Abstract Conference Time-Table Management
Reference manager中文说明书

功能:1.随时为着作文本或目录提供固定化格式2.创建并支持本地数据库3.为以后的再次版印提供方便4.可以使图书馆或研究机构的人员方便的管理当前服务5.从各种在线数据库、CD-ROM、或基于web的数据库收集参考文献目录6.为学生创建学科保存和阅读列表7.为员工创建出版物列表8.特殊目录收集二.打开样本数据库(Open sample database)用窗口上方的open打开,打开后发现文件由上下两个窗口区域组成。
上方为编辑区,以文摘的形式显示,不过显示的内容都是下方所选ID的内容。
默认的参考文献列表显示ref ID, Author, title(如下方窗口所示)。
当然这些内容都可以自己定义。
三.参考文献列表显示的用户化定义(Customize the Reference List Display)在菜单栏选择tools——Reference List Display。
出现Reference List fields to Display 对话框,第一行可以指定显示的顺序,第二行可以修饰以标题形式显示的文本,第三行可以选择用户浏览区(点击第三行可以出现上下栏菜单,可通过此菜单选择)。
改变顺序的方法是(比如将第三栏移到第一栏):将鼠标移到第三栏处,当鼠标箭头变成向下的黑体箭头时,按下鼠标拖动即可(拖动方式类似word 文档)!插入一栏可以点击Insert Col或直接在number of colum方框内入所需要的栏数。
新插入的栏都以ID作为默认的标题(header),可以按上述方法修改。
最后点击OK,此时屏幕提示whether you would like to copy this reference list format to all reference lists,点yes,以后参考文献的显示就按照用户定义的格式。
栏宽的调整:类似word中表格的拖动,只要会用鼠标就会拖动调整。
三.数据库选择顺序的用户化定义(Customize the Database Sort Order)1.在已有的数据库中定义搜索顺序:菜单Tools——选择 Change Database Sort Order。
完整word版基于java会议管理系统设计

基于JAVA的会议管理系统组员:日期: 2013.12.251 绪论开发背景●当今社会竞争日益激烈,公司单位内部会议也不断增多,会议信息量也逐渐增大。
公司内部需要经常通过会议沟通,问题解决以及决策的制定。
而现在公司的会议管理工作繁重且处于无系统流程状态。
手工作业效率很低,不便于管理,而且容易出错。
因此,提高会议效率,发挥会议功能,避免人力物力财力浪费,降低经营成本、达到人力资源效率化,是领导者们推动企业效率的重要课题,他们急切需要有效的“会议管理”。
本会议管理系统应运而生,公司会议室的合理分配,不仅有利于公司资源最大程度的利用,而且有利于提高会议质量。
解决了因资源竞争而产生的一系列问题,避免不同部门间冲突。
加强各部门合作,是企业得以长久生存的保证。
会议管理系统主要有用户管理,会议室管理,会议室查询,会议信息的发布和安排,会议管理,会议查询六大模块。
整个系统各操作界面清新、大方,操作方便,信息化处理是当今社会不可避免的趋势,单一的手工记录操作已不能满足规模日益增大的企业。
此时,该系统将是你最优的选择.开发目的●1.系统地研究会议管理系统的需求分析、总体设计和数据库设计过程。
2.系统地进行程序设计,重点研究应用JAVA和MySql数据库技术进行基于B/S系统的发。
系统范围●系统包括的范围:用户管理,会议查询,会议管理,会议显示,会议室查询,会议室管理。
2 可行性分析1.可行性研究的目的:是用最小的代价在尽可能的时间内确定问题是否能够解决。
由于本系统管理的对象单一,每个数据变化性频繁,计算并不难。
因此,容易采用数据库管理。
2.在运行上可行:本系统为局域网的C/S小型的系统,所耗费的资源非常的小,运行速度快,整体反应,更新等性能好。
在基于JAVA为基础的开发前台的基础上我选择了MySql数据库。
通过JDBC控件来实现JAVA和数据库之间的连接和编辑功能。
3.开发平台及运行环境:工具环境分析(1)体系架构:应用系统功能处理系统数据库(2)模式:C/S(3)总体构成:功能处理系统,数据库,功能处理系统分为前台,后台。
Conference-template-A4(IEEE)(中文版)

Paper Title* (use style: paper title) *Note: Sub-titles are not captured in Xplore and should not be used第一行:第一个给定姓氏第2行:部门。
机构名称(隶属关系)第3行:组织的名称(隶属关系)第4行:城市,国家第5行:电子邮件地址line 1: 4th 第一行:第二个给定姓氏第2行:部门。
机构名称(隶属关系)第3行:组织的名称(隶属关系)第4行:城市,国家第5行:电子邮件地址第1行:第3个名字姓第2行:部门。
机构名称(隶属关系)第3行:组织的名称(隶属关系)第4行:城市,国家第5行:电子邮件地址Abstract—这个电子文档是一个“实时”模板,并且已经在其样式表中定义了您的论文的组成部分[标题,文本,标题等]。
*关键:不要在论文标题或摘要中使用符号,特殊字符,脚注或数学。
. (Abstract)Keywords—component, formatting, style, styling, insert (key words)I.I NTRODUCTION (H EADING 1)该模板在MS Word 2007中进行了修改,并保存为PC的“Word 97-2003文档”,为作者提供了准备电子版论文所需的大部分格式规范。
所有标准纸张组件的规定有三个原因:(1)格式化单张纸时的易用性,(2)自动遵守促进电子产品的同时或稍后生产的电子要求,以及(3)整个样式的一致性会议记录。
内置边距,列宽,行间距和类型样式; 本文档中提供了类型样式的示例,并且在示例后面的括号内以斜体标识。
虽然提供了各种表格文本样式,但是没有规定一些组件,例如多级方程式,图形和表格。
格式化程序需要创建这些组件,并包含以下适用的标准.II.E ASE OF U SEA.Selecting a Template (Heading 2)首先,确认您的纸张尺寸有正确的模板。
Oracle医疗大数据解决方案

幸存
危险人群
预防护理
Oracle 医疗大数据解决方案
Operating Systems
Systems Management
Virtual Machines
Middleware Platform and Management
Business IntelligenceData Integration
Identity & Access Management
Oracle Healthcare Transaction Base (HTB)
临床集成的基础事务性临床数据信息库基于 HL7 参考信息模型 (RIM) 标准规范化的医疗卫生数据模型适用于多个标准医疗卫生领域的域模型,例如患者就医、实验室结果、综合观察、开处方、医务或病历、 过敏症、结构化文档 (CDA)、诊断、疾病/问题……临床文档架构 (CDA R2)支持 CDA 文档保存和查询批量提取数据将 ELT 定向到数据仓库或数据集市IHE XDS.b Repository
Security Gateway
、
Oracle Health Sciences Policy Manager
Oracle Enterprise Manager
Oracle SOA Suite、Oracle Service Bus
数据库网格和 Coherence 缓存
Sun 硬件、Sun 存储、ExaData、ExaLogic
源数据提取HLI ETL
MDI ETL
元数据发布例外管理业务规则OHADI: WIL OHADI: SIL 验证, 标准化, 和转换主索引主数据管理和相关服务
数据集市
OBI-EE/Java报表即席查询 联机分析 数据挖掘“Real” Time
北京市十一学校国际部课程表Timetable - Study In China

北京市十一学校国际教育部课程表 Timetable 语言初级班 (Chinese Language Intensive Class of Beginners)星 期Week 第一节 No.1 第二节No.2 第三节 No.3 第四节No.4 第五节 No.5 第六节 No.6 第七节No.7 第八节 No.8星期一Mon 基础汉语Chinese基础汉语Chinese 体 育 P E 汉语听力 Listening 汉语听力 Listening 汉语会话Conversation 计算机 Computer 体育活动课 Sports Activities星期二Tue汉语听力Listening汉语听力Listening 体 育 P E 基础汉语 Chinese 美 术 Fine Arts 基础汉语 Chinese 基础汉语 Chinese 选修课 Elective Class 星期三Wed基础汉语Chinese基础汉语Chinese 音 乐 Music 汉语会话Conversation 汉语会话Conversation单周:汉语实践课Chinese Practice双周:活动课 Activities单周:汉语实践课Chinese Practice双周:活动课Activities单周:汉语实践课Chinese Practice双周:活动课 Activities星期四Thur 基础汉语Chinese基础汉语Chinese 特色体育Characteristic PE 汉语会话Conversation 汉语会话Conversation 基础汉语 Chinese 美 术Fine Arts 班 会Class Meeting星期五Fri 基础汉语Chinese基础汉语Chinese 音 乐Music 汉语会话Conversation 传统手工课Traditional Handcraft 汉语听力Listening 汉语听力Listening 选修课Elective Class[备注] :1) 每周总课时40 节,包括基础汉语课12节、汉语听力课6节、汉语会话课6节、汉语实践课3节(双周上活动课)、体育课3节、音乐课2节、美术课2节、传统手工课1节、计算机课1节、选修课2节(如中国硬笔书法、软笔书法、中国文化讲座、西班牙语、HSK考试辅导等)、班会1节、体育活动课1节。
基于ASP.NET的学生考勤管理系统设计与实现

2017年第11期信息与电脑China Computer&Communication软件开发与应用基于 的学生考勤管理系统设计与实现陈 芃 吴 彬 朱慧博(宿迁学院 信息工程学院,江苏 宿迁 223800)摘 要:针对传统考勤方式效率低、无法实现对学生考勤情况的动态管理等问题,利用B/S 开发模式,以C#作为开发语言,通过SQL Server 2005管理后台数据库,设计并实现了学生考勤管理系统。
系统设计了基于不同权限的请假管理子系统和考勤管理子系统,实现了在线请假、请假审核、审核查询、考勤录入、考勤查询等功能,满足了任课教师实时掌握学生考勤情况并实施动态管理的需求,解决了学生请假信息不够透明公开的问题。
系统功能设计合理、操作简单方便。
关键词:考勤管理;;SQL Server中图分类号:TP311.5 文献标识码:A 文章编号:1003-9767(2017)11-104-03Design and Implementation of Student Attendance Management System basedon Chen Peng, Wu Bin, Zhu Huibo(School of Information Engineering, Suqian College, Suqian Jiangsu 223800, China)Abstract: The traditional attendance mode can ’t realize the dynamic management of the attendance of students, it ’s efficiencyis low. In view of this phenomenon, the paper uses B/S architecture development model, and C# to design a student attendancemanagement system, the system is also designed through the SQL Server 2005 management background database. It designs the leave management subsystem and attendance management subsystem based on different permissions. It realizes the function of online leave, leave audit, audit inquiries, attendance records, attendance query etc. This management system satisfies the needs that teachers master student attendance in time and implementing dynamic management, and solves the problem that the student leave informationis not transparent enough. The system function design is reasonable and the operation is simple and convenient.Key words: attendance management; ; SQL Server在学校的日常教学工作中,学生考勤管理是一项重要环节,是记录每位学生上课情况、评定平时成绩的重要参考[1]。
Oracle Financials Accounting Hub(FAH)用户手册说明书

Oracle Financials Accounting HubOracle Financials Accounting Hub (FAH) efficiently creates detailed, auditable, reconcilable accounting for external or legacy source systems. FAH includes an accounting transformation engine with extensive validations plus accounting and rules repositories. The transformation engine consistently enforces accounting policies; the repositories provide centralized control, detailed audit trails, and facilitate simultaneously meeting diverse corporate, management, and reporting requirements.K E Y B U S I N E S S B E N E F I T SOracle Financials Accounting Hub is an accounting transformation solution, which enables you to:•Meet compliance requirements with a single source of accounting truth for all external and legacy systems •Store analytic information with accounting for reconciliation and reporting•Maximize efficiency with an enterprise accounting rules engine •Comply with multi-GAAP accounting requirements•Audit GL balances with journal details •Accountant and business user interface•Control and monitor end-to-end processing of transactions through integration with Oracle BPEL Process Manager Fragmented Accounting Approaches Create Many ProblemsMost organizations deploy multiple legacy systems to manage their day to day operations. For many of the system users this results in several problems:∙Difficulty enforcing corporate wide standards.∙Duplicate accounting treatments for each source system.∙Difficulty reconciling accounting with source systems.∙Accounting rule implementation hidden in disparate and opaque program code. Oracle Financials Accounting Hub resolves these problems by centralizing the definition and maintenance of accounting rules in a business user orientated repository. Accounting journals are created with a rules transformation engine, validated, and stored in an auditable format in a single location. Your organization can enhance legal and management reporting, efficiently account for any subsystem, strengthen internal controls and, simultaneously meet diverse and mutually exclusive accounting requirements through multiple representations.Create a Single Source of Accounting TruthOracle Financials Accounting Hub maintains user orientated configurable accounting rules in its rules repository. The repository is also home to the accounting rules for Oracle E-Business Suite applications.Business events can be accounted one or more times in parallel using different accounting rules, currencies, calendars, and charts of accounts. When multiple accounting representations are created for a single business event they are linked and reconcilable.Configurable contextual transaction information is stored with journals for reconciliation, and integrated program hooks allow the ability to add drilldowns to transactions from legacy source systems.K E Y F E A T U R E S•Integrated accounting rules repository •Create accounting rules for everyGAAP•Accounting rules engine•Multiple accounting representations •Sophisticated error handling •Supporting references•Export and import accounting rulesfrom test to production•Subledger accounting inquiries •Reporting on accounting ruledefinitions•Manual adjustments•Predefined validations •Predefined BI Publisher templates •Raw transaction and pass-throughaccounting. Store Analytic Information with Accounting for Reconciliations and Reporting Transaction and supporting reference information can be stored in the accounting repository and used for reporting or to feed analytic systems. In the example below, the industry type is tracked as a supporting reference for analysis of this key business dimension.Figure 1. Supporting References Balance Inquiry in Oracle Financials Accounting HubYou can register any business attribute associated with the external or legacy system as a “source”. Sources can be used to drive accounting rules, included in journal descriptions or stored as supporting references for subsequent reporting and analysis.Optionally, Oracle Financials Accounting Hub can, calculate and store balances for supporting references. Supporting reference balances are a powerful analytic feature since, in effect, they extend the accounting flexfield for certain types of transactions without cluttering General Ledger with subledger detail. For example, geographies, channel, industry, investment type, fund manager or product category can be tracked as supporting references without including these key business dimensions in the accounting flexfield.Efficiently Create Accounting for Multiple Heterogeneous Source Systems Oracle Financials Accounting Hub provides a flexible rules builder for business users to create accounting rules once and deploy them many times across different external and legacy systems.Legacy systems that do pre-accounting can pass journals through the hub to validate and store the accounting in the accounting repository for a single, reliable, enterprise wide view.The example below shows the Journal Line Definition user interface in Oracle Financials Accounting Hub to illustrate that you can define elaborate journal line descriptions, advanced account derivation rules and supporting references for your accounting journal lines.R E L A T E D P R O D U C T SSome of the products that share the centralized accounting repository with Oracle Financials Accounting Hub are:•Oracle Assets•Oracle Cash Management •Oracle Inventory Management •Oracle Order Management •Oracle Payables•Oracle Purchasing•Oracle Projects•Oracle ReceivablesR E L A T E D S E R V I C E SThe following services support Oracle Main Product:•Product Support Services •Professional Services Figure 2. User Defined Journal Lines Definitions in Oracle Financials Accounting HubExternal and legacy systems that do not produce accounting can use the rules builder to map and transform raw transactions. This data can be used to control the journal lines created, build journal descriptions, summarize lines, and define journal line accounts.The rules engine anticipates and uses transaction lifecycles. You can account using a transaction flow-based approach, recognizing that the same information can be used to account for related transactions. This facilitates reconciliation, simplifies rules, and reduces the burden on source systems.The accounting engine offers flexible scheduling, processing, and event options.∙Create accounting for a specific business event, or all events for an application.∙Account for manual adjustments using a web-based user interface (refer to figure 2 below).∙Use integration with Fusion Middleware via Business Events to extend validation and / or send notifications to the appropriate users.Figure 3. Manual Adjustment User Interface in Oracle Financials Accounting HubQuickly Update Accounting Rules to Meet New RequirementsChanges in accounting regulations or corporate structure are quickly accommodated with effective dating of rules. The dates of inbound events are used to determine which accounting rules to apply to incoming transactions. Users can implement the rules in a test system and import them into production. An automatic comparison feature allows users to preview the differences between old and new versions of the rules before completing the import.User Interface for Accountants and Business AnalystsOracle Financials Accounting Hub provides an intuitive, business oriented user interface. Users can create and update rules without IT intervention. For example, the user interface allows analysts to determine whether a line should be a debit or credit, its description, and how it should be summarized as shown in the Journal Line Types example below.Figure 4. User Defined Journal Line Types in Oracle Financials Accounting Hub Rapidly Integrate New SystemsMany organizations need to efficiently integrate new industry-specific systems or recently acquired companies into their existing environment.Oracle Financials Accounting Hub implementations can be done gradually, reducing the implementation risk. In a single Oracle Financials Accounting Hub environment, both journal pass-through solutions as well raw transaction-based accounting solutions can be implemented. Customers can move from a pass-through solution to raw transaction-based accounting as they require. New systems can be added and new products can be launched whilst the system is in use.Sharing and Reusing Accounting RulesThe rules repository allows users to separately define and reuse setups for each component of a journal entry such as the journal lines, descriptions, and summarization criteria. These setups can be reused to rapidly integrate new source systems into Oracle Financials Accounting Hub. Users can quickly create rules, copy and reuse them to meet similar, yet distinct requirements. For example, if several systems areexpected to book fee income, cash receipts, or disbursements to the same general ledger account, a single rule can be created and used to account for each of these systems.Accelerate the Monthly CloseThe period close process is one of the most closely watched financial processes. From staying on top of new financial reporting regulations to increasing the efficiency of the current close process, there is always a focus on this key financial process.Sophisticated Error and Exception HandlingA rapid daily and monthly close requires prompt resolution of accounting errors. Oracle Financials Accounting Hub stores not only the error messages but also the entire journal when it encounters errors. Users can quickly isolate, research, and resolve exceptions with business oriented exception management and on-line inquiries.Error status journals are automatically reprocessed each time the accounting engine executes until they are successfully accounted. Routing and resolution of exceptions can be accelerated using predefined error limits for accounting engine processing.Integrate Source Systems with Oracle BPEL Process ManagerThe Oracle Financials Accounting Hub is based upon a service-oriented architecture and takes advantage of Oracle’s SOA platform and Fusion Middleware. The integration can be used to control and monitor the end-to-end processing of accounting transactions (e.g., retrieval of transactions, pre-processing, error-handling, post-processing and write-back to feeder systems).Enhance Internal Controls and AuditabilityThe centralized architecture of Oracle Financials Accounting Hub provides a number of enhancements to your internal control structure to ensure successful audit and compliance reviews. Some of the best practices features that are available include the following:∙The name and version of the applied rules is stored with each journal entry in the accounting repository.∙Active rules can be locked to prevent changes.∙Rules cannot be used until validated.∙On-line inquiries allow users to view journals based upon the version and name of the rules used to generate the accounting and the ability to view the associated names of the journal line definitions and the journal line types.∙Reporting on accounting rule definitions to enable easy review of all the accounting rules defined.∙Separate security for viewing accounting by role and user.∙Transaction security policies hooks can limit drilldown to source system information. ∙Manual adjustments can be restricted by role and userAuditors and compliance officers can use the rules and accounting repositories as a basis for their engagements.The Oracle Financials Accounting Hub takes full advantage of Oracle Application Object Library and database security features.Transparent, Extensible Validations for Sarbanes-Oxley ComplianceEnforcing consistent accounting validations is difficult in a heterogeneous systemsenvironment. The common accounting rules engine includes a robust collection ofvalidations and balance and control routines. These validations are fully documentedfor complete transparency, a key requirement for Section 404 Sarbanes-Oxleycompliance.Minimize Manual Corrections with Draft AccountingThe draft accounting feature of Oracle Financials Accounting hub minimizes errorcorrections by allowing users to preview their accounting both on-line and in reportsreducing the need for adjusting journals. The rules and transaction information can becorrected before accounting is finalized.Audit Trail from General Ledger Balances to Business EventsUsers can drill from Oracle General Ledger balances to the specific journal lines in theaccounting repository that comprise that balance. Embedded bi-directional flows allowusers to drill from journal lines either to the supporting business events and theaccounting details.SummaryThe core strengths of Oracle Financials Accounting Hub include its ability to create asingle source of accounting truth for multiple external and legacy systems usingbusiness user-defined accounting rules. This enables you and your organization tocomplete a finance transformation of the back-office operations to make them efficientand compliant.C O N T A CFor more information about Oracle Financials Accounting Hub, visit or call +1.800.ORACLE1to speak to an Oracle representative.C O N N E C T W I T H U S/oracle /oracle /oracle Copyright © 2016, Oracle and/or its affiliates. All rights reserved. This document is provided for information purposes only, and the contents hereofwarranties or conditions, whether expressed orally or implied in law, including implied warranties and conditions of merchantability or fitness for a particular purpose. We specifically disclaim any liability with respect to this document, and no contractual obligations are formed either directly or indirectly by this document. This documentmeans, electronic or mechanical, for any purpose, without our prior written permission.Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners. Intel and Intel Xeon are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks are used under license and。
通信常用缩略语
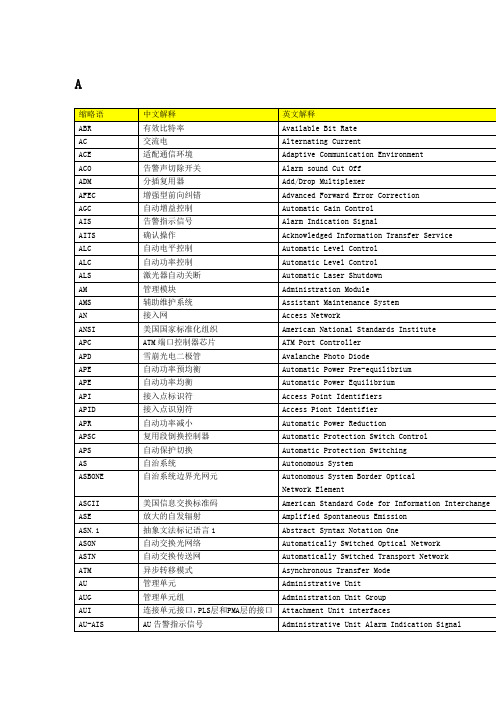
异步转移模式
Asynchronous Transfer Mode
AU
管理单元
Administrative Unit
AUG
管理单元组
Administration Unit Group
AUI
连接单元接口,PLS层和PMA层的接口
Attachment Unit interfaces
AU-AIS
AU告警指示信号
DCF
色散补偿光纤
Dispersion Compensation Fiber
DCG
色散补偿光栅
Dispersion Compensation Grating
DCM
色散补偿模块
Dispersion Compensation Module
DCN
数据通信网
Data Communication Network
ALC
自动电平控制
Automatic Level Control
ALC
自动功率控制
Automatic Level Control
ALS
激光器自动关断
Automatic Laser Shutdown
AM
管理模块
Administration Module
AMS
辅助维护系统
Assistant Maintenance System
AU Pointer Positive Justification
AUG
管理单元组
Administration Unit Group
AUP
管理单元指针
Administration Unit Pointer
AWG
阵列波导光栅
Arrayed Waveguide Grating
Polycom RealPresence Collaboration Server 8.8.1.30

Patch NotesPolycom® RealPresence® Collaboration ServerBuild ID: 8.8.1.3015Released File: OVA, ISO, BIN, QCOW2, Upgrade FileRelease Date: June 26, 2020PurposeThis patch includes fixes for the following issues when applied over the RealPresence Collaboration Server 8.8.1.3 release.EN-171810 Stability15 minutes in the call.EN-166867 Stability A user was unable to make ISDN calls to an RMX 2000 system.EN-159667 General An RMX 1800 system could not display the Global Address Book after aRealPresence Resource Manager failover. The issue resolved after a reboot.EN-178695 Stability An RMX 2000 system became unreachable by RMX Manger while upgrading itto an 8.8.1.x build.These Patch Notes document only the changes from the prerequisite generally available (GA) release. Refer to the Release Notes for that GA release for the complete release documentation.KVM DistributionThe RealPresence Collaboration Server now offers a Kernel-based Virtual Machine (KVM) option for virtual environments. KVM is built into Linux and allows users to turn Linux into a hypervisor that can run multiple virtual machines (VMs).Hardware configuration required for KVM deployment is the same as specified for VMware deployment (Please refer to the Polycom RealPresence Collaboration Server v8.8.1 Release Notes for more details).Prerequisites and Configuration ConsiderationsFor information on prerequisites and configuration considerations, please see the Polycom RealPresence Collaboration Server v8.8.1 Release Notes and the Polycom RealPresence Collaboration Server 8.8.1 Administrator Guide.Installation and Upgrade NotesThe procedure to deploy all of the software components is documented here.Deploying a KVM ImageTo deploy a new server instance on a KVM server:1Obtain the software component image files from your Poly support representative.2For each software component, create a new volume on your KVM server and import the image file.For more on this task, see Create a new volume on the KVM server.3Optionally, set the server to automatically startup.Create a new volume on the KVM serverYou can create a new volume on the KVM server using the Virtual Machine Manager or Virsh command line depending on the toolset available to you.Using Virtual Machine ManagerTo create a new volume on the KVM server using Virtual Machine Manager:1Go to Applications > System Tools > Virtual Machine Manager and click to create a new virtual machine.2Choose Import existing disk image and click Forward.3Enter or browse to the location of the software component image file.4Choose the OS type (Linux) and Version number (CentOS 6.9) and click Forward.5Enter the Memory (RAM) and CPUs required for the chosen software component image as identified in the Prerequisites and Configuration Considerations section and click Forward.6Enter a meaningful name for the VM instance.7Click Network selection and select the network on which the KVM host is defined.8Click Finish.Using Virsh command line toolThe commands in the following procedure can be run to remote KVM servers.When connecting to remote instances, the option --connect qemu://<hostname>/system can be used, where <hostname> is the hostname or IP address of the remote KVM server.Virsh is a command line tool for managing hypervisors and guests. The tool is built on the libvirt management API and can be used as an alternative to other tools like the graphical guest manager (virt-manager) and xm.To create a new volume on the KVM server using Virsh1Determine which storage pool you would like to use:virsh pool-list2Create a new volume on the server:NOTE: We recommend using a raw disk image as it offers increased performance over the qcow2 format.virsh vol-create-as <storage_pool> <volume> <size>GB --format rawWhere:<storage_pool> is the pool determined in step 1.<volume> is the name of the raw disk volume.3Upload the image to the volume:virsh vol-upload --pool <storage_pool> <volume> <path-to-image>4Get the path of the raw disk:virsh vol-path --pool <storage_pool> <volume>Upgrade Information for the RealPresence Collaboration ServerThe following sections provide important general information about upgrading RealPresence Collaboration Servers to this release.Upgrade Package ContentsThe RealPresence® Collaboration Server 8.8.1.4 software upgrade package includes:●The *.upg file for upgrading RealPresence Collaboration Server, Virtual Edition on KVM●The *.qcow2file for deploying RealPresence Collaboration Server, Virtual Edition on KVM. Supported Upgrade PathsUpgrade of RealPresence Collaboration Server from 8.7.4.360 to 8.8.1.4 and subsequent downgrade to 8.7.4.360 has been verified.Resource CapacitiesThe benchmarks for Conferencing and Resource Capacities with KVM deployment is the same as specified for VMware deployment. For information on Resource Capacities, please refer to the Polycom RealPresence Collaboration Server v8.8.1 Release Notes.。
Abstract图形界面的使用

These options control the grid analysis function that calculates the best metal1 and metal2 routing grid pitches and offsets for your standard cells. 默认关闭该功能。
当开关关闭时,整条Net都定义
为Pin,并且每一次改变走向都
增加编号。例如:en1、en2等
A
当开关打开,在boundary的边
缘位置创建Pin,默认情况以
label所在层的最窄宽度为边长
的正方形。
B
第42页/共59页
Adjust Step
Boundary pin max distance to boundary
第16页/共59页
第17页/共59页
第18页/共59页
5、给Layout增加prBoundary
这一层用于规划IP的大小,属于标识层。 今后可以在Layout设计时就加入这层。需 要注意Stream out GDS文件时要在map文件 中添加对这层的说明,否则会丢失。
第19页/共59页
边缘黄色线条就是prBoundary这层 使用时需要到LSW的Edit中开启这一 层的显示。
Abstract界面
第8页/共59页
菜单说明
Verify step Abstract step Extract step Pins step Logial import Layout import Open library
第9页/共59页
菜单说明
第10页/共59页
数据准备及建库流程
• Tech.lef • GDS • Schematic Library • PDK library
Android应用程序后台管理与界面设计

曹明剑
指导教师:
滕云、郑华盛
二 O 一四年 六 月
毕业设计(论文)任务书
I-毕业设计(论文)题目:
Android 应用程序后台管理与界面设计
II-毕 业论文拟采用的原始资料(数据)及目的要求: 原始资料:各类 Java EE-Java SE-Android 相关的相关教材;有关硕士论文资料。
[2]沈世镒,陈鲁生.信息论与编码理论[M].北京:科学出版社,2002 [3]沈世镒,吴忠华.信息论基础与应用[M].北京:高等教育出版社,2004.7 [4]叶中行.信息论基础[M].北京:高等教育出版社,2003.7 [5]姜目丹的.要信求息:论首与先编通码过[M对].合An肥d:ro中id国应科用学技程术序大进学行出数版据社,交2互00的4.7需 求 分 析 , 从 用 户 [及6]S仇DK佩接亮口.中信获息取论各及种其数应据用[,M连].接杭数州据:库浙。江在大后学台出管版理社系,统1中99实9.现7 各种数据的处理与交互, [最7]终傅在祖手芸机.客信户息端论:—基—础《理爱论的与代应驾用》.中北实京现:完电美子交工互业。出版社,2001.8 [8]Jacobason,Nathan.Basic algebra[M].New York:W.H.FREEMAN AND COMPANY.1910.
作者签名:
日期:
学位论文版权使用授权书
本学位论文作者完全了解学校有关保留、使用学位论文的规定,同意学校保留并向国 家有关部门或机构送交论文的复印件和电子版,允许论文被查阅和借阅。本人授权南昌航 空大学可以将本论文的全部或部分内容编入有关数据库进行检索,可以采用影印、缩印或 扫描等复制手段保存和汇编本学位论文。
2.2 后台管理系统功能..................................................................................... 4 2.3 MVC 框架中各项功能的实现.................................................................... 10
JVM for a Heterogeneous Shared Memory System

JVM for a Heterogeneous Shared Memory SystemDeQing Chen,Chunqiang Tang,Sandhya Dwarkadas,and Michael L.ScottComputer Science Department,University of Rochester AbstractInterWeave is a middleware system that supports the shar-ing of strongly typed data structures across heterogeneouslanguages and machine architectures.Java presents spe-cial challenges for InterWeave,including write detection,data translation,and the interface with the garbage col-lector.In this paper,we discuss our implementation ofJ-InterWeave,a JVM based on the Kaffe virtual machineand on our locally developed InterWeave client software.J-InterWeave uses bytecode instrumentation to detectwrites to shared objects,and leverages Kaffe’s class ob-jects to generate type information for correct transla-tion between the local object format and the machine-independent InterWeave wire format.Experiments in-dicate that our bytecode instrumentation imposes lessthan2%performance cost in Kaffe interpretation mode,and less than10%overhead in JIT mode.Moreover,J-InterWeave’s translation between local and wire format ismore than8times as fast as the implementation of ob-ject serialization in Sun JDK1.3.1for double arrays.Toillustrate theflexibility and efficiency of J-InterWeave inpractice,we discuss its use for remote visualization andsteering of a stellar dynamics simulation system writtenin C.1IntroductionMany recent projects have sought to support distributedshared memory in Java[3,16,24,32,38,41].Manyof these projects seek to enhance Java’s usefulness forlarge-scale parallel programs,and thus to compete withmore traditional languages such as C and Fortran in thearea of scientific computing.All assume that applicationcode will be written entirely in Java.Many—particularlythose based on existing software distributed shared mem-ory(S-DSM)systems—assume that all code will run oninstances of a common JVM.has yet to displace Fortran for scientific computing sug-gests that Java will be unlikely to do so soon.Even for systems written entirely in Java,it is appealing to be able to share objects across heterogeneous JVMs. This is possible,of course,using RMI and object serial-ization,but the resulting performance is poor[6].The ability to share state across different languages and heterogeneous platforms can also help build scalable dis-tributed services in general.Previous research on var-ious RPC(remote procedure call)systems[21,29]in-dicate that caching at the client side is an efficient way to improve service scalability.However,in those sys-tems,caching is mostly implemented in an ad-hoc man-ner,lacking a generalized translation semantics and co-herence model.Our on-going research project,InterWeave[9,37],aims to facilitate state sharing among distributed programs written in multiple languages(Java among them)and run-ning on heterogeneous machine architectures.InterWeave applications share strongly-typed data structures located in InterWeave segments.Data in a segment is defined using a machine and platform-independent interface de-scription language(IDL),and can be mapped into the ap-plication’s local memory assuming proper InterWeave li-brary calls.Once mapped,the data can be accessed as ordinary local objects.In this paper,we focus on the implementation of In-terWeave support in a Java Virtual Machine.We call our system J-InterWeave.The implementation is based on an existing implementation of InterWeave for C,and on the Kaffe virtual machine,version1.0.6[27].Our decision to implement InterWeave support directly in the JVM clearly reduces the generality of our work.A more portable approach would implement InterWeave support for segment management and wire-format trans-lation in Java libraries.This portability would come,how-ever,at what we consider an unacceptable price in perfor-mance.Because InterWeave employs a clearly defined internal wire format and communication protocol,it is at least possible in principle for support to be incorporated into other JVMs.We review related work in Java distributed shared state in Section2and provide a brief overview of the Inter-Weave system in Section3.A more detailed description is available elsewhere[8,37].Section4describes the J-InterWeave implementation.Section5presents the results of performance experiments,and describes the use of J-InterWeave for remote visualization and steering.Sec-tion6summarizes our results and suggests topics for fu-ture research.2Related WorkMany recent projects have sought to provide distributed data sharing in Java,either by building customized JVMs[2,3,24,38,41];by using pure Java implementa-tions(some of them with compiler support)[10,16,32]; or by using Java RMI[7,10,15,28].However,in all of these projects,sharing is limited to Java applications. To communicate with applications on heterogeneous plat-forms,today’s Java programmers can use network sock-ets,files,or RPC-like systems such as CORBA[39].What they lack is a general solution for distributed shared state. Breg and Polychronopoulos[6]have developed an al-ternative object serialization implementation in native code,which they show to be as much as eight times faster than the standard implementation.The direct compari-son between their results and ours is difficult.Our exper-iments suggest that J-Interweave is at least equally fast in the worst case scenario,in which an entire object is mod-ified.In cases where only part of an object is modified, InterWeave’s translation cost and communication band-width scale down proportionally,and can be expected to produce a significant performance advantage.Jaguar[40]modifies the JVM’s JIT(just-in-time com-piler)to map certain bytecode sequences directly to na-tive machine codes and shows that such bytecode rewrit-ing can improve the performance of object serialization. However the benefit is limited to certain types of objects and comes with an increasing price for accessing object fields.MOSS[12]facilitates the monitoring and steering of scientific applications with a CORBA-based distributed object system.InterWeave instead allows an application and its steerer to share their common state directly,and in-tegrates that sharing with the more tightly coupled sharing available in SMP clusters.Platform and language heterogeneity can be supported on virtual machine-based systems such as Sun JVM[23] and [25].The Common Language Run-time[20](CLR)under framework promises sup-port for multi-language application development.In com-parison to CLR,InterWeave’s goal is relatively modest: we map strongly typed state across languages.CLR seeks to map all high-level language features to a common type system and intermediate language,which in turn implies more semantic compromises for specific languages than are required with InterWeave.The transfer of abstract data structures wasfirst pro-posed by Herlihy and Liskov[17].Shasta[31]rewrites bi-nary code with instrumentation for access checks forfine-grained S-DSM.Midway[4]relies on compiler support to instrument writes to shared data items,much as we do in the J-InterWeave JVM.Various software shared memory systems[4,19,30]have been designed to explicitly asso-ciate synchronization operations with the shared data they protect in order to reduce coherence costs.Mermaid[42] and Agora[5]support data sharing across heterogeneous platforms,but only for restricted data types.3InterWeave OverviewIn this section,we provide a brief introduction to the design and implementation of InterWeave.A more de-tailed description can be found in an earlier paper[8]. For programs written in C,InterWeave is currently avail-able on a variety of Unix platforms and on Windows NT. J-InterWeave is a compatible implementation of the In-terWeave programming model,built on the Kaffe JVM. J-InterWeave allows a Java program to share data across heterogeneous architectures,and with programs in C and Fortran.The InterWeave programming model assumes a dis-tributed collection of servers and clients.Servers maintain persistent copies of InterWeave segments,and coordinate sharing of those segments by clients.To avail themselves of this support,clients must be linked with a special In-terWeave library,which serves to map a cached copy of needed segments into local memory.The servers are the same regardless of the programming language used by clients,but the client libraries may be different for differ-ent programming languages.In this paper we will focus on the client side.In the subsections below we describe the application programming interface for InterWeave programs written in Java.3.1Data Allocation and AddressingThe unit of sharing in InterWeave is a self-descriptive data segment within which programs allocate strongly typed blocks of memory.A block is a contiguous section of memory allocated in a segment.Every segment is specified by an Internet URL and managed by an InterWeave server running at the host indi-cated in the URL.Different segments may be managed by different servers.The blocks within a segment are num-bered and optionally named.By concatenating the seg-ment URL with a block number/name and offset(delim-ited by pound signs),we obtain a machine-independent pointer(MIP):“/path#block#offset”. To create and initialize a segment in Java,one can ex-ecute the following calls,each of which is elaborated on below or in the following subsections:IWSegment seg=new IWSegment(url);seg.wl_acquire();MyType myobj=new MyType(seg,blkname);myobj.field=......seg.wl_release();In Java,an InterWeave segment is captured as an IWSegment object.Assuming appropriate access rights, the new operation of the IWSegment object communi-cates with the appropriate server to initialize an empty segment.Blocks are allocated and modified after acquir-ing a write lock on the segment,described in more detail in Section3.3.The IWSegment object returned can be passed to the constructor of a particular block class to al-locate a block of that particular type in the segment. Once a segment is initialized,a process can convert be-tween the MIP of a particular data item in the segment and its local pointer by using mip ptr and ptr mip where appropriate.It should be emphasized that mip ptr is primar-ily a bootstrapping mechanism.Once a process has one pointer into a data structure(e.g.the root pointer in a lat-tice structure),any data reachable from that pointer can be directly accessed in the same way as local data,even if embedded pointers refer to data in other segments.In-terWeave’s pointer-swizzling and data-conversion mech-anisms ensure that such pointers will be valid local ma-chine addresses or references.It remains the program-mer’s responsibility to ensure that segments are accessed only under the protection of reader-writer locks.3.2HeterogeneityTo accommodate a variety of machine architectures,In-terWeave requires the programmer to use a language-and machine-independent notation(specifically,Sun’s XDR[36])to describe the data types inside an InterWeave segment.The InterWeave XDR compiler then translates this notation into type declarations and descriptors appro-priate to a particular programming language.When pro-gramming in C,the InterWeave XDR compiler generates twofiles:a.hfile containing type declarations and a.c file containing type descriptors.For Java,we generate a set of Java class declarationfiles.The type declarations generated by the XDR compiler are used by the programmer when writing the application. The type descriptors allow the InterWeave library to un-derstand the structure of types and to translate correctly between local and wire-format representations.The lo-cal representation is whatever the compiler normally em-ploys.In C,it takes the form of a pre-initialized data struc-ture;in Java,it is a class object.3.2.1Type Descriptors for JavaA special challenge in implementing Java for InterWeave is that the InterWeave XDR compiler needs to gener-ate correct type descriptors and ensure a one-to-one cor-respondence between the generated Java classes and C structures.In many cases mappings are straight forward: an XDR struct is mapped to a class in Java and a struct in C,primitivefields to primitivefields both in Java andC,pointersfields to object references in Java and pointers in C,and primitive arrays to primitive arrays. However,certain“semantics gaps”between Java and C force us to make some compromises.For example,a C pointer can point to any place inside a data block;while Java prohibits such liberties for any object reference. Thus,in our current design,we make the following compromises:An InterWeave block of a single primitive data item is translated into the corresponding wrapped class for the primitive type in Java(such as Integer,Float, etc.).Embedded structfields in an XDR struct definition areflattened out in Java and mapped asfields in its parent class.In C,they are translated naturally into embeddedfields.Array types are mapped into a wrapped IWObject(including the IWacquire,wl acquire, and rlpublic class IWSegment{public IWSegment(String URL,Boolean iscreate);public native staticint RegisterClass(Class type);public native staticObject mip_to_ptr(String mip);public native staticString ptr_to_mip(IWObject Ob-ject obj);......public native int wl_acquire();public native int wl_release();public native int rl_acquire();public native int rl_release();......}Figure2:IWSegment Class4.1.1JNI Library for IWSegment ClassThe native library for the IWSegment class serves as an intermediary between Kaffe and the C InterWeave library. Programmer-visible objects that reside within the IWSeg-ment library are managed in such a way that they look like ordinary Java objects.As in any JNI implementation,each native method has a corresponding C function that implements its function-ality.Most of these C functions simply translate their pa-rameters into C format and call corresponding functions in the C InterWeave API.However,the creation of an In-terWeave object and the method RegisterClass need special explanation.Mapping Blocks to Java Objects Like ordinary Java objects,InterWeave objects in Java are created by“new”operators.In Kaffe,the“new”operator is implemented directly by the bytecode execution engine.We modi-fied this implementation to call an internal function new-Block in the JNI library and newBlock calls the Inter-Weave C library to allocate an InterWeave block from the segment heap instead of the Kaffe object heap.Before returning the allocated block back to the“new”operator, newBlock initializes the block to be manipulated cor-rectly by Kaffe.In Kaffe,each Java object allocated from the Kaffe heap has an object header.This header contains a pointer to the object class and a pointer to its own monitor.Since C InterWeave already assumes that every block has a header (it makes no assumption about the contiguity of separate blocks),we put the Kaffe header at the beginning of what C InterWeave considers the body of the block.A correctly initialized J-InterWeave object is shown in Figure3.Figure3:Block structure in J-InterWeaveAfter returning from newBlock,the Kaffe engine calls the class constructor and executes any user cus-tomized operations.Java Class to C Type Descriptor Before any use of a class in a J-InterWeave segment,including the creation of an InterWeave object of the type,the class object must befirst registered with RegisterClass.Register-Class uses the reflection mechanism provided by the Java runtime system to determine the following informa-tion needed to generate the C type descriptor and passes it to the registration function in the C library.1.type of the block,whether it is a structure,array orpointer.2.total size of the block.3.for structures,the number offields,eachfield’s off-set in the structure,and a pointer to eachfield’s type descriptor.4.for arrays,the number of elements and a pointer tothe element’s type descriptor.5.for pointers,a type descriptor for the pointed-to data.The registered class objects and their corresponding C type descriptors are placed in a hashtable.The new-Block later uses this hashtable to convert a class object into the C type descriptor.The type descriptor is required by the C library to allocate an InterWeave block so that it has the information to translate back and forth between local and wire format(see Section3).4.2KaffeJ-InterWeave requires modifications to the byte code in-terpreter and the JIT compiler to implementfine-grained write detection via instrumentation.It also requires changes to the garbage collector to ensure that InterWeave blocks are not accidentally collected.Figure4:Extended Kaffe object header forfine-grained write detection4.2.1Write DetectionTo support diff-based transmission of InterWeave segment updates,we must identify changes made to InterWeave objects over a given span of time.The current C ver-sion of InterWeave,like most S-DSM systems,uses vir-tual memory traps to identify modified pages,for which it creates pristine copies(twins)that can be compared with the working copy later in order to create a diff.J-InterWeave could use this same technique,but only on machines that implement virtual memory.To enable our code to run on handheld and embedded devices,we pursue an alternative approach,in which we instrument the interpretation of store bytecodes in the JVM and JIT. In our implementation,only writes to InterWeave block objects need be monitored.In each Kaffe header,there is a pointer to the object method dispatch table.On most architectures,pointers are aligned on a word boundary so that the least significant bit is always zero.Thus,we use this bit as theflag for InterWeave objects.We also place two32-bit words just before the Kaffe object header,as shown in Figure4.The second word—modification status—records which parts of the object have been modified.A block’s body is logically divided into32parts,each of which corresponds to one bit in the modification status word.Thefirst extended word is pre-computed when initializing an object.It is the shift value used by the instrumented store bytecode code to quickly determine which bit in the modification status word to set(in other words,the granularity of the write detection).These two words are only needed for In-terWeave blocks,and cause no extra overhead for normal Kaffe objects.4.2.2Garbage CollectionLike distributedfile systems and databases(and unlike systems such as PerDiS[13])InterWeave requires man-ual deletion of data;there is no garbage collection.More-over the semantics of InterWeave segments ensure that an object reference(pointer)in an InterWeave object(block) can never point to a non-InterWeave object.As a result, InterWeave objects should never prevent the collection of unreachable Java objects.To prevent Kaffe from acci-dentally collecting InterWeave memory,we modify the garbage collector to traverse only the Kaffe heap.4.3InterWeave C libraryThe InterWeave C library needs little in the way of changes to be used by J-InterWeave.When an existing segment is mapped into local memory and its blocks are translated from wire format to local format,the library must call functions in the IWSegment native library to initialize the Kaffe object header for each block.When generating a description of modified data in the write lock release operation,the library must inspect the modifi-cation bits in Kaffe headers,rather than creating diffs from the pristine and working copies of the segment’s pages.4.4DiscussionAs Java is supposed to be“Write Once,Run Anywhere”, our design choice of implementing InterWeave support at the virtual machine level can pose the concern of the portability of Java InterWeave applications.Our current implementation requires direct JVM support for the fol-lowing requirements:1.Mapping from InterWeave type descriptors to Javaobject classes.2.Managing local segments and the translation be-tween InterWeave wire format and local Java objects.3.Supporting efficient write detection for objects in In-terWeave segments.We can use class reflection mechanisms along with pure Java libraries for InterWeave memory management and wire-format translation to meet thefirst two require-ments and implement J-InterWeave totally in pure Java. Write detection could be solved using bytecode rewrit-ing techniques as reported in BIT[22],but the resulting system would most likely incur significantly higher over-heads than our current implementation.We didn’t do this mainly because we wanted to leverage the existing C ver-sion of the code and pursue better performance.In J-InterWeave,accesses to mapped InterWeave blocks(objects)by different Java threads on a single VM need to be correctly synchronized via Java object monitors and appropriate InterWeave locks.Since J-InterWeave is not an S-DSM system for Java virtual machines,the Java memory model(JMM)[26]poses no particular problems. 5Performance EvaluationIn this section,we present performance results for the J-InterWeave implementation.All experiments employ a J-InterWeave client running on a1.7GHz Pentium-4Linux machine with768MB of RAM.In experiments involving20406080100120_201_co mp r e s s _202_j e s s _205_ra y t r a c e _209_db _213_j a va c _222_m p e g a u d i o _227_m t r t _228_j a c kJVM98 BenchmarksT i m e (s e c .)Figure 5:Overhead of write-detect instrumentation in Kaffe’s interpreter mode01234567_201_c o mp r e s s _202_j e s s _205_r a y t r a c e _209_d b _213_j a v a c _222_m p e g a u d i o _227_m t r t _228_j a c k JVM98 Benchmarks T i m e (s e c .)Figure 6:Overhead of write-detect instrumentation inKaffe’s JIT3modedata sharing,the InterWeave segment server is running on a 400MHz Sun Ultra-5workstation.5.1Cost of write detectionWe have used SPEC JVM98[33]to quantify the perfor-mance overhead of write detection via bytecode instru-mentation.Specifically,we compare the performance of benchmarks from JVM98(medium configuration)run-ning on top of the unmodified Kaffe system to the per-formance obtained when all objects are treated as if they resided in an InterWeave segment.The results appear in Figures 5and 6.Overall,the performance loss is small.In Kaffe’s inter-preter mode there is less than 2%performance degrada-tion;in JIT3mode,the performance loss is about 9.1%.The difference can be explained by the fact that in inter-preter mode,the per-bytecode execution time is already quite high,so extra checking time has much less impact than it does in JIT3mode.The Kaffe JIT3compiler does not incorporate more re-cent and sophisticated technologies to optimize the gener-ated code,such as those employed in IBM Jalepeno [35]and Jackal [38]to eliminate redundant object referenceand array boundary checks.By applying similar tech-niques in J-InterWeave to eliminate redundant instrumen-tation,we believe that the overhead could be further re-duced.5.2Translation costAs described in Sections 3,a J-InterWeave application must acquire a lock on a segment before reading or writ-ing it.The acquire operation will,if necessary,ob-tain a new version of the segment from the InterWeaveserver,and translate it from wire format into local Kaffeobject format.Similarly,after modifying an InterWeavesegment,a J-InterWeave application must invoke a write lock release operation,which translates modified por-tions of objects into wire format and sends the changes back to the server.From a high level point of view this translation re-sembles object serialization ,widely used to create per-sistent copies of objects,and to exchange objects between Java applications on heterogeneous machines.In this sub-section,we compare the performance of J-InterWeave’stranslation mechanism to that of object serialization in Sun’s JDK v.1.3.1.We compare against the Sun im-plementation because it is significantly faster than Kaffe v.1.0.6,and because Kaffe was unable to successfully se-rialize large arrays in our experiments.We first compare the cost of translating a large array of primitive double variables in both systems.Under Sun JDK we create a Java program to serialize double arrays into byte arrays and to de-serialize the byte arrays backagain.We measure the time for the serialization and de-serialization.Under J-InterWeave we create a programthat allocates double arrays of the same size,releases (un-maps)the segment,and exits.We measure the releasetime and subtract the time spent on communication with the server.We then run a program that acquires (maps)the segment,and measure the time to translate the byte arrays back into doubles in Kaffe.Results are shown in Figure 7,for arrays ranging in size from 25000to 250000elements.Overall,J-InterWeave is about twenty-three times faster than JDK 1.3.1in serialization,and 8times faster in dese-rialization.5.3Bandwidth reduction To evaluate the impact of InterWeave’s diff-based wire format,which transmits an encoding of only those bytes that have changed since the previous communication,we modify the previous experiment to modify between 10and 100%of a 200,000element double array.Results appear in Figures 8and 9.The former indicates translation time,the latter bytes transmitted.20406080100120140250005000075000100000125000150000175000200000225000250000Size of double array (in elements)T i m e (m s e c .)Figure 7:Comparison of double array translation betweenSun JDK 1.3.1and J-InterWeave102030405060708090100100908070605040302010Percentage of changesT i m e (m s e c .)Figure 8:Time needed to translate a partly modified dou-ble arrayIt is clear from the graph that as we reduce the per-centage of the array that is modified,both the translationtime and the required communication bandwidth go down by linear amounts.By comparison,object serialization is oblivious to the fraction of the data that has changed.5.4J-InterWeave Applications In this section,we describe the Astroflow application,developed by colleagues in the department of Physics andAstronomy,and modified by our group to take advan-tage of InterWeave’s ability to share data across hetero-geneous platforms.Other applications completed or cur-rently in development include interactive and incremental data mining,a distributed calendar system,and a multi-player game.Due to space limitations,we do not present these here.The Astroflow [11][14]application is a visualization tool for a hydrodynamics simulation actively used in the astrophysics domain.It is written in Java,but employs data from a series of binary files that are generated sepa-rately by a computational fluid dynamics simulation sys-00.20.40.60.811.21.41.61.8100908070605040302010Percentage of changesT r a n s mi s s i o n s i z e (M B )Figure 9:Bandwidth needed to transmit a partly modified double array2040608010012014012416Number of CPUsT i m e (s e c .)Figure 10:Simulator performance using InterWeave in-stead of file I/Otem.The simulator,in our case,is written in C,and runs on a cluster of 4AlphaServer 41005/600nodes under the Cashmere [34]S-DSM system.(Cashmere is a two-level system,exploiting hardware shared memory within SMP nodes and software shared memory among nodes.InterWeave provides a third level of sharing,based on dis-tributed versioned segments.We elaborate on this three-level structure in previous papers [8].)J-InterWeave makes it easy to connect the Astroflow vi-sualization front end directly to the simulator,to create an interactive system for visualization and steering.The ar-chitecture of the system is illustrated in Figure 1(page 1).Astroflow and the simulator share a segment with one header block specifying general configuration parameters and six arrays of doubles.The changes required to the two existing programs are small and limited.We wrote an XDR specification to describe the data structures we are sharing and replaced the original file operations with shared segment operations.No special care is re-quired to support multiple visualization clients or to con-trol the frequency of updates.While the simulation data。
致远A8数据字典-会议

id
主键ID
BIGINT
template_name
会议格式名称
VARCHAR(50)
usedFlag
是否启用
BIT
description
描述
TEXT
template_format
正文类型
VARCHAR(50)contຫໍສະໝຸດ nt会议内容TEXT
create_user
创建者
BIGINT
create_date
会议室ID
bigint
startDatetime
开始使用时间
datetime
endDatetime
结束使用时间
datetime
appId
会议室申请Id
bigint
meetingId
会议Id
bigint
description
描述
varchar
数据表
会议与会对象(mt_conferee)
字段名
中文名
类型
会议数据字典
[说明]
© 2007 UF Seeyon Co., Ltd.
All rights reserved.
This document contains information that is proprietary and confidential to UF Seeyon., which shall not be disclosed outside the recipient's company or duplicated, used or disclosed in whole or in part by the recipient for any purpose other than to evaluate this file. Any other use or disclosure in whole or in part of this information without the express written permission of UF Seeyon. is prohibited.
基于jsp的毕业论文选题系统的界面设计与实现

摘要信息化作为先进生产力的代表,是当今时代发展的大趋势。
在信息化发展的大潮中,信息技术无疑成为了时代的宠儿。
随着信息化技术的兴起与广泛应用,尤其是网络的覆盖越来越普遍,很多高校也都建立起了自己的校园网。
传统的毕业生直接联系导师进行手工报送的选题方式在网络选题面前显得太过麻烦而且费时较长,已经不能适应信息化时代的发展要求,所以基于互联网的毕业论文选题系统就顺势而生了。
毕业论文选题系统将毕业生对毕业设计课题的选定提升到了互联网层面,不仅采用web的方式,使得选题信息查询实时性大大提升,而且它的审核、权限管理、文件接收等一些功能也使得论文选题变得更加严谨。
本系统提供了最灵活的选题方式与开放的课题管理系统,通过用户的身份自动进行相关权限的判断,用户只能对自己权限内容进行操作。
本系统主要采用jsp网络编程技术为主要开发方法,用tomcat作为web 服务器,通过网上课题的公开发布、学生与导师之间的双向选择、选题信息的及时反馈、多角色用户管理简化传统手工报送的繁琐流程,使得学生、导师、管理员的工作更加方便轻松且快捷省事,同时数据库的管理与维护也会变得更加简便易操作。
【关键词】双向选择多角色用户系统开发 jsp目录摘要 (1)Abstract .............................................................................................. 错误!未定义书签。
第1章绪论 . (3)1.1 选题背景、目的及意义 (4)1.2 选题系统的研究范围 (5)第2章系统需求分析 (5)2.1 系统支持环境 (5)2.2 任务概述 (6)2.3 系统功能分析 (6)2.4 系统需要解决的问题 (7)2.4 系统可行性分析 (7)2.4.1 技术可行性 (8)2.4.2 经济可行性 (8)2.4.3 操作可行性 (8)第3章系统设计 (9)3.1 系统的设计原则 (10)3.2 系统物理架构 (11)3.3 系统的逻辑设计 (11)3.4 系统功能设计 (13)3.4.1 教师端 (14)3.4.2 学生端 (14)3.4.3 管理员端 (14)3.5 数据库设计 (15)3.6 系统界面设计 (18)第4章系统实现 (19)4.1 系统登录界面的实现 (19)4.1.1 滚动字幕的实现 (20)4.1.2 图片的插入与滚动显示 (21)4.1.3 超链接的建立与多样化 (22)4.1.4 图片旋转切换的实现 (23)4.1.5 登录权限选择的实现 (25)4.2 系统主界面效果的实现 (26)4.2.1 双语导航的实现 (27)4.2.2 隐藏菜单栏的实现 (28)4.3 系统其他界面的实现 (31)4.3.1 兔斯基害羞表情动画的实现 (33)4.3.2 确认拒绝对话框的实现 (35)4.4 系统功能的实现 (35)4.4.1 登录模块的实现 (35)4.4.2 管理员模块的实现 (36)4.4.3 教师模块的实现 (36)4.4.4 学生模块的实现 (36)第5章系统测试 (37)5.1 可用性测试 (37)5.2 功能测试 (37)5.3 数据库测试 (37)第6章总结 (39)参考文献 (40)致谢 (41)第1章绪论伴随着信息化技术与网络技术的发展,网络开始成为了我们生活中的重要组成部分,与我们的生活息息相关,为我们的学习、工作和生活提供了很大的便利。
工商管理硕士(MBA)研究生 学位论文计划及开题报告书

工商管理硕士(MBA)研究生学位论文计划及开题报告书
学号
姓名
研究方向
指导教师
姓名、职称
培养学院
开题报告时间年月日
河海大学研究生院制表
说明
1.学位论文计划应在导师的指导下按照培养方案要求制定。
2. 开题报告一般安排在第三学期(全日制MBA)或第五学期(在职MBA),由导师主持并邀请同行专家参加。
3.开题报告的时间、地点须提前三天公布,欢迎师生参加旁听。
4.论文计划书及开题报告书(空白表)由商学院发放,完成后交学院汇总后存档,以备研究生院审查。
5.本材料系永久性档案,请用蓝黑、碳素墨水或墨汁等耐久材料书写。
6.本表可以下载打印,打印时请使用A4纸正反打印,不得改变表格内容及格式。
签名部分必须由签名者亲笔签署。
7.有关详细规定请查阅《河海大学研究生工作手册》。
论文计划
MBA学位论文开题报告会会议记录
续下页
(本页不够写可续页)
附:文献综述报告。
斯伦贝谢公司的新一代勘探开发数据模型

Schlumberger Information SolutionsSchlumberger Public Interpreting Seabed DiagramsCopyright NoticeCopyright © 2004-2006 Schlumberger. All rights reserved.No part of this document may be reproduced, stored in an information retrieval system, or translated or retransmitted in any form or by any means, electronic or mechanical, including photocopying and recording, without the prior written permission of the copyright owner. TrademarksSchlumberger trademarks that may appear in this document include, but are not limited to Seabed.All other company or product names mentioned are used for identification purposes only and may be trademarks of their respective owners.Table of ContentsInterpreting Seabed Diagrams (1)Purpose (1)1.1 Document1.2 What is a Seabed Diagram? (1)Example Diagram (2)1.3 Seabed Diagramming Notation (3)Class (6)1.4 AbstractClass (6)1.5 Concrete1.6 Attribute (7)1.7 Attribute Value Domain (7)1.8 Association (7)Multiplicity (9)1.9 AssociationSemantic (10)Delete1.10 AssociationAssociation (12)1.11 Composition1.12 Generalization (13)Appendix A – Association Implementation Techniques Mentioned in the Web Report (14)Appendix B – Associations Referencing Abstract Classes (15)Example B-1 (16)Abstract (17)B.1 SingleImplementation (17)B.1.1 PhysicalIntegrity (17)B.1.1.1 ReferentialB.1.1.2 Multiplicity (17)B.1.1.3 Web Report Representation (17)Example (18)B.1.1.4 DataB.1.2 Assoc (18)B.1.1.5 PhysicalImplementation (18)Integrity (19)B.1.1.6 ReferentialB.1.1.7 Multiplicity (20)B.1.1.8 Web Report Representation (20)Example (20)B.1.1.9 DataInterpreting Seabed DiagramsPurpose1.1 DocumentThe purpose of this document is to explain the various notations used in Seabed diagrams: what they mean, how they translate to the web report, and their implications on the physical database.1.2 What is a Seabed Diagram?A Seabed diagram is a class diagram expressed in the Unified Modeling Language1 (UML) that represents Seabed data elements and the relationships between them. Although the diagrams are meant to be a logical representation of business and data rules, many aspects of the physical database design can be inferred from them. The following example diagram describes the concept of facility composition. This diagram is referenced throughout this document when describing diagramming notations.1The Unified Modeling Language Reference Manual by James Rumbaugh, Ivar Jacobson, Grady Booch; 1999; Addison-WesleyExample DiagramFacility_Equipment_FlagSerial_Number1.3 Seabed Diagramming NotationFollowing are the various diagramming notations used in Seabed diagrams. Click the hyperlink for an explanation of its meaning, how it translates to the web report, and its implication on the physical database design.Abstract ClassFacility_Equipment_FlagConcrete ClassAttributeAttribute Value DomainThe value domain is not normally displayed to improve the readability of the diagrams.AssociationPart_Facility_SpacingAssociation MultiplicityFacility_Equipment_FlagPart_Facility_SpacingAssociation Delete SemanticThe association delete semantic is not normally displayed to improve the readability of the Facility_Equipment_FlagPart_Facility_SpacingComposition AssociationGeneralization1.4 AbstractClassWhat does it tell me? An abstract class is a type of class that represents a generalized structureor “parent” from which other classes inherit attributes and associations.An abstract class acts as the supertype in generalization (“is-a-kind-of”)associations.How is it represented inthe web report?As an Entity with Entity Type = “Abstract”.How is it represented in a physical database? Facility_Equipment_Flag Abstract classes have no direct instances and therefore are not implemented as tables or views in a physical database. Instead, the concrete classes that are children of the abstract class inherit the attributes and associations from the abstract class; and those attributes/associations become columns in the view created from the concrete class. This is explained in further detail in the Generalization section of this document.1.5 ConcreteClassWhat does it tell me?A concrete class is not abstract. A concrete class can have direct instances; therefore it is implemented as a table or view in a physical database.How is it represented inthe web report?As an Entity with Entity Type = “Table” or “View”.How is it represented in a physical database? As a view with the same structure and name as the class. For most classes, there is also a table whose name is the same as the class name with an “_” (underscore) appended to the end of the class name. The Seabed physical database is designed for users to access and update data only through views, rather than by accessing the tables directly. Note: In cases where a concrete class has a generalization association to another concrete class, the child class is implemented only as an updateable view. The parent class is a table with a matching read-only view. This is explained in further detail in the Generalization section of this document.1.6 AttributeWhat does it tell me?An attribute is a property of a class. This example shows that motor type and outer diameter are among many attributes of an ESP motor. How is it represented in the web report? It is listed as a column in the “Columns” section of an Entity. How is it represented in a physical database?As a column in a table or view.1.7Attribute Value DomainWhat does it tell me?The nature of the values that can be inserted into an attribute’s associated column in a database. It determines the datatype, width, and scale with which the column should be implemented. How is it represented in the web report?As the “value domain” of a column. The datatype, width, and scaleassociated with the value domain are represented as the “type” of a column. How is it represented in a physical database?The value domain determines thedatatype, width, and scale of a column.1.8 AssociationWhat does it tell me?An association describes the relationship between two classes. In the example above, the association shows that a facility composition “Refers To” a facility; and that a facility may be “referenced by” a facility composition. The direction of the arrow tells you thatFacility_Composition is the “source class” and Facility is the “target class.” This example also shows that the association name is“Part_Facility”.How is it represented in the web report? Each entity that participates as the target in an association will have that association listed in its “Referenced By” section, with the source class specified in the “From Entity” field, and the association name specified in the “Link” field.Each entity that participates as the source in an association will have that association listed in its “Refers To” section, with the target class specified in the “To Entity” field and the association name specified in the “Link” field.In some circumstances, the association is also represented as a column in the web report. See below.For associations between two concrete classes, the association name is listed as a column in the source entity (since it becomes an FK column in the physical database). If the target class inherits from “IT_Object”, class “_Id” is appended to the association name. The target entity is specified as the “Value Domain” of that column.For associations where the source class is abstract and the target class is concrete, the association is listed as a column in each entity inherited from the source class (since it becomes an FK column in the physical database). The target entity is specified as the “Value Domain” of each column.For associations where the target class is abstract, the web report representation is dependent on the type of technique used to implement the association. See Appendix B – Associations Referencing Abstract Classes for a description of the implementation techniques and how they are represented in the web report.How is it represented in a physical database? For associations between two concrete classes, the association becomes a column in the source table with a foreign key constraint in the target table. The column name corresponds with the name of the association unless the target class inherits from the “IT_Object” class, in which case “_Id” is appended to the end of the column name.For associations where the source class is abstract and the target class is concrete, the association becomes a column in each table whose associated class inherits from the source class. Each column has a foreign key constraint to the target class. The column name corresponds with the name of the association unless the target class inherits from the “IT_Object” class, in which case “_Id” is appended to the end of the column name.For associations where the target class is abstract, the implementation is dependent on the type of technique specified to implement the association. See Appendix B – Associations Referencing Abstract Classes for a description of the implementation techniques and how they are physically implemented.1.9 AssociationMultiplicityWhat does it tell me? The association multiplicity shows how many instances of each class canbe connected across the association. It is written as an expression thatevaluates a range of values, usually with a lower bound and an upperbound. In the example above, the multiplicity on the target side can beinterpreted as, “Each Facility_Composition instance references at least 0and at most 1 Facility instance.” The multiplicity on the source indicatesthat, “Each Facility instance can be referenced by zero or any number ofFacility_Composition instances.”The multiplicity indicates whether or not it is mandatory for one class toreference another:1..1 multiplicity on the target means it is mandatory for the sourceclass to reference the target class, since the source class must reference“at least 1” instance of the target class.0..1 multiplicity on the target side means it is not mandatory for thesource class to reference the target class.How is it represented in the web report? The multiplicity is not shown in the web report. The web report shows only whether it is mandatory for the source Entity to reference the target Entity. In this example, the link and column would have a ‘No’ in the “Required” field, since it is not mandatory for a Facility_Composition instance to reference a Facility instance.How is it represented in a physical database? For associations between two concrete classes, the association becomes a foreign key column in the source table. If the association is mandatory, the foreign key column is implemented with a NOT NULL constraint.For associations where the source class is abstract and the target class is concrete, the association becomes a foreign key column in each table whose associated class inherits from the source class. If the association is mandatory, each foreign key column is implemented with a NOT NULL constraint.For associations where the target class is abstract, see Appendix B – Associations Referencing Abstract Classes for details on how multiplicity for these types of associations is implemented.1.10 Association Delete SemanticFacility_Equipment_Flag Part_Facility_SpacingWhat does it tell me? The delete semantic specifies what happens when the instance of thetarget class that is referenced by an instance of the source class isdeleted. The example above shows that if the Facility instance that isreferenced by the Facility_Composition instance is deleted, then thatFacility_Composition instance is also deleted. In other words, the delete“cascades” to Facility_Composition. Following are definitions of thevarious delete semantics:Cascade: deleting an instance in the target class results in the deletion ofall instances in the source class that reference it. If the association in theexample above were Cascade, the deletion of a Facility instance wouldcause any Facility_Composition instances referring to that Facilityinstance to also be deleted.Cascade!: deleting an instance in the target class results in the deletion ofall instances in the source class that reference it. If the association in theexample above were Cascade!, the deletion of a Facility instance wouldcause any Facility_Composition instances referring to that Facilityinstance to also be deleted. Cascade! is used when a the use of a Cascadedelete semantic would result in two different cascade paths from oneclass to another.Restrict: an attempt to delete an instance in the target class results in anerror if any source instances exist that reference the target instance to bedeleted. All source instances must be deleted before the target can besuccessfully deleted. If the association in the example above wasRestrict, you could not delete a Facility instance if it had anyFacility_Composition instances referring to it.Nullify: the columns in the source containing the reference to the targetinstance are set to null when the target instance is deleted. If theassociation in the example above was Nullify, the deletion of a Facilityinstance would cause any Facility_Composition.Part_Facility_Idcolumns that contained a value referencing that Facility instance to benullified.Control: the inverse of Cascade. Control specifies that the referencedinstance in the target class be deleted when an instance in the source isdeleted. When an attempt is made to delete a target instance, the delete isrestricted. If the association in the example above was Control, theFacility instance would be deleted if any Facility_Composition instancesthat reference it were deleted.Note: There are a few cases where the diagram specifies a delete semantic that is not actually implemented in the physical database. These cases only arise in associations referencing abstract classes, and are described in detail in the next section. To determine the delete semantic that is actually implemented, refer to the web report.How is it represented in the web report? The delete semantic can be inferred from the “Implementation Technique” column for a link in the “Referenced By” or “Refers To” sections.For associations whose target is a concrete class, the Implementation Technique column displays the delete semantic displayed on the diagram.For associations whose target is abstract, the Implementation Technique is determined as follows:For associations that are implemented using the “Assoc” technique and that have a one-to-many cardinality (that is, each source instance can reference one target instance), the implementation technique displays “Assoc to One.” As stated in Appendix B – Associations Referencing Abstract Classes, “Assoc to One” implies a Nullify delete semantic for non-mandatory associations and a Cascade delete semantic for mandatory associations.For associations that are implemented using the “Assoc” technique and that have a many-to-many cardinality (that is, each source instance can reference many target instances), the implementation technique displays “Assoc to Many.” As stated in Appendix B – Associations Referencing Abstract Classes, “Assoc to Many” implies a Nullify delete semantic. For associations that are implemented using the “Single Abstract” technique, the implementation technique displays “Cascade”. As described in Appendix B – Associations Referencing Abstract Classes, all associations implemented with the Single Abstract technique trigger a cascade delete.How is it represented in a physical database? For associations whose target is a concrete class, the delete semantic is enforced using a database referential integrity constraint.For associations whose target is abstract, the delete semantic is enforced using alternate methods, which are described in Appendix B – Associations Referencing Abstract Classes.1.11 Composition AssociationWhat does it tell me? The association is a whole/part relationship that implies a strongownership of the source class (the “part”) by the target class (the“whole”). Composition implies that the lifetime of the instances of thesource class is limited to the lifetime of the instance of the referencedtarget class. By definition, when a target instance is deleted, all thesource instances that reference it must also be deleted.How is it represented in the web report? The target class has a section called “Composed Of” that lists the entities that have a composition association. Whether the target class instance can be associated with “one” or “many” source class instances is specified in the “Cardinality” column.In example above, Borehole lists Borehole_Alias in its “Composed Of” section, with a cardinality of “Many”, since the multiplicity specifies that an instance of Borehole can be referenced by many instances of Borehole_Alias.In the “General Information” section of the source class, “Extension of {target class}” is specified in the “Entity Type” field. In the example above, “Extension of Borehole” is specified as the Entity Type for Borehole_Alias.Additionally, the target class lists the source class in its “Referenced By” section, and the source class lists the target class in its “Refers To” section.How is it represented in a physical database? Both the target class and the source class are implemented as views on tables. The association between them is implemented as a foreign key. If the cardinality of the source class is “One”, its primary key is a foreign key to the target class’ primary key. If the cardinality is “Many”, the extension class has a sequence-generated primary key.1.12 GeneralizationWhat does it tell me? A generalization is a relationship between a generalthing, called the superclass or parent, and a morespecific kind of that thing, called the subclass or child.A generalization is sometimes called an “is-a-kind-of”relationship. The example above shows that an ESPpump is a kind of pump; and that a pump is a kind oftracked facility. It can also be read, “ESP Pump is aspecialization of Pump, which is a specialization ofTracked Facility. Pump is a generalization of ESP Pumpand Tracked Facility is a generalization of Pump.”How is it represented in the web report? In an entity’s “General Information” section, there is a row called “Specializations” that lists each entity that is a subclass of that entity, and there is a row called “Generalizations” that lists each entity that is a superclass of that entity.Note: If there is more than one entity listed in Generalizations, it implies an inheritance hierarchy where the first class in the list is the immediate parent, as opposed to implying direct inheritance from multiple classes. A class cannot inherit directly from more than one class. If the generalization association is between two concrete classes, the “Entity Type” of the child class is “View”.How is it represented in a physical database? If the superclass is abstract and the subclass isconcrete, t he superclass is not visible in the physicaldatabase. The subclass is generated as an updateableview that also includes the attributes and associationsfrom the superclass. There may be a table that has thesame name as the subclass, with a “_” appended at theend.If both the superclass and the subclass are concrete, the superclass is implemented as a table with a “_” appended to the end of the name. It includes all the attributes and associations from all its subclasses, plus an additional column called “Sub_Type” that stores the class name of the subclass for that instance. A read-only view is generated on the superclass with only the attributes and associations of the superclass, plus the Sub_Type column. For each subclass, an updateable view is generated and named for the subclass, which has the attributes and associations for that subclass, plus the attributes and associations inherited from the superclass, plus the Sub_Type column.If both the superclass and the subclass are abstract, the concrete classes that inherit from the abstract class inherit the attributes and associations from the abstract class, and those attributes/associations become columns in the view created from the concrete class.Note: Abstract classes are not implemented as tables in a physical database.Appendix A – Association Implementation Techniques Mentioned in the Web Report•Cascade: deleting an instance in the target class results in the deletion of all instances in the source class that reference it.•Restrict: deleting an instance in the target class results in an error if any source instances exist that reference the deleted target instance. All source instances must be deleted before the target can be successfully deleted.•Nullify: the columns in the source containing the reference to the target instance are set to null when the target instance is deleted.•Control: the inverse of Cascade. Control specifies that the referenced instance in the target class be deleted when an instance in the source class is deleted. This is normally used in situations where the target class is referenced from many source classes and a given target instance is referenced from only one instance in one source class. When an attempt is made to delete a target instance, the delete is restricted.•Assoc to One: specified when an association is implemented using the “Assoc” technique (described in Appendix B – Associations Referencing Abstract Classes), and when theassociation has a one-to-many cardinality; that is, each source instance can reference one target instance and a target can be referenced by many sources.•Assoc to Many: specified when an association is implemented using the “Assoc” technique, (described in Appendix B – Associations Referencing Abstract Classes), and when theassociation has a many-to-many cardinality; that is, each source instance can reference many target instances and a target can be referenced by many sources.Appendix B – Associations Referencing Abstract ClassesRelational databases do not support relationships to abstract classes using declarative foreign keys. However, the Seabed database architecture provides alternate ways of specifying relationships to abstract classes. Currently, there are two techniques to accomplish this: “Single Abstract” and “Assoc.” These techniques are explained in detail below.To help illustrate these techniques, consider the scenario where a user wants to specify that an ESP (Electric Submersible Pump) is an assembly made up of an ESP Pump and an ESP Motor. The Seabed class diagram for this structure, called “Facility Composition”, is shown in Example B-1. Facility Composition is a generic mechanism for defining whole facilities that are an assemblance of parts. To specify that an ESP is made up of a pump and a motor, the user would create two Facility_Composition instances: one would specify the ESP Pump as the Part_Facility and the ESP assembly as the Whole_Facility, and the other Facility Composition instance would have ESP Motor as the Part and the same ESP as the Whole Facility.Specific examples of physical implementation options for these relationships are provided later in this document. In Example B-1, assume that the ESP instance’s primary key (ID) value is 1, the ESP_Pump instance’s primary key value is 5, and the ESP_Motor instance’s primary key value is 9. Also, assume that the first Facility_Composition instance’s primary key value is 7 and the second Facility_Composition instance’s primary key value is 10.Example B-1Facility_Equipm Part_Facility_Spacing Serial_NumRated_PressureB.1 SingleAbstract“Single Abstract” is one alternative for specifying relationships to abstract classes. It is an implementation technique that applies only to one-to-many associations where the target is abstract. In other words, the “single” component of the name refers to the fact that the cardinality on the target side is ‘1’. The “abstract” component of the name refers to the fact that the target is an abstract class. In Example B-1 above, the “Whole_Facility” and “Part_Facility” associations fall into this category.B.1.1 Physical ImplementationWhen the Single Abstract implementation technique is specified for an association, the association is implemented physically as follows:1.The source table is implemented with the following two columns, the combination of whichstore the reference to the target:•{Association Name}_ID: stores the PK value of the target instance.•{Association Name}_TBL: stores the name of the table in which the target instance resides.IntegrityB.1.1.1 ReferentialWhen the Single Abstract implementation technique is specified for an association, the referential integrity is handled as follows:1. A delete trigger is added to each table that implements a concrete class that inherits from thetarget. The trigger deletes the referencing source record instance when the target recordinstance is deleted. This essentially implements a cascade delete for every associationimplemented with the Single Abstract technique.2.There is no referential integrity built in for updates to the {Association Name}_ID or{Association Name}_TBL columns, meaning no data validation is performed. Therefore, the application or user must ensure that the values are valid.B.1.1.2 MultiplicityIf the association specifies a mandatory reference to the target, the {Association Name}_ID and {Association Name}_TBL columns are implemented with NOT NULL constraints.B.1.1.3 Web Report RepresentationWhen the Single Abstract implementation technique is specified for an association, the association is represented in the web report as follows:1.The association is listed in the “Refers To” or “Referenced By” section of the web report.The implementation technique is “Cascade”. If the reference to the abstract class ismandatory, a “Yes” is in the “Required” column.2.Two columns, {Association Name}_ID and {Association Name}_TBL, are listed in the“Columns” section. The _ID column specifies the abstract class as its domain; and the _TBL column specifies Meta_Entity as its domain. If the reference to the abstract class ismandatory, both the _ID and the _TBL columns are specified as “Required.”B.1.1.4 DataExampleIn Example B-1, if the Whole_Facility and Part_Facility associations were implemented using the Single Abstract technique, the table representing the Facility_Composition table would be implemented with the following additional columns:•Whole_Facility_Id, Whole_Facility_Tbl•Part_Facility_Id, Part_Facility_TblThe records created in Facility_Composition to store the fact that an ESP is made up of an ESP pump and motor would have the following values:•Record 1 – for the pump:–Whole_Facility_Id would store a value of ‘1’ (the identifier of the ESP assembly).–Whole_Facility_Tbl would store a value of “ESP.”–Part_Facility_Id would store a value of ‘5’ (the identifier of the ESP_Pump record).–Part_Facility_Tbl would store a value of “ESP_Pump.”•Record 2 – for the motor:–Whole_Facility_Id would store a value of ‘1’ (the identifier of the ESP assembly).–Whole_Facility_Tbl would store a value of “ESP.”–Part_Facility_Id would store a value of ‘9’ (the identifier of the ESP_Motor record).–Part_Facility_Tbl would store a value of “ESP_Motor.”B.1.2 AssocThe other method to specify associations to abstract classes is called “Assoc.” This is the only method to use when the association is many-to-many, but can also be used for one-to-many associations.B.1.1.5 PhysicalImplementationWhen the Assoc implementation technique is specified for an association, the association is physically implemented as follows:1.The table generated from the source class has no columns that reference the target. Instead,information about association instances is stored in a special table called Assoc. The Assoc table is made up of the following columns:•Entity_Type - The name of the entity on the “source” (referencing) side of the。
机械设计制造及其自动化答辩ppt

STC89C52单片机复位电路初始化设备状态,振荡电路产生时钟频率驱动单片机运行。
单片机最小系统
电子秤系统硬件原理图实现压力感知、模数转换、数据传送与显示,具备超限警报及功能设置功能。
硬件系统整体原理介绍
选题背景及意义Background and significance of topic selection
后期调试Late debugging
03
后期调试Late debugging
本章阐述了单片机应用控制系统的调试流程,强调其重要性。调试确保芯片功能正确、引脚连线可靠,被测器件隔离确保测试准确安全。
调试流程与重要性
硬件测试方法与注意项
软件测试的关键与实施
性能优化与效率提升
章节介绍硬件测试方法,包括总线功能和非总线功能器件测试。强调电源稳定、短路保护及电气隔离的重要性,确保测试顺利和结果准确。
在程序开发过程中,我们利用Git等版本控制工具来管理代码的版本和修改记录。这不仅方便我们跟踪代码的变更历史,还为协作开发提供了便利。通过这些工具的综合运用,我们为多功能电子秤的实现提供了有力的技术支持,确保了程序的高效、稳定和可靠。
从软件的系统设计开始,对使用 c语言书写设计的优势进行了详细的论述,同时还对主程序与子程序的流程图进行了设计
MCU多功能电子天平中断程序控制引脚状态,处理信号,计算数据,实现精准测量。
智能化电子称重系统流程涵盖初始化、模块配置、数据采集转换、处理定价、结果显示、体重判定报警、阈值调整及后续操作,实现快速准确称重,提升效率精度,方便用户调整。
模拟数字变换子例程的流程图是一个程序流程图,它详细说明了如何将模拟信号转换为数字信号的过程。在图中,我们可以看到所有的步骤都被清晰地标记出来并按照顺序排列。这可以帮助人们更好地理解程序的工作原理。
基于SSM框架的学术论坛管理系统设计与实现

Design and implementation of academic forum management system using SSM framework
Yang Shiwen, Hou Chaojun
(College of Computational Science, Zhongkai University of Agriculture and Engineering, Guangzhou, Guangdong 510225, China)
取存储的 JavaBean 对象即可实现调用[6]。Spring 框架
极大程度地简化开发成本和提高了开发效率。
⑵ Spring MVC 框架
Spring MVC 框 架 是 MVC 三 层 架 构 中 的
交互体验友好。系统采用的是 Spring+Spring MVC+
Controller 层,开发者可通过使用注解的方式直接设置
操作。系统经使用表明,系统能够在一定程度上加强师生之间课余时间的学术交流,有利于促成良好的学风氛围,可为
高校学术论坛管理系统的设计和实现提供参考。
关键词:Spring;Spring MVC;MyBatis;MySQL;学术论坛管理系统
中图分类号:TP311.52
文献标识码:A
文章编号:1006-8228(2021)02-25-05
数据持久层(Dao 层)。系统主要分为教师端和学生端,
学生在客户端编辑好帖子内容,然后提交发帖,服务
器接收到这个请求,首先将数据传输到 Controller 层
进行处理。Controller 层接收到请求和提交数据,根
据 定 义 的 规 则 调 用 相 应 的 Service 层 进 行 业 务 处 理
Plate—Form组成

数字和DSP系统平台级设计与实现清华大学电子工程系郑友泉yqzheng@数字和DSP 系统平台级设计与实现第2页Platform 组成¾核–Processor IP –Bus/Interconnection –Peripheral IP –Application specific IP ¾软件–Drivers –Firmware –(Real-time) OS –Application software/libraries¾验证–HW/SW Co-Verification –Compliance test suites ¾原型系统–HW emulation –FPGA based prototyping –Platform prototypes (i.e. dedicated prototyping devices)–SW prototyping数字和DSP 系统平台级设计与实现第3页Platform-Based Design¾需要考虑的问题: (以及如何分割)–功能与结构,–(信号)传递与计算.数字和DSP 系统平台级设计与实现第4页SoC, IP andOn-Chip Communication本节内容¾System-on-a-Chip(SoC)¾Intellectual Property(IP)¾On-Chip Communication–Virtual Component Interface (VCI)–On-Chip Bus(OCB)–Network-on-Chip(NoC)数字和DSP系统平台级设计与实现第5页Introduction to SoC and IP数字和DSP系统平台级设计与实现第6页数字和DSP 系统平台级设计与实现第7页SoC: System on Chip¾System–各种元件和/或子系统的集合,其中各种元件和/或子系统相互连接,完成特定的功能.¾A SoC design is a “product creation process”–从明确用户需求开始;–到产品发布为止(具有用户所需要的足够功能)数字和DSP 系统平台级设计与实现第8页SoC: System on Chip¾Also named System-on-a-Chip 、System LSI, System-on-Silicon 、System-on-….¾It used to be System-on-a-board, or System-in-a cabinet, or System-in-package ( SIP )¾System–Hardware)Analog : ADC/DAC, PLL, TxRx, RF)Digital : Processor, Interface, Accelerator)Storage : SRAM, DRAM, FLASH, ROM–Software : RTOS, Device Driver and API, Applications数字和DSP 系统平台级设计与实现第9页SoC: System on Chip¾片上系统结构在单个芯片上集成了各种异构的元件;¾片上系统设计中一个重要的方面就是设计SoC 中不同实体之间的信号/信息传递方式,使得信息传递开销最小化。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Conference Time-Table Management Erik Wilde,Martin Waldbuger,and Beat Kr¨a henmann ETH Z¨u rich(Swiss Federal Institute of Technology)AbstractConference time-tables provide information that is indispens-able for all attendees.Since there are a lot of reusable data structures and tasks,we have designed the Conference Time-Table Management(CTTM)system,which is intended to be used as a reusable component in a large diversity of confer-ence Web sites.CTTM features aflexible concept for time-tables and provides users with personalization and notifica-tion services.1IntroductionConference time-tables are highly structured data,they con-tain a lot of information and are used by a large number of users.A survey we did on the Web however revealed that many time-tables are implemented rather poorly.In almost all cases they use static content,do not allow any personalization,and are never complemented with additional services such as cross-media publishing and notifications for subscribers.The goal of the Conference Time-Table Management (CTTM)system is to provide a reusable platform for ser-vices that will make conference Web sites easier to manage for conference organizers,and more comfortable to use for conference attendees.The primary design goals have been the following:•Reusability:The solution should be easy to integrate into conference Web sites,only few interfaces should be required,and they should be simple and well-documented.•Flexibility:Since different conferences have different styles of organizing and presenting their time-tables,the solution should beflexible enough to accommodate at least the majority of these styles.This also means that from a technical perspective,the solution should inte-grate easily into the large diversity of existing conference Web site implementations.•Simplicity:Integrating our solution into a conference Web site should be simple,in terms of integration inter-faces as well as technical requirements for the platform.•Functionality:The functionality should be extensive enough to persuade conference organizers to use our so-lution.That is,the benefit of added features and experi-enced ease of use should outweigh the cost of installation and integration.As a result of these design goals,it became clear that on the one hand the implementation platform should be kept as simple as possible.On the other hand we needed to choose a platform which made it as easy as possible to implement a solution satisfying the requirements.2DesignThe design of the data model of the time-table is the most important issue of our work.Since this is the input that conference organizers must provide for CTTM,we decided to specify the data model in form of an XML schema.Since none of the available XML schema languages satisfied all our requirements,the schema is specified as a combination of XML Schema and Schematron.As shown in Figure1,the CTTM schema has three major parts.Thefirst part defines the event types,the second part is the the time-table itself(a set of events),and the third part is information about users,which may have special ad-ministrative access rights,or may be regular attendees of the conference.We will examine these three parts more closely in the following sections.It is important to notice that the XML document for a conference changes while CTTM is run-ning,with events being modified and people registering and personalizing their time-table.Figure1:CTTM XML Document We chose to implement such afile-based solution because we did not want to require every CTTM user to run a database,and because we assume that the number of users will be moderate,so thatfile-based operations do not become prohibitively expensive.2.1Events and Time-TablesBefore creating the actual time-table,a conference organizer must define event types,which define the way a particular conference is structured.Event types are defined by a type name and the properties(which are hardcoded into CTTM) that an event may or must have.Event may be allowed to contain events(of specified types),so that it is possible to define a hierarchy of events.The actual conference time-table is a list of events,which are defined by referring to their type,and then defining the properties that they have.In addition,an event may refer to all events in it.For example,a track may be modelled as an event which has a name(a property)and contains referencesto all the events in the track,which again may be hierarchical events(such as sessions),or single events(such as talks).The events are organized as a list of entries,which use standard XML referencing mechanisms.Each event is described by a number of properties,which differ slightly among the types used for a particular confer-ence.The properties that are available are title,date/time, location,speaker/author,and links to additional materials (such as handouts).2.2Users and User RolesSince one of the main features of CTTM is that it supports personalization,it needs to keep track of users and their per-sonalization ers are registered with their name, a password,and any contact information(such as an email address)that they may wish to supply for receiving updates and notifier data is based on the user properties and roles hardcoded into CTTM.User management enables users to login,access their per-sonalized settings,and logout.Settings affect two main areas. One is the personalized display of the time-table,making it possible for conference attendees to create their own time-table,for example only listing two parallel events at a time, offering them a choice between their favorite and a fall-back. The second area are notification services,which enable atten-dees to receive notifications of various events using different channels.For example,if they choose,they may receive a GSM Short Message Service(SMS)notification10minutes ahead of each session start.For administrative purposes,we differentiate between user roles.We support regular users(i.e.,conference attendees), event managers(having management rights for a limited number of events),and administrators(with unrestricted ac-cess rights).Event management rights are necessary for any modification to the time-table itself,while only administra-tors are allowed to change user information(such as deleting users or resetting their password).2.3User InteractionWhile the data model presented in the preceding two sections is the foundation of CTTM,the purpose of the system is to provide an interface that enables conference attendees to ac-cess the data in a simple and intuitive manner.Starting from a number of use cases,we designed an interface that reflects the usage patterns,which are standard sign-up/login/logoffprocedures,time-table management and personalization,and notification management.2.4Cross-Media PublishingOne of the design goals is to keep the whole CTTM solution media neutral.We achieve this be designing all interaction to be built on XML,which can then be transformed to the appropriate format.For example,displaying a custom time-table as HTML or printing it as PDF to take it to the confer-ence should not require any modifications to the CTTM core. Naturally,supporting new output media required adaptation, but we tried to minimize that effort as much as possible.One example are notifications,which can be triggered by event managers and administrators.Instead of integrating an email gateway into CTTM,notifications are delivered as XML.They can easily be transformed to fulfill the require-ments of the gateway,which can be an email system,or a gateway for sending SMS messages.3ImplementationOur implementation platform is Apache’s Cocoon frame-work[1],which basically is a servlet-based implementation of a cross-media publishing framework.Cocoon offers aflex-ible way for defining processing pipelines,which usually con-tain one or more XSLT stages or other transformations.In addition to Cocoon’s XSLT,we also use Extensible Server Pages(XSP)technology,which is similar to the more popu-lar JSP and enables us to execute Java code for some stages within the processing pipeline.The following picture shows an example of a typical CTTM/Cocoon processing pipeline: A new user requests the application form,fills it in,and gets a confirmation that his account has been created.Figure2:CTTM ProcessingSince we are using afile-based approach,it is necessary to keep track of the possible sizes of thefiles.We estimate the file size to be(0.5×#events+1.6×#users)kB,so for a rather large conference with100events and2000users,thefile size would be around3MB,which is manageable.For a live demonstration using the time-table of the WWW2003conference,please visit / projects/cttm/www2003demo.We would like to thank the WWW2003organizers for providing us with the necessary data for creating this demo.On standard PC hardware(and assuming2000users and a3MB XMLfile),the system is able to handle about5hits/sec which require write access (modifications to the XMLfile,most notably users updating their profile),while read hits do not create any relevant per-formance problems(Cocoon has very sophisticated caching mechanisms).4ConclusionsSince conferences usually confront attendees with a large amount of information,we tried to make this more manage-able by creating a generic tool-set.Our Conference Time-Table Management(CTTM)system provides all the features that we believe will make conference time-tables more easy to manage for attendees as well as for organizers.The platform requirements are rather moderate,but also create some limits to the number of users that can be managed reasonably. References[1]Bill Brogden,Conrad D’Cruz,and MarkGaither.Cocoon2Programming:Web Publishing with XML and Java.Sybex,Berkeley,California,Oc-tober2002.。