北京邮电大学 数据结构 实验一 带头结点的单链表构造
北京邮电大学 数据结构 实验一 带头结点的单链表构造

数据结构实验报告实验名称:实验1——单链表的构造学生姓名:XXXXNB班级:XXXX班内序号:学号:XXXX日期:XXXXX1.实验要求根据线性表的抽象数据类型的定义,完成带头结点的单链表的基本功能。
单链表的基本功能:1、构造:使用头插法、尾插法两种方法2、插入:要求建立的链表按照关键字从小到大有序3、删除4、查找5、获取链表长度6、销毁7、其他:可自行定义编写测试main()函数测试线性表的正确性。
2.程序分编程完成单链表的一般性功能如单链表的构造:使用头插法、尾插法两种方法插入:要求建立的链表按照关键字从小到大有序,删除,查找,获取链表长度,销毁用《数据结构》中的相关思想结合C++语言基本知识编写一个单链表结构。
本程序为使用方便,几乎不用特殊的命令,只需按提示输入即可,适合更多的用户使用。
2.1 存储结构单链表的存储结构:2.2 关键算法分析1.头插法自然语言描述:a.在堆中建立新结点b.将a[i]写入到新结点的数据域c.修改新结点的指针域d.修改头结点的指针域,将新结点加入链表中//在构建之初为了链表的美观性构造,进行了排序代码描述://头插法构造函数template<class T>LinkList<T>::LinkList(T a[], int n){for (int i = n - 1; i >= 1; i--)//冒泡排序,对数组进行从小到大排序{for (int j = 0; j < i; j++){if (a[j]>a[j + 1]){T t = a[j + 1];a[j + 1] = a[j];a[j] = t;}}}front = new Node < T >;//为头指针申请堆空间front->next = NULL;//构造空单链表for (int i = n - 1; i >= 0; i--){Node<T>*s = new Node < T >;//建立新结点s->data = a[i];//将a[i]写入新结点的数据域s->next = front->next;//修改新结点的指针域front->next = s;//修改头结点的指针域,将新结点加入到链表中}}2.尾插法自然语言描述:a.在堆中建立新结点b.将a[i]写入到新结点的数据域c.将新结点加入到链表中d.修改修改尾指针代码描述://尾插法构造函数template<class T>LinkList<T>::LinkList(T a[], int n){front = new Node < T > ;Node<T>*r = front;//命名一个新变量进行转换for (int i = 0; i < n; i++){Node<T>*s = new Node < T > ;s->data = a[i];r->next = s;r = s;}r->next = NULL;}时间复杂度:O(n)3.析构函数自然语言描述:a.新建立一个指针,指向头结点b.移动a中建立的指针c.逐个释放指针代码描述:template<class T>LinkList<T>::~LinkList()//析构函数,销毁链表{Node<T> * p = front;while(p){front = p;p = p->next;delete front;}}4.按位查找函数自然语言描述: a.初始化工作指针p和计数器j,p指向第一个结点,j=1b.循环以下操作,直到p为空或者j等于1b1:p指向下一个结点b2:j加1c.若p为空,说明第i个元素不存在,抛出异常d.否则,说明p指向的元素就是所查找的元素,返回元素地址代码描述:template<class T>Node<T>* LinkList<T>::Get(int i)//按位查找{Node<T> * p = front;int j=0;while(p){if(j<i){p = p->next;j++;}else break;}if(!p) throw"查找位置非法";else return p;}时间复杂度:O(n)5.按值查找函数自然语言描述:a.初始化工作指针p和计数器j,p指向第一个结点,j=1b.循环以下操作,找到这个元素或者p指向最后一个结点b1.判断p指向的结点是不是要查找的值,如果是,返回j;b2.否则p指向下一个结点,并且j的值加一c.如果找到最后一个结点还没有找到要查找的元素,返回查找失败信息代码描述:template<class T>int LinkList<T>::Locate(T x)//按值查找{Node<T> * p = front->next;int j = 1;while(p){if(p->data == x) return j;else{p = p->next;j++;}}return -1;}时间复杂度:O(n)6.插入函数自然语言描述:a.在堆中建立新结点b.将要插入的结点的数据写入到新结点的数据域c.修改新结点的指针域d.修改前一个指针的指针域,使其指向新插入的结点的位置代码描述:template<class T>void LinkList<T>::Insert(int i,T x)//插入函数{Node<T> * p = Get(i-1);if(p){Node<T> * s = new Node<T>;s->data = x;s->next = p->next;p->next = s;}else throw"插入位置非法";}时间复杂度:O(n)7.按位删除函数自然语言描述:a.从第一个结点开始,查找要删除的位数i前一个位置i-1的结点b.设q指向第i个元素c.将q元素从链表中删除d.保存q元素的数据e.释放q元素代码描述:template<class T>T LinkList<T>::Delete(int i)//删除函数{Node<T> *p = Get(i-1);Node<T> *q = p->next;T x=q->data;p->next = q->next;delete q;return x;}8.遍历打印函数自然语言描述: a.判断该链表是否为空链表,如果是,报错b.如果不是空链表,新建立一个temp指针c.将temp指针指向头结点d.打印temp指针的data域e.逐个往后移动temp指针,直到temp指针的指向的指针的next域为空代码描述:template<class T>void LinkList<T>::PrintList()//打印链表{Node<T> * p = front->next;while(p){cout<<p->data<<' ';p = p->next;}cout<<endl;}9.获取链表长度函数自然语言描述:a.判断该链表是否为空链表,如果是,输出长度0b.如果不是空链表,新建立一个temp指针,初始化整形数n为0c.将temp指针指向头结点d.判断temp指针指向的结点的next域是否为空,如果不是,n加一,否则return ne.使temp指针逐个后移,重复d操作,直到temp指针指向的结点的next 域为0,返回n代码描述:template<class T>int LinkList<T>::GetLength()//分析链表长度{Node<T> * p = front;int i=0;while(p){p = p->next;i++;}return i-1;}2.3 其他异常处理采用try catch 函数处理异常如在插入时的异常处理:template<class T>void LinkList<T>::Insert(int i, T x){Node<T>*p = front;if (i != 1) p = Get(i - 1);try{if (p){Node<T>*s = new Node < T > ;s->data = x;s->next = p->next;p->next = s;}else throw i;}catch (int i){cout << "插入到位置 " << i << " 处" << "为错误位置"<<endl;}}3. 程序运行结果主函数流程图:测试截图:初始化链表,菜单创建执行功能:4. 总结.调试时出现了一些问题如:异常抛出的处理,书中并未很好的提及异常处理,通过查阅资料,选择用try catch 函数对解决。
北邮数据结构实验报告

北邮数据结构实验报告摘要:本报告基于北邮数据结构实验,通过实际操作和实验结果的分析,总结和讨论了各实验的目的、实验过程、实验结果以及相关的问题和解决方法。
本报告旨在帮助读者了解数据结构实验的基本原理和应用,并为今后的学习和研究提供参考。
1. 实验一:线性表的操作1.1 实验目的本实验旨在掌握线性表的基本操作以及对应的算法实现,包括插入、删除、查找、修改等。
1.2 实验过程我们使用C++语言编写了线性表的相关算法,并在实际编程环境下进行了测试。
通过插入元素、删除元素、查找元素和修改元素的操作,验证了算法的正确性和效率。
1.3 实验结果经过测试,我们发现线性表的插入和删除操作的时间复杂度为O(n),查找操作的时间复杂度为O(n),修改操作的时间复杂度为O(1)。
这些结果与预期相符,并反映了线性表的基本特性。
1.4 问题与解决方法在实验过程中,我们遇到了一些问题,例如插入操作的边界条件判断、删除操作时的内存释放等。
通过仔细分析问题,我们优化了算法的实现,并解决了这些问题。
2. 实验二:栈和队列的应用2.1 实验目的本实验旨在掌握栈和队列的基本原理、操作和应用,并进行实际编程实现。
2.2 实验过程我们使用C++语言编写了栈和队列的相关算法,并在实际编程环境下进行了测试。
通过栈的应用实现表达式求值和逆波兰表达式的计算,以及队列的应用实现图的广度优先遍历,验证了算法的正确性和效率。
2.3 实验结果经过测试,我们发现栈的应用可以实现表达式的求值和逆波兰表达式的计算,队列的应用可以实现图的广度优先遍历。
这些结果证明了栈和队列在实际应用中的重要性和有效性。
2.4 问题与解决方法在实验过程中,我们遇到了一些问题,例如中缀表达式转后缀表达式的算法设计、表达式求值的优化等。
通过查阅资料和与同学的讨论,我们解决了这些问题,并完善了算法的实现。
3. 实验三:串的模式匹配3.1 实验目的本实验旨在掌握串的基本操作和模式匹配算法,并进行实际编程实现。
带头节点的循环单链表

带头节点的循环单链表带头节点的循环单链表是一种特殊的链表结构,它在普通的循环单链表的基础上增加了一个头节点。
本文将详细介绍带头节点的循环单链表的特点、操作以及应用场景。
一、带头节点的循环单链表的特点带头节点的循环单链表与普通的循环单链表相比,多了一个头节点,头节点不存储任何数据,仅作为链表的标志和辅助作用。
头节点的存在使得链表的插入、删除等操作更加方便,同时也能避免一些特殊情况的处理。
1. 初始化链表:创建一个头节点,并将头节点的指针指向自身,表示链表为空。
2. 判断链表是否为空:通过判断头节点的指针是否指向自身,即可判断链表是否为空。
3. 插入节点:在链表的指定位置插入一个新节点。
首先找到插入位置的前一个节点,然后将新节点的指针指向前一个节点的下一个节点,再将前一个节点的指针指向新节点。
4. 删除节点:删除链表中指定位置的节点。
首先找到要删除节点的前一个节点,然后将前一个节点的指针指向要删除节点的下一个节点,最后释放被删除节点的内存空间。
5. 遍历链表:从头节点开始,按照指针的方向遍历链表,直到回到头节点为止,输出每个节点的数据。
三、带头节点的循环单链表的应用场景带头节点的循环单链表在实际应用中有着广泛的应用场景,以下是几个典型的应用场景:1. 约瑟夫环问题:约瑟夫环是一种数学问题,通过使用带头节点的循环单链表可以很方便地解决该问题。
2. 循环队列:循环队列是一种常见的队列结构,使用带头节点的循环单链表可以实现循环队列的操作。
3. 循环链表:带头节点的循环单链表本身就是一种循环链表,可以用于解决一些需要循环访问的问题。
总结:带头节点的循环单链表是一种特殊的链表结构,通过增加一个头节点,使得链表的操作更加方便,并且能够避免一些特殊情况的处理。
带头节点的循环单链表可以用于解决一些需要循环访问的问题,例如约瑟夫环问题和循环队列等。
掌握带头节点的循环单链表的基本操作,对于理解和应用链表结构具有重要的意义。
带头结点的单链表的插入算法

带头结点的单链表的插入算法在计算机科学中,链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
链表有多种形式,其中一种是带头结点的单链表。
带头结点的单链表是在普通的单链表的基础上添加了一个头结点,头结点不存储数据,只用来标识链表的开始。
带头结点的单链表的插入算法是指在链表中插入新的节点的操作。
下面将详细介绍带头结点的单链表的插入算法。
带头结点的单链表的插入算法包括以下几个步骤:1. 首先,创建一个新的节点,该节点包含要插入的数据。
2. 然后,找到插入位置的前一个节点,可以从头结点开始遍历链表,直到找到插入位置的前一个节点为止。
3. 接下来,将新节点的指针指向插入位置的后一个节点。
4. 最后,将插入位置的前一个节点的指针指向新节点。
下面通过一个具体的例子来说明带头结点的单链表的插入算法。
假设有一个带头结点的单链表,初始状态下只有一个头结点。
现在要在链表中插入一个新节点,该节点的数据为10。
1. 首先,创建一个新的节点,节点的数据为10。
2. 然后,从头结点开始遍历链表,直到找到插入位置的前一个节点。
在这个例子中,由于链表只有一个头结点,所以插入位置的前一个节点就是头结点。
3. 接下来,将新节点的指针指向插入位置的后一个节点。
由于链表只有一个头结点,所以插入位置的后一个节点为空。
4. 最后,将插入位置的前一个节点的指针指向新节点。
在这个例子中,将头结点的指针指向新节点。
经过以上操作,新节点就成功地插入到了链表中。
带头结点的单链表的插入算法的时间复杂度为O(n),其中n为链表的长度。
这是因为在最坏情况下,需要遍历整个链表找到插入位置的前一个节点。
带头结点的单链表的插入算法在实际应用中有着广泛的应用。
例如,在图算法中,可以使用带头结点的单链表来表示图的邻接表。
插入节点的操作可以用来添加新的边或顶点。
带头结点的单链表的插入算法是一种常见的数据操作,它可以在链表中插入新的节点。
数据结构实验报告单链表

数据结构实验报告_单链表数据结构实验报告——单链表一、实验目的1.掌握单链表的基本概念和原理。
2.了解单链表在计算机科学中的应用。
3.掌握单链表的基本操作,如插入、删除、遍历等。
4.通过实验,加深对理论知识的理解,提高编程能力。
二、实验内容1.实验原理:单链表是一种线性数据结构,由一系列节点组成,每个节点包含数据域和指针域。
其中,指针域指向下一个节点,最后一个节点的指针域指向空。
单链表的主要操作包括插入、删除、遍历等。
2.实验步骤:(1)创建一个单链表。
(2)实现插入操作,即在链表的末尾插入一个新节点。
(3)实现删除操作,即删除链表中的一个指定节点。
(4)实现遍历操作,即输出链表中所有节点的数据。
3.实验代码:下面是使用Python语言实现的单链表及其基本操作的示例代码。
class Node:def __init__(self, data):self.data = dataself.next = Noneclass LinkedList:def __init__(self):self.head = Nonedef insert(self, data):new_node = Node(data)if self.head is None:self.head = new_nodeelse:current = self.headwhile current.next is not None:current = current.nextcurrent.next = new_nodedef delete(self, data):if self.head is None:returnif self.head.data == data:self.head = self.head.nextreturncurrent = self.headwhile current.next is not None and current.next.data != data:current = current.nextif current.next is None:returncurrent.next = current.next.nextdef traverse(self):current = self.headwhile current is not None:print(current.data)current = current.next4.实验结果:通过运行上述代码,我们可以看到单链表的基本操作得到了实现。
北京邮电大学 计算机学院 数据结构第一次实验报告

printf("Delete failed!\n");
printlist(L,L->head);
return 0;
}
else
{
S=get(L,L->head,min,0);//0和1为开关,进行设置
R=get(L,S,max,1);
if(min>=L->head->data)//判断删除的节点中是否包含头结点
while(S!=NULL)
{
printf("%d--->",S->data);
S=S->next;
}
printf("NULL\n");
}
}
void deletelist(Linklist R)//释放链表
{
Linklist temp;
while(R!=NULL)
{
temp=R;
R=R->next;
scanf("%d",&L->len);
fflush(stdin);
if(L->len<=0)
return 0;
printf("Please input the data:\n");
for(i=0;i<=L->len-1;i++)
{
S=(Linklist)malloc(sizeof(Lnode));
要求:请同学把步骤、调试好的程序及存在的问题写在下面。
第一题实验程序代码:
#include<stdio.h>
#include<stdlib.h>
typedef struct Lnode{
数据结构实验报告-实验一顺序表、单链表基本操作的实现

数据结构实验报告-实验⼀顺序表、单链表基本操作的实现实验⼀顺序表、单链表基本操作的实现l 实验⽬的1、顺序表(1)掌握线性表的基本运算。
(2)掌握顺序存储的概念,学会对顺序存储数据结构进⾏操作。
(3)加深对顺序存储数据结构的理解,逐步培养解决实际问题的编程能⼒。
l 实验内容1、顺序表1、编写线性表基本操作函数:(1)InitList(LIST *L,int ms)初始化线性表;(2)InsertList(LIST *L,int item,int rc)向线性表的指定位置插⼊元素;(3)DeleteList1(LIST *L,int item)删除指定元素值的线性表记录;(4)DeleteList2(LIST *L,int rc)删除指定位置的线性表记录;(5)FindList(LIST *L,int item)查找线性表的元素;(6)OutputList(LIST *L)输出线性表元素;2、调⽤上述函数实现下列操作:(1)初始化线性表;(2)调⽤插⼊函数建⽴⼀个线性表;(3)在线性表中寻找指定的元素;(4)在线性表中删除指定值的元素;(5)在线性表中删除指定位置的元素;(6)遍历并输出线性表;l 实验结果1、顺序表(1)流程图(2)程序运⾏主要结果截图(3)程序源代码#include<stdio.h>#include<stdlib.h>#include<malloc.h>struct LinearList/*定义线性表结构*/{int *list; /*存线性表元素*/int size; /*存线性表长度*/int Maxsize; /*存list数组元素的个数*/};typedef struct LinearList LIST;void InitList(LIST *L,int ms)/*初始化线性表*/{if((L->list=(int*)malloc(ms*sizeof(int)))==NULL){printf("内存申请错误");exit(1);}L->size=0;L->Maxsize=ms;}int InsertList(LIST *L,int item,int rc)/*item记录值;rc插⼊位置*/ {int i;if(L->size==L->Maxsize)/*线性表已满*/return -1;if(rc<0)rc=0;if(rc>L->size)rc=L->size;for(i=L->size-1;i>=rc;i--)/*将线性表元素后移*/L->list[i+=1]=L->list[i];L->list[rc]=item;L->size++;return0;}void OutputList(LIST *L)/*输出线性表元素*/{int i;printf("%d",L->list[i]);printf("\n");}int FindList(LIST *L,int item)/*查找线性元素,返回值>=0为元素的位置,返回-1为没找到*/ {int i;for(i=0;i<L->size;i++)if(item==L->list[i])return i;return -1;}int DeleteList1(LIST *L,int item)/*删除指定元素值得线性表记录,返回值为>=0为删除成功*/ {int i,n;for(i=0;i<L->size;i++)if(item==L->list[i])break;if(i<L->size){for(n=i;n<L->size-1;n++)L->list[n]=L->list[n+1];L->size--;return i;}return -1;}int DeleteList2(LIST *L,int rc)/*删除指定位置的线性表记录*/{int i,n;if(rc<0||rc>=L->size)return -1;for(n=rc;n<L->size-1;n++)L->list[n]=L->list[n+1];L->size--;return0;}int main(){LIST LL;int i,r;printf("list addr=%p\tsize=%d\tMaxsize=%d\n",LL.list,LL.size,LL.Maxsize);printf("list addr=%p\tsize=%d\tMaxsize=%d\n",LL.list,LL.list,LL.Maxsize);while(1){printf("请输⼊元素值,输⼊0结束插⼊操作:");fflush(stdin);/*清空标准输⼊缓冲区*/scanf("%d",&i);if(i==0)break;printf("请输⼊插⼊位置:");scanf("%d",&r);InsertList(&LL,i,r-1);printf("线性表为:");OutputList(&LL);}while(1){printf("请输⼊查找元素值,输⼊0结束查找操作:");fflush(stdin);/*清空标准输⼊缓冲区*/scanf("%d ",&i);if(i==0)break;r=FindList(&LL,i);if(r<0)printf("没有找到\n");elseprintf("有符合条件的元素,位置为:%d\n",r+1);}while(1){printf("请输⼊删除元素值,输⼊0结束查找操作:");fflush(stdin);/*清楚标准缓存区*/scanf("%d",&i);if(i==0)break;r=DeleteList1(&LL,i);if(i<0)printf("没有找到\n");else{printf("有符合条件的元素,位置为:%d\n线性表为:",r+1);OutputList(&LL);}while(1){printf("请输⼊删除元素位置,输⼊0结束查找操作:");fflush(stdin);/*清楚标准输⼊缓冲区*/scanf("%d",&r);if(r==0)break;i=DeleteList2(&LL,r-1);if(i<0)printf("位置越界\n");else{printf("线性表为:");OutputList(&LL);}}}链表基本操作l 实验⽬的2、链表(1)掌握链表的概念,学会对链表进⾏操作。
含头结点的单链表
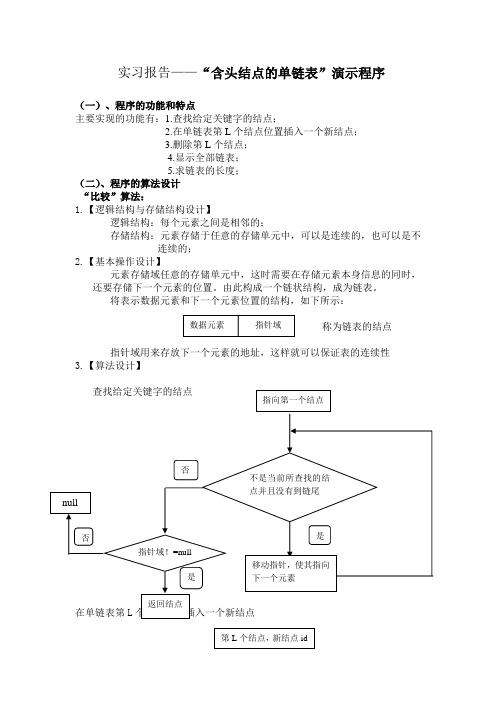
实习报告——“含头结点的单链表”演示程序(一)、程序的功能和特点主要实现的功能有:1.查找给定关键字的结点;2.在单链表第L 个结点位置插入一个新结点;3.删除第L 个结点;4.显示全部链表;5.求链表的长度;(二)、程序的算法设计“比较”算法:1.【逻辑结构与存储结构设计】逻辑结构:每个元素之间是相邻的;存储结构:元素存储于任意的存储单元中,可以是连续的,也可以是不 连续的;2.【基本操作设计】元素存储域任意的存储单元中,这时需要在存储元素本身信息的同时,还要存储下一个元素的位置。
由此构成一个链状结构,成为链表。
将表示数据元素和下一个元素位置的结构,如下所示:称为链表的结点指针域用来存放下一个元素的地址,这样就可以保证表的连续性3.【算法设计】查找给定关键字的结点在单链表第L 个结点位置插入一个新结点数据元素 指针域 指向第一个结点不是当前所查找的结点并且没有到链尾 是移动指针,使其指向下一个元素 否 指针域!=null 否 是 null 返回结点 第L 个结点,新结点id删除第L个结点建立新结点指针P后移L个结点把P之后链表接到新结点的后面把新结点接在p所指结点的后面判断链表是否为空否是使指针p指向所要删结点的前驱null指向要删结点指向要删结点的后驱4.【高级语言代码】查找给定关键字的结点,返回结点LinkNodeNode p=first; //指向第一结点//不是当前结点并且没有到链尾while(p.iData!=id&&p.next!=null)p=p.next;if(p.next!=null) return p;else return null;在单链表第L个结点位置插入一个新结点LinkNodeNode newLinkNodeNode= new LinkNodeNode(id,fd); //诞生新结点newLinkNodeNodeint i=1;LinkNodeNode p=first; //指向第一结点//p指针后移L个结点while(p.next!=null && i++<L) p=p.next;newLinkNodeNode.next=p.next; //把p之后的链表接在新结点的后面p.next=newLinkNodeNode; //把新结点接在p所指结点的后面return true;删除第L个结点if(isEmpty()) return null;LinkNodeNode p=first; //指向第一个结点int i=1;while(p.next!=null && i++<L)p=p.next; //指向要删结点的前驱LinkNodeNode q=p.next; //指向要删结点p.next=q.next; //p指向要删结点的后继return q; //返回已删结点(三)、程序中类的设计“LinkNodeList”类:1.【逻辑结构与存储结构】逻辑结构:每个元素之间是相邻的;存储结构:元素存储于任意的存储单元中,可以是连续的,也可以是不连续的;2.【主要成员变量说明】public LinkNode first; //单链表的头指针【主要成员方法说明】查找给定关键字的结点,返回结点public LinkNode LinkNodeFind(int id)在单链表第L个结点位置插入一个新结点public boolean insertWhere(int L,int id)删除第L个结点public LinkNode deleteWhere(int L)显示全部链表public void listDisplay()返回链表长度(结点数)public int listLength()4.【高级语言代码】链表的结点类class LinkNode{public int iData; //数据域(结点关键字)public LinkNode next; //指针域(指向下一结点)public LinkNode() { //头结点构造方法iData=-1;//数据域赋值//指针域自动初始化为null}public LinkNode(int iD) { //结点构造方法iData=iD; //数据域赋值}public void LinkNodeDisplay(){ //显示自身的数据域System.out.println("["+iData+"]");}}单链表类class LinkNodeList {public LinkNode first; //单链表的头指针public LinkNodeList (){ //构造方法first=new LinkNode(); //空单链表,头指针指向头结点}public boolean isEmpty() { //单链表是否为空return (first.next==null); //头结点的指针为空}//查找给定关键字的结点,返回结点public LinkNode LinkNodeFind(int id) {LinkNode p=first; //指向第一结点//不是当前结点并且没有到链尾while(p.iData!=id&&p.next!=null)p=p.next;if(p.next!=null)return p;elsereturn null;}//在单链表第L个结点位置插入一个新结点public boolean insertWhere(int L,int id) {LinkNode newLinkNode= new LinkNode(id); //诞生新结点newLinkNodeint i=1;LinkNode p=first; //指向第一结点//p指针后移L个结点while(p.next!=null && i++<L) p=p.next;newLinkNode.next=p.next; //把p之后的链表接在新结点的后面p.next=newLinkNode; //把新结点接在p所指结点的后面return true;}//删除第L个结点public LinkNode deleteWhere(int L) {if(isEmpty()) return null;LinkNode p=first; //指向第一个结点int i=1;while(p.next!=null && i++<L)p=p.next; //指向要删结点的前驱LinkNode q=p.next; //指向要删结点p.next=q.next; //p指向要删结点的后继return q; //返回已删结点}//显示全部链表public void listDisplay() {LinkNode p=first.next; //指向第一个结点System.out.println("显示链表:从前到后");while(p!=null) {p.LinkNodeDisplay(); //显示结点p=p.next;}System.out.println("*******");}//返回链表长度(结点数)public int listLength() {LinkNode p=first.next; //指向头结点int i=0;while(p!=null){p=p.next;i++;}return i;}//置链表为空表public void makeEmpty() {first.next=null;}public static void main(String []args) {LinkNodeList s1=new LinkNodeList(); //空链表诞生s1.insertWhere(1,12); //从指定位置插入结点s1.insertWhere(2,34);s1.insertWhere(3,53);s1.insertWhere(4,32);s1.insertWhere(3,76);s1.listDisplay();s1.deleteWhere(4); //删除第4个结点s1.listDisplay();LinkNode t=s1.LinkNodeFind(34); //查找结点if(t!=null) t.LinkNodeDisplay(); //显示该结点//s1.makeEmpty();//s1.listDisplay();System.out.println(s1.listLength());}}(四)、程序的输入输出和运行结果截屏。
北邮数据结构实验--链表排序

链表排序数据结构实验报告1. 实验要求●实验目的:学习、实现、对比各种排序算法,掌握各种排序算法的优劣,以及各种算法使用的情况。
●实验内容:使用链表实现下面各种排序算法,并进行比较。
排序算法:1、插入排序2、冒泡排序3、快速排序4、简单选择排序5、其他要求:1、测试数据分成三类:正序、逆序、随机数据2、对于这三类数据,比较上述排序算法中关键字的比较次数和移动次数(其中关键字交换计为3次移动)。
3、对于这三类数据,比较上述排序算法中不同算法的执行时间,精确到微秒(选作)4、对2和3的结果进行分析,验证上述各种算法的时间复杂度编写测试main()函数测试线性表的正确性2.程序分析2.1 存储结构双循环链表:……..2.2 关键算法分析1.1)插入排序:void clist::insertsort(){x=0;y=0;int m;node*p=front->next->next;while(p!=front){m=p->data ;x++; //用于计比较次数的计数器if(m < p->prior->data ){s=p->prior;while(s!=front&&s->data >m){s->next ->data =s->data ;s=s->prior ;x++;y++; //用于计移动次数的计数器}s->next ->data =m;y++;}p=p->next ;}cout<<"插入排序的比较次数:"<<x<<" "<<"移动次数"<<y<<endl;print();}2)冒泡排序:void clist::bubblesort(){recover();x=0;y=0;int v;node* p=front->prior;while(p!=front){s=p; //s表示本次排序无序元素的范围p=front;r=front->next ;while(r!=s){x++;if(r->data >r->next ->data ) //相邻元素进行比较{v=r->data ; //元素交换r->data =r->next ->data ;r->next ->data =v;p=r;y+=3;}r=r->next ;}}cout<<"冒泡排序的比较次数:"<<x<<" "<<"移动次数"<<y<<endl;print();}3)一趟快速排序:node* clist::partion(node *p,node *q){int pivot=p->data; //选取基准元素while(p!=q){while((p!=q)&&(q->data >=pivot)) //右侧扫描,查找小于轴值的元素{(*m)++;q=q->prior ;}p->data =q->data ;(*n)++;while((p!=q)&&(p->data <=pivot)) //左侧扫描,查找大于轴值的元素{(*m)++;p=p->next;}q->data =p->data ;(*n)++;}p->data=pivot;return p; //返回轴值所在的位置}快速排序:void clist::qsort (node *p,node *q){recover();if(p!=q){node* pivotloc=partion(p,q);if(pivotloc!=p)qsort(p,pivotloc->prior);if(pivotloc!=q)qsort(pivotloc->next,q);}}4)简单选择排序:void clist::sssort(){recover();x=0;y=0;while(p!=front->prior ){s=p; //假设s所指元素是最小的r=s->next ;while(r!=front) //查找最小值的位置{x++;if(r->data <s->data )s=r;r=r->next ;}if(s!=p) //若第一个就是最小元素,则不用交换{int m=p->data ;p->data =s->data ;s->data =m;y+=3;}p=p->next ;}cout<<"简单选择排序的比较次数:"<<x<<" "<<"移动次数"<<y<<endl;print();}3 程序运行结果各种排序算法的比较次数和移动次数满足它们时间复杂度的最好、最坏和平均情况,它们的性能如下:4.总结问题及解决:对于计算快速排序中的移动次数和比较次数,由于它是递归,所以要通过改变计数同时要保持下去,后来想到可以在函数参数中加两个整型的指针,通过地址传递,直接修改这两个指针所指元素的值,也实现了计移动次数和比较次数的目的。
带头结点的单链表

ListInsert
Status ListInsert(LinkList &L, int i, ElemType e){ if( i<1 || i>ListLength(L)+1) return(ERROR); p=L; j=0; while(j<i -1){ p=p->next; j++; }
ListInsert
node =(LNode *) malloc(sizeof(LNode)); if(!node) return(ERROR); node->data = e; node->next=p->next; p->next=node; return(OK); }
ListDelete
L
线性表(List)
复习 带头结点的单链表 部分操作的实现 循环单链表 顺序存储和链式存储的区别 小结和作业
复习
单链表:L
a1
a2
a3
部分操作:
InitList, DestroyList, GetItem, ListLength,ListInsert, ListDelete ListMerge
复习
ListLength
int ListLength(LinkList L){ count=0; p=L;
while( p->next){
count++
p=p->next; } return(count); }
带头结点
int ListLength(LinkList L){ count=0; p=L;
while( p){
北邮算法与数据结构习题参考答案

北邮算法与数据结构习题参考答案作业参考答案一、(带头结点)多项式乘法 C = A×B:void PolyAdd ( list &C, list R) // R 为单个结点{p=C;while ((!p->next) && (p->next->exp>R->exp)) p=p->next; if ((p->next) || (p->next->exp<R->exp)){ R->next=p->next; p->next=R; } else{ p->next->inf += R->inf; delete R;if ( ! p->next->inf ){ R=p->next; p->next=R->next; delete R; } }}void PolyMul ( list A, list B, list &C ){C=new struct node; C->next=NULL; q=B->next; While ( q ){p=A->next;while ( p ){r = new struct node; r->exp = p->exp + q->exp;r->inf = p-> inf * q->inf; PolyAdd(C, r);p=p->next;}q=q->next;}}二、梵塔的移动次数:已知移动次数迭代公式为:M ( n ) = 2M ( n-1 ) + 1初值为:M ( 0 ) = 0则:M ( n ) = 2 ( 2M ( n-2 ) + 1 ) + 1= 4M ( n-2 ) + 3= 8M ( n-3 ) + 7= 2i M ( n-i ) + 2i– 1若n=i ,则M ( n-n ) = 0,故:M ( n ) = 2n M ( n-n ) + 2n– 1= 2n– 1所以,梵塔的移动次数为2n– 1次。
带头结点的单链表(二)

带头结点的单链表(二)【特殊操作训练】——现有以下定义,你的函数可以直接使用,无需再提交。
#define True 11#define False 0#define Ok 111#define Error -111typedef int Status;//状态类型typedef struct{int num;//专家号,不重复,可用于查找专家char name[30];//专家姓名,可能重复}ElemType; //元素类型-----专家信息数据类型---------特别关注“数据元素”-------------// typedef ElemType ET;typedef struct Lnode{ElemType data;struct Lnode *next;}LNode,*LinkList;在招投标系统中,专家信息的更新换代比较频繁,假定采用“单链表”结构存储专家信息,在【无任何基本操作支撑】下,请完成以下“带头结点的单链表”的操作:(1)(30分)void Invert_L(LinkList L)功能:已知一个单链表L,其头结点指针为head,编写程序实现将L逆置。
(即最后一个结点变成第一个结点,原来倒数第二个结点变成第二个结点,如此等等。
)(2)(30)void Delete_L(LinkList L)功能:已知单链表中的元素以专家号值递增有序排列。
试写一高效的算法,删除表中所有专家号值(data.num)相同的多余元素(使得运算后的表中无重复信息),并分析你的算法的时间复杂度。
(3)(40分)Status Merge_L(LinkList La,LinkList Lb,LinkList &Lc)功能:已知两个有序单链表La、Lb,编写程序实现将La、Lb合并成一个有序单链表Lc,同时置La,Lb为空表。
返回值:成功返回Ok;否则,返回Error。
注:Lc的值不可用,必须初始化注意:(1)不用编写main函数,函数中没有任何输入输出语句;(2)所有函数必须同时提交,另外,需要用到特殊的库函数,请自行包含其头文件;否则编译出错;(3)在VC 或VS 环境中调试时,必须建立.CPP源文件。
编写带头结点的单链表中统计结点个数的算法。

编写带头结点的单链表中统计结点个数的算法。
以下是带头结点的单链表统计结点个数的算法:
1. 首先定义一个指针变量p指向链表的第一个结点。
2. 在循环中遍历整个链表,计算每个结点的个数。
在遍历过程中,将当前结点的值赋给变量num。
3. 将当前结点的指针移动到下一个结点,继续循环。
4. 如果当前结点没有对应的下一个结点,则返回结点个数的值。
5. 如果当前结点有对应的下一个结点,则将当前结点的值和下
一个结点的指针合并计算结点个数的值。
下面是实现该算法的C语言代码:
```
int count = 0; // 结点个数
int* ptr; // 指向链表的第一个结点的指针
void dfs(int node) {
ptr = node; // 将当前结点的指针指向链表的第一个结点
count++; // 计算当前结点的个数
}
int main() {
单链表头结点为*head, *p;
p = head; // 指向链表的第一个结点
int num = 0; // 用于记录每个结点的个数
dfs(p); // 遍历整个链表并计算结点个数
return 0;
}
```
该算法的时间复杂度为O(n),空间复杂度为O(n)。
其中,n是链表的结点数。
数据结构(四)——单链表、带头结点的单链表、循环链表及其实现

数据结构(四)——单链表、带头结点的单链表、循环链表及其实现一、链式存储以结点的形式存储数据。
除了存放一个结点的信息外,还需附设指针。
数据在内存中存储是不连续的,每个结点只能也只有它能知道下一个结点的存储位置。
二、单链表单链表是线性表链式存储的一种,其储存不连续。
单链表的数据结构中包含两个变量:数据和指向下一结点的指针。
一个结点只知道下一个结点的地址。
一个单链表必须有一个头指针,指向单链表中的第一个结点。
否则链表会在内存中丢失。
三、单链表的操作和实现1、单链表定义2、创建一个空链表3、打印链表4、查找数据值为x的结点5、查找索引值为index的结点6、在i位置插入一个结点7、在数据y之后插入一个x结点8、删除i位置的结点9、删除值为x的结点1、单链表定义[cpp] view plaincopyprint?1.typedef int datatype;2.3.typedef struct link_node{4.datatype info;5.struct link_node* next;6.}node;2、创建一个空链表[cpp] view plaincopyprint?1.#include"linklist.h"2.3.node* init_linklist(){4.return NULL;5.}3、打印链表[cpp] view plaincopyprint?1.#include"linklist.h"2.3.void display_link_list(node *head){4.if(head == NULL){5.printf("the list is empty!\n");6.}else{7.node *ptr = head;8.while(ptr){9.printf("5%d",ptr->info);10.ptr = ptr->next;11.}12.}13.}4、查找数据值为x的结点[cpp] view plaincopyprint?1.#include"linklist.h"2.3.node *find_node(node* head,datatype x){4.node* ptr= head;5.while(ptr && ptr->info != x)6.ptr= ptr->next;7.return ptr;8.}5、查找索引值为index的结点[cpp] view plaincopyprint?1.#include"linklist.h"2.3.node* find_index(node* head,int index){4.node *ptr = head;5.int pos = 0;6.if(index<0){7.printf("Index Error\n");8.exit(1);9.}10.while(ptr && pos != index){11.ptr=ptr->next;12.pos++;13.}14.return ptr;15.}6、在i位置插入一个结点[cpp] view plaincopyprint?1.#include"linklist.h"2.3.node* insert_link_list_index(node *head,int i ndex,datatype x){4.if(index<0){5.printf("index error\n");6.exit(1);7.}8.if(index == 0){ //在头插入元素,不用判断链表是否为空9.node *q = (node*) malloc(sizeof(node));10.q->info = x;11.q->next = head;12.head = q;13.return head;14.}15.else{16.node *ptr = find_node(head,index-1);17.node* q = (node*)malloc(sizeof(node));18.q->info = x;19.q->next = ptr->next;20.ptr->next = q;21.return head;22.}23.}7、在数据y之后插入一个x结点[cpp] view plaincopyprint?1.#include"linklist.h"2.3.node* intsert_node_yx(node *head,datatype x,datatype y){4.node *q=find_node(head,y);5.if(!q){6.printf("not found the node %d\n");7.return head;8.}9.node *p = (node*)malloc(sizeof(node));10.p->info = x;11.p->next= q->next;12.q->next = p;13.return head;14.}8、删除i位置的结点[cpp] view plaincopyprint?1.#include"linklist.h"2.3.node* del_link_list_index(node* head,int ind ex){4.if(!head){5.printf("the list is empty\n");6.return head;7.}8.node* p=head,*q=NULL;9.if(index == 0){ //第一个元素10.head = head->next;11.}else{12.p=find_index(head,index-1); //上面定义的第5个函数13.if(p && p->next){14.q = p->next;15.p->next= q->next;16.}else{17.printf("the index is not exit\n");18.return head;19.}20.}21.free(q);22.return head;23.}9、删除值为x的结点[cpp] view plaincopyprint?1.#include"linklist.h"2.3.node* del_link_list_node(node* head,datatype x){4.if(!head){5.printf("the list is empty\n");6.return head;7.}8.node* ptr=head,*pre=NULL;9.while(!ptr && ptr->info != x){10.pre = ptr;11.ptr=ptr->next;12.}13.if(!ptr){ //没找到14.printf("no data\n");15.}else if(pre){ //第一个就是16.head=ptr->next;17.}else{ //链表中的某个位置18.pre->next= ptr->next;19.}20.free(ptr);21.return head;22.}三、带头结点的单链表头结点的单链表中,head指示的是所谓的头结点,它不是实际的结点,不是用来储存数据的。
15.带头结点的单链表L,设计一个算法使元素递增有序

15.带头结点的单链表L,设计⼀个算法使元素递增有序#include<stdio.h>#include<stdlib.h>typedef int ElemType;typedef struct LNode{ElemType data;struct LNode *next;}LNode,*LinkList;//尾插法LinkList List_TailInsert(LinkList &L){int x;L=(LinkList)malloc(sizeof(LNode));LNode *s,*r=L;printf("请输⼊单链表各个节点,以9999结束!\n");scanf("%d",&x);while(x!=9999){s=(LNode*)malloc(sizeof(LNode));s->data=x;r->next=s;r=s;scanf("%d",&x);}r->next=NULL;return L;}//带头结点的单链表L,设计⼀个算法使元素递增有序void Sort(LinkList &L){LNode *pre,*p=L->next,*r=p->next;p->next=NULL;//将p与后⾯的链表断开,直接插⼊排序p=r;while(p!=NULL){r=p->next;//找到p的后续节点防⽌断链pre=L;//每次断开的链表中找到合适的p之前的位置while(pre->next!=NULL&&pre->next->data<p->data)pre=pre->next;//执⾏结束就找得到了p之前的位置p->next=pre->next;//将p插⼊到前⾯的有序链表中pre->next=p;p=r;}}int main(){LinkList L;LinkList R;//接收处理结果R=List_TailInsert(L);Sort(R);LNode *p=R;while(p->next!=NULL){p=p->next;printf("->%d",p->data);}}。
带头结点的单链表操作说明

带头结点的单链表操作说明⼀、单链表简介相对于以数组为代表的“顺序表”⽽⾔,单链表虽然存储密度⽐较低(因为数据域才是我们真正需要的,指针域只是⽤来索引,我们并不真正需要它),但是却具有灵活分配存储空间、⽅便数据元素的删除、⽅便元素插⼊等优点单链表是线性表链式存储的⼀种,其储存不连续。
单链表的数据结构中包含两个变量:数据和指向下⼀结点的指针。
⼀个结点只知道下⼀个结点的地址。
⼀个单链表必须有⼀个头指针,指向单链表中的第⼀个结点。
否则链表会在内存中丢失。
⼀般的链表可以不带头结点,头指针直接指向第⼀个节点,如下图:但是这样的链表有⼀个很⼤的问题,就是元素插⼊与删除操作时,需要考虑是否要改动头指针,⽽改动指针如果反应在函数中,那么形参必须使⽤⼆重指针,既加⼤了编写程序的难度,⽽且还降低了可读性,容易出错,因此“带头结点的单链表”使⽤更⽅便,也就是头指针指向的节点不存放数据,只作为链表的开始,这样⼀来,针对第⼀个节点的操作和针对其他节点的操作就完全⼀样的,⼗分⽅便,如图所⽰:⼆、带头结点的单链表各种操作下⾯我们讨论⼀下带头结点的单链表的各种操作1、链表数据结构的声明1using namespace std;2const int MAXSIZE = 1000;3 template <class T>4struct Node5 {6 T data; //数据域7 Node *next; //指针域8 };2、链表模板类的声明1 template <class T>2class LinkList3 {4public:5 LinkList(){front = new Node<T>;} //the constructor function without arguments6 LinkList( T a[], int n); //the constructor function initialized by array of n elements7 ~LinkList();8int GetLength(); //get the length of the LIST9void PrintList(); //print the element of the list10void Insert(int i,T x);// insert element x in the i-th location11 T Delete(int i); //delete the i-th element and return its value12 Node<T> *Get(int i); //get the address of i-th element13int Locate(T x); //find the element whose value is x and return its index14private:15 Node<T> *front; //head pointer16 };3、⽤头插法建⽴新链表,也就是每次插⼊的新节点都在链表的头部,注释部分给出的是尾插法的实现⽅式1 template <class T>2 LinkList<T>::LinkList(T a[], int n)3 {4// insert element at the first location of the existing link list5 front = new Node<T>;6 front->next = NULL;7for(int i=n-1; i>=0; i--)8 {9 Node<T> *s = new Node<T>;10 s->data = a[i];11 s->next = front->next;12 front->next = s;13 }14// insert element at the tail of the existing link list1516/*17 front = new Node<T>;18 Node<T> *r = front;19 for(int i=0; i<n; i++)20 {21 Node<T> *s = new Node<T>;22 s->data = a[i];23 r->next = s;24 r=s;25 }26 r->next = NULL;27*/28 }4、打印链表1 template <class T>2void LinkList<T>::PrintList()3 {4 Node<T> *p = front;5if(p->next==NULL)6 cout<<"link is enpty"<<endl;7else8 {9 p = p->next;10while(p)11 {12 cout<<p->data<<"";13 p = p->next;14 }15 }16 }5、插⼊节点1 template <class T>2void LinkList<T>::Insert(int i,T x)3 {4 Node<T> *p = front;5if(i!= 1) p=Get(i-1); // if not insert the elelment in the first location 6if(p)7 {8 Node<T> *s = new Node<T>;9 s->data = x;10 s->next = p->next;11 p->next = s;12 }13else14 cout<<"error!"<<endl;15 }6、删除节点1 template <class T>2 T LinkList<T>::Delete(int i)3 {4 Node<T> *p = front;5if(i!=1) p = Get(i-1);6 Node<T> *q = p->next;7 p->next = q->next;8 T x = q->data;9delete q;10return x;11 }7、按位查找节点,返回第i个节点的地址1 template <class T>2 Node<T> *LinkList<T>::Get(int i)3 {4 Node<T> *p = front->next;5int j=1;6while(p&&j!=i)7 {8 p = p->next;9 j++;10 }11return p;12 }8、按值查找,返回给定值对应的节点的序号1 template <class T>2int LinkList<T>::Locate(T x)3 {45 Node<T> *p = front->next;6int j=1;7while(p)8 {9if(p->data==x) return j;10 p = p->next;11 j++;12 }13return -1; //search fail14 }9、获取链表长度1 template <class T>2int LinkList<T>::GetLength()3 {4 Node<T> *p = front->next;5int count=0;6while(p)7 {8 p = p->next;9 count++;10 }11return count; //get the length of linklist12 }10、析构函数1 template <class T>2 LinkList<T>::~LinkList()3 {4 Node<T> *p = front;5while(p)6 {7 front = p;8 p = p->next;9 }10 }11、主函数(由于使⽤模板类实现,以上所有代码建议放⼊ .h头⽂件,主函数则放⼊.cpp⽂件所有代码在dev c++环境中测试通过) 1/*2线性表相关成员函数的实现3*/4 #include <iostream>5 #include <cmath>6 #include <stdlib.h>7 #include "linked_list.h"8using namespace std;9int main()10 {11int a[7] = {1,2,3,4,5,6,7};12 LinkList <int> list(a,7);13 list.PrintList();14 cout<<endl;15 cout<<list.Get(3)<<endl;16 Node<int> temp = *list.Get(3);17 cout<<temp.data<<endl;18//cout<<*(list.Get(3))<<endl;19 cout<<list.GetLength()<<endl;20 list.Insert(3,11);21 cout<<list.GetLength()<<endl;22 list.PrintList();23 cout<<list.Locate(5)<<endl;24int x = list.Delete(4);25 cout<<"删除元素:"<<x<<endl;26 list.PrintList();27//int p = list.Locate(1000);28//cout<<"元素4的位置:"<<p<<endl;29 system("pause");30return0;31 }。
结构-单链表的实现(带头)

结构-单链表的实现(带头)数据结构与算法基础---链表链表是⼲什么的在谈这个问题之前,我们先来看另⼀个问题:⼀组数据1,2,3,4,5,6,7,8,9以顺序储存的⽅式存在于内存中。
当我想要在1后⾯插⼊数字6怎么办呢?解:将数字2,3,4,5,6,7,8,9依次在内存中向后移动⼀位,形成1,2,2,3,4,5,6,7,8,9,然后将第⼆个2替换成6。
over这样⼀看顺序结构在执⾏插⼊删除等操作时需要⼀⼤堆步骤,太过于繁琐。
然⽽,链式储存⽅式的出现就很好的解决了这个问题——链式结构的数据不需要呆在⼀起。
数组利⽤顺序储存的⽅式来储存数据,⽽链表利⽤链式储存的⽅式储存数据。
顺序储存:在内存中,⼀个个数据紧挨着储存。
链式储存:在内存中,⼀个个数据分布在内存的各个地⽅。
链式储存可以将⾃⼰存数据的地⽅分成两部分,⼀部分储存数据,另⼀部分指向下⼀个储存数据的节点。
这样就做到了将数据在内存的任意位置存放。
单链表种类基本术语结点:单链表是⼀种链式存取的数据结构,链表中的数据是以结点来表⽰的,每个结点的构成:元素(数据元素的映象) + 指针(指⽰后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
1.单链表的实现(带头链表)1.1定义⼀个结点//使⽤结构体来定义⼀个结点。
注: 只要不是关键字,那就都是变量名,不必因为看着太规范⽽怀疑它为关键字。
typedef struct Node{int data;//储存数据,DATA部分。
struct Node *next;//储存指针,NEXT部分。
}Node,*LinkedList;//Node是结构体struct Node的别名,*LinkedList是⼀个指向struct Node的指针。
1.2初始化结点LinkedList listinit(){Node *L;L=(Node*)malloc(sizeof(Node)); //开辟空间if(L==NULL){ //判断是否开辟空间失败,这⼀步很有必要printf("申请空间失败");//exit(0); //开辟空间失败可以考虑直接结束程序}L->next=NULL; //指针指向空}//检查很有必要,但下⾯那⼏个创建单链表的似乎都没检查。
带头结点的并具有头尾指针的单循环链表

长治学院课程设计任务书课程名称:数据结构课程设计设计题目:带头结点的并具有头尾指针的单循环链表系别:计算机系专业:网络工程学生姓名: 王鲁俊学号: 07407320 起止日期: 2008年 11月08 日~ 2008年12月18 日指导教师:孙俊杰长治学院目录第一章需求分析-------------------------------------------------------------------------3 第二章开发过程-------------------------------------------------------------------------32.1系统目标----------------------------------------------------------------------32.2设计出友好的界面---------------------------------------------------- ---3 2.3实现基本功能----------------------------------------------------------------32.5功能划分----------------------------------------------------------------------3第三章系统设计--------------------------------------------------43.1系统设计方法-------------------------------------------43.2数据结构设计-------------------------------------------43.3数据结构设计概述---------------------------------------43.4数据实体类型-------------------------------------------43.5流程图-------------------------------------------------53.6程序中的源代码-----------------------------------------5第四章附录-----------------------------------------------------13第一章需求分析1.编写带头结点头尾指针的单循环链表,并实现功能如下:1.编写该单循环链表的环境2.保存数据3.建立密码,密码修改4.单循环链表的位置查找.插入.删除.排序等操作第二章开发过程2.1系统目标长治学院本系统的目标是实现单向链表的各种操作,方便用户对数据的各种操作。
c语言实现--带头结点单链表操作

c语⾔实现--带头结点单链表操作可能是顺序表研究的细致了⼀点,单链表操作⼀下⼦就实现了。
这⾥先实现带头结点的单链表操作。
⼤概有以下知识点.1;结点:结点就是单链表中研究的数据元素,结点中存储数据的部分称为数据域,存储直接后继地址的部分称为指针域。
2;结点⽰意图:3;头指针:头指针始终指向链表第⼀个元素,当有头结点时头结点就是链表第⼀个元素。
头指针具有标识左右,故头指针命名为链表的名字,这⾥为linklist。
头指针是⼀定存在的。
4;头结点:引⼊头结点的⽬的是,将链表⾸元结点的插⼊和删除操作与其他结点的插⼊和删除操作统⼀起来。
(即头指针地址不在发⽣变化)5;单链表结点结构体表⽰:1struct LNode2 {3int data; //姑且认为其数据为整型4struct LNode * next;5 };67 typedef struct LNode * linklist6;单链表的操作集合,头⽂件 defs.h1 #ifndef _DEFS_H_2#define _DEFS_H_34 #include<stdio.h>5 #include<stdlib.h>6 #include<malloc.h>78struct LNode //单链表结点的定义9 {10int data;11struct LNode * next;12 }13 typedef struct LNode * linklist1415//操作集合16void InitList(linklist *L); //申请头结点,头指针地址改变17void DestroyList(linklist *L); //须释放头结点,头指针地址改变18void ClearList(linklist L); //保留头结点,头指针地址不变19void ListEmpty(linklist L);20int ListLength(linklist L);21int GetElem(linklist L, int i, int *e);22int LocateElem(linklist L, int e);23int PriorElem(linklist L, int cur_e, int *pri_e);24int NextElem(linklist L, int cur_e, int *nex_e);25int ListInsert(linklist L, int i, int e); //插⼊不改变头指针的值26int ListDelete(linklist L, int i, int *e); //删除操作也不改变头指针的值27void TravelList(linklist L);28#endif7;InitList操作实现1 #include"defs.h"23void InitList(linklist *L) //接受头指针的地址值4 {5 *L = (linklist)malloc(sizeof(struct LNode)); //*L表⽰头指针67if (*L == NULL)8 {9 printf("分配结点失败。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据结构实验报告实验名称:实验1——单链表的构造学生姓名:XXXXNB班级:XXXX班内序号:学号:XXXX日期:XXXXX1.实验要求根据线性表的抽象数据类型的定义,完成带头结点的单链表的基本功能。
单链表的基本功能:1、构造:使用头插法、尾插法两种方法2、插入:要求建立的链表按照关键字从小到大有序3、删除4、查找5、获取链表长度6、销毁7、其他:可自行定义编写测试main()函数测试线性表的正确性。
2.程序分编程完成单链表的一般性功能如单链表的构造:使用头插法、尾插法两种方法插入:要求建立的链表按照关键字从小到大有序,删除,查找,获取链表长度,销毁用《数据结构》中的相关思想结合C++语言基本知识编写一个单链表结构。
本程序为使用方便,几乎不用特殊的命令,只需按提示输入即可,适合更多的用户使用。
2.1 存储结构单链表的存储结构:2.2 关键算法分析1.头插法自然语言描述:a.在堆中建立新结点b.将a[i]写入到新结点的数据域c.修改新结点的指针域d.修改头结点的指针域,将新结点加入链表中//在构建之初为了链表的美观性构造,进行了排序代码描述://头插法构造函数template<class T>LinkList<T>::LinkList(T a[], int n){for (int i = n - 1; i >= 1; i--)//冒泡排序,对数组进行从小到大排序{for (int j = 0; j < i; j++){if (a[j]>a[j + 1]){T t = a[j + 1];a[j + 1] = a[j];a[j] = t;}}}front = new Node < T >;//为头指针申请堆空间front->next = NULL;//构造空单链表for (int i = n - 1; i >= 0; i--){Node<T>*s = new Node < T >;//建立新结点s->data = a[i];//将a[i]写入新结点的数据域s->next = front->next;//修改新结点的指针域front->next = s;//修改头结点的指针域,将新结点加入到链表中}}2.尾插法自然语言描述:a.在堆中建立新结点b.将a[i]写入到新结点的数据域c.将新结点加入到链表中d.修改修改尾指针代码描述://尾插法构造函数template<class T>LinkList<T>::LinkList(T a[], int n){front = new Node < T > ;Node<T>*r = front;//命名一个新变量进行转换for (int i = 0; i < n; i++){Node<T>*s = new Node < T > ;s->data = a[i];r->next = s;r = s;}r->next = NULL;}时间复杂度:O(n)3.析构函数自然语言描述:a.新建立一个指针,指向头结点b.移动a中建立的指针c.逐个释放指针代码描述:template<class T>LinkList<T>::~LinkList()//析构函数,销毁链表{Node<T> * p = front;while(p){front = p;p = p->next;delete front;}}4.按位查找函数自然语言描述: a.初始化工作指针p和计数器j,p指向第一个结点,j=1b.循环以下操作,直到p为空或者j等于1b1:p指向下一个结点b2:j加1c.若p为空,说明第i个元素不存在,抛出异常d.否则,说明p指向的元素就是所查找的元素,返回元素地址代码描述:template<class T>Node<T>* LinkList<T>::Get(int i)//按位查找{Node<T> * p = front;int j=0;while(p){if(j<i){p = p->next;j++;}else break;}if(!p) throw"查找位置非法";else return p;}时间复杂度:O(n)5.按值查找函数自然语言描述:a.初始化工作指针p和计数器j,p指向第一个结点,j=1b.循环以下操作,找到这个元素或者p指向最后一个结点b1.判断p指向的结点是不是要查找的值,如果是,返回j;b2.否则p指向下一个结点,并且j的值加一c.如果找到最后一个结点还没有找到要查找的元素,返回查找失败信息代码描述:template<class T>int LinkList<T>::Locate(T x)//按值查找{Node<T> * p = front->next;int j = 1;while(p){if(p->data == x) return j;else{p = p->next;j++;}}return -1;}时间复杂度:O(n)6.插入函数自然语言描述:a.在堆中建立新结点b.将要插入的结点的数据写入到新结点的数据域c.修改新结点的指针域d.修改前一个指针的指针域,使其指向新插入的结点的位置代码描述:template<class T>void LinkList<T>::Insert(int i,T x)//插入函数{Node<T> * p = Get(i-1);if(p){Node<T> * s = new Node<T>;s->data = x;s->next = p->next;p->next = s;}else throw"插入位置非法";}时间复杂度:O(n)7.按位删除函数自然语言描述:a.从第一个结点开始,查找要删除的位数i前一个位置i-1的结点b.设q指向第i个元素c.将q元素从链表中删除d.保存q元素的数据e.释放q元素代码描述:template<class T>T LinkList<T>::Delete(int i)//删除函数{Node<T> *p = Get(i-1);Node<T> *q = p->next;T x=q->data;p->next = q->next;delete q;return x;}8.遍历打印函数自然语言描述: a.判断该链表是否为空链表,如果是,报错b.如果不是空链表,新建立一个temp指针c.将temp指针指向头结点d.打印temp指针的data域e.逐个往后移动temp指针,直到temp指针的指向的指针的next域为空代码描述:template<class T>void LinkList<T>::PrintList()//打印链表{Node<T> * p = front->next;while(p){cout<<p->data<<' ';p = p->next;}cout<<endl;}9.获取链表长度函数自然语言描述:a.判断该链表是否为空链表,如果是,输出长度0b.如果不是空链表,新建立一个temp指针,初始化整形数n为0c.将temp指针指向头结点d.判断temp指针指向的结点的next域是否为空,如果不是,n加一,否则return ne.使temp指针逐个后移,重复d操作,直到temp指针指向的结点的next 域为0,返回n代码描述:template<class T>int LinkList<T>::GetLength()//分析链表长度{Node<T> * p = front;int i=0;while(p){p = p->next;i++;}return i-1;}2.3 其他异常处理采用try catch 函数处理异常如在插入时的异常处理:template<class T>void LinkList<T>::Insert(int i, T x){Node<T>*p = front;if (i != 1) p = Get(i - 1);try{if (p){Node<T>*s = new Node < T > ;s->data = x;s->next = p->next;p->next = s;}else throw i;}catch (int i){cout << "插入到位置 " << i << " 处" << "为错误位置"<<endl;}}3. 程序运行结果主函数流程图:测试截图:初始化链表,菜单创建执行功能:4. 总结.调试时出现了一些问题如:异常抛出的处理,书中并未很好的提及异常处理,通过查阅资料,选择用try catch 函数对解决。
2.心得体会了解了单链表的基本的操作函数实现,对链式存储结构有了较好的认识3.下一步的改进可以增加完善报错机制,增强程序的健壮性完整源代码://单链表的构造#include<iostream>using namespace std;template<class T>struct Node{T data;//数据域struct Node<T>*next;//指针域};template <class T>class LinkList{public:LinkList(){ front = new Node <T>; front->next = NULL; }//无参构造函数LinkList(T a[], int n);//有参构造函数,使用含有n个元素的数组a初始化单链表~LinkList(); //析构函数,(其在void main 函数最后一句语句之后自动执行,旨在释放栈空间)void PrintList(); //按次序遍历线性表中的各个数据元素int GetLength(); //获取线性表的长度Node <T> * Get(int i); //获取线性表第i个位置上的元素结点地址int Locate(T x); //查找线性表中值为x的元素,找到后返回其位置void Insert(int i, T x);//后插,在线性表的第i个位置上插入值为x的新元素void insert(int i, T x);//前插,在线性表的第i个位置上插入值为x的新元素T Delete(int i); //删除线性表第i个元素,并将该元素返回private:Node <T> * front; //头指针};//头插法构造函数template<class T>LinkList<T>::LinkList(T a[], int n){for (int i = n - 1; i >= 1; i--)//冒泡排序,对数组进行从小到大排序{for (int j = 0; j < i; j++){if (a[j]>a[j + 1]){T t = a[j + 1];a[j + 1] = a[j];a[j] = t;}}}front = new Node < T >;//为头指针申请堆空间front->next = NULL;//构造空单链表for (int i = n - 1; i >= 0; i--){Node<T>*s = new Node < T >;//建立新结点s->data = a[i];//将a[i]写入新结点的数据域s->next = front->next;//修改新结点的指针域front->next = s;//修改头结点的指针域,将新结点加入到链表中}}//尾插法构造函数//template<class T>//LinkList<T>::LinkList(T a[], int n)//{// front = new Node < T > ;// Node<T>*r = front;//命名一个新变量进行转换// for (int i = 0; i < n; i++)// {//Node<T>*s = new Node < T > ;//s->data = a[i];//r->next = s;//r = s;//}//r->next = NULL;//}template<class T>void LinkList<T>::PrintList()//遍历线性表元素并打印到屏幕{Node<T>*p = front->next;while (p){cout << p->data << " ";p = p->next;}cout << endl;}template<class T>LinkList<T>::~LinkList()//析构函数{Node<T>*p = front;//初始化工作指针Pwhile (p)//要释放的结点存在{front = p;p = p->next;delete front;//释放结点}}template<class T>Node <T> * LinkList<T>::Get(int i)//获取线性表第i个位置上的元素结点地址{Node<T>*p = front->next;int k = 1;while (p && (k != i)){p = p->next;k++;}return p;}template<class T>int LinkList<T>::Locate(T x)//按值查找某元素的位置{Node<T>*p = front->next;int k = 1;while (p&&(p->data != x)){p = p->next;k++;}return k;}//后插template<class T>void LinkList<T>::Insert(int i, T x){Node<T>*p = front;if (i != 1) p = Get(i - 1);try{if (p){Node<T>*s = new Node < T > ;s->data = x;s->next = p->next;p->next = s;}else throw i;}catch (int i){cout << "插入到位置 " << i << " 处" << "为错误位置"<<endl;}}template<class T>T LinkList<T>::Delete(int i){Node<T>*p = front;if (i != 1) p = Get(i - 1);//若不是在第一个位置删除,获取第i-1个元素的地址try{if (p && (p->next)){Node<T>*q = p->next;p->next = q->next;T x = q->data;delete q;return x;}else throw i;}catch (int i){cout << "删除位置 " << i << " 处" << "为错误位置" << endl;}}template<class T>int LinkList<T>::GetLength(){Node<T>*p = front->next;int i;for (i = 0; p != NULL; i++){p = p->next;}return i;}void main(){int m=1;int a[7] = { 3, 2, 1, 4, 6, 5, 7 };LinkList<int> list(a, 7);cout << "排序后的链表为:";list.PrintList();cout << "\t\t**************************************************" << endl << "\t\t※※" << endl<< "\t\t※对该单链表的操作※" << endl<< "\t\t※※" << endl<< "\t\t※ 1. 获取线性表的长度※" << endl<< "\t\t※※" << endl<< "\t\t※ 2. 查找值为x的元素,并返回其位置※" << endl<< "\t\t※※" << endl<< "\t\t※ 3. 在线性表的第i个位置上插入值为x的新元素※" << endl<< "\t\t※※" << endl<< "\t\t※ 4. 删除线性表第i个元素,并将该元素返回※" << endl<< "\t\t※※" << endl<< "\t\t**************************************************" << endl << endl;while (m != 0){cout<< "\t\t\t选择你需要的功能:";int choice;cin >> choice;//输入需要的功能switch (choice){case 1:cout << "线性表的长度为:" << list.GetLength()<<endl;//获取线性表的长度break;case 2://查找值为x的元素,并返回其位置{cout << "请输入想查找的元素的值:" << endl;int value;cin >> value;int location = list.Locate(value);cout << "该元素的位置为:" << location << endl;}break;case 3://在线性表的第i个位置上插入值为x的新元素{cout << "请输入想插入的位置值:" << endl;int location_2;//位置值cin >> location_2;cout << "请输入想插入的新元素的值" << endl;int value_1;//元素值cin >> value_1;list.Insert(location_2, value_1);cout << "执行插入操作后的链表为:" << endl;list.PrintList();}break;case 4:// 删除线性表第i个元素,并将该元素返回{cout << "请输入想要删除的元素的位置值:" << endl;int location_3;cin >> location_3;int value_2 = list.Delete(location_3);cout << "删除的元素值为:" << value_2 << endl;}break;default:cout << "!!无此功能项" << endl;break;}cout << " ※※※那您是否想继续?继续请输入 1 不想继续请输入 0 ※※※" << endl;cin >> m;}}。