数据库复习题2(答案)
数据库考试题及答案

数据库考试题及答案一、选择题(每题2分,共20分)1. 数据库管理系统(DBMS)的主要功能不包括以下哪项?A. 数据定义B. 数据操纵C. 数据备份D. 数据加密答案:D2. 在关系数据库中,关系是指什么?A. 数据库B. 表C. 列D. 行答案:B3. SQL语言中,用于查询数据的关键字是?A. SELECTB. INSERTC. UPDATED. DELETE答案:A4. 数据库系统的核心是?A. 数据库管理系统B. 数据库C. 数据库管理员D. 数据库应用系统答案:B5. 以下哪个不是数据库系统的特点?A. 数据共享B. 数据独立性C. 数据冗余度高D. 数据控制答案:C6. 以下哪个不是数据库的三级模式?A. 外模式B. 概念模式C. 内模式D. 物理模式答案:D7. 以下哪个不是数据库的完整性约束?A. 实体完整性B. 参照完整性C. 用户定义完整性D. 数据库完整性答案:D8. 在关系数据库中,表与表之间的联系是通过什么实现的?A. 索引B. 视图C. 外键D. 触发器答案:C9. 以下哪个不是数据库设计阶段?A. 需求分析B. 概念设计C. 逻辑设计D. 物理设计答案:A10. 数据库系统与文件系统相比,以下哪个不是数据库系统的优点?A. 数据冗余度低B. 数据独立性高C. 数据安全性高D. 数据共享性低答案:D二、填空题(每题2分,共20分)1. 数据库管理系统(DBMS)是位于用户与______之间的一层数据管理软件。
答案:操作系统2. 在关系数据库中,表中的行称为______。
答案:记录3. SQL语言中,用于删除数据的关键字是______。
答案:DELETE4. 数据库系统的核心是______。
答案:数据库5. 数据库的三级模式包括外模式、______和内模式。
答案:概念模式6. 数据库的完整性约束包括实体完整性、参照完整性和______。
答案:用户定义完整性7. 在关系数据库中,表与表之间的联系是通过______实现的。
数据库复习题及答案

数据库复习题及答案一、选择题1. 数据库管理系统(DBMS)的主要功能是什么?A. 存储数据B. 管理数据C. 提供数据访问接口D. 所有以上选项答案:D2. 关系数据库中的“关系”指的是什么?A. 数据库文件B. 数据表C. 数据表之间的关系D. 数据库的物理存储答案:C3. SQL语言中的“SELECT”语句用于执行什么操作?A. 插入数据B. 更新数据C. 查询数据D. 删除数据答案:C4. 在数据库中,主键的作用是什么?A. 唯一标识表中的每条记录B. 存储数据C. 用于排序D. 用于数据加密答案:A5. 事务的ACID属性包括哪些?A. 原子性、一致性、隔离性、持久性B. 原子性、一致性、完整性、持久性C. 原子性、隔离性、完整性、持久性D. 原子性、一致性、隔离性、安全性答案:A二、简答题1. 简述数据库的三级模式结构。
答案:数据库的三级模式结构包括外模式、概念模式和内模式。
外模式是用户视图,是用户与数据库交互的接口;概念模式是数据库的全局逻辑结构,描述了数据的逻辑组织;内模式是数据库的物理存储结构,描述了数据在存储介质上的存储方式。
2. 解释什么是范式以及数据库规范化的目的。
答案:范式是数据库设计中用来减少数据冗余和提高数据一致性的标准。
数据库规范化的目的是确保数据库结构的合理性,通过分解数据表来消除数据的重复存储,从而提高数据的一致性和完整性。
三、应用题1. 假设有一个学生信息数据库,包含学生表(Student),课程表(Course),选课表(Enrollment)。
学生表包含学号(StudentID),姓名(Name),年龄(Age);课程表包含课程ID(CourseID),课程名称(CourseName),学分(Credits);选课表包含学号(StudentID),课程ID(CourseID),成绩(Grade)。
请编写SQL 语句,查询所有选修了“数据库原理”课程的学生姓名及其成绩。
数据库模拟试题2(含答案)

模拟试题2一.单项选择题(本大题共15小题,每小题2分,共30分)1.对现实世界进行第二层抽象的模型是[ ] A.概念数据模型B.用户数据模型C.结构数据模型D.物理数据模型2.数据库在磁盘上的基本组织形式是[ ] A.DB B.文件 C.二维表 D.系统目录3.在关系模型中,起导航数据作用的是[ ] A.指针 B.关键码 C.DD D.索引4.查询优化策略中,正确的策略是[ ] A.尽可能早地执行笛卡尔积操作B.尽可能早地执行并操作C.尽可能早地执行差操作D.尽可能早地执行选择操作5.SQL中,“DELETE FROM 表名”表示[ ] A.从基本表中删除所有元组B.从基本表中删除所有属性C.从数据库中撤消这个基本表D.从基本表中删除重复元组6.设关系模式R(A,B,C),F是R上成立的FD集,F={A→B,C→B},ρ={AB,AC}是R的一个分解,那么分解ρ[ ] A.保持函数依赖集F B.丢失了A→BC.丢失了C→B D.丢失了B→C7.在关系模式R分解成数据库模式ρ时,谈论无损联接的先决条件是[ ] A.数据库模式ρ中的关系模式之间有公共属性B.保持FD集C.关系模式R中不存在局部依赖和传递依赖D.存在泛关系8.在关系数据库设计中,子模式设计是在__________阶段进行。
[ ] A.物理设计 B.逻辑设计 C.概念设计 D.程序设计9.如果有9个不同的实体集,它们之间存在着12个不同的二元联系(二元联系是指两个实体集之间的联系),其中4个1:1联系,4个1:N联系,4个M:N 联系,那么根据ER模型转换成关系模型的规则,这个ER结构转换成的关系模式个数为[ ]A.9个 B.13个 C.17个 D.21个10.在DB技术,未提交的随后被撤消了的数据,称为[ ] A.报废的数据 B.过时的数据 C.撤消的数据 D.脏数据11.SQL中的“断言”机制属于DBS的[ ] A.完整性措施 B.安全性措施 C.物理安全措施 D.恢复措施12. ORDB中,同类元素的无序集合,并且允许一个成员可多次出现,称为[ ]A.结构类型 B.集合类型 C.数组类型 D.多集类型13.在OODB中,包含其他对象的对象,称为[ ] A.强对象 B.超对象 C.复合对象 D.持久对象14.在DDBS中,数据传输量是衡量查询时间的一个主要指标,导致数据传输量大的主要原因是[ ] A.场地间距离过大B.数据库的数据量大C.不同场地间的联接操作D.在CPU上处理通信的代价高15.DDBS中,透明性层次越高[ ] A.网络结构越简单B.网络结构越复杂C.应用程序编写越简单D.应用程序编写越复杂二、填空题(本大题共10小题,每小题1分,共10分)16.数据管理技术的发展,与__________、__________和__________有密切的联系。
数据库技术复习题_二_填空题附答案

数据库技术试题二、填空题1. 一个类可以从直接的或间接的祖先中继承所有属性和方法。
采用这个方法提高了软件的共享性。
2. 用树型结构表示实体类型及实体间联系的数据模型称为层次模型。
3. 关系数据库的关系演算语言是以集合操作为基础的DML语言。
4. 在函数信赖中,平凡的函数信赖根据Armstrong推理规则中的自反律就可推出。
5. 分布式数据库中定义数据分片时,必须满足三个条件:完备性条件、重构条件和不相交条件。
6. DB并发操作通常会带来三类问题,它们是丢失更新、不一致分析和读脏数据。
7. 事务必须具有的四个性质是:原子性、一致性、隔离性和持久性。
8. 分布式数据库系统中透明性层次越高,应用程序的编写越简单。
9. 在有泛化/细化联系的对象类型之间,较低层的对象类型称为子类型。
10.目前数据库领域中最常用的数据模型有层次模型, 、网状模型, 、关系模型、面向对象模型。
11.数据管理技术经历了程序管理阶段、文件管理阶段、数据库系统管理阶段三个阶段。
12.SQL语言集数据查询、数据操纵、、数据定义和数据控制功能于一体。
13.数据库系统采用的三级模式结构为外模式、、模式、模式。
14.两个实体型之间的联系类型有一对一联系(1:1)、一对多联系(1:n)、多对多(m:n)三类。
15.数据库中专门的关系运算包括选择、投影、连接、除法。
16.满足第一式(1NF)的关系模式要求不包含重复组的关系。
17.如何构造出一个合适的数据逻辑结构是逻辑结构设计主要解决的问题。
18. 当数据库被破坏后,如果事先保存了日志文件和数据库的副本,就有可能恢复数据库。
19. 并发控制操作的主要方法是采用封锁机制,其类型有②排它锁(或X 锁) ③共享锁(或S 锁)。
20.在关系模式R(S,SN,D)和K(D,,NM)中,R的主码是S,K的主码是D,则D在R中称为外键。
21.对于函数依赖X→Y,如果Y是X的子集,则称X→Y为非平凡函数依赖。
数据库原理复习练习题含答案(二)

数据库原理复习练习题含答案泰山学院信息科学技术学院计算机科学与技术专业数据库系统概论本科试卷(试卷共6页,答题时间120分钟)题号一二三四五总分统分人复核人得分得分阅卷人一、选择题(每小题2分,共20 分。
请将答案填在下面的表格内)题号 1 2 3 4 5 6 78910答案1、数据库管理系统是管理控制数据库的主要软件,简称()。
A、DBB、DBMSC、DBSD、DBT2、反映现实世界中实体及实体间联系的信息模型是()。
A.关系模型B.层次模型C.网状模型D.E-R模型3、关系数据模型的三个组成部分中,不包括()。
A. 数据结构B. 数据操作C.数据控制D. 完整性规则4、下列语句中,()不属于SQL中DML的语句A.SELECTB.CREATEC.INSERTD.DELETE5、一个关系模式属于3NF,是指( )。
A.每个非主属性都不传递依赖于主键B.主键唯一标识关系中的元组C.关系中的元组不能重复D.每个属性都是不可分解的6、设有关系R(A,B,C)R上的函数依赖集F={A→B,A→C}。
则关系R属于( )A.1NFB.2NFC.3NFD.BCNF7、DBMS在运行过程中建立的日志文件,主要用于对数据库的()A.安全性控制 B. 并发调度控制C.数据库恢复 D. 完整性控制8、设关系模式R是3NF模式,那么下列说明不正确的是()。
A.R必是2NF模式 B.R必定不是BCNFC.R可能不是BCNF D.R必定是1NF模式9、.若事务T1已经给数据Q加上了S锁,则事务T2对Q可以()A. 加S锁B. 加X锁C. 加S锁,或X锁D.不能再给Q加任何锁10、SQL提供的触发器机制是对数据库系统采取的一种()措施。
A、完整性控制B、安全性控制C、数据库恢复D、事务并发控制得分阅卷人二、填空题(每题2分,共20分)1、数据模型的三个组成部分是___________ 、数据操作和完整性约束规则。
2、事务故障包括事物内部故障、_________、介质故障、计算机病毒。
数据库考试题目和答案

数据库考试题目和答案****一、单项选择题(每题2分,共20分)1. 数据库管理系统(DBMS)是()。
A. 数据库B. 数据库系统C. 硬件系统D. 操作系统答案:B2. 在关系数据库中,关系至少具有()。
A. 一个候选键B. 两个候选键C. 两个主键D. 一个主键答案:A3. 数据库系统的核心是()。
A. 数据B. 数据库管理系统C. 数据库管理员D. 应用程序答案:B4. 数据库系统的数据独立性包括()。
A. 物理独立性和逻辑独立性B. 物理独立性和数据独立性C. 数据独立性和逻辑独立性D. 数据独立性和物理独立性答案:A5. 以下哪个不是数据库系统的特点?()A. 数据共享B. 数据独立性C. 数据冗余度高D. 数据完整性答案:C6. 数据库系统的基本组成包括()。
A. 数据和应用程序B. 数据和数据库管理系统C. 数据库管理系统和应用程序D. 数据库和数据库管理系统答案:D7. 在数据库中,数据模型主要描述()。
A. 数据的存储方式B. 数据的处理方式C. 数据的组织、数据的操作和数据的约束D. 数据的存储和处理方式答案:C8. 以下哪个不是关系数据库的组成部分?()A. 表B. 视图C. 存储过程D. 文件答案:D9. SQL语言是一种()。
A. 过程式语言B. 非过程式语言C. 机器语言D. 汇编语言答案:B10. 数据库设计中,需求分析阶段的主要任务是()。
A. 设计ER图B. 设计数据库模式C. 确定数据库的存储结构D. 收集和分析用户需求答案:D二、多项选择题(每题3分,共15分)1. 关系数据库管理系统中,以下哪些是关系的基本操作?()A. 选择B. 投影C. 连接D. 排序答案:ABC2. 数据库设计过程中,以下哪些步骤是必要的?()A. 概念性设计B. 逻辑设计C. 物理设计D. 数据库实施答案:ABCD3. 在数据库系统中,以下哪些因素可能导致数据不一致?()A. 数据冗余B. 数据共享C. 数据独立性D. 并发操作答案:AD4. 数据库的完整性约束包括()。
ACCESS数据库复习题二与答案

ACCESS数据库复习题一与答案一、选择题1、Access2003数据库属于( D 关系型)数据库系统。
A.树状B.逻辑型C.层次型D.关系型2、在Access2003中,如果一个字段中要保存长度多于255个字符的文本和数字的组合数据,选择(C备注)数据类型。
(2分)A.文本B.数字C.备注D.字符3、Access2003中,(B删除查询)可以从一个或多个表中删除一组记录。
A.选择查询B.删除查询C.交叉表查询D.更新查询4、Access2003中,使用(B shift )键和鼠标操作,可以同时选中窗体上的多个控件。
A.TabB.ShiftC.CtrlD.Alt5、Access2003中,(D )。
A.允许在主键字段中输入Null值B.主键字段中的数据可以包含重复值C.只有字段数据都不重复的字段才能组合定义为主键D.定义多字段为主键的目的是为了保证主键数据的唯一性6、Access2003中,在数据表中删除一条记录,被删除的记录(D)。
A.可以恢复到原来位置B.能恢复,但将被恢复为最后一条记录C.能恢复,但将被恢复为第一条记录D.不能恢复7、Access2003中,可以使用(D数据表)来创建数据访问页。
A.报表B.窗体C.标签D.数据表8、在中,建立的数据库文件的扩展名为(A)。
A. mdb C. dbcB. dbf D. dct9、Access2003窗体中,能够显示在每一个打印页的底部的信息,它是( D)。
A.窗体页眉B. 窗体页脚C.页面页眉D.页面页脚10、ACCESS2003自动创建的主键,是( A )型数据。
A.自动编号B.文本C.整型D.备注11、在Access2003中,可以使用(D)命令不显示数据表中的某些字段。
A.筛选B.冻结C.删除D.隐藏12、在数据表视图中,当前光标位于某条记录的某个字段时,按( B )键,可以将光标移动到当前记录的下一个字段处。
A.C TRLB.T ABC.S HIFTD.E SC13、要为新建的窗体添加一个标题,必须使用下面(A)控件。
(完整版)数据库期末考试复习试题与答案

A .车次B .日期试题一一、单项选择题(本大题共20小题,每小题2分,共40分) 在每小题列出的四个备选项中只有一个是符合题目要 求的,请将其代码填写在题后的括号内。
错选、多选 或未选均无分。
1 .数据库系统的核心是( B )B. 数据库管理系统C •数据模型 2.下列四项中,不属于数据库系统的特点的是( C ) A •数据结构化 B .数据由DBMS 统一管理和控制 C .数据冗余度大D .数据独立性高3. 概念模型是现实世界的第一层抽象,这一类模型中最著名的模型是 (D ) A •层次模型 B .关系模型 C •网状模型D •实体-联系模型4. 数据的物理独立性是指(C )A •数据库与数据库管理系统相互独立B ・用户程序与数据库管理系统相互独立C •用户的应用程序与存储在磁盘上数据库中的数据是相互独立的D •应用程序与数据库中数据的逻辑结构是相互独立的 5 •要保证数据库的逻辑数据独立性,需要修改的是(A )A •模式与外模式之间的映象B ・模式与内模式之间的映象C •模式D •三级模式6 •关系数据模型的基本数据结构是( D )A .树B .图C .索引D .关系7 .有一名为“列车运营”实体,含有:车次、日期、实际发车时间、实际抵达A •数据库 D .软件工具时间、情况摘要等属性,该实体主码是( C )A .车次B.日期C •车次+日期D •车次+情况摘要8.己知关系R 和S, R A S 等价于( B ) A. (R-S )-S B. S-(S-R )C. (S-R )-RD. S-(R-S )9 •学校数据库中有学生和宿舍两个关系:学生(学号,姓名)和 宿舍(楼名,房间号,床位号,学号)假设有的学生不住宿,床位也可能空闲。
如果要列出所有学生住宿和宿舍分 配的情况,包括没有住宿的学生和空闲的床位,则应执行( A )A.全外联接 B.左外联接C.右外联接D.自然联接 10 .用下面的T-SQL 语句建立一个基本表:CREATE TABLE Stude nt(S no CHAR(4) PRIMARY KEY,Sn ame CHAR(8) NOT NULL, Sex CHAR(2),11.把对关系SPJ 的属性QTY 的修改权授予用户李勇的T-SQL 语句是( CA. GRANT QTY ON SPJ TO '李勇’B. GRANT UPDATE(QTY) ON SPJ TO '李勇'C. GRANT UPDATE (QTY) ON SPJ TO 李勇D. GRANT UPDATE ON SPJ (QTY) TO 李勇12.图1中(B )是最小关系系统ABC图113 •关系规范化中的插入操作异常是指A •不该删除的数据被删除 C •应该删除的数据未被删除AgeINT ) 可以插入到表中的元组是( D A. '5021','刘祥',男,21C. '5021' , NULL ,男,21)B. NULL ,'刘祥',NULL , 21 D. '5021','刘祥',NULL ,NULL(D )B .不该插入的数据被插入 D .应该插入的数据未被插入A)阶段的任D14 •在关系数据库设计中,设计关系模式是数据库设计中(A .逻辑设计B .物理设计15 .在E-R 模型中,如果有3个不同的实体型,3个m:n 联系,根据E-R 模型转 换为关系模型的规则,转换后关系的数目为( C )。
数据库练习题库(含答案)

数据库练习题库(含答案)一、单选题(共98题,每题1分,共98分)1.在需求分析阶段,结构化分析和建模方法是一种较为有效的需求分析方法,下列不属于结构化分析和建模方法优点的是()。
A、可避免过早陷入具体细节B、从局部或子系统开始分析问题,便于建模人员了解业务模型C、图形对象不涉及太多技术术语,便于用户理解模型D、用图形化的模型能直观表示系统功能正确答案:B2.DBMS通过加锁机制允许用户并发访问数据库,这属于DBMS提供的()。
A、数据定义功能B、数据操纵功能C、数据库运行管理与控制功能D、数据库建立与维护功能正确答案:C3.关于数据划分策略,下述说法错误的是()。
A、散列划分釆用某种散列函数,以数据的划分属性作为函数参数,计算数据应存储的磁盘序号B、范围划分根据某个属性的取值,将数据划分为n个部分,分别存储到不同磁盘上C、范围划分有利于范围查询和点查询,但也可能会引起数据分布不均匀及并行处理能力下降问题D、轮转法划分能保证元组在多个磁盘上的平均分配,并具有较高的点查询和范围查询正确答案:D4.存取方法设计属于数据库设计的()阶段的设计任务。
A、逻辑结构设计B、概念结构设计C、系统需求分析D、物理结构设计正确答案:D5.将新插入的记录存储在文件末尾,并使记录随机地分布在文件物理存储空间中的文件结构是()。
A、散列文件B、堆文件C、索引文件D、聚集文件正确答案:B6.关于"死锁”,下列说法中正确的是()。
A、在数据库操作中防止死锁的方法是禁止两个用户同时操作数据库B、只有出现并发操作时,才有可能出现死锁C、当两个用户竞争相同资源时不会发生死锁D、死锁是操作系统中的问题,数据库操作中不存在正确答案:B7.关于数据库应用系统的需求分析工作,下列说法正确的是()。
A、在需求分析阶段,系统需求分析员要与用户充分沟通,并做出各类用户视图B、通过需求分析过程,需要确定出整个应用系统的目标、任务和系统的范围说明C、数据操作响应时间、系统吞吐量、最大并发用户数都是性能需求分析的重要指标D、数据需求分析的主要工作是要辩识出数据处理中的数据处理流程正确答案:C8.如果一个系统定义为关系系统,则它必须( )oA、支持关系数据库B、支持选择、投影和连接运算C、A和B均成立D、A、B都不需要正确答案:C9.联机分析处理包括以下()基本分析功能。
数据库复习题2

复习题21. 设关系r1(A ,B ,C),r2(C ,D ,E)有如下特性:r1有200000个元组,r2有45000个元组,一块中可容纳25个r1元组或30个r2元组。
试估算以下每一种策略计算r1|><|r2所需存取的块数:1) 嵌套循环连接2) 块嵌套循环连接3) 归并连接4) 散列连接解:r1需要8000个块,r2需要1500个块。
假设有一个存储器有M 页。
如果M>8000,那么使用平坦嵌套循环,通过1500+8000次磁盘存取就可以很容易的完成连接操作。
因此我们只考虑M<=8000的情况。
1) 嵌套循环连接:使用r1作为外关系,我们需要进行200 000×1500+8000=300,008,000次磁盘存取。
如果r2是外关系,那么我们需要45 000×8 000+1 500=360 001 500次磁盘存取。
2) 块嵌套循环连接:如果r1是外关系,我们需要8000/(M 2)-⎡⎤⎢⎥×1500+8000次磁盘存取,如果r2是外关系,我们需要1500/(M-2)⎡⎤⎢⎥×8000+1500次磁盘存取。
3) 归并连接假设r1和r2最初没有按连接关键字进行排序,那么总的排序加上输出的耗费为Bs =1500(2 M-1log (1500/M)⎡⎤⎢⎥+1)+8000(2 M-1log (8000/M)⎡⎤⎢⎥+1)次磁盘存取。
假设具有相同连接属性值的所有员组装入内存中,那么总的耗费是Bs +1500+8000次磁盘存取。
4) 散列连接我们假设不发生溢出。
因为r2比较小,所以我们用r2作为创建关系,用r1作为探针关系。
如果M>1500,那么就不需要进行递归分割,于是耗费为3(1500+8000)=28 500次磁盘存取,否则耗费为2(1500+8000)M-1log (1500/M)+2⎡⎤⎢⎥+1500+8000次磁盘存取。
数据库考试试题及答案

数据库考试试题及答案一、选择题(每题2分,共20分)1. 数据库管理系统(DBMS)的主要功能不包括以下哪一项?A. 数据定义B. 数据操纵C. 数据传输D. 数据控制答案:C2. 在关系型数据库中,用于表示实体间一对多关系的是:A. 实体B. 关系C. 属性D. 域答案:B3. SQL语言中,用于创建新表的命令是:A. CREATE TABLEB. CREATE DATABASEC. ALTER TABLED. DROP TABLE答案:A4. 在数据库中,用于唯一标识每个元组的属性集称为:A. 外键B. 主键C. 候选键D. 非键属性答案:B5. 数据库设计中,将E-R图转换为关系模式的过程称为:A. 概念设计B. 逻辑设计C. 物理设计D. 数据定义答案:B6. 以下哪个选项不是数据库的完整性约束?A. 实体完整性B. 参照完整性C. 用户定义完整性D. 视图完整性答案:D7. 在关系型数据库中,用于选择数据的SQL语句是:A. SELECTB. INSERTC. UPDATED. DELETE答案:A8. 数据库的三级模式包括:A. 外模式、概念模式、内模式B. 概念模式、内模式、物理模式C. 外模式、内模式、物理模式D. 逻辑模式、物理模式、存储模式答案:A9. 数据库系统中,用于存储数据的文件称为:A. 数据文件B. 日志文件C. 索引文件D. 系统文件答案:A10. 数据库恢复的基础是:A. 数据备份B. 日志文件C. 事务日志D. 恢复日志答案:B二、填空题(每题2分,共20分)1. 数据库系统的核心是______。
答案:数据库管理系统(DBMS)2. 在关系型数据库中,关系是指一组具有相同______的行的集合。
答案:属性3. 数据库中的视图可以提供______。
答案:逻辑上的独立性4. 事务的四大特性通常被称为ACID,其中I代表______。
答案:隔离性5. 数据库的物理设计阶段主要考虑的是数据的______。
(完整版)数据库试题库(有答案)

复习题一、填空题:1、三类经典的数据模型是_________、_________和_________。
其中,________目前应用最广泛。
2、_________模型是面向信息世界的,它是按用户的观点对数据和信息建模;________模型是面向计算机世界的,它是按计算机系统的观点对数据建摸。
3、关系模型的实体完整性是指______________________________。
在关系模型中,候选码是指_______________________,全码是指_________________________。
4、设Ei 为关系代数表达式,根据关系代数等价变换规则,(E1×E2)×E3 ≡ __________,若选择条件F只涉及E1中的属性,则σF(E1×E2)≡____________。
5、数据依赖是关系中属性间的相互关联,最重要的数据依赖有两种,即_____依赖和多值依赖。
6、在关系规范化过程中,将1NF转化为2NF,要消除______________________,若一个关系模式R∈2NF,并且消除了非主属性对码的传递依赖,则R∈__NF。
7、数据库的保护措施有________控制、_________控制、_________控制和数据库恢复等。
8、事务是并发控制的基本单位,事务的四个性质是_______性、_______性、_______性和________性。
9、并发控制的主要方法是封锁,封锁的类型有两种,即________锁和_______锁。
10、故障恢复的基本手段有____________和_________________。
11、DBMS的中文全称是___________。
12、数据管理的发展经历了人工管理阶段、_________阶段和________阶段。
13、数据库系统的三级模式分别是___________,___________和_________。
数据库试题及答案解析

数据库试题及答案解析一、单项选择题1. 数据库管理系统(DBMS)的主要功能是()。
A. 数据定义B. 数据操纵C. 数据控制D. 全部选项答案:D解析:数据库管理系统(DBMS)的主要功能包括数据定义、数据操纵和数据控制。
数据定义涉及数据库的创建、修改和删除;数据操纵涉及数据的查询、插入、更新和删除;数据控制涉及数据的完整性、安全性和并发控制。
2. 在关系数据库中,关系是指()。
A. 一个表B. 两个表之间的关系C. 多个表之间的关系D. 表的集合答案:A解析:在关系数据库中,关系是指一个表,它由行和列组成,行表示实体,列表示属性。
3. SQL语言中的“SELECT”语句用于()。
A. 数据定义B. 数据操纵C. 数据控制D. 数据查询答案:D解析:SQL语言中的“SELECT”语句用于数据查询,它可以从数据库中检索数据。
4. 数据库的三级模式结构包括()。
A. 外模式、概念模式和内模式B. 外模式、内模式和存储模式C. 概念模式、内模式和存储模式D. 概念模式、存储模式和物理模式答案:A解析:数据库的三级模式结构包括外模式、概念模式和内模式。
外模式是用户视图,概念模式是全局逻辑结构,内模式是存储结构。
5. 数据库设计中,规范化的主要目的是()。
A. 提高查询速度B. 减少数据冗余C. 增加数据安全性D. 降低存储成本答案:B解析:数据库设计中,规范化的主要目的是减少数据冗余,提高数据的一致性和完整性。
二、多项选择题1. 以下哪些是数据库系统的特点?()A. 数据共享B. 数据独立性C. 数据完整性D. 数据安全性答案:ABCD解析:数据库系统的特点包括数据共享、数据独立性、数据完整性和数据安全性。
数据共享指多个用户可以共享数据库中的数据;数据独立性指数据的存储结构和逻辑结构相互独立;数据完整性指数据库中的数据必须满足一定的规则和约束;数据安全性指数据库系统能够保护数据不被未授权访问或破坏。
2. 关系数据库的完整性约束包括()。
数据库安全技术练习题及参考答案第2卷

数据库安全技术练习题及参考答案第2卷1 、关于生产数据库的备份,以下表述最切合实际的是()。
选择一项:a. 数据库必须每天或定时的进行完整备份b. 对于完整备份需要很长时间的情况,我们一般采用停止数据库在进行完整备份c. 事务日志备份就是完整备份的备份,只不过包含了事务日志记录d. 首次完整备份后,一段时期内就不用再做完整备份,而是根据需要进行差异备份或事务日志备份即可参考答案是:首次完整备份后,一段时期内就不用再做完整备份,而是根据需要进行差异备份或事务日志备份即可2 、事务日志不会记录下面的哪个操作()。
选择一项:a. insertb. updatec. selectd. delete参考答案是:select3 、以下哪一项不属于数据库的数据恢复模式()。
选择一项:a. 大容量日志恢复模式b. 小容量日志恢复模式c. 完整恢复模式d. 简单恢复模式参考答案是:小容量日志恢复模式4 、以下描述完整恢复模式的不正确的是()。
选择一项:a. 风险高b. 可以恢复到具体时间点c. 存储空间大d. 记录大容量日志参考答案是:风险高5 、下面不属于数据库备份类型的是()。
选择一项:a. 完整备份b. 差异备份c. 简单备份d. 事务日志备份参考答案是:简单备份6 、事务日志会记录下哪个操作()。
选择一项:a. declareb. selectc. setd. truncate参考答案是:truncate7 、以下说法正确的是()。
选择一项:a. 完整备份+差异备份可以还原到任意时间点b. 完整备份+事务日志备份可以采用简单恢复模式c. 事务日志备份1和事务日志备份2都是以完整备份为基准d. 差异备份1和差异备份2是以完整备份为基准参考答案是:差异备份1和差异备份2是以完整备份为基准8 、关于数据库的备份,以下叙述中正确的是()。
选择一项:a. 差异备份可以还原到任意时刻点,生产数据库一般采用该方法b. 事务日志备份不包含大容量日志,还原后会丢失个别数据c. 完整备份是一般采用压缩备份,减少存储空间d. 文件或文备份任何情况下都不可取参考答案是:完整备份是一般采用压缩备份,减少存储空间9 、以下哪个不是SQL SERVER的备份类型()。
mysql数据库二级考试试题及答案

mysql数据库二级考试试题及答案一、选择题(每题2分,共10分)1. MySQL中,哪个存储引擎支持事务处理?A. MyISAMB. InnoDBC. MEMORYD. ARCHIVE答案:B2. 在MySQL中,如何创建一个新数据库?A. CREATE DATABASE database_name;B. CREATE TABLE database_name;C. CREATE new_database database_name;D. CREATE DATABASES database_name;答案:A3. MySQL中,哪个函数用于获取当前日期?A. NOW()B. CURRENT_DATEC. CURDATE()D. DATE()答案:C4. 在MySQL中,如何添加一个新列到已存在的表中?A. ALTER TABLE table_name ADD COLUMN column_name datatype;B. MODIFY TABLE table_name ADD COLUMN column_name datatype;C. ADD COLUMN table_name column_name datatype;D. CHANGE COLUMN table_name column_name datatype;答案:A5. MySQL中,如何删除一个数据库?A. DELETE DATABASE database_name;B. DROP DATABASE database_name;C. REMOVE DATABASE database_name;D. REMOVE TABLE database_name;答案:B二、填空题(每空1分,共10分)1. 在MySQL中,使用________命令可以查看当前数据库的所有表。
答案:SHOW TABLES2. 如果要查看表的结构,可以使用命令________。
数据库复习题 (2)
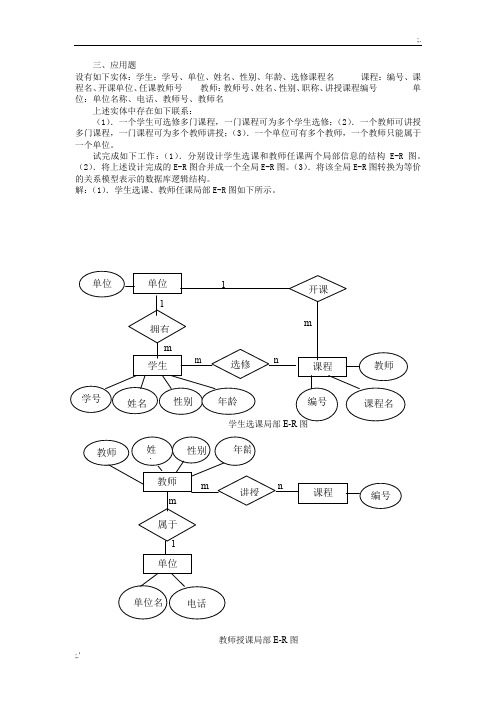
三、应用题设有如下实体:学生:学号、单位、姓名、性别、年龄、选修课程名课程:编号、课程名、开课单位、任课教师号教师:教师号、姓名、性别、职称、讲授课程编号单位:单位名称、电话、教师号、教师名上述实体中存在如下联系:(1).一个学生可选修多门课程,一门课程可为多个学生选修;(2).一个教师可讲授多门课程,一门课程可为多个教师讲授;(3).一个单位可有多个教师,一个教师只能属于一个单位。
试完成如下工作:(1).分别设计学生选课和教师任课两个局部信息的结构E-R图。
(2).将上述设计完成的E-R图合并成一个全局E-R图。
(3).将该全局E-R图转换为等价的关系模型表示的数据库逻辑结构。
解:(1).学生选课、教师任课局部E-R图如下所示。
教师授课局部E-R图(2).合并后的全局E-R图如下所示。
全局E-R图为避免图形复杂,下面给出各实体属性:单位:单位名、电话学生:学号、姓名、性别、年龄教师:教师号、姓名、性别、职称课程:编号、课程号(3).该全局E-R图转换为等价的关系模型表示的数据库逻辑结构如下:单位(单位名,电话)教师(教师号,姓名,性别,职称,单位名)课程(课程编号,课程名,单位名)学生(学号,姓名,性别,年龄,单位名)讲授(教师号,课程编号)选修(学号,课程编号)2、工厂(包括厂名,厂长名)需建立一管理数据库存贮以下信息:一个厂内有多个车间,每个车间有车间号、主任姓名、地址、电话;一个车间有多个工人,每个工人有职工号、姓名、年龄、性别、工种;一个车间生产多种产品,产品有产品号、价格;一个车间生产多种零件,一种零件也可能为多个车间制造,零件有零件号、重量、价格;一种产品由多种零件组成,一种零件也可装配到多种产品中;产品与零件均存入仓库中;厂内有多个仓库,仓库有仓库号、主任姓名、电话。
试(1)画出该系统的实体-联系模型E-R图。
(2)给出相应的关系数据模型。
(1)检索“程军”老师所授课程的课程号(C#)和课程名(CNAME)。
数据库的考试题目及答案

数据库的考试题目及答案一、选择题(每题2分,共20分)1. 数据库管理系统(DBMS)的主要功能不包括以下哪一项?A. 数据定义B. 数据存储C. 数据备份D. 网络通信答案:D2. 在关系型数据库中,以下哪个是基本的数据结构?A. 树B. 图C. 表格D. 链表答案:C3. SQL语言中的“SELECT”语句用于执行哪种操作?A. 查询数据B. 更新数据C. 删除数据D. 插入数据答案:A4. 数据库事务具有哪些特性?(多选)A. 原子性B. 一致性C. 隔离性D. 持久性答案:ABCD5. 在数据库设计中,规范化的主要目的是什么?A. 提高查询速度B. 减少数据冗余C. 增加数据安全性D. 降低存储成本答案:B6. 下列哪个选项不是数据库的完整性约束?A. 实体完整性B. 参照完整性C. 域完整性D. 触发器完整性答案:D7. 数据库中的视图是什么?A. 存储在数据库中的一组数据B. 基于一个或多个表的查询结果C. 数据库的物理存储D. 数据库的逻辑结构答案:B8. 在数据库中,索引的作用是什么?A. 增加数据安全性B. 提高查询效率C. 减少数据冗余D. 限制数据访问答案:B9. 数据库的并发控制主要解决什么问题?A. 数据一致性B. 数据完整性C. 数据安全性D. 数据备份答案:A10. 数据库恢复的主要目的是?A. 恢复丢失的数据B. 恢复损坏的数据C. 恢复系统性能D. 恢复数据库结构答案:A二、填空题(每题2分,共20分)1. 数据库管理系统(DBMS)是位于用户和__操作系统__之间的一层数据管理软件。
2. 在数据库中,__主键__是用来唯一标识表中每条记录的字段。
3. 数据库的__外键__约束用于维护两个表之间的关系。
4. SQL中的__事务__是指一组不可分割的数据库操作序列。
5. 数据库的__范式__理论是用于指导数据库设计的一组规则。
6. 数据库的__备份__操作是为了防止数据丢失而进行的数据复制。
数据库考试试题及答案

数据库考试试题及答案一、选择题(每题2分,共20分)1. 以下哪一个不是数据库管理系统的功能?A. 数据存储B. 数据查询C. 数据安全D. 数据打印答案:D2. 数据库系统的核心是?A. 数据模型B. 数据字典C. 数据库管理系统D. 数据库答案:C3. 以下哪种数据库模型是关系数据库的基础?A. 层次模型B. 网状模型C. 关系模型D. 对象模型答案:C4. 以下哪一项不是SQL语言的特点?A. 非过程化B. 面向集合的操作方式C. 支持事务处理D. 面向过程的编程答案:D5. 在数据库表中,哪个关键字用于唯一标识一行?A. 主键B. 外键C. 候选键D. 复合键答案:A6. 以下哪种索引可以提高查询效率?A. 倒排索引B. B+树索引C. 散列索引D. 位图索引答案:B7. 以下哪个SQL语句用于创建视图?A. CREATE TABLEB. CREATE INDEXC. CREATE VIEWD. CREATE PROCEDURE答案:C8. 在SQL中,以下哪个操作符用于连接两个表?A. UNIONB. JOINC. INTERSECTD. MINUS答案:B9. 数据库系统中的完整性约束包括?A. 实体完整性B. 参照完整性C. 用户定义的完整性D. 所有以上选项答案:D10. 以下哪个SQL语句用于删除表?A. DROP TABLEB. DELETE TABLEC. TRUNCATE TABLED. UPDATE TABLE答案:A二、填空题(每题2分,共20分)11. 数据库管理系统(DBMS)的主要功能包括数据定义、数据操纵、数据查询、数据______。
答案:安全12. 在关系数据库中,实体及实体之间的联系可以用二维表来表示,这种二维表称为______。
答案:关系13. 在SQL中,创建表的命令是______。
答案:CREATE TABLE14. 在SQL中,删除表的命令是______。
数据库练习及答案 (2)

一. 创建一个学生档案表(表名为xsda),其表结构如下:Create Table xsda(xh Char (10) not null unique,xm Char(8),csny Datetime ,gz Decimal(6,1),zy Char (10))1.在xsda表中插入一个学生记录:(2000jsj008,李平)insert into xsda(xh,xm) values(‘2000jsj008’,’李平’)2.把xsda表中80-01-01前出生的人的工资增加20%Update xsda set gz=gz*1.2 where csny<’ 80-01-01’3.查询xsda表中不同专业的人数Select zy ,count(xh) from xsda group by zy4.假如另外还有一个学生成绩表xscj(xh,kch,kccj), xh,kch,kccj分别指学号、课程号、成绩,要求查询姓名为李平的同学的各门课程的成绩。
Select kch,kccj from xsda,xscj where xsda.xh=xscj.xh and xm=’李平’5.xsda、xscj表同上,查询选修了kch为Yy2的学生的xh和XmSelect xh,xm from xsda,xscj where xsda.xh=xscj.xh and kch=’Yy2’二、使用SQL语句创建一个班级表CLASS,属性如下:CLASSNO,DEPARTNO,CLASSNAME;类型均为字符型;长度分别为8、2、20且均不允许为空。
CREATE ___table_____ CLASS(CLASSNO __char____ (8) NOT NULL,DEPARTNO CHAR (2) NOT NULL,CLASSNAME CHAR (__20__) NOT NULL)三、有一个[学生课程]数据库,数据库中包括三个表:学生表:Student由学号(Sno)、姓名(Sname)、性别(Ssex)、年龄(Sage)、所在系(Sdept)五个属性组成,记为:Student(Sno,Sname,Ssex,Sage,Sdept),Sno 为关键字。
数据库试题及答案

数据库试题及答案一、选择题(每题2分,共20分)1. 数据库管理系统(DBMS)的主要功能是()。
A. 数据定义B. 数据操纵C. 数据控制D. 以上都是答案:D2. 在关系型数据库中,关系是指()。
A. 一个表格B. 一个索引C. 一个视图D. 一个查询答案:A3. 以下哪个不是SQL语言的组成部分?()A. DDLB. DMLC. DCLD. TCL答案:D4. 数据库设计中,将E-R图转换为关系模式的过程称为()。
A. 数据定义B. 数据操纵C. 数据转换D. 数据控制答案:C5. 以下哪个选项不是数据库的三级模式?()A. 内模式B. 概念模式C. 存储模式D. 外模式答案:C6. 在数据库中,用于存储数据的逻辑单位是()。
A. 文件B. 记录C. 表D. 字段答案:C7. 数据库系统的数据独立性主要体现在()。
A. 硬件独立性B. 软件独立性C. 逻辑独立性D. 物理独立性答案:C8. 在SQL中,用于创建新表的语句是()。
A. CREATE TABLEB. CREATE INDEXC. CREATE VIEWD. CREATE DATABASE答案:A9. 以下哪个选项是数据库的完整性约束?()A. 主键约束B. 外键约束C. 唯一性约束D. 以上都是答案:D10. 数据库中,用于实现数据共享的机制是()。
A. 视图B. 索引C. 存储过程D. 触发器答案:A二、填空题(每题2分,共20分)1. 数据库系统的核心是________。
答案:数据库管理系统(DBMS)2. 数据库管理系统的主要功能包括数据定义、数据操纵和________。
答案:数据控制3. 在关系型数据库中,表与表之间的关系是通过________来实现的。
答案:外键4. 数据库设计通常分为三个阶段:概念设计、逻辑设计和________。
答案:物理设计5. SQL语言中,用于删除表的语句是________。
答案:DROP TABLE6. 数据库的三级模式包括外模式、概念模式和________。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
复习题(2)1、试分别判断下列图中G1和G2是否互模拟(bisimulation),并说明理由:答案:(1) 在图中标出各点的状态,我们构造关系,可知G2可以模拟G1,下面我们讨论a bca b c cG1G2dd d a a ab cc bG1= G2=是否可模拟,在G2中有一个a 变换可对应到G1中2个变换,即,。
但有两个变换b ,c ,而在G1中仅存在只有b 或只有c 的状态点,可知G1和G2不能互模拟。
(2) 如图,标出各状态点,构造有关系可知其中G1中的点均可由G2中的点模拟,下面我们考虑可知同样其中G2中的点均可由G1中的点模拟. 所以G1和G2为互模拟的。
2、 给定如下数据图(Data Graph):address r1c1c2s2s3s6s7s10company companyname name url address “Widget ”“Trenton ”“Gadget ”“www.gp.fr ”“Paris ”p2p1p3s0s1s4s5s8s9personperson person “Smith ”name position namephone name position “Manager ”“Jones ”“5552121”“Dupont ”“Sales ”employeemanagesceoworks-for works-for works-for ceo试给出其Strong DataGuide 图答案:r1p1,p2,p3c1,c2s0,s4,s8s1,s9s5s2,s6s3,s7s10p2p1,p3personnamepositionphonenameaddressurl ceoemployeemanagesworks-forStrong DataGuide 图3、 Consider the relation, r , shown in Figure 5.27. Give the result of the following query :Figure 5.27Query 1:select building , room number , time_slo_ id , count (*) from rgroup by rollup (building , room number , time_slo_ id )Query 1:select building , room number , time_slo_ id , count (*) from rgroup by cube (building , room number , time_slo_ id )答案:Query 1返回结果集:为以下四种分组统计结果集的并集且未去掉重复数据。
buildingroom numbertime_slo_ idcount (*)产生的分组种数:4种;第一种:group by A,B,CGarfield 359 A 1Garfield 359 B 1Saucon 651 A 1Saucon 550 C 1Painter 705 D 1Painter 403 D 1第二种:group by A,BGarfield 359 A 2Garfield 359 B 2Saucon 651 A 1Saucon 550 C 1Painter 705 D 1Painter 403 D 1第三种:group by AGarfield 359 A 2Garfield 359 B 2Saucon 651 A 2Saucon 550 C 2Painter 705 D 2Painter 403 D 2第四种:group by NULL。
本没有group by NULL 的写法,在这里指是为了方便说明,而采用之。
含义是:没有分组,也就是所有数据做一个统计。
例如聚合函数是SUM的话,那就是对所有满足条件的数据进行求和。
Garfield 359 A 6Garfield 359 B 6Saucon 651 A 6Saucon 550 C 6Painter 705 D 6Painter 403 D 6Query 2:group by后带rollup子句与group by后带cube子句的唯一区别就是:带cube子句的group by会产生更多的分组统计数据。
cube后的列有多少种组合(注意组合是与顺序无关的)就会有多少种分组。
返回结果集:为以下八种分组统计结果集的并集且未去掉重复数据。
building room number time_slo_ id count(*)产生的分组种数:8种第一种:group by A,B,CGarfield 359 A 1Garfield 359 B 1Saucon 651 A 1Saucon 550 C 1 Painter 705 D 1 Painter 403 D 1 第二种:group by A,BGarfield 359 A 2 Garfield 359 B 2 Saucon 651 A 1 Saucon 550 C 1 Painter 705 D 1 Painter 403 D 1 第三种:group by A,CGarfield 359 A 1 Garfield 359 B 1 Saucon 651 A 1 Saucon 550 C 1 Painter 705 D 2 Painter 403 D 2 第四种:group by B,CGarfield 359 A 2 Garfield 359 B 2 Saucon 651 A 1 Saucon 550 C 1 Painter 705 D 1 Painter 403 D 1 第五种:group by AGarfield 359 A 2 Garfield 359 B 2 Saucon 651 A 2 Saucon 550 C 2 Painter 705 D 2 Painter 403 D 2 第六种:group by BGarfield 359 A 2 Garfield 359 B 2 Saucon 651 A 1 Saucon 550 C 1 Painter 705 D 1 Painter 403 D 1 第七种:group by CGarfield 359 A 2 Garfield 359 B 1 Saucon 651 A 2 Saucon 550 C 1Painter 705 D 2Painter 403 D 2第八种:group by NULLGarfield 359 A 6Garfield 359 B 6Saucon 651 A 6Saucon 550 C 6Painter 705 D 6Painter 403 D 64、[Disks and Access Time]Consider a disk with a sector扇区size of 512 bytes,63 sectors per track磁道, 16,383 tracks per surface盘面, 8 double-sided platters柱面(i.e., 16 surfaces). The disk platters rotate at 7,200 rpm (revolutions perminute). The average seek time is 9 msec, whereas the track-to-track seek time is1 msec.Suppose that a page size of 4096 bytes is chosen. Suppose that a file containing 1,000,000 records of 256 bytes each is to be stored on such a disk. No record is allowed to span two pages (use these numbers in appropriate places in yourcalculation).(a) What is the capacity of the disk?(b) If the file is arranged sequentially on the disk, how many cylinders are needed?(c) How much time is required to read this file sequentially?(d) How much time is needed to read 10% of the pages in the file randomly? Answer:(a) Capacity = sector size * num. of sectors per track * num. of tracks per surface * num of surfaces = 512 * 63 * 16383 * 16 = 8 455 200 768(b) File: 1,000,000 records of 256 bytes eachNum of records per page: 4096/256 = 161,000,000/ 16 = 62,500 pages or 62,500 * 8 = 500,000 sectorsEach cylinder has 63 * 16 = 1,008 sectorsSo we need 496.031746 cylinders.(c) We analyze the cost using the following three components:Seek time: This access seeks the initial position of the file (whose cost can be approximated using the average seek time) and then seeks between adjacent tracks 496 times (whose cost is the track-to-track seek time). So the seek time is 0.009 + 496*0.001 = 0.505 seconds.Rotational delay:The transfer time of one track of data is 1/ (7200/60) = 0.0083 seconds.For this question, we use 0.0083/2 as an estimate of the rotational delay (other numbers between 0 and 0.00415 are also fine). So the rotational delay for 497 seeks is 0.00415 * 497 = 2.06255.Transfer time: It takes 0.0083*(500000/63) = 65.8730159 seconds to transfer data in 500,000 sectors.Therefore, total access time is 0.505 + 2.06255 + 65.8730159 = 68.4405659 seconds.(d) number of pages = 6250time cost per page: 0.009 (seek) + 0.0083/2 (rotational delay) + 0.0083*8/63 (transfer) = 0.0142 secondstotal cost = 6250 * 0.0142 = 88.77 seconds5、[Disk Page Layout]The figure below shows a page containing variable lengthrecords. The page size is 1KB (1024 bytes). It contains 3 records, some free space, and a slot directory in that order. Each record has its record id, in the form ofRid=(page id, slot number), as well as its start and end addresses in the page, as shown in the figure.Now a new record of size 200 bytes needs to be inserted into this page. Apply the record insertion operation with page compaction, if necessary. Show the content of the slot directory after the new record is inserted. Assume that you have only the page, not any other temporary space, to work with.Answer:Content of the slot directory, from left to right, is:[(650, 200), (0, 200), (500, 150), (200, 300)], 4, 8506、[Buffer Management for File and Index Accesses]Consider the followingtwo relations:●student(snum:integer, sname:char(30), major:char(25), standing:char(2),age:integer)●enrolled(snum:integer, cname:char(40))The following index is available:A B+ Tree index on the <snum> attribute of the student relation.Assume that the buffer size is large enough to store multiple paths of each B+Tree but not an entire tree.(a) Consider Query 1 and Query 2 that retrieve the snum’s of students who havetaken ‘Database Systems’and ‘Operating Systems’, respectively, from theenrolled table. We know that Query 1 will be executed before Query 2, and both queries are executed using a file scan of the enrolled table.Which replacement policy would you recommend for the buffer manager to use to support this workload?(b) Now assume that we have retrieved the snum’s of students who have taken‘Database Systems’ from the enrolled table. In the exact order of the retrieved snum’s (not necessarily in sorted order),we then retrieve the nam es of thosestudents via repeated lookups in the B+ Tree on <snum>.For these repeated accesses to the index on student.snum, which replacementpolicy would you recommend for efficient buffer management?Query 1:select snumfrom student s, enrolled ewhere s.snum=e.snum and cname like ‘Database Systems’;Query 2:select snumfrom student s, enrolled ewhere s.snum=e.snum and cname like ‘Operating Systems’;Answer:(a) Not LRU. MRU or LRU2.(b) Now we have repeated equality searches over the B+ Tree on <sid>, with no duplicate values in the search key (because the schema does not allow a student to take the same course twice). Two possible answers:- The B+ Tree pages close to the top are repeated accessed but those at the leaf level are rarely reused. So we can use LRU.- LIFO (Last In First Out) is another possible answer. This is because over time, we have cached most nodes close to the top in memory. So the nodes recently read from the disk are mostly close to the leaves. So LIFO will replace those leaf or close-to-leaf nodes to make room for the newly requested nodes.- We also accept other answers if the student can justify well.。