淘宝平台架构师谈海量互联网服务技术架构
淘宝技术架构分享

,HSF 使用的时候需要单独的下载一个hsf.sar 文件放置到jboss 的
;弊端也很明显:增加了环境的复杂度,需要往jboss 下扔sar
设计的主要原因。HSF 工作原理如下图:
HSF SAR 文件到Jboss 的Deploy 目录。
大型分布式的基础支撑。使开发人员无需过多的关注应用是集中式的,还是分布式的,可以更加专注于应用的业务需求的实现,这些纯技术
的需求都由HSF 来解决。
(2)HSF 的系统架构
I. HSF 交互场景图
客户端(消费端)从配置中心获取服务端地址列表—>和服务端建立连接开始远程调用—>服务端更新通过notify(类似B2B 的naplio)
系统通知客户端。服务端和客户端都有对应的监控中心,实时监控服务状态。客户端,配置中心,服务端,notify,之间的通信都是通过TB Remotion
API 去搞定的。
II. TB Remoting 架构图
底层基于分布式框架Mina,主要的代码都是通过
B2B 的Dubbo 也是基于这个NIO 框架的。Mina
商品,付款,确认,退款,评价,社区互动等。
产品:淘宝对产品定义和B2B 有差别,淘宝的业务拆分较细,服务化做的较成熟,所以前台应用对应的业务非常纯粹,如Detail 系统可
能就一个detail 页面,无数据库连接,所有数据来自底层的各种服务化中心,功能专一逻辑清晰纯粹,不过也正因为这样,淘宝的一个产品
淘宝前端应用
HSF接口
UIC IC SC TC
PC
Forest 推送给“淘宝前端应用”
淘宝共享服务
电商平台的技术架构分析

电商平台的技术架构分析电子商务随着互联网的发展变得越来越普及,各种电商平台也相继涌现出来。
而这些平台的背后,则离不开先进的技术支持。
本文将从技术架构的角度,探讨电商平台的发展历程以及其如今使用的基本技术架构。
1. 历史发展早期的电商平台大多采用B/S的架构,即“浏览器/服务器”模式,即用户通过浏览器与服务器进行交互。
此时,平台的架构非常简单,基本上就是前端页面+后台服务器+数据库三者结合,缺点是前端页面不能直接与后台交互,需要借助前端框架或AJAX技术进行实现,繁琐且效率低下。
后来,由于虚拟化技术和云计算技术的兴起,电商平台通过通过采用C/S架构,即“客户端/服务器”模式,进行优化和升级。
此时,通过虚拟化技术,平台将整个数据中心抽象为一个抽象的计算机架构,从而实现了更快的数据处理和更强的扩展性,并且通过云计算技术,平台可以将大量计算资源虚拟化,将运算任务分配给各种不同的云设备,从而达到更好的性能和可用性。
不过,在目前的电商平台中,最常用的仍然是B/S、MVC以及SOA架构。
2. 技术架构(1)B/S架构B/S架构是一种基于Web技术开发的体系结构。
它采用了一种分布式计算的方式,即将部分应用逻辑放在服务器端,形成一种网站应用;同时,客户端只需要安装一个可以与服务器通讯的Web浏览器即可。
当用户在浏览器上输入URL时,浏览器会向服务器发送请求,服务器返回HTML的页面,浏览器再将其解析并渲染出来。
这种模式能够有效地降低客户端的耦合程度,提高用户体验;但是缺点在于服务器将承担更多的计算任务,如果访问量过大,可能会发生崩溃;同时,安全性也存在较大的风险。
(2)MVC架构在MVC架构下,应用程序由三部分组成:模型(Model)、视图(View)和控制器(Controller)。
Model定义了应用程序的数据和逻辑,它们通过Controller调用并修改。
View则表示模型的数据,并负责显示给用户。
Controller是用户与应用程序之间的接口,它负责接受用户输入并相应地改变模型的状态。
淘宝网技术架构一些简单介绍

淘宝网技术架构一些简单介绍1、操作系统我们首先就从应用服务器的操作系统说起。
一个应用服务器,从软件的角度来说他的最底层首先是操作系统。
要先选择操作系统,然后才是操作系统基础上的应用软件。
在淘宝网,我们的应用服务器上采用的是Linux操作系统。
Linux操作系统从1991年第一次正式被公布到现在已经走过了十七个年头,在PC Server上有广泛的应用。
硬件上我们选择PC Server而不是小型机,那么Server的操作系统供我们选择的一般也就是Linux,FreeBSD, windows 2000 Server或者Windows Server 2003。
如果不准备采用微软的一系列产品构建应用,并且有能力维护Linux或者FreeBSD,再加上成本的考虑,那么还是应该在Linux和FreeBSD之间进行选择。
可以说,现在Linux和FreeBSD这两个系统难分伯仲,很难说哪个一定比另外一个要优秀很多、能够全面的超越对手,应该是各有所长。
那么在选择的时候有一个因素就是企业的技术人员对于哪种系统更加的熟悉,这个熟悉一方面是系统管理方面,另外一方面是对于内核的熟悉,对内核的熟悉对于性能调优和对操作系统进行定制剪裁会有很大的帮助。
而应用全面的优化、提升性能也是从操作系统的优化开始的。
2、应用服务器在确定了服务器的硬件、服务器的操作系统之后,下面我们来说说业务系统的构建。
淘宝网有很多业务系统应用是基于JEE规范的系统。
还有一些是C C 构建的应用或者是Java构建的Standalone的应用。
那么我们要选择一款实现了JEE规范的应用服务器。
我们的选择是JBoss Applcation Server。
JBoss AS是RedHat的一个开源的支持JEE规范的应用服务器。
在几年前,如果采用Java技术构建互联网应用或者企业级应用,在开源软件中的选择一般也就是Apache组织的Tomcat、JBoss的 JBoss AS和Resin。
淘宝技术框架分析报告精编版

淘宝技术框架分析报告淘宝作为国内首屈一指的大型电子商务网站,每天承载近30亿PV的点击量,拥有近50PB的海量数据,那么淘宝是如何确保其网站的高可用的呢?本文将对淘宝在构建大型网站过程中所使用到的技术框架做一个总结,并结合吉林银行现有技术框架进行对比分析。
另外,本文还会针对金融互联网以及公司未来技术发展方向给出个人看法。
淘宝技术分析CDN技术及多数据中心策略国内的网络由于运营商不同(分为电信、联通、移动),造成不同运营商网络之间的互访存在性能问题。
为了解决这个问题,淘宝在全国各地建立了上百个CDN节点,当用户访问淘宝网站时,浏览器首先会访问DNS服务器,通过DNS解析域名,根据用户的IP将访问分配到不同的入口。
如果客户的IP属于电信运营商,那么就会被分配到同样是电信的CDN节点,并且保证访问的(这里主要指JS、CSS、图片等静态资源)CDN节点是离用户最近的。
这样就将巨大的访问量分散到全国各地。
另外,面对如此巨大的业务请求,任何一个单独的数据中心都是无法承受的,所以淘宝在全国各主要城市都建立了数据中心,这些数据中心不但保证了容灾,而且各个数据中心都在提供服务。
不管是CDN技术还是多个数据中心,都涉及到复杂的数据同步,淘宝很好的解决了这个问题。
吉林银行现在正在筹建两地三中心,但主要目的是为了容灾,数据中心的利用率差,而淘宝的多个数据中心利用率为100%。
LVS技术淘宝的负载均衡系统采用了LVS技术,该技术目前由淘宝的章文嵩博士负责。
该技术可以提供良好的可伸缩性、可靠性以及可管理型。
只是这种负载均衡系统的构建是在Linux操作系统上,其他操作系统不行,并且需要重新编译Linux操作系统内核,对系统内核的了解要求很高,是一种软负载均衡技术。
而吉林银行则通过F5来实现负载均衡,这是一种硬负载均衡技术。
Session框架Session对于Web应用是至关重要的,主要是用来保存用户的状态信息。
但是在集群环境下需要解决Session共享的问题。
淘宝技术架构介绍, 了解淘宝,了解淘宝的架构需求

pipeline 页面布局
Screen Layout Control
多模板引擎
Jsp Velocity FreeMarker
V2.0 淘宝项目管理工具 AntX
类似maven 脚本编程语言 AutoConfig 依赖管理,冲突检测
V2.1 的需求
提高性能 增加开发效率 降低成本
V2.1 2004.10 – 2007.01
TBStore
Read/Write
Oracle Oracle Oracle Oracle
dump
Search
Read/Write
Node Node
1
2 ……
Node n
V2.1逻辑结构
表示层
Service
业务请求转发
Framework
S
UC
UC 业务流程处理 UC
UC
P
R
AO
AO
AO
AO
I
业务逻辑层
Node 1
Node 2
Node n
V2.1 TaobaoCDN
squid apache+php lighttpd 静态页面(包括php页面)、图片、描述 最初只有杭州和上海两个站点 现在发展到北京、广州、西安、天津、武
汉、济南等近10个站点 现在每天高峰期30G流量/秒
V2.1 session框架
Put/Get Data
Node 1
Node 2
Node n
V2.2 搜索引擎
垂直/水平 分割
AAPPPP
AAPPPP
Merge
Node1
Node2 ……
Node n
Col1
Node 1
淘宝技术框架分析报告文案

淘宝技术框架分析报告淘宝作为国内首屈一指的大型电子商务网站,每天承载近30 亿PV 的点击量,拥有近50PB 的海量数据,那么淘宝是如何确保其网站的高可用的呢?本文将对淘宝在构建大型网站过程中所使用到的技术框架做一个总结,并结合吉林银行现有技术框架进行对比分析另外,本文还会针对金融互联网以及公司未来技术发展方向给出个人看法。
淘宝技术分析CDN 技术及多数据中心策略国内的网络由于运营商不同(分为电信、联通、移动),造成不同运营商网络之间的互访存在性能问题。
为了解决这个问题,淘宝在全国各地建立了上百个CDN 节点,当用户访问淘宝网站时,浏览器首先会访问DNS 服务器,通过DNS 解析域名,根据用户的IP 将访问分配到不同的入口。
如果客户的IP 属于电信运营商,那么就会被分配到同样是电信的CDN 节点,并且保证访问的(这里主要指JS CSS、图片等静态资源)CDN节点是离用户最近的。
这样就将巨大的访问量分散到全国各地。
另外,面对如此巨大的业务请求,任何一个单独的数据中心都是无法承受的,所以淘宝在全国各主要城市都建立了数据中心,这些数据中心不但保证了容灾,而且各个数据中心都在提供服务。
不管是CDN 技术还是多个数据中心,都涉及到复杂的数据同步,淘宝很好的解决了这个问题。
吉林银行现在正在筹建两地三中心,但主要目的是为了容灾,数据中心的利用率差,而淘宝的多个数据中心利用率为100% 。
LVS 技术淘宝的负载均衡系统采用了LVS 技术,该技术目前由淘宝的章文嵩博士负责。
该技术可以提供良好的可伸缩性、可靠性以及可管理型。
只是这种负载均衡系统的构建是在Linux操作系统上,其他操作系统不行,并且需要重新编译Linux 操作系统内核,对系统内核的了解要求很高,是一种软负载均衡技术。
而吉林银行则通过F5 来实现负载均衡,这是一种硬负载均衡技术。
Session 框架Session 对于Web 应用是至关重要的,主要是用来保存用户的状态信息。
淘宝技术框架分析报告文案

淘宝技术框架分析报告淘宝作为国内首屈一指的大型电子商务网站,每天承载近30亿PV的点击量,拥有近50PB的海量数据,那么淘宝是如何确保其网站的高可用的呢?本文将对淘宝在构建大型网站过程中所使用到的技术框架做一个总结,并结合吉林银行现有技术框架进行对比分析。
另外,本文还会针对金融互联网以及公司未来技术发展方向给出个人看法。
淘宝技术分析CDN技术及多数据中心策略国内的网络由于运营商不同(分为电信、联通、移动),造成不同运营商网络之间的互访存在性能问题。
为了解决这个问题,淘宝在全国各地建立了上百个CDN节点,当用户访问淘宝网站时,浏览器首先会访问DNS服务器,通过DNS解析域名,根据用户的IP 将访问分配到不同的入口。
如果客户的IP属于电信运营商,那么就会被分配到同样是电信的CDN节点,并且保证访问的(这里主要指JS、CSS、图片等静态资源)CDN节点是离用户最近的。
这样就将巨大的访问量分散到全国各地。
另外,面对如此巨大的业务请求,任何一个单独的数据中心都是无法承受的,所以淘宝在全国各主要城市都建立了数据中心,这些数据中心不但保证了容灾,而且各个数据中心都在提供服务。
不管是CDN技术还是多个数据中心,都涉及到复杂的数据同步,淘宝很好的解决了这个问题。
吉林银行现在正在筹建两地三中心,但主要目的是为了容灾,数据中心的利用率差,而淘宝的多个数据中心利用率为100%。
LVS技术淘宝的负载均衡系统采用了LVS技术,该技术目前由淘宝的章文嵩博士负责。
该技术可以提供良好的可伸缩性、可靠性以及可管理型。
只是这种负载均衡系统的构建是在Linux操作系统上,其他操作系统不行,并且需要重新编译Linux操作系统内核,对系统内核的了解要求很高,是一种软负载均衡技术。
而吉林银行则通过F5来实现负载均衡,这是一种硬负载均衡技术。
Session框架Session对于Web应用是至关重要的,主要是用来保存用户的状态信息。
但是在集群环境下需要解决Session共享的问题。
淘宝服务端技术架构详解

淘宝服务端技术架构详解目录一、前言 (3)二、单机架构 (4)三、多机部署 (4)四、分布式缓存 (5)五、Session 共享解决方案 (7)六、数据库读写分离 (9)七、CDN 加速与反向代理 (10)八、分布式文件服务器 (11)九、数据库分库分表 (11)十、搜索引擎与NoSQL (13)十一、后序 (13)一、前言以淘宝网为例,简单了解一下大型电商的服务端架构是怎样的。
如图所示最上面的就是安全体系系统,中间的就是业务运营系统,包含各个不同的业务服务,下面是一些共享服务,然后还有一些中间件,其中ECS 就是云服务器,MQS 是队列服务,OCS 是缓存等等,右侧是一些支撑体系服务。
除图中所示之外还包含一些我们看不到的,比如高可用的体现。
淘宝目前已经实现多机房容灾和异地机房单元化部署,为淘宝的业务也提供了稳定、高效和易于维护的基础架构支撑。
这是一个含金量非常高的架构,也是一个非常复杂而庞大的架构,当然这个架构不是一天两天演进成这样的,也不是一开始就设计并开发成这样的,对于初创公司而言,很难在初期就预估到未来流量千倍、万倍的网站架构会是怎样的状况,同时如果初期就设计成千万级并发的流量架构,也很难去支撑这个成本。
因此一个大型服务系统,都是从小一步一步走过来的,在每个阶段找到对应该阶段网站架构所面临的问题,然后不断解决这些问题,在这个过程中,整个架构会一直演进,同时内含的代码也就会演进,大到架构、小到代码都是在不断演进和优化的。
所以说高大上的项目技术架构和开发设计实现不是一蹴而就的,这是所谓的万丈高楼平地起。
二、单机架构从一个小网站说起,一般来说初始一台服务器就够了,文件服务器、数据库以及应用都部署在一台机器上。
也就是俗称的 allinone 架构。
这篇推荐看下:厉害了,淘宝千万并发,14 次架构演进…三、多机部署随着网站用户逐渐增多,访问量越来越大,硬盘、cpu、内存等开始吃紧,一台服务器难以支撑。
淘宝网架构师岳旭强的谈网站架构

淘宝网架构师岳旭强的谈网站架构“一场危机赢得高度关注的时候,它已经不是危机,人们是要处理这个危机。
”——马云2022年是挑战和机遇并存的一年,对大部分人来说,已经习惯了金融危机,并努力解决危机。
在技术圈子也一样,被裁员的肯定也找到了工作,所以都在踏实做技术。
言归正传,先念叨念叨2022年的一些故事,寻个回忆,找个乐子。
数据扩展性探讨和总结金融危机是电子商务的机遇,所以09年是淘宝高速发展的一年。
当一个网站从百万、千万记录的数据规模,增长到亿、十亿、几十亿记录的数据规模时,是一个量变到质变的过程,单纯的硬件升级已经达到了瓶颈,而需要在整体结构上做文章。
09年一年,大部分时间都在数据的扩展性上努力。
对于一个电子商务网站来讲,订单是最核心的数据,也是增长最快的数据。
对于数据的扩展性来讲,最传统也是最简单有效的模式是数据库的分库分表。
当订单和分库分表相遇,会有什么火花迸发出来?09年初碰撞了很久,结果产生的火花很小。
最大的问题在于数据分割的规则,无规则的水平分割肯定会带来数据合并的开销,而按照业务规则拆分,会因为买家和卖家的查询需求不同而导致数据不能分割,唯一可行的火花是把订单双份保存,买家卖家各自一份,只是成本比较高,而且对数据同步的要求非常高。
于是我们初步决定按照双份保存的方式拆分订单,而有一天,仔细查看了订单访问的情况,发现订单数据库90%以上的压力来自于查询,而查询中90%以上的压力来自于非核心业务,仅仅是订单数据的展现,对一致性和实时性的要求很低。
因为数据量大,造成数据库压力大,天然想到的是分散压力,其办法就是分库分表。
有些时候我们想问题不妨直接一点,既然压力大,能不能减小压力呢?通过对订单访问情况的了解,发现昂贵的主数据库,有80%以上的压力给了不重要的需求,这个就是我们优化的关键,所以订单最后采用了读写分离的方案,高成本的主数据库解决事务和重要的查询业务,80%以上不重要的读,交给了低成本的数据库服务器来解决,同时对数据复制的要求也很低,实现无太大难度。
淘宝功能架构图ppt课件
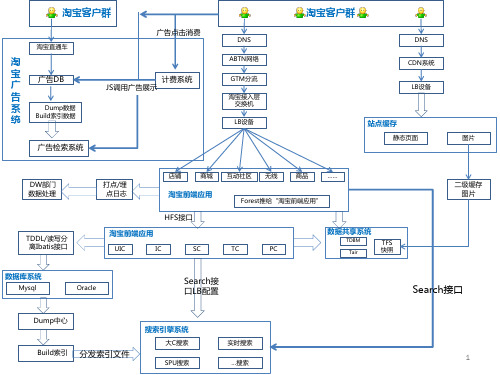
淘宝直通车
淘
宝 广
广告DB
告
系
Dump数据
统
Build索引数据
广告点击消费
计费系统 JS调用广告展示
广告检索系统
DNS
ABTN网络
GTM分流 淘宝接入层
交换机 LB设备
淘宝客户群
DNS CDN系统
LB设备
站点缓存
静态页面
图片
DW部门 数据处理
TDDL/读写分 离Ibatis接口
打点/埋 点日志
SPU搜索
…搜索
1
介绍上图中提到的各个系统缩写意思
1.UIC: 用户中心(User Interface Center),提供所有用户信息相关的读写服务,如基本信息,扩展信息,社区信息,买卖家信用等级等等。 淘宝现在有两类卖家B 和C,这是通过在用户身上打不同的标签实现的,我们这次的无名良品卖家也是通过在用户身上打特殊的标签来区别于淘宝 已有的B 和C 类卖家。淘宝的TOP 平台已经开放了大部分的UIC 接口。 2.IC:商品中心(Item Center),提供所有商品信息的读写服务,比如新发商品,修改商品,删除商品,前后台读取商品相关信息等等,IC 是 淘宝比较核心的服务模块,有专门的产品线负责这块内容,IC 相关接口在TOP 中占的比重也比较大。 3.SC:店铺中心(Shop Center),类似中文站的旺铺,不过淘宝的SC 不提供页面级应用,提供的都是些远程的服务化的接口,提供店铺相关信 息的读写操作。 如:开通店铺,店铺首页,及detail 页面店铺相关信息获取,如店内类目,主营,店铺名称,店铺级别:如普通,旺铺,拓展版, 旗舰版等等。装修相关的业务是SC 中占比重较大的一块,现在慢慢的独立为一个新的服务化中心DC(design center),很多的前台应用已经通过直 接使用DC 提供的服务化接口直接去装修相关的信息。 4.TC:交易中心(Trade Center),提供从创建交易到确认收货的正 向交易流程服务,也提供从申请退款到退款完成的反向交易流程服务. 5.PC:促销中心(Promotion Center),提供促销产品的订购,续费,查询,使用相关的服务化接口,如:订购和使用旺铺,满就送,限时秒 杀,相册,店铺统计工具等等。 6.Forest:淘宝类目体系:提供淘宝前后台类目的读写操作,以及前后台类目的关联操作。 7.Tair:淘宝的分布式缓存方案,和中文站的Memcached 很像。其实也是对memcached 的二次封装加入了淘宝的一些个性化需求。 8.TFS:淘宝分布式文件存储方案(TB File System),专门用户处理静态资源存储的方案,淘宝所有的静态资源,如图片,HTML 页面,文本 文件,页面大段的文本内容如:产品描述,都是通过TFS 存储的。 9.TDBM:淘宝DB 管理中心(TB DB Manager), 淘宝数据库管理中心,提供统一的数据读写操作。 10.RC:评价中心(Rate center),提供评价相关信息的读写服务,如评价详情,DSR 评分等信息的写度服务。 11.HSF:淘宝的远程服务调用框架和平台的Dubbo 功能类似,不过部署方式上有较大差异,所有的服务接口都通过对应的注册中心(config center)获取。
淘宝技术架构简介精品PPT课件

App
App
App
App
App
大用户群消息推送
• Comet服务架构 • 部署容量
– 60万连接/台
用户
长连接
源地址HASH
源地址HASH
• 运行数据
– 30万连接/台
LB1(LVS/NAS)
长轮询集群(Nginx)
LB2(LVS/NAS)
心跳检查
登记IP
监控(ZooKeeper) 机器列表
消息推送(TCP) 消息推送集群
• 好处
– 核心模块跟功能模块去耦合,不必一起编译 – 对于包管理系统来说,不再需要N多包 – 修正某个模块,只需编译相应模块
动态加载模块使用
• 使用方法
dso { load ngx_http_lua_module.so; load ngx_http_memcached_module.so;
}
• 动态库比静态代码性能差? • Wangbin:
• 性能
– 小几十台机器一天几十亿PV – 单机处理能力4万QPS
RESTful接口层
• RESTful接口支持(准备开源)
– TFS
• 分布式文件系统,类似于GFS
– Tair
• 分布式K/V存储系统
• 简化应用开发
– 可返回JSON格式直接让浏览器处理
• 从而不必在服务器端渲染页面
分布式防攻击系统
Nginx 组2
Nginx 组3
App App App App App
App
1
1
2
3
4
5
动态内容的静态化
• 把所有能cache的内容都cache住 • 主动删除cache
LVS集群
淘宝海量数据产品技术架构
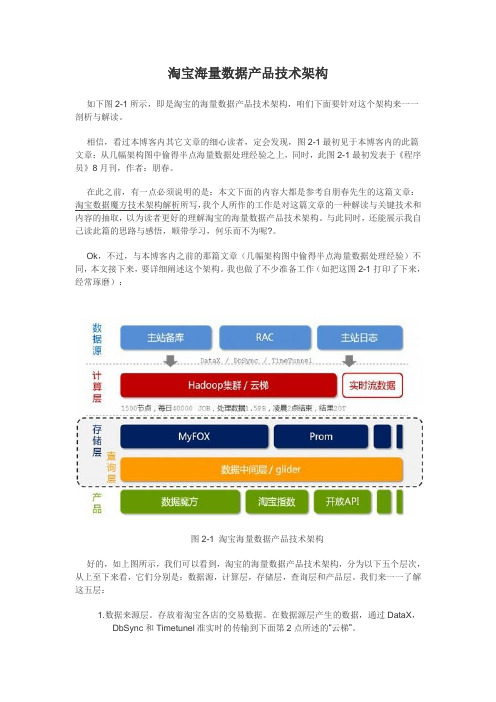
淘宝海量数据产品技术架构如下图2-1所示,即是淘宝的海量数据产品技术架构,咱们下面要针对这个架构来一一剖析与解读。
相信,看过本博客内其它文章的细心读者,定会发现,图2-1最初见于本博客内的此篇文章:从几幅架构图中偷得半点海量数据处理经验之上,同时,此图2-1最初发表于《程序员》8月刊,作者:朋春。
在此之前,有一点必须说明的是:本文下面的内容大都是参考自朋春先生的这篇文章:淘宝数据魔方技术架构解析所写,我个人所作的工作是对这篇文章的一种解读与关键技术和内容的抽取,以为读者更好的理解淘宝的海量数据产品技术架构。
与此同时,还能展示我自己读此篇的思路与感悟,顺带学习,何乐而不为呢?。
Ok,不过,与本博客内之前的那篇文章(几幅架构图中偷得半点海量数据处理经验)不同,本文接下来,要详细阐述这个架构。
我也做了不少准备工作(如把这图2-1打印了下来,经常琢磨):图2-1 淘宝海量数据产品技术架构好的,如上图所示,我们可以看到,淘宝的海量数据产品技术架构,分为以下五个层次,从上至下来看,它们分别是:数据源,计算层,存储层,查询层和产品层。
我们来一一了解这五层:1. 数据来源层。
存放着淘宝各店的交易数据。
在数据源层产生的数据,通过DataX,DbSync和Timetunel准实时的传输到下面第2点所述的“云梯”。
2. 计算层。
在这个计算层内,淘宝采用的是hadoop集群,这个集群,我们暂且称之为云梯,是计算层的主要组成部分。
在云梯上,系统每天会对数据产品进行不同的mapreduce计算。
3. 存储层。
在这一层,淘宝采用了两个东西,一个使MyFox,一个是Prom。
MyFox是基于MySQL的分布式关系型数据库的集群,Prom是基于hadoop Hbase技术的(读者可别忘了,在上文第一部分中,咱们介绍到了这个hadoop的组成部分之一,Hbase—在hadoop之内的一个分布式的开源数据库)的一个NoSQL的存储集群。
淘宝海量数据产品技术架构

淘宝海量数据产品技术架构回顾关系型数据库仍然是王道分库分表、冷热分离NoSQL是SQL的有益补充用冗余避免网络传输和随机读用中间层隔离前后端异构数据源的整合缓存是系统化的工程数据一致性、穿透与雪崩矛盾之美SQLNoSQL计算时机“预算”Hadoop/实时计算引擎“现算”MySQL+中间层Hbase+中间层计算场所本地MySQL单机HbaseRegionServer集中MyFOX中间层Prom中间层数据存储冷7200SATA盘HDFS热15000SAS盘+缓存HDFS+缓存谢谢淘宝海量数据产品技术架构张轩丞(朋春)淘宝网-数据平台与产品部关于张轩丞(朋春)淘宝数据平台与产品部(杭州)vi党,脚本语言爱好者关注NodeJS,cnode社区组织者之一*******************:我是aleafs数据平台与产品淘宝网淘宝卖家供应商消费者搜索、浏览、收藏、交易、评价...一些数字淘宝主站:30亿店铺、宝贝浏览10亿计的在线宝贝数千万量级交易笔数数据产品:50G统计汇总结果千万量级数据查询请求平均20.8ms的响应时间(6月1日)海量数据带来的挑战计算计算的速度处理吞吐量存储存储是为了更方便地查询硬盘、内存的成本查询“大海捞针”全“表”扫描架构总览主站备库RAC主站日志数据源MyFOXProm存储层数据中间层/glider查询层数据魔方淘宝指数开放API产品Hadoop 集群/云梯计算层实时流数据DataX/DbSync/TimeTunnel1500节点,每日40000JOB,处理数据1.5PB,凌晨2点结束,结果20T今天的话题关系型数据库仍然是王道NoSQL是SQL的有益补充用中间层隔离前后端缓存是系统化的工程关系型数据库仍然是王道关系型数据库有成熟稳定的开源产品SQL有较强的表达能力只存储中间状态的数据查询时过滤、计算、排序数据产品的本质拉关系做计算SELECTIF(INSTR(f.keyword,'''')>0,UPPER(TRIM(f.keyword)), CONCAT(b.brand_name,'''',UPPER(TRIM(f.keyword))))ASf0, SUM(f.search_num)ASf1,ROUND(SUM(f.search_num)/AVG(f.uv),2)ASf3FROMdm_fact_keyword_brand_dfINNERJOINdim_brandbO Nf.keyword_brand_id=b.brand_idWHEREkeyword_cat_idIN(''500025 35'')ANDthedate<=''2011-07-09'' ANDthedate>=''2011-07-07''GROUPBYf0ORDERBYSUM(f.search_num)DESCLIMIT0,100存储在DB中的数据分布式MySQL集群字段+条目数分片MyISAM引擎离线批量装载跨机房互备云梯APPMySQL集群数据装载数据查询MyFOX透明的集群中间层—MyFOX透明查询基于NodeJS,1200QPS数据装载路由计算数据装入一致性校验集群管理配置信息维护监控报警MyFOX-数据查询取分片数据(异步并发)取分片结果合并(表达式求值)合并计算缓存路由SQL解析语义理解查询路由字段改写分片SQL计算规则APC 缓存XMyFOX-节点结构MyFOX热节点(MySQL)15kSAS盘,300G12,raid10内存:24G成本:4.5W/T 冷节点(MySQL)7.2kSATA盘,1T12,raid10内存:24G成本:1.6W/T路由表30天无访问的冷数据新增热数据小结根据业务特点分库分表冷热数据分离降低成本,好钢用在刀刃上更有效地使用内存SQL虽牛,但是…如果继续用MySQL来存储数据,你怎么建索引?NoSQL是SQL的有益补充全属性交叉运算不同类目的商品有不同的属性同一商品的属性对有很多用户查询所选择的属性对不确定Prometheus定制化的存储实时计算Prom—数据装载Pro mHbaseHbaseHbase……索引:交易id列表属性对交易1(二进制,定长)交易2Prom—数据查询查索引求交集汇总计算写入缓存Prom—数据冗余明细数据大量冗余牺牲磁盘容量,以得到:避免明细数据网络传输变大量随机读为顺序读小结NoSQL是SQL的有益补充“预算”与“现算”的权衡“本地”与“集中”的协同其他的数据来源Prom的其他应用(淘词、指数等)从isearch获取实时的店铺、商品描述从主站搜索获取实时的商品数…异构数据源如何整合统一?用中间层隔离前后端[pengchun]$tail~/logs/glider-rt2.log127.0.0.1[14/Jun/2011:14:54:29+0800]"GET/glider/db/brand/brandinfo_d/get_hot _brand_top/where…HTTP/1.1"200170.065数据中间层—Glider多数据源整合UNIONJOIN输出格式化PERCENT/RANKOVER…JSON输出Glider架构DispatcherController配置解析请求解析一级缓存actionMyFOXProm二级缓存datasourceJOINUNIONfilter缓存是系统化的工程glider缓存系统前端产品一级缓存data二级缓存URL请求,nocache?nocache?nocache?Min(ttl)ttl,httpheaderetag,httpheader小结用中间层隔离前后端底层架构对前端透明水平可扩展性缓存是把双刃剑降低后端存储压力数据一致性问题缓存穿透与失效。
【架构师必看】淘宝从百万到千万级并发的14次服务端架构演进之路

【架构师必看】淘宝从百万到千万级并发的14次服务端架构演进之路# 概述本⽂以淘宝为例,介绍从⼀百个并发到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让⼤家对架构的演进有⼀个整体的认知,⽂章最后汇总了⼀些架构设计的原则。
# 基本概念在介绍架构之前,为了避免部分读者对架构设计中的⼀些概念不了解,下⾯对⼏个最基础的概念进⾏介绍:分布式系统中的多个模块在不同服务器上部署,即可称为分布式系统,如Tomcat和数据库分别部署在不同的服务器上,或两个相同功能的Tomcat 分别部署在不同服务器上⾼可⽤系统中部分节点失效时,其他节点能够接替它继续提供服务,则可认为系统具有⾼可⽤性集群⼀个特定领域的软件部署在多台服务器上并作为⼀个整体提供⼀类服务,这个整体称为集群。
如Zookeeper中的Master和Slave分别部署在多台服务器上,共同组成⼀个整体提供集中配置服务。
在常见的集群中,客户端往往能够连接任意⼀个节点获得服务,并且当集群中⼀个节点掉线时,其他节点往往能够⾃动的接替它继续提供服务,这时候说明集群具有⾼可⽤性负载均衡请求发送到系统时,通过某些⽅式把请求均匀分发到多个节点上,使系统中每个节点能够均匀的处理请求负载,则可认为系统是负载均衡的正向代理和反向代理系统内部要访问外部⽹络时,统⼀通过⼀个代理服务器把请求转发出去,在外部⽹络看来就是代理服务器发起的访问,此时代理服务器实现的是正向代理。
当外部请求进⼊系统时,代理服务器把该请求转发到系统中的某台服务器上,对外部请求来说,与之交互的只有代理服务器,此时代理服务器实现的是反向代理。
简单来说,正向代理是代理服务器代替系统内部来访问外部⽹络的过程,反向代理是外部请求访问系统时通过代理服务器转发到内部服务器的过程。
# 架构演进单机架构以淘宝作为例⼦,在⽹站最初时,应⽤数量与⽤户数都较少,可以把Tomcat和数据库部署在同⼀台服务器上。
淘宝技术框架分析报告

淘宝技术框架分析报告淘宝作为国首屈一指的大型电子商务,每天承载近30亿PV的点击量,拥有近50PB的海量数据,那么淘宝是如确保其的高可用的呢?本文将对淘宝在构建大型过程中所使用到的技术框架做一个总结,并结合银行现有技术框架进展比照分析。
另外,本文还会针对金融互联网以及公司未来技术开展向给出个人看法。
淘宝技术分析CDN技术及多数据中心策略国的网络由于运营商不同〔分为电信、联通、移动〕,造成不同运营商网络之间的互访存在性能问题。
为了解决这个问题,淘宝在全国各地建立了上百个CDN节点,当用户访问淘宝时,浏览器首先会访问DNS效劳器,通过DNS解析域名,根据用户的IP将访问分配到不同的入口。
如果客户的IP属于电信运营商,那么就会被分配到同样是电信的CDN节点,并且保证访问的〔这里主要指JS、CSS、图片等静态资源〕CDN节点是离用户最近的。
这样就将巨大的访问量分散到全国各地。
另外,面对如此巨大的业务请求,任一个单独的数据中心都是无法承受的,所以淘宝在全国各主要城市都建立了数据中心,这些数据中心不但保证了容灾,而且各个数据中心都在提供效劳。
不管是CDN技术还是多个数据中心,都涉及到复杂的数据同步,淘宝很好的解决了这个问题。
银行现在正在筹建两地三中心,但主要目的是为了容灾,数据中心的利用率差,而淘宝的多个数据中心利用率为100%。
LVS技术淘宝的负载均衡系统采用了LVS技术,该技术目前由淘宝的章文嵩博士负责。
该技术可以提供良好的可伸缩性、可靠性以及可管理型。
只是这种负载均衡系统的构建是在Linux操作系统上,其他操作系统不行,并且需要重新编译Linux操作系统核,对系统核的了解要求很高,是一种软负载均衡技术。
而银行那么通过F5来实现负载均衡,这是一种硬负载均衡技术。
Session框架Session对于Web应用是至关重要的,主要是用来保存用户的状态信息。
但是在集群环境下需要解决Session共享的问题。
目前解决这个问题通常有三种式,第一个是通过负载均衡设备实现会话保持,第二个是采用Session复制,第三个那么是采用集中式缓存。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
林昊,网名BlueDavy,China OSGi User Group Director,淘宝网平台架构部架构师,个人的研究方向主要为Java模块化、动态化系统的构建以及高性能的大型分布式Java系统的构建。
曾编写《OSGi实战》和《OSGi进阶》两篇Opendoc,为OSGi 在中国的推广起到了很大的作用。
王速瑜:数据集群问题:当数据增长到一定的数量级,必须要进行分布部署、备份、容灾、切割扩容等工作。
请问什么程度的数量级需要分布部署,如何合理分布部署,需要考虑哪些情况?
林昊:一般来说,也没有固定的数量级,通常是根据硬件资源的状况以及所能接受的性能状况(例如一次查询必须在3ms内完成)来决定。
当达到性能瓶颈时,通常需要进行数据的拆分或备份等策略,在这个过程中最需要考虑的,就是对应用的影响程度,因此通常会需要一个强大、透明的数据层,以屏蔽数据的拆分或备份、迁移操作给应用带来的影响,另外一方面就是应尽量能做到不停机完成。
当然,这很难,因为需要面对多套数据结构并存、数据冗余和同步等问题。
王速瑜:数据备份问题:对于大容量的数据备份,技术上如何做到不影响正常的服务?如何合理制定冷备、热备的实施策略、方式、时间段?在数据损坏、主服务器硬件损坏等故障情况下,如何最短时间内监控到故障并调度请求到备份服务器等容灾措施?
林昊:对于大容量的数据备份,技术上来说:多数情况下比较好的是选择异步消息通知实现数据备份,或基于高端数据库的特性(例如Oracle的Standby)。
对于冷备、热备的实施,原则要求均为不影响正常业务功能,因此可选的时段只能是系统访问量较低的时段。
方式则需要根据数据量以及备份的速度来决定,多数均为采取相对高频率的进行热备,低频率的进行冷备;在数据损坏、主服务器硬件损坏等故障时,要做到尽快切换,就必须依赖强大的及时监控系统,在主服务器不可用时能够做到迅速报警。
最理想状况就是能够有一种机制,自动切换备库为主库,并通知所有应用转换为连接和使用新的主库,如果做不到自动的话,这个过程就仍然得基于“人肉”来进行操作了。
王速瑜:开放平台设计问题:开放平台API设计中,调用协议设计时有哪些考虑要求?对于请求类的调用协议设计,倾向于call?A=a&B=b这种方式(这种方式对调用者比较方便,但对二进制的传输有一定限制,比如上传图片等),还是基于纯文本的方式,比如WSDL、XML等?对用户鉴权的Token机制是怎样的?有没有对接入方进行QoS的考虑,是怎么做的?
林昊:对于开放平台而言,基本上目前Facebook引领了开放平台的技术,因此在协议上多数都采用Http,接口的设计上则都倾向于REST风格;对于用户鉴权的Token机制上通常都是采用一个公私钥的匹配方式,并且此Token一定是由开放平台公司所提供;开放平台中是肯定会对接入方的QoS有限制的,并且这通常也影响到了开放平台的收费标准,在实现时多数采用基于缓存进行实时费用计算,这点更强的应该是电信行业。
: 王速瑜:跨IDC部署程序模块在业务发展到一定阶段后在所难免,跨IDC的专线资源相对有限。
架构师该如何合理规划和使用同城、跨城的专线进行传输数据,以及专线意外中断的容灾措施?
林昊:跨IDC部署确实会存在很高的技术难度,部署结果的验证是最为关键的地方,其次是部署所耗费的带宽成本和时间成本,对于部署结果验证而言,通常可采用的方法为业务脚本的测试;对于部署所耗费的带宽成本而言,通常需要借助多播技术,对于时间成本而言,通常需要借助自动化的部署系统。
王速瑜:Web2.0网站的海量小文件的存储,如用户头像、相册微缩图等文件,这些文件的特点是尺寸小(100KB以内),数量巨大(数以百万计),这些文件的存储、读取、备份都是问题,请问您是如何提供具体解决方案的?
林昊:目前互联网公司,例如Google、优酷等,对于小文件或大文件的存储都有自己的一套解决方案,而并不会去依赖高端的存储设备来解决。
一方面是成本问题,另外一方面是伸缩问题,因此对于这些文件的存储、读取和备份多数都采用了类似GFS的方案或直接采用Hadoop提供的HDFS方案。
王速瑜:互联网产品部署是一个很关键的环节,很多互联网公司依然采取手工部署发布产品版本的方式,但是这种方式比较复杂而且低效,往往很容易出错,如果同时发布几个产品时,如果产品之间关联比较紧密,其中一个发布出错就会影响到其他的发布,请问作为架构师,您在日常工作中是如何解决这样的问题?您的团队中是否考虑自动化动态部署,具体方案是怎么样的?
林昊:在部署这个问题上,目前好像只有国外的几家互联网公司做的不错,其中最典型的是eBay。
eBay在很多年前就已经做了一套自动化部署系统,在这套系统中,eBay可以将一次发布中的几个产品进行依赖关系的分析,从而决定其发布顺序,并可实现自动的发布、校验和回滚,这套系统相信也是现在中国几家互联网公司都在追求的目标。
王速瑜:作为互联网技术架构师,您能简单总结一下海里互联网服务技术架构方面的理念、原则,方法吗?
林昊:我觉得eBay的五点总结基本已经够全面:
(1)“拆分”,数据库的拆分以及应用的拆分,当然这需要强大的技术的支撑,这点要做到的目标通常是便于应用的无限水平伸缩;
(2)能异步就异步,这需要业务的允许;
(3)能自动就自动,就像自动化的部署系统;
(4)记住所有失败的事情,这点非常重要;
(5)容忍不一致性,这句话的含义是尽量少用强事务,而是采用最终一致性这类方案。
当然,除了上面这五点之外,还有像多用缓存、自行实现关键技术(以控制稳定性、性能和做到及时响应)等。
王速瑜:有很多优秀的软件架构师能力很强,但是由于缺乏海量服务技术应用和实践的机会,不能很好地进行海量服务应用的架构设计,您能给他们一些宝贵建议,分享一下您是如何不断学习成长起来的?您有哪些提高技术视野的方法和途径,比如有哪些书籍可以推荐,哪些优秀的网站可以推荐?
林昊:这个问题提到点子上了,很多架构师不知道如何应对大型、高并发的场景,最主要的原因是没有这样的实践的机会,毕竟目前只有在大型企业系统或互联网才能获得这类难得的实践机会,通常在没有实践机会的情况下是很难完全理解这些技术的。
多数情况下,互联网中的技术方案都是在多次血泪宕机下成长起来的,建议只能是多看各种互联网技术介绍的文章,例如Google共享了很多,还有网上也有很多各家互联网公司技术架构文章的介绍,尤其是那类技术发展历程的介绍,可以设想下如果自己碰到这样的问题,会如何去解决,也许这样能慢慢掌握和理解大型、高并发系统的解决方案。
书籍方面目前国内各种高性能方面的书也开始不断冒出了,例如有《MySQL性能调优与架构设计》、《构建高性能的Web站点》、《构建Oracle高可用环境》等,这些高性能的书通常都来源于作者亲身的经验,是非常值得学习的;另外要知道:如果想做到高性能,通常意味着要对软件(包括OS等)以及硬件技术都有充分的掌握,因此像《深入理解JDK》、《深入理解Linux内核》、《深入理解计算机系统》这些书也是非常值得一看的。
至于网站方面,像/、/这些都是非常不错的网站。