程序复杂性度量
mccabe度量法

mccabe度量法McCabe度量法是一种对代码来说必不可少的质量检查工具。
这一质量检查工具可以让程序员能够清楚地访问和测量代码质量,进而提高程序代码的可读性、可维护性和可靠性。
它有助于提高代码的可重复性和可比较性,以达到质量的最终目标。
McCabe度量法是一种衡量某一特定程序的复杂性度量方法,它被称为“McCabe级别”,因为它由美国软件工程师Thomas J. McCabe,Sr.于1976年发明。
这种度量方法通过计算代码中可能出现的支线及其分支,来测量该程序的复杂性。
这项技术可以帮助程序员了解他们的代码有多复杂,因此可以采取改进的措施改善其可读性,可理解性和可维护性。
McCabe度量法可以通过计算每一个程序函数的入口和出口来计算程序的复杂性。
这一计算的精度取决于它所计算的模块的大小,也就是所谓的“类型数”。
例如,编写一个模块具有10种类型的指令,McCabe计算公式会计算它有11个不同的路径(10种指令加一个路径从入口到出口)。
从理论上讲,程序越复杂,模块中的类型数就越多,因此McCabe度量法的精度也越高。
McCabe度量法的优点在于它的简单性和可扩展性,可以用于许多语言,包括Java、C#和C++,而且可以被用来测量一个非常大的程序,能够有效节省量化复杂度的时间耗费,而这也是测量大型程序的最佳方式。
McCabe度量法在测量程序复杂度方面,具有较高的可信度,即使大型程序也是如此。
此外,McCabe度量法也可以用于识别潜在的错误点,以帮助程序员改进设计。
McCabe度量法的缺点也值得一提,它有一定的限制它无法识别算法的复杂性,而只能识别该算法的实现上的复杂性,这意味着它不能有效识别在产生正确结果的同时使程序变得非常复杂的情况。
还有,McCabe度量法不能识别类的复杂性,而且在大型程序复杂度测量时,它也只能测量某一部分程序,而不能测量整个程序。
总而言之,McCabe度量法是一种有效的质量检查工具,它可以帮助程序员识别和测量程序中的复杂性,从而提高程序代码的可读性、可维护性和可靠性。
程序复杂性度量

程序复杂性度量程序复杂性主要指模块内程序的复杂性。
它直接关联到软件开发费用的多少,开发周期的长短和软件内部潜伏错误的多少。
同时它也是软件可理解性的另一种度量。
减少程序复杂性,可提高软件的简单性和可理解性,并使软件开发费用减少,开发周期缩短,软件内部潜藏错误减少一、代码行度量法度量程序的复杂性,最简单的方法就是统计程序的源代码行数。
此方法基于两个前提:(1)程序复杂性随着程序规模的增加不均衡地增长;(2)控制程序规模的方法最好是采用分而治之的办法。
将一个大程序分解成若干个简单的可理解的程序段。
方法的基本考虑是统计一个程序模块的源代码行数目,并以源代码行数做为程序复杂性的度量。
若设每行代码的出错率为每100行源程序中可能有的错误数目,例如每行代码的出错率为1%,则是指每100行源程序中可能有一个错误。
Thayer曾指出,程序出错率的估算范围是从0.04%~7%之间,即每100行源程序中可能存在0.04~7个错误。
他还指出,每行代码的出错率与源程序行数之间不存在简单的线性关系。
Lipow进一步指出,对于小程序,每行代码的出错率为1.3%~1.8%;对于大程序,每行代码的出错率增加到2.7%~3.2%之间,但这只是考虑了程序的可执行部分,没有包括程序中的说明部分。
Lipow及其他研究者得出一个结论:对于少于100个语句的小程序,源代码行数与出错率是线性相关的。
随着程序的增大,出错率以非线性方式增长。
所以,代码行度量法只是一个简单的,估计得很粗糙的方法。
二、McCabe度量法McCabe度量法是一种基于程序控制流的复杂性度量方法。
McCabe定义的程序复杂性度量值又称环路复杂度,它基于一个程序模块的程序图中环路的个数。
如果把程序流程图中每个处理符号都退化成一个结点,原来联结不同处理符号的流线变成连接不同结点的有向弧,这样得到的有向图就叫做程序图。
计算有向图G的环路复杂性的公式:V(G)=m-n+2其中,V(G)是有向图G中的环路个数,m是图G中有向弧个数,n是图G中结点个数。
基于McCabe的软件复杂性度量与控制策略

( p r n f o p t c n e& T cn lg ,i igCoee M e h u5 4 1, ia Deat t m ue Si c me o C r e eh o yJ y Ug, i o 10 5 Ch ) o an z n
p e t s rs n c o d n u n i t e a a s f ot r o l xt . e s a e a uc n f c O h g u l e eo me t lx y i p ee t c r ig t q a t a v n l i o f i a o ti y s s wa e c mp e y Th t t g h g i g e e t i h q a t d v l p n . i r y s H t i y
性 无 关 环 的 个数 。即 有 向图 G 中 的 孤 数 m 与 结 点 数 n的差 再加
上分离部分 的数 目P 。计算公式定义为 VG = - + 。 ()m n p 对 于一 个 正 常 的 程 序 来说 ,其 程 序 图是 连 通 的 ,也 就 是 说 P
近 出 口点 的 ) ,'i 站 tf . 1
的值 取 1但 通 常 情 况 下 不 是 强 连 通 的 。 因 为从 图 中较 低 的 ( 靠 , 较
能 到过 较 高 的结 点 , 而 。 果 从 出 口点 然 如
画 一 条 虚 弧 , 程 序 图必 然 成 为 强 连 通 有 向 图 。理 由 是 : ) 入 则 ( 从 1 点 ; ) 过 从 出 口点 到 入 口点 的弧 , 以从 出 口点 到 达 入 口点 。 ( 经 3 可
摘 要 : 件 复 杂 性 度 量 与控 制 是 软 件 开 发 面 临 的 主要 问题 。 文通 过 对 软 件 复 杂性 的 定 量分 析 。 出 了软 件 复 杂性 的 控 制 策略 , 策 软 本 提 该 略对 开发 高质 量 、 高可 靠性 与 高 可维 护 性 软 件 有 一 定 的指 导作 用 。 关 键 词 : C b ; 件 ; 杂 性 ; 量 ; 制 Mc ae 软 复 度 控
基于过程蓝图的程序环路复杂性度量方法

i iht ep g a fr t n rq i db h t c b tat m h b tati lme tsr cu edarm ,t n n whc h r rm i o mai eur ytemer si a srce f o n o e i s d r tea src o mpe n tu tr i a g e r h i— pe nainrp ee tt no h r c u le r t rpaig te t dt n li o main a srcin b s n t nr l lme tt e rsna i fte p e r bup n , e lc h r io a n r t b ta t a e o h c t o o o d e i n a i f o o d e o o l f w rp . i tcnq ecnaodtep oe s f n lzn es n xo rg a a dcn t ci h nr l o g a h o ga h Ths eh iu a v i h rcs ay igt y t oa h a fh p r t e o m n sr t tec t w rp o u n g o o f l S ta t rc s f h O h t h po eso t eme s r i i l e a di i a s rt ei lme t n e a u n ss i g mpid n i f tse i O b mpe ne a dmo eef i t a h ta io a tc — e d r fi e h nt rdtVo 3N . 0 6 1 3 o6 .
基 于 过程 蓝 图 的程序 环路 复 杂性 度量 方 法 )
刘 建宾 李建 忠 。 余楚迎 杨 林邦。
尼尔森复杂系数

尼尔森复杂系数1. 什么是尼尔森复杂系数?尼尔森复杂系数(Nielson Complexity Score)是一个用于衡量软件代码复杂性的度量标准。
它是由沃德尼尔森(Thomas J. McCabe)在1976年提出的。
尼尔森复杂系数主要用于衡量在程序中的控制流程复杂性,即衡量程序中的判断和循环语句的数量和嵌套程度。
2. 如何计算尼尔森复杂系数?计算尼尔森复杂系数需要先对程序进行流程图分析。
在分析流程图时,我们需要根据代码中的判断语句和循环语句做出决策节点,并对每个节点进行计数。
同时,我们还需要考虑一些特殊情况,例如函数调用和异常处理语句。
在计算时,我们可以使用以下公式:McCabe复杂度 = 判定节点的数量 + 1这可以很容易地计算出程序的复杂度。
其实,我们所说的程序复杂度指的是程序代码中各部分之间相互作用的难度。
3. 为什么计算尼尔森复杂系数很重要?尼尔森复杂系数是一种很好的方法来评估代码质量和可维护性。
程序的复杂度可以影响软件工程师的工作效率,并且它也会影响程序的可读性和稳定性。
因此,计算尼尔森复杂系数可以帮助软件开发人员更好地了解其代码质量,以便对其进行改进。
此外,尼尔森复杂系数也是软件开发中的重要工具。
它可以帮助开发人员预测代码的维护成本,并制定优化策略。
当程序的复杂度超过某一个标准时,我们就能够发现问题并做出调整。
4. 小结尼尔森复杂系数是一种用于度量程序复杂度的标准。
它可以帮助我们评估代码的质量和可维护性,并为软件开发人员提供优化策略和指南。
在实践中,尼尔森复杂系数广泛应用于软件工程领域,是一种最常用的度量标准之一。
面向对象软件工程中的软件复杂度度量研究

面向对象软件工程中的软件复杂度度量研究引言:面向对象编程是一种广泛应用的软件开发方法,其在软件开发领域中占有重要地位。
随着软件的不断复杂化,软件的质量和性能也变得更加重要。
无论是开发大型商业软件,还是开发小型应用软件,都需要对软件的复杂度进行评估和度量。
软件复杂度是指软件系统的结构、规模、难度和精度等,是评估软件质量和可维护性的重要指标,也是进行软件开发过程中最重要的质量度量之一。
软件复杂度的度量方法:在软件开发领域中,有多种度量软件复杂度的方法和指标。
其中,最常用的度量方式是基于面向对象的软件复杂度度量。
面向对象软件的复杂度是由类、继承、组合、消息传递和多态性等多方面因素影响的。
因此,对于面向对象软件,必须考虑多个因素。
面向对象软件复杂度的度量指标主要包括:1.类的复杂度。
类的复杂度是指一个类中各种元素的组合和层次结构所引起的复杂度,《面向对象软件度量》(OO-Metric)强调了基于类和方法的度量方法。
2.继承的复杂度。
继承的复杂度是指基于继承关系构成的代码结构的复杂度。
继承多层次结构使得代码的复杂度增加。
3.组合的复杂度。
组合的复杂度是指类和对象的相互关联以及它们的拓扑关系,包括引用、嵌套和聚合关系,它们会形成不同的组件、子系统或系统之间的复杂结构。
4.消息传递压力。
消息传递压力是指代码中消息的数量和复杂度,包括同步、异步和回调等方式,它们会导致更高的系统耦合性和降低的可维护性。
5.多态性的复杂度。
多态性的复杂度是指通过多个不同形式来表示同一元素的能力,包括类的代表性、接口和泛型等。
以上指标是衡量面向对象软件复杂度的主要因素,因此必须考虑各种不同因素的充分影响。
接下来,我们将结合具体案例来探讨如何针对不同的复杂度度量因素进行实际操作。
案例分析:以在线图书管理系统为例,通过对不同复杂度因素的度量来评价其软件复杂度。
1.类的复杂度在此示例中,系统中会有图书类和用户类等多个类,每个类中都包含多个方法。
8.3.2计算复杂性的度量方法

关于计算
第八讲
计算复杂性的度量方法
计算复杂性理论
计算复杂性理论研究各种可计算问题在计算过程中资源(如时间、空间等)的耗费情况。
算法的时间度量
从算法中取一种对于研究
问题来说是基本操作的原操作
,以该基本操作重复执行的次
数作为算法执行的时间度量
计算复杂性的度量方法
算法的时间度量
算法的所需时间与问题规模的函数T(n)
(a) X=X+1
(b) for(i=1; i<=n; i++)
X=X+1
(c) for(i=1; i<=n; i++)
for(j=1; j<=n; j++)
X=X+1
以上操作执行的次数分别是
1, n, n^2
如何降低计算复杂度
常见的算法时间复杂度
指数时间
多项式时间
好的算法
多项式时间算法。
计算复杂性的度量方法
确定性问题:只有肯定和否定答案。
P类问题:具有多项式时间
算法的确定性问题形成的计
算复杂性类。
P类问题包含了大量的
已知自然问题,如计算最大
公约数、计算π值、排序问
题、二维匹配问题等。
计算复杂性的度量方法
非确定算法
猜测一个变量的真值赋值
检查该赋值是否满足NP类问题:由非确定性算法在多项式时
间内可计算的判定问题所组成的集合。
NP类问题数量巨大,如完全子图问题、
图的着色问题、汉密尔顿回路问题、以
及旅行销售员问题等。
程序复杂性度量技术分析

程序复杂性度量技术分析孔庆玲;胡志军;刘英;冯阳【摘要】分析了3种复杂性度量方法:Halstead、McCabe和Thayer,Halstead 按照程序中的运算符和操作数的总数对程序的复杂性加以度量.McCabe以程序逻辑流程图的分析为基础建立复杂性的度量.Thayer按程序的逻辑关系、接口、运算特征和输入/输出的特点来度量程序的复杂性,同时分析了程序复杂性与可靠性指标分配之间的关系.【期刊名称】《无线电工程》【年(卷),期】2011(041)002【总页数】4页(P61-64)【关键词】复杂性;度量;可靠性;软件错误【作者】孔庆玲;胡志军;刘英;冯阳【作者单位】中国电子科技集团公司第五十四研究所,河北,石家庄,050081;中国电子科技集团公司第五十四研究所,河北,石家庄,050081;中国电子科技集团公司第五十四研究所,河北,石家庄,050081;中国电子科技集团公司第五十四研究所,河北,石家庄,050081【正文语种】中文【中图分类】TN391.90 引言软件越复杂,一方面在开发和维护过程中所消耗的资源也越多,所以软件的复杂性可以作为软件所需资源投入量的一个间接度量;另一方面在设计中引入错误的可能性也越大,这是一种合乎逻辑的推理,也是一个为实验验证的事实。
尽管软件复杂性与软件中的错误数未必呈现出简单的正比关系,但是存在这种正相趋势是肯定无疑的。
软件不可靠的根本原因是软件中存在错误,所以软件复杂性可以作为软件可靠性的一种间接度量。
复杂性度量是软件开发过程中有应用前景的一个度量。
借助这个度量,设计人员在接受设计任务之初,可以从已有的性质相似的程序中获得经验数据,对现在所面临问题的复杂程度做出判断,借助于复杂性度量还可以对若干设计方案的困难程度加以比较。
1 技术分析目前比较流行的有3种程序复杂性度量方法:Halstead、McCabe和 Thayer。
Halstead使用统计的方法研究程序的复杂性,按照程序中的运算符和操作数的总数对程序的复杂性加以度量。
代码质量管控——程序复杂度

代码质量管控——程序复杂度1. 程序复杂度 ⼀个软件的复杂度主要由构成软件模块程序的复杂度体现,程序的复杂度主要指的是模块程序之间的复杂性。
常⽤衡量程序复杂性的的⽅法有:【1】代码⾏度量法【2】T.McCabe度量法,即圈复杂度【3】Halstead 软件科学法,即Halstead 复杂度1.1 衡量程序复杂度意义 程序复杂度的意义不⾔⽽喻,对于程序员或者项⽬本⾝都具有很⼤意义。
事实证明,软件出现bug的概率和程序的数量、复杂度等成正相关,这是统计学和概率论原理得出,⽽不是程序员的编码⽔平问题,当然也与编码⽔平有⼀定关系。
因此,明确程序的复杂度,对于项⽬进度、软件可靠性、程序质量等等提升的同时,并能计划安排测试、优化代码⼯作量。
【1】提升代码质量,降低bug的概率【2】提升程序员的编码⽔平【3】项⽬规划,针对不同复杂度的模块作出不同的⽅法,如模块重构或者优化【4】错误率预测,定位测试重点,如对复杂度⾼的模块增加测试⼿段2. 代码⾏度量法 代码⾏⽅法度量是⼀种最简单的⽅法,是⼀种很容易让⼈理解的,该⽅法认为,代码⾏越多,软件越容易产⽣漏洞;例如,在初学编程时,很⼤⼀部⼈包括我⾃⼰都是⼏百上千⾏代码塞在⼀个main函数⾥⾯,功能和逻辑耦合在⼀起,不便于阅读和维护。
程序复杂性随着程序规模的增加不均衡的增长,以及控制程序规模的⽅法最好是采⽤分⽽治之的办法。
代码⾏度量法只是⼀个简单的、估计得很粗糙的⽅法。
代码⾏度量指的是代码中的估算⾏数,并不是源代码⽂件中的确切⾏数,该计算不包括空⽩⾏、注释、括号以及成员、类型和命名空间的声明。
⾏数估计过⾼可能表⽰某个对象或⽅法正在尝试执⾏过于复杂的任务,表⽰该实现⽅式不便于维护,可考虑对任务处理代码进⾏分解。
3. Halstead 软件科学法(Halstead 复杂度)3.1 什么是Halstead 复杂度 Halstead 复杂度 (Maurice H. Halstead, 1977) 是软件科学提出的第⼀个计算机软件的分析“定律”,⽤以确定计算机软件开发中的⼀些定量规律。
软件开发实习报告中的代码复杂性分析与简化

软件开发实习报告中的代码复杂性分析与简化一、引言在软件开发实习中,代码复杂性是一个关键问题。
复杂的代码不仅难以理解和维护,还容易引发bug和性能问题。
因此,代码复杂性的分析与简化是软件开发实习报告中的重要内容。
本文将介绍代码复杂性的评估方法和常见的简化技术,并给出一些实践经验。
二、代码复杂性的评估方法1. 圈复杂度(Cyclomatic Complexity):圈复杂度是一种衡量代码复杂性的指标,它表示程序中线性无环路径的数量。
可以使用控制流图来计算圈复杂度,圈复杂度高意味着代码逻辑复杂,可能存在较多的bug。
2. 代码行数:代码行数过多可能表明代码结构不合理,需要进一步简化。
通常,可以使用代码统计工具来测量代码的行数。
3. 代码重复率:代码中的重复代码是一个令人头疼的问题,它增加了维护的难度。
通过代码分析工具,可以检测出重复的代码片段,并进行简化合并。
4. 代码注释率:良好的注释可以提高代码的可读性和可维护性。
评估代码的注释率,可以通过代码分析工具自动计算。
三、代码复杂性的简化技术1. 模块化:将复杂的代码分解为多个简单的模块,各个模块之间相互独立,便于理解和维护。
模块化的具体方法包括抽象、封装等。
2. 重构:通过代码重构技术优化代码结构,提高代码质量。
常见的代码重构方法包括函数提炼、参数化等。
3. 设计模式:使用设计模式可以降低代码的复杂性,提高代码的可读性和可维护性。
常见的设计模式包括工厂模式、单例模式等。
4. 代码优化:对于存在性能问题的代码,可以进行优化,提高代码的执行效率。
代码优化的方法包括算法优化、数据结构优化等。
四、实践经验1. 在编写代码之前,先进行需求分析和设计工作,合理规划代码结构,避免后期频繁修改和调整。
2. 使用专业的代码分析工具,及时发现代码中的问题,并进行修复和优化。
3. 遵循一致的编码规范,提高代码的可读性和可维护性。
4. 定期进行代码审查,及时发现和解决代码中的问题。
软件工程_综合题2
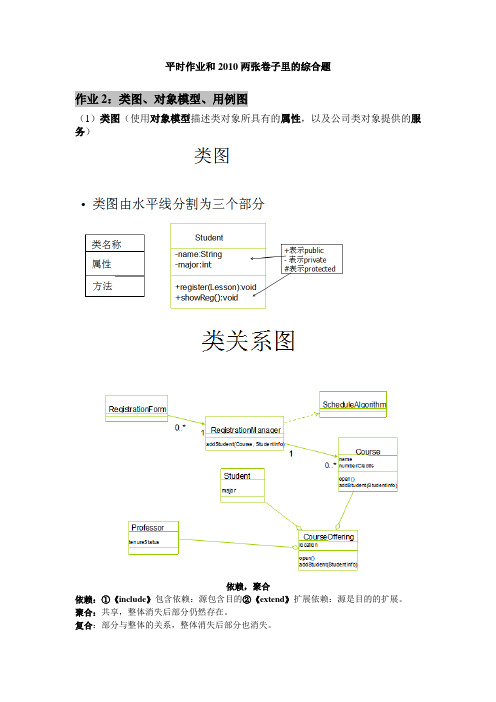
平时作业和2010两张卷子里的综合题作业2:类图、对象模型、用例图(1)类图(使用对象模型描述类对象所具有的属性,以及公司类对象提供的服务)依赖,聚合依赖:①《include》包含依赖:源包含目的②《extend》扩展依赖:源是目的的扩展。
聚合:共享,整体消失后部分仍然存在。
复合:部分与整体的关系,整体消失后部分也消失。
关联,复合关联、继承(泛化)关联、依赖(2)对象图书p81①对象名:类名②属性=属性值③对象间的链可以使类之间关联的实例(3)对象模型对象模型的描述工具:对象图。
0,1:表示有0个或1个。
1+:表示多个不写:表示有且仅有一个。
(4)用例图(参与者,用例,调用关系)画图步骤:(a)(b)(c)(d)作业3:Jackson系统方法(用jackson图可以表示数据结构、程序结构)参考:jackson作业试用Jackson方法编写一程序,要求能依次完成下列工作:——统计起始卡以前的卡片张数,存入A;——打印起始卡的内容;——统计起始卡以后出现的K1卡和K3卡总批数,存入B;——统计起始卡以后出现的K1卡的张数,存入C;——统计起始卡以后出现的K3卡的批数,存入D;——打印终了卡的内容;——打印A,B,C,D 4个统计值。
第一步:画出数据结构图第二步:画程序结构图(基于数据结构图画)第三步:写出程序的过程性表示(伪码)打开卡片文件;读卡片;A:=0;处理前置部分iteruntil出现K1卡;处理非K1卡seqA:=A+1读卡片;处理非K1卡end;处理前置部分end;打印起始卡;B:=0;C:=0;D:=0;读卡片;处理批部分iteruntil出现K2卡;处理批seq统计总批数; {B:=B+1}处理批类select是K1卡处理K1批iterwhile出现K1卡;处理K1卡seqC:=C+1;读卡片;处理K1卡end;处理K1批end;处理批类or是K3卡处理K3批seq;D:=D+1;处理批体iterwhile出现K3卡;读卡片;处理批体end;处理K3批end;处理批类end;处理批end;处理批部分end;打印终止卡;打印A,B,C,D;关闭卡片文件;卡片分析程序end;作业4:画出数据流图(DFD)。
基于拓扑结构的程序复杂性度量研究

量 方法 的研 究 . 传 统 Mc ae复 杂 性 度 量 法 , 对 Cb 提
出 了封 闭 区域个 数 统计 法 和 判 定 结点 个 数 统计 法
词汇 表 : = 1 2 n+ , 预 测 的 H l ed长 度 : =n ×lg/ +n at sa H 1 o2 1 2× 2
lg n o , ,,
杂度 , 并对判定树类拓扑结构程序提出了降低复杂
度 的程序设 计 方法 , 以实 例 进行 对 比验 证 , 明该 证
收 稿 日期 :0 11—4 2 1 —01 基 金 项 目 : 肃 省 科 技 支 撑 项 目( 7 8 K A 5 ) 甘 00 G C 0 0 作者简介: 吕林霞 (9 4), , 西岐 山人 , 16 一 女 陕 副教授
基 于程序 规模 的复 杂 性度 量 法 依 据程 序 规 模 大小来衡 量 程 序 复 杂性 . 型 方 法 是 代 码 行 度 量 典 法. 它是 在 程 序 编 制 完 成 后 统 计 程 序 源 代 码 的行
的一种度量. 降低程序复杂性 , 可提高软件的简单
性 和可 理解性 , 减少 开 发费用 , 缩短 开发 周期 , 减少
度 量 J本文 是 对 基 于拓 扑 结 构 的 程 序 复 杂 性 度 .
数. 这种方法 由于代码行没有公认明确 的定义 , 没
有 考虑程 序拓 扑 结 构 的复 杂 性 等 , 以虽 然 简 单 , 所 但 很粗 糙 . 1 2 基 于程序 数据 流 的复杂 性度量 .
基 于程 序数 据 流 的程 序 复 杂性 度 量 法 分 析程 序 内部 数据 流 的构 成 , 程序 流 进 行 分析 提 取 , 对 计 算 出一些关 键值作 为程 序复 杂性度 量 . 最典 型 的是
mccabe度量法

mccabe度量法《Mccabe度量法》是一种用来评估程序代码复杂度的度量衡。
它也被称为Mccabe算法,是美国计算机科学家Tom McCabe在1976年创造的。
Mccabe度量法是软件工程中测试估算和质量保证领域应用最广泛的度量衡之一,用于衡量程序复杂度。
Mccabe度量法为软件工程提供了一种标准,可以帮助软件工程师控制程序的复杂性,确保软件的可靠性和可维护性。
它的出现,使软件工程的管理和质量检测变得更为重要。
Mccabe度量法基于程序控制流程图来理解程序的复杂性。
它的核心思想是将程序拆解为一系列的基本控制单元,然后计算单元之间的关联性,从而确定程序的整体复杂性。
Mccabe度量法有五个关键指标:程序中块数量、支路及关联数量、入口出口数量、支路复杂度和循环复杂度。
这五个指标可以用来评估程序的复杂度,并能反映出程序的可靠性和可维护性。
Mccabe度量法的基本原理是计算程序的复杂度,它是通过剖析程序中的控制结构来实现的。
它可以提供一个可靠的方法来估算软件系统的复杂度和结构,这对软件开发来说是至关重要的。
Mccabe度量法可用于软件维护和重构,以便更好地管理程序,并减少软件维护成本。
使用Mccabe度量法,软件开发者可以更好地控制程序的复杂性,使其更易于调试、维护和管理。
Mccabe度量法最常用的应用是在测试估算中,它可以帮助软件开发人员判断程序的复杂性,并根据程序的复杂性来计算测试用例的数量。
Mccabe度量法也用于软件质量保证,可以用来监测软件的运行情况,以确保软件的正常运行。
Mccabe度量法借鉴了结构化程序设计的思想,将复杂性量化,使它可以作为软件质量保证和测试估算的标准。
Mccabe度量法可以用来评估软件的复杂度,从而准确地估算测试用例数量,更好地管理软件,并降低软件维护成本。
Mccabe度量法在软件开发和质量保证方面发挥了重要作用,是软件工程的一种重要工具。
基于伪路径的程序复杂性度量方法的研究

程 序复杂 性 主要指模 块 内程序 的复 杂性 ,它 是对 程序静 态特 性和 动态 行为 的理解 难 易程 度 的描 述 . 其 直 接关 联到 软件 开发费用 的多少 ,开发 周期 的长短 以及软 件 内部 潜伏 错误 的多少 . 少程 序复 杂 性 ,可提 减 高 软件 的简单 性 和可理解 性 ,减少 软件 开发 费用 ,缩 短开发 周期 ,并 且减 少软 件 内部潜 伏错 误 . 典 的程 经 序 复杂 性度 量方 法有许 多u5,其 中 Mc ae方法 J - l Cb 被广 泛接 受和 采用 ,该方 法 可 以应 用在 设计模 型度 量 和 源 程序 度量两个方 面 . c ae j 出了圈复杂度 的思想 ,被学术界 视为 著名 的静态 软件度 量方法 之一 ,该方 M C b t提 2 法本 质上是度 量一个 模块 中线性无关 的路径 数 ,但也存在 明显 的不足 ,作 者将就此 进行一定 的分析 改进 .
( G) =/ —r+ l tP r t 式 中 : V ( )是有 向图 G中环路 数 ;/ 为 图 G 中弧数 ;,为 图 G中节 点数 ;P为 图 G中强连通分 量个 数 . G l r t l 在实 际应用 中也 常用 其他 两 种 方 式来 计 算其 复杂 度 :即 ( 等 于程 序 图 中弧 所 封 闭 的 区域 数 和 G) ( ) 于程序 图 中判 定数 +1 G等 . 应 用上 述方 法 可求得 图 1中 a 、b两 图 的环路 复杂度 :
维普资讯
仲恺农 业技 术学院学报 ,9 4 :2 52 O 1( )4 ~4 ,O 6
Jun o n u ̄ i g l ad Tcn/ y ord fZ g , t o 肿 n eho g yfA o
文章编 号 :06 74 20 )4— 02— 10 —07 (0 60 04 0 4
环路复杂度的三种计算方法

环路复杂度的三种计算方法以环路复杂度的三种计算方法为标题,本文将介绍环路复杂度的概念及其三种计算方法:基本路径法、控制流图法和McCabe方法。
一、环路复杂度的概念环路复杂度是衡量程序复杂性的一种度量方法,它用于评估程序中的控制流程的复杂程度。
环路复杂度越高,程序的复杂性就越高,可能导致程序出现错误的风险也越高。
二、基本路径法基本路径法是一种通过计算程序中的基本路径来确定环路复杂度的方法。
基本路径是指从程序的入口到出口的一条路径,该路径覆盖了程序中的所有语句。
基本路径法的计算步骤如下:1. 给程序中的每个语句编号,从1开始。
2. 给程序中的每个控制流边(即语句之间的连接关系)加上标记。
3. 根据程序的控制流图,列出所有可能的基本路径。
4. 对每个基本路径进行计算,计算方法是将路径上的所有语句编号相加,再加上1。
5. 所有基本路径的最大值即为程序的环路复杂度。
基本路径法的优点是准确性高,能够全面地评估程序的复杂性。
但是,它的缺点是计算步骤繁琐,对于大型程序来说,计算量较大。
三、控制流图法控制流图法是一种通过绘制程序的控制流图来计算环路复杂度的方法。
控制流图是一种图形化表示程序控制流程的图,其中节点表示程序的语句,边表示语句之间的连接关系。
控制流图法的计算步骤如下:1. 绘制程序的控制流图。
2. 对控制流图中的每个节点进行标记。
3. 统计控制流图中的环路个数。
4. 环路个数加1即为程序的环路复杂度。
控制流图法的优点是直观易懂,计算步骤相对简单。
但是,它的缺点是可能会漏掉一些复杂的控制流程,导致对程序复杂性的评估不准确。
四、McCabe方法McCabe方法是一种通过计算程序中的判定节点和控制流边的数量来计算环路复杂度的方法。
判定节点是指程序中的条件语句(如if 语句、switch语句等),控制流边是指条件语句中的各个分支。
McCabe方法的计算步骤如下:1. 统计程序中的判定节点数量。
2. 统计程序中的控制流边数量。
一种基于程序结构和程序作用的复杂性度量

一种基于程序结构和程序作用的复杂性度量
艾波
【期刊名称】《北京邮电学院学报》
【年(卷),期】1992(015)004
【摘要】本文提出了一种将程序结构和它对环境状态的作用综合起来进行评估的程序复杂性度量方法.这一方法直观、易于理解、易于计算,并可以处理用其它度量方法无法解释的一些问题。
【总页数】7页(P60-66)
【作者】艾波
【作者单位】无
【正文语种】中文
【中图分类】TP311
【相关文献】
1.一种基于程序结构图的入侵检测方法研究 [J], 徐漫江;姚放吾
2.一种基于Pascal的程序结构语言及其应用 [J], 徐宝文
3.程序复杂性度量的一种新方法 [J], 伦立军;丁雪梅;李英梅
4.程序复杂性度量的一种新方法 [J], 钟珞;石亮
5.程序结构分解及复杂性度量 [J], 吴锡琪;钟珞
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
程序复杂性度量程序复杂性主要指模块内程序的复杂性。
它直接关联到软件开发费用的多少,开发周期的长短和软件内部潜伏错误的多少。
同时它也是软件可理解性的另一种度量。
减少程序复杂性,可提高软件的简单性和可理解性,并使软件开发费用减少,开发周期缩短,软件内部潜藏错误减少一、代码行度量法度量程序的复杂性,最简单的方法就是统计程序的源代码行数。
此方法基于两个前提:(1)程序复杂性随着程序规模的增加不均衡地增长;(2)控制程序规模的方法最好是采用分而治之的办法。
将一个大程序分解成若干个简单的可理解的程序段。
方法的基本考虑是统计一个程序模块的源代码行数目,并以源代码行数做为程序复杂性的度量。
若设每行代码的出错率为每 100行源程序中可能有的错误数目,例如每行代码的出错率为1%,则是指每 100行源程序中可能有一个错误。
Thayer曾指出,程序出错率的估算范围是从0.04%~ 7%之间,即每100行源程序中可能存在0.04~7个错误。
他还指出,每行代码的出错率与源程序行数之间不存在简单的线性关系。
Lipow进一步指出,对于小程序,每行代码的出错率为1.3%~1.8%;对于大程序,每行代码的出错率增加到2.7%~3.2%之间,但这只是考虑了程序的可执行部分,没有包括程序中的说明部分。
Lipow及其他研究者得出一个结论:对于少于100个语句的小程序,源代码行数与出错率是线性相关的。
随着程序的增大,出错率以非线性方式增长。
所以,代码行度量法只是一个简单的,估计得很粗糙的方法。
二、McCabe度量法McCabe度量法是一种基于程序控制流的复杂性度量方法。
McCabe定义的程序复杂性度量值又称环路复杂度,它基于一个程序模块的程序图中环路的个数。
如果把程序流程图中每个处理符号都退化成一个结点,原来联结不同处理符号的流线变成连接不同结点的有向弧,这样得到的有向图就叫做程序图。
计算有向图G的环路复杂性的公式:V(G)=m-n+2其中,V(G)是有向图G中的环路个数,m是图G中有向弧个数,n是图G中结点个数。
以图9-5-1为例,其中,结点数n=11,弧数m=12,则有V(G)=m-n+2=12-11+2=3。
即McCabe环路复杂度度量值为3 。
它也可以看做由程序图中的有向弧所封闭的区域个数。
图 9-5-1 程序图的例子当分支或循环的数目增加时,程序中的环路也随之增加,因此McCabe环路复杂度度量值实际上是为软件测试的难易程度提供了一个定量度量的方法,同时也间接地表示了软件的可靠性。
实验表明,源程序中存在的错误数以及为了诊断和纠正这些错误所需的时间与McCabe环路复杂度度量值有明显的关系。
Myers建议,对于复合判定,例如(A=0)∩(C=D)∪(X='A')算做三个判定。
利用McCabe环路复杂度度量时,有几点说明。
·环路复杂度取决于程序控制结构的复杂度。
当程序的分支数目或循环数目增加时其复杂度也增加。
环路复杂度与程序中覆盖的路径条数有关。
·环路复杂度是可加的。
例如,模块A的复杂度为3 ,模块B的复杂度为4,则模块A与模块B的复杂度是7。
·McCabe建议,对于复杂度超过10的程序,应分成几个小程序,以减少程序中的错误。
Walsh 用实例证实了这个建议的正确性。
他发现,在McCabe复杂度为10的附近,存在出错率的间断跃变。
·McCabe环路复杂度隐含的前提是:错误与程序的判定加上例行子程序的调用数目成正比。
而加工复杂性、数据结构、录入与打乱输入卡片的错误可以忽略不计。
三、Halstead的软件科学Halstead软件科学研究确定计算机软件开发中的一些定量规律,它采用以下一组基本的度量值,这些度量值通常在程序产生之后得出,或者在设计完成之后估算出。
1.程序长度,即预测的Halstead长度令n1表示程序中不同运算符(包括保留字)的个数,令n2表示程序中不同运算对象的个数,令H表示“程序长度”,则有H=n1·log2n1 +n2·log2n2这里,H是程序长度的预测值,它不等于程序中语句个数。
在定义中,运算符包括:算术运算符赋值符(=或:=)数组操作符逻辑运算符分界符(,或;或:)子程序调用符关系运算符括号运算符循环操作符等特别地,成对的运算符,例如“ BEGIN…END ”、“ FOR…TO ”、“REPEAT…UNTIL”、“WHILE…DO”、“IF…THEN…ELSE”、“(…)”等都当做单一运算符。
运算对象包括变量名和常数。
2.实际的Halstead长度设N1为程序中实际出现的运算符总个数,N2为程序中实际出现的运算对象总个数,N为实际的Halstead长度,则有N =N1+N23.程序的词汇表Halstead定义程序的词汇表为不同的运算符种类数和不同的运算对象种类数的总和。
若令n为程序的词汇表,则有n =n1+n2图9-5-2是用FORTRAN语言写出的交换排序的例子。
图 9-5-2 一个交换排序程序的例子因此有:预测的词汇量H=n1·log2n1+n2·log2n2=10·log210+7·log27 =52.87实际的词汇量N=N1+N2=28+22=50程序的词汇表n=n1+n2=10+7=174.程序量V程序量V,可用下式算得V=(N1+N2)·log2(n1+n2)它表明了程序在“词汇上的复杂性”。
其最小值为V*=(2+n2*)·log2(2+n2*)这里,2表明程序中至少有两个运算符:赋值符“:=”和函数调用符“f()”,n2*表示输入/输出变量个数。
对于图9-5-2的例子,利用n1,N1,n2,N2,可以计算得:V=(28+22)·log2(10+7)=204等效的汇编语言程序的 V=328。
这说明汇编语言比FORTRAN语言需要更多的信息量(以bit表示)。
5.程序量比率(语言的抽象级别)L=V*∕V或L=(2∕n1)·(n2∕N2)这里,N2=n2·log2n2。
它表明了一个程序的最紧凑形式的程序量与实际程序量之比,反映了程序的效率。
其倒数:D=1∕L表明了实现算法的困难程度。
有时,用L表达语言的抽象级别,即用L衡量在表达程序过程时的抽象程度。
对于高级语言,它接近于1,对于低级语言,它在0~1之间。
下面列出的是根据经验得出的一些常用语言的语言抽象级别。
6.程序员工作量E=V∕L7.程序的潜在错误Halstead度量可以用来预测程序中的错误。
认为程序中可能存在的差错应与程序的容量成正比。
因而预测公式为B=(N1+N2)·log2(n1+n2)∕3000=V∕3000B表示该程序的错误数。
例如,一个程序对75个数据库项共访问1300次,对150个运算符共使用了1200次,那么预测该程序的错误数:B=(1300+1200)·log2(75+150)∕3000=6.5即预测该程序中可能包含6~7个错误。
Halstead的重要结论之一是:程序的实际 Halstead长度N可以由词汇表n算出。
即使程序还未编制完成,也能预先算出程序的实际Halstead长度N,虽然它没有明确指出程序中到底有多少个语句。
这个结论非常有用。
经过多次验证,预测的 Halstead 长度与实际的Halstead长度是非常接近的。
Halstead度量是目前最好的度量方法。
但它也有缺点:·没有区别自己编的程序与别人编的程序。
这是与实际经验相违背的。
这时应将外部调用乘上一个大于 1的的常数Kf(应在1~5之间,它与文档资料的清晰度有关)。
·没有考虑非执行语句。
补救办法:在统计n1、n2、N1、N2时,可以把非执行语句中出现的运算对象,运算符统计在内。
·在允许混合运算的语言中,每种运算符必须与它的运算对象相关。
如果一种语言有整型、实型、双精度型三种不同类型的运算对象,则任何一种基本算术运算符(+、-、×、/)实际上代表了 4种运算符。
如果语言中有 4种不同类型的算术运算对象,那么每一种基本算术运算符实际上代表了种运算符。
在计算时应考虑这种因数据类型而引起差异的情况。
·没有注意调用的深度。
Halstead公式应当对调用子程序的不同深度区别对待。
在计算嵌套调用的运算符和运算对象时,应乘上一个调用深度因子。
这样可以增大嵌套调用时的错误预测率。
·没有把不同类型的运算对象,运算符与不同的错误发生率联系起来,而是把它们同等看待。
例如,对简单IF语句与WHILE语句就没有区别。
实际上,WHILE语句复杂得多,错误发生率也相应地高一些。
·忽视了嵌套结构(嵌套的循环语句、嵌套IF语句、括号结构等)。
一般地,运算符的嵌套序列,总比具有相同数量的运算符和运算对象的非嵌套序列要复杂得多。
解决的办法是对嵌套结果乘上一个嵌套因子。