习题与答案-5-语法分析-自上而下
习题与答案-5-语法分析-自上而下
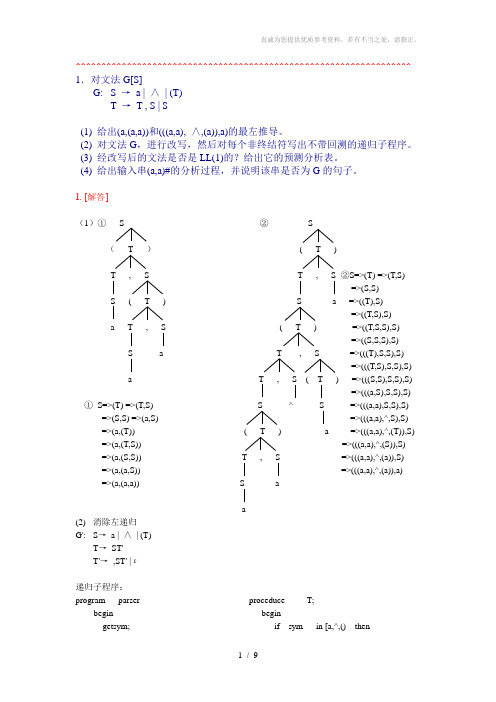
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 1.对文法G[S]G: S →a | ∧| (T)T →T , S | S(1) 给出(a,(a,a))和(((a,a), ∧,(a)),a)的最左推导。
(2) 对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3) 经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4) 给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
1. [解答](1)①S ②S(T )( T )T , S T , S ②S=>(T) =>(T,S)=>(S,S) S ( T ) S a =>((T),S)=>((T,S),S)a T , S ( T ) =>((T,S,S),S)=>((S,S,S),S) S a T , S =>(((T),S,S),S)=>(((T,S),S,S),S)a T , S ( T ) =>(((S,S),S,S),S)=>(((a,S),S,S),S) ①S=>(T) =>(T,S) S ^ S =>(((a,a),S,S),S)=>(S,S) =>(a,S) =>(((a,a),^,S),S) =>(a,(T)) ( T ) a =>(((a,a),^,(T)),S) =>(a,(T,S)) =>(((a,a),^,(S)),S)=>(a,(S,S)) T , S =>(((a,a),^,(a)),S)=>(a,(a,S)) =>(((a,a),^,(a)),a)=>(a,(a,a)) S aa(2) 消除左递归G': S→a | ∧| (T)T→ST'T'→,ST' |ε递归子程序:program parser proceduce T;begin begingetsym; if sym in [a,^,() thenS beginend; S;proceduce S; T;begin end;if sym=’a’ or sym=’^’ then elsegetsym error;elseif sym=’(‘ end;begin getsym; proceduce T’;T; beginIf sym=’)’ then if sym=’,’ thenGetsym; beginElse getsym;Error; S;End; T;Else end;Error; elseEnd; if sym=’)’ thenelseerror;end;预测分析表不含多重定义入口, 所以该文法是LL(1)文法!(4) 分析栈余留串所用产生式或动作1 #S (a,a)# S—>(T)2 #)T( (a,a)# (匹配3 #)T a,a)# T—>ST’4 #)T’S a,a)# S—>a5 #)T’a a,a)# a匹配6 #)T’ ,a)# T’ —>,ST’7 #)T’S, ,a)# ,匹配8 #)T’S a)# S—>a9 #)T’a a)# a匹配10 #)T’ )# T’—>ε11 #) )# )匹配12 # # 接受因为(a,a)#分析成功所以(a,a)为文法的句子步骤分析栈余留串所用产生式或动作1 #S (a,a# S→(T)2 #)T( (a,a# ( 匹配3 #)T a,a# T→ST’4 #)T’S a,a# S→a5 #)T’a a,a# a 匹配6 #)T’,a# T’→,ST’7 #)T’S, ,a# , 匹配8 #)T’S a# S→a9 #)T’a a# a 匹配10 #)T’# 出错^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 2. G: E →TE'E' →+E |εT →FT'T' →T |εF →PF'F' →*F' |εP →(E) | a | b |∧预测分析表^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 3.已知文法G: S →MH | aH →LSo |εK →dML |εL →eHfM →K | bLM判断G是否是LL(1)文法,如果时,构造LL(1)分析表。
语法分析-自上而下分析

经压缩后文法:
S→(abc|bc|c)S’ S’ →abc S’|ε
注意:由于对非终结符的排序不同,最后得到的文法在形 式上可能是不一样的,但是它们是等价的. 按S、Q、R排列, 代入后 S→Qc│c Q→Rb│b R→ Rbca│bca│ca│a 消除R中的直接左递归得 R→ bcaR’│caR’│aR’ R’→ bcaR’│
Z ·
c A d a Z · c A d a b
完成进一步推导Aab 检查,a-a匹配,b-d不匹配(失败) 但是还不能冒然宣布SL(G[Z]) 4. 回溯 即砍掉A的子树 改选A的第二右部 Aa 检查 a-a匹配 d-d匹配
分析工作要部 分地或全部地 退回去重做叫 回溯
建立语法树,末端结点为cad与输入cad相匹配, 建立了最左推导序列 EcAdcad ∴cadL(G(E))
2.回溯问题
什么是回溯?
分析工作要部分地或全部地退回去重做叫回溯
造成回溯的原因
公共左因子的存在 即A→1| 2 某个非终结符号的规则其右部有多个选择,形如
A → 1 | 2 | 3,根据所面临的输入符号不能 准确的确定所要选择时,就可能出现回溯。
回溯带来的问题
集合FIRST、FOLLOW: 1.FIRST集(与前同) 设α是文法G的一个符号串, α (VTVN)*,定义 FIRST(α)={a|α* a. . . , aVT} *ε,则εFIRST(α)。 特别若α
R→Sa|a
Q→Sab|ab|b
4.把Q代入S的右部选择 5.消除S的直接左递归
最后得到文法为:
S→Sabc|abc|bc|c S→(abc|bc|c)S’ S’ →abc S’|ε S→(abc|bc|c)S’ S’ →abc S’|ε
第四章 编译原理语法分析--自上而下

消除左递归 (P69.)
(1)直接左递归:文法存在产生式 A→Aα。 (2)间接左递归:文法不存在产生式 A→Aα, 但存在推导 A + Aα。
消除直接左递归的方法:引入新的非终结符号A‘,将 关于A的如下产生式 A→Aα|β (α非ε且β不以A打头) 替换为 A →βA‘ A‘ →αA‘|ε 注意:不要掉了 A‘ →ε
4
自上而下分析法的思想(P66.)
从文法的开始符号出发,逐步向下推导,不断替换和展开非 终结符,去匹配输入符号串(终结符号串、句子),即寻找输入 串的最左推导,推出句子,(---自上而下的实质) 并按与最左推导相对应的顺序,从文法的开始符号(根结)出 发,自上而下从左到右地建立输入串的语法分析树。---其末 端节点正好与输入符号串相同
3
4.2 自上而下分析法面临的问题
. 本小节首先通过例子P67:
说明自上而下分析的思想 认识自上而下分析时所遇到的主要困难
自上而下分析的主要困难是P66-68 : 文法的左递归性,可能使分析陷入无限循环 回溯的不确定性,要求将已完成的工作推倒重来 为解决这些问题,使得自上而下分析是确定的,考 虑要消除文法左递归和避免回溯。 最后构造确定的有效的自上而下分析器:递归下降 分析器
2
4.1 语法分析器的功能(P66.)
语法分析是编译程序的核心部分。
语法分析是在词法分析识别出单词符号的基础上, 分析并判定(即识别)一串单词符号(称为输入串) 的语法结构是否符合语法规则,是否是文法的一个 句子。
分析判定的方法:
建立输入串α的从文法开始符号S出发的推导 S α1 … αn α 即建立以开始符号S为根的与输入串α相匹配(即α 中的各个符号为叶结点)的语法树
第四章 语法分析——自上而下分析

FOLLOW(Y) =FOLLOE(X)=end
则有LL(1)表:
begin
d
:
end s #
P begind : X end
X
d:X
sY
Y
:sY
第四章 语法分析--自上而下分析
[例3]:给出语言L={1na0n1ma0m|n>0, m>=0} 的LL(1)文 法G[S]并说明其理由。 解:观察句子,发现可分成两部分 1na0n 和 1ma0m两部 分中符号的个数n和m没有制约关系。则可改造成下列 文法:
T FT’
T’ *FT’|
F (E)| i
我们构造每个非终结符的FIRST和FOLLOW集合
解:FIRST(E) = { (, i }
FOLLOW(E’) = {+, }
FOLLOW(E’) = { ), #}
FIRST(T) = {(, i }
FOLLOW(T) = {+, ), # }
第四章 语法分析--自上而下分析
例题与习题解答
[例1]试构造与下列文法G[S]等价的无左递归文法。
G[S]: SSa|Nb|c
(1)
N Sd|Ne|f
(2)
对于(1)我们引入新非终结符S’
则: S NbS’ |cS’
[1]
S’ aS’|
[2]
将 S代入 (2)
N Ne |NbS’d |cS’d |f
5.1 自下而上分析基本问题 其基本问题包括下列问题:
5.1.1归约 5.1.2 规范归约简述
在这一部分应掌握短语和直接短语两个重要
概念
5.1.3 符号栈的使用与语法树的表示
第四章 语法分析--自上而下分析
编译原理第4章语法分析自上而下

(e) 当(d)中所有Yi * ε,(i=1,2,…n),则 FIRST(X)=FIRST(Y1)∪FIRST(Y2)∪…∪FIRST(Yn)∪{ε}
一 . 自上而下语法分析方法
给定文法G和源程序串$。从G的开始符 号S出发,通过反复使用产生式对句型中的 非终结符进行替换(推导),逐步推导出$ 。
是一种产生的方法,面向目标的方法。 分析的主旨是选择产生式的合适的侯选 式进行推导,逐步使推导结果与$匹配。
Ch4 语法分析 4.1 语法分析程序综述 4.1.2 语法分析的方法
计算Select集:
B ε | aD C AD | b
每个产生式的Select集合计算为:D aS | c
Select(SAB)= (first (AB) -{ε}) ∪Follow(S)={b,a,#}
Select(S bC)= first (bC)={b}
因为A B
Select(Aε)=(first (ε) -{}) ∪Follow (A)={c,a,#}
A ε | b B ε | aD C AD | b D aS | c
first(C)={first(A)-{}} ∪first(D) ∪first(b)={a,b, c}
first(D)={a} ∪{c}={a,c}
➢求出每个文法符号的FIRST集合后也就不难求出一个符号 串的FIRST集合
✓若符号串α∈V*,α=X1 X2 … Xn,当X1不能
∪{ε}
ε*,则置 ∈
编译原理考试习题及答案

( T ② S ① a
T ,
T ④ S ③ a
2019/1/29
CH.5.练习题3(P133.)
3.(1) 计算练习2文法G2的FIRSTVT和LASTVT。 S→a||(T) T→T,S|S
(1) 解: (执行相应的算法可求得) FIRSTVT(S)={ a, ∧, ( } FIRSTVT(T)={ , , a, ∧, ( } LASTVT(S)={ a, ∧, ) } LASTVT(T)={ , , a, ∧, ) }
(1) 正规式 1(0|1)*101
0
0
DFA:
3,2
1 0
3,5,2
1 1 0
x
1
1,3,2
1
0
3,4,2
1
3,Y,4,2 I0 I1 1 3 3 3 5 3
I {X} {1,3,2} {3,2} {3,4,2} {3,5,2} {3,Y,4,2}
I0 {3,2} {3,2} {3,5,2} {3,2} {3,5,2}
2019/1/29 22
CH.5.练习题2(P133.)
2.(2).给出(a,(a,a))“移进-归约”的过程。 (2) 解: (a,(a,a))的“移进-归约”过程: 步骤 符号栈 输入串 动作 9 #(T,( S ,a))# 归约 S → a 10 #(T,(T , a ))# 归约 T → S 11 #(T,(T, a ))# 移进 , 12 #(T,(T, a ))# 移进 a 13 #(T,( T,S ))# 归约 S → a 14 #(T, (T ) )# 归约 T → T,S 15 #(T, (T) )# 移进 ) 16 #( T, S )# 归约 S → (T)
自上而下语法分析

<语句>::=<标识符>:=<表达式> |<复合语句> |if <条件表达式>then<语句>[else<语句>] |while<条件表达式>do<语句> |read(<标识符表>) |write(<标识符表>)
5.2
8、构造算符优先分析表 : (1)拓广文法,增加产生式S’→#S#; (2) 计算每个非终结符的firstvt和lastvt; (3) 列表。
二、算符优先分析的若干问题
左符 右符 + * ( ) i
+
*
(
≡
)
函数说明>}
<常量定义>::=const<标识符>=<无符号数>{(,|;) <标
识符>=<无符号数>}
<变量说明>::=var<标识符>:integer{;<标识符表>:integer} <函数说明>::= function<标识符>[(<标识符表>
:integer)] :integer;<分程序>
5.2 算符优先分析法
一、算符优先文法及优先表的构造 二、算符优先分析的若干问题 三、优先函数
5.2 算符优先分析法
习题与答案-5-语法分析-自下而上-优先分析

第六章P1163.有文法G[S]:S—>V V—>T|ViT T—>F|T+F F—>)V*|( (1)给出( + ( i ( 的规范推导。
(2)指出句型F+Fi(的短语,句柄,素短语。
(3)G[S]是否OPG?若是,给出(1)中句子的分析过程。
3. G[S]: S—>VV—>T|ViTT—>F|T+FF—>)V*|((1)S S=>V=>ViT=>ViF=>Vi(=>Ti(=>T+Fi(=>T+(i(V =>F+(i(=>(+(I(V i TT FT + F (F (((2) S 短语 F , F+F , ( , F+Fi(句柄 FV 素短语F+F , (V i TT FT + F (F(3) V N FIRSTVT LASTVTF ) ( * (T ) ( + * ( +V ) ( + i * ( + iS ) ( + i * ( + i由V—>ViT得任意(LASTVT(V))>i , i<任意(FIRSTVT(T)) 由#S#得# = ##<任意(FIRSTVT(S)) , 任意(LASTVT(S))># 由T—>T+F得任意(LASTVT(T))>+ +<任意(FIRSTVT(F)) 由F—>)V*得)=* ) < 任意(FIRSTVT(V))任意(LASTVT(V))>* 由此构造运算符优先关系表如下:i + ) * ( #i > < < > < >+ > > < > < >) < < < = <* > > > >( > > > ># < < < < =由关系表中任何两符号只有一种关系知文法为OPG文法步栈当前符号余留串关系动作0 # (+(i(# #<( 移进1 #( + (i(# (>+ 归约2 #N + (i(# #<+ 移进3 #N+ ( i(# +<( 移进4 #N+( i (# (>i 归约5 #N+N i (# +>i 归约6 #N i (# #<i 移进7 #Ni ( # i<( 移进8 #Ni( # (># 移进9 #NiN # i># 归约10 #N # #=# 成功4.已知文法G[S]为:S—>S;G|G G—>G(T)|H H—>a|(S) T—>T+S|S (1)构造G[S]的算符优先关系表,并判断G[S]是否为算符优先文法。
语法分析-自上而下分析50页文档

语法分析-自上而下分析
16、人民应该为法律而战斗,就像为 了城墙 而战斗 一样。 ——赫 拉克利 特 17、人类对于不公正的行为加以指责 ,并非 因为他 们愿意 做出这 种行为 ,而是 惟恐自 己会成 为这种 行为的 牺牲者 。—— 柏拉图 18、制定法律法令,就是为了不让强 者做什 么事都 横行霸 道。— —奥维 德 19、法律是社会的习惯和思想的结晶 。—— 托·伍·威尔逊 20、人们嘴上挂着的法律,其真节制使快乐增加并使享受加强。 ——德 谟克利 特 67、今天应做的事没有做,明天再早也 是耽误 了。——裴斯 泰洛齐 68、决定一个人的一生,以及整个命运 的,只 是一瞬 之间。 ——歌 德 69、懒人无法享受休息之乐。——拉布 克 70、浪费时间是一桩大罪过。——卢梭
编译原理习题及答案(整理后)

第一章1、将编译程序分成若干个“遍”是为了。
a.提高程序的执行效率b.使程序的结构更加清晰c.利用有限的机器内存并提高机器的执行效率d.利用有限的机器内存但降低了机器的执行效率2、构造编译程序应掌握。
a.源程序b.目标语言c.编译方法d.以上三项都是3、变量应当。
a.持有左值b.持有右值c.既持有左值又持有右值d.既不持有左值也不持有右值4、编译程序绝大多数时间花在上。
a.出错处理b.词法分析c.目标代码生成d.管理表格5、不可能是目标代码。
a.汇编指令代码b.可重定位指令代码c.绝对指令代码d.中间代码6、使用可以定义一个程序的意义。
a.语义规则b.语法规则c.产生规则d.词法规则7、词法分析器的输入是。
a.单词符号串b.源程序c.语法单位d.目标程序8、中间代码生成时所遵循的是- 。
a.语法规则b.词法规则c.语义规则d.等价变换规则9、编译程序是对。
a.汇编程序的翻译b.高级语言程序的解释执行c.机器语言的执行d.高级语言的翻译10、语法分析应遵循。
a.语义规则b.语法规则c.构词规则d.等价变换规则二、多项选择题1、编译程序各阶段的工作都涉及到。
a.语法分析b.表格管理c.出错处理d.语义分析e.词法分析2、编译程序工作时,通常有阶段。
a.词法分析b.语法分析c.中间代码生成d.语义检查e.目标代码生成三、填空题1、解释程序和编译程序的区别在于。
2、编译过程通常可分为5个阶段,分别是、语法分析、代码优化和目标代码生成。
3、编译程序工作过程中,第一段输入是,最后阶段的输出为程序。
4、编译程序是指将程序翻译成程序的程序。
单选解答1、将编译程序分成若干个“遍”是为了使编译程序的结构更加清晰,故选b。
2、构造编译程序应掌握源程序、目标语言及编译方法等三方面的知识,故选d。
3、对编译而言,变量既持有左值又持有右值,故选c。
4、编译程序打交道最多的就是各种表格,因此选d。
5、目标代码包括汇编指令代码、可重定位指令代码和绝对指令代码3种,因此不是目标代码的只能选d。
语法分析——自上而下分析共69页文档

36、“不可能”这个字(法语是一个字 ),只 在愚人 的字典 中找得 到。--拿 破仑。 37、不要生气要争气,不要看破要突 破,不 要嫉妒 要欣赏 ,不要 托延要 积极, 不要心 动要行 动。 38、勤奋,机会,乐观是成功的三要 素。(注 意:传 统观念 认为勤 奋和机 会是成 功的要 素,但 是经过 统计学 和成功 人士的 分析得 出,乐 观是成 功的第 三敢地 走到底 ,决不 回头。 ——左
39、没有不老的誓言,没有不变的承 诺,踏 上旅途 ,义无 反顾。 40、对时间的价值没有没有深切认识 的人, 决不会 坚韧勤 勉。
56、书不仅是生活,而且是现在、过 去和未 来文化 生活的 源泉。 ——库 法耶夫 57、生命不可能有两次,但许多人连一 次也不 善于度 过。— —吕凯 特 58、问渠哪得清如许,为有源头活水来 。—— 朱熹 59、我的努力求学没有得到别的好处, 只不过 是愈来 愈发觉 自己的 无知。 ——笛 卡儿
编译原理练习题及答案

第一章练习题(绪论)一、选择题1.编译程序是一种常用的软件。
A) 应用B) 系统C) 实时系统D) 分布式系统2.编译程序生成的目标代码程序是可执行程序。
A) 一定B) 不一定3.编译程序的大多数时间是花在上。
A) 词法分析B) 语法分析C) 出错处理D) 表格管理4.将编译程序分成若干“遍”将。
A)提高编译程序的执行效率;B)使编译程序的结构更加清晰,提高目标程序质量;C)充分利用内存空间,提高机器的执行效率。
5.编译程序各个阶段都涉及到的工作有。
A) 词法分析B) 语法分析C) 语义分析D) 表格管理6.词法分析的主要功能是。
A) 识别字符串B) 识别语句C) 识别单词D) 识别标识符7.若某程序设计语言允许标识符先使用后说明,则其编译程序就必须。
A) 多遍扫描B) 一遍扫描8.编译方式与解释方式的根本区别在于。
A) 执行速度的快慢B) 是否生成目标代码C) 是否语义分析9.多遍编译与一遍编译的主要区别在于。
A)多遍编译是编译的五大部分重复多遍执行,而一遍编译是五大部分只执行一遍;B)一遍编译是对源程序分析一遍就立即执行,而多遍编译是对源程序重复多遍分析再执行;C)多遍编译要生成目标代码才执行,而一遍编译不生成目标代码直接分析执行;D)多遍编译是五大部分依次独立完成,一遍编译是五大部分交叉调用执行完成。
10.编译程序分成“前端”和“后端”的好处是A)便于移植B)便于功能的扩充C)便于减少工作量D)以上均正确第二章练习题(文法与语言)一、选择题1.文法 G 产生的 (1) 的全体是该文法描述的语言。
A.句型B. 终结符集C. 非终结符集D. 句子2.若文法 G 定义的语言是无限集,则文法必然是 (2) A递归的 B 上下文无关的 C 二义性的 D 无二义性的3. Chomsky 定义的四种形式语言文法中, 0 型文法又称为(A)文法;1 型文法又称为(C)文法;2 型语言可由(G) 识别。
A 短语结构文法B 上下文无关文法C 上下文有关文法D 正规文法E 图灵机F 有限自动机G 下推自动机4.一个文法所描述的语言是(A);描述一个语言的文法是(B)。
自上而下语法分析

5.3.3.1 单个文法符号的FIRST集
FIRST定义:
FIRST() ={a| aβ, a ∈VT, β ∈ Σ*} 若 , 则规定∈ FIRST() 。
2. 消除间接左递归(代入法)
间接左递归的消除需先将间接左递归变为直接 左递归,然后再按第1种方法消除直接左递归 如:文法 G: S→Q | b 可改写为: Q →Pβ | b
5.3.1 左递归的N N替换为N 的候选式。如果N有n个候选式,右边重复n 次,而且每一次重复都有N的不同候选式来代 替N。
第5章 自顶向下语法分析方法
内容
语法分析的任务与分类 自上而下分析面临的问题 LL(1)分析法 递归下降分析程序构造 预测分析程序
5.1 语法分析的任务与分类
1. 任务 对于一个给定w∈VT*,判断w∈L(G)
工作本质:根据产生式识别输入串是否为 一个句子。 2. 语法分析器:是一个程序,它按照P,做 识别w的工作。语法分析只管w在形式上是 否正确,不管其具体含义,比如:“虎打 武松”。
不同排序所得的文法的等价性是显然的
习题1
5.3.1 左递归的消除
A→aB|Bb B→Ac|d
消去该文法的左递归。
习题2 消去文法G[S]: S →Sa|Ab|a A→Sc
的左递归。
5.3.2 回溯的消除
回溯
若当前符号为:a,对A展开,而A→ 1 | 2 | … | n,那 么,要知道哪一个 i是获得以a开头的串的唯一替换式。
化简由第二步所得的文法 即去除那些从开始符号出发永远无法到达的非终结符的产生规则
5.3.1 左递归的消除
例5.3 考虑文法G(S) S→Qc|c Q→Rb|b R→Sa|a
自上而下的语法分析

非终结符
初值 第1次扫描 第2次扫描
M
未定
T
B
D
未定
是
未定
是
未定
是
是
SELECT(T→Ba)={d,e,b,a,ε} SELECT(T→ε) = {d,e,b,a,#} 这两者的交集不为 ∅ 。 故该文法不是 LL(1) 文法。
5.5.2 LL(1)分析一般过程
给定文法: S → aSbS|ε 。求符号串 ab 的 LL(1) 分析过程。
* FIRST(A)= {a|A = a…,且 a∈VT } >
求FIRST集合
G: M T B D
文法规则
→ TB → Ba|ε → Db|eT|ε → d|ε
第一遍 第二遍 第三遍
M T T B B B D D
→ TB → Ba →ε → Db → eT →ε →d →ε
F(M)={ } F(T)={ } F(T)={ε} F(B)={ } F(B)={e} F(B)={e,ε} F(D)={d} F(D)={d,ε}
G2[S]: S→Ap S→Bq A→cA A→a B→dB B→b FIRST(Ap) = { a,c } FIRST(Bq) = { b,d } FIRST(S) = FIRST(Ap) ∪FIRST(Bq) = { a,b,c,d }
SБайду номын сангаас
A p
G3[S]: S→aA S→d A→bAS A→ε
FOLLOW(B)=FOLLOW(B)∪{a}={#,a} FOLLOW(D)=FOLLOW(D)∪{b}={b} FOLLOW(T)=FOLLOW(T)∪FOLLOW(B)={d,e,b,#}∪{#,a} ={d,e,b,a,#}
编译原理分知识点习题自上而下语法分析 (1)

1.设有文法G[S]:S→ABA→bB|AaB→Sb|a试消除该文法的左递归。
解:本题考查消除左递归的方法。
应用消除文法左递归的算法对文法G[S]消除左递归的过程如下:(1)将非终结符排序为:U1=S,U2=A,U3=B(2)进入算法排序:i=1时,对文法无影响i=2,j=1时:A→Aa有直接左递归,消去该直接左递归,得A→bBA’A’→aA’|εi=3,j=1时:改写文法,有B→ABb|aj=2时:改写文法,有B→bBA’Bb|a无左递归。
(3)所以文法G[S]消除左递归后变为:G’[S]:S→ABA→bBA’A’→aA’|εB→bBA’Bb|a2.设有文法G[E]:E→Aa|BbA→cA|eBB→bd试按照递归子程序法为该文法构造语法分析程序。
解:本题考查递归子程序的构造方法。
首先判断文法是否满足递归子程序法对文法的要求,然后再构造递归子程序。
因为:(1)该文法无左递归。
(2)文法的产生式E→Aa|Bb和A→cA|eB的右部有若干选项,判断这两条产生式右部各候选式的终结首符号集合是否两两互不相交。
对产生式E→Aa|Bb,有FIRST(Aa)∩FIRST(Bb)={c,e}∩{b}=ø对产生式A→cA|eB,有FIRST(cA)∩FIRST(eB)={c}∩{e}=ø文法中其他产生式都只有一个非空ε的右部。
综合(1)、(2),该文法可以采用自上而下分析方法进行语法分析而不会出现回朔和无限循环。
下面为该文法的每一个非终结符号构造递归子程序。
假设用READAWORD代表读下一个单词。
用P(E)、P(A)、P(B)分别表示非终结符号E、A、B对应的子程序名。
约定输入符号串以“#”作为输入结束符。
P(E)的递归子程序为:PROCEDURE P(E);BEGINIF WORD IN FIRST(Aa)THENBEGINP(A);READAWORD;IF WORD=’a’THEN READAWORDELSE ERRORENDELSE IF WORD IN FIRST(Bb)THENBEGINP(B);READAWORD;IF WORD=’b’THEN READAWORDELSE ERRORENDELSE ERROREND;P(A)的递归子程序为:PROCEDURE P(A);BEGINIF WORDD=’c’THENBEGINREADAWORD;P(A)ENDELSE IF WORD=’e’THENBEGINREADWORD;P(B)ENDELSE ERROREND;P(B)的递归子程序为:PROCEDURE P(B);BEGINIF WORD=’b’THENBEGINREADAWORD;IF WORD=’d’THEN READAWORDELSE ERRORENDELSE ERROREND;主程序中的主要内容为:READAWORD;P(E);IF WORD=”#”THEN WRITE(“RIGHT!”)ELSE WRITE(“ERROR!”)3.已知文法G[E]:G[E]:E→E+T|TT→T*F|FF→i|(E)请按递归子程序法为其构造语法分析程序。
编译原理复习题

第二高级语言的语法描述6、令文法G6为:N →D|NDD → 0|1|2|3|4|5|6|7|8|9(1)G6 的语言L(G6)是什么?(2)给出句子0127、34和568的最左推导和最右推导。
解答:思路:由N → D|ND可得出如下推导N=>ND=>NDD=>…=>D n(n>=1)可以看出,N最终可以推导出1个或多个(也可以是无穷)D,而D → 0|1|2|3|4|5|6|7|8|9可知,每个D为0~9中的任一个数字,所以,N 最终推导出的就是由0~9这10个数字组成的字符串。
(1)G6 的语言L(G6)是由0~9这10个数字组成的字符串,或{0,1,…,9}+。
(2)句子0127、34和568的最左推导分别为:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 N=>ND=>DD=>3D=>34N=>ND=>NDD=>DDD=>5DD=>56D=>568句子0127、34和568的最右推导分别为:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127N=>ND=>N4=>D4=>34N=>ND=>N8=>ND8=>N68=>D68=>5687、写一个文法,使其语言是奇数集,且每个基数不以0开头。
解答:G(S):S → CD|D D→1|3|5|7|9C → CB|A A→2|4|6|8|DB → A|0或:G(S):S →MWN|N N →1|3|5|7|9 M →1|2|3|4|5|6|7|8|9W → WV|ε V → M|08、令文法为:E→T|E+T|E-TT→F|T*F|T/FF→(E)|i(1)i+i*i、i*(i+i)的最左推导和最右推导;(2)给出i+i+i、i+i*i和i-i-i的语法树。
解答:(1)i+i*i、i*(i+i)的最左推导分别为:E=>T=>E+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*iE=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F)=>i*(i+i)i+i*i、i*(i+i)的最右推导分别为:E=>T=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i=>i+i*iE=>T=>T*F=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=>T*(i+i)=>F*(i+i)=>i*(i+i)(2) E E EE + T E + T E - TT T * F T T * F E - T FF F i F F i T F ii i i i F ii+i+I i+i*ii i-i-i9、证明下面的文法是二义的: S→iSeS|iS|i证明:思路:要证明该文法是二义的,必须找到一个句子,使得该句子具有两个不同的最右推导或两个不同的语法树。
语法分析--自上而下分析的基本问题

语法分析--⾃上⽽下分析的基本问题语法分析基本概念语法分析的前提:对语⾔的语法结构进⾏描述,采⽤正规式和有限⾃动机描述和识别语⾔的单词符号,⽤上下⽂⽆关⽂法来描述语法规则语法分析的任务:分析⼀个⽂法的句⼦的结构语法分析器的功能:按照⽂法的产⽣式(语⾔的语法规则),识别输⼊符号串是否为⼀个句⼦(合式程序)⾃下⽽上(Bottom-up):从输⼊串开始,逐步进⾏归约,直到⽂法的开始符号,归约:根据⽂法的产⽣式规则,把串中出现的产⽣式的右部替换成左部符号,从树叶节点开始,构造语法树,算符优先分析法、LR分析法⾃上⽽下(Top-down):从⽂法的开始符号出发,反复使⽤各种产⽣式,寻找"匹配"的推导,推导:根据⽂法的产⽣式规则,把串中出现的产⽣式的左部符号替换成右部,从树的根开始,构造语法树,递归下降分析法、预测分析程序⾃上⽽下分析⾯临的问题基本思想:从⽂法的开始符号出发,向下推导,推出句⼦,针对输⼊串,试图⽤⼀切可能的办法,从⽂法开始符号(根结点)出发,⾃上⽽下地为输⼊串建⽴⼀棵语法树多个产⽣式候选带来的问题,回溯问题:分析过程中,当⼀个⾮终结符⽤某⼀个候选匹配成功时,这种匹配可能是暂时的,出错时,不得不“回溯”⽂法左递归问题:⼀个⽂法是含有左递归的,如果存在⾮终结符P⾯临的问题⽂法左递归问题回溯问题构造不带回溯的⾃上⽽下分析算法消除⽂法的左递归性消除回溯消除⽂法的左递归直接左递归的消除间接左递归的消除消除左递归的算法由于对⾮终结符排序的不同,最后所得的⽂法在形式上可能不⼀样。
但不难证明,它们都是等价的消除回溯为了消除回溯必须保证:对⽂法的任何⾮终结符,当要它去匹配输⼊串时,能够根据它所⾯临的输⼊符号准确地指派它的⼀个候选去执⾏任务,并且此候选的⼯作结果应是确信⽆疑的FIRST和FOLLOW集合的构造FIRST集合令G是⼀个不含左递归的⽂法,对G的所有⾮终结符的每个候选α定义它的终结⾸符集FIRST(α)为:提取公共左因⼦FOLLOW集合L: 从左到右扫描输⼊串 L: 最左推导 1:每⼀步只需向前查看⼀个符号FIRST和FOLLOW集合的构造构造每个⽂法符号的FIRST集合构造FOLLOW(A)构造每个⾮终结符的FOLLOW集合对最后的FIRST、FOLLOW集合有点迷,真的有点迷,晚上不该看这个的!!o(╥﹏╥)o。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 1.对文法G[S]
G: S →a | ∧| (T)
T →T , S | S
(1) 给出(a,(a,a))和(((a,a), ∧,(a)),a)的最左推导。
(2) 对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3) 经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4) 给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
1. [解答]
(1)①S ②S
(T )( T )
T , S T , S ②S=>(T) =>(T,S)
=>(S,S) S ( T ) S a =>((T),S)
=>((T,S),S)
a T , S ( T ) =>((T,S,S),S)
=>((S,S,S),S) S a T , S =>(((T),S,S),S)
=>(((T,S),S,S),S)
a T , S ( T ) =>(((S,S),S,S),S)
=>(((a,S),S,S),S)
①S=>(T) =>(T,S) S ^ S =>(((a,a),S,S),S)
=>(S,S) =>(a,S) =>(((a,a),^,S),S) =>(a,(T)) ( T ) a =>(((a,a),^,(T)),S) =>(a,(T,S)) =>(((a,a),^,(S)),S)
=>(a,(S,S)) T , S =>(((a,a),^,(a)),S)
=>(a,(a,S)) =>(((a,a),^,(a)),a)
=>(a,(a,a)) S a
a
(2) 消除左递归
G': S→a | ∧| (T)
T→ST'
T'→,ST' |ε
递归子程序:
program parser proceduce T;
begin begin
getsym; if sym in [a,^,() then
S begin
end; S;
proceduce S; T;
begin end;
if sym=’a’ or sym=’^’ then else
getsym error;
elseif sym=’(‘ end;
begin getsym; proceduce T’;
T; begin
If sym=’)’ then if sym=’,’ then
Getsym; begin
Else getsym;
Error; S;
End; T;
Else end;
Error; else
End; if sym=’)’ then
else
error;
end;
LL(1)文法!
(4) 分析栈余留串所用产生式或动作
1 #S (a,a)# S—>(T)
2 #)T( (a,a)# (匹配
3 #)T a,a)# T—>ST’
4 #)T’S a,a)# S—>a
5 #)T’a a,a)# a匹配
6 #)T’ ,a)# T’ —>,ST’
7 #)T’S, ,a)# ,匹配
8 #)T’S a)# S—>a
9 #)T’a a)# a匹配
10 #)T’ )# T’—>ε
11 #) )# )匹配
12 # # 接受
因为(a,a)#分析成功所以(a,a)为文法的句子
步骤分析栈余留串所用产生式或动作
1 #S (a,a# S→(T)
2 #)T( (a,a# ( 匹配
3 #)T a,a# T→ST’
4 #)T’S a,a# S→a
5 #)T’a a,a# a 匹配
6 #)T’,a# T’→,ST’
7 #)T’S, ,a# , 匹配
8 #)T’S a# S→a
9 #)T’a a# a 匹配
10 #)T’# 出错
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 2. G: E →TE'
E' →+E |ε
T →FT'
T' →T |ε
F →PF'
F' →*F' |ε
P →(E) | a | b |∧
预测分析表
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 3.已知文法G: S →MH | a
H →LSo |ε
K →dML |ε
L →eHf
M →K | bLM
判断G是否是LL(1)文法,如果时,构造LL(1)分析表。
因为相同左部的select集互不相交所以该文法是LL(1)文法或者因为预测分析表入口唯一所以该文法是LL(1)文法
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
7.对于一个文法若消除了左递归,提取了左公共因子后是否一定为LL(1)文法?试对下面文法进行改写,并对改写后的文法进行判断。
(2) A→aABe | a B→Bb | d
(3) S→Aa | b A→SB B→ab
7. [解答]
不一定
(2) A→aABe | a
B→Bb | d
改写为
A→aA’
A’→ABe |ε
B→dB’
B’→bB’ |ε
Select(A’→Abe)∩select(A’→ε)=φ
select(B’→bB’)∩select(B’→ε)=φ
所以该文法是LL(1)文法
(3) S→Aa | b
A→SB
B→ab
●排序 B A S
B→ab不含左递归
代入A得A→Sab 不含左递归
代入S得S→Saba | b 消左递归得S→bS’ S’→abaS’ | ε整理得
S→bS’
S’→abaS’ | ε
A→Sab
B→ab
化简文法,消去A,B得
S→bS’
S’→abaS’ | ε
判断select(S’→abaS’)∩select(S’→ε)=φ
所以改写后的文法是LL(1)文法
●排序S A B
S→Aa | b 不含左递归
代入A得A→(Aa|b)B 即A→AaB | bB
消除左递归得A→bBA’A’→aBA’|ε
代入B中B→ab
整理得
S→Aa | b
A→bBA’
A’→aBA’|ε
B→ab
因为select(S→Aa)∩select(S→b)={b}≠φ
所以该文法不是LL(1)文法
可见,当排序不同,得到的文法可能是不同的情形。