基于WEB的智能信息采集及处理
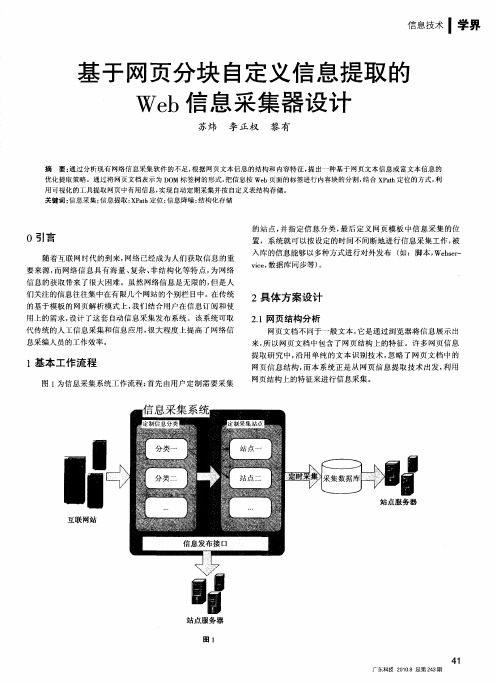
基于网页分块自定义信息提取的Web信息采集器设计
<tb e a l>
分块首先将 不够规范 的 H ML文档整理成格式 良好 的 X T T H ML
文 档 ,这 样 就 可 以像 对 待 一 般 X ML文 档 一样 对 待 X T H ML文 档 , 可 以利 用 各 种 X ML标 准 技 术 来 操 纵 X T H ML文 档 ; 再 将 X T H ML文档 解 析 成 D M 标 签 树 的 形 式 , 后 以标 签 进 行 内容 O 最
的站 点 , 指 定 信 息 分 类 , 后 定 义 网页 模 板 中 信 息 采 集 的位 并 最
0引言
随着 互 联 网 时代 的到 来 , 网络 已经 成 为 人 们 获 取 信 息 的 重 要 来 源 , 网络 信 息 具 有 海 量 、 杂 、 结 构 化 等 特 点 , 网络 而 复 非 为 信 息 的获 取 带 来 了很 大 困 难 。 虽 然 网 络信 息 是无 限 的 , 是 人 但 们 关 注 的 信 息往 往 集 中 在有 限几 个 网站 的 个 别栏 目中 。 传 统 在 的基 于 模 板 的 网 页 解 析 模 式 上 , 们 结 合 用 户 在 信 息 订 阅和 使 我 用 上 的 需 求 , 计 了这 套 自动 信 息 采 集 发 布 系 统 。该 系 统 可 取 设 代 传 统 的 人 工 信 息 采集 和信 息应 用 , 大 程 度 上 提 高 了 网络 信 很 息 采 编人 员 的工 作 效 率 。
学 信技 界I息 术
网页 由 H ML标 签 和 文 本 组 成 ,t dv 文 本 <dv ; 页 T  ̄ < i> U /i> 网 图 3中的 网 页 结构 由三 个 <al 标签 组 成 , 分 别存 放 L — f e b> O G 导航 栏 和 正 文 。 O, 其 网页 结 构 为 :
基于Web信息抽取的技术成果信息采集系统

《 成组技术与生产现代化)2 0 0 7年第 2 4卷第 4 期
维普资讯
上述 特点 为开发 计算 机 自动 采集 程序 提供 了可 能, 即程序 可 以先 读取索 引页 , 过提 取索 引页 中的 通 链 接 , 导航 到 细节 页 ; 来 然后 依据 事先设 计 好 的抽 取 规 则 , 细节页 中抽 取有 用的信 息. 从 信 息抽 取 的算 法 分 两部 分 组成 , 一 部 分是 细 第
摘
要 : 通 过 对 技 术 转 移 中 心技 术 成 果 信 息 收 集 的
分 析 , 出采 用 基 于 w e 提 b格 式 分 析 的技 术 成 果 信 息批 量 自 动 采 集 方案 . W e 对 b信 息 抽 取 的 原理 及 实现 进 行 了分 析 , 并 给 出 了技 术 成果 信 息采 集 的 程 序 实例 . 关 键 词 : We ; 息 抽 取 ; 术 转 移 ; 术 成 果 b信 技 技
1 We b信 息 抽 取
W e 息抽取 是指 通过 对 网页 数 据 的分析 , b信 滤
除 网页 中的广告 、 格式控 制等 “ 噪音 ” 数据 , 抽取有 用 的关键 信息 , 并进 行分类 、 排序 等 的一 系列 过程[ . 4 ]
1 1 We . b网页信 息
中 图分 类 号 : TP 9 31
本 文 研究 对 网 页结 构进 行 分 析 , 取 指定 信 息 抽
的方法 , 以实 现技术 成果信 息 自动下 载 , 分类 保存 .
收 稿 日期 : 0 7 9 1 2 0 —0 — 7 基金项 目: 宁波 市 软 科 学 项 目( 0 6 0 0 5 2 0 A1 0 1 ) 。
基于Web的智能信息采集及处理系统设计与实现

文 编 : o _4 (o 1 _ 6 _ 文 标 码: 章 号 1 380 )_ 2_ 3 o 22 78 0 50 献 识 A
中 分 号 T 3 圈 类 ;P1 1
基 于 We b的智 能信 息采 集及 处理 系统设 计 与 实现
( 北京科技 大学信 息工程 学院,北京 10 8 ) 003
We 采集器一般都是从称为种子的 U L出发, b R 通过协议 向 We b上其他 所需页面作扩展 。研究表 明, b上 3 %的页 We 0 面是重复 的,当面向特定的主题 时,8%以上的 UR 0 L链接是 人们不关心 的,因此 , 在采集中如何进行 U L去重和分析适 R 合主题特征 的 U L是提高采集子 系统效率 的重要因素。 R 同时
www 从诞生以来至今 ,对 We b信息的搜索 正在从 “ 偏
平”走 向 “ 垂直 ” ,从 “ 通用”发展到 “ 个性和智能” 。但是 据调查 目前市场 上绝大部分搜索工具或者产 品都存在 “ 重采
统时, 只需对接 E文件稍作配置就可 以满足不 同的用户需求。 l
1 We 信 息采集子系统 . 2 b
集、 忽视信息的处理和服务” 即对采集的信息缺乏深层次的 ,
加工、处理 ,并且提供主动的信 息发布服务的机制。
经过 l O余年的市场培育 , b用户最需要的是能提供 面 We
ZHANG a , n- a YANG n - u F n LILi n , Bi g r
(co l fnomao n n ier g Unvri f cec n eh oo yB in , e ig10 8 ) S h o fr t na dE gne n , ies yo in e dTc n lg e ig B in 0 0 3 oI i i t S a j j [ src ]Wi erpdd vlp n f[tre, ol t ga depot gWe fr ao xe s eya desd T i p pr ein n Abta t t t ai e eo met nentc lci x lin bi o t ni e tni l d rse . hs a e s sad hh o e nn i nm i s v d g
基于Web的数控机床信息采集技术研究

CX A A公 司 的 “ 能 终 端 ” 品作 为 异 步 串 口服 务 智 产 器 , 用数 控系 统 串 口打 印语 句 , 行 数控 加工 信 利 进 息 采集 技术 研究 。
3 信 息采 集的数 据库 结构
匹配 的通 信 软件则 是 根据 不 同 的应 用 需要 和数 控 系
统 的不 同 自行 研究 开 发或 定 制 , 日本 F N C公 司 以 A U 的 O 系统 为 例 ( 同 ) 要 实 现 P i 下 , C机 与 F N C 的 A U
。
信 息采集原理实 际是基 于 网络 化制 造技 术平 台 , 调用 C C系统 变量 , N 通过 变 量读 和写 C C的各 种 内 N
l 2
在 现 有 的 技 术 条 件 下 , 信 服 务 器 、 络 交 换 通 网 机、 无线 网 卡及 各 类 数 控 机 床 均 有 非 常 成熟 的 产 品 及 附带通 讯 接 口可供 选 择 。异 步 串 口服务 器 及 与 之
发是 整个 远程监 控技 术平 台 的核 心技 术 。本 论 文 以
示, 所有 被管理 数据 均置 于服务 器数据库 中。 ( ) 2 交
图 1 信 息 采 集 的 网 络 化 制 造 技 术 平 台
换 机 : 通信 服 务 器端 和无 线 路 由器端 需 要 传 输 的 将 信 息打包传 输 。 ( ) 线 路 由器 : 3无 利用 不 同的 I P地
设备 是异 步 串 口服务器 。
收稿 日期 :0 0— 6— 1 2 1 0 2
作者简介 : 范彩霞(9 6 , , 17 一)女 河南 _ ̄峡人 , -- -j 黄河科技学 院工学院机械系讲师 , 工学硕士, 主要从事数字化制造研究。 路素青 (94一) 男 , 17 , 河南安阳人 , 黄河科技学院讲师 , 硕士 , 研究 方向 : 工程管理 。
基于Web的定向信息采集系统的设计与实现

图 l系统 框 架
1 8
福
建 电
脑
2 1 年 第 1 期 0 1 l
基 于 We b的定 向信息采集 系统的设计与实现
宋凯伦 ,邱广华 ,李 珊
(南京航 空航 天大 学 经济 管理 学院 江 苏 南京 2 10 1 10)
【 要 】 互联网的快速发展 , 摘 : 导致信息采集技术的不断进步。为解决针对不同We b网站的定向信 息采集 问题 , 文介 绍 了一 种基 于 W e 本 b的定 向信息采 集 系统 的 实现 , 实践证 明 , 系统 具备 良好 的通 用 经 该 性 , 集准确 率高 。 采 .
1 系统框 架 .
获取 网页源 代码
过 滤, vS r p 脚 本 J a c it a
过滤输入标签 过滤图片标签
1 1
图 2 页 面 解 析 流 程
选取 网 页 中 dv t l i 及 a e标签 作为 页面解 析 中最 终 b 系 统 主要分 为 页面 解析 , 息定 制 ( 接采 集 )链 信 链 , 接 的正文 采集 。 自动更 新 四个 模块 。 系统框 架如 图 1 所 获取的网页内容 , 其优点很多 , 最重要 的一点是当前互
示:
联 网中的许 多 网站 , 均采用 dv cs i+ s 或者 dv与 tbe的 i al
嵌套 布局 , 经过对 网页 源代码 中无用 信 息 的过 滤 , 获取 这 两 种标 签 的页 面 内容 往 往 便 能 获得 网页 的 主要 信
基于WebGIS的城市管理信息系统设计与实现

基于WebGIS的城市管理信息系统设计与实现随着城市化进程的加速和信息化的普及,城市管理变得越来越复杂。
如何高效、全面地收集和管理城市数据,成为了城市管理中急待解决的问题。
基于WebGIS的城市管理信息系统应运而生,它将地理信息系统(GIS)技术和Web技术相结合,为城市管理带来了巨大的便利。
一、系统架构基于WebGIS的城市管理信息系统由前端展示系统和后台管理系统两部分组成。
前端展示系统主要负责数据可视化展示和交互操作功能,后台管理系统则负责数据采集、处理和管理。
前端展示系统使用最新的Web技术,采用响应式布局,兼容各种设备和浏览器。
地图界面采用ArcGIS API for JavaScript,能够高效地展示各类数据,并提供缩放、平移、测量、搜索、标注、分析等功能。
用户可以通过地图定位、选择、筛选各种信息,也可以通过图表、表格等方式查看数据。
后台管理系统也使用Web技术,使用Node.js作为后台框架,采用MVC(Model-View-Controller)架构,将业务逻辑、数据模型和视图层分离。
数据库采用关系型数据库MySQL,前后端交互采用RESTful API,保证数据的安全、可靠和高效。
二、数据采集及处理城市管理信息系统需要大量的数据支撑,包括基础地理数据、人口数据、交通数据、环境数据、安全数据等。
这些数据获取的方式主要有两种,一种是利用公共数据资源平台获取,另一种是通过新建传感器获取。
公共数据资源平台包括政府开放数据平台、交通部门数据平台、气象局数据平台等,这些平台已经开放了海量的数据资源,可以供城市管理信息系统使用。
比如交通部门数据平台中包括实时交通拥堵情况、高速公路收费站车流量等数据,可以帮助城市管理人员更好地管控交通。
新建传感器可以帮助获取更多的数据,比如可以新建空气质量传感器、垃圾填埋场渗漏液监测传感器等,将数据实时传输到城市管理信息系统中,让城市管理人员更准确地掌握城市状况。
基于WEB的智能信息采集及处理系统的关键技术

中 国 新 技 术新 产 品
一3 1—
信 息技 术
Caw c—sIr. 嵋 ■瞄 山■ ■ h ho UII 囡团图 团 ■ iN ngZ—'t ■■ ■■ n e oiUPU l a o| en  ̄s dd● u c
基于 WE B的智能信息采集及处理系统的关键技术
谭 媛 媛 王 伟
( 皇岛广播 电视 大学, 秦 河北 秦皇 岛 o 6 0 ) 6 o O
有别于通用 的 We 信 息 集器 , 子系统 速 的进行 U L 找 , b 采 该 R查 因此不能保证 快速 的下 载 最大的特点在于任何 用户的主题采集 都是 在相 和 去 重 。 应的模版 的支撑 下完 成。所 谓模版就 是关 于要 在本 系统 中采用 了文件 目录寻址机制来 实 采集的 We 对象 的特征描述 , b 为了提高下 载的 现 U L的快速去 重 。基本 思想是 首先 将 U L R R 有效性 和效 率 ,将某 一 个具 体 的 网站所 有 的 地址 做 C C 2 R 3 转换 , 生成—个唯一 的 4 字节 3 2 We 页面划分 为 H b b u 页和 Tpc , oi页 表示 为~ 位 的编码 , :8 A B F将 4 如 E C O 3 , 个字节组成两级 个三元组< ,ff。 中 M刻 画 We 页共 性特 目录和一级文件 ,即第一个字 节的首字符作 为 MH,> 其 T b 征, : 如 网站名称 、 网站 U L 址 、 R 地 语言种类 等 ; 第一级 目录名 , 第二 、 j个字符组合作 为二级 目 H 刻画该 we f b资源中 的 H b页面特征 ,即此 录名 , 三 、 字符组合作为文件 名存放在 二 u 第 四个
程 如 图 2所 示 。
1 信 息智能处理子系统 3 该系统预先通过机器学 习建立用户感兴趣 的 内容分类 器 , 当用户某一次 下载 任务完成后 , 发送消息激 活处理子系统 ,系统将 会 自动地处 理下载 的内容 , 包括 自动分类 、 主要 自动摘要和 元数据 分析 , 如创建 正文标题 、 关键 字 、 析作 分 者等。系统流程如图 3 所示。 传统 上 的 we 信息 采集不 具备 对下 载信 b 息 的深层 次加工能力 ,而本 系统不仅 实现机器 的自 动分类 、 和元数据分析 , 提供人机交 摘要 还 互 的机制 , 将处 理的结果 以便捷 预览的方式呈 现, 用户可 以进行 修改 、 以及确认 后入库存 删除 储等操作 , 确保发布信息的正确性和有效性 。 1 4信 息发布子系统 近年来 信息 的发布形 式越来 越备受 关注 , 作为对外信息 服务 的平 台,该子 系统 主要特点 有: 多视角 、 多层次发布采 集信 息, 即从来 源 、 原 始栏 目 、 分类体系 多个视 角交叉进行 展示 , 以 可 灵活的进行信息集 合的交 、 并运算 ; 个性 化信 息 发布 , 用户登 录后利 用个 性化信息定制 界面 , 选 择 自己感兴趣 的信息视角 , 再次登 录后 , 推送给 用户的就是完全个 l化的信息 内容 ;强大的信 生 息检索能力 , 不仅提供 针对独立字段 的检索 , 还 提供 陕速检索 、 的表达式 检索及全文检索。 高级 2若干关键技术
基于移动WEB的小规模快速信息采集系统设计与实现

第2 8卷
第 2 期
电 力 学 报
J OURNAL 0F ELECTRI C P OW ER
V 0 l _ 2 8 No . 2 Ap r .2 0 1 3
2 0 1 3 年 4月
文章编号 :1 0 0 5 — 6 5 4 8 ( 2 0 1 3 ) 0 2 — 0 1 5 2 — 0 4
中图分类号 :T P 3 1 1
文献标 志码 :B
学科分类号 :4 7 40 0
基于移动 WE B的小规模快速信息采集系统设计与实现
朱 云 雷
( 山西大学工程 学院,太原 0 3 0 0 1 3 )
De s i g n a n d I mp l e me n t a t i o n o f Ra p i d i n f o r ma t i o n Co l l e c t i o n S y s t e m Ba s e d o n Mo b i l e W EB Te c h n o l o g y
i nt e r ne t of hi t ng s
摘要 :本文结合 当前小规模管 理信 息系统发展 趋势 和应用
基于Web结构的网站新闻采集系统的设计与实现

Bt ye口P g D t =WCDo nod t ( e u1 a e aa . w la Daa w b r ; )
Ht Co e ml d = En o i g De a l Ge S i g c d n . f ut t t n . r
页 面结 构具 有一 些特 定规 则 ,如 页面 内容 往往 是 以
第3 3卷第 2期 21 02年 3 月
V 13 No o. . 3 2 Ma. 02 r2 1
井 冈山大学 学报( 自然 科学版) J u a o i g n sa ies y( t a S i c) o r l fJ g agh n Unv r t Na rl ce e n n i u n 5 4
W C. e e f l Cr d n il c eDe a l e e Cr d n as i = e e t Ca h . f u t d n a Cr
tas il ;
信 息 ,因此 影 响抽取 效率 和准确 度 。 1 本文 工作 内容 . 4
虽 然 网页类 型和 结构 不 同 ,但一 个 网站 中 的各
文章编号 :17 .0 52 1)2 0 5 -4 6 48 8(0 20 — 0 采集系统 的设计 与实现
陈建 国
(. 南大 学软件 学院 ,湖南 , 长沙 1湖 4 0 8 ;2 厦 门理工 学院 ,福 建 ,厦 门 102 . 3 12 ) 601
将 这些 U L放 入一 个采 集 队列 ,顺序 读取 U L以 R R
1 WE B信息采集和 新闻采集
11 We . b信息 采集 We b信 息采集 是指 通过 We 页面 之 间的链接 b 关系 ,从 We b上 自动地 获取 页面信 息 ,并且 随着链
设计基于web的新闻采集系统

2 0年 1 01 1月 总 3 8期 6
基 于 w eb 的 新 闻 采 集 系 统
杨小 佩 孙吉刚 谢楠
( 徐州 空 军学 院
江 苏 徐 州 2 1 0 ) 2 0 0
吊函夯奏萼:一 一 G3 一— 6
文献标识码: A
文 章 编 号 :0 7 0 7 (0 )1 0 7 - 1 1 0 — 4 52 1 0 - 1 0 0 1
计 与 实 现功 能 。
新 闻采 集 系 统 的 设计 系 统采 用 A PN T或 是 其 它 开 发 技 术 , 用 三 层 架 构 , 据 S .E 采 数 操 作 使 用 微 o — D tA c sA pi t n ci Bo k ) 使得 组 件 将 访 问数 据库 的性 能 和 资 源 管理 方 面 的丰 富 经 l c 。 验 封 装 在 一 起 . 用 数 据 库 系统 是 MyQ Sre。 在.E 应 用 程 常 S L evr NT 序 的可 以很 方 便 的 将 其 作 为 构 造块 使用 ,从 而减 少 了需 要 创 建 、 W W拥有 着 巨大 的信 息资 源 。 W 被称 为海 量资 源库 , 这些 资源 随着 科技发展 还再 以几何 级数 的方式 增长 。其 中有 着许 多有价 值 的信息 ,
面向Web的数据挖掘技术

面向Web的数据挖掘技术[摘要] 随着internet的发展,web数据挖掘有着越来越广泛的应用,web数据挖掘是数据挖掘技术在web信息集合上的应用。
本文阐述了web数据挖掘的定义、特点和分类,并对web数据挖掘中使用的技术及应用前景进行了探讨。
[关键词] 数据挖掘web挖掘路径分析电子商务一、引言近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。
数据挖掘是面向发现的数据分析技术,通过对大型的数据集进行探查。
可以发现有用的知识,从而为决策支持提供有力的依据。
web目前已成为信息发布、交互和获取的主要工具,它是一个巨大的、分布广泛的、全球性的信息服务中心。
它涉及新闻、广告、消费信息、金融管理、教育、政府、电子商务和其他许多信息服务。
面向web的数据挖掘就是利用数据挖掘技术从web文档及web服务中自动发现并提取人们感兴趣的、潜在的有用模型或隐藏的信息。
二、概述1.数据挖掘的基本概念数据挖掘是从存放在数据库、数据仓库、电子表格或其他信息库中的大量数据中挖掘有趣知识的过程。
数据挖掘基于的数据库类型主要有: 关系型数据库、面向对象数据库、事务数据库、演绎数据库、时态数据库、多媒体数据库、主动数据库、空间数据库、遗留数据库、异质数据库、文本型、internet 信息库以及新兴的数据仓库等。
2.web数据挖掘web上有少量的数据信息,相对传统的数据库的数据结构性很强,即其中的数据为完全结构化的数据。
web上的数据最大特点就是半结构化。
所谓半结构化是相对于完全结构化的传统数据库的数据而言。
由于web的开放性、动态性与异构性等固有特点,要从这些分散的、异构的、没有统一管理的海量数据中快速、准确地获取信息也成为web挖掘所要解决的一个难点,也使得用于web的挖掘技术不能照搬用于数据库的挖掘技术。
因此,开发新的web挖掘技术以及对web文档进行预处理以得到关于文档的特征表示,便成为web挖掘的重点。
基于Web的定向医药信息采集系统设计与实现

1 引 言
随着信息技 术的迅猛发展 ,互联 网上 的医药信息
[ 收稿 日期 ]
2 2 —0 —0l 01 3
开展科研课 题研 究 ,建立 医药 信息 服务 系统 、网站 , 或者 医院开 发医药咨询系统 等 ,都需要从互联 网的相
关 网站 、数 据库采集大量 的信 息。通常从互联 网上获
[ 键词 ] 关
医药信 息 采集 ;文档 对 象模 型 ;网页分析 ;定 向采 集
De i n d m plm e a i n fW e — ba e Di e td e c lI r a o Col c i n se sg an I e nt to o b s d r ce M di a n ̄ m t n i l to Sy t m e
DO M 1
3 ’ 系统需求分析 _
3. . 对 网页 内容 的分析 与提取 医 药信 息 采 集 11
系 统 (Me i n If m t n C l ci Ss m, dc e no a o o et n yt i r i l o e
MIS 对 网页 内容 分析 与提取 主要用 于 指定 网站 栏 C)
包 含 有 方 法 ( t d 和 属 性 ( tiue 。基 于 Me o ) h At b t) r
系统 主要完 成信 息采 集规 则 的制定 ,网页 信 息 的采 集 、分析 和保存 等工 作 。信 息采 集 规则 的制定 是 指
用户根 据 自己的需要 定 制信 息 源 、采集 信 息 的格 式 限定 以及采 集任 务 的设 定 等 。网页 采 集是 根 据用 户
取信息都是采用 手工获取 ,不仅 大大增加工作量 ,而
且有时候 是无 法 完 成 的 ;同时 面对 海 量 的互 联 网信
Web信息抽取算法及系统研究

Web信息抽取算法及系统研究随着互联网的发展,海量的数据、信息被储存在一个个网站、系统中,而这些数据中又包含了大量的有价值的信息。
然而,由于数据格式多样、结构复杂,这些有价值的信息往往不能够直接被人工处理或利用。
一直以来,Web信息抽取系统一直是解决这个问题的一种重要手段。
本文将介绍Web信息抽取算法及其系统的研究。
一、Web信息抽取算法Web信息抽取算法是一种将结构化数据从非结构化数据中提取出来的技术。
Web信息抽取算法包括语言模型、启发式规则、统计机器学习、自然语言处理、知识图谱等。
其中,自然语言处理和知识图谱被认为是比较先进的技术。
自然语言处理(NLP)是一种通过模拟人类对语言的理解和处理过程,对各种文本进行处理的技术。
NLP技术的目的是使机器能够对自然语言进行理解、生成、翻译和分析。
在Web信息抽取中,NLP技术可以通过分析文本中的语法、词法和句法等特征,从而找出有价值的信息。
知识图谱(KG)是一种结构化的知识表示方式。
基于知识图谱,机器可以更加准确地理解和处理不同领域的知识,通过对知识之间的关联关系进行抽取和分析,从而帮助机器更好地理解Web中隐藏的知识和信息。
知识图谱可以通过各种方式进行构建和更新,例如:手动标注、数据挖掘、半自动化构建等。
二、Web信息抽取系统Web信息抽取系统是指利用Web信息抽取算法实现自动化数据收集、处理、挖掘和分析的一套系统。
Web信息抽取系统主要包括数据预处理、网页解析、信息抽取和结构化存储等模块。
数据预处理模块主要对Web数据进行去噪、数据清洗,将HTML等非结构化数据转换为可结构化数据,从而为后续的信息抽取、存储等提供基础支持。
网页解析模块是Web信息抽取系统的核心模块。
该模块主要通过解析HTML 等非结构化数据,识别和提取网页中的有价值信息。
网页解析模块一般采用解析树或解析器这种方式来进行实现。
信息抽取模块是指从网页中抽取可用于后续处理和分析的信息。
基于Java_Web的智慧农业信息采集系统的设计与实现

基于Java Web的智慧农业信息采集系统的设计与实现杜朋轩1,2陈芳1,2曹梦川1,2(1.宁夏职业技术学院;2.宁夏职业技术学院软件技术教学创新团队宁夏银川 750021)摘要:中国作为农业大国,其生产环境具备物品多样化、分布范围广泛化等特点,并且农业种植地点位于农村,交通不便利,网络技术不发达,因此在信息采集方面会比较困难。
正是因为信息采集得不够精准、快速,使得很多农作物的生长状况无法第一时间反馈给农户,让其根据农作物的实际情况去做一些调整,以此保证农作物的生产质量和产量。
而随着我国信息技术的发展,智慧农业的应运而生,一种基于Java Web的智慧农业信息采集系统逐渐被设计出来,并实践到智慧农业中,帮助农户对农作物进行监护,有效地保证了农作物的生产质量和产量。
基于Java Web,对智慧农业信息采集系统进行设计和研究。
关键词:Java Web 农业信息 采集系统的设计 智慧农业中图分类号:TP273文献标识码:A文章编号:1672-3791(2023)23-0162-04 Design and Implementation of a Smart Agriculture Information Collection System Based on Java WebDU Pengxuan1,2CHEN Fang1,2CAO Mengchuan1,2(1.Ningxia Polytechnic; 2.Software Technology Teaching Innovation Team of Ningxia Polytechnic, Yinchuan,Ningxia Hui Autonomous Region, 750021 China)Abstract:As a major agricultural country, China's production environment is characterized by diversified items and wide distribution, and agricultural planting sites are located in rural areas with inconvenient transportation and un‐developed network technology, so it is difficult to collect information. It is precisely because information collection is not precise and fast enough that the growth status of many crops cannot be reported to farmers in a timely man‐ner, so that they can make some adjustments based on the actual situation of crops to ensure the production quality and yield of crops. With the development of information technology in China, smart agriculture has emerged. A smart agriculture information collection system based on Java Web has been gradually designed and applied to smart agriculture to help farmers monitor crops, which effectively ensures the production quality and yield of crops. Basedon this, this article studies the design of the smart agriculture information collection system based on Java Web.Key Words: Java Web; Agricultural information; Design of the collection system; Smart agriculture近几年,我国农业部门一直在致力于智慧农业的发展,以期在农业生产过程中节省人力,降低农业生产成本,使滞后的传统农业得到进一步的发展,让现代农业变得更加精准和高效。
基于Web的网站信息采集系统的设计与实现

2信 息 采 集 系 统 的 设 计
21采集 系统 设 计 的 思 路 .
首 先 , 采 集 指 定 网站 的 信 息 , 须 了 解 信 息 的 浏 览 方 式 , 记 录 相 应 的 访 问 路 径 。 大 多 数 网 站 采 用 动 态 网 页 技 术 ( S P P 要 必 并 A P、H
De i n a d I p e e t t n fI f r t n l c i n S se Ba e R W e sg n m lm n a i o o ma i Co l to y t m s d O b o n o e
ZHA O io—fng X a e
( p r n f noma o n ie r gW u iIstt fCo n reW u i 1 1 3Chn ) De at t fr t n E gn ei , x nt ueo mlec , x 4 5 , ia me o I i n i 2
A bsr t t ac :W ih t a d d veo t he rpi e l pm e tofI t m e .c le t nd e pli ng W e n o ain se e i ey a r se n n e t o lc ng a x o t i i b if r to i xtnsv l dd e sd.Thi pe i t m spa rams a
等 ) 建 , 过 参 数 传 递 来 检 索 数 据 库 , 出 对 应 信 息 的 。例 如 人 才 招 聘 网 的通 常 以单 位 名称 作 为 信 息 的起 点链 接 , 开 对 应 的 网页 构 通 输 打 后. 获得 单 位 具体 招 聘 岗 位链 接 , 能 获 得 详 细 的招 聘 信息 。 才 第 二 , 集 所 获 的信 息 必须 存 入 本 地 数 据 库 , 要 对 几个 目标 网站 上 的 信 息 进 行 比较 与 分 析 , 到 统 一 的 数 据 模 型 , 设 计 相 采 需 得 并 应 的数 据 表 , 于将 来 对 不 同 网 站 采 集 来 的 信 息 统 一 进 行 结 构 化 。 便 , 第 三 , 虑 到 可 能 会 对 网 站 进 行 多 次 采 集 , 避 免 重 复 的信 息 存 人 自 己 的数 据 库 内 , 时重 复 处 理 已经 存 在 的 信 息 也 会 降 低 采 考 要 同 集 系统 的工 作 效 率 。 因此 可 以在 记 录每 条 信 息 的 同 时 , 录 其 对 应 的 U L或 相 关 I 便 于 验 证链 接 是 否 已 经 访 问 过 。 记 R D,
网络爬虫技术

网络爬虫技术一、什么是网络爬虫技术?网络爬虫技术(Web Crawling)是一种自动化的数据采集技术,通过模拟人工浏览网页的方式,自动访问并抓取互联网上的数据并保存。
网络爬虫技术是一种基于Web的信息获取方法,是搜索引擎、数据挖掘和商业情报等领域中不可缺少的技术手段。
网络爬虫主要通过对网页的URL进行发现与解析,在不断地抓取、解析、存储数据的过程中实现对互联网上信息的快速获取和持续监控。
根据获取的数据不同,网络爬虫技术又可以分为通用型和特定型两种。
通用型爬虫是一种全网爬取的技术,能够抓取互联网上所有公开的网页信息,而特定型爬虫则是针对特定的网站或者领域进行数据采集,获取具有指定目标和意义的信息。
网络爬虫技术的应用范围非常广泛,例如搜索引擎、电子商务、社交网络、科学研究、金融预测、舆情监测等领域都能够运用网络爬虫技术进行数据采集和分析。
二、网络爬虫技术的原理网络爬虫技术的原理主要分为URL发现、网页下载、网页解析和数据存储四个过程。
1. URL发现URL发现是指网络爬虫在爬取数据时需要从已知的一个初始URL开始,分析该URL网页中包含的其他URL,进而获取更多的URL列表来完成数据爬取过程。
网页中的URL可以通过下列几个方式进行发现:1)页面链接:包括网页中的超链接和内嵌链接,可以通过HTML标签<a>来发现。
2)JavaScript代码:动态生成的链接需要通过解析JavaScript代码进行分析查找。
3)CSS文件:通过分析样式表中的链接来发现更多的URL。
4)XML和RSS文件:分析XML和RSS文件所包含的链接来找到更多的URL。
2.网页下载在获取到URL列表后,网络爬虫需要将这些URL对应的网页下载到本地存储设备,以便进行后续的页面解析和数据提取。
网页下载过程主要涉及 HTTP 请求和响应两个过程,网络爬虫需要向服务器发送 HTTP 请求,获取服务器在响应中返回的 HTML 网页内容,并将所得到的网页内容存储到本地文件系统中。
基于Web的远程监控与数据采集系统

l 系统 整体说 明
基于 We b的远程监控 系统可分为现场监控( 智能终端)监 、 控 中心 ( 括通 信 模 块 、 据 库 服 务 器 、 b服 务 器 ) 客户 端 包 数 We 和 3 系统组成 , 个 智能终端负责现场数据的采集和上报及接受执 行监控 中心下达的控制命 令。监控 中心负责收集整理 比对接 收 的数据及下达相应 的控 制命令 。 客户端负责体现 比对结果 、 告警提示、 人机对话 、 各种 数据 的统计 。
关键词 : 监控 系统 ; b数 据 库 ; 务 器 ; 态服 务 器 AS We 服 动 P 中图分类号 : P 7 T 27 文献标识码 : 文章编号 :6 3 13 ( 0 2 0 .1 80 A 17 .l l2 1 )40 3 .2
基于WEB的智能信息采集及处理系统的关键技术

基于WEB的智能信息采集及处理系统的关键技术作者:谭媛媛王伟来源:《中国新技术新产品》2010年第11期摘要:本文研究的基于Web的智能信息采集及处理系统,一方面采用高效的URL去重和基于模版的下载机制,极大提高了采集Web资源的性能;另一方面应用成熟、先进的自然语言处理技术,对采集信息做智能分类和摘要。
关键词:Web采集;URL去重;智能信息处理;个性化发布1系统架构系统由三个子系统组成,即Web信息采集子系统、信息智能处理子系统和信息发布子系统。
三个子系统可以单独部署和运行,也可以通过接口文件实现整个过程的自动化采集、智能化处理和主动式发布,整体架构如图1所示。
1.1系统整体架构该系统架构不仅适合较大用户的分布式部署采集、加工的需要,也可以适应单用户集中部署的需要。
当用户只需要某个子系统时,只需对接口文件稍作配置就可以满足不同的用户需求。
1.2 Web信息采集子系统Web采集器一般都是从称为种子的URL出发,通过协议向Web上其它所需页面作扩展。
经研究表明Web上30%的页面是重复的,当面向特定的主题时,80%以上的URL链接是我们不关心的,因此在采集中如何进行URL去重和分析适合主题特征的URL是提高采集子系统效率的重要因素。
同时如何获取有效的Web页面信息,过滤广告、导航栏等噪声,将直接影响后续的智能处理的性能。
该子系统的流程如图2所示。
有别于通用的Web信息采集器,该子系统最大的特点在于任何用户的主题采集都是在相应的模版的支撑下完成。
所谓模版就是关于要采集的Web对象的特征描述,为了提高下载的有效性和效率,将某一个具体的网站所有的Web页面划分为Hub页和Topic页,表示为一个三元组。
其中M刻画Web页共性特征,如:网站名称、网站URL地址、语言种类等;Hf刻画该Web资源中的Hub页面特征,即此类Web中哪些URL地址特征是下载时需要解析的;而Tf则是刻画某一类具体的Topic页特征,主要是描述用户最感兴趣的内容的访问路径,如:正文标题、作者、来源等。
基于Deep Web的信息采集系统

基于Deep Web的信息采集系统
王冉冉;王刚;黄青松
【期刊名称】《计算机技术与发展》
【年(卷),期】2007(017)010
【摘要】随着互联网技术的迅速发展,大量结构化的高质量信息被埋入网络,却无法被传统的搜索引擎检索到,进而难以被挖掘利用.针对这一现象,提出了基于DeepWeb的信息采集系统,没计了基于Web的查询方式,并结合数据挖掘的相关技术,获取并挖掘深网信息资源,解决传统手工采集信息的弊端,提高系统的使用效率,避免人工搜集时间和费用上的开销,降低成本,便于维护.并且正在云南省大型仪器协作共用网络平台的建设中尝试实现这个子系统的设计.
【总页数】4页(P171-173,177)
【作者】王冉冉;王刚;黄青松
【作者单位】昆明理工大学,信息工程与自动化学院,云南,昆明,650051;昆明理工大学,信息工程与自动化学院,云南,昆明,650051;昆明理工大学,信息工程与自动化学院,云南,昆明,650051
【正文语种】中文
【中图分类】TP391.1
【相关文献】
1.基于Deep Web的主题搜索引擎的系统设计 [J], 侯毅
2.基于Deep Web的主题搜索引擎的系统设计 [J], 侯毅
3.基于本体和贝叶斯网络的Deep Web集成系统研究 [J], 朱国进;黄琪琪
4.基于本体和贝叶斯网络的Deep Web集成系统研究 [J], 朱国进;黄琪琪;
5.基于Web-Harvest的Web铁路信息采集系统的设计与应用 [J], 汤立;李雪山因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二级 目录名 , 三、 第 四个字 符组 合作为文件名存 放在二级 目录下 ,每个文件 的大小 固定为 4 , K 最后 还剩下 三个字符 一共是 1bt 共 有 4 9 2i , 06 个二进制数 ,与 4 K的文件大小 刚好 一一对应。 这种机制 能够容纳的总页面数 为 2 2 3 ,大约 4 3 亿个 , 几乎包括 目前互联网 E 所有 U L R 链接 。 3 T  ̄ . H ML 2 为 了提高下载页面 的有效性 , 需要过 滤掉 些无用 的噪声信息 。 传统 匕 有两种解决方案 , 是 页面学 习的方式提取熵值最大 的页面分块 ; 二是通过定义访 问路径来提 取需要访 问的感 兴趣 的内容。无论是哪一种方案都 必须有 对页 面的H M T L的解析能力 ,即构 造合适 的数 据结 构来解析 H ML T 的标 签。解析 的难 点在于 目前 的网络 we b页面 的 H M 非 常不 规范 、不 严 T L 格 , 之间即使有错误或 者不严格 的匹配 , 标签 I E 也 能完美 的呈现 。 是为了信息 的精确提取 , 但 必 须要构造严 密的访 问结构 。 3 自动摘要与元数据分析 3 摘要是指通过对文档 内容处理 ,从中提取 图 3 出满 足用户需求 的重要信息 ,经过 重组修 饰后 传 统上 的 We 信 息采集 不具 备对 下载 信 生 成比原文更精炼 的文摘过 程。 目 主要 自动 b 前
一 一
图 1
息 的深层次加 工能力 ,而本系统不仅 实现 机器 文摘技术有三类 : 基于浅层分 析的方法 、 于实 基 基于 话语结构 白方法 。 g 的自 动分类 、 摘要 和元数 据分析 , 还提供人 机交 体分 析的方 法、 本 系 统采用 一种 新 的使 用 自然语 言处 理 互 的机制 , 将处 理的结果以便捷预览 的方 式呈 N P- I  ̄ 动摘要 系统 , 通过融合基于 内容 现, 用户可 以进行修 改 、 删除以及确认后入 库存 ( L ) * 的 自 的方法[ae n C n n 和基 于主题(ae n B sdo o t t e] B do s 储等操作 , 发布信息的正确性 和有效性。 确保 Tp) oi的方法 , 主题 与 内容 相结 合 , 具有 c 将 生成 2 . 4信息发布子系统 近年 来信息 的发布形式 越来 越备受关 注 , 良好连贯性和流 畅性 的摘要。基本思想是首先 作为对外信 息服务的平 台,该子系统 主要 特点 对主题词进行分析, 动态地处理具有抽象标题和
弊端是显而易见 的 , 中文网页有 4 如 亿左右 , 假 设每一个 U L的平均长度 为 2 个 字符 , 么 R 5 那 参 考 文献 存储这些网页的 U L R 地址需要 的空间为 8 左 G 1 1 戴新 陈 ne 上 me 动 右, 很显然面对如此 大的文件 , 这种机制无法快 『尹存 燕. 宇. 家骏Jt t 文本的 自 程如 图 2所示。 计算机 工程 - L2 0 e 2 o V 3 N 3 h 06 o R 因此不能保证 陕速 的下载 摘要技 术. 有别于通用 的 We 信息采 集器 , b 该子系统 速的进行 U L查找 ,
信 息 技 术
CnNw e noea o c ha e T h li nP d: i c ogs d rus t
基于 WE B的智能 信 息采 集及处理
吴 艳
( 阳 电 业局 信 息 中 心 , 南 益 阳 4 3 0 ) 益 湖 10 0
摘 要 : 文研 究 的基 于 We 智 能信 息采 集及 处理 系统 , 方 面采 用 高 效的 U L去 重 和基 于模 版 的 下栽 机 制 , 大提 高 了采 集 本 b的 一 R 极 We b资源 的性 能 ; 一方 面应 用成熟 、 另 先进 的 自然语 言处 理技 术 , 对采 集信 息做 智 能分 类和 摘要 。 关键词 : b 集 , R We 采 U L去 重 , 能信 息处理 , 智 个性 化发 布
1引 言
www 从诞生 以来 至今 , We 信息 的搜 对 b 索 正在从 “ 平 ” 向“ 直”从 “ 偏 走 垂 , 通用 ” 发展 到 “ 陛和智能 ” 个 。但是据调查 目 前市 场上绝 大部 分搜索 工具或者产品都存在 “ 重采集 、 忽视信 息 的处理和服务”即对采集 的信息缺乏深层次 的 , 加工 、 , 处理 并且提供 主动的信息发布服务 的机 制。 经过十余年 的市场培育 , b we 用户最需要的 是能提供面向一定的领域 ,有较好智 能程 度的 信息采集 、 加工和发布的产品, 本文将 构建 和实 现这样 的系统 。
中国新技术新产品
一4l一
图2
z b 2we 信息采集子系统 We 采集器 一般 都是 从称 为种 子 的 U L b R 出发 ,通过协 议 向 We 上其 它所 需 页面作 扩 b 展 。经研究表 明 We 上 3%的页面是重复 的, b 0 当面 向特定 的主题 时 , %以上 的 U L 接是 8 0 R 链 我们不 的 , 因此在采集 中如何进行 U L R 去 重 和分 析适合 主题特 征 的 U L 提高采 集子 R 是 系统 效率 的重要 因素 。同时 如何 获取 有 效 的 We 页 面信 息 , 广告 、 b 过滤 导航栏 等噪声 , 将直 接影 响后续 的智能处 理的性能 。该子系统 的流
有: 多视角 、 多层次发 布采集 信息 , 即从来 源 、 原 始栏 目、 分类体 系多个视角交叉进行展 示 , 可以 灵 活的进 行信息集合 的交 、 并运算 ; 个性化 信息 发布, 用户登 录后 利用个 『化信息 定制界面 , 生 选 择 自己感兴趣 的信息视角 , 再次登 录后 , 推送给 用 户的就是完全个性化 的信 息内容 ;强大 的信 息 检索能力 , 不仅提供针对独立字 段的检索 , 还 提供 陕速检索 、 高 3若干关 键技术
和去重 。在本系统 中采 用了文件 目录寻址机制 来 实 现 U L的快速 去重 。基本 思想是 首先将 R U L R 地址做 C C 2 R 3 转换 , 生成—个唯一 的 4 字 节 3 位 的编 码 , :8 A B F 将 4 字节组 2 如 EC O 3, 个 成两级 目录和一 级文件 ,即第—个字节 的首字 符作为第一级 目录名 , 二 、 第 三个字符组合作 为
最大 的特点在 于任何用户的主题采集 都是在相 应 的模版 的支撑 下完成 。所谓模版 就是关于要 采集 的 We 对 象的特征描 述 , b 为了提 高下 载 的 有 效性 和效 率 ,将 某 一个 具体 的网站 所有 的 we 页面划分为 H b页和 T p 页 ,表示为一 b u oi c 个三元组< ,f f。 中 M刻画 We 页共性特 MH,> 其 T b 征, : 如 网站名称 、 网站 U L R 地址 、 言种类等 ; 语 H 刻画该 we 资源 中的 H b f b u 页面特 征 ,即此 类 We b中哪些 U L R 地址特 征是下载 时需 要解 析 的;而 T 则是刻 画某一类具 体的 Tpc f oi页特 征 ,主要 是描述用户最感兴趣 的内容的访 问路 径, : 如 正文标题 、 者、 源等 。为 了实现对下 作 来 载的 We 资源 的监控 , 最新 的信 息及时地推 b 将 送 给用户 ,触发器可 以为用户 指定 适合需要 的 采 集策略 ,通过设定一定 的间隔时间来激活 下 载机器人 , “ 巡视” 是否存在最新的信息。 2 3信息智能处理子系统 该 系统预先通过 机器学 习建立用户感兴 趣 的 内容分类器 , 当用户某一 次下载任务完成后 , 发送消息激活处理子 系统 ,系统将会 自动地 处 理下载 的内容 , 主要包括 自动分 类 、 自动摘要 和 元数据 分析 , 如创 建正文 标题 、 键字 、 关 分析 作 者等。系统流程如图 3 所示 。
2系统架构
系统由三个子系统组成 , We 信 息采集 即 b 子系统 、信息智能处理子系统 和信 息发布子系 统。 三个 子系统 可以单独部署 和运行 , 以通 也可 过接 口文件实现整个过 程的 自动化采集 、智能 化处理和主动式发布 , 整体架构如 图 1 所示。 1系统整体架构 该系统架 构不仅适 合较 大用户的分布式部 署采集 、 加工 的需要 , 也可 以适应单 用户集 中部 署 的需要 。 当用户只需 要某个子系统 时 , 只需对 接 口文件 稍作 配置 就可 以满 足不 同 的用 户需
3 R 去重 .U L 1 常规的 U L 重有 两种解决思路 , R 去 一是将 所有的 U L R 地址 存人数据库 , 好索引后 , 做 利 用数据 库的查 找来判 断该 U L 否被重 复下 R 是 载; 二是利用文件存储 , U L 过一定转换 , 将 R 通 也是建立基于文件 的查 找索引。这两种方式 的