Windows环境下Kafka与Zookeeper安装配置与启动过程
【Kafka源码】Kafka启动过程

【Kafka源码】Kafka启动过程⼀般来说,我们是通过命令来启动kafka,但是命令的本质还是调⽤代码中的main⽅法,所以,我们重点看下启动类Kafka。
源码下下来之后,我们也可以通过直接运⾏Kafka.scala中的main⽅法(需要指定启动参数,也就是server.properties的位置)来启动Kafka。
因为kafka依赖zookeeper,所以我们需要提前启动zookeeper,然后在server.properties中指定zk地址后,启动。
下⾯我们⾸先看⼀下main()⽅法:def main(args: Array[String]): Unit = {try {val serverProps = getPropsFromArgs(args)val kafkaServerStartable = KafkaServerStartable.fromProps(serverProps)// attach shutdown handler to catch control-cRuntime.getRuntime().addShutdownHook(new Thread() {override def run() = {kafkaServerStartable.shutdown}})kafkaServerStartable.startupkafkaServerStartable.awaitShutdown}catch {case e: Throwable =>fatal(e)System.exit(1)}System.exit(0)}我们慢慢来分析下,⾸先是getPropsFromArgs(args),这⼀⾏很明确,就是从配置⽂件中读取我们配置的内容,然后赋值给serverProps。
第⼆步,KafkaServerStartable.fromProps(serverProps),object KafkaServerStartable {def fromProps(serverProps: Properties) = {KafkaMetricsReporter.startReporters(new VerifiableProperties(serverProps))new KafkaServerStartable(KafkaConfig.fromProps(serverProps))}}这块主要是启动了⼀个内部的监控服务(内部状态监控)。
Kafka安装及配置过程
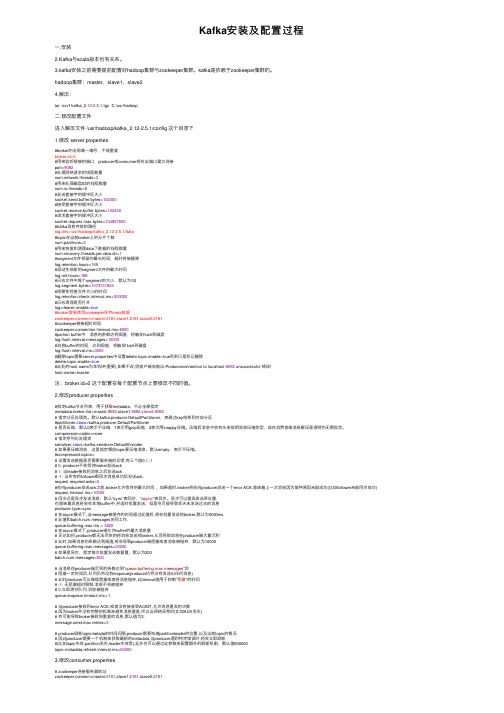
Kafka安装及配置过程⼀.安装2.Kafka与scala版本也有关系。
3.kafka安装之前需要提前配置好hadoop集群与zookeeper集群。
kafka是依赖于zookeeper集群的。
hadoop集群:master,slave1,slave24.解压:tar -zxvf kafka_2.12-2.5.1.tgz -C /usr/hadoop⼆.修改配置⽂件进⼊解压⽂件 /usr/hadoop/kafka_2.12-2.5.1/config 这个⽬录下1.修改 server.properties#broker的全局唯⼀编号,不能重复broker.id=0#⽤来监听链接的端⼝,producer或consumer将在此端⼝建⽴连接port=9092#处理⽹络请求的线程数量work.threads=3#⽤来处理磁盘IO的线程数量num.io.threads=8#发送套接字的缓冲区⼤⼩socket.send.buffer.bytes=102400#接受套接字的缓冲区⼤⼩socket.receive.buffer.bytes=102400#请求套接字的缓冲区⼤⼩socket.request.max.bytes=104857600#kafka消息存放的路径log.dirs=/usr/hadoop/kafka_2.12-2.5.1/data#topic在当前broker上的分⽚个数num.partitions=2#⽤来恢复和清理data下数据的线程数量num.recovery.threads.per.data.dir=1#segment⽂件保留的最长时间,超时将被删除log.retention.hours=168#滚动⽣成新的segment⽂件的最⼤时间log.roll.hours=168#⽇志⽂件中每个segment的⼤⼩,默认为1Glog.segment.bytes=1073741824#周期性检查⽂件⼤⼩的时间log.retention.check.interval.ms=300000#⽇志清理是否打开log.cleaner.enable=true#broker需要使⽤zookeeper保存meta数据zookeeper.connect=master:2181,slave1:2181,slave2:2181#zookeeper链接超时时间zookeeper.connection.timeout.ms=6000#partion buffer中,消息的条数达到阈值,将触发flush到磁盘log.flush.interval.messages=10000#消息buffer的时间,达到阈值,将触发flush到磁盘log.flush.interval.ms=3000#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除delete.topic.enable=true#此处的为本机IP(重要),如果不改,则客户端会抛出:Producerconnection to localhost:9092 unsuccessful 错误!=master注:broker.id=0 这个配置在每个配置节点上要修改不同的值。
Window下zookeeper安装和启动

Window下zookeeper安装和启动请参考和1.下载稳定的最新版本的zookeeper,这⾥下载了zookeeper-3.5.7版本注意 apache-zookeeper-3.5.7-bin.tar.gz 才是启动zookeepr需要的,千万别下载错。
2.解压缩 apache-zookeeper-3.5.7-bin.tar.gz 。
在该⽂件夹下打开cmd命令,使⽤如下命令解压缩⽂件tar -zxvf apache-zookeeper-3.7.7-bin.tar.gz3.复制/conf ⽂件夹下的zoo_sample.cfg 并重命名为zoo.cfg。
修改zoo.cfg⽂件如下(配置log路径)添加如下两⾏三⾏设置log⽂件路径并修改zookeeper的启动端⼝为8082,默认为8080dataDir=C:\\zookeeper\\apache-zookeeper-3.5.7-bin\\datadataLogDir=C:\\zookeeper\\apache-zookeeper-3.5.7-bin\\logadmin.serverPort=8082完整⽂件如下# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial# synchronization phase can takeinitLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.dataDir=C:\\zookeeper\\apache-zookeeper-3.5.7-bin\\datadataLogDir=C:\\zookeeper\\apache-zookeeper-3.5.7-bin\\log# the port at which the clients will connectclientPort=2181# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the# administrator guide before turning on autopurge.## /doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1#change server port, 8080 by defaultadmin.serverPort=80824.修改 bin\zkEnv.cmd⽂件,配置JAVA_HOME,否则启动zookeepr会报错参考添加set JAVA_HOME="C:\java\jdk1.8.0_212-X64"修改后的部分zkEnv.cmd⽂件如下@REM setup java environment variablesset JAVA_HOME="C:\java\jdk1.8.0_212-X64"if not defined JAVA_HOME (echo Error: JAVA_HOME is not set.goto :eof)set JAVA_HOME=%JAVA_HOME:"=%if not exist "%JAVA_HOME%"\bin\java.exe (echo Error: JAVA_HOME is incorrectly set: %JAVA_HOME%echo Expected to find java.exe here: %JAVA_HOME%\bin\java.exegoto :eof)5.启动zookeeper,在/bin⽬录下打开cmd窗⼝,并执⾏命令 zkServer.cmd。
kafka入门教程

kafka入门教程
Kafka是一个分布式流处理平台,被广泛应用于大数据处理和
实时数据流处理的场景。
它具有高吞吐量、可扩展性强、持久性和容错能力、以及多种数据处理模式等特点。
本教程将引导你进入Kafka的世界,教你如何安装、配置和使
用Kafka。
下面是教程内容概述:
1. 下载和安装Kafka
首先,你需要从Kafka的官方网站上下载最新版本的Kafka。
接下来,我们将介绍如何在不同操作系统上进行安装和配置。
2. 配置Kafka
在安装完成后,你需要对Kafka进行一些必要的配置。
这包
括设置Zookeeper连接、主题(Topic)的配置、分区(Partition)的配置等。
3. 创建生产者和消费者
一旦配置完成,你就可以创建Kafka的生产者和消费者实例了。
生产者可将消息发送到指定的主题,消费者则可以订阅特定的主题并消费其中的消息。
4. 发送和接收消息
通过创建生产者并将消息发送至主题,你可以实现向Kafka
集群发送消息的功能。
消费者可以通过订阅主题并接收消息来完成消息消费的功能。
5. Kafka的高级特性
在熟悉基本使用后,你还可以学习一些更高级的Kafka特性,如消息分区、消息持久化、消息的顺序性等。
6. 故障处理和调优
正确处理故障和进行性能优化是使用Kafka的关键。
我们将
介绍一些常见的故障处理和性能优化技巧。
通过本教程,你将能够迅速上手使用Kafka,并了解它的基本
概念和常用功能。
希望这对你入门Kafka有所帮助!。
Zookeeper配置开机启动

Zookeeper配置开机启动ZooKeeper是Hadoop的正式子项目;Hadoop是一个分布式系统基础架构,由Apache基金会所开发;Zookeeper能够用来leader选举;也就是你有N+1台同样的服务器的时候又zookeeper来决定谁是主服务器;当我们配置好zookeeper之后都希望当系统重启之后能够自动启动zookeeper程序;今天小编就为大家介绍如何得配置zookeeper的开机启动本次演示环境是在Centos7下完成的;其他版本的centos都是一样的操作步骤如下:1.请自行下载安装配置zookeeper的服务器环境本经验仅仅介绍如何配置zookeeper的开机自动启动2.首先请登陆你的linux服务器,用cd 命令切换到/etc/rc.d/init.d/目录下3.接着用touch zookeeper创建一个文件4.然后为这个文件添加可执行权限chmod +x zookeeper5.接着用vi zookeeper来编辑这个文件6.接着在zookeeper里面输入如下内容(路径根据实际情况编写)#!/bin/bash#chkconfig:2345 20 90#description:zookeeper#processname:zookeepercase $1 instart) su root /usr/local/sw/zookeeper/bin/zkServer.sh start;;stop) su root /usr/local/sw/zookeeper/bin/zkServer.sh stop;;status) su root /usr/local/sw/zookeeper/bin/zkServer.sh status;;restart) su root /usr/local/sw/zookeeper/bin/zkServer.sh restart;;*) echo "require start|stop|status|restart" ;;esac输入:wq 保存退出7.这个时候我们就可以用service zookeeper start/stop来启动停止zookeeper服务了8.最后一点我们需要开机自动启动,所以需要添加到启动里面。
kafka+zookeeper篇(组件、原理、使用场景、面试)

kafka zookeeper篇(组件、原理、使用场景、面试)Kafka与Zookeeper的结合:1. Kafka是一个开源流处理平台,提供流数据生产和消费的服务。
它主要用于构建实时数据流管道和应用,如日志收集、消息分发、流数据处理等。
2. Zookeeper是一个分布式协调服务,提供分布式应用程序的数据同步、配置管理和服务发现等功能。
Kafka依赖于Zookeeper来管理集群的元数据信息和协调集群中的broker节点。
Kafka与Zookeeper的结合原理:1. Kafka集群中的每个broker节点都会将自己注册到Zookeeper中,并保存自身的元数据信息,如配置信息和broker状态等。
2. Zookeeper保存了整个Kafka集群的元数据信息,包括Topic信息、Partition信息和Broker信息等。
这些信息对Kafka的分布式协调非常重要,可以确保Kafka 集群的正常运行。
3. 当Kafka客户端进行生产或消费操作时,它会首先与Zookeeper进行交互,获取集群的状态信息和元数据信息,然后根据这些信息进行相应的操作。
Kafka与Zookeeper的使用场景:1. Kafka在实时数据处理领域广泛应用,如日志收集、消息分发和流数据处理等。
它可以处理大量的数据流,并提供高吞吐量和低延迟的服务。
2. Zookeeper常用于分布式系统中的协调和服务发现。
它可以管理分布式节点的状态信息和元数据信息,提供一致性和可靠性保证。
Kafka与Zookeeper的面试问题:1. Kafka是什么?它有哪些特点?2. Zookeeper是什么?它有哪些功能?3. Kafka与Zookeeper的关系是什么?它们是如何结合的?4. Kafka如何保证数据的安全性和可靠性?5. Zookeeper在Kafka中的作用是什么?它如何管理Kafka集群的元数据信息?。
kafka在windows下的安装和配置

kafka在windows下的安装和配置博主最近在学习有关kafka的配置安装以及在spring的集成使⽤。
但⽹上关于kafka的配置参考资料基本都是于linux下的配置,于是博主在整理了相关windows下kafka的配置记录在博客⾥。
由于是简单配置所以在这⾥只建了⼀个topic以及⼀个producer和两个consumer。
在官⽹上下载 zookeeper和kafka(我下的版本kafka_2.11-0.11.0.0,这个版本中bin⽬录下有windows⽬录),注意不要下载源码包(名字中带有src),否则启动的时候会报错。
1、配置好jdk环境2、解压zookeeper到指定⽬录,找到解压后⽬录中conf⽂件夹中zoo_sample - 副本.cfg⽂件,复制在conf中改名为zoo.cfg。
在bin⽂件夹中打开zkServer.bat启动zookeeper。
⾄此,zookeeper启动完成。
3、解压kafka到指定⽬录。
查看kafka根⽬录中config⽂件夹下server.properties,确认其中关于zookeeper的连接端⼝和zookeep中zoo.cfg的端⼝⼀致。
3.1、启动kafka 在cmd中进⼊kafka根⽬录。
输⼊以下命令: .\bin\windows\kafka-server-start.bat .\config\server.properties kafka启动成功 3.2、创建topic 在cmd中进⼊kafka\bin\windows⽬录,输⼊以下命令: kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test 创建成功 3.3、创建kafka producer 在cmd中进⼊kafka\bin\windows⽬录,输⼊以下命令: kafka-console-producer.bat --broker-list localhost:9092 --topic test 注意这⾥的端⼝和server.properties的端⼝号⼀致。
windows下部署kafka日记_20150514

1.修改 log4j.properties 文件中的“kafka.logs.dir=logs ”为“kafka.logs.dir=/tmp/logs”。
2.修 改 test-log4j.properties 文 件 中 的 4 处 “ File=logs/server.log ” 为
“File=/tmp/logs/server.log”。
打开命令提示符窗口,在 kafka_2.11-0.8.2.1/bin 目录下执行如下命令: kafka-console-producer.bat --broker-list localhost:9093 --topic my-replicated-topic 启动成功后,即可在此窗口输入测试内容,回车后即可发送成功。
十二、未解决的异常信息
命令提示符还会输入一些异常信息,还未解决。但是目前看,不影响使用。 1. 启动 kafka 时: [2015-05-14 17:36:50,027] INFO Initiating client connection, connectString=localhost:2181 sessionTimeout=6000 watcher=org.I0Itec.zkclient.ZkClient@2e716cb7 (org.apache.zo okeeper.ZooKeeper) [2015-05-14 17:36:50,058] INFO Opening socket connection to server 127.0.0.1/127.0.0.1:2181. Will not attempt to authenticate using SASL (ng.SecurityException: 无 法定位登录配置) (org.apache.zookeeper.ClientCnxn) [2015-05-14 17:36:50,063] INFO Socket connection established to 127.0.0.1/127.0.0.1:2181, initiating session (org.apache.zookeeper.ClientCnxn) [2015-05-14 17:36:50,110] INFO Session establishment complete on server 127.0.0.1/127.0.0.1:2181, sessionid = 0x14d51c7fc560000, negotiated timeout = 6000 (org.apache.zoo keeper.ClientCnxn) [2015-05-14 17:36:50,112] INFO zookeeper state changed (SyncConnected) (org.I0Itec.zkclient.ZkClient) [2015-05-14 17:36:50,273] INFO Loading logs. (kafka.log.LogManager) [2015-05-14 17:36:50,323] INFO Recovering unflushed segment 0 in log my-replicated-topic-0.
kafka安装及配置过程

kafka安装及配置过程⼀、安装kafka根据Scala版本不同,⼜分为多个版本,我不需要使⽤Scala,所以就下载官⽅推荐版本kafka_2.12-2.4.0.tgz。
使⽤tar -xzvf kafka_2.12-2.4.0.tgz 解压为了使⽤⽅便,可以创建软链接kafka0⼆、Zookeeper配置当前下载的kafka程序⾥⾃带Zookeeper,可以直接使⽤其⾃带的Zookeeper建⽴集群,也可以单独使⽤Zookeeper安装⽂件建⽴集群。
1. 单独使⽤Zookeeper安装⽂件建⽴集群Zookeeper的安装及配置可以参考另⼀篇博客,⾥⾯有详细介绍2. 直接使⽤其⾃带的Zookeeper建⽴集群kafka⾃带的Zookeeper程序脚本与配置⽂件名与原⽣Zookeeper稍有不同。
kafka⾃带的Zookeeper程序使⽤bin/zookeeper-server-start.sh,以及bin/zookeeper-server-stop.sh来启动和停⽌Zookeeper。
⽽Zookeeper的配制⽂件是config/zookeeper.properties,可以修改其中的参数(1)启动Zookeeperbin/zookeeper-server-start.sh -daemon config/zookeeper.properties加-daemon参数,可以在后台启动Zookeeper,输出的信息在保存在执⾏⽬录的logs/zookeeper.out⽂件中。
对于⼩内存的服务器,启动时有可能会出现如下错误os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error='Not enough space' (errno=12)可以通过修改bin/zookeeper-server-start.sh中的参数,来减少内存的使⽤,将下图中的-Xmx512M -Xms512M改⼩。
Ubuntu18.04设置Zookeeper和kafka开机自启动

Ubuntu18.04设置zookeeper和kafka开机自启动1 进入/etc/init.d/目录cd /etc/init.d/2 创建zookeeper文件touch zookeeper3 赋予文件权限sudo chmod +x zookeeper4命令写入执行脚本vim zookeeper#! /bin/sh### BEGIN INIT INFO# Short-Description: Zookeeper# Description: Zookeeper# Provides: flex# Required-Start: $local_fs $network# Required-Stop: $local_fs# Default-Start: 2 3 4 5# Default-Stop: 0 1 6### END INIT INFOcase "$1" instart)su -l root -c ' /usr/local/hcj/zookeeper-3.3.4/bin/zkServer.sh start'exit 0;;stop)su -l root -c ' /usr/local/hcj/zookeeper-3.3.4/bin/zkServer.sh stop' exit 0;;*) echo 'require start|stop'exit 1;;esac5重新载入配置文件systemctl reload zookeeper6设置启动开机自启动systemctl enable zookeeper7重启reboot8查看是否启动成功sudo jps9 kafka自启动vim /etc/rc-local#添加以下启动脚本cd /home/hcj/kafka/kafka_2.11-1.0.2bash bin/kafka-server-start.sh -daemon config/server.properties bash bin/kafka-server-start.sh -daemon config/server1.properties bash bin/kafka-server-start.sh -daemon config/server2.properties如果启动不成功修改启动文件配置vim kafka-run-class.sh将JAVA_MAJOR_VERSION=$($JAVA -version 2>&1 | sed -E -n 's/.* version "([^.-]*).*"/\1/p')修改为JAVA_MAJOR_VERSION=$($JAVA -version 2>&1 | sed -E -n 's/.* version "([^.-]*).*/\1/p')[Unit]# Zookeeper服务的描述Description=Zookeeper Service# 服务依赖—在什么服务之后启动,一般为在网络服务启动后启动After=network.target[Service]# 服务类型—如果是shell脚本的方式,则Type=forking,否则不指定作何值(也就是去掉该配置项)Type=forking# 启动环境参数# 此脚本指定了Zookeeper日志和Java的目录Environment=ZOO_LOG_DIR=/usr/local/hcj/zookeeper-3.3.4/log/Environment=JAVA_HOME=/usr/local/hcj/jdk1.8.0_231# 启动命令ExecStart=/usr/local/hcj/zookeeper-3.3.4/bin/zkServer.sh start# 停止命令ExecStop=/usr/local/hcj/zookeeper-3.3.4/bin/zkServer.sh stop# 重启命令ExecReload=/usr/local/hcj/zookeeper-3.3.4/bin/zkServer.sh restart[Install]WantedBy=multi-user.target。
ZooKeeper设置开机启动

ZooKeeper设置开机启动1 在init.d⽬录下新建脚本⽂件进⼊到/etc/rc.d/init.d⽬录下,命令是:cd /etc/rc.d/init.d新建⼀个名为zookeeper的⽂件,命令是:touch zookeeper如图:1.1⽂件内容的第⼀种⽅案(推荐)使⽤vim命令修改⽂件内容,⽂件内容的写法有很多,除了上⾯的第⼀种⽅案,⽤下⾯的这种也可以:#!/bin/bash#chkconfig: 2345 10 90#description: service zookeeperexport JAVA_HOME=/opt/java/jdk1.8.0_121export ZOO_LOG_DIR=/opt/zookeeper/logZOOKEEPER_HOME=/opt/zookeeper/zookeeper-3.4.10su root ${ZOOKEEPER_HOME}/bin/zkServer.sh "$1"1.2⽂件内容的第⼆种⽅案使⽤vim命令修改⽂件内容,⽂件内容是:#!/bin/bash#chkconfig: 2345 10 90#description: service zookeeperexport JAVA_HOME=/usr/java/jdk1.7.0_45export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.6case "$1" in start) su root ${ZOOKEEPER_HOME}/bin/zkServer.sh start;; start-foreground) su root ${ZOOKEEPER_HOME}/bin/zkServer.sh start-foreground;; stop) su root ${ZOOKEEPER_HOME}/bin/zkServer.sh stop;; status) su root ${ZOOKEEPER_HOME}/bin/zkServer.sh status;; restart) su root ${ZOOKEEPER_HOME}/bin/zkServer.sh restart;; upgrade)su root ${ZOOKEEPER_HOME}/bin/zkServer.sh upgrade;; print-cmd)su root ${ZOOKEEPER_HOME}/bin/zkServer.sh print-cmd;; *) echo "requirestart|start-foreground|stop|status|restart|print-cmd";;esac1.3 其他说明注意1:新建⽂件的命令是touch,编辑⽂件的命令⽤vi和vim都⾏。
kafka使用手册

kafka使用手册Kafka是一种开源的分布式消息传递系统,由于其高效性以及可扩展性,近年来在大数据应用领域中越来越得到广泛的使用。
下面就来介绍一下如何使用Kafka。
安装Kafka首先需要从Apache Kafka官方网站上下载最新版本的Kafka。
下载完成后,解压缩到本地磁盘中。
启动Kafka启动Kafka需要依次启动多个服务,以下是完整的启动顺序:- ZooKeeper服务- Kafka服务首先启动ZooKeeper服务,进入到Kafka解压缩后的目录,运行以下命令:$ bin/zookeeper-server-start.sh config/zookeeper.properties接着启动Kafka服务,同样是在Kafka目录下运行以下命令:$ bin/kafka-server-start.sh config/server.properties创建Topic在Kafka中,消息以Topic为单位进行传输。
每个Topic会被分成多个Partition,每一个Partition顺序存储消息。
创建Topic可以使用以下命令:$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic <topic-name>- --zookeeper:指定ZooKeeper的地址。
- --replication-factor:指定同一Topic消息的备份数量,大于1时表示开启了数据冗余。
- --partitions:指定Topic分区的数量。
- --topic:指定Topic的名字。
生产消息使用命令行工具进行消息生产,可以使用以下命令:$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic <topic-name>- --broker-list:指定了Kafka Broker的地址列表。
Windows环境下Kafka与Zookeeper安装配置与启动过程

Windows环境下Kafka与Zookeeper安装配置与启动过程1.软件下载1.1下载jdk1.8.0_601.2 下载zookeeper-3.4.9.tar.gz1.3下载kafka_2.12-0.10.2.0.tgz2.环境准备安装配置java环境,配置jdk1.8为操作系统java运行时环境2.1安装jdk1.8将网站下载的jdk1.8.0_60压缩包解压缩到c:\program files\java目录下,如下图:2.2 配置java环境如图在“控制面板--系统和安全--系统”页,鼠标点击“高级系统设置”,在弹出的“系统属性”页面选择高级tab页:点击“环境变量”按钮后,在弹出的环境变量对话框中点击“系统变量”栏中的“新建”按钮,在弹出的“新建系统变量”窗口中输入如下::点确定确定后,再配置JRE_HOME同时打开一个cmd窗口在其中输入:SET JA V A_HOME=C:\Program Files\Java\jdk1.8.0_60SETCLASSPATH=.;%JA V A_HOME%/lib/dt.jar;%JA V A_HOME%/lib/tools.jar;%JRE_HOME%\lib\;%JRE_HOME%\lib\r t.jar;%JRE_HOME%\lib\jce.jar;%JRE_HOME%\lib\metadata-extractor-2.4.0-beta-1.jar;%JRE_HOME%\lib\mediautil-1.0.jar;SET Path=%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin;在命令行输入java -version,输出如下,表明系统已启用java配置3.Zookeeper安装配置3.1 解压与目录设计在目录e:\apache\zookeeper\下解压文件zookeeper-3.4.9.tar.gz,并将解压文件夹改名为zk0,复制该文件夹到相同目录下分别改名为zk1、zk2.3.2在zk0\zk1\zk2目录下都创建空文件夹data和logs,如下图3.2在data目录中创建文件myid,设置zookeeper服务器的序号。
Kafka在windows下的配置使用

Kafka在windows下的配置使⽤下⾯就开始配置和使⽤1、下载2、下载完成之后,直接解压,⽬录结构是这样的bin⽬录是各种启动⽂件,config是相关参数配置⽂件,logs是⾃建的⽇志⽂件,libs是使⽤到的相关jar⽂件启动⽂件中有windows项,⽤例直接启动相关服务。
3、修改配置参数进⼊config⽬录,编辑 server.properties⽂件,找到并编辑log.dirs= D:\\Tools\\kafka_2.11-1.0.0\\logs,找到并编辑zookeeper.connect=localhost:2181。
表⽰本地运⾏。
(Kafka会按照默认,在9092端⼝上运⾏,并连接zookeeper的默认端⼝:2181)4、启动服务,在dos服务下输⼊下⾯命令进⾏启动D:\tools\kafka_2.12-2.1.0\bin\windows\zookeeper-server-start.bat D:\tools\kafka_2.12-2.1.0\config\zookeeper.properties⾸先启动,zookeeper服务,对应加载zookeeper的配置⽂件,kafka依赖zookeeper监控其状态D:\tools\kafka_2.12-2.1.0\bin\windows\kafka-server-start.bat D:\tools\kafka_2.12-2.1.0\config\server.properties然后启动kafka服务,对应加载相应配置⽂件查看现有主题 topic查看 broker6、编写测试类查看相关状况import org.apache.kafka.clients.consumer.ConsumerRebalanceListener;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import mon.TopicPartition;import java.util.Arrays;import java.util.Collection;import java.util.Properties;/*** Created by songxiaofei on 2018-12-27.*/public class ConsumerMessage {public static void main(String[] args){Properties props = new Properties();props.put("bootstrap.servers", "10.1.9.3:9092");props.put("group.id", "test");props.put("mit", "true");props.put("mit.interval.ms", "1000");props.put("key.deserializer", "mon.serialization.StringDeserializer");props.put("value.deserializer", "mon.serialization.StringDeserializer");final KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(props);consumer.subscribe(Arrays.asList("buy"),new ConsumerRebalanceListener() {public void onPartitionsRevoked(Collection<TopicPartition> collection) {}public void onPartitionsAssigned(Collection<TopicPartition> collection) {//将偏移设置到最开始consumer.seekToBeginning(collection);}});while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records)System.out.printf("offset = %d, key = %s, value = %s%n,checksum=%s", record.offset(), record.key(), record.value(),record.checksum());}}}执⾏代码,可以查看相关⽇志,⽤来查看kafka的配置情况D:\tools\Java\jdk1.8.0_31\bin\java "-javaagent:D:\tools\JetBrains\IntelliJ IDEA 2018.1\lib\idea_rt.jar=64422:D:\tools\JetBrains\IntelliJ IDEA 2018.1\bin" -Dfile.encoding=UTF-8 -classpath D:\tools\Java\jdk1.8.0_31\jre\lib\charsets.jar;D:\tools\Java\j log4j:WARN No such property [maxFileSize] in org.apache.log4j.DailyRollingFileAppender.log4j:WARN No such property [maxBackupIndex] in org.apache.log4j.DailyRollingFileAppender.2019-01-16 15:56:36,600 [main] [org.apache.kafka.clients.consumer.ConsumerConfig]-[INFO] ConsumerConfig values:metric.reporters = []metadata.max.age.ms = 300000partition.assignment.strategy = [org.apache.kafka.clients.consumer.RangeAssignor]reconnect.backoff.ms = 50sasl.kerberos.ticket.renew.window.factor = 0.8max.partition.fetch.bytes = 1048576bootstrap.servers = [10.1.9.3:9092]ssl.keystore.type = JKSmit = truesasl.mechanism = GSSAPIinterceptor.classes = nullexclude.internal.topics = truessl.truststore.password = nullclient.id =ssl.endpoint.identification.algorithm = nullmax.poll.records = 2147483647check.crcs = truerequest.timeout.ms = 40000heartbeat.interval.ms = 3000mit.interval.ms = 1000receive.buffer.bytes = 65536ssl.truststore.type = JKSssl.truststore.location = nullssl.keystore.password = nullfetch.min.bytes = 1send.buffer.bytes = 131072value.deserializer = class mon.serialization.StringDeserializergroup.id = testretry.backoff.ms = 100sasl.kerberos.kinit.cmd = /usr/bin/kinit = nullsasl.kerberos.ticket.renew.jitter = 0.05ssl.trustmanager.algorithm = PKIXssl.key.password = nullfetch.max.wait.ms = 500sasl.kerberos.min.time.before.relogin = 60000connections.max.idle.ms = 540000session.timeout.ms = 30000metrics.num.samples = 2key.deserializer = class mon.serialization.StringDeserializerssl.protocol = TLSssl.provider = nullssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]ssl.keystore.location = nullssl.cipher.suites = nullsecurity.protocol = PLAINTEXTssl.keymanager.algorithm = SunX509metrics.sample.window.ms = 30000auto.offset.reset = latest7、使⽤命令⾏创建topicD:\tools\kafka_2.12-2.1.0\bin\windows\kafka-topics.bat --create --zookeeper localhost:12181 --replication-factor 1 --partitions 1 --topic hello查看已有的topicD:\tools\kafka_2.12-2.1.0\bin\windows\kafka-topics.bat --list --zookeeper 127.0.0.1:12181创建⼀个消息⽣产者,同时创建⼀个消息消费者,去接收消息⽣产者发来的消息D:\tools\kafka_2.12-2.1.0\bin\windows\kafka-console-producer.bat --broker-list 127.0.0.1:9092 --topic hello 创建⼀个消息⽣产者D:\tools\kafka_2.12-2.1.0\bin\windows\kafka-console-consumer.bat --bootstrap-server 127.0.0.1:9092 --topic hello --from-beginning 创建⼀个消息消费者。
WindowsZookeeper安装过程及启动图解

WindowsZookeeper安装过程及启动图解
⼆,下载下来解压后,在根⽬录添加data和log⽂件夹
三,将conf⽬录下的zoo_sample.cfg⽂件,复制⼀份,重命名为zoo.cfg,修改zoo.cfg配置⽂件,dataDir和dataLogDir dataDir=G:\\zookeeper\\zookeeper3.5.6\\
datadataLogDir=G:\\zookeeper\\zookeeper3.5.6\\log
四,设置环境变量,在系统环境变量添加ZOOKEEPER_HOME名,地址是指向你的zk包地址
ZOOKEEPER_HOME:本⽂我的zookeeper根⽬录是-G:\zookeeper\zookeeper
然后找到path添加,以下两条配置
1》%ZOOKEEPER_HOME%\bin
2》%ZOOKEEPER_HOME%\conf
五,进⼊本地的G:\zookeeper\zookeeper3.5.6\bin
点击 zkServer.cmd 进⾏启动
PS,如果遇到zkServer.cmd打开闪退的现象,我们应该进⾏⼀下来显⽰错误在哪⾥,右键编辑zkServer.cmd
在结尾的位置添加pause,然后双击运⾏zkServer.cmd,就会显⽰错误信息,⽽不是闪退的zkServer.cmd
六,如果以上步骤没问题,我们打开zkServer.cmd,然后打开zkCli.cmd,证明zookeeper已经配置成功,如下图
以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。
Windows下zookeeper安装及配置

Windows下zookeeper安装及配置zookeeper有单机、伪集群、集群三种部署⽅式,可根据⾃⼰对可靠性的需求选择合适的部署⽅式。
本章主要讲述单机部署⽅式。
系统要求zookeeper可以运⾏在多种系统平台上⾯,表1展⽰了zk⽀持的系统平台,以及在该平台上是否⽀持开发环境或者⽣产环境。
表1:zookeeper⽀持的运⾏平台系统开发环境⽣产环境Linux⽀持⽀持Solaris⽀持⽀持FreeBSD⽀持⽀持Windows⽀持不⽀持MacOS⽀持不⽀持zookeeper是⽤Java编写的,运⾏在Java环境上,因此,在部署zk的机器上需要安装Java运⾏环境。
为了正常运⾏zk,我们需要JRE1.6或者以上的版本。
⼀、下载进⼊要下载的版本⽬录,选择tar.gz⽂件下载⼆、解压解压zookeeper-3.4.10.tar.gz⽂件到D:\zookeeper-3.4.10三、配置⽂件修改3.1、进⼊D:\zookeeper-3.4.10\conf⽬录拷贝zoo_sample.cfg⽂件为zoo.cfg.3.2、编辑zoo.cfg,添加下图内容:ticktime时长单位为毫秒,为zk使⽤的基本时间度量单位。
例如,1 * tickTime是客户端与zk服务端的⼼跳时间,2 * tickTime是客户端会话的超时时间。
tickTime的默认值为2000毫秒,更低的tickTime值可以更快地发现超时问题,但也会导致更⾼的⽹络流量(⼼跳消息)和更⾼的CPU使⽤率(会话的跟踪处理)。
dataDir⽆默认配置,必须配置,⽤于配置存储快照⽂件的⽬录。
dataLogDir⽇志路径clientPortzk服务进程监听的TCP端⼝,默认情况下,服务端会监听2181端⼝。
四、配置环境变量4.1、添加变量 ZOOKEEPER_HOME变量值:D:\zookeeper-3.4.104.2、修改变量 path添加内容:;%ZOOKEEPER_HOME%/bin;%ZOOKEEPER_HOME%/conf 五、启动运⾏D:\zookeeper-3.4.10\bin\⽬录下的zkServer.cmd,出现如下界⾯代表安装成功:。
zookeeper+kafka 集群工作原理

Zookeeper与Kafka集群工作原理:技术报告一、概述在现代分布式系统中,Zookeeper和Kafka是两个重要的组件,它们各自扮演着不同的角色,并在共同协作中,提供了强大的分布式服务。
Zookeeper是一个分布式协调服务,主要用于管理分布式系统的状态,而Kafka则是一个分布式流平台,用于处理和传输实时数据。
二、Zookeeper工作原理Zookeeper的核心是一个分布式协调服务,它为分布式系统提供了一个集中式的配置管理、命名服务、状态同步等服务。
Zookeeper通过一种称为ZNode(节点)的数据结构来存储数据,这些数据结构类似于文件系统中的目录和文件。
Zookeeper的工作原理基于Paxos算法,这是一种解决分布式系统一致性的算法。
Zookeeper集群中的每个节点都维护了一份数据副本,并通过互相之间的通信来保持数据的一致性。
Zookeeper的集群架构保证了高可用性和容错性,即使部分节点发生故障,整个系统仍能正常工作。
三、Kafka集群工作原理Kafka是一个分布式流平台,它被设计用来处理和传输大量的实时数据。
Kafka集群由多个Kafka broker组成,每个broker负责存储一部分数据。
生产者负责将数据发送到Kafka集群,而消费者则从集群中读取数据。
Kafka的数据存储在称为topic的流中。
当数据被生产者发送到topic时,它被存储在broker中,并可以由消费者读取。
Kafka的强大之处在于它的高吞吐量和低延迟,这使得它能够处理大量的实时数据流。
Kafka的另一个重要特性是它的分布式特性。
在Kafka中,每个broker都是一个独立的节点,可以独立地接收和存储数据。
此外,Kafka还提供了副本机制,即一个topic的数据可以在多个broker上存储副本,以提供数据冗余和容错性。
四、Zookeeper与Kafka的协同工作尽管Zookeeper和Kafka各自具有不同的功能和特性,但它们经常一起使用,以提供更为完整的分布式系统解决方案。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Windows环境下Kafka与Zookeeper安装配置与启动过程1.软件下载
1.1下载jdk1.8.0_60
1.2 下载zookeeper-3.4.9.tar.gz
1.3下载kafka_
2.12-0.10.2.0.tgz
2.环境准备
安装配置java环境,配置jdk1.8为操作系统java运行时环境
2.1安装jdk1.8
将网站下载的jdk1.8.0_60压缩包解压缩到c:\program files\java目录下,如下图:
2.2 配置java环境
如图在“控制面板--系统和安全--系统”页,鼠标点击“高级系统设置”,在弹出的“系统属性”页面选择高级tab页:
点击“环境变量”按钮后,在弹出的环境变量对话框中点击“系统变量”栏中的“新建”按钮,在弹出的“新建系统变量”窗口中输入如下:
:
点确定确定后,再配置JRE_HOME
同时打开一个cmd窗口在其中输入:
SET JA V A_HOME=C:\Program Files\Java\jdk1.8.0_60
SET
CLASSPATH=.;%JA V A_HOME%/lib/dt.jar;%JA V A_HOME%/lib/tools.jar;%JRE_HOME%\lib\;%JRE_HOME%\lib\r t.jar;%JRE_HOME%\lib\jce.jar;%JRE_HOME%\lib\metadata-extractor-2.4.0-beta-1.jar;%JRE_HOME%\lib\mediautil-1.0.jar;
SET Path=%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin;
在命令行输入java -version,输出如下,表明系统已启用java配置
3.Zookeeper安装配置
3.1 解压与目录设计
在目录e:\apache\zookeeper\下解压文件zookeeper-3.4.9.tar.gz,并将解压文件夹改名为zk0,复制该文件夹到相同目录下分别改名为zk1、zk2.
3.2在zk0\zk1\zk2目录下都创建空文件夹data和logs,如下图
3.2在data目录中创建文件myid,设置zookeeper服务器的序号。
Myid的内容分别为0、1、2
3.3配置zookeeper的属性
配置zk0\zk1\zk2目录下的config/zoo.cfg文件。
tickTime=2000
initLimit=5
syncLimit=2
dataDir=E:/Apache/zookeeper/zk0/data dataLogDir=E:/Apache/zookeeper/zk0/logs clientPort=2181
server.0=127.0.0.1:2888:3888
server.1=127.0.0.1:2889:3889
server.2=127.0.0.1:2890:3890
tickTime=2000
initLimit=5
syncLimit=2
dataDir=E:/Apache/zookeeper/zk1/data dataLogDir=E:/Apache/zookeeper/zk1/logs clientPort=2182
server.0=127.0.0.1:2888:3888
server.1=127.0.0.1:2889:3889
server.2=127.0.0.1:2890:3890
tickTime=2000
initLimit=5
syncLimit=2
dataDir=E:/Apache/zookeeper/zk2/data dataLogDir=E:/Apache/zookeeper/zk2/logs clientPort=2183
server.0=127.0.0.1:2888:3888
server.1=127.0.0.1:2889:3889
server.2=127.0.0.1:2890:3890
3.4启动zookeeper server
开三个cmd窗口,依次执行如下指令:
E:
cd E:\Apache\zookeeper\zk0\bin
zkServer.cmd
E:
cd E:\Apache\zookeeper\zk2\bin
zkServer.cmd
E:
cd E:\Apache\zookeeper\zk1\bin
zkServer.cmd
在三个窗口未同时启动前,前面开的窗口会报警:三个窗口都启动后,如下表明zookeeper正常启动:3.5启动zkclient测试zk server
cd E:\Apache\zookeeper\zk0\bin
zkCli.cmd -server 127.0.0.1:2182
在新开的windows的cmd窗口执行如下命令:create /zk hello
create /zk/subzk
get /zk
Ls /zk
反馈如下:
至此,zookeeper安装完毕
4.Kafka安装配置
4.1 目录配置
解压kafka_2.12-0.10.2.0.tgz的内容到E:\Apache\kafka目录下,并将文件命名为kafka0,复制该文件夹到相同目录,命名为kafka1,如图
在这两个文件夹下创建logs和matrix文件夹,如图
4.2 server.properties配置
修改两个kafka实例的config/server.properties文件,内容分别如下:
broker.id=0
port=9092
work.threads=2
num.io.threads=2
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=./logs
num.partitions=2
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.segment.bytes=536870912
log.cleanup.interval.mins=10
zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
4.3 启动kafka server
在新开的windows的cmd窗口执行如下命令:
E:
cd E:\Apache\kafka\kafka0
.\bin\windows\kafka-server-start.bat .\config\server.properties
4.4 创建主题
创建主题,命名为“test2”,replication factor=2(因为2个Kafka服务器在运行)。
如果集群中所运行的Kafka 服务器不止2个,可以相应增加replication-factor,从而提高数据可用性和系统容错性。
在新开的windows的cmd窗口执行如下命令:
E:
cd E:\Apache\kafka\kafka0\bin\windows
kafka-topics.bat --create --zookeeper 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 --replication-factor 2 --partitions 2
--topic test2
4.5启动producer
在新开的windows的cmd窗口执行如下命令:
E:
cd E:\Apache\kafka\kafka0\bin\windows
kafka-console-producer.bat --broker-list 127.0.0.1:9092,127.0.0.1:9093 --topic test2
4.6 启动consumer
E:
cd E:\Apache\kafka\kafka0\bin\windows
kafka-console-consumer.bat --zookeeper 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 --topic test2
4.7 producer和consumer联合测试
如下图,在producer的窗口中输入文本,回车后会同步显示在2个consumer窗口中。