计算以年龄和视力为样本数据的协方差
协方差分析

中国疾病预防控制中心
如果我们考虑试验开始前动物初始体重的影 响,这时一般方法是选初始重量相同的动 物作为一组,分别接受另一因素的不同水 平处理,此时用方差分析也无问题。 但若可供试验的动物很少,初始体重又有明 显差异,无法选到相同体重的动物,那就 只好认为初始体重X与最终体重Y有回归关 系,采用协方差分析的方法排除初始体重 的影响,再来比较因素, 例如饲料种类,对 增重的影响了。
中国疾病预防控制中心
二、协方差分析的应用条件
各组观察指标服从正态分布和相互独立。 各组观察指标服从正态分布和相互独立。 各样本总体方差齐。 各样本总体方差齐。 各总体协变量X与观察变量 间存在线性关 各总体协变量 与观察变量Y间存在线性关 与观察变量 且斜率相同(回归线平行)。 系且斜率相同(回归线平行)。 协变量与处理因素之间不存在交互作用。 协变量与处理因素之间不存在交互作用。
协方差分析 (Analysis of Covariance,ANCOVA)
2011.04.20
中国疾病预防控制中心
讲授提纲: 讲授提纲
协方差分析的意义 协方差分析的应用条件 协方差分析的基本原理 协方差分析的基本步骤 完全随机设计(CRD)协方差分析的应用
中国疾病预防控制中心
一、协方差分析的意义
中国疾病预防控制中心
三、协方差分析的基本原理
协方差分析是将回归分析和方差分析结合的一 种统计分析方法, 它利用协变量与观察指标间 的线性回归关系扣除协变量的影响, 再对观察 指标做方差分析。所比较的是处理因素各水 平的修正均数;修正均数指各组协变量相等 的情况下,各组应变量的均数,其公式:
Yk = yk −bxk +bx = yk −b(xk −x)
中国疾病预防控制中心
主成分分析和因子分析实例

主成分分析和因子分析实例假设我们有一份关于中国大学生健康状况的调查数据集,共包含10个变量:体重、身高、视力、听力、血压、血糖、心率、睡眠时间、体育锻炼时间和饮食习惯。
我们希望通过主成分分析和因子分析来了解这些变量之间的关系以及它们对健康状况的影响。
首先,进行主成分分析。
主成分分析旨在找到能最好地解释数据方差的新变量,即主成分。
我们可以利用主成分分析来降低数据的维度,并找出最重要的变量。
我们计算主成分的步骤如下:1.标准化数据:将所有变量标准化,使其均值为0,标准差为1,以消除不同变量间的量纲差异。
2.计算协方差矩阵:计算标准化后的变量间的协方差矩阵。
3.计算特征值和特征向量:对协方差矩阵进行特征值分解,得到特征值和特征向量。
4.选择主成分:选择前几个特征值最大的特征向量作为主成分。
5.计算主成分得分:将原始数据与选定的主成分的特征向量相乘,得到主成分得分。
在完成上述计算后,我们可以得到主成分的解释力和贡献度。
解释力衡量了每个主成分对原始数据的解释程度,而贡献度则表示每个主成分对原始数据方差的贡献程度。
我们可以根据解释力和贡献度来解读主成分。
另一种常用的降维方法是因子分析。
因子分析也可以帮助我们找到数据中隐藏的因子,并揭示变量之间的关系。
我们进行因子分析的步骤如下:1.标准化数据:同样地,我们需要先对原始数据进行标准化。
2.估计因子模型:根据原始数据的协方差矩阵或相关矩阵,估计潜在因子模型。
最常用的是主成分法估计和极大似然估计。
3.提取因子:提取潜在因子,以解释原始数据中的变异。
我们可以使用特征值大于1的因素作为主要因子。
4.旋转因子:为了更好地理解因子的含义,我们可以对因子进行旋转。
常用的旋转方法有方差最大旋转法和直角旋转法。
5.计算因子得分:根据旋转后的因子载荷矩阵和标准化后的数据,计算每个样本在因子上的得分。
通过因子分析,我们可以得到每个变量对于潜在因子的载荷值,代表了变量与潜在因子之间的关系强度。
三个样本的协方差

三个样本的协方差协方差是统计学中用来衡量两个变量之间关系的一种方法。
在实际应用中,我们常常需要计算多个样本之间的协方差。
本文将介绍如何计算三个样本的协方差,并以示例说明相关概念。
一、协方差的定义协方差表示两个变量之间的相关程度,可以通过以下公式计算:Cov(X, Y) = Σ[(Xi - X_mean) * (Yi - Y_mean)] / (N - 1)其中,X和Y分别表示两个变量,Xi和Yi表示第i个观测值,X_mean和Y_mean分别表示X和Y的均值,N表示观测值的数量。
二、计算三个样本的协方差假设我们有三个样本A、B和C,每个样本包含n个观测值。
我们可以按照以下步骤计算三个样本之间的协方差。
1. 计算每个样本的均值首先,我们需要计算每个样本的均值。
对于样本A,可以使用以下公式计算均值:A_mean = ΣAi / n同样地,对于样本B和样本C,也可以分别计算出它们的均值。
2. 计算样本A和样本B的协方差接下来,我们计算样本A和样本B之间的协方差。
根据协方差的定义,可以使用以下公式计算:Cov(A, B) = Σ[(Ai - A_mean) * (Bi - B_mean)] / (n - 1)其中,Ai和Bi表示样本A和样本B的第i个观测值。
3. 计算样本A和样本C的协方差同样地,我们可以计算样本A和样本C之间的协方差,使用以下公式:Cov(A, C) = Σ[(Ai - A_mean) * (Ci - C_mean)] / (n - 1)4. 计算样本B和样本C的协方差最后,我们计算样本B和样本C之间的协方差,使用以下公式:Cov(B, C) = Σ[(Bi - B_mean) * (Ci - C_mean)] / (n - 1)这样,我们就计算出了三个样本之间的协方差。
三、示例假设我们有三个样本A、B和C,每个样本包含4个观测值。
观测值如下:样本A: 2, 4, 6, 8样本B: 1, 3, 5, 7样本C: 0, 2, 4, 6首先,我们计算每个样本的均值:A_mean = (2 + 4 + 6 + 8) / 4 = 5B_mean = (1 + 3 + 5 + 7) / 4 = 4C_mean = (0 + 2 + 4 + 6) / 4 = 3接下来,计算样本A和样本B之间的协方差:Cov(A, B) = [(2 - 5) * (1 - 4) + (4 - 5) * (3 - 4) + (6 - 5) * (5 - 4) + (8 - 5) * (7 - 4)] / (4 - 1) = 4然后,计算样本A和样本C之间的协方差:Cov(A, C) = [(2 - 5) * (0 - 3) + (4 - 5) * (2 - 3) + (6 - 5) * (4 - 3) + (8 - 5) * (6 - 3)] / (4 - 1) = 7最后,计算样本B和样本C之间的协方差:Cov(B, C) = [(1 - 4) * (0 - 3) + (3 - 4) * (2 - 3) + (5 - 4) * (4 - 3) + (7 - 4) * (6 - 3)] / (4 - 1) = 7通过计算,我们得到样本A和样本B的协方差为4,样本A和样本C的协方差为7,样本B和样本C的协方差为7。
协方差分析

3、统计分析(1) 建立数据文件变量视图:建立3个变量数据视图:先要分析两组中年龄与胆固醇是否有线性关系,且比较回归洗漱是否相等,比较粗略的做法是画散点图,选择菜单:图形-》旧对话框-》散点图,如图:进入图形对话框:将胆固醇、年龄、组分别选入Y轴、X轴、设置标记:点击确定开始画图可以看出,大致呈直线关系。
更为精确的作法是检验年龄与分组之间是否存在交互作用,即年龄的作用是否受分组的影响。
接下来开始协方差分析,首先进入菜单:进入对话框将胆固醇选入“因变量”,组选入“固定因子”,年龄选入“协变量”,见图:点击右边“模型”按钮,在“构建项”下拉菜单中选择“主效应”,将“组”和“年龄”选入右边框中,然后在“构建项”下拉菜单中选择“交互”,同时选中“组”和“年龄”,一并选入右边的框中,见图:点击“继续”按钮回到“单变量”主界面:单击“选项”按钮,进入如下对话框:选中“描述性分析”:点击“继续”按钮回到主界面,单击“确定”即可。
4、结果解读这是各组的描述性统计分析。
这是主要的统计分析结果,一个典型的方差分析表,解释一下:1、表格的第一行“校正模型”是对模型的检验,零假设是“模型中所有的因素对因变量均无影响”(这里包括分组、年龄及他们的交互作用),其P<0.001,拒绝零假设,说明存在对因变量有影响的因素。
2、表格的第二行是回归分析的常数项,通常无实际意义。
3、表格的第三行、第四行是对组和年龄的检验,P均<0.05,有统计学意义,说明分组和年龄对胆固醇的影响均有统计学意义。
4、表格的第五行是对分组和年龄的交互作用的检验,其P=0.935>0.05,说明分组和年龄无交互作用,也就是说,年龄对胆固醇的影响不随分组的不同而不同,这也是协方差分析的基本条件之一。
这里是满足的。
方差、标准差和协方差三者之间的定义与计算

⽅差、标准差和协⽅差三者之间的定义与计算理解三者之间的区别与联系,要从定义⼊⼿,⼀步步来计算,同时也要互相⽐较理解,这样才够深刻。
⽅差⽅差是各个数据与平均数之差的平⽅的平均数。
在概率论和数理统计中,⽅差(英⽂Variance)⽤来度量随机变量和其数学期望(即均值)之间的偏离程度。
在许多实际问题中,研究随机变量和均值之间的偏离程度有着很重要的意义。
标准差⽅差开根号。
协⽅差在概率论和统计学中,协⽅差⽤于衡量两个变量的总体误差。
⽽⽅差是协⽅差的⼀种特殊情况,即当两个变量是相同的情况。
可以通俗的理解为:两个变量在变化过程中是否同向变化?还是反⽅向变化?同向或反向程度如何?你变⼤,同时我也变⼤,说明两个变量是同向变化的,这是协⽅差就是正的。
你变⼤,同时我变⼩,说明两个变量是反向变化的,这时协⽅差就是负的。
如果我是⾃然⼈,⽽你是太阳,那么两者没有相关关系,这时协⽅差是0。
从数值来看,协⽅差的数值越⼤,两个变量同向程度也就越⼤,反之亦然。
可以看出来,协⽅差代表了两个变量之间的是否同时偏离均值,和偏离的⽅向是相同还是相反。
公式:如果有X,Y两个变量,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到⼀个乘积,再对这每时刻的乘积求和并求出均值,即为协⽅差。
⽅差,标准差与协⽅差之间的联系与区别:1. ⽅差和标准差都是对⼀组(⼀维)数据进⾏统计的,反映的是⼀维数组的离散程度;⽽协⽅差是对2组数据进⾏统计的,反映的是2组数据之间的相关性。
2. 标准差和均值的量纲(单位)是⼀致的,在描述⼀个波动范围时标准差⽐⽅差更⽅便。
⽐如⼀个班男⽣的平均⾝⾼是170cm,标准差是10cm,那么⽅差就是10cm^2。
可以进⾏的⽐较简便的描述是本班男⽣⾝⾼分布是170±10cm,⽅差就⽆法做到这点。
3. ⽅差可以看成是协⽅差的⼀种特殊情况,即2组数据完全相同。
4. 协⽅差只表⽰线性相关的⽅向,取值正⽆穷到负⽆穷。
利⽤实例来计算⽅差、标准差和协⽅差样本数据1:沪深300指数2017年3⽉份的涨跌额(%), [0.16,-0.67,-0.21,0.54,0.22,-0.15,-0.63,0.03,0.88,-0.04,0.20,0.52,-1.03,0.11,0.49,-0.47,0.35,0.80,-0.33,-0.24,-0.13,-0.82,0.56]1. 计算沪深300指数2017年3⽉份的涨跌额(%)的⽅差# Sample Date - SH000300 Earning in 2017-03datas = [0.16, -0.67, -0.21, 0.54, 0.22, -0.15, -0.63, 0.03, 0.88, -0.04, 0.20, 0.52, -1.03, 0.11, 0.49, -0.47, 0.35, 0.80, -0.33, -0.24, -0.13, -0.82, 0.56]mean1 = sum(datas)/len(datas) # result = 0.0060869565217391355square_datas = []for i in datas:square_datas.append((i-mean1)*(i-mean1))variance = sum(square_datas)/len(square_datas)print(str(variance))# result = 0.25349338374291114# 当然如果你使⽤了numpy,那么求⽅差将会⼗分的简单:import numpy as npdatas = [0.16, -0.67, -0.21, 0.54, 0.22, -0.15, -0.63, 0.03, 0.88, -0.04, 0.20, 0.52, -1.03, 0.11, 0.49, -0.47, 0.35, 0.80, -0.33, -0.24, -0.13, -0.82, 0.56] variance = np.var(datas)print(str(variance))# result = 0.2534933837432. 计算沪深300指数2017年3⽉份的涨跌额(%)的标准差import math# Sample Date - SH000300 Earning in 2017-03datas = [0.16, -0.67, -0.21, 0.54, 0.22, -0.15, -0.63, 0.03, 0.88, -0.04, 0.20, 0.52, -1.03, 0.11, 0.49, -0.47, 0.35, 0.80, -0.33, -0.24, -0.13, -0.82, 0.56] mean1 = sum(datas)/len(datas)square_datas = []for i in datas:square_datas.append((i-mean1)*(i-mean1))variance = sum(square_datas)/len(square_datas)standard_deviation = math.sqrt(variance)print(str(standard_deviation))# result = 0.5034812645401129#当然如果你使⽤了numpy,那么求标准差将会⼗分的简单:import numpy as np# Sample Date - SH000300 Earning in 2017-03datas = [0.16, -0.67, -0.21, 0.54, 0.22, -0.15, -0.63, 0.03, 0.88, -0.04, 0.20, 0.52, -1.03, 0.11, 0.49, -0.47, 0.35, 0.80, -0.33, -0.24, -0.13, -0.82, 0.56] standard_deviation2 = np.std(datas, ddof = 0)print(str(standard_deviation2))# result =0.50348126454请注意 ddof = 0 这个参数,这个是很重要的,只是稍后放在⽂末说明,因为虽然重要,但是却⼗分好理解。
计量经济学-名词解释及简答

一、名词解释第一章1、计量经济学:计量经济学是以经济理论和经济数据的事实为依据,运用数学、统计学的方法,借助计算机为辅助工具,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
2、虚拟变量数据:虚拟变量数据是人为构造的,通常取值为1或0的,用来表征政策等定性事实的数据。
3、计量经济学检验:计量经济学检验主要是检验模型是否符合计量经济方法的基本假定。
4、政策评价:政策评价是利用计量经济模型对各种可供选择的政策方案的实施后果进行模拟测算,从而对各种政策方案做出评价第二章1、回归平方和:回归平方和用ESS 表示,是被解释变量的样本估计值与其平均值的离差平方和。
2、拟和优度检验:拟和优度检验指检验模型对样本观测值的拟合程度,用2R 表示,该值越接近1,模型对样本观测值拟合得越好。
3、相关关系:当一个或若干个变量X 取一定数值时,与之相对应的另一个变量Y 的值虽然不确定,但却按某种规律在一定范围内变化,变量之间的这种关系,称为不确定性的统计关系或相关关系,可表示为Y=f(X ,u),其中u 为随机变量。
4、高斯-马尔科夫定理:在古典假定条件下,O LS 估计式是其总体参数的最佳线性无偏估计式。
第三章1、偏回归系数:在多元线性回归模型中,回归系数j (j=1,2,……,k )表示的是当控制其他解释变量不变的条件下,第j 个解释变量的单位变动对被解释变量平均值的影响,这样的回归系数称为偏回归系数。
2、多重可决系数:“回归平方和”与“总离差平方和”的比值,用2R 表示。
3、修正的可决系数:用自由度修正多重可决系数2R 中的残差平方和与回归平方和。
4、回归方程的显著性检验(F 检验):对模型中被解释变量与所有解释变量之间的线性关系在总体上是否显著做出推断。
5、回归参数的显著性检验(t 检验):当其他解释变量不变时,某个回归系数对应的解释变量是否对被解释变量有显著影响做出推断。
6、无多重共线性假定:假定各解释变量之间不存在线性关系,或者说各解释变量的观测值之间线性无关,在此条件下,解释变量观测值矩阵X 列满秩Rank(X)=k ,此时,方阵X`X 满秩, Rank(X`X)=k从而X`X 可逆,(X`X) 存在。
10.协方差分析-09 PPT课件

a. R Squared = .671 (Adjusted R Squared = .643)
有关参数估计
Par ameter Esti mates Dependent Variable: 胆固醇 Parameter Intercept YEAR [GROUP=1] [GROUP=2] a. This 95% Confidence Interval B Std. Error t Sig. Lower Bound Upper Bound 1.656 1.028 1.610 .121 -.471 3.783 9.417E-02 .018 5.162 .000 5.643E-02 .132 -.895 .406 -2.207 .038 -1.735 -5.619E-02 a 0 . . . . . parameter is set to zero because it is redundant.
一、协方差分析概述
1、关于协变量
在实际研究过程中,实验结果常常受一些非 处理因素(即混杂因素)的影响,在统计学上把 这些混杂因素称为协变量。 若忽视协变量(混杂因素)的作用,直接对
资料进行分析,则会因为混杂因素的影响而得出
片面的结论。
一、协方差分析概述
2、基本思想
协方差分析是将直线回归和方差分析结合应用的一种 统计方法,用来消除混杂因素对分析指标的影响。其基本
a y bx
一、协方差分析概述
应用条件要求 1= 2,但由于抽样误差b1与
b2不一定恰恰相等,故取公共斜率(bc)
组内l xy bc 组内l xx
, 则:y1 y 1 bc ( x1 x 1 ) , y2 y 2 bc ( x 2 x 2 )
概率论§4.3 协方差和相关系数

性质4 性质4 设X,Y 为随机变量,则有 , 为随机变量, D(X±Y)=D(X)+D(Y)±2Cov(X,Y) ± ± 性质5 性质5 设X,Y 为任意随机变量,则有 , 为任意随机变量, [Cov(X, Y)]2 ≤ D(X) D(Y) 证明: 证明: [Cov(X, Y)]2 =(E{[ X-E(X)][Y-E(Y)]})2 ≤ E{[X-E(X)]2}·E{[Y-E(Y)]2} = D(X)·D(Y) 柯西柯西许瓦兹 不等式
5
协方差的性质
性质1 协方差的计算与X, 性质1 协方差的计算与 ,Y 的次序无关 Cov(X, Y) = Cov(Y, X) 性质2 性质2 对任意常数 a1,a2,b1,b2 有 Cov(a1X+b1, a2Y+b2) = a1a2Cov(X, Y) 性质3 为随机变量, 性质3 设X1,X2 , Y1,Y2为随机变量,则有 Cov(X1+X2, Y)=Cov(X1, Y)+Cov(X2, Y) Cov(X, Y1+Y2)=Cov(X, Y1)+Cov(X, Y2)
= 4D(X) + D(Y) −4Cov( X,Y )
= 4×1+ 4 − 4×1 = 4
12
Cov(ξ,η) = Cov( X −2Y,2X −Y )
= 2Cov( X, X ) −4Cov(Y, X ) −Cov( X,Y) + 2Cov(Y,Y)
= 2D(X) −5Cov( X,Y ) + 2D(Y)
同理可得
5 E(Y ) = 12
2
15
D(X)=E(X2)−E2(X) − 同理可得
5 7 2 11 = −( ) = 144 12 12
spss协方差分析的基本原理-最棒的

协方差分析的基本原理1.协方差分析的提出无论是单因素方差分析还是多因素方差分析,它们都有一些人为可以控制的控制变量。
在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。
如果忽略这些因素的影响,则有可能得到不正确的结论。
例如,研究3种不同的教学方法的教学效果的好坏。
检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。
又比如,考查受教育程度对个人工资是否有显著影响,这时必须考虑工作年限因素。
一般情况下,工作年限越长,工资就越高。
在研究此问题时必须排除工作年限因素的影响,才能得出正确的结论。
再如,如果要了解接受不同处理的小白鼠经过一段时间饲养后体重增加量有无差别,已知体重的增加和小白鼠的进食量有关,接受不同处理的小白鼠其进食量可能不同,这时为了控制进食量对体重增加的影响,可在统计阶段利用协方差分析(Analysis of Covariance),通过统计模型的校正使得各组在“进食量”这个变量的影响上相等,即将进食量作为协变量,然后分析不同处理对小白鼠体重增加量的影响。
为了更加准确地控制变量不同水平对结果的影响,应该尽量排除其它在实验设计阶段难以控制或者是无法严格控制的因素对分析结果的影响。
利用协方差分析就可以完成这样的功能。
协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。
协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。
前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。
协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。
协方差cov计算公式

第一篇协方差cov计算公式:协方差与协方差矩阵标签协方差协方差矩阵统计引言最近在看主成分分析(PCA),其中有一步是计算样本各维度的协方差矩阵。
以前在看算法介绍时,也经常遇到,现找了些资料复习,总结如下。
协方差通常,在提到协方差的时候,需要对其进一步区分。
(1)随机变量的协方差。
跟数学期望、方差一样,是分布的一个总体参数。
(2)样本的协方差。
是样本集的一个统计量,可作为联合分布总体参数的一个估计。
在实际中计算的通常是样本的协方差。
随机变量的协方差在概率论和统计中,协方差是对两个随机变量联合分布线性相关程度的一种度量。
两个随机变量越线性相关,协方差越大,完全线性无关,协方差为零。
定义如下。
cov(X,Y)=E[(XE[X])(YE[Y])]当X,Y是同一个随机变量时,X与其自身的协方差就是X的方差,可以说方差是协方差的一个特例。
cov(X,X)=E[(XE[X])(XE[X])]或var(X)=cov(X,X)=E[(XE[X])2]由于随机变量的取值范围不同,两个协方差不具备可比性。
如X,Y,Z分别是三个随机变量,想要比较X与Y的线性相关程度强,还是X与Z的线性相关程度强,通过cov(X,Y)与cov(X,Z)无法直接比较。
定义相关系数η为η=cov(X,Y)var(X)var(Y)通过X的方差var(X)与Y的方差var(Y)对协方差cov(X,Y)归一化,得到相关系数η,η的取值范围是[1,1]。
1表示完全线性相关,1表示完全线性负相关,0表示线性无关。
线性无关并不代表完全无关,更不代表相互独立。
样本的协方差在实际中,通常我们手头会有一些样本,样本有多个属性,每个样本可以看成一个多维随机变量的样本点,我们需要分析两个维度之间的线性关系。
协方差及相关系数是度量随机变量间线性关系的参数,由于不知道具体的分布,只能通过样本来进行估计。
设样本对应的多维随机变量为X=[X1,X2,X3,...,Xn]T,样本集合为{xj=[x1j,x2j,...,xnj]T|1jm},m为样本数量。
统计学中的相关系数计算方法

统计学中的相关系数计算方法统计学是一门重要的学科,广泛应用于各个领域,包括经济学、社会学、生物学等等。
在统计学中,相关系数是一种常用的分析工具,用于评估两个变量之间的线性关系强度和方向。
而正确计算相关系数是非常重要的,因为它们能够提供有关变量之间关系的有价值的信息。
本文将介绍两种常见的相关系数计算方法——皮尔逊相关系数和斯皮尔曼相关系数。
1. 皮尔逊相关系数皮尔逊相关系数是最常用的相关系数之一,用来测量两个连续变量之间的线性关系强度。
它的取值范围在-1到1之间,其中-1表示完全负相关,1表示完全正相关,0表示没有线性关系。
皮尔逊相关系数的计算公式如下:\[ r = \frac{{\sum{(X_i-\bar{X})(Y_i-\bar{Y})}}}{{\sqrt{\sum(X_i-\bar{X})^2}\sqrt{\sum(Y_i-\bar{Y})^2}}} \]其中,\( X_i \) 是第一个变量的第i个观测值,\( Y_i \) 是第二个变量的第i个观测值,\( \bar{X} \) 是第一个变量的均值,\( \bar{Y} \) 是第二个变量的均值。
通过计算样本数据的协方差和两个变量的标准差来得到相关系数。
2. 斯皮尔曼相关系数斯皮尔曼相关系数用于评估两个变量之间的单调关系,即不仅仅限于线性关系。
它通过对两个变量的秩次进行计算,将原始数据转换为秩次数据,从而避免了对原始数据的要求。
斯皮尔曼相关系数的计算公式如下:\[ \rho = 1 - \frac{{6\sum{d_i^2}}}{{n(n^2-1)}} \]其中,\( d_i \) 是两个变量的秩次差值,n是样本观测值的个数。
斯皮尔曼相关系数的取值范围也在-1到1之间,其中-1表示完全负相关,1表示完全正相关,0表示没有单调关系。
3. 相关系数的解读无论使用皮尔逊相关系数还是斯皮尔曼相关系数,对于相关系数的解读,需要了解以下几点:- 当相关系数接近-1或1时,表示存在强相关性。
《医学统计学课件:以三年级眼科学生为例》

欢迎来到《医学统计学课件:以三年级眼科学生为例》!在这个课程中,我 们将深入研究眼科学生的数据收集和基本统计学概念,帮助您更好地理解和 应用医学统计学。
课程简介
本节简要介绍医学统计学课程的内容和目标,以及对三年级眼科学生作为例子的选择原因。
眼科学生的数据收集方法
我们将探讨针对眼科学生的数据收集方法,包括问卷调查、观察记录等,并说明如何确保数据的准确性和,我们将学习数据预处理和清洗的重要性,包括缺失值处理、异常值检测和去除,以及数据格式的转 换。
基本统计学的概念
在这一部分中,我们将介绍医学统计学中的一些基本概念,如总体和样本、 参数和统计量、假设检验和置信区间等。
频率分布表和直方图
我们将学习如何使用频率分布表和直方图来描述和可视化数据的分布情况, 以便更好地理解眼科学生数据的特征。
数据的中心位置和离散度
本节将介绍如何计算和解释数据的中心位置和离散度,如均值、中位数、标 准差等,以便更好地理解眼科学生数据的统计特征。
描述性统计分析
我们将进行详细的描述性统计分析,包括平均数、百分位数、方差、偏度、 峰度等,以便更好地洞察眼科学生数据的分布和趋势。
北京市定福庄中学选修三第三单元《成对数据的统计分析》检测卷(有答案解析)
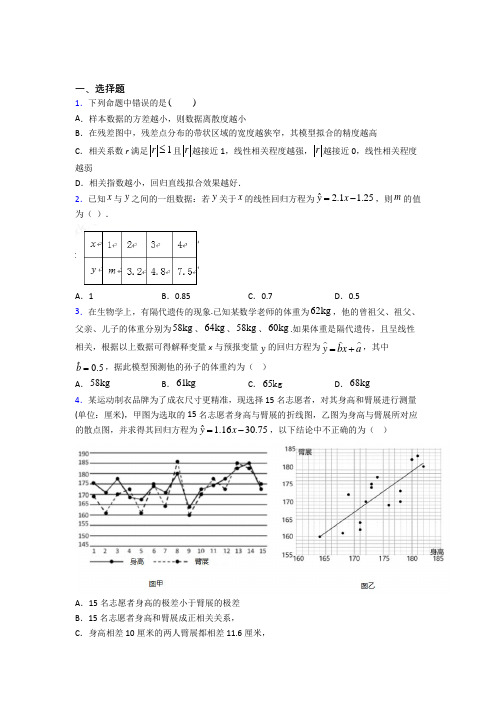
一、选择题1.下列命题中错误的是( )A .样本数据的方差越小,则数据离散度越小B .在残差图中,残差点分布的带状区域的宽度越狭窄,其模型拟合的精度越高C .相关系数r 满足1r ≤且r 越接近1,线性相关程度越强,r 越接近0,线性相关程度越弱D .相关指数越小,回归直线拟合效果越好.2.已知x 与y 之间的一组数据:若y 关于x 的线性回归方程为ˆ 2.1 1.25yx =-,则m 的值为( ).A .1B .0.85C .0.7D .0.53.在生物学上,有隔代遗传的现象.已知某数学老师的体重为62kg ,他的曾祖父、祖父、父亲、儿子的体重分别为58kg 、64kg 、58kg 、60kg .如果体重是隔代遗传,且呈线性相关,根据以上数据可得解释变量x 与预报变量y 的回归方程为y bx a =+,其中0.5b =,据此模型预测他的孙子的体重约为( )A .58kgB .61kgC .65kgD .68kg4.某运动制衣品牌为了成衣尺寸更精准,现选择15名志愿者,对其身高和臂展进行测量(单位:厘米),甲图为选取的15名志愿者身高与臂展的折线图,乙图为身高与臂展所对应的散点图,并求得其回归方程为 1.160.5ˆ37yx =-,以下结论中不正确的为( )A .15名志愿者身高的极差小于臂展的极差B .15名志愿者身高和臂展成正相关关系,C .身高相差10厘米的两人臂展都相差11.6厘米,D .可估计身高为190厘米的人臂展大约为189.65厘米5.为了研究某大型超市开业天数与销售额的情况,随机抽取了5天,其开业天数与每天的销售额的情况如表所示:开业天数 10 203040 50 销售额/天(万元)62758189根据上表提供的数据,求得关于的线性回归方程为0.6754.9y x =+,由于表中有一个数据模糊看不清,请你推断出该数据的值为( ) A .68B .68.3C .71D .71.36.某公司在2014~2018年的收入与支出情况如下表所示:收入x (亿元) 2.2 2.4 3.8 5.2 6.0 支出y (亿元)0.21.52.02.53.8根据表中数据可得回归直线方程为0.7y x a =+,依此估计如果2019年该公司收入为8亿元时的支出为( ) A .4.502亿元 B .4.404亿元 C .4.358亿元D .4.856亿元7.下列有关统计知识的四个命题正确的是( )A .衡量两变量之间线性相关关系的相关系数r 越接近1,说明两变量间线性关系越密切B .在回归分析中,可以用卡方2x 来刻画回归的效果,2x 越大,模型的拟合效果越差C .线性回归方程对应的直线ˆˆˆy bx a =+至少经过其样本数据点中的一个点D .线性回归方程0.51y x =+中,变量x 每增加一个单位时,变量y 平均增加1个单位 8.在吸烟与患肺病这两个分类变量的计算中,下列说法正确的是( )A .若从统计量中求出有95%的把握认为吸烟与患肺病有关系,是指有5%的可能性使得推断出现错误B .从独立性检验可知,有99%的把握认为吸烟与患肺病有关系时,我们说某人吸烟,那么他有99%的可能患有肺病C .若2K 的观测值为 6.635k =,我们有99%的把握认为吸烟与患肺病有关系,那么在100个吸烟的人中必有99人患有肺病D .以上三种说法均不正确9.由变量x 与y 相对应的一组数据()12,y 、()24,y 、()3 6,y 、()48,y 、()5 10,y 得到的线性回归方程为ˆ 1.212yx =+,则12345y y y y y ++++等于( ) A .88B .90C .92D .9610.某研究员为研究某两个变量的相关性,随机抽取这两个变量样本数据如下表:若依据表中数据画出散点图,则样本点(,)(1,2,3,4,5)i i x y i =都在曲线1y =附近波动.但由于某种原因表中一个x 值被污损,将方程1y =作为回归方程,则根据回归方程1y =和表中数据可求得被污损数据为( )A . 4.32-B .1.69C .1.96D .4.3211.陕西关中的秦腔表演朴实,粗犷,细腻,深刻,再有电子布景的独有特效,深得观众喜爱.戏曲相关部门特意进行了“喜爱看秦腔”调查,发现年龄段与爱看秦腔的人数比存在较好的线性相关关系,年龄在[]40,44,[]45,49,[]50,54,[]55,59的爱看人数比分别是0.10,0.18,0.20,0.30.现用各年龄段的中间值代表年龄段,如42代表[]40,44.由此求得爱看人数比y 关于年龄段x 的线性回归方程为0.4188y kx =-.那么,年龄在[]60,64的爱看人数比为( ) A .0.42B .0.39C .0.37D .0.3512.下面给出四种说法:①设a 、b 、c 分别表示数据15、17、14、10、15、17、17、16、14、12的平均数、中位数、众数,则a b c <<;②在线性回归模型中,相关指数2R 表示解释变量对于预报变量变化的贡献率,2R 越接近于1,表示回归的效果越好;③绘制频率分布直方图时,各小长方形的面积等于相应各组的组距; ④设随机变量ξ服从正态分布2(4,2)N ,则142()P ξ>=. 其中不正确的是( ). A .①B .②C .③D .④13.设两个变量x 和y 之间具有线性相关关系,它们的相关系数为r ,y 关于x 的回归直线方程为y kx b =+,则( )A .k 与r 的符号相同B .b 与r 的符号相同C .k 与r 的符号相反D .b 与r 的符号相反二、解答题14.某研究机构对高三学生的记忆力x 和判断力y 进行统计分析,得下表数据.(1)请根据表中提供的数据,求出关于的线性回归方程ˆˆybx a =+;(2)预测记忆力为19的同学的判断力.(附参考公式:1221ˆni ii nii x y nx ybxnx==-=-∑∑,ˆa y bx=-) 15.疫苗能够使人体获得对病毒的免疫力,是保护健康人群最有效的手段.新冠肺炎疫情发生以来,军事医学科学院陈薇院土领衔的团队开展应急科研攻关,研制的重组新型冠状病毒疫苗(腺病毒载体),于4月12日开始招募志愿者,进入二期临床试验.根据普遍规律,志愿者接种疫苗后体内会产生抗体,人体中检测到抗体,说明有抵御病毒的能力.科研人员要定期从接种疫苗的志愿者身上采集血液样本,检测人体中抗体含量水平(单位:miu/mL ,百万国际单位/毫升).(1)IgM 作为人体中首先快速产生的抗体,是人体抗感染免疫的“先头部队”.经采样分折,志愿者身体中IgM 含量水平()miu/mL y 与接种天数x (接种后每满24小时为一天,*x N ∈)近似满足函数关系:100.1,10,10xx x y e x -≤⎧=⎨>⎩,经研究表明,IgM 含量水平不低于0.2miu/mL 时是免疫的有效时段,试估计接种一次后IgM 含量水平有效时段可经历的时间(向下取整).(参考数据: 2.718e ≈)(2)IgG 虽然是接种后产生比较慢的抗体,却是血清和体液中含量最高的抗体,也是亲和力最强、人体内分布最广泛、具有免疫效应的抗感染“主力军”.科研人员每间隔3天检测一次(检测次数依次记为i t ,1,2,3,4,5,6,7i =)某志愿者人体中IgG 的含量水平,记作()()miu/mL 1,2,3,4,5,6,7i z i =,得到相关数据如下表:①请画出散点图,并根据散点图判断线性拟合模型与指数拟合模型·t z c d =哪种更适合拟合z 与t 的关系(不必说明理由);②研究人员发现,上述数据中存在一组异常数据应当予以剔除.试根据余下的六组数据,利用①中选择的拟合模型计算回归方程,并估计原异常数据对应的i z 值.附:回归系数与估计值均保留两位小数,由七组数据计算出的参考数据见下表,其中ln u z =.参考公式:线性回归直线ˆˆya bx =+的斜率和截距的最小二乘估计分别为:2()()ˆ()ii ix x y y bx x --=-∑∑,a y bx =-16.某工厂A,B两条生产线生产同款产品,若产品按照一、二、三等级分类,则每件可分别获利10元、8元、6元,现从A,B生产线的产品中各随机抽取100件进行检测,结果统计如下图:(1)根据已知数据,列出产品等级与生产线的列联表,并判断是否有99%的把握认为一等级产品与生产线有关?(2)分别计算两条生产线抽样产品获利的方差,以此作为判断依据,说明哪条生产线的获利更稳定?附:22()()()()()n ad bcKa b c d a c b d-=++++()2P K k≥0.0500.0100.001k 3.841 6.63510.82817.冬天的北方室外温度极低,若轻薄保暖的石墨烯发热膜能用在衣服上,可爱的医务工作者行动会更方便.石墨烯发热膜的制作:从石墨中分离出石墨烯,制成石墨烯发热膜.从石墨分离石墨烯的一种方法是化学气相沉积法,使石墨升华后附着在材料上再结晶.现有A材料、B材料供选择,研究人员对附着在A、B材料上再结晶各做了50次试验,得到如下等高条形图.(1)由上面等高条形图,填写22⨯列联表,判断是否有99%的把握认为试验成功与材料有关?(2)研究人员得到石墨烯后,再制作石墨烯发热膜有三个环节:①透明基底及UV 胶层;②石墨烯层;③表面封装层.每个环节生产合格的概率均为23,且各生产环节相互独立.已知生产1吨的石墨烯发热膜的固定成本为1万元,若生产不合格还需进行修复,且生产1吨石塑烯发热膜的每个环节修复费用均为1000元.如何定价,才能实现每生产1吨石墨烯发热膜获利可达1万元以上的目标?附:参考公式:()()()()()22n ad bc K a b c d a c b d -=++++,其中n a b c d =+++.()20P K k ≥0.100 0.050 0.010 0.005 0.001 k2.7063.8416.6357.87910.82818.新型冠状病毒肺炎COVID-19疫情发生以来,在世界各地逐渐蔓延.在全国人民的共同努力和各级部门的严格管控下,我国的疫情已经得到了很好的控制.然而,小王同学发现,每个国家在疫情发生的初期,由于认识不足和措施不到位,感染人数都会出现快速的增长.下表是小王同学记录的某国连续8天每日新型冠状病毒感染确诊的累计人数.日期代码x12345678累计确诊人数y .481631517197122为了分析该国累计感染人数的变化趋势,小王同学分别用两个模型:①2ˆy bx a=+,②ˆy dx c=+对变量x和y的关系进行拟合,得到相应的回归方程并进行残差分析,残差图如下(注:残差ˆˆi i ie y y=-):经过计算得()()81728i iix x y y=--=∑,()82142iix x=-=∑,()()816868i iiz z y y=--=∑,()8213570iiz z=-=∑,其中2i iz x=,8118iiz z==∑.(1)根据残差图,比较模型①,②的拟合效果,应该选择哪个模型?并简要说明理由;(2)根据(1)问选定的模型求出相应的回归方程(系数均保留两位小数);(3)由于时差,该国截止第9天新型冠状病毒感染确诊的累计人数尚未公布.小王同学认为,如果防疫形势没有得到明显改善,在数据公布之前可以根据他在(2)问求出的回归方程来对感染人数做出预测,那么估计该地区第9天新型冠状病毒感染确诊的累计人数是多少?附:回归直线的斜率和截距的最小二乘估计公式分别为:()()()81821ˆi iiiix x y ybx x==--=-∑∑,ˆˆa y bx=-19.下表是某学生在4月份开始进人冲刺复习至高考前的5次大型联考数学成绩(分);(1)请画出上表数据的散点图;(2)①请根据上表提供的数据,用最小二乘法求出y 关于x 的线性回归方程;②若在4月份开始进入冲刺复习前,该生的数学分数最好为116分,并以此作为初始分数,利用上述回归方程预测高考的数学成绩,并以预测高考成绩作为最终成绩,求该生4月份后复习提高率.(复习提高率=100%⨯净提高分卷面总分,分数取整数)附:回归直线的斜率和截距的最小二乘估计公式分别为1221ˆni ii nii x y nxybxnx ==-=-∑∑,a y bx =-.20.“每天锻炼一小时,健康工作五十年,幸福生活一辈子.”一科研单位为了解员工爱好运动是否与性别有关,从单位随机抽取30名员工进行了问卷调查,得到了如下列联表:男性 女性 合计爱好 10不爱好 8合计30已知在这30人中随机抽取1人抽到爱好运动的员工的概率是815. (1)请将上面的列联表补充完整,并据此资料分析能否有把握认为爱好运动与性别有关? (2)若从这30人中的女性员工中随机抽取2人参加一活动,记爱好运动的人数为X ,求X 的分布列、数学期望.21.某学生对其亲属30人的饮食习惯进行了一次调查,并用如图所示的茎叶图表示30人的饮食指数(说明:图中饮食指数低于70的人,饮食以蔬菜为主;饮食指数高于70的人,饮食以肉类为主).(1)根据以上数据完成下列22⨯列联表:(2)能否有99%的把握认为其亲属的饮食习惯与年龄有关?并写出简要分析.参考公式和数据:22()()()()()n ad bc K a b c d a c b d -=++++,n a b c d =+++.22.西尼罗河病毒(WNV )是一种脑炎病毒,WNV 通常是由鸟类携带,经蚊子传播给人类.1999年8-10月,美国纽约首次爆发了WNV 脑炎流行.在治疗上目前尚未有什么特效药可用,感染者需要采取输液及呼吸系统支持性疗法,有研究表明,大剂量的利巴韦林含片可抑制WNV 的复制,抑制其对细胞的致病作用.现某药企加大了利巴韦林含片的生产,为了提高生产效率,该药企负责人收集了5组实验数据,得到利巴韦林的投入量x (千克)和利巴韦林含片产量y (百盒)的统计数据如下:由相关系数可以反映两个变量相关性的强弱,,认为变量相关性很强;||[0.3,0.75]r ∈,认为变量相关性一般;||[0,0.25]r ∈,认为变量相关性较弱.(1)计算相关系数r ,并判断变量x 、y 相关性强弱;(2)根据上表中的数据,建立y 关于x 的线性回归方程ˆˆˆybx a =+;为了使某组利巴韦林含片产量达到150百盒,估计该组应投入多少利巴韦林? 25.69≈.参考公式:相关系数()()niix x y y r --=∑ˆˆˆybx a =+中,()()()121niii ni i x x y y b x x ==--=-∑∑,ˆˆay bx =-. 23.某大学生参加社会实践活动,对某公司1月份至6月份销售某种配件的销售量及销售单价进行了调查,销售单价x 和销售量y 之间的一组数据如下表所示:(1)根据1至5月份的数据,求出y 关于x 的回归直线方程;(2)若由回归直线方程得到的估计数据与剩下的检验数据的误差不超过0.5元,则认为所得到的回归直线方程是理想的,试问(1)中所得到的回归直线方程是否理想? (3)预计在今后的销售中,销售量与销售单价仍然服从(1)中的关系,若该种机器配件的成本是2.5元/件,那么该配件的销售单价应定为多少元才能获得最大利润?(注:利润=销售收入-成本).参考公式:回归直线方程ˆˆˆybx a =+,其中1221ˆni i i n i i x ynxy b x nx==-=-∑∑,55211392,502.5,i ii i i x yx ====∑∑24.某食品店为了了解气温对销售量的影响,随机记录了该店1月份中5天的日销售量y (单位:千克)与该地当日最低气温x (单位:°C )的数据,如下表:(1)求出y 与x 的回归方程y =b x +a ;(2)判断y 与x 之间是正相关还是负相关;若该地1月份某天的最低气温为6°C ,请用所求回归方程预测该店当日的营业额.附:回归方程y =b x +a ;中,b =()1221()==--∑∑ni ii nii x y nxyxn x ,a =y ﹣bx25.随着我国经济的发展,居民收入逐年增长.某地区2014年至2018年农村居民家庭人均纯收入y (单位:千元)的数据如下表:(1)求y 关于t 的线性回归方程;(2)利用(1)中的回归方程,分析2014年至2018年该地区农村居民家庭人均纯收入的变化情况,并预测2019年该地区农村居民家庭人均纯收入为多少?附:回归直线的斜率和截距的最小二乘估计公式分别为()()()121niii nii tty y b tt==--=-∑∑,a y bt =-.26.某商场为提高服务质量,随机调查了50名男顾客和50名女顾客,每位顾客对该商场的服务给出满意或不满意的评价,得到下面列联表:(2)能否有95%的把握认为男、女顾客对该商场服务的评价有差异?附:22()()()()()n ad bc K a b c d a c b d -=++++.【参考答案】***试卷处理标记,请不要删除一、选择题 1.D 解析:D 【分析】运用相关系数、变量间的相关关系来进行判定 【详解】对于A ,样本数据的方差越小,则数据离散度越小正确对于B ,在残差图中,残差点分布的带状区域的宽度越狭窄,其模型拟合的精度越高正确 对于C ,相关系数r 满足1r ≤且r 越接近1,线性相关程度越强,r 越接近0,线性相关程度越弱正确对于D ,相关指数越小说明残差平方和越大,则拟合效果越差,故D 错误 故选D 【点睛】本题考查对变量间的相关关系进行判定,结合残差图、相关系数来进行分析即可得到结果,较为基础2.D解析:D 【解析】由表格可知 2.5x =, 15.54my +=,由线性回归方程必过样本中心点可得: 4y =,则0.5m =,故选D.点睛:函数关系是一种确定的关系,相关关系是一种非确定的关系.事实上,函数关系是两个非随机变量的关系,而相关关系是非随机变量与随机变量的关系.如果线性相关,则直接根据用公式求,a b ,写出回归方程,回归直线方程恒过点(,)x y .3.B解析:B 【分析】由已知得出数据,()58,58,()64,62,()58,60,根据回归直线过样本中心点,可求得(),x y ,计算求得a ,代入62x =,即可得出结果.【详解】由已知,体重是隔代遗传,且呈线性相关,得出数据,()58,58,()64,62,()58,60, 所以()(),=60,60x y ,代入y bx a =+,其中0.5b =,求得=30a , 即0.530y x =+.62x =时, 0.56230y =⨯+=61.故选:B 【点睛】本题主要考查线性回归方程的相关计算,考查学生分析问题的能力,属于中档题.4.C解析:C【分析】对于A ,身高极差大约是25,臂展极差大于等于30,故A 正确; 对于B ,很明显根据散点图以及回归方程得到,故B 正确;对于C ,身高相差10厘米的两人展臂的估计值相差11.6厘米,但不是准确值,故C 错误;对于D ,身高为190厘米,代入回归方程可得展臂等于189.65厘米,但不是准确值,故D 正确.【详解】对于A ,身高极差大约是25,臂展极差大于等于30,故A 正确;对于B ,很明显根据散点图以及回归方程得到,身高矮展臂就会短一些,身高高一些, 展臂就会长一些,故B 正确;对于C ,身高相差10厘米的两人展臂的估计值相差11.6厘米,但不是准确值,回归方程上的点并不都是准确的样本点,故C 错误;对于D ,身高为190厘米,代入回归方程可得展臂等于189.65厘米,但不是准确值,故D 正确.故选:C . 【点睛】本题主要考查相关关系,考查回归方程及其应用,意在考查学生对这些知识的理解掌握水平.5.A解析:A 【分析】根据表中数据计算x ,再代入线性回归方程求得y ,进而根据平均数的定义求出所求的数据. 【详解】根据表中数据,可得1(1020304050)305x =⨯++++=,代入线性回归方程ˆ0.6754.9yx =+中, 求得0.673054.975y =⨯+=,则表中模糊不清的数据是7556275818968⨯----=, 故选:A. 【点睛】本题考查了线性回归方程过样本中心点的应用问题,是基础题.6.D解析:D 【分析】先求 3.92x =,2y =,根据0.7a y x =-,求解0.744a =-,将8x =代入回归直线方程为0.7y x a =+,求解即可. 【详解】2.2 2.43.8 5.2 6.03.925x ++++==,0.2 1.5 2.0 2.5 3.825y ++++==0.720.7 3.920.744a y x =-=-⨯=-即0.70.744y x =-令8x =,则0.780.744 4.856y =⨯-= 故选:D 【点睛】本题考查回归分析,样本中心点(),x y 满足回归直线方程,是解决本题的关键.属于中档题.7.A解析:A 【解析】分析:利用“卡方”的意义、相关指数的意义及回归分析的适用范围,逐一分析四个答案的真假,可得答案.详解:A. 衡量两变量之间线性相关关系的相关系数r 越接近1,说明两变量间线性关系越密切,正确;B. 在回归分析中,可以用卡方2x 来刻画回归的效果,2x 越大,模型的拟合效果越差,错误对分类变量X 与Y 的随机变量的2x 观测值来说, 2x 越大,“X 与Y 有关系”可信程度越大; 故B 错误;C. 线性回归方程对应的直线y bx a =+至少经过其样本数据点中的一个点,错误,回归直线y bx a =+可能不经过其样本数据点中的任何一个点;D. 线性回归方程0.51y x =+中,变量x 每增加一个单位时,变量y 平均增加1个单位,错误,由回归方程可知变量x 每增加一个单位时,变量y 平均增加0.5个单位. 故选A.点睛:本题考查回归分析的意义以及注意的问题.是对回归分析的思想、方法小结.要结合实例进行掌握.8.A解析:A 【解析】要正确认识观测值的意义,观测值同临界值进行比较得到一个概率,这个概率是推断出错误的概率,若从统计量中求出有95%的把握认为吸烟与患肺病有关系,是指有5%的可能性使得推断出现错误 故选A9.D解析:D 【分析】求出x ,代入ˆ 1.212yx =+,可得y ,则12345y y y y y ++++可求解.【详解】由题中所给的点,可以求得24681065x ++++==,代入ˆ 1.212yx =+,可得 1.261219.2y =⨯+=, 所以12345519.296y y y y y ++++=⨯=, 故选:D. 【点睛】该题考查的是有关回归直线方程的应用,涉及到的知识点有回归直线过样本中心点,属于简单题目.10.C解析:C 【分析】令i m =,根据线性回归中心点在回归直线上,求出y ,得出m ,即可求解.【详解】设缺失的数据为),1,2,3,4,5i x m i ==,则样本(),i i m y 数据如下表所示:其回归直线方程为,由表中数据可得,11.1 2.1 2.3 3.3 4.2 2.65y =++++=(),由线性回归方程ˆ1ym =+得, 1.6m =,即10.21 2.2 3.2 1.65++=(),解得 1.96x =.故选:C . 【点睛】本题考查线性回归方程的应用,换元是解题的关键,掌握回归中心点在线性回归直线上,考查计算求解能力,属于中档题.11.D解析:D 【分析】根据题意,可列出y 关于x 的表格,求出,x y ,代入0.4188y kx =-,求出k ,即可求解 【详解】由题,对数据进行处理,得出如下表格:求得49.5x =,0.195y =,因样本中心(,x y 过线性回归方程,将(,x y 代入0.4188y kx =-,得0.0124k =,即0.01240.4188y x =-,年龄在[]60,64对应的x 为62,将62x =代入0.01240.4188y x =-得:0.0124620.41880.35y =⨯-=,对应的爱看人数比为:0.35 故选:D 【点睛】本题考查线性回归方程的应用,样本中心(),x y 过线性回归方程是一个重要特征,属于中档题12.C解析:C 【分析】对于A ,根据数据求出的平均数,众数和中位数即可判断; 对于B ,相关指数R 2越接近1,表示回归的效果越好; 对于C ,根据频率分布直方图判定;对于D ,设随机变量ξ服从正态分布N (4,22),利用对称性可得结论; 【详解】解:①将数据按从小到大的顺序排列为:10、12、14、14、15、15、16、17、17、17,中位数:()1515215b =+÷=;()101214141515161717171014.7a =+++++++++÷=;这组数据的平均数是14.7.因为此组数据中出现次数最多的数是17, 所以17c =是此组数据的众数; 则a b c <<;②2R 越接近于1,表示回归的效果越好,正确;③根据频率分布直方图的意义,因为小矩形的面积之和等于1,频率之和也为1, 所以有各小长方形的面积等于相应各组的频率;故③错; ④∵随机变量ξ服从正态分布()24,2N ,∴正态曲线的对称轴是4x =, ∴1(4)2P ξ>=.故④正确. 故选C :. 【点睛】本题主要考查命题的真假判断,涉及统计的基础知识:频率分布直方图和线性回归及分类变量X ,Y 的关系,属于基础题.13.A解析:A 【分析】根据相关系数知相关系数的性质:r 1≤,且r 越接近1,相关程度越大;且r 越接近0,相关程度越小.r 为正,表示正相关,回归直线方程上升,选出正确结果. 【详解】相关系数r 为正,表示正相关,回归直线方程上升, r 为负,表示负相关,回归直线方程下降,k ∴与r 的符号相同. 故选A . 【点睛】本题考查用相关系数来衡量两个变量之间相关关系的方法,当相关系数为正时,表示两个变量正相关,当相关系数大于0.75时,表示两个变量有很强的线性相关关系.二、解答题14.(1)ˆ0.7 2.3yx =-;(2)记忆力为19的同学的判断力约为11. 【分析】(1)根据题意及公式1221ˆni ii ni i x y nx ybx nx==-=-∑∑算出ˆb,根据公式ˆa y bx =-算出a 即可得出答案;(2)将19x =代入(1)中的回归方程计算即可. 【详解】 解:(1)由题意416283105126158i ii x y==⨯+⨯+⨯+⨯=∑,68101294x +++==,235644y +++==,4222221681012344i i x ==+++=∑,所以2158494140.73444920ˆb-⨯⨯===-⨯,ˆˆ40.79 2.3a y bx =-=-⨯=-, 故线性回归方程为ˆ0.7 2.3y x =- (2)当19x =时,解得ˆ11y= 所以由回归直线方程预测,记忆力为19的同学的判断力约为11. 【点睛】线性回归分析问题的类型及解题方法: (1)求线性回归方程:公式法:利用公式,求出回归系数ˆ,ba .待定系数法:利用回归直线过样本点中心求系数. (2)利用回归方程进行预测:把回归直线方程看作一次函数,求函数值.(3)利用回归直线判断正、负相关:决定正相关还是负相关的是系数ˆb. 15.(1)11天;(2)①见解析,指数拟合模型·t z c d =适合拟合z 与t 的关系;②1.55 【分析】(1)由函数的单调性可知10x ≤时,0.1y x =单调递增,10x >时,10-=x y e 单调递减,得到10x =时,y 达到峰值,再由100.2-<x e 求解不等式得答案; (2)①画出散点图,根据图像可得答案;②求出对于的ˆb 与ˆa 的值,可得z 关于t 的回归方程,通过回归方程估计异常数据.【详解】 解:(1)10x ≤时,0.1y x =单调递增,10x >时,10-=x y e 单调递减,得到10x =时,y 达到峰值,由100.2-<x e 得110ln 0.2lnln 55x -<==-, 10ln5x ∴>+,因为1ln52<<, 11x ∴>,所以估计接种一次后IgM 含量水平有效时段可经历的时间为11天; (2)①散点图如下:根据散点图判断指数拟合模型·t z c d =更适合拟合z 与t 的关系; ②根据散点图可得第4组数据异常,应当予以剔除 由·t z c d =得()ln ln ln ln tu z cdc td ===+6611662222222222110.67 1.58()()39.874 4.85646ˆ0.3512356764()ii i i i i iii i tt u u t unt ubtt tnt ====⨯----⋅-⨯-⨯⨯∴===≈+++++-⨯--∑∑∑∑,0.67 1.580.3540.966a u bt ⨯-=-=-⨯=-, 故ln 0.960.35u z t ==-+, 0.960.35t z e -+∴=当4t =时,0.960.3540.444 1.55z ee -+⨯=== 估计原异常数据对应的4z 值为1.55. 【点睛】方法点睛:(1)正确理解计算ˆb与ˆa 的公式和准确的计算是求线性回归方程的关键. (2)回归直线方程ˆˆˆy a bx=+必过样本点中心(),x y . 16.(1)列联表见解析,没有99%的把握认为一等级的产品与生产线有关;(2)1.6;2.36;A 生产线的获利更稳定. 【分析】(1)由题中数据完成列联表,求出卡方值,和6.635比较即可判断; (2)根据方差公式求出方差即可判断. 【详解】(1)根据已知数据可建立列联表如下:2()200(20653580)()()()()55145100100n ad bc K a b c d a c b d -⨯⨯-⨯==++++⨯⨯⨯2001500150018005.6436.63555145100100319⨯⨯==≈<⨯⨯⨯所以没有99%的把握认为一等级的产品与生产线有关 (2)A 生产线随机抽取的100件产品获利的平均数为:11(1020860620)8100x =⨯⨯+⨯+⨯=(元) 获利方差为222211(108)20(88)60(68)20 1.6100s ⎡⎤=⨯-⨯+-⨯+-⨯=⎣⎦ B 生产线随机抽取的100件产品获利的平均数为: 21(1035840625)8.2100x =⨯⨯+⨯+⨯=(元) 获利方差为222221(108.2)35(88.2)40(68.2)25 2.36100s ⎡⎤=⨯-⨯+-⨯+-⨯=⎣⎦所以2212s s <,则A 生产线的获利更稳定.【点睛】本题考查独立性检验和利用方差判断数据的稳定性,在计算的时候,注意数据的正确性以及计算公式的熟悉性.17.(1)列联表见解析;有99%的把握认为试验成功与材料有关;(2)2.1万元/吨. 【分析】(1)根据所给等高条形图,得到22⨯的列联表,利用公式,求得2K 的观测值,比较即可得到结论;(2)设修复费用为X 万元.得出X 可得0,0.1,0.2,0.3,求得相应的概率,得到X 的分布列,利用公式求得数学期望. 【详解】(1)根据所给等高条形图,得到22⨯的列联表:2K 的观测值()10045205301250507525K ⨯⨯-⨯==⨯⨯⨯,由于12 6.635>,故有99%的把握认为试验成功与材料有关.(2)生产1吨的石墨烯发热膜,所需的修复费用为X 万元.易知X 可得0,0.1,0.2,0.3.()3280327P X ⎛⎫=== ⎪⎝⎭,()21321120.13327P X C ⎛⎫==⨯= ⎪⎝⎭, ()2231260.23327P X C ⎛⎫==⨯= ⎪⎝⎭,()2110.3327P X ⎛⎫===⎪⎝⎭, 则X的分布列为:(分布列也可以不列)修复费用的期望:()100.10.20.30.127272727E X =⨯+⨯+⨯+⨯=. 所以石墨烯发热膜的定价至少为0.111 2.1++=万元/吨,才能实现预期的利润目标. 【点睛】求随机变量X 的期望与方差的方法及步骤: 理解随机变量X 的意义,写出X 可能的全部值;。
协方差的意义和计算公式

协方差的意义和计算公式学过概率统计的孩子都知道,统计里最基本的概念就是样本的均值,方差,或者再加个标准差。
首先我们给你一个含有n个样本的集合,依次给出这些概念的公式描述,这些高中学过数学的孩子都应该知道吧,一带而过。
均值:标准差:方差:很显然,均值描述的是样本集合的中间点,它告诉我们的信息是很有限的,而标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均。
以这两个集合为例,[0,8,12,20]和[8,9,11,12],两个集合的均值都是10,但显然两个集合差别是很大的,计算两者的标准差,前者是8.3,后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。
之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计”。
而方差则仅仅是标准差的平方。
为什么需要协方差?上面几个统计量看似已经描述的差不多了,但我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。
面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子欢迎程度是否存在一些联系啊,嘿嘿~协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义:来度量各个维度偏离其均值的程度,标准差可以这么来定义:协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐就越受女孩子欢迎,嘿嘿,那必须的~结果为负值就说明负相关的,越猥琐女孩子越讨厌,可能吗?如果为0,也是就是统计上说的“相互独立”。
从协方差的定义上我们也可以看出一些显而易见的性质,如:协方差多了就是协方差矩阵上一节提到的猥琐和受欢迎的问题是典型二维问题,而协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算个协方差,那自然而然的我们会想到使用矩阵来组织这些数据。
协方差 样本量

协方差是一种用于刻画两个随机变量相似程度的统计量。
在统计学中,协方差的计算公式为:
协方差= 1/(n-1) Σ[(xi-xavg)(yi-yavg)]
其中,n为样本量,xi和yi是每个样本点的取值,xavg 和yavg分别是x和y的平均值。
样本量n在计算协方差时起到重要的作用。
首先,样本量的大小直接影响到协方差计算的精度。
在样本量较小的情况下,协方差的估计值可能会受到较大的随机误差的影响,因此其准确性可能会较低。
随着样本量的增加,协方差的估计值将逐渐趋近于真实的协方差值,其准确性也会相应提高。
其次,样本量的大小还决定了协方差计算的稳定性。
在样本量较小的情况下,协方差的计算结果可能会受到极端值的影响,导致计算结果不稳定。
而在样本量较大的情况下,极端值对协方差计算结果的影响将被降低,使得协方差的计算结果更加稳定。
因此,在进行协方差计算时,需要选择适当的样本量,以确保计算结果的准确性和稳定性。
一般来说,样本量越大,计算结果的准确性和稳定性就越高。
但在实际应用中,受到各种因素的限制,样本量可能无法无限增加。
因此,在选择
样本量时需要综合考虑各种因素,以达到最佳的协方差计算效果。
协方差分析理论与案例

协⽅差分析理论与案例协⽅差分析理论与案例假设我们有N 个个体的K 个属性在T 个不同时期的样本观测值,⽤it y ,it x ,…,N,t=1,…,T,k=1,…,K 表⽰。
⼀般假定y 的观测值是某随机实验的结果,该实验结果在属性向量x 和参数向量θ下的条件概率分布为(,)f y x θ。
使⽤⾯板数据的最终⽬标之⼀就是利⽤获取的信息对参数θ进⾏统计推断,譬如常假设假定的y 是关于x 的线性函数的简单模型。
协⽅差分析检验是识别样本波动源时⼴泛采⽤的⽅法。
⽅差分析:常指⼀类特殊的线性假设,这类假设假定随机变量y 的期望值仅与所考察个体所属的类(该类由⼀个或多个因素决定)有关,但不包括与回归有关的检验。
⽽协⽅差分析模型具有混合特征,既像回归模型⼀样包含真正的外⽣变量,同时⼜像通常的⽅差⼀样允许每个个体的真实关系依赖个体所属的类。
常⽤来分析定量因素和定性因素影响的线性模型为:*,1,,,1,,it it itit it y x u i N t T αβ'=++== 从两个⽅⾯对回归系数估计量进⾏检验:⾸先,回归斜率系数的同质性;其次,回归截距系数的同质性。
检验过程主要有三步:(1) 检验各个个体在不同时期的斜率和截距是否都相等;(2) 检验(各个体或各时期的)回归斜率(向量)是否都相等; (3) 检验各回归截距是否都相等。
显然,如果接受完全同同质性假设(1),则检验步骤中⽌。
但如果拒绝了完全同质性性假设,则(2)将确定回归斜率是否相同。
如果没有拒绝斜率系数的同质性假设,则(3)确定回归截距是否相等。
(1)是从(2)、(3)分离出来的。
基本思想:在作两组或多组均数1y ,2y ,…,k y 的假设检验前,⽤线性回归分析⽅法找出协变量X 与各组Y 之间的数量关系,求得在假定X 相等时修定均数1y ',2y ',…,k y '然后⽤⽅差分析⽐较修正均数间的差别,这就是协⽅差分析的基本思想。
numpy计算协方差

numpy计算协方差协方差是描述两个变量之间关系的量,在数据分析和机器学习领域扮演非常重要的角色。
在NumPy 中,可以通过`numpy.cov()` 来计算样本数据的协方差。
`numpy.cov()` 的函数原型为:pythonnumpy.cov(m, y=None, rowvar=True, bias=False, ddof=None, fweights=None, aweights=None)其中,参数的含义如下:- `m`:样本数据矩阵,其中每行代表一个变量,每列代表一个观测值。
- `y`:该参数已被废弃,不再使用。
- `rowvar`:一个布尔值,指定矩阵中每行是否代表一个变量。
如果是`False`,则每列代表一个变量。
- `bias`:一个布尔值,指定是否计算偏差。
如果是`True`,则计算样本偏差的协方差(除以N-1),否则计算总体方差的协方差(除以N)。
- `ddof`:自由度的减少量,用于计算无偏估计的方差和标准差。
- `fweights`:一个数组,用于指定样本每个观测值的权重,每个观测值会根据其权重被重复计算多次。
- `aweights`:一个数组,用于指定每个变量的权重,可以用于给各个变量分配不同的重要性权重。
在计算协方差矩阵之前,需要将每个变量的平均值减去,这样可以让矩阵中心在原点,方便协方差的计算。
可以使用`numpy.mean()` 函数来计算每列的平均值,然后将其减去。
例如,假设我们有一个n \times m 的样本数据矩阵`X`,可以使用以下代码计算出每列的平均值并减去:python# 计算每列的平均值mean = numpy.mean(X, axis=0)# 减去平均值X = X - mean然后,我们可以使用`numpy.cov()` 函数来计算协方差矩阵。
以下是一个例子:pythonimport numpy# 创建一个二维的数据矩阵X = numpy.array([[1, 2, 3, 4, 5],[5, 4, 3, 2, 1],[0, 1, 0, 1, 0]])# 计算每列的平均值mean = numpy.mean(X, axis=0)# 减去平均值X = X - mean# 计算协方差矩阵cov = numpy.cov(X, rowvar=False)# 打印协方差矩阵print(cov)输出结果如下:[[ 2.5 -2.5 0. ][-2.5 2.5 0. ][ 0. 0. 0.5]]协方差矩阵是一个对称矩阵,对角线上的元素是每个变量的方差,非对角线上的元素是每对变量之间的协方差。