SPSS时间序列分析-spss操作步骤
spss(时间序列分析)

• 横截面数据也常称为变量的一个简单随机样本,也即假设每个数据 都是来自于总体分布的一个取值,且它们之间是相互独立的(独立 同分布)。
• 而时间序列的最大特点是观测值并不独立。时间序列的一个目的
是用变量过去的观测值来预测同一变量的未来值。 • 下面看一个时间序列的数据例子。 • 例1. 某企业从1990年1月到2002年12月的月销售数据(单位:百
三、指数平滑模型
• 时间序列分析的一个简单和常用的预测模型叫做指数平滑
(exponential smoothing)模型。
• 指数平滑只能用于纯粹时间序列的情况,而不能用于含有独立变量 时间序列的因果关系的研究。
• 指数平滑的原理为:利用过去观测值的加权平均来预测未来的 观测值(这个过程称为平滑),且离现在越近的观测值要给以越重
Seanal adjusted series SA
Seas factors SF
YEAR
图3 销售数据的季节因素分离
第十七页,共70页。
120
可以看出,逐月的销
100 售额大致沿一个指数
80 曲线呈增长趋势。
60
↘
40
20
0
-20 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002
3. saf_1:季节因素(seasonal factor) ,记为{SFt }; 4. stc_1:去掉季节及随机扰动后的趋势及循环因素(trend-
cycle series),记为{TCt }。
第十五页,共70页。
• 这些分解出来的序列或成分与原有时间序列 之间有如下的简单和差关系:
SPSS随机时间序列分析技巧教材

SPSS随机时间序列分析技巧教材SPSS(Statistical Package for the Social Sciences)是一款用于统计分析和数据挖掘的软件工具。
它提供了丰富的功能和功能,可以用于各种统计分析任务。
其中一个强大的功能是随机时间序列分析,它可以帮助用户了解和解释时间序列数据的模式和趋势。
本文将介绍一些SPSS中常用的随机时间序列分析技巧。
1. 数据导入:首先,将时间序列数据导入SPSS中。
确保数据以适当的格式存储,并正确地标识时间变量。
SPSS支持多种数据格式,如CSV、Excel等。
2. 数据检查:在进行时间序列分析之前,需要对数据进行一些基本的检查。
可以使用SPSS中的描述性统计量来检查数据的一般概况,比如数据的均值、方差、最大值和最小值等。
如果数据存在缺失值、异常值或离群值,需要进行适当的数据清洗。
3. 时间序列图:时间序列图可以帮助用户直观地了解数据的模式和趋势。
SPSS提供了绘制时间序列图的功能,用户可以选择不同的图形类型,如折线图、散点图等。
通过观察时间序列图,用户可以判断数据是否存在趋势、季节性或周期性等特征。
4. 时间序列分解:时间序列分解是将时间序列数据分解为趋势、周期和随机成分的过程。
SPSS提供了用于时间序列分解的函数和工具,用户可以根据需要选择不同的分解方法,如移动平均法、指数平滑法等。
分解后的时间序列可以帮助用户更好地理解数据的结构和组成。
5. 自相关分析:自相关分析是研究时间序列数据自身相关性的一种方法。
SPSS提供了自相关分析的功能,用户可以计算自相关系数,并绘制自相关图。
自相关分析可以帮助用户判断时间序列数据是否具有持续性,即当前的值是否与以前的值相关。
6. 平稳性检验:平稳性是时间序列分析的一个重要概念,它指的是时间序列数据的均值和方差在时间上保持稳定。
SPSS提供了多种平稳性检验方法,如ADF检验、KPSS检验等。
通过进行平稳性检验,用户可以判断时间序列数据是否适合进行随机时间序列分析。
spss的操作流程

spss的操作流程
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学研究、市场调查、医学研究等领域。
SPSS具有强大的数据处理和分析功能,可以帮助研究人员快速、准确地进行数据分析和统计。
SPSS的操作流程主要包括数据导入、数据清洗、数据分析和结果呈现四个步骤。
首先是数据导入。
在SPSS中,可以通过多种方式导入数据,如从Excel文件、文本文件、数据库等导入数据。
在导入数据时,需要注意数据的格式是否正确,确保数据的准确性和完整性。
接下来是数据清洗。
数据清洗是数据分析的重要步骤,通过数据清洗可以去除异常值、缺失值,处理重复数据等。
在SPSS中,可以使用数据筛选、数据排序、数据转换等功能进行数据清洗,确保数据的质量和准确性。
然后是数据分析。
在SPSS中,可以进行各种统计分析,如描述统计、相关分析、回归分析、方差分析等。
通过数据分析可以揭示数据之间的关系、趋势和规律,为研究人员提供科学依据和决策支持。
最后是结果呈现。
在SPSS中,可以生成各种图表、表格来展示
数据分析的结果,如柱状图、折线图、散点图等。
通过结果呈现可以直观地展示数据分析的结果,帮助研究人员更好地理解数据和进行决策。
总的来说,SPSS的操作流程包括数据导入、数据清洗、数据分析和结果呈现四个步骤。
通过SPSS的强大功能和简便操作,研究人员可以快速、准确地进行数据分析和统计,为科研工作提供有力支持。
时间序列预测技术之——SPSS软件操作

下面看看如何采用SPSS软件进行时间序列的预测!这里我用PASW Statistics 18软件,大家可能觉得没见过这个软件,其实就是SPSS18.0,不过现在SPSS已经把产品名称改称为PASW了!我们通过案例来说明:(本案例并不想细致解释预测模型的预测的假设检验问题,1-太复杂、2-相信软件)假设我们拿到一个时间序列数据集:某男装生产线销售额。
一个产品分类销售公司会根据过去 10 年的销售数据来预测其男装生产线的月销售情况。
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。
时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:• 此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?• 此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?这时候我们就可以看到时间序列图了!我们看到:此序列显示整体上升趋势,即序列值随时间而增加。
上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。
季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。
时间序列预测模型的建立是一个不断尝试和选择的过程。
第十一章SPSS的时间序列分析

3.1 AR(自回归)模型
一般地,如果和p个过去值有关则是p阶自回归模型, 记为AR(p),表达式为: xt 0 1 xt 1 2 xt 2 p xt p t
(B) xt t
或者
其中, (B) 1 1 B 2 B 2 p B p
1 - 12
第三节 时间序列的图形化观察
4、互相关图(CCF) 对两个互相对应的时间序列进行相关性分 析,检验一个序列与另一个序列的滞后 序列之间的相关性 Analyze>Forecasting>Cross Correlations 举例: GDP与通信业务收入,0阶滞后相关性最显 著
1 - 13
3.2 MA模型
(Moving Average Model)
3.3 ARMA模型
(Auto Regression Moving Average model)
3.4 ARIMA模型
( Autoregressive Integrated Moving Average Model )
1 - 22
3.1 AR(自回归)模型
1 - 15
第六节 ARIMA模型
ARIMA模型全称为自回归移动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),是由博克 思(Box)和詹金斯(Jenkins)于70年代初提出的著名时间序列 预测方法,所以又称为box-jenkins模型、博克思-詹金斯法。
第十一章 SPSS的时间序列分析
1-1
第一节 时间序列分析概述
一、相关概念 时间序列:有序的数列:y1,y2,y3,…yt 理解: 1、有先后顺序且时间间隔均匀的数列; 2、随机变量族或随机过程的一个“实现” ,即在每一个固定时间点t上,现象yt看 作是一个随机变量, y1,y2,y3,…yt是一系 列随机变量所表现的一个结果。
课题_第11章 SPSS在时间序列预测中的应用 SPSS19.0软件使用教程

第11章SPSS在时间序列预测中的应用SPSS19.0软件使用教程在进入SPSS后,具体工作流程如下:1.将数据输入SPSS,并存盘以防断电。
2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采用的检验方法。
3.按题目要求进行统计分析。
4.保存和导出分析结果。
下面就按这几步依次讲解。
§1.1 数据的输入和保存1.1.1 SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
特别的,工具栏下方的是数据栏,数据栏下方则是数据管理窗口的主界面。
该界面和EXCEL极为相似,由若干行和列组成,每行对应了一条记录,每列则对应了一个变量。
由于现在我们没有输入任何数据,所以行、列的标号都是灰色的。
请注意第一行第一列的单元格边框为深色,表明该数据单元格为当前单元格。
对Windows操作界面不熟悉的朋友可参见SAS入门第一课中的相关内容。
对数据表界面操作不熟悉的朋友可先学习一下EXCEL的操作(因为它的帮助是中文的)。
有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer按钮,即可进入上面的主界面。
1.1.2 定义变量该资料是定量资料,设计为成组设计,因此我们需要建立两个变量,一个变量代表血磷值,习惯上取名为X,另一个变量代表观察对象是健康人还是克山病人,习惯上取名为GROUP。
对数据的统计分析格式不太熟悉的朋友请先学习统计软件第一课。
选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:该变量定义对话框在SPSS 10.0版中已被取消,这里的操作只适合9.0~7.0版的用户。
对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
spss教程第四章---时间序列分析

第四章时间序列分析由于反映社会经济现象的大多数数据是按照时间顺序记录的,所以时间序列分析是研究社会经济现象的指标随时间变化的统计规律性的统计方法。
.为了研究事物在不同时间的发展状况,就要分析其随时间的推移的发展趋势,预测事物在未来时间的数量变化。
因此学习时间序列分析方法是非常必要的。
本章主要内容:1. 时间序列的线图,自相关图和偏自关系图;2. SPSS 软件的时间序列的分析方法−季节变动分析。
§4.1 实验准备工作§4.1.1 根据时间数据定义时间序列对于一组示定义时间的时间序列数据,可以通过数据窗口的Date菜单操作,得到相应时间的时间序列。
定义时间序列的具体操作方法是:将数据按时间顺序排列,然后单击Date →Define Dates打开Define Dates对话框,如图4.1所示。
从左框中选择合适的时间表示方法,并且在右边时间框内定义起始点后点击OK,可以在数据库中增加时间数列。
图4.1 产生时间序列对话框§4.1.2 绘制时间序列线图和自相关图一、线图线图用来反映时间序列随时间的推移的变化趋势和变化规律。
下面通过例题说明线图的制作。
例题4.1:表4.1中显示的是某地1979至1982年度的汗衫背心的零售量数据。
试根据这些的数据对汗衫背心零售量进行季节分析。
(参考文献[2])表4.1 某地背心汗衫零售量一览表单位:万件1979 1980 1981 19821 23 30 18 222 33 37 20 323 69 59 92 1024 91 120 139 1555 192 311 324 3726 348 334 343 3247 254 270 271 2908 122 122 193 1539 95 70 62 7710 34 33 27 1711 19 23 17 3712 27 16 13 46解:根据表4.1的数据,建立数据文件SY-11(零售量),并对数据定义相应的时间值,使数据成为时间序列。
spss时间序列分析教程

3.3时间序列分析3.3.1时间序列概述1.基本概念(1)一般概念:系统中某一变量的观测值按时间顺序(时间间隔相同)排列成一个数值序列,展示研究对象在一定时期内的变动过程,从中寻找和分析事物的变化特征、发展趋势和规律。
它是系统中某一变量受其它各种因素影响的总结果。
(2)研究实质:通过处理预测目标本身的时间序列数据,获得事物随时间过程的演变特性与规律,进而预测事物的未来发展。
它不研究事物之间相互依存的因果关系。
(3)假设基础:惯性原则。
即在一定条件下,被预测事物的过去变化趋势会延续到未来。
暗示着历史数据存在着某些信息,利用它们可以解释与预测时间序列的现在和未来。
近大远小原理(时间越近的数据影响力越大)和无季节性、无趋势性、线性、常数方差等。
(4)研究意义:许多经济、金融、商业等方面的数据都是时间序列数据。
时间序列的预测和评估技术相对完善,其预测情景相对明确。
尤其关注预测目标可用数据的数量和质量,即时间序列的长度和预测的频率。
2.变动特点(1)趋势性:某个变量随着时间进展或自变量变化,呈现一种比较缓慢而长期的持续上升、下降、停留的同性质变动趋向,但变动幅度可能不等。
(2)周期性:某因素由于外部影响随着自然季节的交替出现高峰与低谷的规律。
(3)随机性:个别为随机变动,整体呈统计规律。
(4)综合性:实际变化情况一般是几种变动的叠加或组合。
预测时一般设法过滤除去不规则变动,突出反映趋势性和周期性变动。
3.特征识别认识时间序列所具有的变动特征,以便在系统预测时选择采用不同的方法。
(1)随机性:均匀分布、无规则分布,可能符合某统计分布。
(用因变量的散点图和直方图及其包含的正态分布检验随机性,大多数服从正态分布。
)(2)平稳性:样本序列的自相关函数在某一固定水平线附近摆动,即方差和数学期望稳定为常数。
样本序列的自相关函数只是时间间隔的函数,与时间起点无关。
其具有对称性,能反映平稳序列的周期性变化。
特征识别利用自相关函数ACF:ρk=γk/γ0其中γk是y t的k阶自协方差,且ρ0=1、-1<ρk<1。
实验八-spss11中的时间序列分析

实验八spss11中的时间序列分析一、实验目的了解spss11中时间序列分析的简单方法二、实验原理介绍1.SPSS中时间序列分析简要介绍依时间顺序排列起来的一系列观测值称为时间序列,跟大部分的统计不同,这类资料的先后顺序是不能忽视的,更关键的是观测值之间不独立。
因此,这类数据不能用普通的统计方法解决。
时间序列分析(Time series)是专门用于分析这种时间序列资料的统计模型。
它考虑的不是变量之间的因果关系,而是重点考察变量在时间方面的发展变化规律,并为之建立数学模型。
时间序列分析的方法可以分为两大类:Time domain和Frequency domain。
前者将时间序列看成是过去一些点的函数,或者认为序列具有时间系统变化的趋势,它可以用不多的参数来加以描述,或者说可以通过差分、周期等还原成随机序列。
后者则认为时间序列是由数个正弦波成分叠加而成,当序列的确来自一些周期函数集合时,该方法特别有用。
不同的专业领域习惯用不同的方法:经济学习惯用Time domain,而电力工程专家则对Frequency domain更感兴趣。
下面讲述的都是Time domain由于时间序列模型的复杂性,它在spss中横跨了数据整理、统计分析和绘图三大部分,具体来说是:✧预处理模块:包括用于填充序列缺失值的Transform | replace Missing Values过程,建立时间变量的Data | Define dates过程和将序列平稳化的Transform | Create TimeSeries过程。
✧图形化观察/分析:时间序列在分析中高度依赖图形。
Spss为其提供了特有的观察工具:序列图(Sequence Chart)、自相关/偏自相关图(Autocorrelation Function,ACF & Autocorrelation Function,PACF)、交叉相关图(Crosscorrelation Function,CCF)、周期图(Periodogram)和谱密度图(Spectral Chart)。
spss基本操作流程

spss基本操作流程SPSS(Statistical Package for the Social Sciences)是一款专业的统计分析软件,广泛应用于社会科学、商业和医学等领域。
它提供了丰富的统计分析功能,可以帮助用户对数据进行分析、处理和可视化。
下面将介绍SPSS的基本操作流程。
首先,打开SPSS软件并创建一个新的数据文件。
在菜单栏中选择“File” -> “New” -> “Data”,然后输入变量的名称和数据类型。
可以选择导入外部数据文件,如Excel文件或文本文件。
接下来,输入数据。
在数据文件中,每一行代表一个观测值,每一列代表一个变量。
可以手动输入数据,也可以导入外部数据文件。
在输入数据时,要确保数据的准确性和完整性。
然后,进行数据清洗和处理。
在菜单栏中选择“Transform” -> “Recode”或“Compute”,可以对数据进行重编码或计算新的变量。
还可以使用“Select Cases”功能选择特定的观测值进行分析。
接下来,进行统计分析。
在菜单栏中选择“Analyze”,可以进行各种统计分析,如描述统计、相关分析、回归分析等。
选择相应的分析方法,并设置变量和参数,然后运行分析。
最后,进行结果展示和解释。
在分析完成后,SPSS会生成相应的结果报告。
可以查看结果表格、图表和统计指标,对分析结果进行解释和讨论。
还可以导出结果报告,以便进一步分析或分享给他人。
总的来说,SPSS的基本操作流程包括创建数据文件、输入数据、数据清洗和处理、统计分析以及结果展示和解释。
通过熟练掌握SPSS的操作流程,可以更好地进行数据分析和研究工作,为决策提供科学依据。
希望以上介绍对您有所帮助。
SPSS使用教程

描述样本数据一般的,一组数据拿出来,需要先有一个整体认识。
除了我们平时最常用的集中趋势外,还需要一些离散趋势的数据。
这方面EXCEL就能一次性的给全了数据,但对于SPSS,就需要用多个工具了,感觉上表格方面不如EXCEL好用。
个人感觉,通过描述需要了解整体数据的集中趋势和离散趋势,再借用各种图观察数据的分布形态。
对于SPSS提供的OLAP cubes(在线分析处理表),Case Summary(观察值摘要分析表),Descriptives (描述统计)不太常用,反喜欢用Frequencies(频率分析),Basic Table(基本报表),Crosstabs(列联表)这三个,另外再配合其它图来观察。
这个可以根据个人喜好来选择。
一.使用频率分析(Frequencies)观察数值的分布。
频率分布图与分析数据结合起来,可以更清楚的看到数据分布的整体情况。
以自带文件Trends chapter 13.sav为例,选择Analyze->Descriptive Statistics->Frequencies,把hstarts选入Variables,取消在Display Frequency table前的勾,在Chart里面histogram,在Statistics选项中如图1图1分别选好均数(Mean),中位数(Median),众数(Mode),总数(Sum),标准差(Std. deviation),方差(Variance),范围(range),最小值(Minimum),最大值(Maximum),偏度系数(Skewness),峰度系数(Kutosis),按Continue返回,再按OK,出现结果如图2图2表中,中位数与平均数接近,与众数相差不大,分布良好。
标准差大,即数据间的变化差异还还小。
峰度和偏度都接近0,则数据基本接近于正态分布。
下面图3的频率分布图就更直观的观察到这样的情况图3二.采用各种图直观观察数据分布情况,如采用柱型图观察归类的比例等。
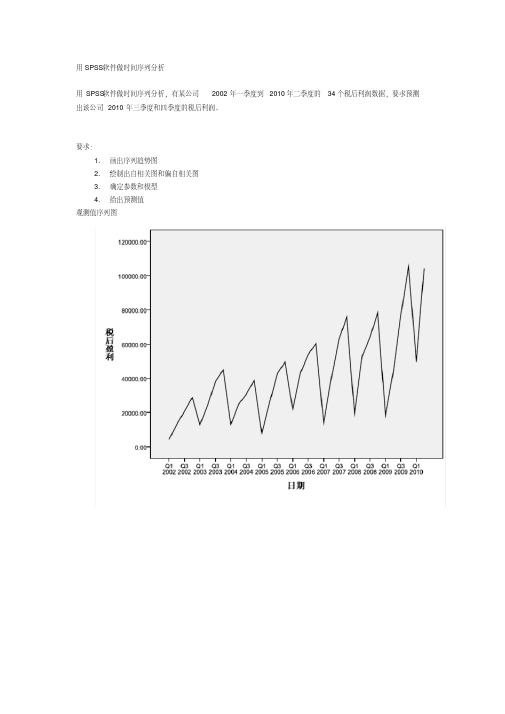
用SPSS软件做时间序列分析[论文设计]
![用SPSS软件做时间序列分析[论文设计]](https://img.taocdn.com/s3/m/96c9da719a6648d7c1c708a1284ac850ad02047f.png)
用SPSS软件做时间序列分析
用SPSS软件做时间序列分析,有某公司2002年一季度到2010年二季度的34个税后利润数据,要求预测出该公司2010年三季度和四季度的税后利润。
要求:
1.画出序列趋势图
2.绘制出自相关图和偏自相关图
3.确定参数和模型
4.给出预测值
观测值序列图
2
税后盈利
3、确定参数和模型时间序列建模程序
模型摘要
4、给出预测值
2010年第三季度 139621.02万元2010年第四季度170144.55万元
剔除季节成分后,平滑处理及剔除循环波动因素的序列图
SEASON、MOD_6、MUL、EQU、4 中税后利润的季节性调整序列
给出预测值
2010年第三季度127487.38347万元2010年第四季度 140349.91149万元。
实验spss中的时间序列分析

实验八spss11中的时间序列分析一、实验目的了解spss11中时间序列分析的简单方法二、实验原理介绍1.SPSS中时间序列分析简要介绍依时间顺序排列起来的一系列观测值称为时间序列,跟大部分的统计不同,这类资料的先后顺序是不能忽视的,更关键的是观测值之间不独立。
因此,这类数据不能用普通的统计方法解决。
时间序列分析(Time series)是专门用于分析这种时间序列资料的统计模型。
它考虑的不是变量之间的因果关系,而是重点考察变量在时间方面的发展变化规律,并为之建立数学模型。
时间序列分析的方法可以分为两大类:Time domain和Frequency domain。
前者将时间序列看成是过去一些点的函数,或者认为序列具有时间系统变化的趋势,它可以用不多的参数来加以描述,或者说可以通过差分、周期等还原成随机序列。
后者则认为时间序列是由数个正弦波成分叠加而成,当序列的确来自一些周期函数集合时,该方法特别有用。
不同的专业领域习惯用不同的方法:经济学习惯用Time domain,而电力工程专家则对Frequency domain更感兴趣。
下面讲述的都是Time domain由于时间序列模型的复杂性,它在spss中横跨了数据整理、统计分析和绘图三大部分,具体来说是:✧预处理模块:包括用于填充序列缺失值的Transform | replace Missing Values过程,建立时间变量的Data | Define dates过程和将序列平稳化的Transform | Create TimeSeries过程。
✧图形化观察/分析:时间序列在分析中高度依赖图形。
Spss为其提供了特有的观察工具:序列图(Sequence Chart)、自相关/偏自相关图(Autocorrelation Function,ACF & Autocorrelation Function,PACF)、交叉相关图(Crosscorrelation Function,CCF)、周期图(Periodogram)和谱密度图(Spectral Chart)。
用SPSS软件做时间序列分析
滞后
偏自相关 标准 误差
1
.728
.171
2
-.168
.171
3
.108
.171
4
-.053
.171
5
.206
.171
6
.000
.171
7
.076
.171
8
-.015
.171
9
.014
.171
10
.034
.171
11
-.121
.171
12
-.066
.171
13
-.059
.171
14
.115
.171
滞后
自相关
标准 误差 a
Box-Ljung 统计量
值
df
Sig. b
1
.728
.164
19.633
1
.000
2
.450
.162
27.383
2
.000
3
.310
.159
31.169
3
.000
4
.207
.157
32.911
4
.000
5
.219
.154
34.941
5
.000
6
.241
.151
37.484
6
2
.115
.171
3
.107
.1715
-.279
.171
6
-.010
.171
7
.046
.171
8
.268
.171
9
-.130
利用spss17.0的专家建模器实现arima模型及时间序列分析

第二步,数据的导入,可以是excel文件,也可以直接复制粘贴过来。这 里以excel的源文件为例。 文件——打开 ;界面如下
打开后的界面如下:
第三步:用时间序列分析 分析——预测——创建模型 界面如下,提示的定义日期可以根据数据的日示 数据集处:
输出查看器:
输出查看器
预测值
输出查看器的图形
第七步:设置图表 建议在拟合值出画勾。这样可以鲜明看到拟合值与预测值的比较
第八步:保存选项 在预测值处画勾,并将‘预测值(p)’改为‘预测值’
第九步:选项栏,点击第二个选项,如果定义了日期,则日期处填写想 要预测日期的最后一个日期;如果没有定义日期,则看已知数据的个数, 加上自己要预测的个数,键入即可。 最后点击确定。
第四步:选择变量,将要分析预测的变量转入因变量,自变 量可有可无。
此处仅选x1进行分析,放到因变量的栏里 如下图:
第五步:可以在界面的中间找到条件选项点开:
点开条件选项,可以选择模型类别,默认的为‘所有模型’, 此处以arima模型为例。
在条件选项下还可以选择对离群值的设置。
第六步:设置统计量,注意要在显示预测值的空白处画勾,
SPSS时间序列分析-spss操作步骤

第六十一页,编辑于星期五:八点 四十八分。
时间序列习题参考答案(14)
ARIMA模型参数表显示模型中所有参数的值,及由模型标识符标识的每个模型。它列出了模型中所 有的变量,包括因变量和由专家建模确定有显著性的自变量。现在我们清楚地看到在模型统计量表中的两个 预测因子分别是邮寄商品目录的数量和用于订购的开放式电话线数量。它们都有显著性意义(Sig.小于 0.05)。
时间序列习题参考答案(7)
在滞后12处的重要的顶点暗示在数据中存在周期为12(12个季度)的季节成分。检查偏自相关函数图 同样可得到这个十分明确的结论。
返回
第五十五页,编辑于星期五:八点 四十八分。
时间序列习题参考答案(8)
四、建立时间序列模型
返回
第五十六页,编辑于星期五:八点 四十八分。
时间序列习题参考答案(9)
返回
第二十五页,编辑于星期五:八点 四十八分。
时间序列分析实例输出(1)
模型拟合
返回
第二十六页,编辑于星期五:八点 四十八分。
时间序列分析实例输出(2)
模型统计数据
返回
第二十七页,编辑于星期五:八点 四十八分。
时间序列分析实例输出(3)
预测部分结果
数据编辑器中的新变量
返回
第二十八页,编辑于星期五:八点 四十八分。
返回
第四十三页,编辑于星期五:八点 四十八分。
Options对话框
返回
第四十四页,编辑于星期五:八点 四十八分。
互相关实例输出
模型描述
样品处理摘要 返回
第四十五页,编辑于星期五:八点 四十八分。
互相关实例输出(1)
互相关系数表
男女服装销售量的互相关图
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
返回
时间序列习题参考答案(12)
该模型描述表包含每个估计模型名称和模型类型。在本例中,因变量是男子服装销售 量,系统分配的名称是Model_1。专家建模得出的最佳拟合模型为ARIMA(0,0,0)(0,1,0), 它是1阶季节差分自回归综合移动平模型。
返回
时间序列分析实例输出(2)
模型统计数据
返回
时间序列分析实例输出(3)
预测部分结果
数据编辑器中的新变量
返回
应用时间序列模型
(Apply models )
返回
Apply time Series models对话框
返回
自相关
(Autocorrelations )
返回
Autocorrelations对话框
返回
时间序列习题参考答案(15)
五、预测1999年3月的邮寄商品目录的数量和用于订购的开放式电话线数量。
返回
时间序列习题参考答案(16)
在数据编辑窗中显示新变量Predicted_mail_Model_1 and Predicted_phone_Model_2, 包括其模型预测值。这些预测值被添加到121至123的记录中。下面用这些值做相应变 换后来预测1999年3月的男装销售量。
返回
谱图选择对话框
返回
频谱分析实例输出
模型描述
周期图
密度图
返回
互相关
Cross -Autocorrelation
返回
Cross-Autocorrelation对话框
返回
Options对话框
返回
互相关实例输出
模型描述
样品处理摘要
返回
互相关实例输出(1)
互相关系数表
男女服装销售量的互相关图
返回
时间序列习题参考答案
1、 时间序列是指一个依时间顺序做成的观察资料的集合。时间序列分析过程中最常用的 方法是:指数平滑、自回归、综合移动平均及季节分解。
2、 先对数据进行必要的预处理和观察,直到它变成稳态后再用这些过程对其进行分析。 根据对数据建模前的预处理工作的先后顺序,将它分为三个步骤:首先,对有缺失值 的数据进行修补,其次将数据资料定义为相应的时间序列,最后对时间序列数据的平 稳性进行计算观察。
是否只与时间间隔有关而与所处的时间无关。 6、在时间序列分析中,为检验时间序列的平稳性,经常要用一阶差分、二阶差分,有时为
选择一个合适的时间序列的模型还要对原时间序列数据进行对数转换或平方根转换等。 这就需要在已经建立的时间序列的数据库中,再建一个新的时间序列的变量。在SPSS 的Create Time Series中可根据现有的数字型时间序列变量的函数建立一个新的变量。
返回
时间序列习题参考答案(14)
ARIMA模型参数表显示模型中所有参数的值,及由模型标识符标识的每个模型。 它列出了模型中所有的变量,包括因变量和由专家建模确定有显著性的自变量。现在 我们清楚地看到在模型统计量表中的两个预测因子分别是邮寄商品目录的数量和用于 订购的开放式电话线数量。它们都有显著性意义(Sig.小于0.05)。
返回
时间序列习题参考答案(1)
7、一、定义时间序列
(说明:1、对data17-07a.sav和data17-07.sav都要做这个工作。2、在第四步起data1707.sav)
返回
时间序列习题参考答案(2)
二、序列图分析
返回
时间序列习题参考答案(3)
返回
时间序列习题参考答案(4)
序列图显示了许多峰值,其中许多峰值是等间隔 出现的,有很清楚的上升趋势。等间隔的峰值暗 示存在时间序列的周期成分。考虑到销售的季节 性,高峰典型地发生在假期期间,你不必对数据 中发现的年季节成分感到吃惊。
返回
Options选项卡
返回
自相关分析实例输出
模型描述
样品处理摘要
自相关表
返回
自相关分析实例输出(1)
自相关图
偏自相关表
偏自相关图
返回
季节分解法
Seasonal Deccomposition
返回
季节分解主对话框
返回
季节分解法分析实例输出
模型描述
季节因素
数据文件中增加的4个新变量
返回
频谱分析 Spectral Analyze
模型的季节性说明了在序列图中见到的季节性峰值,1阶差分反映了数据中明显的上升 趋势。
返回
时间序列习题参考答案(13)
模型统计表给出了汇总信息和对每个估计模型最佳拟合的统计量。每个模型的结果 用模型描述表中提供的模型标识符被标识。模型包含你最初指定的5个候选预测因子中 的两个预测因子。所以专家建模已经识别出两个可以用来预测的自变量。尽管时间序 列模型主动提供了许多不同的最佳拟合统计量,但我们只选择了平稳值。该统计量提 供了由模型解释的序列中总变异的百分比的估计,当有趋势或季节性模式时平稳是最 适宜的,就像本例的情况一样。本例是个很大的值说明拟合很好。Ljung-Box统计量同 改良的Box-Pierce统计量一样知名,提供了模型是否被正确地指定的象征。显著性值小 于0.05暗示在观察值序列中存在不是由模型解释的结构。本例0.984的显著性值说明它 是不显著的,所以我们可以肯定正确地指定了模型。专家建模侦查出9个异常值。这些 点中的每一个都已适当地被模拟处理,所以不需要你从序列中移走它们。
Time Serises Modeler 对话框Variables选项卡
返回
专家建模标准模型选项卡
返回
判断异常值选项卡
指数平滑标准模型选项卡
返回
ARIMA ia Model选项卡
返回
侦查异常值的选项卡
返回
自变量转换选项卡
返回
时间序列模型Statistics选项卡
返回
Time Serises Modler Plots选项卡
3、 修补缺失值可在Transform菜单的Replace Missing Values过程中进行。修补缺失值 的方法共有五种,它们分别是:
⑴、Series mean; ⑵、Mean of nearby points; ⑶、Median of nearby points; ⑷、Linear interpolation; ⑸、Linear trend at point。 4、 定义时间变量可在Data菜单的Define dates过程里实现。 5、 判断序列是否平稳可以看它的均数和方差是否不再随时间的变化而变化、自相关系数
返回
17 习题
1、 时间序列的基本概念。 时间序列分析过程中有哪几种常用的方法? 2、 对数据用时间序列模型进行拟合处理前,应做哪些准备工作? 3、 在哪个过程中可进行缺失值的修补?修补缺失值的方法共有几种? 4、 在哪个过程中可定义时间变量? 5、 时间序列分析是建立在序列的平稳的条件上的,怎样判断序列是否平稳? 6、为什么要建一个时间序列的新变量?在SPSS的哪个过程中来建时间序列的新
在影响销售量的邮寄商品目录的数量每月增加2000份,而电话数量还是按原 先变化规律的前提下,1999年3月时男装的销售量的预测值为21580.96。
返回
预测的必要条件: 取得真实的数据 选择正确的方法
挖掘更多信息
返回 返回
也有峰值似乎没有成为季节性模式的一部分,这 表示邻近的数据点显著偏离。这些点可能是异常 值,它可以而且应该由Expert Modeler解决。
返回
时间序列习题参考答案(5)
三、自相关分析
返回
时间序列习题参考答案(6)
表中显示的是自相关计算结果,从左向右,依次列出的是:滞后数、自相关系数 值值、标准误差、Box-ljung统计量(值、自由度、原假设成立的概率值)。由于原假 设(假设基本过程是独立的,也即假定时间序列所反映的随机过程是白噪声)成立的 概率值都小于0.05,所以全部自相关均有显著性意义。
返回
时间序列习题参考答案(7)
在滞后12处的重要的顶点暗示在数据中存在周期为12(12个季度)的季节成分。 检查偏自相关函数图同样可得到这个十分明确的结论。
返回
时间序列习题参考答案(8)
四、建立时间序列模型
返回
时间序列习题参考答案(9)
返回
时间序列习题参考答案(10)
返回
时间序列习题参考答案(11)
返回
创建时间序列对话框
运行函数Lag时的结果说明
返回
序列图
Sequence Charts
返回
序列图过程 主对话框
返回
时间轴参考线对话框
返回
定义时间轴的格式对话框
返回
序列图应用实例输出
模型描述表
样品处理摘要
含有基准线的序列图
返回
建立时间序列模型
Create models
返回
时间序列建模提示框
第17章 时间序列分析
Time Series
返回
目录
各种时间序列分析过程 修补缺失值与创建时间序列
序列图
操作 实例
建立时间序列模型
操作 实例
应用时间序列模型
操作
自相关
操作 实例
季节分解法
操作 实例
频谱分析法
频谱分析操作 实例
互相关
操作 实例
习题17及参考答案
结束
返回
各种时间序列分析过程
返回
修补缺失值过程与对话框
返回
Time Serises Modler Output Filter对话框
返回
Time Serises Modler Save选项卡
返回
时间序列模型 Option选项卡
返回
时间序列分析实例输出
模型描述