一个编译器实验的设计与实现
C语言编译器前端的设计与实现 实训报告

第 1 章 绪论
1.1 C 语言及编译器概述
C 语言是在 70 年代初问世的。一九七八年由美国电话电报公司(AT&T)贝尔实验室正式 发表了 C 语言。同时由 B.W.Kernighan 和 D.M.Ritchit 合著了著名的“THE C PROGRAMMING LANGUAGE”一书。通常简称为《K&R》,也有人称之为《K&R》标准。但是,在《K&R》中并 没有定义一个完整的标准 C 语言,后来由美国国家标准学会在此基础上制定了一个 C 语言 标准,于一九八三年发表。通常称之为 ANSI C。C 语言是一种结构化语言。它层次清晰, 便于按模块化方式组织程序,易于调试和维护。C 语言的表现能力和处理能力极强。它不仅 具有丰富的运算符和数据类型,便于实现各类复杂的数据结构。它还可以直接访问内存的 物理地址,进行位(bit)一级的操作。由于 C 语言实现了对硬件的编程操作,因此 C 语言集 高级语言和低级语言的功能于一体。既可用于系统软件的开发,也适合于应用软件的开发。 此外,C 语言还具有效率高,可移植性强等特点。因此广泛地移植到了各类各型计算机上, 从而形成了多种版本的 C 语言。
2.3.1 自顶向下的语法分析...........................................................................................5 2.3.2 自底向上的语法分析...........................................................................................5 2.4 语义分析.........................................................................................................................6 2.5 符号表.............................................................................................................................6 2.6 类型检查.........................................................................................................................7 第 3 章 系统详细设计..................................................................................................................8 3.1 系统设计基本思路.........................................................................................................8 3.2 词法分析模块设计.........................................................................................................8 3.3 语法分析模块设计.......................................................................................................11 3.4 语义分析模块设计.......................................................................................................14 第 4 章 结束语............................................................................................................................16 参考文献...................................................................................................................................... 16 附录: 附录 1:词法分析核心代码............................................................................................17 附录 2:语法分析核心代码............................................................................................18
编译技术实验报告词法(3篇)

第1篇一、实验目的本次实验旨在通过实践加深对编译技术中词法分析阶段的理解,掌握词法分析的基本原理和方法,能够实现一个简单的词法分析器,并对源代码进行初步的符号化处理。
二、实验环境1. 操作系统:Windows 102. 编程语言:Java3. 开发工具:Eclipse IDE4. 实验素材:实验提供的C语言源代码三、实验原理词法分析是编译过程中的第一个阶段,其主要任务是将源代码中的字符序列转换成一系列的词法单元(Token)。
词法单元是构成源程序的基本单位,如标识符、关键字、运算符等。
词法分析的基本原理如下:1. 字符流:从源代码中逐个读取字符,形成字符流。
2. 状态转换:根据字符流中的字符,在有限状态自动机(FSM)中转换状态。
3. 词法单元生成:当状态转换完成后,生成对应的词法单元。
4. 错误处理:在分析过程中,如果遇到无法识别的字符或状态,进行错误处理。
四、实验步骤1. 设计词法分析器:根据C语言的语法规则,设计有限状态自动机,定义状态转换图。
2. 实现状态转换函数:根据状态转换图,实现状态转换函数,用于将字符流转换为词法单元。
3. 实现词法单元生成函数:根据状态转换结果,生成对应的词法单元。
4. 测试词法分析器:使用实验提供的C语言源代码,测试词法分析器的正确性。
五、实验结果与分析1. 词法分析器设计:根据C语言的语法规则,设计了一个包含26个状态的状态转换图。
状态转换图包括以下状态:- 初始状态:用于开始分析。
- 标识符状态:用于分析标识符。
- 关键字状态:用于分析关键字。
- 运算符状态:用于分析运算符。
- 数字状态:用于分析数字。
- 字符串状态:用于分析字符串。
- 错误状态:用于处理非法字符。
2. 状态转换函数实现:根据状态转换图,实现了状态转换函数。
该函数用于将字符流转换为词法单元。
3. 词法单元生成函数实现:根据状态转换结果,实现了词法单元生成函数。
该函数用于生成对应的词法单元。
高级编译器设计与实现

高级编译器设计与实现编译器是一种将高级语言转换为机器语言的软件工具。
它是软件开发中至关重要的一环,负责将人类可读的源代码转换为计算机可执行的机器代码。
编译器的设计和实现对于软件开发的效率和质量有着重要的影响。
本文将探讨高级编译器的设计与实现,并介绍其中的关键技术和挑战。
编译器的设计与实现是一个复杂的过程,需要深入理解编程语言的语法和语义,以及目标硬件的体系结构。
在设计编译器时,需要考虑如何解析源代码、构建中间表示、进行优化和生成目标代码等问题。
编译器需要能够正确解析源代码。
解析器负责将源代码转换为抽象语法树(AST),它表示了源代码的语法结构。
解析器需要遵循编程语言的语法规则,并检查源代码中的语法错误。
解析器可以使用递归下降、LL(k)分析等技术来实现。
然后,编译器需要构建中间表示(IR),它是一种介于源代码和目标代码之间的抽象表示。
IR可以是一种树形结构,也可以是一种线性表示。
IR的设计需要考虑如何有效地表示源代码的语义,并支持后续的优化和代码生成。
优化是编译器设计中的一个重要环节。
优化器负责对中间表示进行各种优化,以提高生成的目标代码的执行效率和质量。
优化技术包括常量折叠、循环优化、内联展开等。
优化器需要根据目标硬件的特点和限制,选择合适的优化策略。
编译器需要将优化后的中间表示转换为目标代码。
代码生成器负责将中间表示转换为目标代码,并进行一些必要的指令选择和调度。
代码生成器需要考虑目标硬件的指令集和寄存器分配等问题。
高级编译器的设计与实现面临着许多挑战。
首先,编程语言的语法和语义通常是复杂的,解析器和语义分析器需要能够处理各种语法结构和语义规则。
其次,优化器需要能够找到和应用各种优化策略,以提高目标代码的性能和效率。
此外,代码生成器需要能够生成高效的目标代码,并充分利用目标硬件的特性。
在编译器设计与实现的过程中,还需要考虑软件工程的实践和原则。
模块化和可重用性是编译器设计中的重要原则,可以通过使用设计模式和良好的软件架构来实现。
编译器设计与实现技术研究

编译器设计与实现技术研究随着计算机软硬件的不断更新,编译器作为一个重要的软件工具,也不断地发展和完善。
编译器是一种将高级语言代码转换成低级代码的程序,它可以将程序员编写的高级语言代码翻译成机器能够识别的汇编代码或者机器语言代码。
编译器的设计和实现技术对于软件开发有着至关重要的作用。
1.编译器的基本工作原理编译器的基本工作原理是将高级语言代码逐步解析成机器能够识别的低级代码。
首先,编译器将高级语言代码进行词法分析,将语句中的标识符、关键字、运算符等转换成对应的记号。
接着,编译器将这些记号进行语法分析,转换成语法树。
语法树表示了给定程序的语法结构,是编译器生成中间代码的重要依据。
编译器根据语法树生成中间代码,并对中间代码进行优化。
最后,编译器将优化后的中间代码转换成机器能够识别的机器码或者汇编代码。
2.编译器的设计与实现技术编译器的设计与实现技术主要包括以下几个方面:2.1.词法分析器词法分析器用于将高级语言代码转换成标记流。
它的主要任务是将输入的文本流转换为一个个逐个扫描的Token 序列,将每个Token 分类为特定的Token 类型,如标识符、关键字、运算符等。
常见的词法分析器生成器有 Flex 和 Lex。
2.2.语法分析器语法分析器用于将标记流转变成一棵语法树。
语法分析器的主要任务是将从词法分析器得到的Token 序列转换成一棵语法树,在语法树上进行语义分析和优化。
常见的语法分析器生成器有 Bison 和 Yacc。
2.3.中间代码生成器中间代码生成器用于将语法树转换成中间代码。
中间代码生成器的主要任务是将语法分析器生成的语法树转换成中间代码。
中间代码表示高级语言代码的语义,是生成目标代码的中间步骤。
常见的中间代码有三地址码、四元式、抽象语法树等。
2.4.中间代码优化器中间代码优化器用于对中间代码进行优化。
中间代码优化器的主要任务是提高目标代码的性能、减小目标代码的大小以及提高编译器的运行效率。
基于Pascal的编译器设计与实现

基于Pascal的编译器设计与实现一、引言编译器是一种将高级语言翻译成机器语言的程序,它在计算机科学领域扮演着至关重要的角色。
Pascal是一种结构化程序设计语言,由Niklaus Wirth于1968年设计并于1970年首次发布。
本文将探讨基于Pascal的编译器设计与实现,介绍编译器的基本原理、Pascal语言特性以及如何将Pascal代码转换为目标机器代码的过程。
二、编译器的基本原理编译器通常由词法分析器、语法分析器、语义分析器、中间代码生成器、优化器和代码生成器等模块组成。
其中,词法分析器负责将源代码转换成单词流,语法分析器将单词流转换成语法树,语义分析器检查语法树是否符合语义规则,中间代码生成器将语法树转换成中间代码,优化器对中间代码进行优化,最后由代码生成器将优化后的中间代码转换成目标机器代码。
三、Pascal语言特性Pascal是一种结构化程序设计语言,具有严格的语法规则和清晰的程序结构。
它支持过程和函数的定义,具有强大的数据类型系统和丰富的控制结构。
Pascal还提供了丰富的标准库函数,方便程序员进行开发。
四、基于Pascal的编译器设计在设计基于Pascal的编译器时,首先需要编写词法分析器和语法分析器来解析Pascal源代码。
词法分析器负责将源代码转换成单词流,而语法分析器则将单词流转换成抽象语法树。
接着需要实现语义分析器来检查抽象语法树是否符合Pascal语言规范,并生成中间代码。
最后通过优化器和代码生成器将中间代码转换成目标机器代码。
五、编译过程详解词法分析:词法分析阶段将源代码按照规定的单词规则进行划分,生成单词流。
语法分析:语法分析阶段将单词流转换成抽象语法树,检查源代码是否符合Pascal语言的语法规则。
语义分析:语义分析阶段检查抽象语法树是否符合Pascal语言的语义规则,并进行类型检查等操作。
中间代码生成:中间代码生成阶段将经过语义分析的抽象语法树转换成中间表示形式,如三地址码或者四元式。
编译原理c语言编译器的设计与实现
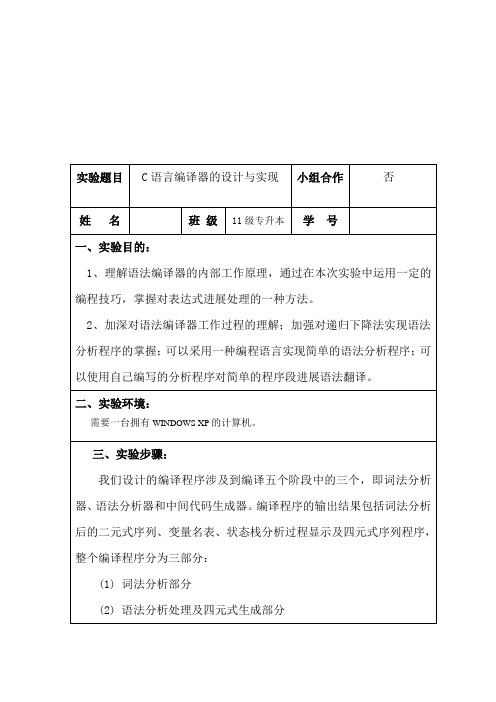
经编译程序运行后得到的输出结果如下:
1〕词法分析得出的相应的名字的号码和他的值2〕列举程序中所有的变量
3〕状态栈的移进-归约过程1.
4〕最后产生的四元式中间代码
一、实验总结:
通过此次实验,让我知道了词法分析的功能是输出把它组织成单个程序,让我理解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;对语法规那么有明确的定义;编写的分析程序可以进展正确的语法分析;对于遇到的语法错误,可以做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程;实验报告要求用文法的形式对语法定义做出详细说明,说明语法分析程序的工作过程,说明错误处理的实现。
通过该实验的操作,我理解编译原理课程兼有很强的理论性和理论性,是计算机专业的一门非常重要的专业根底课程,它在系统软件中占有非常重要的地位,是计算机专业学生的一门主修课。
为了让学生可以更好地掌握编译原理的根本理论和编译程序构造的根本方法和技巧,融会贯穿本课程所学专业理论知识,进步他们的软件设计才能,。
编译原理实验报告1

03091337 李璐 03091339 宗婷婷一、上机题目:实现一个简单语言(CPL)的编译器(解释器)二、功能要求:接收以CPL编写的程序,对其进行词法分析、语法分析、语法制导翻译等,然后能够正确的执行程序。
三、试验目的1.加深编译原理基础知识的理解:词法分析、语法分析、语法制导翻译等2.加深相关基础知识的理解:数据结构、操作系统等3.提高编程能力4.锻炼独立思考和解决问题的能力四、题目说明1.数据类型:整型变量(常量),布尔变量(常量)取值范围{…, -2, -1, 0, 1, 2, …}, {true, false}2、运算表达式:简单的代数运算,布尔运算3、程序语句:赋值表达式,顺序语句,if-else语句,while语句五、环境配置1.安装Parser Generator、Visual C++;2.分别配置Parser Generator、Visual C++;3.使用Parser Generator创建一个工程编写l文件mylexer.l;编译mylexer.l,生成mylexer.h与mylexer.c;4.使用VC++创建Win32 Console Application工程并配置该项目;加入mylexer.h与mylexer.c,编译工程;执行标识符数字识别器;注意:每次修改l文件后,需要重新编译l文件,再重新编译VC工程六、设计思路及过程设计流程:词法分析LEX的此法分析部分主要利用有限状态机进行单词的识别,在分析该部分之前,首先应该对YACC的预定义文法进行解释。
在YACC中用%union扩充了yystype的内容,使其可以处理char型,int型,node型,其中Node即为定义的树形结点,其定义如下:typedef enum { TYPE_CONTENT, TYPE_INDEX, TYPE_OP } NodeEnum;/* 操作符 */typedef struct {int name; /* 操作符名称 */int num; /* 操作元个数 */struct NodeTag * node[1]; /* 操作元地址可扩展 */} OpNode;typedef struct NodeTag {NodeEnum type; /* 树结点类型 *//* Union 必须是最后一个成员 */union {int content; /* 内容 */int index; /* 索引 */OpNode op; /* 操作符对象 */};} Node;extern int Var[26];结点可以是三种类型(CONTENT,INDEX,OP)。
高级编译器设计与实现

高级编译器设计与实现高级编译器是一种能够将高级语言代码转换为机器语言代码的软件工具。
它是计算机科学领域中的一个重要分支,广泛应用于各种软件开发领域。
高级编译器的设计和实现是一项复杂的任务,需要深入了解计算机体系结构、编程语言、算法和数据结构等方面的知识。
高级编译器的设计和实现需要遵循一定的原则和流程。
首先,需要选择合适的编程语言作为目标语言,并确定编译器的输入和输出格式。
其次,需要设计和实现词法分析器、语法分析器、语义分析器、代码生成器等模块,以实现将高级语言代码转换为机器语言代码的功能。
同时,还需要考虑编译器的性能、可靠性、可维护性等方面的问题。
在高级编译器的设计和实现中,词法分析器是一个重要的模块。
它负责将源代码中的字符序列转换为单词序列,并将单词序列传递给语法分析器进行进一步处理。
词法分析器的设计和实现需要考虑多种因素,如识别关键字、标识符、常量、运算符等单词,处理注释和空格等无关字符,以及错误处理等问题。
语法分析器是高级编译器中另一个重要的模块。
它负责将单词序列转换为语法树,并检查语法错误。
语法分析器的设计和实现需要考虑多种因素,如选择合适的语法分析算法(如递归下降分析、LR分析等),处理语法错误和歧义,以及生成中间代码等问题。
语义分析器是高级编译器中的另一个重要模块。
它负责对语法树进行语义分析,并生成中间代码。
语义分析器的设计和实现需要考虑多种因素,如类型检查、作用域分析、常量折叠等问题。
代码生成器是高级编译器中的最后一个重要模块。
它负责将中间代码转换为目标机器语言代码。
代码生成器的设计和实现需要考虑多种因素,如选择合适的代码生成算法(如线性扫描、基本块划分等),优化代码生成质量和效率等问题。
总之,高级编译器的设计和实现是一项复杂的任务,需要深入了解计算机体系结构、编程语言、算法和数据结构等方面的知识。
在设计和实现过程中,需要遵循一定的原则和流程,并考虑多种因素,如性能、可靠性、可维护性等问题。
c语言子集编译器实验报告书

c语言子集编译器实验报告书C语言子集编译器实验报告书一、引言编译器是一种将高级语言代码转换为机器语言代码的工具。
本报告旨在介绍我们设计和实现的C语言子集编译器。
该编译器可以接受符合C语言子集语法规范的源代码,并将其转换为目标机器的可执行文件。
本报告将详细介绍编译器的设计思路、实现过程和测试结果。
二、设计思路我们的编译器主要分为四个阶段:词法分析、语法分析、语义分析和代码生成。
首先,词法分析器将源代码分解为一个个的词法单元,如关键字、标识符、运算符等。
然后,语法分析器将词法单元按照语法规则进行组合,构建出抽象语法树。
接下来,语义分析器对抽象语法树进行语义检查,确保源代码的合法性。
最后,代码生成器将抽象语法树翻译成目标机器的汇编代码,并生成可执行文件。
三、实现过程1.词法分析词法分析器采用有限状态自动机的方式进行实现。
它读取源代码字符流,并根据预定义的正则表达式规则逐个识别出词法单元。
识别出的词法单元被作为输入传递给语法分析器。
2.语法分析语法分析器采用递归下降的方式进行实现。
它根据C语言子集的语法规则,逐步展开抽象语法树的各个节点。
在展开的过程中,语法分析器将词法单元与语法规则进行匹配,确保源代码的语法正确性。
3.语义分析语义分析器在语法分析的基础上,进一步检查源代码的语义错误。
它通过符号表来管理变量和函数的声明和引用,并进行类型检查和作用域检查等。
如果发现语义错误,语义分析器将报告错误信息,并中断编译过程。
4.代码生成代码生成器根据语义分析器生成的抽象语法树,将其翻译成目标机器的汇编代码。
它会为每个变量分配内存空间,并生成相应的加载和存储指令。
最后,代码生成器将生成的汇编代码输出到一个文件中,并调用目标机器的汇编器和链接器生成可执行文件。
四、测试结果为验证编译器的正确性和性能,我们设计了一系列测试用例,涵盖了C语言子集的各种语法和语义规则。
经过测试,编译器能够正确处理各种情况下的源代码,并生成符合预期的可执行文件。
编译原理实验报告

编译原理实验报告一、实验目的编译原理是计算机科学中的重要课程,旨在让学生了解编译器的基本工作原理以及相关技术。
本次实验旨在通过设计和实现一个简单的编译器,来进一步加深对编译原理的理解,并掌握实际应用的能力。
二、实验环境本次实验使用了Java编程语言及相关工具。
在开始实验前,我们需要安装Java JDK并配置好运行环境。
三、实验内容及步骤1. 词法分析词法分析是编译器的第一步,它将源代码分割成一系列词法单元。
我们首先实现一个词法分析器,它能够将输入的源代码按照语法规则进行切割,并识别出关键字、标识符、数字、运算符等。
2. 语法分析语法分析是编译器的第二步,它将词法分析得到的词法单元序列转化为语法树。
我们使用自顶向下的LL(1)语法分析算法,根据文法规则递归地构建语法树。
3. 语义分析语义分析是编译器的第三步,它对语法树进行检查和转换。
我们主要进行类型检查、语法错误检查等。
如果源代码存在语义错误,编译器应该能够提供相应的错误提示。
4. 代码生成代码生成是编译器的最后一步,它将经过词法分析、语法分析和语义分析的源代码翻译为目标代码。
在本次实验中,我们将目标代码生成为Java字节码。
5. 测试与优化完成以上步骤后,我们需要对编译器进行测试,并进行优化。
通过多个测试用例的执行,我们可以验证编译器的正确性和性能。
四、实验心得通过完成这个编译器的实验,我收获了很多。
首先,我对编译原理的知识有了更深入的理解。
在实验过程中,我深入学习了词法分析、语法分析、语义分析和代码生成等关键技术,对编译器的工作原理有了更系统的了解。
其次,我提高了编程能力。
实现一个完整的编译器需要处理复杂的数据结构和算法,这对我的编程能力是一个很好的挑战。
通过实验,我学会了合理地组织代码,优化算法,并注意到细节对程序性能的影响。
最后,我锻炼了解决问题的能力。
在实验过程中,我遇到了很多困难和挑战,但我不断地调试和改进代码,最终成功地实现了编译器。
简单编译器实现课程设计

简单编译器实现课程设计一、课程目标知识目标:1. 学生能理解编译器的基本工作原理和组成部分;2. 学生掌握简单编译器的构建方法和步骤;3. 学生了解编程语言中的语法、词法分析过程;4. 学生掌握使用编程语言(如Python)实现简单编译器的能力。
技能目标:1. 学生能够运用所学知识,独立设计并实现一个简单的编译器;2. 学生能够运用调试工具,对编译器进行调试和优化;3. 学生能够运用所学技能,解决编译过程中遇到的问题;4. 学生能够通过小组合作,提高团队协作和沟通能力。
情感态度价值观目标:1. 学生培养对计算机科学和编程的兴趣,激发自主学习编程的热情;2. 学生认识到编译器在计算机科学中的重要性,增强对程序设计的敬畏心;3. 学生通过课程学习,培养勇于挑战困难、解决问题的信心和毅力;4. 学生在小组合作中,学会尊重他人意见,培养团队精神和协作意识。
课程性质:本课程为实践性课程,结合理论知识,让学生动手实践,实现一个简单的编译器。
学生特点:学生具备一定的编程基础,对编译原理有初步了解,具有较强的学习能力和动手能力。
教学要求:教师需引导学生掌握编译原理的基本知识,注重实践操作,培养学生解决问题的能力和团队协作能力。
通过课程学习,使学生能够将所学知识应用于实际项目中。
二、教学内容1. 编译器原理概述:介绍编译器的基本概念、工作原理和组成部分,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等。
教材章节:第1章 编译原理概述2. 词法分析:讲解词法分析的过程和方法,以及正则表达式和有限自动机的应用。
教材章节:第2章 词法分析3. 语法分析:介绍语法分析的方法,包括自上而下和自下而上的分析技术,以及LL(1)、LR(1)等语法分析算法。
教材章节:第3章 语法分析4. 语义分析:讲解语义分析的过程和任务,如类型检查、符号表管理等。
教材章节:第4章 语义分析5. 中间代码生成与代码优化:介绍中间代码的表示方法,以及常见的代码优化技术。
一种可重构处理器的编译器的设计与实现

2 1 年第4 00 期
中图分类号 :P 3 T 32 文献标识码 : A 文章 编号 : 0 25 (00)4— 0 9— 4 1 9— 5 2 2 1 0 0 5 0 0
一
种 可 重 构 处 理 器 的 编 译 器 的 设 计 与 实 现
施 健 ,谢 憬 ,毛 志 刚
( 上海 交 通 大 学微 电 子学 院 ,上 海 20 4 ) 0 2 0
对 带有编 译指 示 的不 同应 用程 序 完成对 可重 构 阵 列 的重 构 工作 。 对 数 字信 号 处理 应 用的仿 真 结
果显 示 ,经过 CR o P翻 译 的代 码 的性 能 十 分接 近 于需要 花 费 大量 精 力 手 动 配 置 的 最 理 想代 码 的
性能 。
关键 词 :编 译器 ;可重构 处理 器 ;数字信 号处 理 ;译指 示 ;并行 计算
活性 和 A I 的高 效 性 很 好 地 结 合 了起 来 , 为 未 SC 成
行程 序并 行化 , 本 文 需 要解 决 的 问题 。虽 然 目前 是 有一 些并 行 的编 译 器 , 比如 S I2 UF 。但 是 目标 机 器
编译原理编译器综合实验报告

编译原理编译器综合实验报告
本次综合实验的目标是设计和实现一个简单的编译器,用于将一种高级程序语言转化为等效的目标代码。
该编译器的设计基于编译原理的相关知识和技术。
在实验中,我们首先进行了语法分析的设计与实现。
通过使用自顶向下的递归下降方法,我们构建了一个语法分析器,该分析器能够识别源代码中的语法结构,并生成相应的语法树。
为了提高语法分析的效率,我们还使用了一些常见的优化技术,如LL(1)文法的设计和FIRST集合的计算。
接下来,我们进行了语义分析的设计与实现。
在语义分析阶段,我们对语法树进行了类型检查和语义检查。
通过遍历语法树,我们检查了变量的声明和使用情况,以及表达式的合法性。
同时,我们还进行了符号表的设计与管理,用于记录变量和函数的相关信息。
我们进行了中间代码生成的设计与实现,在中间代码生成阶段,我们将语法树转化为一种中间表示形式,以方便后续的优化和目标代码生成。
为了提高中间代码的质量,我们使用了一些常见的优化技术,如常量折叠和公共子表达式消除。
我们进行了目标代码生成的设计与实现,在目标代码生成阶段,我们将中间代码转化为目标代码,以便于在特定的硬件平台上执行。
为了生成高效的目标代码,我们使用了一些常见的优化技术,如寄存器分配和指令选择。
通过本次综合实验,我们深入了解了编译器的各个阶段,了解了
编译原理的基本原理和技术。
同时,我们也学会了如何设计和实现一个简单的编译器,并通过实践掌握了相关的编程技能。
这对我们进一步学习和研究编译原理以及相关领域的知识具有重要意义。
c语言子集编译器实验报告书 -回复

c语言子集编译器实验报告书-回复C语言子集编译器实验报告书为了深入理解编译原理和实践C语言的编译过程,我们小组决定设计和实现一个C语言子集编译器。
本报告将详细介绍我们的实验目标、所采取的实验方法、主要成果和遇到的困难及解决办法等相关内容。
一、实验目标我们的实验目标是设计和实现一个基于C语言子集的编译器。
C语言是一种高级编程语言,对于程序员来说非常重要。
能够编写一个能够正确解析、分析和生成目标代码的编译器对于我们研究和理解底层编程原理具有重要意义。
二、实验方法1. 语法分析器的设计与实现语法分析是编译器的核心部分,用于将源代码转换为可以执行的中间表示。
我们选择使用自上而下的递归下降方法进行语法分析器的设计。
首先,我们仔细研究了C语言的语法规范,并根据其语法规范设计了文法。
然后,我们使用LL(1)文法,并手动实现了对应的递归下降的语法分析器。
2. 词法分析器的设计与实现词法分析器用于将源代码转换为一个个的词法单元(token),即基本的语法单元。
我们使用有限状态自动机(FSM)来设计并实现词法分析器。
首先,我们构建了一个有限状态自动机的状态转移图,然后使用代码实现了相应的状态转移过程。
3. 中间代码生成和代码优化在语法分析的过程中,我们将生成中间表示形式的代码来进一步处理和优化。
我们选择使用三地址码作为中间表示形式,并实现了相应的中间代码生成算法。
此外,我们还进行了局部和全局的代码优化,包括常量合并、无用代码删除等操作。
三、主要成果经过一段时间的实验和努力,我们成功地设计和实现了一个C语言子集编译器。
该编译器能够正确地将C语言子集的源代码转换为目标代码,并生成中间表示形式的代码。
通过该编译器的实验,我们深入理解了编译原理的相关知识,对于C语言的语法、词法和语义有了更加深入的了解。
四、遇到的困难及解决办法在实验的过程中,我们遇到了一些困难,但通过团队合作和不懈的努力,我们最终克服了这些困难。
首先,我们遇到了语法分析器的设计和实现问题。
编译原理课程设计报告-简单文法的编译器的设计与实现

提供全套毕业论文,各专业都有课程设计报告设计题目:简单文法的编译器的设计与实现班级:计算机1206组长学号:20123966组长姓名:指导教师:设计时间:2014年12月摘要编译原理是计算机科学与技术专业一门重要的专业课, 它具有很强的理论性与实践性,目的是系统地向学生介绍编译系统的结构、工作原理以及编译程序各组成部分的设计原理和实现技术,在计算机本科教学中占有十分重要的地位。
计算机语言之所以能由单一的机器语言发展到现今的数千种高级语言,就是因为有了编译技术。
编译技术是计算机科学中发展得最迅速、最成熟的一个分支,它集中体现了计算机发展的成果与精华。
本课设是词法分析、语法分析、语义分析的综合,外加上扩展任务中间代码的优化和目标代码的生成,主要是锻炼学生的逻辑思维能力,进一步理解编译原理的方法和步骤。
关键词:编译原理,前端,目标代码,后端目录摘要 (3)1. 概述 (6)2. 课程设计任务及要求 (8)2.1 设计任务 (8)2.2 设计要求 (9)3. 算法及数据结构 (10)3.1算法的总体思想 (10)3.2 词法分析器模块 (11)3.2.1 功能 (11)3.2.2 数据结构 (11)3.2.3 算法 (12)3.3 语法分析器模块 (13)3.3.1功能 (13)3.3.2 数据结构 (13)3.3.3算法 (14)3.4 中间代码产生器模块 (24)3.4.1 功能 (24)3.4.2 数据结构 (24)3.4.3 算法 (25)3.5 优化器模块 (27)3.5.1 功能 (27)3.5.2 数据结构 (27)3.5.3 算法 (28)3.6 目标代码生成器模块 (30)3.6.1功能 (30)3.6.2 数据结构 (30)3.6.3 算法 (31)4. 程序设计与实现 (32)4.1 程序流程图 (32)4.2 程序说明 (33)4.3 实验结果 (35)5. 结论 (42)6. 参考文献 (43)7. 收获、体会和建议 (44)1 概述在计算机上执行一个高级语言程序一般要分为两步;第一步,用一个编译程序把高级语言翻译成机器语言程序;第二步,运行所得的机器语言程序求得计算结果。
编译器的设计与实现

编译器的设计与实现一、引言编译器是将高级语言代码转换为机器语言的程序,它是计算机科学中的重要组成部分。
编译器的设计和实现涉及到多个方面,包括语法分析、词法分析、代码生成等。
本文将从这些方面介绍编译器的设计和实现。
二、语法分析语法分析是编译器中的一个重要环节,其主要任务是将源代码转换为抽象语法树(AST),以便后续处理。
在进行语法分析时,需要先定义一个文法规则集合,用于描述源代码的结构和语义。
然后使用自顶向下或自底向上的算法来解析源代码,并生成对应的AST。
1. 文法规则集合文法规则集合是描述源代码结构和语义的形式化表示。
常用的文法表示方式有巴克斯-瑙尔范式(BNF)和扩展巴克斯-瑙尔范式(EBNF)。
其中BNF表示方式较为简单,其基本形式如下:<非终结符> ::= <产生式>其中“非终结符”表示一个符号,可以由多个产生式组成;“产生式”则描述了非终结符所能生成的字符串。
2. 自顶向下算法自顶向下算法是一种基于文法规则集合的语法分析算法。
其基本思想是从文法的起始符号开始,递归地展开非终结符,直到生成整个源代码。
自顶向下算法可以用递归下降分析、LL分析等方式实现。
3. 自底向上算法自底向上算法是一种基于输入源代码的语法分析算法。
其基本思想是从输入源代码开始,逐步构建AST,直到生成整个抽象语法树。
自底向上算法可以用LR分析、LALR分析等方式实现。
三、词法分析词法分析是编译器中的另一个重要环节,其主要任务是将源代码转换为单词序列(Token),以便后续处理。
在进行词法分析时,需要先定义一个单词集合,用于描述源代码中可能出现的单词类型和格式。
然后使用有限状态自动机(DFA)或正则表达式来解析源代码,并生成对应的Token序列。
1. 单词集合单词集合是描述源代码中可能出现的单词类型和格式的形式化表示。
常用的单词表示方式有正则表达式和有限状态自动机(DFA)。
2. 有限状态自动机有限状态自动机是一种描述字符串匹配过程的数学模型。
c0编译器设计实现报告
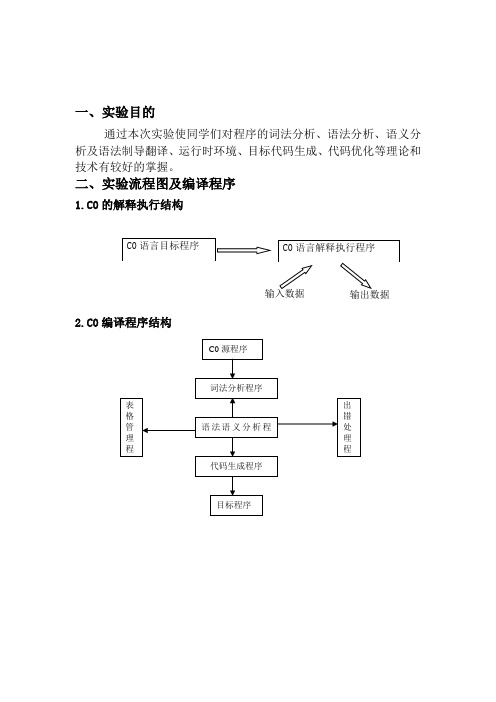
一、实验目的通过本次实验使同学们对程序的词法分析、语法分析、语义分析及语法制导翻译、运行时环境、目标代码生成、代码优化等理论和技术有较好的掌握。
二、实验流程图及编译程序1.C0的解释执行结构2.C0编译程序结构C0语言解释执行程序 C0语言目标程序 输入数据 输出数据词法分析程序语法语义分析程代码生成程序表格管理程序出错处理程序C0源程序目标程序3.执行过程三、名字表设计: Name Kind Lev AdrKind 的类型有:para (全局变量) variable (普通变量) 启动 置初值 调用getsym 取单词 调用block 过程 当前单词是否为源程序结束符‘.’? 源程序中是否有错误? 出错n 打印错误 调用解释过程interpreter 解释执行目标程序 结束voidpro(void函数)ma(main函数)lev:为变量或者函数的层数adr:入口地址四、模块划分1、基础模块(1)写入名字表void enter();(2)查找名字表(想找名字所在的位置,返回在名字表中的位置) int position()返回值为下标i为它在表中位置(3)初始化符号集Void init ()(4)错误处理:n为错误序号,用到的err为错误数Void error(int n)输出n所对应错误2、词法分析模块 int getsym()/*词法分析模块getsym()进行词法分析,里面用到了读取模块getch()用到的变量*有:ssym,word,wsym词法分析结果:输出当前符号或字母的类型放入sym中*/(1)读取模块(获取一行单词)int getch()输出:一个字母,存到ch里(2)生成虚拟机代码int gen(enum f,int l)3、语法语义模块int block()编译程序主体(1)变量声明处理模块int vardefine();(2)语句处理模块int statement();(3)表达式处理模块int expression();(4)项处理模块int term();(5)因子处理模块int factor();(6)If语句处理模块int ifstatement( );(7)语句列处理int statementArray( );(8)while循环处理模块。
PL0语言编译器的设计与实现

PL0语⾔编译器的设计与实现⼀、设计任务1.1程序实现要求PL/0语⾔可以看成PASCAL语⾔的⼦集,它的编译程序是⼀个编译解释执⾏系统。
PL/0的⽬标程序为假想栈式计算机的汇编语⾔,与具体计算机⽆关。
PL/0的编译程序和⽬标程序的解释执⾏程序都是⽤JAVA语⾔书写的,因此PL/0语⾔可在配备JDK的任何机器上实现。
其编译过程采⽤⼀趟扫描⽅式,以语法分析程序为核⼼,词法分析和代码⽣成程序都作为⼀个独⽴的过程,当语法分析需要读单词时就调⽤词法分析程序,⽽当语法分析正确需要⽣成相应的⽬标代码时,则调⽤代码⽣成程序。
⽤表格管理程序建⽴变量、常量和过程标⽰符的说明与引⽤之间的信息联系。
⽤出错处理程序对词法和语法分析遇到的错误给出在源程序中出错的位置和错误性质。
当源程序编译正确时,PL/0编译程序⾃动调⽤解释执⾏程序,对⽬标代码进⾏解释执⾏,并按⽤户程序的要求输⼊数据和输出运⾏结果。
1.2 PL/0语⾔的BNF描述(扩充的巴克斯范式表⽰法)<prog> → program <id>;<block><block> → [<condecl>][<vardecl>][<proc>]<body><condecl> → const <const>{,<const>};<const> → <id>:=<integer><vardecl> → var <id>{,<id>};<proc> → procedure <id>([<id>{,<id>}]);<block>{;<proc>}<body> → begin <statement>{;<statement>}end<statement> → <id> := <exp>|if <lexp> then <statement>[else <statement>]|while <lexp> do <statement>|call <id>([<exp>{,<exp>}])|<body>|read (<id>{,<id>})|write (<exp>{,<exp>})<lexp> → <exp> <lop> <exp>|odd <exp><exp> → [+|-]<term>{<aop><term>}<term> → <factor>{<mop><factor>}<factor>→<id>|<integer>|(<exp>)<lop> → =|<>|<|<=|>|>=<aop> → +|-<mop> → *|/<id> → l{l|d} (注:l表⽰字母)<integer> → d{d}注释:<prog>:程序;<block>:块、程序体;<condecl>:常量说明;<const>:常量;<vardecl>:变量说明;<proc>:分程序; <body>:复合语句;<statement>:语句;<exp>:表达式;<lexp>:条件;<term>:项; <factor>:因⼦;<aop>:加法运算符;<mop>:乘法运算符; <lop>:关系运算符。
编译原理实验动态演示系统的设计与实现

编译原理实验动态演示系统的设计与实现编译原理实验是计算机相关专业的一门重要课程,通过实验学习可以加深对编译原理知识的理解和掌握。
本文将详细介绍编译原理实验动态演示系统的设计与实现。
首先,我们需要明确编译原理实验的内容和目标。
编译原理实验通常包括词法分析、语法分析、语义分析、中间代码生成、目标代码生成等环节。
其目标是实现一个将高级语言程序转换为机器指令的编译器软件。
基于这个目标,我们设计并实现了一个Web应用——编译原理实验动态演示系统。
该系统可以通过图形化界面演示编译原理实验的各个环节的处理过程,帮助学生更加直观地理解和掌握编译原理的相关知识。
系统主要包括两个模块——实验演示模块和实验题目模块。
实验演示模块可以展示编译原理实验的各个环节的处理过程,并提供相应的解释和说明。
实验题目模块则可以根据用户选择的实验内容生成相应的编译器源代码,并提供测试程序以便用户对生成的编译器进行测试和调试。
实验演示模块主要基于Java Applet技术实现,将各个环节的处理过程以动画的形式展示在用户前面,并提供了相应的控制和解释。
通过这种方式,用户可以更加深入地理解编译原理的各个环节和处理过程,便于他们掌握和应用相关知识。
实验题目模块则基于Web技术实现,通过用户选择下拉列表的方式,生成相应的编译器源代码,并提供测试程序以便用户对生成的编译器进行测试和调试。
该模块中还提供了一些实验材料和参考资料,以便用户更好地完成实验和理解相关知识。
综上所述,编译原理实验动态演示系统是一个基于Web技术和Java Applet技术的教学工具,通过图形化界面演示编译原理实验的各个环节的处理过程,并提供编译器生成和测试的功能,便于学生更好地理解和掌握编译原理的相关知识。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一个编译器实验的设计与实现摘要:本文介绍了一个适合描述球类比赛战术特点的脚本描述语言,并把该语言作为实验题目进行实验教学,介绍了学生设计并实现的脚本描述语言编译器,该脚本描述语言的词法和文法描述定义,给出词法分析器和语法分析器的结构设计,最后介绍实现中采用的关键技术。
关键词:脚本描述语言;词法分析器;语法分析器1球类脚本描述语言随着社会文明的发展与进步,体育比赛已经成为人民文化生活中不可缺少的组成部分。
2008年,北京成功举办了第29届奥林匹克运动会,运动员共打破38项世界纪录,取得了骄人的成绩。
作为本次奥运会科技攻关课题组的成员,我们参加了国家乒乓球队攻关项目的研究工作,为中国乒乓球队设计实现了一个基于视频标注的技、战术分析系统。
我们采用编译技术翻译乒乓球脚本描述语言,实时、准确地记录并分析比赛中发生的各种技、战术细节,为教练员提供客观翔实的分析数据。
作为“编译原理”的任课教师,我们认为该课对学生系统掌握计算机基础理论十分重要,但由于学生在今后工作中很难用到编译技术,就会产生厌学思想,因此为学生设计一个好的编译原理实验成为当务之急。
为此,我们结合承担的科研课题,设计了一个既让学生感兴趣,又能加深他们对编译原理思想理解的实验。
根据球类比赛的特点和脚本描述语言的设计要求,球类比赛可分为两种:一是比赛需主、客队同台(场)竞技,如沙滩排球、乒乓球、篮球、足球和网球等;二是主、客队轮流上场,比赛对手不是同台竞技,如台球和保龄球等。
第一种球类比赛具有以下特点:(1)进攻/防守形成博弈;(2)博弈双方的技术动作具有相似性。
为此,我们把第一种比赛的相关技、战术描述抽象成如下形式:队员+技术动作+技术动作发生区域+技术动作结束区域我们的设计目标主要针对第一种比赛。
脚本描述语言的语法结构如图1所示。
其中单词由英文字母构成,可以采用汉语拼音的字首进行编码;句子由单词加分隔符“●”构成。
图2是一个乒乓球比赛脚本描述语言的案例。
2解释器的设计与实现根据球类比赛技、战术分析的需求,设计的解释器由词法器、语法器和语义分析模块三部分组成,如图3所示。
其中词法分析器负责词法分析的预处理和输入单词的解释;语法分析器负责分析输入码的语法结构检查和解释;在词法和语法分析器的基础上,语义分析模块负责比赛技战术的分类与统计工作。
下面分别介绍上述逻辑部件的设计与实现。
2.1词法分析器根据第1节对球类比赛脚本描述语言语法结构的设计以及球类比赛描述的特点,我们对该描述语言的单词符号进行设计。
单词符号有以下4种:(1) 技术动作描述符:一般由四类字符组成,英文字母、数字、“+”和“-”。
其中,英文字母是技术动作的编码,由一个编码映射表支持词法解释;数字用于描述技术动作发生的区域,该语言总是把比赛场地分割成若干个不同的区域;“+”和“-”是两个特殊符号,一般用于一些极其特殊的技、战术描述,如乒乓球中的“擦边球”或“擦网”等。
(2) 间隔符:用于区分不同的技术动作,一般用“●”表示。
(3) 保留字:为了明确标示比赛视频的开始和结束、每一小节或单局比赛的开始和结束、比赛中的暂停和开始,设计了一些保留字,如Match: Start、Match: End、Set1:Start、Set1:End等。
(4) 控制符:用于比赛中的比分调整,如ap03:05、*p02:05。
上述单词符号构成单词的词法分析状态转换描述如图4所示。
上述词法分析的算法如下:算法1一个乒乓球脚本描述语言的词法分析算法Input: 基于乒乓球比赛脚本简码的技战术输入码Output: 描述语言完全码Step1: 词法检测、运动区域补偿Word=Read(code); // 输入一个单词符号//Do while word‘’If field(word, Last_position )=‘●’then breakelse if field(word,start_position )and field(word,target_position )= num then return //词法检测结束//else if field(previous_word,target_position)=numthen field(word, start_position)=field(previous_word,target_position); word=read(code);enddoStep2: 词法检测、动作补偿Word=Read(code); //输入一个单词符号//Do while word‘’If field(word, style_position )‘’then break;else if word.artribute=offence and field(word,start_position )=right_domain //该动作为进攻动作//then field(word, style_position)=‘z’;else if word.artribute=offence and field(word,start_position )=left_domain //该动作为进攻动作//then field(word, style_position)=‘f’;else print(‘an error be found’);word=read(code);enddoend在上面的算法中,每一个单词由四位码构成,field(word, style_position)是单词的第一位,表示动作的方式;field(word, act_position)是单词的第二位,表示动作的类型;field(word, start_position)是单词的第三位,表示球的起点;field(word, target_position)是单词的第四位,表示球飞行的结束位置。
该算法需要两次遍历输入码,因此算法的复杂性为O(L)。
2.2语法分析器根据图1所示的脚本描述语言结构,它的文法G如图5所示:其中:S为开始符号,表示一个输入码,T为非终结符,它可以是ε 字;C1为动作方式码,它只能产生一个表示动作方式终结符号;C2为动作分类码,它只能产生一个表示动作的终结符号;N1为动作起始区域,它只能产生一个表示区域的终结符号,N2为动作终止区域,它只能产生一个表示区域的终结符号。
例如:乒乓球比赛的输入码为:ZX16●FB66●T62● ZH23●ZH33●ZH33●ZH31。
它表示:正手发下旋球从1区到6区●对方反手摆短从6区到6区●反手挑到2区●对手正手弧圈球从2区到3区●正手弧圈球从3区到3区●对手正手弧圈球从3区到3区●正手弧圈球至对方1区后得分。
定理:文法G是LL(1)文法。
证明:为每一个非终结符求FIRST()集和FOLLOW()集如下:FIRST(S)={w, ε}; FIRST(T)={w,ε}; FIRST(S’)={●,ε};FIRST(W)={w};FOLLOW(S)={#}, FOLLOW(T)={● , #}; FIRST(S’)={#}; FOLLO W(W)={●, #}由LL(1)文法的条件可知,G文法满足:FIRST(αi) FIRST(αj)=;FOLLOW(A) FOLLOW(A) = 因此,G是LL(1)文法。
对文法G的语法分析可以采用递归下降法或预测分析表法。
由于脚步描述语言中采用的文法符号可以自定义,符号的数量并不多,所以建议采用预测分析表来实现。
下面是一个改进的预测分析表算法。
算法2基于预测分析的语法分析算法首先把“#”,然后把文法开始符号“S”推进栈charstack;把第一个输入符号读进a(char类型);Flag = TRUE;Do while (Flag){取栈(charstack)顶的元素放入X(char类型)中If( X是文法中终结符号中的一个){If(X==a) Then把下一个符号读进a把栈顶的元素删除elseFlag = FALSE; //词法错误}else if (X==’#’){if (X==a) then Flag = TRUE; //词法分析结束else Flag = FALSE; //词法分析错误}else{找出X在二维数组中的行数Row; //用二维数组表示预测分析表找出a在二维数组中的列数Column; //CString m_strTemp[4[6]If (m_strTemp[Row][Column]!=“ ” && m_strTemp[Row][Column]!=“E”) //E代表ε把栈顶元素删除;把m_strTemp[Row][Column]中的元素从后往前推入栈中;else if (m_strTemp[Row][Column]==“E”) then 删除栈顶元素;else Flag = FALSE;}}算法2的执行时间为O(M*N),M和N分别为预测分析表的行和列下标。
3实验设计根据第2节对球类脚本描述语言中词法、语法分析器的讨论,我们设计了两个实验:实验一:基于球类脚本描述语言的词法分析器的设计与实现。
实验目的:通过本实验,学生掌握词法分析器的体系结构、各功能部件的设计与实现方法,为进一步学习语法分析器奠定基础,能够灵活掌握词法分析的原理和技术。
实验条件:图6给出了一个乒乓球台的分割图,用于表示击球的区域;表1和表2分别用于描述击球的方式和动作,这些描述信息可以供学生设计乒乓球脚本描述语言时参考。
实验要求: 画出脚本描述语言的体系结构图,并定义各个功能模块的实现策略 定义一个小型球类脚本描述语言,可以参照乒乓球比赛的技战术描述需求定义,具体形式如图6所示 完成一个实验报告,分析具体输出结果的语义实验二:基于文法G的语法分析器设计与实现实验目的:通过本实验,学生掌握语法分析器的体系结构、各功能部件的设计与实现方法,为进一步学习语义分析器奠定基础,能够灵活掌握语法分析的原理和技术。
实验条件:表3给出了预测分析表结构,学生根据所设计的描述语言填写具体预测动作。
实验要求: 给出非简化G文法,对其进行消除左递归操作 在实验一定义的球类脚本描述语言基础上设计具体的符号表 手工完成预测分析表的构造,如表3所示,并用数组结构存储 完成一个实验报告,分析具体输出结果的语义4结论笔者在本文中设计了一个球类比赛脚本描述语言编译器实验,给出球类脚本描述语言的语法结构,包括词法和文法规则;给出了词法分析器和语法分析器实现需要的关键算法,为学生进一步实现奠定了基础;给出词法分析器和语法分析器实验模板,为学生完成实验规范了必要的格式和实验要求。