生物信息学习题
生物信息学习题

一:名词解释1.生物信息学2.NCBI3.PubMed4.生物芯片5.BLAST6.UniProt7.电子克隆8.EMBL二:填空题1.基因芯片可以分为2. 人类基因组全序列分析分两大步骤即制图和测序,并最终绘制出四张图谱:3. 分子系统发生分析主要分为三个步骤即4. 国际上最主要的三大核酸序列数据库分别是5. 蛋白质得分矩阵有7. 文献是掌握科研进展的最直接方式,目前由NCBI维护的大型文献资源是。
3. 用于核酸序列比对中常见的三种得分矩阵,分别为4. 根据生物芯片探针分子类型的不同,可以将生物芯片哪三种,5. 核酸序列分析所获得的信息主要有(举例说明四个)6. 限制性酶切分析是分子生物学实验中的日常工作之一,这方面最好的限制酶数据库是三:选择题1、如果试图确定一个新蛋白质序列属于哪一个蛋白质家族,或该序列可能包含何种结构域或功能位点,应使用:()A: PROSITE数据库 B: DDBJ数据库C: PIR数据库 D: PDB数据库2、构建序列进化树的一般步骤不包括:()A:建立DNA文库 B:建立数据模型 C:建立取代模型 D:建立进化树3、BLAST教案所程序中,哪个方法是不存在的?()A:BLASTP B:BLASTN C:BLASTX D:BLASTQ4. 以下常见的几个物种,哪一个目前还没有完成全基因组测序:()A: 茶树 B: 玉米 C: 水稻 D: 小鼠5、向核酸序列数据库(GenBank/EMBL/DDBJ)提交数据,应该使用下面哪个软件:()。
A: Blast B:Sequin C:SRS D:Swiss-Model6、在蛋白质序列数据库中比较查询手头未知的蛋白质序列,应使用Blast中哪个具体的算法:()。
A:BLASTX B:tBLASTN C:BLASTP D:BLASTN7、下列中属于一级蛋白质结构数据库的是:()A:EMBL B:DDBJ C:PDB D:SWISS-PROT8、下面不属于SWISS-PROT蛋白质数据库的注释范畴的是:()A: 与其它蛋白质的相似性 B: 蛋白质的二级结构C: 由于缺乏该蛋白质而引起的疾病 D: 核酸的功能描述9、下列属于蛋白质二级结构预测的软件程序是()A: BLASTX B:SOPMA C:DNAstar D:GO10. 如果做DNA结构分析,应该考虑用下面哪个数据库:()A:GenBank B: PIR C:NDB D:UniProt四:简单题1.简述Entrez的设计概念和使用方法?2. 简述生物大分子PDB存储的生物分子种类和数据结构特点?3.简述生物信息学的研究意义?4 简述蛋白质序列分析的基本内容以及常用的软件?5. 简述Swiss-Prot的数据结构?6、简述序列多重比对的意义?7、简述生物信息学的发展历史?五:论述题1.论述蛋白质相互作用研究的意义,传统的实验方法和计算预测方法的应用?2.论述后基因组时代生物信息学面临的挑战和研究策略?3.论述生物信息学的应用?4. 论述如何利用基因芯片数据做聚类分析。
生物信息学复习题

生物信息学复习题生物信息学是一门结合生物学、计算机科学、信息学和数学的交叉学科,它利用计算机技术来处理和分析生物数据。
以下是一些生物信息学复习题,供同学们参考:1. 生物信息学的定义和应用领域- 生物信息学是如何定义的?- 生物信息学在哪些领域有应用?2. 基因组学基础- 什么是基因组学?- 基因组测序的基本原理是什么?3. 序列比对- 序列比对的目的是什么?- 简述局部比对和全局比对的区别。
4. BLAST算法- BLAST算法的原理是什么?- 如何使用BLAST进行序列相似性搜索?5. 基因表达数据分析- 基因表达数据有哪些类型?- 描述基因表达数据的预处理步骤。
6. 蛋白质结构预测- 蛋白质结构预测的重要性是什么?- 简述几种常见的蛋白质结构预测方法。
7. 系统生物学和网络分析- 系统生物学研究的是什么?- 网络分析在系统生物学中的应用。
8. 生物信息学中的数据库- 列举几个常见的生物信息学数据库。
- 解释数据库在生物信息学研究中的作用。
9. 生物信息学中的编程语言- 哪些编程语言在生物信息学中常用?- 简述Python在生物信息学中的应用。
10. 伦理和隐私问题- 在生物信息学研究中可能遇到哪些伦理问题?- 如何保护生物信息数据的隐私?11. 案例研究- 描述一个生物信息学在医学研究中的应用案例。
- 分析该案例中使用的方法和技术。
12. 未来趋势- 预测生物信息学未来的发展趋势。
- 讨论生物信息学如何影响未来的科学研究和医疗保健。
通过这些问题的复习,同学们可以更全面地了解生物信息学的基础概念、关键技术和应用领域。
希望这些复习题能够帮助同学们更好地准备考试和理解生物信息学的重要性。
2012生物信息学复习题

2012生物信息学复习题一、选择题1. 根据PAM打分矩阵,下列哪个氨基酸最不容易突变?A) 丙氨酸 B) 谷氨酰胺 C) 甲硫氨酸 D) 半胱氨酸2. 下列哪个句子最好描述了两序列全局比对和局部比对的不同?A) 全局比对通常用于DNA序列,而局部比对通常用于蛋白质序列;B) 全局比对允许间隙,而局部比对不允许间隙;C) 全局比对寻求全局最大化,而局部比对寻求局部最大化;D) 全局比对比对整条序列,而局部比对寻找最佳匹配子序列3. 与PAM打分矩阵比较,BLOSUM打分矩阵的最大区别在哪里?A) 它最好用于比对相关性很近的序列; B) 它是基于近相关蛋白的全局多序列比对;C) 它是基于远相关蛋白的局部多序列比对; D) 它结合了局部和全局比对信息4. 全局比对算法(如Needleman-Wunsch算法)是这样一种算法:A) 把两条比较的蛋白质放到一个矩阵中,然后通过穷尽搜索每一个可能的比对组合来寻找最佳分值的比对;B) 把两条比较的蛋白质放到一个矩阵中,然后通过迭代递归的方法找到最佳的分值;C) 把两条比较的蛋白质放到一个矩阵中,然后通过寻找最佳子序列的方法来找到最佳的比对;D) 能用于蛋白质,但不能用于DNA序列5. 数据库搜索中或双序列比对中,敏感性定义为:A) 搜索算法寻找真阳性(即同源序列)和避免假阳性(即不相干序列,但具有高相似分值)的能力;B) 搜索算法寻找真阳性(即同源序列)和避免假阳性(即没有被搜索算法报告的同源序列)的能力;C) 搜索算法寻找真阳性(即同源序列)和避免假阴性(即不相干序列,但具有高相似分值)的能力;D ) 搜索算法寻找真阳性(即同源序列)和避免假阴性(即没有被搜索算法报告的同源序列)的能力;6. 如有一小段DNA序列,基本上它能编码多少种蛋白?A)1 B)2 C)3 D)67. 有一段DNA序列,如想知道在主要的蛋白质数据库中哪一个与该DNA编码的蛋白最接近,你会选择用哪一个程序?A)blastn B)blastp C)blastx D)tblastx E)tblastn8. blast检索的哪一种输出估计了假阳性的数目?A)E值 B)Bit score C)Percent identity D)Percent positives9. 将下面哪个blast参数改变后会得到更少的检索结果?A)关闭low-complexity filter B)将期望值从1变为0C)提高极限值 D)将打分矩阵从PAM30改为PAM7010.极值分布A)描述了对数据库的query的scores的分布 B)比正态分布的总面积大C)对称 D)形状可用两个参数来描述,即 µ(平均值)和 λ(衰减系数)11.当blast检索的E值减小时A)K值也减小 B)score变大 C)概率p值变大 D)极值分布偏斜率减小12.标准化的blast score(也称为bit scores)A)是没有单位 B)可在不同的blast检索之间比较,即使使用了不同的打分矩阵C)与使用的打分矩阵无关 D)可在不同的blast检索之间比较,但前提是使用相同的打分矩阵13.在EMBL和NCBI数据库中未加工的DNA序列(与注释序列相比)是A)完全重叠了 B)很大程度上重叠了,不过序列不同 C)相对只有一点重叠14.下面的哪种工作,PSI-BLAST搜索最为有效A)在老鼠中找一个人类蛋白质的同源蛋白 B)在数据库查询中找到更多的匹配蛋白 C)在数据库查询中找到更多的匹配DNA序列 D)用模式序列或者信号序列加强数据库搜索15.下面的哪种blast程序是用氨基酸的信号序列在一个蛋白质家族中寻找匹配的?A)PSI-BLAST B)PHI-BLAST C)MS BLAST D)WormBLAST16.下面的哪种blast 程序用来分析免疫球蛋白最好?A)RPS-BLAST B)PHI-BLAST C)IgBLAST D)ProDom17.在一个位点特异性打分矩阵中,列中可以有20种氨基酸。
生物信息技术复习题
生物信息技术复习题一、简答题1、简述信息的9个性质。
2、简述医学信息系统的特点3、简述电子病历的组成元素。
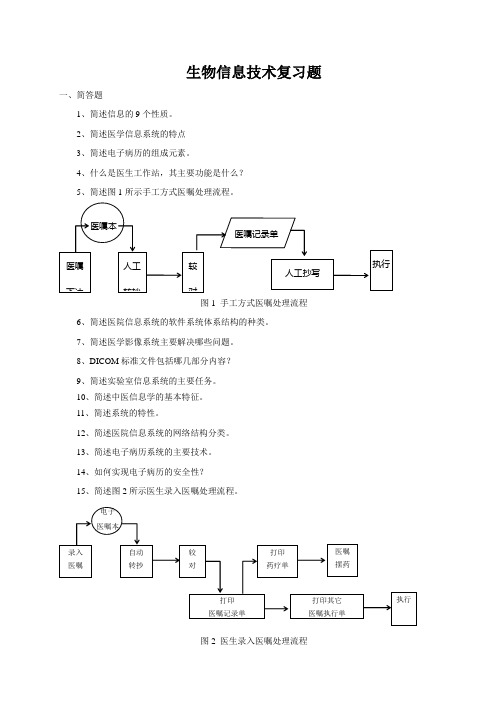
4、什么是医生工作站,其主要功能是什么?5、简述图1所示手工方式医嘱处理流程。
图1 手工方式医嘱处理流程6、简述医院信息系统的软件系统体系结构的种类。
7、简述医学影像系统主要解决哪些问题。
8、DICOM标准文件包括哪几部分内容?9、简述实验室信息系统的主要任务。
10、简述中医信息学的基本特征。
11、简述系统的特性。
12、简述医院信息系统的网络结构分类。
13、简述电子病历系统的主要技术。
14、如何实现电子病历的安全性?15、简述图2所示医生录入医嘱处理流程。
图2 医生录入医嘱处理流程16、简述门急诊系统各业务流程细分及功能。
17、简述医学影像系统的组成18、简述DICOM 标准的网络层次结构。
19、简述静脉药物配置中心的作用。
20、中医信息学要解决的基本问题、主要任务和主要内容。
二、英文专业名词解释(共15分,每题3分)(1)HIS (2)EPR (3)CIS (4)PACS (5)PIV A (1)LIS (2)CPR (3)MIS (4)DICOM (5)MIMIS三、分析说明(共35分,第1题20分,第2题15分)1、如图3所示医院信息系统信息处理的层次,分析并说明其体系结构。
图3 医院信息系统信息处理的层次1. 综合的OLTP2. 面向管理的OLTP3. 面向临床的 OLTP4.综合的 OLAP5. 面向管理的OLAP6. 面向临床的 OLAP8. 临床决策支持(DSS)7. 管理决策支持(DSS) 第一层 联机事物处理OLTP第二层 联机事物分析OLAP第三层 决策支持DSS2、如图4所示工作流程,试分析并说明该住院管理工作流程。
图4 住院管理工作流程3、如图5所示静脉药物配置中心人员构成,试分析说明静脉配置中心的工作流程。
图5 静脉药物配置中心人员构成4、试分析并说明如图6所示门诊医生工作站数据流图中数据流。
生物信息学应用实例习题报告

《生物信息学》应用实例习题报告第1题(11分)请从( )数据库中查看编号为P62694的蛋白质的详细信息:(1)这个蛋白质的中文名字是什么(1分)?(2)属于:植物,动物,还是真菌(1分)?(3)四个糖基化位点在哪里(2分)?(4)这个蛋白质包含一个叫1的结构域,该结构域在纤维素酶降解不可溶纤维素中起着重要的作用。
请找出这个结构域在该蛋白质氨基酸序列中的位置(1分)。
(5)找出该蛋白质1结构域在数据库中对应的相关XX结构,写出(1分),贴出结构图片(1分),说出解析该结构所使用的实验方法(1分).(6)通过搜索,从数据库中找出和这个蛋白质序列水平上最相似的3条序列,不包括该蛋白质自己本身(截屏就可以,3分).第2题(13分)用双序列比对工具()对下列两条蛋白质序列分别作全局比对(算法)和局部比对(算法),参数选择默认值。
分别给出比对结果(截图即可,4分)及对应的和(4分),并说说看两个比对结果的区别(5分)。
XX1〉2第3题(16分)用 - ()为下面10条蛋白质序列创建多序列比对,多序列比对的输出顺序要和输入顺序一致,结果截图(4分)。
比对结果用以颜色方案上色,调整字体大小、换行等,以最佳妆容贴图至此处(4分)。
用根据已创建的多序列比对构建系统发生树。
参数要求:算法、1000、 50%、其他参数可默认。
给出填写完毕的建树参数设置界面截图(3分),给出截图(3分),指出分子树中哪个(或哪几个)物种作为最为合理(2分)。
XX〉〉XXXXXX〉〉XXXX第4题(25分)有位老师需要你帮她预测一个蛋白质的结构,该蛋白质氨基酸序列如下:XX00206|672-818(1)请用同源建模软件()预测该蛋白质的三维结构,保存预测模型文件,结果页面截图,大约需要3分钟(5分).(2)用模型质量评估软件()和3D()评估预测的结构模型,评估结果截图,并根据结果描述下模型的质量如何(5分)。
(3)老师告诉你这个蛋白质能够XX结合XX同源双体,想麻烦你再给她预测一下双体的结构.请用()做蛋白质-蛋白质分子对接,返回结果页面截图,保存对接结果文件(需要等待15分钟左右,5分)。
生物信息学习题

第六章 分子系统发生分析(问题与练习)
1、构建系统发生树,应使用
A、BLAST
B、FASTA
C、UPGMA
D、Entrez
2、构建系统树的主要方法有
、
、
等。
3、根据生物分子数据进行系统发生分析有哪些优点?
4、在 5 个分类单元所形成的所有可能的有根系统发生树中,随机抽取一棵树是反映真实关
系的树的可能性是多少?从这些分类单元所有可能的无根系统发生树中,随机选择一棵
库
8、TreeBASE 系统主要用于
A、发现新基因 B、系统生物学研究 C、类群间系统发育关系研究 D、序列比对
二、 问答题
1、 为什么说 SWISS-PROT 是最重要的蛋白质一级数据库?
2、 构建蛋白质二级数据库的基本原则是什么?
3、 构建蛋白质二级数据库的主要方法有哪些?
4、 叙述 SCOP 数据库对蛋白质分类的主要依据
第八章 后基因组时代的生物信息学(问题与练习)
1、 比较生物还原论与生物综合论的异同 2、 简述“后基因组生物信息学”的基本研究思路 3、 后基因组生物信息学的主要挑战是什么? 4、 功能基因组系统学的基本特征是什么? 5、 说明后基因组生物信息学对信息流动的最新理解 6、 列举几种预测蛋白质-蛋白质相互作用的理论方法 7、 解释从基因表达水平关联预测蛋白质-蛋白质相互作用的理论方法 8、 解释基因保守近邻法预测蛋白质-蛋白质相互作用的理论方法 9、 解释基因融合法预测蛋白质-蛋白质相互作用的理论方法 10、解释种系轮廓发生法预测蛋白质-蛋白质相互作用的理论方法
1、蛋白质得分矩阵类型有 、
、、
和
等。
2、对位排列主要有局部比对和 三、运算题 1、画出下面两条序列的简单点阵图。将第一条序列放在 x 坐标轴上,将第二条序列放在 y
15 生物化学习题与解析汇报--细胞信息转导

细胞信息转导一、选择题( 一 )A 型题1 .下列哪种物质不是细胞间信息分子A .胰岛素B . COC .乙酰胆碱D .葡萄糖E . NO2 .通过核内受体发挥作用的激素是A .乙酰胆碱B .肾上腺素C .甲状腺素D . NOE .表皮生长因子3 .下列哪种物质不是第二信使A . cAMPB . cGMPC . IP 3D . DAGE . cUMP4 .膜受体的化学性质多为A .糖蛋白B .胆固醇C .磷脂D .酶E .脂蛋白5 .下列哪种转导途径需要单跨膜受体A . cAMP - 蛋白激酶通路B . cAMP - 蛋白激酶通路C .酪氨酸蛋白激酶体系D . Ca 2+ - 依赖性蛋白激酶途径E .细胞膜上 Ca 2+ 通道开放6 .活化 G 蛋白的核苷酸是A . GTPB . CTPC . UTPD . ATPE . TTP7 .生成 NO 的底物分子是A .甘氨酸B .酪氨酸C .精氨酸D .甲硫氨酸E .胍氨酸8 .催化 PIP 2 水解为 IP 3 的酶是A .磷脂酶 AB .磷脂酶 A 2C .磷脂酶 CD . PKAE . PKC9 .第二信使 DAG 的来源是由A . PIP 2 水解生成B .甘油三脂水解而成C .卵磷脂水解产生D .在体内合成E .胆固醇转化而来的10 . IP 3 受体位于A 、细胞膜B 、核膜C 、内质网D 、线粒体内膜E 、溶酶体11 . IP 3 与内质网上受体结合后可使胞浆内A . Ca 2+ 浓度升高B . Na 2+ 浓度升高C . cAMP 浓度升高D . cGMP 浓度下降E . Ca 2+ 浓度下降12 .激活的 G 蛋白直接影响下列哪种酶的活性A .磷脂酶 AB .蛋白激酶 AC .磷脂酶 CD .蛋白激酶 CE .蛋白激酶 G13 .关于激素,下列叙述正确的是A .都由特殊分化的内分泌腺分泌B .激素与受体结合是可逆的C .与相应的受体共价结合,所以亲和力高D .激素仅作用于细胞膜表面E .激素作用的强弱与其浓度成正比14 . 1 , 4 , 5 - 三磷酸肌醇作用是A .细胞膜组成成B .可直接激活 PKC C .是细胞内第二信使D .是肌醇的活化形式E .在细胞内功能15 .酪氨酸蛋白激酶的作用是A .分解受体中的酪氨B .使蛋白质中大多数酪氨酸磷酸化C .使各种含有酪氨酸的蛋白质活化D .使蛋白质结合酪氨酸E .使特殊蛋白质分子上酪氨酸残基磷酸化16 . cGMP 能激活A . PKAB . PKC C . PKGD . PLCE . PTK17 . MAPK 属于A .蛋白丝 / 苏氨酸激酶B .蛋白酪氨酸激酶C .蛋白半胱氨酸激酶D .蛋白天冬氨酸激酶E .蛋白谷氨酸激酶18 .蛋白激酶的作用是使蛋白质或酶A .磷酸化B .去磷酸化C .乙酰化D .去乙酰基E .合成19 .胰岛素受体具有下列哪种酶的活性A . PKAB . PKGC . PKCD . Ca 2+ -CaM 激酶E .酪氨酸蛋白激酶20 . DAG 能特异地激活A . PK AB . PKC C . PKGD . PLCE . PTK(二) B 型题A .胰岛素B .胰高血糖素C .肾上腺素D .促性腺激素E .甲状腺素1 .可通过细胞膜,并与细胞核内受体结合的激素是2 .抑制腺苷酸环化酶,激活磷酸二脂酶,使 cAMP 下降的激素是A 、细胞膜B 、细胞浆C 、细胞核D 、内质网E 、线粒体3 .腺苷酸环化酶位于4 .雌激素受体位于A . cAMPB . cGMPC . IP 3D . DAGE . Ca 2+5 . NO 的第二信使是6 .胰高血糖素的第二信使是(三) X 型题1 .受体与配体结合的特点是A .高度专一性B .高度亲和力C .可饱和性D .可逆性E .可调节性2 .下列哪些是膜受体激素A .甲状腺素B .胰岛素C .肾上腺素D .维生素 D 3E .胰高血糖素3 .通过 G 蛋白偶联通路发挥作用的激素有A .胰高血糖素B .抗利尿激素C .促肾上腺皮质激素D .肾上腺素E .促甲状腺激素释放激素4 .在信息传递过程中,不产生第二信使的是A .活性 VitD 3B .雌激素C .雄激素D .糖皮质激素E .甲状旁腺素5 . 90% 以上的 Ca 2+ 储存于A .内质网B .高尔基体C .线粒体D .细胞核E .细胞浆二、是非题1 .细胞外化学信号有可溶性的和膜结合型的两种形式,细胞表面分子是重要的膜结合型的细胞外信号。
生物信息学复习题

生物信息学复习题### 生物信息学复习题#### 一、选择题1. 生物信息学主要研究的是什么?A. 生物学数据的收集和存储B. 生物学数据的分析和解释C. 生物学实验的设计和执行D. 生物学仪器的操作和维护2. 下列哪一项不是生物信息学中常用的数据库?A. GenBankB. PDBC. PubMedD. Google Scholar3. 序列比对的目的是什么?A. 确定序列间的同源性B. 预测蛋白质的三维结构C. 鉴定基因的功能D. 计算基因的表达量#### 二、填空题1. 生物信息学中的BLAST工具主要用于__________。
2. 基因表达分析中常用的芯片技术包括__________和__________。
3. 在蛋白质结构预测中,同源建模依赖于__________数据库中的已知结构。
4. 转录组测序(RNA-Seq)可以用于研究__________和__________。
#### 三、简答题1. 描述基因组注释的一般流程。
2. 阐述生物信息学在药物设计中的应用。
3. 解释什么是系统发育树,并说明其在进化研究中的意义。
#### 四、计算题1. 给定一段DNA序列,计算其GC含量。
(示例序列:ATCGTACGTAGCTAGCTAG)2. 如果一个蛋白质序列的分子量为12345 Da,其氨基酸的平均分子量为110 Da,计算该蛋白质序列中氨基酸的数量。
#### 五、论述题1. 讨论生物信息学在个性化医疗中的作用和挑战。
2. 分析高通量测序技术对生物信息学领域的影响。
通过以上题目的复习,可以帮助学生掌握生物信息学的基础知识和技能,包括对生物数据的分析、解释和应用。
这些知识点不仅涵盖了生物信息学的基础理论,还涉及到实际应用,如药物设计、个性化医疗等,为学生提供了一个全面的复习框架。
《生物信息学》练习题剖析

1、在Genbank中查找以下6个植物蛋白序列:protein1:NP_974673.2; protein2: NP_187969.1; protein3: NP_190855.1; protein4: NP_565618.1; protein5: NP_200511.1; protein6: NP_191407.1 (以FASTA格式)。
(1)用EBI上的ClustalW2工具对其进行多序列比对,分析各蛋白序列之间的同源性。
序列比对结果比对结果表明:protein1:NP_974673.2和protein4: NP_565618.1的亲缘关系最近。
(2)利用Phylip软件,选择距离法构建其进化树(要求写出具体的建树步骤)。
1.将蛋白序列保存为FASTA格式,存于txt文档;2.用Clustalx打开txt文本,保存为*.phy文件;3.用seqboot程序打开phy文件,输出结果文件*_seqboot4.用protdist程序打开*_seqboot文件,输出为*_protdist文件5. 用neighbor程序打开*_protdist文件,输出为*_neighbor文件6. 用consense程序打开*_neighbor文件,输出为*_consense文件7.用dratree程序打开*_consense文件得到进化树。
(注:由于seqboot软见无法正常运行,因此进化树无法显示)(3)任意选取其中的一个蛋白进行蛋白质一级序列分析、二级结构预测及三维结构的模拟。
选择protein3: NP_190855.1一级结构网址:/tools/protparam.htmlNumber of amino acids: 456 氨基酸数目Molecular weight: 51154.5 相对分子质量Theoretical pI: 8.69 理论 pI 值Amino acid composition 氨基酸组成Ala (A) 30 6.6%Arg (R) 28 6.1%Asn (N) 15 3.3%Asp (D) 27 5.9%Cys (C) 5 1.1%Gln (Q) 18 3.9%Glu (E) 28 6.1%Gly (G) 37 8.1%His (H) 16 3.5%Ile (I) 16 3.5%Leu (L) 42 9.2%Lys (K) 32 7.0%Met (M) 5 1.1%Phe (F) 17 3.7%Pro (P) 16 3.5%Ser (S) 46 10.1%Thr (T) 21 4.6%Trp (W) 8 1.8%Tyr (Y) 19 4.2%Val (V) 30 6.6%Pyl (O) 0 0.0%Sec (U) 0 0.0%(B) 0 0.0%(Z) 0 0.0%(X) 0 0.0%正/负电荷残基数Total number of negatively charged residues (Asp + Glu): 55Total number of positively charged residues (Arg + Lys): 60Atomic composition: 原子组成Carbon C 2270Hydrogen H 3531Nitrogen N 645Oxygen O 686Sulfur S 10Formula: C2270H3531N645O686S10 分子式Total number of atoms: 7142 总原子数Extinction coefficients: 消光系数Extinction coefficients are in units of M-1 cm-1, at 280 nm measured in water.Ext. coefficient 72560Abs 0.1% (=1 g/l) 1.418, assuming all pairs of Cys residues form cystines Ext. coefficient 72310Abs 0.1% (=1 g/l) 1.414, assuming all Cys residues are reducedEstimated half-life: 半衰期The N-terminal of the sequence considered is M (Met).The estimated half-life is: 30 hours (mammalian reticulocytes, in vitro).>20 hours (yeast, in vivo).>10 hours (Escherichia coli, in vivo).Instability index: 不稳定系数The instability index (II) is computed to be 48.99This classifies the protein as unstable.Aliphatic index: 75.26 脂肪系数Grand average of hydropathicity (GRAVY): -0.554 总平均亲水性/tools/protscale.html蛋白质亲疏水性分析所用氨基酸标度信息Ala: 1.800 Arg: -4.500 Asn: -3.500 Asp: -3.500 Cys: 2.500 Gln: -3.500 Glu: -3.500 Gly: -0.400 His: -3.200 Ile: 4.500 Leu: 3.800 Lys: -3.900 Met: 1.900 Phe: 2.800 Pro: -1.600 Ser: -0.800 Thr: -0.700 Trp: -0.900 Tyr: -1.300 Val: 4.200 : -3.500 : -3.500 : -0.490分析所用参数信息Weights for window positions 1,..,9, using linear weight variation model:1 2 3 4 5 6 7 8 91.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00edge center edge跨膜结构预测结果(没有跨膜结构)信号肽分析:二级结构预测三级结构预测网站/~phyre2、在拟南芥基因组数据库中(/)查找编号分别为At4G33050, At3G13600,At3G52870或At2G26190基因,针对所查找的基因进行初步的生物信息学分析(每人任选其中一个基因)。
生物信息学复习题已附答案

本卷的答案仅做参考,如有疑问欢迎提出。
后面的补充复习题要靠你们自己整理答案了。
生物信息学复习题一、填空题1、识别基因主要有两个途径即基因组DNA外显子识别和基于EST策略的基因鉴定。
2、表达序列标签是从mRNA 中生成的一些很短的序列(300-500bp),它们代表在特定组织或发育阶段表达的基因。
3、序列比对的基本思想,是找出检测基因和目标序列的相似性,就是通过在序列中插入空位的方法使所比较的序列长度达到一致。
比对的数学模型大体分为两类,分别是整体比对和局部比对。
4、2-DE的基本原理是根据蛋白质等电点和分子量不同,进行两次电泳将之分离。
第一向是等电聚焦分离,第二向是SDS-PAGE分离。
5、蛋白质组研究的三大关键核心技术是双向凝胶电泳技术、质谱鉴定技术、计算机图像数据处理与蛋白质数据库。
二、判断题1、生物体的结构和功能越复杂的种类就越多,所需要的基因也越多,C值越大,这是真核生物基因组的特点之一。
(对)2、CDS一定就是ORF。
(对)3、两者之间有没有共同的祖先,可以通过序列的同源性来确定,如果两个基因或蛋白质有着几乎一样的序列,那么它们高度同源,就具有共同的祖先。
(错)4、STS,是一段200-300bp的特定DNA序列,它的序列已知,并且在基因组中属于单拷贝。
(对)5、非编码DNA是“垃圾DNA”,不具有任何的分析价值,对于细胞没有多大的作用。
(错)6、基因树和物种树同属于系统树,它们之间可以等同。
(错)7、基因的编码序列在DNA分子上是被不编码的序列隔开而不连续排列的。
( 对)8、对任意一个DNA序列,在不知道哪一个碱基代表CDS的起始时,可用6框翻译法,获得6个潜在的蛋白质序列。
(对)9、一个机体只有一个确定的基因组,但基因组内各个基因表达的条件和表达的程度随时间、空间和环境条件而不同。
(对)10、外显子和内含子之间没有绝对的区分,一个基因的内含子可以是另一个基因的外显子,同一个基因在不同的生理状况或生长发育的不同阶段,外显子组成也可以不同。
生物信息学习题

1单选(以下哪位科学家获得了两次诺贝尔奖?A.桑格(Frederick Sanger)B.沃森(James Waston)C.霍利(Robert W.Holley)D.克里克(Francis Crick)2单选(被称为“DNA之父”的是哪位科学家?A.摩尔根(Thomas H.Morgen)B.沃森(James Waston)C.查加夫(Erwin Chargaff)D.桑格(Frederick Sanger)3单选(被称为“计算机之父,人工智能之父”的是哪位科学家?A.莱布尼兹(Gottfried W Leibniz)B.图灵(Alan Mathison Turing)C.帕斯卡(Blaise Pascal)D.桑格(Frederick Sanger)4单选(被称为“现代实验生物学奠基人”的是哪位科学家?A.摩尔根(Thomas H.Morgen)B.达尔文(Charles Darwin)C.桑格(Frederick Sanger)D.孟德尔(Gregor J.Mendel)5单选(被称为“遗传学的奠基人,现代遗传学之父”的是哪位科学家A.孟德尔(Gregor J.Mendel)B.沃森(James Waston)C.查加夫(Erwin Chargaff)D.摩尔根(Thomas H.Morgen)1单选(从GenBank的哪一项注释中可以找到关于编码蛋白的信息?A.CDSB.SOURCEC.RBSD.ORIGIN2单选(以下关于GenBank的描述,哪个是正确的?A.GenBank里的一条数据库记录对应一个完整的基因。
B.真核生物的基因经常是分段存储在多条GenBank数据库记录里。
C.真核生物的基因都是整个存储在GenBank的一条数据库记录里。
D.原核生物的基因都是分片段存储在多条GenBank数据库记录里。
3多选(以下关系式正确的是?A.1T=1,000GB.1G=1,000MC.1G=1,000,000KD.1T=1,000,000M4(GenBank数据库中的检索号(Accession)和基因座名(Locus)指的都是一条序列在数据库中的编号,他们永远都是相同的。
生物信息学基础考试试题

生物信息学基础考试试题生物信息学基础考试试题回答一、选择题(每题5分,共20题)1. 生物信息学的定义是什么?A. 研究生物的基本信息B. 利用计算机科学分析生物学数据C. 研究生物的遗传编码D. 生物学的一个分支学科答案:B2. 以下哪个是常用的生物信息学数据库?A. NCBIB. C++C. DNAD. Photosynthesis答案:A3. 在DNA序列中,碱基A配对的是?A. TB. CC. GD. U答案:A4. 以下哪个是生物信息学中常用的序列比对算法?A. BLASTB. MATLABC. PCRD. ELISA答案:A5. 基因组学是研究什么的科学?A. 蛋白质结构B. DNA修复C. 基因组DNA的组成和功能D. 细胞分裂答案:C6. 哪种技术可用于测定DNA序列?A. 单克隆抗体技术B. RNA干扰技术C. 半制备列序法D. 高效液相色谱法答案:C7. 生物信息学中的序列模拟是指什么?A. 通过计算机模拟生物进化过程B. 利用计算机模拟DNA合成过程C. 模拟生物对某种药物的反应D. 利用计算机模拟细胞分裂过程答案:A8. 以下哪个是生物信息学的一个重要应用领域?A. 化学合成B. 建筑设计C. 新药研发D. 环境保护答案:C9. 哪个工具常用于分析生物信息中的调控网络?A. PhotoshopB. CytoscapeC. ExcelD. SPSS答案:B10. 蛋白质结构预测是生物信息学的一个重要研究方向,以下哪种是蛋白质的一级结构?A. α螺旋B. 葡萄糖C. 多肽链D. 抗原答案:C11. 生物信息学与生物医学工程有什么相似之处?A. 都研究细胞生物学B. 都属于理学院系C. 都涉及到计算机科学D. 都使用相同的实验方法答案:C12. 在基因组测序中,什么是基因组装?A. 利用计算机将碎片序列拼接成连续的基因组B. 测定基因组中的突变位点C. 研究基因间的调控关系D. 将RNA转录为蛋白质的过程答案:A13. 以下哪个不属于生物信息学的软件工具?A. BLASTB. PhotoshopC. RD. Python答案:B14. 哪种常见的DNA测序技术被广泛应用于基因组学研究?A. Sanger测序B. 吉姆斯法则C. CRISPR-Cas9技术D. 免疫印迹法答案:A15. 生物信息学中的反向遗传学用于研究什么?A. DNA复制B. 基因的转录和翻译C. RNA干扰D. 基因组的组装答案:B16. 哪种方法可用于鉴定基因表达谱中的关键基因?A. 蛋白质降解法B. 基因芯片技术C. 聚合酶链式反应D. 免疫组化技术答案:B17. 生物信息学研究中常用的基因表达定量方法是什么?A. Western BlotB. ELISAC. qPCRD. 蛋白质组学答案:C18. 生物信息学中的系统生物学研究的是什么?A. 各个细胞器的功能B. 化学元素与生物体的相互作用C. 生物学过程中的相互关系D. 各个动物种群的遗传特征答案:C19. 下面哪个数据库不是用于蛋白质结构预测的?A. PDBB. UniProtC. Swiss-ProtD. Entrez Gene答案:D20. 生物信息学中常用的序列对比方法是什么?A. 水平基因转移B. Smith-Waterman算法C. 单克隆抗体制备D. RNA干扰技术答案:B二、简答题(每题10分,共5题)1. 编程语言在生物信息学中的作用是什么?编程语言在生物信息学中扮演着重要角色。
生物信息学复习题百度文库合集

生物信息学,一、名词解释:1、生物信息学:生物分子信息的获取、存贮、分析和利用;以数学为基础,应用计算机技术,研究生物学数据的科学。
2、相似性(similarity):两个序列(核酸、蛋白质)间的相关性。
3、同源性(homology):生物进化过程中源于同一祖先的分支之间的关系。
4、同一性(identity):两个序列(核酸、蛋白质)间未发生变异序列的关系。
5、序列比对(alignment):为确定两个或多个序列之间的相似性以至于同源性,而将它们按照一定的规律排列。
6、生物数据库检索(database query,数据库查询):对序列、结构以及各种二次数据库中的注释信息进行关键词匹配查找。
7、生物数据库搜索(database search):通过特定序列相似性比对算法,找出核酸或蛋白质序列数据库中与待检序列具有一定程度相似性的序列。
二、简答题:1、分子生物学的三大核心数据库是什么?它们各有何特点?GenBank核酸序列数据库;SWISS-PROT蛋白质序列数据库;PDB生物大分子结构数据库;2、简述生物信息学的发生和发展。
20世纪50年代,生物信息学开始孕育;20世纪60年代,生物分子信息在概念上将计算生物学和计算机科学联系起来;20世纪70年代,生物信息学的真正开端;20世纪70年代到80年代初期,出现了一系列著名的序列比较方法和生物信息分析方;20世纪80年代以后,出现一批生物信息服务机构和生物信息数据库;20世纪90年代后,HGP促进生物信息学的迅速发展。
3、生物信息学的主要方法和技术是什么?数学统计方法;动态规划方法;机器学习与模式识别技术;数据库技术及数据挖掘;人工神经网络技术;专家系统;分子模型化技术;量子力学和分子力学计算;生物分子的计算机模拟;因特网(Internet)技术4、常见的DNA测序方法有哪些?各有何技术特点和优缺点?Maxam-Gilbert DNA化学降解法:优点:可测完全未知序列及CG富含区;缺点:操作繁琐;Sanger双脱氧链终止法:优点:简便,可测较长片段;缺点:需已知部分序列或加接头;焦磷酸测序:优点:廉价、高通量;缺点:一次测序片段短。
细胞生物学习题:细胞核与遗传信息的流向

细胞核与遗传信息的流向A型题:1.通常在电镜下可见核外膜与细胞质中哪中细胞器相连A.高尔基复合体B.溶酶体C.线粒体D.粗面内质网E.滑面内质网2.核仁的功能是A.合成DNAB.合成mRNAC.合成rRNAD.合成tRNAE.合成异染色质3.真核细胞与原核细胞最大的差异是A.核大小不同B.核结构不同C.核物质不同D.核物质分布不同E.有无核膜4.关于X染色质哪种说法是错误的A.间期细胞核中无活性的异染色质B.出现胚胎发育的第16~18天C.在卵细胞的发生过程中可恢复其活性D.由常染色质转变而来E.在细胞周期中形态不变5.核仁的大小取决于A.细胞内蛋白质的合成速度B.核仁组织者的多少C.染色体的大小D.内质网的多少E.核骨架的大小6.Np=Vn/(Vc-Vn)代表的关系是A.细胞核与细胞质体积之间的固定关系B.细胞质与细胞体积之间的固定关系B.细胞核与细胞体积之间的固定关系 D.细胞质与细胞核数量之间的固定关系E.细胞核与细胞数量之间的固定关系7.间期细胞核内侧数量较多粗大的浓染颗粒是A.常染色质B.异染色质C.核仁D.X染色质E.核骨架8.遗传信息主要贮存在A.染色质B.核仁C.核膜D.核基质E.核仁组织者9.在等径细胞中,核的形态为A.杆状B.球形C.卵圆形D.分叶状E.扁平球状10.核小体的化学成分是A.RNA和非组蛋白B.RNA和组蛋白C.DNA和组蛋白D.DNA和非组蛋白E.DNA、RNA和组蛋白11.位于染色体着丝点和臂两侧,由高度重复序列组成的染色质是A.常染色质B.结构异染色质C.功能异染色质D.核仁相随染色质E.X染色质12.核小体中的组蛋白八聚体是指A.2H1+2H2B+2 H3+2 H4B.2H1+2H2A+2 H2B+2 H3C. 2H1+2H2A+2 H3+2 H4D. 2H2A+2 H2B+2 H3+2 H4E. 2H1+2H2A+2 H2B+2 H413.细胞核中遗传物质的复制规律是A.常染色质和异染色质tRNA同时复制B.异染色质复制多,常染色质复制少C.常染色质复制多,异染色质复制少D.异染色质先复制E.常染色质先复制14.细胞核中的NORA.可转录mRNAB.可转录tRNAC.异染色质不转录D.可装配核糖体亚单位E.合成核糖体蛋白质15.人类的X染色体在核型分析时应在A.A组B.B组C.C组D.D组E.E组16.在DNA分子中,若A+T为60%,则G的含量为A.40%B.20%C.30%D.15%E.10%17.一段mRNA的顺序是5ˊAUG GCG GUG AAU GGC UAA3ˊ它的翻译产物是A.6肽B.5肽C.4肽D.3肽E.以上都不是18.tRNA柄部3ˊ端的碱基顺序是A.UAAB.AUGC.ACCD.UAGA19.密码子决定于A.mRNA上3个连续的核苷酸B.蛋白质上3个连续的氨基酸C.tRNA上3个连续的碱基D.反密码子E.tRNA柄部3ˊ端CCA20.一个tRNA的反密码子为3ˊUGC5ˊ,它能识别的mRNA的密码子是A. 5ˊACG3ˊB. 5ˊUGC3ˊC. 5ˊTCG3ˊD. 3ˊACG5ˊE. 3ˊTCG5ˊ21.原核细胞遗传信息表达时A.转录和翻译同时进行B.转录和翻译不同时进行C.转录和翻译同地进行D.转录和翻译不同地进行E. 转录和翻译同时同地进行22.组蛋白在基因调节系统中的调节作用是A.参加DNA转录B.催化DNA转录C.激活DNA转录D.抑制DNA转录E.与DNA转录无关23.真核细胞的遗传信息流向是A.mRNA→DNA→蛋白质B.DNA→mRNA→蛋白质C.DNA→rRNA→蛋白质D.DNA→tRNA→蛋白质E.DNA→hnRNA→蛋白质24.DNA复制过程中所需的引物是A.RNAB. tRNAC. rRNAD.mRNAE.hnRNA25.翻译是指A.mRNA的合成B.tRNA运输蛋白质C.rRNA的合成D.核糖体大小亚基的解聚E.以mRNA为膜板合成蛋白质的过程B型题:A.核膜B.核孔复合体C.核仁D.核基质E.染色质26.由8对辐射对称排列的小球状亚单位构成的复合体是27.细胞核中各种酶、无机盐和水存在于28.细胞中的DNA主要存在于29.由脂质双层为主体形成的结构是30.rRNA的合成中心是A.DNAB.mRNAC.核糖体D.tRNAE.溶酶体31.蛋白质生物合成的场所是32.可与组蛋白结合形成染色体的是33.蛋白质生物合成的直接膜板是34.在细胞中的与消化功能有关的细胞器A.核小体B.核膜C.核基质D.核仁E.染色质35.由两层膜构成的,具有多孔结构的是36.为透明的胶状物质,可作为细胞核执行多种生理活动所必须的内环境37.在电镜下为一具有较高电子密度的一团稀疏的无外膜包被的海绵状结构是38.在间期核中可被碱性染料着色的结构是39.其外侧附着有核糖体并可与粗面内质网相连的是40.构成核糖体的大小亚基来自于41.组成染色质和染色体的最基本结构单位是42.从形成过程看,实际上是包裹核物质的内质网的一部分,其结构是A.着丝粒B.着丝点C.随体D.端粒E.次缢痕43.人类某些染色体短臂上的圆形突出物44.位于染色体末端由异染色质构成的结构是45.染色体臂上与核仁形成有关的部位称为46.有丝分裂时纺锤体微管的附着点是47.中期染色体连结姐妹染色单体的结构是C型题:A.常染色质B.异染色质C.二者均是D.二者均不是48.在间期核中处于伸展状态的是49.在间期核中处于凝集状态的是50.在间期核中具有转录活性的是51.在间期核中处于转录静止状态的是52.主要成分是DNA和组蛋白的是53.在S期早期复制的是54.在S期晚期复制的是A.结构异染色质B.功能异染色质C.二者均是D.二者均不是55.在所有类型细胞和全部发育过程都保持紧密结构的是56.可随不同细胞类型和不同发育时期而发生变化的异染色质是57.在间期细胞中不具有转录活性的是58.在间期细胞中可有转录活性的是59. X染色质属于60.着丝粒区域的主要成分是A.rRNAB.tRNAC.二者都是D.二者都不是61.由RNA聚合酶催化产生的是62.可与蛋白质结合形成核糖体的是63.决定多肽链氨基酸顺序的是64.可转运活化氨基酸的是65.是细胞核内DNA的转录产物X型题:66.哪些是染色质的结构A.组蛋白B.螺线管C.超螺线管D.DNAE.核小体67.哪些结构是由异染色质组成的A.着丝粒B.随体C.X染色质D.次缢痕E.染色体长臂68.核仁中的核酸有A.DNAB.mRNAC.tRNAD.rRNAE.mtRNA69.细胞核的化学成分A.DNAB.RNAC.组蛋白D.非组蛋白E.脂肪70.核被膜的主要功能是A.屏障功能B.控制核质间的物质和信息交换C.参与染色质和染色体的定位D.参与蛋白质的合成E.作为染色质复制时的附着点71.细胞核的大小与哪些因素有关A.细胞类型B.细胞体积C.细胞发育阶段D.细胞机能形态E.遗传物质多少72.在蛋白质合成旺盛的细胞中A.核糖体增多B.核仁体积增大C.核孔数目增多D.异染色质增多E.粗面内质网增多73.光学显微镜下可观察到的结构是A.核仁B.染色体C.染色质D.核小体E.核膜74. mRNA分子中的密码子AUG具有哪些功能A.代表终止子B.代表甲硫氨酸C.代表赖氨酸D.代表起始密码子E.代表谷氨酸名词解释:1.同源染色体2.常染色质3.异染色质4.随体5.核仁组织区6.核骨架7.核孔复合体8.密码子9.简并 10.基因 11.复制子填空题:1.间期核的超微结构由、、和组成。
生物化学习题与解析--细胞信息转导

细胞信息转导一、选择题( 一 )A 型题1 .下列哪种物质不是细胞间信息分子A .胰岛素B . COC .乙酰胆碱D .葡萄糖E . NO2 .通过核内受体发挥作用的激素是A .乙酰胆碱B .肾上腺素C .甲状腺素D . NOE .表皮生长因子3 .下列哪种物质不是第二信使A . cAMPB . cGMPC . IP 3D . DAGE . cUMP4 .膜受体的化学性质多为A .糖蛋白B .胆固醇C .磷脂D .酶E .脂蛋白5 .下列哪种转导途径需要单跨膜受体A . cAMP - 蛋白激酶通路B . cAMP - 蛋白激酶通路C .酪氨酸蛋白激酶体系D . Ca 2+ - 依赖性蛋白激酶途径E .细胞膜上 Ca 2+ 通道开放6 .活化 G 蛋白的核苷酸是A . GTPB . CTPC . UTPD . ATPE . TTP7 .生成 NO 的底物分子是A .甘氨酸B .酪氨酸C .精氨酸D .甲硫氨酸E .胍氨酸8 .催化 PIP 2 水解为 IP 3 的酶是A .磷脂酶 AB .磷脂酶 A 2C .磷脂酶 CD . PKAE . PKC9 .第二信使 DAG 的来源是由A . PIP 2 水解生成B .甘油三脂水解而成C .卵磷脂水解产生D .在体内合成E .胆固醇转化而来的10 . IP 3 受体位于A 、细胞膜B 、核膜C 、内质网D 、线粒体内膜E 、溶酶体11 . IP 3 与内质网上受体结合后可使胞浆内A . Ca 2+ 浓度升高B . Na 2+ 浓度升高C . cAMP 浓度升高D . cGMP 浓度下降E . Ca 2+ 浓度下降12 .激活的 G 蛋白直接影响下列哪种酶的活性A .磷脂酶 AB .蛋白激酶 AC .磷脂酶 CD .蛋白激酶 CE .蛋白激酶 G13 .关于激素,下列叙述正确的是A .都由特殊分化的内分泌腺分泌B .激素与受体结合是可逆的C .与相应的受体共价结合,所以亲和力高D .激素仅作用于细胞膜表面E .激素作用的强弱与其浓度成正比14 . 1 , 4 , 5 - 三磷酸肌醇作用是A .细胞膜组成成B .可直接激活 PKC C .是细胞内第二信使D .是肌醇的活化形式E .在细胞内功能15 .酪氨酸蛋白激酶的作用是A .分解受体中的酪氨B .使蛋白质中大多数酪氨酸磷酸化C .使各种含有酪氨酸的蛋白质活化D .使蛋白质结合酪氨酸E .使特殊蛋白质分子上酪氨酸残基磷酸化16 . cGMP 能激活A . PKAB . PKC C . PKGD . PLCE . PTK17 . MAPK 属于A .蛋白丝 / 苏氨酸激酶B .蛋白酪氨酸激酶C .蛋白半胱氨酸激酶D .蛋白天冬氨酸激酶E .蛋白谷氨酸激酶18 .蛋白激酶的作用是使蛋白质或酶A .磷酸化B .去磷酸化C .乙酰化D .去乙酰基E .合成19 .胰岛素受体具有下列哪种酶的活性A . PKAB . PKGC . PKCD . Ca 2+ -CaM 激酶E .酪氨酸蛋白激酶20 . DAG 能特异地激活A . PK AB . PKC C . PKGD . PLCE . PTK(二) B 型题A .胰岛素B .胰高血糖素C .肾上腺素D .促性腺激素E .甲状腺素1 .可通过细胞膜,并与细胞核内受体结合的激素是2 .抑制腺苷酸环化酶,激活磷酸二脂酶,使 cAMP 下降的激素是A 、细胞膜B 、细胞浆C 、细胞核D 、内质网E 、线粒体3 .腺苷酸环化酶位于4 .雌激素受体位于A . cAMPB . cGMPC . IP 3D . DAGE . Ca 2+5 . NO 的第二信使是6 .胰高血糖素的第二信使是(三) X 型题1 .受体与配体结合的特点是A .高度专一性B .高度亲和力C .可饱和性D .可逆性E .可调节性2 .下列哪些是膜受体激素A .甲状腺素B .胰岛素C .肾上腺素D .维生素 D 3E .胰高血糖素3 .通过 G 蛋白偶联通路发挥作用的激素有A .胰高血糖素B .抗利尿激素C .促肾上腺皮质激素D .肾上腺素E .促甲状腺激素释放激素4 .在信息传递过程中,不产生第二信使的是A .活性 VitD 3B .雌激素C .雄激素D .糖皮质激素E .甲状旁腺素5 . 90% 以上的 Ca 2+ 储存于A .内质网B .高尔基体C .线粒体D .细胞核E .细胞浆二、是非题1 .细胞外化学信号有可溶性的和膜结合型的两种形式,细胞表面分子是重要的膜结合型的细胞外信号。
生物信息学期末复习题

9)预测基因的一般步骤是什么?答案:⑴获取DNA目标序列⑵查找ORF并将目标序列翻译成蛋白质序列,利用相应工具查找ORF并将DNA序列翻译成蛋白质序列⑶在数据库中进行序列搜索,利用BLAST进行ORF核苷酸序列和ORF翻译的蛋白质序列搜索⑷进行目标序列与搜索得到的相似序列的全局对比⑸查找基因家族进行多序列比对,获得比对区段的基因家族信息⑹查找目标序列中的特定模序,分别在Prosite、BLOCK、Motif数据库中进行profile、模块(block)、模序(motif)检索⑺预测目标序列蛋白质结构,利用PredictProtein(EMBL)、NNPREDICT等预测目标序列的蛋白质二级结构。
15)在基因组序列分析方面,科学家关注哪些信息?答案:就人类基因组而言,编码区域在人类基因组所占的比例不超过3%。其余97%是非编码序列。对于非编码序列,人们了解得比较少,尚不清楚其含义或功能。然而,非编码区域对于生命活动具有重要的意义。这部分序列主要包括内含子、简单重复序列、移动元件(mobile element)及其遗留物、伪基因(pseudo gene)等。
3)简要介绍FASTA序列格式答案:FASTA格式,又叫Pearson格式,是最简单的,使用最多的格式。它的基本形式分为三个部分:⑴第一行:大于号(﹥)表示一个新的序列文件的开始,为标记符。后面可以加上文字说明,gi号,GenBank检索号,LOCUS名称等信息。⑵第二行:序列本身,为DNA的标准符号,通常大小写均可。⑶结束:无特殊标志,但建议多留一个空行,以便将序列和其他内容区分开。
16)为什么要进行序列片段组装?在进行序列片段组装时会遇到哪些问题?答案:大规模基因组测序得到待测序列的一系列序列片段,这些序列片段覆盖待测序列,序列片段之间也存在着相互覆盖或者重叠。遇到的问题:碱基标识错误;不知道片段的方向;存在重复区域;缺少覆盖。
中科院生物信息学复习题

1.什么是生物信息学,如何理解其含义?答:生物信息学有三个方面的含义:1)生物信息学是一个学科领域,包含着基因组信息的获取、处理、存储、分配、分析和解释的所有方面。
2)生物信息学是把基因组DNA序列信息分析作为源头,破译隐藏在DNA序列中的遗传语言,特别是非编码区的实质;同时在发现了新基因信息之后进行蛋白质空间结构模拟和预测;其本质是识别基因信号。
3)生物信息学的研究目标是揭示“基因组信息结构的复杂性及遗传语言的根本规律”。
它是当今自然科学和技术科学领域中“基因组、“信息结构”和“复杂性”这三个重大科学问题的有机结合。
怎样理解生物信息学:生物信息学是把基因组DNA序列信息分析作为源头,找到基因组序列中代表蛋白质和RNA基因的编码区;同时阐明基因组中大量存在的非编码区的信息实质,破译隐藏在DNA 序列中的遗传语言规律:在此基础上,归纳、整理与基因组遗传信息释放及其调控相关的转录谱和蛋白谱数据,从而认识代谢、发育、分化、进化的规律。
其还利用基因组中编码区信息进行蛋白空间结构模拟和蛋白功能预测,并将此类信息与生物体和生命过程中的生理生化信息结合,阐明其分子机制,最终进行蛋白、核酸分子设计、药物设计、个体化医疗保健设计。
2.如何利用数据库信息发现新基因,基本原理?答:利用数据库资源发现新基因,根据数据源不同,可分2种不同的查找方式:1)从大规模基因组测序得到的数据出发,经过基因识别发现新基因:利用大规模拼接好的基因组,使用不同数据方法,进行标识查找,并将找到的可能的新基因同数据库中已有的基因对比,从而确定是否为新基因。
可分为:①基于信号,如剪切位点、序列中的启动子与终止子等。
②基于组分,即基因家族、特殊序列间比较,Complexity analysis,Neural Network2)利用EST数据库发现新基因和新SNPs:数据来源于大量的序列小片段,EST较短,故关键在正确拼接。
方法有基因组序列比对、拼接、组装法等。
【免费下载】生物信息学课后题及答案

生物信息学课后习题及答案(由10级生技一、二班课代表整理)一、绪论1.你认为,什么是生物信息学?采用信息科学技术,借助数学、生物学的理论、方法,对各种生物信息(包括核酸、蛋白质等)的收集、加工、储存、分析、解释的一门学科。
2.你认为生物信息学有什么用?对你的生活、研究有影响吗?(1)主要用于:在基因组分析方面:生物序列相似性比较及其数据库搜索、基因预测、基因组进化和分子进化、蛋白质结构预测等在医药方面:新药物设计、基因芯片疾病快速诊断、流行病学研究:SARS、人类基因组计划、基因组计划:基因芯片。
(2)指导研究和实验方案,减少操作性实验的量;验证实验结果;为实验结果提供更多的支持数据等材料。
3.人类基因组计划与生物信息学有什么关系?人类基因组计划的实施,促进了测序技术的迅猛发展,从而使实验数据和可利用信息急剧增加,信息的管理和分析成为基因组计划的一项重要的工作。
而这些数据信息的管理、分析、解释和使用促使了生物信息学的产生和迅速发展。
4简述人类基因组研究计划的历程。
通过国际合作,用15年时间(1990-2005)至少投入30亿美元,构建详细的人类基因组遗传图和物理图,确定人类DNA的全部核苷酸序列,定位约10万基因,并对其他生物进行类似研究。
1990,人类基因组计划正式启动。
1996,完成人类基因组计划的遗传作图,启动模式生物基因组计划。
1998完成人类基因组计划的物理作图,开始人类基因组的大规模测序。
Celera公司加入,与公共领域竞争启动水稻基因组计划。
1999,第五届国际公共领域人类基因组测序会议,加快测序速度。
2000,Celera公司宣布完成果蝇基因组测序,国际公共领域宣布完成第一个植物基因组——拟南芥全基因组的测序工作。
2001,人类基因组“中国卷”的绘制工作宣告完成。
2003,中、美、日、德、法、英等6国科学家宣布人类基因组序列图绘制成功,人类基因组计划的.目标全部实现。
2004,人类基因组完成图公布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
GTATCACACG ACTCAGCGCA GCATTTGCCC
GTATCACATA GCTCAGCGCA GCATTTGCCC
6、对于下列距离矩阵,用 UPGMA 构建系统发生树。
ABCDE
A0
B3 0
C6 5 0
D 9 9 10 0
E 12 11 13 9 0 7、对下面距离矩阵,用 UPGMA 法构建系统发生树
ABCDE
A0
B8 0
Байду номын сангаас
C4 8 0
D6 8 6 0
E8 4 8 8 0 8、 对下面距离矩阵,用邻近归并法构建系统发生树
ABCDE F
A0 5 4 7 6 8
B
0 7 10 9 11
C
0768
D
059
E
08
F
0
9、为了发现最简约树,主要有哪几类搜索策略,各自有什么特点?
10、利用最大似然法构造系统发生树的本质是什么?
第六章 分子系统发生分析(问题与练习)
1、构建系统发生树,应使用
A、BLAST
B、FASTA
C、UPGMA
D、Entrez
2、构建系统树的主要方法有
、
、
等。
3、根据生物分子数据进行系统发生分析有哪些优点?
4、在 5 个分类单元所形成的所有可能的有根系统发生树中,随机抽取一棵树是反映真实关
系的树的可能性是多少?从这些分类单元所有可能的无根系统发生树中,随机选择一棵
5 '- ATGCTTGCGGATAGA-3 '。
2、若一条 mRNA 序列 5 '-AUG GGA UGU CGC CGA AAC-3 '被核糖体翻译,将形成怎样
的氨基酸的序列?若将第一个核苷酸删掉而将另一个 A 加到 mRNA 序列的 3 ' - 端,又
将形成怎样的氨基酸序列?
三、问答题
1、 有哪些信息可用于发现基因?
5、向核酸数据库 GenBank/EMBL/DDBJ 提交数据,应使用下列哪个软件
A、BLAST
B、Sequin
C、SRS
D、TreeBASE
6、在蛋白质序列数据库中比较查询蛋白质序列,应使用
A、BLASTn
B、BLASTp
C、tBLASTn
D、BLASTx
7、Profiles 数据库是
A、蛋白质序列数据库 B、核酸序列数据库 C、蛋白质二级数据库 D、蛋白质结构数据
第三章 生物信息学资源与数据挖掘工具(问题与练习)
一、 单项选择题(从每题的 A、B、C、D 四个被选答案中选择一个最佳答案。)
1、 如果我们试图做蛋白质亚细胞定位分析,应使用
A、NDB 数据库 B、SWISS-PROT 数据库 C、GenBank 数据库 D、PDB 数据库
2、如果试图确定一个新蛋白质序列属于哪一个蛋白质家族,或该序列可能包含何种结构域
1、蛋白质得分矩阵类型有 、
、、
和
等。
2、对位排列主要有局部比对和 三、运算题 1、画出下面两条序列的简单点阵图。将第一条序列放在 x 坐标轴上,将第二条序列放在 y
坐标轴上。 TGAACTCCCTCAGATATTA CGAACCCTCACATATTAGCG
2、对两个核酸序列 ACACACTA 和 AGCACACA 进行全局比对
或功能位点,应使用
A、PROSITE 数据库 B、DDBJ 数据库 C、PDB 数据库
D、PIR 数据库
3、在蛋白质一级数据库基础上,构建二级数据库应使用
A、近邻归并法
B、序列比对
C、基因融合法
D、Entrez
4、做 DNA 结构分析可使用
A、GenBank 数据库 B、PIR 数据库
C、NDB 数据库 D、BLOCKS 数据库
第八章 后基因组时代的生物信息学(问题与练习)
1、 比较生物还原论与生物综合论的异同 2、 简述“后基因组生物信息学”的基本研究思路 3、 后基因组生物信息学的主要挑战是什么? 4、 功能基因组系统学的基本特征是什么? 5、 说明后基因组生物信息学对信息流动的最新理解 6、 列举几种预测蛋白质-蛋白质相互作用的理论方法 7、 解释从基因表达水平关联预测蛋白质-蛋白质相互作用的理论方法 8、 解释基因保守近邻法预测蛋白质-蛋白质相互作用的理论方法 9、 解释基因融合法预测蛋白质-蛋白质相互作用的理论方法 10、解释种系轮廓发生法预测蛋白质-蛋白质相互作用的理论方法
2、 陈述 BLASTn、BLASTp 和 BLASTx 软件的用途
3、 解释正则表达式 C-Y-X2-[DG]-G-X-[ST]的含义
4、 试从密码子使用偏向性角度说明编码区和非编码区的区别
第五章 序列比对(问题与练习)
一、名词解释 序列比对
二、问答题
直系同源
并系同源
序列对位排列的主要用途
三、填空题
1、基序(motif) 2、SNP
3、基因家族
4、概念性翻译
第四章 序列分析(问题与练习)
一、名词解释
1、可读框(ORF) 2、剪切变体 3、表达标签序列(EST) 4、电子克隆
5、同义置换
6、“垃圾”DNA(junk DNA)
7、概念性翻译
二、运算题
1、按照 5 ' -端到 3 ' -端的顺序写出下列核苷酸的互补序列:
第七章 生物芯片(问题与练习)
1、 解释生物芯片的概念 2、 陈述生物芯片产生的历史背景 3、 根据支持介质划分,生物芯片有哪几种? 4、 根据制备方法划分,生物芯片有哪几种? 5、 根据探针划分,生物芯片有哪几种? 6、 基因芯片的基本原理 7、 基因芯片技术的四个步骤 8、 进行探针设计时需要考虑的主要因素 9、 列举检测芯片杂交信号的主要仪器 10、列举生物芯片的应用领域
5、试陈述 GenBank 数据库中一条记录下的主要信息
6、 解释正则表达式 C-Y-X2-[DG]-G-X-[ST]的含义
三、 填空题
1、目前国际上最常用的核酸序列数据库有 、
和
。
2、列举至少四种权威的蛋白质二级数据库 、 、 和
。
3、列举至少五种 NCBI 的服务项目 、 、
、和等
四、 名词解释
正确的树的可能性比前一种情况大还是小?
5、对于下列 5 条序列的比对构造一个距离矩阵,其中序列之间的距离值为比对中失配的碱
基数目,但是颠换的权值为转换的两倍。
GTGCTGCACG GCTCAGTATA GCATTTACCC
ACGCTGCACG GCTCAGTGCG GTGCTTACCC
GTGCTGCACG GCTCGGCGCA GCATTTACCC
1、 细胞学说的基本内容 2、 简述细胞分裂周期的全过程 3、 细胞分裂有哪些方式? 4、 说明细胞的分类 5、 简述原核细胞的基本内容 6、 真核细胞的基本结构 7、 陈述蛋白质的生物学功能 8、 试按你的理解对 20 种氨基酸进行分类 9、 画图说明肽键的形成过程 10、 何谓蛋白质一级结构? 11、 何谓蛋白质二级结构? 12、 何谓蛋白质超二级结构? 13、 何谓蛋白质四级结构? 14、 描述核酸的基本组成 15、 叙述 DNA 结构的基本内容 16、 图示目前公认的中心法则 17、 何为蛋白质剪切 18、 何为 GT-AG 规则? 19、 说明原核、真核生物基因的结构特征 20、 阐述 DNA 复制机制的最新进展 21、 阐述基因转录调控模型 22、 总结蛋白质转译的基本机制 23、 总结遗传密码破译的过程 24、 何谓操纵子? 25、 叙述基因表达调控的几个层次
库
8、TreeBASE 系统主要用于
A、发现新基因 B、系统生物学研究 C、类群间系统发育关系研究 D、序列比对
二、 问答题
1、 为什么说 SWISS-PROT 是最重要的蛋白质一级数据库?
2、 构建蛋白质二级数据库的基本原则是什么?
3、 构建蛋白质二级数据库的主要方法有哪些?
4、 叙述 SCOP 数据库对蛋白质分类的主要依据
第一章 生物信息学引论(问题与练习)
1、 什么是生物信息学? 2、 生物信息学的主要研究任务是什么? 3、 我国生物信息学的主要发展方向是什么? 4、 简述你所了解的人类基因组计划 5、 简述你所了解的生物信息学的基本方法和前沿技术 6、 生物信息学目前的主要研究内容
第二章 生物学基础(问题与练习)