编译原理教程(第二版)胡元义课后答案第二章
编译原理第二版课后习答案教学文稿

编译原理第二版课后习答案《编译原理》课后习题答案第一章第 1 章引论第 1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第 2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
编译原理第二章习题解答

部分习题解答
© 西安电子科技大学 ·软件学院
难点
第2章习题
1. 根据模式,写出正规式 2. 依据 NFA/DFA,写出正规式
计算量大
3. 正规式NFA 4. NFADFA: ε_闭包,smove 5. DFA最小化
© 西安电子科技大学 ·软件学院
2
1. 根据模式写出正规式
一般思路:(1)分析题意 (2)列举一些最简单的例子 (3)寻找统一规律*,考虑所有可能情况**
© 西安电子科技大学 ·软件学院
13
其它
习题2.9 构造 10*1 的最小DFA
解: 活用 Thompson 算法
(1) 分解为三部分:1,0*,1;
(2) 画出三者的状态转换图:
1
0
1
0 2
1
3
4
(3) 连接运算:子图首尾相连
1
0 1
0
11
4
这已经是最小的DFA
© 西安电子科技大学 ·软件学院
14
11
其它
关于:正规式 -> NFA -> DFA -> DFA最小化: 说明:(一般)逐步计算 正规式->NFA: (1)呆板Thompson算法:
自上而下分解正规式—— 语法树, 自下而上构造NFA —— 后续遍历; 特点:每个运算对应一次构造,繁琐! (2)活用Thompson算法: 分解正规式:得到若干规模适中的子正规式; 为每个子正规式:画出其最简的状态转换图(子图); 按Thompson算法,将子图组合,得到完整的图。
长度为4:0011, 1100,
? 0101, 0110, 1001, 1010
b) 前4个串: 由00和11组成的串 正规式B*, B= 00 | 11
编译原理第二版作业答案_第2章

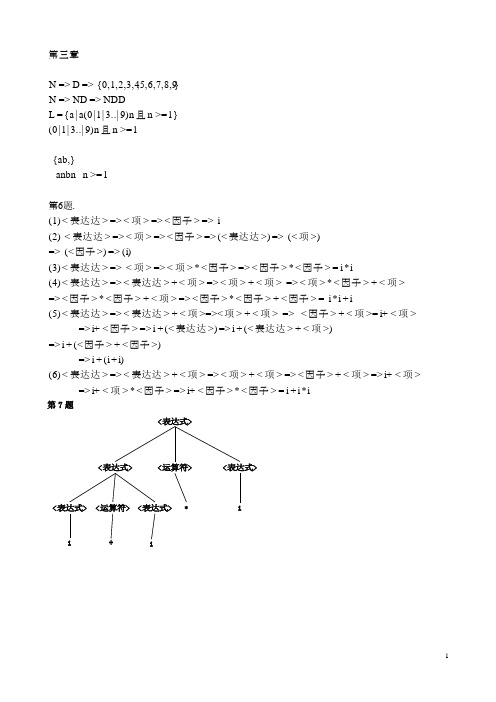
第二章 文法和语言p48 4、6(6)、11、 12(2)(6)、18(2)4 证明文法G=({E,O},{(,),+,*,v ,d},P ,E )是二义的,其中P 为 E → EOE | (E) | v | d O → + | * 证明:因为E=〉 EOE =〉EOEOE =〉EOEOv =〉EOE+v=〉EOv+v =〉E*v+v =〉v*v+v , 句子v*v+v 有两棵不同的语法树所以文法G 是二义的。
问题:1)只有文字说明,比如v*v+v 有两棵语法树,但没有画出语法树或者最左(最右)推导过程2)给出的是不同句子(v*v+d v+v*d )的语法树 6、已知文法G :EEEE OO v*v+ vE EE E O O v+v* v〈表达式〉∷=〈项〉|〈表达式〉+〈项〉〈项〉∷=〈因子〉|〈项〉*〈因子〉〈因子〉∷=(〈表达式〉)| i试给出下述表达式的推导及语法树(6)i+i*i推导过程:〈表达式〉=〉〈表达式〉+〈项〉E=〉E+T =〉〈表达式〉+〈项〉*〈因子〉=〉E+ T*F=〉〈表达式〉+〈项〉* i =〉E+ T*i=〉〈表达式〉+ 〈因子〉* i =〉E+F*i=〉〈表达式〉+ i* i =〉E+i*i=〉〈项〉+ i* i =〉T +i*i=〉〈因子〉+ i* i =〉F +i*i=〉i +i*i =〉i +i*i 共8步推导语法树:〈表达式〉+〈因子〉〈项〉i 〈因子〉i〈项〉〈项〉〈因子〉i*11、一个上下文无关文法生成句子abbaa的推导树如下:(1)给出该句子相应的最左推导和最右推导(2)该文法的产生式集合P可能有哪些元素?(3)找出该句子的所有短语、简单短语、句柄。
(1)最左推导:S=〉ABS=〉aBS=〉aSBBS=〉aBBS=〉abBS=〉abbS =〉abbAa=〉abbaa最右推导:S =〉ABS=〉ABAa=〉ABaa=〉ASBBaa=〉ASBbaa=〉ASbbaa=〉Abbaa=〉abbaa(2)该文法的产生式集合P可能有下列元素:S→ABS | Aa|εA→a B→SBB|b(3)因为字符串中的各字符有相对的位置关系,为了能相互区别,给相同的字符标上不同的数字。
编译原理第二版课后习答案

编译原理第二版课后习答案编译原理是计算机科学领域中的一门重要学科,它主要研究程序的自动翻译技术,将高级语言编写的程序转换为机器能够执行的低级语言。
编译原理的基本概念和技术是计算机专业学生必须学会的知识之一,而编译原理第二版课后习题则是帮助学生更好地理解课程内容和提高编译器开发能力的重要资源。
本篇文章将对编译原理第二版课后习题进行分析和总结,并提供一些参考答案和解决问题的思路。
一、词法分析词法分析是编译器的第一步,它主要将输入的字符流转换为有意义的词法单元,例如关键字、标识符、常量和运算符等。
在词法分析过程中,我们需要编写一个词法分析程序来处理输入的字符流。
以下是几道词法分析相关的习题:1. 如何使用正则表达式来表示浮点数?答案:[+|-]?(\d+\.\d+|\d+\.|\.\d+)([e|E][+|-]?\d+)?这个正则表达式可以匹配所有的浮点数,包括正负小数、整数和指数形式的浮点数。
2. 什么是语素?举例说明。
答案:语素是构成单词的最小承载语义的单位,例如单词“man”,它由两个语素“ma”和“n”组成。
“ma”表示男性,“n”表示名词。
3. 采用有限状态自动机(Finite State Automata)实现词法分析的优点是什么?答案:采用有限状态自动机(Finite State Automata)实现词法分析的优点是运行速度快,消耗内存小,易于编写和调试,具有可读性。
二、语法分析语法分析是编译器的第二步,它主要检查词法分析生成的词法单元是否符合语法规则。
在语法分析过程中,我们需要编写一个语法分析器来处理词法单元序列。
以下是几道语法分析相关的习题:1. 什么是上下文无关文法?答案:上下文无关文法(Context-Free Grammar, CFG)是一种形式语言,它的语法规则不依赖于上下文,只考虑规则左边的非终结符号。
EBNF是一种常见的上下文无关文法。
2. LR分析表有什么作用?答案:LR分析表是一种自动机,它的作用是给定一个输入符号串,判断其是否符合某个文法规则,并生成语法树。
(完整word版)编译原理课后答案

第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。
《编译原理》课后习题答案第二章

有代表性的符号串:a,a0,aa,a00,a0a,aa0
习题2
3.(1)E T T/F F/F (E)/F (E+T)/F (T+T)/F (F+F)/F (i+i)/i
(2)E E+T E+T+T E+T*F+F E+T*F+i E+T*T*F+i
M:M(0,a)=1 M(0,b)=2
M(1,a)=1 M(1,b)=4
M(2,a)=1 M(2,b)=3
M(3,a)=3 M(3,b)=2
M(4,a)=0 M(4,b)=5
M(5,a)=5 M(5,b)=1
化简:
1.分化
① {0,1} {2,3,4,5}
② {0,1} {2,4} {3,5}
2.合并
=M(M(D,1),1011)
=M(M(C,1),011)
=M(M(F,0),11)
=M(M(E,1),1)
=M(C,1)
=F
∴DFA D能接受字符串0011011
8.解:将状态转换图列表,即:
由左图可知,该状态转换图直接对应的是确定有穷状态自动机DFA
DFA D=({0,1,2,3,4,5},{a,b},M,0,{0,1})
A::=bc|bAc
(2)Z::=AB
A::=ab|aAb
B::=b|Bb
7. 解:题中要求文法是:
Z::=1|3|5|7|9|Z1|Z3|Z5|Z7|Z9|A1|A3|A5|A7|A9
A::=2|4|6|8|A0|A2|A4|A6|A8|Z0|Z2|Z4|Z6|Z8
编译原理(第二版)清华大学---答案详解

第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1) 编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2) 源程序:源语言编写的程序称为源程序。
(3) 目标程序:目标语言书写的程序称为目标程序。
(4) 编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5) 后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6) 遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
编译原理作业题答案编译原理课后题答案

第二章高级语言的语法描述6、令文法G 6为:N →D|ND D → 0|1|2|3|4|5|6|7|8|9(1)G 6 的语言L (G 6)是什么?(2)给出句子01270127、、34和568的最左推导和最右推导。
解答:思路:由N N →→ D|ND 可得出如下推导N =>=>ND ND ND=>=>=>NDD NDD NDD=>…=>=>…=>=>…=>D D n(n >=1=1))可以看出,N 最终可以推导出1个或多个(也可以是无穷)D ,而D D →→ 0|1|2|3|4|5|6|7|8|9可知,每个D 为0~9中的任一个数字,所以,中的任一个数字,所以,N N N 最终推导出的就是由最终推导出的就是由0~9这10个数字组成的字符串。
(1)G 6 的语言L (G 6)是由0~9这10个数字组成的字符串个数字组成的字符串,,或{0{0,,1,1,……,9}+。
(2)(2)句子句子01270127、、34和568的最左推导分别为的最左推导分别为: : N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>NDDD NDDD NDDD=>=>=>DDDD DDDD DDDD=>=>=>0DDD 0DDD 0DDD=>=>=>01DD 01DD 01DD=>=>=>012D 012D 012D=>=>=>0127 0127 N =>=>ND ND ND=>=>=>DD DD DD=>=>=>3D 3D 3D=>=>=>34 34N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>DDD DDD DDD=>=>=>5DD 5DD 5DD=>=>=>56D 56D 56D=>=>=>568 568 句子01270127、、34和568的最右推导分别为的最右推导分别为: :N =>=>ND ND ND=>=>=>N7N7N7=>=>=>ND7ND7ND7=>=>=>N27N27N27=>=>=>ND27ND27ND27=>=>=>N127N127N127=>=>=>D127D127D127=>=>=>0127 0127 N =>=>ND ND ND=>=>=>N4N4N4=>=>=>D4D4D4=>=>=>34 34N =>=>ND ND ND=>=>=>N8N8N8=>=>=>ND8ND8ND8=>=>=>N68N68N68=>=>=>D68D68D68=>=>=>568 5687、写一个文法,使其语言是奇数集,且每个基数不以0开头。
编译原理第二章 习题与答案(修改后)

第2章习题2-1 设有字母表A1 ={a,b,c,…,z},A2 ={0,1,…,9},试回答下列问题:(1) 字母表A1上长度为2的符号串有多少个?(2) 集合A1A2含有多少个元素?(3) 列出集合A1(A1∪A2)*中的全部长度不大于3的符号串。
2-2 试分别构造产生下列语言的文法:(1){a n b n|n≥0};(2){a n b m c p|n,m,p≥0};(3){a n#b n|n≥0}∪{c n#d n|n≥0};(4){w#w r# | w∈{0,1}*,w r是w的逆序排列 };(5)任何不是以0打头的所有奇整数所组成的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
2-3 试描述由下列文法所产生的语言的特点:(1)S→10S0S→aA A→bA A→a(2)S→SS S→1A0A→1A0A→ε(3)S→1A S→B0A→1A A→CB→B0B→C C→1C0C→ε(4)S→aSS S→a2-4 试证明文法S→AB|DC A→aA|a B→bBc|bc C→cC|c D→aDb|ab为二义性文法。
2-5 对于下列的文法S→AB|c A→bA|a B→aSb|c试给出句子bbaacb的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2-6 化简下列各个文法(1) S→aABS|bCACd A→bAB|cSA|cCC B→bAB|cSB C→cS|c(2) S→aAB|E A→dDA|e B→bE|fC→c AB|dSD|a D→eA E→fA|g(3) S→ac|bA A→c BC B→SA C→bC|d2-7 消除下列文法中的ε-产生式(1) S→aAS|b A→cS|ε(2) S→aAA A→bAc|dAe|ε2-8 消除下列文法中的无用产生式和单产生式(1) S→aB|BC A→aA|c|aDb B→DB|C C→b D→B(2) S→SA|SB|A A→B|(S)|( ) B→[S]|[ ](3) E→E+T|T T→T*F|F F→P↑F|P P→(E)|i第2章习题答案2-1 答:(1) 26*26=676(2) 26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz, a00,a01,...,zzz},共有26+26*36+26*36*36=34658个2-2 解:(1) 对应文法为G(S)=({S},{a,b},{ S→ε| aSb },S)(2) 对应文法为G(S)=({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε },S)(3)对应文法为G(S)=({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#, Y→cYd|# },S)(4) G(S)=({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5) G(S)=({S,A,B,I,J},{0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|ε, I→J|2|4|6|8, J→1|3|5|7|9},S)(6)对应文法为S→0A|1B|ε,A→0S|1C,B→0C|1S,C→1A|0B2-3 解:(1) 本文法构成的语言集为:L(G)={(10)n ab m a0n|n,m≥0}。
编译原理 (第2版) 第二版 课后习题答案2
(4)NFA
2.解:构造DFA矩阵表示
0
1
{z}
{x}
{Z}*
{X,z}
{y}
{X,z}*
{X,z}
{X,y}
{y}
{X,y}
{X,y}
{X,y,z}
{x}
{X,y,z}*
{X,y,z}
{X,y}
其中0表示初态,*表示终态
用0,1,2,3,4,5分别代替{X}{Z}{X,z}{y}{X,y}{X,y,z}
SELECT(E’->+E)={+}
SELECT(E’->ε)=FOLLOW(E’)= {#,)}
SELECT(T->FT’)=FIRST(F)= {(,a,b,^}
SELECT(T’ —>T)=FIRST(T)= {(,a,b,^)
SELECT(T’->ε)=FOLLOW(T’)= {+,#,)}
FIRST(S) = { begin }
FIRST(A) = FIRST(B)∪FIRST(A’)∪{ξ} = {a , if , ; ,ξ}
FIRST(A’) ={ ; ,ξ}
FIRST(B) = FIRST(C)∪FIRST(D) ={ a , if }
FIRST(C) = {a}
FIRST(D) = FIRST(E)= { if }
A-> a A’ { a }
A’->ξ{ $ , a, b }
A’-> C { a , b }
B->a B B { a }
B -> b B’ { b }
B’->ξ{ $ , a , b }
B’-> C { a, b }
编译原理教程 第二章

第2章 词法分析
状态(即结点)数是有限的,其中必有一初始状态以及若 干终止状态,终止状态(终态)的结点用双圈表示以区别于其 它状态。图2-3给出了用于识别标识符、无符号整数、无符 号数的状态转换图,其初始状态均用0状态表示。
第2章 词法分析
(a) 标识符;(b) 无符号整数;(c) 无符号数
第2章 词法分析
对于给定的字母表Σ,正规式和正规集的递归定义如下: (1) ε和Ф都是Σ上的正规式,它们所表示的正规集分别 为{ε}和Ф。 (2) 对任一个a∈Σ,a是Σ上的一个正规式,它所表示的 正规集为{a}。 (3) 如果R和S是Σ上的正规式,它们所表示的正规集分 别为L(R) 和L(S),则: ① R∣S是Σ上的正规式,它所表示的正规集为 L(R)∪L(S); ② R·S是Σ上的正规式,它所表示的正规集为L(R) L(S); ③ (R)*是Σ上的正规式,它所表示的正规集为(L(R))*; ④ R也是Σ上的正规式,它所表示的正规集为L(R)。
第2章 词法分析
为了理解正规式与正规集的含义,我们以程序语言中的 标识符为例予以说明。程序语言中使用的标识符是一个以字 母开头的字母数字串,如果字母用letter表示,数字用digit表 示,则标识符可表示为
letter (letter∣digit)* 其中,letter与 (letter∣digit)*的并置表示两者的连接;括号 中的“∣”表示letter或digit两者选一;“ * ”表示零次或多 次引用由“ * ”标记的表达式;(letter∣digit)*是letter∣digit 的零次或多次并置,即表示一长度为0、1、2、…的字母数 字串;letter (letter∣digit)*表示以字母开头的字母数字串, 也即标识符集。letter (letter∣digit)*就是表示标识符的正规 式,而标识符集就是这个正规式所表示的正规集。
清华大学编译原理第二版课后习答案

Lw.《编译原理》课后习题答案第一章第 1 章引论第 1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第 2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
盛威网()专业的计算机学习网站1《编译原理》课后习题答案第一章目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
最新编译原理第二章 习题与答案(修改后)word版本

第2章习题2-1 设有字母表A1 ={a,b,c,…,z},A2 ={0,1,…,9},试回答下列问题:(1) 字母表A1上长度为2的符号串有多少个?(2) 集合A1A2含有多少个元素?(3) 列出集合A1(A1∪A2)*中的全部长度不大于3的符号串。
2-2 试分别构造产生下列语言的文法:(1){a n b n|n≥0};(2){a n b m c p|n,m,p≥0};(3){a n#b n|n≥0}∪{c n#d n|n≥0};(4){w#w r# | w∈{0,1}*,w r是w的逆序排列 };(5)任何不是以0打头的所有奇整数所组成的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
2-3 试描述由下列文法所产生的语言的特点:(1)S→10S0S→aA A→bA A→a(2)S→SS S→1A0A→1A0A→ε(3)S→1A S→B0A→1A A→CB→B0B→C C→1C0C→ε(4)S→aSS S→a2-4 试证明文法S→AB|DC A→aA|a B→bBc|bc C→cC|c D→aDb|ab为二义性文法。
2-5 对于下列的文法S→AB|c A→bA|a B→aSb|c试给出句子bbaacb的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2-6 化简下列各个文法(1) S→aABS|bCACd A→bAB|cSA|cCC B→bAB|cSB C→cS|c(2) S→aAB|E A→dDA|e B→bE|fC→c AB|dSD|a D→eA E→fA|g(3) S→ac|bA A→c BC B→SA C→bC|d2-7 消除下列文法中的ε-产生式(1) S→aAS|b A→cS|ε(2) S→aAA A→bAc|dAe|ε2-8 消除下列文法中的无用产生式和单产生式(1) S→aB|BC A→aA|c|aDb B→DB|C C→b D→B(2) S→SA|SB|A A→B|(S)|( ) B→[S]|[ ](3) E→E+T|T T→T*F|F F→P↑F|P P→(E)|i第2章习题答案2-1 答:(1) 26*26=676(2) 26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz, a00,a01,...,zzz},共有26+26*36+26*36*36=34658个2-2 解:(1) 对应文法为G(S)=({S},{a,b},{ S→ε| aSb },S)(2) 对应文法为G(S)=({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε },S)(3)对应文法为G(S)=({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#, Y→cYd|# },S)(4) G(S)=({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5) G(S)=({S,A,B,I,J},{0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|ε, I→J|2|4|6|8, J→1|3|5|7|9},S)(6)对应文法为S→0A|1B|ε,A→0S|1C,B→0C|1S,C→1A|0B2-3 解:(1) 本文法构成的语言集为:L(G)={(10)n ab m a0n|n,m≥0}。
编译原理(第2版)课后习题答案详解

编译原理(第
第1章引论
第1题
解释下列术语:
(1)编译程序
(2)源程序
(3)目标程序
(1)INT 0 A(2)OPR 0 0(3)CAL L A
答案:
PL/0编译程序所产生的目标代码中有3条非常重要的特殊指令,这3条指令在code中的位置和功能以及所完成的操作说明如下:
INT 0 A
在过程目标程序的入口处,开辟A个单元的数据段。A为局部变量的个数+3。OPR 0 0
在过程目标程序的出口处,释放数据段(退栈),恢复调用该过程前正在运行的过程的数据段基址寄存器B和栈顶寄存器T的值,并将返回地址送到指令地址寄存器P中,以使
该文法是否为二义的?为什么?
答案:
对于串abc
(1)S=>Ac=>abc (2)S=>aB=>abc
即存在两不同的最右推导。所以,该文法是二义的。
或者:
对输入字符串abc,能构造两棵不同的语法树,所以它是二义的。
第9题
考虑下面上下文无关文法:
S→SS*|SS+|a
(1)表明通过此文法如何生成串aa+a*,并为该串构造语法树。
最右推导2〈表达式〉〈表达式〉〈运算符〉〈表达式〉〈表达式〉〈运算符〉〈表达式〉〈运算符〉〈表达式〉〈表达式〉〈运算符〉〈表达式〉〈运算符〉a〈表达式〉〈运算符〉〈表达式〉* a〈表达式〉〈运算符〉a * a〈表达式〉+ a * a a + a * a
编译原理第二版课后习答案

《编译原理》课后习题答案第一章第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成各部分的主要功能是什么并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
编译原理及实践教程第2章参考答案

第2章参考答案:1:解答:略!2.解答:字母表:是元素的有穷非空集合Σ字母表:是元素的有穷非空集合Σ符号串: 由字母表中的符号组成的任何有穷序列称为符号串,推导: 连续使用产生式右部去替换左部某个非终结符的过程,得到的连续序列称为一个推导。
句型:设G(s)是一文法,如果符号串x是从开始符号推导出来的,即有s=>x,则称x是文法G(s)的一个句型。
(在语法树的推导过程中的任何时刻,没有后代的端末结点自左至右排列起来就是一个句型)句子:若x仅由终结符号组成,则称x为G(S)的句子最左推导: 在整个推导过程中,任何一步推导α=>β都是对α中最左边的非终结符进行替换。
如果一个文法存在某个句子对应两棵不同的语法树,则说这个文法是二义的语法树:推导的形式化表示,有助于理解句子语法结构的层次3.解答:略!4. 解答:A:① B:③ C:① D:②5. 解答:用E表示<表达式>,T表示<项>,F表示<因子>,上述文法可以写为:E → T | E+TT → F | T*FF → (E) | i最左推导:E=>E+T=>E+T+T=>T+T+T=>F+T+T=>i+T+T=>i+F+T=>i+i+T=>i+i+F=>i+i+iE=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*i最右推导:E=>E+T=>E+F=>E+i=>E+T+i=>E+F+i=>E+i+i=>T+i+i=>F+i+i=>i+i+iE=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i =>i+i*ii+i+i和i+i*i的语法树如下图所示。
编译原理第二章习题答案

* i
=> 〈表达式〉
〈运算符〉
i * i
=>〈表达式〉+i * i
=>1+1*1
所以,该文法是二义的。
9.文法G⑸为:
S->Ac|aB
A->ab
B->bc
该文法是否为பைடு நூலகம்义的为什么
[答案]
对于串abc
(l)S=>Ac=>abc
⑵S=>aB=>abc
即存在两不同的最右推导
所以,该文法是二义的。
最右推导:
S=>ABS=>ABAa=>ABaa=>ASBBaa=>ASBbaa=>ASbbaa=>A £ bbaa=>a £ bbaa
(2)产生式有:S-ABS |Aa|£
A~*a
B—SBB|b
(3)该句子的短语有8ibib2a283、ai、bi> b2、bib2、82^3、a2;
!
直接短语有ai、bi、b2、a2:
4•已知文法G[Z]:
Z->aZb|ab
<
写出L(G[Z])的全部元素。
[答案]
Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbb
L(G[Z])={anbn|n>=l}
5.给出语言{aBc叫n>=l,m>=O}|ft上下文无关文法。
[分析]
本题难度不大,主要是考上下文无关文法的基本概念。上下文无关文法的基 本定义是:A->P,AeVn, P G (VnUVt)\注意关键问题是保证a"bn的成立, 即“a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解 决。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二章 词法分析 对图2-21的DFA进行最小化。首先将状态分为非终态 集和终态集两部分:{0,1,2,5}和{3,4,6,7}。由终态集 可知,对于状态3、6、7,无论输入字符是a还是b的下一 状态均为终态集,而状态4在输入字符b的下一状态落入 非终态集,故将其化为分 {0,1,2,5}, {4}, {3,6,7} 对于非终态集,在输入字符a、b后按其下一状态落 入的状态集不同而最终划分为
重新命名
图2-9 习题2.5的状态转换矩阵
第二章 词法分析
a 0 a 1 b 2
b b 3
a a 4
图2-10 习题2.5的最简DFA
第二章 词法分析 2.6 有语言L={w|w∈(0,1)+,并且w中至少有两个
1,又在任何两个1之间有偶数个0},试构造接受该语
言的确定有限状态自动机(DFA)。
M′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图
2-3所示。
第二章 词法分析 表2-2 状态转换矩阵
f 状态 0 1 2 字符
a 2 — 2
b 1 2 2
第二章 词法分析 将图2-3所示的DFA M′最小化。首先,将M′的状 态分成终态组{1,2}与非终态组{0}。其次,考察{1,2},
0 0 0 1 1 0 2 0 3 1 4 0 5 1 0 0 6
图2-13 习题2.6的最简DFA
第二章 词法分析 2.7 已知正规式((a|b)*|aa)*b和正规式(a|b)*b。
(1) 试用有限自动机的等价性证明这两个正规式
是等价的;
(2) 给出相应的正规文法。 【解答】 图2-14所示。 (1) 正规式((a|b)*|aa)*b对应的NFA如
第二章 词法分析
3
a X 1
a 2 b Y
a
4
b
图2-14 正规式((a|b)*|aa)*b对应的NFA
第二章 词法分析 用子集法将图2-14所示的NFA确定化为DFA,如图 2-15所示。
I Ia Ib S 1 2 3 a 2 2 2 b 3 3 3
{X,1,2,4} {1,2,3,4} {1,2,4,Y} 重新命名 {1,2,3,4} {1,2,3,4} {1,2,4,Y} {1,2,4,Y} {1,2,3,4} {1,2,4,Y}
图2-12 习题2.6的状态转换矩阵
第二章 词法分析 由图2-12可看出非终态2和4的下一状态相同,终 态6和8的下一状态相同,即得到最简状态为
{0}、{1}、{2,4}、{3}、{5}、{6,8}、{7}
按顺序重新命名为0、1、2、3、4、5、6,则得到 最简DFA,如图2-13所示。
第二章 词法分析
b 3 3 3
图2-18 图2-17确定化后的状态转换矩阵
第二章 词法分析 比较图2-18与图2-15,重新命名后的转换矩阵是 完全一样的,也即正规式(a|b)*b可以同样得到化简后 的DFA如图2-16所示。因此,两个自动机完全一样,即 两个正规文法等价。 (2) 对图2-16,令A对应状态1,B对应状态2,则 相应的正规文法G[A]为 G[A]:A→aA|bB|b B→aA|bB|b
正规式(a|b)*b对应的NFA如图2-17所示。
第二章 词法分析 表2-3 合并后的状态转换矩阵
S 1 2 a 1 1 b 2 2
第二章 词法分析
a b 1 a 2 b
图2-16 习题2.7的最简DFA
第二章 词法分析
a b
X
1
2
Y
b
图2-17 正规式(a|b)*b对应的NFA
定的有限自动机,其中f定义如下:
试构造相应的确定有限自动机M′。 【解答】 对照自动机的定义M=(S,Σ ,f,So,Z), 由f的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。 先画出NFA M相应的状态图,如图2-2所示。
第二章 词法分析
a a b b
X
}
请用正规表达式表示这个程序段可能的执行序列。
第二章 词法分析 【解答】 用正规表达式表示程序段可能的执行
序列为A(TBI)*。
2.9
将图2-19所示的非确定有限自动机(NFA)变
换成等价的确定有限自动机(DFA)。
第二章 词法分析
b 2 b a b 3 a b 4 b a Y
d. 单词自身值
。
d. M1和M2状态数和有向边条数相等
第二章 词法分析 (3) DFA M(见图2-1)接受的字集为 。 a. 以0开头的二进制数组成的集合
b. 以0结尾的二进制数组成的集合
c. 含奇数个0的二进制数组成的集合 d. 含偶数个0的二进制数组成的集合 【解答】 (1) c (2) c (3) d
第二章 词法分析
I {X} {1} {2} {3} {4} {5} {Y} {6}
Ia {1} {2} {1} — {Y} — {6} {Y}
Ib — {3} — {4} {5} {4} — —
S 0 1 2 3 4 5 7 6
a 1 2 1 — 7 — 6 7
b — 3 — 4 5 4 — —
{0}, {1}, {2}, {5}, {4}, {3,6,7}
按顺序重新命名为0、1、2、3、4、5,得到最简DFA 如图2-22所示。
G[A]可进一步化简为G[S]:S→aS|bS|b(非终结符 B对应的产生式与A对应的产生式相同,故两非终结符 等价,即可合并为一个产生式)。
第二章 词法分析 2.8 下列程序段以B表示循环体,A表示初始化,
I表示增量,T表示测试:
I=1;
while (I<=n) { sun=sun+a[I]; I=I+1;
【解答】 对于语言L,w中至少有两个1,且任意 两个1之间必须有偶数个0;也即在第一个1之前和最后 一个1之后,对0的个数没有要求。据此我们求出L的正 规式为0*1(00(00)*1)*00(00)*10*,画出与正规式对应的 NFA,如图2-11所示。
第二章 词法分析
0 2 0 1 0 3
器需要一个单词符号时就调用这个子程序。每次调用
时,词法分析器就从输入串中识别出一个单词符号交 给语法分析器。
第二章 词法分析 2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确 f(x,a)={x,y} f(y,a)=Φ f{x,b}={y} f{y,b}={x,y}
图2-15 图2-14确定化后的状态转换矩阵
第二章 词法分析 由于对非终态的状态1、2来说,它们输入a、b的 下一状态是一样的,故状态1和状态2可以合并,将合
并后的终态3命名为2,则得到表2-3(注意,终态和非终
态即使输入a、b的下一状态相同也不能合并)。 由此得到最简DFA,如图2-16所示。
图2-7 最简NFA
第二章 词法分析 2.5 设有L(G)={a2n+1b2ma2p+1| n≥0,p≥0,m≥1}。 (1) 给出描述该语言的正规表达式;
(2) 构造识别该语言的确定有限自动机(可直接用
状态图形式给出)。 【解答】 该语言对应的正规表达式为 a(aa)*bb(bb)*a(aa)* ,正规表达式对应的NFA如图2-8 所示。
第二章 词法分析
2
5
6
a X a 1
a b 3 b
b 4
b a
a Y
a
图2-8 习题2-5的NFA
第二章 词法分析 用子集法将图2-8确定化,如图2-9所示。 由图2-9重新命名后的状态转换矩阵可化简为(也
可由最小化方法得到)
{0,2} {1} {3,5} {4,6} {7} 按顺序重新命名为0、1、2、3、4后得到最简的 DFA,如图2-10所示。
第二章 词法分析 用子集法将图2-17所示的NFA确定化为如图2-18所 示的状态转换矩阵。
第二章 词法分析
I {X,1,2} {1,2} {1,2,Y}
Ia {1,2} {1,2} {1,2}
Ib {1,2,Y} {1,2,Y} {1,2,Y} 重新命名
S 1 2 3
a 2 2 2
a a X 1
图2-19 习题2.9的NFA
第二章 词法分析 其中,X为初态,Y为终态。 【解答】 用子集法将NFA确定化,如图2-20所示。
第二章 词法分析
I {X} {1} {3} {2,3,Y} {3,Y} {3,4} {3,4,Y}
Ia {1} {2,3,Y} — {2,3,Y} {2,3,Y] {3,4} {2,3,4,Y}
由于{1,2}a={1,2}b={2}{1,2},所以不再将其划分了,
也即整个划分只有两组:{0}和{1,2}。令状态1代表 {1,2},即把原来到达2的弧都导向1,并删除状态2。
最后,得到如图2-4所示的化简了的DFA M′。
第二章 词法分析
a 0 b 1 b 2 a, b
图2-3 习题2.3的DFA M′
第二章 词法分析
0 X 0 Y 1
图2-1 习题2.1的DFA M
第二章 词法分析 2.2 什么是扫描器?扫描器的功能是什么? 【解答】 扫描器就是词法分析器,它接受输入
的源程序,对源程序进行词法分析并识别出一个个单
词符号,其输出结果是单词符号,供语法分析器使用。 通常是把词法分析器作为一个子程序,每当词法分析
Y
b
图2-2 习题2.3的NFA M
第二章 词法分析 用子集法构造状态转换矩阵,如表2-1所示。 表2-1 状态转换矩阵
I {x} {y} {x,y} Ia {x,y} — {x,y} Ib {y} {x,y} {x,y}