研究生定量研究方法Stata上机操作试题
stata操作习题答案

stata操作习题答案Stata操作习题答案Stata是一种统计分析软件,广泛应用于学术研究、商业分析和政府统计等领域。
它具有强大的数据处理和分析能力,可以帮助用户快速、准确地进行数据分析和统计建模。
在学习和使用Stata软件的过程中,经常会遇到各种操作习题,通过解答这些习题可以帮助我们更好地掌握Stata软件的使用方法和数据分析技巧。
下面我们来看一些常见的Stata操作习题及其答案:1. 如何导入数据文件到Stata中进行分析?答案:可以使用命令“use 文件路径\文件名”来导入Stata数据文件,也可以在Stata的界面中通过“File”菜单中的“Open”选项来导入数据文件。
2. 如何查看数据文件的前几行和变量的属性?答案:可以使用命令“browse”来查看数据文件的前几行,使用命令“describe”来查看数据文件中变量的属性。
3. 如何进行描述性统计分析?答案:可以使用命令“summarize”来进行描述性统计分析,该命令可以输出数据文件中各个变量的均值、标准差、最小值、最大值等统计量。
4. 如何进行回归分析?答案:可以使用命令“regress”来进行回归分析,该命令可以帮助用户进行线性回归模型的拟合和参数估计。
5. 如何进行数据可视化分析?答案:可以使用命令“histogram”、“scatter”等来进行数据可视化分析,这些命令可以帮助用户绘制直方图、散点图等图形,直观地展现数据的分布和关系。
通过解答以上习题,我们可以更加熟练地掌握Stata软件的操作方法和数据分析技巧,为我们在学术研究和实际工作中的数据分析工作提供有力的支持。
希望大家在学习和使用Stata软件的过程中能够多多练习,不断提升自己的数据分析能力。
stata上机实验第一讲

添加标签
1。为整个数据添加标签:例如,将数据命名
为“工资表”。 菜单:Data->Labels->Label dataset 命令:label data “工资表“ 2。为变量增加标签,例如,给变量wage增 加标签“年工资总额” 菜单:Data->Labels->Label variables 命令 label variable wage “年工资总额"
1。所有的系统自带数据可以利用sysuse命令
打开。 2。Use命令只能打开 C:\data 或者 D:\data 中的数据。 3。如果需要打开其他文件夹的数据,必须改 变目录(例如,将自己的数据放入D:\abc) cd "D:\abc” 或者直接 file------open
先学习几条最简单的命令
Stata的菜单介绍
最重要的菜单项:
Data菜单 Graphic菜单
Statistics菜单
每执行一个菜单性会自动产生相应的命令。
(以summarize为例)。 我们的讲述尽量兼顾到命令操作和菜单操作 两种方法,以命令方式为主。
安装指南
解压 setup.rar
运行 setup 安装时选择 Stata SE
装到: C:\Program file\stata10 中。 将所用系统自带的一些系统数据、应用程序、 帮助文件安装到 C:\Program file\stata10\ado\base 中 将所有升级程序安装到: C:\Program file\stata10\ado\update 中
Stata数据的录入
1。直接录入。
stata上机考试题及答案

stata上机考试题及答案1. 请使用Stata软件打开给定的数据集,并计算变量`income`的平均值。
答案:在Stata命令窗口输入`summarize income`,即可得到`income`变量的平均值。
2. 计算变量`age`的标准差,并将其保存为新变量`age_sd`。
答案:在Stata命令窗口输入`egen age_sd = sd(age)`,即可计算并保存变量`age`的标准差。
3. 请对数据集中的变量`height`和`weight`进行相关性分析,并输出结果。
答案:在Stata命令窗口输入`correlate height weight`,即可进行相关性分析并输出结果。
4. 使用Stata绘制变量`income`的直方图,并设置直方图的标题为“Income Distribution”。
答案:在Stata命令窗口输入`histogram income, title("Income Distribution")`,即可绘制并设置直方图的标题。
5. 根据变量`education`的值,将数据集分为三组:低教育水平(`education`值为1),中等教育水平(`education`值为2),高教育水平(`education`值为3)。
然后分别计算每组的平均`income`。
答案:在Stata命令窗口输入以下命令:```bysort education: summarize income```即可根据`education`变量的值分组,并计算每组的平均`income`。
6. 请使用Stata的回归分析功能,分析变量`income`与`education`和`age`之间的关系。
答案:在Stata命令窗口输入`regress income education age`,即可进行回归分析。
7. 绘制变量`income`与`education`的散点图,并在图中添加一条最佳拟合线。
斯托克,沃森计量经济学第四章实证练习stata操作及答案

斯托克,沃森计量经济学第四章实证练习stata操作及答案E4.1E4.2E4.3E4.4VARIABLES aheage 0.605(0.0245)Constant 1.082(0.688)Observations 7,711R-squared 0.029Robust standard errors in parentheses*** p<0.01, ** p<0.05, * p<0.11.①截距估计值estimated intercept:1.082②斜率估计值estimated slope:0.605回归方程:ahe= 1.082+0.605*age③当工人年长1岁,平均每小时工资增加0.605美元。
2.Bob: 0.605*26+1.082=16.812(美元)Alexis: 0.605*30+1.082=19.232(美元)答:预测Bob的收入为每小时16.812美元,Alexis为19.232美元。
3.年龄不能解释不同个体收入变化的大部分。
因为R-squared反映了因变量的全部变化能通过回归关系被自变量充分解释的比例,而分析得R-squared的值为0.029,解释度低,说明年龄不能解释不同个体收入变化的大部分。
1.答:两者看上去有微弱的正相关关系2.VARIABLES course_evalbeauty 0.133(0.0550)Constant 3.998(0.0449)Observations 463R-squared 0.036Robust standard errors in parentheses*** p<0.01, ** p<0.05, * p<0.1①截距估计值:3.998斜率估计值:0.133回归方程:Course_Eval=3.998+0.133*beauty//mean beautyMean estimation Number of obs = 463Mean Std.Err. 95% Conf. Interval beauty 4.75e-08 0.0367 -0.0720 0.0720②截距的估计值=Course_Eval的样本均值-斜率估计值*Beauty 的样本均值计算得Beauty的样本均值趋近于零,所以截距的估计值等于Course_Eval的样本均值。
stata上机实验第二讲

逐步回归法
• 逐步回归法分为逐步剔除和逐步加入。 • 逐步剔除又分为逐步剔除(Backward selection)和逐步分 层剔除(Backward hierarchical selection) • 1、逐步剔除 • stepwise, pr(显著性水平): 回归方程 • 例如:对auto数据 • Stepwise,pr(0.05):reg price mpg rep78 headroom trunk weight length turn displacement gear_ratio foreign • 2、逐个分层剔除 • Stepwise,pr(0.05) hier:reg price mpg rep78 headroom trunk weight length turn displacement gear_ratio foreign • 去掉foreign 重新做一遍
• wald检验:test mpg (Prob > chi2 =0.2878) • LR检验: lrtest r0 r1 (Prob > chi2 =0.2896) • 均接受原假设 所以 b3=0 成立
• 自己联系:将方程2改为: price=b0+b1*weight+b2*length+b3*mpg+b 4*foreign+ε
Stata上机实验
大样本OLS
• 大样本OLS经常采用稳健标准差估计 (robust) • 稳健标准差是指其标准差对于模型中可能 存在的异方差或自相关问题不敏感,基于 稳健标准差计算的稳健t统计量仍然渐进分 布t分布。因此,在Stata中利用robust选项 可以得到异方差稳健估计量。
约束回归
• • • • 定义约束条件 constraint define n 条件 约束回归语句 Cnsreg 被解释变量 解释变量, constraints(条件编号)
stata练习题

stata练习题Stata练习题Stata是一种统计分析软件,被广泛用于社会科学研究和数据分析。
在使用Stata进行数据分析时,经常会遇到各种练习题,这些练习题可以帮助我们更好地掌握Stata的使用方法和数据分析技巧。
本文将介绍一些常见的Stata练习题,并提供相应的解答和分析。
一、数据导入与清洗在进行数据分析之前,首先需要将数据导入到Stata中,并进行必要的数据清洗工作。
常见的数据导入问题包括数据格式转换、缺失值处理等。
例如,假设我们有一份包含学生姓名、年龄和成绩的Excel数据表,我们需要将其导入到Stata中并进行分析。
可以使用命令“import excel”将Excel数据导入到Stata中,然后使用命令“drop”或“replace”删除或替换缺失值。
二、描述性统计分析描述性统计分析是数据分析的基础,它可以帮助我们了解数据的基本情况。
在Stata中,可以使用命令“summarize”、"tabulate"等进行描述性统计分析。
例如,我们可以使用命令“summarize”计算学生成绩的平均值、标准差等统计量,使用命令“tabulate”计算学生性别的频数和比例。
三、数据可视化数据可视化是数据分析的重要手段,可以帮助我们更直观地理解数据的分布和关系。
在Stata中,可以使用命令“histogram”、"scatter"等进行数据可视化。
例如,我们可以使用命令“histogram”绘制学生成绩的直方图,使用命令“scatter”绘制学生年龄和成绩之间的散点图。
四、假设检验假设检验是统计分析中常用的方法,用于检验研究假设的合理性。
在Stata中,可以使用命令“ttest”、"regress"等进行假设检验。
例如,我们可以使用命令“ttest”检验男女学生成绩是否存在显著差异,使用命令“regress”检验学生成绩与年龄之间的线性关系。
定量研究方法(研究生)讲义

定量研究方法讲义(研究生)下篇数据分析1.Stata: 数据录入与整理2.SPSS内容复习:比较平均数、一元回归、多元回归、虚拟变量、因子分析3.STATA:界面和命令Stata的界面主要是由四个窗口构成,分述如下:1.结果窗口:位于界面右上部,软件运行中的所有信息,如所执行的命令、执行结果和出错信息等均在这里列出。
窗口中会使用不同的颜色区分不同的文本,如白色表示命令,红色表示错误信息。
2.命令窗口:位于结果窗口下方,相当于DOS软件中的命令行,此处用于键入需要执行的命令,回车后即开始执行,相应的结果则会在结果窗口中显示出来。
3.命令回顾窗口:即review窗口,位于界面左上方,所有执行过的命令会依次在该窗口中列出,单击后命令即被自动拷贝到命令窗口中;如果需要重复执行,用鼠标双击相应的命令即可。
4.变量名窗口:位于界面左下方,列出当前数据及中的所有变量名称,。
除以上四个默认打开的窗口外,在Stata中还有数据编辑窗口、程序文件编辑窗口、帮助窗口、绘图窗口、Log窗口等,如果需要使用,可以用Window或Help菜单将其打开。
数据录入:参看《STATA教程》第3-8页。
4.STATA:数据转换和整理常用命令:generate (gen) 新变量名=表达式例如(导报):gen income=a27/ a30summarize (su) 变量名例如:su a28g a28hbysort 变量名:命令变量名例如:bysort sex: su ageThe by-qualifier tells Stata to execute the subsequent command repeatedly along the different values of varlist1 (not all commands support this feature, though). This Tobias Pfaff, Institute for Economic Education, University of Münster 11/28requires the data to be sorted by varlist1. Using bysort instead of by makes previous sorting redundant. An example would be to summarize happiness scores by gender:If例如(导报):su a5 if a1==1 & a2>=30 (大于30岁的男性的婚姻状况)recode例如用导报数据将文化程度重新赋值:recode a3 (1 2 3=1) (4=2) (5=3) (6=4) (7 8=5), gen (edu) describe 描述codebooktabulate交互分类导报数据性别与宗教信任的交互分类tab a1 a4, row expected虚拟变量可以用tab命令例如导报数据,将教育程度变为虚拟变量:quietly tab ra3, gen (edu)2. Stata:一元回归数据:GSS1991散点图. scatter prestg80 educ3. Stata:多元回归穆勒的数据5.Stata:多元回归中的虚拟变量数据:GSS2000先将reg16重新赋值变成虚拟变量:加入教育程度作为自变量后:又例:海峡导报数据性别(a1)与社团参与因子一(v311)加入年龄之后如何在文章中展示回归模型分析结果:例1:胡荣《妇女在村级选举中的政治参与》表3 影响男性在村级选举中参与的诸因素的回归分析预测变量模型I 模型II性别 4.667(0.153)**** 4.246(0.139)**** 选举是否符合规范0.818(0.145)**** 0.859(0.152)**** 选举竞争程度选举拉票因子 3.058(0.204)**** 2.617(0.175)****选举承诺因子-1.384(-0.092)** -1.150(-0.076)** 村庄离县城距离-0.179(-0.152)**** -0.217(-0.183)**** 是否党员 6.040(0.141)**** 是否当过村组干部 6.759(0.161)**** 是否参军 2.264(0.038)年龄0.343(0.314)年龄的平方-4.279E-03(-0.371)* 上学年限 5.014E-02(0.012)常数 4.944**** -2.622N 710 694 Adjusted R Square 11.9% 18.3%F 20.098 15.090例2: 胡荣《城市居民信任的构成及影响因素》a 参考类别为“女”例3:胡荣:《经济发展与竞争性的村委会选举》表5:影响选举竞争程度及选举规范性的回归分析(括号内为标准回归系数)解释变量模型1:村民参与程度模型2:选举竞争程度模型3:选举规范程度人均集体收入-1.24E-04(-0.041) 2.963E-04(0.23)****4.660E-04(0.105)**村民相对生活水平0.292(0.146)*** 6.275E-02(0.074)!0.55(0.186)****人均家庭收入-1.52E-05(-0.42) -2.98E-07(-0.002)3.666E-05(0.069)!受教育年限 3.794E-02(0.084)* 2.905E-04(0.002)-5.23E-02(-0.079)*离县城距离-1.81E-02(-0.143)*** -2.09E-03(-0.039)-9.10E-03(-0.049)外出村民比例 1.876(0.105)** 2.523(0.328)****0.776(0.029)村民参与程度 3.046E-02(0.071)! 0.181 (0.123)**选举竞争程度 1.097(0.32)****N 564 564 564 Constant 0.787* 2.76**** -2.061**** Adjusted R2 4.8% 13.9% 21.3%说明:!P≤0.1 *P≤0.05, **P≤0.01, ***P≤0.001 **** P≤0.0005例4:胡荣《社会资本与村民在村级选举中的地域性自主参与》表 6 影响村民在村级选举中参与程度的因素(回归分析)预测变量回归系数标准回归系显著性水平性别a 3.374 0.128 0.001年龄0.364 0.388 0.055年龄的平方-0.004 -0.424 0.031上学年限0.033 0.010 0.829是否党员b 3.580 0.097 0.011是否当过村组干部c 4.061 0.113 0.002村庄离县城距离-0.130 -0.128 0.000选举规范实施程度 1.419 0.154 0.000社会资本:信任因子-0.636 -0.048 0.173社会交往因子0.230 0.017 0.627社区安全因子0.261 0.020 0.578亲属联系因子-0.362 -0.027 0.446社区归属感因子 1.274 0.097 0.007社团因子 1.513 0.117 0.001 竞选激烈程度:竞选承诺因子 1.954 0.151 0.000关系拉票因子-0.573 -0.044 0.230 常数-7.194 0.148N 698Adjusted R Square 17.2%F检定值10.072 0.000a 参考类别为“女性”;b 参考类别为“非党员”;c 参考类别为“未当过村组干部”例5:《农民上访与政治任任的流失》表6影响农民政治信任因素的多元回归分析a参考变量为“女性”b参考变量为“非党员”c参考变量为“未当过村干部或小组长”d参考变量为“未上访过”e参考变量为“未受过不公待遇”6.Stata :多项式回归(polynominal regression)这是25个国家的GNP (单位为$1000)与妇女预期寿命(年)的散点图:l i f e x p e c t妇女预期寿命随着GNP 的增长而增长:GNP 增长一个单位($1000),相应地妇女的平均寿命增加0.63年。
研究生定量研究方法Stata上机操作试题

研究生定量研究方法Stata上机操作试题1.根据海峡导报调查数据,运用bysort命令,以个人月收入为因变量,以性别、教育程度、年龄为自变量,分别建立不同宗教信仰者的多元回模型。
2.根据200GSS数据,以in come为因变量,以age、degree和sex为自变量,建立多元回归模型,要求:a)运用xi命令将degree和sex变为虚拟变量;b)看一看年龄对收入的影响是否呈直线,如果不是直线,请进行相关的转换,并计算出那个年龄点的收入最高;c)对模型结果进行解释。
3.根据下表因子分析的数据,请计算出3个因子的特征值及解释方差。
rotated factor 1aadings Cpattern matrix) and unique variances讥ir iable Factorl Fa匚tor2Fitctori Uni queuessc35a0.1516 6 80020.21100.2922c35b0.0877(k 79450.115?0-347?c35c0.20110-71920.27200.3683c35d0.27570,62180.15150.5144c35e0.0^26□.19000.74760-4021c35f-0.02650-04340.87170.2376C35g0.046021860.82&60.2668c35h0.2567(k 37280.60210.4325C35l0.58440,49770.092S0.4022O.fel/70,换O.L3240-4U8Sc35k0.84030-17250.1045O_25XLC3510.79800.1407-0.05780.3400C35m O.«6O8 6 O?770-02540-2576 4.根据2000GSS数据,以in come为因变量,以educ、sex为自变量,建立性别与教育程度对收入影响的相互作用模型,并对结果进行解释5.根据海峡导报数据,以是否外出旅游为因变量,自变量为性别、年龄家庭收入和教育程度,建立逻辑斯蒂回归。
stata期末考试题目

stata期末考试题目# Stata 期末考试题目## 一、选择题(每题2分,共20分)1. 在Stata中,以下哪个命令用于描述性统计分析?- A. `summarize`- B. `regress`- C. `tabulate`- D. `generate`2. 以下哪个选项不是Stata的内置数据类型?- A. `float`- B. `string`- C. `byte`- D. `double`3. 要生成一个新变量,其值为现有变量的两倍,应使用以下哪个命令? - A. `generate newvar = var * 2`- B. `create newvar = var * 2`- C. `newvar = var * 2`- D. `multiply var by 2`4. 在Stata中,以下哪个命令用于线性回归分析?- A. `regress y x1 x2`- B. `linear y x1 x2`- C. `regression y x1 x2`- D. `model y x1 x2`5. 以下哪个命令用于绘制散点图?- A. `scatter y x`- B. `plot y x`- C. `graph y x`- D. `line y x`## 二、简答题(每题10分,共30分)1. 解释Stata中的`merge`命令是如何工作的,并给出一个使用该命令的例子。
2. 描述`statsby`命令的基本功能,并简述其在统计分析中的应用。
3. 阐述使用`outreg2`命令输出回归结果的优势。
## 三、计算题(每题25分,共50分)1. 假设你有一个包含学生考试成绩和相关变量的数据集。
请写出以下分析的Stata命令序列:- 计算平均分。
- 根据成绩将学生分为“优秀”、“良好”、“一般”、“较差”四个等级。
- 进行成绩与性别的交互作用分析。
2. 你正在研究不同教育水平对工资的影响。
stata上机实验操作
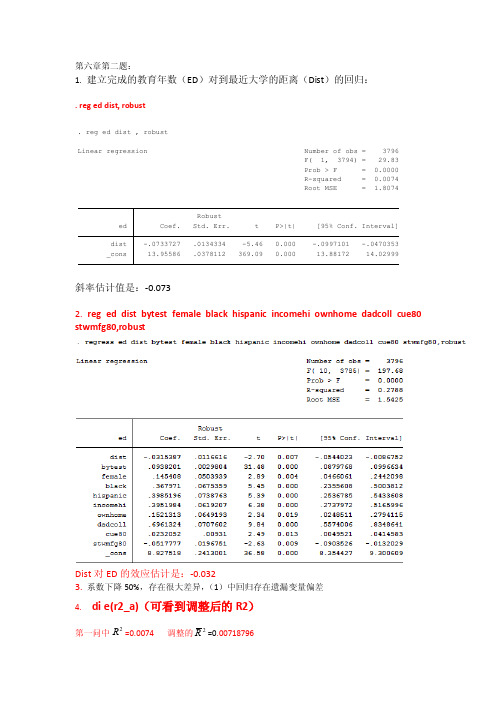
第六章第二题:1. 建立完成的教育年数(ED )对到最近大学的距离(Dist )的回归:. reg ed dist, robust斜率估计值是:-0.0732. reg ed dist bytest female black hispanic incomehi ownhome dadcoll cue80 stwmfg80,robustDist 对ED 的效应估计是:-0.0323. 系数下降50%,存在很大差异,(1)中回归存在遗漏变量偏差4. di e(r2_a)(可看到调整后的R2)第一问中=0.0074 调整的2R =0.00718796_cons 13.95586 .0378112 369.09 0.000 13.88172 14.02999dist -.0733727 .0134334 -5.46 0.000 -.0997101 -.0470353ed Coef. Std. Err. t P>|t| [95% Conf. Interval]RobustRoot MSE = 1.8074R-squared = 0.0074Prob > F = 0.0000F( 1, 3794) = 29.83Linear regression Number of obs = 3796. reg ed dist , robust2R第二问中=0.2788 2R = 0.27693235可以得到第二问中的拟合效果要优于第一问。
第二问中相似的原因:因为n 很大。
5. Dadcoll 父亲有没有念过大学:系数为正(0.6961324)衡量父亲念过大学的学生接受的教育年数平均比其父亲没有年过大学的学生多。
-.0517777 1)原因:这些参数在一定程度上构成了上大学的机会成本。
2)它们的系数估计值的符号应该如此。
当Stwmfg80增加时,放弃的工资增加,所以大学入学率降低了;因而Stwmfg80的系数对应为负。
计量经济学stata上机教程

计量经济学stata上机教程2014计量经济学上机教程1Stata操作基础主要内容:1. Stata的特点与功能2. Stata的界面管理3. Stata的命令语法4. 数据处理5. 统计描述、制图与输出结果6. log文档与do文档7. 常用函数8. Stata的帮助系统与学习资源9. 课后练习1. Stata的特点与功能, 将统计功能与计量分析完整地结合起来。
不仅可以实现诸多统计分析方法,比如描述统计、假设检验、方差分析、主成分分析等,而且可以实现多种计量经济模型的估计和检验,包括经典单方程回归模型、方程组模型、微观数据模型(离散选择模型、计数模型、截断模型、归并模型等)、时间序列数据模型(ARMA、VAR、GARCH等)以及面板数据分析。
, 强大的数据处理功能。
, 精致的作图功能。
, 丰富的网络资源。
Stata 12有各种版本,其中尤以SE(特殊版)最为常用。
用户可以在命令栏中输入about命令查看所安装的版本信息。
2--per ml sodium hydroxide [c (NaOH) =1.000 mol/L] potassium hydrogen phthalate standard solution of quality g. ... After dilution to 1000mL. 1.1.2 0.000 35mol/L iodine solution: dissolve 20 g of potassium iodide in Cheng You (30~40) 500mL mL water bottle; 5mL iodine stock solution, and then diluted to scale and mix. This solution every other day to prepare. 1.1.3 acetate buffer (PH5.3): dissolve 87g sodium acetate (CH3COONa • 3H2O) 400mL water and 10.5mL in glacial acetic acid is dissolved in a small amount of water. volume and then mixing the two together and add water to 500mL, using regulation to PH5.3. 1.1.40.5mol/L sodium chloride: 14.5 g of sodium chloride dissolved in boiled water, and constant volume to 500mL. 1.1.5 soluble starch: pure before use should determine its value. Accurate said take amount starch (equivalent to dry state 1g) Yu 250mL high type beaker in the, added80~90mL distilled water, Yu asbestos online in constantly mixing Xia quickly heating to boiling, then with fire keep micro-boiling 3min, stamped and cooling to at room temperature, transfer to 100mL capacity bottle in the, into 40 ? water bath in the makes solution reached this temperature, and in 40 ? Shi with distilled water (40 ?) set capacity, this starch solution placed 40 ? thermostat water bath in the for determination samples with. 1.2 the instrument a) constant temperaturewater bath: (40+-0.2) 0C. B) spectrophotometer. 1.3 procedures 1.3.1 preparation of samples: weighing 50mL 10G sample不同的版本对于样本容量、变量个数、矩阵阶数等有着不同的限制,用户可以通过以下命令了解和改变这些设定:memory 显示目前存储空间query memory 查看目前实际设定的存储空间set memory 10m 设定存储空间的大小set matsize 250 设定最大矩阵阶数set maxvar 2500 设定最大变量数(最小设定为2048)help limits 显示Stata的各种极限 2. Stata的界面管理, 首次打开Stata,将会出现一个询问是否进行更新的对话框。
stata 上机

使用已保存的Stata数据 1 use “c:\myfile\mydata.dta”, clear 2 sysuse auto (录入系统数据) 3 webuse sorghum (录入网络数据) 手动录入 Input [type] varname [[type] varname]…… Input str10 name age Name age 1. mike 22 2. bruce 28 …… end
命令格式2: clustermat singlelinkage matname [,options] 比如: cluster singlelinkage x1 x2 x3, name(l2slnk) cluster single a1-a60, measure(matching) name(slink) cluster s x*, measure(L(1.5)) clustermat singlelinkage D, clear 其中,clear(将内存信息替换为聚类信息)
如果多个变量为同一类型,可以用括号括起来 Input str10 (name class) double score 从其他文件拷贝和粘贴 Excel或其他数据表直接copy和paste 从其他文件导入 Insheet [varlist] using filename [,option] Insheet using c:\data1.txt
webuse metabolic manova y1 y2 = group test group1 versus group2,3,4 manovatest, showorder matrix c1= (3,-1,-1,-1,0) manovatest, test(c1)
stata上机实验第四讲

误差项存在自相关:非主对角线上的元素不
为0 。
2 . n 1
.
2
.. ... ... ...
n2
n2 . 2
n 1
考察英国政府如何根据长期利率(r20)的变
化来调整短期利率(rs),数据集为 ukrates.dta (1)做如下回归:rst r 20t 1 t ,其中:
5,000
国产拟合 整体拟合
1。仅截距发生变化。我们以国产还是进口作为虚
拟变量,为了熟悉虚拟变量的产生过程,这里不用 foreign,而是产生一个新的虚拟变量dummy(虚拟 变量的生成要灵活运用gen语句和replace语句)。 gen dummy = 0 replace dummy = 1 if foreign==1 reg price dummy weight 和前面做的回归比较,dummy反映了进口车和国产 车常数项即截距的差异,斜率基本没有变化。
理论分析:加入虚拟变量后,方程变为
price = b0+b1*dummy+b2*weight +u 国产车,即dummy=0时:
方程变为:price = b0+b2*weight+u 进口车,即dummy=1时: 方程变为:price = (b0+b1)+b2*weight+u 结论:截距变化但斜率未变。
rst rst rst 1 Nhomakorabea归方程为:
r 20t 1 r 20t 1 r 20t 2
use ukrates,clear tsset month reg D.rs LD.r20
硕士研究生考试 试卷级别

硕士研究生考试试卷级别第一部分:选择题(共40分)1. 以下哪个选项最能揭示出一篇实证研究论文的研究目的?A. 论文中的图表数量B. 论文中的研究问题C. 论文中的参考文献数量D. 论文中的研究方法描述2. 以下哪个选项不属于实证研究所需的数据收集方法?A. 问卷调查B. 访谈C. 实地考察D. 文献综述3. 制定清晰的研究问题对于一项研究的成功至关重要,以下哪个选项最不符合有效的研究问题的要求?A. "企业文化对员工工作满意度的影响有多大?"B. "市场竞争对企业销售额的影响如何?"C. "教育水平对个体收入的影响程度是多少?"D. "消费者对某特定产品的满意度如何提高?"4. 哪个选项最能揭示出一个理论研究论文的特点?A. 论文中的实证研究结果B. 论文中的研究方法描述C. 论文中的理论框架和假设D. 论文中的案例分析5. 利用SPSS进行数据分析时,下列哪个选项可以对数据集进行描述性统计分析?A. 相关分析B. 卡方检验C. 方差分析D. 频数分析6. 对于一篇定性研究论文,以下哪个选项最重要?A. 样本的数量B. 统计分析结果C. 正确的调研方法D. 富有深度的描述分析7. 制定研究假设是实证研究的重要步骤之一,下列哪个选项最能体现出正确制定假设的要求?A. "A因素对B因素有积极影响。
"B. "个体x在某条件下与个体y之间的关系是线性的。
"C. "H0: A因素对B因素没有影响。
"D. "观察研究对象的行为会得出明确结论。
"8. 对于一篇文献综述论文,下列哪个选项最能体现其研究目的?A. 文献中引用的作者数量B. 文献中的理论框架和假设C. 文献中的方法描述D. 文献中提供的研究结论9. 在构建研究模型时,以下哪个选项最不符合模型构建的要求?A. 模型中包含的变量能够涵盖问题的各个方面。
stata期末考试题目及答案

stata期末考试题目及答案一、选择题(每题2分,共20分)1. 在Stata中,用于生成新变量的命令是:A. generateB. replaceC. dropD. rename答案:A2. 下列哪个命令可以用来描述数据集中的变量?A. describeB. listC. tabulateD. sum答案:A3. 若要计算变量x和y的平均值,应使用以下哪个命令?A. mean x yB. summarize x yC. average x yD. meanby x y答案:B4. 以下哪个命令可以用于回归分析?A. regressB. correlateC. tabulateD. describe答案:A5. 要将数据集保存为.dta格式,应使用哪个命令?A. saveB. exportC. writeD. saveas答案:A6. 在Stata中,如何查看当前数据集中的所有变量?A. listB. describeC. showD. display答案:B7. 要对数据集中的连续变量进行分组,应使用哪个命令?A. groupB. byC. tabulateD. collapse答案:D8. 以下哪个命令可以用来绘制散点图?A. scatterB. lineC. barD. histogram答案:A9. 若要对数据集中的变量进行标准化处理,应使用哪个命令?A. standardizeB. normalizeC. genD. replace答案:A10. 在Stata中,如何生成一个随机数序列?A. randomB. runiformC. rnormalD. genr答案:B二、简答题(每题5分,共30分)1. 解释Stata中“merge”命令的基本用法。
答案:Stata中的“merge”命令用于合并两个数据集。
基本用法是指定要合并的两个数据集的关键字(即两个数据集中共有的变量),然后使用“1:1”、“1:m”或“m:1”等比例来指示数据集之间的关系。
stata上机实验第二讲

例二: use wage2, clear reg lnwage educ tenure exper expersq 1。教育(educ)和工作时间(tenure)对工资的
影响相同。 test educ=tenure 2。工龄(exper)对工资没有影响 test exper 或者 test exper =0 3。检验 educ和 tenure的联合显著性 test educ tenure 或者 test (educ=0) (tenure=0)
在的异方差或自相关问题不敏感,基于稳健 标准差计算的稳健t统计量仍然渐进分布t分布。 因此,在Stata中利用robust选项可以得到异 方差稳健估计量。
约束回归
定义约束条件
constraint define n 条件 约束回归语句
Cnsreg 被解释变量 解释变量, constraints(条
对数 平方项 n次方
指数 交乘项 虽然对函数形式的选择有检验方法,但最好 还是从“经济意义”角度确定。
例题
例一:利用wage2的数据检验明瑟(mincer)工
资方程的简单形式: Ln(wage)=b0+b1*educ+b2*exper +b3*exper^2+ u
例二:利用phillips的数据拟合预期增强的菲
自己练习:为下列变量增加标签
educ:受教育位任期。
为变量值增加标签 例如:为变量marrid添加数值标签marry:
1=married; 0=Unmarried 菜单:Data->Labels->Label values->Define or modify label values Data->Labels->Label values->Assign label values to variable 命令: . label define marry 1 “married” 0 “unmarried" . label values married marry
stata练习题

【习题】1. 使用auto 数据,请使用两种方法在结果窗口列出所有观测值所有变量的值。
2. 请写出stata 的基本语法结构,并且解释其各个组成部分的含义。
3. 使用auto 数据,请使用三种方法对国内国外汽车价格进行描述性统计分析。
4. 使用nhanes2数据,利用倒数10个观测值估计模型height=a0+a1sex+a2race+a3age[提示:该模型估计命令为reg]5. 使用auto 数据,使用倒数50个观测值中属于国内的子数据集,估计模型price= a0+a1weight +a2length[提示:该模型估计命令为reg]6. 使用数据gxmpl3,生成变量dm ,使其当hincome>35000时等于1,不满足该条件时等于0.7. 使用数据gxmpl3,根据目前各变量的数值指出,其最优存储类型应为什么?请使用两种方法将其改为最优存储类型。
8. 请问如果58代表的是以毫秒为单位的时间,那么在stata 中其对应的是哪一秒?如果其代表的是以日为单位的时间,其对应的是哪一日?以周为单位,对应的是哪一周?以月为单位,对应的是哪一月?以季度为单位,对应的是哪一季度?以半年为单位,对应的是哪一半年?9. 使用census 数据,使用两种方法生成一字符型变量region2,使该变量的值分别对应region 中的NE ,N Cntrl, South, West ,根据这一变量,计算西部地区的平均离婚率;之后根据region 计算西部地区的平均离婚率。
10. 将数据census5同census12合并。
11. 检查如下do 文件,请问变量x 为字符型变量还是数值型变量,运行这一结果之后,x 的值是?12. 检查如下do 文件,指出其中的错误,并且修改。
最后请使用两种方法将此数据集修改最有效的存储类型。
13. 运行如程序:clear; set obs 2; gen str24 x=”25”.请使用两种方法将变量x 的值生成为数值型。
stata考试复习题库
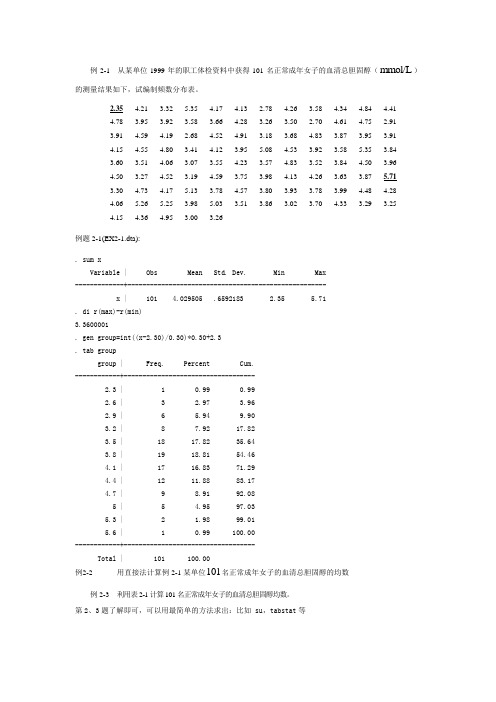
例2-1 从某单位1999年的职工体检资料中获得101名正常成年女子的血清总胆固醇(mmol/L)的测量结果如下,试编制频数分布表。
2.35 4.213.32 5.354.17 4.13 2.78 4.26 3.58 4.34 4.84 4.414.78 3.95 3.92 3.58 3.66 4.28 3.26 3.50 2.70 4.61 4.75 2.913.914.59 4.19 2.68 4.52 4.91 3.18 3.68 4.83 3.87 3.95 3.914.15 4.55 4.80 3.41 4.12 3.955.08 4.53 3.92 3.58 5.35 3.843.60 3.514.06 3.07 3.55 4.23 3.57 4.83 3.52 3.84 4.50 3.964.50 3.27 4.52 3.19 4.59 3.75 3.98 4.13 4.26 3.63 3.875.713.304.73 4.175.13 3.78 4.57 3.80 3.93 3.78 3.99 4.48 4.284.065.26 5.25 3.98 5.03 3.51 3.86 3.02 3.70 4.33 3.29 3.254.15 4.36 4.95 3.00 3.26例题2-1(EX2-1.dta):. sum xVariable | Obs Mean Std. Dev. Min Max-------------+-----------------------------------------------------x | 101 4.029505 .6592183 2.35 5.71. di r(max)-r(min)3.3600001. gen group=int((x-2.30)/0.30)*0.30+2.3. tab groupgroup | Freq. Percent Cum.------------+-----------------------------------2.3 | 1 0.99 0.992.6 | 3 2.973.962.9 | 6 5.94 9.903.2 | 8 7.92 17.823.5 | 18 17.82 35.643.8 | 19 18.81 54.464.1 | 17 16.83 71.294.4 | 12 11.88 83.174.7 | 9 8.91 92.085 | 5 4.95 97.035.3 | 2 1.98 99.015.6 | 1 0.99 100.00------------+-----------------------------------Total | 101 100.00例2-2用直接法计算例2-1某单位101名正常成年女子的血清总胆固醇的均数例2-3 利用表2-1计算101名正常成年女子的血清总胆固醇均数。
2021年计量经济学考研真题题库

2021年计量经济学考研真题题库计量经济学作为一门融合了经济学、统计学和数学的交叉学科,对于考研学子来说具有一定的难度和挑战性。
为了帮助广大考生更好地备考2021 年计量经济学考研,以下是对该年度部分真题的整理和解析。
一、选择题1、下列哪个模型通常用于处理时间序列数据中的自相关问题?()A 多元线性回归模型B 自回归移动平均模型(ARMA)C 双重差分模型D 随机效应模型答案:B解析:自回归移动平均模型(ARMA)是专门用于处理时间序列数据中自相关问题的常见模型。
多元线性回归模型主要用于分析多个自变量对因变量的线性影响;双重差分模型常用于政策评估;随机效应模型则用于处理面板数据中的个体效应。
2、在计量经济学中,异方差性是指()A 误差项的方差随自变量的变化而变化B 误差项的均值随自变量的变化而变化C 自变量之间存在线性关系D 因变量之间存在线性关系答案:A解析:异方差性指的是误差项的方差不是常数,而是随着自变量的取值不同而变化。
这会影响模型的有效性和参数估计的准确性。
3、以下哪种方法常用于检验多重共线性?()A 怀特检验B 方差膨胀因子(VIF)C 拉格朗日乘数检验D 豪斯曼检验答案:B解析:方差膨胀因子(VIF)是常用的检验多重共线性的方法。
如果 VIF 值较大,通常表明存在较严重的多重共线性。
二、简答题1、请简要说明计量经济学中内生性问题的来源及解决方法。
答:内生性问题主要来源于遗漏变量、测量误差、反向因果等。
解决内生性问题的方法包括工具变量法、两阶段最小二乘法、差分模型、固定效应模型等。
工具变量需要满足相关性和外生性两个条件;两阶段最小二乘法是工具变量法的一种应用;差分模型通过消除个体固定效应来解决内生性;固定效应模型则可以控制不随时间变化的个体特征。
2、简述计量经济学中虚拟变量的含义及应用。
答:虚拟变量也称为哑变量,是用来表示定性变量的。
例如性别(男、女)、地区(东部、中部、西部)等。
虚拟变量在模型中的应用可以更准确地反映定性因素对因变量的影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
研究生定量研究方法Stata上机操作试题
1.根据海峡导报调查数据,运用bysort命令,以个人月收入为因变量,以性别、
教育程度、年龄为自变量,分别建立不同宗教信仰者的多元回模型。
2.根据200GSS数据,以income 为因变量,以age、degree和sex为自变量,
建立多元回归模型,要求:
a)运用xi命令将degree和sex变为虚拟变量;
b)看一看年龄对收入的影响是否呈直线,如果不是直线,请进行相关的转
换,并计算出那个年龄点的收入最高;
c)对模型结果进行解释。
3.根据下表因子分析的数据,请计算出3个因子的特征值及解释方差。
4.根据2000GSS数据,以income为因变量,以educ、sex为自变量,建立性别
与教育程度对收入影响的相互作用模型,并对结果进行解释。
5.根据海峡导报数据,以是否外出旅游为因变量,自变量为性别、年龄家庭收
入和教育程度,建立逻辑斯蒂回归。
请你对下表的结果进行解释。