probit的spss处理
SPSS数据的预处理

SPSS数据的预处理SPSS是研究社会科学数据和其他统计分析领域中常用的软件之一。
在进行分析之前,我们需要进行预处理来准备我们的数据集。
数据的清理在进行数据分析之前,我们需要了解数据集中的每个变量并确保它们是正确的,并且符合我们的需要。
在数据清理过程中,我们需要进行以下操作:处理缺失值在数据集中,某些变量可能会缺乏部分值,我们需要进行缺失值处理,以便于数据的分析和处理。
填补缺失值的方法主要有以下几种:1.删除缺失值:删除含有缺失值的行或者列,但是需要注意删除的行和列如果数据量较大,可能会对后续的分析产生影响。
2.插补法:使用其他观测下的变量的平均值、中位数,众数等来填补缺失值。
在SPSS中,我们可以通过Transform->Replace Missing Values来进行缺失值的填补。
其中的缺失值可以设置被替换的数值类型,如我们可以用平均数代替缺失值,也可以用最近邻样本的替换策略等。
处理异常值当数据集中存在异常值时,需要使用删除或替换方法对其进行去除或更正。
异常值是指由于测量、数据输入或其他原因导致的不合理的数据值。
对于极端的异常数据值,删除数据可能是最好的解决方案。
在SPSS中,我们可以使用Analyze->Descriptive Statistics->Explore来寻找异常值,它会检查所有数据和变量,并给我们提供总体统计、中心趋势度量和分布度量等描述。
数据的转换在进行分析之前,我们还需要对数据进行转换来满足分析的要求。
最常见的转换包括下列几种:变量归一化某些变量或变量的值可能存在不同的测量单位,为了能够在同等条件下进行比较,需要对数据进行标准化处理。
在SPSS中,我们可以使用Transform->Recode Into Same Variables来进行数据的归一化操作。
例如,我们可以将数值变量转换为区间变量或类别变量。
变量离散化连续型数据为了进行分析常需要将其转换为类别变量。
probit模型 结构方程实证模型

probit模型结构方程实证模型摘要:一、什么是Probit 模型二、Probit 模型的应用范围三、如何在Eviews 中进行Probit 模型的估计四、Probit 模型的优点与局限性正文:一、什么是Probit 模型Probit 模型是一种用于分析二元变量(0-1 变量)的统计模型,该模型基于逻辑斯蒂函数,可以计算出某个变量成为1 的概率。
Probit 模型被广泛应用于社会科学、生物统计学、医学统计学等领域,以解决分类问题和预测问题。
二、Probit 模型的应用范围Probit 模型的应用范围非常广泛,包括以下几个方面:1.分类问题:Probit 模型可以用于对样本进行分类,例如对某一批产品进行质量分类,或者对病人进行疾病分类等。
2.预测问题:Probit 模型可以用于对未来事件进行预测,例如预测某个学生是否会被某所大学录取,或者预测某个病人是否会康复等。
3.评估问题:Probit 模型可以用于对某个方案或政策的效果进行评估,例如评估某种治疗方法对疾病的治疗效果等。
三、如何在Eviews 中进行Probit 模型的估计在Eviews 中进行Probit 模型的估计,可以通过以下几个步骤完成:1.打开Eviews 软件,导入需要分析的数据文件。
2.在Eviews 中,选择“equation”命令,进入方程命令窗口。
3.在方程命令窗口中,输入以下命令:```equation probit1.binary(dn) y c x```其中,y 表示因变量(0-1 变量),x 表示自变量,c 表示其他控制变量,dn 表示二元变量(0-1 变量)。
4.输入完命令后,按回车键,Eviews 会自动进行Probit 模型的估计。
5.估计完成后,可以查看Probit 模型的结果,包括参数估计值、标准误差、z 统计量、p 值等。
四、Probit 模型的优点与局限性Probit 模型的优点包括:1.可以解决二元变量的分类和预测问题。
probit模型原理

probit模型原理Probit模型是一种常用的概率模型,主要用于处理分类问题。
其原理是利用正态分布的累积分布函数(CDF)将线性预测变量与响应变量联系起来。
本文将详细阐述Probit模型的原理。
1.引言Probit模型与Logistic回归模型有很多相似之处。
它们都是常见的二分类模型,都是基于概率建模。
不过,两个模型采用的概率分布不同。
Logistic回归模型采用的是Sigmoid函数,而Probit模型采用的是正态分布的累积分布函数。
Sigmoid函数是一种S 形函数,它将线性预测变量映射到[0,1]的区间内,表示分类概率。
Probit模型主要应用于金融、医学、社会学等领域。
Probit模型可以用于预测客户是否会违约、病人是否会复发以及某项政策是否会受到反对等问题。
掌握Probit模型的原理对于数据科学家而言是非常重要的。
2.1 Probit函数在介绍Probit模型之前,我们先来了解一下Probit函数的概念。
Probit函数是指正态分布的累积分布函数(CDF),它的函数表达式如下:$ Φ(x)= \int_{-∞}^{x} \frac{1}{√2π} e^ \frac{-t^2}{2} dt $x为正态分布的随机变量值,而Φ(x)则是x之前所有可能取值的概率,符号“Φ”是表示累积分布函数的习惯记法。
- 值域在[0,1]之间,其斜率在均数处最大(或最小),从而找到方程的封锁点。
- 密度函数在均值处取得最大值。
- 累积分布函数关于均值对称。
- 均值和标准差可以反向计算。
Probit函数在模型分析中扮演了重要的角色。
Probit模型将一个或多个线性预测变量(x1,x2,…,xp)与二元响应变量y之间建立联系。
模型的假设是,当$x_1,x_2,…,x_p$的线性组合越大,binary 响应变量y的概率也越大。
为了将线性关系转换为概率,Probit模型使用了正态分布的累积分布函数,如下所示:$Φ(\beta_0+∑_{i=1}^{p} x_i\beta_i)$β0为截距,βi为系数,x i为第 i 个预测变量,Φ为 Probit函数。
SPSS分析调查问卷数据的方法

SPSS分析调查问卷数据的方法当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以p为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Sp处理:第一步:定义变量我们知道在p中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段()以上为问卷中常见的单项选择题型的变量设置,下面将对一些特殊情况的变量设置也作一下说明.1.开放式题型的设置:诸如你所在的省份是_____这样的填空题即为开放题,设置这些变量的时候只需要将Value、Miing两项不设置即可.2.多选题的变量设置:这类题型的设置有两种方法即多重二分法和多重分类法,在这里我们只对多重二分法进行介绍.这种方法的基本思想是把该题每一个选项设置成一个变量,然后将每一个选项拆分为两个选项项,即选中该项和不选中该项.现在举例来说明在p中的具体操作.比如如下一例:请问您通常获取新闻的方式有哪些()1报纸2杂志3电视4收音机5网络在p中设置变量时可为此题设置五个变量,假如此题为问卷第三题,那么变量名分别为3_1、3_2、3_3、3_4、3_5,然后每一个选项有两个选项选中和不选中,只需在Value一项中为每一个变量设置成1=选中此项、0=不选中此项即可.使用该窗口,我们可以把一个问卷中的所有问题作为变量在这个窗口中一次定义。
第二步:数据录入Sp数据录入有很多方式,大致有一下几种:1.读取SPSS格式的数据2.读取E某cel等格式的数据3.读取文本数据(Fi某ed和Delimiter)4.读取数据库格式数据(分如下两步)(1)配置ODBC(2)在SPSS中通过ODBC和数据库进行但是对于问卷的数据录入其实很简单,只要在p的数据录入窗口中直接输入就可以了,只是在这里有几点注意的事项需要说明一下.1.在数据录入窗口,我们可以看到有一个表格,这个表格中的每一行代表一份问卷,我们也称为一个个案.在数据录入完成后,我们要做的就是我们的关键部分,即问卷的统计分析了,因为这时我们已经把问卷中的数据录入我们的软件中了.第三步:统计分析有了数据,可以利用SPSS的各种分析方法进行分析,但选择何种统计分析方法,即调用哪个统计分析过程,是得到正确分析结果的关键。
SPSS详细操作:广义估计方程

SPSS详细操作:广义估计方程SPSS详细操作:广义估计方程2017-03-18 17:40一、问题与数据在临床研究中,经常会比较两种治疗方式对患者结局的影响,并且多次测量结局。
例如,为了研究两种降压药物对血压的控制效果是否存在差异,研究者会对两个人群服药后在不同时间点记录血压值,然后评价降压效果。
或者对两组动物分别施加两种干预,连续记录多个时间点的结局,然后比较两种干预的效果。
这种设计可以用如下示意图表示:另外,有时研究只需要收集一个时间点的数据,但是一个研究对象会提供多个部位的数据点。
例如,研究者想评价冠心病患者在冠脉搭桥术后应用阿司匹林是否可以有效降低患者血管的再堵塞,评价的方法是术后1年做冠脉造影观察血管是否堵塞,但是每个患者可能会在同一次手术中对多条冠状动脉血管进行搭桥,因此有的患者可能会贡献多组数据。
这种设计可以用如下示意图表示:以上两种设计,不管是临床试验还是动物试验都非常常见,它的特点在于数据间非独立,同一个体间数据具有相关性。
对于这样的设计类型,该如何分析呢?今天我们来介绍另外一种非常好的方法——广义估计方程(GEE)。
GEE既可以处理连续型结局变量也可以处理分类型结局变量,它实际上代表了一种模型类别,即在传统模型的基础上对相关性数据进行了校正,可以拟合Logistic回归、泊松回归、Probit回归、一般线性回归等广义线性模型。
本文将以阿司匹林预防冠脉搭桥后血管再堵塞为例介绍运用SPSS进行GEE的操作方法。
以下为数据格式:表1. 数据格式每名患者贡献数据量不等。
如编号为1的患者只对一根血管进行了搭桥手术,编号为2的患者则有两根血管进行搭桥手术。
表2. 变量赋值(注:本例中数据纯属虚构,分析结果不能产生任何结论。
性别为待调整变量。
)二、SPSS分析方法1. 数据录入SPSS首先在SPSS变量视图(Variable View)中新建上述表2中变量,然后在数据视图(Data View)中录入数据。
SPSS详细操作:广义估计方程
SPSS详细操作:广义估计方程SPSS详细操作:广义估计方程2017-03-18 17:40一、问题与数据在临床研究中,经常会比较两种治疗方式对患者结局的影响,并且多次测量结局。
例如,为了研究两种降压药物对血压的控制效果是否存在差异,研究者会对两个人群服药后在不同时间点记录血压值,然后评价降压效果。
或者对两组动物分别施加两种干预,连续记录多个时间点的结局,然后比较两种干预的效果。
这种设计可以用如下示意图表示:另外,有时研究只需要收集一个时间点的数据,但是一个研究对象会提供多个部位的数据点。
例如,研究者想评价冠心病患者在冠脉搭桥术后应用阿司匹林是否可以有效降低患者血管的再堵塞,评价的方法是术后1年做冠脉造影观察血管是否堵塞,但是每个患者可能会在同一次手术中对多条冠状动脉血管进行搭桥,因此有的患者可能会贡献多组数据。
这种设计可以用如下示意图表示:以上两种设计,不管是临床试验还是动物试验都非常常见,它的特点在于数据间非独立,同一个体间数据具有相关性。
对于这样的设计类型,该如何分析呢?今天我们来介绍另外一种非常好的方法——广义估计方程(GEE)。
GEE既可以处理连续型结局变量也可以处理分类型结局变量,它实际上代表了一种模型类别,即在传统模型的基础上对相关性数据进行了校正,可以拟合Logistic回归、泊松回归、Probit回归、一般线性回归等广义线性模型。
本文将以阿司匹林预防冠脉搭桥后血管再堵塞为例介绍运用SPSS进行GEE的操作方法。
以下为数据格式:表1. 数据格式每名患者贡献数据量不等。
如编号为1的患者只对一根血管进行了搭桥手术,编号为2的患者则有两根血管进行搭桥手术。
表2. 变量赋值(注:本例中数据纯属虚构,分析结果不能产生任何结论。
性别为待调整变量。
)二、SPSS分析方法1. 数据录入SPSS首先在SPSS变量视图(Variable View)中新建上述表2中变量,然后在数据视图(Data View)中录入数据。
SPSS常用分析方法操作步骤

SPSS常用分析方法操作步骤SPSS是一款常用的统计分析软件,可以用于数据处理、数据分析、数据可视化等任务。
下面将介绍SPSS常用的分析方法及其操作步骤。
一、描述性统计1.打开SPSS软件,在菜单栏选择“统计”-“概要统计”-“描述性统计”。
2.将需要进行描述性统计的变量拉入“变量”框中,点击“统计”按钮选择需要计算的统计量,例如均值、中位数、标准差等。
3.点击“图表”按钮可以选择绘制直方图、箱线图等图表形式。
确定参数后点击“OK”按钮,即可得到描述性统计结果。
二、相关分析1.打开SPSS软件,在菜单栏选择“分析”-“相关”-“双变量”。
2.将需要进行相关分析的变量拉入“变量1”和“变量2”框中,点击“OK”按钮即可得到相关系数。
3.如果需要进行多变量相关分析,可以选择“分析”-“相关”-“多变量”来进行操作。
三、T检验1.打开SPSS软件,在菜单栏选择“分析”-“比较手段”-“独立样本T检验”或“相关样本T检验”。
2.将需要进行T检验的变量拉入“因子”框中,点击“OK”按钮即可得到T检验结果。
四、方差分析1.打开SPSS软件,在菜单栏选择“分析”-“一般线性模型”-“一元方差分析”。
2.将需要进行方差分析的因变量拉入“因变量”框中,将因子变量拉入“因子”框中,点击“OK”按钮即可得到方差分析结果。
3.如果需要进行多因素方差分析,可以选择“分析”-“一般线性模型”-“多元方差分析”来进行操作。
五、回归分析1.打开SPSS软件,在菜单栏选择“回归”-“线性”。
2.将需要进行回归分析的因变量和自变量拉入对应的框中,点击“统计”按钮选择需要计算的统计量,例如R平方、标准误差等。
3.如果想同时进行多个自变量的回归分析,可以选择“方法”选项卡,在“逐步回归”中进行设置。
六、聚类分析1.打开SPSS软件,在菜单栏选择“分析”-“分类”-“聚类”。
2.将需要进行聚类分析的变量拉入“加入变量”框中,点击“聚类变量”按钮选择需要进行聚类的变量。
SPSS常用分析方法操作步骤

SPSS常用分析方法操作步骤SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,它提供了多种分析方法,可以帮助用户进行数据分析和统计推断。
下面是一些SPSS常用分析方法的操作步骤,供参考。
1.描述性统计分析:- 打开SPSS软件,导入数据文件(.sav或者.csv格式)。
-菜单栏选择"分析",然后选择"描述性统计",再选择"统计"。
-在弹出的对话框中,选择要进行描述性统计分析的变量,并选择要计算的统计量(如均值、标准差、最大值、最小值等)。
-点击"确定"进行分析,结果将显示在输出窗口中。
2.T检验:-导入数据文件,选择"分析",然后选择"比较手段",再选择"独立样本T检验"(或相关样本T检验)。
-在弹出的对话框中,选择要进行T检验的自变量和因变量,并指定群组变量(如性别)。
-可以选择自定义选项,如置信水平、方差齐性检验等。
-点击"确定"进行分析,结果将显示在输出窗口中。
3.方差分析:-导入数据文件,选择"分析",然后选择"比较手段",再选择"单因素方差分析"(或多因素方差分析)。
-在弹出的对话框中,选择要进行方差分析的自变量和因变量,并指定分组变量(如教育程度)。
-可以选择自定义选项,如置信水平、效应大小等。
-点击"确定"进行分析,结果将显示在输出窗口中。
4.相关分析:-导入数据文件,选择"分析",然后选择"相关",再选择"双变量"(或多变量)。
-在弹出的对话框中,选择要进行相关分析的变量,并进行相关系数类型的选择(如皮尔逊相关系数、斯皮尔曼等级相关系数)。
SPSS分析调查问卷数据的方法

SPSS分析调查问卷数据的方法当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Spss处理:第一步:定义变量大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View, Variable View两个标签,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。
在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、l abel(变量标签) 、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类).我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段( )?A:20—29 B:30—39 C:40—49 D:50--59那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, wi dth宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。
Values用于定义具体变量值的标签,单击Value框右半部的省略号,会弹出变量值标签对话框,在第一个文本框里输入1,第二个输入20—29,然后单击添加即可.同样道理我们可做如下设置,即1=20—29、2=30—39、3=40—49、4=50--59;Missing,用于定义变量缺失值, 单击missing框右侧的省略号,会弹出缺失值对话框, 界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值”,最多可以定义3个值;最后一项为“缺失值范围加可选的一个缺失值”,在此我们不设置缺省值,所以选中第一项如图;Colo mns,定义显示列宽,可自己根据实际情况设置;Align,定义显示对齐方式,有居左、居右、居中三种方式;Measure,定义变量类型是连续、有序分类还是无序分类。
spss检验回归方程的显着性

spss检验回归方程的显着性
在回归过程中包括:Liner:线性回归,Curve Estimation:曲线估计,Binary Logistic:二分变量逻辑回归,Multinomial Logistic:多分变量逻辑回归,Ordinal序回归,Probit:概率单位回归Nonlinear:非线性回归。
1、回归分析就是探索两种及其以上变量之间的关系,运用十分广泛,按照自变量和因变量之间的函数关系类型可以分为线性回归分析和非线性回归分析。
回归分析不仅可以分析数据,更可以用来预测一些数据的发展情况,从而应用非常广泛。
2、拟合优度检验:检验样本数据聚集在样本回归直线周围的密集程度,从而判断回归方程对样本数据的代表程度。
回归方程的拟合优度检验一般用判定系数R2实现。
回归方程的显著性检验(F检验):是对因变量与所有自变量之间的线性关系是否显著的一种假设检验。
回归方程的显著性检验一般采用F检验。
3、在回归分析中,变量y称为因变量,处于被解释的特殊地位;而在相关分析中,变量y与变量x处于平等的地位。
在回归分析中,因变量y是随机变量,自变量x可以是随机变量,也可以是非随机的确定变量;而在相关分析中,变量x和变量y都是随机变量。
相关分析师测定变量之间的关系密切程度,所使用的工具是相关系数;而回归分析则是侧重于考察变量之间的数量变化规律。
利用SPSS软件计算杀虫剂的LC50
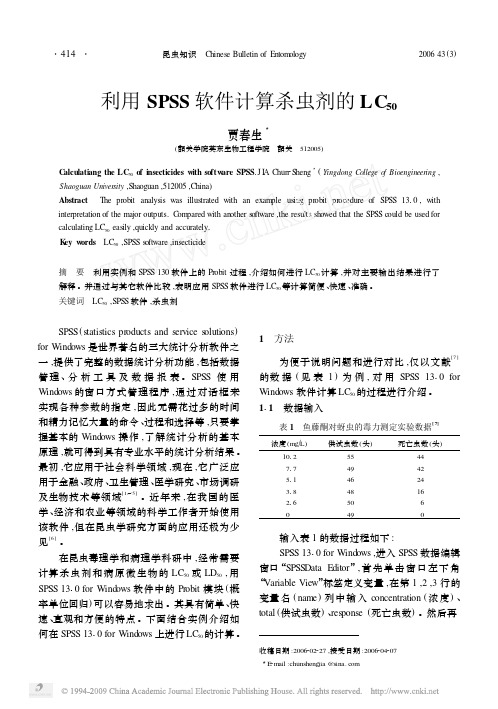
利用SPSS 软件计算杀虫剂的LC 50贾春生3(韶关学院英东生物工程学院 韶关 512005)C alculatiang the LC 50of insecticides with softw are SPSS .J I A Chun 2Sheng 3(Yingdong College o f Bioengineering ,Shaoguan Univer sity ,Shaoguan ,512005,China )Abstract The probit analysis was illustrated with an exam ple using probit procedure of SPSS 1310,with interpretation of the major outputs.C om pared with another s oftware ,the results showed that the SPSS could be used for calculating LC 50easily ,quickly and accurately.K ey w ords LC 50,SPSS s oftware ,insecticide摘 要 利用实例和SPSS 130软件上的Probit 过程,介绍如何进行LC 50计算,并对主要输出结果进行了解释。
并通过与其它软件比较,表明应用SPSS 软件进行LC 50等计算简便、快速、准确。
关键词 LC 50,SPSS 软件,杀虫剂收稿日期:2006202227,接受日期:20062042073E 2mail :chunshengjia @ SPSS (statistics products and service s olutions )for Windows 是世界著名的三大统计分析软件之一,提供了完整的数据统计分析功能,包括数据管理、分析工具及数据报表。
SPSS数据分析—Probit回归模型
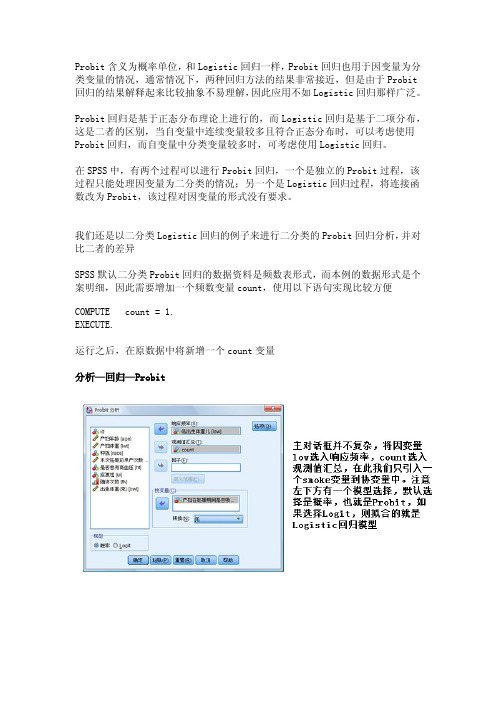
Probit含义为概率单位,和Logistic回归一样,Probit回归也用于因变量为分类变量的情况,通常情况下,两种回归方法的结果非常接近,但是由于Probit 回归的结果解释起来比较抽象不易理解,因此应用不如Logistic回归那样广泛。
Probit回归是基于正态分布理论上进行的,而Logistic回归是基于二项分布,这是二者的区别,当自变量中连续变量较多且符合正态分布时,可以考虑使用Probit回归,而自变量中分类变量较多时,可考虑使用Logistic回归。
在SPSS中,有两个过程可以进行Probit回归,一个是独立的Probit过程,该过程只能处理因变量为二分类的情况;另一个是Logistic回归过程,将连接函数改为Probit,该过程对因变量的形式没有要求。
我们还是以二分类Logistic回归的例子来进行二分类的Probit回归分析,并对比二者的差异
SPSS默认二分类Probit回归的数据资料是频数表形式,而本例的数据形式是个案明细,因此需要增加一个频数变量count,使用以下语句实现比较方便
COMPUTE count = 1.
EXECUTE.
运行之后,在原数据中将新增一个count变量
分析—回归—Probit
下面我们再看一个频数资料的Probit回归的例子
例:想通过研究某种毒素的浓度与致死量的关系,来分析这种毒素的毒性,数据
以频数表的形式组成,如下
c表示毒素浓度,total为每组的小鼠数量,dead为死亡数量分析—回归—Probit。
probit的spss处理

probit的spss处理当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Sps s处理:第一步:定义变量大多数情况下我们需要从头定义变量,在打开SP SS后,我们可以看到和excel相似的界面,在界面的左下方可以看到DataView, Va ri able Vi ew两个标签,只需单击左下方的Var iable Vie w标签就可以切换到变量定义界面开始定义新变量。
在表格上方可以看到一个变量要设置如下几项:na me(变量名)、ty pe(变量类型)、w idth(变量值的宽度)、dec imal s(小数位) 、la bel(变量标签)、Va lues(定义具体变量值的标签)、M issing(定义变量缺失值)、Col omns(定义显示列宽)、Align(定义显示对齐方式)、M easure(定义变量类型是连续、有序分类还是无序分类).我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段( )? A:20—29 B:30—39 C:40—49 D:50--59那么我们的变量设置可如下: n ame即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeri c, w idth宽度为4,d ecim als即小数位数位为0(因为答案没有小数点),labe l即变量标签为“年龄段查询”。
关于logistic回归模型以及probit模型的几点看法

1.logistic回归模型(包括有序和无序)操作:SPSS——分析——回归(若因变量只是定类数据,则选择二元logistic 或多元logistic;若因变量是定序数据,则需要选择“有序”),在出现的框框中,有因变量、因子、协变量三项。
其中,因变量即为被解释变量,因子和协变量即为解释变量,因子是分类数据,协变量是连续型变量。
注意:(1)做回归模型之前需要检验自变量之间有无多重共线性(方法就是运用因变量和自变量建立线性回归模型)具体如下:分析——回归——线性——因变量及自变量转进相应位置,之后点击“统计”,勾选“共线性诊断”,然后点击“确定”。
如果结果结果中Tolerance(容差或容忍度)小于0.1或者VIF(方差膨胀因子)大于10,或者特征根等于0,或者条件指数大于30,则表示存在共线性。
此时,再运用回归模型就不合适,需要先让共线性问题解决之后才能运用模型继续进行估计。
(2)做回归模型之前还需要做平行性检验。
(方法是分析——回归——有序——输出——勾选平行性检验,此检验的原假设为回归自变量系数相等,如果自变量系数相等则可以用有序logistic回归模型,所以最终需要接受原假设,即P大于0.05)结果分析(针对有序回归模型而言):在似然比检验中,只要P值小于0.05,就说明模型有效,反之无效在回归结果中只要P值小于0.05,同样说明,自变量对因变量的影响是显著的。
2.probit回归模型(包括有序和无序)操作:分析——回归——概率;若做的是有序probit模型,可以分析——广义线性模型——有序概率总结:SPSS做probit模型不太方便,可以用stata软件做3.联系与区别(1)联系:二者都可以应用于因变量为分类变量的情况,并且两种方法的结果比较接近。
(2)区别:probit回归是基于正态分布进行的,而logistic回归是基于二项分布。
(3)具体选择哪一种模型:当自变量中连续变量较多且符合正态分布时,可以考虑运用probit回归模型,而当自变量中分类变量较多时,可以考虑使用logistic回归模型。
probit的spss处理

probit的spss处理当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以sps s为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Spss处理:第一步:定义变量大多数情况下我们需要从头定义变量,在打开SPS S后,我们可以看到和exce l相似的界面,在界面的左下方可以看到D ataView, Variab le View两个标签,只需单击左下方的Var iabl e View标签就可以切换到变量定义界面开始定义新变量。
在表格上方可以看到一个变量要设置如下几项:n ame(变量名)、type(变量类型)、width(变量值的宽度)、decima ls(小数位) 、label(变量标签) 、Values(定义具体变量值的标签)、Missin g(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measur e(定义变量类型是连续、有序分类还是无序分类).我们知道在s p ss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段( )?A:20—29 B:30—39 C:40—49 D:50--59那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Num eric, width 宽度为4,decima ls即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。
SPSS操作指南

SPSS操作指南频数分析Analyze/第二个Descriptive S/Frequencies/(Variable变量),/Charts/Histograms层次聚类Analyze/Classify/Hiera/变量购物环境服务质量/标注个案商厦编号/Method!Within-group linkage#Euclidean distance/Statis tics 勾第一个R of s 2_3描述就是Coeffic的值很小第一组的值最小距离最近4可以代表5 K_means聚类Analyze/Classify/K_/变量,个案依据(Label Cases)省市/Number of Cluster 3/(迭代)lterate10和0/Options 前2个倒数2个判别分析Analyze/classify/Discrimmant/分组变量(Grouping Variable)录取结果Define Range1和3/Independents(),/Statistics全选/Classify Plot全选右上第二个分组左上第一个左下一数据分组单变量值分组Transform--Automatic recode--基本工资New name 什么1/最低值覆盖原数据分组(same)Transform --Recode into same/Old and new/左边Range,value through HIGHE850/Value1/Add/Range851through900/Valu e2/Add……类推不覆盖原数据分组Transform --Recode into Different/大框选变量/Name XX1/变量名/Old and new/左边Range,value through分位数分组Transform/VBinning/大框变量基本工资/Continue/第二格Binned VariableXX2/Make Cutpoints(可视化封装)/Scanned Cases点击/数量3(4段砍3刀)P67数据合并Date/Merge Files方差分析方差齐性检验Analyze/Compare means/One way ANOVA/DependentList 因变量)F(因子)Options--选Descriptive,Homogeneity of va(齐性) 图中相伴概率sig 0.515大于显著性水平0.05,不应拒绝零假设,认为控制变量的总体方差无显著差异。
剂量反应曲线Spss

剂量反应曲线Spss
剂量反应曲线是用曲线表示的剂量反应关系,即以表示量反应强度的计量单位或表示质反应的百分率或比值为纵坐标,以剂量为横坐标,绘制散点图所得到的曲线
剂量反应关系通常用于医学研究中,其常用于计算半数致死量
LD50值。
LD50即指能引起50%的实验动物死亡的剂量或浓度。
比如流行病研究中研究某种暴露(干预)对于结局的潜在关系情况,比如研究某化学药物对于老鼠的毒性关系情况,即测试并且记录不同剂量水平时,老鼠的死亡数据情况。
一般剂量反应是使用Probit 模型进行分析并且计算得到LD50值等(Probit模型法即为Bliss法计算LD50值)。
1、S形曲线:是典型剂量反应曲线,多见于剂量一质反应关系中,分为对称S形曲线和非对称S形曲线两种形式。
2、直线:化学物质剂量的变化与反应的改变成正比。
3、抛物线:为一条线陆哨后平缓的曲线,医学教育网搜集整理类似于数学中的对数曲线,又称为对数曲线型。
剂量反应曲线的转换S形曲线可以是对称还是非对称的。
对非对称S形曲线,把横坐标改为对数剂量,再把纵坐标改为概率单位,即可成为一条直线。
转换得到的直线可以建立数学方程,计算出曲线斜率及各剂量对应的反应率,全面反映化学物的剂量反应特征。
probit方法

probit方法
Probit方法是一种常用的统计分析方法,用于研究二元变量之间的关系。
它是一种基于正态分布的概率模型,可以用来预测一个事件发生的概率。
Probit方法的基本原理是将一个二元变量(如是否购买某个产品)与一组自变量(如年龄、性别、收入等)联系起来,然后使用正态分布函数来计算事件发生的概率。
这个概率可以用来预测未来的行为或者评估某个政策的效果。
Probit方法的优点在于它可以处理连续的自变量,并且可以提供一个连续的概率分布。
这使得它在经济学、社会学、心理学等领域中得到了广泛的应用。
例如,它可以用来研究消费者的购买行为、投资者的决策行为、选民的投票行为等。
Probit方法的应用还可以扩展到多元变量的分析。
例如,可以使用多元Probit方法来研究一个人在不同领域的行为,如购买不同类型的产品、参加不同类型的活动等。
这种方法可以提供更全面的分析结果,帮助研究者更好地理解人们的行为模式。
Probit方法是一种非常有用的统计分析方法,可以用来研究二元变量之间的关系,并提供一个连续的概率分布。
它在经济学、社会学、心理学等领域中得到了广泛的应用,可以帮助研究者更好地理解人们的行为模式,预测未来的行为或者评估某个政策的效果。
常用SPSS数据处理方法

常用SPSS数据处理方法,你都会吗?数据编辑处理是在统计和分析数据时,第一步要做的。
尤其是当面对大量数据时,数据处理是一个重要的过程,可以达到提高处理效率及精度的目的。
为配合进行更好的分析,研究过程过可能涉及到以下数据处理工作:1、定义变量名2、制定数据标签3、数据编码4、计算变量5、无效样本处理6、特殊值处理等定义变量定义变量,就是给每个指标起名字。
每个变量都需要有对应的变量名,以便得到更规范的表格呈现和操作体验,spssau中通过“标题修改”定义变量名,一般用于以下情况:●上传数据后,对不规范标题修改●完成数据编码后,进行标题修改●完成生成变量后,进行标题修改●有多余无意义的标题,进行删除标题(一次只能删除一个标题)数据标签除了标题名需要定义,数据标签也是一个重要的属性。
数据标签用于标识数据中的数字代表的意义,对数据的含义进行解释说明,比如用1表示男,用2表示女。
数据标签仅影响表格展示,完全不影响分析结果。
数据编码量表问卷中经常会使用到反向计分,反项题得到数据在分析以前,要先进行重新编码。
数据编码通常除了用于处理反项题,还会用于数据组合。
比如1代表高中,2代表大专,3代表本科,4代表硕士,5代表博士。
希望组合成三组分别是:本科以下,本科,硕士及以上.则可处理为:1->1,2->1,3->2,4->3,5->3,最终数字1代表本科以下,2代表本科,3代表硕士及以上无效样本在数据分析之前,首先需要进行数据查看,包括数据中是否有异常值,无效样本等。
如果有无效样本则需要进行处理,然后再进行分析。
另外如果数据中有异常值也需要进行处理后再进行分析。
无效样本会干扰分析研究,扭曲数据结论等,因而在分析前先对无效样本进行标识显示尤其必要。
如果数据来源为问卷,则很可能出现无效样本,因为填写问卷的样本是否真实填写无从判定;如果数据库下载或者使用二手数据等,也可能出现大量缺失数据等无效样本。
probit模型参数含义结果解读 -回复

probit模型参数含义结果解读-回复probit模型是一种用于进行二分类问题的概率模型,它采用了以标准正态分布为基础的累积分布函数来建模。
在probit模型中,我们使用最大似然估计方法来估计模型的参数。
本文将详细介绍probit模型的参数含义以及如何解读这些参数。
首先,我们来了解一下probit模型的基本形式。
在一个二分类问题中,我们有一个因变量y,它的取值为0或1,表示两个不同的类别。
我们还有一组自变量x,它们是用来预测y的变量。
probit模型的基本假设是:对于给定的自变量值x,y的概率服从一个标准正态分布。
probit模型的累积分布函数(CDF)可以用来表示y的概率。
CDF给出了标准正态分布中随机变量小于或等于某个特定值的概率。
probit模型假设y的概率可以通过自变量的线性组合来表示,即:P(y=1 x) = Φ(β0 + β1x1 + β2x2 + …+ βnxn)其中,P(y=1 x)表示在给定自变量值x的条件下,y取值为1的概率。
Φ表示标准正态累积分布函数。
β0、β1、…、βn是probit模型的参数,它们用于描述自变量对因变量的影响。
接下来,我们将逐步解释每个参数的含义和解读方法。
1. β0:截距项β0是probit模型的截距项,它表示当所有自变量(x1, x2, ..., xn)都为零时,y取值为1的概率。
如果β0为正,那么在其他条件不变的情况下,y为1的概率增加;如果β0为负,那么y为1的概率减少。
2. β1, β2, …, βn:自变量的系数β1, β2, …, βn是自变量的系数,它们表示自变量对因变量的影响大小。
系数的符号表示自变量的影响方向,正系数表示自变量与y的关系为正相关,负系数表示自变量与y的关系为负相关。
系数的大小表示影响的程度,绝对值越大表示影响越大。
3. Odds Ratio(OR):几率比几率比是probit模型中用于衡量因变量y的概率随自变量的变化而变化的程度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2、偏相关分析:它描述的是当控制了一个或几个另外的变量的影响条件下两个变量间的相关性,如控制年龄和工作经验的影响,估计工资收入与受教育水平之间的相关关系
3、相似性测度:两个或若干个变量、两个或两组观测量之间的关系有时也可以用相似性或不相似性来描述。相似性测度用大值表示很相似,而不相似性用距离或不相似性来描述,大值表示相差甚远
第四步:结果保存
我们的spss软件会把我们统计分析的多有结果保存在一个窗口中即结果输出窗口(output),由于spss软件支持复制和粘贴功能,这样我们就可以把我们想要的结果复制﹑粘贴到我们的报告中,当然我们也可以在菜单中执行file->save来保存我们的结果,一般情况下,我们建议保存我们的数据,结果可不保存.因为只要有了数据,如果我们想要结果的,我们可以随时利用数据得到结果.
单一样本的T检验:检验单个变量的均值是否与给定的常数之间存在差异。
独立样本的T检验:检验两组不相关的样本是否来自具有相同均值的总体(均值是否相同,如男女的平均收入是否相同,是否有显著性差异)
配对T检验:检验两组相关的样本是否来自具有相同均值的总体(前后比较,如训练效果,治疗效果)
One-Way ANOVA:一元(单因素)方差分析,用于检验几个(三个或三个以上)独立的组,是否来自均值相同的总体。
2.数值分析:
SPSS 数值统计分析过程均在Analyze菜单中,包括:
(1)、Reports和Descriptive Statistics:又称为基本统计分析.基本统计分析是进行其他更深入的统计分析的前提,通过基本统计分析,用户可以对分析数据的总体特征有比较准确的把握,从而选择更为深入的分析方法对分析对象进行研究。Reports和Descriptive Statistics命令项中包括的功能是对单变量的描述统计分析。
请问您通常获取新闻的方式有哪些( )
1 报纸 2 杂志 3 电视 4 收音机 5 网络
在spss中设置变量时可为此题设置五个变量,假如此题为问卷第三题,那么变量名分别为3_1、3_2、3_3、3_4、3_5,然后每一个选项有两个选项选中和不选中,只需在Value一项中为每一个变量设置成1=选中此项、0=不选中此项即可.
probit的spss处理
当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.
Spss处理:
第一步:定义变量
以上为问卷中常见的单项选择题型的变量设置,下面将对一些特殊情况的变量设置也作一下说明.
1.开放式题型的设置:诸如你所在的省份是_____这样的填空题即为开放题,设置这些变量的时候只需要将Value 、Missing两项不设置即可.
2.多选题的变量设置:这类题型的设置有两种方法即多重二分法和多重分类法,在这里我们只对多重二分法进行介绍.这种方法的基本思想是把该题每一个选项设置成一个变量,然后将每一个选项拆分为两个选项项,即选中该项和不选中该项.现在举例来说明在spss中的具体操作.比如如下一例:
以下是进行均值比较及检验的过程:
MEANS过程:不同水平下(不同组)的描述统计量,如男女的平均工资,各工种的平均工资。目的在于比较。术语:水平数(指分类变量的值数,如sex变量有2个值,称为有两个水平)、单元Cell(指因变量按分类变量值所分的组)、水平组合
T test 过程:对样本进行T检验的过程
1.作图分析:
在SPSS中,除了生存分析所用的生存曲线图被整合到Analyze菜单中外,其他的统计绘图功能均放置在graph菜单中。该菜单具体分为以下几部分::
(1)Gallery:相当于一个自学向导,将统计绘图功能做了简单的介绍,初学者可以通过它对SPSS的绘图能力有一个大致的了解。
(2)Interactive:交互式统计图。
3.我们知道一行代表一份问卷,所以有几分问卷,就要有几行的数据.
在数据录入完成后,我们要做的就是我们的关键部分,即问卷的统计分析了,因为这时我们已经把问卷中的数据录入我们的软件中了.
第三步:统计分析
有了数据,可以利用SPSS的各种分析方法进行分析,但选择何种统计分析方法,即调用哪个统计分析过程,是得到正确分析结果的关键。这要根据我们的问卷调查的目的和我们想要什么样的结果来选择.SPSS有数值分析和作图分析两类方法.
我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:
1.请问你的年龄属于下面哪一个年龄段( )?
A:20—29 B:30—39 C:40—49 D:50--59
Descriptive Statistics包括的统计功能有:
Frequencies(频数分析):作用:了解变量的取值分布情况
Descriptives(描述统计量分析):功能:了解数据的基本统计特征和对指定的变量值进行标准化处理
Explore(探索分析):功能:考察数据的奇异性和分布特征
Crosstabs(交叉分析):功能:分析事物(变量)之间的相互影响和关系
(5)、Regression(回归分析):功能:寻求有关联(相关)的变量之间的关系在回归过程中包括:Liner:线性回归;Curve Estimation:曲线估计;Binary Logistic: 二分变量逻辑回归;Multinnal 序回归;Probit:概率单位回归;Nonlinear:非线性回归;Weight Estimation:加权估计;2-Stage Least squares:二段最小平方法;Optimal Scaling 最优编码回归;其中最常用的为前面三个.
大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View, Variable View两个标签,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、label(变量标签) 、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类).
Report Summaries in Columns:列形式输出报告
(2)、Compare Means(均值比较与检验):能否用样本均值估计总体均值?两个变量均值接近的样本是否来自均值相同的总体?换句话说,两组样本某变量均值不同,其差异是否具有统计意义?能否说明总体差异?这是各种研究工作中经常提出的问题。这就要进行均值比较。
(3)Map:统计地图。
(4)下方的其他菜单项是我们最为常用的普通统计图,具体来说有:
条图
散点图
线图
直方图
饼图
面积图
箱式图
正态Q-Q图
正态P-P图
质量控制图
Pareto图
自回归曲线图
高低图
交互相关图
序列图
频谱图
误差线图
作图分析简单易懂,一目了然,我们可根据需要来选择我们需要作的图形,一般来讲,我们较常用的有条图,直方图,正态图,散点图,饼图等等,具体操作很简单,大家可参阅相关书籍,作图分析更多情况下是和数值分析相结合来对试卷进行分析的,这样的效果更好.
8.K related Samples Test 两个相关样本检验
(7)、Data Reduction(因子分析)
(8)、Classify(聚类与判别)等等
以上就是数值统计分析Analyze菜单下几项用于分析的数值统计分析方法的简介,在我们的变量定义以及数据录入完成后,我们就可以根据我们的需要在以上几种分析方法中选择若干种对我们的问卷数据进行统计分析,来得到我们想要的结果.
那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, width宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。Values用于定义具体变量值的标签,单击Value框右半部的省略号,会弹出变量值标签对话框,在第一个文本框里输入1,第二个输入20—29,然后单击添加即可.同样道理我们可做如下设置,即1=20—29、2=30—39、3=40—49、4=50--59;Missing,用于定义变量缺失值, 单击missing框右侧的省略号,会弹出缺失值对话框, 界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值”,最多可以定义3个值;最后一项为“缺失值范围加可选的一个缺失值”,在此我们不设置缺省值,所以选中第一项如图;Colomns,定义显示列宽,可自己根据实际情况设置;Align,定义显示对齐方式,有居左、居右、居中三种方式;Measure,定义变量类型是连续、有序分类还是无序分类。
Reports包括的统计功能有:
OLAP Cubes(OLAP报告摘要表):功能: 以分组变量为基础,计算各组的总计、均值和其他统计量。而输出的报告摘要则是指每个组中所包含的各种变量的统计信息。
Case Summaries(观测量列表):察看或打印所需要的变量值
Report Summaries in Row:行形式输出报告
3.Runs test 游程检验
4.1-Sample Kolmogorov-Smirnov test 一个样本柯尔莫哥洛夫-斯米诺夫检验