链表的选择排序
大连东软数据结构题库全6

2③ 一组记录的关键码为{46,79,56,38,40,84},则利用快速排序的方法,以第一 个记录为基准得到的一次划分结果为( C ) 。 A.{38,40,46,56,79,84} C.{40,38,46,56,79,84} B. {40,38,46,79,56,84} D. {40,38,46,84,56,79}
6.10.3 知识点ቤተ መጻሕፍቲ ባይዱ冒泡排序
一、选择题 1③ 若用冒泡排序方法对序列{10, 14, 26, 29, 41, 52}从大到小排序, 需进行 ( C 次比较。 A. 3 B. 10 C. 15 D. 25 ) )
2 对n个不同的排序码进行冒泡排序,在下列哪种情况下比较的次数最多。 ( B A. 从小到大排列好的 B. 元素逆序 C. 元素无序 D. 元素基本有序
6.10 习题
6.10.1 知识点:直接插入排序
一、选择题 1② 用直接插入排序方法对下面四个序列进行排序(由小到大) ,元素比较次数最少的 是( C ) 。 A. 94,32,40,90,80,46,21,69 C. 21,32,46,40,80,69,90,94 B. 32,40,21,46,69,94,90,80 D. 90,69,80,46,21,32,94,40
6.10.4 知识点:快速排序
一、选择题 1③ 有一组数据{15,9,7,8,20,-1,7,4}, 用快速排序的划分方法进行一趟划分 后数据的排序为 ( A ) (按递增序) 。 A.下面的 B,C,D 都不对。 C.{20,15,8,9,7,-1,4,7} B.{9,7,8,4,-1,7,15,20} D. {9,4,7,8,7,-1,15,20}
F ) 2② 在初始数据表已经有序时, 快速排序算法的时间复杂度为 O ( n log 2 n ) 。 ) 3② 在待排数据基本有序的情况下, 快速排序效果最好。 【南京理工大学 1997】
写出以单链表为存储结构的一组数据的简单选择排序算法。

写出以单链表为存储结构的一组数据的简单选择排序算法。
以下是单链表存储结构的简单选择排序算法的实现:
```python
def selection_sort(link_list):
n = len(link_list)
for i in range(n):
min_idx = i
for j in range(i+1, n):
if link_list[j] < link_list[min_idx]:
min_idx = j
link_list[i], link_list[min_idx] = link_list[min_idx], link_list[i]
return link_list
```
算法的基本思路是,遍历待排序的链表,找到未排序部分中的最小值,然后将该值与链表的第一个元素交换位置,然后再遍历剩余的元素,继续按照此方法进行排序,直到整个链表都被排序。
在上面的实现中,我们通过 `min_idx` 变量来保存当前未排序部分中的最小值的索引。
在第一次遍历时,min_idx 等于 i,因为在未排序部分中,第一个元素通常是最小的。
在后续的遍历中,我们不断地寻找未排序部分中的最小值,并将其与链表的第一个元素交换位置,最后返回排好序的链表。
c语言 链表 提高查询的方法

(原创实用版3篇)编写:_______________审核:_______________审批:_______________单位:_______________时间:_______________序言下面是本店铺为大家精心编写的3篇《c语言链表提高查询的方法》,供大家借鉴与参考。
下载后,可根据实际需要进行调整和使用,希望能够帮助到大家,谢射!(3篇)《c语言链表提高查询的方法》篇1在 C 语言中,链表是一种常见的数据结构,可以用来解决许多实际问题。
链表的查询操作通常包括查找节点、查找节点的某个子节点、查找节点的前一个节点等。
下面介绍一些提高链表查询效率的方法:1. 插入和删除操作在链表中插入和删除节点时,需要遍历链表找到插入或删除位置。
这会耗费时间,特别是当链表很长时。
为了提高效率,可以使用二分查找或哈希表等算法来查找节点。
例如,可以使用二分查找算法来查找链表中的节点。
首先,定义一个指针指向链表的头节点,然后使用二分查找算法查找目标节点。
如果目标节点不存在,则返回 NULL。
如果目标节点存在,则返回该节点的指针。
2. 节点排序有时候,需要对链表中的节点进行排序。
可以使用插入排序、选择排序、快速排序等算法来完成。
无论哪种算法,都需要遍历链表,因此会耗费时间。
为了提高效率,可以使用归并排序或堆排序等算法。
例如,可以使用堆排序算法来对链表中的节点进行排序。
首先,将链表中的节点看作是一个堆,每次取出堆顶元素,并将剩余元素重新调整为堆。
重复这个过程,直到链表为空。
由于堆排序的时间复杂度为 O(nlogn),因此比插入排序和选择排序更高效。
3. 缓存节点在链表中查询节点时,有时候需要多次遍历链表。
为了避免重复遍历,可以使用缓存节点的方法。
具体来说,可以在链表中定义一个指针,用于缓存最近查询的节点。
这样,如果需要查询同一个节点,可以直接返回缓存节点,而无需再次遍历链表。
例如,可以在链表中定义一个指针 pre,用于缓存最近查询的节点。
单链表上容易实现的排序方法

单链表上容易实现的排序方法嘿,朋友们!今天咱来聊聊单链表上那些容易实现的排序方法。
你想想啊,单链表就像是一串珠子,每个珠子都有它自己的位置和信息。
那怎么把这些珠子排得整整齐齐呢?咱先说冒泡排序吧!这就好像是在一群小朋友里,让矮个子一个一个地慢慢往前站,把高个子往后挤。
每次都把最大的那个“珠子”给浮到最上面去。
虽然它比较简单直接,但有时候可能会有点慢悠悠的哦!就像你着急出门,却发现钥匙找半天,是不是有点让人着急呀?再来看看插入排序。
这就像是玩扑克牌的时候整理手牌,拿到一张牌,就看看该把它插到哪里合适。
嘿,这多形象呀!它可以一点点地把链表变得有序,虽然可能步骤多了点,但效果还是不错的哟!还有选择排序呢!这就好像是在一群选手中挑出最厉害的那个,然后把其他的依次排好。
是不是挺有意思的?它也能完成排序的任务呢!那咱为啥要用这些排序方法呀?这还用问吗?就像你收拾房间,总不能让东西乱七八糟地堆着吧!把链表排好序,才能更方便我们查找和使用其中的数据呀!不然找个数据都得费半天劲,那多麻烦呀!这些排序方法各有各的特点和用处。
就像不同的工具,有的适合干这个,有的适合干那个。
我们得根据具体情况来选择合适的排序方法,可不能瞎用哦!不然可能会事倍功半呢!比如说,如果链表的数据量不是特别大,那冒泡排序或者插入排序可能就挺合适的。
但要是数据量大得吓人,那可能就得考虑更高效的方法啦!总之呢,单链表上的排序方法就像是我们生活中的各种小技巧,学会了它们,就能让我们的编程之路更加顺畅。
所以呀,大家可得好好掌握这些方法哦!可别小瞧了它们,它们能帮我们解决大问题呢!现在,你是不是对单链表上的排序方法有了更清楚的认识啦?。
算法设计与分析基础习题参考答案

算法设计与分析基础习题参考答案5..证明等式gcd(m,n)=gcd(n,m mod n)对每⼀对正整数m,n都成⽴.Hint:根据除法的定义不难证明:●如果d整除u和v, 那么d⼀定能整除u±v;●如果d整除u,那么d也能够整除u的任何整数倍ku.对于任意⼀对正整数m,n,若d能整除m和n,那么d⼀定能整除n和r=m mod n=m-qn;显然,若d能整除n和r,也⼀定能整除m=r+qn和n。
数对(m,n)和(n,r)具有相同的公约数的有限⾮空集,其中也包括了最⼤公约数。
故gcd(m,n)=gcd(n,r)6.对于第⼀个数⼩于第⼆个数的⼀对数字,欧⼏⾥得算法将会如何处理?该算法在处理这种输⼊的过程中,上述情况最多会发⽣⼏次? Hint:对于任何形如0<=m并且这种交换处理只发⽣⼀次.7.a.对于所有1≤m,n≤10的输⼊, Euclid算法最少要做⼏次除法?(1次)b. 对于所有1≤m,n≤10的输⼊, Euclid算法最多要做⼏次除法?(5次)gcd(5,8)习题1.21.(农夫过河)P—农夫W—狼G—⼭⽺C—⽩菜2.(过桥问题)1,2,5,10---分别代表4个⼈, f—⼿电筒4. 对于任意实系数a,b,c, 某个算法能求⽅程ax^2+bx+c=0的实根,写出上述算法的伪代码(可以假设sqrt(x)是求平⽅根的函数)算法Quadratic(a,b,c)//求⽅程ax^2+bx+c=0的实根的算法//输⼊:实系数a,b,c//输出:实根或者⽆解信息D←b*b-4*a*cIf D>0temp←2*ax1←(-b+sqrt(D))/tempx2←(-b-sqrt(D))/tempreturn x1,x2else if D=0 return –b/(2*a)else return “no real roots”else //a=0if b≠0 return –c/belse //a=b=0if c=0 return “no real numbers”else return “no real roots”5.描述将⼗进制整数表达为⼆进制整数的标准算法a.⽤⽂字描述b.⽤伪代码描述解答:a.将⼗进制整数转换为⼆进制整数的算法输⼊:⼀个正整数n输出:正整数n相应的⼆进制数第⼀步:⽤n除以2,余数赋给Ki(i=0,1,2...),商赋给n第⼆步:如果n=0,则到第三步,否则重复第⼀步第三步:将Ki按照i从⾼到低的顺序输出b.伪代码算法DectoBin(n)//将⼗进制整数n转换为⼆进制整数的算法//输⼊:正整数n//输出:该正整数相应的⼆进制数,该数存放于数组Bin[1...n]中i=1while n!=0 do {Bin[i]=n%2;n=(int)n/2;i++;}while i!=0 do{print Bin[i];i--;}9.考虑下⾯这个算法,它求的是数组中⼤⼩相差最⼩的两个元素的差.(算法略) 对这个算法做尽可能多的改进.算法MinDistance(A[0..n-1])//输⼊:数组A[0..n-1]//输出:the smallest distance d between two of its elements习题1.31.考虑这样⼀个排序算法,该算法对于待排序的数组中的每⼀个元素,计算⽐它⼩的元素个数,然后利⽤这个信息,将各个元素放到有序数组的相应位置上去.a.应⽤该算法对列表‖60,35,81,98,14,47‖排序b.该算法稳定吗?c.该算法在位吗?解:a. 该算法对列表‖60,35,81,98,14,47‖排序的过程如下所⽰:b.该算法不稳定.⽐如对列表‖2,2*‖排序c.该算法不在位.额外空间for S and Count[]4.(古⽼的七桥问题)习题1.41.请分别描述⼀下应该如何实现下列对数组的操作,使得操作时间不依赖数组的长度. a.删除数组的第i 个元素(1<=i<=n)b.删除有序数组的第i 个元素(依然有序) hints:a. Replace the i th element with the last element and decrease the array size of 1b. Replace the ith element with a special symbol that cannot be a value of the array ’s element(e.g., 0 for an array of positive numbers ) to mark the i th position is empty . (―lazy deletion ‖)第2章习题2.17.对下列断⾔进⾏证明:(如果是错误的,请举例) a. 如果t(n )∈O(g(n),则g(n)∈Ω(t(n)) b.α>0时,Θ(αg(n))= Θ(g(n)) 解:a. 这个断⾔是正确的。
华清远见数据结构考试题A卷

华清远见数据结构考试题A卷一、选择题1.下面哪种排序法对123456798在空间和时间上最优( )A.快速排序B.冒泡排序C.插入排序D.堆排序2.就排序算法所用的辅助空间而言,堆排序,快速排序,归并排序的关系是( )A.堆排序<快速排序 <归并排序B.堆排序<归并排序<快速排序C.堆排序>归并排序>快速排序D.堆排序>快速排序>归并排序E.以上答案都不对3.一株二叉树的以某种遍历方式的序列为A、B、C、D、E、F、G, .若该二叉树的根结点为E,则它的一种可能的前序遍历为___ ,相应的后序遍历为__A. ECBADFG, BDCAFGEB. ECBADFG, EFACDBGC. ECBADGF, EACBDGFD. EACBDGF, BDCAFGE(常见题型,给出树的前序遍历和中序遍历,中序和后续遍历,推出二叉树)4.关于图和树,下面说法正确的是_A.树和图都允许有环B.图的深度遍历和广度遍历结果可能一样C.二叉树是每个节点都有两个孩子节点的树D.二叉树的前序遍历和后序遍历结果肯定不一样5.完成在双循环链表结点 p之后插入s的操作是( )A. p->next=s ; s->priou=p; p->next: >priou=s ;s->next=p->next;B. p->next->priou=s; p->next=s; s->priou=p; s->next=p->next;C. s->priou=p; s->next=p->next; p->next=s; p->next->priou=s ;D. s->priou=p; s->next=p->next; p->next->priou=s; p->next=s;二、填空题1. 用链表表示的数据的简单选择排序,结点的域为数据域data,指针域next :链表首指针为head,链表无头结点。
掌握数据结构中的链表和数组的应用场景

掌握数据结构中的链表和数组的应用场景链表和数组都是常用的数据结构,它们在不同的场景下有不同的应用。
一、链表的应用场景:1.链表适合动态插入和删除操作:链表的插入和删除操作非常高效,只需修改指针的指向,时间复杂度为O(1)。
因此,当需要频繁进行插入和删除操作时,链表是一个很好的选择。
-操作系统中的进程控制块(PCB):操作系统需要频繁地创建、停止、销毁进程,使用链表存储这些PCB,可以方便地插入、删除和管理进程。
-聊天记录:在聊天应用中,新的消息会动态插入到聊天记录中,使用链表存储聊天记录可以方便地插入新消息。
2.链表节省内存空间:每个节点只需存储当前元素和指向下一个节点的指针,不需要像数组一样预分配一块连续的内存空间,因此链表对内存空间的利用更加灵活。
-操作系统中的内存管理:操作系统使用链表来管理空闲内存块和已分配的内存块,可有效节省内存空间。
3.链表支持动态扩展:链表的长度可以随时变化,可以动态地扩容和缩容。
-缓存淘汰算法:在缓存中,如果链表已满,当有新数据需要加入缓存时,可以通过删除链表头部的节点来腾出空间。
4.链表可以快速合并和拆分:将两个链表合并成一个链表只要调整指针的指向即可,时间复杂度为O(1)。
-链表排序:在排序算法中,链表归并排序利用链表快速合并的特性,使得归并排序在链表上更高效。
二、数组的应用场景:1.随机访问:数组可以根据索引快速访问元素,时间复杂度为O(1)。
-图像处理:图像通常以像素点的形式存储在数组中,可以通过索引快速访问某个特定像素点的颜色信息。
2.内存连续存储:数组的元素在内存中是连续存储的,可以利用硬件缓存机制提高访问效率。
-矩阵运算:矩阵可以通过二维数组来表示,利用矩阵的连续存储特性,可以高效地进行矩阵运算。
3.大数据存储:数组可以预先分配一块连续的内存空间,非常适合存储大量的数据。
-数据库中的数据表:数据库中的数据表通常使用数组来实现,可以快速存取和处理大量的数据。
C语言实现单向链表及其各种排序(含快排,选择,插入,冒泡)

C语⾔实现单向链表及其各种排序(含快排,选择,插⼊,冒泡) #include<stdio.h>#include<malloc.h>#define LEN sizeof(struct Student)struct Student //结构体声明{long num;int score;struct Student* next;};int n;struct Student* creat() //创建单向链表{struct Student *head=NULL, *p_before, *p_later;p_before = p_later = (struct Student*) malloc(LEN);scanf_s("%ld%d", &p_before->num, &p_before->score);while (p_before->num!=0){n++;if (n == 1) head = p_before;else p_later->next = p_before;p_later = p_before;p_before = (struct Student*) malloc(LEN);scanf_s("%ld%d", &p_before->num, &p_before->score);}p_later->next = NULL;free(p_before);return head;}struct Student* sort(struct Student* list) //冒泡排序,当初写的是内容交换⽽不是指针交换,我知道这不是好的做法,但⽇⼦⼀久,当下没时间和热情改了,⼤家原谅,{ //等有时间了⼀定改struct Student *p, *q;int temp1,i;long temp2;for (p = list, i =1; i < n;i++,p=p->next)for (q = p->next;q!= NULL;q=q->next)if (p->score < q->score){temp1 = p->score;p->score = q->score;q->score = temp1;temp2 = p->num;p->num = q->num;q->num = temp2;}return list;}struct Student* sort1(struct Student* h) //插⼊排序(下边这堆注释是当初写完代码后⼜分析时加的,这⾥必须承认,我参考了⽹上的⼀些代码。
链式结构上排序算法的研究

Ke r s h i a l ; u b e s r a g r h ; n e t n s r lo i m ; h o e S r a g r h ; n lss o lo t ms y wo d :c a n tb e b b l o t l o t m i s r o o t g rt i i a h c o s O l o t m a ay i fag r h t i i
实现 ,必须先定义链表 的结点 ,可定义如下的链式结构 :
tp dfn lmt e / lm y e为 it y ee t e y ; e tp i e p/ e n 型
sr tno e tuc d
, 果 h a 指 结 点 的 nx 成 员 为 e d则 结 束循 环 / 如 ed所 et n, f p h a- nx;p结点 总是 从 链 表 的头 结 点 开 始 = ed > et/ / q p > e t/ = 一 nx; q总 是 指 向”P所 指结 点 ”的下 一 结 点 /
下 :对 于链 表 每 一 个 结 点 可 看 成 是 竖 着 排 列 的 “ 泡 ” 气 ,然 后
J
】
p=q; q=q ->ne t x;
e =p; nd
分别 从头结点 向尾节点扫 描 。在扫 描 的过 程 中时刻注 意两个 相邻元 素的顺序 ,保证前 一结点元 素 的数 据域小 于后一 节点
ls. e p o r m mi he e ag rtm son c mp e ,a d an lz e om a eo he e ag rt it.W r g a ng t s lo ih o utr n ay e P r r nc ft s lo i f hms .
(nomao n ier gC l g f a zo i nv r t L nh u7 0 7 ) Ifr t nE gne n ol e nh uCt U iesy, az o 3 0 0 i i e oL y i
链式存储结构上选择排序算法的研究与实现

参 考文 献
[】严蔚敏 ,吴伟 民.数据结构 [ ] 1 M .清华大学出版社 , 19 . 97 [】耿 国华 .数据结构 ( 言版 ) 【 2 c语 M】.西安 :西安 电子科
1 ) }
[]达文姣 ,任志 国 ,等 .链式 结构上 排序 算法 的研究 []. 7 J
电脑编程 与维护 ,2 1 ,() - . 0 1 3 :12
在线 性表上 的选择 排序 ,最好情况 下 的时间复杂度 是 O () n ,最差和平均情况下 的时间复杂度是 O (2,辅 助空间为 n) O () 1 ,算法一般不稳定 。在单链 表和静态链表 上的选择 排序 的时间复杂度 、空间复杂度 、稳定性与在线性 表上完全相 同。 所 以从实现过 程和算法 的分析 ,可 以很 明显 地发 现两种算 法
算 法实现描述如下 :
v i e csr s n l t N1 od S l t t( i i e o l k s S[ )
, / 静态链表上的选择排序算法
{
会有 多余 的结 点存 在 ,所 以数 据所 占的存储 空 间 良 费较少 。
链式结构上 的排序 只改变链 的指 向 ,而不会 改变数 据元素所 占节点 的位 置 ,即不会移 动数据元 素 ,从 而节省 了移动数据
sr c o e tu tn d
} }
) Βιβλιοθήκη 3选择排序算法在静态链表上实现
为了描述 插入排序 在静 态链表 上 的排序过程 ,定义 静态
链 表的结构 :
f ee y ed t, lmt a ;数据域 p a/ s ut o e* e t  ̄针 域 t c d nx; d r n H
链表排序(冒泡、选择、插入、快排、归并、希尔、堆排序)

链表排序(冒泡、选择、插⼊、快排、归并、希尔、堆排序)这篇⽂章分析⼀下链表的各种排序⽅法。
以下排序算法的正确性都可以在LeetCode的这⼀题检测。
本⽂⽤到的链表结构如下(排序算法都是传⼊链表头指针作为参数,返回排序后的头指针)struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}};插⼊排序(算法中是直接交换节点,时间复杂度O(n^2),空间复杂度O(1))class Solution {public:ListNode *insertionSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.if(head == NULL || head->next == NULL)return head;ListNode *p = head->next, *pstart = new ListNode(0), *pend = head;pstart->next = head; //为了操作⽅便,添加⼀个头结点while(p != NULL){ListNode *tmp = pstart->next, *pre = pstart;while(tmp != p && p->val >= tmp->val) //找到插⼊位置{tmp = tmp->next; pre = pre->next;}if(tmp == p)pend = p;else{pend->next = p->next;p->next = tmp;pre->next = p;}p = pend->next;}head = pstart->next;delete pstart;return head;}};选择排序(算法中只是交换节点的val值,时间复杂度O(n^2),空间复杂度O(1))class Solution {public:ListNode *selectSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.//选择排序if(head == NULL || head->next == NULL)return head;ListNode *pstart = new ListNode(0);pstart->next = head; //为了操作⽅便,添加⼀个头结点ListNode*sortedTail = pstart;//指向已排好序的部分的尾部while(sortedTail->next != NULL){ListNode*minNode = sortedTail->next, *p = sortedTail->next->next;//寻找未排序部分的最⼩节点while(p != NULL){if(p->val < minNode->val)minNode = p;p = p->next;}swap(minNode->val, sortedTail->next->val);sortedTail = sortedTail->next;}head = pstart->next;delete pstart;return head;}};快速排序1(算法只交换节点的val值,平均时间复杂度O(nlogn),不考虑递归栈空间的话空间复杂度是O(1))这⾥的partition我们参考(选取第⼀个元素作为枢纽元的版本,因为链表选择最后⼀元素需要遍历⼀遍),具体可以参考这⾥我们还需要注意的⼀点是数组的partition两个参数分别代表数组的起始位置,两边都是闭区间,这样在排序的主函数中:void quicksort(vector<int>&arr, int low, int high){if(low < high){int middle = mypartition(arr, low, high);quicksort(arr, low, middle-1);quicksort(arr, middle+1, high);}}对左边⼦数组排序时,⼦数组右边界是middle-1,如果链表也按这种两边都是闭区间的话,找到分割后枢纽元middle,找到middle-1还得再次遍历数组,因此链表的partition采⽤前闭后开的区间(这样排序主函数也需要前闭后开区间),这样就可以避免上述问题class Solution {public:ListNode *quickSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.//链表快速排序if(head == NULL || head->next == NULL)return head;qsortList(head, NULL);return head;}void qsortList(ListNode*head, ListNode*tail){//链表范围是[low, high)if(head != tail && head->next != tail){ListNode* mid = partitionList(head, tail);qsortList(head, mid);qsortList(mid->next, tail);}}ListNode* partitionList(ListNode*low, ListNode*high){//链表范围是[low, high)int key = low->val;ListNode* loc = low;for(ListNode*i = low->next; i != high; i = i->next)if(i->val < key){loc = loc->next;swap(i->val, loc->val);}swap(loc->val, low->val);return loc;}};快速排序2(算法交换链表节点,平均时间复杂度O(nlogn),不考虑递归栈空间的话空间复杂度是O(1))这⾥的partition,我们选取第⼀个节点作为枢纽元,然后把⼩于枢纽的节点放到⼀个链中,把不⼩于枢纽的及节点放到另⼀个链中,最后把两条链以及枢纽连接成⼀条链。
作业答案

3
数 1、算法二 据 结 template<class ElemType> 构 bool SqList<ElemType>::OInsert(const ElemType &e)
{
之
测 验
}
/* 寻找插入位置,同时数据块向后搬移 */ for(i=len-1; i>=0&&e<elem[i] ; i--) elem[i+1]=elem[i]; elem[i] = e; len++; // 表长增1 return true;
8
非递归算法
数 据 结 构
之
测 验
9
int Value ( int n) { SqStack S; Tn=0; while( n >0 ) { S.Push( n); n = n/2; } while( ! S.StackEmpty()) { S.Pop( k ); Tn=2*Tn +k ; } return Tn ; } /* 若参数不合适(n<1),结果为0 */
已知线性表中的元素以值递增有序排列,并以单链表作存储结构。 试写一算法,删除表中所有值大于mink且小于maxk的元素。 Status ListDelete(LinkList L,char mink, char maxk) { LinkList p,q; if (mink<1 && maxk<1 && mink> maxk) return ERROR; p = L; while (p->next&&p->next->data<mink) p=p->next; while (p->next &&p->next->data<=maxk) { q = p->next; p->next = q->next; free(q); } return OK; }
数据结构常用操作

数据结构常用操作数据结构是计算机科学中的关键概念,它是组织和管理数据的方法。
常用的数据结构包括数组、链表、树、图和队列等。
在实际的编程中,我们经常需要对数据结构进行一些操作,如添加、删除和查找等。
以下是一些常用的数据结构操作。
1.添加元素:将新元素插入到数据结构中。
对于数组,可以通过在指定索引位置赋值来添加元素。
对于链表,可以通过创建新节点并调整指针来实现。
对于树和图,可以添加新节点或边来扩展结构。
2.删除元素:从数据结构中移除指定元素。
对于数组,可以通过将元素设置为特定值来删除。
对于链表,可以遍历链表并删除匹配的节点。
对于树和图,可以删除指定节点或边。
3.查找元素:在数据结构中指定元素。
对于有序数组,可以使用二分查找来提高效率。
对于链表,可以遍历链表并比较每个节点的值。
对于树和图,可以使用深度优先(DFS)或广度优先(BFS)等算法进行查找。
4.遍历元素:按照其中一种顺序遍历数据结构中的所有元素。
对于数组和链表,可以使用循环来遍历每个元素。
对于树,可以使用先序、中序或后序遍历来访问每个节点。
对于图,可以使用DFS或BFS来遍历每个节点。
5.排序元素:对数据结构中的元素进行排序。
对于数组,可以使用快速排序、归并排序等常用算法。
对于链表,可以使用插入排序或选择排序等算法。
对于树和图,可以使用DFS或BFS进行遍历并将元素排序。
6.查找最小/最大值:在数据结构中查找最小或最大值。
对于有序数组,最小值在索引0的位置。
对于链表,可以遍历链表并比较每个节点的值。
对于树,可以遍历树的左子树或右子树来找到最小或最大值。
7.合并数据结构:将两个数据结构合并成一个。
对于有序数组,可以先将两个数组合并成一个,然后再排序。
对于链表,可以将一个链表的尾节点连接到另一个链表的头节点。
对于树和图,可以将两个结构合并成一个,保持其关系。
8.拆分数据结构:将一个数据结构拆分成多个。
对于有序数组,可以根据一些值将数组拆分为两个子数组。
数据结构c++顺序表、单链表的基本操作,查找、排序代码

} return 0; }
实验三 查找
实验名称: 实验3 查找 实验目的:掌握顺序表和有序表的查找方法及算法实现;掌握二叉排序 树和哈希表的构造和查找方法。通过上机操作,理解如何科学地组织信 息存储,并选择高效的查找算法。 实验内容:(2选1)内容1: 基本查找算法;内容2: 哈希表设计。 实验要求:1)在C++系统中编程实现;2)选择合适的数据结构实现查 找算法;3)写出算法设计的基本原理或画出流程图;4)算法实现代码 简洁明了;关键语句要有注释;5)给出调试和测试结果;6)完成实验 报告。 实验步骤: (1)算法设计 a.构造哈希函数的方法很多,常用的有(1)直接定址法(2)数字分析法;(3) 平方取中法;(4)折叠法;( 5)除留余数法;(6)随机数法;本实验采用的是除 留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈 希地址 (2)算法实现 hash hashlist[n]; void listname(){ char *f; int s0,r,i; NameList[0].py="baojie"; NameList[1].py="chengቤተ መጻሕፍቲ ባይዱoyang"; ……………………………… NameList[29].py="wurenke"; for(i=0;i<q;i++){s0=0;f=NameList[i].py; for(r=0;*(f+r)!='\0';r++) s0+=*(f+r);NameList[i].k=s0; }} void creathash(){int i;
v[k-1]=v[k]; nn=nn-1; return ; } int main() {sq_LList<double>s1(100); cout<<"第一次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.ins_sq_LList(0,1.5); s1.ins_sq_LList(1,2.5); s1.ins_sq_LList(4,3.5); cout<<"第二次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.del_sq_LList(0); s1.del_sq_LList(2); cout<<"第三次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); return 0; } 运行及结果:
可对链式存储排序的方法

可对链式存储排序的方法链式存储是一种常见的数据结构,它通过指针将数据元素按照一定的顺序链接在一起。
在某些情况下,我们需要对链式存储中的数据进行排序,以便更好地利用和管理这些数据。
本文将介绍几种可对链式存储排序的方法。
方法一:冒泡排序冒泡排序是一种简单直观的排序方法,它通过相邻元素之间的比较和交换来实现排序。
对于链式存储,可以使用两个指针分别指向当前节点和下一个节点,通过比较节点的值来确定是否需要交换位置。
重复这个过程直到链表中所有节点都按照指定的顺序排列。
方法二:插入排序插入排序是一种稳定的排序方法,它通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
对于链式存储,可以使用一个指针指向当前节点,另一个指针指向已排序的序列。
通过比较节点的值来确定插入位置,然后将节点插入到相应位置。
方法三:选择排序选择排序是一种简单直观的排序方法,它通过每次从未排序的序列中选择最小(或最大)的元素,放到已排序序列的末尾。
对于链式存储,可以使用两个指针分别指向当前节点和最小节点,通过比较节点的值来确定最小节点,然后将最小节点与当前节点交换位置。
方法四:归并排序归并排序是一种稳定的排序方法,它通过将两个有序序列合并成一个有序序列来实现排序。
对于链式存储,可以使用递归的方式将链表分成两个子链表,然后分别对两个子链表进行排序,最后将两个有序子链表合并成一个有序链表。
方法五:快速排序快速排序是一种常用的排序方法,它通过选择一个基准元素,将序列分成左右两个子序列,然后分别对左右两个子序列进行排序。
对于链式存储,可以使用两个指针分别指向当前节点和基准节点,通过比较节点的值来确定节点的位置,然后递归地对左右两个子链表进行排序。
方法六:堆排序堆排序是一种基于二叉堆的排序方法,它通过构建最大堆或最小堆来实现排序。
对于链式存储,可以使用一个指针指向当前节点,另一个指针指向堆的根节点。
通过比较节点的值和堆的根节点的值来确定是否需要交换位置,然后递归地对剩余的节点进行堆调整,最后得到有序的链表。
选择排序在链表中的实现图解
①
l ③
④m后移
temp1
4 ④ q m
16
2
1 ② n p
5
8
6
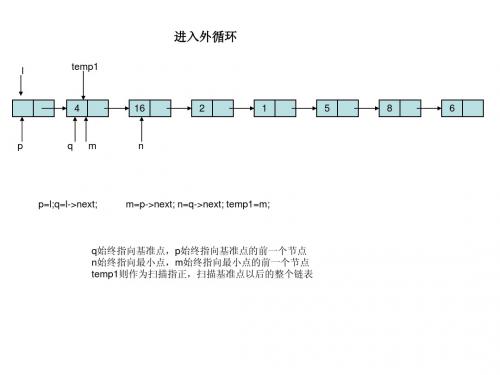
if(m!=p->next || (m==p->next && m->data>n->data)) { p->next=n; //①基准点的前一个节点指向最小点 p=n; //②p后移 m->next=q; //③最小点的前一个节点指向基准点 m=q; //④m后移 q=q->next;⑤ n=n->next;⑥ p->next=q;⑦ m->next=n;⑧ } q始终指向基准点,p始终指向基准点的前一个节点 n始终指向最小点,m始终指向最小点的前一个节点 temp1则作为扫描指正,扫描基准点以后的整个链表
q始终指向基准点,p始终指向基准点的前一个节点 n始终指向最小点,m始终指向最小点的前一个节点 temp1则作为扫描指正,扫描基准点以后的整个链表
①基准点的前一个节点指向最小点
①
l temp1
4
16
2
1
5
8
6
p
q
m
n
if(m!=p->next || (m==p->next && m->data>n->data)) { p->next=n; //①基准点的前一个节点指向最小点 p=n; ② m->next=q; ③ m=q; ④ q=q->next⑤; n=n->next; ⑥ p->next=q; ⑦ m->next=n; ⑧ } q始终指向基准点,p始终指向基准点的前一个节点 n始终指向最小点,m始终指向最小点的前一个节点 temp1则作为扫描指正,扫描基准点以后的整个链表
数据结构试题库

数据结构试题库一、单项选择题1.下列程序段所代表的算法的时间复杂度为(D)。
x=n;y=0;while(x>=(y+1)*(y+1))y++;(A)O(n)(B)O(n2)(C)O(log2n)(D)O(n)2345(B)。
6叉树中任一结点的平均查找长度最小,则应选择下面哪个序列输入(C)。
(A)45,24,53,12,37,96,30(B)30,24,12,37,45,96,53(C)37,24,12,30,53,45,96(D)12,24,30,37,45,53,967.有一组数值{5,12,9,20,3},用以构造哈夫曼树,则其带权路径长度WPL值为(D)。
(A)93(B)96(C)123(D)1038.已知一个有向图G的顶点v={v1,v2,v3,v4,v5,v6},其邻接表如下图所示,根据有向图的深度优先遍历算法,从顶点v1出发,所得到的顶点遍历序列是(B)。
(A)v1,v2,v3,v6,v4,v5(B)v1,v2,v3,v6,v5,v4 (C)v1,v2,v5,v6,v3,v4(D)v1,v2,v5,v3,v4,v69.设有10. 12. 13. D )存14. 一个带头结点head 的循环单链表为空的判断条件是(C )。
(A)head==NULL(B)head->next==NULL(C)head->next==head(D)head!=NULL15. 若链队列HQ 中只有一个结点,则队列的头指针和尾指针满足下列条件(D )。
(A)HQ->rear->next==HQ->front(B)HQ->front->next==HQ->rear->next(C)HQ->front==HQ->rear(D)HQ->front->next==HQ->rear16.从一个栈顶指针为HS的链栈中删除一个结点时,用x保存被删除结点的值,则应执行操作为(A)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
排序采用选择法:把30 接到80后面45接到90后面90替原来45的位置***************************预备知识:NODE *v,*u,*p,*h;U,v,h,p都是指针,它们只是地址性的可以指向结构而链表中的表有next指针**************************************** 链表排序h45 65 54 80 90 30要实现45和90 的交换:30要接到80后面45要接到90后面90要接到h后面90 45 65 54 80 30要实现45和80 的交换:30 接到54后面45接到80后面80要接到90后面。
即插入到90后面所以一般情况需要用:两个指针vold v 指出45两个指针mold max 指出最大这样可以方便的实现v 或max,移走或被替换时,其它的可以接上。
但如果要被替换的是第一个,如45被90替换。
h,vold,v max45 65 54 80 90 30Max指向90,30 放到80后面,h,vold,v max45 65 54 80 30 9045 放到90后面,h,v,vold都跟着45移动,max h,vold,v90 45 65 54 80 30h=max还要一个游动指针,u,用于不断和v比较为了继续进行,下一轮开始前应该为:h ,vold v,max u90 45 65 54 80 30vold要指向90, v指向45, u指向54所以对于第一次交换后还要移动voldif(vold==v) 时,vold=h;总之一个比较可行的程序为:while (v->next != NULL) //省去空的v,//选择法{ for(max=v,uold= u = v->next; u->next != NULL;uold=u, u = u->next) { if (u->score > max->score ) { mold=uold; max = u; } //找到最大的} //u已移动,但队列未动// u->next == NULL即u是最后一个表,跳出循环,// 还要判别u指向的表是最大吗?if(u->score>max->score) {mold =uold; max=u;} //最后一个if (max!= v) {mv->next= max->next;max->next =v;if(vold==v) { h=max; }else { vold->next=max; }}。
可见用以上方法指针比较多,而且指针移动比较麻烦。
因为一开始,不能够用vold=vold->next;方式。
并且上述程序还未完全调通***************************************为此,一种常用的方法,引入一个空表接到h的后面先比较45 和65 :if( v->next->score < u->next->score ) ,……….比出最大后,90要插入到u的位置时,要做下面的步骤:1. 30 接到80后面 . max独立出来2. max->next =u;3. v->next=max;v=v-.>next, u=v->next将来输出时return h->next;, 就可以把空表让过具体分析:引进一个vNODE *v=(NODE*)malloc(sixeof(NODE));V uh p p1 p2 p3 p4 p5 p6v->next =h; h=v; 把v 插入h 和p1(45)之间先比较p1==u(45)和p2 (65)为了适合循环: v->next->score , u->next->score 表示要比较的数据:u->score==45,p2.score == 65P=v; u=v->next ; (v->next==u )u->score==45 , v->next->score ==45p2==u->next==65p2.score= u->next->score==65for(p=v,u=v->next; u->next!=NILL; u=u->next) if( p->next->score < u->next->score) p=u;找出最大的表u->next->score==(90), 然后交换(90) (45)) 把30 接到80后面: 90 的指针要保存45接到90后面90替代45位置一、90要独立出来,同时30 接到80后面,需要两个指针:1. p=u?, u=p->next : p指向80 u指向9090要独立出来,所以要用指针u指向它,以免丢掉,u要移走,所以先用p指向802. p->next =u->next : 30 接到80后面二、: 45接到90后面,u->next=v->next;三、90替代45位置v->next =u :V=v->next, u=v-.next 准备下一轮NODE *bubblesort(NODE *h){NODE *v,*u,*p;v = (NODE *)malloc(sizeof(NODE));v->next =h; h=v;while (v->next != NULL) //选择法{ for(p = v, u = v->next; u->next != NULL; u = u->next) if (u->next->score > p->next->score ) p = u; //找到最大的//u已移动,但队列未动if (p != v) { u = p->next; p->next = u->next; //oku->next =v->next; v->next =u; } v=v->next;} return h->next; //h;}*******************************14.Sort()排序由于学生信息采用的是单链表存储结构,所以选用直接插入算法较为简单。
直接插入算法的基本方法是:每步将一个待排序的记录按其排序码值的大小插到前面已经排好序的表中,直到全部插入为止。
基于这样的方法首先将链表的头结点看作是已排好序的结点,然后取下一个结点作为待排序的结点,插入到已排好序的表中。
由于单链表的特性,所以具体的思路如下:(1)先将原表头结点作为新排好序表的头结点h,原表下一个结点作为原表头结点h1。
设原表如图1l—所示,表中只列出总分数据。
图.11设新表头结点即h是新链表,h1是旧链表(2)原表头结点为待排序结点,将其总分与新表结点的总分进行比较,如果待排序结点总分大,则插在新表的头,否则插入在其后,原表头结点后移一位,如图.12所示。
(3)重复第二步,即将原表头结点的总分和新表结点的总分进行比较,如果待排序结点总分小,则移动新表指针,直到找到合适的位置将其插入,直到原表为空,所有结点排序完毕,如图.13所示。
这个排序算法实际上是先从原表删除头结点,然后在新表中查找到合适的位置,进行插入。
待排序结点的插入位置总是插在表头、表尾和表中间三种情况之一,由于单链表的特性,实际插入结点时,并不需要移动和交换结点信息,而是只改变指针关系,所以排序时间主要用在比较上。
排好序后将其名次数据写入数据域order中。
STUDENT *sort(STUDENT *h){ int i=0; /*保存名次*/STUDENT *p,*q,*t,*hl; /*定义临时指针*/hl=h->next; /*将原表头指针所指的下一个结点作为头指针*/h1->next=NULL; /*第一个结点为新表的头结点*/ ???while(hl!=NULL) /*当原表不为空时,进行排序*/{ t=hl; /*取原表的头结点*/hl=hl->next; /*原表头结点指针后移*/p=h; /*设定移动指针P,从头指针开始,即,h1中的每一个,从h的头比较起*/q=h; /*设定移动指针q作为P的前一个==pold,初值为头指针*/原表取第一个和新表从头进行比较while(t->sum < p->sum && p!=NULL) /*进行总分比较*/ { q=p; /*待排序点值小,则新表指针后移*/p=p->next; } /*直到t->sum >p->sum时,t插到p的前面if(p==q) /*说明待排序点值最大,应排在首位*/{ t->next=p; /*待排序点的后继为p*/h=t; } /*新头结点为待排序点*/else /*待排序点应插入在中间某个位置q和P之间,如果P为空则是尾部*/{ t->next=p; /*t的后继是P*/q->next=t; } /*q的后继是t*/}p=h; /*排序完成p指针回到链表头,准备填写名次*/ //因为是降序i=1即第一名,i=2, 第二名while(p!=NULL) /* P不为空时,进行下列操作*/{ i++; /*结点序号*/p->order=i; /*将名次赋值*/p=p->next; /*指针后移*/}printf("sort sucess!!!\n"); /*排序成功*/return h; /*返回头指针*/}。