stata操作介绍之时间序列-(四)分析
stata操作介绍之时间序列-四

ARIMA模型
dfuller 检验: . dfuller fylltemp, lag(3)
说明:P值为0.089,大于0.05,故不能拒绝原假设,说明该 变量满足稳定性检验;
ARIMA模型
dfgls检验: . dfgls fylltemp, maxlag(3) notrend
说明:P值为0.0,小于0.05,故拒绝原假设,说明该变量不 满足稳定性检验;
说明:由上图可知,常数项与一期滞后变量系数都是统计显 著的,卡方检验也显著。
ARIMA模型
生成残差: . predict fylres, res . corrgram fylres ,lags(9)
说明:由图可知,统计量对应的P值为0.6574,不能拒绝原 假设,即认为残差不存在自相关。因此,认为变量fylltemp 使用AR(1)进行分析是合适的。
平滑分析
生成移动平均值(1):
. gen water3=(water[ _n-1]+water[ _n]+water[ _n+1])/3
平滑分析
生成移动平均值(2): . tssmooth ma water5=water,window(2 1 2)
注:tssmooth:表示移动平均值平滑(加权或不加权); window(2 1 2):表示使用该值的前两个值、该值与该值的
说明:由图可知,lag为0时,交叉相关性最强(线条最长), 且为负。
自相关分析
交叉相关表: . xcorr wNAO fylltemp if year >=1970 & year <=1990,lags(7) table
ARIMA模型
时间序列中的自相关集成移动平均模型 (autoregressive integrated moving average简称 ARIMA),是指将非平稳时间序列转化为平稳时间 序列,然后将因变量仅对它的滞后值以及随机误差 项的现值和滞后值进行回归所建立的模型。
与时间序列相关的STATA命令及其统计量的解析完整版

与时间序列相关的S T A T A命令及其统计量的解析Document serial number【NL89WT-NY98YT-NC8CB-NNUUT-NUT108】与时间序列相关的S T A T A命令及其统计量的解析残差U 序列相关:①DW 统计量——针对一阶自相关的(高阶无效)STATA 命令:1.先回归2.直接输入dwstat统计量如何看:查表②Q 统计量——针对高阶自相关correlogram-Q-statisticsSTATA 命令:1.先回归reg2.取出残差predict u,residual(不要忘记逗号)3. wntestq u Q统计量如何看:p 值越小(越接近0)Q 值越大——表示存在自相关具体自相关的阶数可以看自相关系数图和偏相关系数图:STATA 命令:自相关系数图:ac u( 残差) 或者窗口操作在 Graphics ——Time-series graphs ——correlogram(ac)偏相关系数图:pac u 或者窗口操作在Graphics——Time-series graphs—— (pac)自相关与偏相关系数以及Q 统计量同时表示出来的方法:corrgram u或者是窗口操作在Statistics——Time-series——Graphs—— Autocorrelations&Partial autocorrelations③LM 统计量——针对高阶自相关STATA 命令:1.先回归reg2.直接输入命令estate bgodfrey,lags(n) 或者窗口操作在 Statistics——Postestimation(倒数第二个)——Reports andStatistics(倒数第二个) ——在里面选择 Breush-Godfrey LM(当然你在里面还可以找到方差膨胀因子还有DW 统计量等常规统计量)LM 统计量如何看:P 值越小(越接近 0)表示越显着(显着拒绝原假设),存在序列相关具体是几阶序列相关,你可以把滞后期写为几,当然默认是 1,(通常的方法是先看图,上面说的自相关和偏相关图以及Q 值,然后再利用LM 肯定)。
stata操作介绍之时间序列分析

【例1】使用文件“cpi.dta”的数据来对tsset命令的应用 进行说明。该例子是我国1983年1月年至2007年8月的居 民消费价格指数CPI。部分数据如表2所示: 表2 我国居民消费价格指数CPI Year
1983 1983 1983 1983 1983 1983 1983
month
daily weekly monthly quarterly harfyearly yearly generic format(%fmt) 时间周期 delta(#) delta((exp)) delta(#units) delta((exp)units)
注:(1)units表示时间单位,对于%tc,允许的时间单位包括:second、seconds、secs、secs、 minutes、minute、mine、min、hours、hour、days、weeks、week。对于其他%t的格式,Stata自动 获得其时间单位,delta选项经常与%tc格式一起使用。 STATA从入门到精通 Page 4
【例2】继续使用上例的数据来对tssmooth命令的应用进 行说明。在本例中对该组数据进行修匀,以便消除不规则 变动的影响,得到时间序列长期趋势,本例修匀的方法是 利用之前的1个月和之后的2个月及本月进行平均。
Page 9
STATA从入门到精通
二、
ARIMA模型的估计、单位根与协整
时间序列模型一般分为四类,分别是自回归过程、移动平均过程、自 回归移动平均过程、单整自回归移动平均过程。 自回归过程 如果一个剔出均值和确定性成分的线性过程可表达为 xt = 1xt-1 + 2 xt-2 + … + p xt-p + ut 其中i, i = 1, … p 是自回归参数,ut 是白噪声过程,则称xt为p阶自 回归过程,用AR(p)表示。xt是由它的p个滞后变量的加权和以及ut相 加而成。
stata操作介绍之时间序列分析

时间序列构成分析就是要观察现象在一个相当长的时期内, 由于各个影响因素的影响,使事物发展变化中出现的长期趋 势、季节变动、循环变动和不规则变动。
通过测定和分析过去一段时间之内现象的发展趋势,可以认 识和掌握现象发展变化的规律性,为统计预测提供必要的条 件,同时也可以消除原有时间序列中长期趋势的影响,更好 地研究季节变动和循环变动等问题。测定和分析长期趋势的 主要方法是对时间序列进行修匀。
timevar的格式为%tc, 0=1jan1960 00:00:00.000,1=1jan1960 00:00:00.001 即0代表1960年1月1日的第一秒,1为1960年1月1日的第二秒,依次后推。 timevar的格式为%td,0=1jan1960,1=2jan1960;即0为1960年第一天,1 为1960年第二天,依次后推。 timevar的格式为%tw,0=1960w1,1=1960w2;即0为1960年第一周,1 为1960年第二周,依次后推。 timevar的格式为%tm,0=1,1=;即0为1960年第一月,1为1960年第二 月,依次后推。 timevar的格式为%tq,0=1960q1,1=1960q2;即0为1960年第一季,1为 1960年第二季,依次后推。 timevar的格式为%th,0=1960h1,1=1960h2;即0为从1960起的第一个半 年,1为从1960年起第二个半年,依次后推。 timevar的格式为%ty,1960=1960,1961=1960 timevar的格式为%tg
义时间单位,或者定义时间周期(即timevar两个观测值 之间的周期数)。Options的相关描述如表1所示。
Page 3
STATA从入门到精通
时间单位
格式说明
Clocktime
时间序列Stata操作 题4-7
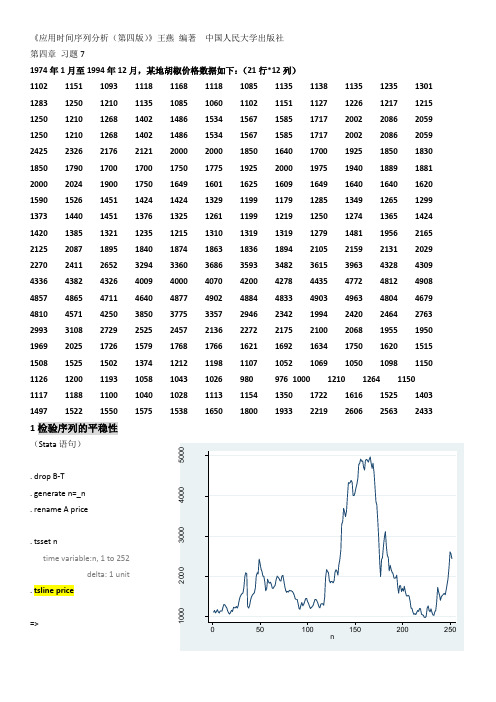
《应用时间序列分析(第四版)》王燕编著中国人民大学出版社第四章习题71974年1月至1994年12月,某地胡椒价格数据如下:(21行*12列)1102 1151 1093 1118 1168 1118 1085 1135 1138 1135 1235 1301 1283 1250 1210 1135 1085 1060 1102 1151 1127 1226 1217 1215 1250 1210 1268 1402 1486 1534 1567 1585 1717 2002 2086 2059 1250 1210 1268 1402 1486 1534 1567 1585 1717 2002 2086 2059 2425 2326 2176 2121 2000 2000 1850 1640 1700 1925 1850 1830 1850 1790 1700 1700 1750 1775 1925 2000 1975 1940 1889 1881 2000 2024 1900 1750 1649 1601 1625 1609 1649 1640 1640 1620 1590 1526 1451 1424 1424 1329 1199 1179 1285 1349 1265 1299 1373 1440 1451 1376 1325 1261 1199 1219 1250 1274 1365 1424 1420 1385 1321 1235 1215 1310 1319 1319 1279 1481 1956 2165 2125 2087 1895 1840 1874 1863 1836 1894 2105 2159 2131 2029 2270 2411 2652 3294 3360 3686 3593 3482 3615 3963 4328 4309 4336 4382 4326 4009 4000 4070 4200 4278 4435 4772 4812 4908 4857 4865 4711 4640 4877 4902 4884 4833 4903 4963 4804 4679 4810 4571 4250 3850 3775 3357 2946 2342 1994 2420 2464 2763 2993 3108 2729 2525 2457 2136 2272 2175 2100 2068 1955 1950 1969 2025 1726 1579 1768 1766 1621 1692 1634 1750 1620 1515 1508 1525 1502 1374 1212 1198 1107 1052 1069 1050 1098 1150 1126 1200 1193 1058 1043 1026 980 976 1000 1210 1264 1150 1117 1188 1100 1040 1028 1113 1154 1350 1722 1616 1525 1403 1497 1522 1550 1575 1538 1650 1800 1933 2219 2606 2563 2433 1检验序列的平稳性(Stata语句). drop B-T. generate n=_n. rename A price. tsset ntime variable:n, 1 to 252delta: 1 unit . tsline price=>p r i c e由时序图观测得price 变化落差很大,该序列不平稳...。
stata操作介绍之时间序列分析

时间单位
格式说明
Clocktime
daily weekly monthly quarterly harfyearly yearly generic format(%fmt) 时间周期
timevar的格式为%tc, 0=1jan1960 00:00:00.000,1=1jan1960 00:00:00.001 即0代表1960年1月1日的第一秒,1为1960年1月1日的第二秒,依次后推。 timevar的格式为%td,0=1jan1960,1=2jan1960;即0为1960年第一天,1 为1960年第二天,依次后推。 timevar的格式为%tw,0=1960w1,1=1960w2;即0为1960年第一周,1 为1960年第二周,依次后推。 timevar的格式为%tm,0=1,1=;即0为1960年第一月,1为1960年第二 月,依次后推。 timevar的格式为%tq,0=1960q1,1=1960q2;即0为1960年第一季,1为 1960年第二季,依次后推。 timevar的格式为%th,0=1960h1,1=1960h2;即0为从1960起的第一个半 年,1为从1960年起第二个半年,依次后推。 timevar的格式为%ty,1960=1960,1961=1960 timevar的格式为%tg
数据=修匀部分+粗糙部分,运用Stata进行修匀使用 tssmooth命令,其基本命令格式如下所示:
tssmooth smoother[type] newvar = exp [if] [in] [, ...]
其中平s滑mo的o种t类her[type]有一系sm列oo目ther录[ty,pe]如下表3所示:
运用stata进行时间序列分析报告报告材料

运用stata进行时间序列分析1 时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96.dta, clear list in 1/20 gen Lgnp = L.gnp tsset date list in 1/20 gen Lgnp = L.gnp 2)检查是否有断点:tsreport, report use gnp96.dta, clear tsset date tsreport, report drop in 10/10 list in 1/12 tsreport, report tsreport, report list /*列出存在断点的样本信息*/ 3)填充缺漏值:tsfill tsfill tsreport, report list list in 1/12 4)追加样本:tsappend use gnp96.dta, clear tsset date list in -10/-1 sum tsappend , add(5)/*追加5个观察值*/ list in -10/-1 sum 2 5)应用:样本外预测:predict reg gnp96 L.gnp96 predict gnp_hat list in -10/-1 6)清除时间标识:tsset, clear tsset, clear 1.2变量的生成与处理1)滞后项、超前项和差分项help tsvarlist use gnp96.dta, clear tsset date gen Lgnp = L.gnp96 /*一阶滞后*/ gen L2gnp = L2.gnp96 gen Fgnp = F.gnp96 /*一阶超前*/ gen F2gnp= F2.gnp96 gen Dgnp = D.gnp96 /*一阶差分*/ gen D2gnp = D2.gnp96 list in 1/10 list in -10/-1 2)产生增长率变量:对数差分gen lngnp = ln(gnp96)gen growth = D.lngnp gen growth2 = (gnp96-L.gnp96)/L.gnp96 gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/10 1.3日期的处理日期的格式help tsfmt 基本时点:整数数值,如-3, -2, -1, 0, 1, 2, 3 .... 1960年1月1日,取值为0;3 显示格式:定义含义默认格式%td 日%tdDlCY %tw 周%twCY!ww %tm 月%tmCY!mn %tq 季度%tqCY!qq %th 半年%thCY!hh %ty 年%tyCY 1)使用tsset 命令指定显示格式use B6_tsset.dta, clear tsset t, daily list use B6_tsset.dta, clear tsset t, weekly list 2)指定起始时点cap drop month generate month = m(1990-1)+ _n - 1 format month %tm list t month in 1/20 cap drop year gen year = y(1952)+ _n - 1 format year %ty list t year in 1/20 3)自己设定不同的显示格式日期的显示格式%d (%td)定义如下:%[-][t]d<描述特定的显示格式> 具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l n d j h q w _ . , :- / ' !c C Y M L N D J W 定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写)4 M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年(1 or 2)q 一年中的第几季度(1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号):display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !!to display an exclamation point)样式1:Format Sample date in format ----------------------------------- %td07jul1948 %tdM_d,_CY July 7, 1948 %tdY/M/D 48/07/11 %tdM-D-CY 07-11-1948 %tqCY.q 1999.2 %tqCY:q 1992:2 %twCY,_w 2010, 48 ----------------------------------- 样式2:Format Sample date in format ---------------------------------- %d 11jul1948 %dDlCY 11jul1948 %dDlY 11jul48 %dM_d,_CY July 11, 1948 %dd_M_CY 11 July 1948 %dN/D/Y 07/11/48 %dD/N/Y 11/07/48 %dY/N/D 48/07/11 %dN-D-CY 07-11-1948 ---------------------------------- clear set obs 100 5 gen t = _n + d(13feb1978)list t in 1/5 format t %dCY-N-D /*1978-02-14*/ list t in 1/5 format t %dcy_n_d /*1978 2 14*/ list t in 1/5 use B6_tsset, clear list tsset t, format(%twCY-m)list 4)一个实例:生成连续的时间变量use e1920.dta, clear list year month in 1/30 sort year month gen time = _n tsset time list year month time in 1/30 generate newmonth = m(1920-1)+ time - 1 tsset newmonth, monthly list year month time newmonth in 1/30 1.4图解时间序列1)例1:clear set seed 13579113 sim_arma ar2, ar(0.7 0.2)nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _t tsline ar2 ma2 * 亦可采用twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t 2)例2:增加文字标注sysuse tsline2, clear tsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in))/// ttext(3470 28nov2002 "thanks" /// 3470 25dec2002 "x-mas", orient(vert))6 3)例3:增加两条纵向的标示线sysuse tsline2, clear tsset day tsline calories, tline(28nov2002 25dec2002)* 或采用twoway line 命令local d1 = d(28nov2002)local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签tsline calories, tlabel(, format(%tdmd))ttitle("Date (2002)")tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA模型ARIMA模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
stata时间序列数据的实证过程

stata时间序列数据的实证过程Stata时间序列数据的实证过程引言时间序列数据是经济学和金融学研究中常见的数据类型,通过对时间序列数据进行实证分析,可以揭示出数据的动态变化规律,为决策提供有价值的参考。
Stata作为一种流行的统计软件,提供了丰富的功能和工具,可以帮助研究人员进行时间序列数据的实证分析。
本文将以Stata为工具,介绍时间序列数据的实证过程。
一、数据准备在进行时间序列数据的实证分析之前,首先需要准备好相关的数据。
一般来说,时间序列数据应包含两个主要的变量:时间变量和观测变量。
时间变量可以是年份、季度、月份等,而观测变量则是我们要研究的经济指标或金融数据。
在Stata中,可以使用import命令或者直接在软件中导入外部数据文件,将数据导入到Stata的工作环境中。
二、数据处理与描述性统计分析在导入数据之后,我们可以对数据进行处理和描述性统计分析,以了解数据的基本特征。
Stata提供了一系列的命令和函数,可以帮助我们完成这些任务。
例如,我们可以使用summarize命令对观测变量进行基本统计描述,如均值、标准差等。
此外,我们还可以使用generate命令创建新的变量,对数据进行变换和处理。
三、时间序列图形分析时间序列图形是了解数据动态变化的重要工具,可以直观地反映数据的趋势和周期性。
在Stata中,我们可以使用tsline命令绘制时间序列图形。
该命令可以根据时间变量和观测变量,绘制出变量随时间变化的折线图。
通过观察时间序列图形,我们可以初步判断数据是否存在趋势、季节性或周期性。
四、平稳性检验平稳性是时间序列分析的重要前提,它要求数据的均值和方差在时间上保持不变。
在Stata中,可以使用adf命令进行单位根检验,判断时间序列数据是否平稳。
单位根检验的原假设是存在单位根,即数据不平稳;而备择假设是不存在单位根,即数据平稳。
通过adf命令的输出结果,我们可以得到单位根检验的统计量和p值,判断数据是否平稳。
stata时间序列分析

In a regression you could type: or regress y x F1.x F2.x regress y x F(1/5).x
7
PU/DSS/OTR
Times Series: lag operators (difference)
To generate the difference between current a previous values use the “D” operator generate unempD1=D1.unemp /* D1 = y t – yt-1 */ generate unempD2=D2.unemp /* D2 = (y t – yt-1) – (yt-1 – yt-2) */ list datevar unemp unempD1 unempD2 in 1/5
use /training/tsdata.dta
gen date1=substr(date,1,7) gen datevar=quarterly(date1,"yq") format datevar %tq browse date date1 datevar
Time Series: date variable
Time series data is data collected over time for a single or a group of variables, for example GDP, exports, imports, etc.,from 1960 to 2009. For this kind of data the first thing to do is to check the variable that contains the time and make sure is the one you need: yearly, monthly, quarterly, daily, etc. The next step is to verify it is in the correct format. In the example below the time variable is store in “date” but it is a string variable not a date variable. In Stata you need to convert this string variable to a date variable.* A closer inspection of the variable, for the years 2000 the format changes, we need to create a new variable with a uniform format. Type the following:
时间序列模型分析的各种stata命令

时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着BoxandJenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset命令usegnp96.dta,clearlistin1/20genLgnp=L.gnptssetdatelistin1/20genLgnp=L.gnp2)检查是否有断点:tsreport,reportusegnp96.dta,cleartssetdatetsreport,reportdropin10/10listin1/12tsreport,reporttsreport,reportlist/*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport,reportlistlistin1/124)追加样本:tsappendusegnp96.dta,cleartssetdatelistin-10/-1sumtsappend,add(5)/*追加5个观察值*/listin-10/-1sum5)应用:样本外预测:predictreggnp96 L.gnp96predictgnp_hatlistin-10/-16)清除时间标识:tsset,cleartsset,clear1.2变量的生成与处理1)滞后项、超前项和差分项helptsvarlistusegnp96.dta,cleartssetdategenLgnp=L.gnp96/*一阶滞后*/genL2gnp=L2.gnp96genFgnp=F.gnp96/*一阶超前*/genF2gnp=F2.gnp96genDgnp=D.gnp96/*一阶差分*/genD2gnp=D2.gnp96listin1/10listin-10/-12)产生增长率变量:对数差分genlngnp=ln(gnp96)gengrowth=D.lngnpgengrowth2=(gnp96-L.gnp96)/L.gnp96gendiff=growth-growth2/*表明对数差分和变量的增长率差别很小*/ listdategnp96lngnpgrowth*diffin1/101.3日期的处理日期的格式helptsfmt基本时点:整数数值,如-3,-2,-1,0,1,2,3....1960年1月1日,取值为0;1)使用useB6_tsset.dta,cleartssett,dailylistuseB6_tsset.dta,cleartssett,weeklylist2)指定起始时点capdropmonthgeneratemonth=m(1990-1)+_n-1formatmonth%tmlisttmonthin1/20capdropyeargenyear=y(1952)+_n-1formatyear%tylisttyearin1/203)自己设定不同的显示格式日期的显示格式%d(%td)定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符cymlndjhqw_.,:-/'!cCYMLNDJW定义如下:candC世纪值(个位数不附加/附加0)yandY不含世纪值的年份(个位数不附加/附加0)m三个英文字母的月份简写(第一个字母大写)M英文字母拼写的月份(第一个字母大写)nandN数字月份(个位数不附加/附加0)dandD一个月中的第几日(个位数不附加/附加0)jandJ一年中的第几日(个位数不附加/附加0)h一年中的第几半年(1or2)q一年中的第几季度(1,2,3,or4)wandW一年中的第几周(个位数不附加/附加0)_displayablank(空格).displayaperiod(句号),displayacomma(逗号):displayacolon(冒号)-displayadash(短线)/displayaslash(斜线)'displayaclosesinglequote(右引号)!cdisplaycharacterc(code!!todisplayanexclamationpoint) 样式1:FormatSampledateinformat-----------------------------------%td07jul1948%tdM_d,_CYJuly7,1948%tdY/M/D48/07/11%tdM-D-CY07-11-1948%tqCY.q1999.2%tqCY:q1992:2%twCY,_w2010,48-----------------------------------样式2:FormatSampledateinformat----------------------------------%d11jul1948%dDlCY11jul1948%dDlY11jul48%dM_d,_CYJuly11,1948%dd_M_CY11July1948%dN/D/Y07/11/48%dD/N/Y11/07/48%dY/N/D48/07/11%dN-D-CY07-11-1948---------------------------------- clearsetobs100gent=_n+d(13feb1978)listtin1/5formatt%dCY-N-D/*1978-02-14*/listtin1/5formatt%dcy_n_d/*1978214*/listtin1/5useB6_tsset,clearlisttssett,format(%twCY-m)list4)一个实例:生成连续的时间变量usee1920.dta,clearlistyearmonthin1/30sortyearmonthgentime=_ntssettimelistyearmonthtimein1/30 generatenewmonth=m(1920-1)+time-1 tssetnewmonth,monthly listyearmonthtimenewmonthin1/301.4图解时间序列1)例1:clearsetseedsim_armaar2,ar(0.70.2)nobs(200)sim_armama2,ma(0.70.2)tsset_ttslinear2ma2*亦可采用twowayline命令绘制,但较为繁琐twowaylinear2ma2_t2)例2:增加文字标注sysusetsline2,cleartssetdaytslinecalories,ttick(28nov200225dec2002,tpos(in))///ttext(347028nov2002"thanks"///347025dec2002"x-mas",orient(vert))3)例3:增加两条纵向的标示线sysusetsline2,cleartssetdaytslinecalories,tline(28nov200225dec2002)*或采用twowayline 命令locald1=d(28nov2002)locald2=d(25dec2002)linecaloriesday,xline(`d1'`d2')4)例4:改变标签tslinecalories,tlabel(,format(%tdmd))ttitle("Date(2002)")tslinecalories,tlabel(,format(%td))二、ARIMA 模型和SARMIA 模型ARIMA 模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
运用stata进行时间序列分析

运用stata进行时间序列分析运用stata进行时间序列分析1 时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、 VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令 1.1时间序列数据的处理 1)声明时间序列:tsset 命令 use gnp96.dta, clear list in 1/20 gen Lgnp = L.gnp tsset date list in 1/20 gen Lgnp = L.gnp 2)检查是否有断点:tsreport, report use gnp96.dta, clear tsset date tsreport, report drop in 10/10 list in 1/12 tsreport, report tsreport, report list /*列出存在断点的样本信息*/ 3)填充缺漏值:tsfill tsfill tsreport, report list list in 1/12 4)追加样本:tsappend use gnp96.dta, clear tsset date list in -10/-1 sum tsappend , add(5) /*追加5个观察值*/ list in -10/-1 sum 2 5)应用:样本外预测:predict reg gnp96 L.gnp96 predict gnp_hat list in -10/-1 6)清除时间标识:tsset, clear tsset, clear 1.2变量的生成与处理 1)滞后项、超前项和差分项 help tsvarlist use gnp96.dta, clear tsset date gen Lgnp = L.gnp96 /*一阶滞后*/ gen L2gnp = L2.gnp96 gen Fgnp = F.gnp96 /*一阶超前*/ gen F2gnp = F2.gnp96 gen Dgnp = D.gnp96 /*一阶差分*/ gen D2gnp = D2.gnp96 list in 1/10 list in -10/-1 2)产生增长率变量:对数差分 gen lngnp = ln(gnp96)gen growth = D.lngnp gen growth2 = (gnp96-L.gnp96)/L.gnp96 gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/10 1.3日期的处理日期的格式 help tsfmt 基本时点:整数数值,如 -3, -2, -1, 0, 1, 2, 3 .... 1960年1月1日,取值为 0; 3 显示格式:定义含义默认格式%td 日%tdDlCY %tw 周%twCY!ww %tm 月%tmCY!mn %tq 季度%tqCY!qq %th 半年%thCY!hh %ty 年%tyCY 1)使用tsset 命令指定显示格式use B6_tsset.dta, clear tsset t, daily list use B6_tsset.dta, clear tsset t, weekly list 2)指定起始时点 cap drop month generate month = m(1990-1) + _n - 1 format month %tm list t month in 1/20 cap drop year gen year = y(1952)+ _n - 1 format year %ty list t year in 1/20 3)自己设定不同的显示格式日期的显示格式 %d (%td)定义如下:%[-][t]d<描述特定的显示格式> 具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符 c y m l n d j h q w _ . , :- / ' !c C Y M L N D J W 定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写)4 M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年 (1 or 2)q 一年中的第几季度 (1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号):display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !!to display an exclamation point)样式1:Format Sample date in format ----------------------------------- %td 07jul1948 %tdM_d,_CY July 7, 1948 %tdY/M/D 48/07/11 %tdM-D-CY 07-11-1948 %tqCY.q 1999.2 %tqCY:q 1992:2 %twCY,_w 2010, 48 ----------------------------------- 样式2:Format Sample date in format ---------------------------------- %d 11jul1948 %dDlCY 11jul1948 %dDlY 11jul48 %dM_d,_CY July 11, 1948 %dd_M_CY 11 July 1948 %dN/D/Y 07/11/48 %dD/N/Y 11/07/48 %dY/N/D 48/07/11 %dN-D-CY 07-11-1948 ---------------------------------- clear set obs 100 5 gen t = _n + d(13feb1978)list t in 1/5 format t %dCY-N-D /*1978-02-14*/ list t in 1/5 format t %dcy_n_d /*1978 2 14*/ list t in 1/5 use B6_tsset, clear list tsset t, format(%twCY-m)list 4)一个实例:生成连续的时间变量 use e1920.dta, clear list year month in 1/30 sort year month gen time = _n tsset time list year month time in 1/30 generate newmonth = m(1920-1) + time - 1 tsset newmonth, monthly list year month time newmonth in 1/30 1.4图解时间序列 1)例1:clear set seed 13579113 sim_arma ar2, ar(0.7 0.2)nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _t tsline ar2 ma2 * 亦可采用 twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t 2)例2:增加文字标注sysuse tsline2, clear tsset day tsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" /// 3470 25dec2002 "x-mas",orient(vert))6 3)例3:增加两条纵向的标示线sysuse tsline2, clear tsset day tsline calories, tline(28nov2002 25dec2002)* 或采用 twoway line 命令 local d1 = d(28nov2002)local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签 tsline calories, tlabel(, format(%tdmd))ttitle("Date (2002)")tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA模型 ARIMA模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
stata操作介绍之时间序列-

虽然pperron 检验和dfgls检验拒绝了变量 fylltemp具有稳定性的假设,但是dfuller 检验 不能拒绝原假设,还是可以认为该变量具有 稳定性。
ARIMA模型
自相关表: . corrgram fylltemp,lags(4)
说明:该变量的自相关关系随着滞后期的增加而减少,偏自 相关关系在一期自后滞后消失,故适合模型AR(1)来分析该 变量。
注:本部分继续使用ch52.dta数据。
自相关分析
自相关表: . corrgram fylltemp,lags(9)
说明:大多数P值都小于0.05,故认为fylltemp具有显著的自相 关性;相关关系或偏相关关系越强,相应的线条越长;
自相关分析
自相关图: . ac fylltemp,lags(9)
平滑分析
生成移动平均值(1):
. gen water3=(water[ _n-1]+water[ _n]+water[ _n+1])/3
平滑分析
生成移动平均值(2): . tssmooth ma water5=water,window(2 1 2)
注:tssmooth:表示移动平均值平滑(加权或不加权); window(2 1 2):表示使用该值的前两个值、该值与该值的
平滑分析-滞后变量
生成n阶滞后变量的两种方法: . gen wNAO_n=wNAO[ _n-1] . gen wNAO_n=Ln.wNAO 注:第二种方法中的''Ln''表示Lag(n);
平滑分析-滞后变量
生成一阶滞后变量: . gen wNAO_1=wNAO[ _n-1]
生成二阶滞后变量: . gen wNAO_2=L2.wNAO
时间序列模型分析的各种stata命令

时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96.dta, clearlist in 1/20gen Lgnp = L.gnptsset datelist in 1/20gen Lgnp = L.gnp2)检查是否有断点:tsreport, reportuse gnp96.dta, cleartsset datetsreport, reportdrop in 10/10list in 1/12tsreport, reporttsreport, report list /*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport, report listlist in 1/124)追加样本:tsappenduse gnp96.dta, cleartsset datelist in -10/-1sumtsappend , add(5) /*追加5个观察值*/list in -10/-1sum5)应用:样本外预测: predictreg gnp96 L.gnp96predict gnp_hatlist in -10/-16)清除时间标识: tsset, cleartsset, clear1.2变量的生成与处理1)滞后项、超前项和差分项 help tsvarlistuse gnp96.dta, cleartsset dategen Lgnp = L.gnp96 /*一阶滞后*/gen L2gnp = L2.gnp96gen Fgnp = F.gnp96 /*一阶超前*/gen F2gnp = F2.gnp96gen Dgnp = D.gnp96 /*一阶差分*/gen D2gnp = D2.gnp96list in 1/10list in -10/-12)产生增长率变量: 对数差分gen lngnp = ln(gnp96)gen growth = D.lngnpgen growth2 = (gnp96-L.gnp96)/L.gnp96gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/101.3日期的处理日期的格式 help tsfmt基本时点:整数数值,如 -3, -2, -1, 0, 1, 2, 3 ....1960年1月1日,取值为 0;1)使用 tsset 命令指定显示格式use B6_tsset.dta, cleartsset t, dailylistuse B6_tsset.dta, cleartsset t, weeklylist2)指定起始时点cap drop monthgenerate month = m(1990-1) + _n - 1format month %tmlist t month in 1/20cap drop yeargen year = y(1952) + _n - 1format year %tylist t year in 1/203)自己设定不同的显示格式日期的显示格式 %d (%td) 定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l nd j h q w _ . , : - / ' !cC Y M L ND J W定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写) M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年 (1 or 2)q 一年中的第几季度 (1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号): display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !! to display an exclamation point)样式1:Format Sample date in format-----------------------------------%td 07jul1948%tdM_d,_CY July 7, 1948%tdY/M/D 48/07/11%tdM-D-CY 07-11-1948%tqCY.q 1999.2%tqCY:q 1992:2%twCY,_w 2010, 48-----------------------------------样式2:Format Sample date in format----------------------------------%d 11jul1948%dDlCY 11jul1948%dDlY 11jul48%dM_d,_CY July 11, 1948%dd_M_CY 11 July 1948%dN/D/Y 07/11/48%dD/N/Y 11/07/48%dY/N/D 48/07/11%dN-D-CY 07-11-1948----------------------------------clearset obs 100gen t = _n + d(13feb1978)list t in 1/5format t %dCY-N-D /*1978-02-14*/list t in 1/5format t %dcy_n_d /*1978 2 14*/list t in 1/5use B6_tsset, clearlisttsset t, format(%twCY-m)list4)一个实例:生成连续的时间变量use e1920.dta, clearlist year month in 1/30sort year monthgen time = _ntsset timelist year month time in 1/30generate newmonth = m(1920-1) + time - 1tsset newmonth, monthlylist year month time newmonth in 1/301.4图解时间序列1)例1:clearset seed 13579113sim_arma ar2, ar(0.7 0.2) nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _ttsline ar2 ma2* 亦可采用 twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t2)例2:增加文字标注sysuse tsline2, cleartsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" ///3470 25dec2002 "x-mas", orient(vert)) 3)例3:增加两条纵向的标示线sysuse tsline2, cleartsset daytsline calories, tline(28nov2002 25dec2002) * 或采用 twoway line 命令 local d1 = d(28nov2002) local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签tsline calories, tlabel(, format(%tdmd)) ttitle("Date (2002)") tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA 模型ARIMA 模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 平滑分析 • 自相关分析 • ARIMA模型
平滑分析
大多数时间序列数据都具有上下起伏的波动,对 于时间序列数据的识别十分困难。平滑分析可以把 数据分为两个部分:一部分逐渐发生变化,便于分 析处理;另一部分则含有突变的成份。
时间平滑:用某时刻及其前后若干时刻的值进行 加权平均,所得值作为该时刻的替代值以滤去小扰 动的方法。
平滑分析-滞后变量
生成n阶滞后变量的两种方法:
. gen wNAO_n=wNAO[ _n-1] . gen wNAO_n=Ln.wNAO 注:第二种方法中的''Ln''表示Lag(n);
平滑分析-滞后变量
生成一阶滞后变量: . gen wNAO_1=wNAO[ _n-1] 生成二阶滞后变量: . gen wNAO_2=L2.wNAO
自相关分析
交叉相关表: . xcorr wNAO fylltemp if year >=1970 & year <=1990,lags(7) table
ARIMA模型
时间序列中的自相关集成移动平均模型 (autoregressive integrated moving average简称 ARIMA),是指将非平稳时间序列转化为平稳时间 序列,然后将因变量仅对它的滞后值以及随机误差 项的现值和滞后值进行回归所建立的模型。 ARIMA模型根据原序列是否平稳以及回归中所含 部分的不同,包括移动平均过程(MA)、自回归过 程(AR)、自回归移动平均过程(ARMA)以及 ARIMA过程。
平滑分析
趋势图:
. graph two line water5 date, clwidth(thick) || line water date , clwidth(thin) clpattern(solid)
平滑分析
波动幅度:
. gen ch=water- water5 . list in 1/5
平滑分析
该部分以1983年1月到7月Milford城镇的 自来水消费量为例。 文件:ch51.dta
导入数据: . use "C:\Users\Administrator\Desktop\时间 序列\数据\ch51.dta", clear
平滑分析
描述性统计: . describe
平滑分析
生成日期变量(一):
平滑分析-滞后变量
平滑分析-滞后变量
三种滞后回归方法:
. reg fylltemp wNAO wNAO_1 wNAO_2 if year >=1970 & year <=1990 . reg fylltemp wNAO L.wNAO L2.wNAO if year >=1970 & year <=1990 . reg fylltemp L(0/2).wNAO if year >=1970 & year <=1990
平滑分析-滞后变量
回归结果:
相关分析
自相关系数是对变量自身与其滞后变量之 间相关关系的估计。偏相关系数是在消除其 他变量影响的条件下,所计算的某两变量之 间的相关系数。交叉相关是分析两个时间序 列之间的关系。
注:本部分继续使用ch52.dta数据。
自相关分析
自相关表: . corrgram fylltemp,lags(9)
平滑分析
波动幅度: . graph two line ch date
平滑分析-滞后变量
导入数据: . use "C:\Users\Administrator\Desktop\时间序列\数 据\ch52.dta", clear
描述性统计: . describe 时间设置: . tsset year,yearly
平滑分析
生成移动平均值(1):
. gen water3=(water[ _n-1]+water[ _n]+water[ _n+1])/3
平滑分析
生成移动平均值(2): . tssmooth ma water5=water,window(2 1 2)
注:tssmooth:表示移动平均值平滑(加权或不加权); window(2 1 2):表示使用该值的前两个值、该值与该值的 后两个值进行平均计算;
说明:大多数P值都小于0.05,故认为fylltemp具有显著的自相 关性;相关关系或偏相关关系越强,相应的线条越长;
自相关分析
自相关图: . ac fylltemp,lags(9)
注:阴影部分是95%的置信区间;
自相关分析
偏相关图: . pac fylltemp,lags(9) yline(0) ciopts(bstyle(outline))
. gen date=mdy( month ,day, year) . list in 1/5
平滑分析
设置时间(二): . tsset date, format(%d) . list in 1/5
平滑分析
趋势图:
. graph two line water date, ylabel(300(100)900)
平滑分析-滞后变量
时间平滑: . tssmooth ma fylln= fylltemp:
. graph two spike fylltemp year,base(1.67) yline(1.67) || line fylln year ,clpattern(solid)
ARIMA模型
ARIMA模型操作步骤:
1、对变量进行检验,若变量具有稳定性,进行第二步,否 则,不能使用ARIMA模型; 2、做出变量的自相关图; 3、根据变量的自相关图,选择合适的模型; 4、根据选定的模型进行分析,并检验系数是否显著。若有 的系数不显著,所选择的模型可能存在问题;若所有系数都 显著,进行第五步; 5、检验残差是否具有自相关性。若残差具有自相关性,则 所选择的模型存在问题;若残差不具有自相关性,则所选择 的模型是合适的。
注:ciopts(bstyle(outline))表示将偏相关图中阴影部分改为 矩阵区域。
自相关分析
交叉相关图:
. xcorr wNAO fylltemp if year >=1970 & year <=1990,lags(7) xlabel(-9(1)9,grid)
说明:由图可知,lag为0时,交叉相关性最强(线条最长), 且为负。