SQLite3和SQLite数据库的操作
sqlite数据库linux系统使用方法 -回复

sqlite数据库linux系统使用方法-回复SQLite 是一种轻量级的嵌入式数据库系统,它是在Linux操作系统中应用广泛的数据库之一。
在本文中,我们将一步一步回答如何在Linux系统中使用SQLite数据库。
第一步:安装SQLite首先,我们需要安装SQLite数据库软件。
在大多数Linux发行版中,SQLite 通常已经预装在系统中,所以你可以通过以下命令来验证是否已安装SQLite:sqlite3 version如果看到类似于“3.31.1”的版本号,则表示已成功安装SQLite。
如果未安装,你可以使用以下命令在Ubuntu中安装:sudo apt-get updatesudo apt-get install sqlite3第二步:创建数据库安装完成后,我们可以使用SQLite命令行界面(CLI)来创建一个新的数据库。
打开终端并输入以下命令:sqlite3 mydatabase.db在这个命令中,`mydatabase.db`是我们要创建的数据库的名称。
如果该数据库不存在,SQLite将会自动创建它。
如果文件已经存在,SQLite将会打开该数据库。
第三步:创建表格一旦我们创建了数据库,我们就可以在其中创建表格来存储数据。
在SQLite中,表格是用于组织和存储数据的基本结构。
要创建一个表格,我们需要定义表格的名称,并指定每个列的名称和数据类型。
例如,我们可以创建一个名为`users`的表格来存储用户信息,如下所示:CREATE TABLE users (id INTEGER PRIMARY KEY,name TEXT,age INTEGER,email TEXT);在上面的示例中,我们创建了一个名为`users`的表格,它有四个列:`id`,`name`,`age`和`email`。
`id`列被指定为主键,它用于唯一标识每个用户。
第四步:插入数据一旦我们创建了表格,我们可以使用`INSERT INTO`语句将数据插入到表格中。
sqlite3常用命令

sqlite3常用命令SQLite是一种轻量级的关系型数据库管理系统,被广泛应用于移动应用、嵌入式系统和Web应用程序开发等领域。
SQLite不需要服务器端配置,只需要一个磁盘文件即可存储数据。
本文介绍SQLite3常用的命令。
1.打开数据库要使用SQLite3,首先需要在终端中打开需要管理的数据库文件。
在命令行中输入下面的命令:```sqlite3数据库文件名```例如:```sqlite3 mydata.db```打开了mydata.db数据库文件,就可以在终端中使用SQLite功能了。
2.显示表格执行命令“.tables”可以查看当前数据库中所有的表格,返回当前数据库中的所有表格的名称。
3.显示表格结构执行命令“PRAGMA table_info(表名)”可以查看表结构。
例如执行命令“PRAGMA table_info(products)”可以查看表products的结构,返回表中的每一列的名称、数据类型、是否允许为空等信息。
4.查询数据查询数据时可以使用SQL语句“SELECT”,可以使用不同的参数来获取需要的数据。
其中最常用的参数有“*”(表示所有列)、“DISTINCT”(表示返回不同值)、“WHERE”(表示筛选符合条件的值)等。
例如,要查询表格products中的所有数据,可以使用如下语句:```SELECT * FROM products;```5.插入数据插入数据是数据库应用中常见的操作。
可以通过SQL语句“INSERT INTO”和“VALUES”来执行插入操作。
例如,要插入一个新的产品记录到表格products中,可以使用如下语句:```INSERT INTO products VALUES(1, 'Product A', 100.0);``` 其中,“1”表示记录的编号,“Product A”表示产品名称,“100.0”表示产品价格。
6.修改数据可以使用SQL语句“UPDATE”和“SET”来修改数据库中的数据。
sqlite2和sqlite3使用命令

sqlite2和sqlite3使用命令SQLite 是一个轻量级的关系型数据库管理系统,它提供了一系列命令来管理数据库。
以下是 SQLite2 和 SQLite3 的一些常用命令及示例:**1. 创建数据库**```sqlsqlite3 dbname.db```这将创建一个名为 `dbname.db` 的数据库。
**2. 连接到数据库**```sqlsqlite2 dbname.db```这将连接到名为 `dbname.db` 的数据库。
**3. 创建表**```sqlCREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,...);```这将创建一个名为 `table_name` 的表,其中包含多个列。
**4. 插入数据**```sqlINSERT INTO table_name (column1, column2, column3, ...)VALUES (value1, value2, value3, ...);```这将向 `table_name` 表中插入一行数据。
**5. 查询数据**```sqlSELECT column1, column2, column3, ...FROM table_name;```这将从 `table_name` 表中查询出指定的列。
**6. 更新数据**```sqlUPDATE table_nameSET column1 = value1, column2 = value2, column3 = value3, ... WHERE condition;```这将更新 `table_name` 表中符合条件的数据。
**7. 删除数据**```sqlDELETE FROM table_nameWHERE condition;```这将从 `table_name` 表中删除符合条件的数据。
sqlite数据库linux系统使用方法 -回复

sqlite数据库linux系统使用方法-回复SQLite是一种轻型的关系型数据库管理系统,以其简单易用、高效稳定而闻名。
在Linux系统中,我们可以利用SQLite来管理和操作数据库。
本文将一步一步介绍SQLite数据库在Linux系统中的使用方法。
一、安装SQLite1. 打开终端,输入以下命令安装SQLite:`sudo apt-get update``sudo apt-get install sqlite3`二、创建数据库1. 在终端中,输入以下命令创建一个新的数据库:`sqlite3 test.db`(这里的test.db是数据库名称,可以根据实际情况自己命名)三、创建表格1. 在数据库中,输入以下命令创建一个新的表格:`CREATE TABLE students (id INTEGER PRIMARY KEY, name TEXT, age INTEGER);`(这里的students是表格名称,id、name和age是表格的列名,分别表示学生的编号、姓名和年龄,INTEGER和TEXT表示列的数据类型)四、插入数据1. 输入以下命令向表格中插入数据:`INSERT INTO students (id, name, age) VALUES (1, 'Tom', 20);` (这里的id、name和age对应了表格中的列名,1、'Tom'和20表示要插入的具体数据)五、查询数据1. 输入以下命令查询表格中的数据:`SELECT * FROM students;`(这里的*表示查询所有列,FROM students表示从表格students中查询数据)六、更新数据1. 输入以下命令更新表格中的数据:`UPDATE students SET age = 21 WHERE id = 1;`(这里的SET age = 21表示将age列的值更新为21,WHERE id = 1表示只更新id为1的数据)七、删除数据1. 输入以下命令删除表格中的数据:`DELETE FROM students WHERE id = 1;`(这里的FROM students表示从表格students中删除数据,WHEREid = 1表示只删除id为1的数据)八、备份和恢复数据库1. 备份数据库可以使用以下命令:`sqlite3 test.db .dump > backup.sql`(这里的test.db是要备份的数据库名称,backup.sql是备份文件名称)2. 恢复数据库可以使用以下命令:`sqlite3 test.db < backup.sql`(这里的test.db是要恢复的数据库名称,backup.sql是备份的数据库文件名称)九、退出SQLite1. 输入以下命令退出SQLite:`.exit`以上就是SQLite数据库在Linux系统中的基本使用方法。
sqlite 连接语句

sqlite 连接语句SQLite是一种轻量级的数据库引擎,适用于嵌入式系统和移动设备等场景。
在使用SQLite连接数据库时,可以使用以下语句进行连接操作:1. 打开数据库连接:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 如果数据库不存在,将自动创建一个新的数据库```2. 创建表格:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 获取一个游标对象cursor = conn.cursor()# 创建一个表格cursor.execute('CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER)')```3. 插入数据:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 获取一个游标对象cursor = conn.cursor()# 插入一条数据cursor.execute("INSERT INTO users (name, age) VALUES ('John', 25)")# 提交事务mit()```4. 查询数据:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 获取一个游标对象cursor = conn.cursor()# 查询所有数据cursor.execute("SELECT * FROM users") result = cursor.fetchall()# 遍历结果for row in result:print(row)```5. 更新数据:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db') # 获取一个游标对象cursor = conn.cursor()# 更新数据cursor.execute("UPDATE users SET age = 26 WHERE id = 1")# 提交事务mit()```6. 删除数据:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 获取一个游标对象cursor = conn.cursor()# 删除数据cursor.execute("DELETE FROM users WHERE id = 1")# 提交事务mit()```7. 执行多个SQL语句:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 获取一个游标对象cursor = conn.cursor()# 执行多个SQL语句cursor.executescript('''CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER);INSERT INTO users (name, age) VALUES ('John', 25);INSERT INTO users (name, age) VALUES ('Tom', 30);INSERT INTO users (name, age) VALUES ('Alice', 28);''')# 提交事务mit()```8. 使用参数化查询:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 获取一个游标对象cursor = conn.cursor()# 使用参数化查询name = 'John'age = 25cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", (name, age))# 提交事务mit()```9. 使用事务:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 获取一个游标对象cursor = conn.cursor()# 开始事务conn.execute("BEGIN TRANSACTION")# 执行SQL语句cursor.execute("INSERT INTO users (name, age) VALUES ('John', 25)")# 提交事务mit()```10. 关闭数据库连接:```pythonimport sqlite3# 打开一个SQLite数据库连接conn = sqlite3.connect('database.db')# 关闭数据库连接conn.close()```以上是使用SQLite连接数据库的一些常用语句,通过这些语句可以实现数据库的连接、创建表格、插入数据、查询数据、更新数据、删除数据等操作。
SQLite3的基本使用

SQLite3的基本使⽤|SQLite3简介SQLite3只是⼀个轻型的嵌⼊式数据库引擎,占⽤资源⾮常低,处理速度⽐Mysql还快,专门⽤于移动设备上进⾏适量的数据存取,它只是⼀个⽂件,不需要服务器进程。
常⽤术语:表(table)、字段(column,列,属性)、记录(row,record)。
|SQL(structured query language)语句特点:不区分⼤⼩写,每条语句后加";"结尾。
关键字:select、insert、update、delete、from、creat、where、desc、order、by、group、table、alter、view、index等,数据库中不能使⽤关键字命名表和字段。
数据定义语句(DDL:Data Definition Language)新建表⟹ create:create table 表名 (字段名1 字段类型1,字段名2 字段类型2,。
); create table if not exists 表名 (字段名1 字段类型1,字段名2 字段类型2,。
); CREATE TABLE IF NOT EXISTS t_person (id integer PRIMARY KEY AUTOINCREMENT, name text NOT NULL, age integer NOT NULL);删除表⟹ drop:dorp table 表名;drop table if exists 表名; DROP TABLE IF EXISTS t_person;数据操作语句(DML:Data Manipulation language)添加表中的数据⟹ insert:insert into 表名 (字段1,字段2,。
) values (字段1的值,字段2的值);字符串内容⽤单引号。
INSERT INTO t_person (name, age) VALUES ('⼤明', 22);修改表中的数据⟹ update:update 表名 set 字段1 =字段1的值,字段2 =字段2的值,。
sqlite 基本操作

sqlite 基本操作SQLite是一种轻量级的关系型数据库管理系统,它提供了一套简单易用的操作接口,使得开发者可以方便地进行数据库的创建、查询、更新和删除等基本操作。
本文将介绍SQLite的基本操作,包括数据库的创建与连接、表的创建与删除、数据的插入与查询、数据的更新与删除等内容。
一、数据库的创建与连接1. 创建数据库:使用SQLite提供的命令或者API,可以创建一个新的数据库文件。
可以指定数据库文件的路径和名称,也可以使用默认的名称。
2. 连接数据库:连接数据库是指在应用程序中与数据库建立起通信的通道。
通过连接数据库,可以执行后续的操作,包括创建表、插入数据、查询数据等。
二、表的创建与删除1. 创建表:在数据库中,表是用于存储数据的结构化对象。
通过使用SQLite提供的命令或者API,可以创建一个新的表。
在创建表时,需要指定表的名称和表的字段,以及每个字段的类型和约束。
2. 删除表:当不再需要某个表时,可以使用SQLite提供的命令或者API,将其从数据库中删除。
删除表的操作将会删除表中的所有数据,因此在执行删除操作前应慎重考虑。
三、数据的插入与查询1. 插入数据:在已创建的表中,可以通过使用SQLite提供的命令或者API,向表中插入新的数据。
插入数据时,需要指定数据要插入的表和字段,以及每个字段对应的值。
2. 查询数据:查询数据是使用SQLite最常见的操作之一。
通过使用SQLite提供的命令或者API,可以从表中检索出满足特定条件的数据。
查询操作可以使用各种条件和操作符,以及排序和分组等功能。
四、数据的更新与删除1. 更新数据:在已有的表中,可以使用SQLite提供的命令或者API,更新表中的数据。
更新数据时,需要指定要更新的表和字段,以及每个字段对应的新值。
可以使用各种条件和操作符,以确定要更新的数据行。
2. 删除数据:删除数据是使用SQLite的另一个常见操作。
通过使用SQLite提供的命令或者API,可以从表中删除满足特定条件的数据。
列出sqlite数据库的管理命令和使用格式

一、sqlite数据库管理命令1.1 创建数据库创建一个新的SQLite数据库可以使用如下命令:```sqlite3 database_name.db```1.2 查看数据库列表使用如下命令可以查看当前系统中存在的数据库列表:```sqlite3 .databases```1.3 打开已有数据库使用如下命令可以打开一个已经存在的数据库文件:```sqlite3 database_name.db```1.4 查看数据库表格```sqlite3> .tables```1.5 查看表格结构```sqlite3> .schema table_name```1.6 退出sqlite命令行```sqlite3> .quit```1.7 管理sqlite数据库使用如下命令可以对SQLite数据库进行管理操作,如备份、恢复等功能:```sqlite3.exesqlite> .backup m本人n backup.dbsqlite> .restore m本人n backup.db```二、SQLite数据库使用格式2.1 启动SQLite数据库要启动SQLite数据库,需要打开终端并使用sqlite3命令,然后在sqlite命令行中执行相应的操作。
2.2 创建表格在SQLite命令行中可以使用CREATE TABLE语句来创建新的表格,语法格式如下:```CREATE TABLE table_name (column1 datatype,column2 datatype,...);```2.3 插入数据通过使用INSERT INTO语句可以向表格中插入数据,语法格式如下:```INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);```2.4 查询数据使用SELECT语句可以从表格中查询数据,语法格式如下:```SELECT column1, column2, ...FROM table_nameWHERE condition;```2.5 更新数据通过使用UPDATE语句可以更新表格中的数据,语法格式如下:```UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;```2.6 删除数据通过使用DELETE FROM语句可以删除表格中的数据,语法格式如下:```DELETE FROM table_nameWHERE condition;```2.7 关闭数据库在使用完SQLite数据库后,可以使用如下命令来关闭数据库:```sqlite3> .exit```以上就是关于SQLite数据库的管理命令和使用格式的内容,希望对读者有所帮助。
SQLITE的基本使用说明

Sqlite3:Sqlite3命令行Linux操作

Sqlite3:Sqlite3命令⾏Linux操作1.查看sqlite版本[istester@ idoxu]$ sqlite3 -version2.进⼊sqlite后台操作指定⼀个完整⽂件的路径名,打开或者创建数据库(⽂件不存在,则创建),同时进⼊sqlite后台操作程序。
[istester@ idoxu]$ sqlite3 dome.db3.查看所有数据库#查看所有数据库sqlite>.database4.查看所有表#查看所有表sqlite>.table5.查看所有表的创建语句#查看所有表的建表语句sqlite>.schema6.查看某个表的创建语句#查看某表的建表语句sqlite>.schema table_name7.增删改查命令1)建⽴数据表create table table_name(field1 type1, field2 type1, ...);table_name是要创建数据表名称,fieldx是数据表内字段名称,typex则是字段类型。
例,建⽴⼀个简单的学⽣信息表,它包含学号与姓名等学⽣信息:create table student_istester(stu_no interger primary key, name text);2)添加数据记录insert into table_name(field1, field2, ...) values(val1, val2, ...);values为需要存⼊字段的值。
例,往学⽣信息表添加数据:insert into student_istester(stu_no, name) values(0001, alex);3)修改数据记录update table_name set field1=val1, field2=val2 where expression;where是sql语句中⽤于条件判断的命令,expression为判断表达式例,修改学⽣信息表学号为0001的数据记录:update student_istester set stu_no=0001, name=hence where stu_no=0001;4)删除数据记录delete from table_name [where expression];不加判断条件则清空表所有数据记录。
sqlite3命令方式操作大全

SQLite3命令操作大全SQLite库包含一个名字叫做sqlite3的命令行,它可以让用户手工输入并执行面向SQLite数据库的SQL命令。
本文档提供一个样使用sqlite3的简要说明.一.qlite3一些常用Sql语句操作创建表: create table表名(元素名类型,…);删除表: drop table表名;插入数据: insert into表名values(, , ,) ;创建索引: create [unique] index索引名on 表名(col….);删除索引:drop index索引名(索引是不可更改的,想更改必须删除重新建)删除数据: delete from 表名;更新数据: update表名set字段=’修改后的内容’ where 条件;增加一个列: Alter table表名add column字段数据类型;选择查询:select字段(以”,”隔开) from 表名where 条件;日期和时间: S elect datetime('now')日期: select date('now');时间: select time('now');总数:select count(*) from table1;求和:select sum(field1) from table1;平均:select avg(field1) from table1;最大:select max(field1) from table1;最小:select min(field1) from table1;排序:select 字段from table1 order by 字段(desc或asc);(降序或升序)分组:select 字段from table1 group by 字段,字段…;限制输出:select 字段from table1 limit x offset y;=select字段from table1 limit y , x;(备注:跳过y行,取x行数据)(操作仍待完善)…SQLite支持哪些数据类型些?NULL值为NULLINTEGER值为带符号的整型,根据类别用1,2,3,4,6,8字节存储REAL 值为浮点型,8字节存储TEXT值为text字符串,使用数据库编码(UTF-8, UTF-16BE or UTF-16-LE)存储BLOB值为二进制数据,具体看实际输入但实际上,sqlite3也接受如下的数据类型:smallint 16 位元的整数interger 32 位元的整数decimal(p,s) p 精确值和s 大小的十进位整数,精确值p是指全部有几个数(digits)大小值,s是指小数点後有几位数。
sqlite3 中文手册

sqlite3 中文手册引言概述:SQLite是一种轻量级的关系型数据库管理系统,广泛应用于移动设备和嵌入式系统中。
它具有简单易用、高效稳定的特点,而且还支持中文语言。
本文将详细介绍SQLite3中文手册的内容,包括基本概念、数据库操作、数据类型、查询语句和事务管理等方面。
正文内容:1. 基本概念1.1 数据库管理系统(DBMS)的定义和作用1.2 SQLite3的特点和优势1.3 SQLite3与其他数据库管理系统的比较1.4 SQLite3的安装和配置2. 数据库操作2.1 数据库的创建和删除2.2 表的创建和删除2.3 数据的插入、更新和删除2.4 数据库的备份和恢复2.5 数据库的导入和导出3. 数据类型3.1 SQLite3支持的数据类型3.2 数据类型的定义和使用3.3 数据类型的转换和比较3.4 数据类型的约束和索引3.5 数据类型的存储和检索4. 查询语句4.1 SELECT语句的基本语法和用法4.2 WHERE子句的使用和常见操作符4.3 ORDER BY子句的排序规则和示例4.4 GROUP BY子句的分组和聚合函数4.5 JOIN语句的连接和多表查询5. 事务管理5.1 事务的定义和特性5.2 事务的开始和提交5.3 事务的回滚和保存点5.4 事务的并发和锁定机制5.5 事务的隔离级别和并发控制总结:综上所述,SQLite3中文手册详细介绍了数据库管理系统的基本概念和SQLite3的特点,以及数据库操作、数据类型、查询语句和事务管理等方面的内容。
通过学习这些知识,我们可以更好地理解和应用SQLite3,提高数据库的管理和查询效率。
希望本文对读者有所帮助,进一步掌握SQLite3的使用技巧。
Sqlite3使用教程

Sqlite3使用教程OS X自从10.4后把SQLite这套相当出名的数据库软件,放进了作业系统工具集里。
OS X包装的是第三版的SQLite,又称SQLite3。
这套软件有几个特色:∙软件属于公共财(public domain),SQLite可说是某种「美德软件」(virtueware),作者本人放弃着作权,而给使用SQLite的人以下的「祝福」(blessing):o May you do good and not evil. 愿你行善莫行恶o May you find forgiveness for yourself and forgive others. 愿你原谅自己宽恕他人o May you share freely, never taking more than you give. 愿你宽心与人分享,所取不多于你所施予∙支援大多数的SQL指令(下面会简单介绍)。
∙一个档案就是一个数据库。
不需要安装数据库服务器软件。
∙完整的Unicode支援(因此没有跨语系的问题)。
∙速度很快。
目前在OS X 10.4里,SQLite是以/usr/bin/sqlite3的形式包装,也就说这是一个命令列工具,必须先从终端机(Terminal.app或其他程序)进入shell之后才能使用。
网络上有一些息协助使用SQLite的视觉化工具,但似乎都没有像CocoaMySQL(配合MySQL数据库使用)那般好用。
或许随时有惊喜也未可知,以下仅介绍命令列的操作方式。
SQLite顾名思议是以SQL为基础的数据库软件,SQL是一套强大的数据库语言,主要概念是由「数据库」、「资料表」(table)、「查询指令」(queries)等单元组成的「关联性数据库」(进一步的概念可参考网络上各种关于SQL及关联性数据库的文件)。
因为SQL的查询功能强大,语法一致而入门容易,因此成为现今主流数据库的标准语言(微软、Oracle等大厂的数据库软件都提供SQL语法的查询及操作)。
sqlite3的使用

sqlite3的使用
SQLite是一个开源的嵌入式关系型数据库,它支持标准的SQL语法和常见的数据库操作。
下面是SQLite的一些基本使用方法:
1. 安装SQLite:下载适合你操作系统的SQLite安装包,并按照官方提供的安装说明进行安装。
2. 连接数据库:使用命令行或者GUI工具打开SQLite数据库,可以使用以下命令连接到一个数据库文件。
3. 创建表格:在SQLite中,可以使用`CREATE TABLE`语句创建新的表格。
例如,创建一个名为`users`的表格,包含`id`和`name`两个列。
4. 插入数据:使用`INSERT INTO`语句向表格中插入数据。
例如,向`users`表格中插入一条数据。
5. 查询数据:使用`SELECT`语句从表格中查询数据。
例如,查询`users`表格中的所有数据。
6. 更新数据:使用`UPDATE`语句更新表格中的数据。
例如,更新`users`表格中`id`为1的记录的`name`列。
7. 删除数据:使用`DELETE FROM`语句删除表格中的数据。
例如,删除`users`表格中`id`为1的记录。
这只是SQLite的一些基本用法示例,SQLite还支持更复杂的查询、索引、事务等功能。
你可以参考SQLite官方文档或者其他相关资源来深入学习和了解SQLite的更多用法。
sqlite入门基础(一):sqlite3_open,sqlite3_exec,slite。。。
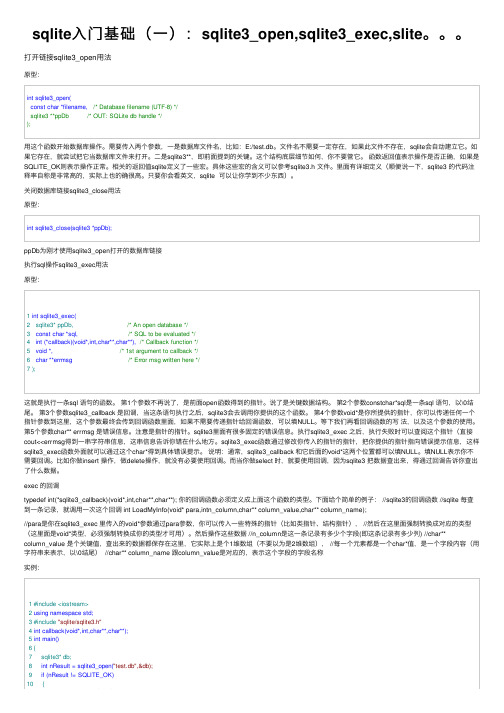
sqlite⼊门基础(⼀):sqlite3_open,sqlite3_exec,slite。
打开链接sqlite3_open⽤法原型:int sqlite3_open(const char *filename, /* Database filename (UTF-8) */sqlite3 **ppDb /* OUT: SQLite db handle */);⽤这个函数开始数据库操作。
需要传⼊两个参数,⼀是数据库⽂件名,⽐如:E:/test.db。
⽂件名不需要⼀定存在,如果此⽂件不存在,sqlite会⾃动建⽴它。
如果它存在,就尝试把它当数据库⽂件来打开。
⼆是sqlite3**,即前⾯提到的关键。
这个结构底层细节如何,你不要管它。
函数返回值表⽰操作是否正确,如果是SQLITE_OK则表⽰操作正常。
相关的返回值sqlite定义了⼀些宏。
具体这些宏的含义可以参考sqlite3.h ⽂件。
⾥⾯有详细定义(顺便说⼀下,sqlite3 的代码注释率⾃称是⾮常⾼的,实际上也的确很⾼。
只要你会看英⽂,sqlite 可以让你学到不少东西)。
关闭数据库链接sqlite3_close⽤法原型:int sqlite3_close(sqlite3 *ppDb);ppDb为刚才使⽤sqlite3_open打开的数据库链接执⾏sql操作sqlite3_exec⽤法原型:1 int sqlite3_exec(2 sqlite3* ppDb, /* An open database */3 const char *sql, /* SQL to be evaluated */4 int (*callback)(void*,int,char**,char**), /* Callback function */5 void *, /* 1st argument to callback */6 char **errmsg /* Error msg written here */7 );这就是执⾏⼀条sql 语句的函数。
Sqlite3使用教程

Sqlite3使用教程SQLite是一种轻型的关系型数据库管理系统,是一种嵌入式数据库引擎。
它是开源的,不需要独立的服务器进程或者操作系统权限,可以直接访问普通的文件。
它在很多应用中被广泛使用,包括Web浏览器、移动设备等。
下面是SQLite3的使用教程。
一、安装SQLite3二、创建数据库打开命令行窗口,使用以下命令创建一个数据库:sqlite3 test.db这个命令会创建一个名为test.db的数据库文件,如果该文件不存在的话。
如果已经存在同名的文件,则会打开该文件。
三、创建表在SQLite中,创建表的语法与其他数据库管理系统类似。
以下是创建一个名为students的表的示例:CREATE TABLE studentsid INTEGER PRIMARY KEY,name TEXT,age INTEGER这个表包含三个列:id,name和age。
四、插入数据数据的插入使用INSERT语句。
以下是插入一条数据的示例:INSERT INTO students (id, name, age) VALUES (1, 'John', 25);这个命令将id为1,name为'John',age为25的数据插入到students表中。
五、查询数据数据的查询使用SELECT语句。
以下是查询students表中所有数据的示例:SELECT * FROM students;这个命令将返回students表中的所有数据。
六、更新数据数据的更新使用UPDATE语句。
以下是将id为1的数据的age更新为30的示例:UPDATE students SET age = 30 WHERE id = 1;这个命令将更新students表中id为1的数据的age为30。
七、删除数据数据的删除使用DELETE语句。
以下是删除id为1的数据的示例:DELETE FROM students WHERE id = 1;这个命令将删除students表中id为1的数据。
常用sqlite命令

常用sqlite命令
SQLite 是一个轻量级的关系型数据库管理系统,通常用于嵌入式系统和桌面应用程序。
以下是 SQLite 中常用的命令和操作:
1.创建数据库
2.显示数据库列表
3.创建表
4.显示表结构
5.插入数据
6.查询数据
7.更新数据
8.删除数据
9.删除表
10.创建索引
11.创建视图
12.删除视图
13.创建触发器 (在SQLite中,触发器是特殊的存储过程,它会在指定的
事件发生时自动执行)
14.查看触发器 (例如,查看所有触发器:.triggers tablename ) 你
可以使用.schema查看表和触发器的创建语句。
) 触发器可以使用CREATE TRIGGER语句来定义。
触发器的语法比较复杂,但基本结构如下:CREATE TRIGGER trigger_name trigger_event ON table_name FOR EACH ROW BEGIN -- trigger body END;其中,trigger_event可以是INSERT, UPDATE, DELETE或UPDATE OF column_name等。
触发器的具体用法和功能取决于你的需求。
15. 执行 SQL 文件使用.read filename.sql可以执行一个 SQL 文件。
16. 关闭 SQLite 提示符使用.quit或者.exit 可以退出 SQLite 提示符。
这些是 SQLite 中常用的命令和操作,但SQLite 的功能远不止这些。
你可以查看 SQLite 的官方文档以获取更详细的信息和更多高级功能。
SQLite3命令操作大全

SQLite3命令操作⼤全SQLite库包含⼀个名字叫做sqlite3的命令⾏,它可以让⽤户⼿⼯输⼊并执⾏⾯向SQLite数据库的SQL命令。
本⽂档提供⼀个样使⽤sqlite3的简要说明.⼀.qlite3⼀些常⽤Sql语句操作⼀:命令<1>打开某个数据库⽂件中sqlite3 test.db<2>查看所有的命令介绍(英⽂).help<3>退出当前数据库系统.quit<4>显⽰当前打开的数据库⽂的位置.database在当前的数据库⽂件中创建⼀张新表(语句) [注:以;结尾,<>中是我们可变的内容]create table <table_name>(表头信息1,表头信息2,表头信息3...);例如:create table people(NAME,SEX,AGE);<5>显⽰数据库中所有的表名sqlite>.tables<6>查看表中表头的信息.schema<7>显⽰调整成列模式sqlite> .mode column<8>显⽰表头sqlite> .header on创建表: create table 表名(元素名类型,…);删除表: drop table 表名;插⼊数据: insert into 表名 values(, , ,) ;创建索引: create [unique] index 索引名on 表名(col….);删除索引: drop index 索引名(索引是不可更改的,想更改必须删除重新建)删除数据: delete from 表名;更新数据: update 表名 set 字段=’修改后的内容’ where 条件;增加⼀个列: Alter table 表名 add column 字段数据类型;选择查询: select 字段(以”,”隔开) from 表名 where 条件;⽇期和时间: Select datetime('now')⽇期: select date('now');时间: select time('now');总数:select count(*) from table1;求和:select sum(field1) from table1;平均:select avg(field1) from table1;最⼤:select max(field1) from table1;最⼩:select min(field1) from table1;排序:select 字段 from table1 order by 字段(desc或asc) ;(降序或升序)分组:select 字段 from table1 group by 字段,字段… ;限制输出:select字段fromtable1 limit x offset y;= select 字段 from table1 limit y , x;(备注:跳过y⾏,取x⾏数据)(操作仍待完善)…SQLite⽀持哪些数据类型些?NULL 值为NULLINTEGER 值为带符号的整型,根据类别⽤1,2,3,4,6,8字节存储REAL 值为浮点型,8字节存储TEXT 值为text字符串,使⽤数据库编码(UTF-8, UTF-16BE or UTF-16-LE)存储BLOB 值为⼆进制数据,具体看实际输⼊但实际上,sqlite3也接受如下的数据类型:smallint 16 位元的整数interger 32 位元的整数decimal(p,s) p 精确值和 s ⼤⼩的⼗进位整数,精确值p是指全部有⼏个数(digits)⼤⼩值,s是指⼩数点後有⼏位数。
《SQLite3—创建数据库、创建及删除表、添加字段和获取数据》

《SQLite3—创建数据库、创建及删除表、添加字段和获取数据》1.创建数据库$sqlite3 DatabaseName.db查询数据库列表:可以使⽤ SQLite 的 .database 命令来检查它是否在数据库列表中退出sqlite>提⽰符:sqlite>.quit导出数据库:$sqlite3 testDB.db .dump > testDB.sql上⾯的命令将转换整个 testDB.db 数据库的内容到 SQLite 的语句中,并将其转储到 ASCII ⽂本⽂件 testDB.sql 中。
您可以通过简单的⽅式从⽣成的 testDB.sql 恢复,如下所⽰:$sqlite3 testDB.db < testDB.sql2.创建表CREATE TABLE语法:CREATE TABLE database_name.table_name(column1 datatype PRIMARY KEY(one or more columns),column2 datatype,column3 datatype,.....columnN datatype,); CREATE TABLE 是告诉数据库系统创建⼀个新表的关键字。
CREATE TABLE 语句后跟着表的唯⼀的名称或标识。
您也可以选择指定带有table_name的database_name。
实例:创建了⼀个 COMPANY 表,ID 作为主键,NOT NULL 的约束表⽰在表中创建纪录时这些字段不能为 NULL:sqlite> CREATE TABLE COMPANY(ID INT PRIMARY KEY NOT NULL,NAME TEXT NOT NULL,AGE INT NOT NULL,ADDRESS CHAR(50),SALARY REAL); 其中ID就是作为主键。
主键的意思就是唯⼀标识符。
不会出现重复。
ID,NAME,AGE这些都是列,也就是字段。
sqlite3 常用指令

sqlite3 常用指令SQLite3是一个轻量级的数据库管理系统,常用于嵌入式设备和移动设备上。
以下是一些SQLite3常用指令:1. 连接数据库,`sqlite3 <database_name>`。
这个指令可以用来连接到指定的SQLite数据库。
2. 创建表格,`CREATE TABLE <table_name> (<column1_name> <column1_type>, <column2_name> <column2_type>, ...);`。
这个指令用来创建一个新的表格,指定表格名称和列的名称及数据类型。
3. 插入数据,`INSERT INTO <table_name> (<column1_name>, <column2_name>, ...) VALUES (<value1>, <value2>, ...);`。
这个指令用来向表格中插入新的数据。
4. 查询数据,`SELECT <column1_name>, <column2_name>, ... FROM <table_name> WHERE <condition>;`。
这个指令用来从表格中查询数据,可以指定条件来过滤查询结果。
5. 更新数据,`UPDATE <table_name> SET <column1_name> =<new_value1>, <column2_name> = <new_value2> WHERE<condition>;`。
这个指令用来更新表格中的数据。
6. 删除数据,`DELETE FROM <table_name> WHERE<condition>;`。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. 虽然 SQL 标准定义了三种类型的外连接:LEFT、RIGHT、FULL,但 SQLite 只支持 左外连接(LEFT OUTER JOIN)
2. LEFT JOIN 关键字会从左表 (table1) 那里返回所有的行,即使在右表 (table2) 中没有匹配的行
29.sqlite> SELECT column1 [, column2 ]
26.sqlite> SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
DISTINCT 关键字与 SELECT 语句一起使用,来消除所有重复的记录,并只获取唯一一次记录。即获取的结果集没有完全重复的多条记录
3.GROUP BY 常与合计函数,如SUM(column)一起使用,表示在分组后的集合内执行此函数
24.sqlite> SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
6.$sqlite3 testDB.db .dump > testDB.sql (将整个 testDB.db 数据库的内容转换为 SQLite 的语句,并将其转储到 ASCII 文本文件 testDB.sql 中)
7.$sqlite3 testDB.db < testDB.sql (将sql文件中的SQLite语句还原成数据库)
1.格式化sqlite3的显示:
sqlite>.header on
sqlite>.mode column (设置输出模式,column 左对齐的列;line 每行一个值)
sqlite>.timer on
sqlite>.width column1_width column2_width ... (为 "column" 模式设置列宽度。)
2.SQLite 是不区分大小写的,但也有一些命令是大小写敏感的,比如 GLOB 和 glob 在 SQLite 的语句中有不同的含义
3.sqlite语句要以分号";"结尾
4.$sqlite3 DatabaseName.db 创建一个新的数据库
5.sqlite>.databases 查看数据库列表
.....
columnN datatype,
);
11.sqlite>.tables 列出附加数据库中的所有表
12.sqlite>.schema table_name (得到表的完整信息,即create table 语句)
13.sqlite> DROP TABLE (database_name.)table_name; 删除表定义及其所有相关数据
LIMIT count(amount of rows) OFFSET num(row num)
从表中自上而下,偏移num行,取count行出来
22.sqlite> SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
18.sqlite> DELETE FROM table_name
WHERE [condition];
使用带有 WHERE 子句的 DELETE 查询来删除选定行,否则所有的记录都会被删除。
19.SQLite Like 子句:
1. 这里有两个通配符与 LIKE 运算符一起使用:百分号(%)代表零个、一个或多个数字或字符;下划线(_)代表一个单一的数字或字符。这些符号可以被组合使用。
2.对结果集的每条记录有:table1中的每一行依次与table2的所有行结合,设table1有a行,table2有b行,则交叉连接后的结果集有a*b行
2.由于交叉连接(CROSS JOIN)有可能产生非常大的表,使用时必须谨慎,只在适当的时候使用它们
2. 内连接 - INNER JOIN : sqlite> SELECT ... FROM table1 [INNER] JOIN table2 ON conditional_expression ...
2.为了使用 UNION,每个 SELECT 被选择的列数必须是相同的,相同数目的列表达式,相同的数据类型,并确保它们有相同的顺序,但它们不必具有相同的长度
SQL 定义了三种主要类型的连接:
1. 交叉连接 - CROSS JOIN : sqlite> SELECT ... FROM table1 CROSS JOIN table2 ...
1.把第一个表的每一行与第二个表的每一行进行匹配。如果两个输入表分别有 x 和 y 列,则结果表有 x+y 列。
17.sqlite> UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
如果您想修改 COMPANY 表中 ADDRESS 和 SALARY 列的所有值,则不需要使用 WHERE 子句
(数据库名称 main 和 temp 被保留用于主数据库和存储临时表及其他临时数据对象的数据库。这两个数据库名称可用于每个数据库连接,且不应该被用于附加,否则将得到一个警告消息)
9.sqlite> DETACH DATABASE 'Alias-Name'; 把命名数据库从一个数据库连接分离和游离出来,连接是之前使用 ATTACH 语句附加的。无法分离 main 或 temp 数据库
20.SQLite Glob 子句:
1. 与 LIKE 运算符不同的是,GLOB 是大小写敏感的
2. 星号(*)代表零个、一个或多个数字或字符;问号(?)代表一个单一的数字或字符。这些符号可以被组合使用。
21.sqlite> SELECT column1, column2, columnN
FROM table_name
1.SELECT column1, column2, columnN FROM table_name1, table_name2, ...; 获取指定列组成的结果表
2.SELECT * FROM t来自ble_name1, table_name2, ...; 获取所有列组成的结果表
16. 获取sqlite3的schema信息:(相当于sqlite3中有一个sqlite_master表,此表中有type、tbl_name、sql等字段),于是:
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
1.GROUP BY 子句用于与 SELECT 语句一起使用,来对相同的数据进行分组
2.GROUP BY 子句放在 WHERE 子句之后,放在 ORDER BY 子句之前
10.sqlite> CREATE TABLE (database_name.)table_name( 用于在任何给定的数据库创建一个新表
column1 datatype PRIMARY KEY(one or more columns),
column2 datatype,
column3 datatype,
4.PRIMARY Key 约束:唯一标识数据库表中的各行/记录。 一个表只能有一个主键,它可以由一个或多个字段组成。当多个字段作为主键,它们被称为复合键
5.CHECK 约束:CHECK 约束确保某列中的所有值满足一定条件。
28.SQLite Joins: 用于结合两个或多个数据库中表的记录
2.sqlite> INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN); 为所有列添加数据
15. SQLite 的 SELECT 语句用于从 SQLite 数据库表中获取数据,以结果表的形式返回数据。这些结果表也被称为结果集。
3.HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前(HAVING 之前必要要有GROUP BY 子句)
25. 对select 语句的关键字 小结:
1.书写顺序: s...f....w....g....h....o
2.解析顺序: f...w....g....h....s....o
27.SQLite 约束:约束可以是列级或表级。列级约束仅适用于列,表级约束被应用到整个表。
以下是在 SQLite 中常用的约束:
1.NOT NULL 约束:确保某列不能有 NULL 值。
2.DEFAULT 约束:当某列没有指定值时,为该列提供默认值。
3.UNIQUE 约束:确保某列中的所有值是不同的。
1. sqlite> SELECT tbl_name FROM sqlite_master WHERE type = 'table'; 列出所有在数据库中创建的表
2. sqlite> SELECT sql FROM sqlite_master WHERE type = 'table' AND tbl_name = 'COMPANY'; 列出关于 COMPANY 表的完整信息
14. 向数据库的某个表中添加新的数据行
1.sqlite> INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) 为指定列添加数据