基于聚类分析——嘉实基金公司各产品绩效差异研究
基于聚类分析模型的区域经济差异性分析

基于聚类分析模型的区域经济差异性分析作者:***来源:《中国市场》2021年第14期[摘要]我国各地区在经济发展过程中,经济发展不协调。
适当的区域经济差异能够使资源得到合理的优化和配置,促进经济的发展。
区域经济差异过大,地区的基尼系数就会提高,容易造成社会矛盾,不利于和谐社会的建设。
文章以四川省为研究对象,利用聚类分析和主成分分析法对区域的经济差异进行了实证研究。
通过研究发现,四川省区域经济差异性较大,有12个市(州)综合经济发展得分为负数,发展水平明显较差,有6个市(州)经济发展综合经济发展水平处于最低水平,仅有3个市(州)的综合经济发展水平处于良好状态。
[关键词]区域经济差异;聚类分析;主成分分析[DOI]10.13939/ki.zgsc.2021.14.0041 引言世界各国在经济发展过程中都存在一定的区域经济差异,我国幅员辽阔,每个地区都拥有独特的自然资源和文化背景,区域经济差异在我国尤为明显[1]。
区域经济差异对地区的发展有积极和消极的影响,要控制在一定的范围内。
适度的区域经济差异的积极影响表现在,区域经济存在一定的差异,可以使一些地区获得发展优势,吸引人才和资源的涌入,能够对资源进行优化和配置,促进经济的发展,经济发展较快的地区可以对其他的地区形成示范效应,激励其他地区采取一定的政策促进经济发展[2]。
然而,区域经济差异较大时,就会产生一系列的消极影响,过度的区域经济差异,各地区经济发展不协调,容易使各地区之间产生矛盾,不利于建设和谐社会[3]。
因此,区域经济差异要控制在一定的范围内,充分发挥区域经济差异的经济作用。
四川地处中国西部,面积居中国第5位,辖21个市(州),是我国的资源大省、人口大省、经济大省,2017年地区生产总值在31个省市自治区中位列第6位,但区域内部地形状况、人口分布和经济规模差异很大。
为了完成全面建成小康社会的目标,有必要对四川省区域经济差异进行分析,从定量角度测量四川省区域经济差异的程度。
聚类分析和因子分析在绩效考评中的应用

聚类分析和因子分析在绩效考评中的应用
刘秋彤;张应应
【期刊名称】《统计学与应用》
【年(卷),期】2022(11)1
【摘要】采用R软件编程,运用聚类分析和因子分析的方法来进行绩效考评。
首先采用系统聚类分析法得到四种不同距离的谱系图及绩效考评分类表。
其次采用因子分析选取教学因子和科研因子,利用回归法计算教师们的前两个因子得分,以及他们的两类综合得分。
由第一类算法计算的综合得分平等地对待两个因子,由第二类算法计算的综合得分以因子的方差贡献率为权重进行加权。
最后对教师绩效进行综合分析,得出对教师的绩效进行分类时,当无具体名额限制时,采用系统聚类分析法,当有具体名额限制时,采用因子分析法。
按与系统聚类法得到的分类的相合性,得出因子分析的第二类算法优于第一类算法,并采用第二类算法的计算结果来对有名额限制时的教师进行分类。
【总页数】15页(P135-149)
【作者】刘秋彤;张应应
【作者单位】重庆大学数学与统计学院统计与精算学系;重庆大学分析数学与应用重庆市重点实验室
【正文语种】中文
【中图分类】TP3
【相关文献】
1.360度绩效考评法在护士综合素质考评中的应用
2.因子分析和聚类分析在黑龙江省三级医院绩效评价中的应用
3.因子分析和聚类分析在黑龙江省三级医院绩效评价中的应用
4.医学院校二级院系绩效评价研究与实践——因子分析法与聚类分析法的应用
5.因子分析和聚类分析在柑橘皮膳食纤维面包质地评价中的应用
因版权原因,仅展示原文概要,查看原文内容请购买。
基于因子—聚类分析的河北省经济发展水平差异研究
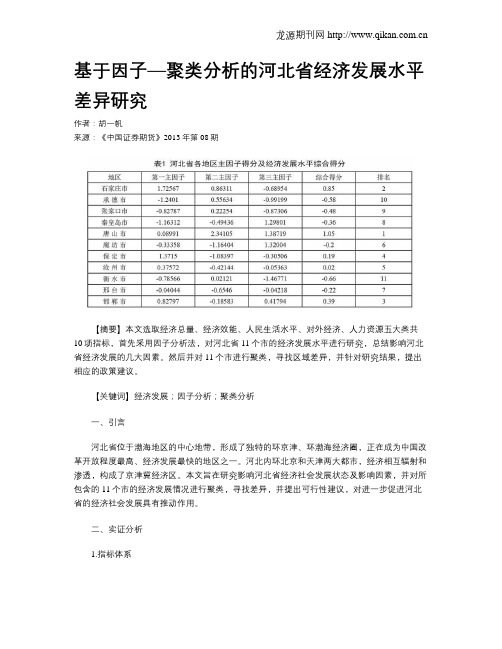
基于因子—聚类分析的河北省经济发展水平差异研究作者:胡一帆来源:《中国证券期货》2013年第08期【摘要】本文选取经济总量、经济效能、人民生活水平、对外经济、人力资源五大类共10项指标,首先采用因子分析法,对河北省11个市的经济发展水平进行研究,总结影响河北省经济发展的几大因素。
然后并对11个市进行聚类,寻找区域差异,并针对研究结果,提出相应的政策建议。
【关键词】经济发展;因子分析;聚类分析一、引言河北省位于渤海地区的中心地带,形成了独特的环京津、环渤海经济圈,正在成为中国改革开放程度最高、经济发展最快的地区之一。
河北内环北京和天津两大都市,经济相互辐射和渗透,构成了京津冀经济区。
本文旨在研究影响河北省经济社会发展状态及影响因素,并对所包含的11个市的经济发展情况进行聚类,寻找差异,并提出可行性建议,对进一步促进河北省的经济社会发展具有推动作用。
二、实证分析1.指标体系对于经济发展的指标体系的设计,要从经济总量,经济质量和经济效能,指标的全面性、代表性和可操作性等方面考虑。
在借鉴了相关文献资料的理论和方法的基础上,本文选取了五大类10个指标构成的指标体系。
具体如下:经济总量指标:地区总人口、地区生产总值、固定资产投资总额、第三产业总产值。
经济效能指标:规模以上工业企业水消费(取水总量)、规模以上工业企业能源消耗情况。
人民生活水平指标:在岗职工平均工资、社会消费品零售总额。
对外经济指标:外商直接投资额。
人力资源指标:人才资源总量。
2.样本选取及数据来源本文选择了河北省11个市2011年相关指标数据,所有数据取自《河北经济年鉴2012》。
3.分析过程本文数据操作,均使用软件SPSS 19.0进行。
本文首先采用因子分析方法,对原始数据进行标准化,使各指标的均值为0,方差为1。
对标准化后的数据进行因子分析,将10个变量抽象为少数几个抽象的因子。
本文中提取因子的方法选取主成份法。
为了能更加明确地表示因子与原始指标间的关系,使得每个因子在一些指标上的载荷较大,而在另一些指标上的载荷较小。
基金经理择时能力对开放式基金业绩的影响——基于多维视角的实证检验

基金经理择时能力对开放式基金业绩的影响——基于多维视角的实证检验易力; 廖胤凯; 邓黎明【期刊名称】《《湖南师范大学自然科学学报》》【年(卷),期】2019(042)006【总页数】9页(P64-71,85)【关键词】择时能力; 基金业绩; 波动性; 流动性; 投资者情绪【作者】易力; 廖胤凯; 邓黎明【作者单位】湖南师范大学商学院中国长沙 410081【正文语种】中文【中图分类】F830.39基金经理择时能力是衡量基金经理对市场走势进行预测的一种投资能力,其表现是影响基金投资业绩的一个重要因素。
首先,市场走势是不断变化的,Treynor和Mazuy[1]认为基金经理能否成功预测市场走势可以通过分析基金所持投资组合的系统风险的变化来检验,即系统风险等于目标风险加上一个零均值正态分布的随机项。
当基金经理预期市场上涨(下跌)时,通过使随机项为正值(负值)来提高(降低)基金的系统风险,以增加(减少)基金的收益(损失)。
因而在CAPM模型中,如果基金经理拥有择时能力,那么系统风险与业绩之间是负相关的,表明系统风险被低估时,业绩阿尔法将会被高估,因此,评价基金业绩时要综合考虑基金经理择时能力的重要影响。
其次,市场维度亦客观存在,正如Zheng等[2]所指出,除了市场收益,基金经理也可能会不断地对其他的市场维度即波动、流动和情绪走势进行预测,以多维择时实现基金资产增值。
因为当市场弱势有效时,精明的基金经理不可能只对单一的收益择时,他们会充分利用公共或私人信息对其他的市场维度进行择时。
由于市场转换存在不确定性,基金规模、换手率以及费率等基金特征也可能决定基金经理会采取不同维度的择时策略,增持某种维度组合系统风险,减持其他维度组合系统风险,从而对基金业绩产生差异化影响。
因此,研究这些差异性为解决基金经理择时能力与基金业绩关系问题在理论上提供了新的解释。
那么,基金经理择时能力差异能不能影响到基金超额收益的获取?基金经理择时能力对基金业绩的影响是否具有交互效应?研究这些问题对基金公司依据择时业绩差异考核与选拔基金经理人才以及对基金投资者识别合理的业绩指标都有较好的指导意义,同时对行为金融学在开放式基金领域的研究也有一定的理论意义。
基于聚类分析的上市公司股票价值研究——以20支中国“工业4.0”概念股为例

基于聚类分析的上市公司股票价值研究——以20支中国“工业4.0”概念股为例摘要:本文以我国20家“工业4.0”上市公司2017年的年度数据为研究对象,主要从盈利能力、偿债能力、营运能力、发展能力中选取各公司8项细分财务指标,并借助SPSS软件进行数据整理和聚类分析。
实证分析结果反映出各类上市公司的经营绩效和股票价值,借此发现目前具有相对优势的“工业4.0”企业,为股票投资者提供有效的投资建议。
关键词:“工业4.0”;经营绩效;聚类分析;股票投资一、研究意义和目的当前“工业4.0”的发展受到越来越多人的瞩目,在“中国制造2025”战略提出背景下,资本市场也为众多投资者提供了大量的投资机会。
据此,本文意在对我国若干“工业4.0”上市公司的相关财务分析指标进行聚类分析,以此反映上市公司的经营绩效和股票价值。
根据聚类分析的结果,寻找出聚为一类的不同企业所共有的特点,并对其未来发展趋势进行预测,得出合理的分析结果,既能帮助公司所有者和经营者了解自身运营过程中的优势和不足,为其提供策略引导,也能为股票投资者提供行之有效的投资建议,以确定最优的投资方案。
二、文献综述国内学者对公司的经营绩效和上市公司的股票表现进行了大量研究,并取得了一些成果。
归璐(2017)经过杜邦分析法构建上市公司的综合业绩评价体系,认为其财务绩效可通过相关股票指标得以反映[1]。
陶冶和马健(2005)运用聚类分析和判别分析方法,对38家中小企业板上市公司的其盈利、成长和扩张能力进行定量分析,据此归结出整个板块股票的分类及其特点[2]。
李庆东(2005)应用聚类分析方法对股票市场石油化工板块进行了分析和分类,认为行业跨度较大的企业,很多时候也可能存在聚为一类的结果[3]。
郭俊峰(2015)选取十支上市公司的股票,将聚类分析法与相对价值理论相结合,指出了股票投资中易被忽略的因素,强调了股票价值的挖掘方法[4]。
杨林等(2014)以金融业股票投资价值为研究对象,利用因子分析法和聚类分析方法,体现股票投资价值的四项指标,认为在金融业上市公司中银行类股票值得关注、较为安全、适宜投资[5]。
基于因子分析和聚类分析的商业银行财务竞争力差异评价
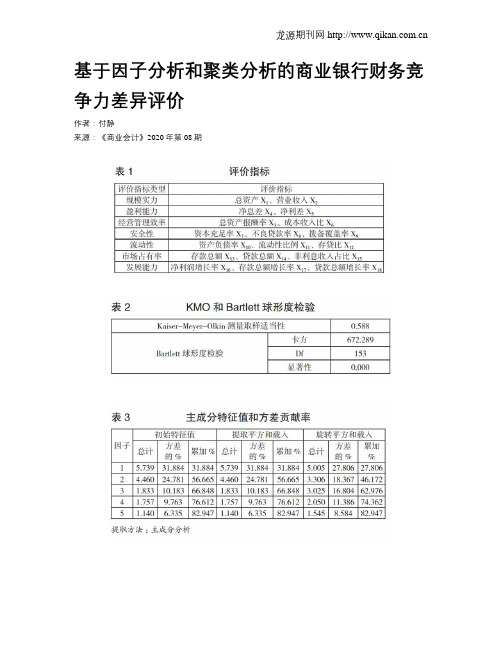
基于因子分析和聚类分析的商业银行财务竞争力差异评价作者:付静来源:《商业会计》2020年第08期【摘要】; 随着利率市场化的推进,科技金融时代的到来,银行业面临的挑战日益加大,在错综复杂的环境中占据有利地位,稳固自身的财务竞争力显得尤为重要。
基于此,文章采用因子分析和聚类分析方法,选取规模实力、盈利能力、发展能力、安全性、经营管理效率、流动性作为评价指标,分析我国28家商业银行的财务竞争力,客观评价我国各商业银行财务竞争力的差异。
【关键词】; ;商业银行;财务竞争力;因子分析;聚类分析【中图分类号】; F275; 【文献标识码】; A; 【文章编号】; 1002-5812(2020)08-0071-04商业银行作为我国金融体系的核心部分,对于整个金融行业的发展起着重要作用,也对国家宏观经济的发展发挥着不可估量的作用。
互联网金融、大数据、云平台和人工智能的发展促使商业银行出现了多元化发展趋势,商业银行间的竞争日趋激烈。
商业银行的财务竞争力包含安全性、流动性、规模性、盈利性等多个方面,财务竞争力的稳步提升能够为商业银行的发展提供保障,也能为国家经济的发展提供支撑。
一、文献综述近年来,国内学者对于商业银行财务竞争力的研究逐渐增多,如郭翠荣、刘亮(2012)选取我国16家商业银行的规模、盈利、市场占有等20个指标,通过对数据进行同向化和标准化处理开展因子分析,对各商业银行的财务竞争力进行排名,得到各商业银行之间的差距。
雷前超、李芬芬(2016)利用聚类分析方法对我国16家上市商业银行5年的数据进行分析,探讨不同类型商业银行的优劣势。
彭芳春、张泉(2016)对我国沪深A股16家上市商业银行的经营绩效进行了主成分分析,研究各商业银行经营绩效的差异。
赵彦峰、陈如意等(2019)研究了我国上市城商行的财务竞争力,研究表明综合竞争力较强的是东部和西部城商行,规模竞争力较强的是西部城商行,各城商行之间盈利能力的差异较大。
基于聚类分析的相对比较评估方法实证分析

基于聚类分析的相对比较评估方法实证分析【摘要】相对比较评估方法是企业价值评估的一种重要方法,但是该方法在使用时存在可比公司难以选择、评估结果容易被操纵的问题。
文章针对这一问题,利用因子分析和聚类分析模型建立可比公司的相似度模型,提出能提高可比公司相似度的相对比较评估方法,并利用SPSS统计软件进行实证,验证该方法的可行性和准确性,为相对比较评估方法在我国的应用提供实证依据。
【关键词】相对比较评估方法;因子分析;聚类分析;实证分析企业价值评估作为一项综合性的资产评估,是帮助企业实现财务管理目标的有力手段之一,在企业经济活动中应用广泛。
现有的企业价值评估方法主要有成本法、相对比较评估法和收益现值法;主要的评估模型有现金流折现模型、股利折现模型、剩余收益模型、期权定价模型和EV A模型等。
相对比较评估方法由于使用简单、易于理解而在实践中得到了广泛的应用,然而该方法也极易被误用,特别是在可比公司的选择方面,尤其在我国,市场发育还没有健全,很难找到在风险和增长等方面完全一样的参照企业,人们有时只凭主观经验选择可比公司,容易造成人为操纵的结果。
为了找到相似度更高的可比公司,本文将建立基于因子分析和聚类分析的相似度模型,对可比公司进行选择。
一、相对比较评估方法简介由定义可以看出,使用相对比较评估方法要具备两个条件:一是为了便于对可比公司进行价格比较,必须将市场价格标准化,通常做法是用股票市场价格除以利润、账面价值、营业收入等指标计算出一些数值作为比较乘数;二是需要找出与被评估企业相似的可比公司,并根据其市场价值进行差异调整。
(一)常用的比较乘数3.股票价格/销售额(P/S)近年来很多评估人员开始使用P/S乘数,该乘数较P/E或P/B乘数而言,有很多优势:首先,P/S乘数在使用时没有条件限制,而市盈率及市净率可能会因为是负值而在评估时变得没有参考意义;其次,由于股票价格、销售收入受会计政策的影响较小,P/S乘数不容易被人为扩大。
基于因子分析和聚类分析的互联网上市企业财务绩效评价

基于因子分析和聚类分析的互联网上市企业财务绩效评价本文选取20家互联网上市公司作为样本,利用因子分析方法提取四个主因子对公司的财务状况进行了分析,得出综合得分,再利用聚类分析方法对这20个样本进行分类,最后用SPSS对每类各因子得分及总得分做统计描述,找出每类的特点,有针对性地提出建议和策略。
标签:因子分析;聚类分析;互联网上市企业;财务绩效1 概述当今我国互联网已成为全球互联网发展的重要组成部分。
互联网全面渗透到经济社会的各个领域,成为生产建设、经济贸易、科技创新、公共服务等的新型平台和变革力量,推动着我国向信息社会发展。
然而,随着中国互联网如火如荼的发展,越来越多的互联网企业却遭到“成长的烦恼”。
科学的财务绩效评价是了解企业的有效途径。
因此,研究互联网企业财务绩效评价问题具有重要的意义。
利用因子分析和聚类分析相结合的方法对上市公司进行绩效评价的研究很普遍,但很少有学者將这种方法应用在互联网上市公司财务绩效评价的研究上。
基于这种背景,本文选取20家互联网上市公司作为样本,利用统计分析软件SPSS16.0对样本公司的财务状况进行因子分析和聚类分析。
先利用因子分析法计算出这20家公司的因子得分和综合得分并得出排名,再对每家公司因子得分进行聚类,把20家企业分成五类,最后对每一类公司各因子得分进行统计描述,以便对每类公司提出不同的发展战略。
2 互联网上市企业财务绩效评价指标体系的构建2.1 样本的选取与数据来源互联网企业上市之初往往存在“泡沫”,所以本文以2009年12月31日以前在美国纳斯达克证券交易所和香港证券交易所上市的互联网企业作为研究对象。
符合上述要求的互联网企业有23家,但为了保证数据的有效性,本文剔除了少数资料不完全的上市公司,如:网龙、第九城市、酷6网。
最终得到20家上市公司2012 年样本数据。
本文数据来源于BVD-Osiris全球上市公司分析库、上市公司年报(腾讯)、新浪财经网(http:///usstock/quotes/BIDU.html)。
基于因子分析和聚类分析角度的财务状况分析——以A股生物制品行业上市公司为例

经济研究基于因子分析和聚类分析角度的财务状况分析——以A股生物制品行业上市公司为例庞 晴,张子宁(河北经贸大学会计学院,河北 石家庄 050090)摘 要:以A股生物制品行业的29家上市公司作为研究对象,选取11个财务指标进行综合财务分析。
首先利用因子分析法提取三个公共因子,分别为偿债能力因子、营运及盈利能力因子和成长能力因子,然后以各个公司在三个公共因子上的得分为基础,通过聚类分析,将29家上市公司分为三类,比较分析不同类别公司的财务状况,并提出解决对策。
关键词:因子分析;聚类分析;财务研究0 引言因子分析法是一种多元统计方法,根据相关性大小把变量分组,使得不同的组之间形成新的变量,这样,在尽量减少信息丢失的前提下,用较少的变量来替代原来较多的变量,达到“降维”的目的,然后再根据各变量方差贡献率确定权重,进而计算出综合得分。
而聚类分析可以根据研究对象的不同特点将其分成不同类别,同一类中的对象有很大的相似性,不同类的对象有很大的相异性,进而可以直观地描述不同聚类中公司的特征。
本文主要采用因子分析法,运用SPSS Clementine数据分析软件将选用的财务指标进行预处理,并建立因子分析模型,提取公共因子。
然后以各个研究对象在公共因子上的得分为基础进行聚类分析,并计算出每类的平均综合得分,以此对A股上市公司中生物制品行业的29家公司的2019年财务状况作出综合评价。
1 样本选取及数据来源本文选取了A股上市公司中生物制品行业的29家公司作为研究对象,共选取11个反映企业财务综合状况的财务指标进行分析,分别为X1流动比率、X2速动比率、X3现金比率、X4流动资产周转率、X5总资产周转率、X6总资产报酬率、X7销售净利率、X8净资产收益率、X9营业收入增长率、X10营业利润增长率、X11净利润增长率。
所用数据来源于万德数据库。
2 基于因子分析的实证研究为检验收集的数据是否适合进行因子分析,对其进行KMO 和Bartlett检验。
基于熵值法和聚类分析的我国种植业上市公司财务绩效评价研究

600313
农作物种子选育加工、化肥农资贸易和养殖业务。
北京
600354
农作物制种和棉花收购加工业务
甘肃
600359
种植业、农副产品初加工及销售。
新疆
600371
玉米为主的农副产品深加工的技术研究和生产经营。 黑龙江
600506
库尔勒香梨为主的新疆水果的种植、加工和销售等。 新疆
600540
棉花种植,粮棉种子研发、繁育和销售。
企业管理 QIYEGUANLI
基于熵值法和聚类分析的我国种植业上市公司 财务绩效评价研究 *
赵 晶,陈 军 * (新疆师范大学,新疆 乌鲁木齐 830017)
摘要:通过收集我国 18 家种植业上市公司 2018 年的财 务数据,从偿债能力、营运能力、盈利能力、成长能力 4 个切 入点对相应的财务指标进行处理。 运用熵值法确定各项指标 的权重,对种植业上市公司的发展水平进行分析与评价。 对 我国种植业上市公司的财务绩效进行聚类分析,最终构建起 我国种植业上市公司财务绩效评价模型。 结果表明,我国种 植业上市公司经营业绩呈现较为明显的两极分化现象,且种 植行业缺少龙头企业;种植业上市公司在营运能力方面差异 较大,应通过控制总资产周转率和存货周转率来提高其营运 能力,提升经营业绩水平。
新疆
600598
水稻、大豆、小麦、玉米、尿素等作物的生产、销售
黑龙江
000713
农作物种子等的生产与销售。
安徽
000998
杂交水稻、辣椒、瓜类种子培育、繁殖、推广和销售。
湖南
002041
玉米种子生产、自育农作物杂交种子销售。
山东
注:数据来源于国泰安数据库
全面、客观的评价,从而分析影响种植业上市公司经
基于聚类分析——嘉实基金公司各产品绩效差异研究

《应用统计软件》课程实验报告年级专业__09 保险_姓名_ 郭见鹄___学号_090142881_指导教师_ 王周伟__上海师范大学金融学院2012 年 5月成绩评定:实验项目二基于聚类分析——嘉实基金公司各产品绩效差异研究摘要嘉实基金(HARVEST FUND MANAGEMENT CO.,LTD.)拥有证券投资基金设立与管理、全国社保基金投资管理人、企业年金投资管理人、基金公司开展境外证券投资管理业务和基金管理公司特定客户资产管理业务资格。
截至2011年12月31日,资产管理规模超过2274亿元,居行业前列。
目前,嘉实旗下管理2只封闭式基金、28只开放式基金及多个社保组合和企业年金账户,共同基金产品线和资产管理业务种类齐全。
研究多个基金产品的绩效时,往往需要按一定的标准进行分类。
运用聚类分析法将各个基金按其业务发展的特点,进行分类符合实际。
本文主要采用理论分析与实证分析相结合的形式。
利用《金融界》数据库,将选出的各项指标进行量化,结合层次聚类和K-均值聚类两种方法,从不同角度对各基金进行划分,并建立指标分类过程和体系。
对嘉实基金公司旗下具有典型意义的、共14个基金产品的绩效进行分类。
同时,运用SPSS软件,将实证结果以图表的形式反映出来,为分类的依据及合理性提供佐证,分析每一类别基金的显著特征和绩效差异,从而得出结论,并对嘉实基金管理公司的发展提出建议。
关键词:嘉实基金产品;绩效差异;聚类分析AbstractHARVEST FUND has the establishment of securities investment funds , fund investment management, enterprise annuity management, the administration of overseas securities investment business and specific qualification for the customers’asset management business. As of December 31, 2011, the scale of assets under management is over 227,400,000,000 yuan, which ranks the forefront of industry.At present, HARVEST FUND manages 2 closed-end funds,28 open-end funds ,social fund portfolio and enterprise annuity accounts. The mutual fund product line and asset management business are of diversity. When studying the performance of multiple fund products, we often need a certain standard to classify. It is practical to apply clustering method to the classification of each fund according to its business characteristics.This paper combines theoretical analysis with empirical analysis .By using the JRJ database, the selected indicators are quantified and combined with two methods of hierarchical clustering and K - means clustering .From different angles, the funds are divided. Then the process and system of classification are established. A total of 14 fund products which are with typical significance are chosen for the performance classification. At the same time, in use of the SPSS software, the empirical results are reflected in the form of graphs and tables , which provide evidence on rationality and basis of the classification .Through the analysis on each category of fund characteristics and performance difference, conclusions can be got, which may help to make proposals on the development of Harvest Fund Management Company.Key words: Harvest Fund Products; Performance Differences; Cluster Analysis目录实验项目二基于聚类分析——嘉实基金公司各产品绩效差异研究 (3)摘要 (3)Abstract (4)1、绪论 (6)1.1研究背景 (6)1.2研究目的和意义 (6)1.3研究对象和范围 (6)1.4研究方法 (7)2、相关理论回顾 (8)2.1 聚类分析的思想和原理 (8)2.2 层次聚类 (9)2.3 K-均值聚类 (9)3、样本选择与数据收集 (11)3.1 样本的选择 (11)3.2 数据的处理 (11)4、实证研究结果分析 (14)5、结论 (21)参考文献 (22)附件:主要操作步骤 (23)1、绪论1.1研究背景1999年3月,嘉实基金(HARVEST FUND MANAGEMENT CO.,LTD.)经中国证监会批准成立,并于2005年6月成为合资基金管理公司,目前嘉实的股东为中诚信托有限责任公司、立信投资有限责任公司与德意志资产管理公司。
聚类分析及判别分析案例
一、案例背景随着现代人力资源管理理论的迅速发展,绩效考评技术水平也在不断提高。
绩效的多因性、多维性,要求对绩效实施多标准大样本科学有效的评价。
对企业来说,对上千人进行多达50~60个标准的考核是很常见的现象。
但是,目前多标准大样本大型企业绩效考评问题仍然困扰着许多人力资源管理从业人员。
为此,有必要将当今国际上最流行的视窗统计软件SPSS应用于绩效考评之中。
在分析企业员工绩效水平时,由于员工绩效水平的指标很多,各指标之间还有一定的关联性,缺乏有效的方法进行比较。
目前较理想的方法是非参数统计方法。
本文将列举某企业的具体情况确定适当的考核标准,采用主成分分析以及聚类分析方法,比较出各员工绩效水平,从而为企业绩效管理提供一定的科学依据。
最后采用判别分析建立判别函数,同时与原分类进行比较。
聚类分析二、绩效考评的模型建立1、为了分析某企业绩效水平,按照综合性、可比性、实用性与易操作性的选取指标原则,本文选择了影响某企业绩效水平的成果、行为、态度等6个经济指标(见表1)。
2、对某企业,搜集整理了28名员工2009年第1季度的数据资料。
构建1个28×6维的矩阵(见表2)。
3、应用SPSS数据统计分析系统首先对变量进行及主成分分析,找到样本的主成分及各变量在成分中的得分。
去结果中的表3、表4、表5备用。
表 5成份得分系数矩阵a成份1 2Zscore(X1) .227 -.295Zscore(X2) .228 -.221Zscore(X3) .224 -.297Zscore(X4) .177 -.173Zscore(X5) .186 .572Zscore(X6) .185 .587提取方法 :主成份。
构成得分。
a. 系数已被标准化。
4、从表3中可得到前两个成分的特征值大于1,分别为3.944与1.08,所以选取两个主成分。
根据累计贡献率超过80%的一般选取原则,主成分1与主成分2的累计贡献率已达到了83.74%的水平,表明原来6个变量反映的信息可由两个主成分反映83.74%。
基于因子分析和聚类分析对不同红小豆品种(系)性状的综合评价

基于因子分析和聚类分析对不同红小豆品种(系)性状的综合评价周桂梅刘振兴陈健亚秀秀孟庆祥(唐山市农业科学研究院,河北唐山063001)摘要为筛选出综合性状好的优良红小豆品种(系),对22个红小豆品种(系)的生育期、株高、底荚高度、主茎节数、主茎分枝数、单株荚数、荚长、单荚粒数、百粒重、产量这10个性状进行变异分析、因子分析和聚类分析。
结果表明:结合变异系数和因子载荷可以看出,株高、主茎分枝数、单株荚数、百粒重可以作为红小豆形态要求的选择标准。
通过建立综合评价模型,综合评价居前3位的品种(系)是渝红豆4号、保红201219-1、THM2011-28,可作为优异资源加以利用。
通过聚类分析,将22个红小豆品种(系)划分为4个大类群,大部分品种(系)聚集在第Ⅰ类群和第Ⅲ类群,以后应加强资源的多样性开发利用。
关键词红小豆;品种(系);因子分析;聚类分析;性状中图分类号S521.037文献标识码A文章编号1007-5739(2023)09-0041-04DOI:10.3969/j.issn.1007-5739.2023.09.012开放科学(资源服务)标识码(OSID):Comprehensive Evaluation on Characters of Different Adzuki Bean Varieties(Lines)Based on Factor Analysis and Cluster AnalysisZHOU Guimei LIU Zhenxing CHEN Jian YA Xiuxiu MENG Qingxiang(Tangshan Academy of Agricultural Sciences,Tangshan Hebei063001)Abstract In order to screen out adzuki bean varieties(lines)with good comprehensive characters,variation analysis,factor analysis and cluster analysis were carried out on10characters(growth period,plant height,bottom pod height,node number and branching of main stem,pod number per plant,pod length,seed number per pod,100-seed weight and yield)of22adzuki bean varieties(lines).The results showed that,based on the coefficient of variation and factor loading,plant height,main stem branching,pod number per plant and100-seed weight could be used as selection criteria of adzuki bean.Through the establishment of a comprehensive evaluation model,the top three varieties(lines)in comprehensive evaluation were Yuhongdou4,Baohong201219-1,THM2011-28,which could be used as excellent resources.Through cluster analysis,22adzuki bean varieties(lines)were divided into4groups,most of them clustered in the group I and the group III.In the future,the diversfied development and utilization of resources should be strengthened.Keywords adzuki bean;variety(line);factor analysis;cluster analysis;character我国红小豆种植面积、总产量均居世界第1位。
聚类分析及聚类结果评估算法研究

研究方法
本研究采用文献调查和实验研究相结合的方法。首先,我们对聚类分析的各 种算法进行梳理与评价,了解其优缺点及适用场景。其次,我们针对某一具体应 用领域,收集相关数据并进行预处理、特征选择等步骤。随后,我们采用多种聚 类算法对数据进行聚类分析,并应用聚类结果评估算法对聚类效果进行评估。
实验结果及分析
通过实验,我们发现聚类分析在不同领域的应用中均取得了较好的效果。例 如,在数据挖掘领域,我们采用k-means和谱聚类算法对一个商品销售数据集进 行聚类,成功地将相似的商品聚集在一起,为商家提供了有价值的销售策略建议。 在生物信息学领域,我们利用层次聚类算法对基因表达数据进行分析,准确地识 别了不同类别样本间的差异表达基因。
结论本次演示对KMeans聚类算法的研究现状、应用领域、未来发展方向进行 了综述。KMeans聚类算法作为一种经典的聚类方法,已经得到了广泛的应用,并 在各个领域取得了良好的效果。然而,随着大数据时代的不断发展,KMeans聚类 算法仍需要进一步的研究和改进,以更好地适应不断变化的应用需求和提高算法 的性能和准确性。
KMeans聚类算法的研究现状 KMeans聚类算法是一种基于划分的聚类方法, 其基本思想是将数据集划分为若干个簇,使得每个簇内的数据点相似性较高,同 时不同簇之间的数据点差异较大。自KMeans聚类算法提出以来,已经有许多研究 者对其进行了研究,并提出了许多改进算法。
传统的KMeans算法采用欧几里得距离作为相似性度量,这种度量方式容易受 到量纲和异常值的影响。因此,一些研究者提出了其他的相似性度量方式,如马 氏距离、余弦相似性等,以增强KMeans算法的鲁棒性。另外,KMeans算法的初始 化也会影响聚类结果,因此,一些研究者提出了多种初始化方法,如K-means++、 K-means||等,以改善聚类效果。
基于因子-聚类分析的河北省区域经济发展水平差异研究

抽取的主因子
正交旋转因子 贡献率/ 累积贡献率/ % %
序号 特征值 贡献率, 累积贡献率/ 特征值 % %
因子具有显著的代表性 ,可以反映原始变量所
表示 的绝大部分信息量.选取最大方差正交旋
转法进行因子旋转 ,抽取 的主因子及将 因子进 行旋转后 的因子贡献率见表 2 .
作者简介:李佩 ( 96 ,女 ,河北邢台人,在读硕士,从事区域经济发展战略研究.E m i i i9695 6. r 18 一) - al p 180 2@1 3 o :le cn
第 2期
李佩 ,等 :基于 因子一 聚类分析 的河北省区域经济发展水平差异研究
8 1
1 研究方法与数据来源
经 济 总量
据 的客观性 、可获取性等原则 , 从产业 结构 、经济效益 、经济总 量 、居 民生活水平和经济外 向性 等5 个方面 , 选取 l 个指标 , 7 构
12 指标 权 重及 评价模 型 的确定 _
人均国内生产总值;人均工业产值;人均社会固定资产投资 ;人均财政收入 ; 人均社会消费品零售额 ;国内生产总值密度;农业人口人均农林牧渔业产值 地区生产总值;地方财政收入;社会消费品零售总额;全社会固定资产投资
086 — .2 00 5 0 9 025 09 2 018 -) . 2 05 1 .5 . 8 .7 . .3 4O5 0 3 . 092 - .3 00 5 013 040 08 9 012 — . 1 .1 0 39 .2 .1 . . . 6 5 0 00 2 069 -.5 016 023 007 O 8 O03 O15 .6 062 .8 . .4 . 0 . .0 6 9 4 070 -. 7 0 1 009 012 0 2 014 一.l . 4 0 6 . 7 . .6 . 8 . 0 0 6 9 4 O10
聚类分析在开放式基金绩效研究中的应用

聚类分析在开放式基金绩效研究中的应用闫云娟;冯大一【摘要】聚类分析在基金绩效的研究方面有很大的挖掘空间.为研究基金的绩效,从基金的规模发展、收益如何及成长性3个层面进行了考察,选取了2008年1月到2008年6月共24周的数据,其中任意选取30只基金,以其周收益率为基本数据计算并建立了6个指标.通过Q聚类分析方法,分析了这30只基金在整个股市大幅下跌的表现情况.以此来判断基金的绩效,来帮助投资者做出较为准确的投资.【期刊名称】《华东交通大学学报》【年(卷),期】2008(025)005【总页数】4页(P77-80)【关键词】开放式基金;聚类分析;系统聚类法【作者】闫云娟;冯大一【作者单位】华东交通大学,基础科学学院,江西,南昌,330013;华东交通大学,基础科学学院,江西,南昌,330013【正文语种】中文【中图分类】O212.4;F830.59截止到2008年6月,我国基金已经发展到311支.随着我国证券市场如火如荼的快速发展,基金投资已成为许多人的投资手段,如何抓住机会,规避风险已成为众多投资者所关心的问题.除了关注各项政策等定性因素以外,我们还可以利用基金过去已有的信息来得到一些定量的信息.目前对基金业绩的考察可以通过直接比较,即将基金与某个标准来进行比较,其优点是一目了然但不能充分利用数据得到其内在联系;另外还可以间接比较,就是将基金与该基金相似的一组进行比较,对同类型的基金业绩进行比较分析来评定其业绩的优劣.本文利用系统聚类分析的方法期望得到业绩突出,收益良好的投资基金. 传统方法通常应用多个指标来定性分析业绩.聚类分析就是分析如何对样品(或变量)进行量化分类的方法.通常聚类分析分为Q型聚类和R型聚类[1].Q型是对样品进行分类处理,R型是对变量进行分类处理.本文应用Q型聚类的方法来处理数据,其优点就是能够应用多个变量对样本进行分类.聚类分析所得到的结果比传统方法得到的结果更客观、全面、细致.2.1 样品相似性的度量距离作为对样品之间的相似程度的度量是聚类分析的基础.样品的相似程度可用两点间距离公式来度量.从不同角度定义有以下三种:设每个样品有p个指标从不同方面描述其性质,形成一个p维向量.Xi与Xj是来自均值向量为μ,协方差为∑的总体G中的p维样品.马氏距离又称为广义欧几里德距离,它考虑了观测变量的关系.本文采用的是欧氏距离,即欧几里德距离来度量样品间的距离.2.2 类间距离在系统聚类之前,我们首先要定义类间距离,由类间距离的不同定义产生了不同的系统聚类法.常用的类间距离有8种之多,与之相应的系统聚类法也有8种.本文只介绍3种比较常用的方法,分别为:设类Gp与Gq合并成新的一类,记为Gr.Dkr表示任意一类Gk与Gr的距离.即用Gp,Gq每两两样品间距离的平均值作为这两类之间的距离.2.3 系统聚类法基本思想:距离相近的样品先聚类,距离相远的样品后聚类,过程一直进行下去,每个样品总能聚到合适的类里去.系统聚类过程是:假设共有n个样品,第一步将每个样品聚成一类,共有n类;第二步根据所确定的样本距离,把距离较近的两类样品聚为一类,其他样品仍自聚一类,共聚n-1类;第三步将距离最近的两个类进一步聚成一类,共聚n-2类;以上步骤一直进行下去,最后将所有的样品都聚成一类.为了直观的反映系统聚类过程,通常我们会画出其聚类谱系图.本文采用类平均距离法进行系统聚类.3.1 数据的选取本文共选取了2008年1月到2008年6月共24周的数据,其中任意选取30只基金,以其周收益率为基本数据而计算并建立了以下一系列指标.原始数据由中国证券报与和讯基金网获得.由于篇幅有限且原始数据量比较大,文中只给出了6个指标数据和聚类的结果.3.2 聚类分析指标体系的选取[2]X1为上市时间,X2为夏普指数,X3为夏普指数,X4为特雷诺指数,X5为单位净值,X6为是基金变动率[3],由于2008年只统计出第1季度的基金规模,所以本文采用2008第1季度与2007年全年的基金规做比较.(1)周收益率计算方法:rit=(navit-navi,t-1)/navi,t-1其中:rit表示第i只基金在第t周的周收益率;navit表示第i只基金在第t周周末的单位净值;navi,t-1表示第i只基金在第t-1周周末的单位净值.(2)詹森指数[4]:它是对基金超额收益的一种衡量指标,其越大,则越能体现基金经理的才能,基金越优.其中:E(rit)为第i只基金在整个研究期间的平均周收益率;βi为系统风险;rp表示基金的平均周投资收益率;rf为周无风险收益率,本文以2008年1年的定期存款利率4.14%为这24周的无风险利率,所以周无风险利率为0.086 25%;rm为市场组合周收益率;rmt为市场基准周收益率.(3)特雷诺指数:T=(rp-rf)/β,它表示投资组合平均收益率超出无风险收益率部分(超额收益率)与投资组合的值之商,即基金承担单位系统风险所获得的超额收益[5].(4)夏普指数:sp=(rp-rf)/σ,其中σ表示基金周收益率的标准差.夏普指数实际上是投资组合平均周收益率超出周无风险收益率部分(超额收益率)与投资组合收益率的标准差之商,即基金承担单位风险(包括系统风险和非系统风险)所获得的超额收益.指标数据见表1.3.2 聚类分析结果在进行系统聚类之前,为消除量纲的影响,首先将数据标准化处理,根据SPSS [6]软件计算得聚类谱系图(见图1).从中我们发现大成沪深、嘉实300距离最近,首先聚为一类,随后以中银收益、鹏华动力、华宝兴业、红利ETF、深100ETF、广发大盘、交银蓝筹、万家180、中海优质、华安创新、易方达积、南方避险的顺序聚为第一类.这类基金上市时间较长,规模变化不大,就基金经理在应对这半年来股市大幅下跌显得比较有经验,有一定的避险能力,尽管随着沪证和深证股指的整体下滑,这些基金的回报率也在下滑,但基金管理人的选股及结构投资能力仍值得我们看好,如果市场重新活跃,该基金是一个不错的选择.第二类是以如下顺序聚为一类的:华夏大盘、上投摩根阿尔法、上投摩根内需动力、交银成长、华夏优势、华夏红利、太达荷银、华夏回报、南方多利、180 ETF.这类基金上市时间较长,同时我们可以看出在最近半年如此低糜的状态下,他们抵御风险的能力还是不错的,因此我们还是可以考虑做长期投资.第三类是华安宝利、50 ETF、嘉实理财、金鹰中小、长城久泰顺、招商债券这类基金规模变化较大,回报率不高,在这段时间内业绩表现不好.【相关文献】[1]朱建平.应用多元统计分析[M].北京:科学出版社,2006.62-90.[2]张海燕.利用回归分析对基金业绩进行评价[J].中国民航学报,2003,21(7):64-65. [3]李凯,史金艳,武珊.基于聚类分析的封闭式基金折价问题实证研究[J].预测,2006,25(2):60-61.[4]胡猛,向嘉华.证券投资基金务实[M].北京.社会科学文献出版社1999.110-130. [5]王敬,王颖.基于主成分分析的基金绩效评价模型研究[J].大连理工大学学报2005,46(2):72-77.[6]章文波,陈红艳.实用数据统计分析及SPSS12应用[M].北京:人民邮电出版社,2006.178-200.。
基于因子分析和聚类分析的创业板上市公司综合评价

分析。综合考虑模型的简洁性和准确性,最终提取出 五类比较恰当。
四个公共因子,得到正交旋转后的因子得分系数矩
2、聚类方法选择
阵(见表 1)。可以看到,因子一主要与速动比率、流
本文采用了实际中广泛使用的分层聚类方法。
动比率、资产负债率等显著正相关,可度量公司偿债 先把每一个样本点各自看做一类。然后根据样本点
为盈利因子;因子四主要解释固定资产和应收账款 分层聚类分析,按类间平均链锁法(Between- groups
周转率,与营运能力有关,因此命名为营运因子。由 linkage)计算距离,选择欧氏距离的平方作为相似性
此可以得到各个样本公司在各因子上的因子得分 测度,并构建谱系聚类图,直观地反映出聚类的过程
者参考了其他学者的研究 ,鉴于“上市公司都是以 具有较高的高科技含量和高经济附加值为特征的企 业,固定资产并不是总资产的主要部分,很多创业板 上市公司以较小的固定资产却创造出巨大的财富, 所以固定资产周转率作为衡量创业板上市公司的高 成长性与高收益的财务指标具有重要的参考价值”, 增加了固定资产周转率作为衡量营运能力的指标之 一。即最终选取了净资产收益率、总资产报酬率、销 售毛利率、销售净利率、营业收入增长率、净利润增 长率、流动比率、速动比率、资产负债率、已获利息倍 数、存货周转率、应收账款周转率、固定资产周转率 共十三个指标,从盈利能力、成长能力、偿债能力、营 运能力四个方面对创业板上市公司进行综合考评。
基金经理特征与基金业绩:基于模糊集定性比较研究

基金经理特征与基金业绩:基于模糊集定性比较研究
杨齐;乔婷
【期刊名称】《河北金融》
【年(卷),期】2022()2
【摘要】运用模糊集定性比较分析方法(fsQCA),研究在牛市和熊市中,多个基金经理特征的组合对股票型和偏股型混合基金业绩的联合影响。
通过分析发现,在牛市中有四种基金经理特征,将其归纳为“专业主导型”“运气-能力主导型”“关系主导型”,在熊市中有五种基金经理特征,分别为“运气-关系主导型”“运气-能力主导型”“信心-专业主导型”“能力-关系主导型”。
这些构型为基金经理的职业规划、个人风格的建立提供了借鉴,为基金管理公司和投资者依据自身偏好和基金特点选择相应的基金经理提供了依据。
【总页数】7页(P50-56)
【作者】杨齐;乔婷
【作者单位】甘肃政法大学商学院
【正文语种】中文
【中图分类】F830.91
【相关文献】
1.经理人特征与基金业绩关系分析--基于中国股票型基金的一项实证研究
2.基金经理个人特征、基金特征与基金业绩相关性的实证研究
3.基金管理人持基激励与基金业绩——基金经理个人特征的调节效应研究
4.基金经理人特征与基金业绩——
基于阳光私募基金的实证分析5.基金业绩影响因素研究——基于基金经理特征视角
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《应用统计软件》课程实验报告年级专业__09 保险_姓名_ 郭见鹄___学号_090142881_指导教师_ 王周伟__上海师范大学金融学院2012 年 5月成绩评定:实验项目二基于聚类分析——嘉实基金公司各产品绩效差异研究摘要嘉实基金(HARVEST FUND MANAGEMENT CO.,LTD.)拥有证券投资基金设立与管理、全国社保基金投资管理人、企业年金投资管理人、基金公司开展境外证券投资管理业务和基金管理公司特定客户资产管理业务资格。
截至2011年12月31日,资产管理规模超过2274亿元,居行业前列。
目前,嘉实旗下管理2只封闭式基金、28只开放式基金及多个社保组合和企业年金账户,共同基金产品线和资产管理业务种类齐全。
研究多个基金产品的绩效时,往往需要按一定的标准进行分类。
运用聚类分析法将各个基金按其业务发展的特点,进行分类符合实际。
本文主要采用理论分析与实证分析相结合的形式。
利用《金融界》数据库,将选出的各项指标进行量化,结合层次聚类和K-均值聚类两种方法,从不同角度对各基金进行划分,并建立指标分类过程和体系。
对嘉实基金公司旗下具有典型意义的、共14个基金产品的绩效进行分类。
同时,运用SPSS软件,将实证结果以图表的形式反映出来,为分类的依据及合理性提供佐证,分析每一类别基金的显著特征和绩效差异,从而得出结论,并对嘉实基金管理公司的发展提出建议。
关键词:嘉实基金产品;绩效差异;聚类分析AbstractHARVEST FUND has the establishment of securities investment funds , fund investment management, enterprise annuity management, the administration of overseas securities investment business and specific qualification for the customers’asset management business. As of December 31, 2011, the scale of assets under management is over 227,400,000,000 yuan, which ranks the forefront of industry.At present, HARVEST FUND manages 2 closed-end funds,28 open-end funds ,social fund portfolio and enterprise annuity accounts. The mutual fund product line and asset management business are of diversity. When studying the performance of multiple fund products, we often need a certain standard to classify. It is practical to apply clustering method to the classification of each fund according to its business characteristics.This paper combines theoretical analysis with empirical analysis .By using the JRJ database, the selected indicators are quantified and combined with two methods of hierarchical clustering and K - means clustering .From different angles, the funds are divided. Then the process and system of classification are established. A total of 14 fund products which are with typical significance are chosen for the performance classification. At the same time, in use of the SPSS software, the empirical results are reflected in the form of graphs and tables , which provide evidence on rationality and basis of the classification .Through the analysis on each category of fund characteristics and performance difference, conclusions can be got, which may help to make proposals on the development of Harvest Fund Management Company.Key words: Harvest Fund Products; Performance Differences; Cluster Analysis目录实验项目二基于聚类分析——嘉实基金公司各产品绩效差异研究 (3)摘要 (3)Abstract (4)1、绪论 (6)1.1研究背景 (6)1.2研究目的和意义 (6)1.3研究对象和范围 (6)1.4研究方法 (7)2、相关理论回顾 (8)2.1 聚类分析的思想和原理 (8)2.2 层次聚类 (9)2.3 K-均值聚类 (9)3、样本选择与数据收集 (11)3.1 样本的选择 (11)3.2 数据的处理 (11)4、实证研究结果分析 (14)5、结论 (21)参考文献 (22)附件:主要操作步骤 (23)1、绪论1.1研究背景1999年3月,嘉实基金(HARVEST FUND MANAGEMENT CO.,LTD.)经中国证监会批准成立,并于2005年6月成为合资基金管理公司,目前嘉实的股东为中诚信托有限责任公司、立信投资有限责任公司与德意志资产管理公司。
嘉实拥有证券投资基金设立与管理、全国社保基金投资管理人、企业年金投资管理人、基金公司开展境外证券投资管理业务和基金管理公司特定客户资产管理业务资格。
截至2011年12月31日,资产管理规模超过2274亿元,居行业前列。
嘉实基金管理公司在同行业中具有较大的影响力,其打造出了具有不同风格稳定投资观的品牌基金,是数百万客户的投资选择。
在业绩、产品、服务这三个方面,其综合实力也不容小觑。
在如今变幻莫测的市场环境中,有如此的卓越的业绩,其背后的原因值得我们探究。
1.2研究目的和意义目前,嘉实旗下管理2只封闭式基金、28只开放式基金及多个社保组合和企业年金账户,共同基金产品线和资产管理业务种类齐全。
研究多个基金产品的绩效时,往往需要按一定的标准进行分类。
运用聚类分析法将各个基金按其业务发展的特点,进行分类符合实际。
本文以研究嘉实基金管理公司各基金产品的绩效差异为目的,建立一定的指标分类体系,将不同绩效特征的基金加以区分。
从实证得到的研究结果,分析比较嘉实基金管理公司旗下各基金产品的差异性,对不同基金产品存在的问题,基金管理公司未来的发展提出相应的建议,也会基金投资者提供参考标准。
1.3研究对象和范围本文选取了嘉实基金公司旗下具有典型意义的14个基金产品,主要涉及12个开放式基金:嘉实增长、嘉实稳健、嘉实成长、嘉实货币、嘉实短债、嘉实300、嘉实海外、嘉实策略、嘉实主题、嘉实债券、嘉实服务、嘉实优质。
其中,既有股票型或者混合型,也有债券型基金即嘉实债券、嘉实短债,还有货币型基金和指数型基金:如嘉实货币、嘉实300。
另外,样本中还包含了2个封闭式基金:基金丰和、基金泰和。
每个样本测得多个变量,这些指标包括基金运作时间、基金资产总值、管理费用(率)、单位净收益、基金净值增长率、累积净值增长率,基金经理的累积任职时间等。
1.4研究方法本文主要采用理论分析与实证分析相结合的形式。
利用《金融界》数据库,将选出的各项指标进行量化,结合层次聚类和K-均值聚类两种方法,从不同角度对各基金进行划分,并建立指标分类过程和体系。
同时运用SPSS软件,将实证结果以图表的形式反映出来,为分类的依据及合理性提供佐证,分析每一类别基金的显著特征和绩效差异,从而得出结论,并对嘉实基金管理公司的发展提出建议。
2、相关理论回顾2.1 聚类分析的思想和原理2.1.1 聚类分析的基本原理聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。
聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy) 。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。
传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。
采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS 、SAS 等。
根据样本的观测数据测度变量之间的相似性程度可以使用夹角余弦、Pearson 相关系数等工具,也称为相似系数。
变量间的相似系数越大,说明它们越相近。
根据变量来测度样本之间的相似程度则使用“距离”。
把离得比较近的归为一类,而离得比较远的放在不同的类。
2.1.2 相似性的度量聚类分析中是用“距离”或“相似系数”来度量对象之间的相似性。
在对样本进行分类时,度量样本之间的相似性使用点间距离。
点间距离的计算方法主要有: 欧氏距离(Euclidean distance)平方欧氏距离(Squared Euclidean distance) Block 距离(Block distance)Chebychev 距离(Chebychev distance) 马氏距离(Minkovski distance) 最常用的是平方欧氏距离。
在对变量进行分类时,度量变量之间的相似性常用相似系数,测度方法有 夹角余弦 :∑=-pi i iy x12)(∑=-pi i iy x12)(∑=-p i ii y x 1ii y x -max qpi qii y x ∑=-1∑∑∑=iiii i iixy y x y x22cos θPearson 相关系数 :2.2层次聚类层次聚类又称系统聚类。