stata上机实验第五讲
stata上机实验第五讲..

• xtreg Fixed-, between- and random-effects, and population-averaged linear models • xtregar Fixed- and random-effects linear models with an AR(1) disturbance • xtgls Panel-data models using GLS • xtpcse OLS or Prais-Winsten models with panelcorrected standard errors • xtrchh Hildreth-Houck random coefficients models • xtivreg Instrumental variables and two-stage least squares for panel-data models
use grunfeld,clear xtset company year xtdes xtline invest(要等一下) 混合回归:reg invest mvalue kstock(扩大样本量) 固定效应:xtreg invest mvalue kstock ,fe(看F值 的P值) 随机效应:xtreg invest mvalue kstock ,re
面板数据
一些面板数据教材
• 面板数据分析 (美)萧政 著 • 横截面与面板数据的经济计量分析 伍德里 奇 著,王忠玉 译 • Baltagi. Econometric Analysis of Panel Data
• 最新动态可关注期刊: Journal of Econometrics
面板数据一些前沿问题
面板数据的格式
company 1 1 1 1 2 year 1951 1952 1953 1954 1951 invest 755.9 891.2 1304.4 1486.7 588.2 mvalue 4833 4924.9 6241.7 5593.6 2289.5
stata上机实验第五讲..
• 怎样选择固定效应和随机效应? • 随机效严格要求个体效应与解释变量不相 关,即 • Cov(ai,XitB)=0 • 而固定效应模型并不需要这个假设条件。 • 这是两种模型选择的关键。
面板数据基本命令
• 1、指定个体截面变量和时间变量:xtset • 2、对数据截面个数、时间跨度的整体描述: xtdes。分组内、组间和样本整体计算各个变量的 基本统计量xtsum。采用列表的方式显示某个变 量的分布xttab,较少使用。 • 3、list、sum、des、tabstat、histogram、 kdensity等命令都可以用。 • 4、对每个个体分别显示该变量的时间序列图: xtline。 • 5、静态面板数据基本回归命令:xtreg,系统默 认GLS估计。
tab company,gen(dum) drop dum1 reg invest mvalue kstock dum* 与上述方法比较一下: xi:reg invest mvalue kstock pany 结果完全一样。
组间估计法
• 对于随机效应模型,还可以采用“组间估 计量”。对于那些每个个体的时间序列数 据较不准确或“噪音”较大的数据,可对 每个个体取时间平均值,然后用平均值来 回归。 xtreg invest mvalue kstock ,be 由于损失了较多信息量,组间估计法并不 常用。
1953 1954 1951 1952 1953 1954
645.5
641 459.3 135.2 157.3 179.5 189.6
2159.4
2031.3 2115.5 1819.4 2079.7 2371.6 2759.9
面板数据模型
• 考虑如下模型: • Yit=Xitb+Uit • uit=ai+εit
数据分析与Stata软件应用(微课版)上机实训参考答案

上机实训1.完成Stata 16.0的安装,并展示其工作界面。
Stata软件安装较为简单,按照安装向导一步一步进行即可。
用户选择接受Stata软件安装协议,并输入用户名等相关信息后,选择StataSE,并由用户指定安装路径后即可进行软件的初步安装。
软件初步安装完成后,需要创建桌面快捷方式,双击桌面快捷方式进行信息注册,并根据自己电脑操作系统的位数进行相应属性的修改后,生成新的桌面快捷方式,并删除原有桌面快捷方式,此时软件安装工作完成,可以双击Stata软件桌面快捷方式或在程序中寻找Stata软件,打开软件并进行数据分析工作。
上机实训参考答案1. 统计得到3个班级学生的基本信息,包括班级(class)、性别(sex)、年龄(age)、体重(height)和身高(weight),数据详情如表2-8所示。
表2-8 习题1数据详情将数据导入Stata软件,并形成名为xiti1.dta的数据文件(1)根据体重数据按照从小到大的顺序将观测个案排序。
(2)将身高大于165厘米的观测个案挑选出来。
(3)计算新变量体重身高比,其数值等于体重/身高。
上机实训参考答案1.某地区统计了1980~1982年3年间不同年龄组下的课外体育培训参与率,数据详情如表3-12所示。
其中年龄组分为5组,定义为1:14岁及以下;2:15~18岁;3:19~20岁;4:21~24岁;5:25岁以上。
数据包括3个变量,即年份(year)、课外体育培训参与率(rate)、年龄组(group)。
表3-12 实训1数据导入数据,保存为名为xiti2.dta的数据文件(1)分析不同年份的课外体育培训参与率和不同年龄组的课外体育培训参与率的平均水平。
(2)制作不同年份、不同年龄组下的交叉列联表,并就变量间的独立性进行分析。
(3)绘制不同年份、不同年龄组下课外体育培训参与率的条形图。
上机实训参考答案1.在某项医学试验中,对不同的群体测定尿铅含量,选定24个观测个案,将这24名观测个案分为男女两组,同时观测个案可分为3个年龄组。
stata上机实验第五讲 工具变量(IV)

究竟该用OLS 还是IV
即解释变量是否真的存在内生性? 假设能够找到方程外的工具变量。 1。如果所有解释变量都是外生变量,则OLS
比IV 更有效。在这种情况下使用IV,虽然估 计量仍然是一致的,会增大估计量的方差。2。 如果存在内生解释变量,则OLS 是不一致的, 而IV 是一致的。
豪斯曼检验(Hausman specification test)原假设: H0 :所有解释变量均为外生变量。 H1:至少有一个解释变量为内生变量。
检验方法: estat firststage 1。初步判断可以用偏R2(partial R2) (剔除掉模型中原有外生变量的影响)。 2。 Minimum eigenvalue statistic(最小特征 值统计量),经验上此数应该大于10。
ivregress 2sls lw80 expr80 tenure80 (s80 iq=med kww mrt age), first
使用grilic.dta估计教育投资的回报率。
变量说明:lw80(80年工资对数),s80 (80年时受教育年限),expr80(80年时工 龄),tenure80(80年时在现单位工作年 限), iq(智商),med(母亲的教育年 限),kww(在‘knowledge of the World of Work’测试中的成绩),mrt(婚姻虚拟变量, 已婚=1),age(年龄)。
ivregress 2sls lw80 expr80 tenure80 (s80 iq=med kww mrt age), first estat overid ivregress gmm lw80 expr80 tenure80 (s80 iq=med kww mrt age) estat overid
Stata操作讲义知识讲解

Stata操作讲义知识讲解S t a t a操作讲义Stata操作讲义第一讲 Stata操作入门第一节概况Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。
它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。
Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。
另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。
由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。
但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。
更为令人叹服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。
Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。
用户可随时到Stata网站寻找并下载最新的升级文件。
事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata 自身成了几大统计软件中升级最多、最频繁的一个。
计量经济学stata上机命令整理

计量经济学上机命令整理实验一edit 打开数据编辑器browse 打开数据浏览器rename 对变量重新命名labelsavedescribe 对数据集简要描述sort 排序例如:list in -10/-1list 显示变量的数值Generate 缩小:gen 生成新的变量后面可以接if条件句Replace 替换append 覆盖Summarize 缩写:su 总结后面可以接if条件句实验二twoway (scatter y x)(connected ey_x x) 在该散点图上,做出条件均值点sc y x||lfit y x 画出线图和散点图Reg y x 做出回归Rename ** y **指原变量名用于修改变量名字graph twoway scatter y x 画出y x 的二维散点图Line y x 做出y x 的线条图egen Ey_x=mean(y),by(x) 求在同一x水平下,求y的均值实验三Regress y x1 x2 ........做多元回归Precict e,re 预测方差Sort e 按照方差排序Cor y x 测试y与x的相关程度Pwcorr y x 也是测试y与x的相关程度Set obs 90 (90为任意一个数字),增加一个或者多个样本值Replace x=980 in 90 为第90个样本值赋值(980为任意一个数字)Predict yhat 预测y的估计值Display invttail(n,p) n为自由度;p为概率(一般为0.025)。
用来求t分布的t 值Display ttail(n,t)知道t值求T<t的右端概率Destring (变量名,可省略),replace ignore("-$") 将其他类型的数据转化为数值型Hist e残差直方图hist e,norm加了一条正态分布线Two connected y x 二维图连线Two connected y x,yline(0) 在y=0处画一条线(也可x=0)Kdensity e,normal 对残差画出密度图Sktest e 利用e的偏锋度做是否符合正态分布的检验gen low=yhat-t*se gen high=yhat+t*se 预测置信区间Twoway lfitci y x 置信区间与回归之间作图实验四(第五章)Gen lny=log(y)生成y的对数Gen lnx=log(x)生成x的对数Drop y或者x 删除变量Predict se,stdp 预测所有的标准误实验五(第六章)虚拟变量Tab quarter,gen(d) quarter代表变量,对变量quarter生成虚拟变量d Gen d1_x=d1*x 或者是(d2,d3,d4与x2,x3,x4)生成交互作用的虚拟变量Reg y x1 x2...d2 d3 d4.....(d1通常省略,常数项)Egen ybar=mean(y) 生成y的均值实验六(第八章:多重共线性)Gen t=0Replace t=1 if x<(或>或>=或<=)数值Test (t=0)(t_x=0)做假设联合检验,求出新的F值Test (lnx2+lnx3=1) 求出新的F检验统计量Cor lnx2-lnx6 求lnx2与lnx3到Lnx6之间的相关程度,找出是否存在多重共线性问题Pcorr lnx2 lnx3-lnx6 也是测量变量之间的相关程度Estat vif 估计方差膨胀因子(方差膨胀因子越大,说明两个此变量与y的共线性越高,应该考虑删除)实验七八(第九十章)Predict e,reGen e2=e^2Est store m1 记录原回归的内容Est tab m1 m2 展示上述记录过的回归内容并作出比较Est tab m1 m2.....,seEstat imtest 怀特检验Estat hettest BP检验Regress y x2 x3...,robust 校正后的怀特检验自相关检验Regress y x...Est store m1Predict e,reSc e obs,yline(0)Tsset obs或者其他变量,用来表示时间变化Dwstat 进行DW检验并查表得出自相关程度Gen rho=1-d/2 rho 代表ρ估计Prais y x,corc (one,two...)括号可接可不接表示从OLS残差中估计ρ Gen dy1=y-l.y*ρ1Gen dx1=y-l.y*ρ1Gen dy2=y-l.y*ρ2Gen dx2=y-l.y*ρ2 (rho=ρ)Replace dy1=sqrt(1-rho^2)*y if ......补充第一个样本值比如ifobs==1958 Replace dx1=sqrt(1-rho^2)*x if .......。
《计量经济学》上机实验参考答案

《计量经济学》上机实验参考答案实验一:线性回归模型的估计、检验和预测(3 课时)实验设备:个人计算机,计量经济学软件Eviews,外围设备如U 盘。
实验目的:(1)熟悉Eviews 软件基本使用功能;(2)掌握一元线性回归模型的估计、检验和预测方法;正态性检验;(3)掌握多元线性回归模型的估计、检验和预测方法;(4)掌握多元非线性回归模型的估计方法;(5)掌握模型参数的线性约束检验与参数的稳定性检验。
实验方法与原理:Eviews 软件使用,普通最小二乘法(OLS),拟合优度评价、t 检验、F 检验、J-B 检验、预测原理。
实验要求:(1)熟悉和掌握描述统计和线性回归分析;(2)选择方程进行一元线性回归;(3)选择方程进行多元线性回归;(4)进行经济意义检验、拟合优度评价、参数显著性检验和回归方程显著性检验;(5)掌握被解释变量的点预测和区间预测;(6)估计对数模型、半对数模型、倒数模型、多项式模型模型等非线性回归模型。
实验内容与数据1(第2 章思考与练习:三、简答、分析与计算题第12 小题):12. 表1 数据是从某个行业的5 个不同的工厂收集的,请回答以下问题:ˆˆˆˆ(1)估计这个行业的线性总成本函数:yˆt= b0 + b1 x t ;(2)b0 和b1 的经济含义是什么?;(3)估计产量为10 时的总成本。
表1 某行业成本与产量数据参考答案:(1)总成本函数(标准格式):yˆt = 26.27679 + 4.25899xts = (3.211966) (0.367954)t = (8.180904) (11.57462)R 2 = 0.978098 S.E = 2.462819 DW =1.404274 F =133.9719ˆˆ(2) b0 =26.27679 为固定成本,即产量为0 时的成本;b1 =4.25899 为边际成本,即产量每增加1 单位时,总成本增加了4.25899 单位。
Stata实验指导、统计分析与应用chap05

这个命令语句是在缺失样本的具体数据,只通过样本的统
例如,在检验砖的抗断强度的例子中,假设并不知道
方差为1.21,而进行检验其均值为32.5,这时就需要用 到ttest命令了,具体命令如下: ttest kdqd=32.5 这时就可以得到如图5.2所示的检验结果,在结果图中, 可以看到表格中显示了样本的特性,主要包括样本容 量、样本均值、标准误差、标准差、置信区间。表格 下面是进行的t检验的内容,其中最重的的指标是 “Ha: mean != 32.5”的部分,不难发现检验得到的p 值为0.0302,所以应当拒绝原假设,即不能认为这批 砖的平均抗断强度为32.5。
标准差是否为1.1。
三、实验操作指导
1.正态分布、方差已知的均值检验 在这种情形下,由于Stata没有提供直接的命令进行检验,所
以需要用户自行构建正态分布的统计量进行检验,命令语句 为: quietly summarize
scalar crit=invnormal(1-0.05/2) scalar p=(1-normal(abs(z)))/2 scalar list z crit p 在这一组命令语句中,第一个命令语句是为了求出样本的均 值的大小,并且不显示计算的结果;第二个命令语句是输入 了正态分布统计量的计算公式,目的是为了算出正态分布统 计量的大小;第三个命令语句是为了求出置信度为95%的正 太分布临界值的大小;第四个命令语句输入了p值的计算公式, 是为了求出p值的大小;第五个命令语句是为了列出这些统计 量的大小,以便进行判断。
例如,利用english.dta数据库中的数据,分析两个班
的英语成绩方差是否相等,所使用到的命令为: sdtest score1==score2 执行这一命令,可得到如图5.6所示的结果,这个图中 的表格展示了数据的情况,包括两个变量及其总体的 样本容量、均值、标准误、标准差、置信区间的信息。 在表格的下方展示了方差检验的结果,从中不难看出, 检验的p值为0.3362,不能拒绝原假设,即认为两个班 英语成绩的方差相等。
第五讲 多值、排序与计数模型 高级计量经济学及Stata应用课件

• 这些解释变量都只依赖于个体,而不依赖于方案 ,故应使用多项logit或多项probit回归。
2020/7/27
陈强 计量及Stata应用 (c) 2014
20
数据特征
• use nomocc2.dta, clear • sum
• 解释变量xij,既随个体i而变,也随方案j而变。
• 系数 β 表明,xij对随机效用Uij的作用不依赖于方 案j。比如,乘车时间依个体与方案而变,但乘车 时间太长所带来的负效用是一致的。
2020/7/27
陈强 计量及Stata应用 (c) 2014
9
条件Logit (续)
• 根据与多项Logit类似的推导,
2020/7/27
陈强 计量及Stata应用 (c) 2014
18
混合logit的Stata命令
• asclogit y x1 x2 x3,case(varname) alternatives(varname) casevars(varname) base(#) or
• “asclogit”表示“alternative-specific conditional logit”
• 如果假设 i1, ,iJ 服从J维正态分布,可
得“多项probit”(multinomial probit)模型
• 但多项Probit的计算涉及高维积分,不易计 算,较少使用。
2020/7/27
陈强 计量及Stata应用 (c) 2014
7
随方案而变的解释变量
• 多项Logit仅考虑不随方案而变的解释变量(比如, 个体收入),但有些解释变量既随个体,也随方案 而变。比如,在选择交通工具时,乘车时间既因 个体而异,也因交通工具而异。
stata1-5讲义

果一般而言是没有意义的并容易产生误导。可是如何让大家相信这种滥用和误用
计量模型所导致的偏误呢?
由于在社会科学中,被广泛认同的数理模型很少,讨论估计量是否一致或有
偏误的最好办法是假设我们已知某个理论公式及其相应参数,然后按照这个公式
通过蒙特卡洛方法生成假设数据,再来看在什么条件下用什么方法可以获得一致
(2)将其解压到 D:/stata9。 (3)点击 setup 安装>>改变安装路径到 D:/stata9>>选择 Stata/SE 版本。
1.2 启用和退出
(1) 程序→Stata,即可进入 Stata,启动后出现文件对话框,要求输入注册单 位和密码等。
中国人民大学 陈传波
9
chrisccb@
的或渐近正态的估计结果,这种方法已被国外的统计和计量教材大量采用。
本书正是在这两个方面突出了自己的特色。作者 9 年来潜心钻研 STATA,
利用 STATA 处理过农村住户数据、人口普查数据(部分)等大量数据,积累了
丰富的数据处理经验。本书的前 9 讲集中介绍数据处理的知识和技巧,后 9 讲通
过蒙特卡洛模拟帮助读者从直观上理解数理统计和计量的基本理论,并掌握相应
本书从第 10 讲开始,运用蒙特卡洛模拟方法,将基于随机变量的数理统计 和计量经济学的核心思想和方法的黑箱打开,让读者在如同做游戏一样的感觉中 深刻理解抽样分布、假设检验、回归分析等方法的强大魔力和无处不在的陷阱, 这有利于读者批判性地理解他人基于统计数据得出的结论,也很利于读者在自己 运用统计和计量分析时正确对待和解释估计结果。
中国人民大学 陈传波
8
chrisccb@
STATA 十八讲1入门
1 STATA 入门
STATA第五讲

&
“与” 或“和” 或 “非” 或“不”
>
大于
– 运算的优先级(从高到 低):!(或~),^,-(负 号),/,*,-(减), +,!=(或 ~=),>,<,<=,>=,==,&,| 当 忘记或者无法确定优先序的 时候,最好用括号将优先序 表达出来,在最里层括号中 的表示式将被优先执行
* /
| ~ !
第五讲、命令语句结构与运算符
• 字符运算
– 当需要把两个字符进行连接时,同样可以用加号(+)来完成。比如,把 “我”和“爱你”合并在一起,命令为: – scalar a= “I”+ “Love U”//将字符I和Love U连接并赋予a。注意:引 号必须是在英文半角状态,否则出错。 – scalar list a// 显示a的内容 – 不可以将不同类型的数据进行相加,否则将出错。例如,把数值型数据2 和字符型数据3相加就会出错。 – scalar a= 5+ “3”//将数值2和字符3相加,结果出错 – type mismatch – r(109);
第五讲、命令语句结构与运算符
• 条件语句(if exp)
– [by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options] 当我们 只想对满足某些条件的数据进行某类操作时,则应当考虑使用条件语句。 – 例1:假定某客户只想查看进口车的价格 – cd d:/mystata – use myauto.dta, clear – list price if foreign==1 – 例2:假定某客户只想查看价格高过10000的进口汽车信息 – list if (price>10000)&(foreign==1) – 例3:假定某客户想分类查看价格高过10000或低于6000的进口汽车和国产汽车信息 – by foreign: list if (price>10000)|(price<6000)
计量经济学stata上机教程

计量经济学stata上机教程2014计量经济学上机教程1Stata操作基础主要内容:1. Stata的特点与功能2. Stata的界面管理3. Stata的命令语法4. 数据处理5. 统计描述、制图与输出结果6. log文档与do文档7. 常用函数8. Stata的帮助系统与学习资源9. 课后练习1. Stata的特点与功能, 将统计功能与计量分析完整地结合起来。
不仅可以实现诸多统计分析方法,比如描述统计、假设检验、方差分析、主成分分析等,而且可以实现多种计量经济模型的估计和检验,包括经典单方程回归模型、方程组模型、微观数据模型(离散选择模型、计数模型、截断模型、归并模型等)、时间序列数据模型(ARMA、VAR、GARCH等)以及面板数据分析。
, 强大的数据处理功能。
, 精致的作图功能。
, 丰富的网络资源。
Stata 12有各种版本,其中尤以SE(特殊版)最为常用。
用户可以在命令栏中输入about命令查看所安装的版本信息。
2--per ml sodium hydroxide [c (NaOH) =1.000 mol/L] potassium hydrogen phthalate standard solution of quality g. ... After dilution to 1000mL. 1.1.2 0.000 35mol/L iodine solution: dissolve 20 g of potassium iodide in Cheng You (30~40) 500mL mL water bottle; 5mL iodine stock solution, and then diluted to scale and mix. This solution every other day to prepare. 1.1.3 acetate buffer (PH5.3): dissolve 87g sodium acetate (CH3COONa • 3H2O) 400mL water and 10.5mL in glacial acetic acid is dissolved in a small amount of water. volume and then mixing the two together and add water to 500mL, using regulation to PH5.3. 1.1.40.5mol/L sodium chloride: 14.5 g of sodium chloride dissolved in boiled water, and constant volume to 500mL. 1.1.5 soluble starch: pure before use should determine its value. Accurate said take amount starch (equivalent to dry state 1g) Yu 250mL high type beaker in the, added80~90mL distilled water, Yu asbestos online in constantly mixing Xia quickly heating to boiling, then with fire keep micro-boiling 3min, stamped and cooling to at room temperature, transfer to 100mL capacity bottle in the, into 40 ? water bath in the makes solution reached this temperature, and in 40 ? Shi with distilled water (40 ?) set capacity, this starch solution placed 40 ? thermostat water bath in the for determination samples with. 1.2 the instrument a) constant temperaturewater bath: (40+-0.2) 0C. B) spectrophotometer. 1.3 procedures 1.3.1 preparation of samples: weighing 50mL 10G sample不同的版本对于样本容量、变量个数、矩阵阶数等有着不同的限制,用户可以通过以下命令了解和改变这些设定:memory 显示目前存储空间query memory 查看目前实际设定的存储空间set memory 10m 设定存储空间的大小set matsize 250 设定最大矩阵阶数set maxvar 2500 设定最大变量数(最小设定为2048)help limits 显示Stata的各种极限 2. Stata的界面管理, 首次打开Stata,将会出现一个询问是否进行更新的对话框。
stata上机实验操作
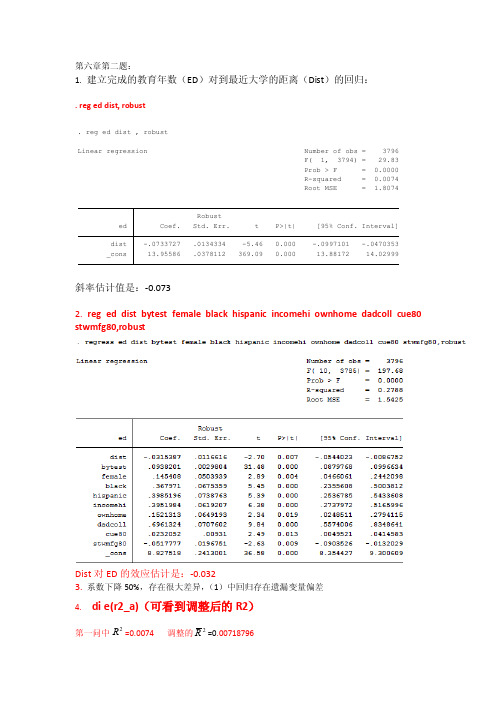
第六章第二题:1. 建立完成的教育年数(ED )对到最近大学的距离(Dist )的回归:. reg ed dist, robust斜率估计值是:-0.0732. reg ed dist bytest female black hispanic incomehi ownhome dadcoll cue80 stwmfg80,robustDist 对ED 的效应估计是:-0.0323. 系数下降50%,存在很大差异,(1)中回归存在遗漏变量偏差4. di e(r2_a)(可看到调整后的R2)第一问中=0.0074 调整的2R =0.00718796_cons 13.95586 .0378112 369.09 0.000 13.88172 14.02999dist -.0733727 .0134334 -5.46 0.000 -.0997101 -.0470353ed Coef. Std. Err. t P>|t| [95% Conf. Interval]RobustRoot MSE = 1.8074R-squared = 0.0074Prob > F = 0.0000F( 1, 3794) = 29.83Linear regression Number of obs = 3796. reg ed dist , robust2R第二问中=0.2788 2R = 0.27693235可以得到第二问中的拟合效果要优于第一问。
第二问中相似的原因:因为n 很大。
5. Dadcoll 父亲有没有念过大学:系数为正(0.6961324)衡量父亲念过大学的学生接受的教育年数平均比其父亲没有年过大学的学生多。
-.0517777 1)原因:这些参数在一定程度上构成了上大学的机会成本。
2)它们的系数估计值的符号应该如此。
当Stwmfg80增加时,放弃的工资增加,所以大学入学率降低了;因而Stwmfg80的系数对应为负。
计量经济学stata上机教程
计量经济学stata上机教程2014计量经济学上机教程1Stata操作基础主要内容:1. Stata的特点与功能2. Stata的界面管理3. Stata的命令语法4. 数据处理5. 统计描述、制图与输出结果6. log文档与do文档7. 常用函数8. Stata的帮助系统与学习资源9. 课后练习1. Stata的特点与功能, 将统计功能与计量分析完整地结合起来。
不仅可以实现诸多统计分析方法,比如描述统计、假设检验、方差分析、主成分分析等,而且可以实现多种计量经济模型的估计和检验,包括经典单方程回归模型、方程组模型、微观数据模型(离散选择模型、计数模型、截断模型、归并模型等)、时间序列数据模型(ARMA、VAR、GARCH等)以及面板数据分析。
, 强大的数据处理功能。
, 精致的作图功能。
, 丰富的网络资源。
Stata 12有各种版本,其中尤以SE(特殊版)最为常用。
用户可以在命令栏中输入about命令查看所安装的版本信息。
2--per ml sodium hydroxide [c (NaOH) =1.000 mol/L] potassium hydrogen phthalate standard solution of quality g. ... After dilution to 1000mL. 1.1.2 0.000 35mol/L iodine solution: dissolve 20 g of potassium iodide in Cheng You (30~40) 500mL mL water bottle; 5mL iodine stock solution, and then diluted to scale and mix. This solution every other day to prepare. 1.1.3 acetate buffer (PH5.3): dissolve 87g sodium acetate (CH3COONa • 3H2O) 400mL water and 10.5mL in glacial acetic acid is dissolved in a small amount of water. volume and then mixing the two together and add water to 500mL, using regulation to PH5.3. 1.1.40.5mol/L sodium chloride: 14.5 g of sodium chloride dissolved in boiled water, and constant volume to 500mL. 1.1.5 soluble starch: pure before use should determine its value. Accurate said take amount starch (equivalent to dry state 1g) Yu 250mL high type beaker in the, added80~90mL distilled water, Yu asbestos online in constantly mixing Xia quickly heating to boiling, then with fire keep micro-boiling 3min, stamped and cooling to at room temperature, transfer to 100mL capacity bottle in the, into 40 ? water bath in the makes solution reached this temperature, and in 40 ? Shi with distilled water (40 ?) set capacity, this starch solution placed 40 ? thermostat water bath in the for determination samples with. 1.2 the instrument a) constant temperaturewater bath: (40+-0.2) 0C. B) spectrophotometer. 1.3 procedures 1.3.1 preparation of samples: weighing 50mL 10G sample不同的版本对于样本容量、变量个数、矩阵阶数等有着不同的限制,用户可以通过以下命令了解和改变这些设定:memory 显示目前存储空间query memory 查看目前实际设定的存储空间set memory 10m 设定存储空间的大小set matsize 250 设定最大矩阵阶数set maxvar 2500 设定最大变量数(最小设定为2048)help limits 显示Stata的各种极限 2. Stata的界面管理, 首次打开Stata,将会出现一个询问是否进行更新的对话框。
《STATA第五讲》课件

总结词:在Stata编程中,宏和循环结构的使用可能会 带来一些问题。
错误与调试
详细描述:熟悉常见的语法错误提示,根据错误提示检 查代码;采用逐步调试方法,设置断点、单步执行和查 看变量值,定位和修正逻辑错误。
2023
REPORTING
THANKS
感谢观看
2023
PART 06
Stata常见问题解答
REPORTING
数据处理问题解答
总结词
当遇到数据导入困难时,可能是由于文件格 式、编码或分隔符不正确所致。
详细描述
确保数据文件格式(如.csv、.dta等)与 Stata软件兼容;检查文件编码(如UTF-8 、ANSI等),确保与软件设置一致;确认 数据字段分隔符(如逗号、制表符等)是否 正确。
Stata是一种统计分析软件,专门用于数据管理和统 计分析。
02
它提供了广泛的数据分析工具,包括描述性统计、 回归分析、方差分析、生存分析等。
03
Stata具有易于使用的界面和强大的编程语言,使数 据分析变得简单而高效。
Stata的用途
数据分析
Stata提供了各种数据分析工具, 可以帮助用户进行数据探索、描 述性统计和复杂统计分析。
Cox比例风险模型
研究多个因素对生存时间的影响,并假设风险函 数与时间无关。
ABCD
Kaplan-Meier曲线
非参数方法描述生存函数随时间的变化。
时间依赖性Cox模型
在某些情况下,风险函数可能随时间变化,可以 使用此模型进行描述。
2023
PART 04
Stata编程基础
REPORTING
Stata命令基础
数据管理
Stata具有强大的数据管理功能, 可以方便地导入、导出数据,进 行数据清洗和整理。
stata上机实验第五讲

固定效应模型
对于特定的个体i而言,ai 表示那些不随时间
改变的影响因素,如个人的消费习惯、国家 的社会制度、地区的特征、性别等,一般称 其为“个体效应” (individual effects)。如果 把“个体效应”当作不随时间改变的固定性 因素, 相应的模型称为“固定效应”模型。
固定效应模型
ivregress 2sls lw80 expr80 tenure80 (s80 iq=med kww mrt age), first estat firststage
过度识别检验
检验工具变量是否与干扰项相关,即工具变量是否
为外生变量。目前仅限于在过度识别的情况下,进 行过度识别检验。 2SLS根据Sargan统计量进行过度识别检验 ,GMM 使用Hansen J Test进行过度识别检验。 命令均为: estat overid 检验工具变量的外生性 H0:所有工具变量都是外生的。 H1:至少有一个工具变量不是外生的,与扰动项相 关。
xtgls命令xtglsinvestmvaluekstockpanelsiidpooledolsxtglsinvestmvaluekstockpanelhet截面异方差xtglsinvestmvaluekstockcorrar1所有个体具有相同的自相关系数xtglsinvestmvaluekstockcorrpsar1每个个体有自己的自相关系数xtglsinvestmvaluekstockpanelcorr截面间相关且异方差xtglsinvestmvaluekstockpanelcorrcorrar1异方差序列相关和截面相关?2xtpcseinvestmvaluekstockols估计面板稳健性标准差xtpcseinvestmvaluekstockcorrar1praiswinsten估计个体具有共同的自相关系数xtpcseinvestmvaluekstockcorrpsar1每个截面有自己的自相关系数xtpcseinvestmvaluekstockcorrar1hetonly不考虑截面相关xtpcse命令
Stata操作讲义知识讲解

操S义讲作atatStata操作讲义第一讲 Stata操作入门第一节概况Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。
它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。
Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。
另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。
由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。
但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。
更为令人叹服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。
Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。
用户可随时到Stata网站寻找并下载最新的升级文件。
事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。
Stata实验指导书.doc-武汉理工大学

实验指导书武汉理工大学政治与行政学院2013年4月实验一STATA基本介绍实验目的掌握什么是STATA?该软件具有什么功能?熟悉STATA菜单各项的含义,数据输入、存储以及数据运算与处理等。
实验内容1.什么是STATA2.STATA的菜单3.数据输入与保存4、数据文件的合并与汇总5.数据编辑整理6.变量重新赋值7.数据的运算与新变量的生成8.数据的排序9.数据分组基本步骤当打开STATA后,展现在我们面前的界面如下:菜单栏共有11个选项,常用的有以下8个选项:1.文件:文件管理菜单,有关文件的调入、存储、显示和打印等;2.编辑:编辑菜单,有关文本内容的选择、拷贝、剪贴、寻找和替换等; 3.显示:显示菜单,有关状况栏、工具条、网格线是否显示,以及数据显示的字体类型、大小等设置;4.数据:数据管理菜单,有关数据变量定义、数据格式选定、观察对象的选择、排序、加权、数据文件的转换、连接、汇总等;5.转换:数据转换处理菜单,有关数值的计算、重新赋值、缺失值替代等;6.分析:统计菜单,有关一系列统计方法的应用;7.图形:作图菜单,有关统计图的制作;8.使用程序:用户选项菜单,有关命令解释、字体选择、文件信息、定义输出标题、窗口设计等;实验报告自己草拟10名学生的序号、姓名、统计学成绩、管理学成绩、每天学习时间特征资料。
(以自己的姓名作为第一号,并以自己的名字设为文件名)要求:(1)添加性别数据特征;粘贴处(2)按统计学成绩由高到低排序;粘贴处(3)按统计学成绩数量标志进行等距分组,并进行汇总统计。
粘贴处(4)计算生成统计学与管理学两科的总成绩与平均成绩两个变量。
粘贴处实验二STATA统计绘图实验目的掌握条形图、线形图、散点图、直方图等常用统计图的绘制方法与技巧。
实验内容1.条形图2.线形图单线形图(Simple)多线形图(Multiple)垂线形图(Drop-line)3.散点图简单散点图(Simple)——显示一对相关变量关系;重叠散点图(Overlay) ——显示多对相关变量关系;矩阵散点图(Matrix) ——显示多个相关变量关系;3维散点图(3-D) ——显示3个相关变量关系。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
怎样选择固定效应和随机效应?
随机效严格要求个体效应与解释变量不相关,
即 Cov(ai,XitB)=0 而固定效应模型并不需要这个假设条件。 这是两种模型选择的关键。
面板数据基本命令
1。指定个体截面变量和时间变量:xtset
2。对数据截面个数、时间跨度的整体描述:
xtdes。 3。对每个个体分别显示该变量的时间序列图: xtline。 4。静态面板数据基本回归命令:xtreg。
几点注意事项: 1。2SLS只能通过stata完成,利用定义手动计算的
结果是错误的,因为残差序列是错误的。 2。不可能单独为每个内生变量指定一组特定的工 具变量, 所有外生变变量都作为自己的工具变量。 3。在大样本下,IV 估计是一致的,但在小样本下, IV 估计并非无偏估计量,有些情况下偏误可能很严 重。
company 1 1 1 1 2 year 1951 1952 1953 1954 1951 invest 755.9 891.2 1304.4 1486.7 588.2 mvalue 4833 4924.9 6241.7 5593.6 2289.5
2
2 2 3 3 3 3
1952
1953 1954 1951 1952 1953 1954
弱工具变量检验
工具变量Z与 X 的相关性较低时,2SLS 估计
量存在偏误,Z 称为“弱工具变量”。 检验方法: estat firststage 1。初步判断可以用偏R2(partial R2) (剔除掉模型中原有外生变量的影响)。 2。 Minimum eigenvalue statistic(最小特征 值统计量),经验上此数应该大于10。
固定效应模型
对于特定的个体i而言,ai 表示那些不随时间
改变的影响因素,如个人的消费习惯、国家 的社会制度、地区的特征、性别等,一般称 其为“个体效应” (individual effects)。如果 把“个体效应”当作不随时间改变的固定性 因素, 相应的模型称为“固定效应”模型。
固定效应模型
3。面板数据格式不符合要求的处理。 例如如下表格格式该如何处理? 处理方法: 扁平数据变长条数据的命令:reshape use invest2,clear edit reshape long invest kstock, i(company) j(year)
company
invest2002
645.5
641 459.3 135.2 157.3 179.5 189.6
2159.4
2031.3 2115.5 1819.4 2079.7 2371.6 2759.9
面板数据模型
考虑如下模型:
Yit=Xitb+Uit uit=ai+εit
其中, i=1,2,… N ; t=1, 2,…T uit称为复合扰动项。
固定效应模型的公式变为:
Yit=ai+Xitb+εit 回归结果是每个个体都有一个特定的截距项。
随机效应模型
随机效应模型将个体效应ai视为随机因素,即
把个体效应设定为干扰项的一部分。公式将 变为: Yit=Xitb+(ai+εit) 回归的结果是随机效应模型的所有的个体具 有相同的截距项,个体的差异主要反应在随 机干扰项的设定上。
use grunfeld,clear xtset company year xtdes xtline invest 混合回归:reg invest mvalue kstock 固定效应:xtreg invest mvalue kstock ,fe 随机效应:xtreg invest mvalue kstock ,re
几个常见问题
1。既然固定效应每个个体都有单独的截距项,
如何获得每个个体的截距项? xi:reg invest mvalue kstock pany 即LSDV方法或者添加虚拟变量法。
2。非平衡面板如何处理?
use nlswork,clear xtset idcode year xtdes 这是一份典型的大n小t型非平衡面板数据。 方法一:下载命令xtbalance提取成一个平衡面板数 据,但不推荐使用,因为会损失大量样本。 方法二:利用算法填补缺失值,需要经济理论和算 法的支撑。
建立方程: lw80 s80 exp r80 tenure80 1 2 3
use grilic.dta,clear reg lw80 s80 expr80 tenure80
对方程进行分析: 1。遗漏变量问题:认为方程遗漏了“能力”这个 变量,加入iq(智商)作为“能力”的代理变量。 2。测量误差问题:iq(智商)对“能力”的测量存 在误差。 3。变量内生性问题:s80可能与扰动项中除“能力” 以外的其他因素相关,因此是内生变量。
广义矩估计法:GMM
基本思想:
求解如下一般化目标函数,使之最小化 J(b_GMM) = n*g(b_GMM)'*W*g(b_GMM) 其中,W 为权重矩阵 在球型扰动项的假定下,2SLS 是最有效的。但如 果扰动项存在异方差或自相关,则广义矩估计方法 效果更好。 GMM方法又分为两步GMM法和迭代GMM方法。
quietly reg lw80 s80 expr80 tenure80 iq est store ols quietly ivregress 2sls lw80 expr80 tenure80 (s80 iq=med kww mrt age) est store iv hausman iv ols
Hausman检验
基本思想:如果 Corr(a_i,x_it) = 0, Fe 和 Re
都是一致的,但Re更有效。 如果 Corr(a_i,x_it)!= 0, Fe 仍然一致,但Re 是有偏的。 因此原假设是Corr(a_i,x_it) = 0,即应该采用 随机效应。
xtreg invest mvalue kstock ,fe est store fixed xtreg invest mvalue kstock ,re est store random hausman fixed random 本题接受原假设,即应该用随机效应。
结果解读
固定效应 随机效应
特别注意: 1。三个R2哪个重要? 2。固定效应为什么有两个F检验? 3。corr(u_i, Xb) 的含义。 4。 sigma_u、sigma_e、rho的含义。
模型选择
固定效应还是混合OLS?
可以直接观测F值 随机效应还是混合OLS? 先用随机效应回归,然后运行xttest0 固定效应还是随机效应? Hausman检验
16.8 17.4 17 17.5 16.4 16.3
16.7 17 17.1 17.3 16.1 16.3
其他回归方法
1。聚类稳健的标准差 通常可以假设不同个体之间的扰动项相互独立,但
一些面板数据教材
面板数据分析 (美)萧政 著
横截面与面板数据的经济计量分析 伍德里奇
著,王忠玉 译 Baltagi. Econometric Analysis of Panel Data
最新动态可关注期刊:
Journal of Econometrics
面板数据一些前沿问题
面板向量自回归模型(Panel VAR) 面板单位根检验(Panel Unit Root test) 面板协整分析(Panel Cointegeration) 门槛面板数据模型(Panel Threshold) 面板联立方程组 面板空间计量
ivregress 2sls lw80 expr80 tenure80 (s80 iq=med kww mrt age), first estat firststage
过度识别检验
检验工具变量是否与干扰项相关,即工具变量是否
为外生变量。目前仅限于在过度识别的情况下,进 行过度识别检验。 2SLS根据Sargan统计量进行过度识别检验 ,GMM 使用Hansen J Test进行过度识别检验。 命令均为: estat overid 检验工具变量的外生性 H0:所有工具变量都是外生的。 H1:至少有一个工具变量不是外生的,与扰动项相 关。
使用grilic.dta估计教育投资的回报率。
变量说明:lw80(80年工资对数),s80
(80年时受教育年限),expr80(80年时工 龄),tenure80(80年时在现单位工作年 限), iq(智商),med(母亲的教育年 限),kww(在‘knowledge of the World of Work’测试中的成绩),mrt(婚姻虚拟变量, 已婚=1),age(年龄)。
究竟该用OLS 还是IV
即解释变量是否真的存在内生性?
假设能够找到方程外的工具变量。 1。如果所有解释变量都是外生变量,则OLS
比IV 更有效。在这种情况下使用IV,虽然估 计量仍然是一致的,会增大估计量的方差。2。 如果存在内生解释变量,则OLS 是不一致的, 而IV 是一致的。
豪斯曼检验(Hausman specification test)原假设: H0 :所有解释变量均为外生变量。 H1:至少有一个解释变量为内生变量。
二阶段最小二乘法:2SLS
主要思想:进行两阶段回归。
假设方程为: y=b1x1+b2x2+u
其中x1是外生变量,x2是内生变量,找到两 个变量z1和z2,作为x2的工具变量。 第一阶段回归:reg x2 x1 z1 z2 x2结合了z1 和z2的信息,此时取出x2的拟合值x2_hat。 第二阶段回归: reg y x1 x2_hat
ivregress 2sls lw80 expr80 tenure80 (s80 iq=med kww mrt age), first estat overid ivregress gmm lw80 expr80 tenure80 (s80 iq=med kww mrt age) estat overid