SPSS对连续型变量分组,截点值设置(一)
SPSS软件学习_spss统计描述过程

11
分布曲线形状:偏度的含义
偏度:
大于0表示=正偏=右偏=均值在中位数的右边
左偏
右偏
均值 中位数 众数
众数 中位数 均值
63
12
分布曲线形状:峰度的布
峰度大于0
13
二、描述统计量过程
Frequency
Horsepower
70
60
50
40
30
20
10
Std. Dev = 38.52
Mean = 104.8
0
N = 400.00
50.0 70.0 90.0 110.0 130.0 150.0 170.0 190.0 210.0 230.0
60.0 80.0 100.0 120.0 140.0 160.0 180.0 200.0 220.0
中位数适用于任意分布类型的资料。用中 位数来描述连续变量会损失很多信息,对于 对称分布资料,优先考虑使用均数,仅仅均 数不能使用时才用中位数加以描述;
中位数对于定序变量、连续变量均可以使 用。对定序变量通常采用中位数(不是众数) 来反映更多、更精确的信息。
36
4.2.3 其它集中趋势描述指标
1. 截尾均数 数据排序 去掉最两端的数据(常用的截尾均数有5% 截尾均数,即两端去掉5%的数据,在SPSS 中Explore中可以实现)
如果截尾均数与原均数相差不大,说明 数据不存在极端值,反之相反。
37
2.几何平均数
常用于计算百分比、比率、指数、增长率等 指标的平均数
几何平均数 算术平均数 公式(要求 xi > 0 )
SPSS统计工具应用智慧树知到答案章节测试2023年

第一章测试1.结果输出窗口保存的文件以什么为后缀() A:rtf B:spo C:sav D:sps 答案:B2.下面不属于SPSS的缺点是() A:数据收集和数据清洗功能弱 B:与OFFICE等办公软件兼容性差 C:处理数据量级较低 D:非专业统计软件答案:B3.下面不属于SPSS的优点是() A:易用性强 B:帮助功能强大 C:编程能力强D:基本统计方法较全面答案:C4.IBM SPSS品牌中的计数功能产品是() A:SPSS Amos B:PASW C:SPSSStatistic D:SPSS Modeler 答案:C5.SPSS中的“统计辅导”帮助功能以个案的形式讲解各模块的主要分析方法的基本操作和结果解释。
A:错 B:对答案:A6.SPSS可以同时打开多个结果输出窗口,并将输出结果同时输出在所有输出窗口中。
A:对 B:错答案:B7.SPSS的结果输出窗口中也有分析菜单,所以统计分析操作可以在输出窗口执行。
A:错 B:对答案:B8.社会经济问题研究中常用采用的统计数据分析方法是严格设计支持下的统计方法。
A:对 B:错答案:B ## 第二章测试9.SPSS数据变量类型不包括() A:字符型 B:日期型 C:逻辑型 D:数值型答案:C10.同学们的考核等级变量属于什么计量尺度() A:定类尺度 B:定比尺度 C:定序尺度 D:定距尺度答案:C11.SPSS中定义变量尺度属性称为() A:变量类型 B:度量标准 C:变量值标签 D:变量角色答案:B12.将EXCEL的xlsx文件录入SPSS的方式不包括() A:复制、粘贴 B:直接打开 C:数据库导入 D:文本数据导入答案:D13.如果性别变量用1和2表示男和女,那么可以直接计算平均性别和性别标准差。
A:错 B:对答案:A14.定义变量名越详细越好,方便了解变量的含义。
A:错 B:对答案:A15.分类变量输入SPSS时,最好用数值表示,并在值标签中定义类别含义,最后还需要定义合适的计量尺度。
SPSS随机分组操作步骤

SPSS随机分组操作步骤SPSS(19.0)随机分组操作步骤1.输入原始数据纵向输入原始数据,包括原编号、分组依据的变量,变量列降序排列(Sort Descending)。
2.生成随机种子转换(Transform)→随机数字生成器(Random Number Generators)勾选“活动生成器初始化(Active Generator Initialization)”中的“设置起点(Set Starting Value)”,选中“固定值(Fixed Value)”,默认2,000,000,单击“确定(OK)”。
3.生成随机数字转换(Transform)→计算变量(Compute Variable)目标变量(Target Variable):random函数组(Function Group):随机数字(Random Number)函数和随机变量(Functions and Special Variables):Rv.Uniform,双击选中数字表达式(Numberic Expression):RV.UNIFORM(1,100)→单击“确定(OK)”。
4.输入分组后新编号假设分为a个组,每组n个样本,输入a个1,a个2,……a个n。
5.分组转换(Transform)→个案排秩(Rank Cases)变量(Variable(s)):random排序标准(By):新编号列将秩1指定给(Assign Rank 1 to )“最大值”(Largest value)→单击“确定(OK)”。
“Rrandom”列升序排列(Sort Ascending)。
“Rrandom”列即分组后的组别,“新编号”列即分组后的编号。
SPSS操作要点

SPSS操作程序一、装程序SPSS11.50打开光盘后,在一记事本文件上找到一个序号12345和两个号码。
头一空中可不填号码。
第二次出现空格时可以填写的一个号码;按Update后,再填第二个号码。
以下只要跟着走就行了。
二、定义变量:点击下方的V ariable view,以下定义:1.变量名name:不多于8个字符。
不能与SPSS的保留字相同(查书)。
2.变量类型Type:默认类型为标准数值型Numeric。
一般采用此型。
即使是类别型变量,其代码也是数量型的。
也可使用带逗点的数值型(Comma),整数部分用逗点分节;也可使用圆点数值型(Dot),其小数点与分节点的使用正好互换;对于很小的或很大的数字可用科学计数法型(Scientific Notation)。
3.默认变量值的总长度Width为8,也可改变。
4.小数位数(Decimals),默认为2,也可改变。
bel变量标签:对变量名的说明,可定义,也可不定义。
gender6.V alues变量值标签:适用于类别变量。
点击该格后,在上空格中填写1,在下空格中填写“男”,点击Add后,在下框中出现“1=男”。
7.missing缺损值:点击该格后,默认为“no missing values”。
若要定义缺损值,可选Discrete missing values,在空格中可填写3个离散缺损值,也可选择一个范围,加一个离散值。
8.定义变量显示宽度Column。
第三步的长度实际是变量值的长度,本步还包括变量名的长度。
如第三步定义的With不小于变量名的长度,此步可不操作。
9.对齐方式Alignment10.measure变量的测度类型。
分为Scale、Ordinal、Nominal三种,分别指等距变量或比率变量、等级变量、名义变量。
通常也可让其处于默认状态。
三、变量的整理和转换(一)观察量的排序打开数据窗口,Data—Sort Cases—把作为排序数据的变量(称为BY变量)名送入到右边的Sort by 框中—选择升序排列(Ascending)/降序排列(Descending)—OK。
连续性变量的描述

Horsepower、Time to Accelerate from 0 to 60 mph (accel) 三个变量的变化情况。
28
SPSS12.0统计软件
垂线图
29
SPSS12.0统计软件
半对数线图
30
SPSS12.0统计软件
14
SPSS12.0统计软件
统计图的种类
➢ 单变量图:连续性变量:直方图(茎叶图)、箱图 分类变量:简单条图、饼图
➢ 双变量图:连续因变量:线图、散点图 分类因变量:复式条图
➢ 多变量图:散点图矩阵等
15
SPSS12.0统计软件
统计图的基本要求
➢ 应按照资料的性质与分析目的恰当地选用图形; ➢ 标题位于图形正下方; ➢ 统计图的高:宽接近5:7为宜; ➢ 图中不同的事物用不同的图案或颜色区别,并附图例; ➢ 涉及到坐标轴的图形注意标目、尺度和单位等;
误差线图
31
SPSS12.0统计软件
练习
练习二:某地调查居民心理问题的存在现状,资料如下表所示,试绘制 合适的统计图比较不同性别和年龄组的居民心理问题检出情况。
某地男女性年龄别心理问题检出率比较
年龄分组
心理问题检出率(%)
男性
女性
15-
10.57
19.73
25-
11.57
11.98
35-
9.57
15.5
Model Year (modu lo 100)
列变量
St ati s t i cs
行变量
Number o f Cy linders
Tot al
[指南]spss教程-均值检验
![[指南]spss教程-均值检验](https://img.taocdn.com/s3/m/f51fa87b1fb91a37f111f18583d049649b660e25.png)
在统计学中,我们往往从样本的特性推知随机变量总体的特性。
但由于总体中个体之间存在差异,样本的统计量和总体的参数之间会有误差。
因此,均值不相等的样本未必来自不同分布的总体,而均值相等的样本未必来自有相同分布的总体。
也就是说,如何从样值的差异推知总体的差异,这就是均值比较的内容。
SPSS提供了均值比较过程,在主菜单栏单击“Analyze”菜单下的“Compare Means”项,该项下有5个过程,如图4-1。
图4- 1 均值检验菜单平均数比较Means过程用于统计分组变量的的基本统计量。
这些基本统计量包括:均值(Mean)、标准差(Standard Deviation)、观察量数目(Num Cases)、方差(Variance)。
Means过程还可以列出方差表和线性检验结果。
[例子]调查了棉铃虫百株卵量在暴雨前后的数量变化,统计暴雨前和暴雨后的统计量,其数据如下:暴雨前 110 115 133 133 128 108 110 110 140 104 160 120 120暴雨后 90 116 101 131 110 88 92 104 126 86 114 88 112该数据保存在“DATA4-1.SAV”文件中。
1)准备分析数据在数据编辑窗口输入分析的数据,如图4-2所示。
或者打开需要分析的数据文件“DATA4-1.SAV”。
图4-2 数据窗口2)启动分析过程在SPSS主菜单中依次选择“Analyze→Compare Means→Means”。
出现对话框如图4-3。
图4-3 Means设置窗口3)设置分析变量从左边的变量列表中选中“百株卵量”变量后,点击变量选择右拉按钮,该变量就进入到因子变量列表“Dependent List:”框里,可以从左边变量列表里选择一个或多个变量进行统计。
从左边的变量列表中选中“调查时候”变量,点击“Independent List”框左边的右拉按钮,该变量就进入分组变量“Independe t”框里,用户可以从左边变量列表里选择一个或多个分组变量。
spss统计分析及应用教程-第2章 数据的基本操作

•适用于大型数据集选项 •文件已经按分组变量排序(File is already sorted on break variable(s)) 一般情况下,特别是个案个数较多的数据文件,在进 行分类汇总前,用户需要将个案数据根据中断变量(即分组 变量)进行排序:否则,分类汇总无法进行。如果用户已经 手动完成排序,即可选择该选项,SPSS将忽略排序的步骤, 自动开始分类汇总。 •在汇总之前排序文件(Sort file before aggregating) 如果用户选择“分类汇总”前,并未对数据文件中的 数据按照中断变量进行排序,也没有关系。SPSS提供了汇 总之前先对文件进行排序的功能。选择该选项,SPSS将先 对数据进行排序,然后再进行分类汇总。
第2章 数据的基本操作
实验一 建立与编辑数据文件
实验目的
理解建立数据文件的原理和方法; 掌握编辑数据文件的菜单功能; 熟练应用SPSS软件编辑数据文件。
实验一 建立与编辑数据文件
准备知识
测度(Measurement)含义
所谓测度是指按照某种法则给现象、事物或事件分派一定的数字或 符号、通过测度来刻划事物的特征或属性。一般来说,任何事物或 事件都具有直接的或者潜在的可测性,但是可测的程度或者水平是 不同的。统计学中,通常将测度分为:Scale(定比测度,或比率 测度)、 Ordinal (定序测度、或顺序测度)、Nominal(定类测 度,或名义测度)。这3种测度水平以Scale测度的测度水平最高, Ordinal测度次之,Nominal测度的测度水平最低。
(3)定义新变量及其类 型。在“目标( Target Variable)”栏中定义目 标变量。单击“类型与标 签(Type&Label)按钮, 打开如图所示的类型和标 签对话框。
SPSS命令汇总

一.数据预处理个案号定位:Data->Go to case应用:定位到查询号码的个案变量值定位:Edit->Find应用:定位到搜索变量值的个案插入个案:Data->Insert Cases应用:在前面插入一空白行插入变量:Data->Insert Variable应用:在前面插入一空白列纵向合并:Data->Merge File->Add Cases应用:合并个案横向合并:Data->Merge File->Add Variables应用:合并变量数据排序:Data->Sort Cases应用:能判定数据从最小到最大的范围,能目测异常值变量计算Transform->Compute应用:如果增加“所得税”变量,以及“税后收入”变量,如何写表达式计数Transform->Count应用:将变量的值发生的次数累计,存入一个新变量中可以用于选择案例(Select Cases)的预处理数据选取:Data->Select Cases(怎样OK ?)应用:从收集的数据中筛选数据按指定条件抽样(If…)⏹随机抽样(Random…)⏹选取某一区域(Based …)⏹过滤变量选取样本(Use filter variable)数据加权:Data-Weight Cases应用:当数据文件中的数据,是表示案例发生的次数时,就需要用该数据进行加权数据自动重新编码:Transform-> Automatic Recode应用:用于离散数据或变量值较少的重新编码(一个值为一组)例如:男→1, 女→2数据重新编码:Transform-> Recode应用:对连续型(定距)数据进行分组分成几组合适:K=1+lg(n)/lg(2), n为样本点数每个组的组距:(Max-Min)/K分位数分组:Transform→Categorize Variable s(没找到)应用:变量排序后选择分为几组分类汇总:Data->Aggregate应用:按指定的分类变量进行分组,计算其它变量的组内总值、平均值、极值等可以进行多重分类汇总数据转置:Data->Transpose应用:选定一转置变量进行行列互换数据拆分:Data->Split File应用:以某一变量的有序分组进行数据编排二.基本统计分析个案汇总:Analyze->Reports->Case Summaries应用:按某个变量(sex)的值(m,f)对另一个变量(salary)进行分组,求各组的统计量大小(均值)初步判断各组之间的差异大小。
SPSS 10.0高级教程十四:Survival菜单详解(1)

SPSS 10.0高级教程十四:Survival菜单详解对于急性病的疗效考核,一般可以用治愈率、病死率等指标来评价,但对于肿瘤、结核及其他慢性疾病,其预后不是短期内所能明确判断的,这时可以对病人进行长期随访,统计一定期限后的生存和死亡情况以判断疗效,这就是生存分析。
生存分析是用于以处理生存时间(survival time)为反应变量、含有删失数据一类资料的统计方法。
所谓生存时间,狭义地讲是从某个标准时点起至死亡止,即患者的存活时间。
例如,患有某病的病人从发病到死亡或从确诊到死亡所经历的时间。
广义地说,“死亡”可定义为某研究目的“结果”的发生,如宫内节育器的失落,疾病的痊愈,女孩月经初潮的到来等(生存分析中往往统指各“死亡”为失效)。
此类资料的生存时间变量多不符从正态分布,且常含有删失值,故不适于用传统的数据分析方法如t检验或线性回归进行分析。
根据不同的研究目的和资料类型,可采用不同的分析方法,如寿命表、Kaplan-Meier法、Cox回归模型等分析方法进行分析。
而这正是下面我将要给大家介绍的主要内容。
“喂,你在这里说的都是些什么呀?又是删失、又是Cox的,搞的我一头雾水。
”那位给我提意见了。
列位看官切莫着急,且听在下慢漫道来。
所谓删失值,就是因各种原因对随访对象的随访可能失访或终检(censoring),如研究对象由于其他原因死亡、研究者与病人失去了联系及直到对资料作总结时随访对象还活着但尚未发生所规定的事件。
这种数据就叫做删失值,也叫做截尾数据。
能处理截尾数据是生存分析的一个优点。
Cox回归是一种多变量的生存分析方法。
这是本世纪60~70年代发展起来的、应用于生存资料分析的比例分险模型(the proportional hazard model)。
1972年,英国统计学家D.R. Cox的研究工作使得比例分险模型的理论和实用性更大地推进了一步。
因此许多统计学者就把它称为Cox比例风险或Cox回归。
SPSS的变量设置和基本操作
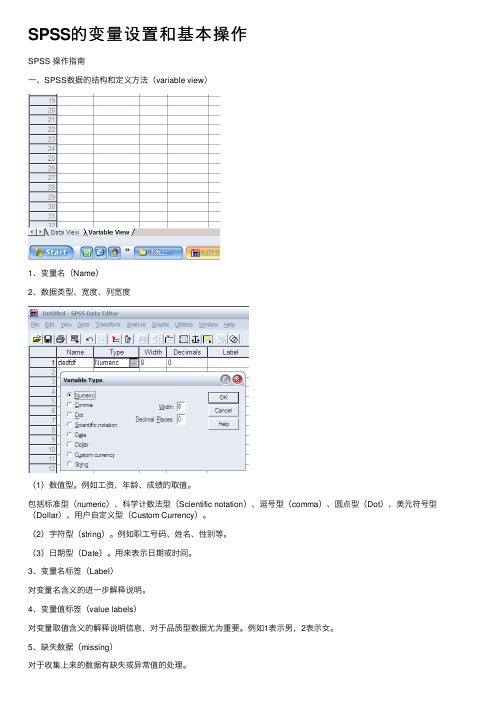
SPSS的变量设置和基本操作SPSS 操作指南⼀、SPSS数据的结构和定义⽅法(variable view)1、变量名(Name)2、数据类型、宽度、列宽度(1)数值型。
例如⼯资、年龄、成绩的取值。
包括标准型(numeric)、科学计数法型(Scientific notation)、逗号型(comma)、圆点型(Dot)、美元符号型(Dollar)、⽤户⾃定义型(Custom Currency)。
(2)字符型(string)。
例如职⼯号码、姓名、性别等。
(3)⽇期型(Date)。
⽤来表⽰⽇期或时间。
3、变量名标签(Label)对变量名含义的进⼀步解释说明。
4、变量值标签(value labels)对变量取值含义的解释说明信息,对于品质型数据尤为重要。
例如1表⽰男,2表⽰⼥。
5、缺失数据(missing)对于收集上来的数据有缺失或异常值的处理。
字符型变量或数值型变量,可以是1⾄3个特定的离散值(discrete missingvalues)数值型变量,哟过户缺失值可以在⼀个连续的闭区间内并同时再附加⼀个区间以外的离散值(Range plus one optional discrete)6、度量尺度(measure)定距型数据(Scale),通常是指诸如⾝⾼、体重、收⼊等的连续型数据。
也包括诸如⼈数、商品件数等离散型数据。
包括了等距量表和等⽐量表。
定序型数据(ordinal)具有内在的固有⼤⼩或⾼低顺序,不同于定距型数据,⼀般可以⽤数值或字符表⽰。
如职称变量可以有低级、中级、⾼级三个取值,可以分别为1、2和3表⽰。
定类型数据(norminal)没有内在固有⼤⼩或⾼低顺序,⼀般以数值或字符表⽰的分类数据。
如性别、民族等。
操作:仔细看看居民储蓄的数据,理解数据结构的含义。
⼆、分类汇总的操作界⾯调整⾄左下⾓的data view。
1、分类汇总按照某分类进⾏分类汇总计算。
例如想知道不同户⼝的居民取款⾦额是否较⼤差距。
如何设置SPSS的相关参数?

如何设置SPSS的相关参数?我们在使用SPSS之前,需要对SPSS的相关参数设置好,今天小编就来教大家如何设置SPSS的参数吧,先来了解下常规设置和查看设置吧!1.打开SPSS之后,进入主界面,在上方的菜单栏中找到——编辑选项卡。
2.在编辑选项弹出的下拉菜单中,点击最下方的——选项按钮。
3.打开的选项对话框中的下方有很多的选项,在不同的选项卡中可以设置不同的选项内容,我们今天来讲讲查看器和常规设置吧!4.我们鼠标左键点击——常规,常规的选项是关于SPSS中的一些比较常用的参数。
5.然后我们点击上方的——查看器选项,在查看器中可以设置字体和图标的格式等等。
6.将相关设置好之后,点击下方的确定按钮,这个在我们重新打开软件的时候不需要再次设置。
SPSS在使用之前是可以进行参数设置的,今天小编来给大家讲解一些相关的参数,比如数据、货币、输出标签和图表,一起来学习吧!1.打开SPSS之后,点击上方的编辑选项卡,弹出的下拉菜单中在最下方找到——选项。
2.在打开的选项对话框中点击上方的——数据选项,可以设置数据处理过程中的相关参数。
3.点击上方的货币选项卡,可以设置自定义的设置数值处理的输出格式的相关参数。
4.在输出标签选项卡中,可以设置输出结果的标签选项。
5.在图标的选项卡中可以对输出图标的参数进行设置,比如字体或者图表的高宽比等等。
SPSS的相关参数讲解的差不多了,今天小编说一下关于枢轴表、文件位置、脚本、多重归因、语法编辑器等等参数的设置。
1.我们首先打开SPSS软件,之后点击编辑——选项的选项,打开参数设置面板。
2.点击上方的枢轴表选项,可以设置新的枢轴表输出的缺省值的外观模式。
3.点击上方的——文件位置选项卡,可以设置打开和保存文件的电脑位置,以及日志文件的存放位置。
4.找到上方——脚本按钮,主要用于指定默认的语言脚本。
5.在导航栏的——多重归因选项下设置与多重归因相关参数的设置。
6.语法编辑器的选项主要用于设置语法编辑器的外观和相应的参数设置。
SPSS数据录入(一)

精选课件
14
录入数据的第一步是定义变量属性,随后才能进行 数据录入。
(一)单选题的录入 单选题的录入可以采用字符直接录入、字符代码+值 标签、数值代码+值标签三种方式。
精选课件
15
(二)多选题的录入
1.多重二分法(Multiple Dichotomy Method) 所谓多重二分法,是在编码的时候,对应每一个选项都要定义
一、常用基本概念 (1)spss算术表达式 spss算术表达式是由常量、spss变
量名、spss的算术运算符、圆括号等组成的式子。 (2)spss函数 spss提供了多达70多种函数,分为八大类:
算术函数、统计函数、分布函数、逻辑函数、字符串函数、 日期时间函数、缺失值函数和其它函数。 (3)spss条件表达式 通过spss的算术表达式和函数可以对 所有记录计算一个结果,如果仅希望对部分记录进行计算, 则应当利用spss的条件表达式指定对那些记录进行计算。
精选课件
5
1.1 数据格式概述
1.1.1 统计软件中数据的录入格式 (1)不同观测对象的数据不能在同一记录中出现,即同一
观测数据应当独占一行。 (2)每一个观测量指标或影响因素只能占据一列的位置,
即同一指标的数量观测值都应当录入到同一个变量中去。
即:一个观测占一行,一个变量占一列
精选课件
6
1.1.2 变量属性介绍
一个变量,有几个选项就有几个变量,这些变量均为二分类, 他们各自代表对一个选项的选择结果。P16 H3b 2.多重分类法(Multiple Category Method) 多重分类法,也是利用多个变量对一个多选题的答案进行定义, 应该用多少个变量,由被访者实际可能给出的最多答案数而 定。P16 H4
spss中的百分位值分割点

spss中的百分位值分割点
在SPSS中,可以使用`DESCRIPTIVES`命令来计算变量的百分位值分割点。
例如,假设你有一个名为"变量名"的数值型变量,你想计算其25、50和75百分位值分割点,可以执行以下步骤:
1. 打开SPSS软件并加载数据文件。
2. 在菜单栏选择"Transform" -> "Compute Variable"。
3. 在弹出的对话框中,输入一个新的变量名,比如"分割点"。
4. 在"Numeric Expression"框中输入以下公式:`PERCENTILE.INC(变量名,百分位值)`。
例如,计算25百分位值分割点的公式为:`PERCENTILE.INC(变量名, 25)`。
5. 单击"OK"按钮以执行计算变量操作。
6. 在数据视图中,你将看到一个新的名为"分割点"的变量,其中包含了你所计算的百分位值分割点。
请注意,这里的百分位值范围在0到100之间,你可以根据需要自行更改百分位值来计算不同的分割点。
对连续变量的分组

对连续变量的分组
对连续变量进行分组有多种方法,以下是一些常见的方法:
1. 等宽分组:将变量的取值范围划分为等宽的若干个区间。
这种方法适合于取值范围较大且分布均匀的变量。
2. 等深分组:将变量的取值范围划分为等深的若干个区间,使每个区间内的数据数量相等。
这种方法适合于取值范围较大且分布不均匀的变量。
3. 分位数分组:根据变量的分位数将数据划分为若干个组。
可以将数据划分为四分位数、五分位数或十分位数等。
这种方法适合于对数据的相对大小感兴趣的情况。
4. 卡方分组:根据卡方统计量将数据分组,使组内的数据满足独立性假设。
这种方法适合于有特定目标的数据分析,比如对分组结果进行统计检验或建模。
5. 聚类分组:使用聚类算法将数据分为若干个组。
聚类算法会根据数据的相似性将数据点聚合在一起,形成不同的组。
这种方法适合于对数据的内在关系感兴趣的情况。
以上是对连续变量进行分组的一些常见方法,选择合适的方法要根据具体的数据特点和目标来定。
需要注意的是,在进行分组时要考虑样本数量的平衡,以及分组结果是否能够满足后续的分析需求。
SPSS的变量设置和基本操作

SPSS的变量设置和基本操作SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件,可帮助研究者在社会科学领域进行数据分析。
在使用SPSS进行分析之前,需要对变量进行设置和进行一些基本操作。
本文将介绍SPSS的变量设置和基本操作。
一、变量设置在使用SPSS之前,必须先进行变量设置,包括变量属性和数据类型的定义。
变量属性可以是数值型、字符型或日期型;数据类型可以是连续型、离散型或自定义型。
以下是一些常见的变量设置步骤:1. 打开SPSS软件并新建数据文件(Data Editor)。
2. 在数据文件中选择“变量视图”(Variable View),可以看到一个表格,每一行代表一个变量。
3.在第一列输入变量名。
变量名应具有描述性且易于理解。
4. 在第二列选择变量类型。
可以选择数值型(Numeric)、字符型(String)或日期型(Date)。
5. 在第三列选择变量宽度(Width),即变量所占的字符数或数字位数。
根据实际需要进行设置。
6. 在第四列选择小数位数(Decimals)。
对于数值型变量,可以设置其精度。
二、变量操作除了变量设置之外,还需要进行一些基本的变量操作,如变量输入、导入、导出、修改和删除等。
以下是一些常见的变量操作步骤:2. 变量导入:可以将数据从其他文件导入到SPSS中进行分析。
选择“文件”(File)→“打开”(Open),然后选择需要导入的数据文件。
3. 变量导出:可以将分析结果导出到其他文件格式中,如Excel、CSV等。
选择“文件”→“导出”→“数据”(Export)。
5. 变量删除:可以删除不需要的变量。
选择相应的变量列,右键点击,并选择“删除”(Delete)。
三、变量操作技巧除了基本的变量设置和操作之外,还有一些变量操作的技巧可以提高效率和准确性。
2. 变量筛选:对于大量变量的数据文件,可以使用变量筛选功能,只显示需要的变量。
SPSS基础教程讲解

SPSS基础教程讲解SPSS基础⽬录第⼀章SPSS简介1.1 SPSS概述1.2 SPSS窗⼝1、数据编辑窗⼝(data editor)2、输出窗⼝(Viewer)3.程序编辑窗⼝1.3SPSS系统参数的设置1.3.1 Options选择对话框1.3.2通⽤参数设置1.3.3结果输出窗⼝参数设置1.3.4 Currency窗⼝参数设置第⼆章数据⽂件的编辑与管理2.1 建⽴与保存数据⽂件2.1.1定义新变量1变量名(Name):2.变量类型(Type)3变量长度(Width):4变量⼩数点占位(Decimal):5变量标签(Lable):6变量值标签(Values):7缺失值的定义⽅式(Missing):8变量的显⽰宽度(Columns):9变量显⽰的对齐⽅式(Align)10变量的度量⽅式(Measure):2.1.2数据的输⼊2.1.3数据的保存2.2读如其他格式的数据⽂件例2.2.1读⼊EXCEL数据⽂件student.xls,并保存为同名的SPSS数据集student.sav 2.3 File菜单中的其他条⽬2.4数据⽂件的编辑2.4.1单元值的查找2.4.2增加或删除⼀个观测2.4.3分析数据的排序2.4.4分析数据集的转置2.4.5选取数据的观测⼦集2.4.6分析数据归类分组汇总2.4.7缺失值的替代2.5数据变量的操作2.5.1增加或删除⼀个变量2.5.2从原有变量构造新变量2.5.3数据排秩2.5.4产⽣计数变量2.5.5数据重新编码2.5.6产⽣⾃动分组变量2.5.7变量集的定义和使⽤2.6 数据⽂件的合并与拆分2.6.1数据⽂件的纵向合并2.6.2数据⽂件的横向合并2.6.3数据⽂件的拆分第⼀章SPSS简介1.1 SPSS概述Statistical package for Social Science,社会科学统计软件包是⼀个组合式软件包,它集数据整理、分析过程、结果输出等功能于⼀⾝,是世界上著名的统计分析软件之⼀。
管理统计学(SPSS)

从左框中选择一变量移如中间框,显示”变量名?”,右 边输出变量框被击活,输入新变量名称,单击旧值和新值 按钮,,弹出一个新窗口
在旧值栏中选择一项输入原值,在新值栏中输入新值, 单击添加按钮。
实例
❖ 对某班学生的身高数据作统计分组. 思考:操作步骤?
第三节 用SPSS作参数假设检验
一、均值过程: 按分组变量计算因变量的描述统计量,如均值、
婚否
已婚 未婚 已婚 已婚 已婚 未婚 已婚 未婚 已婚 未婚
职称
讲师 助教 副教授 教授 副教授 助教 讲师 助教 副教授 助教
籍贯
四川省 陕西省 辽宁省 四川省 海南省 北京市 甘肃省 山东省 山西省 四川省
基本工资
1380 1050.5 1580 2010 1580 1380 1380 1050.5 1580 1050
点击: 分析 非参数检验 二项式
送入变量差。 点击分割点 ,输入分界点0,检验是否有p=0.5
二、单样本T检验
在读入数据后,从主菜单分析开始,依次点击: 分析 比较均值
单样本T检验 系统弹出一个窗口
在检验值 0 格中,填入总体均值假设0值, 点击选项按钮,弹出对话框
选择1-的值
实例:
❖ 某单位女职工160人,男职工206人,工作性质 不同,对相应的平均年薪作比较。
❖ 已知去年某小学五年级学生400米的平均成绩是 100秒,今年该校测得60个五年级学生400米的 成绩,检验该校五年级学生400米的平均成绩是 否仍为100秒(有无提高或下降)。
❖ 在对一项广告的效应进行的电话追 踪调查中,30名被追踪者中有20名会连 同产品一起想起新广告用语。试求在 看过该广告的所有人中会想起新广告 用语的所占的比重的置信区间。
SPSS基本操作步骤详解

SPSS基本操作步骤详解本文采用SPSS21.0版本,其它版本操作步骤大体相同一、基本步骤(一)检查数据在进行项目分析或统计分析之前,要检核输入的数据文件有无错误,即检核missing。
例,“XX量表”采用Likert scale五点量表式填答,每个题项的数据只有五个水平:1,2,3,4,5。
1.执行次数分布表的程序Analyze(分析)→Descriptive statistics(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Frequencies(频率)→Statistics(统计量)→Minimum (最小值)、Maximum(最大值)→Continue(继续)→OK(确定)2.执行描述统计量的程序Analyze(分析)→(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Descriptives(描述)→Options(选项)→Minimum(最小值)、Maximum(最大值)【此处一般为默认状态即可】→Continue(继续)→OK(确定)(二)反项计分若是分析的预试量表中没有反向题,则此操作步骤可以省略;量表或问卷题中如果有反向题,则在进行题项加总之前将反向题反向计分,否则测量分数所表示的意义刚好相反。
例,“XX量表”采用Likert scale五点量表式填答,反向题重向编码计分:1→5,2→4,3→3【可不写】,4→2,5→1。
Transform(转换)→Recode into same Variables(重新编码为相同变量)→将要反向的题目键入至Variables(变量)框中【例,a1,a3,a5】→Old and new values(旧值和新值)→在左边Old value—value中键入1,在右边New value—value中键入5,Add (添加)→……依次进行此步骤……在左边Old value—value中键入5,在右边New value —value中键入1,Add(添加)→Continue(继续)→OK(确定)【注意不同量表计分方式不同,因而反向编码计分也不同,常见的有四点量表、五点量表和六点量表等】(三)题项加总量表题项加总的目的在于便于进行观察值得高低分组。