模式匹配(正则表达式)
匹配模式的分类及具体应用

匹配模式的分类及具体应用匹配模式是指对于一些特定的字符串进行匹配,从而得到想要的结果。
它被广泛应用于计算机领域,尤其是在数据处理、搜索引擎、网络爬虫等方面。
根据不同的需求和用途,匹配模式可以分为以下几种:1.精确匹配模式:精确匹配模式是最基本的模式之一,它只能匹配完全相同的字符串。
这种模式很少应用于实际场景,因为大部分情况下所需匹配的字符串并不是完全一致的。
2.模糊匹配模式:模糊匹配模式是一种常见的模式,它可以匹配一些相似的字符串。
在模糊匹配中,常用的算法有模式匹配算法、编辑距离算法等。
这种模式常用于大型搜索引擎中,以提高搜索的准确度。
3.正则表达式匹配模式:正则表达式匹配模式是一种强大的字符串匹配工具,它通过一些特定的符号和规则,可以匹配符合一定规则的字符串。
正则表达式广泛应用于各种编程语言中,如Python、Java 等,用于字符串的提取、过滤及替换操作。
4.文本匹配模式:文本匹配模式是一种针对大文本的匹配方式,通过复杂的算法、分析和数据挖掘技术,可以对海量的文本进行匹配和分析,从而得到所需的结果。
文本匹配常用于情感分析、舆情监测等领域。
在实际应用中,匹配模式的选择取决于不同的需求和场景。
例如,在网络爬虫中,若需要爬取某个网站中的所有URL,可以使用正则表达式匹配模式;若需要对用户的搜索内容进行分析,可以使用文本匹配模式等。
不同的模式擅长解决不同的问题,比较一下它们的优劣,并在实际应用中灵活运用,是解决问题的关键。
总之,匹配模式是一项重要的计算机技术,在我们的日常工作和生活中都扮演着至关重要的角色。
在不断学习和实践中,我们应该熟悉各种模式的特点和应用,才能更好地解决实际问题,提高工作效率。
python 正则表达式 模糊匹配和精确匹配

python 正则表达式模糊匹配和精确匹配在Python中,正则表达式(regex)是用于模式匹配和数据提取的强大工具。
模糊匹配和精确匹配是两种常用的匹配方式。
模糊匹配:模糊匹配通常用于查找与给定模式相似的字符串。
在Python的正则表达式中,可以使用.*来匹配任意字符(包括空字符)出现任意次数。
例如,正则表达式a.*b将匹配所有以a开始,以b结束的字符串,其中a和b之间的字符数量和内容可以变化。
pythonimport repattern = 'a.*b'text = 'apple banana orange a b'matches = re.findall(pattern, text)print(matches) # 输出: ['apple banana orange a b']精确匹配:精确匹配用于查找与给定模式完全一致的字符串。
在Python的正则表达式中,可以使用^和$分别表示字符串的开头和结尾。
例如,正则表达式^hello$将只匹配字符串hello,而不匹配包含hello的更长字符串。
pythonimport repattern = '^hello$'text = 'hello world'matches = re.findall(pattern, text)print(matches) # 输出: []要使用正则表达式进行模糊匹配和精确匹配,您需要使用Python的re模块。
上面的例子演示了如何使用re模块的findall函数来查找与给定模式匹配的所有字符串。
正则表达式的全局匹配模式

正则表达式的全局匹配模式⾸先,要明确⼀点,所有的正则表达式都有⼀个lastIndex属性,⽤于记录上⼀次匹配结束的位置。
如果不是全局匹配模式,那lastIndex的值始终为0,在匹配过⼀次后,将会停⽌匹配。
正则表达式的全局匹配模式,就是在创建正则表达式的时候使⽤g标识符或者将global属性设置为true,在全局匹配模式下,正则表达式会对指定要查找的字符串执⾏多次匹配。
每次匹配使⽤当前正则对象的lastIndex属性的值作为在⽬标字符串中开始查找的起始位置。
如果找不到匹配的项lastIndex的值会被重新设置为0。
理解了上⾯的话,下⾯代码的结果就很清晰了:1var regex = /abc/g;2var str = '123#abc';3 console.log(stIndex); // 04 console.log(regex.test(str)); // true5 console.log(stIndex); // 76 console.log(regex.test(str)); // false7 console.log(stIndex); // 08 console.log(regex.test(str)); // true9 console.log(stIndex); // 710 console.log(regex.test(str)); // false今天在写表单验证的时候遇到⼀个问题,每当偶数次点击的时候就会报错,就是这个问题造成的,解决⽅法也很简单,就是去掉正则表达式⾥⾯的g。
关于RegExp.prototype.exec(str)⽅法和String.prototype.math(rgExp)⽅法:RegExp.prototype.exec(str)⽅法返回NULL或返会⼀个数组,在数组的第0个元素存放的是在字符串str中查找到的匹配内容,1到n个元素返回的是在模式中使⽤括号"()"指定的⼦匹配项的内容。
SQL中常用模糊查询的四种匹配模式正则表达式

SQL中常⽤模糊查询的四种匹配模式正则表达式执⾏数据库查询时,有完整查询和模糊查询之分。
⼀般模糊语句如下:SELECT 字段 FROM 表 WHERE 某字段 Like 条件其中关于条件,SQL提供了四种匹配模式:1、%:表⽰任意0个或多个字符。
可匹配任意类型和长度的字符,有些情况下若是中⽂,请运⽤两个百分号(%%)表⽰。
⽐如 SELECT * FROM [user] WHERE u_name LIKE '%三%'将会把u_name为“张三”,“张猫三”、“三脚猫”,“唐三藏”等等有“三”的记录全找出来。
另外,如果须要找出u_name中既有“三”⼜有“猫”的记录,请运⽤ and条件SELECT * FROM [user] WHERE u_name LIKE '%三%' AND u_name LIKE '%猫%'若运⽤ SELECT * FROM [user] WHERE u_name LIKE '%三%猫%'虽然能搜索出“三脚猫”,但不能搜索出符合条件的“张猫三”。
2、_:表⽰任意单个字符。
匹配单个任意字符,它常⽤来限定表达式的字符长度语句:⽐如 SELECT * FROM [user] WHERE u_name LIKE '_三_'只找出“唐三藏”这样u_name为三个字且中间⼀个字是“三”的;再⽐如 SELECT * FROM [user] WHERE u_name LIKE '三__';只找出“三脚猫”这样name为三个字且第⼀个字是“三”的;3、[ ]:表⽰括号内所列字符中的⼀个(类似正则表达式)。
指定⼀个字符、字符串或范围,要求所匹配对象为它们中的任⼀个。
⽐如 SELECT * FROM [user] WHERE u_name LIKE '[张李王]三'将找出“张三”、“李三”、“王三”(⽽不是“张李王三”);如 [ ] 内有⼀系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e”SELECT * FROM [user] WHERE u_name LIKE '⽼[1-9]'将找出“⽼1”、“⽼2”、……、“⽼9”;4、[^ ] :表⽰不在括号所列之内的单个字符。
js正则匹配公式

js正则匹配公式在JavaScript中,可以使用正则表达式(Regular Expression)来匹配公式。
正则表达式是一种模式匹配的工具,它可以用于搜索和匹配字符串中满足特定模式的内容。
以下是几个常见的正则表达式示例,用于匹配公式:1. 匹配整数或浮点数:- `/^\d+$/`:匹配正整数。
- `/^-?\d+$/`:匹配整数(包括负整数)。
- `/^\d+(\.\d+)?$/`:匹配正浮点数(包括整数和小数)。
- `/^-?\d+(\.\d+)?$/`:匹配浮点数(包括整数、小数和负数)。
2. 匹配加减乘除运算:- `/^\d+(\.\d+)?\s*[\+\-\*\/]\s*\d+(\.\d+)?$/`:匹配两个数字之间的加、减、乘、除运算(如1+2、3-4、5*6、7/8)。
3. 匹配带括号的表达式:- `/^\([\d\+\-\*\/\s]+\)$/`:匹配带有括号的表达式(如(1+2)、(3-4*5))。
4. 匹配常见数学函数:- `/^(sin|cos|tan|sqrt)\([\d\+\-\*\/\s]+\)$/`:匹配常见数学函数(如sin(90)、cos(45+30))。
通过使用正则表达式的`test()`方法,可以判断一个字符串是否符合指定的正则表达式模式,如下所示:```javascriptvar formula = "1+2";var regex = /^\d+(\.\d+)?\s*[\+\-\*\/]\s*\d+(\.\d+)?$/;if (regex.test(formula)) {console.log("匹配成功");} else {console.log("匹配失败");}```以上仅是一些常见的正则表达式示例,实际情况可能更加复杂,具体的匹配规则需要根据公式的具体语法和要求来确定。
wps表格正则表达式

在WPS表格中,可以使用正则表达式来进行模式匹配和替换操作。
以下是一些常用的正则表达式模式:
1. 匹配数字:^[0-9]*$
2. 匹配n位数字:^\d{n}$
3. 匹配至少n位数字:^\d{n,}$
4. 匹配m-n位数字:^\d{m,n}$
5. 匹配零和非零开头的数字:^(0|[1-9][0-9]*)$
6. 匹配非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7. 匹配带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
在WPS表格中,可以使用RegexString()函数来进行正则表达式的匹配操作。
该函数接受两个参数:正则表达式模式和待匹配的字符串。
例如,如果要在WPS表格中判断字符串是否由数字组成,可以使用以下公式:
=RegexString("^[0-9]*$", A1)
其中,A1是待匹配的字符串。
如果返回结果为TRUE,表示字符串符合指定的正则表达式模式;如果返回结果为FALSE,表示字符串不符合模式。
实用技巧在Shell脚本中使用正则表达式进行模式匹配

实用技巧在Shell脚本中使用正则表达式进行模式匹配Shell脚本是一种强大的工具,它可以帮助我们完成各种任务。
而正则表达式是一种强大的模式匹配工具,可以帮助我们在文本中查找和处理特定的模式。
在Shell脚本中使用正则表达式进行模式匹配,可以让我们更加高效地进行文本处理。
本文将介绍一些实用的技巧,帮助您在Shell脚本中灵活使用正则表达式进行模式匹配。
一、基本的正则表达式在Shell脚本中,我们可以使用基本的正则表达式(BRE)进行模式匹配。
BRE提供了一些基本的元字符和转义字符,用于标识和匹配特定的模式。
1. 点字符(.):匹配任意一个字符,除了换行符。
2. 星号字符(*):匹配前面的字符零次或多次。
3. 问号字符(?):匹配前面的字符零次或一次。
4. 方括号([]):匹配方括号中包含的任意一个字符。
可以使用连字符(-)表示范围。
5. 反斜杠字符(\):用于转义元字符,例如\.表示匹配点字符本身。
下面是一个例子,演示如何在Shell脚本中使用正则表达式进行模式匹配:```shell#!/bin/bashstr="Hello World"if [[ $str =~ ^Hello.*$ ]]; thenecho "匹配成功"elseecho "匹配失败"fi```上述示例中,使用`=~`操作符来进行正则表达式的匹配。
`^Hello.*$`表示以Hello开头的字符串。
如果匹配成功,输出"匹配成功",否则输出"匹配失败"。
二、高级的正则表达式除了基本的正则表达式之外,我们还可以使用扩展的正则表达式(ERE)进行更加灵活和强大的模式匹配。
ERE提供了更多的元字符和转义字符,可以满足更复杂的匹配需求。
1. 加号字符(+):匹配前面的字符一次或多次。
2. 竖线字符(|):匹配多个模式中的任意一个。
3. 圆括号(()):用于分组匹配,可以使用后向引用来引用分组中的内容。
正则匹配原则

正则匹配(Regular Expression Matching)是一种用于查找和匹配文本模式的方法,通常通过使用正则表达式来描述所需的模式。
以下是正则匹配的一些基本原则:1.字符匹配:正则表达式可以用来匹配特定的字符,例如字母、数字、符号等。
使用字符本身可以进行精确匹配,例如字符a匹配字母a。
2.字符类匹配:使用字符类(Character Classes)可以匹配一组字符中的任意一个。
例如,字符类[abc]可以匹配字母a、b或c中的任意一个。
3.通配符匹配:通配符(Wildcard)用于匹配任意字符。
常用的通配符是.,表示匹配任意单个字符。
例如,正则表达式a.可以匹配以字母a开头,后面紧跟任意一个字符的字符串。
4.重复匹配:通过使用重复限定符(Repetition Quantifiers),可以指定某个模式重复出现的次数。
例如,*表示重复零次或更多次,+表示重复一次或更多次,?表示重复零次或一次。
5.边界匹配:边界匹配(Anchors)用于匹配字符串的开头和结尾。
例如,^表示匹配字符串的开头,$表示匹配字符串的结尾。
6.分组匹配:使用圆括号可以将模式分组,从而进行更复杂的匹配操作。
例如,(abc)+表示匹配至少一个由字母abc组成的字符串。
7.转义字符:某些特殊字符在正则表达式中具有特殊的含义,如果要匹配这些字符本身,需要使用转义字符\。
例如,匹配.字符本身需要使用\.。
8.贪婪匹配:默认情况下,正则表达式会尽可能匹配最长的字符串。
如果需要匹配最短的字符串,可以使用非贪婪限定符*?、+?、??等。
总的来说,正则匹配原则是根据需求构建合适的正则表达式,通过匹配文本模式来实现文本搜索、替换等操作。
正则表达式提供了灵活和强大的模式匹配功能,但在使用时需要谨慎处理,确保匹配结果符合预期。
模式匹配(正则表达式)

替换操作符的选项如下表: 选项 g i e m o s x 描述 改变模式中的所有匹配 忽略模式中的大小写 替换字符串作为表达式 将待匹配串视为多行 仅赋值一次 将待匹配串视为单行 忽略模式中的空白
注:e选项把替换部分的字符串看作表达式,在替换之前先计算其值,如: $string = "0abc1"; $string =~ s/[a-zA-Z]+/$& x 2/e; # now $string = "0abcabc1"
=~:检验匹配是否成功:$result = $var =~ /abc/;若在该字符串中找到了该 模式,则返回非零值,即true,不匹配 则返回0,即false。 !~:则相反。
这两个操作符适于条件控制中,如: if ($question =~ /please/) { print ("Thank you for being polite!\n"); } else { print ("That was not very polite!\n"); }
注:split函数每次遇到分割模式,总是开始 一个新单词。 (1)若$line以空格打头,则@array的第 一个元素即为空元素。但其可以区分是否真 有单词。 (2)若$line中只有空格,则@array则为 空数组。且上例中TAB字符被当作一个单词。 注意修正。
2、字符 [ ]和[^] [ ]:意味着匹配一组字符中的一个,如 /a[0123456789]c/将匹配a加数字加c的字符 串。与+联合使用例:/d[eE]+f/匹配def、dEf、 deef、dEf、dEEEeeeEef等。 ^:表示除其之外的所有字符,如: /d[^eE]f/匹配d加非e字符加f的字符串。 3、字符 *和? 它们与+类似,区别在于 *:匹配0个、1 个或多个相同字符,?:匹配0个或1个该字 符。如/de*f/匹配df、def、deeeef等; /de?f/匹配df或def。
正则匹配以a开头,中间任意个b,以c结尾的字符串

正则匹配以a开头,中间任意个b,以c结尾的字符串在计算机科学领域,正则表达式是一种模式匹配引擎,用于从一个文本中搜索指定的字符序列。
它通常用于搜索具有特定特征的字符串,以及修改,提取或生成某些字符串。
正则表达式也称为正则表达式(Regex)或正则表达式。
正则表达式通常以一种语言来编写,以指定某个文本串或文本模式的模式。
本文将解释如何使用正则表达式来匹配以“a”开头,中间任意个“b”,以“c”结尾的字符串。
首先,我们必须了解什么是正则表达式。
正则表达式是一种文字文本处理和搜索的工具,也被称为正则表达式(Regex)。
它可以识别模式和可以编写任意模式的语言。
它可以找到文本中指定模式的文本串,并按照您指定的模式执行操作,例如搜索、替换或提取。
正则表达式可以在各种编程语言,文本编辑器,文档处理程序和数据库等中使用。
在正则表达式中,可以使用一些特殊的符号建立模式,以匹配文本中的字符串。
正则表达式中使用的重要符号是“^”,“$”和“.”。
^表示匹配任意字符串的开头字符,$表示它们的结尾字符,而点表示要匹配的字符。
下面来匹配以a开头,中间任意个b,以c结尾的字符串。
为此,我们需要使用^a代表开头为a,中间任意个b用.*b表示,最后以c 结尾用$c表示,因此正则表达式为^a.*b$c 。
例如,如果我们需要匹配的文本为“abcb”,那么我们可以使用^a.*b$c正则表达式匹配它:^a.*b$c 。
正则表达式也可以用于替换字符串中的字符。
例如,如果我们想要替换字符串中的所有a为b,则可以使用正则表达式替换字符,即将所有a替换为b:a->b 。
此外,也可以使用正则表达式来提取文本中的特定字符串,例如提取从开头到结尾的字符序列,^a->$c 。
正则表达式是一种强大的文本处理工具,它可以帮助我们快速而准确地匹配以a开头,中间任意个b,以c结尾的字符串。
它可以看做是一种特殊的文本处理器,可以用于搜索指定的字符串,替换指定的字符串,以及提取文本中的特定字符串。
Python正则表达式模式匹配和替换

Python正则表达式模式匹配和替换正文:Python正则表达式(Regular Expression)是一种用来匹配、搜索和替换文本的强大工具。
它通过使用一种特殊的字符序列,可以帮助我们快速地定位、匹配和提取符合特定模式的字符串。
在本文中,我们将探讨Python正则表达式的应用,包括模式匹配和替换的实例。
一、正则表达式的基本语法要使用Python的正则表达式模块re,我们需要先导入该模块。
以下是一个基本的Python正则表达式语法示例:import repattern = r"abc"# 定义一个正则表达式模式"abc"match = re.search(pattern, "abcdefg")# 在字符串中搜索匹配模式if match:print("找到了匹配的模式")else:print("未找到匹配的模式")以上代码中,我们首先导入re模块,然后定义一个字符串模式"abc",接着使用re模块的search函数,在字符串"abcdefg"中搜索是否存在匹配模式"abc"。
如果找到则输出"找到了匹配的模式",否则输出"未找到匹配的模式"。
二、元字符和限定符在正则表达式中,有一些特殊字符被称为元字符,用于表示模式中的一些特定意义。
例如,使用点号(.)表示任何字符,而使用星号(*)表示任意数量的前一个字符。
以下是一些常用的元字符和限定符的示例:- . :匹配任意单个字符- * :匹配前一个字符的零次或多次出现- + :匹配前一个字符的一次或多次出现- ? :匹配前一个字符的零次或一次出现- \d :匹配任意一个数字- \w :匹配任意一个字母或数字或下划线- \s :匹配任何空白字符三、模式匹配与提取除了基本的元字符和限定符,正则表达式还可以使用一些特殊的语法来进行模式匹配和提取。
正则匹配规则表

正则匹配规则表
正则匹配规则表是一种由正则表达式表示的模式匹配规则集合。
正则表达式是一种用于描述字符串模式的字符序列,通过正则表达式可以匹配符合特定模式的字符串。
以下是常用的正则匹配规则表:
1. 基本匹配规则:
- \d:匹配任意数字字符。
- \w:匹配任意字母数字字符。
- \s:匹配任意空白字符。
- . :匹配除换行符外的任意字符。
- []:匹配括号内的任意一个字符。
- [^]:匹配不在括号内的任意一个字符。
2. 重复匹配规则:
- *:匹配前一个字符0次或多次。
- +:匹配前一个字符1次或多次。
- ?:匹配前一个字符0次或1次。
- {n}:匹配前一个字符恰好n次。
- {n,}:匹配前一个字符至少n次。
- {n,m}:匹配前一个字符至少n次,最多m次。
3. 边界匹配规则:
- ^:匹配字符串的开始。
- $:匹配字符串的结束。
- \b:匹配单词的边界。
4. 分组匹配规则:
- ():将括号内的表达式作为一组。
- | :匹配多个表达式中的一个。
- \1、\2、...:引用前面分组的匹配结果。
5. 特殊字符匹配规则:
- \:转义字符。
- \d、\w、\s等:匹配特殊字符。
这些匹配规则可以结合使用,通过正则表达式引擎对指定文本进行匹配。
根据匹配规则的不同,可以实现字符串的验证、提取、替换等操作。
正则匹配的规则

正则匹配的规则正则匹配(RegularExpressionMatching)是一种用来对字符串进行模式匹配的方法。
正则表达式(RegularExpression)是由一系列字符组成的字符串,用来描述、匹配一系列文本或者字符串的规则。
1.文本匹配规则:用来匹配文本中的字符,包括字母、数字、特殊字符等。
例如,正则表达式`[azAZ]`可以匹配一个大小写字母。
常见的匹配规则有:字符匹配:用来匹配特定的字符,例如`a`可以匹配字符`a`。
字符类匹配:用方括号括起来的字符集合,例如`[azAZ]`可以匹配任意一个字母。
元字符匹配:具有特殊含义的字符,例如`.`可以匹配任意一个字符。
2.量词规则:用来指定匹配的次数或范围。
例如,`*`表示匹配前面的元素零次或多次。
常见的量词有:`*`:匹配零次或多次。
`+`:匹配一次或多次。
`?`:匹配零次或一次。
`{n}`:匹配恰好n次。
`{n,}`:匹配至少n次。
3.边界规则:用来指定匹配的位置。
例如,`^`表示匹配文本的开头,`$`表示匹配文本的结尾。
常见的边界规则有:`^`:匹配开头。
`$`:匹配结尾。
`\b`:匹配单词边界。
4.分组规则:用来将正则表达式的一部分进行分组,方便后续引用或者对分组内的内容进行特殊处理。
例如,`(ab)`表示将`ab`进行分组。
常见的分组规则有:`()`:将括号内的内容进行分组。
`(?:)`:用来分组,但不会捕获分组内容。
5.预定义字符集规则:用来匹配一些常见的字符集合。
例如,`\d`表示匹配任意一个数字,`\s`表示匹配任意一个空白字符。
常见的预定义字符集规则有:`\d`:匹配任意一个数字。
`\w`:匹配任意一个字母、数字或下划线。
`\s`:匹配任意一个空白字符。
以上是正则匹配的常见规则,通过组合使用这些规则,可以构建出复杂的正则表达式来进行字符串的匹配和处理。
在实际应用中,正则匹配广泛用于文本处理、数据抽取、数据验证等场景。
高级Shell脚本技巧使用正则表达式进行模式匹配和替换

高级Shell脚本技巧使用正则表达式进行模式匹配和替换高级Shell脚本技巧:使用正则表达式进行模式匹配和替换Shell脚本是一种用于自动化任务的编程语言,它在Unix和Linux 系统中得到广泛应用。
在Shell脚本的编写过程中,正则表达式是一个非常有用的工具,可以帮助我们进行字符模式的匹配和替换操作。
本文将介绍一些高级Shell脚本技巧,以便更好地使用正则表达式进行模式匹配和替换。
1. 正则表达式的基本语法在Shell脚本中,正则表达式可以用于模式匹配和替换。
正则表达式的基本语法如下:- 普通字符:表示与该字符本身匹配。
- 元字符:具有特殊意义的字符,如.、*、+等。
- 字符类:用[ ]表示,可以匹配括号内的任意一个字符。
- 元字符类:用\(\)表示,可以匹配括号内的整个字符序列。
- 量词:用{ }表示,表示前面的表达式出现的次数。
- 锚字符:^表示行的开头,$表示行的结尾。
2. 使用正则表达式进行模式匹配在Shell脚本中,我们可以使用正则表达式来匹配字符串,并执行相应的操作。
下面是一个例子,展示如何使用正则表达式进行模式匹配:```shell#!/bin/bashstr="Welcome to Shell scripting"pattern="Shell"if [[ $str =~ $pattern ]]; thenecho "Pattern found"elseecho "Pattern not found"fi```在上面的例子中,我们定义了一个字符串`str`和一个正则表达式`pattern`。
使用`=~`操作符,我们可以将字符串和正则表达式进行匹配。
如果匹配成功,则输出"Pattern found",否则输出"Pattern not found"。
3. 使用正则表达式进行模式替换除了模式匹配,正则表达式还可以用于模式替换。
MySQL中的正则表达式和模式匹配技巧

MySQL中的正则表达式和模式匹配技巧引言:正则表达式是一种强大的工具,可以在字符串中搜索、匹配、替换等操作。
在MySQL中,通过使用正则表达式,可以进行高效的数据查询与处理。
本文将介绍MySQL中的正则表达式和模式匹配技巧,帮助读者更好地掌握和应用这一功能。
一、正则表达式基础知识1. 正则表达式逻辑符号- ^:匹配字符串的开头- $:匹配字符串的结尾- .:匹配任意单个字符- *:匹配前一个字符的零个或多个副本- +:匹配前一个字符的一个或多个副本- ?:匹配前一个字符的零个或一个副本- []:匹配括号内的任意一个字符- [^]:匹配不在括号内的任意一个字符- ():将括号中的字符作为一个整体进行匹配2. 正则表达式通配符- \d:匹配数字字符- \D:匹配非数字字符- \w:匹配单词字符(字母、数字、下划线)- \W:匹配非单词字符- \s:匹配空白字符(空格、制表符、换行等)- \S:匹配非空白字符二、MySQL中的正则表达式函数1. REGEXP和NOT REGEXPREGEXP函数用于判断一个字符串是否匹配指定的正则表达式,而NOT REGEXP则用于判断是否不匹配。
例如,SELECT * FROM table WHERE column REGEXP 'pattern';2. RLIKE和NOT RLIKERLIKE和NOT RLIKE是REGEXP和NOT REGEXP的别名,用法和功能相同。
例如,SELECT * FROM table WHERE column RLIKE 'pattern';3. REGEXP_LIKEREGEXP_LIKE函数用于判断一个字符串是否匹配指定的正则表达式,但其返回结果是布尔类型,即TRUE或FALSE。
例如,SELECTREGEXP_LIKE(column, 'pattern') FROM table;4. REGEXP_REPLACEREGEXP_REPLACE函数用于替换字符串中匹配正则表达式的部分。
C语言中的正则表达式与模式匹配

C语言中的正则表达式与模式匹配在C语言中,正则表达式是一种强大的工具,可用于模式匹配和文本搜索。
正则表达式可以帮助我们有效地处理字符串,并从中提取出我们所需要的信息。
本文将介绍C语言中的正则表达式和模式匹配的原理、用法以及实际应用。
一、正则表达式基础概念正则表达式是由一系列字符组成的模式,它描述了一种字符串匹配的规则。
在C语言中,我们可以使用正则表达式来匹配和搜索符合某种模式的字符串。
正则表达式使用一些特殊的字符和字符类来表示不同的匹配规则,如以下几个常用的:1. 字符匹配- 在正则表达式中,普通字符表示需要精确匹配的字符。
例如,正则表达式"cat"可以匹配字符串中的"cat",但无法匹配"rat"或"distract"。
- 正则表达式还可以使用转义字符"\\"来匹配特殊字符。
例如,正则表达式"\\$"可以匹配字符串中的"$"。
2. 元字符- 元字符是一些具有特殊含义的字符,用于描述匹配规则。
例如,元字符"."可以匹配任意单个字符,而元字符"*"表示前一个字符可以出现零次或多次。
- C语言中常用的元字符包括"."、"*"、"+"、"?"等,它们可以根据需要组合使用以构建更加复杂的匹配规则。
3. 字符类- 字符类用于匹配指定范围内的字符。
例如,字符类"[abc]"可以匹配字符串中的"a"、"b"或"c"。
- 正则表达式还可以使用一些预定义的字符类,如"\d"表示匹配任意一个数字字符,"\w"表示匹配任意一个字母、数字或下划线字符。
正则表达式全局匹配模式(g修饰符)

正则表达式全局匹配模式(g修饰符)正则表达式g修饰符:g修饰符⽤语规定正则表达式执⾏全局匹配,也就是在找到第⼀个匹配之后仍然会继续查找。
语法结构:构造函数⽅式:new RegExp("regexp","g")对象直接量⽅式:/regexp/g浏览器⽀持:IE浏览器⽀持此元字符。
⽕狐浏览器⽀持此元字符。
⾕歌浏览器⽀持此元字符。
实例代码:实例⼀:var str="this is an antzone good";var reg=/an/;console.log(str.match(reg));以上代码只能够匹配第⼀个"an",因为并没有进⾏全局匹配,在第⼀个匹配成功之后,就不再继续匹配了。
实例⼆:var str="this is an antzone good";var reg=/an/g;console.log(str.match(reg));以上代码能够匹配到两个"an"。
下⾯是补充本⽂章来详细介绍js中正则表达式的全局匹配模式 /g⽤法,代码如下:var str = "123#abc";var re = /abc/ig;console.log(re.test(str)); //输出tureconsole.log(re.test(str)); //输出falseconsole.log(re.test(str)); //输出tureconsole.log(re.test(str)); //输出false在创建正则表达式对象时如果使⽤了“g”标识符或者设置它了的g lobal属性值为ture时,那么新创建的正则表达式对象将使⽤模式对要将要匹配的字符串进⾏全局匹配。
在全局匹配模式下可以对指定要查找的字符串执⾏多次匹配。
每次匹配使⽤当前正则对象的lastIndex属性的值作为在⽬标字符串中开始查找的起始位置。
正则匹配大写字母数字的方法

正则匹配大写字母数字的方法
正则表达式是一种强大的文本模式匹配工具,它可以用于匹配字符串中的各种元素。
如果您需要匹配大写字母和数字,下面是一些常用的正则表达式模式:
1. 匹配只包含大写字母和数字的字符串:^[A-Z0-9]+$
这个模式将匹配只包含大写字母和数字的任何字符串。
^ 表示字符串的开头,$ 表示字符串的结尾。
[A-Z0-9] 表示可以匹配大写字母和数字。
2. 匹配包含大写字母和数字的字符串:[A-Z0-9]
这个模式将匹配任何包含大写字母和数字的字符串。
3. 匹配以大写字母开头的字符串:^[A-Z]
这个模式将匹配任何以大写字母开头的字符串。
4. 匹配以数字开头的字符串:^[0-9]
这个模式将匹配任何以数字开头的字符串。
5. 匹配长度为 n 的字符串:^.{n}$
这个模式将匹配长度为 n 的任何字符串。
. 表示可以匹配任何字符。
6. 匹配长度为 n 或以上的字符串:^.{n,}$
这个模式将匹配长度为 n 或以上的任何字符串。
7. 匹配长度为 n 到 m 的字符串:^.{n,m}$
这个模式将匹配长度为 n 到 m 的任何字符串。
以上是一些常用的正则表达式模式,可以用于匹配大写字母和
数字。
根据您的需求,可以选择适合自己的模式进行匹配。
漫话规则引擎(2):模式匹配算法
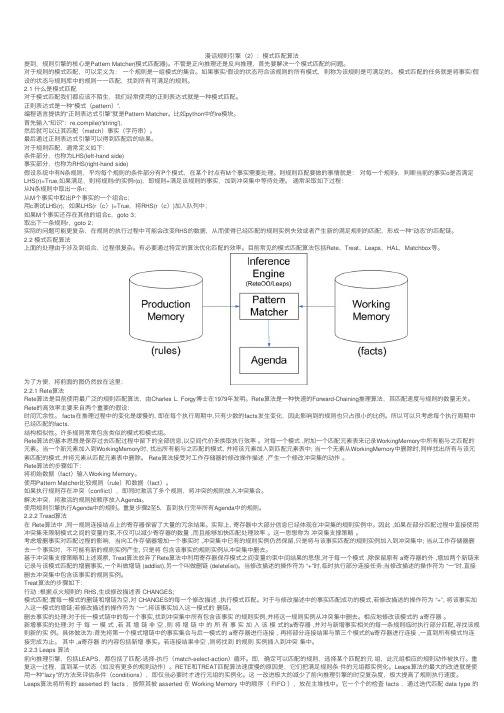
漫话规则引擎(2):模式匹配算法提到,规则引擎的核⼼是Pattern Matcher(模式匹配器)。
不管是正向推理还是反向推理,⾸先要解决⼀个模式匹配的问题。
对于规则的模式匹配,可以定义为:⼀个规则是⼀组模式的集合。
如果事实/假设的状态符合该规则的所有模式,则称为该规则是可满⾜的。
模式匹配的任务就是将事实/假设的状态与规则库中的规则⼀⼀匹配,找到所有可满⾜的规则。
2.1 什么是模式匹配对于模式匹配我们都应该不陌⽣,我们经常使⽤的正则表达式就是⼀种模式匹配。
正则表达式是⼀种“模式(pattern)”,编程语⾔提供的“正则表达式引擎”就是Pattern Matcher。
⽐如python中的re模块。
⾸先输⼊“知识”:pile(r'string'),然后就可以让其匹配(match)事实(字符串)。
最后通过正则表达式引擎可以得到匹配后的结果。
对于规则匹配,通常定义如下:条件部分,也称为LHS(left-hand side)事实部分,也称为RHS(right-hand side)假设系统中有N条规则,平均每个规则的条件部分有P个模式,在某个时点有M个事实需要处理。
则规则匹配要做的事情就是:对每⼀个规则r,判断当前的事实o是否满⾜LHS(r)=True,如果满⾜,则将规则r的实例r(o),即规则+满⾜该规则的事实,加到冲突集中等待处理。
通常采取如下过程:从N条规则中取出⼀条r;从M个事实中取出P个事实的⼀个组合c;⽤c测试LHS(r),如果LHS(r(c))=True,将RHS(r(c))加⼊队列中;如果M个事实还存在其他的组合c,goto 3;取出下⼀条规则r,goto 2;实际的问题可能更复杂,在规则的执⾏过程中可能会改变RHS的数据,从⽽使得已经匹配的规则实例失效或者产⽣新的满⾜规则的匹配,形成⼀种“动态”的匹配链。
2.2 模式匹配算法上⾯的处理由于涉及到组合,过程很复杂。
有必要通过特定的算法优化匹配的效率。
Linux命令高级技巧使用grep命令进行模式匹配和搜索的高级用法

Linux命令高级技巧使用grep命令进行模式匹配和搜索的高级用法Linux命令高级技巧:使用grep命令进行模式匹配和搜索的高级用法grep命令是Linux系统中一种非常常用的文本搜索工具,它能够根据给定的模式匹配来搜索文件中的内容。
虽然grep命令非常便捷和易用,但是它还有一些高级的用法和技巧,可以帮助我们更加高效地使用。
一、使用正则表达式进行模式匹配正则表达式(Regular Expression)是一种用来匹配和操作字符串的强大工具,grep命令支持使用正则表达式进行模式匹配。
1. 匹配任意字符正则表达式中,点(.)代表匹配任意字符。
当我们在grep命令后加上.,就可以匹配文件中的任意一个字符。
举例:假设我们要在一个文本文件中查找包含“linux”这个单词的行,可以使用以下命令:```bashgrep "linux" file.txt```2. 匹配特定字符通过使用方括号([]),可以指定需要匹配的特定字符集合。
比如,[abc]表示匹配a、b、c三个字符中的任意一个;[a-z]表示匹配任意小写字母。
举例:假设我们要查找包含以“a”开头的三个字母单词的行,可以使用以下命令:```bashgrep "a[a-z][a-z]" file.txt```3. 匹配重复字符正则表达式支持通过使用特殊字符*、+来匹配重复出现的字符。
*表示匹配前面的字符出现零次或多次,+表示匹配前面的字符出现一次或多次。
举例:假设我们要查找重复出现的字符,可以使用以下命令:```bashgrep "oo" file.txt```该命令能够匹配文件中出现两个连续字符“oo”的行。
二、grep命令的高级选项除了支持基本的模式匹配,grep命令还提供了一些高级选项,进一步增强了搜索的功能。
1. -i选项:忽略大小写使用-i选项可以忽略搜索时的大小写区分。
举例:假设我们要查找包含“linux”这个单词的行,不区分大小写,可以使用以下命令:```bashgrep -i "linux" file.txt```2. -v选项:反向匹配使用-v选项可以反向匹配,即只输出不包含指定模式的行。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
}
elsif ($varname =~ /^@[A-Za-z][_0-9a-zA-Z]*$/)
{ print ("$varname is a legal array variable\n");
}
elsif ($varname =~ /^[A-Za-z][_0-9a-zA-Z]*$/)
/de{1,3}f/匹配def,deef和deeef;/de{3}f/匹 配deeef;/de{3,}f/匹配不少于3个e在d和f之 间;/de{0,3}f/匹配不多于3个e在d和f之间。
11、指定选项 字符"|"指定两个或多个选择来匹配模式。如:
/def|ghi/匹配def或ghi。 例:检验数字表示合法性
(1)若$line以空格打头,则@array的第 一个元素即为空元素。但其可以区分是否真 有单词。
(2)若$line中只有空格,则@array则为 空数组。且上例中TAB字符被当作一个单词。 注意修正。
2、字符 [ ]和[^] [ ]:意味着匹配一组字符中的一个,如
/a[0123456789]c/将匹配a加数字加c的字符 串。与+联合使用例:/d[eE]+f/匹配def、dEf、 deef、dEf、dEEEeeeEef等。
Perl语言程序设计
正则表达式(Regular Expression)
一、简介
模式指在字符串中寻找的特定序列 的字符,由斜线包含:/def/即模式def。 其
用法如结合函数split将字符串用某 模式分成多个单词:@array = split(/ /, $line);
二、匹配操作符 =~、!~
=~:检验匹配是否成功:$result = $var =~ /abc/;若在该字符串中找到了该 模式,则返回非零值,即true,不匹配 则返回0,即false。 !~:则相反。
6、锚模式
锚 ^ 或 \A $ 或 \Z \b \B
描述 仅匹配串首 仅匹配串尾 匹配单词边界 单词内部匹配
例1: /^def/:只匹配以def打头的字符串; /def$/:只匹配以def结尾的字符串; /^def$/:只匹配字符串def(?)。 \A和\Z在多行匹配时与^和$不同。
例2:检验变量名的类型: if ($varname =~ /^\$[A-Za-z][_0-9a-zA-Z]*$/)
匹配def,defghi,abcdef。
7、模式中的变量替换
将句子分成单词: $pattern = "[\\t ]+"; @words = split(/$pattern/, $line);
8、字符范围转义
E 转义字符 描述
范围
\d
任意数字
[0-9]
\D
除数字外的任意字 [^0-9]
ห้องสมุดไป่ตู้
符
\w
任意单词字符
{ print ("$varname is a legal file variable\n");
}
else
{ print ("I don't understand what $varname is.\n");
}
例3:\b在单词边界匹配:
/\bdef/匹配def和defghi等以def打头的单 词,但不匹配abcdef;
/def\b/匹配def和abcdef等以def结尾的 单词,但不匹配defghi;
/\bdef\b/只匹配字符串def;注意: /\bdef/可匹配$defghi,因为$并不被看作是 单词的部分。
例4: \B在单词内部匹配: /\Bdef/匹配abcdef等,但不匹配def; /def\B/匹配defghi等; /\Bdef\B/匹配cdefg、abcdefghi等,但不
^:表示除其之外的所有字符,如: /d[^eE]f/匹配d加非e字符加f的字符串。 3、字符 *和?
它们与+类似,区别在于 *:匹配0个、1 个或多个相同字符,?:匹配0个或1个该字 符。如/de*f/匹配df、def、deeeef等; /de?f/匹配df或def。
4、转义字符 如果你想在模式中包含通常被看作特殊
“+”:意味着一个或多个相同的字符,如: /de+f/指def、deef、deeeeef等。它尽量匹 配尽可能多的相同字符,如/ab+/在字符串 abbc中匹配的将是abb,而不是ab。
当一行中各单词间的空格多于一个时, 可以如下分割:
@array = split (/ +/, $line);
注:split函数每次遇到分割模式,总是开始 一个新单词。
意义的字符,须在其前加斜线“\”。如:/\*+/ 中\*即表示字符*,而不是上面提到的一个或 多个字符的含义。斜线的表示为/\\/。在 PERL5中可用字符对\Q和\E来转义。
5、匹配任意字母或数字 上面提到模式/a[0123456789]c/匹配字母
a加任意数字加c的字符串,另一种表示方法 为:/a[0-9]c/,类似的,[a-z]表示任意小写 字母,[A-Z]表示任意大写字母。任意大小写 字母、数字的表示方法为:/[0-9a-zA-Z]/。
[_0-9a-zA-Z]
\W
任意非单词字符 [^_0-9a-zA-Z]
\s
空白
[ \r\t\n\f]
\S
非空白
[^ \r\t\n\f]
例:/[\da-z]/匹配任意数字或小写字母。
9、匹配任意字符 字符“.”匹配除换行外的所有字符,通常
与*合用。
10、匹配指定数目的字符 字符对{}指定所匹配字符的出现次数。如:
这两个操作符适于条件控制中,如: if ($question =~ /please/)
{ print ("Thank you for being polite!\n");
} else
{ print ("That was not very polite!\n");
}
三、模式中的特殊字符
PERL在模式中支持一些特殊字符,可以 起到一些特殊的作用。 1、字符“ +”
if ($number =~ /^-?\d+$|^-?0[xX][\da-fA-F]+$/)
{ print ("$number is a legal integer.\n");
} else
{ print ("$number is not a legal integer.\n");