
,
xi'
1
]
(i=1,2,…,n-1)
内都有样本观测值 xi(i=1,2,…,n-1)落入其中.
2.求出各组的频数和频率:统计出样本观测值在每个区间
(
xi'
,
x' i 1
]
中出
现的次数 ni ,它就是这区间或这组的频数.计算频率