Stata_画图专题(2):基础绘图命令
第三章 statar软件教程-基础图形绘制

year 1930 1931 1932 1933 1934 1935 1936 1937 1938 1939 1940
le 59.7 61.1 62.1 63.3 61.1 61.7 58.5 60 63.5 63.7 62.9
Page 6
STATA从入门到精通
3.2.2散点显示选项(marker_options)的设定
散点的形状选项可以简写为ms( ),括号中填充的是各种形状,表3-5总结了散点图形状的各种选择。
2. 散点的颜色mcolor(colorstylelist) 散点的颜色选择非常丰富,包括从黑到白的灰阶、蓝色、黄色、红色,还可以使用RGB或者CMYK进 行数字调色,. 3. 散点的大小msize(markersizestylelist) msize(markersizestylelist)选项用于控制每个散点的大小,这个选项的取值从最小的vtiny到最大的 ehuge。这些取值都是有含义的:第一个层次是tiny,第二个层次是small,第三个层次是medium,接 着是large和huge, 4. 散点的整体设定 可以通过另外一个选项来同时设定这五个方面,也就是设定散点图的整体显示效果,这个选项就是 markerstyle( )。 其的取值如下:p1 - p15 设定散点图整体样式;p1box - p15box 设定箱线图整体样式;p1dot p15dot 设定点图图整体样式。
所谓“markers”就是在纸上画点的用笔手法,所以散点显示选项(marker_options)的设定包括了 散点的形状、颜色、大小等等。这其中,散点的形状msymbol(symbolstylelist)、散点的颜色 mcolor(colorstylelist)和散点的大小msize(markersizestylelist)是比较重要的三个选项. 1. 散点的形状msymbol(symbolstylelist)
Stata绘图学习手册

Stata绘图学习⼿册转载请联系本⽂主要包括常见绘图的散点图、直⽅图、条形图、饼图等相关操作命令以及图⽰。
⼀.Stata图形汇总介绍graph twoway ⼆维图scatter 散点图histogram 直⽅图line 折线图area 区域图lfit 线性拟合图qfit ⾮线性拟合图kdensity 密度函数图function 函数图graph matrix 矩阵图graph bar 条形图graph dot 点图graph box 箱形图graph pie 饼图ac 相关系数图pac 偏相关系数图irf 脉冲相应函数图⼆.Stata 图形制作命令结构命令结构graph-command (plot-command, plot-options) (plot-command , plot-options) , graph-options或者graph-command plot-command,plot-options || plot-command , plot-options || , graph-options * graph-command定义图的类型,plot-command 定义曲线类型,同⼀个图中如果有多条曲线可以⽤括号分开,也可以⽤“| *”分开,曲线有其⾃⾝的选项,plot-command 定义曲线类型,同⼀个图中如果有多条曲线可以⽤括号分开,也可以⽤“| *”分开,曲线有其⾃⾝的选项,⽽整个图也有其选项。
例如twoway为graph-command中的命令之⼀,⽽scatter为plot-command *中的命令之⼀。
曲线选项和图选项,例如 * twoway (scatter mpg weight) , title("美国汽车") //图选项:标题 * twoway (scatter mpg weight , msymbol(Oh)) //曲线选项,点的类型上述命令没反应了直接敲 * twoway (scatter mpg weight , msymbol(Oh)) , title("美国汽车") //同时⽤图与曲线选项命令可以简写,如下列命令等价*sysuse auto, cleargraph twoway scatter mpg weighttwoway scatter mpg weight三.散点图散点图在各个绘图中占有重要作⽤,散点图具有表明变量之间关系的作⽤,因此在统计分析中得到⼴泛应⽤散点图的功能与意义:对数据进⾏预处理的重要图形之⼀,散点图深受专家学者的喜爱,散点图主要作⽤在于描绘某变量随着另⼀个变量变化的⼤致趋势,进⾏对变量之间的相关关系进⾏研究help twoway scattersysuse uslifeexp2, clearscatter le year, title("Scatterplot") subtitle("Life expectancy at birth, U.S.") note("1") caption("Source: National Vital Statistics Report, Vol. 50 No. 6") scheme(economist)四.直⽅图直⽅图⼜称为柱状图,是⼀种统计报告图,⼀般⽤横轴表⽰数据类型,纵轴表⽰分布状况,直⽅图可以表⽰分布状况变化,例如分别有⼀组数据,分别为地区,31个省份,然后分别为有⾼校的个数,分别字母region和number表⽰直⽅图命令为histogram number, frequency sysuse sp500histogram volumehistogram volume, frequency分组绘制直⽅图sysuse auto, clearhistogram mpg, percent discrete///by(foreign, col(1) note(分组指标:汽车产地)///title("图3:不同产地汽车⾥数")///subtitle("直⽅图") ///) ///ytitle(百分⽐) xtitle(汽车⾥数)五.折线图或者曲线标绘图折线图或者曲线标绘图是双向关系图中的⼀种,⽤线条的升降来表⽰变量或者现象之间的关系,与散点图的区别在于⽤线连接,可以看出整体趋势,但是弱化了每⼀个具体点上⾯的数值⼤⼩sysuse uslifeexp, cleargenerate diff = le_wm - le_bmlabel var diff "Difference"line le_wm year, yaxis(1 2) xaxis(1 2)|| line le_bm year|| line diff year|| lfit diff year|| lfit diff year||,ylabel(0(5)20, axis(2) gmin angle(horizontal)) ylabel(0 20(10)80, gmax angle(horizontal))ytitle("", axis(2))xlabel(1918, axis(2)) xtitle("", axis(2))ylabel(, axis(2) grid)ytitle("Life expectancy at birth (years)")title("White and black life expectancy")subtitle("USA, 1900-1999")note("Source: National Vital Statistics, Vol 50, No. 6" "(1918 dip caused by 1918 Influenza Pandemic)")六.条形图矩形的长度来表⽰相互独⽴的变量⼤⼩help graph bar命令格式1:graph bar yvars [if] [in] [weight] [, options]graph bar yvars [if] [in] [weight] [, options]graph hbar yvars [if] [in] [weight] [, options]基本⽤法: graph bar yvars ...sysuse nlsw88, cleargraph bar wage, over(race)累加柱体或者横向条形图sysuse educ99gdp, cleargraph hbar (mean) public private, over(country)重叠柱体sysuse nlsw88, cleargraph bar (mean) hours wage, over(race) over(married)七.饼图百分⽐图⽤圆形或者扇形内⼤⼩来表⽰总体中各部分所占⽐例的⼤⼩命令为帮助⽂件为help graph pie菜单式操作为Menu>raphics > Pie chartSyntaxSlices as totals or percentages of each variablegraph pie varlist [if] [in] [weight] [, options]Slices as totals or percentages within over() categories graph pie varname [if] [in] [weight], over(varname) [options] Slices as frequencies within over() categoriesgraph pie [if] [in] [weight], over(varname) [options]input sales marketing research developmentsales marketing research develop~t1. 12 14 2 82. end. label var sales "Sales". label var market "Marketing". label var research "Research". label var develop "Development". graph pie sales marketing research development, plabel(_all name, size(*1.5) color(white)) (Note 1) legend(off) (Note 2)plotregion(lstyle(none)) (Note 3)title("Expenditures, XYZ Corp.")subtitle("2002")note("Source: 2002 Financial Report (fictional data)")。
stata常用作图指令包你满意

S tata tata 作图常用指令作图常用指令作图常用指令1.1.茎叶图茎叶图茎叶图stem x1,line(2)(做x1的茎叶图,每一个十分位的树茎都被拆分成两段来显示,前半段为0~4,后半段为5~9)stem x1,width(2)(做x1的茎叶图,每一个十分位的树茎都被拆分成五段来显示,每个小树茎的组距为2)stem x1,round(100)(将x1除以100后再做x1的茎叶图)2.2.直方图直方图直方图 histogram mpg, discrete frequency normal xlabel(1(1)5)(discrete 表示变量不连续,frequency 表示显示频数,normal 加入正太分布曲线,xlabel 设定x 轴,1和5为极端值,(1)为单位)histogram price, fraction norm(fraction 表示y 轴显示小数,除了frequency 和fraction 这两个选择之外,该命令可替换为“percent”百分比,和“density”密度;未加上discrete 就表示将price 当作连续变量来绘图)histogram price, percent by(foreign)(按照变量“foreign”的分类,将不同类样本的“price”绘制出来,两个图分左右排布)histogram mpg, discrete by(foreign, col(1))(按照变量“foreign”的分类,将不同类样本的“mpg”绘制出来,两个图分上下排布)histogram mpg, discrete percent by(foreign, total) norm(按照变量“foreign”的分类,将不同类样本的“mpg”绘制出来,同时绘出样本整体的“总”直方图)3.3.二变量图二变量图二变量图graph twoway lfit price weight || scatter price weight(作出price和weight的回归线图——“lfit”,然后与price和weight的散点图相叠加)twoway scatter price weight,mlabel(make)(做price和weight的散点图,并在每个点上标注“make”,即厂商的取值) twoway scatter price weight || lfit price weight,by(foreign)(按照变量foreign的分类,分别对不同类样本的price和weight做散点图和回归线图的叠加,两图呈左右分布)twoway scatter price weight || lfit price weight,by(foreign,col(1))(按照变量foreign的分类,分别对不同类样本的price和weight做散点图和回归线图的叠加,两图呈上下分布)twoway scatter price weight [fweight= displacement],msymbol(oh)(画出price和weight的散点图,“msybol(oh)”表示每个点均为中空的圆圈,[fweight= displacement]表示每个点的大小与displacement的取值大小成比例)twoway connected y1 time, yaxis(1) || y2 time, yaxis(2)(画出y1和y2这两个变量的时间点线图,并将它们叠加在一个图中,左边“yaxis(1)”为y1的度量,右边“yaxis(2)”为y2的)twoway line y1 time,yaxis(1) || y2 time,yaxis(2)(与上图基本相同,就是没有点,只显示曲线)graph twoway scatter var1 var4 || scatter var2 var4 || scatter var3 var4(做三个点图的叠加)graph twoway line var1 var4 || line var2 var4 || line var3 var4(做三个线图的叠加)graph twoway connected var1 var4 || connected var2 var4 || connected var3 var4(叠加三个点线相连图)更多变量4.4.更多变量更多变量graph matrix a b c y(画出一个散点图矩阵,显示各变量之间所有可能的两两相互散点图)graph matrix a b c d,half(生成散点图矩阵,只显示下半部分的三角形区域)graph matrix price mpg weight length,half by( foreign,total col(1) ) (根据foreign变量的不同类型绘制price等四个变量的散点图矩阵,要求绘出总图,并上下排列)其他图形5.5.其他图形其他图形graph box y,over(x) yline(.22)(对应x的每一个取值构建y的箱型图,并在y轴的0.22处划一条水平线) graph bar (mean) y,over(x)对应x的每一个取值,显示y的平均数的条形图。
stata基础命令

stata基础命令Stata基础命令Stata是一种功能强大的统计分析软件,广泛应用于学术研究和商业分析领域。
本文将介绍Stata的一些基础命令,帮助读者快速掌握Stata的使用方法。
1. 数据导入与查看命令在Stata中,可以使用"import"命令将外部数据导入到Stata的工作环境中。
例如,可以使用"import excel"命令导入Excel表格中的数据,或使用"import delimited"命令导入以逗号分隔的文本文件。
导入数据后,可以使用"browse"命令查看数据集的内容,或使用"describe"命令查看数据集的结构信息。
2. 数据清洗与变量处理命令在进行数据分析之前,通常需要对数据进行清洗和变量处理。
Stata 提供了一系列命令来完成这些任务。
例如,可以使用"drop"命令删除不需要的变量或观察值,使用"rename"命令修改变量名,使用"generate"命令创建新的变量,使用"recode"命令对变量进行重新编码等。
3. 描述性统计与绘图命令Stata提供了各种命令来计算和展示数据的描述性统计信息。
例如,可以使用"summarize"命令计算变量的均值、标准差和分位数等统计量,使用"tabulate"命令生成变量的频数表,使用"histogram"命令绘制变量的直方图,使用"scatter"命令绘制两个变量的散点图等。
4. 统计模型与假设检验命令在Stata中,可以使用各种命令来拟合统计模型和进行假设检验。
例如,可以使用"regress"命令拟合线性回归模型,使用"logit"命令拟合二元Logistic回归模型,使用"anova"命令进行方差分析,使用"ttest"命令进行两样本t检验等。
stata常用命令-数据处理-基本绘图

stata常用命令-数据处理-基本绘图cd //change directory 改变原有路径,即设置本次工作的存储位置cd "E:\研二第一学期==\孙老师,空间分析==\空间分析,结课论文==\maoyu\maoyu" //修改原有路径doedit //打开某个dofiledoedit D:\stata11\ado\personal\Net_course_A\A1_intro.do //完整路径doedit A1_intro.do //部分路径,当该文件在当前工作目录中do //执行某个写好的dofile文件do E:\maoyu\myron.dodo D:\stata11\profile.doshellout //打开工作目录中的某个文件shellout Stata_A_dofiles.pdfshellout E:\suns\A.xlsshellout "E:\suns\A.xls"cdout //打开当前工作目录ado // 呈现已经安装的外部命令use //调入数据use "E:\研二第一学期==\孙老师,空间分析==\空间分析,结课论文==\maoyu\maoyu\IndividualA_C2_maoyu.dta",clear//clear 意味着覆盖之前打开的数据clear //清除已经导入的数据sysdir //显示系统目录,如stata安装位置help //打开帮助文档,如help logisticview browse //打开某个网页链接,如view browse "https:///people/78197287/"view browse "/bbs/forum-67-1.html" //人大经济论坛// //两个斜杠代表命令结束,一般在斜杠后作备注/// // 三个斜杠代表换行,一个完整命令与句未结束,下一行接着上一行的Ctrl+D //快速执行当前do文档中的所有命令语句help window manage //界面风格设定帮助Edit-->Preference //界面风格设定按钮选择* //行开头使用星号代表该行处于非命令执行状态,可作文字说明pwd // 显示stata当前工作的路径edit // 打开数据编辑器,可在里面进行复制粘贴,如从excel中复制数据//粘贴时它会提示你是选择第一行作为变量名还是作为数据本身//当然,也可以在数据编辑器里多数据进行手动修改,一般不建议手动修改。
stata-做图

Stata 作图简介1.直方图命令:histogram varname (变量名), (options ),这里的options 是可选择的,如果不写,则按照默认作图。
例如,举一个收入,受教育程度与工作经验以及种族的例子。
. cd e:/data e:\data. use exp2.dta,clear Describe Summary. histogram educ (这里我们不加选项,默认做直方图),得到如下图形D e n s i t y默认时,stata 将数据确定为连续型,如果我们需要stata 做离散直方图的话,加上选项discrete .histogram educ,discrete (选项用英文逗号隔开)D e n s i t y还可以给直方图加上密度图像。
D e n s i t y.histogram educ,normal (这个选项就可以做正态分布密度图像)D e n s i t y用stata 做 kernel density estimationkernel density estimation is a non-parametric way of estimating the probability density function of a random variable. As an illustration, given some data about a sample of a population, kernel density estimation makes it possible to extrapolate the data to the entire population. 在stata 中kernel density estimation 的命令是, . kdensity educ. kdensity educ,normal (加上这个选项后,添加数据的正态密度函数做比较)D e n s i t yStata 散点图简介最标准写法 graph twoway scatter varlist,(option) 例如,我们想做income 和educ 的散点关系图.graph twoway scatter income educi n c o m e也可以简写成.scatter income educ当然我们为了作图需要可以改变图标的形状,大小,颜色等等,这些都通过选项来完成 .scatter income educ,m(d) mc(red) msize(vlarge)i n c o m e利用stata 作图命令显示fit values.twoway (scatter income educ)(lfit income educ) (注意这里的命令lfit ,就是用直线的方式画出fit values 。
STATA入门2 命令语句

2命令语句2.1掌握命令语句的格式[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]注:[ ]表示可有可无的项,显然只有command是必不可少的,下面结合例子分项来讲解命令的各个组成部分。
2.2命令command[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options] . use auto, clear//打开美国汽车数据文件auto.dta,后面的clear表示先清除内存中可能存在的数据集. summarize /*很多命令可单独使用,单独使用时,一般是对所有变量进行操作,等价于后面加上代表所有变量的_all。
*/ . summarize _all //注意到该命令输出结果与上一个命令完全一样. sum //与前一命令等价,sum为summarize的略写. su // su是summarize的最简化略写,不能再简化为s. s //简写前提是不引起混淆。
执行这个命令将出现错误信息注意,在用list做练习的时候可能会遇到结果窗口停止,其右下角出现一个蓝色的“more ‘,按键盘上任何一个键,屏幕滚动一行。
这一现象与第一讲中“set more on”的设置有关,请参考1.6.12.3变量varlist[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]varlist表示一个变量,或者多个变量,多个变量之间用空格隔开。
. use auto, clear. sum price //求价格的观察值个数,平均值,方差,最小值和最大值. su p //变量和命令均可略写,注意到两个结果完全一样. su t //分数据中有两个变量的开首字母为t(trunk和turn),所以STATA认为t为模糊的省略。
stata绘图基本知识

例1
绘制散点图旳基本语法 [twoway] scatter varlist [if] [in] [weight] [, option] 下列三个命令是等价旳 graph twoway scatter…… twoway scatter…… scatter……
connect(1)表白以直线旳方式连接相邻旳两个点; msymbol(i)表白散点旳显示方式为“看不见”, 假如我们将括号中旳i改为O,那么这个选项旳意思就是以“黑圈”旳
绘制标绘图和拟合图 绘制一次拟合图形 twoway lfit yvar xvar [if] [in] [weight] [,option]
绘制二次拟合图 twoway qfit yvar xvar [if] [in] [weight] [,option]
绘制lowess拟合图形 twoway lowess yvar xvar [if] [in] [,option]
此次主要简介
绘制散点图 散点显示选项、散点标签选项、连线选项、振荡选项
二维绘图选项 坐标轴尺度选项、坐标轴刻度选项、坐标轴标题选项、
轴线选择选项、scale选项旳设定。
绘制曲线标绘图和连线标绘图 绘制拟合图形(一次拟合图形和二次拟合图形) 绘制条形图 绘制箱线图
详细例题涉及旳知识点
gmin命令表达在最小值处增长网格线 gmax命令表达在最大值处增长网格线
例6
by选项旳设定 by旳根据是分类变量,例如性别、民族、国内国外等, by选项旳语法为:by(varlist[,byopts])
选项total表达除了对每一种组别分别作图外,还要添加一种具有全部 样本旳图形;
为y轴变量,而将最终一种变 当成x轴变量。
散点显示选项(marker_options)
stata的plot用法

stata的plot用法Stata是一款广泛使用的统计分析软件,它提供了丰富的绘图功能,可以帮助用户更好地理解数据。
在Stata中,plot命令是绘制图形的主要命令之一,它可以绘制各种类型的图形,包括散点图、线图、柱状图等。
本文将介绍Stata中plot命令的用法。
一、plot命令的基本语法plot命令的基本语法如下:plot yvar xvar1 xvar2 ..., options其中,yvar表示纵轴变量,xvar1、xvar2等表示横轴变量,options 表示绘图选项。
下面我们将详细介绍各个参数的用法。
二、绘制散点图散点图是一种常用的数据可视化方式,可以帮助我们观察两个变量之间的关系。
在Stata中,我们可以使用plot命令绘制散点图,具体语法如下:plot yvar xvar, options其中,yvar表示纵轴变量,xvar表示横轴变量,options可以指定图形的样式、颜色等参数。
例如,下面的代码可以绘制一张简单的散点图:sysuse autoplot mpg weight, title("Scatter plot of mpg and weight")xlabel("Weight") ylabel("Miles per gallon")该命令将绘制一张以汽车重量为横轴、每加仑油耗为纵轴的散点图,图形标题为“Scatter plot of mpg and weight”。
三、绘制线图线图是一种常用的数据可视化方式,可以帮助我们观察变量随时间变化的趋势。
在Stata中,我们可以使用plot命令绘制线图,具体语法如下:plot yvar xvar, options其中,yvar表示纵轴变量,xvar表示横轴变量,options可以指定图形的样式、颜色等参数。
例如,下面的代码可以绘制一张简单的线图:webuse sp500tsset dateplot sp500, title("S&P 500 index") xlabel(, format(%tm)) ylabel("Index")该命令将绘制一张以时间为横轴、S&P 500指数为纵轴的线图,图形标题为“S&P 500 index”。
第二讲stata画图和线性回归基础共25页文档

回归结果解读
MSS:回归平方和 df1 自由度
RSS:残差平方和 df2
TSS:总平方和
df3
MMS=MSS/df1 RMS=RSS/df2 TMS=TSS/df3
F值 R2=MSS/TSS 调整的R2 Root MSE=sqrt(RMS)
Coef:回归系数 Std.Err:标准误差 方差协方差矩阵的对角线元素的开方(vce) 95%下限=估计值-t临界值下限*标准误差 95%下限=估计值+t临界值上限*标准误差
+b3*exper^2+ u
例二:利用phillips的数据拟合预期增强的菲 利普斯曲线为
in ft in fte1 (u n e m t0 ) u t
其中,unemt表示第t期的失业率(%), inft 表示第t期的通货膨胀率(%),infte表 示预期通货膨胀率,μ0表示自然失业率 (%)。
Stata 画图和回归基础
Stata作图
stata 提供各种曲线类型,包括点 (scatter)、线(line)、面(area),直 方图(histogram)、
条形图(bar)、饼图(pie)、函数曲线 (function)以及矩阵图(matrix)等。
同时,对时间序列数据有以ts 开头的一系列 特殊命令,如tsline。还有一类是对双变量 的回归拟合图(lfit、qfit 、lowess)等。
模型常用的其他形式:
对数 半对数 平方项 n次方 指数 交乘项
虽然对函数形式和自变量的选取有选择和检 验的方法,但最好还是从“经济意义”角度 确定。
例如:考察消费受收入影响的方程,即使参 数项不显著,也不能把它删除掉。
例题
例一:利用wage2的数据检验明瑟(mincer) 工资方程的简单形式: Ln(wage)=b0+b1*educ+b2*exper
第二讲stata画图和线性回归基础

调整的R2
Root MSE=sqrt(RMS)
Coef:回归系数
Std.Err:系数的标准误差
t统计量 t的临界值
95%置信区间
自由度 R2=MSS/TSS p值
模型常用的其他形式:
对数 半对数 平方项 n次方 指数 交乘项
虽然对函数形式和自变量的选取有选择和检 验的方法,但最好还是从“经济意义”角度 确定。
例如:考察消费受收入影响的方程,即使参 数项不显著,也不能把它删除掉。
例题
例一:利用wage2的数据检验明瑟(mincer) 工资方程的简单形式: Ln(wage)=b0+b1*educ+b2*exper
+b3*exper^2+ u
例二:利用phillips的数据拟合预期增强的菲 利普斯曲线为
inft infte 1(unemt 0 ) ut
e(mss) model sum of squares
e(df_m) model degrees of freedom
e(rss) residual sum of squares
e(df_r) residual degrees of freedom
e(r2)
R-squared
e(r2_a) adjusted R-squared
e(F)
F statistic
e(rmse) root mean squared error
可以使用命令 eret list 查看。
回归结果解读
MSS:回归平方和 df1 MMS=MSS/df1
RSS:残差平方和 df2
RMS=RSS/df2
TSS:总平方和
df3
பைடு நூலகம்
Stata_画图专题(2):基础绘图命令汇编

节链接
1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8
图形名称
函数图 散点图 直方图 条形图 点统计图 箱线图
饼图 矩阵图
表 1: Stata 中常用图形
命令关键词
说明
twoway function
[twoway] scatter
[twoway] histogram graph bar graph dot graph box graph pie graph matrix
绘制普通的数学、统计函数图形(与数据库数据无关) 用两组数据构成多个坐标点,考察坐标点的分布a 由一系列高度不等的纵向条纹或线段表示某一组数据分布情况b 用于显示多组数据间某些项目的比较情况,如均值、频数等 用点来描绘统计量的值,进而进行组与组间的比较 只用 5 个点c 对数据集做简单的总结,又因形状如箱子而得名 显示一个数据系列中各项的大小与其占比 将多个变量两两做散点图后类似矩阵元素般放入图中
• “堆叠”,即表示多个柱状图叠在一起(看累计总值及每组占比),命令是 stack。
其余的选项请 help graph bar 来查看。上述两行命令区别是第二行命令只是水平 (horizontal) 形式的条形图。
表 3: 描述统计命令 命令 含义
mean median
二,Stata实用命令之图形绘制
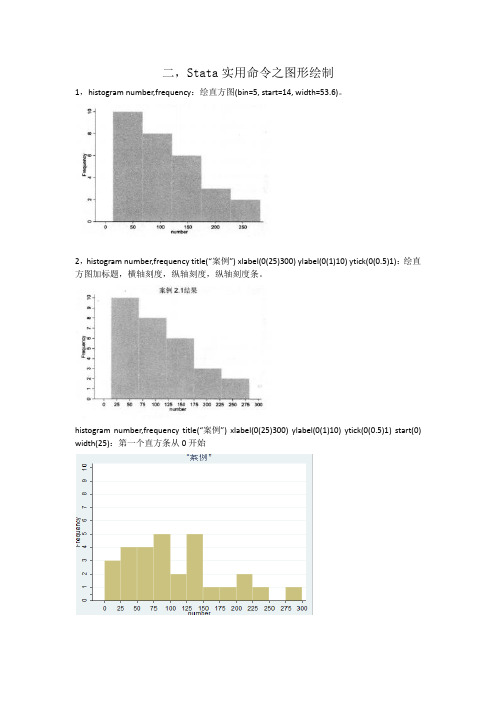
二,Stata实用命令之图形绘制1,histogram number,frequency:绘直方图(bin=5, start=14, width=53.6)。
2,histogram number,frequency title(“案例”) xlabel(0(25)300) ylabel(0(1)10) ytick(0(0.5)1):绘直方图加标题,横轴刻度,纵轴刻度,纵轴刻度条。
histogram number,frequency title(“案例”) xlabel(0(25)300) ylabel(0(1)10) ytick(0(0.5)1) start(0) width(25):第一个直方条从0开始3,graph twoway scatter SG TZ:散点图。
graph twoway scatter SG TZ,title("1234") xlabel(56(2)80) ylabel(150(10)190) ytick(150(5)190):散点图增加标题/坐标数据/刻度。
graph twoway scatter SG TZ,title("1234") xlabel(56(2)80) ylabel(150(10)190) ytick(150(5)190) msymbol(D) mcolor(yellow):散点图增加标题/坐标数据/刻度/散点形状/散点颜色。
提示:help colorstyle4,graph twoway line total first year:曲线图。
graph twoway line total first year,title(“案列”) xlabel(1997(2)2012) ylabel(0(10)80) xtick(1997(1)2012) legend(label(1 “总进球数”) label(2 ”第一射手进球数”))graph twoway line total first year,title(“案列”) xlabel(1997(2)2012) ylabel(0(10)80) xtick(1997(1)2012) legend(label(1 “总进球数”) label(2 ”第一射手进球数”)) clpattern(solid dash):solid实线——代表第一个自变量,dash虚线——第二个自变量。
stata基本命令

stata基本命令+实例+数据+结果--必看,经典2009-08-25 12:29Stata 常用命令save命令FileSave As例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata 格式文件。
STATA数据库的维护排序SORT 变量名1 变量名2 ……变量更名rename 原变量名新变量名STATA数据库的维护删除变量或记录drop x1 x2 /* 删除变量x1和x2drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5)drop if x<0 /* 删去x1<0的所有记录drop in 10/12 /* 删去第10~12个记录drop if x==. /* 删去x为缺失值的所有记录drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录drop _all /* 删掉数据库中所有变量和数据STATA的变量赋值用generate产生新变量generate 新变量=表达式generate bh=_n /* 将数据库的内部编号赋给变量bh。
generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个3……。
直到数据库结束。
generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。
generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。
egen产生新变量set obs 12egen a=seq() /*产生1到N的自然数egen b=seq(),b(3) /*产生一个序列,每个元素重复#次egen c=seq(),to(4) /*产生多个序列,每个序列从1到#egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2encode 字符变量名,gen(新数值变量名)作用:将字符型变量转化为数值变量。
STATA-第三章-正态检验与基本作图命令
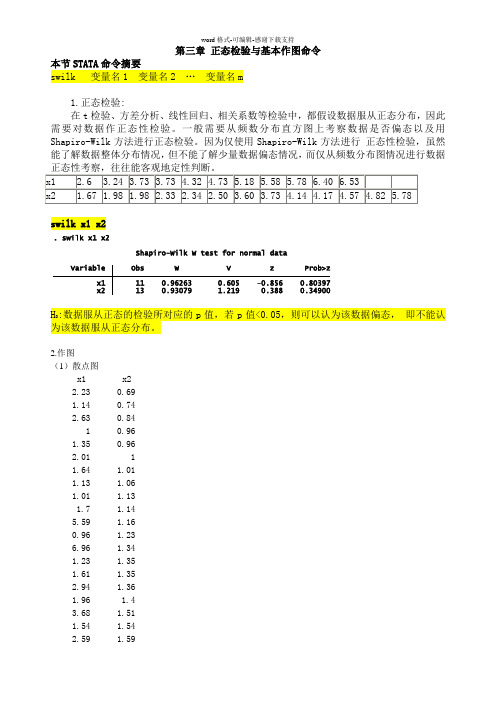
第三章 正态检验与基本作图命令 本节STATA 命令摘要swilk 变量名1 变量名2 … 变量名m1.正态检验:在t 检验、方差分析、线性回归、相关系数等检验中,都假设数据服从正态分布,因此需要对数据作正态性检验。
一般需要从频数分布直方图上考察数据是否偏态以及用Shapiro-Wilk 方法进行正态检验。
因为仅使用Shapiro-Wilk 方法进行 正态性检验,虽然能了解数据整体分布情况,但不能了解少量数据偏态情况,而仅从频数分布图情况进行数据正态性考察,往往能客观地定性判断。
x1 2.6 3.24 3.73 3.73 4.32 4.73 5.18 5.58 5.78 6.40 6.53x2 1.67 1.98 1.98 2.33 2.34 2.50 3.60 3.73 4.14 4.17 4.57 4.82 5.78swilk x1 x2H 0:数据服从正态的检验所对应的p 值,若p 值<0.05,则可以认为该数据偏态, 即不能认为该数据服从正态分布。
2.作图(1)散点图x1x2 2.230.69 1.140.74 2.630.84 10.96 1.350.96 2.011 1.641.01 1.131.06 1.011.13 1.71.14 5.591.16 0.961.23 6.961.34 1.231.35 1.611.352.941.36 1.961.4 3.681.51 1.541.542.59 1.59x2 13 0.93079 1.219 0.388 0.34900 x1 11 0.96263 0.605 -0.856 0.80397Variable Obs W V z Prob>zShapiro-Wilk W test for normal data. swilk x1 x24.5 1.613.92 1.6410.33 1.78.23 1.742.07 1.964.9 2.016.84 2.076.42 2.083.72 2.236 2.491.352.591.062.630.74 2.940.96 31.16 3.682.083.720.69 3.920.68 4.50.84 4.811.34 4.91.4 5.121.51 5.212.49 5.591.74 61.59 6.421.36 6.843 6.964.81 8.235.21 10.33输入:scatter x1 x2(第一个输入变量为纵轴,第二个为横轴)(2)连线散点图scatter x1 x2,connect(1) // connect(1)表示以直线的方式连接相邻的两个点.(3)去散点连线图scatter x1 x2,connect(1) msymbol(i) // msymbol(i)表示散点看不见;msymbol(o)表示以黑圆方式显示。
STATA软件应用(二)作图、统计描述

/*包含缺失值 /*不显示频数 /*不显示数值标记
分类变量资料的描述
两个变量交叉分类描述 tabulate变量1 变量2 [,cell column missing nofreq nolabel] tab2 变量1 变量2 变量3…… [,tabulate_options]
detail /* 详细描述,缺失时为简单描述 centile(# [# ...]) /* 指定需要计算的百分位数 meansd /* 指定百分位数用近似正态法,缺失时为直接算法 cci /* 指定百分位数的可信区间用保守算法 normal /* 指定百分位数的可信区间用近似正态法 level(#) /* 指定百分位数的可信区间的可信限
箱式图
180 120 140 160
Before
After
Before
After
Male
Female
例ex6
散点图:反应变量之间的关系
graph y x
71
gra y x,c(.) s(O)
y
63 30 x 39
线图
gra y x,c(l) s(d)
71
y
63 30 x 39
线图
gra y x,c(l[-]) s(p) sort
115.4 114.8 116.3 125.6 123 114.7 120.7 124.1
122.5 126.1 120 118.4 121 120.8 120.7 116.8
121.5 113.2 117.7 123.8 119.5 119.6 120.2 112.2
124.4 112.7 122.8 124.4 117.4 114.9 122.4 118.4 120.6 120.7 118.9 123.1 120 127.1
最新stata操作介绍之制图和统计分析(二)教学内容

. describe
• summarize命令: • summarize可以计算和导出描述性统计量的最大值、最小值、均值
和标准差等。summarize的命令格式如下: . summarize [varlist] [if] [in] [weight][,options]
• 完整直线图图例:
数据处理与运算
二、统计分析
•描述性统计
统计分析的第一步就是计算出描述性统计量。这些描述性统计 量使用简单的数字来表示变量的分布特征,包括集中趋势、离散趋 势等。
Stata中实现描述性统计分析的命令主要有: describe; summarize;
tabstat;
• describe 命令: • describe命令用于产生一个对数据集的简明总结表格,其格式如下:
• 例: . tabstat sales,by(advert) statistics(sum mean sd cv median)
此课件下载可自行编辑修改,仅供参考! 感谢您的支持,我们努力做得更好! 谢谢!
• 例:
. summarize sales prices advert
• tabstat命令: tabstat与summarize相似,但它的灵活性高于summarize。该命令可
以通过statistics( )添加各种所需要的统计量。 • tabstat命令格式如下:
. tabstat [varlist] [if] [in] [weight][,options]
stata操作介绍之制图和统 计分析(二)
数据处理与运算
一、Stata制图
Stata制图命令: 1、单个直线图的命令主体:
stata基本命令
stata基本命令+实例+数据+结果--必看,经典2009-08-25 12:29Stata 常用命令save命令FileSave As例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata 格式文件。
STATA数据库的维护排序SORT 变量名1 变量名2 ……变量更名rename 原变量名新变量名STATA数据库的维护删除变量或记录drop x1 x2 /* 删除变量x1和x2drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5)drop if x<0 /* 删去x1<0的所有记录drop in 10/12 /* 删去第10~12个记录drop if x==. /* 删去x为缺失值的所有记录drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录drop _all /* 删掉数据库中所有变量和数据STATA的变量赋值用generate产生新变量generate 新变量=表达式generate bh=_n /* 将数据库的内部编号赋给变量bh。
generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个3……。
直到数据库结束。
generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。
generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。
egen产生新变量set obs 12egen a=seq() /*产生1到N的自然数egen b=seq(),b(3) /*产生一个序列,每个元素重复#次egen c=seq(),to(4) /*产生多个序列,每个序列从1到#egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2encode 字符变量名,gen(新数值变量名)作用:将字符型变量转化为数值变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.2 scatter:散点图
命令格式
[
]
[ ][ ][
][
]
twoway scatter varlist if in weight , options
[
][
]
scatter varlist || lfit varlist || line varlist
其中下划线、方括号的含义与前面相同,不赘述。此处 varlist 是变量列表,一般二维的散点图 就是两个变量;[options] 是可选参数,参数很多,请 help scatter 来查看。常用的有 “连线” connect(l) 和 “去散点” msymbol(i),在下面的结果中可以看到。在第二行的命令中给出了散 点图的用途 —“构造回归曲线” lfit。第二行命令的意思是(1)画出散点图,(2)拟合回归直 线并(3)按点的先后顺序连接起来。上述三个可以组合起来使用。
• “堆叠”,即表示多个柱状图叠在一起(看累计总值及每组占比),命令是 stack。
其余的选项请 help graph bar 来查看。上述两行命令区别是第二行命令只是水平 (horizontal) 形式的条形图。
表 3: 描述统计命令 命令 含义
mean median
p1 p50 p99
sd sum count max/min first/last
string functions
programming functions
datetime_functions time-series functions
matrix functions
三角函数、取整、对/指数、最值等 伯努利、卡方、正态、几何分布等 符合某一概率分布的随机数组 字符串拼接、提取、长度及 ASCII 码等 e/r/s 型返回值及其他编程方面的函数 对于日期/时间数据的转化、提取等
均值(默认) 中位数 第 1 分位数 中位数 第 99 分位数 标准差 总和 计数 最大/小值 第一/最后值
图 2: 散点图
1.3 histogram:直方图
命令格式
[
]
[ ][ ][
][
]
twoway histogram varname if in weight , options
其中 varname 指某一变量,因为画直方图只能对一个变量画。其余的只介绍 “分组” 选项 bin(),括号内是将数据等分的组数。其余的选项请 help histogram 来查看。
15,000
10,000
Price
5,000
0
1900
1910
1920 Year
1930
1940
(3) 去散点,保留连线
2,000
3,000 Weight (lbs.)
4,000
5,000
(4) 价格和车重的散点图
3
40
15,000
15,000
10,000
Price
10,000
5,000
5,000
节链接
1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8
图形名称
函数图 散点图 直方图 条形图 点统计图 箱线图
饼图 矩阵图
表 1: Stata 中常用图形
命令关键词
说明
twoway function
[twoway] scatter
[twoway] histogram graph bar graph dot graph box graph pie graph matrix
// Twoway Function Graph (1) // Twoway Function Graph (2) // Twoway Function Graph (3) // Twoway Function Graph (4)
.4
10
8
.3
6
.2
y
y
4
.1
2
0
0
−2
−1
0
1
2
x
(1) y = x2 + 2 · x + 1, x ∈ (−2, 2)
命令范例及结果
1 // 直方图: histogram
2
3 sysuse auto, clear 4 twoway histogram price 5 histogram price, bin(20)
// Histogram Graph (1) // Histogram Graph (2)
1.0e−04 2.0e−04 3.0e−04 4.0e−04
tin(d1, d2), twithin(d1, d2) 求矩阵行列式、逆、相关系数、分解等
命令范例及结果
1 // 函数图:twoway function
2
3 twoway function y=x^2+2*x+1, range(-2 2) 4 twoway function y=normalden(x), range(-4 4) 5 twoway function exp(-x/6)*sin(x), range(0 12.57) 6 tw function logit(x)
命令范例及结果
1 // 散点图:scatter
2
3 sysuse uslifeexp2, clear 4 twoway scatter le year 5 tw scatter le year, connect(l) 6 scatter le year, connect(l) msymbol(i)
7
[ ][ ][
][
]
graph hbar yvars if in weight , options
其中 yvars 是变量列表,值的大小由 y 轴来刻画;而条形图中 x 轴代表的是类别,其宽度都是 一样的。比如有两组数据:男生人数 45 人和女生人数 50 人,那么条形图的主要用途是对比两 组人的数量(y 轴值)。在命令中,yvars 除了要填多个变量,而且在变量列表前还需加上需对 比的统计量2。表 3 中列举了常用的一些。若想如实反映3,则命令为 (axis)。注意:这些统计 量需放置于变量列表 yvars 之前,且需要用英文括号括起来。
编号
1 2 3 4 5 6 7 8
函数类别
数学函数
概率分布及密度函数
随机数函数 字符串函数
编程函数 日期及时间函数
选择时间间隔 矩阵函数
表 2: Stata 中的函数类别 帮助关键词 常用举例
math functions density functions
random-number functions
3.0e−04
2.0e−04
Density
Density
1.0e−04
0
0
5,000
10,000 Price
(1) 组数默认
15,000
0
图 3: 直方图
5,000
10,000 Price
(2) 分 20 组
15,000
4
1.4 graph bar:条形图
命令格式
[ ][ ][
][
]
graph bar yvars if in weight , options
a一般用于判断两变量之间是否存在某种关联或总结坐标点的分布模式。包括线性相关、非线性相关和不相关等 b一般用横轴表示数据类型(组距自定),纵轴表示分布情况(如频数等) c这 5 个点分别为:下边缘、下分位数 (Q1)、中位数、上分位数 (Q3) 和上边缘。上下边缘非最大、最小值,而是排 除异常值后的最值。具体请查看统计学教科书或 /view/1376547.htm?fromId=1326550。箱 线图的构造见第 7 页图 6
−4
−2
0
2
4
x
(2) 正态密度函数
1
5
.5
0
y
y
0
−5
−.5
0
5
10
15
x
(3) exp(−x/6) · sin(x), x ∈ (0, 12.57)
0
.2
.4
.6
.8
1
x
(4) logit(x后来讲到 display, generate, egen 等命令、编程时都是会用到的。表 2 中其余的函 数类别我们之后会分别在日期/时间、随机模拟、矩阵、编程等专题中详细介绍。
// Scatter Graph (1) // Scatter Graph (2) // Scatter Graph (3)
// Scatter Graph (4) // Scatter Graph (5) // Scatter Graph (6) // 对上图数据预排序后再作图,结果略
65
65
60
0
0
2,000
3,000 Weight (lbs.)
4,000
Price
Fitted values
5,000
(5) 保留散点图并拟合回归直线
2,000
3,000 Weight (lbs.)
4,000
Price
Price
5,000
(6) 保留散点图并依次连接a(请对比 (2))
a此图无意义,但若为运动轨迹则有意义。若想从左到 右连接图中散点,则需先对数据排序(或加 sort 选项)
1.1 twoway function:函数图
命令格式
[[ ] ]
[ ][ ][
]
twoway function y = f(x) if in , options
其中下划线为命令的最简写形式,即 twoway 可简写为 tw;方括号内的部分均可省略,即可省 略 “y =” 这个部分;f (x) 是这个命令的主体,可以是一般数学函数式,也可以是 Stata 内已有