保险仓库数据模型设计
保险业决策支持系统的数据仓库的设计与实现
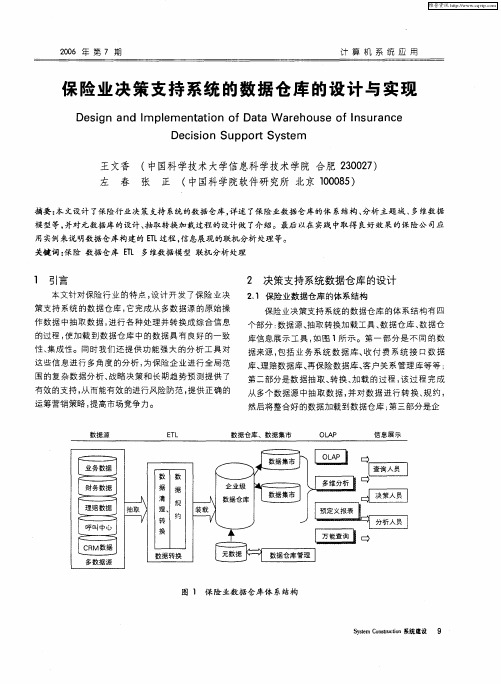
第二部分是数 据抽取 、 转换 、 加载 的过 程 , 过 程完 成 该
从多个数据源 中抽取 数 据 , 对数据 进行 转 换 、 约 , 并 规
然后将整合好 的数据加载 到数据仓库 ; 第三部分 是企
数据源
EL T
数据仓库 、数据集市
OL P A
信息展示
图 1 保 险业数据仓库体 系结构
的 EL T 过程。
的多个维度 表组成 。事 实是决策 者分析 的 目标数 据 ,
如保额、 费、 续 费、 款金额 等。维是 事实 的信 息 保 手 赔
属性 , 是观察事 实的角度 , 也 如保单的承保机构 、 险种 、
起 保 日期、 经办 人、 代理 人等。本文以保单分析事 实表 为例构造 其星型模 式如 图 2所示 , 们可 以汇 总各个 我 层次的承 保公司的保费收入情况 、 手续 费情 况等 , 也可 以从险种 、 起保 日期、 经办人等 角度按照各 种层次进行
维普资讯
20 年 第 7 期 06
计 算 机 系 统 应 用
保 险业 决 策 支持 系统 的数 据 仓 库 的 设 计 与 实现
De i n a d I p e e t ton o t a e o s fI s r n e sg n m l m n a i fDa a W r h u e o n u a c
邮编
联系电话 上级机构
数据格式 、 访问方法及使 用限制 、 数据源 的业 务内容说明、 数据源 的更 新频率 、 据抽取 需 数 设置的参数、 抽取 的进度安排等信息 。
2 3 2 预 处理数 据元数 据 ..
据 的对 应规 则 , 包括 数 据源 的关 系表和 数据
保险业数据仓库的设计

保险业数据仓库的设计
崔新友;杨柳;雷磊
【期刊名称】《科技信息》
【年(卷),期】2010(000)019
【摘要】本文通过深入了解保险行业的领域知识以及对数据仓库技术的学习研究,详细阐述了数据挖掘技术以及数据仓库技术在保险业客户分析中的应用;其次从保险业的基本流程入手,详细阐述了客户细分、客户风险等领域的背景知识,介绍数据仓库技术在该领域分析中的应用,然后从数据仓库概念入手,分别介绍了数据仓库概念模型和逻辑模型的设计与实现.
【总页数】3页(P110-111,115)
【作者】崔新友;杨柳;雷磊
【作者单位】中国人民解放军武汉军械士官学校,湖北,武汉,430075;中国人民解放军69080部队,新疆,乌鲁木齐,830002;中国人民解放军武汉军械士官学校,湖北,武汉,430075
【正文语种】中文
【相关文献】
1.面向保险业的数据仓库模型分析与设计 [J], 吴菊华;曹强;莫赞;孙德福
2.保险业呼叫中心的数据仓库设计与实现 [J], 李先
3.保险业决策支持系统的数据仓库的设计与实现 [J], 王文香;左春;张正
4.基于数据仓库技术的保险业统计分析系统设计 [J], 陈冠星
5.基于数据仓库技术的保险业统计分析系统设计 [J], 陈冠星
因版权原因,仅展示原文概要,查看原文内容请购买。
etl关于保险的项目

etl关于保险的项目在保险领域,ETL(提取、转换、加载)是数据仓库和业务智能项目中的关键组成部分。
ETL过程涉及从不同数据源中提取数据,对数据进行转换和清理,然后将其加载到目标数据库或数据仓库中,以支持报表、分析和决策。
以下是关于保险领域中可能涉及的ETL项目的一些常见方面:数据提取(Extract):数据源:保险公司通常有各种不同的数据源,包括保单系统、理赔系统、保费系统、客户关系管理系统等。
数据格式:数据可能以不同的格式存储,如关系数据库、平面文件(如CSV 或Excel)、日志文件等。
数据抽取方法:ETL工具通常使用各种方法(增量抽取、全量抽取等)从这些源系统中提取数据。
数据转换(Transform):数据清洗:清理、修复和处理数据质量问题,例如缺失值、重复值、错误值等。
数据转换:对数据进行计算、合并、拆分、聚合等操作,以满足目标数据仓库的结构和需求。
数据规范化:统一数据格式、单位和命名规则,以确保一致性。
数据加载(Load):目标数据库:将转换后的数据加载到目标数据库或数据仓库中。
数据索引和分区:在数据库中创建适当的索引和分区,以提高查询性能。
自动化加载:设计自动化的任务和工作流程,以定期更新数据仓库中的数据。
保险数据模型:设计数据模型:根据业务需求和报表分析的要求设计保险数据模型。
关联不同数据源:在数据仓库中建立关联,以便在分析中能够获取全面的业务视图。
监控和维护:ETL监控:设置监控任务,以检测ETL过程中的错误、延迟或其他异常情况。
维护计划:制定定期维护计划,确保ETL过程的持续有效性。
在保险ETL项目中,确保数据的准确性、一致性和时效性非常关键,因为这些数据将用于业务决策、风险评估和监管报告等方面。
采用合适的ETL工具和最佳实践能够有效地支持保险业务的数据管理需求。
数据仓库的数据模型设计和数据库系统的数据模型设计有什么不同

数据仓库的数据模型设计和数据库系统的数据模型设计
有什么不同
1.目的和应用:
数据仓库的数据模型设计主要用于支持分析和决策支持系统。
它的目标是将来自多个操作性数据库的数据集成在一个统一的存储中,以便于查询和分析。
数据库系统的数据模型设计主要用于支持业务应用系统的操作和事务处理。
2.数据结构:
3.数据粒度:
4.数据复杂性:
5.数据访问模式:
数据仓库的数据模型设计支持复杂的查询操作,如多维分析和数据挖掘等。
因此,数据仓库的数据模型设计通常需要进行优化,以提高查询性能和响应时间。
数据库系统的数据模型设计则更注重事务处理和并发控制等方面的性能优化。
总结起来,数据仓库的数据模型设计和数据库系统的数据模型设计主要在目的、数据结构、数据粒度、数据复杂性和数据访问模式等方面有所不同。
数据仓库的数据模型设计更注重于支持分析和决策支持系统,采用星型或雪花型的数据结构,关注大量和高层次的数据,需要复杂的数据转换和清洗过程,并进行查询性能优化。
数据库系统的数据模型设计更注重于支持业务应用系统的操作和事务处理,采用关系模型的结构,关注细节
和实时的操作数据,不需要涉及复杂的数据处理过程,并进行事务和并发性能的优化。
保险仓库数据模型设计

保险仓库数据模型设计简介本文档旨在设计一个保险仓库的数据模型,以支持保险管理系统的数据存储和处理。
保险仓库是用于存储和管理保险数据的系统,包括保险合同、投保人信息、受益人信息等。
本文将详细介绍保险仓库的数据模型设计。
数据模型设计1.保险合同(InsuranceContract)–合同ID(ContractID):保险合同的唯一标识符,用于区分不同合同。
–合同号(ContractNumber):保险合同的编号,用于唯一标识一个合同。
–投保人ID(PolicyHolderID):保险合同的投保人的唯一标识符。
–受益人ID(BeneficiaryID):保险合同的受益人的唯一标识符。
–保险产品ID(InsuranceProductID):保险合同所关联的保险产品的唯一标识符。
–生效日期(EffectiveDate):保险合同的生效日期。
–失效日期(ExpirationDate):保险合同的失效日期。
–保单状态(PolicyStatus):保险合同的当前状态,如正常、注销、终止等。
2.投保人(PolicyHolder)–投保人ID(PolicyHolderID):投保人的唯一标识符。
–姓名(Name):投保人的姓名。
–性别(Gender):投保人的性别。
–出生日期(DateOfBirth):投保人的出生日期。
–身份证号(IDNumber):投保人的身份证号码。
–联系方式(Contact):投保人的联系方式,如手机号、邮箱等。
3.受益人(Beneficiary)–受益人ID(BeneficiaryID):受益人的唯一标识符。
–姓名(Name):受益人的姓名。
–性别(Gender):受益人的性别。
–出生日期(DateOfBirth):受益人的出生日期。
–身份证号(IDNumber):受益人的身份证号码。
–联系方式(Contact):受益人的联系方式,如手机号、邮箱等。
4.保险产品(InsuranceProduct)–产品ID(ProductID):保险产品的唯一标识符。
基于数据仓库技术的保险业统计分析系统设计论文

基于数据仓库技术的保险业统计分析系统设计论文基于数据仓库技术的保险业统计分析系统设计论文保险业是指将通过契约形式集中起来的资金,用以补偿被保险人的经济利益业务的行业。
以下是店铺今天为大家精心准备的:基于数据仓库技术的保险业统计分析系统设计相关论文。
内容仅供参考,欢迎阅读!基于数据仓库技术的保险业统计分析系统设计全文如下:摘要:通过分析保险行业的核心业务,采用数据仓库技术,对保险企业中的海量历史数据进行集成和统计分析,得到精确的业务运行分析报告,对业务及客户进行趋势分析,以便及时作出正确决策并根据自身需要监测业务运营。
关键词:数据仓库;保险业;ETL;多维数据;统计分析1 数据仓库简介数据仓库(Data Warehouse,DW)是随着关系数据库、并行处理和分布式技术的飞速发展而产生的[1],W?H?Inmon出版了《Building the Data Warehouse》一书,给出了数据仓库的定义:数据仓库是一个面向主题的、集成的、非易失的、随时间变化的用来支持管理人员决策的数据集合[2]。
数据仓库包含的是整个企业视图的粒度化数据。
数据仓库系统通常对多个异构数据源有效集成,集成后按照主题进行重组[3]。
存放在数据仓库中的数据通常不再修改,用作进一步的分析型数据处理。
数据仓库系统的建立和开发以企事业单位的现有业务系统和大量业务数据的积累为基础[4],其开发是一个循环迭代过程,通常需要企业有一定的业务数据积累,开发人员将这些历史数据通过ETL输入到数据仓库中,进行分析和统计,以建立决策支持辅助系统,为企事业单位管理者提供决策支持。
2 保险业需求分析随着保险业发展及保险市场竞争的加剧,保险公司在管理和运营方面面临着更高的要求,来自监管、竞争、技术更新及全球化等各方面的压力不断考验着保险企业。
保险业发展的核心动力表现在以下几个方面:①进入新分市场及提高业务质量;②巩固客户忠诚度,适应客户多变的需求;③高效的运营;④精确的风险及成本控制;⑤消除各种技术壁垒。
人寿保险公司数据仓库的设计与实现

人寿保险公司数据仓库的设计与实现
杨杉
【期刊名称】《人天科学研究》
【年(卷),期】2011(010)001
【摘要】数据仓库技术可以为决策分析提供更好的支持,是数据分析和知识挖掘的发展方向。
结合某人寿保险公司的实际情况,详细分析和设计了该人寿保险公司的数据仓库,包括数据仓库体系结构、概念模型、逻辑模型、物理模型,并在此基础上利用SQL Server 2000实现了数据仓库。
保险公司可以利用该数据仓库进行数据挖掘,发现有价值的客户信息,制定相应的市场策略。
【总页数】3页(P129-131)
【作者】杨杉
【作者单位】四川大学锦城学院计算机科学与软件工程系,四川成都611731【正文语种】中文
【中图分类】TP311.52
【相关文献】
1.人寿保险公司数据仓库的设计与实现 [J], 杨杉
2.内部审计:构建中国人寿安全屏障——中国人寿保险公司审计专访 [J], 张祈
3.泰康人寿:奋力走在保险信息化建设的前列——访泰康人寿保险公司信息技术部负责人付刚 [J], 郝京
4.A.国务院、中央金融工委任命中国人民保险公司、中国人寿保险公司和中国再保
险公司党政领导班子成员 [J],
5.太平人寿蝉联“年度卓越中资人寿保险公司”称号 [J], 王佳丽
因版权原因,仅展示原文概要,查看原文内容请购买。
保险仓库数据模型设计

保险仓库数据模型设计1. 引言保险仓库是一个用于存储和管理保险相关数据的系统。
在设计保险仓库的数据模型时,需要考虑系统所需的数据类型、数据关系以及数据管理和维护的方式。
本文将对保险仓库的数据模型设计进行详细阐述。
2. 数据模型概述数据模型是用来描述一个系统中的数据结构、数据类型、数据关系以及数据约束的概念模型。
在设计保险仓库的数据模型时,需要考虑保险仓库中的各个实体和它们之间的关系,以及各个实体的属性和约束。
3. 数据实体和属性保险仓库中包含多个实体,每个实体都有其特定的属性。
下面是保险仓库中一些关键实体及其属性的描述:3.1 保险公司实体•保险公司ID:唯一标识保险公司的编号,主键•保险公司名称:公司的名称,字符串类型•成立日期:公司成立的日期,日期类型•地址:公司的地址,字符串类型•联系人:公司的联系人,字符串类型3.2 保险产品实体•保险产品ID:唯一标识保险产品的编号,主键•产品名称:保险产品的名称,字符串类型•产品类型:保险产品的类型,字符串类型•保费:保险产品的保费,浮点数类型•承保范围:保险产品的承保范围,字符串类型3.3 保险合同实体•合同ID:唯一标识保险合同的编号,主键•保险公司ID:保险合同所属的保险公司ID,外键•保险产品ID:保险合同所属的保险产品ID,外键•保险起期:保险合同的起保日期,日期类型•保险止期:保险合同的终止日期,日期类型•被保险人:保险合同所涉及的被保险人,字符串类型4. 数据关系保险仓库中有多个实体之间存在着数据关系,下面是保险仓库中一些关键实体之间的数据关系描述:•保险公司和保险产品之间是一对多的关系,一个保险公司可以拥有多种保险产品。
•保险合同和保险公司之间是多对一的关系,一个保险公司可以有多个保险合同。
•保险合同和保险产品之间是多对一的关系,一个保险产品可以被多个保险合同所使用。
5. 数据约束为了保证数据的完整性和一致性,保险仓库中的数据需要满足一定的约束条件。
保险行业工作中的数据分析与建模

保险行业工作中的数据分析与建模保险行业是一个信息密集型的行业,每天都产生大量的数据。
这些数据包括来自客户的个人信息、保单信息、理赔信息等。
为了更好地了解客户需求、评估风险、制定政策和提供个性化服务,保险公司需要进行数据分析与建模。
本文将探讨保险行业工作中的数据分析与建模的重要性,并介绍一些常用的数据分析与建模方法。
一、数据分析的意义数据分析是指对收集到的大量数据进行整理、加工和分析,从而得出有价值的信息和结论的过程。
在保险行业中,数据分析能够帮助公司更好地了解客户需求和行为,优化保险产品和服务,提高市场竞争力。
首先,数据分析可以帮助保险公司了解客户的需求和行为。
通过分析客户的个人信息、保单信息和理赔信息,可以获得客户的风险偏好、投保习惯、理赔经历等信息。
这些信息对于保险公司优化产品设计、制定个性化的市场策略非常重要。
其次,数据分析可以帮助保险公司进行风险评估和控制。
通过分析大量的历史数据和行业统计数据,可以将客户的风险进行分类和评估,从而合理制定保费和理赔政策,降低保险公司的风险暴露。
最后,数据分析可以帮助保险公司提高运营效率和服务质量。
通过分析客户行为和需求,可以优化保险产品和服务流程,提升客户满意度和忠诚度。
同时,通过数据分析还可以发现运营过程中的潜在问题和机会,及时采取相应措施。
二、数据分析的方法在保险行业中,常用的数据分析方法包括统计分析、机器学习和数据挖掘等。
统计分析是一种基于历史数据和样本的分析方法,通过计算均值、方差、相关系数等统计指标,来推断总体特征和进行风险评估。
在保险行业中,可以利用统计分析方法来计算保费的期望值和标准差,评估保单的风险等级,预测赔付率等。
机器学习是一种通过训练算法来发现数据中的模式和规律的方法。
在保险行业中,可以利用机器学习方法来构建预测模型,预测客户的理赔概率、保费违约率、客户流失率等。
常用的机器学习算法包括决策树、神经网络、支持向量机等。
数据挖掘是一种通过自动或半自动的方法从大量数据中发现有价值的信息的方法。
面向保险业的数据仓库模型分析与设计

面向保险业的数据仓库模型分析与设计吴菊华;曹强;莫赞;孙德福【摘要】The insurance industry has gone through the computer informationlization construction development during the last decade, the scale of business data is constantly increasing. Enterprise executives face tremendous information from different business systems and more severe competition pressure, they need faster and more accurate analysis for the issue of enterprise decision-making. In this paper, based on the ECIF project of a life insurance company, data warehouse modeling problems and solutions are elaborated and analysed from business and management perspective of the entire insurance industry. The boundary of the data warehouse system is defined, the subject field is determined, and the insurance subject-oriented data warehouse model is built with conceptual model, logical model and physical model. Since the number and type of indicators in different industry differ from each other, the data warehouse indicators for the insurance industry is also tested. The whole process has a good reference value for the building of the insurance industry data warehouse.%保险业经历了十几年的计算机信息化建设发展,业务的数据规模也在不断地增大,需要对企业决策问题进行更准确的深度分析。
保险行业数据仓库(PDF 12页)

构建保险数据仓库的一个实例一、前言几乎所有行业都面对着激烈的竞争,正确及时的决策是企业生存与发展的最重要环节。
越来越多的企业认识到,只有靠充分利用、发掘其现有数据,才能实现更大的效益。
日常的业务应用生成了大量的数据,这些数据若用于决策支持则会带来显著的附加值。
若再加上行业分析报告、独立的市场调查、评测结果和顾问评估等外来数据时,上述处理过程产生的效益可进一步增强。
数据仓库正是汇总这些信息的基础,进而支持数据发掘、多维数据分析等当今尖端技术和传统的查询及报表功能。
这些对于在当今激烈的竞争中保持领先是至关重要的。
调查研究表明,大多数企业并不缺少数据,而是受阻于过量的冗余数据和数据不一致;而且它们变得越来越难于访问、管理和用于决策支持;其数据量正以成倍的速度增长。
这样,信息中心面临着不断增长的决策支持的需求,但是,开发应用变得越来越复杂和耗费人力。
那么怎样把大量的数据转换成可靠的、商用的信息以便于决策支持呢?数据仓库正广泛地被公认为是最好的解决方案。
PLATINUM technology 是世界上最大的数据仓库完整解决方案提供商之一。
在许多行业,我们都已经成功实施了数据仓库。
我们的成功来自于以下方面。
PLATINUM technology. Inc.保险业数据仓库解决方案全面提供商丰富的行业知识成功的用户实例完善的咨询服务先进的数据仓库构造过程完整的数据仓库产品系列24-10-98我们为国内一家保险公司建立的数据仓库系统,是结合了国际先进的保险业管理模式和中国国情的系统。
因此,我们的经验应该说具有实践意义和针对我国情况的现实性。
二、为什么需要数据仓库背景——保险公司在最近几年得到了迅猛的发展,未来预计将以更快的速度增长。
高速发展的保险公司面临激烈的竞争,从而产生越来越多的预测与决策支持需求。
比如想了解:您能够确定哪些险种正在恶化或已成为不良险种?您能够用有效的方式制定新增和续保的政策吗?您的理赔过程有欺诈的可能吗?您的理赔过程有不必要的额外花费吗?您现在能得到的报表是否只是月报或季报?数据仓库技术正是解决这些需求的最先进技术。
人寿保险公司保险业务数据仓库设计与实现

大连理工大学硕士学位论文人寿保险公司保险业务数据仓库设计与实现姓名:***申请学位级别:硕士专业:系统工程指导教师:迟忠先20020301人寿保险公司保险业务数据仓库设计与实现摘要保险行业需要利用数据仓库技术提高信息化水平,通过数据仓库来管理和运用好自己的数据,建立决策支持系统,从而增强企业的竞争力。
保险行业的原始业务数据频繁变更,不符合传统的数据仓库的理论,所以在实现保险行业数据仓库的过程中有很多的困难。
本文结合大连人寿保险公司保险业务数据仓库项目来阐述针对目前存在问题的解决方法。
本文分析了数据仓库在保险行业的应用情况,剖析了大连人保险寿数据仓库存在的问题,从而总结出大连人寿保险公司的数据仓库项目的需求。
通过运用查询优化技术、数据仓库索引技术、带中间库的三层结构和数据仓库数据自动更新方案成功地建立了大连人寿保险业务数据仓库系统。
本文详细地介绍了以上技术的理论设计和实现方法。
该系统达到了预想的效果,在大连人寿保险公司运行良好。
最后本文总结了在这个项目中的经验和得失,对人寿保险企业数据仓库系统的未来发展提出了展望。
关键词:数据仓库中间库查询优化数据抽取数据更新索引技术人寿保险公司保险业务数据仓库设计与实现AbstractInsurancecompaniesneedittoimprovethetheirorganization’sperformance,tomakebetteruseoftheirdata,toimplementdecision—supportsystem(DSS),tomaintaintheircompany’scompetitireedge.Theoperatingdataofinsuranceindustryisverydifferentfromothers’becauseitshistoriealdataismodifiedfrequently.ForthedataenvironmentdoesnotaccordthetheoryofDW,buiIdingtheinsurancedatawarehousingisaveryhardproject.ThispaperintroducesthemeanstodealwiththequestionandChinaLifeInsuranceCompanyDalJanBranchDataWarehousingproject.TheDWapplicationsininsurancecompanies,thequestionsinDalianBranchDWprojectandtherequirementofthisprojectareanalyzedinthepaper.Byusingqueryoptimization,databaseindex,middlebaseandautomaticdataupdatetechnique,theDWprojectisverysuccessful.Theacademicdesign,themethodofimplementandthefutureofInsuranceindustrydatawarehousingareintroduced.Keywords:datawarehousing,middIebase.queryoptimization.dataextracting.dataupdate,databaseindex人爵保险公司保险业务数据仓库设计与实现1绪论1.1数据仓库技术的发展数据仓库(DataWarehouse简称DW)是信息处理技术发展的必然产物。
人寿保险公司数据仓库的设计与实现

人寿保险公司数据仓库的设计与实现作者:杨杉来源:《软件导刊》2011年第01期摘要:数据仓库技术可以为决策分析提供更好的支持,是数据分析和知识挖掘的发展方向。
结合某人寿保险公司的实际情况,详细分析和设计了该人寿保险公司的数据仓库,包括数据仓库体系结构、概念模型、逻辑模型、物理模型,并在此基础上利用SQL Server 2000实现了数据仓库。
保险公司可以利用该数据仓库进行数据挖掘,发现有价值的客户信息,制定相应的市场策略。
关键词:数据仓库;人寿保险;模型设计;实现中图分类号:TP311.52文献标识码:A文章编号:1672-7800(2011)01-0129-03作者简介:杨杉(1983-),女,四川成都人,硕士,四川大学锦城学院计算机科学与软件工程系教师,研究方向为数据挖掘、管理信息系统和决策技术。
0引言随着我国保险市场的开放,保险企业迫切地需要提高企业内部的科学决策能力,增强在市场经营等方面的正确判断能力。
保险公司普遍的现状是:汇集了大量客户信息和业务数据,但这些数据分散在各种不同的业务系统和不同地点的机器中,有些代码缺乏统一的协调,大量数据得不到有效处理。
本文结合某人寿保险公司的实际情况,设计和建立符合该人寿保险公司特点的数据仓库,为后续进行数据挖掘提供了支持,将大大提高企业的管理水平和业务能力,从而提供更好的产品和服务,赢得更多客户。
1数据仓库概述数据仓库是计算机和数据应用发展到一定阶段的必然产物,它建立的目的是为了建立一种体系化的数据存储环境,将分析决策所需的大量数据从传统的操作环境中分离出来,使分散、不一致的操作数据转换成集成、统一的信息。
数据仓库技术主要解决了传统数据库面临的如下三大难题:第一,历史数据量很大;第二,辅助决策信息涉及许多部门的数据,而不同系统的数据难以集成;第三,由于访问数据的能力不足,它对大量数据的访问性能明显下降。
数据仓库技术至今仍然处于不断发展、丰富和完善之中。
保险领域基于大模型的企业知识管理项目的设计理念

保险领域基于大模型的企业知识管理项目的设计理念在保险领域,基于大模型的企业知识管理项目的设计理念旨在有效管理和利用大量的数据和知识资源,以改善决策、提高效率、降低风险和增强客户体验。
以下是一些设计理念和关键要点:1.数据整合和仓库:设计理念的基础是建立强大的数据整合和仓库系统。
这些系统能够汇总来自各个部门和数据源的信息,包括客户信息、索赔数据、保单信息、市场趋势等。
数据整合可以采用现代数据湖或数据仓库技术,确保数据的一致性和可访问性。
2.数据分析和挖掘:利用大数据分析和数据挖掘技术,可以深入了解客户需求、风险趋势、市场机会等方面。
这有助于制定更好的定价策略、风险评估和市场推广计划。
3.知识管理系统:设计理念包括建立知识管理系统,以有效地捕获、组织和分享内部和外部知识。
这包括文件、合同、政策、法规、专业知识和最佳实践。
知识管理系统可以帮助员工更好地理解和应对客户需求,并确保决策和行为与最新的信息一致。
4.智能决策支持:利用人工智能(AI)和机器学习技术,为员工提供决策支持工具,以更准确地评估风险、定价保单和处理索赔。
这有助于提高决策的一致性和效率。
5.客户体验优化:基于大模型的知识管理项目的设计理念还包括通过分析客户数据和反馈,提供个性化的服务和推荐。
这可以改善客户体验,增加客户满意度。
6.合规和风险管理:保险公司需要合规和风险管理系统,以确保遵守法规和监管要求。
大模型的知识管理项目应该包括这些方面,以减轻潜在的法律和合规风险。
7.培训和发展:知识管理项目应包括培训和员工发展计划,以确保员工具备使用系统和工具的技能,以及充分了解业务领域的知识。
8.安全性和隐私:在设计理念中,必须考虑数据安全和客户隐私的保护。
采用适当的安全措施来保护敏感信息,并确保合规性。
综上所述,基于大模型的企业知识管理项目的设计理念旨在建立一套完善的系统,以提高保险公司的运营效率、客户体验和决策能力,同时确保合规性和风险管理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
分析集市模型概念
维表(二)
➢
维表的应用
✓
基于维属性的过滤(切片、切块等)
✓
基于维属性的各种聚集操作
✓
报表中各类标签的主要来源
✓
事实表通过维表进行引用
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
分析集市模型概念
事实表与维表的比较
Facts
业务分析需求举例
2006和2007年度各险种份额对比
✓ 与上一年相比,各险种所占
的份额有何差异?
2006
2007
✓ 每个机构在各险种所占份额
是多少?
车险
财产险
货运险
其它险
车险
财产险
货运险
其它险
2006年度各机构在各险种上的份额
车险
财产险
货运险
其它险
时间
机构
险种
机构3
机构2
机构1
0%
20%
40%
60%
时间戳与数据版本
业务信息的不同版本的时间链
时间戳(start_date/end_date)
员工姓名
职位
离职时间
start_date
end_date
张三
初级核保人
2006-5-21
2007-12-3
张三
中级核保人
2007-12-3
9999-12-31
李四
业务员
2004-3-12
2006-10-8
李四
业务经理
2006-10-8
2008-5-9
李四
业务经理
2008-5-9
9999-12-31
2008-5-9
以上start_date为红色的是该数据实例被创建时的版本,该值从逻辑上看应该
为数据的业务创建日期,比如入职日期,但为了避免受到数据质量的影响,
我们通常把每个数据实例的第一个版本的start_date置为1900-01-01
分析集市模型概念
维度建模
➢
一种非规范化的关系模型
➢
✓
由一组属性构成的表所组成
✓
表跟表之间的关系通过关键字和外键来定义
以良好的可理解性和方便的产生报表来进行数据组织,很少考虑
修改的性能
➢
通过SQL或者相关的工具实现数据的查询和维护
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
分析集市模型设计步骤
需求
整理指标维度矩阵
设计集市层模型
设计分析层模型
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
维度指标矩阵
维度指标矩阵是把
需求转化为多维模
型的重要工具
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
承保中间表场景示例
保单号
批单号
保险起期
保险金额
保费
核保日期
批改原因
start date
end date
0001
---
2006-3-7
12000
80
2006-3-4
N/A
1900-1-1
2006-5-18
Dimensions
➢
属性个数少(窄)
➢
属性个数多(宽)
➢
记录行数多(大)
➢
记录行数少(小)
➢
数值型指标
➢
描述性属性
➢
随着时间的推移,数据
➢
静态的,很少发生变化
增长
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
分析主题域数据 (Analytical Subject Areas)
据通过核心原子数据相关主题域数据经过汇总计算得到。核心原子数据和分析数据分别映射到不同的数
据集市中。
其中,典型的分析主题域如通用承保分析(Universal
underwriting analysis)如下图:
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
0002
0003
2006-4-19
22300
138
2006-5-21
加保
2006-5-21
9999-12-31
0003
---
2007-1-12
120000
890
2007-1-8
N/A
1900-1-1
9999-12-31
0004
---
2007-5-2
57000
500
2007-4-22
N/A
1900-1-1
分析集市模型概念
维表(一)
➢
每一张维表对应现实世界中的一个对象或者概念
➢
例如:客户、产品、保单、标的、案件
维表的特征
✓
包含了众多描述性的属性列
如保单维表里的销售渠道、保费区间、风险等级等
✓
通常情况下,跟事实表相比,行数相对较小
通常< 10万条
✓
内容相对固定
几乎就是一类查找表
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
•中间表
分析层
活动
理赔
产品
财务账户
ETL过程
源系统模型
车险
理赔
实物
资金供应
事件
协议
ODS模型
核心
•基本上与业务数据同构
•保留详细交易数据
角色
地理位置
收付费处
理
AT&T
收付
财务
•面向业务应用
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
1011
2008-9-12
1000
2010102
1011
2008-9-13
-300
2010102
1011
2008-9-12
2200
2010201
2031
2008-9-12
100
2010202
2001
2008-9-12
1000
2010202
2001
2008-9-13
1200
2010202
2001
2008-9-14
-2200
机构
险种
日期
期末未决
2010102
1011
2008-9-12
1000
2010102
1011
2008-9-13
700
2010102
1011
2008-9-14
2900
2010201
2031
2008-9-12
100
2010201
2031
2008-9-13
100
2010201
2031
2008-9-14
收付费分析的星型结构
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
分析层模型介绍
“承保理赔分析事实表”、“收付费分析事实表”、“核赔效率分
析事实表”都是经轻度汇总生成的表,它们全部都是事务型事实表
中间事实表都是经过版本化的历史表,保存最细粒度的数据
在事务型事实表上计算时点值,建议在维度较细的Cube上使用事务型事实。
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
中间层历史数据的版本化
数据仓库中的历史数据决不会被删除或覆盖,因此需要加入数据
版本特性来区分随时间变化的业务信息,使得在任一给定时间点
中间事实表主要用于生成轻度汇总表的过渡,除此之外,通过冗余
相关属性,中间事实表的设计也考虑了其它无法从直接从分析层计
算的指标的计算
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
事务型事实和快照型事实
事务型
机构
险种
日期
快照型
未决变化
2010102
✓
模型介绍
✓
模型运用方法与技巧
✓
相关技术问题
© 2006 FEnet Software Co., Ltd. All Rights Reserved.
模型在整个系统架构中的定位
元 需求模型
数
据
•最终用户
•数据集市
•Cube
分析层/数据
集市模型
数据仓库
•面向分析主题
•轻度汇总数据
•Star Schema 建模
0001
0001
2006-3-7
0
0
2006-5-18
注销
2006-5-18
9999-12-31
0002
---
2006-4-19
22300
120
2006-4-7
N/A
1900-1-1
2006-5-10
0002