编译原理LR语法分析器的控制程序实验报告(整理).pptx
编译原理-实验5-LR分析法

编译原理-实验5-L R(1)分析法(总6页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--实验5《LR(1)分析法设计与实现》实验学时: 2 实验地点:实验日期:一、实验目的构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
二、实验内容程序输入/输出示例(以下仅供参考):对下列文法,用LR(1)分析法对任意输入的符号串进行分析:(1)E-E+T(2)E-E—T(3)T-T*F(4)T-T/F(5)F-(E)(6)F-i输出的格式如下:(1)LR(1)分析程序,编制人:姓名,学号,班级(2)输入一个以#结束的符号串(包括+—*/()i#):在此位置输入符号串(3)输出过程如下:步骤状态栈符号栈剩余输入串动作10#i+i*i#移进(4)输入符号串为非法符号串(或者为合法符号串)备注:1.在“所用产生式”一列中如果对应有推导则写出所用产生式;如果为匹配终结符则写明匹配的终结符;如分析异常出错则写为“分析出错”;若成功结束则写为“分析成功”。
2.在此位置输入符号串为用户自行输入的符号串。
注意:1.表达式中允许使用运算符(+-*/)、分割符(括号)、字符i,结束符#;2.如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好);3.对学有余力的同学,测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。
同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照。
三、实验方法用C语言,通过对LR(1)文法的正确理解编写代码。
四、实验步骤1.对语法规则有明确的定义;2.编写的分析程序能够对实验一的结果进行正确的语法分析;3.对于遇到的语法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程。
五、实验结果六、实验结论#include<>#include<>char*action[10][3]={"S3#","S4#",NULL,/*ACTION*/NULL,NULL,"acc","S6#","S7#",NULL,"S3#","S4#",NULL,"r3#","r3#",NULL,NULL,NULL,"r1#","S6#","S7#",NULL,NULL,NULL,"r3#","r2#","r2#",NULL,NULL,NULL,"r2#"};int goto1[10][2]={1,2,/*QOTO*/0,0,0,5,0,8,0,0,0,0,0,9,0,0,0,0,0,0};char vt[3]={'a','b','#'};/*存放非终结符*/char vn[2]={'S','B'};/*存放终结符*/char *LR[4]={"E->S#","S->BB#","B->aB#","B->b#"};/*存放产生式*/ int a[10];char b[10],c[10],c1;int top1,top2,top3,top,m,n;void main(){int g,h,i,j,k,l,p,y,z,count;char x,copy[10],copy1[10];top1=0;top2=0;top3=0;top=0;a[0]=0;y=a[0];b[0]='#';count=0;z=0;printf("----------------请输入表达式(以#结尾)--------------\n"); do{scanf("%c",&c1);c[top3]=c1;top3=top3+1; }while(c1!='#');printf("步骤\t状态栈\t\t符号栈\t\t输入串\t\tACTION\tGOTO\n"); do{ y=z;m=0;n=0; /*y,z指向状态栈栈顶*/g=top;j=0;k=0;x=c[top];count++;printf("%d\t",count);while(m<=top1){/*输出状态栈*/printf("%d",a[m]);m=m+1;}printf("\t\t");while(n<=top2){/*输出符号栈*/printf("%c",b[n]);n=n+1;}printf("\t\t");while(g<=top3){/*输出输入串*/printf("%c",c[g]);g=g+1;}printf("\t\t");while(x!=vt[j]&&j<=2)j++;if(j==2&&x!=vt[j]){printf("error\n");return;}if(action[y][j]==NULL){printf("error\n");return;}elsestrcpy(copy,action[y][j]);if(copy[0]=='S'){/*处理移进*/z=copy[1]-'0';top1=top1+1;top2=top2+1;a[top1]=z;b[top2]=x;top=top+1;i=0; while(copy[i]!='#'){printf("%c",copy[i]);i++;}printf("\n");}if(copy[0]=='r'){/*处理归约*/i=0;while(copy[i]!='#'){printf("%c",copy[i]);i++;}h=copy[1]-'0';strcpy(copy1,LR[h]);while(copy1[0]!=vn[k])k++;l=strlen(LR[h])-4;top1=top1-l+1;top2=top2-l+1;y=a[top1-1];p=goto1[y][k];a[top1]=p;b[top2]=copy1[0];z=p;printf("\t");printf("%d\n",p);}}while(action[y][j]!="acc");printf("acc\n");getchar();}七、实验小结经过这个实验的练习,通过对程序的分析,让我进一步了解LR(1)算法的思想以及它的进一步程序实现,让我对它的了解从简单的理论上升到程序实现的级别,有理论上升到实际,让我更清楚它的用途。
北邮编译原理LR语法分析程序实验报告

LR语法分析程序实验报告说明:该程序使用实现对算术表达式自底向上的语法分析,并且在对输入表达式进行分析的过程中,输出分析动作,移进或者用哪个产生式进行规约,该程序使用的是LR语法分析程序,手动构造了识别所有活前缀的DFA,为给定文法构造LR分析表,并通过预测分析表对输入的表达式进行分析,并将栈顶状态和预测分析过程详细输出,如果匹配成功则接受,如果匹配不成功则返回错误信息。
特别的是,该程序参照书上129页的有关LR分析的错误处理与恢复表对一些可能出现的错误进行报错和局部恢复,在action表中设置相应的错误处理过程入口,调用相应的过程进行错误处理和恢复,使语法分析能继续进行。
给定文法的产生式为:E->E+T | TT->T*F | FF-> id | (E)源代码:#include<iostream>#include<stack>using namespace std;stack<char> symbol;stack<int> state;char sen[50];char sym[12][6]={//符号表{'s','e','e','s','e','e'},{'e','s','e','e','e','a'},{'r','r','s','r','r','r'},{'r','r','r','r','r','r'},{'s','e','e','s','e','e'},{'r','r','r','r','r','r'},{'s','e','e','s','e','e'},{'s','e','e','s','e','e'},{'e','s','e','e','s','e'},{'r','r','s','r','r','r'},{'r','r','r','r','r','r'},{'r','r','r','r','r','r'}};char snum[12][6]={//数字表{5,1,1,4,2,1},{3,6,5,3,2,0},{2,2,7,2,2,2},{4,4,4,4,4,4},{5,1,1,4,2,1},{6,6,6,6,6,6},{5,1,1,4,2,1},{5,1,1,4,2,1},{3,6,5,3,11,4},{1,1,7,1,1,1},{3,3,3,3,3,3},{5,5,5,5,5,5}};int go2[12][3]={//goto表{1,2,3},{0,0,0},{0,0,0},{0,0,0},{8,2,3},{0,0,0},{0,9,3},{0,0,10},{0,0,0},{0,0,0},{0,0,0},{0,0,0}};void action(int i,char *&a,char &how,int &num,char &A,int &b)//action函数[i,a] {int j;switch(*a){case 'i':j=0;break;case '+':j=1;break;case '*':j=2;break;case '(':j=3;break;case ')':j=4;break;case '#':j=5;break;default:j=-1;break;}printf("%c\t\t",*a);if(j!=-1){how=sym[i][j];num=snum[i][j];if(how=='r'){switch(num){case 1:A='E',b=3;cout<<"reduce by E->E+T"<<endl;break;case 2:A='E',b=1;cout<<"reduce by E->T"<<endl;break;case 3:A='T',b=3;cout<<"reduce by T->T*F"<<endl;break;case 4:A='T',b=1;cout<<"reduce by T->F"<<endl;break;case 5:A='F',b=3;cout<<"reduce by F->(E)"<<endl;break;case 6:A='F',b=1;cout<<"reduce by F->id"<<endl;break;default:break;}}}}int go(int t,char A)//goto[t,A]{switch(A){case 'E':return go2[t][0];break;case 'T':return go2[t][1];break;case 'F':return go2[t][2];break;}}void error(int i,int j,char *&a)//error处理函数{switch(j){case 1://期望输入id或左括号,但是碰到+,*,或$,就假设已经输入id了,转到状态5 cout<<"error:缺少运算对象id"<<endl;symbol.push('i');//必须有这个,如果假设输入id的话,符号栈里必须有....printf("i\t\t");state.push(5);printf("5\t\t");break;case 2://从输入中删除右括号a++;cout<<"error:不配对的右括号"<<endl;break;case 3://期望碰到+,但是输入id或左括号,假设已经输入算符+,转到状态6 cout<<"error:缺少运算符"<<endl;symbol.push('+');printf("+\t\t");state.push(6);printf("6\t\t");break;case 4://缺少右括号,假设已经输入右括号,转到状态11cout<<"error:缺少右括号"<<endl;symbol.push(')');printf(")\t\t");state.push(11);printf("11\t\t");break;case 5:a++;cout<<"error:*号无效,应该输入+号!"<<endl;case 6:a++;}}int main(){int s;char *a;char how;int num;int b;char A;cout<<"请输入表达式(以i表示标识符,以#结束):"<<endl;while(1){cin>>sen;a=sen;state.push(0);//先输入0状态printf("\t\t-------分析过程-------\n");printf("符号栈栈顶\t状态栈栈顶\t当前读入符号\t分析动作\n");printf(" \t\t0\t\t");while(*a!='\0'){b=0;num=0;how='\0';A='\0';s=state.top();action(s,a,how,num,A,b);if(how=='s')//移进{cout<<"Shift"<<endl;symbol.push(*a);printf("%c\t\t",*a);state.push(num);printf("%d\t\t",num);a++;}else if(how=='r')//规约{for(int i=0;i<b;i++){if(!state.empty())state.pop();if(!symbol.empty())symbol.pop();}int t=state.top();symbol.push(A);printf("%c\t\t",A);state.push(go(t,A));printf("%d\t\t",go(t,A));}else if(how=='a')//接受break;else{error(s,num,a);//错误处理}}cout<<"accept"<<endl;}return 0;}输入的表达式正确则不报错并接受:输入错误的表达式i*(i+i*i#报错并进行恢复:输入错误的表达式i+*i#报错并恢复:输入错误表达式i*ii+i)#进行报错并恢复:。
编译原理实验二LL(1)语法分析实验报告

专题3_LL(1)语法分析设计原理与实现李若森 13281132 计科1301一、理论传授语法分析的设计方法和实现原理;LL(1) 分析表的构造;LL(1)分析过程;LL(1)分析器的构造。
二、目标任务实验项目实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的 LL(1)文法的LL(1)分析程序。
G[E]:E→TE’E’→ATE’|εT→FT’T’→MFT’|εF→(E)|iA→+|-M→*|/设计说明终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;(2)LL(1)分析程序应能发现输入串出错;(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析重点解决LL(1)表的构造和LL(1)分析器的实现。
三、实现过程实现LL(1)分析器a)将#号放在输入串S的尾部b)S中字符顺序入栈c)反复执行c),任何时候按栈顶Xm和输入ai依据分析表,执行下述三个动作之一。
构造LL(1)分析表构造LL(1)分析表需要得到文法G[E]的FIRST集和FOLLOW集。
构造FIRST(α)构造FOLLOW(A)构造LL(1)分析表算法根据上述算法可得G[E]的LL(1)分析表,如表3-1所示:表3-1 LL(1)分析表主要数据结构pair<int, string>:用pair<int, string>来存储单个二元组。
该对照表由专题1定义。
map<string, int>:存储离散化后的终结符和非终结符。
vector<string>[][]:存储LL(1)分析表函数定义init:void init();功能:初始化LL(1)分析表,关键字及识别码对照表,离散化(非)终结符传入参数:(无)传出参数:(无)返回值:(无)Parse:bool Parse( const vector<PIS> &vec, int &ncol );功能:进行该行的语法分析传入参数:vec:该行二元式序列传出参数:emsg:出错信息epos:出错标识符首字符所在位置返回值:是否成功解析。
实验三编译原理综合实验报告——(LR(0)语法分析的实现)

m_pTree->SetControlInfo(IDC_TREE1, RESIZE_BOTH);
m_pTree->SetControlInfo(IDOK, ANCHORE_BOTTOM | ANCHORE_RIGHT);
void CAnalyzeDlg::OnOK()
{
// TODO: Add extra validation here
//CDialog::OnOK();
}
void CAnalyzeDlg::OnCancel()
{
// TODO: Add extra cleanup here
六、实验原理、数据(程序)记录
(一)实验原理:
利用LR(k)类分析算法的四个步骤,分别实现"移进"、"归约"、"成功"、"报错"的分析能力。同时采用相应的数据结构实现分析表的描述。
(二)程序框架:
#include "stdafx.h"
#include "GoData.h"
GoData::GoData()
assert(j != -1);
out.WriteString(GetStepInfo(iStep, Status, Symbol, m_input.Right(m_input.GetLength() - iPos), ToDo, j));
for(i = 0; i < m_g.GetPrecept(ToDo.two).GetRight().length(); i++)
编译原理报告二 LR分析器

LR分析器一、目的和要求通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
1、选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析程序和LR 分析分析程序,并至少完成两个题目。
2、选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
⑴实验前的准备按实验的目的和要求,编写语法分析程序,同时考虑相应的数据结构。
⑵调试调试例子应包括符合语法规则的算术表达式,以及分析程序能够判别的若干错例。
⑶输出对于所输入的算术表达式,不论对错,都应有明确的信息告诉外界。
⑷扩充有余力的同学,可适当扩大分析对象。
譬如:①算术表达式中变量名可以是一般标识符,还可含一般常数、数组元素、函数调用等等。
②除算术表达式外,还可扩充分析布尔、字符、位等不同类型的各种表达式。
③加强语法检查,尽量多和确切地指出各种错误。
⑸编写上机实习报告。
二、背景知识※自下而上分析技术-LR(K)方法LR(K)方法是一种自下而上的语法分析方法,是当前最广义的无回溯的“移进- 归约”方法。
它根据栈中的符号串和向前查看的k(k 0)个输入符号,就能唯一确定分析器的动作是移进还是归约,以及用哪个产生式进行归约。
优点:文法适用范围广;识别效率高;查错能力强;可自动构造。
逻辑组成:总控程序+LR分析表LR分析器的结构:一个LR分析器实际是一个带先进后出存储器(栈)的确定下推自动机,它由一个输入串、一个下推栈和一个带有分析表的总控程序组成。
栈中存放着由“历史”和“展望”材料抽象而来的各种“状态”。
任何时候,栈顶的状态都代表了整个的历史和已推测出的展望。
为了有助于明确归约手续,我们把已归约出的文法符号串也同时放进栈里。
LR分析器的每一动作都由栈顶状态和当前输入符号所唯一确定。
LR分析器模型图分析器的任何一次移动都是根据栈顶状态S m和当前输入符号a i,去查看ACTION表并执行ACTION(S m,a i)规定的动作,直至分析成功或失败。
(完整word版)编译原理报告二LR分析器

LR分析器一、目的和要求通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
1、选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析程序和LR分析分析程序,并至少完成两个题目。
2、选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
⑴实验前的准备按实验的目的和要求,编写语法分析程序,同时考虑相应的数据结构。
⑵调试调试例子应包括符合语法规则的算术表达式,以及分析程序能够判别的若干错例。
⑶输出对于所输入的算术表达式,不论对错,都应有明确的信息告诉外界。
⑷扩充有余力的同学,可适当扩大分析对象。
譬如:①算术表达式中变量名可以是一般标识符,还可含一般常数、数组元素、函数调用等等。
②除算术表达式外,还可扩充分析布尔、字符、位等不同类型的各种表达式。
③加强语法检查,尽量多和确切地指出各种错误。
⑸编写上机实习报告。
二、背景知识※自下而上分析技术-LR(K)方法LR(K)方法是一种自下而上的语法分析方法,是当前最广义的无回溯的“移进- 归约”方法。
它根据栈中的符号串和向前查看的k(k³0)个输入符号,就能唯一确定分析器的动作是移进还是归约,以及用哪个产生式进行归约。
优点:文法适用范围广;识别效率高;查错能力强;可自动构造。
逻辑组成:总控程序+LR分析表LR分析器的结构:一个LR分析器实际是一个带先进后出存储器(栈)的确定下推自动机,它由一个输入串、一个下推栈和一个带有分析表的总控程序组成。
栈中存放着由“历史”和“展望”材料抽象而来的各种“状态”。
任何时候,栈顶的状态都代表了整个的历史和已推测出的展望。
为了有助于明确归约手续,我们把已归约出的文法符号串也同时放进栈里。
LR分析器的每一动作都由栈顶状态和当前输入符号所唯一确定。
LR分析器模型图分析器的任何一次移动都是根据栈顶状态S m和当前输入符号a i,去查看ACTION表并执行ACTION (S m,a i)规定的动作,直至分析成功或失败。
编译原理LR(0)分析器(C语言)

编译原理实验报告《LL(1)语法分析器构造》(推荐文档)

《LL(1)分析器的构造》实验报告一、实验名称LL(1)分析器的构造二、实验目的设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。
三、实验内容和要求设计并实现一个LL(1)语法分析器,实现对算术文法:G[E]:E->E+T|TT->T*F|FF->(E)|i所定义的符号串进行识别,例如符号串i+i*i为文法所定义的句子,符号串ii+++*i+不是文法所定义的句子。
实验要求:1、检测左递归,如果有则进行消除;2、求解FIRST集和FOLLOW集;3、构建LL(1)分析表;4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。
四、主要仪器设备硬件:微型计算机。
软件: Code blocks(也可以是其它集成开发环境)。
五、实验过程描述1、程序主要框架程序中编写了以下函数,各个函数实现的作用如下:void input_grammer(string *G);//输入文法Gvoid preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k);//将文法G预处理得到产生式集合P,非终结符、终结符集合U、u,int eliminate_1(string *G,string *P,string U,string *GG);//消除文法G中所有直接左递归得到文法GGint* ifempty(string* P,string U,int k,int n);//判断各非终结符是否能推导为空string* FIRST_X(string* P,string U,string u,int* empty,int k,int n);求所有非终结符的FIRST集string FIRST(string U,string u,string* first,string s);//求符号串s=X1X2...Xn的FIRST集string** create_table(string *P,string U,string u,int n,int t,int k,string* first);//构造分析表void analyse(string **table,string U,string u,int t,string s);//分析符号串s2、编写的源程序#include<cstdio>#include<cstring>#include<iostream>using namespace std;void input_grammer(string *G)//输入文法G,n个非终结符{int i=0;//计数char ch='y';while(ch=='y'){cin>>G[i++];cout<<"继续输入?(y/n)\n";cin>>ch;}}void preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k)//将文法G预处理产生式集合P,非终结符、终结符集合U、u,{int i,j,r,temp;//计数char C;//记录规则中()后的符号int flag;//检测到()n=t=k=0;for( i=0;i<50;i++) P[i]=" ";//字符串如果不初始化,在使用P[i][j]=a时将不能改变,可以用P[i].append(1,a)U=u=" ";//字符串如果不初始化,无法使用U[i]=a赋值,可以用U.append(1,a) for(n=0;!G[n].empty();n++){ U[n]=G[n][0];}//非终结符集合,n为非终结符个数for(i=0;i<n;i++){for(j=4;j<G[i].length();j++){if(U.find(G[i][j])==string::npos&&u.find(G[i][j])==string::npos)if(G[i][j]!='|'&&G[i][j]!='^')//if(G[i][j]!='('&&G[i][j]!=')'&&G[i][j]!='|'&&G[i][j]!='^')u[t++]=G[i][j];}}//终结符集合,t为终结符个数for(i=0;i<n;i++){flag=0;r=4;for(j=4;j<G[i].length();j++){P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';/* if(G[i][j]=='('){ j++;flag=1;for(temp=j;G[i][temp]!=')';temp++);C=G[i][temp+1];//C记录()后跟的字符,将C添加到()中所有字符串后面}if(G[i][j]==')') {j++;flag=0;}*/if(G[i][j]=='|'){//if(flag==1) P[k][r++]=C;k++;j++;P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';r=4;P[k][r++]=G[i][j];}else{P[k][r++]=G[i][j];}}k++;}//获得产生式集合P,k为产生式个数}int eliminate_1(string *G,string *P,string U,string *GG)//消除文法G1中所有直接左递归得到文法G2,要能够消除含有多个左递归的情况){string arfa,beta;//所有形如A::=Aα|β中的α、β连接起来形成的字符串arfa、betaint i,j,temp,m=0;//计数int flag=0;//flag=1表示文法有左递归int flagg=0;//flagg=1表示某条规则有左递归char C='A';//由于消除左递归新增的非终结符,从A开始增加,只要不在原来问法的非终结符中即可加入for(i=0;i<20&&U[i]!=' ';i++){ flagg=0;arfa=beta="";for(j=0;j<100&&P[j][0]!=' ';j++){if(P[j][0]==U[i]){if(P[j][4]==U[i])//产生式j有左递归{flagg=1;for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[j][temp]);if(P[j+1][4]==U[i]) arfa.append("|");//不止一个产生式含有左递归}else{for(temp=4;P[j][temp]!=' ';temp++) beta.append(1,P[j][temp]);if(P[j+1][0]==U[i]&&P[j+1][4]!=U[i]) beta.append("|");}}}if(flagg==0)//对于不含左递归的文法规则不重写{GG[m]=G[i]; m++;}else{flag=1;//文法存在左递归GG[m].append(1,U[i]);GG[m].append("::=");if(beta.find('|')!=string::npos) GG[m].append("("+beta+")");else GG[m].append(beta);while(U.find(C)!=string::npos){C++;}GG[m].append(1,C);m++;GG[m].append(1,C);GG[m].append("::=");if(arfa.find('|')!=string::npos) GG[m].append("("+arfa+")");else GG[m].append(arfa);GG[m].append(1,C);GG[m].append("|^");m++;C++;}//A::=Aα|β改写成A::=βA‘,A’=αA'|β,}return flag;}int* ifempty(string* P,string U,int k,int n){int* empty=new int [n];//指示非终结符能否推导到空串int i,j,r;for(r=0;r<n;r++) empty[r]=0;//默认所有非终结符都不能推导到空int flag=1;//1表示empty数组有修改int step=100;//假设一条规则最大推导步数为100步while(step--){for(i=0;i<k;i++){r=U.find(P[i][0]);if(P[i][4]=='^') empty[r]=1;//直接推导到空else{for(j=4;P[i][j]!=' ';j++){if(U.find(P[i][j])!=string::npos){if(empty[U.find(P[i][j])]==0) break;}else break;}if(P[i][j]==' ') empty[r]=1;//多步推导到空else flag=0;}}}return empty;}string* FIRST_X(string* P,string U,string u,int* empty,int k,int n){int i,j,r,s,tmp;string* first=new string[n];char a;int step=100;//最大推导步数while(step--){// cout<<"step"<<100-step<<endl;for(i=0;i<k;i++){//cout<<P[i]<<endl;r=U.find(P[i][0]);if(P[i][4]=='^'&&first[r].find('^')==string::npos) first[r].append(1,'^');//规则右部首符号为空else{for(j=4;P[i][j]!=' ';j++){a=P[i][j];if(u.find(a)!=string::npos&&first[r].find(a)==string::npos)//规则右部首符号是终结符{first[r].append(1,a);break;//添加并结束}if(U.find(P[i][j])!=string::npos)//规则右部首符号是非终结符,形如X::=Y1Y2...Yk{s=U.find(P[i][j]);//cout<<P[i][j]<<":\n";for(tmp=0;first[s][tmp]!='\0';tmp++){a=first[s][tmp];if(a!='^'&&first[r].find(a)==string::npos)//将FIRST[Y1]中的非空符加入first[r].append(1,a);}}if(!empty[s]) break;//若Y1不能推导到空,结束}if(P[i][j]==' ')if(first[r].find('^')==string::npos)first[r].append(1,'^');//若Y1、Y2...Yk都能推导到空,则加入空符号}}}return first;}string FIRST(string U,string u,string* first,string s)//求符号串s=X1X2...Xn的FIRST集{int i,j,r;char a;string fir;for(i=0;i<s.length();i++){if(s[i]=='^') fir.append(1,'^');if(u.find(s[i])!=string::npos&&fir.find(s[i])==string::npos){ fir.append(1,s[i]);break;}//X1是终结符,添加并结束循环if(U.find(s[i])!=string::npos)//X1是非终结符{r=U.find(s[i]);for(j=0;first[r][j]!='\0';j++){a=first[r][j];if(a!='^'&&fir.find(a)==string::npos)//将FIRST(X1)中的非空符号加入fir.append(1,a);}if(first[r].find('^')==string::npos) break;//若X1不可推导到空,循环停止}if(i==s.length())//若X1-Xk都可推导到空if(fir.find(s[i])==string::npos) //fir中还未加入空符号fir.append(1,'^');}return fir;}string** create_table(string *P,string U,string u,int n,int t,int k,string* first)//构造分析表,P为文法G的产生式构成的集合{int i,j,p,q;string arfa;//记录规则右部string fir,follow;string FOLLOW[5]={")#",")#","+)#","+)#","+*)#"};string **table=new string*[n];for(i=0;i<n;i++) table[i]=new string[t+1];for(i=0;i<n;i++)for(j=0;j<t+1;j++)table[i][j]=" ";//table存储分析表的元素,“ ”表示error for(i=0;i<k;i++){arfa=P[i];arfa.erase(0,4);//删除前4个字符,如:E::=E+T,则arfa="E+T"fir=FIRST(U,u,first,arfa);for(j=0;j<t;j++){p=U.find(P[i][0]);if(fir.find(u[j])!=string::npos){q=j;table[p][q]=P[i];}//对first()中的每一终结符置相应的规则}if(fir.find('^')!=string::npos){follow=FOLLOW[p];//对规则左部求follow()for(j=0;j<t;j++){if((q=follow.find(u[j]))!=string::npos){q=j;table[p][q]=P[i];}//对follow()中的每一终结符置相应的规则}table[p][t]=P[i];//对#所在元素置相应规则}}return table;}void analyse(string **table,string U,string u,int t,string s)//分析符号串s{string stack;//分析栈string ss=s;//记录原符号串char x;//栈顶符号char a;//下一个要输入的字符int flag=0;//匹配成功标志int i=0,j=0,step=1;//符号栈计数、输入串计数、步骤数int p,q,r;string temp;for(i=0;!s[i];i++){if(u.find(s[i])==string::npos)//出现非法的符号cout<<s<<"不是该文法的句子\n";return;}s.append(1,'#');stack.append(1,'#');//’#’进入分析栈stack.append(1,U[0]);i++;//文法开始符进入分析栈a=s[0];//cout<<stack<<endl;cout<<"步骤分析栈余留输入串所用产生式\n";while(!flag){// cout<<"步骤分析栈余留输入串所用产生式\n"cout<<step<<" "<<stack<<" "<<s<<" ";x=stack[i];stack.erase(i,1);i--;//取栈顶符号x,并从栈顶退出//cout<<x<<endl;if(u.find(x)!=string::npos)//x是终结符的情况{if(x==a){s.erase(0,1);a=s[0];//栈顶符号与当前输入符号匹配,则输入下一个符号cout<<" \n";//未使用产生式,输出空}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(x=='#'){if(a=='#') {flag=1;cout<<"成功\n";}//栈顶和余留输入串都为#,匹配成功else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(U.find(x)!=string::npos)//x是非终结符的情况{p=U.find(x);q=u.find(a);if(a=='#') q=t;temp=table[p][q];cout<<temp<<endl;//输出使用的产生式if(temp[0]!=' ')//分析表中对应项不为error{r=9;while(temp[r]==' ') r--;while(r>3){if(temp[r]!='^'){stack.append(1,temp[r]);//将X::=x1x2...的规则右部各符号压栈i++;}r--;}}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}step++;}if(flag) cout<<endl<<ss<<"是该文法的句子\n";}int main(){int i,j;string *G=new string[50];//文法Gstring *P=new string[50];//产生式集合Pstring U,u;//文法G非终结符集合U,终结符集合uint n,t,k;//非终结符、终结符个数,产生式数string *GG=new string[50];//消除左递归后的文法GGstring *PP=new string[50];//文法GG的产生式集合PPstring UU,uu;//文法GG非终结符集合U,终结符集合uint nn,tt,kk;//消除左递归后的非终结符、终结符个数,产生式数string** table;//分析表cout<<" 欢迎使用LL(1)语法分析器!\n\n\n";cout<<"请输入文法(同一左部的规则在同一行输入,例如:E::=E+T|T;用^表示空串)\n";input_grammer(G);preprocess(G,P,U,u,n,t,k);cout<<"\n该文法有"<<n<<"个非终结符:\n";for(i=0;i<n;i++) cout<<U[i];cout<<endl;cout<<"该文法有"<<t<<"个终结符:\n";for(i=0;i<t;i++) cout<<u[i];cout<<"\n\n 左递归检测与消除\n\n";if(eliminate_1(G,P,U,GG)){preprocess(GG,PP,UU,uu,nn,tt,kk);cout<<"该文法存在左递归!\n\n消除左递归后的文法:\n\n"; for(i=0;i<nn;i++) cout<<GG[i]<<endl;cout<<endl;cout<<"新文法有"<<nn<<"个非终结符:\n";for(i=0;i<nn;i++) cout<<UU[i];cout<<endl;cout<<"新文法有"<<tt<<"个终结符:\n";for(i=0;i<tt;i++) cout<<uu[i];cout<<endl;//cout<<"新文法有"<<kk<<"个产生式:\n";//for(i=0;i<kk;i++) cout<<PP[i]<<endl;}else{cout<<"该文法不存在左递归\n";GG=G;PP=P;UU=U;uu=u;nn=n;tt=t;kk=k;}cout<<" 求解FIRST集\n\n";int *empty=ifempty(PP,UU,kk,nn);string* first=FIRST_X(PP,UU,uu,empty,kk,nn);for(i=0;i<nn;i++)cout<<"FIRST("<<UU[i]<<"): "<<first[i]<<endl;cout<<" 求解FOLLOW集\n\n";for(i=0;i<nn;i++)cout<<"FOLLOW("<<UU[i]<<"): "<<FOLLOW[i]<<endl; cout<<"\n\n 构造文法分析表\n\n"; table=create_table(PP,UU,uu,nn,tt,kk,first);cout<<" ";for(i=0;i<tt;i++) cout<<" "<<uu[i]<<" ";cout<<"# "<<endl;for( i=0;i<nn;i++){cout<<UU[i]<<" ";for(j=0;j<t+1;j++)cout<<table[i][j];cout<<endl;}cout<<"\n\n 分析符号串\n\n";cout<<"请输入要分析的符号串\n";cin>>s;analyse(table,UU,uu,tt,s);return 0;}3、程序演示结果(1)输入文法(2)消除左递归(3)求解FIRST和FOLLOW集(4)构造分析表(5)分析符号串匹配成功的情况:匹配失败的情况五、思考和体会1、编写的LL(1)语法分析器应该具有智能性,可以由用户输入任意文法,不需要指定终结符个数和非终结符个数。
编译原理课程设计-LR分析器总控程序的实现

合肥工业大学计算机与信息学院课程设计课程:编译原理专业班级:计算机科学与技术09-2班学号:姓名:一:设计题目题目: LR分析器总控程序的实现设计内容及要求:对P.101中的文法,按图5.5LR分析表构造LR分析器。
要求程序按P.102例5.7那样,对于输入串i*i+i,输出LR分析器的工作过程。
改进:可以自行输入输入串,能按重新按钮重新开始,外加了一个计时器。
二:设计目的进一步了解了LR分析器的整个工作过程,将LR分析器以图形界面的形式展现了出来,有利加深了对LR分析过程的掌握。
三:实验原理本程序是用windows编的,大体的思想是这样的:通过建立一个符号栈,状态栈,输入栈(结构体类型定义的)分别用来存放符号,状态,输入串,将LR 分析表构造成为一个二维数组table[13][9],其中0--11表示状态结点,21--26表示规约标号,-1表示error(出错),12表示acc(接受),在acation函数里面通过i等于多少来判断到底是规约还是移进。
在Main_OnCommand()函数中通过switch....case..来判断每次及下一步所要执行的操作。
运行的时候,首先要输入一个以#结尾的输入串,然后单击开始——>下一步.....,如果规约成功,则弹出一个规约成功的对话框,否则弹出一个规约失败的对话框。
当然在运行的过程中如果出现什么差错,都可以单击重新开始按钮重新输入输入串重新开始。
四:实验代码#include "stdAfx.h"#include <windows.h>#include <windowsx.h>#include "resource.h"#include "MainDlg.h"char *str2[6]={"E->E+T","E->T","T->T*F","T->F","F->(E)","F->i"};int flag=0;#define MAX 20typedef struct{int stack1[MAX];int top1;}status;typedef struct{char stack2[MAX];int top2;}symbol_instr;char index_char[9]={'i','+','*','(',')','#','E','T','F'};//为二维数数组的纵坐标//LR分析表//0--11表示状态结点,21--26表示规约标号,//-1表示error(出错),12表示acc(接受)int table[13][9] = {{ 5,-1,-1, 4,-1,-1, 1, 2, 3},\{-1, 6,-1,-1,-1,12,-1,-1,-1},\{-1,22, 7,-1,22,22,-1,-1,-1},\{-1,24,24,-1,24,24,-1,-1,-1},\{ 5,-1,-1, 4,-1,-1, 8, 2, 3},\{-1,26,26,-1,26,26,-1,-1,-1},\{ 5,-1,-1, 4,-1,-1,-1, 9, 3},\{ 5,-1,-1, 4,-1,-1,-1,-1,10},\{-1, 6,-1,-1,11,-1,-1,-1,-1},\{-1,21, 7,-1,21,21,-1,-1,-1},\{-1,23,23,-1,23,23,-1,-1,-1},\{-1,25,25,-1,25,25,-1,-1,-1}};//规约规则struct rule{char x;int y;}r[6]={{'E',3},{'E',1},{'T',3},{'T',1},{'F',3},{'F',1}}; //后面的代表A—>@中@的长度BOOL WINAPI Main_Proc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam) {switch(uMsg){HANDLE_MSG(hWnd, WM_INITDIALOG, Main_OnInitDialog);HANDLE_MSG(hWnd, WM_COMMAND, Main_OnCommand);HANDLE_MSG(hWnd,WM_CLOSE, Main_OnClose);}return FALSE;}void init_stack1(HWND hwnd,status *p){if( !p)MessageBox(hwnd,TEXT("出错"),TEXT("警告"),MB_OK|MB_ICONHAND);p->top1 = -1;}void push1(HWND hwnd,status *&p,int x){if(p->top1 < MAX-1){p->top1++;p->stack1[p->top1] = x;}else MessageBox(hwnd,TEXT("出错"),TEXT("警告"),MB_OK|MB_ICONHAND);}int pop1(HWND hwnd,status *p){int x;if(p->top1 != 0){x = p->stack1[p->top1];p->top1--;return x;}else{MessageBox(hwnd,TEXT("状态栈为空"),TEXT("警告"),MB_OK|MB_ICONHAND);//printf("\n状态栈1空!\n");return 0;}}void out_stack(HWND hwnd,status *p){if(p->top1 <0)MessageBox(NULL,TEXT("状态栈为空"),TEXT("警告"),MB_OK|MB_ICONHAND);//printf("\n状态栈3空!\n");int i;TCHAR str[256];for(i=0;i<=p->top1;i++)wsprintf(&str[i],"%d",p->stack1[i]);SetDlgItemText(hwnd,IDC_EDIT1,str);}int get_top1(HWND hwnd,status *p){int x;if(p->top1 != -1){x = p->stack1[p->top1];return x;}else{MessageBox(hwnd,TEXT("状态栈为空"),TEXT("警告"),MB_OK|MB_ICONHAND);//printf("\n状态栈2空!\n");return 0;}}void init_stack2(HWND hwnd,symbol_instr *p){if( !p)MessageBox(hwnd,TEXT("出错"),TEXT("警告"),MB_OK|MB_ICONHAND);p->top2= -1;}void push2(HWND hwnd,symbol_instr *p,char x){if(p->top2 < MAX-1){p->top2++;p->stack2[p->top2] = x;p->stack2[p->top2+1]='\0';}else MessageBox(hwnd,TEXT("出错"),TEXT("警告"),MB_OK|MB_ICONHAND);}char pop2(HWND hwnd,symbol_instr *p){char x;if(p->top2 != -1){x = p->stack2[p->top2];p->top2--;p->stack2[p->top2+1]='\0';return x;}else{MessageBox(hwnd,TEXT("符号栈为空"),TEXT("警告"),MB_OK|MB_ICONHAND);//printf("\n符号栈1空!\n");return 0;}}void out_stack1(HWND hwnd,symbol_instr *p){if(p->top2 <0)MessageBox(hwnd,TEXT("符号栈为空"),TEXT("警告"),MB_OK|MB_ICONHAND);//printf("\n状态栈3空!\n");SetDlgItemText(hwnd,IDC_EDIT2,p->stack2);}void out_stack2(HWND hwnd,symbol_instr *p){if(p->top2 <0)MessageBox(hwnd,TEXT("符号栈为空"),TEXT("警告"),MB_OK|MB_ICONHAND);//printf("\n状态栈3空!\n");SetDlgItemText(hwnd,IDC_EDIT3,p->stack2);}char get_top2(HWND hwnd,symbol_instr *p){char x;if(p->top2 != -1){x = p->stack2[p->top2];return x;}else{MessageBox(hwnd,TEXT("符号栈为空"),TEXT("警告"),MB_OK|MB_ICONHAND);//printf("\n符号栈2空!\n");return 0;}}void print(HWND hwnd,status *status_p,symbol_instr *symbol_p,symbol_instr *instr_p){out_stack(hwnd,status_p); //输出状态栈的内容out_stack1(hwnd,symbol_p); //输出符号栈的内容out_stack2(hwnd,instr_p); //输出输入串}int get_index_char(char i){for(int j=0;j<9;j++){if(index_char[j] == i)return j;}return -1;}int goto_char(HWND hwnd,status *status_p,symbol_instr *instr_p){char x;int y,z;x = get_top2(hwnd,instr_p); //输入栈的内容y = get_top1(hwnd,status_p); //状态栈栈顶内容z = get_index_char(x); //得到i,*等相当于二维数组return table[y][z];}void action(HWND hwnd,status *status_p,symbol_instr *symbol_p,symbol_instr *instr_p){int i,j,x;char a;i = goto_char(hwnd,status_p,instr_p);//规约出错if(i == -1)MessageBox(hwnd,TEXT("规约出错!"),TEXT("结束"),MB_OK|MB_ICONEXCLAMATION);//规约成功if(i == 12){MessageBox(hwnd,TEXT("规约成功!"),TEXT("结束"),MB_OK|MB_ICONEXCLAMATION);flag=1;}//移进动作if(i>=0 && i<=11){push1(hwnd,status_p,i);a = pop2(hwnd,instr_p);push2(hwnd,symbol_p,a);print(hwnd,status_p,symbol_p,instr_p);}//规约动作if(i>=21 && i<=26){x = r[i-21].y;for(j=0;j<x;j++){pop1(hwnd,status_p);pop2(hwnd,symbol_p);}push2(hwnd,instr_p,r[i-21].x);SetDlgItemText(hwnd,IDC_EDIT4,str2[i-21]);}}void CALLBACK TimerProc(HWND hwnd,UINT message,UINT iTimerID,DWORD dwTime) {SYSTEMTIME stLocal;TCHAR buf[256];GetLocalTime(&stLocal);wsprintf(buf,"%d年%d月%d 日%d:%d:%d",stLocal.wYear,stLocal.wMonth,stLocal.wDay,stLocal.wHour,stLocal.wM inute,stLocal.wSecond);SetDlgItemText(hwnd,IDC_EDIT5,buf);}BOOL Main_OnInitDialog(HWND hwnd, HWND hwndFocus, LPARAM lParam){SetTimer(hwnd,0,1000,TimerProc);return TRUE;}status *status_p=new status;symbol_instr *symbol_p=new symbol_instr;symbol_instr *instr_p=new symbol_instr ;void Main_OnCommand(HWND hwnd, int id, HWND hwndCtl, UINT codeNotify){switch(id){case IDC_BUTTON1:{init_stack1(hwnd,status_p); //初始化各栈init_stack2(hwnd,symbol_p);init_stack2(hwnd,instr_p);//压进栈初始元素push1(hwnd,status_p,0);push2(hwnd,symbol_p,'#');char x;TCHAR msg[256];GetDlgItemText(hwnd,IDC_EDIT3,msg,sizeof(msg));unsigned int i;for(i=0;i < strlen(msg);i++)push2(hwnd,symbol_p,msg[i]);//然后由符号栈弹出,压进输入栈while( symbol_p->top2 != 0){x = pop2(hwnd,symbol_p);push2(hwnd,instr_p,x);}print(hwnd,status_p,symbol_p,instr_p);//打印初始分析表*/ }break;case IDC_BUTTON2:{action(hwnd,status_p,symbol_p,instr_p);}break;case IDC_BUTTON3:{SetDlgItemText(hwnd,IDC_EDIT1,TEXT(""));SetDlgItemText(hwnd,IDC_EDIT2,TEXT(""));SetDlgItemText(hwnd,IDC_EDIT3,TEXT(""));SetDlgItemText(hwnd,IDC_EDIT4,TEXT(""));}break;default:break;}}void Main_OnClose(HWND hwnd){EndDialog(hwnd, 0);}四:实验结果(1)当输入i*i+i#时最终弹出规约成功的对话框:(2)当输入ii*i#时,最终会弹出规约出错的对话框如下:。
编译原理 LR分析法实验报告

实验五、LR分析法实验报告计算机与信息技术学院程序功能描述通过设计、编写和构造LR(0)项目集规范簇和LR 分析表、对给定的符号串进行LR 分析的程序,了解构造LR(0)分析表的步骤,对文法的要求,能够从文法G 出发生成LR(0)分析表,并对给定的符号串进行分析。
要求以表格或图形的方式实现。
G[E]:E→aA∣bBA→cA∣dB→cB∣d设计要求:(1)构造LR(0)项目集规范簇;要求输入LR(0)文法时,可以直接输入,也可以读取文件,并能够以表格的形式输出项目集规范簇集识别活前缀的有穷自动机(2)构造LR(0)分析表。
要求要求输入LR(0)文法时,可以直接输入,也可以读取文件;输出项目集规范簇,可以调用前一处理部分的结果,输出为LR(0)分析表(3)LR(0)分析过程【移进、归约、接受、报错】的实现。
要求调用前一部分处理结果的分析表,输入一个符号串,依据LR(0)分析表输出与句子对应的语法树,或直接以表格形式输出分析过程。
主要数据结构描述程序结构描述1.首先要求用户输入规则,并保存,分析出规则的数目,规则里的非终结符号和终结符号等信息,为下一步分析备用。
2.根据产生式构造分析表,首先分析每个状态里有哪些产生式,逐步将状态构造完整,最后的规约状态数应该等于产生式的个数。
3.在构造状态的时候,首先将所有的内容均填为出错情况,在每一步状态转换时可以将移进项目填进action表中,对于最后的规约项目,则再用规约覆盖掉之前填的移进。
4.要求用户输入分析串,并保存在输入序列数组中。
5.每一步根据当前的状态栈栈顶状态和输入符号查分析表,若是移进,则直接将符号和相应的状态添进栈中,否则弹出与产生式右部相同个数的字符和状态,并用剩下的状态和产生式的左部在goto表中进行查找,将非终结符和得到的状态压入两个栈内。
6.无论是规约还是移进都要输出当前三个栈内保存内容的情况。
7.如果碰到acc则输出accept,若碰到error则输出error,否则则继续进行规约和移进,不进行结果输出,直至输出接受或出错。
编译原理语法分析实验报告

编译原理语法分析实验报告一、实验目的本实验主要目的是学习和掌握编译原理中的语法分析方法,通过实验了解和实践LR(1)分析器的实现过程,并对比不同的文法对语法分析的影响。
二、实验内容1.实现一个LR(1)的语法分析器2.使用不同的文法进行语法分析3.对比不同文法对语法分析的影响三、实验原理1.背景知识LR(1)分析器是一种自底向上(bottom-up)的语法分析方法。
它使用一个分析栈(stack)和一个输入缓冲区(input buffer)来处理输入文本,并通过移进(shift)和规约(reduce)操作进行语法分析。
2.实验步骤1)构建文法的LR(1)分析表2)读取输入文本3)初始化分析栈和输入缓冲区4)根据分析表进行移进或规约操作,直至分析过程结束四、实验过程与结果1.实验环境本实验使用Python语言进行实现,使用了语法分析库ply来辅助实验。
2.实验步骤1)构建文法的LR(1)分析表通过给定的文法,根据LR(1)分析表的构造算法,构建出分析表。
2)实现LR(1)分析器使用Python语言实现LR(1)分析器,包括读取输入文本、初始化分析栈和输入缓冲区、根据分析表进行移进或规约操作等功能。
3)使用不同的文法进行语法分析选择不同的文法对编写的LR(1)分析器进行测试,观察语法分析的结果。
3.实验结果通过不同的测试案例,实验结果表明编写的LR(1)分析器能够正确地进行语法分析,能够识别出输入文本是否符合给定文法。
五、实验分析与总结1.实验分析本实验通过实现LR(1)分析器,对不同文法进行语法分析,通过实验结果可以观察到不同文法对语法分析的影响。
2.实验总结本实验主要学习和掌握了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程,并通过实验提高了对语法分析的理解。
六、实验心得通过本次实验,我深入学习了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程。
在实验过程中,我遇到了一些问题,但通过查阅资料和请教老师,最终解决了问题,并完成了实验。
编译原理 实验报告实验三 语法分析(LR分析程序)
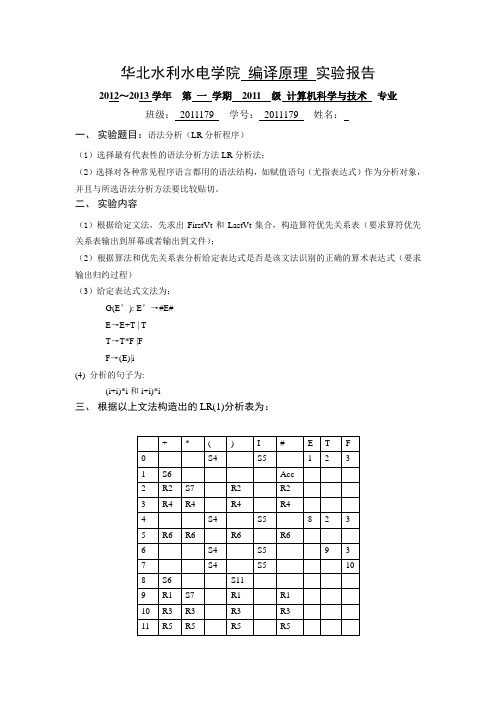
华北水利水电学院编译原理实验报告2012~2013学年第一学期2011 级计算机科学与技术专业班级:2011179 学号:2011179 姓名:一、实验题目:语法分析(LR分析程序)(1)选择最有代表性的语法分析方法LR分析法;(2)选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
二、实验内容(1)根据给定文法,先求出FirstVt和LastVt集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件);(2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)(3)给定表达式文法为:G(E’): E’→#E#E→E+T | TT→T*F |FF→(E)|i(4) 分析的句子为:(i+i)*i和i+i)*i三、根据以上文法构造出的LR(1)分析表为:四、程序源代using System;using System.Text;using System.IO;namespace Syntax_Analyzer{class Syntax{StreamReader myStreamReader;int t;int[] lengh;int l =0;string[] grammar;int s=0;string[] Word;int w=0;int[] wordNum ;int n =0;int[,] LR;public Syntax(){lengh = new int[7];grammar=new string[7];Word=new string[100];wordNum = new int[100];LR=new int[30,30];}public void analyzer(){//读入grammarSyntax myTextRead=new Syntax();Console.WriteLine("-----------------------------语法分析开始---------------------------------\n");//***************************//循环读取文法//***************************string strStart;strStart="grammar.txt";myTextRead.myStreamReader=new StreamReader(strStart);string strBufferStart;int uu=0;do{strBufferStart =myTextRead.myStreamReader.ReadLine();if(strBufferStart==null)break;foreach (String subString in strBufferStart.Split()){grammar[uu]=subString; //每行文法存入grammar[]uu++;}}while (strBufferStart!=null);myTextRead.myStreamReader.Close();//***************************//循环读取lengh//***************************strStart="lengh.txt";myTextRead.myStreamReader=new StreamReader(strStart);uu=0;do{strBufferStart =myTextRead.myStreamReader.ReadLine();if(strBufferStart==null)break;foreach (String subString in strBufferStart.Split()){lengh[uu]=Convert.ToInt32(subString); //每行文法存入grammar[]uu++;}}while (strBufferStart!=null);myTextRead.myStreamReader.Close();//****************************// 读入文件,进行语法分析////****************************string strReadFile;strReadFile="input.txt";myTextRead.myStreamReader=new StreamReader(strReadFile);string strBufferText;int wid =0;Console.WriteLine("分析读入程序(记号ID):\n");do{strBufferText =myTextRead.myStreamReader.ReadLine();if(strBufferText==null)break;foreach (String subString in strBufferText.Split()){if(subString!=""){int ll;if(subString!=null){ll= subString.Length; //每一个长度}else{break;}int a=ll+1;char[] b = new char[a];StringReader sr = new StringReader(subString);sr.Read(b, 0, ll); //把substring 读到char[]数组里int sort=(int)b[0];// word[i] 和wordNum[i]对应//先识别出一整个串,再根据开头识别是数字还是字母Word[wid]=subString;if(subString.Equals("+")){wordNum[wid]=0;}else{if(subString.Equals("*")){wordNum[wid]=1;}else{if(subString.Equals("(")){wordNum[wid]=2;}else{if(subString.Equals(")")){wordNum[wid]=3;}else{if(subString.Equals("i")){wordNum[wid]=4;}}}}}Console.Write(subString+"("+wordNum[wid]+")"+" ");wid++;}}Console.WriteLine("\n");}while (strBufferText!=null);wordNum[wid]=5;myTextRead.myStreamReader.Close();//*********************************//读入LR分析表////***********************************string strLR;strLR="LR-table.txt";myTextRead.myStreamReader=new StreamReader(strLR);string strBufferLR;int pp=0;do{strBufferLR =myTextRead.myStreamReader.ReadLine();if(strBufferLR==null)break;else{int j=0;foreach (String subString in strBufferLR.Split()){if(subString!=null){int lllr=Convert.ToInt16(subString);LR[pp,j]=lllr; //把行与列读入数组j++;}}}pp++;}while (strBufferLR!=null);myTextRead.myStreamReader.Close();int[] state = new int[100];string[] symbol =new string[100];state[0]=0;symbol[0]="#";int p1=0;int p2=0;Console.WriteLine("\n按文法规则归约顺序如下:\n");//***************//归约算法//***************while(true){int j,k;j=state[p2];k=wordNum[p1];t=LR[j,k]; //当出现t为的时候if(t==0){//错误类型string error = "" ;if (k == 0)error = "+";elseif (k == 1)error = "*";elseif (k == 2)error = "(";elseif (k == 3)error = ")";elseif (k == 4)error = "i";elseerror = " 其它错误!";Console.WriteLine("\n检测结果:");Console.WriteLine("代码中存在语法错误");Console.WriteLine("错误状况:错误状态编号为"+j+" 读头下符号为"+error);break;}else{if(t==-100) //-100为达到接受状态{Console.WriteLine("\n");Console.WriteLine("\n检测结果:");Console.WriteLine("代码通过语法检测");break;}if(t<0&&t!=-100) //归约{string m=grammar[-t];Console.Write(m+" "); //输出开始符int length=lengh[-t];p2=p2-(length-1);Search mySearch=new Search();int right=mySearch.search(m);if(right==0){Console.WriteLine("\n");Console.WriteLine("代码中有语法错误");break;}int a=state[p2-1];int LRresult= LR[a,right];state[p2]=LRresult;symbol[p2]=m;}if(t>0){p2=p2+1;state[p2]=t;symbol[p2]=Convert.ToString(wordNum[p1]);p1=p1+1;}}}myTextRead.myStreamReader.Close();Console.WriteLine("-----------------------------语法分析结束---------------------------------\n");Console.Read();}}class Search{public int search(string x){string[] mysymbol=new string[3];mysymbol[0]="E";mysymbol[1]="T";mysymbol[2]="F";int r = 0;for(int s=0;s<=2;s++){if(mysymbol[s].Equals(x))r=s+6 ;}return r;}}}五、测试结果输入”( i + i ) * i”字符串,分析如下图所示输入”i + i ”字符串,分析如下图所示六、小结(包括收获、心得体会、存在的问题及解决问题的方法、建议等)本次实验是LR分析法,LR分析法是一种有效的自上而下分析技术,在自左向右扫描输入串时就能发现其中的任何错误。
编译原理-LR语法分析器的控制程序实验报告

编译原理实验报告学号姓名时间专业班级实验题目:LR语法分析器的控制程序实验目的:手工模拟控制程序计算,对源程序进行LR 语法分析主要是分析表的构造实验内容与步骤:1.将要进行LR 语法分析的源程序和LR 语法分析器控制程序放在同一文件夹中。
2.用 C 语言编写 LR 语法分析器控制程序,程序代码如下:#include <fstream.h>#include <iostream.h>#include <stdlib.h>#include <string.h>struct code_val{char code;char val[20];};const char *p[]={//产生式"S→ E","E → E+T","E → T","T → T*F","T → F","F → (E)","F → i"};const char TNT[ ]="+*()i#ETF";//LR 分析表列的字符const int M[][9]={//LR 分析表数字化,列字符 +*()i#ETF用数字 012345678 标识。
{ 0, 0, 4, 0, 5,0, 1, 2, 3},//0 表示出错, s4 用 4 表示。
{ 6, 0, 0, 0, 0,99},//Acc 用 99 表示{-2, 7, 0,-2, 0,-2},//r2 用 -2 表示{-4,-4, 0,-4, 0,-4},{ 0, 0, 4, 0, 5, 0, 8, 2, 3},{-6,-6, 0,-6, 0,-6}, { 0, 0,4, 0, 5, 0, 0, 9, 3},{ 0, 0, 4, 0, 5, 0, 0, 0,10},{ 6, 0, 0,11},{-1, 7, 0,-1, 0,-1},{-3,-3, 0,-3, 0,-3},{-5,-5, 0,-5, 0,-5}};int col(char);void main(){//列定位函数原型int state[50]={0};//状态栈初值char symbol[50]={'#'};//符号栈初值int top=0;//栈顶指针初值ofstream cout("par_r.txt");//语法分析结果输出至文件par_r.txtifstream cin("lex_r.txt");// lex_r.txt 存放词法分析结果,语法分析器从该文件输入数据。
北邮编译原理实验 LR语法分析 实验报告

LR语法分析实验报告班级:2010211308 姓名:杨娜学号:10211369一.题目:LR语法分析程序的设计与实现二.设计目的:(1)了解语法分析器的生成工具和编译器的设计。
(2)了解自上而下语法分析器的构造过程。
(3). 理解和掌握LR语法分析方法的基本原理;根据给出的LR)文法,掌握LR分析表的构造及分析过程的实现。
(4)掌握预测分析程序如何使用分析表和栈联合控制实现LR分析。
三.实验内容:编写语法分析程序,实现对算术表达式的语法分析,要求所分析算数表达式由如下的文法产生:E->E+T|E-T|TT->T/F|T*F|FF->i|n|(E)四.实验要求:编写LR语法分析程序,要求如下:(1)构造识别所有活动的DFA(2)构造LR分析表(3)编程实现算法4.3,构造LR分析程序五.算法流程分析程序可分为如下几步:六.算法设计1.数据结构s :文法开始符号line :产生式的个数G[i][0] :产生式的标号Vt[] :终结符Vn[] :非终结符id :项目集编号Prjt *next :指示下一个项目集Prjt[]:存储项目的编号,prjt[0]项目编号的个数Pointafter[] :圆点后的字符,pointafter[0]为字符个数Prjset*actorgo[]:存储出度Pointbefore:圆点前面的字符Form:动态数组下标,同时作为符号的编号Vn[] :非终结符序列Vt[]:终结符序列2.LR分析器由三个部分组成(1)总控程序,也可以称为驱动程序。
对所有的LR分析器总控程序都是相同的。
(2)分析表或分析函数,不同的文法分析表将不同,同一个文法采用的LR分析器不同时,分析表将不同,分析表又可以分为动作表(ACTION)和状态转换(GOTO)表两个部分,它们都可用二维数组表示。
(3)分析栈,包括文法符号栈和相应的状态栈,它们均是先进后出栈。
分析器的动作就是由栈顶状态和当前输入符号所决定。
LR语法分析实验报告

目录引言 (1)第一章概述 (2)1.1设计题目及内容 (2)1.2设计环境 (2)第二章设计的基本原理 (3)2.1 LR分析器的基本理 (3)2.2 LR分析器工作过程算法 (3)第三章程序设计 (5)3.1总体方案设计 (5)3.2各模块设计 (5)第四章程序测试和结论以及心得................................ ..7 参考文献. (7)附录程序清单 (8)一概述1.1设计题目及内容设计题目:根据LR分析表构造LR分析器内容:已知文法G:(1)E→E+T(2) E→T(3) T→T*F(4) T→F(5) F→(E)(6) F→Irj 表示按第j个产生式进行规约acc 表示接受空格表示出错标志,报错根据以上文法和LR分析表,构造LR分析器,并要求输出LR工作过程。
1.2设计环境:硬件设备:一台PC机软件设备:Windows 2000/XP OS ,VC++6.0实现语言:C语言二设计的基本原理2.1 基本原理:1.LR方法的基本思想:在规范规约的过程中,一方面记住已移进和规约出的整个符号串,即记住“历史”,另一方面根据所用的产生式推测未来可能碰到的输入符号,即对未来进行“展望”。
当一串貌似句柄的符号串呈现于分析栈的顶端时,我们希望能够根据记载的“历史”和“展望”以及“现实”的输入符号等三个方面的材料,来确定栈顶的符号串是否构成相对某一产生式的句柄。
2.LR分析器实质上是一个带先进后出存储器(栈)的确定有限状态自动机。
3.LR分析器的每一步工作是由栈顶状态和现行输入符号所唯一决定的。
4.为清晰说明LR分析器实现原理和模型:LR分析器的核心部分是一张分析表。
这张分析表包括两个部分,一是“动作”(ACTION)表,另一是“状态转换”(GOTO)表。
他们都是二维数组。
ACTION(s,a)规定了当状态s面临输入符号a时应采取什么动作。
GOTO(s,X)规定了状态s面对文法符号X(终结符或非终结符)时下一状态是什么。
编译原理-LR语法分析器的控制程序实验报告

编译原理实验报告实验目的:手工模拟控制程序计算,对源程序进行LR 语法分析 主要是分析表的构造实验内容与步骤:1•将要进行LR 语法分析的源程序和LR 语法分析器控制程序放在同一文件夹 中。
2.用C 语言编写LR 语法分析器控制程序,程序代码如下:#in elude <fstream.h> #in clude <iostream.h> #i nclude <stdlib.h> #in clude <stri ng.h> struct code_val{char code;char val[20]; };con st char *p[]={// 产生式"S T E","E T E+T","E T T","T T T*F","T T F","F T (E)","F T i };const char TNT[ ]="+*()i#ETF"; con st int M[][9]={{ 0, 0, 4, 0, 5,0, 1,2, 3}, { 6, 0, 0, 0, 0,99}, {-2, 7, 0,-2, 0,-2}, {-4,-4, 0,-4, 0,-4}, { 0, 0, 4, 0, 5, 0, 8, 2, 3}, {-6,-6, 0,-6, 0,-6},{ 0, 0, 4, 0, 5, 0, 0, 9, 3}, { 0, 0, 4, 0, 5, 0, 0, 0,10}, { 6, 0, 0,11}, {-1,7, 0,-1,0,-1}, {-3,-3, 0,-3, 0,-3}, {-5,-5, 0,-5, 0,-5} };//LR 分析表列的字符//LR 分析表数字化,列字符 +*()i#ETF 用数字012345678标识。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
必要。
do{ cout<<j++<<')'<<'\t';
//输出 step,并非必要。
for(i=0;i<=top;i++)cout<<state[i];cout<<'\t';//输出状态栈内容,并非必要。
for(i=0;i<=top;i++)cout<<symbol[i]; //输出符号栈内容,并非必要。
cout<<'\t'<<t.code<<endl;
//输出当前输入符号(单词种别),并非必要。
action=M[state[top]][col(t.code)];
Байду номын сангаас
if(action>0 && action!=99){
//移进
state[++top]=action;
symbol[top]=t.code; cin>>t.code>>t.val;
struct code_val t;
//结构变量,存放单词二元式。
cin>>t.code>>t.val;
//读一单词
int action;
int i,j=0;
//输出时使用的计数器,并非必要。
cout<<"step"<<'\t'<<"状态栈"<<'\t'<<"符号栈"<<'\t'<<"输入符号"<<endl;//输出标题并非
学海无 涯
编译原理 实验报告
学号
姓名
专业
班级
实验题目: LR 语法分析器的控制程序
时间
实验目的: 手工模拟控制程序计算,对源程序进行 LR 语法分析 主要是分析表的构造
实验内容与步骤:
1. 将要进行 LR 语法分析的源程序和 LR 语法分析器控制程序放在同一文件夹 中。
2. 用 C 语言编写 LR 语法分析器控制程序,程序代码如下:
{ 0, 0, 4, 0, 5, 0, 0, 0,10},
{ 6, 0, 0,11},
{-1, 7, 0,-1, 0,-1},
{-3,-3, 0,-3, 0,-3},
{-5,-5, 0,-5, 0,-5}
};
1
学海无 涯
int col(char); void main()
//列定位函数原型
{
int state[50]={0};
symbol[++top]=p[-action][0];
} else if(action==99){
cout<<'\t'<<"Acc"<<endl;
//接受
break;
}
else{
//出错
cout<<"Err in main()>"<<action<<endl;
break;
}
}while(1);
} int col(char c) //将字符+* ()i#ETF 分别转换为数字 012345678
{ for(int i=0;i<(int)strlen(TNT);i++)
2
学海无 涯
if(c==TNT[i])return i;
cout<<"Err in col char>"<<c<<endl;
exit(0);
//终止程序运行
} 3. 查看生成的 par_r.txt 文件,对文件中的内容进行分析,更深刻理解 LR 语法分析的分析
//读一单词
}
else if(action < 0){
//归约
if(strcmp(p[-action]+3,"ε")) //ε产生式的右部符号串长度为 0,无需退栈。 top=top-(strlen(p[-action])-3); //"→"为汉字,占二字节,故减 3。
state[top+1]=M[state[top]][col(p[-action][0])]; //产生式左部符号
//状态栈初值
char symbol[50]={'#'};
//符号栈初值
int top=0;
//栈顶指针初值
ofstream cout("par_r.txt");
//语法分析结果输出至文件 par_r.txt
ifstream cin("lex_r.txt"); // lex_r.txt 存放词法分析结果,语法分析器从该文件输入数据。
过程。
par_r.txt 文件:
step 状态栈 符号栈 输入符号
0) 0 # i
1) 05 #i *
2) 03 #F *
3) 02 #T *
4) 027 #T* i
5) 0275 #T*i+
6) 02710 #T*F +
7) 02 #T +
8) 01 #E +
9) 016 #E+ i
10) 0165 #E+i#
#include <fstream.h>
#include <iostream.h>
#include <stdlib.h>
#include <string.h>
struct code_val{
char code;char val[20];
};
const char *p[]={
//产生式
"S→E","E→E+T","E→T","T→T*F","T→F","F→(E)","F→i"
11) 0163 #E+F #
12) 0169 #E+T #
13) 01 #E #
Acc
分析与体会: 此通过上下文无关文法作为语法分析的基础,配合实例,探讨了编译原
理构造中的自上而下语法分析法,并初步完成了语法分析器的实现。
手工模拟控制程序计算,对源程序进行 LR 语法分析 通过本次实验,进一步对 C 语言的知识进行了复习,并编写代码对源 程序进行 LR 语法分析,把其分析后的结果输入并保存到文件 par_r.tx 中。对 LR 分析有了更深的理解。LR(0)分析表构造的思想和方法是构造其他 LR 分 析表的基础。
};
const char TNT[ ]="+*()i#ETF";
//LR 分析表列的字符
const int M[][9]={
//LR 分析表数字化,列字符+*()i#ETF 用数字 012345678 标识。
{ 0, 0, 4, 0, 5,0, 1, 2, 3},
//0 表示出错,s4 用 4 表示。
3
{ 6, 0, 0, 0, 0,99},
//Acc 用 99 表示
{-2, 7, 0,-2, 0,-2},
//r2 用-2 表示
{-4,-4, 0,-4, 0,-4},
{ 0, 0, 4, 0, 5, 0, 8, 2, 3},
{-6,-6, 0,-6, 0,-6},
{ 0, 0, 4, 0, 5, 0, 0, 9, 3},