提取PDF里面图片的方法
JAVA 提取PDF中文本、图片
Java 提取PDF中文本和图片PDF常携带大量且还原度高的信息内容,有时为了获得一些必要的数据我们需要从PDF 中读取文本和图片信息。
下面这篇文章将介绍通过Java实现提取PDF的文本和图片。
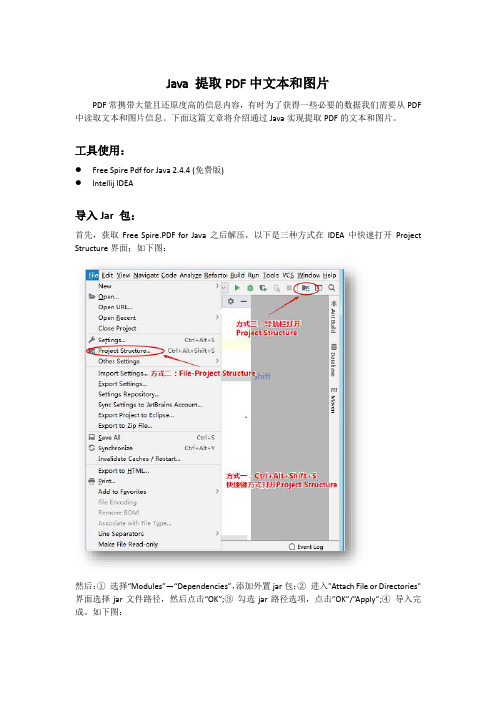
工具使用:●Free Spire Pdf for Java 2.4.4 (免费版)●Intellij IDEA导入Jar 包:首先,获取Free Spire.PDF for Java之后解压,以下是三种方式在IDEA中快速打开Project Structure界面;如下图:然后:①选择“Modules”—“Dependencies”,添加外置jar包;②进入"Attach File or Directories"界面选择jar文件路径,然后点击“OK”;③勾选jar路径选项,点击”OK”/”Apply”;④导入完成。
如下图:测试源文档参考如下:Java 代码示例参考:【示例 1】提取PDF 中文本内容步骤一:添加命名空间; import com.spire.pdf.*; import java.io.FileWriter ;步骤二:创建PDF实例和加载PDF源文件;//创建PDF实例PdfDocument doc = new PdfDocument();//加载PDF源文件doc.loadFromFile("data/PDF_3.pdf");步骤三:使用StringBuilder方法定义一个字符缓冲区实例,for循环遍历整个PDF文档;// 遍历PDF文档StringBuilder buffer = new StringBuilder();for(int i = 1; i<doc.getPages().getCount(); i++){PdfPageBase page = doc.getPages().get(i);buffer.append(page.extractText());}步骤四:定义一个writer实例将数据写到缓冲区,使用write()将缓冲区的数据写入text.txt 文件并保存。
怎么从pdf中提取图片?pdf格式文档中图片怎么提取出来?

怎么从pdf中提取图片?pdf格式文档中图片怎么提取出来?
如果一个文件中的图片比较少,一张一张去保存,倒也不算是什么费劲的事情,但是一个文件中的图片若是很多,一张一张去保存,就不仅费劲,而且费时间了!今天,小枫想为大家分享的,便是怎么从pdf中提取图片?你知道pdf格式文档中的图片怎么提取出来吗?
鉴于PDF文件是一种特殊的文件,这种特殊的格式既不能在Windows系统中直接打开,也不能在Windows系统中直接编辑,所以我们这里要提取PDF文件中的图片,就需要依赖其他的工具来完成了。
今天小枫想为大家安利的,便是自用的迅捷PDF转换器了,在小枫看来,这款软件至少有两大优势让人无法拒绝!
第一、功能多
打开迅捷PDF转换器,你可以看到,这款软件主打的其实是PDF格式转换的功能,通过这款软件,我们可以将PDF文件转成word格式、excel格式、PPT格式、TXT格式、图片格式,html格式,此外,我们也可以将excel、word等格式的文件直接转换成PDF。
而除了格式转换之外,这款软件还能对PDF进行一系列的操作,例如我们这里需要的提取图片,还有加密解密、压缩、合并分割、添加水印等等。
第二、操作简单
软件的功能很多,操作我们就不一一介绍了,这里就以提取图片为例,让你感受一下它的操作有多简单吧!
先点击上方的PDF操作,就可以在左侧的菜单中找到PDF图片提取了,单击选中,之后点击右侧上方的添加文件,将需要提取图片的PDF文件给添加进来,之后,在界面下方的输出图片格式这里设定一个格式,然后点击开始转换就可以了。
简单的三个步骤即可将一个PDF文件中的图片给提取出来,你说它简单不简单呢?操作简单功能还多的一款软件,你说它值不值得被推荐呢?。
PDF Image Extraction Wizard批量导出PDF文档中的图片 1
小软件批量导出PDF文档中的图片
一个PDF文档中有许多精美的图片,如果你想得到这些图片,你会怎么办?一张张的拷贝到画图软件再保存,不把你的手脚累的发酸才怪!笔者教你一招,可以轻松快速的拥有PDF文档中的图片。
我们的利器就是PDF Image Extraction Wizard 这款小软件。
1 软件下载地址为:/soft/25735.html,该软件为绿色软件,无需安装,点击解压文件夹中的Pdfwiz文件即可使用。
2 在“PDF文件”框中通过浏览选择需要导出图片的PDF文件,在“输出文件夹”框中选择图片保存的文件夹(图1)。
3 在“图像的基本名称”框中填写文件的名称,提取的图像将以“基本名称#.ext”来命名(图2)。
#表示序号,ext表示图片的格式,可以是jpg或者bmp格式的图片。
4 点击“继续”,在出现的窗口中输入提取图片的PDF文件页码范围。
如果文档进行了加密,还需要输入密码(图3)。
5 点击“继续”,软件即开始从PDF文档中提取图像(图4),稍等片刻即可显示图片提取已经完成,并显示提取的图片数量(图5)。
软件退出时,会自动打开保存图片的文件夹,非常的方便(图6)。
pdfplumber使用详解

pdfplumber使用详解PDFPlumber是一个用于解析PDF文件的Python库。
它可以提取PDF 中的文本、表格、图片等信息,从而实现对PDF文件的文本数据分析和提取。
PDFPlumber的安装非常简单,只需在命令行中运行以下命令即可:```pip install pdfplumber```安装完成后,就可以使用PDFPlumber库了。
下面是PDFPlumber的一些常用方法和使用示例:1.打开PDF文件:```import pdfplumberpdf = pdfplumber.open('path/to/pdf')````open(`方法接受PDF文件的路径作为参数,返回一个`PDF`对象。
可以使用相对或绝对路径来指定PDF文件的位置。
2.获取PDF文件的页面数量:```num_pages = len(pdf.pages)```可以使用`len(`函数获取`pages`属性的长度。
3.获取PDF页面对象:```page = pdf.pages[0]```可以使用索引来获取特定页面的对象。
注意,索引从0开始。
4.获取PDF页面的文本内容:```text = page.extract_text```可以使用`extract_text(`方法获取PDF页面中的文本内容。
返回的文本内容将是一个字符串。
5.获取PDF页面的表格信息:```tables = page.extract_tables```可以使用`extract_tables(`方法获取PDF页面中的表格信息。
返回的是一个二维列表,每个子列表表示表格中的一行数据。
6.获取PDF页面的图片信息:```images = page.imagesfor i, image in enumerate(images):image.save(f"image_{i}.png", format="PNG")```可以使用`images`属性获取PDF页面中的图片信息。
C#从PDF文档中提取文字和图片

Dim fileName As [String] = "获取文本.txt" File.WriteAllText(fileName, content.ToString())
Dim images As IList(Of Image) = New List(Of Image)() For Each page As PdfPageBase In pdf.Pages If page.ExtractImages() IsNot Nothing Then For Each image As Image In page.ExtractImages() images.Add(image) Next End If Next pdf.Close()
[] Dim pdf As New PdfDocume;)
Dim content As New StringBuilder() For Each page As PdfPageBase In pdf.Pages content.Append(page.ExtractText()) Next
Dim index As Integer = 0 For Each image As Image In images
Dim imageFileName As [String] = [String].Format("Image-{0}.png", System.Math.Max(System.Threading.Interlocked.Increment(index),index - 1)) image.Save(imageFileName, ImageFormat.Png) Next
C#从 PDF 文档中提取文字和图片 Spire.PDF for .NET 是一款功能强大的 PDF 控件,用于在 .NET 程序中创建、读取、写入、编辑和操 作 PDF 文档。使用 Spire.PDF 类库,开发人员可以新建一个 PDF 文档或者对已有的 PDF 文档进行处 理,且无需安装任何第三方插件。Spire.PDF for .NET 支持的功能十分全面,如文档安全性设置(电 子签名),提取 PDF 文本、附件、图片,PDF 合并和拆分,更新 Metadata,设置 Section,绘制图 形、插入图片、表格制作和加工、导入数据等。 下面我们简单介绍如何使用 Spire.PDF 从 PDF 文档中提取文本和图片。程序员可以直接使用 page.ExtractText() 方法来提取 PDF 文档中的所有文字 和 page.ExtractImages 方法来提取 PDF 文档中 的所有图片。并将提取到的文本和图片保存到本地路径以作他用。 [C#]
PDF中提取高清图片的方法介绍

PDF中提取高清图片的方法介绍
PDF中提取高清图片的方法有?想要将PDF文件中的图片提取出来,那么我们是怎么将PDF文档中的图片提取出来的呢?下面我就简单的给大家介绍一下从PDF中如何提取图片的吧。
1、从PDF中提取图片的简答方法可以直接进行在线提取,我们可
以进行选择文档处理处的PDF图片获取;
2、这时可以选择自定义一下页码的选择,选择需要转换的格式等;
3、定义完成之后就可以进行文件的拖拽上传和文件的打开了;
4、选择好之后就可以获取图片了,将鼠标移至开始获取处,点击
开始获取即可;
5、图片的获取是需要一定的时间的,我们需要等进度条到百分百
之后就算是转换完成了;
6、转换完成之后就可以进行文件的直接打开,或是在线下载了。
好了,小编所介绍的PDF图片获取你们学会了么?希望对你们有所帮助。
Java 添加、提取PDF中的图片(基于Spire.Cloud.SDK for Java)

Java 添加、提取PDF中的图片Spire.Cloud.SDK for Java提供了PdfImagesApi接口可用于添加图片到PDF文档addImage()、提取PDF中的图片extractImages(),具体操作步骤和Java代码示例可参考以下内容。
一、导入jar文件。
(有2种方式)(推荐)方式1. 创建Maven项目程序,通过maven仓库下载导入。
以IDEA为例,新建Maven项目,在pom.xml文件中配置maven仓库路径,并指定spire.cloud.sdk的依赖,如下:<repositories><repository><id>com.e-iceblue</id><name>cloud</name><url>/repository/maven-public/</url></repository></repositories><dependencies><dependency><groupId> cloud </groupId><artifactId>spire.cloud.sdk</artifactId><version>3.5.0</version></dependency><dependency><groupId> com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.1</version></dependency><dependency><groupId> com.squareup.okhttp</groupId><artifactId>logging-interceptor</artifactId><version>2.7.5</version></dependency><dependency><groupId> com.squareup.okhttp </groupId><artifactId>okhttp</artifactId><version>2.7.5</version></dependency><dependency><groupId> com.squareup.okio </groupId><artifactId>okio</artifactId><version>1.6.0</version></dependency><dependency><groupId> io.gsonfire</groupId><artifactId>gson-fire</artifactId><version>1.8.0</version></dependency><dependency><groupId>io.swagger</groupId><artifactId>swagger-annotations</artifactId><version>1.5.18</version></dependency><dependency><groupId> org.threeten </groupId><artifactId>threetenbp</artifactId><version>1.3.5</version></dependency></dependencies>完成配置后,点击“Import Changes” 即可导入所有需要的jar文件。
python三种方法提取pdf中的图片

python三种⽅法提取pdf中的图⽚有时我们需要将⼀份或者多份PDF⽂件中的图⽚提取出来,如果采取在线的⽹站实现的话⼜担⼼图⽚泄漏,⼿动操作⼜觉得⿇烦,其实⽤Python也可以轻松搞定!今天就跟⼤家系统分享⼏种Python提取 PDF 图⽚的⽅法。
其实没有⾮常完美的⽅法,每种⽅法提取效率都不是百分之百,因此可以考虑⽤多种⽅法进⾏互补,主要将涉及:基于fitz库和正则搜索提取图⽚基于pdf2image库的两种⽅法提取图⽚基于 fitz 库和正则搜索fitz 是 pymupdf 的⼦模块,需要先⽤命令⾏安装 pymupdf:pip install pymupdf但注意导⼊时使⽤import fitz导⼊模块!下⾯的代码就利⽤fitz库提取图⽚需要通过正则匹配图⽚元素,将模板元素转化为像素后再以图⽚形式写出import fitzimport reimport osfile_path = r'C: xx xx.pdf' # PDF ⽂件路径dir_path = r'C: xx' # 存放图⽚的⽂件夹def pdf2image1(path, pic_path):checkIM = r"/Subtype(?= */Image)"pdf = fitz.open(path)lenXREF = pdf._getXrefLength()count = 1for i in range(1, lenXREF):text = pdf._getXrefString(i)isImage = re.search(checkIM, text)if not isImage:continuepix = fitz.Pixmap(pdf, i)new_name = f"img_{count}.png"pix.writePNG(os.path.join(pic_path, new_name))count += 1pix = Nonepdf2image1(file_path, dir_path)运⾏提取⽰例⽂件后结果如下:可以看到,有⼀些很⼩的⾊块也被提取成图⽚,那么怎么过滤掉它们呢?有⼀个简单的⽅法是通过⼤⼩过滤,pix 像素在 fitz 库中存在⼀个重要的⽅法 pix.size 可以反映像素多少,简单的⾊素块该值较低,可以通过设置⼀个阈值过滤。
pdf印章提取方法

提取PDF文件中的印章可以通过以下两种方法:
方法一:使用Illustrator软件
右键点击PDF文件,选择“打开方式”,然后使用Illustrator 软件打开含有印章的PDF文件。
选择印章所在的那一页,在下面设置印章所在页的页数,这里以7-7为例。
按住Shift键,分别双击选择两个印章,然后按Ctrl+C复制。
新建一个空白文件,把复制的印章按Ctrl+V粘贴进去。
按住Ctrl+S保存,输入名字,点击导出即可。
方法二:使用办公
点击下载并打开《办公》,使用左侧的“PDF处理”功能,选择“PDF提取图片”功能,点击“添加文件”导入准备好的PDF 文件。
设置好提取图片的范围,一般完整印章在最后一页可以找到,选中最后一页,设置好图片的格式为png,转换的时
候不会压缩质量。
返回首页,选择“图片处理”——“抠图换背景”将刚刚转
换好的图片导入进来,将印章抠出保存即可。
可以根据需要和习惯选择合适的方法,如有疑问可以咨询专业人士。
使用python的pdfminer库提取pdf中的图像之填坑记

使⽤python的pdfminer库提取pdf中的图像之填坑记本地环境:win10 x64,python3.8 x64安装:pip install pdfminer使⽤:按照官⽅给的⽅法使⽤⼀波,发现windows下没给适配,运⾏pdf2txt.py直接弹出来编辑器编辑源代码了,需要⽤python+绝对路径+参数的⽅法调⽤python (gcm pdf2txt.py).source -o outputfilename -O output_dir input.pdf-o:输出⽂件名,可以通过⽂件拓展命指定转换⽬标类型-O:输出资源⽬录,⽐如转换成HTML⽂件,图⽚⽂件存放⽬录就在这⾥指定跑⼀波直接跑不通可还⾏,找来源代码瞅瞅看对filter调⽤的⽅法,filter应该是个list,直接 filters = stream.get_filters() 修改为 filters = list(stream.get_filters())再试⼀波,这波没报错。
但是输出的⽂件夹⾥只有⼀张图,我pdf⾥上百张图都去哪⾥了打开唯⼀的图⽚发现是最后⼀张图,盲猜⼀波pdf⽂件中的图⽚都是这个名字,pdf2txt在解析抽取图像的时候,只是简单的⽤图像在pdf⾥的名字保存,导致每次保存⼀张重名图像都会把⽼图替换掉。
刚刚出错的⽂件名叫image.py应该是和图像处理相关的,应该能找到图像保存的逻辑。
果然!在这⾥给⽂件名加个递增前缀应该能解决问题。
定义⼀个⽣成递增前缀滴函数,并在产⽣⽂件名时加上这个前缀from time import timedef prefix_():return str(int(time()*10**6))name = f'{prefix_()}_{}.{ext}'再跑⼀次可以看到该有的都有了。
解析如何提取pdf中的图片内容(附图文教程)

版权问题
确保有权使用
在提取PDF中的图片内容之前, 请确保您有权使用这些内容,避 免侵犯版权。
避免商业用途
如果您打算将提取的图片用于商 业目的,请务必获得版权持有人 的许可。
提取的图片质量
选择高分辨率
在提取PDF中的图片时,尽量选择高 分辨率的图片,以便获得更好的图像 质量。
避免失真
在提取过程中,尽量避免图片失真和 压缩,以保持原始图像的清晰度和细 节。
2. 在网站页面上方 的工具栏中选择“ 编辑”->“从PDF 中提取图片”。
4. 点击“开始”, 等待提取过程完成。
1. 打开iLovePDF网 站,上传需要提取 图片的PDF文件。
3. 在弹出的对话框 中,选择保存位置 和文件名。
5. 提取完成后,可 以在指定位置查看 提取的图片。
04
注意事项与建议
FreePDFFiller不仅提供在线的PDF编辑功能 ,还支持提取PDF中的图片。用户只需上传 PDF文件,即可在线提取其中的图片。
ilovepdf
ilovepdf也提供在线的PDF处理工具,其 中包括提取PDF中图片的功能。用户上传 PDF后,系统会自动提取其中的图片。
使用命令行工具提取
pdftk
PDF与图片提取的关联性
PDF文件的特点
PDF是一种跨平台的文件格式,可以包含文字、图片、表格等多种元素。由于其 高度的可读性和可编辑性,PDF已成为数字出版和办公自动化的重要工具。
图片提取的重要性
在处理PDF文件时,有时需要提取其中的图片以进行编辑、修改或重新使用。例 如,在制作电子书或电子杂志时,可能需要从PDF中提取图片以丰富内容或美化 版面。
5. 点击“保存”,等待提取过程完成。
pdf 分离过程

pdf 分离过程
PDF(Portable Document Format)是一种常用的文件格式,分离过程通常指的是将PDF文件中的页面或内容进行分离、提取或拆分。
以下是关于PDF分离的可能方法:
1. 拆分页面
- 使用软件工具:诸如Adobe Acrobat、PDFelement等PDF编辑软件,提供了页面拆分功能。
用户可以手动选择要分离的页面,然后将其另存为新的PDF文件。
2. 提取内容
- 复制粘贴:对于文本或图片等可复制内容,可通过复制粘贴的方式将其提取到其他文档或软件中。
- 转换工具:有些在线或软件工具能够将PDF中的文字或图片转换成其他格式,如Word、图片格式等,进行进一步处理。
3. 按内容类型分离
- 图像提取:一些软件或在线工具可以单独提取PDF中的图片内容。
- 文本提取:文本内容也可通过复制粘贴或专门的文本提取工具进行分离。
4. 按页范围分离
- 命令行工具:通过一些命令行工具或代码脚本,可以指定页码范围来实现PDF的分离,比如使用Python的PyPDF2库等。
5. 在线工具
- PDF拆分网站:一些在线服务提供了PDF文件拆分功能,用户上传文件后可以选择拆分方式和范围,然后下载拆分后的文件。
这些方法可以根据用户的需求,选择合适的方式进行PDF文件的分离,从而提取出特定的内容或按需拆分页面。
pypdf方法

PyPDF 是Python 中的一个库,可以用来处理PDF 文件。
下面是一些PyPDF 的常用方法:1.读取PDF 文件:使用PyPDF 的PdfFileReader()类可以读取PDF 文件的内容。
可以通过调用getPage()方法获取每一页的内容,然后使用extractText()方法提取文本。
2.合并PDF 文件:使用PyPDF 的PdfFileWriter()类可以合并多个PDF 文件。
可以通过调用addPage()方法将每一页添加到输出文件中,然后使用write()方法将输出写入文件。
3.旋转PDF 页面:使用PyPDF 的PdfFileWriter()类可以在输出PDF 文件中旋转页面。
可以通过调用addPage()方法添加需要旋转的页面,并设置旋转角度,然后使用write()方法将输出写入文件。
4.加密PDF 文件:使用PyPDF 的PdfFileReader()和PdfFileWriter()类可以对PDF 文件进行加密。
可以通过调用encrypt()方法设置密码,然后使用write()方法将加密后的内容写入文件。
5.提取PDF 中的图片:使用PyPDF 的ImageReader()类可以从PDF 文件中提取图片。
可以通过调用extractImages()方法提取所有图片,并返回一个包含所有图片的字典。
6.将PDF 转换为图片:使用PyPDF 的ImageReader()类可以将PDF 文件转换为图片。
可以通过调用extractImages()方法获取每一页的图像,并使用图像处理库将其转换为图片。
7.拆分PDF 文件:使用PyPDF 的PdfFileReader()和PdfFileWriter()类可以将PDF 文件拆分成多个文件。
可以通过调用extractText()方法获取每一页的文本,并使用文本处理库将其拆分成多个文本文件。
这些是PyPDF 的常用方法,可以根据具体需求选择合适的方法来处理PDF 文件。
如何把pdf文件中图片提取出来

怎样把pdf文件中图片提取出来目前图片编辑这项工作是一项十分火爆且受欢迎的工作。
它的日常工作当中有一项提取文件当中的图片,进行编辑整理。
说得是把文件、文章内的图片提取出来,再整理到一个文件夹当中,当做图片素材的贮备。
像word这类文档中的图片很好提取,但是怎么样把pdf 文件中图片提取出来呢?下面小编就将告诉大家把pdf文件中图片提取出来的操作方法。
1.word文档中的图片直接进行复制粘贴就可将图片提取出来,保存在电脑当中。
可是提取pdf文件中的图片,首先需要准备好提取工具:pdf转换器。
2.开始鼠标双击打开pdf转换器,接着点击转换器界面内左侧的PDF的其他操作。
3.接下来鼠标单击界面中下方的添加文件选项,在弹出的窗口内找到本地已经存储得,要提取图片的pdf文件,鼠标左击选中该文件,并点击窗口右下角的打开选项。
4.紧接着,先要选择提取出来的图片将以什么图片格式进行保存。
在输出图片格式后可根据个人需求,进行选择。
5.然后在转换器界面内上方的输出目录后,鼠标点击自定义选项,再点击右侧的浏览选项,选择提取出得图片的保存地址。
6.之后就可以点击状态文字下方的播放小图标,pdf转换器就将进行图片提取的操作。
7.当图片提取操作完成后,鼠标点击播放图标右侧的小文件夹图标,即可查看提取的图片了。
这样也就意味着pdf文件中的图片成功提取出来了。
怎么样把pdf文件中图片提取出来的操作过程,小编已经在上方文章内详细地告诉了大家。
其实这项操作本身并不困难,小伙伴们只要熟练运用pdf转换器。
不论在任何文件当中提取文件都会变得轻而易举。
1秒教你怎么提取PDF文件中的图片内容,图片随意收!

1秒教你怎么提取PDF文件中的图片内容,图片随意收!
在查看PDF文件的时候,看见好看的图片却总是因为格式问题无法提取和保存,这种时候我们应该怎么办呢?别担心,看完这篇文章立马解决你的问题!
想要提取PDF文件中的图片内容,那么就需要利用这一款迅捷PDF转换器,这款软件不仅是一款专业的PDF文件转换器,而且这款软件还具备PDF文件分割、合并、图片获取、压缩等功能。
一、打开迅捷PDF转换器
二、点击操作
将迅捷PDF转换器下载到电脑以后,运行这一个软件后,找到【文件转图片】,并点击,即可进行提取PDF文件图片操作。
三、点击添加文件
点击下方的【添加文件】按钮,就可以在迅捷PDF转换器中添加自己所想要转换为图片的PDF格式文件。
四、选择文件
选择自己想要转化为图片的文字,并将其添加到迅捷PDF转换器中。
添加完成后可以在【输出目录】中选择修改自己想要储存的位置。
五、开始转换
将所有一切内容选择完成修改后就可以开始转换了,这样软件就会自动提取PDF文档中的图片内容了。
你想要的图片也就出来啦~
以上就是怎么提取PDF文件中的图片内容的操作过程了大家看明白了吗,是不是也觉得十分简单呢?只需要用这款迅捷PDF转换器就可以轻松将图片提取出来,以后如果还有这样的图片提取任务,就不会觉得一筹莫展啦~。
pdfminer 解析pdf

pdfminer 解析pdf引言概述:PDF是一种常见的文件格式,而解析PDF文件的需求也越来越多。
在解析PDF文件的过程中,pdfminer是一个非常有用的工具。
本文将详细介绍pdfminer的功能和使用方法,以及其在解析PDF文件中的应用。
正文内容:1. pdfminer的功能1.1 PDF文件解析:pdfminer可以将PDF文件解析成文本、图片、表格等各种元素,方便后续的处理和分析。
1.2 文本提取:pdfminer可以提取PDF文件中的文本内容,包括正文、标题、页眉页脚等,方便进行文本分析和关键词提取。
1.3 图片提取:pdfminer可以提取PDF文件中的图片,包括矢量图和位图,方便进行图像处理和识别。
1.4 表格解析:pdfminer可以解析PDF文件中的表格,提取表格数据,并将其转换成结构化的数据格式,方便进行数据分析和处理。
1.5 元数据提取:pdfminer可以提取PDF文件的元数据,包括作者、标题、关键词等,方便进行文档管理和检索。
2. pdfminer的使用方法2.1 安装pdfminer:可以通过pip命令安装pdfminer,也可以从官方网站下载源代码进行安装。
2.2 解析PDF文件:使用pdfminer的解析器类可以对PDF文件进行解析,提取所需的内容。
2.3 设置解析参数:pdfminer提供了一些参数,可以根据需要设置解析的深度、解析的元素类型等。
2.4 处理解析结果:pdfminer将解析结果以树状结构进行存储,可以通过遍历树状结构获取所需的内容。
2.5 导出解析结果:pdfminer可以将解析结果导出为文本文件、HTML文件等,方便进行后续的处理和分析。
3. pdfminer在解析PDF文件中的应用3.1 文本分析:通过提取PDF文件中的文本内容,可以进行文本分析,如情感分析、文本分类等。
3.2 图像处理:通过提取PDF文件中的图片,可以进行图像处理,如图像识别、图像压缩等。
利用C#批量从pdf中提取图片和文字(亲身实践绝对有效)

最近由于工作原因,需要从pdf中提取里面的图片和文字,网上这方面的资料很少,最后费了九牛二虎之力终于搞定了,用的编程语言是C#,用到的工具包是itextSharp,主要代码如下,希望有相同需求的朋友可以少走些弯路。
方法一:从pdf中提取图片private void ExtractImage(string pdfFile){PdfReader pdfReader = new PdfReader(pdfFile);for (int pageNumber = 1; pageNumber <=pdfReader.NumberOfPages; pageNumber++){PdfReader pdf = new PdfReader(pdfFile);PdfDictionary pg = pdf.GetPageN(pageNumber);PdfDictionary res =(PdfDictionary)PdfReader.GetPdfObject(pg.Get(PdfName.RESOURCES));PdfDictionary xobj =(PdfDictionary)PdfReader.GetPdfObject(res.Get(PdfName.XOBJECT));try{foreach (PdfName name in xobj.Keys){PdfObject bj = xobj.Get(name);if (obj.IsIndirect()){PdfDictionary tg =(PdfDictionary)PdfReader.GetPdfObject(obj);string width = tg.Get(PdfName.WIDTH).ToString();string height = tg.Get(PdfName.HEIGHT).ToString();//ImageRenderInfo imgRI =ImageRenderInfo.CreateForXObject((GraphicsState)newMatrix(float.Parse(width), float.Parse(height)), (PRIndirectReference)obj, tg);ImageRenderInfo imgRI =ImageRenderInfo.CreateForXObject(new GraphicsState(), (PRIndirectReference)obj, tg);RenderImage(imgRI);}}}catch{continue;}}}方法二:将图片保存到文件private void RenderImage(ImageRenderInfo renderInfo){count++;PdfImageObject image = renderInfo.GetImage();using (Dotnet dotnetImg = image.GetDrawingImage()){if (dotnetImg != null){using (MemoryStream ms = new MemoryStream()){dotnetImg.Save(ms, ImageFormat.Tiff);Bitmap d = new Bitmap(dotnetImg);d.Save(@"");}}}}方法三:从pdf中提取文本public void ExtractTextFromPDFPage(string pdfFile){PdfReader reader = new PdfReader(pdfFile);int n = reader.NumberOfPages;for (int i = 1; i <= n; i++){string text = PdfTextExtractor.GetTextFromPage(reader, i);}try { reader.Close(); }catch { }}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
提取PDF图片具体操作
Word编辑提取PDF图片+专业PDF编辑软件提取
Word编辑提取PDF图片
专业PDF编辑软件提取
一、使用
word编辑
提取PDF
图片
Word图片导出的第一种方法
打开Word文档,单击文件——另存为——在保存类型下 面选择“网页”的保存类型——确定。切换到保存路径 下可以看到一个后缀名为.files文件夹,双击打开该文件 夹,这个文件夹下面就是Word文档导出的所有图片。
结语
捷速PDF编辑器是一款能够实现PDF文件的编辑与阅读的 文字处理软件,可以对PDF文件的内容进行添加与修改、 彻底的解决了PDF文件无法编辑难以阅读的问题。是PDF 编辑器中速度最快、功能最全、效果最好的一款PDF编辑 器工具。
THANKS
Word图片导出的第二种方法
如果对图片没有大小和分辨率等限制,可以 直接使用截图工具(比如QQ截图)截取。
Word图片导出的第三种方法
如果图片不太多,或者需要某一张图片,可 以在word中复制图片,打开系统自带的画图 工具,粘贴图片,然后另存为JPG等格式。
二捷速PDF编辑的使用
提取PDF里面图片的方法
PDF编辑
目录
03
结语
02
提取图片
01
前言
前言
PDF文件方便阅读与传送,但很不容易编辑,这是众所 周知的事。可是很多情况下,我们都必须对PDF文件进 行编辑。如果是文字的PDF文件,我们实在不会还可以 手工录入或者使用OCR识别,那如果需要提取PDF文件 里的图片呢?
首先,需要电脑上下载安 装PDF编辑器,只需要上网搜 索“捷速PDF编辑器”,找到 相关网站,下载下来,安装运 行就可以了。
打开软件,点击“文件” 中的“打开”就会弹出对话框 ,到保存PDF文件的文件夹把 需要编辑的文件打开。
捷速PDF转换器的使用
在左边页数里点击需要编辑 的页面,就可以看到PDF显 示的内容。 点击“编辑文件”就可以进行 编辑了,为了方便编辑,可 以先进行缩放。 将PDF编辑好后,点击保存 按钮对文件操作生效。