matlab正则表达式
matlab regexp用法

'Cat'、'cAt'、'CAt'、'caT'、'CaT'、'cAT'、'CAT'。
为了方便,下面的叙述中字符串和正则表达式的''都省略不写。
2.1 句点符号
. —— 匹配任意一个(只有一个)字符(包括空格)。
假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以 't' 字母开头,以 'n' 字母结束;另外,有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符 —— 句点符号 '.' 。这样,完整的表达式就是 t.n,它匹配 tan、ten、tin 和 ton,还匹配 t#n、tpn 甚至 t n,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格,即:正则表达式 t.n 匹配 ten、tin、ton、t n、tpn、t#n、t@n 等。
names 为匹配到的命名标记的标记名。
用法 2:
若不需要所有的输出,可以用下面的方式有选择的输出。
[v1 v2 ...] = regexpi('str', 'expr', 'q1', 'q2', ...)
'q1'、'q2' ...... 为 'start'、'end'、'tokens'、'tokensExtents'、'match'、'names' 之一,意义与前文相同。v1、
matlab字符串函数

matlab字符串函数MATLAB 是一款广泛应用于科学计算、算法开发、数据分析和可视化的强大软件。
字符串处理是 MATLAB 中常见的任务之一。
本文将详细介绍 MATLAB 中常用的字符串函数,并提供基本示例。
1.字符串基本操作字符串是一组字符的序列,在 MATLAB 中可以使用单引号或双引号来创建字符串。
例如:```str1 = 'hello, world';str2 = "hello, world";```MATLAB 中的字符串可以使用各种运算符进行操作,比如连接字符串、重复字符串、删除字符串等。
以下是一些常见的字符串操作:- 连接字符串:使用加号运算符可以将两个字符串合并为一个字符串。
例如:```str1 = 'hello';str2 = 'world';str3 = str1 + " " + str2;% str3 = 'hello world'```- 复制字符串:使用乘法运算符可以将一个字符串重复多次。
例如:```str1 = 'hello';str2 = str1 * 3;% str2 = 'hellohellohello'- 删除字符串:使用 delete 函数可以删除一个字符串的一部分。
例如:```str1 = 'hello, world';str2 = delete(str1, 6:11);% str2 = 'hello'```2.字符串查找和替换在处理字符串时,通常需要查找一个子串或将一个子串替换为另一个字符串。
MATLAB 提供了一些函数来完成这些任务。
- 查找子串:使用 findstr 函数可以查找一个子串在另一个字符串中的位置。
例如:```str1 = 'hello, world';pos = findstr(str1, 'world');% pos = 8```- 替换子串:使用 strrep 函数可以将一个字符串中的所有出现的一个子串替换为另一个字符串。
MATLAB正则表达式简介

第1章 regexp
下面以 regexp 为例,将正则表达式的内容分为以下几个部分,并结合 matlab 实例,对其逐个进行讲解:
元字符含义和使用(特殊字符、类字符) 多字符的匹配 在特定位置的匹配 根据上下文的匹配 逻辑判断 标记(token) 动态正则表达式 注释 多正则表达式和多字符串的匹配 regexp:在字符串 str 中根据正则表达式 expression 匹配符合的字符串,并将匹 配到的字符串以及字符串的开始、末尾位置输出;使用者也可以根据需要填写需要 输出的其他参数。
正则表达式在日常生活中随处可见,只是大家并不关注。如搜索引擎中用通配 符代表任意字符、在注册网站中所输入的用户名密码都需要特殊的格式和大小、 office 中的查找和替换等都基于正则表达式。
由于其十分强大,因此,在很多程序语言中都有与正则表达式相关的内容。虽 然,在不同语言中,其细节有所差别,但总体思想是一样的。以下以 Matlab 平台 为例,来介绍正则表达式:
1.1 输入输出参数和格式
[startindex,endindex,out1,…outN]=regexp(str,expression,outkey1,…outkeyN) 函数输入中,str 为字符串,expression 为正则表达式的形式;outkey1 到 outkeyN,为用户可根据需要输入的其他参数。 函数输出中,startindex 为所匹配的子字符串的起始位置,endindex 为所匹配 的子字符串的结束位置。out1 到 outN 是用户自己需要输出的参数,和输入中的 outkey1 到 outkeyN 一一对应。 例如: [startindex,endindex,tokenindex,expmatch,tok,tokname,nomatch]=regexp(str,expres sion,’start’,’end’,’tokenextents’,’match’,’tokens’,’names’,’split’) 以下是 regexp 的输入参数的含义以及对应的输出参数,此处仅简单的说明。 具体的应用实例会单独给出,并在之后各种正则表达式的应用中给予逐个说明。 ‘start’:所匹配子字符串开始位置的索引,输出到 startindex。 ‘end’:所匹配子字符串结束位置的索引,输出到 endindex。 ‘tokenExtents’:标识(token)的开始和结束位置的索引,输出到 tokenindex。
matlab查找替换功能正则表达式

英文回答:Regular expressions in MATLAB serve as a powerful tool for identifying and replacing patterns within strings or text files. The utilization of built-in functions such as regexprep and regexpi provides the capability to seek out specific patterns and substitute them with designated values. For instance, regexprep can be employed to replace all instances of a word within a given text with an alternative word, while regexpi can be utilized for conducting a case-insensitive search and replace operation. Furthermore, apart from these pre-existing functions, MATLAB also offers a range of regex functions tailored for more intricate pattern identification and replacement tasks.MATLAB中的正则表达式是识别和替换字符串或文本文件中的图案的有力工具。
利用内置功能,如regexprep和regexpi,提供了寻找具体模式并以指定值替代的能力。
可以使用regexprep,将特定文本中的所有单词实例替换为替代单词,而regexpi可用于进行对大小写不敏感的搜索和替换操作。
matlab 正则表达

matlab 正则表达【原创版】目录1.MATLAB 与正则表达式的概述2.MATLAB 中的正则表达式基本语法3.MATLAB 中正则表达式的应用实例4.总结正文一、MATLAB 与正则表达式的概述MATLAB 是一种广泛应用于科学计算、数据分析、可视化等领域的编程语言。
在 MATLAB 中,正则表达式作为一种强大的文本处理工具,可以帮助用户进行复杂的数据处理和分析。
二、MATLAB 中的正则表达式基本语法在 MATLAB 中,正则表达式主要通过`regexp`函数进行操作。
以下是一些基本的正则表达式语法:1.字符类:用于匹配某一类字符- [abc]:匹配 a、b 或 c- [^abc]:匹配除 a、b、c 之外的任意字符- [a-zA-Z]:匹配所有英文字母- d:匹配数字,等价于 [0-9]- D:匹配非数字,等价于 [^0-9]- s:匹配空白字符(空格、制表符、换行符等)- S:匹配非空白字符- w:匹配单词字符(字母、数字、下划线),等价于 [a-zA-Z0-9_] - W:匹配非单词字符2.量词:用于指定字符或字符类出现的次数-?:出现 0 次或 1 次- *:出现 0 次或多次- +:出现 1 次或多次- {n}:出现 n 次- {n,}:出现 n 次或多次- {n,m}:出现 n 到 m 次3.边界匹配符:用于指定匹配的位置- ^:匹配行首- $:匹配行尾- b:匹配单词边界- B:匹配非单词边界4.分组和捕获:用于将正则表达式的一部分组合在一起,以便进行特定操作- (pattern):匹配 pattern 并捕获结果,可以通过1、2等引用- (?:pattern):匹配 pattern 但不捕获结果三、MATLAB 中正则表达式的应用实例以下是一个 MATLAB 中正则表达式的应用实例,用于提取字符串中的数字:```matlabstr = "这是一个包含数字 123 的字符串";pattern = "[0-9]";result = regexp(str, pattern);disp(result) % 输出:123```四、总结MATLAB 中的正则表达式功能强大,可以帮助用户处理复杂的文本数据。
matlab正则表达式

matlab正则表达式
Matlab正则表达式是一种强大而灵活的文本搜索技术,它可以帮助程序员在复杂的文本文档中搜索特定文本模式。
它被广泛应用于许多程序语言,包括Matlab。
Matlab正则表达式提供了一种非常有用的工具,可以快速搜索文本文件,提取所需的信息。
Matlab正则表达式的核心概念是使用特殊的字符模式进行文本搜索。
这些字符模式可以匹配文本中的任何字符,包括字母、数字、标点符号和其他特殊字符。
Matlab正则表达式可以被用来搜索特定的文本模式,例如,可以使用正则表达式来检索文本文件中的电话号码、地址或者URL。
Matlab正则表达式也可以用来替换文本中的文字。
例如,可以使用正则表达式来替换文本文件中的某些单词或短语。
此外,Matlab 正则表达式还可以用于拆分文本文件,以提取特定的数据。
Matlab正则表达式可以被用来实现许多有用的文本处理任务,它可以大大缩短程序员的编码时间。
因此,Matlab正则表达式是一项非常有用的工具,可以帮助程序员在文本文件中搜索、替换和拆分特定的文本模式。
matlab 正则运算 提取汉字

标题:使用MATLAB进行正则运算提取汉字一、概述MATLAB是一种强大的数学软件,具有丰富的函数库和灵活的编程接口。
在数据处理和文本处理方面,MATLAB也有很强的能力。
本文将介绍如何使用MATLAB进行正则运算,提取文本中的汉字。
二、正则表达式简介正则表达式是一种用于描述字符串模式的方法,其可以用于搜索、替换和分割字符串。
在MATLAB中,正则表达式在处理文本时非常有用,可以实现快速、灵活地文本处理。
三、MATLAB中的正则表达式函数MATLAB提供了一系列的正则表达式函数,主要包括regexp、regexprep等。
这些函数可以根据指定的正则表达式模式,对字符串进行匹配、替换等操作。
在提取汉字的过程中,我们将使用regexp函数。
四、提取汉字的正则表达式在正则表达式中,汉字的Unicode编码范围为\u4e00-\u9fa5。
我们可以使用[\u4e00-\u9fa5]来表示一个汉字字符。
结合正则表达式的量词,我们可以构造出提取汉字的模式。
五、使用MATLAB进行汉字提取下面我们将以一个例子来演示如何使用MATLAB进行汉字的提取。
```matlabstr = '提取这段文本中的汉字字符xxx。
';pattern = '[\u4e00-\u9fa5]';result = regexp(str, pattern, 'match');disp(result)```以上代码将会输出提取到的汉字字符。
六、注意事项在使用正则表达式提取汉字时,需要注意文本的编码格式。
如果文本包含Unicode编码的汉字字符,则可以直接通过正则表达式进行提取。
但如果文本是其它编码格式,如UTF-8、GBK等,则需要先进行编码转换。
七、总结通过本文的介绍,相信读者已经了解了如何使用MATLAB进行正则表达式操作,提取文本中的汉字。
正则表达式作为一种强大的文本处理工具,可以帮助用户快速、灵活地处理文本数据。
matlab正则化详细使用
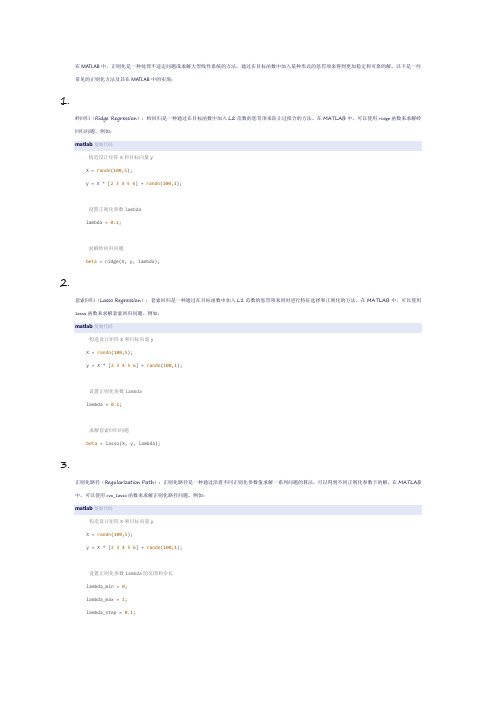
在MATLAB中,正则化是一种处理不适定问题或求解大型线性系统的方法,通过在目标函数中加入某种形式的惩罚项来得到更加稳定和可靠的解。
以下是一些常见的正则化方法及其在MATLAB中的实现:1.岭回归(Ridge Regression):岭回归是一种通过在目标函数中加入L2范数的惩罚项来防止过拟合的方法。
在MATLAB中,可以使用ridge函数来求解岭回归问题。
例如:matlab复制代码构造设计矩阵X和目标向量yX = randn(100,5);y = X * [23456] + randn(100,1);设置正则化参数lambdalambda = 0.1;求解岭回归问题beta = ridge(X, y, lambda);2.套索回归(Lasso Regression):套索回归是一种通过在目标函数中加入L1范数的惩罚项来同时进行特征选择和正则化的方法。
在MATLAB中,可以使用lasso函数来求解套索回归问题。
例如:matlab复制代码构造设计矩阵X和目标向量yX = randn(100,5);y = X * [23456] + randn(100,1);设置正则化参数lambdalambda = 0.1;求解套索回归问题beta = lasso(X, y, lambda);3.正则化路径(Regularization Path):正则化路径是一种通过沿着不同正则化参数值求解一系列问题的算法,可以得到不同正则化参数下的解。
在MATLAB 中,可以使用cvx_lasso函数来求解正则化路径问题。
例如:matlab复制代码构造设计矩阵X和目标向量yX = randn(100,5);y = X * [23456] + randn(100,1);设置正则化参数lambda的范围和步长lambda_min = 0;lambda_max = 1;lambda_step = 0.1;求解正则化路径问题beta = cvx_lasso(X, y, lambda_min, lambda_max, lambda_step);这些是MATLAB中常见的正则化方法,具体使用时需要根据问题的特点和需求选择合适的方法。
Matlab中的自然语言处理与文本挖掘

Matlab中的自然语言处理与文本挖掘自然语言处理(Natural Language Processing, NLP)和文本挖掘(Text Mining)是计算机科学与人工智能领域中的热门研究方向。
随着大数据时代的到来,我们对海量文本数据进行高效处理和深度挖掘的能力变得越来越重要。
作为一种功能强大且易于使用的编程环境,Matlab提供了丰富的工具和算法,使得在自然语言处理和文本挖掘中实现复杂的任务变得轻而易举。
一、自然语言处理的基础自然语言处理是指将自然语言(人类日常使用的语言)与计算机技术相结合,使得计算机能够理解、分析和生成语言。
在自然语言处理中,对文本数据进行预处理是非常重要的一步。
Matlab提供了许多用于文本预处理的函数,例如清理文本、分词、去除停用词等。
1. 清理文本文本通常包含各种特殊符号、标点符号和数字等非字符内容,这些内容对于后续的文本分析和挖掘是无关紧要的。
Matlab提供了一个强大的正则表达式引擎,可以方便地对文本进行规范化和清洗。
通过使用正则表达式,我们可以轻松地去除文本中的特殊字符、标点符号和数字等。
2. 分词分词是将一段连续的文本序列切割成一个个具有意义的单词或词组的过程。
在自然语言处理中,分词是文本挖掘和语义分析的基础。
Matlab提供了多种分词算法和工具包,例如基于规则的分词算法和基于机器学习的分词算法。
通过将文本进行分词,可以得到文本的基本单位,为后续的文本处理和挖掘提供基础。
3. 去除停用词停用词是指那些在文本中频繁出现但没有实际意义的词语,例如“的”、“是”、“在”等。
在文本挖掘中,去除停用词可以提高模型的效果和性能。
Matlab提供了常用的停用词列表,并且可以方便地自定义停用词表。
通过去除停用词,可以过滤掉文本中的噪声,提取出更具有意义和信息的词语。
二、文本挖掘的应用文本挖掘是指通过自动化的方法从文本数据中提取出有价值的知识或模式,从而实现对文本数据的理解和分析。
Matlab正则表达式总结

Matlab正则表达式总结S = REGEXP(STRING,EXPRESSION) :从string中匹配符合表达式express的字符串。
返回值s表示符合表达式的每个字符串的首个字符的索引。
express:由通配符和一般性文字字符组成。
常用通配符介绍:1.以下通配符可以精确匹配某些字符通配符说明--------------- --------------------------------. 匹配任意一个字符[] 匹配中括号中的任意一个字符[^] 匹配中括号中的字符除外的任意一个字符\w 匹配小写字母a到z、大写字母A到Z、数字0到9、字符‘_’中的任意一个字符\W 匹配不在[^a-z_A-Z0-9]范围内的任意一个字符\d 匹配数字[0-9]中的任意一个数字\D 匹配除数字外的一个字符\s 匹配分隔符[\t\r\n\f\v]\S 不匹配分隔符[^ \t\r\n\f\v]2. 以下通配符用于逻辑分组的表达式或者指定上下文位置。
这些通配符不匹配任何字符。
Metacharacter Meaning--------------- --------------------------------() Group subexpression| Match subexpression before or after the |^ Match expression at the start of string$ Match expression at the end of string\< Match expression at the start of a word\> Match expression at the end of a word3.以下通配符表示匹配字符的次数。
Metacharacter Meaning--------------- --------------------------------* 匹配0或更多次+ 匹配1或更多次? 匹配0或1次{n,m} 匹配n和m中间的次数基本用例Example:str = 'bat cat can car coat court cut ct caoueouat';pat = 'c[aeiou]+t';regexp(str, pat)returns [5 17 28 35]Example:str = {'Madrid, Spain' 'Romeo and Juliet' 'MATLAB is great'};pat = '\s';regexp(str, pat)returns {[8]; [6 10]; [7 10]}Example:str = {'Madrid, Spain' 'Romeo and Juliet' 'MATLAB is great'};pat = {'\s', '\w+', '[A-Z]'};regexp(str, pat)returns {[8]; [1 7 11]; [1 2 3 4 5 6]}REGEXP输出:regexp支持六个输出,通过在输入参数中写入相应字段,获得对应输出。
MatLab归一化(正则化)函数

MatLab归⼀化(正则化)函数mapminmax语法[Y,PS] = mapminmax(YMIN,YMAX)[Y,PS] = mapminmax(X,FP)Y = mapminmax('apply',X,PS)X = mapminmax('reverse',Y,PS)dx_dy = mapminmax('dx',X,Y,PS)dx_dy = mapminmax('dx',X,[],PS)name = mapminmax('name');fp = mapminmax('pdefaults');names = mapminmax('pnames');remconst('pcheck',FP);描述mapminmax将矩阵中每⼀⾏规范化到[YMIN,YMAX]范围内。
mapminmax(X,YMIN,YMAX)中参数YMIN,YMAX是可选的。
Matlab中⽂论坛X为N*Q的矩阵或者每⼀元素为1*TS细胞元组的N*Q的矩阵。
YMIN Y中每个⾏的最⼩值(默认为-1)YMAX Y中每个⾏的最⼤值(默认为1) 返回值:Y M*Q的矩阵(M=Q)PS 处理过程的设置,实现对数据的⼀致处理mapminmax(X,FP) 参数为⼀个结构:FP.ymin, FP.ymaxmapminmax('apply',X,PS) 对X根据PS中的配置做同样的规范化,返回Ymapminmax('reverse',Y,PS) 根据规范化后的Y及PS中的配置反归⼀化,返回Xmapminmax('dx',X,Y,PS) returns the M x N x Q derivative of Y with respect to X.mapminmax('dx',X,[],PS) returns the derivative, less efficiently.mapminmax('name') 返回处理⽅法的名字mapminmax('pdefaults') 返回默认的处理参数的结构mapminmax('pdesc')返回处理参数的描述mapminmax('pcheck',FP) 如果任意⼀个参数⾮法返回错误信息举例下⾯是如何规范化⼀个矩阵的过程,这个规范化将每⼀⾏的最⼩值与最⼤值映射到区间[-1,1] x1 = [1 2 4; 1 1 1; 3 2 2; 0 0 0][y1,PS] = mapminmax(x1)下⼀步,对新的值应⽤同样的处理⽅法 x2 = [5 2 3; 1 1 1; 6 7 3; 0 0 0]y2 = mapminmax('apply',x2,PS)将y1反归⼀化回x1x1_again = mapminmax('reverse',y1,PS)算法mapminmax假设x的值为实数,并且每⼀⾏的元素值不相等y = (ymax - ymin)*(x - xmin)/(xmax - xmin) + ymin;。
MATLAB正则表达式简介
[startindex,endindex,out1,…outN]=regexp(str,expression,outkey1,…outkeyN) 函数输入中,str 为字符串,expression 为正则表达式的形式;outkey1 到 outkeyN,为用户可根据需要输入的其他参数。 函数输出中,startindex 为所匹配的子字符串的起始位置,endindex 为所匹配 的子字符串的结束位置。out1 到 outN 是用户自己需要输出的参数,和输入中的 outkey1 到 outkeyN 一一对应。 例如: [startindex,endindex,tokenindex,expmatch,tok,tokname,nomatch]=regexp(str,expres sion,’start’,’end’,’tokenextents’,’match’,’tokens’,’names’,’split’) 以下是 regexp 的输入参数的含义以及对应的输出参数,此处仅简单的说明。 具体的应用实例会单独给出,并在之后各种正则表达式的应用中给予逐个说明。 ‘start’:所匹配子字符串开始位置的索引,输出到 startindex。 ‘end’:所匹配子字符串结束位置的索引,输出到 endindex。 ‘tokenExtents’:标识(token)的开始和结束位置的索引,输出到 tokenindex。
第1章 regexp
下面以 regexp 为例,将正则表达式的内容分为以下几个部分,并结合 matlab 实例,对其逐个进行讲置的匹配 根据上下文的匹配 逻辑判断 标记(token) 动态正则表达式 注释 多正则表达式和多字符串的匹配 regexp:在字符串 str 中根据正则表达式 expression 匹配符合的字符串,并将匹 配到的字符串以及字符串的开始、末尾位置输出;使用者也可以根据需要填写需要 输出的其他参数。
matlab的正则表达式

matlab的正则表达式regexp——⽤于对字符串进⾏查找,⼤⼩写敏感;regexpi——⽤于对字符串进⾏查找,⼤⼩写不敏感;regexprep——⽤于对字符串进⾏查找并替换。
第⼀部分——单个字符的匹配1 句点符号 '.' ——匹配任意⼀个(只有⼀个)字符(包括空格)。
例如:t.n,它匹配tan、 ten、tin和ton,还匹配t#n、tpn甚⾄t nMatlab例⼦程序:clear;clcstr='ten,&8yn2tin6ui>&ton, t n,-356tpn, t#n,4@).,t@nT&nY';pat='t.n';[o11,o22,o33]=regexpi(str,pat,'start','end','match');%输出起始位置和⼦串匹配结果:2 ⽅括号符号 '[oum]' ——匹配⽅括号中的任意⼀个例如:t[aeio]n只匹配tan,Ten,tin和toN等。
3 ⽅括号中的连接符 '[c1-c2]' ——匹配从字符c1开始到字符c2结束的字母序列4 \n 等 ——特殊字符下⾯是⼀些匹配单个字符的转义字符正则表达式及所匹配的值。
\xN或\x{N} 匹配⼋进制数值为N的字符\oN或\o{N} 匹配⼗六进制数值为N的字符\a Alarm(beep)\b Backspace\t ⽔平Tab\n New line\v 垂直Tab\f 换页符\r 回车符\e Escape\c 某些在正则表达式中有语法功能或特殊意义的字符c,要⽤\c来匹配,⽽不能直接⽤c匹配,如.⽤正则表达式.匹配,⽽\⽤正则表达式\匹配5 \w,\s和\d——类表达式和上⾯的\n等表中的转义字符有所不同,\w,\s,\d等匹配的不是某个特定的字符,⽽是某⼀类字符。
具体说明如下:\w匹配任意的单个⽂字字符,相当于[a-zA-Z0-9_];\s匹配任意的单个空⽩字符,相当于[\t\f\n\r];\d匹配任意单个数字,相当于[0-9]; d:digital\S匹配除空⽩符以外的任意单个字符,相当于[^\t\f\n\r]——⽅括号中的^表⽰取反;\W匹配任意单个字符,相当于[^a-zA-Z0-9_];\D匹配除数字字符外的任意单个字符,相当于[^0-9]。
matlab 正则表达

matlab 正则表达
正则表达式是一种强大的文本处理工具,可以用来匹配、查找和替换特定的文本模式。
它广泛应用于文本处理、字符串处理、数据提取等方面。
下面我将向你介绍一些常见的正则表达式用法。
1. 字符匹配
正则表达式可以用来匹配指定的字符或字符集合。
例如,表达式[a-z]可以匹配任意小写字母,[A-Z]可以匹配任意大写字母。
如果你想匹配数字,可以使用\d,如果你想匹配空白字符,可以使用\s。
2. 重复匹配
正则表达式可以指定一个字符或字符集合的重复次数。
例如,表达式a{3}可以匹配连续出现三次的字符a,表达式a{2,4}可以匹配连续出现两次到四次的字符a。
3. 边界匹配
正则表达式可以用来匹配特定位置的字符,例如,表达式^表示匹配字符串的开头,表达式$表示匹配字符串的结尾。
这样可以确保我们只匹配符合特定条件的文本。
4. 分组和捕获
正则表达式可以使用括号来分组,从而对分组内的字符进行操作。
例如,表达式(ab)+可以匹配一个或多个连续的"ab"。
通过使用括号,我们可以对这些分组进行捕获,以便后续处理。
除了上述基本用法外,正则表达式还包括了许多其他的特性和语法。
了解这些用法可以帮助我们更好地利用正则表达式来处理文本。
正则表达式的强大之处在于它可以灵活地处理各种文本模式,并且可以在不同的编程语言中使用。
然而,使用正则表达式也需要一定的经验和技巧,因为它的语法比较复杂。
希望通过本文的介绍,你能对正则表达式有更深入的了解,并能够灵活运用它来解决实际问题。
matlab 正则

matlab 正则MATLAB是一种强大的编程语言和数学计算软件,具有广泛的用途。
正则表达式也是MATLAB中一个重要的部分,有助于处理和操作字符串数组。
本文将分步骤介绍如何在MATLAB中使用正则表达式。
第一步:创建字符串在MATLAB中,可以创建一个字符串变量来存储一个特定的文本串。
例如:str = 'This is a test string.';可以通过这种方式创建简单的字符串,可以将其作为一个单独的字符串或者字符串数组来使用。
在使用正则表达式时,我们通常会使用字符串数组,因为这允许我们对多个字符串进行匹配。
第二步:匹配文本在MATLAB中,我们可以使用正则表达式来匹配文本。
正则表达式是一个特殊的文本模式,可以用来搜索和替换字符串。
以下是MATLAB的一些常用正则表达式函数:regexprep:使用正则表达式替换字符串。
regexp:在字符串中查找正则表达式。
regexpi:在字符串中查找正则表达式,不区分大小写。
regexptranslate:将MATLAB转换成正则表达式语言。
例如:a = {'abc'; 'defg'; 'hijk'};regexp(a, 'abc')这将返回一个逻辑数组,告诉我们哪些字符串与正则表达式匹配。
这里匹配的是字符串数组中的第一个字符串“abc”。
第三步:使用元字符和元字符组正则表达式通常使用元字符来定义模式。
例如,句点(.)匹配任何字符。
元字符组允许我们定义一组字符,只要匹配其中任意一个字符即可。
以下是MATLAB中的元字符和元字符组:\:转义字符,将下一个字符解释为普通字符。
^:匹配开头,例如^Hello匹配以Hello开头的字符串。
$:匹配结尾,例如World$匹配以World结尾的字符串。
[]:元字符组,例如[abc]匹配a,b或c。
[ - ]:字符范围,例如[a-z]匹配任何小写字母。
matlab 正则 删除字符

matlab 正则删除字符MATLAB是一种强大的数值计算和科学计算软件,它提供了丰富的函数库和工具箱,能够帮助用户解决各种数学和工程问题。
在MATLAB 中,我们可以使用正则表达式来处理文本数据,包括删除字符等操作。
正则表达式是一种用来描述和匹配字符串模式的工具,它可以在文本中进行搜索、替换和提取等操作。
在MATLAB中,我们可以使用正则表达式函数`regexp`来实现对字符串的操作。
删除字符是正则表达式的一种常见应用,它可以帮助我们去除文本中的特定字符,从而得到我们想要的结果。
下面我们将通过一个例子来演示如何使用MATLAB正则表达式删除字符。
假设我们有一个字符串s,其中包含一些特殊字符(如标点符号、空格等),我们希望将这些特殊字符删除,只保留字符串中的字母和数字。
我们可以使用如下代码实现:```matlabs = 'Hello, MATLAB! 1234567890';pattern = '[^a-zA-Z0-9]';s = regexprep(s, pattern, '');disp(s);```在上述代码中,我们首先定义了一个字符串s,其中包含了一些特殊字符。
然后我们定义了一个正则表达式模式`[^a-zA-Z0-9]`,该模式表示除了字母和数字之外的任意字符。
最后,我们使用`regexprep`函数将字符串s中匹配模式的字符替换为空字符。
运行上述代码,输出结果为`HelloMATLAB1234567890`,可以看到所有的特殊字符都被成功删除了。
除了删除字符,正则表达式还可以用于其他的文本处理操作,比如搜索、替换、提取等。
在MATLAB的帮助文档中,我们可以找到更多关于正则表达式的详细信息和示例代码。
MATLAB中的正则表达式是一种强大的工具,它可以帮助我们处理文本数据,包括删除字符等操作。
通过灵活运用正则表达式,我们可以更方便地处理和分析文本数据,提高工作效率。
matlab正则

matlab正则正则表达式是一种用于匹配、查找和替换文本中特定模式的工具。
它在计算机科学和信息处理领域被广泛应用。
正则表达式可以用于搜索字符串中的特定模式并对其进行操作。
在MATLAB中,正则表达式可以通过内置的函数`regexp`来实现。
该函数接受两个参数:要搜索的字符串和正则表达式模式。
它返回一个包含匹配的模式的字符串数组。
例如,假设我们有一个包含一些电子邮件地址的字符串数组,我们想要找到其中所有以".com"结尾的电子邮件地址。
我们可以使用以下代码来实现:```matlabemails = ["***************","*****************", "***************"];pattern = '\.com$';matches = regexp(emails, pattern);```在上面的代码中,我们定义了一个正则表达式模式`'\.com$'`。
这个模式用于匹配以".com"结尾的字符串。
然后,我们使用`regexp`函数来搜索`emails`数组中的所有匹配项,并将结果存储在`matches`数组中。
除了搜索和匹配,正则表达式还可以用于替换字符串中的特定模式。
MATLAB中的`regexprep`函数可以用于此目的。
它接受三个参数:要搜索的字符串、正则表达式模式和要替换的字符串。
例如,假设我们有一个包含日期的字符串数组,我们想将所有的日期替换为"YYYY-MM-DD"的格式。
我们可以使用以下代码来实现:```matlabdates = ["01/01/2022", "02/02/2022", "03/03/2022"];pattern = '(\d{2})/(\d{2})/(\d{4})';replacement = '$3-$1-$2';newDates = regexprep(dates, pattern, replacement);```在上面的代码中,我们定义了一个正则表达式模式`'(\d{2})/(\d{2})/(\d{4})'`,用于匹配"MM/DD/YYYY"格式的日期。
matlab 正则表达 -回复

matlab 正则表达-回复Matlab 正则表达式是一种强大的工具,用于在文本中进行模式匹配和提取特定内容。
它基于正则表达式语法,并提供了丰富的函数来处理文本。
在本文中,我们将探讨使用Matlab 正则表达式进行模式匹配和相关操作的各个方面。
首先,让我们从正则表达式的基础知识开始。
正则表达式是一种用于描述字符串模式的字符序列。
它由普通字符和特殊字符组成。
普通字符在模式中直接匹配自身,而特殊字符有特殊的含义,并在匹配时执行特定的操作。
下面是一些常见的特殊字符:1. \d :匹配任意一个数字。
2. \w :匹配任意一个字母、数字或下划线。
3. \s :匹配任意一个空白字符(包括空格、制表符、换行符等)。
4. \D :匹配任意一个非数字字符。
5. \W :匹配任意一个非字母、数字或下划线字符。
6. \S :匹配任意一个非空白字符。
在Matlab 中,您可以使用如下函数来进行正则表达式操作:1. regexp :该函数用于在字符串中查找匹配正则表达式的内容。
它返回一个匹配对象数组。
2. regexpi :与regexp 函数类似,但不区分大小写。
3. regexprep :该函数用于在字符串中替换匹配正则表达式的内容。
4. regexdecode :该函数用于解码基于正则表达式规则编码的字符串。
5. regexprep 需要1、2 等来表示正则表达式引用的分组。
下面是一个简单的例子,我们将使用正则表达式来匹配字符串中的电话号码。
matlabstr = '我的电话号码是:(123)456-7890';pattern = '\(\d{3}\)\d{3}-\d{4}';result = regexp(str, pattern, 'match');disp(result);上述代码中,我们定义了一个字符串`str`,其中包含了一个电话号码,并使用正则表达式`\(\d{3}\)\d{3}-\d{4}` 来匹配电话号码的模式。
matlab中的条件表达式

matlab中的条件表达式Matlab中的条件表达式是程序中非常重要的一部分,它们能够根据一定的条件判断来决定程序的执行流程。
在Matlab中,条件表达式通常使用if语句来实现,通过判断条件的真假来决定是否执行某个代码块。
条件表达式通常由一个逻辑表达式组成,逻辑表达式可以使用比较运算符(如<、>、==等)来比较数值或字符串,也可以使用逻辑运算符(如&&、||、~等)来组合多个逻辑条件。
在判断条件的过程中,Matlab会将逻辑表达式转化为一个布尔值(true或false),当条件为真时,执行if语句中的代码块;当条件为假时,跳过if语句中的代码块,继续执行后面的代码。
下面以一个简单的例子来说明条件表达式的使用。
假设有一个程序需要判断一个学生的成绩是否合格,如果成绩大于等于60分,则输出“合格”,否则输出“不合格”。
```matlabscore = 75;if score >= 60disp('合格');elsedisp('不合格');end```在上述代码中,首先定义了一个变量score,并将其赋值为75。
然后使用if语句来判断score的值是否大于等于60,如果是,则执行disp('合格')语句;如果否,则执行disp('不合格')语句。
最后,使用end来结束if语句的定义。
除了简单的if语句外,Matlab还提供了其他形式的条件表达式,如if-elseif-else语句和switch-case语句。
if-elseif-else语句可以用来判断多个条件,根据不同的条件执行不同的代码块。
switch-case语句则可以根据一个表达式的值来选择执行不同的代码块。
这些条件表达式的使用方式类似,但在实际应用中根据具体情况选择合适的条件表达式可以使程序更加简洁和易于理解。
在实际编程中,条件表达式的灵活运用可以使程序的逻辑更加清晰和高效。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
/s/blog_5ecfd9d90100lf8q.html matlab里面的正则表达式(2010-08-26 13:17:17)转载标签:matlab正则表达regular expression 教育分类:matlab及perl学习1. 引言正则表达式就是一个表达式(也是一串字符),它定义了某种字符串模式——利用正则表达式,可以对大段的文字进行复杂的查找、替换等。
本文将以Matlab 为编程语言,讲解正则表达式的概念和使用方法,并将在文末以实例说明正则表达式的实践应用。
Matlab 提供的正则表达式函数有三个:regexp——用于对字符串进行查找,大小写敏感;regexpi——用于对字符串进行查找,大小写不敏感;regexprep——用于对字符串进行查找并替换。
简要介绍一下这三个函数,以regexpi 为例——读者可以先跳过这里,看过全文之后再来看这里。
用法1:[start end extents match tokens names] = regexpi('str', 'expr')start 为匹配字符串的起始位置;end 为匹配字符串的终止位置;extents 为扩展内容,和'tokens'指示符一起用,指示出现tokens 的位置;match 即找到的匹配字串;tokens 匹配正则表达式中标记(tokens)的字串;names 为匹配到的命名标记的标记名。
用法2:若不需要所有的输出,可以用下面的方式有选择的输出。
[v1 v2 ...] = regexpi('str', 'expr', 'q1', 'q2', ...)'q1'、'q2' ...... 为'start'、'end'、'tokens'、'tokensExtents'、'match'、'names' 之一,意义与前文相同。
v1、v2...... 的输出顺序与q1、q2...... 一致。
2. 单个字符的匹配我们先从简单的开始——以regexpi 函数为例,不区分字符的大小写。
假设你要搜索'cat',搜索用的正则表达式就是'cat',这与文本编辑工具里常用的CTRL+F 是一样的,即正则表达式'cat' 匹配'cat'、'Cat'、'cAt'、'CAt'、'caT'、'CaT'、'cAT'、'CAT'。
为了方便,下面的叙述中字符串和正则表达式的''都省略不写。
2.1 句点符号. ——匹配任意一个(只有一个)字符(包括空格)。
假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以't' 字母开头,以'n' 字母结束;另外,有一本英文字典,你可以用正则表达式搜索它的全部内容。
要构造出这个正则表达式,你可以使用一个通配符——句点符号'.' 。
这样,完整的表达式就是t.n,它匹配tan、ten、tin 和ton,还匹配t#n、tpn 甚至t n,还有其他许多无意义的组合。
这是因为句点符号匹配所有字符,包括空格,即:正则表达式t.n 匹配ten、tin、ton、t n、tpn、t#n、t@n 等。
Matlab 程序实例:clear;clcstr='ten,&8yn2tin6ui>&ton, t n,-356tpn,$$$$t#n,4@).,t@nT&nY';pat='t.n';o1=regexpi(str,pat,'start') %用'start'指定输出o1 为匹配正则表达式的子串的起始位置o2=regexpi(str,pat,'end') %用'end'指定输出o2 为匹配正则表达式的子串的结束位置o3=regexpi(str,pat,'match') %用'match'指定输出o3 为匹配正则表达式的子串[o11,o22,o33]=regexpi(str,pat,'start','end','match') %同时输出起始位置和字串输出为:o22 = 3 8 13 18 23 28 33 36o33 = 'ten' 'tin' 'ton' 't n' 'tpn' 't#n' 't@n' 'T&n'o1 = 1 10 18 23 31 39 48 51o2 = 3 12 20 25 33 41 50 53o3 = 'ten' 'tin' 'ton' 't n' 'tpn' 't#n' 't@n' 'T&n'o11 = 1 10 18 23 31 39 48 51o22 = 3 12 20 25 33 41 50 53o33 = 'ten' 'tin' 'ton' 't n' 'tpn' 't#n' 't@n' 'T&n'2.2 方括号符号[oum] ——匹配方括号中的任意一个。
为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号([])里面指定看来有意义的字符。
此时,只有方括号里面指定的字符才参与匹配。
也就是说,正则表达式t[aeio]n 只匹配tan、Ten、tin 和toN等。
但Tmn、taen 不匹配,因为在方括号之内你只能匹配单个字符。
Matlab 程序实例:clear;clcstr='ten,&8yn2tin6ui>&ton, t n,-356tpn,$$$$t#n,4@).,t@nT&nY';pat='t[aeiou]n';[o11,o22,o33]=regexpi(str,pat,'start','end','match') %í?ê±ê?3??eê?????oí×ó′?o11 = 1 10 18o22 = 3 12 20o33 = 'ten' 'tin' 'ton'2.3 方括号中的连接符'[c1-c2]' ——匹配从字符c1 开始到字符c2 结束的字母序列(按字母表中的顺序)中的任意一个。
例如[a-c] 匹配a、b、c、A、B、C,即正则表达式t[a-z]n 匹配tan、tbn、tcn、tdn、ten、……、txn、tyn、tzn。
Matlab 程序实例:clear;clcstr='ten,&8yn2tin6ui>&ton, t n,-356tpn,$$$$t#n,4@).,t@nT&nY';pat='t[a-z]n';[o11,o22,o33]=regexpi(str,pat,'start','end','match')o11 = 1 10 18 31o22 = 3 12 20 33o33 = 'ten' 'tin' 'ton' 'tpn'2.4 特殊字符\.等——即由'\' 引导的,代表有特殊意义或不能直接输入的单个字符。
在使用fprintf 函数输出时我们常用'\n' 来代替回车符,这里也是同样的道理,用\n 在正则表达式中表示回车符。
类似的还有\t 横向制表符,'\*' 表示'*' 等。
后一种情况用在查询在正则表达式中有语法作用的字符,详见下文。
下面是一些匹配单个字符的转义字符正则表达式及所匹配的值。
\xN 或\x{N} 匹配八进制数值为N 的字符\oN 或\o{N} 匹配十六进制数值为N 的字符\a Alarm(beep)\b Backspace\t 水平Tab\n New line\v 垂直Tab\f 换页符\r 回车符\e Escape\c 某些在正则表达式中有语法功能或特殊意义的字符c,要用\c 来匹配,而不能直接用 c 匹配,例如. 用正则表达式\. 匹配,而\ 用正则表达式\\ 匹配。
Matlab 程序实例:clear;clcstr='l.[a-c]i.$.a';pat1='.';pat2='\.';o=regexpi(str,pat1,'match')o1=regexpi(str,pat2,'match')输出为:o = 'l' '.' '[' 'a' '-' 'c' ']' 'i' '.' '$' '.' 'a'o1 = '.' '.' '.'2.5 类表达式\w、\s 和\d 等——匹配某一类字符中的一个。
和上面的\n 等表中的转义字符有所不同,\w、\s、\d 等匹配的不是某个特定的字符,而是某一类字符。
具体说明如下:\w 匹配任意的单个文字字符,相当于[a-zA-Z0-9_];\s 匹配任意的单个空白字符,相当于[\t\f\n\r];\d 匹配任意单个数字,相当于[0-9];\S 匹配除空白符以外的任意单个字符,相当于[^\t\f\n\r] ——方括号中的^表示取反;\W 匹配任意单个字符,相当于[^a-zA-Z0-9_];\D 匹配除数字字符外的任意单个字符,相当于[^0-9]。