BP神经网络及深度学习研究 - 综述
基于BP模型神经网络的研究综述

基于BP模型神经网络的研究综述摘要:基于BP模型的神经网络是一种用于前向多层神经网络的反传学习算法,目前为止应用最为广泛且最重要的一种训练前向神经网络的学习算法。
本文详细介绍BP算法原理并剖析其性能不足的几个方面,简要介绍优化算法,对模型未来的发展方向进行展望。
关键词:BP模型;神经网络;梯度下降法1.BP神经网络模型BP网络是一种用于前向多层神经网络的反传学习算法,是目前应用最广泛的神经网络模型之一。
它是由鲁梅尔哈特提出后受到广泛重视[1]。
BP 网络由输入层、隐层和输出层三部分构成,每层由许多并行运算的简单神经元组成,网络的层与层之间的神经元采用全互连方式,但同层神经元之间并无相互连接。
2.BP 网络学习算法2.1基于ep的BP算法的学习过程学习的最终结果是通过一系列的训练过程不断调整连接权值,使得对任一输入都能得到所期望的输出。
学习的方法是需要用一组训练样例对神经网络进行训练,每个样例都包含样例的输入及期望的输出两部分。
样例训练就是首先将样例通过BP神经网络正向的进行计算,通过输入层经各隐层逐层处理并计算每个单元的实际输出值;然后计算实际输出与期望输出之间的差值,如果该误差不能达到预定的要求,则沿着原来的连接通路逐层返回,利用两者的误差按照一定的原则对各层节点的权值进行相应的调整,使得最后得到的误差逐渐减小,满足要求即可停止2.2基于E的BP算法的学习过程2.3BP神经网络模型的性能分析BP 网络的理论依据坚实,推导过程严谨,物理概念清楚,通用性强。
但是,人们在使用过程中发现 BP 网络也存在许多不足之处,主要包括以下几个方面:2.3.1收敛速度慢由于BP算法本质上为梯度下降法,而它所要优化的目标函数又非常复杂,因此,误差曲面存在平坦区域[2]。
在这些区域中,误差梯度变化较小,即使权值的调整量很大,误差依然下降缓慢,使训练过程几乎停顿。
2.3.2易陷入局部极小BP 网络的训练是从某一起始点开始的斜面逐渐达到误差的最小值。
BP神经网络研究综述【文献综述】

文献综述电气工程及自动化BP神经网络研究综述摘要:现代信息化技术的发展,神经网络的应用范围越来越广,尤其基于BP算法的神经网络在预测以及识别方面有很多优势。
本文对前人有关BP神经网络用于识别和预测方面的应用进行归纳和总结,并且提出几点思考方向以作为以后研究此类问题的思路。
关键词:神经网络;数字字母识别;神经网络的脑式智能信息处理特征与能力使其应用领域日益扩大,潜力日趋明显。
作为一种新型智能信息处理系统,其应用贯穿信息的获取、传输、接收与加工各个环节。
具有大家所熟悉的模式识别功能,静态识别例如有手写字的识别等,动态识别有语音识别等,现在市场上这些产品已经有很多。
本文查阅了中国期刊网几年来的相关文献包括相关英文文献,就是对前人在BP神经网络上的应用成果进行分析说明,综述如下:(一)B P神经网络的基本原理BP网络是一种按误差逆向传播算法训练的多层前馈网络它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阀值,使网络的误差平方最小。
BP网络能学习和存贮大量的输入- 输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程.BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer),如图上图。
其基本思想是通过调节网络的权值和阈值使网络输出层的误差平方和达到最小,也就是使输出值尽可能接近期望值。
(二)对BP网络算法的应用领域的优势和其它神经网络相比,BP神经网络具有模式顺向传播,误差逆向传播,记忆训练,学习收敛的特点,主要用于:(1)函数逼近:用输入向量和相应的输出向量训练一个网络以逼近一个函数;(2)模式识别:用一个待定的输出向量将它与输入向量联系起来;(3)数据压缩:减少输出向量维数以便于传输或存储;(4)分类:把输入向量所定义的合适方式进行分类;]9[BP网络实质上实现了一个从输入到输出的映射功能,,而数学理论已证明它具有实现任何复杂非线性映射的功能。
BP算法文献综述

人工神经网络的技术前沿11115028 王媛媛1.人工神经网络的起源自古以来,各界研究工作者对于“人脑”“生物智能”一直表现着极大的研究兴趣.采用某种工程技术的手段设计出具有生物神经网络的某些结构功能的软硬件智能设施被称为“人工神经网络技术”【1】。
举例来讲,“识别人脸"是大脑的基本功能,正常成人可以正确辨别认识的人脸。
但计算机要准确做到这一点却比较困难,因为计算机智能针对具体的模型机型指令编程,若没有精确的模型,程序也就无法编制。
故而如何针对人脑所具有的各项智能活动做出有效的计算机或硬件模拟,就是人工神经网络的主要研究内容。
人工神经网络起源于20世纪初期,主要由两方面因素催生。
一方面经过生物学家数学家的不懈努力,采用数学模型来描述神经元的基本生物活动成为可能.神经元是神经活动的基础原件,了解神经元的工作机制是创建人工神经网络科学的基础。
另外一方面,19世纪比较具有代表性的牛顿力学或者欧式几何都是线性科学,而生物智能活动如此纷繁复杂,不可能用简单的线性数学模型进行模拟,提出一种非线性的可有效模拟神经网络活动的模型算法迫在眉睫。
人工神经网络的发展并不是偶然,而是在当时的科学背景下应运而生.2.人工神经网络的发展人工神经网络算法真正发展于20世纪40年代初,至今发展也不超过一百年,虽然其存在的时间较短,但其发展过程可谓一波三折,经历很多挫折,也取得很多进展.1943年,心理学家W.S。
Mcculloch和数学家W。
Pitts总结了生物神经元的一些基本特性,共同提出M—P模型,第一次用数学语言描述了神经元的活动【2】。
虽然其神经元的功能较弱,但M—P模型的提出为人工神经网络奠定了基础,自此发展开来。
心理学家D。
O。
Hebb于1949年提出神经元之间的突触联系强度可变的假设,他认为人脑的学习活动室发生在突触上的,而其联系的强度会随着神经元的活动而变化【3】。
他的假设为人工神经网络的学习活动研究提供了基础.1958年,Rosenblatt提出了著名的感知机模型,这是第一个真正意义上的神经网络,它基本上满足了神经生理学的一切先验知识,可用于模式识别、联想记忆等方面【4】。
基于MATLAB的BP神经网络实现研究

方法与实验设计
基于MATLAB的BP神经网络实现主要包括以下几个步骤:
1、数据预处理:首先需要对数据进行预处理,包括数据清洗、归一化等操 作。
2、网络设计:根据问题特点选择合适的网络结构,并确定输入层、输出层 和隐藏层的节点数。
3、训练模型:使用MATLAB中的神经网络工具箱进行模型训练。
2、在防止过拟合方面,可以研究更有效的正则化方法和技术,以避免模型 在训练过程中产生过拟合问题。
3、在网络结构设计方面,可以研究更加智能的自适应网络结构设计方法, 以简化人工设计网络的复杂度。
4、可以进一步拓展BP神经网络在其他领域的应用研究,例如自然语言处理、 生物信息学等。
谢谢观看
结论与展望
本次演示研究了基于MATLAB的BP神经网络实现方法,通过实验设计和实验结 果分析,可以得出以下结论:
1、BP神经网络在解决分类、逼近和优化等问题方面具有较好的性能,证实 了其在实际应用中的价值。
2、在超参数调整方面,学习率和迭代次数对模型性能具有重要影响,需要 根据实际问题进行调整。
2、函数逼近:BP神经网络可以用于逼近复杂的非线性函数。例如,在控制 系统、信号处理等领域,可以利用BP神经网络对系统进行建模和预测。
3、优化问题:BP神经网络可以应用于求解各种优化问题。例如,利用BP神 经网络实现函数的最小化、多目标优化等。
然而,目前的研究还存在着一些问题。首先,由于BP神经网络的训练速度较 慢,可能需要进行大量的迭代才能得到较好的结果。其次,BP神经网络的训练过 程中容易出现过拟合问题,这可能导致模型的泛化能力下降。最后,BP神经网络 的性能受到初始参数的影响较大,如何选择合适的参数也是亟待解决的问题。
4、模型评估与优化:通过验证数据集评估模型的性能,并进行参数调整和 优化。
《2024年深度学习相关研究综述》范文

《深度学习相关研究综述》篇一一、引言随着科技的飞速发展,深度学习作为人工智能领域的重要分支,已经成为当前研究的热点。
深度学习以其强大的特征学习和表示学习能力,在图像识别、语音识别、自然语言处理、机器翻译等多个领域取得了显著的成果。
本文旨在全面综述深度学习的基本原理、发展历程、主要应用以及当前面临的挑战与未来发展趋势。
二、深度学习的基本原理与发展深度学习是基于神经网络的一种机器学习方法,其核心思想是通过构建多层神经网络来模拟人脑的思维方式,实现从原始数据中自动提取高级特征和抽象表示的目的。
深度学习的理论基础主要来源于人工神经网络、统计学和优化理论等学科。
随着硬件技术的进步和计算能力的提升,深度学习的发展经历了从浅层学习到深层学习的过程。
早期的神经网络模型由于计算资源的限制,通常只有几层结构,难以处理复杂的任务。
而随着深度学习算法的改进和计算机性能的飞跃,深度神经网络的层数不断增加,能够更好地处理大规模数据和复杂任务。
三、深度学习的主要应用1. 图像识别:深度学习在图像识别领域取得了显著的成果,如人脸识别、物体检测、图像分类等。
通过训练深度神经网络,可以自动提取图像中的特征,实现高精度的识别效果。
2. 语音识别:深度学习在语音识别领域也取得了重要突破,如语音合成、语音转文字等。
通过构建大规模的语音数据集和复杂的神经网络模型,可以实现高度逼真的语音合成和高效的语音转文字功能。
3. 自然语言处理:深度学习在自然语言处理领域也有广泛的应用,如机器翻译、情感分析、问答系统等。
通过构建语言模型和上下文感知模型,可以有效地理解和生成自然语言文本。
4. 机器翻译:深度学习在机器翻译领域的应用已经取得了巨大的成功。
通过训练大规模的平行语料库和复杂的神经网络模型,可以实现高质量的翻译效果。
四、当前面临的挑战与未来发展趋势尽管深度学习在多个领域取得了显著的成果,但仍面临一些挑战和问题。
首先,深度学习的可解释性仍然是一个亟待解决的问题。
BP人工神经网络算法的探究及其应用

BP人工神经网络算法的探究及其应用
BP人工神经网络算法是一种基于反向传播原理的人工神经网络,具有很好的非线性拟合能力和适应性,被广泛应用于数据挖掘、图像识别、自然语言处理等领域。
BP网络的基本结构由输入层、隐藏层和输出层组成。
输入层接收外界输入的数据,隐藏层进行信息处理和转化,输出层则输出网络的结果。
BP算法主要包括前向传播和反向传播两个过程。
在前向传播过程中,网络通过输入层接收输入信息,经过隐藏层的处理后,产生输出结果。
在反向传播过程中,网络根据误差信号,将误差一步步向前传播,不断调整各个层次之间的连接权值,直至误差最小化,从而实现网络训练和学习。
BP网络算法具有很强的泛化能力和适应性。
它不需要先验知识,不断通过调整权值来精确匹配输入数据与输出结果之间的关系,适用于处理各种复杂的非线性问题。
BP算法还具有很好的稳定性和鲁棒性,在模型参数调整过程中不易陷入局部极小值,训练后的网络具有很强的泛化能力和鲁棒性。
BP神经网络算法已经成功应用于图像识别、自然语言处理、文本分类、金融风险评估等领域。
例如,基于BP算法的手写数字识别系统,在MNIST(美国国家标准与技术研究所)数据集上取得了较好的识别率,已经被广泛应用于银行卡号识别等场景;基于BP算法的股票预测模型,在对历史股票数据进行训练后,能够对未来股票价格变化做出预测,帮助金融从业人员做出更为准确的投资决策。
总之,BP神经网络算法作为一种基于反向传播原理的人工神经网络,具有很强的非线性拟合能力和适应性,能够广泛应用于各个领域。
预计在未来,随着人工智能技术的不断发展和完善,BP算法将会带来更多的应用和领域的拓展。
BP网络以及深度学习的研究

BP 神经网络1 BP 网图:三层BP 网信号正向传播和误差反向传播)(k k net f o = ∑==mj j jk k y net 0ω k=1,2……l 有l 个输出(l 常常为1)。
中间隐层有m 层:)(j j net f y = ∑==ni i ij j x net 0υ i=1,2,……m n 个输入。
j=1,2……m其中Sigmoid 函数:xex f -+=11)( (单极性) ko knet E∂∂-=δ1.1 计算流程不同样本误差:21)(∑=-=lk M kM kMo dEE=((T-Ok)'*(T-Ok))/2;一般使用211)(21∑∑==-=lk p kp kMp o dE 总1.2 影响参数:1.2.1 隐层节点数nn=n m + +a ,其中 m 为输出神经元数, n 为输入神经元数, a 为[1,10]之间的常数。
nn=n 2log nn=2n+1; nn=mn1.2.2 学习率学习率η,太大会影响训练稳定性,太小使训练收敛速度慢。
一般在0.01--0.8之间。
我取0.2E min 一般在0.1--之间。
1.3 样本/输入1.3.1 训练样本训练样本数:M εwn ≈,w n 为权值阈值总数,一般为连接权总数的5~10倍。
训练数据必须作平衡处理,不同类别的样本需要交叉输入,轮流输入--时间延长。
1.3.2 输入形式字符:形状格填充、边缘距离 曲线:采样 变化大可以密集采样 输出:不同的输出用不同的码表示1.3.3 归一化:样本分布比较均匀 [0,1]区间:minmax min x x x x x i i--=。
《2024年深度学习相关研究综述》范文

《深度学习相关研究综述》篇一一、引言深度学习作为人工智能领域的一个重要分支,近年来在学术界和工业界引起了广泛的关注。
它通过模拟人脑神经网络的运作方式,实现对复杂数据的处理和识别,从而在计算机视觉、自然语言处理、语音识别等多个领域取得了显著的成果。
本文将对深度学习的基本原理、发展历程、主要应用以及当前研究热点进行综述。
二、深度学习的基本原理与发展历程深度学习是机器学习的一个分支,其核心思想是通过构建多层神经网络来模拟人脑神经网络的运作方式。
它通过大量的训练数据,使模型学习到数据的内在规律和表示方法,从而实现更加精准的预测和分类。
自深度学习概念提出以来,其发展经历了几个重要阶段。
早期的神经网络由于计算能力的限制,模型深度较浅,无法充分挖掘数据的内在规律。
随着计算能力的不断提升,尤其是GPU等硬件设备的普及,深度学习的模型深度逐渐增加,取得了显著的成果。
同时,随着数据量的不断增长和大数据技术的不断发展,深度学习的应用领域也在不断扩大。
三、深度学习的主要应用1. 计算机视觉:深度学习在计算机视觉领域的应用非常广泛,包括图像分类、目标检测、人脸识别等。
通过深度神经网络,可以实现图像的自动识别和分类,从而在安防、医疗、自动驾驶等领域发挥重要作用。
2. 自然语言处理:深度学习在自然语言处理领域也取得了显著的成果,包括语音识别、文本分类、机器翻译等。
通过深度神经网络,可以实现对人类语言的自动理解和生成,从而在智能问答、智能助手等领域发挥重要作用。
3. 语音识别:深度学习在语音识别领域也具有广泛的应用,如语音合成、语音识别等。
通过训练深度神经网络模型,可以实现高质量的语音合成和准确的语音识别。
4. 其他领域:除了上述应用外,深度学习还在推荐系统、医疗影像分析、无人驾驶等领域发挥了重要作用。
四、当前研究热点1. 模型优化:针对深度学习模型的优化是当前研究的热点之一。
研究者们通过改进模型结构、优化算法等方式,提高模型的性能和计算效率。
bp神经网络3篇

bp神经网络第一篇:BP神经网络的基本原理BP神经网络是一种最为经典的人工神经网络之一,它在模拟神经元之间的信息传输和处理过程上有很高的效率,可以被应用于多种领域,如图像处理、模式识别、预测分析等。
BP神经网络的核心思想是通过将神经元之间的权值调整来达到优化网络结构的目的,从而提高网络的准确率和泛化能力。
BP神经网络包含三个基本部分:输入层、隐层和输出层。
其中,输入层用于接收原始数据,隐层是神经元之间信号处理的地方,而输出层则用于输出最终的结果。
与其他的神经网络不同,BP神经网络使用了反向传播算法来调整神经元之间的权值。
这个算法是一种基于梯度下降的优化方法,通过最小化目标函数来优化权值,从而获得最小的误差。
具体来说,反向传播算法分为两个步骤:前向传播和反向传播。
前向传播是指从输入层开始,将数据经过神经元的传递和处理,一直到输出层,在这个过程中会计算每一层的输出值。
这一步完成后,就会得到预测值和实际值之间的误差。
接着,反向传播将会计算每个神经元的误差,并将误差通过链式法则向后传播,以更新每个神经元的权值。
这一步也被称为误差反向传播,它通过计算每个神经元对误差的贡献来更新神经元之间的权值。
总的来说,BP神经网络的优点在于其具有灵活性和较高的准确率。
但同时也存在着过拟合和运算时间过长等问题,因此在实际应用中需要根据实际情况加以取舍。
第二篇:BP神经网络的应用BP神经网络作为一种人工智能算法,其应用范围非常广泛。
以下是BP神经网络在不同领域的应用案例。
1. 图像处理BP神经网络在图像处理方面的应用主要有两个方面:图像分类和图像增强。
在图像分类方面,BP神经网络可以通过对不同特征之间的关系进行学习,从而对图像进行分类。
在图像增强方面,BP神经网络可以根据图像的特征进行修复和增强,从而提高图像的质量。
2. 股票预测BP神经网络可以通过对历史数据的学习来预测未来股市趋势和股票价格变化,对投资者提供参考依据。
3. 语音识别BP神经网络可以对人声进行测量和分析,从而识别出人说的话,实现语音识别的功能。
深度学习之BP神经网络

深度学习之BP神经⽹络模型、策略、算法: 在深度学习中,⽆论多么复杂的结构,终究逃不过三种构造,那就是模型、策略、算法,它们都是在这三种结构基础上进⾏的变形、扩展、丰富 模型:构建参数、函数,确定学习⽅式 策略:策略的重点时损失函数,即构造出⼀种能都使得损失最⼩的函数结构 算法:不断迭代,深度学习BP神经⽹络基本概念: BP神经⽹络是⼀种多层的前馈神经⽹络,其主要的特点是:信号是前向传播的,⽽误差是反向传播的。
它模拟了⼈脑的神经⽹络的结构,⽽⼈⼤脑传递信息的基本单位是神经元,⼈脑中有⼤量的神经元,每个神经元与多个神经元相连接。
BP神经⽹络,类似于上述,是⼀种简化的⽣物模型。
每层神经⽹络都是由神经元构成的,单独的每个神经元相当于⼀个感知器。
输⼊层是单层结构的,输出层也是单层结构的,⽽隐藏层可以有多层,也可以是单层的。
输⼊层、隐藏层、输出层之间的神经元都是相互连接的,为全连接。
总得来说,BP神经⽹络结构就是,输⼊层得到刺激后,会把他传给隐藏层,⾄于隐藏层,则会根据神经元相互联系的权重并根据规则把这个刺激传给输出层,输出层对⽐结果,如果不对,则返回进⾏调整神经元相互联系的权值。
这样就可以进⾏训练,最终学会,这就是BP神经⽹络模型。
BP神经⽹络简介:BP神经⽹络已⼴泛应⽤于⾮线性建摸、函数逼近、系统辨识等⽅⾯,但对实际问题,其模型结构需由实验确定,⽆规律可寻。
⼤多数通⽤的神经⽹络都预先预定了⽹络的层数,⽽BP ⽹络可以包含不同的隐层。
但理论上已经证明,在不限制隐含节点数的情況下,两层(只有⼀个隐层)的BP⽹络可以实现任意⾮线性映射。
在模式样本相对较少的情況下,较少的隐层节点,可以实现模式样本空间的超平⾯划分,此时,选择两层BP⽹络就可以了。
当模式样本数很多时,减⼩⽹络规模,增加⼀个隐层是有必要的,但是BP⽹络隐含层数⼀般不超过两层。
BP神经⽹络训练流程图:BP神经⽹络算法公式:在三层BP神经⽹络中,输⼊向量,也就是输⼊层神经元为:隐藏层输⼊向量,也就是隐藏层神经元:输出层输出向量,也就是输出层神经元:期望输出向量可以表⽰为:输⼊层到隐藏层之间的权值⽤数学向量可以表⽰为:这⾥⾯的列向量vj为隐藏层第 j 个神经元对应的权重;隐藏层到输出层之间的权值⽤数学向量可以表⽰为: 上式中的列向量wk为输出层第 k 个神经元对应的权重。
机器学习-BP(back propagation)神经网络介绍
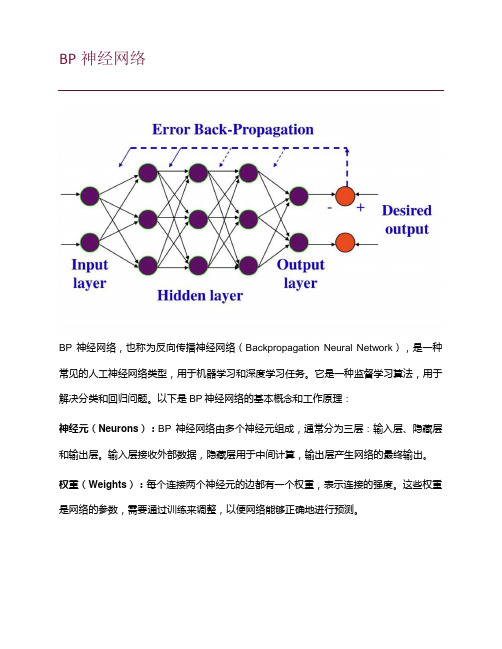
BP神经网络BP神经网络,也称为反向传播神经网络(Backpropagation Neural Network),是一种常见的人工神经网络类型,用于机器学习和深度学习任务。
它是一种监督学习算法,用于解决分类和回归问题。
以下是BP神经网络的基本概念和工作原理:神经元(Neurons):BP神经网络由多个神经元组成,通常分为三层:输入层、隐藏层和输出层。
输入层接收外部数据,隐藏层用于中间计算,输出层产生网络的最终输出。
权重(Weights):每个连接两个神经元的边都有一个权重,表示连接的强度。
这些权重是网络的参数,需要通过训练来调整,以便网络能够正确地进行预测。
激活函数(Activation Function):每个神经元都有一个激活函数,用于计算神经元的输出。
常见的激活函数包括Sigmoid、ReLU(Rectified Linear Unit)和tanh(双曲正切)等。
前向传播(Forward Propagation):在训练过程中,输入数据从输入层传递到输出层的过程称为前向传播。
数据经过一系列线性和非线性变换,最终产生网络的预测输出。
反向传播(Backpropagation):反向传播是BP神经网络的核心。
它用于计算网络预测的误差,并根据误差调整网络中的权重。
这个过程分为以下几个步骤:1.计算预测输出与实际标签之间的误差。
2.将误差反向传播回隐藏层和输入层,计算它们的误差贡献。
3.根据误差贡献来更新权重,通常使用梯度下降法或其变种来进行权重更新。
训练(Training):训练是通过多次迭代前向传播和反向传播来完成的过程。
目标是通过调整权重来减小网络的误差,使其能够正确地进行预测。
超参数(Hyperparameters):BP神经网络中有一些需要人工设置的参数,如学习率、隐藏层的数量和神经元数量等。
这些参数的选择对网络的性能和训练速度具有重要影响。
BP神经网络在各种应用中都得到了广泛的使用,包括图像分类、语音识别、自然语言处理等领域。
BP神经网络及深度学习研究

BP 神经网络及深度学习研究1 引言人工神经网络(Artificial Neural Network ,即ANN ),作为对人脑最简单的一种抽象和模拟,是人们模仿人的大脑神经系统信息处理功能的一个智能化系统,是20世纪80 年代以来人工智能领域兴起的研究热点。
人工神经网络以数学和物理方法以及信息处理的角度对人脑神经网络进行抽象,并建立某种简化模型,旨在模仿人脑结构及其功能的信息处理系统。
人工神经网络最有吸引力的特点就是它的学习能力。
因此从20世纪40年代人工神经网络萌芽开始,历经两个高潮期及一个反思期至1991年后进入再认识与应用研究期, 涌现出无数的相关研究理论及成果,包括理论研究及应用研究。
最富有成果的研究工作是多层网络BP 算法,Hopfield 网络模型,自适应共振理论,自组织特征映射理论等。
因为其应用价值,该研究呈愈演愈烈的趋势,学者们在多领域中应用错误!未找到引用源。
人工神经网络模型对问题进行研究优化解决。
人工神经网络是由多个神经元连接构成,因此欲建立人工神经网络模型必先建立人工神经元模型,再根据神经元的连接方式及控制方式不同建立不同类型的人工神经网络模型。
现在分别介绍人工神经元模型及人工神经网络模型。
1.1 人工神经元模型仿生学在科技发展中起着重要作用,人工神经元模型的建立来源于生物神经元结构的仿生模拟,用来模拟人工神经网络错误!未找到引用源。
人们提出的神经元模型有很多,其中最早提出并且影响较大的是1943年心理学家McCulloch 和数学家W. Pitts 在分析总结神经元基本特性的基础上首先提出的MP 模型。
该模型经过不断改进后,形成现在广泛应用的BP 神经元模型。
人工神经元模型是由人量处理单元厂泛互连而成的网络,是人脑的抽象、简化、模拟,反映人脑的基本特性。
一般来说,作为人工神经元模型应具备三个要素:(1) 具有一组突触或连接,常用ij w 表示神经元i和神经元j 之间的连接强度。
BP神经网络的研究分析及改进应用

BP神经网络的研究分析及改进应用一、本文概述本文旨在对BP(反向传播)神经网络进行深入的研究分析,并探讨其在实际应用中的改进策略。
BP神经网络作为领域的重要分支,已经在模式识别、预测分析、自适应控制等多个领域展现出强大的应用潜力。
然而,随着数据规模的扩大和应用场景的复杂化,传统的BP 神经网络也暴露出诸如训练速度慢、易陷入局部最优解、泛化能力弱等问题。
因此,本文希望通过理论分析和实证研究,提出针对性的改进方法,以提升BP神经网络的性能,进一步拓展其应用范围。
本文将首先回顾BP神经网络的基本原理和发展历程,分析其在现有应用中的优势和局限。
接着,从算法优化、网络结构设计和硬件加速等方面探讨改进BP神经网络的途径。
算法优化方面,将研究如何结合现代优化理论,如遗传算法、粒子群优化等,改进BP神经网络的权值更新规则和训练策略。
网络结构设计方面,将探讨如何通过增加隐藏层、调整神经元连接方式等方式提升网络的复杂度和表达能力。
硬件加速方面,将研究如何利用专用硬件(如神经网络处理器、图形处理器等)提高BP神经网络的训练速度和推理效率。
本文将通过具体的应用案例,验证所提出改进方法的有效性。
这些案例将涵盖不同领域的数据集,旨在全面评估改进BP神经网络在不同场景下的表现。
通过本文的研究,我们期望能够为BP神经网络的发展和应用提供新的思路和方法,推动其在领域的更广泛应用。
二、BP神经网络的基本原理BP神经网络,即反向传播神经网络,是一种基于误差反向传播算法的多层前馈网络。
它的基本原理主要包括两个过程:前向传播和反向传播。
前向传播过程中,输入信号从输入层开始,通过隐藏层,最终到达输出层。
在每一层,每个神经元的输出都是其输入与权重的加权和,再经过激活函数的转换得到。
这个过程主要是将输入的信息逐层传递,直到得到网络的输出结果。
然而,由于网络初始权重的随机性,初次前向传播得到的结果往往与实际期望的输出存在误差。
这时就需要进行反向传播过程。
BP神经网络综述

《BP神经网络的优化算法》综述姓名:***学号:南京理工大学摘 要:本文对于BP 算法存在的缺陷,简介了几种BP 神经网络优化算法的基本原理,并比较了这几种优化算法的优缺点,给出了它们可以应用的场合。
关键词:BP 神经网络,优化算法1. 引言人们常把误差反向传播算法的多层前馈网络直接称为BP 网络。
BP 网络学习训练中采用有导师学习方式,在调整权值过程中采用梯度下降技术,使网络总误差最小。
其算法思想是:学习训练过程由正向信号传播和反向误差传播构成。
正向传播时,输入样本从输入层进入,经各隐层逐层处理后,传向输出层。
若输出层的实际输出与期望的输出不符,则转入误差的反向传播阶段。
误差反传是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号作为修正各单元权值的依据。
这种信号正向传播与误差反向传播的各层权值调整过程,周而复始地进行的。
一直进行到网络输出的误差减少到可以接受的程度,或进行到预先设定的学习次数。
(1) 正向信号传输计算隐层的输出、输入为0()1,2,...,1,2,...,i j n j ij ii y f net j l net w x j l =====∑(1)式中,j x 为输入层第j 个节点的输出;ij w 为隐层神经元j 与输入层神经元i 之间的连接权重;f (*)是转换函数。
输出层节点的输出、输入为0()1,2,...,1,2,...,k k n k jk jj o f net k l net w x k l =====∑(2)式中,jk v 为隐层节点与输出层节点之间的权重;f (*)是转换函数。
定义网络的输出误差函数为22111()()22m k k k E T O t o ==-=-∑(3) 将式(3)展开至隐层,有2211011(())[()]22m m l k k k jk j k k j E t f net t f v y ====-=-∑∑∑(4) 进一步展开至输入层,有221010011{(()]}{(()]}22m l m l n k jk j k jk ij i k j k j i E t f v f net t f v f w x ======-=-∑∑∑∑∑(5) (2) 反向传播计算有文献[1]可得三层感知器的BP 学习算法权值调整计算公式1()(1))(1)o jk k j k k k k jm y o ij j i kjk j j i k v y t o o o y w x v y y x ηδηηδηδ=∆==--∆==-∑(6)其中1()(1)()(1)o k k k k k m yo j kjk j j k t o o o v y y δδδ==--=-∑(7)(3) 算法步骤实际应用中有2种方法可以调整权值和阈值:单样本训练和成批训练。
深度学习研究综述

深度学习研究综述引言:深度学习是一种机器学习的方法,它模仿了人类大脑的工作方式,通过多层神经网络来学习和理解数据。
深度学习在许多领域中都取得了巨大的成功,包括计算机视觉、自然语言处理和语音识别。
本综述将概述深度学习的起源、发展和应用,并提出一些未来的研究方向。
一、深度学习的起源和发展深度学习最早可以追溯到20世纪80年代,当时的研究人员开始对多层神经网络进行研究。
然而,由于计算资源的限制和算法的不成熟,深度学习并没有得到广泛的应用。
进入21世纪后,随着计算机性能的提高和大数据的普及,深度学习开始迎来了新的发展机遇。
2024年,谷歌研究员Geoffrey Hinton等人提出了一种称为“深度信念网络”的算法,这是深度学习在实际应用中取得突破的重要一步。
随后,一系列针对深度学习算法的改进被提出,包括卷积神经网络、循环神经网络和生成对抗网络等。
二、深度学习的应用领域1. 计算机视觉:深度学习在计算机视觉领域取得了显著的成果。
通过对大量的图像数据进行训练,深度学习可以实现图像分类、目标检测和图像生成等任务。
例如,谷歌的AlphaGo利用深度学习技术在围棋比赛中战胜了人类世界冠军。
2. 自然语言处理:深度学习在自然语言处理领域也有很大的应用潜力。
通过对大量的文本数据进行训练,深度学习可以实现机器翻译、文本分类和情感分析等任务。
例如,谷歌的语音助手Google Assistant就是通过深度学习实现自然语言理解和生成。
3. 语音识别:深度学习在语音识别领域也发挥了重要作用。
通过对大量的语音数据进行训练,深度学习可以实现准确的语音识别和语音合成。
例如,苹果的语音助手Siri就是通过深度学习实现语音交互。
三、深度学习的未来研究方向1.提高模型的鲁棒性和泛化能力:目前的深度学习模型往往对输入的扰动非常敏感,对于未见过的样本也很难进行准确的预测。
未来的研究应该致力于开发更鲁棒的深度学习模型,以应对各种挑战。
2.解决数据稀缺和标注困难的问题:深度学习需要大量的数据进行训练,但在许多领域中,数据往往是稀缺的或者难以标注的。
神经网络学习之BP神经网络

神经网络学习之 BP神经网络/u013007900/article/details/50118945目录第一章概述第二章BP算法的基本思想第三章BP网络特性分析3.1 BP网络的拓扑结构 (4)3.2 BP网络的传递函数 (5)3.3 BP网络的学习算法 (6)第四章BP网络的训练分解4.1前向传输(Feed-Forward前向反馈) (8)4.2逆向反馈(Backpropagation) (9)4.3 训练终止条件 (10)第五章BP网络运行的具体流程 (10)5.1网络结构 (10)5.2变量定义 (10)5.3误差函数: (11)第六章BP网络的设计 (14)6.1 网络的层数 (14)6.2 隐层神经元的个数 (15)6.3 初始权值的选取 (15)6.4 学习速率 (15)BP网络的局限性 (15)BP网络的改进 (16)第一章概述神经网络是1986年由Rumelhart和McCelland为首的科研小组提出,参见他们发表在Nature 上的论文Learning representations by back-propagating errors。
BP神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
第二章BP算法的基本思想多层感知器在如何获取隐层的权值的问题上遇到了瓶颈。
既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
•正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。
若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。
bp神经网络的应用综述

bp神经网络的应用综述近年来,随着人工智能(AI)发展的飞速发展,神经网络技术也在迅速发展。
BP神经网络是一种能够将输入大量信息并有效学习并做出正确决策的广泛应用的深度学习算法。
它的强大的学习能力令人印象深刻,从很多方面来看都是一种具有潜在潜力的技术。
在科学和工程方面,BP神经网络的应用非常广泛。
它可以用于模式识别,数据挖掘,图像处理,语音识别,机器翻译,自然语言处理和知识发现等等。
当可用的数据量很大时,BP神经网络可以有效地自动分析和提取有用的信息,从而有效地解决问题。
例如,在图像处理领域,BP神经网络可以用于图像分类、目标检测和图像语义分析。
它能够以准确的速度检测目标图像,包括人脸、行人、汽车等等,这在过去难以实现。
在机器翻译等技术中,BP神经网络可以用于语义分析,以确定机器翻译的正确语义。
此外,BP神经网络还可以用于人工智能的自动控制,例如机器人与机器人感知、模式识别、语音识别和控制系统。
除此之外,BP神经网络还可以用作在计算机游戏和科学研究中的决策支持系统,以便帮助决策者做出正确的决策。
总而言之,BP神经网络是一种具有广泛应用的深度学习算法,它能够自动处理大量复杂的信息,并能够做出正确的决策。
它可以用于各种科学和工程任务,如模式识别、机器翻译、图像处理、语音识别、机器人感知及自动控制等领域。
此外,它还可以用于决策支持系统,以便帮助决策者做出正确的决策。
BP神经网络在许多领域都具有巨大的潜力,希望以后能得到更多的研究和应用。
因为随着计算机技术的发展,BP神经网络在未来有望发挥更大的作用,帮助人们实现和科学研究的突破。
BP神经网络的潜力巨大,尽管它的应用前景十分广阔,但许多研究仍然存在挑战。
因此,有必要开展更多的研究,并利用其强大的特性,尽可能多地发掘它的潜力,以便最大限度地利用它的优势。
我们期待着BP神经网络会给人类的发展带来更多的惊喜。
BP神经网络及深度学习研究---综述

BP神经网络及深度学习研究摘要:人工神经网络是一门交叉性学科,已广泛于医学、生物学、生理学、哲学、信息学、计算机科学、认知学等多学科交叉技术领域,并取得了重要成果。
BP(Back Propagation)神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
本文将主要介绍神经网络结构,重点研究BP神经网络原理、BP神经网络算法分析及改进和深度学习的研究。
关键词:BP神经网络、算法分析、应用1引言人工神经网络(Artificial Neural Network,即ANN ),作为对人脑最简单的一种抽象和模拟,是人们模仿人的大脑神经系统信息处理功能的一个智能化系统,是20世纪80 年代以来人工智能领域兴起的研究热点。
人工神经网络以数学和物理方法以及信息处理的角度对人脑神经网络进行抽象,并建立某种简化模型,旨在模仿人脑结构及其功能的信息处理系统。
人工神经网络最有吸引力的特点就是它的学习能力。
因此从20世纪40年代人工神经网络萌芽开始,历经两个高潮期及一个反思期至1991年后进入再认识与应用研究期,涌现出无数的相关研究理论及成果,包括理论研究及应用研究。
最富有成果的研究工作是多层网络BP算法,Hopfield网络模型,自适应共振理论,自组织特征映射理论等。
因为其应用价值,该研究呈愈演愈烈的趋势,学者们在多领域中应用[1]人工神经网络模型对问题进行研究优化解决。
人工神经网络是由多个神经元连接构成,因此欲建立人工神经网络模型必先建立人工神经元模型,再根据神经元的连接方式及控制方式不同建立不同类型的人工神经网络模型。
现在分别介绍人工神经元模型及人工神经网络模型。
1.1人工神经元模型仿生学在科技发展中起着重要作用,人工神经元模型的建立来源于生物神经元结构的仿生模拟,用来模拟人工神经网络[2]。
人们提出的神经元模型有很多,其中最早提出并且影响较大的是1943年心理学家McCulloch和数学家W. Pitts 在分析总结神经元基本特性的基础上首先提出的MP模型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
BP网络的基本结构如图21所示,其模型拓扑结构包括输入层(input)、隐层(hidden layer)和输出层(output layer)三层结构。
输入层各神经元负责接收来自外界的输入信息,并传递给中间层各神经元;中间层是内部信息处理层,负责信息变换,根据信息变化能力的需求。中间层可以设计为单隐层或者多隐层结构;最后一个隐层传递到输出层各神经元的信息,经进一步处理后,完成一次学习的正向传播处理过程,由输出层向外界输出信息处理结果。隐层节点一般采用Sigmoid型函数,输入和输出节点可以采用Sigmoid型函数或者线性函数。
(3)网络的结构设计,即隐节点数的选择,尚无理论指导,具有很大的盲目性。
(4)新加入的样本对已经学好的样本影响较大,且每个输入样本的特征数目要求相同,泛化能力较差。
针对BP算法存在的缺陷,目前国内外已有不少人对BP网络进行了大量的研究,提出了各种不同的改进方案,如优化训练输入参数,加入动量参数,以及学习步长的适应调整,采用带动量的自学习率BP算法,动态全参数自调整学习算法,记忆式初值权值和阀值方法,快速自适应学习算法等,这些方案均提高BP神经网络收敛速度。
作用函数是反映下层输入对上层节点刺激脉冲强度的函数又称刺激函数,一般取为(0,1)内连续取值Sigmoid函数:
它反映了神经元的饱和特性。上式中,Q为表示神经元非线性的参数,称增益值(Gain),也称调节参数。Q值越大,S形曲线越陡峭;反之,Q值越小,S形曲线越平坦;一般取Q=1。
(3)误差计算模型
关键词:BP神经网络、算法分析、应用
1
人工神经网络(Artificial Neural Network,即ANN),作为对人脑最简单的一种抽象和模拟,是人们模仿人的大脑神经系统信息处理功能的一个智能化系统,是20世纪80年代以来人工智能领域兴起的研究热点。人工神经网络以数学和物理方法以及信息处理的角度对人脑神经网络进行抽象,并建立某种简化模型,旨在模仿人脑结构及其功能的信息处理系统。
深度学习是关于自动学习要建模的数据的潜在(隐含)分布的多层(复杂)表达的算法。换句话来说,深度学习算法自动的提取分类需要的低层次或者高层次特征。高层次特征,一是指该特征可以分级(层次)地依赖其他特征,例如:对于机器视觉,深度学习算法从原始图像去学习得到它的一个低层次表达,例如边缘检测器,小波滤波器等,然后在这些低层次表达的基础上再建立表达,例如这些低层次表达的线性或者非线性组合,然后重复这个过程,最后得到一个高层次的表达。
图(a)前向网络
图(b)有反馈前向网络
图(c)层内互边前向网络
图(d)互联网络
图12神经网络拓扑结构图
2
BP神经网络是一种按误差逆传播BP(Back Propagation)算法训练的多层前馈网络,由它最初是由Pau1werboSS在1974年提出,但未传播,直到20世纪80年代中期Rumelhart[4]、Hinton和Williams、DavidParker[5]和YannLeCun[6]重新发现了BP算法,同时因此算法被包括在《并行分布处理》(ParallelDistributedProcessing),此算法才广为人知。目前BP算法已成为应用最广泛的神经网络学习算法,据统计有近90%的神经网络应用是基于BP算法的。
人工神经网络最有吸引力的特点就是它的学习能力。因此从20世纪40年代人工神经网络萌芽开始,历经两个高潮期及一个反思期至1991年后进入再认识与应用研究期,涌现出无数的相关研究理论及成果,包括理论研究及应用研究。最富有成果的研究工作是多层网络BP算法,Hopfield网络模型,自适应共振理论,自组织特征映射理论等。因为其应用价值,该研究呈愈演愈烈的趋势,学者们在多领域中应用[1]人工神经网络模型对问题进行研究优化解决。
DeepLearning训练过程具体如下:
(1)使用自下上升非监督学习
采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,是和传统神经网络区别最大的部分(这个过程可以看作是feature learning过程):
具体的,先用无标定数据训练第一层,训练时先学习第一层的参数(这一层可以看作是得到一个使得输出和输入差别最小的三层神经网络的隐层),由于模型capacity的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到第n-1层后,将n-1层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数;
3
BP算法现在已成为目前应用最广泛的神经网络学习算法,它在函数逼近、模式识别、分类、数据压缩等领域有着更加广泛的应用。但它存在学习收敛速度慢、容易陷入局部极小点而无法得到全局最优解、且对初始权值的选取很敏感等缺点。具体如下:
(1)在权值调整上采用梯度下降法作为优化算法,极易陷入局部极小。
(2)学习算法的收敛速度很慢,收敛速度还与初始权值和传输函数的选择有关。
人工神经网络是由多个神经元连接构成,因此欲建立人工神经网络模型必先建立人工神经元模型,再根据神经元的连接方式及控制方式不同建立不同类型的人工神经网络模型。现在分别介绍人工神经元模型及人工神经网络模型。
1.1
仿生学在科技发展中起着重要作用,人工神经元模型的建立来源于生物神经元结构的仿生模拟,用来模拟人工神经网络[2]。人们提出的神经元模型有很多,其中最早提出并且影响较大的是1943年心理学家McCulloch和数学家W.Pitts在分析总结神经元基本特性的基础上首先提出的MP模型。该模型经过不断改进后,形成现在广泛应用的BP神经元模型。人工神经元模型是由人量处理单元厂泛互连而成的网络,是人脑的抽象、简化、模拟,反映人脑的基本特性。一般来说,作为人工神经元模型应具备三个要素:
(1)具有一组突触或连接,常用 表示神经元i和神经元j之间的连接强度。
(2)具有反映生物神经元时空整合功能的输入信号累加器 。
(3)具有一个激励函数 用于限制神经元输出。激励函数将输出信号限制在一个允许范围内。
一个典型的人工神经元模型如图11所示。
图11人工神经元模型
其中 为神经元i的输入信号, 为连接权重,b为外部刺激, 为激励函数, 为神经元的输出,其输出计算公式如。
其中, 为学习因子; 输出节点 的计算误差; 为输出节点 的计算输出; 为动量因子。
BP模型把一组输入输出样本的函数问题转变为一个非线性优化问题,并使用了优化技术中最普通的梯度下降法。如果把神经网络看成是输入到输出的映射,则这个映射是一个高度非线性映射。BP算法程序框图如图22所示。
图22BP学习算法框图
BP神经网络学习是由信息的正向传播和误差的反向传播两个过程组成。BP神经网络的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP网络的神经元采用的传递函数通常是Sigmoid型可微函数,所以可以实现输入和输出间的任意非线性映射,这使得它在诸如信号处理、计算机网络、过程控制、语音识别、函数逼近、模式识别及数据压缩等领域均取得了成功的应用。
1.2
建立神经元模型后,将多个神经元进行连接即可建立人工神经网络模型。神经网络的类型多种多样,它们是从不同角度对生物神经系统不同层次的抽象和模拟。从功能特性和学习特性来分,典型的神经网络模型主要包括感知器、线性神经网络、BP网络、径向基函数网络、自组织映射网络和反馈神经网络等。一般来说,当神经元模型确定后,一个神经网络的特性及其功能主要取决于网络的拓扑结构及学习方法。从网络拓扑结构角度来看,神经网络可以分为以下四种基本形式[3]:前向网络、有反馈的前向网络、层内互边前向网络和互连网络。
神经网络结构如图12,其中子图的图(a)为前向网络结构,图(b)有反馈的前向网络结构、图(c)层内互边前向网络结构和图(d)互连网络结构。
根据有无反馈,亦可将神经网络划分为:无反馈网络和有反馈网络。无反馈网络为前馈神经网络(Feed Forward NNs,FFNNs),有反馈网络为递归神经网络和(Recurrent NNs,RNNs)。
BP算法存在的问题:
(1)梯度越来越稀疏:从顶层越往下,误差校正信号越来越小;
(2)收敛到局部最小值:尤其是从远离最优区域开始的时候(随机值初始化会导致这种情况的发生);
(3)一般,我们只能用有标签的数据来训练:但大部分的数据是没标签的,而大脑可以从没有标签的的数据中学习;
深度学习[8]是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,是神经网络的发展。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
(2)BP算法的数值优化
采用共轭梯度法和Levenberg-Marqardt算法可以提高数值精度。共轭梯度法选择与梯度相反的方向作为第一方向,直至收敛。而Levenberg-Marqardt算法是牛顿法的变形,用以最小化那些作为其他非线性函数平方和的函数,这非常适合于性能指数是均方误差的神经网络训练。
(2)自顶向下的监督学习
基于第一步得到的各层参数进一步fine-tune整个多层模型的参数,这一步是一个有监督训练过程;第一步类似神经网络的随机初始化初值过程,由于DL的第一步不是随机初始化,而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果;所以DeepLearning效果好很大程度上归功于第一步的feature learning过程
比较典型的改进方法如下:
(1)启发式改进
为了使学习速率足够大,又不易产生振荡,根据Rumelhart的建议,在权值调整算式中,加入“动量项”,,即
其中上式第二项为常规BP算法的修正量,第三项为动量项,其中 为调节因子。
通过可变学习步长可以提高收敛速度。可变学习速度(可变步长)的基本思想为:先设一初始步长:若一次迭代后误差函数E增大,则将步长乘以小于1的常数,沿原来方向重新计算下一个迭代点;若一次迭代后误差函数E减少,则将步长乘以大于l的常数。