PowerPC栈帧分析
32位PowerPC构架通用寄存器分析及总结三

32位PowerPC构架通用寄存器分析及总结三4.6SR(Segment Registers)寄存器OEA定义了16个32位的SR寄存器,段寄存器SR可以使用mtsr/mfsr,mtsrin/mfsrin指令进程访问。
随着CR[0]位(我们称之为T位)的值的不同,CR寄存器有两种不同的格式。
当T位为1时格式如下:CR[1]位:系统模式保护位CR[2]位:用户模式保护位CR[3]位:不可执行保护位CR[4:7]位:保留位CR[8:31]位:VSID位,我们在4.5节页面地址映射中已经看到该位段的作用。
当T位为0时格式如下:CR[1]位:系统模式保护位CR[2]位:用户模式保护位CR[3]位:不可执行保护位CR[3:11]位:Bus unit IDCR[12:31]位:Device-specific data for I/O controller备注:这个位段,我现在不清楚,暂时附上datasheet原文,以后再修改O(∩_∩)O~4.7 DAR(Data Address Register)寄存器存放访存指令产生的引发中断的有效地址,比较简单。
格式如下:4.8 SPRG0–SPRG3寄存器提供给操作系统使用,格式如下:SPRG0:操作系统可能会加载一个独立的物理地址到该寄存器中,来标识一个内存区域是第一级的中断句柄专用的。
SPRG2:可以被第一级的中断来保存通用寄存器的内容,该内容可以作为内存中保存其它通用寄存器的基地址。
SPRG2和SPRG3可以在操作系统需要时使用!备注:E600有8个SPRGs寄存器。
4.9 DSISR寄存器用来决定DSI中断的中断源,格式如下:4.10 SRR0(Machine Status Save/Restore Register 0)寄存器当发生中断时,SRR0用来保持中断发生的那一刻MSR的状态,当中断返回结束执行rfi指令时,SRR0用来恢复MSR寄存器的值,它也可以用来保持系统调用之前的那条指令的有效地址,当系统中断结束时会执行rfi指令,汇编SPR0保持的地址赋值给NIA(Next Instruction Address)寄存器(也就是我们通常说的PC寄存器)格式如下:4.11 SRR1(Machine Status Save/Restore Register 1)该寄存器同4.104.12 FPECR(Floating-Point Exception Cause Register)FPECR寄存器用来支持产生浮点中断的原因。
32位PowerPC常用指令集总结

32位PowerPC常用指令集总结第一部分PowerPC 精简指令集计算机(RISC)简介PowerPC 体系结构是一种精减指令集计算机(Reduced Instruction Set Computer,RISC)体系结构,定义了200 多条指令。
PowerPC 之所以是RISC,原因在于大部分指令在一个单一的周期内执行,而且通常只执行一个单一的操作(比如将内存加载到寄存器,或者将寄存器数据存储到内存)。
PowerPC 体系结构分为三个级别(或者说是“book”)。
通过对体系结构以这种方式进行划分,为实现可以选择价格/性能比平衡的复杂性级别留出了空间,同时还保持了实现间的代码兼容性。
Book I. 用户指令集体系结构(Power ISA User Instruction Set Architecture)定义了通用于所有PowerPC 实现的用户指令和寄存器的基本集合。
这些是非特权指令,为大多数程序所用。
Book II. 虚拟环境体系结构(Power ISA Virtual Environment Architecture)定义了常规应用软件要求之外的附加的用户级功能,比如高速缓存管理、原子操作和用户级计时器支持。
虽然这些操作也是非特权的,但是程序通常还是通过操作系统调用来访问这些函数。
Book III. 操作环境体系结构(Power ISA Operating Environment Architecture)定义了操作系统级需要和使用的操作。
其中包括用于内存管理、异常向量处理、特权寄存器访问、特权计时器访问的函数。
Book III 中详细说明了对各种系统服务和功能的直接硬件支持。
由于我目前手上的开发板是基于e600内核,所以我在学习PowerPC指令集的过程中,顺便总结了e600内核常用的指令集,如果大家发现我总结的指令集有错误或者不准确的地方,欢迎留言指出来,O(∩_∩)O~第二部分e600指令集飞思卡尔的e600内核实现了booke内核构架中64位指令集的中的32位指令(即在e600的32位寄存器中,第0位相当于booke中的64寄存器的第32位,第31位相当于booke中64寄存器的第63位),E600内核采用大端编码方式,指令的第0位是MSB(Most Significant Bit)位,第31位是LSB(Least Significant Bit)。
栈和栈帧[概述]
![栈和栈帧[概述]](https://img.taocdn.com/s3/m/6d7031ca5122aaea998fcc22bcd126fff7055d87.png)
首先,来熟悉一下概念:第一,它使调用者和被调用者达成某种约定。
这个约定定义了函数调用时函数参数的传递方式,函数返回值的返回方式,寄存器如何在调用者和被调用者之间进行共享;第二,它定义了被调用者如何使用它自己的stack frame 来完成局部变量的存储和使用。
2. 压栈和出栈在RISC 计算机中主要参与计算的是寄存器,saved registers 就是指在进入一个函数后,如果某个保存原函数信息的寄存器会在当前函数中被使用,就应该将此寄存器保存到堆栈上,当函数返回时恢复此寄存器值。
而且由于RISC 计算机大部分采用定长指令或者定变长指令,一般指令长度不会超过32个位。
而现代计算机的内存地址范围已经扩展到32 位甚至64位,这样在一条指令里就不足以包含有效的内存地址,所以RISC计算机一般借助于一个返回地址寄存器RA(return address) 来实现函数的返回。
几乎在每个函数调用中都会使用到这个寄存器,所以在很多情况下RA 寄存器会被保存在堆栈上以避免被后面的函数调用修改,当函数需要返回时,从堆栈上取回RA 然后跳转。
移动SP 和保存寄存器的动作一般处在函数的开头,这个压栈过程也叫做function prologue;恢复这些寄存器状态的动作一般放在函数的最后,出栈过程也叫做function epilogue。
压栈出栈指令各个CPU也不相同。
Stack Frame 中所存放的内容和存放顺序,则由目标体系架构的调用约定(calling convention)定义。
下面,我们看看图形化的函数栈帧,以栈向下增长为例来了解几种常用CPU的stack frame 组织方式。
3. MIPS栈帧先看MIPS的栈帧布局图:此图描述的是一种典型的MIPS stack frame 组织方式。
在这张图中,sp(stack pointer)/s8(栈基址,又称fp)就是当前函数的栈指针,它指向栈顶的位置。
Callee Frame 所示即为当前函数(被调用者)的frame,Caller Frame 是当前函数的调用者的frame。
PowerPC和ARM的优缺点介绍

PowerPC和ARM的优缺点介绍1. 高性能:PowerPC处理器具有强大的性能,可以处理复杂的任务和多线程操作。
它们运行速度快且稳定,且通常比ARM处理器具有更高的时钟频率。
2. 并行处理:PowerPC处理器支持SIMD指令集,可以同时执行多个数据操作。
这使得它们在图形渲染、视频编码和其他需要高度并行处理的应用中表现出色。
3. 可扩展性:PowerPC处理器可以通过添加多个处理核心来实现多核处理。
这使得它们成为需要高度并行计算的工作站和服务器的理想选择。
4. 内存管理:PowerPC处理器具有灵活的内存管理系统,可以有效地管理应用程序和数据的内存使用。
这使得它们在处理大型数据集和内存密集型应用程序时表现出色。
虽然PowerPC有很多优点,但也存在一些缺点:1. 安装基数小:相对于x86架构和ARM架构,PowerPC的安装基数较小。
这意味着开发和优化适用于PowerPC的软件可能需要更多投资和精力。
2. 价格昂贵:PowerPC处理器通常较昂贵,这使得它们不适合于低成本市场和普通消费者。
3. 兼容性问题:PowerPC处理器与x86架构的软件不兼容,这使得迁移和使用现有软件可能需要额外的工作。
ARM是一种面向低功耗和小型设备的处理器架构,它广泛应用于智能手机、平板电脑、嵌入式系统等设备中。
以下是ARM的优点:1.低功耗:ARM处理器以其低功耗而著称。
它们在节能方面表现出色,这使得它们成为移动设备和嵌入式系统的理想选择。
2.小型化:ARM处理器的设计非常精简,可以集成在小型封装中。
这使得它们适合于小型设备,如智能手机和可穿戴设备。
3.易于集成:ARM处理器的设计模块化,易于与其他硬件组件集成。
这使得它们在嵌入式系统和自定义设备中的集成工作变得更加简单。
4.软件兼容性:由于ARM处理器在移动设备市场的广泛应用,很多软件和操作系统都已优化适用于ARM架构。
这大大增加了ARM处理器的可用性。
与此同时,ARM也存在一些缺点:1. 性能较低:相对于PowerPC和x86架构,ARM处理器的性能通常较低。
基于PowerPC的移动通信系统进程堆栈深度分析的方法研究

第12卷 第4期集美大学学报(自然科学版)Vol .12 No .4 2007年10月Journal of J i m ei University (Na t u ral Science )Oct .2007 [收稿日期]655[作者简介]贺冰琰(—),女,讲师,硕士,从事嵌入式操作系统、计算机网络研究[文章编号]1007-7405(2007)04-0356-04基于PowerPC 的移动通信系统进程堆栈深度分析的方法研究贺冰琰(集美大学计算机工程学院,福建厦门361021)[摘要]介绍了基于Po werPC 的移动通信系统中两种计算运行期时应用进程堆栈使用深度的方法:1)个体累加法;2)总体测试法.主要阐述了两种方法的基本原理并给出了具体的实现代码.[关键词]Po we rPC;G NU 编译器;垂直层次结构;移动通信系统;堆栈[中图分类号]TP 393109[文献标志码]A0 引言在移动通信系统中,经常发生应用子系统的应用进程的堆栈溢出或其他堆栈使用问题而导致的系统故障或系统崩溃,造成整个系统的服务中断.应用子系统的应用进程是整个系统使用堆栈最多、最频繁的模块,也是出现问题最多的模块.因此,确保应用子系统合理使用堆栈以及在最坏情况下能够分配到足够的堆栈是至关重要的,这就需要对子系统中的每个进程的堆栈使用深度进行有效的计算和分析.本文提出了两种检测运行期时进程的堆栈使用深度的方法.1 Po werPC 处理器的堆栈结构确保永不发生堆栈溢出的唯一途径就是:先分析代码确定程序的最大堆栈用量,然后检查是否分配了足够的堆栈.测试不大可能触发导致系统出现最坏情况的特定的瞬时输入组合.在本系统中,设备单板主处理器采用的是嵌入式微处理器P owerPC,设备软件的开发采用Torna 2do 集成开发环境.Tornado 是开发基于Vx W orks 实时嵌入式应用系统的平台,V x W orks 使用G NU 的GCC 编译器.了解PowerPC 处理器的堆栈帧结构和G NU 编译器的压栈方式,就可得到设备软件子系统中应用进程堆栈的使用深度.因此,首先从设备单板上一个应用进程的一段C /AS M 的混合代码入手,研究堆栈的结构.exte rn “C ”V O I D P_S_SER _S APEntry (WORD16wState,WORD16wSigl,VO I D 3pSiglPa ra,VO I D 3pVa rP ){ 0x526d92c P_S_SER _S APEn try:st w u r1,0xffd8(r1)//1:把寄存器r1的内容放入r1-0x 28的内存单元,并且r1=r1-0x 28.r1是堆栈指针0x526d930 +0x004: mfs p r r0,LR //2:把返回地址寄存器的内容赋给r0,以便保存到堆栈0x526d934 +0x008: st w r29,0x 1c (r1)0x526d938 +0x00c: st w r30,0x 20(r1)0x526d93c +0x010: st w r31,0x 24(r1)//3:保存需要使用的寄存器的值到堆栈中200-0-11974. 第3期贺冰琰:基于Po werPC 的移动通信系统进程堆栈深度分析的方法研究0x526d940 +0x014: st w r0,0x 2c (r1)//4:保存返回地址到堆栈中0x526d944 +0x018: or r31,r1,r1 //把r1赋给r31,使用r31对堆栈进行寻址0x526d948 +0x01c: sth r3,0x8(r31)0x526d94c +0x020: sth r4,0xa (r31)0x526d950 +0x024: st w r5,0x c (r31)0x526d954 +0x028: st w r6,0x 10(r31)//5:保存传入的函数参数到堆栈中以上斜体部分的代码是函数的宣言部分,由编译器自动生成.T_P_S_SE R _SAP 3p t V a r;pt Var =stati c _cast <T_P_S_SER_S AP 3>(pVarP );0x526d958 +0x 02c:l w z r0,0x 10(r31)0x526d95c +0x030:st w r0,0x 14(r31)//此处可以看到局部变量pt Va r 在堆栈中的位置s w itch(wState)0x526d960 +0x 034:lhz r9,0x8(r31)由此,可以绘出函数的堆栈帧的具体情况(如图1所示).通过函数宣言的5个步骤完成了一个函数压栈的基本操作.PPC 处理器提供32个用户寄存器r 0~r 31,G NU 编译器使用寄存器的基本规则是:寄存器r 1作为堆栈指针SP;寄存器r3~r 11用于函数参数的传递;寄存器r13~r 31根据代码的具体情况进行使用[1].由于函数的不同,G NU 编译器产生的代码也不同,从而使压栈操作的第3步和第5步有所不同,压入的寄存器个数不同,但是不影响堆栈帧的基本结构.因此,当一个函数func1调用另一个函数func2时会形成如图2所示的堆栈帧.2 计算运行期时应用进程堆栈使用深度的方法由堆栈帧结构可以获得一些检测应用进程堆栈使用深度的方法,通过堆栈指针r1的不同使用情况判断出堆栈的使用深度.本文主要进行了个体累加法和总体测试法这两种方法的尝试.211 个体累加法1)功能描述这种方法的基本思想是对进程中每层调用的函数的局部堆栈进行累积,从而得到进程堆栈最大使用深度[]由于每次函数调用后堆栈指针发生变化,那么可以认为的变化量′就是函数的局部堆栈使用深度的大小宏UDG STK ()实现计算进程最大堆栈使用深度的功能通过这种方法还可以知道进程中哪些函数使用堆栈过大,针对这些函数可以进一步分析和优化7532.r1r1r1-r 1.J E ..集美大学学报(自然科学版)第12卷2)实现流程a .定义全局变量ty pedef struct tag T_StkChk { WORD32d w B aseSP; //进程堆栈基值WORD32d w MaxStk Dp t ; //进程最大堆栈深度WORD32d wCurStk Dp t ; //进程当前堆栈深度WORD32d wStkS i ze; //进程预设的堆栈大小}T _StkChk;T_St kChk t StkChk ={0,0,0,40960};b .定义如下宏#define GET BASESP ()__as m __("st w 1,%0":"=m "(tStk Chk 1d w B aseSP ));//得到进程的堆栈基值#define J UDGESTK()__a s m __("st w 1,%0":"=m "(tStk Chk 1d wCurStk Dp t));//得到当前函数堆栈的r1tSt kChk 1dwCurStk Dp t =tStkChk 1d w B aseSP -tStkChk 1d wCurStk Dp t ;//计算进程当前的堆栈深度if (tStk Chk 1d wCurStk Dp t >t StkChk 1dw M axSt kDp t )//是否大于进程最大堆栈深度tSt kChk 1dw M axStk Dp t =tStkChk 1d wCurStk Dpt;//如果是赋值给最大深度OSS_ASSERT (tStk Chk 1d w MaxStk Dp t <t StkChk 1d wStkSize );//断言最大深度小于预期的深度c .定义全局函数VO I D PrintStk ()//用于打印进程最大堆栈的使用深度{OSS_Printf (PRT_SER _S AP,"\r \n M axSk Dp t =0x%4x!",StkChk 1d w MaxStk Dpt);}d .使用方法在进程的入口处使用宏GET BASESP ()得到进程堆栈的基值.exte rn "C "V O I D P_S_SER _S APEntry (WORD16wState,WORD16wSigl,VO I D 3pSiglPa ra,VO I D 3pVa rP ){ T_P_S_SER_S AP 3p t Var;pt Va r =static_ca st <T_P _S_SER _S AP 3>(pVarP);GET BASESP ();}在进程的每个函数的入口处使用宏JUDGESTK ()检测进程堆栈使用深度.VO I D CS APAppCB::P rocessEvent (WORD16wSi gl,const VO I D 3pSiglPa ra ){ JU D G ESTK();}212 总体测试法1)功能描述这种方法是把进程的堆栈分配到一块静态分配的内存上,该块内存已经初始化为0.调用函数ChkStk ()检查内存时只要找到第一个不为0的地方,就可得到进程堆栈深度.这种方法的优点在于实时地反映进程的堆栈使用深度.2)实现流程a .定义全局变量定义的数组大小是堆栈的大小加上16作为保护;PPC 的堆栈是向低的地址增长的;PPC 是4字节对齐的,地址一定要是4的倍数,因此取数组的下标要注意.定义全局数组作为进程的堆栈:B Y TE g_ucStk [4096+16];B Y TE 3g_pucStk;WORD32d wStkPoint ;g_pucStk =&g_ucStk[4092].b .定义宏#f R LS ()____(",%""="(S ));____("z ,%""="(_S ));用于替换系统的堆栈到自己分配的内存上#f R STS ()____("z ,%""="(S ));用于恢复堆栈指针853de ine EP P as m st w 10:m dw tkPo i nt a s m l w 10:m g puc tk //de ine E P as m l w 10:m d w t kPoint // 第3期贺冰琰:基于Po werPC 的移动通信系统进程堆栈深度分析的方法研究c .定义全局函数VO I D ChkStk (){ WORD32d w Lp;for (dw Lp =0;d wLp <MAX_STK_S IZ E;d w Lp ++){ if (0==g_ucStk [d w Lp ]){ OSS_Printf (PRT_SE R _S AP,"\r \n M axSk Dpt =0x%4x !",MAX_STK_SIZE -d w Lp +1);break;}}}d .使用方法进程入口处使用宏R EP LSP ()替换堆栈区;在进程中每个OSS_Set NextState ()使用宏RE 2STSP ()恢复SP;在Shell 中使用函数ChkStk ()得到结果.3 两种方法的应用举例在应用子系统里每个应用进程实际就是一个大的函数,P_S_SendMsg()是一个发送消息进程,采用个体累加法来获取P_S_Send M sg ()进程的最大堆栈使用深度.首先在P_S_SendMsg ()进程的入口处调用GETBASESP (),然后在P_S_Send M sg ()中的每个函数入口处都添加宏JU D G ESTK ().如果P_S_Send M sg ()有100个函数,需要在这100个函数的入口处添加宏JUDGESTK (),最后在Shell 中使用函数PrintStk ()得到结果.如果子系统功能复杂,进程中函数众多,使用该方法则相对麻烦.采用总体测试法来获取P_S_Send M sg ()进程的实时堆栈使用深度,根据前面介绍的使用方法在P_S_Send M sg()增加代码,首先在进程入口处添加REPLSP (),然后在P_S_Send M sg ()中的每个OSS_Set NextState ()函数入口处都添加宏RESTSP (),最后在Shell 中使用函数C hkStk ()得到结果.显然总体测试法比较简单.本文提出的两种方法都已经经过实际的应用测试,可以准确地反馈运行期时进程的堆栈使用深度,对程序代码的优化和堆栈的合理使用具有一定的借鉴意义.[参考文献][1]MOT ORO LA I N C 1Upc860Powe rcem icc use r πs manual [E B /OL ].[2005201210].http://w w w 1free scale 1co m /doc /ref_m anual/MPC860u m 1pdf .[2]SE AN M B E ATT Y .嵌入式软件设计中查找缺陷的几个技巧[E B /OL ].[2004205216].htt p://w w w .ee tchina .co m /ART_8800336240_617693_dea37411200405.HT M.S tudy of Stack D epth Ca lcul a ti on for the P r ocess i n theM ob ile C o mm un i ca ti on Syste m Ba sed on Power PCHE B ing 2yan(Sch ool of Co mputer Engi neering,Ji me i Univ e rsity,Xiamen 361021,China)Abstra ct:T wo m ethods of stack depth calcula tion about the r unning ti m e app licati on pr ocess in the mo 2bile c ommunication syste m ba sed on e m bedded PowerPC p r oce ss or were intr oduced .O ne was “individual cu 2m ulati on ”,the otherwas “collectivity test ”.The basic p rinci p les and code realizati on of the t w om ethodswas yK y ;G NU ;y;y ;(责任编辑 朱雪莲)953intr oduced mainl.e wor ds:Po werPC co mp iler v ertica l hie r a r ch mobile co mmunicati on s ste m stack。
Powerpc构架系统内核和内核模块调试.

Powerpc构架系统内核和内核模块调试Powerpc构架系统内核和内核模块调试类别:嵌入式系统作者:易松华,华清远见嵌入式学院深圳中心讲师。
说明:此文档的目标系统为freescale MPC8349E-mITX,对其他采用POWERPC,MIPS,ARM的芯片的系统亦具有参考意义。
此文档中内核调试为了简化,采用目标系统中的UBOOT初始化目标板,并通过UBOOT或者BDI2000加载内核到目标板的RAM中。
1.BDI2000配置:下面是MPC8349E-mITX的BDI2000配置文件,; BDI-2000 Configuration file for the MPC8349E-mITX ; Tip: If after a reset, the BDI-2000 fails to halt at 0x100, ; you may need to power-down the board for a few seconds. [INIT] ; we use UBOOT to initialize the board [TARGET] CPUTYPE 8349 JTAGCLOCK 1 ;STARTUP RESET STARTUP RUN BREAKMODE HARD STEPMODE HWBP BOOTADDR 0x00000100 ;If you're getting "Writing to workspace failed" errors during flash operations, ;then try uncommenting this line instead. This moves the FLASH windowto ;high memory, leaving low memory available for DDR. RCW0xb060a000 0x04040000 ;Set the HRCW to boot the image at 0xFE000000 MMU XLAT ;0xc0000000 PTBASE 0xf0 ; [HOST] IP 192.168.7.90 FILE $u-boot.bin LOAD MANUAL PROMPT 8349E-mITX-GP> DUMPitx-dump.bin [Flash] CHIPTYPE AM29BX16 CHIPSIZE 0x800000 BUSWIDTH 16 ;WORKSPACE 0x1000 FORMAT BIN0xfe000000 ;flash_image.bin is an image file of an entire 8MBflash region. ;Flash this file at 0xfe0000000 to restore all of flash. ;ERASE 0xFE000000 0x10000 127 ; 127 sectors @ 64KBeach ;ERASE 0xFE7F0000 0x2000 8 ; 8 sectors @ 8KB each ;FILE $flash_image.bin ;Use these lines if you just want to flash U-Boot ERASE 0xfe000000 0x10000? 4; Erase 384KB, each sector is64KB FILE? mpc8349e/u-boot131-mitx-gp.bin [REGS] FILE $reg8349e.def 以上配置文件的【HOST】段的IP要改为主机IP,关键的字段MMU XLAT 和PTBASE 是POWERPC和MIPS经常需要设置的,关于PTBASE的具体设置,超出本文范围,详细情况请参考BDI2000的手册 2.内核修改和配置为了能够调试内核,需要在内核中的Makefile中增加如下调试选项:CFLAGS 增加C代码调试选项-g –ggdb AFLAGS 增加汇编代码调试选项:-Wa,-L -gdwarf-2 去掉CFLAGS编译选项中-fomit-frame-pointer GCC的-fomit-frame-pointer选项是优化函数栈回溯(stack backtrace)的,我们调试的时候需要提供函数回溯能力,所以我们要去掉这个选项,当然,有的系统系统不受它的影响,或者说它不起作用,为了统一,我们统一去掉它。
PowerPC简介及编程要点

PowerPC简介及编程一,PowerPC芯片PowerPC是早期Motorola和IBM联合为Apple的MAC机开发的CPU芯片,商标权同时属于IBM和Motorola,并成为他们的主导成品.IBM主要的PowerPC产品有PowerPC604s(深蓝内部的CPU),PowerPC750,PowerPCG3(1.1GHz).Motorola主要有MC和MPC系列.尽管他们产品不一样,但都采用PowerPC的内核.这些产品大都用在嵌入式系统中.Motorola的MPC860简介MPC860 PowerQUICC (Quad Integrated Communications Controller) 内部集成了微处理器和一些控制领域的常用外围组件, 特别适用于通信产品. 包括器件的适应性, 扩展能力和集成度等. MPC860 PowerQUICC集成了两个处理块.一个处理块是嵌入的PowerPC核, 另一个是通信处理模块( CPM, Communications Processor Module), 通信处理模块支持四个串行通信控制器(SCC, Serial Communication Controller), 实际上它有八个串行通道: 四个SCC,两个串行管理控制器(SMC, Serial Management Channels), 一个串行外围接口电路( SPI, Serial Peripheral Interface ) 和一个I2C( Inter-Integrated Circuit ) 接口. 由于CPM分担了嵌入式PowerPC核的外围工作任务, 这种双处理器体系结构功耗要低于传统的体系结构的处理器.单出口, 嵌入式PowerPC核32比特版本(与PowerPC结构定义完全兼容)32x32位通用寄存器(GPRs, General Purpose Registers)o4K数据Cache和4K指令Cache, 分别带有一个MMU.o存储管理单元(MMU)32-输入翻译后备缓冲器( TLBs )o32位数据,地址线∙存储控制器(八个存储体)o单线存储模块无逢接口,静态随即存取存储器(RAM), EPROM, FLASH MEMORY或DRAM等。
power pc指令类型特点

power pc指令类型特点
PowerPC(PPC)是一种RISC(精简指令集计算机)架构,其指令集具有一些特点,包括以下内容:
1.精简指令集:PowerPC采用了精简指令集(RISC)的设计原则,其指令集相对较小且精简。
这有助于提高指令执行速度和简化处理器的设计。
2.固定长度指令:PowerPC的指令长度通常是固定的,这使得指令的解码和执行更加高效。
指令通常是32位长,但也有64位版本。
3.多寄存器操作:PowerPC支持多寄存器操作,允许在一条指令中同时对多个寄存器执行操作。
这提高了并行性和性能。
4.延迟槽:PowerPC采用了延迟槽的设计,允许在分支指令之后执行前一个指令。
这可以提高分支指令的效率。
5.浮点运算支持:PowerPC架构具有强大的浮点运算支持,包括一组浮点寄存器和一套浮点指令。
6.立即数操作:PowerPC允许立即数操作,即在指令中直接指定常数值,而不需要从内存中加载。
7.负载/存储架构:PowerPC采用了典型的负载/存储架构,即大部分操作都是在寄存器之间进行,而内存访问需要专门的负载(Load)和存储(Store)指令。
8.大端序和小端序:PowerPC支持两种字节序,即大端序和小端序,这允许在不同体系结构之间进行数据交换。
这些特点使PowerPC成为一种高性能和灵活的架构,广泛用于多种应用领域,包括个人计算机、服务器、嵌入式系统和超级计算机。
不过,需要注意的是,随着时间的推移,一些基于PowerPC架构的产品逐渐被其他架构所取代。
IBM PowerPC 汇编简介

IBM PowerPC 汇编简介/developerworks/cn/linux/hardware/ppc/assembly/#resourcesHollis Blanchard (hollis@), 软件开发人员, IBM简介:目前汇编语言在编程领域并未广为人知,而 PowerPC 汇编更是异乎寻常的陌生。
Hollis Blanchard 从 PowerPC 的角度对汇编语言作了概述并对比了三种体系结构 ia32、ppc 和 ppc64 的示例。
标记本文!发布日期: 2004 年 3 月 09 日通常,高级语言都具有向程序员隐藏许多普通的和重复性细节这一非常好的优点,这样程序员就可以专注于他们的目标。
然而,有时程序员必须使用较低级语言,例如当编写直接处理硬件的代码或编写对性能极其敏感的代码的时候。
汇编语言是最接近硬件的编程语言,这就很自然使它成为上述那些情况下最终使用的一种语言。
本文假设您对计算机设计(例如,您应该知道处理器中有寄存器并能访问内存)和操作系统(系统调用、异常和进程堆栈)有基本了解。
本文对于不熟悉汇编的 PowerPC 程序员以及已知道 ia32 汇编并想扩展眼界的程序员都很有用。
PowerPC 简介PowerPC 体系结构规范(PowerPC Architecture Specification)发布于 1993 年,它是一个 64 位规范 ( 也包含 32 位子集 )。
几乎所有常规可用的 PowerPC(除了新型号 IBM RS/6000 和所有 IBM pSeries 高端服务器)都是 32 位的。
PowerPC 处理器有广泛的实现范围,包括从诸如 Power4 那样的高端服务器 CPU 到嵌入式CPU 市场(任天堂 Gamecube 使用了 PowerPC)。
PowerPC 处理器有非常强的嵌入式表现,因为它具有优异的性能、较低的能量损耗以及较低的散热量。
除了象串行和以太网控制器那样的集成 I/O,该嵌入式处理器与“台式机”CPU 存在非常显著的区别。
32位PowerPC经常使用指令集总结

32位PowerPC常用指令集总结第一部分PowerPC 精简指令集计算机(RISC)简介PowerPC 体系结构是一种精减指令集计算机(Reduced Instruction Set Computer,RISC)体系结构,定义了200 多条指令。
PowerPC 之所以是RISC,原因在于大部分指令在一个单一的周期内执行,而且通常只执行一个单一的操作(比如将内存加载到寄存器,或者将寄存器数据存储到内存)。
PowerPC 体系结构分为三个级别(或者说是“book”)。
通过对体系结构以这种方式进行划分,为实现可以选择价格/性能比平衡的复杂性级别留出了空间,同时还保持了实现间的代码兼容性。
Book I. 用户指令集体系结构(Power ISA User Instruction Set Architecture)定义了通用于所有PowerPC 实现的用户指令和寄存器的基本集合。
这些是非特权指令,为大多数程序所用。
Book II. 虚拟环境体系结构(Power ISA Virtual Environment Architecture)定义了常规应用软件要求之外的附加的用户级功能,比如高速缓存管理、原子操作和用户级计时器支持。
虽然这些操作也是非特权的,但是程序通常还是通过操作系统调用来访问这些函数。
Book III. 操作环境体系结构(Power ISA Operating Environment Architecture)定义了操作系统级需要和使用的操作。
其中包括用于内存管理、异常向量处理、特权寄存器访问、特权计时器访问的函数。
Book III 中详细说明了对各种系统服务和功能的直接硬件支持。
由于我目前手上的开发板是基于e600内核,所以我在学习PowerPC指令集的过程中,顺便总结了e600内核常用的指令集,如果大家发现我总结的指令集有错误或者不准确的地方,欢迎留言指出来,O(∩_∩)O~第二部分e600指令集飞思卡尔的e600内核实现了booke内核构架中64位指令集的中的32位指令(即在e600的32位寄存器中,第0位相当于booke中的64寄存器的第32位,第31位相当于booke中64寄存器的第63位),E600内核采用大端编码方式,指令的第0位是MSB(Most Significant Bit)位,第31位是LSB(Least Significant Bit)。
PowerPC汇编指令集简析
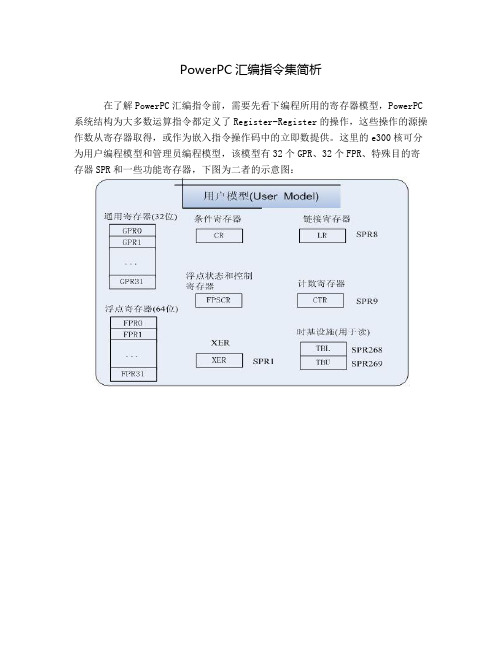
PowerPC汇编指令集简析在了解PowerPC汇编指令前,需要先看下编程所用的寄存器模型,PowerPC 系统结构为大多数运算指令都定义了Register-Register的操作,这些操作的源操作数从寄存器取得,或作为嵌入指令操作码中的立即数提供。
这里的e300核可分为用户编程模型和管理员编程模型,该模型有32个GPR、32个FPR、特殊目的寄存器SPR和一些功能寄存器,下图为二者的示意图:上面这些寄存器可能不太好理解,因为名字和Intel汇编不一样,其实,可以这样理解,GPR就相当于EAX/EBX/ECX,而CTR则完全就是ECX的功能,是吧?区别就是没有堆栈而已咯。
CR被分为8段,每段4位,分别代表LT、GT、EQ和SO(小于、大于、等于和溢出);LR用于记录跳转地址;特殊寄存器XER用于记录溢出和进位标志;FPSCR用于记录浮点运算类型和异常等。
再看下指令集,大部分的CPU指令集可分为:数据读写、数值计算、流程控制和设备管理四个部分,由于PowerPC使用RISC,指令字长为32bit,Endian一般是可调的,默认为大端,另外,PowerPC没有栈,所以程序需要自己实现相关操作。
首先为运算和逻辑指令,列举如下:它们与通用寄存器有关,源数据来自GPR 或16 位立即数,目的是GPR 寄存器,操作为32 位,GPR 中存放32 位更新数据。
大多数指令都可以根据字面意思理解其作用,注意还有一个“cntlzw”指令,意为计算字中的第一个0,用于在一个字中找到1时将一个指令中的0的数量找出,它在决定例外寄存器中最高优先服务时有用。
下面是数据读写指令,它们对数据在存储器中核通用寄存器中的传送很有用,若数据小于传送长度(单字,半字或字节),指令会使数据变位为32位,将不同位填0或符号扩展。
指令列举如下:这里需要注意的是上面列举的lbz和lhz两个指令并不完全等同于moval,[ebx]和mov ax,[ebx+10]这两个,因为前面两个是将字节和半字加载到r3时还清空了高位,而后两条指令只是加载数据到eax,并不会清空高位。
32位PowerPC常用指令集总结材料

32位PowerPC常用指令集总结第一部分PowerPC 精简指令集计算机(RISC)简介PowerPC 体系结构是一种精减指令集计算机(Reduced Instruction Set Computer,RISC)体系结构,定义了200 多条指令。
PowerPC 之所以是RISC,原因在于大部分指令在一个单一的周期内执行,而且通常只执行一个单一的操作(比如将内存加载到寄存器,或者将寄存器数据存储到内存)。
PowerPC 体系结构分为三个级别(或者说是“book”)。
通过对体系结构以这种方式进行划分,为实现可以选择价格/性能比平衡的复杂性级别留出了空间,同时还保持了实现间的代码兼容性。
Book I. 用户指令集体系结构(Power ISA User Instruction Set Architecture)定义了通用于所有PowerPC 实现的用户指令和寄存器的基本集合。
这些是非特权指令,为大多数程序所用。
Book II. 虚拟环境体系结构(Power ISA Virtual Environment Architecture)定义了常规应用软件要求之外的附加的用户级功能,比如高速缓存管理、原子操作和用户级计时器支持。
虽然这些操作也是非特权的,但是程序通常还是通过操作系统调用来访问这些函数。
Book III. 操作环境体系结构(Power ISA Operating Environment Architecture)定义了操作系统级需要和使用的操作。
其中包括用于内存管理、异常向量处理、特权寄存器访问、特权计时器访问的函数。
Book III 中详细说明了对各种系统服务和功能的直接硬件支持。
由于我目前手上的开发板是基于e600内核,所以我在学习PowerPC指令集的过程中,顺便总结了e600内核常用的指令集,如果大家发现我总结的指令集有错误或者不准确的地方,欢迎留言指出来,O(∩_∩)O~第二部分e600指令集飞思卡尔的e600内核实现了booke内核构架中64位指令集的中的32位指令(即在e600的32位寄存器中,第0位相当于booke中的64寄存器的第32位,第31位相当于booke中64寄存器的第63位),E600内核采用大端编码方式,指令的第0位是MSB(Most Significant Bit)位,第31位是LSB(Least Significant Bit)。
栈和栈帧

第二,它定义了被调用者如何使用它自己的stack frame 来完成局部变量的存储和使用。
2. 压栈和出栈在RISC 计算机中主要参与计算的是寄存器,saved registers 就是指在进入一个函数后,如果某个保存原函数信息的寄存器会在当前函数中被使用,就应该将此寄存器保存到堆栈上,当函数返回时恢复此寄存器值。
而且由于RISC 计算机大部分采用定长指令或者定变长指令,一般指令长度不会超过32个位。
而现代计算机的内存地址范围已经扩展到32 位甚至64位,这样在一条指令里就不足以包含有效的内存地址,所以RISC计算机一般借助于一个返回地址寄存器RA(return address) 来实现函数的返回。
几乎在每个函数调用中都会使用到这个寄存器,所以在很多情况下RA 寄存器会被保存在堆栈上以避免被后面的函数调用修改,当函数需要返回时,从堆栈上取回RA 然后跳转。
移动SP 和保存寄存器的动作一般处在函数的开头,这个压栈过程也叫做function prologue;恢复这些寄存器状态的动作一般放在函数的最后,出栈过程也叫做function epilogue。
压栈出栈指令各个CPU也不相同。
Stack Frame 中所存放的内容和存放顺序,则由目标体系架构的调用约定(calling convention)定义。
下面,我们看看图形化的函数栈帧,以栈向下增长为例来了解几种常用CPU的stack frame 组织方式。
3. MIPS栈帧先看MIPS的栈帧布局图:此图描述的是一种典型的MIPS stack frame 组织方式。
在这张图中,sp(stack pointer)/s8(栈基址,又称fp)就是当前函数的栈指针,它指向栈顶的位置。
Callee Frame 所示即为当前函数(被调用者)的frame,Caller Frame 是当前函数的调用者的frame。
general register area根据需要保存ra、gp、s8等caller的寄存器信息,保存位置和顺序暂时没有发现明确的规律。
PowerPC_学习

Techtalk of Power PC历史1:POWERPOWER 是 Power Optimization With Enhanced RISC 的缩写,是 IBM 的很多服务器、工作站和超级计算机的主要处理器。
POWER 芯片起源于 801 CPU,是第二代RISC 处理器。
POWER 芯片在 1990 年被 RS 或 RISC System/6000 UNIX 工作站(现在称为 eServer 和 pSeries)采用,POWER 的产品有 POWER1、POWER2、POWER3,现在最高端的是 POWER4。
POWER4 处理器是目前单个芯片中性能最好的芯片。
801的设计非常简单。
但是由于所有的指令都必须在一个时钟周期内完成,因此其浮点运算和超量计算(并行处理)能力很差。
POWER 体系结构就着重于解决这个问题。
POWER 芯片采用了 100 多条指令,是非常优秀的一个 RISC 体系结构。
以下对每种 POWER 芯片简单进行一下介绍;更详细的内容请参考参考资料中的链接。
∙POWER1发布于 1990 年:每个芯片中集成了 800,000 个晶体管。
与当时其他的 RISC 处理器不同,POWER1 进行了功能划分,这为这种功能强大的芯片赋予了超量计算的能力。
它还有单独的浮点寄存器,可以适应从低端到高端的 UNIX 工作站。
最初的 POWER1 芯片实际上是在一个主板上的几个芯片;后来很快就变成一个 RSC(RISC 单一芯片),其中集成了100 多万个晶体管。
POWER1 微处理器的 RSC 实现被火星探险任务用作中央处理器,它也是后来 PowerPC 产品线的先驱。
∙POWER2发布于 1993 年,一直使用到 1998 年:每个芯片中集成了 1500 万个晶体管。
POWER2 芯片中新加了第二个浮点处理单元(FPU)和更多缓存。
PSSC 超级芯片是 POWER2 这种 8 芯片体系结构的一种单片实现,使用这种芯片配置的一个 32 节点的 IBM 深蓝超级计算机在 1997 年击败了国际象棋冠军Garry Kasparov。
“POWER”的力量——深度透视PowerPC家族

“POWER”的力量——深度透视PowerPC家族FireFOX
【期刊名称】《《微型计算机》》
【年(卷),期】2004(000)002
【摘要】PowerPC是一种高度可伸缩的RISC处理器架构,之前一直服务于超级计算机,2003年PowerPC出现许多可喜的变化。
面向下一代超级计算机的Power5处理器发布,PowerPC970为苹果选中并成为受到广泛关注的大热门,针对索尼PS3的Cell处理器设计完成,微软考虑将Xbox2转向PowerPC架构……
【总页数】6页(P107-112)
【作者】FireFOX
【作者单位】
【正文语种】中文
【中图分类】TP332
【相关文献】
1.进驻桌面:PowerPC主宰苹果电脑——深度透视PowerPC家族(二) [J], BackFIRE
2.基于PowerPC的移动通信系统进程堆栈深度分析的方法研究 [J], 贺冰琰
3."POWER"的力量--深度透视PowerPC家族 [J], FireFox
4.PowerPC家族日趋兴旺 IBM和Motolora携手奉献高档芯片 [J], Mike
Feibus;伍颖文
5.Xilinx的V5新增FXT家族,FPGA嵌入PowerPC440 [J], 迎九
因版权原因,仅展示原文概要,查看原文内容请购买。
嵌入式系统架构:RISC家族之PowerPC

嵌入式系统架构:RISC家族之PowerPCPowerPC 是一种RISC 多发射体系结构。
二十世纪九十年代,IBM(国际商用机器公司)、Apple(苹果公司)和Motorola(摩托罗拉)公司开发PowerPC 芯片成功,并制造出基于PowerPC 的多处理器计算机。
PowerPC 架构的特点是可伸缩性好、方便灵活。
第一代PowerPC 采用0.6 微米的生产工艺,晶体管的集成度达到单芯片300 万个。
Motorola 公司将PowerPC 内核设计到SOC 芯片之中,形成了Power QUICC(Quad Integrated Communications Controller),Power QUICC II 和Power QUICC III 家族的数十种型号的嵌入式通信处理器。
Motorola 的基于PowerPC 体系结构的嵌入式处理器芯片有MPC505、821、850、860、8240、8245、8260、8560 等近几十种产品,其中MPC860 是Power QUICC 系列的典型产品,MPC8260 是Power QUICC II 系列的典型产品,MPC8560 是Power QUICC III 系列的典型产品。
Power QUICC 系列微处理器一般有三个功能模块组成,嵌入式PowerPC 核(EMPCC),系统接口单元(SIU)以及通信处理器(CPM)模块,这三个模块内部总线都是32 位。
除此之外Power QUICC 中还集成了一个32 位的RISC 内核。
Power PC 核主要执行高层代码,而RISC 则处理实际通信的低层通信功能,两个处理器内核通过高达8K 字节的内部双口RAM 相互配合,共同完成MPC854 强大的通行控制和处理功能。
CPM 以RISC 控制器为核心构成,除包括一个RISC 控制器外,还包括七个串行DMA(SDMA)通道、两个串行通信控制器(SCC)、一个通用串行总线通道(USB)、两个串行管理控制器(SMC)、一个I2C 接口和一个串行外围电路(SPI),可以通过灵活的编程方式实现对Ethemet、USB、T1/E1,ATM 等的支持以及对UART,HDLC 等多种通信协议的支持。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
PowerPC栈帧分析1 .PowerPC寄存器的使用规则通用寄存器的用途:r0 在函数开始(function prologs)时使用。
r1 堆栈指针,相当于ia32架构中的esp寄存器,idapro把这个寄存器反汇编标识为sp。
r2 内容表(toc)指针,idapro把这个寄存器反汇编标识为rtoc。
系统调用时,它包含系统调用号(这个好像跟系统有关吧)。
r3 作为第一个参数和返回值。
r4-r10 函数或系统调用开始的参数。
r11 用在指针的调用和当作一些语言的环境指针。
r12 它用在异常处理和glink(动态连接器)代码。
r13 保留作为系统线程ID。
r14-r31 作为本地变量,非易失性。
专用寄存器的用途:lr 链接寄存器,它用来存放函数调用结束处的返回地址。
ctr 计数寄存器,它用来当作循环计数器,会随特定转移操作而递减。
xer 定点异常寄存器,存放整数运算操作的进位以及溢出信息。
msr 机器状态寄存器,用来配置微处理器的设定。
cr 条件寄存器,它分成8个4位字段,cr0-cr7,它反映了某个算法操作的结果并且提供条件分支的机制。
2.栈帧的使用规则PowerPC寄存器没有专用的Pop,Push指令来执行堆栈操作,所以PowerPC构架使用存储器访问指令stwu,lwzu来代替Push和Pop指令。
PowerPC处理器使用GPR1来将这个堆栈段构成一个单向链表,这个单链表的每一个数据成员,我们称之为堆栈帧(Stack Frame),每一个函数负责维护自己的堆栈帧。
PowerPC体系结构中栈的增长方向是从高地址到低地址,堆的增长方式是从低地址到搞地址,当两者相遇时就会产生溢出。
堆栈帧的格式如下:各部分名词解释:函数参数域(Function Parameter Area):这个区域的大小是可选的,即如果如果调用函数传递给被调用函数的参数少于六个时,用GPR4至GPR10这个六个寄存器就可以了,被调用函数的栈帧中就不需要这个区域;但如果传递的参数多于六个时就需要这个区域。
局部变量域(Local Variables Area):通上所示,如果临时寄存器的数量不足以提供给被调用函数的临时变量使用时,就会使用这个域。
CR寄存器:即使修改了CR寄存器的某一个段CRx(x=0至7),都有保存这个CR寄存器的内容。
通用寄存器GPR:当需要保存GPR寄存器中的一个寄存器器GPRn时,就需要把从GPRn到GPR31的值都保存到堆栈帧中。
浮点寄存器FPR:使用规则共GPR寄存器。
3. PowerPC的汇编指令和栈操作PowerPC寄存器没有专用的push和pop指令来执行堆栈操作,所以PowerPC构架使用存储器访问指令stwu、lwzu来代替push和pop指令。
4.函数执行时栈帧的建立与消亡过程函数栈的建立与消亡过程如下图所示:4.1函数栈的建立与消亡过程说明如前所属,PowerPC体系结构中栈的增长方向是从高地址到低地址,故形成过程可以概括为如下几点:1)调用函数r1指向栈顶(SP),用间接寻址方式分配一定大小栈空间;2)r31指向栈顶,以r31为基值将参数压入栈内;3)进入被调函数,跳转到被调函数的SP处;4)被调函数同样进行栈分配及参数压栈操作;5)被调函数执行完毕之后,跳转LR,返回到被调用处的下一条指令,继续后续操作(此时的SP即为调用函数的SP)4.2举例说明栈操作过程以下以一个简单的函数调用,说明PowerPC栈的操作过程。
函数例子如下:int calltest2( int a){int t1=5;int t2 = 6;int result =0;char * p =0;*p =a;}int calltest1( int a){int t1=3;int t2 = 4;int result =0;result = calltest2( t2);t1 =3;}void calltest( ){int t1=7;int t2 = 9;int result =0;result = calltest1( t1);t1 =3;}利用反汇编工具,生成汇编代码及分析如下:int calltest2( int a){Calltest2栈帧建立分析:stwu r1,-48(r1):分配48字节的栈帧,r1指向栈顶;(powerpc省略了EBP,所以一上来即进行一次间接寻址)stw r31,44(r1):保存r31的原值,以后恢复;or r31,r1,r1:让r31指向栈顶r1(r31=r1 or r31)stw r3,8(r31):第一个形参0x401d4f0 calltest2: stwu r1,-48(r1)0x401d4f4 +0x004: stw r31,44(r1)0x401d4fc +0x00c: stw r3,8(r31)局部变量赋值:li r0 5(t1,t2.result)int t1=5;0x401d500 +0x010: li r0,0x5 # 50x401d504 +0x014: stw r0,12(r31)int t2 = 6;0x401d508 +0x018: li r0,0x6 # 60x401d50c +0x01c: stw r0,16(r31)int result =0;0x401d510 +0x020: li r0,0x0 # 00x401d514 +0x024: stw r0,20(r31)char * p =0;0x401d518 +0x028: li r0,0x0 # 00x401d51c +0x02c: stw r0,24(r31)加载函数调用参数到r9*p =a;0x401d520 +0x030: lwz r9,24(r31)0x401d524 +0x034: lbz r0,11(r31)保存r9到r00x401d528 +0x038: stb r0,0(r9)}r11=r1,r31=r11-4=r1-4,恢复r31的值0x401d52c +0x03c: lwz r11,0(r1)0x401d530 +0x040: lwz r31,-4(r11)0x401d534 +0x044: or r1,r11,r11blr:跳转到LR地址,返回calltest1中调用calltest2的下一条指令地址0x401d57c的继续指向0x401d538 +0x048: blrint calltest1( int a){0x401d53c calltest1: stwu r1,-48(r1)将LR内容存入r0(存在函数调用时需要用到LR,用来存放函数调用结束处的返回地址)0x401d540 +0x004: mfspr r0,LR0x401d544 +0x008: stw r31,44(r1)0x401d548 +0x00c: stw r0,52(r1)0x401d54c +0x010: or r31,r1,r10x401d550 +0x014: stw r3,8(r31)局部变量赋值(t1,t2,result)int t1=3;0x401d558 +0x01c: stw r0,12(r31)int t2 = 4;0x401d55c +0x020: li r0,0x4 # 40x401d560 +0x024: stw r0,16(r31)int result =0;0x401d564 +0x028: li r0,0x0 # 00x401d568 +0x02c: stw r0,20(r31)函数调用result = calltest2( t2);0x401d56c +0x030: lwz r3,16(r31)0x401d570 +0x034: bl 0x401d4f0 # calltest2 0x401d574 +0x038: or r0,r3,r30x401d578 +0x03c: stw r0,20(r31)t1 =3;0x401d57c +0x040: li r0,0x3 # 30x401d580 +0x044: stw r0,12(r31)}0x401d584 +0x048: lwz r11,0(r1)0x401d588 +0x04c: lwz r0,4(r11)0x401d58c +0x050: mtspr LR,r00x401d590 +0x054: lwz r31,-4(r11)0x401d594 +0x058: or r1,r11,r11返回calltest函数的下一条指令地址0x401d5d8的继续指向0x401d598 +0x05c: blrvoid calltest( ){0x401d59c calltest: stwu r1,-48(r1)0x401d5a0 +0x004: mfspr r0,LR0x401d5a4 +0x008: stw r31,44(r1)0x401d5a8 +0x00c: stw r0,52(r1)0x401d5ac +0x010: or r31,r1,r1int t1=7;0x401d5b0 +0x014: li r0,0x7 # 70x401d5b4 +0x018: stw r0,8(r31)int t2 = 9;0x401d5b8 +0x01c: li r0,0x9 # 90x401d5bc +0x020: stw r0,12(r31)int result =0;0x401d5c0 +0x024: li r0,0x0 # 00x401d5c4 +0x028: stw r0,16(r31)调用函数calltrst1:将t1(r31+8)加载到r3中,然后跳转到calltest1地址处(0x401d53c)result = calltest1( t1);0x401d5c8 +0x02c: lwz r3,8(r31)0x401d5cc +0x030: bl 0x401d53c # calltest10x401d5d0 +0x034: or r0,r3,r3保存result返回值0x401d5d4 +0x038: stw r0,16(r31)调用完成,开始后续指令操作t1 =3;0x401d5d8 +0x03c: li r0,0x3 # 30x401d5dc +0x040: stw r0,8(r31)}0x401d5e0 +0x044: lwz r11,0(r1)0x401d5e4 +0x048: lwz r0,4(r11)0x401d5e8 +0x04c: mtspr LR,r00x401d5ec +0x050: lwz r31,-4(r11)0x401d5f0 +0x054: or r1,r11,r110x401d5f4 +0x058: blr下面利用断点调试跟踪栈内存执行过程1)在进入calltest但未执行任何指令(参数还未赋值)时,查看寄存器及内存分布如下:r0 = c7cbd8 r1/sp = a8ce6c0 r2 = 0 r3 = 0r4 = 0 r5 = 0 r6 = 0 r7 = 0r8 = 0 r9 = 0 r10 = 0 r11 = a8ce738r12 = 401d59c r13 = 0 r14 = 0 r15 = 0r16 = 0 r17 = 0 r18 = 0 r19 = 0r20 = 0 r21 = 0 r22 = 0 r23 = 0r24 = 0 r25 = 0 r26 = 0 r27 = 0r28 = 0 r29 = 0 r30 = 0 r31 = a8ce6c0msr = b030 lr = c7cbd8 ctr = 0 pc = 401d5b0cr = 0 xer = 0 mq = eeeeeeee内存空间为此时sp=0xa8ce6c0,r31指向r1,pc=0x401d5b02)执行到result=0(局部变量赋值完成,但没有调用caltest1)在紧跟SP之后,SP+8即为局部变量存储区,此时此时sp=0xa8ce6c03)再执行result=calltest(t1),跳进calltest1之后但未进行任何操作r0 = 401d5d0 r1/sp = a8ce690 r2 = 0 r3 = 7r4 = 0 r5 = 0 r6 = 0 r7 = 0r8 = 0 r9 = 0 r10 = 0 r11 = a8ce738r12 = 401d59c r13 = 0 r14 = 0 r15 = 0r16 = 0 r17 = 0 r18 = 0 r19 = 0r20 = 0 r21 = 0 r22 = 0 r23 = 0r24 = 0 r25 = 0 r26 = 0 r27 = 0r28 = 0 r29 = 0 r30 = 0 r31 = a8ce690msr = b030 lr = 401d5d0 ctr = 0 pc = 401d554cr = 0 xer = 0 mq = 0此时SP=0Xa8ce690,相对于原SP。