DKnowledge Discovery in Databases Workshop was held
DataMining分析方法

如有你有帮助,请购买下载,谢谢!数据挖掘Data Mining第一部 Data Mining的觀念............... 错误!未定义书签。
第一章何謂Data Mining ..................................................... 错误!未定义书签。
第二章Data Mining運用的理論與實際應用功能............. 错误!未定义书签。
第三章Data Mining與統計分析有何不同......................... 错误!未定义书签。
第四章完整的Data Mining有哪些步驟............................ 错误!未定义书签。
第五章CRISP-DM ............................................................... 错误!未定义书签。
第六章Data Mining、Data Warehousing、OLAP三者關係為何. 错误!未定义书签。
第七章Data Mining在CRM中扮演的角色為何.............. 错误!未定义书签。
第八章Data Mining 與Web Mining有何不同................. 错误!未定义书签。
第九章Data Mining 的功能................................................ 错误!未定义书签。
第十章Data Mining應用於各領域的情形......................... 错误!未定义书签。
第十一章Data Mining的分析工具..................................... 错误!未定义书签。
第二部多變量分析....................... 错误!未定义书签。
第一章主成分分析(Principal Component Analysis) ........... 错误!未定义书签。
知识发现的五个过程是如何实现的

知识发现的五个过程是如何实现的由于计算机数据采集工具以及关系数据库技术的发展,目前各行业存储了大量的数据,航空航天、气象、医疗、农业等行业尤为突出。
传统的数据分析手段难以应付,导致越来越严重的数据灾难,迫使决策者出现或是穷于应付,或是置之不理的事实。
关系数据库提供的简单查询及报表生成功能,只能获得数据的表层信息,而不能获得数据属性的内在关系和隐含的信息,即淹没了包含的知识,造成了资源的浪费。
为了使消耗大量财力与物力所收集与整理的宝贵数据资源得以利用,有效解决数据丰富性及知识贫乏性的矛盾,需要新技术智能、自动地分析处理原始数据,促使了数据库中的知识发现(KDD, Knowledge Discovery in Database),也有人称为数据挖掘(Data Mining)技术的出现。
到目前为止已经出现了许多知识发现技术,分类方法也有很多种,按被挖掘对象分有基于关系数据库、多媒体数据库;按挖掘的方法分有数据驱动型、查询驱动型和交互型;按知识类型分有关联规则、特征挖掘、分类、聚类、总结知识、趋势分析、偏差分析、文本采掘。
知识发现技术可分为两类:基于算法的方法和基于可视化的方法。
大多数基于算法的方法是在人工智能、信息检索、数据库、统计学、模糊集和粗糙集理论等领域中发展来的。
典型的基于算法的知识发现技术包括:或然性和最大可能性估计的贝叶斯理论、衰退分析、最近邻、决策树、K一方法聚类、关联规则挖掘、Web和搜索引擎、数据仓库和联机分析处理(On—line Analytical Processing,OLAP) 、神经网络、遗传算法、模糊分类和聚类、粗糙分类和规则归纳等。
知识发现过程的步骤:1.问题的理解和定义:数据挖掘人员与领域专家合作.对问题进行深入的分析.以确定可能的解决途径和对学习结果的评测方法。
2.相关数据收集和提取:根据问题的定义收集有关的数据。
在数据提取过程中,可以利用数据库的查询功能以加快数据的提取速度。
大数据基础与实务(商科版)教学课件项目五 数据挖掘和分析

知识准备
一 数据挖掘
(一)数据挖掘的定义
定义
数据挖掘(Data Mining),又称之 为数据库文件的专业知识发觉 (Knowledge-Discovery in Databases, KDD),它是指从大量的数据中通过算 法搜索隐藏于其中信息的过程。
数据挖掘通常与计算机科 学有关,并通过统计、在线分 析处理、情报检索、机器学习、 专家系统和模式识别等诸多方 法来实现上述目标。
02 大数据分析技术主要包括有哪些?
谢谢观看
(5)基于图的方法。
知识准备
三 数据挖掘和机器学习的关系
(一)相同点
01
都使用数据
机器学习有时被用作进行 有用数据挖掘的一种手段
04
02
都用于解决复杂的问题
03
均属于数据科学的范畴
知识准备
三 数据挖掘和机器学习的关系
(二)不同点
时间Байду номын сангаас
目的
使用
因素
联系
能力
实用性
课堂研讨
我们写一段程序让计算机自己进行一个学习过程, 直到达到一个满意程度。那么学习的目的是什么? 怎样学习?满意程度又是如何定义的呢?
知识准备
四 大数据分析的应用
(二)数据分析对电商的作用
营销管理 客户管理 智能推荐
知识准备
四 大数据分析的应用
(三)数据分析对金融的作用 数据技术对金融行业的影响巨大,金融业对信息系统的实际应用前景还是非常大的,
金融业对信息系统的实用性要求很高,且积累了大量的客户交易数据。
客户行为分析
01
3.聚类
4.分类
5.关联
2.回归
6.时间序列
数据挖掘在Web中的应用研究

数据挖掘在Web中的应用研究摘要:web中的数据挖掘技术是一种新型的技术,web自身的特点,决定了web数据挖掘技术具有更多的特点,而且应用也非常广泛,不仅能够提取页面的信息,进行站点设计分析,而且在电子商务方面也具有非常广阔的应用前景。
本文对数据挖掘技术在web中的应用进行分析。
关键词:数据挖掘技术;web应用;网络技术中图分类号:tp352 文献标识码:a 文章编号:1007-9599 (2012)18-0000-02随着网络技术的快速发展,网络上数据资源的越来越丰富,人们迫切需要将这些数据转换成有用的信息和知识,进而促生了数据挖掘(data mining,dm)和知识发现(knowledge discovery,kd)领域。
信息技术的发展,对web应用提出更高了要求,为了能够满足人们对信息获取的要求,研究基于web的数据挖掘技术,以便人们能够更加智能、更加自动地抽取数据以及信息中的知识。
1 数据挖掘技术相关概述1.1 基本概念数据挖掘技术主要是指寻找隐藏在大量数据中有价值的信息,从中寻找其规律,揭示出隐含的、具有潜在价值的知识,从而为决策支持提供有力依据的过程。
数据挖掘的目标主要包括特征、趋势以及相关性等多个方面的信息。
随着网络应用的普及,网络中信息量迅速增加,传统的知识发现(kdd:knowledge discovery indatabases)技术和方法已经不能满足人们从web中获取信息的需要,基于网络技术提供对各类数据的深层次实时分析,提供决策支持服务,就使得基于web的数据挖掘技术应运而生,这种技术将传统的数据挖掘和web应用技术相互结合起来,实现高度自动化的分析和归纳性的推理。
图1为web数据挖掘原理流程:2.3 在购物网站的应用web数据技术采用web-dms系统可以构建一个基于web 的挖掘的购物网站和交易环境,还能够充分利用站点上积累的信息,从而更好地服务于企业和客户。
在购物网站中采用web 数据挖掘技术不仅能够通过了解购物者的行为习惯,选择提供最佳的服务方式、消费习惯,还能够分析购物者的个人爱好[3],从而提供更加贴切的商品推介。
大数据外文翻译文献

大数据外文翻译文献(文档含中英文对照即英文原文和中文翻译)原文:What is Data Mining?Many people treat data mining as a synonym for another popularly used term, “Knowledge Discovery in Databases”, or KDD. Alternatively, others view data mining as simply an essential step in the process of knowledge discovery in databases. Knowledge discovery consists of an iterative sequence of the following steps:· data cleaning: to remove noise or irrelevant data,· data integration: where multiple data sources may be combined,·data selection : where data relevant to the analysis task are retrieved from the database,·data transformation : where data are transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations, for instance,·data mining: an essential process where intelligent methods are applied in order to extract data patterns,·pattern evaluation: to identify the truly interesting patterns representing knowledge based on some interestingness measures, and ·knowledge presentation: where visualization and knowledge representation techniques are used to present the mined knowledge to the user .The data mining step may interact with the user or a knowledge base. The interesting patterns are presented to the user, and may be stored as new knowledge in the knowledge base. Note that according to this view, data mining is only one step in the entire process, albeit an essential one since it uncovers hidden patterns for evaluation.We agree that data mining is a knowledge discovery process. However, in industry, in media, and in the database research milieu, the term “data mining” is becoming more popular than the longer term of “knowledge discovery in databases”. Therefore, in this book, we choose to use the term “data mining”. We adop t a broad view of data mining functionality: data mining is the process of discovering interestingknowledge from large amounts of data stored either in databases, data warehouses, or other information repositories.Based on this view, the architecture of a typical data mining system may have the following major components:1. Database, data warehouse, or other information repository. This is one or a set of databases, data warehouses, spread sheets, or other kinds of information repositories. Data cleaning and data integration techniques may be performed on the data.2. Database or data warehouse server. The database or data warehouse server is responsible for fetching the relevant data, based on the user’s data mining request.3. Knowledge base. This is the domain knowledge that is used to guide the search, or evaluate the interestingness of resulting patterns. Such knowledge can include concept hierarchies, used to organize attributes or attribute values into different levels of abstraction. Knowledge such as user beliefs, which can be used to assess a pattern’s interestingness based on its unexpectedness, may also be included. Other examples of domain knowledge are additional interestingness constraints or thresholds, and metadata (e.g., describing data from multiple heterogeneous sources).4. Data mining engine. This is essential to the data mining system and ideally consists of a set of functional modules for tasks such ascharacterization, association analysis, classification, evolution and deviation analysis.5. Pattern evaluation module. This component typically employs interestingness measures and interacts with the data mining modules so as to focus the search towards interesting patterns. It may access interestingness thresholds stored in the knowledge base. Alternatively, the pattern evaluation module may be integrated with the mining module, depending on the implementation of the data mining method used. For efficient data mining, it is highly recommended to push the evaluation of pattern interestingness as deep as possible into the mining process so as to confine the search to only the interesting patterns.6. Graphical user interface. This module communicates between users and the data mining system, allowing the user to interact with the system by specifying a data mining query or task, providing information to help focus the search, and performing exploratory data mining based on the intermediate data mining results. In addition, this component allows the user to browse database and data warehouse schemas or data structures, evaluate mined patterns, and visualize the patterns in different forms.From a data warehouse perspective, data mining can be viewed as an advanced stage of on-1ine analytical processing (OLAP). However, data mining goes far beyond the narrow scope of summarization-styleanalytical processing of data warehouse systems by incorporating more advanced techniques for data understanding.While there may be many “data mining systems” on the market, not all of them can perform true data mining. A data analysis system that does not handle large amounts of data can at most be categorized as a machine learning system, a statistical data analysis tool, or an experimental system prototype. A system that can only perform data or information retrieval, including finding aggregate values, or that performs deductive query answering in large databases should be more appropriately categorized as either a database system, an information retrieval system, or a deductive database system.Data mining involves an integration of techniques from mult1ple disciplines such as database technology, statistics, machine learning, high performance computing, pattern recognition, neural networks, data visualization, information retrieval, image and signal processing, and spatial data analysis. We adopt a database perspective in our presentation of data mining in this book. That is, emphasis is placed on efficient and scalable data mining techniques for large databases. By performing data mining, interesting knowledge, regularities, or high-level information can be extracted from databases and viewed or browsed from different angles. The discovered knowledge can be applied to decision making, process control, information management, query processing, and so on. Therefore,data mining is considered as one of the most important frontiers in database systems and one of the most promising, new database applications in the information industry.A classification of data mining systemsData mining is an interdisciplinary field, the confluence of a set of disciplines, including database systems, statistics, machine learning, visualization, and information science. Moreover, depending on the data mining approach used, techniques from other disciplines may be applied, such as neural networks, fuzzy and or rough set theory, knowledge representation, inductive logic programming, or high performance computing. Depending on the kinds of data to be mined or on the given data mining application, the data mining system may also integrate techniques from spatial data analysis, Information retrieval, pattern recognition, image analysis, signal processing, computer graphics, Web technology, economics, or psychology.Because of the diversity of disciplines contributing to data mining, data mining research is expected to generate a large variety of data mining systems. Therefore, it is necessary to provide a clear classification of data mining systems. Such a classification may help potential users distinguish data mining systems and identify those that best match their needs. Data mining systems can be categorized according to various criteria, as follows.1) Classification according to the kinds of databases mined.A data mining system can be classified according to the kinds of databases mined. Database systems themselves can be classified according to different criteria (such as data models, or the types of data or applications involved), each of which may require its own data mining technique. Data mining systems can therefore be classified accordingly.For instance, if classifying according to data models, we may have a relational, transactional, object-oriented, object-relational, or data warehouse mining system. If classifying according to the special types of data handled, we may have a spatial, time -series, text, or multimedia data mining system , or a World-Wide Web mining system . Other system types include heterogeneous data mining systems, and legacy data mining systems.2) Classification according to the kinds of knowledge mined.Data mining systems can be categorized according to the kinds of knowledge they mine, i.e., based on data mining functionalities, such as characterization, discrimination, association, classification, clustering, trend and evolution analysis, deviation analysis , similarity analysis, etc.A comprehensive data mining system usually provides multiple and/or integrated data mining functionalities.Moreover, data mining systems can also be distinguished based on the granularity or levels of abstraction of the knowledge mined, includinggeneralized knowledge(at a high level of abstraction), primitive-level knowledge(at a raw data level), or knowledge at multiple levels (considering several levels of abstraction). An advanced data mining system should facilitate the discovery of knowledge at multiple levels of abstraction.3) Classification according to the kinds of techniques utilized.Data mining systems can also be categorized according to the underlying data mining techniques employed. These techniques can be described according to the degree of user interaction involved (e.g., autonomous systems, interactive exploratory systems, query-driven systems), or the methods of data analysis employed(e.g., database-oriented or data warehouse-oriented techniques, machine learning, statistics, visualization, pattern recognition, neural networks, and so on ) .A sophisticated data mining system will often adopt multiple data mining techniques or work out an effective, integrated technique which combines the merits of a few individual approaches.什么是数据挖掘?许多人把数据挖掘视为另一个常用的术语—数据库中的知识发现或KDD的同义词。
知识发现与数据挖掘

高级人工智能 史忠植
21
经典的Apriori算法
(1) L[1]={large 1-itemsets}; (2) for (k=2; L[k-1]不为空; k++) do begin (3) C[k]=apriori-gen(L[k-1]); // 新候选物品集 (4) For all transactions t∈D do begin (5) C=subset(C[k],t); // t中的候选物品集 (6) For all candidates c∈C do
第九章 知识发现和数据挖掘
数据库中知识发现
史忠植 中科院计算所
2019/9/3
高级人工智能 史忠植
1
知识发现 关联规则 数据仓库 知识发现工具
2019/9/3
高级人工智能 史忠植
2
知识发现
知识发现是指从数据集中抽取和精炼新的模式。 范围非常广泛:经济、工业、农业、军事、社会 数据的形态多样化:数字、符号、图形、图像、声音 数据组织各不相同:结构化、半结构化和非结构 发现的知识可以表示成各种形式
(7) c.count++;
(8) end; (9) L[k]={c∈C[k]|c.count>=minsup};
(10) end; (11) Answer = L[1]∪L[2]∪…
2019/9/3
高级人工智能 史忠植
22
apriori-gen(L[k-1]) 分成两步:
join算法:从两个L[k-1]物品集生成候选 物品集C[k]
数据仓库(Data Warehouse)是面向主题的,集 成的,内容相对稳定的、不同时间的数据集合,用以 支持经营管理中的决策制定过程。
认识搜索引擎

实验四认识搜索引擎一、实验目的1、认识搜索引擎2、了解搜索引擎原理及使用方法3、在线查找搜索引擎学时安排:2学时二、实验内容1、在IE浏览器输入网址:/web/searchengine.htm,或是利用Google搜索引擎查询【认识搜索引擎】,找到该网页,了解搜索引擎的原理极其发展过程。
2、打开/index.htm和/,查看站点中文搜索引擎指南网(搜网)和搜索快报,了解搜索引擎有关新闻、使用技巧、排名规则、以及在商业上的应用。
3、在线查找搜索引擎,列出你所熟悉的中文引擎的前5名,英文引擎的前5名4、列出至少20个搜索引擎(包括一个能够搜索—搜索引擎的引擎,报告中请注明)5、使用不同的英文搜索引擎分别给出歌德巴赫猜想(Goldbach's conjecture)和世界名画《蒙娜丽莎》(Mona Lisa )的英文详细介绍网址,并分别给出内容的英文简介。
6、针对你的选题自选检索词利用英文搜索引擎检索,记录检索结果三、实验报告1、搜索引擎的原理搜索引擎的原理,可以看做三步:从互联网上抓取网页→建立索引数据库→在索引数据库中搜索排序。
1.从互联网上抓取网页利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。
2.建立索引数据库由分析索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的所有关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面文字中及超链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。
3.在索引数据库中搜索排序当用户输入关键词搜索后,由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。
因为所有相关网页针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序,相关度越高,排名越靠前。
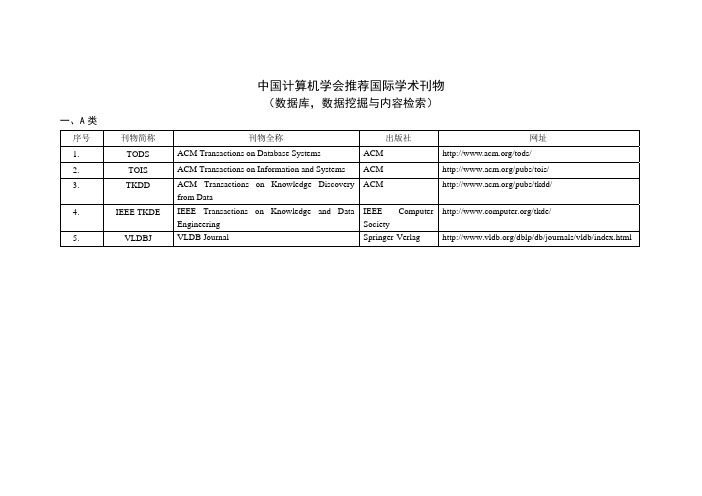
中国计算机学会推荐国际学术刊物与会议-数据库,数据挖掘,内容检索
Sons, Ltd.
SAM.html
一、A 类
序号 1. 2. 3.
会议简称 SIGMOD SIGKDD
PODS
4.
ICDE
5.
SIGIR
6.
VLDB
中国计算机学会推荐国际学术会议 (数据库,数据挖掘与内容检索)
会议全称
出版社
网址
ACM Conference on Management of Data
ACM Transactions on Information and Systems ACM
/pubs/tois/
ACM Transactions on Knowledge Discovery from Data IEEE Transactions on Knowledge and Data Engineering VLDB Journal
出版社
网址
Computing and Informatics
Institute Informatics,
Slovakia
DATA BASE for Advances in Information ACM
Systems
of http://www.cai.sk/ /database
一、A 类
序号 1. 2. 3.
4.
5.
刊物简称 TODS TOIS TKDD
IEEE TKDE
VLDBJ
中国计算机学会推荐国际学术刊物
(数据库,数据挖掘与内容检索)
刊物全称
出版社
网址
ACM Transactions on Database Systems
ACM
/tods/
/
ACM International Conference on Web ACM Search and Data Mining
From Data Mining to Knowledge Discovery in Databases

s Data mining and knowledge discovery in databases have been attracting a significant amount of research, industry, and media atten-tion of late. What is all the excitement about?This article provides an overview of this emerging field, clarifying how data mining and knowledge discovery in databases are related both to each other and to related fields, such as machine learning, statistics, and databases. The article mentions particular real-world applications, specific data-mining techniques, challenges in-volved in real-world applications of knowledge discovery, and current and future research direc-tions in the field.A cross a wide variety of fields, data arebeing collected and accumulated at adramatic pace. There is an urgent need for a new generation of computational theo-ries and tools to assist humans in extracting useful information (knowledge) from the rapidly growing volumes of digital data. These theories and tools are the subject of the emerging field of knowledge discovery in databases (KDD).At an abstract level, the KDD field is con-cerned with the development of methods and techniques for making sense of data. The basic problem addressed by the KDD process is one of mapping low-level data (which are typically too voluminous to understand and digest easi-ly) into other forms that might be more com-pact (for example, a short report), more ab-stract (for example, a descriptive approximation or model of the process that generated the data), or more useful (for exam-ple, a predictive model for estimating the val-ue of future cases). At the core of the process is the application of specific data-mining meth-ods for pattern discovery and extraction.1This article begins by discussing the histori-cal context of KDD and data mining and theirintersection with other related fields. A briefsummary of recent KDD real-world applica-tions is provided. Definitions of KDD and da-ta mining are provided, and the general mul-tistep KDD process is outlined. This multistepprocess has the application of data-mining al-gorithms as one particular step in the process.The data-mining step is discussed in more de-tail in the context of specific data-mining al-gorithms and their application. Real-worldpractical application issues are also outlined.Finally, the article enumerates challenges forfuture research and development and in par-ticular discusses potential opportunities for AItechnology in KDD systems.Why Do We Need KDD?The traditional method of turning data intoknowledge relies on manual analysis and in-terpretation. For example, in the health-careindustry, it is common for specialists to peri-odically analyze current trends and changesin health-care data, say, on a quarterly basis.The specialists then provide a report detailingthe analysis to the sponsoring health-care or-ganization; this report becomes the basis forfuture decision making and planning forhealth-care management. In a totally differ-ent type of application, planetary geologistssift through remotely sensed images of plan-ets and asteroids, carefully locating and cata-loging such geologic objects of interest as im-pact craters. Be it science, marketing, finance,health care, retail, or any other field, the clas-sical approach to data analysis relies funda-mentally on one or more analysts becomingArticlesFALL 1996 37From Data Mining to Knowledge Discovery inDatabasesUsama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth Copyright © 1996, American Association for Artificial Intelligence. All rights reserved. 0738-4602-1996 / $2.00areas is astronomy. Here, a notable success was achieved by SKICAT ,a system used by as-tronomers to perform image analysis,classification, and cataloging of sky objects from sky-survey images (Fayyad, Djorgovski,and Weir 1996). In its first application, the system was used to process the 3 terabytes (1012bytes) of image data resulting from the Second Palomar Observatory Sky Survey,where it is estimated that on the order of 109sky objects are detectable. SKICAT can outper-form humans and traditional computational techniques in classifying faint sky objects. See Fayyad, Haussler, and Stolorz (1996) for a sur-vey of scientific applications.In business, main KDD application areas includes marketing, finance (especially in-vestment), fraud detection, manufacturing,telecommunications, and Internet agents.Marketing:In marketing, the primary ap-plication is database marketing systems,which analyze customer databases to identify different customer groups and forecast their behavior. Business Week (Berry 1994) estimat-ed that over half of all retailers are using or planning to use database marketing, and those who do use it have good results; for ex-ample, American Express reports a 10- to 15-percent increase in credit-card use. Another notable marketing application is market-bas-ket analysis (Agrawal et al. 1996) systems,which find patterns such as, “If customer bought X, he/she is also likely to buy Y and Z.” Such patterns are valuable to retailers.Investment: Numerous companies use da-ta mining for investment, but most do not describe their systems. One exception is LBS Capital Management. Its system uses expert systems, neural nets, and genetic algorithms to manage portfolios totaling $600 million;since its start in 1993, the system has outper-formed the broad stock market (Hall, Mani,and Barr 1996).Fraud detection: HNC Falcon and Nestor PRISM systems are used for monitoring credit-card fraud, watching over millions of ac-counts. The FAIS system (Senator et al. 1995),from the U.S. Treasury Financial Crimes En-forcement Network, is used to identify finan-cial transactions that might indicate money-laundering activity.Manufacturing: The CASSIOPEE trou-bleshooting system, developed as part of a joint venture between General Electric and SNECMA, was applied by three major Euro-pean airlines to diagnose and predict prob-lems for the Boeing 737. To derive families of faults, clustering methods are used. CASSIOPEE received the European first prize for innova-intimately familiar with the data and serving as an interface between the data and the users and products.For these (and many other) applications,this form of manual probing of a data set is slow, expensive, and highly subjective. In fact, as data volumes grow dramatically, this type of manual data analysis is becoming completely impractical in many domains.Databases are increasing in size in two ways:(1) the number N of records or objects in the database and (2) the number d of fields or at-tributes to an object. Databases containing on the order of N = 109objects are becoming in-creasingly common, for example, in the as-tronomical sciences. Similarly, the number of fields d can easily be on the order of 102or even 103, for example, in medical diagnostic applications. Who could be expected to di-gest millions of records, each having tens or hundreds of fields? We believe that this job is certainly not one for humans; hence, analysis work needs to be automated, at least partially.The need to scale up human analysis capa-bilities to handling the large number of bytes that we can collect is both economic and sci-entific. Businesses use data to gain competi-tive advantage, increase efficiency, and pro-vide more valuable services to customers.Data we capture about our environment are the basic evidence we use to build theories and models of the universe we live in. Be-cause computers have enabled humans to gather more data than we can digest, it is on-ly natural to turn to computational tech-niques to help us unearth meaningful pat-terns and structures from the massive volumes of data. Hence, KDD is an attempt to address a problem that the digital informa-tion era made a fact of life for all of us: data overload.Data Mining and Knowledge Discovery in the Real WorldA large degree of the current interest in KDD is the result of the media interest surrounding successful KDD applications, for example, the focus articles within the last two years in Business Week , Newsweek , Byte , PC Week , and other large-circulation periodicals. Unfortu-nately, it is not always easy to separate fact from media hype. Nonetheless, several well-documented examples of successful systems can rightly be referred to as KDD applications and have been deployed in operational use on large-scale real-world problems in science and in business.In science, one of the primary applicationThere is an urgent need for a new generation of computation-al theories and tools toassist humans in extractinguseful information (knowledge)from the rapidly growing volumes ofdigital data.Articles38AI MAGAZINEtive applications (Manago and Auriol 1996).Telecommunications: The telecommuni-cations alarm-sequence analyzer (TASA) wasbuilt in cooperation with a manufacturer oftelecommunications equipment and threetelephone networks (Mannila, Toivonen, andVerkamo 1995). The system uses a novelframework for locating frequently occurringalarm episodes from the alarm stream andpresenting them as rules. Large sets of discov-ered rules can be explored with flexible infor-mation-retrieval tools supporting interactivityand iteration. In this way, TASA offers pruning,grouping, and ordering tools to refine the re-sults of a basic brute-force search for rules.Data cleaning: The MERGE-PURGE systemwas applied to the identification of duplicatewelfare claims (Hernandez and Stolfo 1995).It was used successfully on data from the Wel-fare Department of the State of Washington.In other areas, a well-publicized system isIBM’s ADVANCED SCOUT,a specialized data-min-ing system that helps National Basketball As-sociation (NBA) coaches organize and inter-pret data from NBA games (U.S. News 1995). ADVANCED SCOUT was used by several of the NBA teams in 1996, including the Seattle Su-personics, which reached the NBA finals.Finally, a novel and increasingly importanttype of discovery is one based on the use of in-telligent agents to navigate through an infor-mation-rich environment. Although the ideaof active triggers has long been analyzed in thedatabase field, really successful applications ofthis idea appeared only with the advent of theInternet. These systems ask the user to specifya profile of interest and search for related in-formation among a wide variety of public-do-main and proprietary sources. For example, FIREFLY is a personal music-recommendation agent: It asks a user his/her opinion of several music pieces and then suggests other music that the user might like (<http:// www.ffl/>). CRAYON(/>) allows users to create their own free newspaper (supported by ads); NEWSHOUND(<http://www. /hound/>) from the San Jose Mercury News and FARCAST(</> automatically search information from a wide variety of sources, including newspapers and wire services, and e-mail rele-vant documents directly to the user.These are just a few of the numerous suchsystems that use KDD techniques to automat-ically produce useful information from largemasses of raw data. See Piatetsky-Shapiro etal. (1996) for an overview of issues in devel-oping industrial KDD applications.Data Mining and KDDHistorically, the notion of finding useful pat-terns in data has been given a variety ofnames, including data mining, knowledge ex-traction, information discovery, informationharvesting, data archaeology, and data patternprocessing. The term data mining has mostlybeen used by statisticians, data analysts, andthe management information systems (MIS)communities. It has also gained popularity inthe database field. The phrase knowledge dis-covery in databases was coined at the first KDDworkshop in 1989 (Piatetsky-Shapiro 1991) toemphasize that knowledge is the end productof a data-driven discovery. It has been popular-ized in the AI and machine-learning fields.In our view, KDD refers to the overall pro-cess of discovering useful knowledge from da-ta, and data mining refers to a particular stepin this process. Data mining is the applicationof specific algorithms for extracting patternsfrom data. The distinction between the KDDprocess and the data-mining step (within theprocess) is a central point of this article. Theadditional steps in the KDD process, such asdata preparation, data selection, data cleaning,incorporation of appropriate prior knowledge,and proper interpretation of the results ofmining, are essential to ensure that usefulknowledge is derived from the data. Blind ap-plication of data-mining methods (rightly crit-icized as data dredging in the statistical litera-ture) can be a dangerous activity, easilyleading to the discovery of meaningless andinvalid patterns.The Interdisciplinary Nature of KDDKDD has evolved, and continues to evolve,from the intersection of research fields such asmachine learning, pattern recognition,databases, statistics, AI, knowledge acquisitionfor expert systems, data visualization, andhigh-performance computing. The unifyinggoal is extracting high-level knowledge fromlow-level data in the context of large data sets.The data-mining component of KDD cur-rently relies heavily on known techniquesfrom machine learning, pattern recognition,and statistics to find patterns from data in thedata-mining step of the KDD process. A natu-ral question is, How is KDD different from pat-tern recognition or machine learning (and re-lated fields)? The answer is that these fieldsprovide some of the data-mining methodsthat are used in the data-mining step of theKDD process. KDD focuses on the overall pro-cess of knowledge discovery from data, includ-ing how the data are stored and accessed, howalgorithms can be scaled to massive data setsThe basicproblemaddressed bythe KDDprocess isone ofmappinglow-leveldata intoother formsthat might bemorecompact,moreabstract,or moreuseful.ArticlesFALL 1996 39A driving force behind KDD is the database field (the second D in KDD). Indeed, the problem of effective data manipulation when data cannot fit in the main memory is of fun-damental importance to KDD. Database tech-niques for gaining efficient data access,grouping and ordering operations when ac-cessing data, and optimizing queries consti-tute the basics for scaling algorithms to larger data sets. Most data-mining algorithms from statistics, pattern recognition, and machine learning assume data are in the main memo-ry and pay no attention to how the algorithm breaks down if only limited views of the data are possible.A related field evolving from databases is data warehousing,which refers to the popular business trend of collecting and cleaning transactional data to make them available for online analysis and decision support. Data warehousing helps set the stage for KDD in two important ways: (1) data cleaning and (2)data access.Data cleaning: As organizations are forced to think about a unified logical view of the wide variety of data and databases they pos-sess, they have to address the issues of map-ping data to a single naming convention,uniformly representing and handling missing data, and handling noise and errors when possible.Data access: Uniform and well-defined methods must be created for accessing the da-ta and providing access paths to data that were historically difficult to get to (for exam-ple, stored offline).Once organizations and individuals have solved the problem of how to store and ac-cess their data, the natural next step is the question, What else do we do with all the da-ta? This is where opportunities for KDD natu-rally arise.A popular approach for analysis of data warehouses is called online analytical processing (OLAP), named for a set of principles pro-posed by Codd (1993). OLAP tools focus on providing multidimensional data analysis,which is superior to SQL in computing sum-maries and breakdowns along many dimen-sions. OLAP tools are targeted toward simpli-fying and supporting interactive data analysis,but the goal of KDD tools is to automate as much of the process as possible. Thus, KDD is a step beyond what is currently supported by most standard database systems.Basic DefinitionsKDD is the nontrivial process of identifying valid, novel, potentially useful, and ultimate-and still run efficiently, how results can be in-terpreted and visualized, and how the overall man-machine interaction can usefully be modeled and supported. The KDD process can be viewed as a multidisciplinary activity that encompasses techniques beyond the scope of any one particular discipline such as machine learning. In this context, there are clear opportunities for other fields of AI (be-sides machine learning) to contribute to KDD. KDD places a special emphasis on find-ing understandable patterns that can be inter-preted as useful or interesting knowledge.Thus, for example, neural networks, although a powerful modeling tool, are relatively difficult to understand compared to decision trees. KDD also emphasizes scaling and ro-bustness properties of modeling algorithms for large noisy data sets.Related AI research fields include machine discovery, which targets the discovery of em-pirical laws from observation and experimen-tation (Shrager and Langley 1990) (see Kloes-gen and Zytkow [1996] for a glossary of terms common to KDD and machine discovery),and causal modeling for the inference of causal models from data (Spirtes, Glymour,and Scheines 1993). Statistics in particular has much in common with KDD (see Elder and Pregibon [1996] and Glymour et al.[1996] for a more detailed discussion of this synergy). Knowledge discovery from data is fundamentally a statistical endeavor. Statistics provides a language and framework for quan-tifying the uncertainty that results when one tries to infer general patterns from a particu-lar sample of an overall population. As men-tioned earlier, the term data mining has had negative connotations in statistics since the 1960s when computer-based data analysis techniques were first introduced. The concern arose because if one searches long enough in any data set (even randomly generated data),one can find patterns that appear to be statis-tically significant but, in fact, are not. Clearly,this issue is of fundamental importance to KDD. Substantial progress has been made in recent years in understanding such issues in statistics. Much of this work is of direct rele-vance to KDD. Thus, data mining is a legiti-mate activity as long as one understands how to do it correctly; data mining carried out poorly (without regard to the statistical as-pects of the problem) is to be avoided. KDD can also be viewed as encompassing a broader view of modeling than statistics. KDD aims to provide tools to automate (to the degree pos-sible) the entire process of data analysis and the statistician’s “art” of hypothesis selection.Data mining is a step in the KDD process that consists of ap-plying data analysis and discovery al-gorithms that produce a par-ticular enu-meration ofpatterns (or models)over the data.Articles40AI MAGAZINEly understandable patterns in data (Fayyad, Piatetsky-Shapiro, and Smyth 1996).Here, data are a set of facts (for example, cases in a database), and pattern is an expres-sion in some language describing a subset of the data or a model applicable to the subset. Hence, in our usage here, extracting a pattern also designates fitting a model to data; find-ing structure from data; or, in general, mak-ing any high-level description of a set of data. The term process implies that KDD comprises many steps, which involve data preparation, search for patterns, knowledge evaluation, and refinement, all repeated in multiple itera-tions. By nontrivial, we mean that some search or inference is involved; that is, it is not a straightforward computation of predefined quantities like computing the av-erage value of a set of numbers.The discovered patterns should be valid on new data with some degree of certainty. We also want patterns to be novel (at least to the system and preferably to the user) and poten-tially useful, that is, lead to some benefit to the user or task. Finally, the patterns should be understandable, if not immediately then after some postprocessing.The previous discussion implies that we can define quantitative measures for evaluating extracted patterns. In many cases, it is possi-ble to define measures of certainty (for exam-ple, estimated prediction accuracy on new data) or utility (for example, gain, perhaps indollars saved because of better predictions orspeedup in response time of a system). No-tions such as novelty and understandabilityare much more subjective. In certain contexts,understandability can be estimated by sim-plicity (for example, the number of bits to de-scribe a pattern). An important notion, calledinterestingness(for example, see Silberschatzand Tuzhilin [1995] and Piatetsky-Shapiro andMatheus [1994]), is usually taken as an overallmeasure of pattern value, combining validity,novelty, usefulness, and simplicity. Interest-ingness functions can be defined explicitly orcan be manifested implicitly through an or-dering placed by the KDD system on the dis-covered patterns or models.Given these notions, we can consider apattern to be knowledge if it exceeds some in-terestingness threshold, which is by nomeans an attempt to define knowledge in thephilosophical or even the popular view. As amatter of fact, knowledge in this definition ispurely user oriented and domain specific andis determined by whatever functions andthresholds the user chooses.Data mining is a step in the KDD processthat consists of applying data analysis anddiscovery algorithms that, under acceptablecomputational efficiency limitations, pro-duce a particular enumeration of patterns (ormodels) over the data. Note that the space ofArticlesFALL 1996 41Figure 1. An Overview of the Steps That Compose the KDD Process.methods, the effective number of variables under consideration can be reduced, or in-variant representations for the data can be found.Fifth is matching the goals of the KDD pro-cess (step 1) to a particular data-mining method. For example, summarization, clas-sification, regression, clustering, and so on,are described later as well as in Fayyad, Piatet-sky-Shapiro, and Smyth (1996).Sixth is exploratory analysis and model and hypothesis selection: choosing the data-mining algorithm(s) and selecting method(s)to be used for searching for data patterns.This process includes deciding which models and parameters might be appropriate (for ex-ample, models of categorical data are differ-ent than models of vectors over the reals) and matching a particular data-mining method with the overall criteria of the KDD process (for example, the end user might be more in-terested in understanding the model than its predictive capabilities).Seventh is data mining: searching for pat-terns of interest in a particular representa-tional form or a set of such representations,including classification rules or trees, regres-sion, and clustering. The user can significant-ly aid the data-mining method by correctly performing the preceding steps.Eighth is interpreting mined patterns, pos-sibly returning to any of steps 1 through 7 for further iteration. This step can also involve visualization of the extracted patterns and models or visualization of the data given the extracted models.Ninth is acting on the discovered knowl-edge: using the knowledge directly, incorpo-rating the knowledge into another system for further action, or simply documenting it and reporting it to interested parties. This process also includes checking for and resolving po-tential conflicts with previously believed (or extracted) knowledge.The KDD process can involve significant iteration and can contain loops between any two steps. The basic flow of steps (al-though not the potential multitude of itera-tions and loops) is illustrated in figure 1.Most previous work on KDD has focused on step 7, the data mining. However, the other steps are as important (and probably more so) for the successful application of KDD in practice. Having defined the basic notions and introduced the KDD process, we now focus on the data-mining component,which has, by far, received the most atten-tion in the literature.patterns is often infinite, and the enumera-tion of patterns involves some form of search in this space. Practical computational constraints place severe limits on the sub-space that can be explored by a data-mining algorithm.The KDD process involves using the database along with any required selection,preprocessing, subsampling, and transforma-tions of it; applying data-mining methods (algorithms) to enumerate patterns from it;and evaluating the products of data mining to identify the subset of the enumerated pat-terns deemed knowledge. The data-mining component of the KDD process is concerned with the algorithmic means by which pat-terns are extracted and enumerated from da-ta. The overall KDD process (figure 1) in-cludes the evaluation and possible interpretation of the mined patterns to de-termine which patterns can be considered new knowledge. The KDD process also in-cludes all the additional steps described in the next section.The notion of an overall user-driven pro-cess is not unique to KDD: analogous propos-als have been put forward both in statistics (Hand 1994) and in machine learning (Brod-ley and Smyth 1996).The KDD ProcessThe KDD process is interactive and iterative,involving numerous steps with many deci-sions made by the user. Brachman and Anand (1996) give a practical view of the KDD pro-cess, emphasizing the interactive nature of the process. Here, we broadly outline some of its basic steps:First is developing an understanding of the application domain and the relevant prior knowledge and identifying the goal of the KDD process from the customer’s viewpoint.Second is creating a target data set: select-ing a data set, or focusing on a subset of vari-ables or data samples, on which discovery is to be performed.Third is data cleaning and preprocessing.Basic operations include removing noise if appropriate, collecting the necessary informa-tion to model or account for noise, deciding on strategies for handling missing data fields,and accounting for time-sequence informa-tion and known changes.Fourth is data reduction and projection:finding useful features to represent the data depending on the goal of the task. With di-mensionality reduction or transformationArticles42AI MAGAZINEThe Data-Mining Stepof the KDD ProcessThe data-mining component of the KDD pro-cess often involves repeated iterative applica-tion of particular data-mining methods. This section presents an overview of the primary goals of data mining, a description of the methods used to address these goals, and a brief description of the data-mining algo-rithms that incorporate these methods.The knowledge discovery goals are defined by the intended use of the system. We can distinguish two types of goals: (1) verification and (2) discovery. With verification,the sys-tem is limited to verifying the user’s hypothe-sis. With discovery,the system autonomously finds new patterns. We further subdivide the discovery goal into prediction,where the sys-tem finds patterns for predicting the future behavior of some entities, and description, where the system finds patterns for presenta-tion to a user in a human-understandableform. In this article, we are primarily con-cerned with discovery-oriented data mining.Data mining involves fitting models to, or determining patterns from, observed data. The fitted models play the role of inferred knowledge: Whether the models reflect useful or interesting knowledge is part of the over-all, interactive KDD process where subjective human judgment is typically required. Two primary mathematical formalisms are used in model fitting: (1) statistical and (2) logical. The statistical approach allows for nondeter-ministic effects in the model, whereas a logi-cal model is purely deterministic. We focus primarily on the statistical approach to data mining, which tends to be the most widely used basis for practical data-mining applica-tions given the typical presence of uncertain-ty in real-world data-generating processes.Most data-mining methods are based on tried and tested techniques from machine learning, pattern recognition, and statistics: classification, clustering, regression, and so on. The array of different algorithms under each of these headings can often be bewilder-ing to both the novice and the experienced data analyst. It should be emphasized that of the many data-mining methods advertised in the literature, there are really only a few fun-damental techniques. The actual underlying model representation being used by a particu-lar method typically comes from a composi-tion of a small number of well-known op-tions: polynomials, splines, kernel and basis functions, threshold-Boolean functions, and so on. Thus, algorithms tend to differ primar-ily in the goodness-of-fit criterion used toevaluate model fit or in the search methodused to find a good fit.In our brief overview of data-mining meth-ods, we try in particular to convey the notionthat most (if not all) methods can be viewedas extensions or hybrids of a few basic tech-niques and principles. We first discuss the pri-mary methods of data mining and then showthat the data- mining methods can be viewedas consisting of three primary algorithmiccomponents: (1) model representation, (2)model evaluation, and (3) search. In the dis-cussion of KDD and data-mining methods,we use a simple example to make some of thenotions more concrete. Figure 2 shows a sim-ple two-dimensional artificial data set consist-ing of 23 cases. Each point on the graph rep-resents a person who has been given a loanby a particular bank at some time in the past.The horizontal axis represents the income ofthe person; the vertical axis represents the to-tal personal debt of the person (mortgage, carpayments, and so on). The data have beenclassified into two classes: (1) the x’s repre-sent persons who have defaulted on theirloans and (2) the o’s represent persons whoseloans are in good status with the bank. Thus,this simple artificial data set could represent ahistorical data set that can contain usefulknowledge from the point of view of thebank making the loans. Note that in actualKDD applications, there are typically manymore dimensions (as many as several hun-dreds) and many more data points (manythousands or even millions).ArticlesFALL 1996 43Figure 2. A Simple Data Set with Two Classes Used for Illustrative Purposes.。
数据挖掘在高校教学管理中的应用

数据挖掘在高校教学管理中的应用【摘要】教育已进入大数据时代,然而高校教务管理中对数据的处理方式相对落后。
本文针对这一问题,将数据挖掘技术应用到高校教学管理中,从教务管理系统收集的数据中提取出有用信息,为高校教学管理者制定相关决策提供正确有力的数据支持和保障。
【关键词】教学管理;数据挖掘;关联规则;聚类;变化和偏差分析随着教育信息化的加速发展,教务管理系统已在各高校广泛使用。
教务管理系统积累的数据与日俱增,蕴藏了大量的有价值信息。
但目前对这些数据的处理还仅仅是简单的数据查询、备份、报表和汇总。
利用数据挖掘技术对这些数据进行分析,深入挖掘,综合评价,得出的有用信息,可以有效地为教学服务,辅助完成学生管理、成绩分析、培养方案制定、教学计划制定、教师评价等工作[1]。
本文将对数据挖掘技术在教学管理中的应用,进行概括和分析。
1.数据挖掘技术概述1.1 数据挖掘的概念数据挖掘(Data Mining),又称为数据库中的知识发现(Knowledge Discovery in Database),就是从大量、不完整而且是带有噪声以及模糊和随机的实际应用数据中,提取出隐含、未知但又潜在有用的信息和知识的过程[2]。
广义的讲,数据挖掘意味着从大量事实或观察数据的集合中寻找模式的决策支持过程。
数据挖掘融合的技术主要包括数据库技术、机器学习、人工智能、统计学等,通过对数据进行分析,做出归纳性推理,挖掘出潜在信息,辅助完成正确性决策。
1.2 数据挖掘的过程和方法数据挖掘的过程可总结为四个阶段:确定挖掘对象、数据准备、数据挖掘、结果的解释和评价。
其中数据准备阶段包括:数据选择、数据预处理和数据变化等步骤。
数据挖掘的分析方法需根据待挖掘对象的类型、数据规模和类型进行选择。
主要包括:聚类分析、关联规则、变化和偏差分析等[3]。
聚类分析是一种研究如何将研究对象按照多个方面的特征进行综合分类的无监督的学习过程。
它将待挖掘的数据集分成若干不同的类或者簇,使同一类的数据对象尽可能相近被分到同一个簇中,不同类的数据对象尽可能相异将会处于不同的簇中。
什么是数据挖掘

数据挖掘发展阶段
4
第一阶段:电子邮件阶段 第二阶段:信息发布阶段 第三阶段: EC(Electronic Commerce),即电子商务阶段 第四阶段:数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、 随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜 在有用的信息和知识的过程。
Mining的工具更符合企业需求; 3. 纯就理论的基础点来看,Data Mining和统计分析有应用上的差别,毕竟Data
Mining目的是方便企业终端用户使用而非给统计学家检测用的。
小结
8
数据挖掘的定义。 数据挖掘与统计学的区别
Data Mining 和统计分析有什么不同
6
硬要去区分Data Mining和Statistics的差异其实是没有太大意义的。一般 将之定义为Data Mining技术的CART、CHAID或模糊计算等等理论方法,也都 是由统计学者根据统计理论所发展衍生,换另一个角度看,Data Mining有 相当大的比重是由高等统计学中的多变量分析所支撑。
什么是数据挖掘
内容要点
1
掌握数据挖掘的定义。
数据挖掘
2
它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称: KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于 其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析 处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别 等诸多方法来实现上述目标。
Data Mining 和统计分析有什么不同
7
为什么Data Mining的出现会引发各领域的广泛注意呢?主要原因在相较于 传统统计分析而言,Data Mining有下列几项特性:
KDD Knowledge Discovery in Databases

KDD Knowledge Discovery in Databases百科名片知识发现知识发现(KDD:Knowledge Discovery in Databases)是从数据集中别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
知识发现将信息变为知识,从数据矿山中找到蕴藏的知识金块,将为知识创新和知识经济的发展作出贡献。
该术语于1989年出现,Fayyad定义为"KDD"是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程”。
目录详细解释1.KDD基本过程(the process of the KDD)2.常用KDD过程模型 (KDD process model)编辑本段详细解释数据库知识发现(knowledge discovery in databases,KDD)的研究非常活跃。
在上面的定义中,涉及几个需要进一步解释的概念:“数据集”、“模式”、“过程”、“有效性”、“新颖性”、“潜在有用性”和“最终可理解性”。
数据集是一组事实 F(如关系数据库中的记录)。
模式是一个用语言L来表示的一个表达式E,它可用来描述数据集F的某个子集凡上作为一个模式要求它比对数据子集FE的枚举要简单(所用的描述信息量要少)。
过程在KDD中通常指多阶段的处理,涉及数据准备、模式搜索、知识评价以及反复的修改求精;该过程要求是非平凡的,意思是要有一定程度的智能性、自动性(仅仅给出所有数据的总和不能算作是一个发现过程)。
有效性是指发现的模式对于新的数据仍保持有一定的可信度。
新颖性要求发现的模式应该是新的。
潜在有用性是指发现的知识将来有实际效用,如用于决策支持系统里可提高经济效益。
最终可理解性要求发现的模式能被用户理解,目前它主要是体现在简洁性上。
有效性、新颖性、潜在有用性和最终可理解性综合在一起称为兴趣性。
由于知识发现是一门受到来自各种不同领域的研究者关注的交叉性学科,因此导致了很多不同的术语名称。
数据挖掘中的名词解释

第一章1,数据挖掘(Data Mining), 就是从存放在数据库, 数据仓库或其他信息库中的大量的数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
2,人工智能(Artificial Intelligence)它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支, 它企图了解智能的实质, 并生产出一种新的能以人类智能相似的方式做出反应的智能机器。
3,机器学习(Machine Learning)是研究计算机怎样模拟或实现人类的学习行为, 以获取新的知识或技能, 重新组织已有的知识结构使之不断改善自身的性能。
4,知识工程(Knowledge Engineering)是人工智能的原理和方法, 对那些需要专家知识才能解决的应用难题提供求解的手段。
5,信息检索(Information Retrieval)是指信息按一定的方式组织起来, 并根据信息用户的需要找出有关的信息的过程和技术。
数据可视化(Data Visualization)是关于数据之视觉表现形式的研究;其中, 这种数据的视觉表现形式被定义为一种以某种概要形式抽提出来的信息, 包括相应信息单位的各种属性和变量。
6,联机事务处理系统(OLTP)实时地采集处理与事务相连的数据以及共享数据库和其它文件的地位的变化。
在联机事务处理中, 事务是被立即执行的, 这与批处理相反, 一批事务被存储一段时间, 然后再被执行。
7,8, 联机分析处理(OLAP)使分析人员, 管理人员或执行人员能够从多角度对信息进行快速一致, 交互地存取, 从而获得对数据的更深入了解的一类软件技术。
决策支持系统(decision support)是辅助决策者通过数据、模型和知识, 以人机交互方式进行半结构化或非结构化决策的计算机应用系统。
它为决策者提供分析问题、建立模型、模拟决策过程和方案的环境, 调用各种信息资源和分析工具, 帮助决策者提高决策水平和质量。
数据挖掘的前期准备

数据挖掘的前期准备无线电管理各类数据库标准的制订,科学地定义了数据模型。
网格化监测等项目的推广,加强了数据的时空关联属性,数据世界描述现实世界的能力明显增强。
然而.传统的数据分析技术已无力应对当今的海量数据。
令人庆幸的是,专用于破解此类难题的数据挖掘技术已枕戈待旦。
在整个数据挖掘过程中,近80%的时问都是在准备数据,可见,前期准备对数据挖掘具有重要意义。
文/管军伟数据挖掘(Data Mining,简称DM)是从大量的数据中挖掘出隐含的、未知的、用户可能感兴趣的和对决策有潜在价值的知识和规则。
数据挖掘融合了数据库、统计学、人工智能等学科的知识,能够提供多种功能:概念描述——根据数据的微观特征来表征数据集:关联分析一揭示事物之间的依赖或者关联关系;预测分析一根据历史数据和当前数据,预测未来数据;聚类分析一发现内在的规则,识别出紧密相关的观测值组群:异常检测一识别出特征显著不同于其他数据的观测值。
严格地说,数据挖掘是数据库知识发现( KnowledgeDiscovery in Databases,简称KDD)的一个步骤(如图1所示),但在实际中,两者通常被等同视之,笔者也循例统一使用“数据挖掘”一词加以表述。
数据挖掘一开始就是面向应用的,它封装了相关学科中复杂高深的理论和技术,大幅降低了应用门槛。
然而,成功的数据挖掘并非一蹴而就,需要从几个方面着手准备:正确认识数据挖掘一般来说,数据挖掘处理的数据规模都很大,挖掘出来的结果是不确定的,只有结合领域知识才能判断其价值。
数据挖掘既要担负发现潜在规则的任务,还要应对新数据的管理和规则维护。
规则的发现基于大样本的统计规律,当置信度达到某一阈值时,就可以认为规则成立。
显而易见,数据挖掘不同于传统的决策支持系统。
传统的决策支持系统通常是先建立一系列的假设,然后通过数据查询和分析来验证或否定假设,最终得到自己的结论,它在本质上是一个演绎推理的过程。
而数据挖掘是按照给定的算法,自动地对数据进行归纳、分析和推理,从中发掘出潜在的模式,它在本质上是一个归纳的过程。
知识发现和数据挖掘

知识发现和数据挖掘知识发现和数据挖掘是当今信息时代中不可忽视的重要领域。
随着互联网和智能技术的迅猛发展,人类积累、储存和处理的数据量呈指数级增长,这就对我们发现、挖掘和利用数据中蕴含的知识提出了挑战和机遇。
在这篇文章中,我们将深入探讨知识发现和数据挖掘的概念、方法和应用,以及其对个人和社会的重要意义。
一、知识发现和数据挖掘的概念知识发现和数据挖掘,简称KDD(Knowledge Discovery in Databases),是一种从大规模数据中自动提取未知、有用且潜在的信息和知识的过程。
它融合了数据处理、人工智能、机器学习和统计学等多个学科,通过运用各种数据挖掘算法和技术,从海量数据中提取模式、规律和关联,以帮助人们做出决策、预测趋势和发现新的知识。
二、数据挖掘的方法数据挖掘是知识发现的一个重要部分,它以数据为基础,通过挖掘数据中的信息和知识来推动科学研究和社会进步。
数据挖掘方法包括聚类分析、关联规则挖掘、分类分析、回归分析等。
聚类分析是将数据对象分为若干个类别,使得同一类别内的数据对象相似度较高;关联规则挖掘是通过寻找数据项之间的频繁集合来发现它们之间的关系;分类分析是通过建立模型,根据已有数据的属性进行分类预测;回归分析是根据已有数据的属性和目标变量之间的关系建立数学模型,以进行预测分析。
三、知识发现和数据挖掘的应用知识发现和数据挖掘在各个领域都具有广泛的应用价值。
在商业领域,它被用于市场分析、客户关系管理、销售预测等,通过挖掘消费者行为模式和市场趋势,帮助企业制定营销策略和提高竞争力。
在医疗领域,它被用于疾病诊断、药物开发和个性化治疗等,通过挖掘大量的医疗数据,帮助医生做出准确的诊断和治疗决策。
在社交媒体领域,它被用于个性化推荐、舆情分析等,通过挖掘用户的兴趣和行为,为用户提供个性化的服务和内容。
四、知识发现和数据挖掘对个人和社会的重要意义知识发现和数据挖掘对于个人和社会的重要性不言而喻。
数据挖掘给我们的生活带来的改变

数据挖掘给人们生活带来的改变摘要:随着网络、数据库技术的迅速发展以及数据库管理系统的广泛应用,人们积累的数据越来越多,其中蕴藏着大量的信息,数据挖掘(Data Mining)就是从大量的实际应用数据中提取隐含信息和知识,它利用了数据库、人工智能和数理统计等多方面的技术,是一类深层次的数据分析方法。
本文简要阐述了大数据的研究现状与重大意义,探讨通过对数据进行挖掘,分析,给人们的生活带来的改变。
关键字:大数据、知识获取、数据挖掘、应用及改变一、引言近年来,随着互联网、物联网、云计算、三网融合等IT与通信技术的迅猛发展,数据的快速增长成了许多行业共同面对的严峻挑战和宝贵机遇,因而信息社会已经进入了大数据时代。
大数据的涌现不仅改变着人们的生活与工作方式、企业的运作模式,甚至还引起科学研究模式的根本性改变。
数据是知识的源泉。
但是,拥有大量的数据与拥有许多有用的知识完全是两回事。
过去几年中,从数据库中发现知识这一领域发展的很快。
广阔的市场和研究利益促使这一领域的飞速发展。
计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。
收集数据是为了得到信息,然而大量的数据本身并不意味信息。
我们只有通过对数据进行挖掘,分析、筛选、比较、综合、才能提取出知识和规则。
二、知识获取与数据挖掘一般说来,知识获取(Knowledge Discovery inDatabases,称称KDD)意为数据库中知识获取,它代表从低层次数据中提取高层次知识的全过程,包括数据信息的收集,数据原型的确定,相关函数的分析,知识的抽取和数据模式分析。
统计学中常指的是无假设证实所进行的数据测量和分析。
而数据挖掘则是指从数据中自动地抽取模型。
数据挖掘包括许多步骤:从大规模数据库中(或从其他来源)取得数据;选择合适的特征属性;挑选合适的样本策略;剔除数据中不正常的数据并补足不够的部分;用恰当的降维、变换使数据挖掘过程与数据模型相适合或相匹配;辨别所得到的是否是知识则需将得到的结果信息化或可视化,然后与现有的知识相结合比较。
KDD中的几个关键问题研究

KDD中的几个关键问题研究KDD中的几个关键问题研究KDD(Knowledge Discovery in Databases,数据库中的知识发现)是数据挖掘和机器学习领域的关键技术之一,它涉及数据的收集、清洗、转换、建模和分析等多个环节,旨在从大规模数据中发现有价值的信息和知识。
然而,在进行KDD的过程中,会面临一些关键问题,包括数据预处理、特征选择、模型构建和结果解释等方面。
本文将围绕这几个问题展开探讨。
首先,数据预处理是KDD中的一个关键环节。
原始数据往往存在噪声、缺失值和不一致性等问题,因此需要对数据进行清洗和重构。
数据清洗旨在去除噪声和异常值,使数据更加可靠和准确;数据重构则是通过填补缺失值、归一化、规范化等方式,使数据具有更好的可比性和一致性。
数据预处理的好坏直接影响到后续步骤的准确性和可靠性,因此,如何有效地进行数据预处理是KDD中的一个重要问题。
其次,特征选择是KDD中的另一个关键环节。
在大规模数据中,存在很多特征,但其中只有一部分对于所关注的问题具有重要性。
通过特征选择可以剔除对问题无关的特征,减少特征的维度,并提高模型的性能和可解释性。
特征选择的方法包括过滤式、包裹式和嵌入式等多种,每种方法都有其优缺点和适用场景,选择合适的方法进行特征选择是KDD中的一项重要任务。
第三,模型构建是KDD中的核心环节。
在大规模数据中,构建一个准确、高效和可解释的模型是KDD的终极目标。
模型的选择和构建涉及到多种机器学习方法和算法,包括决策树、支持向量机、神经网络等。
同时,模型的性能评估和调优也是模型构建过程中的关键问题。
通过交叉验证、学习曲线和模型评估指标等方法,可以评估模型的准确性和泛化能力,进一步优化模型的性能。
最后,结果解释是KDD中的一个重要环节。
在KDD的过程中,可以得到大量的信息和知识,但如何解释和理解这些结果并转化为业务价值是一个关键问题。
结果解释涉及到可视化、解释性分析和模型解释等多个方面。
《数据挖掘基础知识》

❖ 聚类用于市场细分,将顾客按其行为或特征模式 的相似性划分为若干细分市场,以采取有针对性 的营销策略;
❖ 分类用于预测哪些人会对邮寄广告和产品目录、 赠券等促销手段有反应,还可用于顾客定级、破产 预测等。
《数据挖掘基础知识》
1.1数据挖掘的社会需求
现实情况:人类积累的数据量以每月高于15%的速度增 加,如果不借助强有力的挖掘工具,仅依靠人的能力来 理解这些数据是不可能的。现在人们已经评估出世界上 信息的数量每二十个月翻一番,并且数据库的数量与大 小正在以更快的速度增长。
1.1数据挖掘的社会需求
著名的“啤酒尿布”案例:美国加州某个超级卖场通过数 据挖掘发现,下班后前来购买婴儿尿布的男顾客大都购买 啤酒。于是经理当机立断,重新布置货架,把啤酒类商品 布置在婴儿尿布货架附近,并在二者之间放置佐酒食品, 同时还把男士日常用品就近布置。这样,上述几种商品的 销量大增。
---空间数据挖掘(SDM)的特点
❖ 数据源十分丰富,数据量非常庞大,数据类 型多,存取方法复杂;
❖ 应用领域十分广泛,只要与空间位置相关的 数据,都可对其进行挖掘;
❖ 挖掘方法和算法非常,而且大多数算法比较 复杂,难度大;
❖ 知识的表达方式多样,对知识的理解和评价 依赖于对人对客观世界的认知程度。
1.8数据挖掘的发展趋势—WEB挖掘
❖ Web 数据的收集,结构转换等预处理技术的 研究;
❖ 现有的数据挖掘方法在适应性和时效性方面 的研究
❖ 基于Web 挖掘和信息检索的智能搜索引擎及 相关技术的研究;
❖ Web 挖掘在特定领域如电子商务领域的应用 研究;
幻灯片浙江工业大学(精)

主要研究内容
书籍本身及其销售的基本数据的采集 搜集并研读「RFID技术应用」之相关资料与文献 了解RFID技术特质与技术限制 利用数据挖掘的相关技术分析出书籍相关性 (1)建立以销售数据为基础之关联推论法则 (2)建立以文字数据为基础之关联推论法则 (3)建立以经验法则为基础之关联推论法则 数据挖掘后的信息处理
一般而言,于图书门市中,读者若想取得所需书籍之相关书籍信息, 往往需藉由本身之阅读经验进行推测。另一方面,当图书门市书籍日 益增多,所需考虑之相关条件繁多时,读者之决策负荷亦大幅增加。 此外,由于读者对于图书门市之书籍摆设不甚了解,将造成读者搜寻 图书之时间增加。 目前相关研究多仅针对图书馆抑或电子图书馆之图书检索方式进行深 入探讨,并未针对一般消费者于图书零售门市中进行书籍选购时所发 生之困惑进行深度探究。表现为: (1) 传统以数据挖掘方法进行书籍关联性推论之成效并不显着,未能 充分应用于书籍销售建议活动。 (2) 由于零售卖场之书目繁多,造成读者难以迅速取得所需书籍。 (3) 传统书籍搜寻之方式过于耗时且耗费人力。
预期结果
通过深入的探讨和研究,力争发表论文一篇。而此系统一旦研发成功,即 可运用于图书销售门市中,帮助零售商获得更大的利润。待技术成熟,也 可以推广至学校图书馆系统中,使学生能够在最短的时间内得到需求的 最大化满足。
以RFID技术为基础之书籍推荐系统
组长:陆眉 成员:段超 何建林 章喆 杜飞航 指导老师:陈庆章
相关背景
RFID技术
RFID是一种简单的无线系统,只有两个基本器件,该系统用于控制、 检测和跟踪物体。系统由一个询问器(或阅读器)和很多应答器(或 标签)组成。 最基本的RF系统由三部分组成: 1、标签(Tag,即射频卡):由耦合元件及芯片组成,标签含有 内置天线,用于和射频天线间进行通信。 2、阅读器:读取(在读写卡中还可以写入)标签信息的设备。 3、天线:在标签和读取器间传递射频信号。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Data Mining: An AI PerspectiveXindong Wu 1, Senior Member, IEEEDaWaK 2003: 5th International Conference on DataWarehousing and Knowledge Discovery (September 3-5, 2003, Prague, Czech Repblic)Abstract --Data mining, or knowledge discovery in databases (KDD), is an interdisciplinary area that integrates techniques from several fields including machine learning, statistics, and database systems, for the analysis of large volumes of data. This paper reviews the topics of interest from the IEEE International Conference on Data Mining (ICDM) from an AI perspective. We discuss common topics in data mining and AI, including key AI ideas that have been used in both data mining and machine learning.PKDD-2003: 7th European Conference on Principlesand Practice of Knowledge Discovery in Databases (September 22-26, 2003, Cavtat-Dubrovnik, Croatia) SAS M2003: 6th Annual Data Mining TechnologyConference (October 13-14, 2003, Las Vegas, NV, USA)Data Warehousing & Data Mining for EnergyCompanies (October 16-17, 2003, Houston, TX, USA) Index Terms —Data Mining, Artificial Intelligence, Machine Learning.CAMDA 2003: Critical Assessment of MicroarrayData Analysis (November 12-14, 2003, Durham, NC, USA)I. T HE IEEE I NTERNATIONAL C ONFERENCE ON D ATA M ININGDATA mining is a fast-growing area. The first Knowledge Discovery in Databases Workshop was heldin August 1989, in conjunction with the 1989 InternationalJoint Conference on Artificial Intelligence, and this workshopseries became the International Conference on KnowledgeDiscovery and Data Mining in 1995. In 2003, there were atotal of 15 data mining conferences, most of which are listedat /meetings/meetings-2003-past.html:ICDM-2003: 3rd IEEE International Conference on Data Mining (November 19 - 22, 2003, Melbourne, FL,USA)The Australasian Data Mining Workshop (December 8,2003, Canberra, Australia,http://datamining.csiro.au/adm03/)These 15 conferences do not include various artificialintelligence (AI), statistics and database conferences (and theirworkshops) that also solicited and accepted data miningrelated papers, such as IJCAI, ICML, ICTAI, COMPSTAT,AI & Statistics, SIGMOD, VLDB, ICDE, and CIKM.Data Warehousing and Data Mining in DrugDevelopment (January 13-14, 2003, Philadelphia, PA,USA)First Annual Forum on Data Mining Technology forMilitary and Government Applications (February25-26, 2003, Washington DC, USA)SPIE Conference on Data Mining and KnowledgeDiscovery: Theory, Tools, and Technology V (21-22April 2003,/Conferences/Programs/03/or/conferences/index.cfm?fuseaction=5098)Among various data mining conferences, KDD and ICDM arearguably (or unarguably) the two premier ones in the field.ICDM was established in 2000, sponsored by the IEEEComputer Society, and had its first annual meeting in 2001.Figure 1 shows the number of paper submissions to eachKDD and ICDM conference.Topics of interest from the ICDM 2003 call for papers[/~xwu/icdm-03.shtml] are listed here:PAKDD-03: 7th Pacific-Asia Conference onKnowledge Discovery and Data Mining (April 30 -May 2, 2003, Seoul, Korea)1. Foundations of data miningSDM 03: 3rd SIAM International Conference on DataMining (May 1-3, 2003, San Francisco, CA, USA)2. Data mining and machine learning algorithms andmethods in traditional areas (such as classification,regression, clustering, probabilistic modeling, andassociation analysis), and in new areasMLDM 2003: Machine Learning and Data Mining(July 5-7, 2003, Leipzig, Germany)KDD-2003, 9th ACM SIGKDD InternationalConference on Knowledge Discovery and Data Mining(August 24-27, 2003, Washington DC, USA)3. Mining text and semi-structured data, and miningtemporal, spatial and multimedia data4. Data and knowledge representation for data miningIDA-2003, 5th International Symposium on IntelligentData Analysis (August 28-30, 2003, Berlin, Germany)5. Complexity, efficiency, and scalability issues in datamining1Xindong Wu is with the Department of Computer Science, University ofVermont Burlington, VT 05405, USA (e-mail: xwu@).1. [R281] Clustering of Streaming Time Series isMeaningless: Implications for Previous and Future Research, by Jessica Lin, Eamonn Keogh, and Wagner Truppel2. [R405] A High-Performance Distributed Algorithm forMining Association Rules, by Ran Wolff, Assaf Schuster, and Dan Trock3. [R493] TSP: Mining Top-K Closed Sequential Patterns,by Petre Tzvetkov, Xifeng Yan, and Jiawei Han4. [R528] ExAMiner: Optimized Level-wise FrequentPattern Mining with Monotone Constraints, by Francesco Bonchi, Fosca Giannotti, Alessio Mazzanti, and Dino Pedreschi5. [R565] Reliable Detection of Episodes in EventSequences, by Robert Gwadera, Mikhail Atallah, and Wojciech Szpankowski6. [R620] On the Privacy Preserving Properties of RandomData Perturbation Techniques, by Hillol Kargupta, Souptik Datta, Qi Wang, and Krishnamoorthy SivakumarIII. C OMMON T OPICS IN D ATA M INING AND AIA. Data Mining Papers on Machine Learning Topics Machine learning in AI is the most relevant area to datamining, from the AI perspective. ICML 2003[/conferences/icml03/] especially invited paper submissions on the following topics:1. Applications of machine learning, particularly:a. exploratory research that describes novel learning tasks;b. applications that require non-standardtechniques or shed light on limitations ofexisting learning techniques; andc. work that investigates the effect of the developers' decisions about problem formulation, representation or data quality on the learning process. 2. Analysis of learning algorithms that demonstrategeneralization ability and also lead to better understanding of the computational complexity of learning.3. The role of learning in spatial reasoning, motor control, and more generally in the performance of intelligent autonomous agents.4. The discovery of scientific laws and taxonomies, and the induction of structured models from data.5. Computational models of human learning.6. Novel formulations of and insights into data clustering.7. Learning from non-static data sources: incrementalinduction, on-line learning and learning from data streams. Apart from Topic 5, all other topics above are relevant in significant ways to the topics of the 2003 IEEE InternationalConference on Data Mining listed in Section 1. Topic 2 is relevant to topics 2 and 5 in Section 1, Topic 3 overlaps with topics 3 and 1 in Section 1, and Topic 1 above and topic 17 in Section 1 both deal with applications. In practice, it is rather difficult to clearly distinguish a data mining application from a machine learning application, as long as an induction/learning task in involved. In fact, data mining and machine learning share the emphases on efficiency, effectiveness, and validity [Zhou 2003].Meanwhile, every best paper from ICDM 2001, 2002 and 2003 in Section 2 can fit in the above ICML 2003 topics. With the exception of data pre-processing and post-processing, which might not involve any particular mining task, a data mining paper can generally find its relevance to a machine learning conference.B. Three Fundamental AI Techniques in Data MiningAI is a broader area than machine learning. AI systems are knowledge processing systems. Knowledge representation, knowledge acquisition, and inference including search and control, are three fundamental techniques in AI.Knowledge representation . Data mining seeks to discover interesting patterns from large volumes of data. These patterns can take various forms, such asassociation rules, classification rules, and decision trees, and therefore, knowledge representation (Topic 4of ICDM 2003 in Section 1) becomes an issue ofinterest in data mining.Knowledge acquisition . The discovery process sharesvarious algorithms and methods (Topics 2 and 6) with machine learning for the same purpose of knowledge acquisition from data [Wu 1995] or learning from examples.Knowledge inference . The patterns discovered fromdata need to be verified in various applications (Topics 7 and 17) and so deduction of mining results is an essential technique in data mining applications.Therefore, knowledge representation, knowledge acquisition and knowledge inference, the three fundamental techniques inAI are all relevant to data mining.Meanwhile, data mining was explicitly listed in the IJCAI2003 call for papers [/1024/index.html] as an area keyword.C. Key Methods Shared in AI and Data MiningAI research is concerned with the principles and design of rational agents [Russell and Norvig 2003], and data mining systems can be good examples of such rational agents. Most AI research areas (such as reasoning, planning, natural language processing, game playing and robotics) have concentrated on the development of symbolic and heuristic methods to solve complex problems efficiently. These methods have also found extensive use in data mining.。