时间序列模型分析报告地各种stata命令
stata操作介绍之时间序列-四

ARIMA模型
dfuller 检验: . dfuller fylltemp, lag(3)
说明:P值为0.089,大于0.05,故不能拒绝原假设,说明该 变量满足稳定性检验;
ARIMA模型
dfgls检验: . dfgls fylltemp, maxlag(3) notrend
说明:P值为0.0,小于0.05,故拒绝原假设,说明该变量不 满足稳定性检验;
说明:由上图可知,常数项与一期滞后变量系数都是统计显 著的,卡方检验也显著。
ARIMA模型
生成残差: . predict fylres, res . corrgram fylres ,lags(9)
说明:由图可知,统计量对应的P值为0.6574,不能拒绝原 假设,即认为残差不存在自相关。因此,认为变量fylltemp 使用AR(1)进行分析是合适的。
平滑分析
生成移动平均值(1):
. gen water3=(water[ _n-1]+water[ _n]+water[ _n+1])/3
平滑分析
生成移动平均值(2): . tssmooth ma water5=water,window(2 1 2)
注:tssmooth:表示移动平均值平滑(加权或不加权); window(2 1 2):表示使用该值的前两个值、该值与该值的
说明:由图可知,lag为0时,交叉相关性最强(线条最长), 且为负。
自相关分析
交叉相关表: . xcorr wNAO fylltemp if year >=1970 & year <=1990,lags(7) table
ARIMA模型
时间序列中的自相关集成移动平均模型 (autoregressive integrated moving average简称 ARIMA),是指将非平稳时间序列转化为平稳时间 序列,然后将因变量仅对它的滞后值以及随机误差 项的现值和滞后值进行回归所建立的模型。
与时间序列相关的STATA命令及其统计量的解析完整版

与时间序列相关的S T A T A命令及其统计量的解析Document serial number【NL89WT-NY98YT-NC8CB-NNUUT-NUT108】与时间序列相关的S T A T A命令及其统计量的解析残差U 序列相关:①DW 统计量——针对一阶自相关的(高阶无效)STATA 命令:1.先回归2.直接输入dwstat统计量如何看:查表②Q 统计量——针对高阶自相关correlogram-Q-statisticsSTATA 命令:1.先回归reg2.取出残差predict u,residual(不要忘记逗号)3. wntestq u Q统计量如何看:p 值越小(越接近0)Q 值越大——表示存在自相关具体自相关的阶数可以看自相关系数图和偏相关系数图:STATA 命令:自相关系数图:ac u( 残差) 或者窗口操作在 Graphics ——Time-series graphs ——correlogram(ac)偏相关系数图:pac u 或者窗口操作在Graphics——Time-series graphs—— (pac)自相关与偏相关系数以及Q 统计量同时表示出来的方法:corrgram u或者是窗口操作在Statistics——Time-series——Graphs—— Autocorrelations&Partial autocorrelations③LM 统计量——针对高阶自相关STATA 命令:1.先回归reg2.直接输入命令estate bgodfrey,lags(n) 或者窗口操作在 Statistics——Postestimation(倒数第二个)——Reports andStatistics(倒数第二个) ——在里面选择 Breush-Godfrey LM(当然你在里面还可以找到方差膨胀因子还有DW 统计量等常规统计量)LM 统计量如何看:P 值越小(越接近 0)表示越显着(显着拒绝原假设),存在序列相关具体是几阶序列相关,你可以把滞后期写为几,当然默认是 1,(通常的方法是先看图,上面说的自相关和偏相关图以及Q 值,然后再利用LM 肯定)。
stata操作介绍之时间序列分析

时间序列构成分析就是要观察现象在一个相当长的时期内, 由于各个影响因素的影响,使事物发展变化中出现的长期趋 势、季节变动、循环变动和不规则变动。
通过测定和分析过去一段时间之内现象的发展趋势,可以认 识和掌握现象发展变化的规律性,为统计预测提供必要的条 件,同时也可以消除原有时间序列中长期趋势的影响,更好 地研究季节变动和循环变动等问题。测定和分析长期趋势的 主要方法是对时间序列进行修匀。
timevar的格式为%tc, 0=1jan1960 00:00:00.000,1=1jan1960 00:00:00.001 即0代表1960年1月1日的第一秒,1为1960年1月1日的第二秒,依次后推。 timevar的格式为%td,0=1jan1960,1=2jan1960;即0为1960年第一天,1 为1960年第二天,依次后推。 timevar的格式为%tw,0=1960w1,1=1960w2;即0为1960年第一周,1 为1960年第二周,依次后推。 timevar的格式为%tm,0=1,1=;即0为1960年第一月,1为1960年第二 月,依次后推。 timevar的格式为%tq,0=1960q1,1=1960q2;即0为1960年第一季,1为 1960年第二季,依次后推。 timevar的格式为%th,0=1960h1,1=1960h2;即0为从1960起的第一个半 年,1为从1960年起第二个半年,依次后推。 timevar的格式为%ty,1960=1960,1961=1960 timevar的格式为%tg
义时间单位,或者定义时间周期(即timevar两个观测值 之间的周期数)。Options的相关描述如表1所示。
Page 3
STATA从入门到精通
时间单位
格式说明
Clocktime
stata命令大全(全)

*
*-- F(4,373) = 855.93检验除常数项外其他解释变量的联合显著性
*-- corr(u_i, Xb)=-0.2347
*-- sigma_u, sigma_e, rho
* rho = sigma_uA2/(sigma_uA2+sigma_eA2)
*空间计量分析:SLM模型与SEM模型
*说明:STATA与Matlab结合使用。常应用于空间溢出效应(R&D)、财政 分权、地方政府公共行为等。
、常用的数据处理与作图
*指定面板格式
xtset id year(id为截面名称,year为时间名称)
xtdes /*数据特征*/
xtsum logy h /*数据统计特征*/
drop if id==2/*注意用==*/
*如何得到连续year或id编号(当完成上述操作时, 为形成panel格式,需要用egen命令)
ege n year_ new二group(year)
xtset id year_ new
**保留变量或保留观测值
keep inv /*删除变量*/
**或
keep if year==2000
dis e(sigma_u)A2/(e(sigma_u)A2+e(sigma_e)A2)
个体效应是否显著?
*F(28,373) =338.86 HO: al=a2 = a3 = a4 = a29
*Prob > F = 0.0000表明,固定效应高度显著
*---如何得到调整后的R2即adj-R2?
ereturn list
考虑中国29个省份的C-D生产函数
stata命令大全(全)

********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
与时间序列相关的STATA_命令及其统计量的解析

与时间序列相关的STATA命令及其统计量的解析残差U序列相关:⑩W统计量一一针对一阶自相关的(高阶无效)STATA命令:1. 先回归2. 直接输入dwstat统计量如何看:查表GQ统计量---- 针对高阶自相关correlogram-Q-statisticsSTATA命令:1. 先回归reg2. 取出残差predict u,residual(不要忘记逗号)3 ・wntestq u Q统计量如何看:p值越小(越接近0)Q值越大表示存在自相关具体自相关的阶数可以看自相关系数图和偏相关系数图:STATA命令:自相关系数图:ac u(残差)或者窗口操作在Graphics -------- Time-series graphs ------- c orrelogram(ac)偏相关系数图:pac u 或者窗口操作在Graphics -------- Time-series graphs ------ (pac)自相关与偏相关系数以及Q统计量同时表示出来的方法:corrgram u 或者是窗口操作在Statistics ----- Time-series ------ G raphs ----- Autocorrelations&Partial autocorrelations③L M统计量 ----针对高阶自相关STATA命令:1 .先回归reg2. 直接输入命令estate bgodfrey,lags(n)或者窗口操作在Statistics——Postestimation(倒数第二个) ------ Reports and Statistics(倒数第二个)------- 在里面选择Breush-Godfrey LM (当然你在里面还可以找到方差膨胀因子还有DW统计量等常规统计量)LM统计量如何看:P值越小(越接近0)表示越显著(显著拒绝原假设),存在序列相关具体是几阶序列相关,你可以把滞后期写为几,当然默认是1,(通常的方法是先看图,上面说的自相关和偏相关图以及Q值,然后再利用LM肯定)。
stata命令大全(全)
********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
与时间序列相关的STATA_命令及其统计量的解析资料

与时间序列相关的STATA 命令及其统计量的解析残差U 序列相关:①DW 统计量——针对一阶自相关的(高阶无效)STATA 命令:1.先回归2.直接输入dwstat统计量如何看:查表②Q 统计量——针对高阶自相关correlogram-Q-statisticsSTATA 命令:1.先回归reg2.取出残差predict u,residual(不要忘记逗号)3.wntestq u Q统计量如何看:p 值越小(越接近0)Q 值越大——表示存在自相关具体自相关的阶数可以看自相关系数图和偏相关系数图:STATA 命令:自相关系数图:ac u( 残差) 或者窗口操作在Graphics ——Time-series graphs —— correlogram(ac)偏相关系数图:pac u 或者窗口操作在Graphics——Time-series graphs—— (pac)自相关与偏相关系数以及Q 统计量同时表示出来的方法:corrgram u 或者是窗口操作在Statistics——Time-series——Graphs—— Autocorrelations&Partial autocorrelations③LM 统计量——针对高阶自相关STATA 命令:1.先回归reg2.直接输入命令estate bgodfrey,lags(n) 或者窗口操作在Statistics——Postestimation(倒数第二个)——Reports and Statistics(倒数第二个) ——在里面选择Breush-Godfrey LM(当然你在里面还可以找到方差膨胀因子还有DW 统计量等常规统计量)LM 统计量如何看:P 值越小(越接近0)表示越显著(显著拒绝原假设),存在序列相关具体是几阶序列相关,你可以把滞后期写为几,当然默认是1,(通常的方法是先看图,上面说的自相关和偏相关图以及Q 值,然后再利用LM 肯定)。
时间序列模型分析的各种stata命令

时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更就是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象与过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1、1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96、dta, clearlist in 1/20gen Lgnp = L、gnptsset datelist in 1/20gen Lgnp = L、gnp2)检查就是否有断点:tsreport, reportuse gnp96、dta, cleartsset datetsreport, reportdrop in 10/10list in 1/12tsreport, reporttsreport, report list /*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport, report listlist in 1/124)追加样本:tsappenduse gnp96、dta, cleartsset datelist in -10/-1sumtsappend , add(5) /*追加5个观察值*/list in -10/-1sum5)应用:样本外预测: predictreg gnp96 L、gnp96predict gnp_hatlist in -10/-16)清除时间标识: tsset, cleartsset, clear1、2变量的生成与处理1)滞后项、超前项与差分项 help tsvarlistuse gnp96、dta, cleartsset dategen Lgnp = L、gnp96 /*一阶滞后*/gen L2gnp = L2、gnp96gen Fgnp = F、gnp96 /*一阶超前*/gen F2gnp = F2、gnp96gen Dgnp = D、gnp96 /*一阶差分*/gen D2gnp = D2、gnp96list in 1/10list in -10/-12)产生增长率变量: 对数差分gen lngnp = ln(gnp96)gen growth = D、lngnpgen growth2 = (gnp96-L、gnp96)/L、gnp96gen diff = growth - growth2 /*表明对数差分与变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/101、3日期的处理日期的格式 help tsfmt基本时点:整数数值,如 -3, -2, -1, 0, 1, 2, 3 、、、、1960年1月1日,取值为 0;1)使用use B6_tsset、dta, cleartsset t, dailylistuse B6_tsset、dta, cleartsset t, weeklylist2)指定起始时点cap drop monthgenerate month = m(1990-1) + _n - 1format month %tmlist t month in 1/20cap drop yeargen year = y(1952) + _n - 1format year %tylist t year in 1/203)自己设定不同的显示格式日期的显示格式 %d (%td) 定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l nd j h q w _ 、 , : - / ' !cC Y M L ND J W定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写)M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年 (1 or 2)q 一年中的第几季度 (1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格)、 display a period(句号), display a comma(逗号): display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !! to display an exclamation point) 样式1:Format Sample date in format-----------------------------------%td 07jul1948%tdM_d,_CY July 7, 1948%tdY/M/D 48/07/11%tdM-D-CY 07-11-1948%tqCY、q 1999、2%tqCY:q 1992:2%twCY,_w 2010, 48-----------------------------------样式2:Format Sample date in format----------------------------------%d 11jul1948%dDlCY 11jul1948%dDlY 11jul48%dM_d,_CY July 11, 1948%dd_M_CY 11 July 1948%dN/D/Y 07/11/48%dD/N/Y 11/07/48%dY/N/D 48/07/11%dN-D-CY 07-11-1948----------------------------------clearset obs 100gen t = _n + d(13feb1978)list t in 1/5format t %dCY-N-D /*1978-02-14*/list t in 1/5format t %dcy_n_d /*1978 2 14*/list t in 1/5use B6_tsset, clearlisttsset t, format(%twCY-m)list4)一个实例:生成连续的时间变量use e1920、dta, clearlist year month in 1/30sort year monthgen time = _ntsset timelist year month time in 1/30generate newmonth = m(1920-1) + time - 1tsset newmonth, monthlylist year month time newmonth in 1/301、4图解时间序列1)例1:clearset seed 13579113sim_arma ar2, ar(0、7 0、2) nobs(200)sim_arma ma2, ma(0、7 0、2)tsset _ttsline ar2 ma2* 亦可采用 twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t2)例2:增加文字标注sysuse tsline2, cleartsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" ///3470 25dec2002 "x-mas", orient(vert)) 3)例3:增加两条纵向的标示线 sysuse tsline2, clear tsset daytsline calories, tline(28nov2002 25dec2002) * 或采用 twoway line 命令 local d1 = d(28nov2002) local d2 = d(25dec2002)line calories day, xline(`d1' `d2') 4)例4:改变标签tsline calories, tlabel(, format(%tdmd)) ttitle("Date (2002)") tsline calories, tlabel(, format(%td))二、ARIMA 模型与SARMIA 模型ARIMA 模型的基本思想就是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
stata时间序列代码

stata时间序列代码
Stata的时间序列分析功能非常强大,可以用于各种时间序列分析任务,包括:
1.时间序列的描述性统计分析
2.时间序列的趋势、季节性和残差分析
3.时间序列的平稳性检验
4.时间序列的预测
以下是一些常用的Stata时间序列代码:
描述性统计分析
●use data.dta
●describe y
这段代码将显示变量y的描述性统计,包括均值、中位数、标准差、最小值、最大值等。
趋势、季节性和残差分析
●tsset y
●tsplot y
●detrend y
●deseasonalize y
●autoreg y
这段代码将显示变量y的趋势、季节性和残差分析结果。
平稳性检验
●adf y
●kpss y
这段代码将使用ADF和KPSS检验来检验变量y的平稳性。
预测
●ar y
●arima y
这段代码将使用AR和ARIMA模型来预测变量y。
时间序列模型分析的各种stata命令

时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着BoxandJenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset命令usegnp96.dta,clearlistin1/20genLgnp=L.gnptssetdatelistin1/20genLgnp=L.gnp2)检查是否有断点:tsreport,reportusegnp96.dta,cleartssetdatetsreport,reportdropin10/10listin1/12tsreport,reporttsreport,reportlist/*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport,reportlistlistin1/124)追加样本:tsappendusegnp96.dta,cleartssetdatelistin-10/-1sumtsappend,add(5)/*追加5个观察值*/listin-10/-1sum5)应用:样本外预测:predictreggnp96 L.gnp96predictgnp_hatlistin-10/-16)清除时间标识:tsset,cleartsset,clear1.2变量的生成与处理1)滞后项、超前项和差分项helptsvarlistusegnp96.dta,cleartssetdategenLgnp=L.gnp96/*一阶滞后*/genL2gnp=L2.gnp96genFgnp=F.gnp96/*一阶超前*/genF2gnp=F2.gnp96genDgnp=D.gnp96/*一阶差分*/genD2gnp=D2.gnp96listin1/10listin-10/-12)产生增长率变量:对数差分genlngnp=ln(gnp96)gengrowth=D.lngnpgengrowth2=(gnp96-L.gnp96)/L.gnp96gendiff=growth-growth2/*表明对数差分和变量的增长率差别很小*/ listdategnp96lngnpgrowth*diffin1/101.3日期的处理日期的格式helptsfmt基本时点:整数数值,如-3,-2,-1,0,1,2,3....1960年1月1日,取值为0;1)使用useB6_tsset.dta,cleartssett,dailylistuseB6_tsset.dta,cleartssett,weeklylist2)指定起始时点capdropmonthgeneratemonth=m(1990-1)+_n-1formatmonth%tmlisttmonthin1/20capdropyeargenyear=y(1952)+_n-1formatyear%tylisttyearin1/203)自己设定不同的显示格式日期的显示格式%d(%td)定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符cymlndjhqw_.,:-/'!cCYMLNDJW定义如下:candC世纪值(个位数不附加/附加0)yandY不含世纪值的年份(个位数不附加/附加0)m三个英文字母的月份简写(第一个字母大写)M英文字母拼写的月份(第一个字母大写)nandN数字月份(个位数不附加/附加0)dandD一个月中的第几日(个位数不附加/附加0)jandJ一年中的第几日(个位数不附加/附加0)h一年中的第几半年(1or2)q一年中的第几季度(1,2,3,or4)wandW一年中的第几周(个位数不附加/附加0)_displayablank(空格).displayaperiod(句号),displayacomma(逗号):displayacolon(冒号)-displayadash(短线)/displayaslash(斜线)'displayaclosesinglequote(右引号)!cdisplaycharacterc(code!!todisplayanexclamationpoint) 样式1:FormatSampledateinformat-----------------------------------%td07jul1948%tdM_d,_CYJuly7,1948%tdY/M/D48/07/11%tdM-D-CY07-11-1948%tqCY.q1999.2%tqCY:q1992:2%twCY,_w2010,48-----------------------------------样式2:FormatSampledateinformat----------------------------------%d11jul1948%dDlCY11jul1948%dDlY11jul48%dM_d,_CYJuly11,1948%dd_M_CY11July1948%dN/D/Y07/11/48%dD/N/Y11/07/48%dY/N/D48/07/11%dN-D-CY07-11-1948---------------------------------- clearsetobs100gent=_n+d(13feb1978)listtin1/5formatt%dCY-N-D/*1978-02-14*/listtin1/5formatt%dcy_n_d/*1978214*/listtin1/5useB6_tsset,clearlisttssett,format(%twCY-m)list4)一个实例:生成连续的时间变量usee1920.dta,clearlistyearmonthin1/30sortyearmonthgentime=_ntssettimelistyearmonthtimein1/30 generatenewmonth=m(1920-1)+time-1 tssetnewmonth,monthly listyearmonthtimenewmonthin1/301.4图解时间序列1)例1:clearsetseedsim_armaar2,ar(0.70.2)nobs(200)sim_armama2,ma(0.70.2)tsset_ttslinear2ma2*亦可采用twowayline命令绘制,但较为繁琐twowaylinear2ma2_t2)例2:增加文字标注sysusetsline2,cleartssetdaytslinecalories,ttick(28nov200225dec2002,tpos(in))///ttext(347028nov2002"thanks"///347025dec2002"x-mas",orient(vert))3)例3:增加两条纵向的标示线sysusetsline2,cleartssetdaytslinecalories,tline(28nov200225dec2002)*或采用twowayline 命令locald1=d(28nov2002)locald2=d(25dec2002)linecaloriesday,xline(`d1'`d2')4)例4:改变标签tslinecalories,tlabel(,format(%tdmd))ttitle("Date(2002)")tslinecalories,tlabel(,format(%td))二、ARIMA 模型和SARMIA 模型ARIMA 模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
时间序列Stata指令
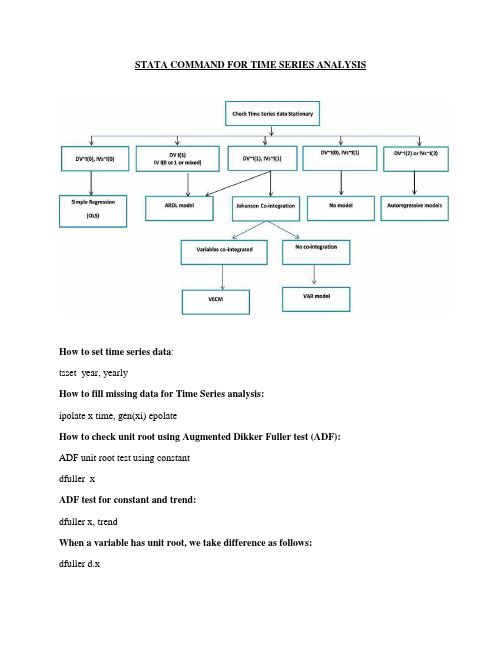
STATA COMMAND FOR TIME SERIES ANALYSISHow to set time series data:tsset year, yearlyHow to fill missing data for Time Series analysis:ipolate x time, gen(xi) epolateHow to check unit root using Augmented Dikker Fuller test (ADF):ADF unit root test using constantdfuller xADF test for constant and trend:dfuller x, trendWhen a variable has unit root, we take difference as follows:dfuller d.xADF test after differencing for constant and trend:dfuller d.x, trendIf you want to have summary statistics:sum y x1 x2 x3 x4How to run correlation matrix for your data:correlate y x1 x2 x3 x4Command for running regression model:regress y x1 x2 x3 x4If you want to check normality after running regression model, run two commands consecutively:predict myResiduals, rsktest myResidualsAfter regression, you can check for serial correlation using either of the following: dwstat or estat bgodfreyUse the following command for heteroskedasticity test :Prob value below 10% means there is heteroskedasticity problem in the modelestat hottestIf you want to see whether the model is mis-specified or if some variables are omitted: estat ovtestCommand for selecting optimum lags for your model is given below:varsoc y x1 x2 x3 x4, maxlag(4)the asterisk (*) indicates the appropriate lag selectedCommand for testing co-integration:vecrank y x1 x2 x3 x4, trend(constant)When co-integration is established, run VECM otherwise unrestricted VAR model is appropriate.Assuming variables are co-integrated, we run VECM using the following command:vec y x1 x2 x3 x4, trend(contant)The long-run causality must be negative, significant and in between 0 to 1, representing error correction term or speed of adjustment.Command to run impulse response function (you must estimate VECM or VAR model before running it) as follows:First you use the following command to create file:irf create order1, step(10) set(myirf1)Command for impulse response of all independent variables on dependent variable:irf graph irf, irf(order1) impulse(y x1 x2 x3 x4) response(smd)Assuming there is no co-integration, you run VAR model as a replacement for VECM as follows: (Note VAR model is for short run effect only)var y x1 x2 x3 x4, lags(1/4)If you want to check how variables jointly affect the dependent variables, use Granger causality test as follows:vargrangerDiagnostic checking for VAR model: Run the following tests:Lagrange multiplier test to check if residuals are auto-correlated or not (whether model is well-specified):varlmarJarque-Bera test to check whether residuals are normally distributed or not:varnorm, jberajbera stands for Jarque-BeraProb value below 10% shows residuals are not normally distributedTime Series Autoregressive Distributed Lag (ARDL) Model:ardl y x1 x2 x3 x4, lag(2 1 1 1 1) ecThe value must be negative, significant and in between 0 to 1, representing error correction term or speed of adjustmentTo confirm existence of long-run relationship, we run bound test as follows:estat btestbtest stand for bound testThe long-run cointegration is possible if the F statistics value is above the critical value. Command for Zivot-Andrews unit root test (structural break):zandrews xzandrews d.xGregory-Hansen Cointegration testCommand for g-hansen test with change in level:ghansen y x1 x2 x3 x4, break(level) lagmethod(aic) maxlags(4)Command for g-hansen test under regime change;ghansen y x1 x2 x3 x4, break(regime) lagmethod(fixed) maxlags(4)Command for g-hansen test with change in regime and trend:ghansen y x1 x2 x3 x4, break(regimetrend) lagmethod(downt) level(0.99) trim(0.1) Command for Non-linear Autoregressive Distributed Lag (NARDL) for frequency data nardl y x1 x2 x3 x4, p(2) q(4) constraints (1/2) plot bootstrapt (500) level (95)p(2) stands for lags of dependent variable, q(4) lags for explanatory variablesCommand for non-linear Autoregressive Distributed Lag (NARDL) for fewer observations nardl y x1 x2 x3 x4The results include positive and negative coefficients otherwise asymmetric effectSteps for running Toda and Yamamoto Granger-non causality testAfter testing for unitrootEstimate var model to select appropriate lag as followsvar y x1 x2 x3 x4, lags(1/4)varsocAssuming lag 3 is selected for the model, then run var model to include exogenous variables: var y x1 x2 x3 x4, lags(1/2) exog(13.y 13.x1 13.x2 13.x3 13.x4)Then run Toda Yamamoto causality test as follows:vargranger。
STATA面板数据模型操作命令

STATA面板数据模型操作命令STATA是一个强大的统计分析软件,可以进行各种数据操作和模型建立。
对于面板数据,即具有时间序列和跨个体的数据,STATA提供了多种命令来进行数据的操作和模型的拟合。
以下是一些常用的STATA面板数据模型操作命令:1. xtset命令:用于设置数据集的面板结构,将数据按个体和时间次序排序。
例如,xtset country year可以将数据按照国家和年份排序。
2. xtreg命令:用于拟合面板数据的固定效应模型。
例如,xtreg y x1 x2, fe可以拟合一个包含固定效应的面板数据模型,其中y为因变量,x1和x2为解释变量。
3. xtfe命令:用于估计固定效应模型的固定效应,即个体固定效应模型。
例如,xtfe y x1 x2可以计算出个体固定效应。
4. xtgls命令:用于估计面板数据的一般化最小二乘回归模型。
例如,xtgls y x1 x2可以拟合一个包含一般固定效应的面板数据模型。
5. xtmixed命令:用于估计混合效应模型,即个体和时间固定效应模型。
例如,xtmixed y x1 x2 , country:, var(can)可以在个体和时间固定效应下估计一个模型。
6. xtreg, re命令:用于估计面板数据的随机效应模型。
例如,xtreg y x1 x2, re可以计算出随机效应模型。
7. xtivreg命令:用于估计面板数据的双向固定效应或双向随机效应的工具变量回归模型。
例如,xtivreg y (x1 = z1) (x2 = z2), fe可以计算出一个包含工具变量的双向固定效应模型。
8. xtdpd命令:用于估计面板数据的动态面板数据模型。
例如,xtdpd y x1 x2, lags(2)可以进行一个包含两期滞后的动态面板数据模型估计。
9. xtregar命令:用于估计拓展的面板数据模型。
例如,xtregar y x1 x2, fe(ec)可以在考虑了异方差和异方差的面板数据模型下进行估计。
时间序列Stata

gen t = _n + d(13feb1978) list t in 1/5 format t %dCY-N-D list t in 1/5 format t %dcy_n_d list t in 1/5 /*1978-02-14*/
/*1978 2 14*/
use B6_tsset, clear list tsset t, format(%twCY-m) list 4)一个实例:生成连续的时间变量 use e1920.dta, clear list year month in 1/30 sort year month gen time = _n tsset time list year month time in 1/30 generate newmonth = m(1920-1) + time - 1 tsset newmonth, monthly list year month time newmonth in 1/30 1.4 图解时间序列 1)例 1: clear set seed 13579113 sim_arma ar2, ar(0.7 0.2) nobs(200) sim_arma ma2, ma(0.7 0.2) tsset _t tsline ar2 ma2 * 亦可采用 twoway line 命令绘制,但较为繁琐 twoway line ar2 ma2 _t 2)例 2:增加文字标注 sysuse tsline2, clear tsset day tsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" /// 3470 25dec2002 "x-mas", orient(vert))
stata操作介绍之时间序列-

虽然pperron 检验和dfgls检验拒绝了变量 fylltemp具有稳定性的假设,但是dfuller 检验 不能拒绝原假设,还是可以认为该变量具有 稳定性。
ARIMA模型
自相关表: . corrgram fylltemp,lags(4)
说明:该变量的自相关关系随着滞后期的增加而减少,偏自 相关关系在一期自后滞后消失,故适合模型AR(1)来分析该 变量。
注:本部分继续使用ch52.dta数据。
自相关分析
自相关表: . corrgram fylltemp,lags(9)
说明:大多数P值都小于0.05,故认为fylltemp具有显著的自相 关性;相关关系或偏相关关系越强,相应的线条越长;
自相关分析
自相关图: . ac fylltemp,lags(9)
平滑分析
生成移动平均值(1):
. gen water3=(water[ _n-1]+water[ _n]+water[ _n+1])/3
平滑分析
生成移动平均值(2): . tssmooth ma water5=water,window(2 1 2)
注:tssmooth:表示移动平均值平滑(加权或不加权); window(2 1 2):表示使用该值的前两个值、该值与该值的
平滑分析-滞后变量
生成n阶滞后变量的两种方法: . gen wNAO_n=wNAO[ _n-1] . gen wNAO_n=Ln.wNAO 注:第二种方法中的''Ln''表示Lag(n);
平滑分析-滞后变量
生成一阶滞后变量: . gen wNAO_1=wNAO[ _n-1]
生成二阶滞后变量: . gen wNAO_2=L2.wNAO
与时间序列相关的STATE命令及其统计量的解析

与时间序列相关的STATE命令及其统计量的解析与时间序列相关的STATA 命令及其统计量的解析残差U 序列相关:①DW 统计量——针对一阶自相关的(高阶无效)STATA 命令:1.先回归2.直接输入dwstat 统计量如何看:查表②Q 统计量——针对高阶自相关correlogram-Q-statistics STATA 命令:1.先回归reg 2.取出残差predict u,residual(不要忘记逗号)3. wntestq u Q 统计量如何看:p 值越小(越接近0)Q 值越大——表示存在自相关具体自相关的阶数可以看自相关系数图和偏相关系数图:STATA 命令:自相关系数图:ac u( 残差)或者窗口操作在Graphics ——Time-series graphs ——correlogram(ac)偏相关系数图:pac u 或者窗口操作在Graphics——Time-series graphs—— (pac)自相关与偏相关系数以及Q 统计量同时表示出来的方法:corrgram u 或者是窗口操作在 Statistics——Time-series——Graphs—— Autocorrelations&Partial autocorrelations ③LM 统计量——针对高阶自相关 STATA 命令:1.先回归reg 2.直接输入命令 estate bgodfrey,lags(n)或者窗口操作在 Statistics——Postestimation(倒数第二个)——Reports and Statistics(倒数第二个)——在里面选择 Breush-Godfrey LM(当然你在里面还可以找到方差膨胀因子还有DW 统计量等常规统计量)LM 统计量如何看:P 值越小(越接近 0)表示越显著(显著拒绝原假设),存在序列相关具体是几阶序列相关,你可以把滞后期写为几,当然默认是 1,(通常的方法是先看图,上面说的自相关和偏相关图以及Q 值,然后再利用LM 肯定)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH 族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96.dta, clearlist in 1/20gen Lgnp = L.gnptsset datelist in 1/20gen Lgnp = L.gnp2)检查是否有断点:tsreport, reportuse gnp96.dta, cleartsset datetsreport, reportdrop in 10/10list in 1/12tsreport, reporttsreport, report list /*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport, report listlist in 1/124)追加样本:tsappenduse gnp96.dta, cleartsset datelist in -10/-1sumtsappend , add(5) /*追加5个观察值*/list in -10/-1sum5)应用:样本外预测: predictreg gnp96 L.gnp96predict gnp_hatlist in -10/-16)清除时间标识: tsset, cleartsset, clear1.2变量的生成与处理1)滞后项、超前项和差分项help tsvarlist use gnp96.dta, cleartsset dategen Lgnp = L.gnp96 /*一阶滞后*/gen L2gnp = L2.gnp96gen Fgnp = F.gnp96 /*一阶超前*/gen F2gnp = F2.gnp96gen Dgnp = D.gnp96 /*一阶差分*/gen D2gnp = D2.gnp96list in 1/10list in -10/-12)产生增长率变量: 对数差分gen lngnp = ln(gnp96)gen growth = D.lngnpgen growth2 = (gnp96-L.gnp96)/L.gnp96gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/101.3日期的处理日期的格式help tsfmt基本时点:整数数值,如-3, -2, -1, 0, 1, 2, 3 ....1960年1月1日,取值为0;显示格式:1)使用tsset 命令指定显示格式use B6_tsset.dta, cleartsset t, dailylistuse B6_tsset.dta, cleartsset t, weeklylist2)指定起始时点cap drop monthgenerate month = m(1990-1) + _n - 1format month %tmlist t month in 1/20cap drop yeargen year = y(1952) + _n - 1format year %tylist t year in 1/203)自己设定不同的显示格式日期的显示格式%d (%td) 定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l nd j h q w _ . , : - / ' !cC Y M L ND J W定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写) M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年(1 or 2)q 一年中的第几季度(1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号): display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !! to display an exclamation point)样式1:Format Sample date in format-----------------------------------%td 07jul1948%tdM_d,_CY July 7, 1948%tdY/M/D 48/07/11%tdM-D-CY 07-11-1948%tqCY.q 1999.2%tqCY:q 1992:2%twCY,_w 2010, 48-----------------------------------样式2:Format Sample date in format----------------------------------%d 11jul1948%dDlCY 11jul1948%dDlY 11jul48%dM_d,_CY July 11, 1948%dd_M_CY 11 July 1948%dN/D/Y 07/11/48%dD/N/Y 11/07/48%dY/N/D 48/07/11%dN-D-CY 07-11-1948----------------------------------clearset obs 100gen t = _n + d(13feb1978)list t in 1/5format t %dCY-N-D /*1978-02-14*/list t in 1/5format t %dcy_n_d /*1978 2 14*/list t in 1/5use B6_tsset, clearlisttsset t, format(%twCY-m)list4)一个实例:生成连续的时间变量use e1920.dta, clearlist year month in 1/30sort year monthgen time = _ntsset timelist year month time in 1/30generate newmonth = m(1920-1) + time - 1 tsset newmonth, monthlylist year month time newmonth in 1/301.4图解时间序列1)例1:clearset seed 13579113sim_arma ar2, ar(0.7 0.2) nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _ttsline ar2 ma2* 亦可采用twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t2)例2:增加文字标注sysuse tsline2, cleartsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in)) ///ttext(3470 28nov2002 "thanks" ///3470 25dec2002 "x-mas", orient(vert)) 3)例3:增加两条纵向的标示线sysuse tsline2, cleartsset daytsline calories, tline(28nov2002 25dec2002) * 或采用 twoway line 命令 local d1 = d(28nov2002) local d2 = d(25dec2002) line calories day, xline(`d1' `d2')4)例4:改变标签tsline calories, tlabel(, format(%tdmd)) ttitle("Date (2002)") tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA 模型ARIMA 模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。
ARIMA(1,1)模型:t t t t y y εθερα+++=--11 2.1 ARIMA 模型预测的基本程序:1) 根据时间序列的散点图、自相关函数和偏自相关函数图以ADF 单位根检验其方差、趋势及其季节性变化规律,对序列的平稳性进行识别。
一般来讲,经济运行的时间序列都不是平稳序列。
2)对非平稳序列进行平稳化处理。
如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理,如果数据存在异方差,则需对数据进行技术处理,直到处理后的数据的自相关函数值和偏相关函数值无显著地异于零。
3)根据时间序列模型的识别规则,建立相应的模型。
若平稳序列的偏相关函数是截尾的,而自相关函数是拖尾的,可断定序列适合AR模型;若平稳序列的偏相关函数是拖尾的,而自相关函数是截尾的,则可断定序列适合MA模型;若平稳序列的偏相关函数和自相关函数均是拖尾的,则序列适合ARMA 模型。
4)进行参数估计,检验是否具有统计意义。
5)进行假设检验,诊断残差序列是否为白噪声。
6)利用已通过检验的模型进行预测分析。
2.2 ARIMA模型中AR和MA阶数的确定方法:clearsim_arma y_ar, ar(0.9) nobs(300)line y_ar _t, yline(0)ac y_ar /*AR过程的ACF 具有“拖尾”特征,长期记忆*/pac y_ar /*AR过程的PACF 具有“截尾”特征*/sim_arma y_ma, ma(0.8)line y_ma _t, yline(0)ac y_ma /*MA过程的ACF 具有“截尾”特征,短期记忆*/ pac y_ma /*MA过程的PACF 具有锯齿型“拖尾”特征*/2.3 ARIMA模型中涉及的检验:use /data/r11/wpi1 ,cleartsset tgen d_wpi = D.wpidfuller wpi /*单位根检验*/dfuller d_wpiwntestq wpi /*白噪声检验:Q检验*/wntestq d_wpiwntestb wpi,table /*累积统计Q检验并以列表显示*/wntestb d_wpi,tablewntestb wpi /*画出累积统计量Q*/wntestb d_wpi /*画出累积统计量Q*/corrgram wpi ,lag(24) /*自相关、偏相关、Q统计量*/corrgram d_wpi ,lag(24)2.4 ARIMA模型和SARIMA模型的估计ARIMA模型:use /data/r11/wpi1 ,cleargen d_wpi = D.wpiarima wpi,arima(1,1,1)/* 没有漂移项即常数项的命令是noconstant */ * 或者下面的这种形式也行arima D.wpi,ar(1) ma(1)SARIMA模型:use /data/r11/air2,clearline air tgenerate lnair=ln(air)arima lnair,arima(0,1,1) sarima(0,1,1,12) noconstant2.5 ARIMA模型的一个真实应用——美国批发物价指数use /data/r11/wpi1 ,cleardfuller wpi /*单位根检验*/gen d_wpi = D.wpidfuller d_wpiarima wpi,arima(1,1,1) /* 没有漂移项即常数项的命令是noconstant */ * 或者下面的这种形式也行arima D.wpi,ar(1) ma(1)ac D.ln_wpi,ylabels(-.4(.2).6)pac D.ln_wpi,ylabels(-.4(.2).6)arima D.ln_wpi,ar(1) ma(1/4)estat ic /* LL 越大越好, AIC 和BIC 越小越好*/arima D.ln_wpi,ar(1) ma(1 4) /*季节效应*/ estat ic* 残差检验predict r,reswntestq r /*白噪声检验:Q检验*/wntestb r,table /*累积统计Q检验并以列表显示*/ wntestb r /*画出累积统计量Q*/corrgram r ,lag(24) /*自相关、偏相关、Q统计量*/* 样本内预测predict y_hat0 /* y的拟合值*/* 样本外预测list in -15/-1tsappend, add(8)list in -15/-1predict y_hat1 /* y 的样本外一步预测值*/list in -15/-1gen Dln_wpi = D.ln_wpisumpredict y_hat_dy0, dynamic(124) /*动态预测*/predict y,y /*对未差分变量的预测*/predict fy,y dynamic(124)gen fwpi=exp(fy) /*实际wpi的预测值*/gen ywpi=exp(y)line wpi fwpi ywpi t in -20/-1三、ARCH 模型传统的计量经济学对时间序列变量的第二个假设:假定时间序列变量的波动幅度(方差)是固定的,不符合实际,比如,人们早就发现股票收益的波动幅度是随时间而变化的,并非常数。