NCBI序列数据库概述(2017.3.16)
NCBI各数据库简介

NCBI各数据库简介本篇文献转自以下网址:/experiment/fenzi/237847.html随着ncbi数据库各种资源的涌现,NCBI已经成为科研工作者必不可少的工具了。
那么各位小伙伴们,你能说出NCBI有多少数据库吗?有哪些实用的工具吗?不知道的就进来看看吧!美国国立生物技术信息中心(National Center for BiotechnologyInformation),即我们所熟知的NCBI是由美国国立卫生研究院(NIH)于1988年创办。
创办NCBI的初衷是为了给分子生物学家提供一个信息储存和处理的系统。
除了建有GenBank核酸序列数据库(该数据库的数据资源来自全球几大DNA数据库,其中包括日本DNA数据库DDBJ、欧洲分子生物学实验室数据库EMBL以及其它几个知名科研机构)之外,NCBI还可以提供众多功能强大的数据检索与分析工具。
目前,NCBI提供的资源有Entrez、Entrez Programming Utilities、MyNCBI、PubMed、PubMed Central、EntrezGene、NCBI Taxonomy Browser、BLAST、BLAST Link (BLink)、ElectronicPCR等共计36种功能。
而且都可以在NCBI的主页上找到相应链接,其中多半是由BLAST功能发展而来的。
1NCBI数据库更新进展1.1 PubMed搜索功能的增强NCBI对PubMed进行了几项改进工作,改动最大的是搜索界面和摘要浏览界面。
其中,搜索界面中新增了“Advanced Search”选项(这实际上是对以往“Limits”和“Preview/Index”功能的整合),并且增加了一个新的窗口,用户可以在此窗口下通过“论文作者名”、“论文所属杂志名称”、“论文出版日期”等限定条件进行搜索。
而且,“论文作者名”和“论文所属杂志名称”还设有文本框自动填充功能。
NCBI数据库和软件

美国国立医学图书馆(NLM)于1988年11月4日建立国家生物技术信息中心(National Center of Biotechnology Information,简称NCBI)。
该中心的主要任务为:为储存和分析分子生物学、生物化学、遗传学知识创建自动化系统;从事研究基于计算机的信息处理过程的高级方法,用于分析生物学上重要的分子和化合物的结构与功能;促进生物学研究人员和医护人员应用数据库和软件;努力协作以获取世界范围内的生物技术信息。
NCBI首先创建GenBank数据库,在重点开发GenBank的同时,又于1991年开发了Entrez 数据库检索系统。
该系统整合了GenBank、EMBL、PIR和SWISS-PROT等数据库的序列信息以及MEDLINE 有关序列的文献信息,并通过相关链接,将他们有机地结合在一起。
PubMed一个关于生物医药科学的检索系统,包括引用、摘要和杂志的索引术语。
它包括直接由出版商提供给NCBI 的文献引用以及链接到在出版商网址上的全文的URLs。
PubMed 包括MEDLINE 和PREMEDLINE的完整内容。
它还包括一些被MEDLINE认为超出范围的文章和杂志,(这些文章或杂志)由于内容或在某一时期不在索引范围内。
因此PubMed 是比MEDLINE的更大的集合。
Books同书籍出版商合作NCBI为网络改编了教科书,并把他们链接到PubMed-生物医药书目数据库。
这是为了给PubMed提供背景信息,这样使用者可以探究在PubMed搜索结果中不熟悉的概念。
目前收录的书有: Molecular Biology of the Cell, 3rd ed. Alberts B., Bray D., Lewis J., Raff M., Roberts K., Watson J.D., 1994, Garland Publishing.Nucleotide该数据库由国际核苷酸序列数据库成员美国国立卫生研究院GenBank、日本DNA数据库(DDBJ)和英国Hinxton Hall的欧洲分子生物学实验室数据库(EMBL)三部分数据组成。
NCBI简介

NCBI简介简介⼤型数据库分成若⼲⼦库,有许多好处。
⾸先,可以把数据库查询限定在某⼀特定部分,以便加快查询速度。
其次,基因组计划快速测序得到的⼤量序列尚未加以注释,将它们单独分类,有利于数据库查询和搜索时“有的放⽮”。
GenBank将这些数据按⾼通量基因组序列(High Throughput Genomic Sequences,HTG)、表达序列标记(Expressed SequenceTags,EST)、序列标记位点(Sequence Tagged Sites,STS)和基因组概览序列(Genome Survey Sequences,GSS)单独分类。
尽管这些数据尚未加以注释,它们依然是GenBank的重要组成部分。
可通过Entrez数据库查询系统对GenBank进⾏查询。
这个系统将核酸、蛋⽩质序列和基因图谱、蛋⽩质结构数据库整合在⼀起。
此外,通过该系统的⽂献摘要数据库MEDLINE,可获取有关序列的进⼀步信息。
在万维⽹上,进⼊NCBI的主页,可以⽤BLAST程序对GenBank数据库进⾏未知序列的同源性搜索(详见第六章)。
完整的GenBank数据库包括序列⽂件,索引⽂件以及其它有关⽂件。
索引⽂件是根据数据库中作者、参考⽂献等⼦段建⽴的,⽤于数据库查询。
GenPept是由GenBank中的核酸序列翻译⽽得到的蛋⽩质序列数据库,其数据格式为FastA。
GenBank 曾以CD-ROM光盘的形式分发,价格⽐较便宜。
随着数据库容量的增长,⼀套最新版的GenBank需要12张光盘存放,不仅⽣产成本很⾼,也不便于使⽤。
现在,光盘分发的⽅式已经停⽌,可以通过⽹络下载GenBank数据库。
GenBank中最常⽤的是序列⽂件。
序列⽂件的基本单位是序列条⽬,包括核⽢酸碱基排列顺序和注释两部分。
⽬前,许多⽣物信息资源中⼼通过计算机⽹络提供该数据库⽂件。
下⾯,我们介绍序列⽂件的结构。
序列⽂件由单个的序列条⽬组成。
序列条⽬由字段组成,每个字段由关键字起始,后⾯为该字段的具体说明。
ncbi 基因序列

ncbi基因序列引言NCBI(National Center for Biotechnology Information)是美国国家生物技术信息中心,致力于生物医学和遗传学研究。
其数据库中包含了大量的基因序列数据,为生命科学研究提供了重要的资源。
本文将全面、详细、完整地探讨NCBI基因序列,包括其数据库结构、数据内容以及应用等方面。
NCBI基因序列数据库结构NCBI基因序列数据库主要由以下几个部分组成:1. GenBankGenBank是NCBI最重要的数据库之一,存储了大量的基因序列数据。
它包含了来自不同生物物种的DNA、RNA以及蛋白质序列的信息。
GenBank中的数据被分为多个不同的类别,例如转录本(transcript)和基因(gene)等。
用户可以通过GenBank来查询、浏览和下载基因序列信息。
2. RefSeqRefSeq是NCBI维护的一个基因序列数据库,与GenBank不同的是,它主要包含了一些已知的、已经经过验证的基因序列。
RefSeq数据库提供了高质量的基因注释信息,可以帮助研究者更好地理解基因的结构和功能。
3. SRASRA(Sequence Read Archive)是NCBI的一个存储测序数据的数据库。
它包含了来自不同生物物种的DNA和RNA测序数据,包括原始的测序片段(reads)以及组装好的序列。
SRA数据库为研究者提供了丰富的数据资源,可以用于各种生物信息学和基因组学分析。
NCBI基因序列数据内容NCBI基因序列数据库中的数据内容非常丰富。
除了基因序列本身外,还包括了基因的注释信息、功能预测、调控元件等。
下面列举了部分常见的数据内容:1. 基因序列基因序列是NCBI基因序列数据库中最基本的数据内容之一。
它包含了DNA、RNA或蛋白质的碱基序列信息。
基因序列可以通过基因的唯一标识符进行查询,研究者可以通过分析基因序列来了解基因的结构和功能。
2. 基因注释基因注释是对基因序列进行解读和注释的过程,旨在揭示基因的结构和功能。
ncbi 序列 gene= 基因名称

序号1. 背景介绍NCBI,全称为National Center for Biotechnology Information,是美国国家生物技术信息中心,是一个致力于生物医学和遗传学研究的综合性数据库和资源评台。
NCBI的序列数据库中包含了大量的基因序列信息,科研人员可以通过这个数据库获取各种生物信息,进行科学研究和相关应用。
2. NCBI序列数据库的重要性NCBI序列数据库是目前全球最大、最全面的生物信息数据库之一,其包含了来自于各种不同生物体的基因组序列、注释信息、蛋白质序列等,这些信息为生物学、医学和农业等领域的科研工作者提供了极大的便利。
研究人员可以通过NCBI数据库来寻找自己感兴趣的基因序列,进行基因功能预测、重建系统进化树、进行药物研发等工作。
3. 如何使用NCBI序列数据库要使用NCBI序列数据库,首先需要进入NCBI的冠方全球信息站,然后在数据库搜索栏中输入所需的基因名称。
在搜索结果中,科研人员可以看到与所输入基因名相关的实验信息、文献信息以及基因序列等。
NCBI数据库还提供了一系列的工具和软件,用于辅助科研人员进行序列比对、分析序列的功能信息等。
4. 重要应用NCBI序列数据库的应用非常广泛,比如在医学研究领域,科研人员可以利用该数据库来寻找人类疾病相关的基因序列,进行疾病的基因检测和病因研究。
在农业领域,研究人员可以利用数据库中的植物基因序列信息,进行作物的基因改良和新品种培育。
利用基因序列信息,还可以进行物种鉴定、资源开发等相关工作。
5. 数据库更新与维护NCBI序列数据库是一个非常庞大的数据库,其中包含了海量的生物信息,因此数据库的更新和维护工作也很重要。
NCBI的维护人员会不断地收集、整理和更新最新的生物信息,确保数据库中的信息是最新、最全面的。
数据库的安全性和稳定性的保障也是维护人员所关注的重点之一。
6. 结语NCBI序列数据库是一个极其重要的生物信息资源库,其对于生物学、医学、农业等领域的科研工作起到了至关重要的作用。
NCBI_功能详细介绍

NCBI_功能详细介绍NCBI(National Center for Biotechnology Information,国家生物技术信息中心)是美国国立卫生研究院(NIH)的一个部门,旨在为科学家、研究者和医生提供生物信息学数据库和工具,以促进生物医学研究和医疗实践的发展。
NCBI提供了一系列的数据库和工具,涵盖了基因组学、遗传学、生物技术和生物信息学的多个领域,为用户提供了许多功能和资源。
以下是NCBI提供的一些主要功能:1. PubMed:PubMed是一个免费的生物医学文献数据库,收录了来自全球各地的医学和生物医学研究的学术文章和论文摘要。
它是全球最大的生物医学文献数据库之一,每年更新数量庞大的文献。
研究人员、医生和学生可以使用PubMed来查找相关的研究论文,以支持他们的研究和临床实践。
3. BLAST:BLAST(Basic Local Alignment Search Tool)是一个用于比对和分析生物序列的工具。
它可以对输入的DNA或蛋白质序列与数据库中的序列进行比对,以寻找相似的序列片段或相应的功能注释。
BLAST被广泛用于基因组学、生物技术和分子生物学的研究中。
4. Entrez:Entrez是一个综合性引擎和浏览器,用于访问NCBI提供的不同数据库中的信息。
用户可以使用Entrez工具来查找特定的文章、序列、结构、基因、文献、蛋白质、基因组、生物样本等信息,并浏览相关的文献和数据。
6. dbSNP:dbSNP是一个单核苷酸多态性数据库,记录了人类和其他物种的基因组中的单核苷酸变异信息。
它是一个重要的资源,用于研究人员研究遗传变异与疾病风险和治疗反应之间的关系,以及个体间的遗传差异。
总之,NCBI提供了许多重要的生物信息学数据库和工具,为科学家、研究者和医生提供了进行生物医学研究和临床实践所需的关键资源。
它在基因组学、遗传学、生物技术和生物信息学的研究中起到了非常重要的作用,并对生物医学领域的发展做出了巨大贡献。
美国国立生物技术信息中心NCBI的数据库资源

美国国立生物技术信息中心(NCBI)的数据库资源生命学院生物技术专业2002级周帅学号021402142[摘要]除了提供GenBank核酸序列数据库以外,美国国家生物技术信息中心还提供对于GenBank中数据的分析,检索资源,另外还通过其提供一系列的有价值的生物数据及信息。
NCBI 数据的检索资源包括Entrez, PubMed, LocusLink 以及Taxonomy浏览器。
数据分析资源包括BLAST,电子PCR,开放阅读框寻觅器,序列提交工具,唯一人类基因序列集合,基因同源物数据库,单核苷酸多态性数据库(dbSNP),人类基因组测序,人类基因组基因图谱,分类学浏览器,人-鼠同源基因图谱, 异常癌症基因组计划(CCAP),Entrez 基因组,垂直同源基因簇(COGs)数据库,反转录病毒基因分类工具,癌症基因组剖析计划(CGAP),基因表达连续分析图谱(SAGEmap),综合性基因表达(GEO),在线孟德尔人类遗传(OMIM),三维蛋白质结构的分子模型数据库(MMDB)以及保守序列数据库(CDD)。
BLAST程序通过增加一些的应用程序实现搜索某些特殊数据的最优化方式。
所有的资源可以通过NCBI的首页得到:。
引言作为美国国家卫生研究院(NIH)的国立医学图书馆(NLM)的一个分支,美国国家生物技术信息中心(NCBI)成立于1988,其目标是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。
除了提供由各个科研院所直接提供的GenBank 核酸序列数据库以外,NCBI还提供对于GenBank中数据检索系统和计算工具以帮助分析GenBank的数据以及其他的NCBI提供的可利用的生物信息数据。
NCBI首页()所提供的可用数据涵盖了部分基因的代表性短序列、完整的基因组、蛋白质结构以及一些遗传疾病的临床描述。
NCBI提供了一系列的计算工具以帮助分析各种类型的数据。
总体来说,NCBI的整套数据库资源分为7大类:数据库检索系统,相似序列检索程序,基因序列分析数据库,染色体序列数据库,基因组分析数据库,基因表达与显型分析数据库,以及蛋白质结构和建模数据库。
NCBI序列数据库概述(2017.3.16)

6.BioProject
• 随着NCBI中归档的数据集的量和复杂性的快速增 加,对收集和组织相关元数据的需求也在快速增 加。尽管以前已经为一些归档数据库收集了元数 据,但是在Nபைடு நூலகம்BI没有集中的方式收集这些信息, 并跨数据库使用它们。最近建立了BioProject数据 库以促进提交到NCBI、EBI和DDBJ数据库的项目数 据的组织和分类。它捕获有关研究项目的描述性 信息,导致到归档数据库的大量提交,将跨多个 归档的相关数据整合在一起,并充当了一个中心 入口,通过该入口告知用户数据的可用性。
3.Genome
• NCBI收录了超过1000种已经完成测序的生 物体全部基因组序列和定位数据,及正在 进行测序的物种阶段性发布的基因组信息。 • Genome涉及的物种涉及所有的生物领域: 细菌、古细菌、真核生物,以及许多病毒、 噬菌体、类病毒、质粒和含遗传物质的细 胞器。
4.蛋白质数据库
• NCBI Protein数据库收录来源于GenPept、 RefSeq、Swiss-Prot、PIR、PRF及PDB等蛋白 质数据资源的蛋白质序列和注释数据; • Protein Cluster数据库提供存在一定联系的 蛋白质集合信息,并与蛋白质注释、结构、 结构域、家族相关数据库之间交互访问; • Structure数据路是由蛋白质三维结构数据库 PDB衍生而来的大分子模建数据库,提供蛋 白质三维结构信息及相关的可视化和结构 化比对工具
NCBI序列数据库
时间:2017.3.16
一、NCBI概述
• 1988年11月美国国家健康研究所(NIH)、 国家医学图书馆(NLM)发起成立; • 1992年,NCBI建立GenBank核酸序列数据库, 将美国专利商标局存储的专利序列并入 GenBank管理并与EMBL、DDBJ实现数据资 源的交换与共享; • GenBank、EMBL、DDBJ并称世界三大生物 序列信息数据库。
NCBI数据库及其应用精品PPT课件

NCBI数据库检索
1. ENTREZ高级检索系统:
在检索框中输入检索词,检索词间默认 逻辑关系为AND
还可用来检索核酸与蛋白质序列、 MEDLINE相关文献或专利(PubMed)、 基 因组及MMDB分子结构模型库信息。
• 显示格式 :
Summary Report格式 GenBank Report格式 FASTA Report格式
★2210130101------刘思远 ★2210130102------肖泽友 ★2210130103------江宜铮
NCBI分子生物学数据库 http://
美国国立医学图书馆(NLM)于1988 年11月4日建立国家生物技术信息中心 (National Center of Biotechnology Information,简称NCBI)。
Sequin:
可供MAC、PC\Windows、UNIX 用户使用的递交软件,可输入有关 数据的详细资料。
三、检索途径与方法
• 基本检索 - Basic Search
• 高级检索 - Advanced Search
•
(preview/index)
• 限定检索 - Limits Search
• 期刊检索 – Journal Databases
• 显示格式选择 Display旁的下拉菜单,选择记录格式: summary默认、brief、Abstract、Citation、 ASN.1、MEDLINE、XML等格式 • 纯文本格式 Sent to-Text
2、排序
无序(Sort) 著者(Author) 刊名(Journal) 出版日期(Pub Date)
• 主题词检索 - MeSH Databases
NCBI简介及序列编号说明

一:NCBI简介NCBI的GenBank与DDBJ(DNA Data Bank of Japan)、EMBL的EBI数据库共同组成国际DNA 数据库,每日都交换更新数据和信息,并主持两个国际年会-国际DNA数据库咨询会议和国际DNA数据库协作会议,互相交换信息,因此三个库的数据实际上是相同的。
GenBank 有来自于70,000多种生物的核苷酸序列。
每条纪录都有编码区(CDS)特征的注释,还包括氨基酸的翻译。
(是美国国家生物技术信息中心(National Center for Biotechnology Information ,NCBI)建立的DNA序列数据库,从公共资源中获取序列数据,主要是科研人员直接提供或来源于大规模基因组测序计划( Benson等,1998)。
Entrez 是美国国家生物技术信息中心所提供的在线资源检索器。
该资源将GenBank序列与其原始文献出处链接在一起。
Entrez 是由NCBI主持的一个数据库检索系统。
它包括核酸,蛋白以及Medline文摘数据库,在这三个数据库中建立了非常完善的联系。
因此,可以从一个DNA序列查询到蛋白产物以及相关文献,而且,每个条目均有一个类邻(neighboring)信息,给出与查询条目接近的信息。
)DDBJ主要向研究者收集DNA序列信息并赋予其数据存取号,信息来源主要是日本的研究机构,亦接受其他国家呈递的序列。
EBI的主要任务:⑴为科学界建立和维护生物学数据库,提供免费的数据和生物信息服务,支持生物学数据的存储和挖掘,促进科技进步;⑵通过生物信息学的基础研究继续推动生物学发展;⑶为各个层次的科学工作者提供生物信息学培训;⑷支持帮助边缘尖端科技成果向工业界的转化;⑸协调欧洲生物数据的提供。
RefSeq是NCBI数据库的参考序列。
RefSeq资料库是NCBI将GenBank的序列再做详细整理的non-redundent序列资料库,它的序列格式和GenBank几乎完全相同,但因为是完全不同的独立资料库,为与GenBank区别,RefSeq的Accession Number格式和GenBank不同。
生物数据库介绍——NCBI

⽣物数据库介绍——NCBINCBI(National Center for Biotechnology Information,美国国家⽣物技术信息中⼼)除了维护GenBank核酸序列数据库外,还提供数据分析和检索资源。
NCBI资源包括Entrez、Entrez编程组件、MyNCBI、PubMed、PudMed Central、PubReader、Gene、the NCBI Taxonomy Browser、BLAST、Pimer-Blast、COBALT、RefSeq、UniGene、HomoloGene、ProtEST、dbMHC、dbSNP、dbVar、Epigenomics、the Genetic Testing Registry、Genome和相关⼯具、⽐对查看器、跟踪存档、Sequence Read Archive、BioProject、BioSample、ClinVar、MedGen、HIV-1/⼈类蛋⽩质相互作⽤数据库、Gene Expression Omnibus、Probe、Online Mendelian Inheritance in Animals、the Molecular Modeling Database、the Conserved Domain Database、the Conserved Domain Architecture Retrieval Tool、Biosystem、Protein Clusters and thePubChem suite of small molecule databases,所有这些资源可以在NCBI主页找到。
Databases⼀个提供有关基因组组装结构,装配名称和其他元数据,统计报告以及基因组序列数据链接等信息的数据库。
⼀个有关培养物、动植物样本和其他⾃然样本的精选元数据集。
记录显⽰样本状态,有关馆藏的机构的信息,以及NCBI中相关数据链接。
NCBI简介及序列编号说明
一:NCBI简介NCBI的GenBank与DDBJ(DNA Data Bank of Japan)、EMBL的EBI数据库共同组成国际DNA 数据库,每日都交换更新数据和信息,并主持两个国际年会-国际DNA数据库咨询会议和国际DNA数据库协作会议,互相交换信息,因此三个库的数据实际上是相同的。
GenBank 有来自于70,000多种生物的核苷酸序列。
每条纪录都有编码区(CDS)特征的注释,还包括氨基酸的翻译。
(是美国国家生物技术信息中心(National Center for Biotechnology Information ,NCBI)建立的DNA序列数据库,从公共资源中获取序列数据,主要是科研人员直接提供或来源于大规模基因组测序计划( Benson等,1998)。
Entrez 是美国国家生物技术信息中心所提供的在线资源检索器。
该资源将GenBank序列与其原始文献出处链接在一起。
Entrez 是由NCBI主持的一个数据库检索系统。
它包括核酸,蛋白以及Medline文摘数据库,在这三个数据库中建立了非常完善的联系。
因此,可以从一个DNA序列查询到蛋白产物以及相关文献,而且,每个条目均有一个类邻(neighboring)信息,给出与查询条目接近的信息。
)DDBJ主要向研究者收集DNA序列信息并赋予其数据存取号,信息来源主要是日本的研究机构,亦接受其他国家呈递的序列。
EBI的主要任务:⑴为科学界建立和维护生物学数据库,提供免费的数据和生物信息服务,支持生物学数据的存储和挖掘,促进科技进步;⑵通过生物信息学的基础研究继续推动生物学发展;⑶为各个层次的科学工作者提供生物信息学培训;⑷支持帮助边缘尖端科技成果向工业界的转化;⑸协调欧洲生物数据的提供。
RefSeq是NCBI数据库的参考序列。
RefSeq资料库是NCBI将GenBank的序列再做详细整理的non-redundent序列资料库,它的序列格式和GenBank几乎完全相同,但因为是完全不同的独立资料库,为与GenBank区别,RefSeq的Accession Number格式和GenBank不同。
NCBI分子生物学数据库网络生物医学教学

基因map view
向 下 找
15显示结果
(四) EST (表达序列标签数据库)
expressed sequence tags
• 得到的部分 cDNA序列,长度一般为200~500bp
• 表达序列标签(EST)在基因组作图、克隆基因、新 基因的识别、蛋白质组研究等许多方面具有重要 的用途. <<生物技术通讯>>2003年 第14卷 第01 期,题目:表达序列标签及其应用 作者: 陈红歌, 贾新成,本文介绍了E用.
可直接进行交互访问使用。通过相关链
接,Entrez将这些数据库有机地结合在 一起,可以进行序列、结构、生物分类 及文献数据的相关交叉检索。
注意
All Databases 在NCBI主页) 的搜索框中(输入presenilin 1)搜 索的结果是一致的。
二、数据库资源
(一) Nucteotide (核苷酸序列数据库)
Protein数据库中提供的 “Blink”(BLAST Link)链接为Entrez所有 蛋白序列在Blast数据库中的结果显示。它与 “Related Sequences”链接不同, Related Sequences链接显示了相似序列文 献的题目,而Blink链接则显示其图形的信息, 图中不仅显示了该蛋白序列的主要信息,还
(七) PopSet (种群组数据库)
该数据库收录来自种群研究、种系发生研究或 突变研究的数据。包括核酸和蛋白质序列数据库
(八) OMIM (人类孟德尔遗传数据库)
该数据库收集了人类基因与遗传疾病的各种信 息,包括原文、图片和参考信息,同事还可以链 接到Entre系统的Medline数据库中相关文献和序
• 所有已知的核苷酸序列 • 与之相关的生I物L6 学信息 • 参考文献
NCBI所有数据库简介
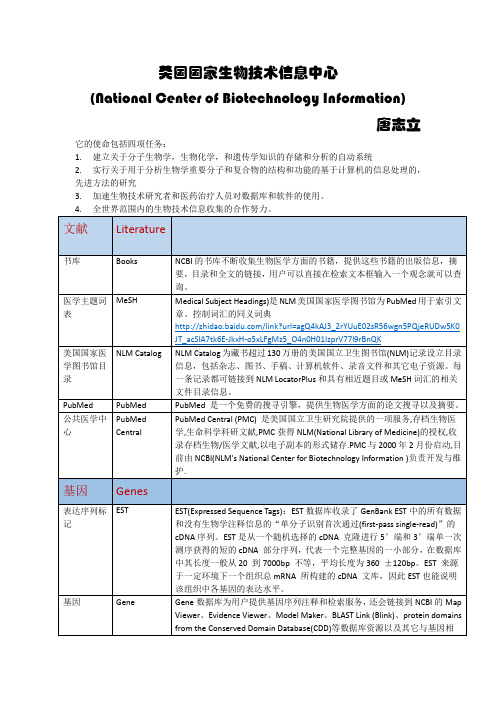
美国国家生物技术信息中心(National Center of Biotechnology Information)唐志立它的使命包括四项任务:1. 建立关于分子生物学,生物化学,和遗传学知识的存储和分析的自动系统2. 实行关于用于分析生物学重要分子和复合物的结构和功能的基于计算机的信息处理的,先进方法的研究3. 加速生物技术研究者和医药治疗人员对数据库和软件的使用。
山东师范大学2016年4月10日星期日30则留学生经典笑话,英语不好伤不起!凭你在国内口语练得多么娴熟,去了国外,照样有犯痴呆傻的时候!1、有次房东问我:did u eat anyting yet? 我说:no.她听后重复了一遍:so u didn’t eat anyting. 我说:yes.房东老太太犹豫了下又问:did u eat? 我说:no.她接着说:so u didn’t eat. 我说:yes. 估计她当时要崩溃了……2、刚上班不久,有个公司的A/R打电话来催支票,我循例问了一下他是哪间公司打来的,那男的很有礼貌的说:This is xxx calling from Beach Brother.听懂了很开心,不过由于对公司名字还不熟,心想先用笔记下来公司名,省得等下忘记了,正得意忘形之间,顺嘴开始拼写人家公司的名字,还说得一本正经:b.i.t.c.h.bitch, correct? 那男的终于还是没能忍住怒火,近似于怒吼似的对我喊道:NO!B.E.A.C.H.BEACH! 接下来的一年里,没再跟这间公司有过任何生意往来……3、我男朋友以前在温哥华乘skytrain 的时候,一个白人女人说:I am sorry. 他直接说:you are welcome. 对方都呆了。
4、第一次跟老外去打painball,玩的是抢旗的那种。
由于第一次玩,一直跟着个看起来很专业的队友跑,一路上躲着子弹跑到对方的base. 我们人都挂了,对方就剩一个人在看老家,就听那老外跟我说了一大堆术语,我也没听懂。
NCBI分子数据库介绍

NCBI分子数据库介绍信息来源:中国生命科学论坛更新时间:2003-10-12 2:33:00核酸序列(nucleotides)· Entrez核酸- 用accession number,作者姓名,物种,基因/蛋白名字,以及很多其它的文本术语来搜索核酸序列记录(在GenBank + PDB中)。
更多的关于Entrez的信息见下。
如果要检索大量数据,也可使用Batch Entrez (批量Entrez)。
· RefSeq - NCBI数据库的参考序列。
校正的,非冗余集合,包括基因组DNA contigs,已知基因的mRNAs和蛋白,在将来,整个的染色体。
Accession numbers用NT_xxxxxx, NM_xxxxxx, NP_xxxxxx, 和NC_xxxxxx的形式来表示。
· dbEST - 表达序列标签数据库,短的、单次(测序)阅读的cDNA序列。
也包括来自于差异显示和RACE实验的cDNA序列。
· dbGSS -基因组调查序列的数据库,短的、单次(测序)阅读的cDNA序列,exon trap获得的序列,cosmid/BAC/YAC末端,及其他。
· dbSTS -序列标签位点的数据库,短的在基因组上可以被唯一操作的序列,用于产生作图位点。
· dbSNP - 单核苷酸多态性数据库,包括SNPs,小范围的插入/缺失,多态重复单元,和微卫星变异。
完整的基因组·参见Genome 和Maps 部分,包括各种物种资源,人,小鼠,大鼠,酵母,线虫,疟原虫,细菌,病毒,viroids,质粒。
· UniGene - 被整理成簇的EST和全长mRNA 序列,每一个代表一种特定已知的或假设的人类基因,有定位图和表达信息以及同其它资源的交叉参考。
序列数据可以以cluster 形式在Unigene 网页下载,完整的数据可以从FTP站点repository/UniGene 目录下下载。
NCBI数据库的使用与功能介绍

数据下载与保存
数据下载
用户可以下载NCBI数据库中的数据,支持多种数据格式,如FASTA、 GenBank、GFF等,方便用户进行数据分析和处理。
数据保存
用户可以将检索到的数据保存到本地计算机中,方便随时查看和使用。同时, NCBI数据库还支持数据导出功能,方便用户将数据分享给其他研究人员。
数据可视化
蛋白质组学研究中的应用
蛋白质序列
NCBI数据库收录了大量蛋白质序列,为蛋白质组学研究提供了基础数据。
蛋白质功能研究
通过NCBI数据库,研究人员可以了解蛋白质的结构、相互作用和功能,从而深入探究生命活动的本质。
生物信息学研究中的应用
基因组学与蛋白质组学数据整合
NCBI数据库提供了多种生物信息学工具,可以将基因组学和蛋白质组学数据进行整合, 为系统生物学和药物研发等领域提供支持。
04
NCBI数据库的案例分析
基因组学研究中的应用
基因组测序
NCBI数据库提供了大量基因组测序数 据,包括人类、动物、植物和微生物 等物种,为基因组学研究提供了丰富 的资源。
基因注释
研究人员可以利用NCBI数据库中的基 因注释信息,了解基因的功能、位置 和表达情况,为基因功能研究和疾病 治疗提供依据。
发展
NCBI数据库不断发展壮大,推出了多个知名的子数据库和工具,如GenBank、PubMed、PubMed Central、Gene、NCBI Taxonomy等,为生物医学研究提供了全方位的信息支持。同时,NCBI数据 库也不断更新和改进检索和分析工具,提高数据质量和用户体验。
02
NCBI数据库的使用方法源自新技术与新方法的融合新技术应用
NCBI需要关注新兴技术的发展,如人工智 能、云计算等,将这些技术应用于数据处理 、分析和管理中,提高数据库的技术水平和 应用范围。
NCBI功能详细介绍

GenBank Overview大体信息•什么是GenBank?GenBank是一个有来自于70,000多种生物的核苷酸序列的数据库。
每条纪录都有编码区(CDS)特点的注释,还包括氨基酸的翻译。
GenBank属于一个序列数据库的国际合作组织,包括EMBL和DDBJ。
•纪录样本- 关于GenBank的各个字段的详细描述,和同Entrez搜索字段的交叉索引。
•访问GenBank - 通过Entrez Nucleotides来查询。
用accession number,作者姓名,物种,基因/蛋白名字,还有许多其他的文本术语来查询。
关于Entrez更多的信息请看下文。
用BLAST来在GenBank和其他数据库中进行序列相似搜索。
用E-mail来访问Entrez和BLAST能够通过Query 和BLAST效劳器。
另外一种选择是能够用FTP下载整个的GenBank和更新数据。
•增加统计- 参见发布通知的(每一个分类的统计),(每一个物种的统计),(GenBank增加)末节。
•发布通知,最新- 最近和即将有的转变,GenBank的分类,数据增加统计,GenBank的引用。
•发布通知,旧- 同上相同,是过去发布的统计。
•遗传密码- 15个遗传密码的概要。
用来确保GenBank中纪录的编码序列被正确的翻译。
(向)GenBank提交(数据)•关于提交序列数据,收到accession number,和对纪录作更新的一样信息。
•BankIt - 用于一条或少数条提交的基于WWW的提交工具软件。
(请在提交前用VecScreen去除载体)•Sequin - 提交软件程序,用于一条或很多条的提交,长序列,完整基因组,alignments,人群/种系/突变研究的提交。
能够独立利用,或用基于TCP/IP的“network aware”模式,能够链接到其他NCBI 的资源和软件比如Entrez和PowerBLAST。
(请在提交前用VecScreen去除载体)•ESTs - 表达序列标签,短的、单次(测序)阅读的cDNA序列。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
RefSeq (reference sequence):GenBank中的 数据是由用户提交数据构成,具有较高的 冗余度和差错率,为更好的实现特征序列 的查询,NCBI在GenBank数据基础上针对每 个基因不同的数据类型提取一个可靠地注 释条目作为参考条目,组成RefSeq。
2.Gene
• Gene:基因数据库收录全部已测序物种的基 因注释信息,包括基因的名称、染色体定 位、基因序列和编码产物(mRNA、蛋白质) 情况基因功能和相关文献信息等; • 与GenBank、OMIM、遗传多态数据库等 NCBI子库及KEGG、Gene Ontology等外源性 数据库进行交叉引用; • 基因数据库是目前最权威的基因注解数据 库。
三、NCBI提供的重要支持工具
• BLAST:BLAST是由NCBI开发的序列相似性搜 索程序,检索速度快,有助于识别基因和 基因特征; • Primer-BLAST:可用于多方面生物医学研究过 程的核酸引物设计; • NCBI提供的其他软件工具还包括:开放阅 读框搜索、电子PCR和序列提交工具Sequin 和BankIt等。
Байду номын сангаас
二、NCBI中的重要子库
NCBI收录的生物数据依据不同的类别、层次、 存储质量和应用特征等划分为众多相对独立, 而又交叉引用的子库 1.GenBank与RefSeq 2.Gene 3.Genome 4.蛋白质数据库 5.遗传多态数据库 6.BioProject 7.其他
• • • • • • •
1.GenBank与RefSeq
GenBank是NIH遗传序列数据库,集成了所有 公开可获得的已注释DNA序列。根据其不同的 研究属性,分属于Nucleotide、GSS、EST三个 子库 • Nucleotide:收录绝大多数常规的核酸序列; • GSS(Genome Survey Sequence):收录测序起 始段用来进行序列或基因示踪、重复序列或基 因数量预判等的各种短读长序列; • EST(Expressed Sequence Tag):收录cDNA及 cDNA特征序列信息。
5.遗传多态数据库
• NCBI中的dbSNP、dbVar、dbGaP和ClinVar四个 子库涉及DNA多态或变异信息。 • dbSNP:收录了所有物种中发现的短序列多态 的突变信息; • dbVar:主要收录较大规模的基因组变异,包括 大片段的插入、缺失、异位、倒置和拷贝数多 态等信息资源; • dbGaP:收录大量以遗传多态为分子标记物的基 因型和表型关联性研究数据; • ClinVar:收录临床中发现或报道的有证据支持 的与人类疾病或健康状态有关的变异位点,并 与多个疾病和卫生系统数据库进行交互引用。
7.其他
• GEO(Gene Expression Omnibus)接受和管理各研究机 构提交的基因芯片或测序技术获得的不同生理、病理状 态个体或细胞系基因(包括非编码基因)表达数据。 • Epigenomics:是一个表观基因组数据查询和浏览相结合 的数据库。提供DNA甲基化、组蛋白修饰等表观遗传学 数据集下载、基因序列、表观遗传状态的定位比较和可 视化等。 • Unigene:针对每一个基因建立一个独立的数据系统,分 别将不同来源的基因序列、蛋白质相似性、基因表达、 染色体定位、cDNA序列、mRNA序列、EST序列等进行罗 列和比较,旨在为研究者提供全面、丰富的信息资源, 更好地对基因的功能和注释信息的可靠性进行梳理。
3.Genome
• NCBI收录了超过1000种已经完成测序的生 物体全部基因组序列和定位数据,及正在 进行测序的物种阶段性发布的基因组信息。 • Genome涉及的物种涉及所有的生物领域: 细菌、古细菌、真核生物,以及许多病毒、 噬菌体、类病毒、质粒和含遗传物质的细 胞器。
4.蛋白质数据库
• NCBI Protein数据库收录来源于GenPept、 RefSeq、Swiss-Prot、PIR、PRF及PDB等蛋白 质数据资源的蛋白质序列和注释数据; • Protein Cluster数据库提供存在一定联系的 蛋白质集合信息,并与蛋白质注释、结构、 结构域、家族相关数据库之间交互访问; • Structure数据路是由蛋白质三维结构数据库 PDB衍生而来的大分子模建数据库,提供蛋 白质三维结构信息及相关的可视化和结构 化比对工具
NCBI序列数据库
时间:2017.3.16
一、NCBI概述
• 1988年11月美国国家健康研究所(NIH)、 国家医学图书馆(NLM)发起成立; • 1992年,NCBI建立GenBank核酸序列数据库, 将美国专利商标局存储的专利序列并入 GenBank管理并与EMBL、DDBJ实现数据资 源的交换与共享; • GenBank、EMBL、DDBJ并称世界三大生物 序列信息数据库。
6.BioProject
• 随着NCBI中归档的数据集的量和复杂性的快速增 加,对收集和组织相关元数据的需求也在快速增 加。尽管以前已经为一些归档数据库收集了元数 据,但是在NCBI没有集中的方式收集这些信息, 并跨数据库使用它们。最近建立了BioProject数据 库以促进提交到NCBI、EBI和DDBJ数据库的项目数 据的组织和分类。它捕获有关研究项目的描述性 信息,导致到归档数据库的大量提交,将跨多个 归档的相关数据整合在一起,并充当了一个中心 入口,通过该入口告知用户数据的可用性。