20个常用的正则表达式 匹配
正则匹配常用写法

正则表达式是一种用于匹配字符串模式的工具,常用写法如下:
1. 匹配单个字符:
-使用句点(.)匹配除换行符外的任何字符。
-使用字符类([ ])匹配指定范围内的字符。
例如,[a-z]匹配任何小写字母。
-使用转义字符(\)来匹配特殊字符,如\d 匹配数字字符。
2. 匹配数量:
-使用星号(*)表示前一个字符可以出现零次或多次。
-使用加号(+)表示前一个字符可以出现一次或多次。
-使用问号(?)表示前一个字符可以出现零次或一次。
-使用大括号({n})表示前一个字符出现n 次。
-使用大括号({n, m})表示前一个字符出现n 到m 次。
3. 匹配位置:
-使用插入符号(^)匹配字符串的开始位置。
-使用美元符号($)匹配字符串的结束位置。
-使用字边界(\b)匹配单词的边界位置。
4. 分组和引用:
-使用括号(( ))来创建分组,并使用竖杠(|)表示逻辑OR。
例如,(cat|dog) 匹配"cat" 或"dog"。
-使用反斜杠加数字(\n)来引用先前的分组。
例如,
(\w)\1 匹配重复的字母。
这只是正则表达式的基础写法,正则表达式还有更多的语法和特性,可以根据具体需求进行更复杂的模式匹配。
不同编程语言和工具对正则表达式的实现略有不同,可以参考相应文档和教程来学习更多正则表达式的写法和用法。
常用正则表达式大全!(例如:匹配中文、匹配html)

常⽤正则表达式⼤全!(例如:匹配中⽂、匹配html)⼀、常见正则表达式 匹配中⽂字符的正则表达式: [u4e00-u9fa5] 评注:匹配中⽂还真是个头疼的事,有了这个表达式就好办了 匹配双字节字符(包括汉字在内):[^x00-xff] 评注:可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1) 匹配空⽩⾏的正则表达式:ns*r 评注:可以⽤来删除空⽩⾏ 匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? /> 评注:⽹上流传的版本太糟糕,上⾯这个也仅仅能匹配部分,对于复杂的嵌套标记依旧⽆能为⼒ 匹配⾸尾空⽩字符的正则表达式:^s*|s*$ 评注:可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式 匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)* 评注:表单验证时很实⽤ 匹配⽹址URL的正则表达式:^(http|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?$ 评注:⽹上流传的版本功能很有限,上⾯这个基本可以满⾜需求匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 评注:表单验证时很实⽤ 匹配国内电话号码:d{3}-d{8}|d{4}-d{7} 评注:匹配形式如 0511-******* 或 021-******** 匹配腾讯QQ号:[1-9][0-9]{4,} 评注:腾讯QQ号从10000开始 匹配中国邮政编码:[1-9]d{5}(?!d) 评注:中国邮政编码为6位数字 匹配⾝份证:d{15}|d{18} 评注:中国的⾝份证为15位或18位 匹配ip地址:d+.d+.d+.d+ 评注:提取ip地址时有⽤ 匹配特定数字: ^[1-9]d*$ //匹配正整数 ^-[1-9]d*$ //匹配负整数 ^-?[1-9]d*$ //匹配整数 ^[1-9]d*|0$ //匹配⾮负整数(正整数 + 0) ^-[1-9]d*|0$ //匹配⾮正整数(负整数 + 0) ^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数 ^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数 ^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数 ^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配⾮负浮点数(正浮点数 + 0) ^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配⾮正浮点数(负浮点数 + 0) 评注:处理⼤量数据时有⽤,具体应⽤时注意修正 匹配特定字符串: ^[A-Za-z]+$ //匹配由26个英⽂字母组成的字符串 ^[A-Z]+$ //匹配由26个英⽂字母的⼤写组成的字符串 ^[a-z]+$ //匹配由26个英⽂字母的⼩写组成的字符串 ^[A-Za-z0-9]+$ //匹配由数字和26个英⽂字母组成的字符串 ^w+$ //匹配由数字、26个英⽂字母或者下划线组成的字符串 在使⽤RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下: 只能输⼊数字:“^[0-9]*$” 只能输⼊n位的数字:“^d{n}$” 只能输⼊⾄少n位数字:“^d{n,}$” 只能输⼊m-n位的数字:“^d{m,n}$” 只能输⼊零和⾮零开头的数字:“^(0|[1-9][0-9]*)$” 只能输⼊有两位⼩数的正实数:“^[0-9]+(.[0-9]{2})?$” 只能输⼊有1-3位⼩数的正实数:“^[0-9]+(.[0-9]{1,3})?$” 只能输⼊⾮零的正整数:“^+?[1-9][0-9]*$” 只能输⼊⾮零的负整数:“^-[1-9][0-9]*$” 只能输⼊长度为3的字符:“^.{3}$” 只能输⼊由26个英⽂字母组成的字符串:“^[A-Za-z]+$” 只能输⼊由26个⼤写英⽂字母组成的字符串:“^[A-Z]+$” 只能输⼊由26个⼩写英⽂字母组成的字符串:“^[a-z]+$” 只能输⼊由数字和26个英⽂字母组成的字符串:“^[A-Za-z0-9]+$” 只能输⼊由数字、26个英⽂字母或者下划线组成的字符串:“^w+$” 验证⽤户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间,只能包含字符、数字和下划线。
常用的正则表达式代码汇总

常⽤的正则表达式代码汇总常⽤的正则表达式代码汇总常⽤的正则表达式代码汇总:1。
^\d+$ //匹配⾮负整数(正整数 + 0)2。
^[0-9]*[1-9][0-9]*$ //匹配正整数3。
^((-\d+)|(0+))$ //匹配⾮正整数(负整数 + 0)4。
^-[0-9]*[1-9][0-9]*$ //匹配负整数5。
^-?\d+$ //匹配整数6。
^\d+(\.\d+)?$ //匹配⾮负浮点数(正浮点数 + 0)7。
^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ //匹配正浮点数8。
^((-\d+(\.\d+)?)|(0+(\.0+)?))$ //匹配⾮正浮点数(负浮点数 + 0)9。
^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ //匹配负浮点数10。
^(-?\d+)(\.\d+)?$ //匹配浮点数11。
^[A-Za-z]+$ //匹配由26个英⽂字母组成的字符串12。
^[A-Z]+$ //匹配由26个英⽂字母的⼤写组成的字符串13。
^[a-z]+$ //匹配由26个英⽂字母的⼩写组成的字符串14。
^[A-Za-z0-9]+$ //匹配由数字和26个英⽂字母组成的字符串15。
^\w+$ //匹配由数字、26个英⽂字母或者下划线组成的字符串16。
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$ //匹配email地址17。
^[a-zA-z]+://匹配(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$ //匹配url18。
匹配中⽂字符的正则表达式: [\u4e00-\u9fa5]19。
匹配双字节字符(包括汉字在内):[^\x00-\xff]20。
正则表达式150种表达方式

正则表达式150种表达方式1、删除所有数字。
只要查找:\d就OK。
为了不留空行:替换处:\d2、删除所有英文字母。
只要查找:\a就OK。
为了不留空行:替换处:\d3、删除除换行符以外的所有。
只要查找:. 为了不留空行:替换处:\d4、既删除英文字母又删除数字。
只要查找:\w。
为了不留空行:替换处:\d5、删除数字加字母加等于(如:3a=或3zz=)只要查找:\d+\a+\=。
为了不留空行:替换处:\d6、删除换行。
只要查找:$。
替换处:\d(还原查找:\a+=\f。
替换:\0\n)。
如在换行后加一空格,查找:(\a)$。
替换:\0 \d。
7、删除空行只要查找:^$。
为了不留空行:替换处:\d8、删除首尾空格。
只要查找:^\s*|\s*$就OK9、删除行前数字及顿号。
只要查找:\d+、替换为空10、删除末尾标点符号。
只要查找:\P+$|\P+\s+$,“|”前面是没有空格的,“|”后面有空格,P后的加是为了……而用的。
11、删除末尾空格。
只要查找:\s+$。
替换为空。
12、删除第一个字如:“的我们”中的“的”只要查找:^\的。
13、删除第几个字。
查找:查找:^().(.+)。
替换:\1\2。
去掉前面的拼音:查找:^\a+替换为空。
第一个括号里可加“.”且可变。
14、删含的。
查:.*的.*替:\d。
的头查:.*=的.*替:\d。
的尾查:\a.*\c.*的$替:\d(留它不匹配)●删非的行查:^[^的]+$替:\d15、删除几码以上的码查:^(...)...替:\1。
删第几位码。
查:^(...).(.+)替:\1\2(变成\1,\2则其位则改成,了)首括号的.可变。
16、删除各类型的几字词,但必须是码前词后或纯词。
三字词:查找:^\~f{}\f{3}$替换:\d。
替换:\d “3”可以改。
17、删除11字词及其以上的词条查找(自定义格式):\a{}\=(\c|\P|\p){11,}。
替换:\d。
11可改。
字母、数字、下划线、符号等组合常用正则表达式

字母、数字、下划线、符号等组合常⽤正则表达式字母、数字、下划线、符号等组合常⽤正则表达式1.由数字、26个英⽂字母或者下划线组成的字符串:^[0-9a-zA-Z_]{1,}$2.⾮负整数(正整数 + 0 ):^/d+$3. 正整数:^[0-9]*[1-9][0-9]*$4.⾮正整数(负整数 + 0):^((-/d+)|(0+))$5. 负整数 :^-[0-9]*[1-9][0-9]*$6.整数:^-?/d+$7.⾮负浮点数(正浮点数 + 0):^/d+(/./d+)?$8.正浮点数 :^(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*))$9. ⾮正浮点数(负浮点数 + 0):^((-/d+(/./d+)?)|(0+(/.0+)?))$10.负浮点数 :^(-(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*)))$11. 浮点数 :^(-?/d+)(/./d+)?$12.由26个英⽂字母组成的字符串 :^[A-Za-z]+$13. 由26个英⽂字母的⼤写组成的字符串 :^[A-Z]+$14.由26个英⽂字母的⼩写组成的字符串 :^[a-z]+$15. 由数字和26个英⽂字母组成的字符串 :^[A-Za-z0-9]+$16.由数字、26个英⽂字母或者下划线组成的字符串 :^/w+$17.email地址 :^[/w-]+(/.[/w-]+)*@[/w-]+(/.[/w-]+)+$18.url:^[a-zA-z]+://(/w+(-/w+)*)(/.(/w+(-/w+)*))*(/?/S*)?$19. 年-⽉-⽇:/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/20.⽉/⽇/年:/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/21.Emil:^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$22. 电话号码:(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?23.IP地址:^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$24. 匹配中⽂字符的正则表达式:[/u4e00-/u9fa5]25.匹配双字节字符(包括汉字在内):[^/x00-/xff]26. 匹配空⾏的正则表达式:/n[/s| ]*/r27.匹配HTML标记的正则表达式:/<(.*)>.*<///1>|<(.*) //>/28.匹配⾸尾空格的正则表达式:(^/s*)|(/s*$)29.匹配Email地址的正则表达式:/w+([-+.]/w+)*@/w+([-.]/w+)*/./w+([-.]/w+)*30. 匹配⽹址URL的正则表达式:^[a-zA-z]+://(//w+(-//w+)*)(//.(//w+(-//w+)*))*(//?//S*)?$31. 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$32. 匹配国内电话号码:(/d{3}-|/d{4}-)?(/d{8}|/d{7})?33.匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$34. 只能输⼊数字:^[0-9]*$35.只能输⼊n位的数字:^/d{n}$36.只能输⼊⾄少n位的数字:^/d{n,}$37.只能输⼊m~n位的数字:^/d{m,n}$38.只能输⼊零和⾮零开头的数字:^(0|[1-9][0-9]*)$39.只能输⼊有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$40. 只能输⼊有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$41.只能输⼊⾮零的正整数:^/+?[1-9][0-9]*$42. 只能输⼊⾮零的负整数:^/-[1-9][0-9]*$43.只能输⼊长度为3的字符:^.{3}$44. 只能输⼊由26个英⽂字母组成的字符串:^[A-Za-z]+$45.只能输⼊由26个⼤写英⽂字母组成的字符串:^[A-Z]+$46. 只能输⼊由26个⼩写英⽂字母组成的字符串:^[a-z]+$47.只能输⼊由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$48. 只能输⼊由数字和26个英⽂字母或者下划线组成的字符串:^/w+$49.验证⽤户密码(正确格式为:以字母开头,长度在5~17 之间,只能包含字符、数字和下划线)^[a-zA-Z]/w{5,17}$50.验证是否包含有 ^%&',;=?$/"等字符:[^%&',;=?$/x22]+51.只能输⼊汉字:^[\u4e00-\u9fa5]{0,}$52、只含有汉字、数字、字母、下划线不能以下划线开头和结尾^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$53、只含有汉字、数字、字母、下划线,下划线位置不限^[a-zA-Z0-9_\u4e00-\u9fa5]+$54、2~4个汉字@"^[\u4E00-\u9FA5]{2,4}$55、第⼀位是【1】开头,第⼆位则则有【3,4,5,7,8】,第三位则是【0-9】,第三位之后则是数字【0-9】。
python常用的正则表达式大全
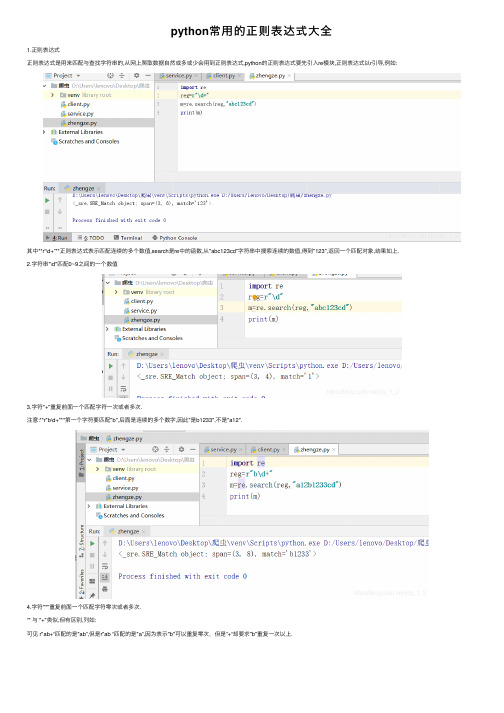
python常⽤的正则表达式⼤全1.正则表达式正则表达式是⽤来匹配与查找字符串的,从⽹上爬取数据⾃然或多或少会⽤到正则表达式,python的正则表达式要先引⼊re模块,正则表达式以r引导,例如:其中**r“\d+”**正则表达式表⽰匹配连续的多个数值,search是re中的函数,从"abc123cd"字符串中搜索连续的数值,得到"123",返回⼀个匹配对象,结果如上.2.字符串"\d"匹配0~9之间的⼀个数值3.字符"+"重复前⾯⼀个匹配字符⼀次或者多次.注意:**r"b\d+"**第⼀个字符要匹配"b",后⾯是连续的多个数字,因此"是b1233",不是"a12".4.字符"*"重复前⾯⼀个匹配字符零次或者多次.“" 与 "+"类似,但有区别,列如:可见 r"ab+“匹配的是"ab”,但是r"ab “匹配的是"a”,因为表⽰"b"可以重复零次,但是”+“却要求"b"重复⼀次以上.5.字符"?"重复前⾯⼀个匹配字符零次或者⼀次.匹配结果"ab”,重复b⼀次.6.字符".“代表任何⼀个字符,但是没有特别声明时不代表字符”\n".结果“.”代表了字符"x".7."|"代表把左右分成两个部分 .结果匹配"ab"或者"ba"都可以.8.特殊字符使⽤反斜杠"“引导,例如”\r"、"\n"、"\t"、"\"分别表⽰回车、换⾏、制表符号与反斜线⾃⼰本⾝.9.字符"\b"表⽰单词结尾,单词结尾包括各种空⽩字符或者字符串结尾.结果匹配"car",因为"car"后⾯是⼀个空格.10."[]中的字符是任选择⼀个,如果字符ASCll码中连续的⼀组,那么可以使⽤"-"字符连接,例如[0-9]表⽰0-9的其中⼀个数字,[A-Z]表⽰A-Z的其中⼀个⼤写字符,[0-9A-z]表⽰0-9的其中⼀个数字或者A-z的其中⼀个⼤写字符.11."^"出现在[]的第⼀个字符位置,就代表取反,例如[ ^ab0-9]表⽰不是a、b,也不是0-9的数字.12."\s"匹配任何空⽩字符,等价"[\r\n 20\t\f\v]"13."\w"匹配包括下划线⼦内的单词字符,等价于"[a-zA-Z0-9]"14."$"字符⽐配字符串的结尾位置匹配结果是最后⼀个"ab",⽽不是第⼀个"ab"15.使⽤括号(…)可以把(…)看出⼀个整体,经常与"+"、"*"、"?"的连续使⽤,对(…)部分进⾏重复.结果匹配"abab","+“对"ab"进⾏了重复16.查找匹配字符串正则表达式re库的search函数使⽤正则表达式对要匹配的字符串进⾏匹配,如果匹配不成功返回None,如果匹配成功返回⼀个匹配对象,匹配对象调⽤start()函数得到匹配字符的开始位置,匹配对象调⽤end()函数得到匹配字符串的结束位置,search虽然只返回匹配第⼀次匹配的结果,但是我们只要连续使⽤search函数就可以找到字符串全部匹配的字符串.匹配找出英⽂句⼦中所有单词我们可以使⽤正则表达式r”[A-Za-z]+\b"匹配单词,它表⽰匹配由⼤⼩写字母组成的连续多个字符,⼀般是⼀个单词,之后"\b"表⽰单词结尾.程序开始匹配到⼀个单词后m.start(),m.end()就是单词的起始位置,s[start:end]为截取的单词,之后程序再次匹配字符串s=s[end:],即字符串的后半段,⼀直到匹配完毕为⽌就找出每个单词.总结到此这篇关于python常⽤正则表达式的⽂章就介绍到这了,更多相关python正则表达式内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
实用正则表达式匹配和替换大全

实⽤正则表达式匹配和替换⼤全正则表达式⾮常有⽤,查找、匹配、处理字符串、替换和转换字符串,输⼊输出等。
⽽且各种语⾔都⽀持,例如.NET正则库,JDK正则包, Perl, JavaScript等各种脚本语⾔都⽀持正则表达式。
下⾯整理⼀些常⽤的正则表达式。
字符描述\将下⼀个字符标记为⼀个特殊字符、或⼀个原义字符、或⼀个向后引⽤、或⼀个⼋进制转义符。
例如,'n' 匹配字符 "n"。
'\n' 匹配⼀个换⾏符。
序列 '\\' 匹配 "\" ⽽ "\(" 则匹配 "("。
^匹配输⼊字符串的开始位置。
如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。
$匹配输⼊字符串的结束位置。
如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。
*匹配前⾯的⼦表达式零次或多次。
例如,zo* 能匹配 "z" 以及 "zoo"。
*等价于{0,}。
+匹配前⾯的⼦表达式⼀次或多次。
例如,'zo+' 能匹配 "zo" 以及"zoo",但不能匹配 "z"。
+ 等价于 {1,}。
匹配前⾯的⼦表达式零次或⼀次。
例如,"do(es)?" 可以匹配 "do" 或"does" 中的"do" 。
? 等价于 {0,1}。
{n}n是⼀个⾮负整数。
匹配确定的n次。
例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。
20个常用的正则表达式

20个常用的正则表达式摘要:1.正则表达式的概念2.为什么需要正则表达式3.20 个常用的正则表达式a.匹配数字b.匹配字母c.匹配字符串d.匹配空白字符e.匹配特殊字符f.匹配范围g.匹配零次或多次h.匹配一次或多次i.匹配两次或多次j.匹配正则表达式k.匹配非正则表达式l.匹配开头m.匹配结尾n.匹配子字符串o.匹配连续字符p.匹配非连续字符q.匹配可选字符r.匹配分组s.匹配替换t.匹配转义字符u.匹配反向引用v.匹配贪婪与懒惰匹配w.匹配并匹配下一个字符x.匹配字符集合y.匹配字符范围z.匹配Unicode 字符正文:正则表达式是一种强大的文本处理工具,它可以用来检查文本是否符合某种模式、提取文本中的特定部分或者替换文本中的某些内容。
在Python 等编程语言中,正则表达式被广泛应用于文本分析、网页抓取、数据分析等领域。
本文将介绍20 个常用的正则表达式,帮助你更好地掌握正则表达式的使用。
1.匹配数字:`d` 匹配任意数字,`d+` 匹配一个或多个数字,`d{3}` 匹配三个数字。
2.匹配字母:`[a-zA-Z]` 匹配任意字母,`[a-zA-Z]+` 匹配一个或多个字母,`[a-zA-Z]{3}` 匹配三个字母。
3.匹配字符串:`".*"` 匹配任意字符串,`".*?"` 匹配一个或多个字符串,`".*?{"` 匹配一个包含在大括号内的字符串。
4.匹配空白字符:`s` 匹配任意空白字符,包括空格、制表符、换行符等,`s+` 匹配一个或多个空白字符。
5.匹配特殊字符:`[!@#$%^&*(),.?":{}|<>]` 匹配任意特殊字符。
6.匹配范围:`-` 匹配数字范围,如`d-` 匹配0-9 的数字,`[a-zA-Z]` 匹配所有字母。
7.匹配零次或多次:`*` 匹配前面的字符出现零次或多次,如`d*` 匹配零个或多个数字。
20个常用的正则表达式 单字母

正则表达式(Regular Expression)是一种用于匹配字符串的强大工具。
它通过使用特定的符号和字符来描述和匹配一系列字符串,能够满足我们在处理文本时的各种需求。
在这篇文章中,我们将深入探讨20个常用的单字母正则表达式,并通过实例来展示它们的使用方法。
1. \b在正则表达式中,\b表示单词的边界。
它可以用来匹配单词的开头或结尾,用于查找特定单词而不是单词的一部分。
2. \d\d表示任意一个数字字符。
它可以用来匹配任何数字,例如\d+可以匹配一个或多个数字字符。
3. \w\w表示任意一个字母、数字或下划线字符。
它可以用来匹配单词字符,例如\w+可以匹配一个或多个单词字符。
4. \s\s表示任意一个空白字符,包括空格、制表符、换行符等。
它可以用来匹配空白字符,例如\s+可以匹配一个或多个空白字符。
5. \.\.表示匹配任意一个字符,包括标点符号和空格等。
它可以用来匹配任意字符,例如\.可以匹配任意一个字符。
6. \A\A表示匹配字符串的开始。
它可以用来确保匹配发生在字符串的开头。
7. \Z\Z表示匹配字符串的结束。
它可以用来确保匹配发生在字符串的结尾。
8. \b\b表示单词的边界。
它可以用来匹配单词的开头或结尾,用于查找特定单词而不是单词的一部分。
9. \D\D表示任意一个非数字字符。
它可以用来匹配任何非数字字符。
10. \W\W表示任意一个非单词字符。
它可以用来匹配任何非单词字符。
11. \S\S表示任意一个非空白字符。
它可以用来匹配任何非空白字符。
12. \[\[表示匹配方括号。
它可以用来匹配包含在方括号内的字符。
13. \]\]表示匹配方括号。
它可以用来匹配包含在方括号内的字符。
14. \(\(表示匹配左括号。
它可以用来匹配包含在左括号内的字符。
15. \)\)表示匹配右括号。
它可以用来匹配包含在右括号内的字符。
16. \{\{表示匹配左花括号。
它可以用来匹配包含在左花括号内的字符。
17. \}\}表示匹配右花括号。
正则表达式实用语法大全

正则表达式基本符号:^ 表示匹配字符串的开始位置 (例外用在中括号中[ ] 时,可以理解为取反,表示不匹配括号中字符串)$ 表示匹配字符串的结束位置* 表示匹配零次到多次+ 表示匹配一次到多次 (至少有一次)表示匹配零次或一次. 表示匹配单个字符| 表示为或者,两项中取一项( ) 小括号表示匹配括号中全部字符[ ] 中括号表示匹配括号中一个字符范围描述如[0-9 a-z A-Z]{ } 大括号用于限定匹配次数如 {n}表示匹配n个字符 {n,}表示至少匹配n个字符{n,m}表示至少n,最多m\ 转义字符如上基本符号匹配都需要转义字符如 \* 表示匹配*号\w 表示英文字母和数字 \W 非字母和数字\d 表示数字 \D 非数字常用的正则表达式匹配中文字符的正则表达式: [\u4e00-\u9fa5]匹配双字节字符(包括汉字在内):[^\x00-\xff]匹配空行的正则表达式:\n[\s| ]*\r匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/匹配首尾空格的正则表达式:(^\s*)|(\s*$)匹配IP地址的正则表达式:/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*匹配网址URL的正则表达式:http://(/[\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?sql语句:^(select|drop|delete|create|update|insert).*$1、非负整数:^\d+$2、正整数:^[0-9]*[1-9][0-9]*$3、非正整数:^((-\d+)|(0+))$4、负整数:^-[0-9]*[1-9][0-9]*$5、整数:^-?\d+$6、非负浮点数:^\d+(\.\d+)?$7、正浮点数:^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$8、非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$9、负浮点数:^(-((正浮点数正则式)))$10、英文字符串:^[A-Za-z]+$11、英文大写串:^[A-Z]+$12、英文小写串:^[a-z]+$13、英文字符数字串:^[A-Za-z0-9]+$14、英数字加下划线串:^\w+$15、E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$16、URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$ 或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$17、邮政编码:^[1-9]\d{5}$18、中文:^[\u0391-\uFFE5]+$19、电话号码:^((\d2,3)|(\d{3}\-))?(0\d2,3|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$20、手机号码:^((\d2,3)|(\d{3}\-))?13\d{9}$21、双字节字符(包括汉字在内):^\x00-\xff22、匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数)23、匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/>24、匹配空行:\n[\s| ]*\r25、提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *=*('|")?(\w|\\|\/|\.)+('|"| *|>)?26、提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*27、提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?28、提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)29、提取信息中的中国手机号码:(86)*0*13\d{9}30、提取信息中的中国固定电话号码:(\d3,4|\d{3,4}-|\s)?\d{8}31、提取信息中的中国电话号码(包括移动和固定电话):(\d3,4|\d{3,4}-|\s)?\d{7,14}32、提取信息中的中国邮政编码:[1-9]{1}(\d+){5}33、提取信息中的浮点数(即小数):(-?\d*)\.?\d+34、提取信息中的任意数字:(-?\d*)(\.\d+)?35、IP:(\d+)\.(\d+)\.(\d+)\.(\d+)36、电话区号:/^0\d{2,3}$/37、腾讯QQ号:^[1-9]*[1-9][0-9]*$38、帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$39、中文、英文、数字及下划线:^[\u4e00-\u9fa5_a-zA-Z0-9]+$。
c++ 正则表达式语法

C++ 中的正则表达式语法主要基于 Perl 语言,并包含一些来自其他语言(如 POSIX)的元素。
下面是一些常用的正则表达式语法:1..:匹配除换行符(\n 或 \r)之外的任何字符。
2.^:匹配行的开头。
3.$:匹配行的结尾。
4.\\(:匹配开括号。
5.\\):匹配闭括号。
6.\\[:匹配方括号开头的字符集。
7.\\]:匹配方括号闭合的字符集。
8.\\d:匹配任意数字,等同于[0-9]。
9.\\D:匹配任意非数字字符,等同于[^0-9]。
10.\\s:匹配任何空白字符,包括空格、制表符、换页符等。
11.\\S:匹配任何非空白字符。
12.\\w:匹配任意字母数字字符,等同于[a-zA-Z0-9_]。
13.\\W:匹配任意非字母数字字符,等同于[^a-zA-Z0-9_]。
14.*:零次或多次重复前面的字符。
15.+:一次或多次重复前面的字符。
16.:零次或一次重复前面的字符。
17.{n}:n 次重复前面的字符。
18.{n,}:至少 n 次重复前面的字符。
19.{n,m}:至少 n 次,但不超过 m 次重复前面的字符。
20.\\|:表示或,比如a\\|b匹配 a 或 b。
21.( ):用于分组。
22.(?: ):非捕获分组,用于分组但不捕获结果。
23.(?= ):正向肯定预查,检查后面是否紧跟着某个模式,但不消耗这些字符。
24.(?! ):正向否定预查,检查后面是否不紧跟着某个模式,但不消耗这些字符。
25.(?< ):正向肯定后查,查找后面是否紧跟着某个模式,但不消耗这些字符。
26.(?<= ):正向肯定后查,查找后面是否紧跟着某个模式,并消耗这些字符。
27.(?<! ):正向否定后查,查找后面是否不紧跟着某个模式,但不消耗这些字符。
28.(?<! ):正向否定后查,查找后面是否不紧跟着某个模式,并消耗这些字符。
29.[...]:表示一个字符集(character set)。
常用的正则表达式操作符

匹配一连串的(最少一个)abc或def;abc和def将匹配。
[A-E]
匹配任意大写的A、B、C、D或E。
[^A-E]
匹配除A、B、C、D和E之外的任意字符。
X?
匹配出现零次或一次的大写字母X。
X*
匹配零个或任意个大写X。
X+
匹配一个或多个字母X。
X{n}
精确匹配n个字母X。
X{n,m}
匹配最少n个并且不超过m个字母X。如果省略m,表达式将尝试匹配最少n个X。
脱字号匹配出现在行首或字符串开始位置的空字符串
常用的正则表达式操作符
操作符
用途
.(句号)
匹配任意单个字符。
^(脱字号)
匹配出现在行首或字符串开始位置的空字符串。
$(ቤተ መጻሕፍቲ ባይዱ元符号)
匹配出现在行末的空字符串。
A
匹配大写字母A。
a
匹配小写字母a。
\d
匹配任意一位数字。
\D
匹配任意单个非数字字符。
\w
匹配任意单个字母数字字符,同义词是[:alnum:]。
正则表达式学习笔记——常用的20个正则表达式校验

正则表达式学习笔记——常⽤的20个正则表达式校验1 . 校验密码强度密码的强度必须是包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间。
/^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$/2. 校验中⽂字符串仅能是中⽂。
/^[\\u4e00-\\u9fa5]{0,}$/3. 由数字、26个英⽂字母或下划线组成的字符串/^\\w+$/4. 校验E-Mail 地址同密码⼀样,下⾯是E-mail地址合规性的正则检查语句。
/[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?/5. 校验⾝份证号码下⾯是⾝份证号码的正则校验。
15 或 18位。
15位:/^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$/18位:/^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$/6. 校验⽇期“yyyy-mm-dd“格式的⽇期校验,已考虑平闰年。
/^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468] [048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/7. 校验⾦额⾦额校验,精确到2位⼩数。
/^[0-9]+(.[0-9]{2})?$/8. 校验⼿机号下⾯是国内 13、15、18开头的⼿机号正则表达式。
bash中的正则

bash中的正则在Bash中,你可以使用正则表达式(Regular Expressions)来匹配和操作文本。
Bash支持基础的正则表达式语法,但功能相对有限。
以下是一些常用的正则表达式元字符和示例:1.. :匹配任意单个字符(除了换行符)。
bashecho "abc" | grep "a.c" # 匹配"abc" 和"ac"2.*:匹配前面的字符或子模式零次或多次。
bashecho "aaa" | grep "a*" # 匹配整个字符串3.^:匹配字符串的开头。
bashecho "abc" | grep "^a" # 匹配"abc" 和"a"4.$:匹配字符串的结尾。
bashecho "abc" | grep "c$" # 匹配"abc" 和"c"5.[...]:匹配方括号内的任意单个字符。
bashecho "abc" | grep "[ab]" # 匹配"a" 和"b"6.[^...]:匹配不在方括号内的任意单个字符。
bashecho "abc" | grep "[^ab]" # 匹配"c"7.\:转义特殊字符。
bashecho "a.c" | grep "a\.c" # 匹配"a.c"(注意点号前的反斜杠)8.( ... ):分组。
bashecho "abbc" | grep "(ab)bc" # 匹配"abbc",其中"ab" 被分组捕获9.|:或。
常用的正则表达式实例整理

常⽤的正则表达式实例整理收集在业务中经常使⽤的正则表达式实例,⽅便以后进⾏查找,减少⼯作量。
1. 校验基本⽇期格式var reg1 = /^\d{4}(\-|\/|\.)\d{1,2}\1\d{1,2}$/;var reg2 = /^(^(\d{4}|\d{2})(\-|\/|\.)\d{1,2}\3\d{1,2}$)|(^\d{4}年\d{1,2}⽉\d{1,2}⽇$)$/;2. 校验密码强度密码的强度必须是包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间。
var reg = /^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$/;3. 校验中⽂字符串仅能是中⽂。
var reg = /^[\\u4e00-\\u9fa5]{0,}$/;4. 由数字、26个英⽂字母或下划线组成的字符串var reg = /^\\w+$/;5. 校验E-Mail 地址同密码⼀样,下⾯是E-mail地址合规性的正则检查语句。
var reg =/[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?/;6. 校验⾝份证号码下⾯是⾝份证号码的正则校验。
15 或 18位。
15位: var reg = /^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$/;18位:var reg = /^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$/;7. 校验⽇期 “yyyy-mm-dd” 格式的⽇期校验,已考虑平闰年。
var reg =/^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/;8. 校验⾦额⾦额校验,精确到2位⼩数。
匹配数字的正则表达式

匹配数字的正则表达式正则表达式是一种用于匹配字符串的模式,它可以用来匹配数字、字母、符号等不同类型的字符。
匹配数字的正则表达式通常由数字和特殊字符组成,下面介绍几种常见的匹配数字的正则表达式:1. 匹配整数:^[0-9]*$解释:^表示字符串开头,$表示字符串结尾,[0-9]表示匹配0-9中任意一个数字,*表示前面的字符可以出现0次或多次。
因此,^[0-9]*$表示一个由0个或多个数字组成的字符串。
2. 匹配正整数:^[1-9][0-9]*$解释:[1-9]表示匹配1-9中任意一个数字(不能为0),[0-9]*表示后面可以跟任意个数字。
因此,^[1-9][0-9]*$表示一个由至少一位数字组成的字符串。
3. 匹配负整数:^-[1-9][0-9]*$解释:^表示字符串开头,-[1-9]表示负号后面必须跟一个非零数字,[0-9]*表示后面可以跟任意个数字。
因此,^-[1-9][0-9]*$表示一个由负号和至少一位非零数字组成的字符串。
4. 匹配浮点数(包括小数点):^[+-]?([0-9]*\.[0-9]+|[0-9]+)$解释:^[+-]?表示字符串开头可以是正号或负号(可选),([0-9]*\.[0-9]+|[0-9]+)表示小数部分和整数部分的匹配,其中[0-9]*\.[0-9]+表示小数部分,[0-9]+表示整数部分。
因此,^[+-]?([0-9]*\.[0-9]+|[0-9]+)$表示一个由可选的正负号、整数或带小数点的数字组成的字符串。
5. 匹配手机号码:^1[3|4|5|7|8][0-9]{9}$解释:^1表示以1开头,[3|4|5|7|8]表示第二位只能是3、4、5、7、8中的一个,[0-9]{9}表示后面必须跟着任意九个数字。
因此,^1[3|4|5|7|8][0-9]{9}$表示一个合法的中国手机号码。
以上是常见的匹配数字的正则表达式,可以根据具体需求进行修改和扩展。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
正则表达式是一种强大的工具,它可以帮助我们在文本中查找特定的模式,进行匹配和替换。
在日常编程和文本处理中,掌握一些常用的正则表达式匹配规则是非常重要的。
在本文中,我将介绍20个常用的正则表达式匹配,帮助你更好地理解和应用正则表达式。
1. ^(脱字符):
- 含义:匹配输入字符串的开始位置。
- 举例:^hello 匹配以“hello”开头的字符串。
2. $:
- 含义:匹配输入字符串的结束位置。
- 举例:world$ 匹配以“world”结尾的字符串。
3. \b:
- 含义:匹配单词边界。
- 举例:\bthe\b 匹配单词“the”。
4. \d:
- 含义:匹配一个数字字符。
- 举例:\d+ 匹配一个或多个数字。
5. \D:
- 含义:匹配一个非数字字符。
- 举例:\D+ 匹配一个或多个非数字字符。
6. \w:
- 含义:匹配包括下划线的任何单词字符。
- 举例:\w+ 匹配一个或多个单词字符。
7. \W:
- 含义:匹配任何非单词字符。
- 举例:\W+ 匹配一个或多个非单词字符。
8. .:
- 含义:匹配除换行符以外的任何单个字符。
- 举例:b.t 匹配“bat”、“bit”等。
9. *:
- 含义:匹配前面的子表达式零次或多次。
- 举例:\d* 匹配零个或多个数字。
10. +:
- 含义:匹配前面的子表达式一次或多次。
- 举例:\d+ 匹配一个或多个数字。
11. ?:
- 含义:匹配前面的子表达式零次或一次。
- 举例:\d? 匹配零个或一个数字。
12. []:
- 含义:匹配方括号内的任意一个字符。
- 举例:[aeiou] 匹配元音字母。
13. [^]:
- 含义:匹配除了方括号内的任意一个字符。
- 举例:[^aeiou] 匹配非元音字母。
14. ( ):
- 含义:标记一个子表达式的开始和结束位置。
- 举例:(abc)+ 匹配“abc”、“abcabc”等。
15. |:
- 含义:指定两项之间的一个选择。
- 举例:cat|dog 匹配“cat”或“dog”。
16. \s:
- 含义:匹配任何空白字符。
- 举例:\s+ 匹配一个或多个空白字符。
17. \S:
- 含义:匹配任何非空白字符。
- 举例:\S+ 匹配一个或多个非空白字符。
18. \E:
- 含义:结束非转义序列。
- 举例:(?i)I am \E(?-i)PETER 匹配“I am PETER”、“I am peter”等。
19. \A:
- 含义:匹配输入字符串开始的位置。
- 举例:\Ahello 匹配以“hello”开头的字符串。
20. \Z:
- 含义:匹配输入字符串的结尾位置,或者紧随输入结尾的换行符前的位置。
- 举例:world\Z 匹配以“world”结尾的字符串。
这些正则表达式的匹配规则可以帮助你更好地处理文本,实现字符串的匹配与替换。
掌握这些正则表达式的应用,对于编程和日常工作中的文本处理都有着重要的意义。
希望通过本文的介绍,你对常用的正则表达式匹配有了更深入的了解和掌握。
我的个人观点是,正则表达式是一种非常强大且灵活的工具,它能够
帮助我们在文本处理中更高效地完成各种复杂的匹配和替换操作。
然而,正则表达式也是一门强大而复杂的技能,需要不断的实践和学习,才能掌握其中的精髓。
希望你在学习和应用正则表达式的过程中能够
不断积累经验,提升自己的技能水平。
本文介绍了20个常用的正则表达式匹配规则,对每个规则进行了解释和举例。
希望通过本文的学习,你能够更好地掌握正则表达式的应用,提高自己在文本处理中的技能水平。
祝你在使用正则表达式时能够游
刃有余,轻松处理各种复杂的匹配需求。