N10_第5章(1)DataBase
数据库课本例题

第二章创建与管理数据库1. 创建数据库student,并指定数据库的数据文件所在位置、初始容量、最大容量和文件增长量。
2. 创建数据库teaching,并指定数据库的数据文件和日志文件的所在位置、初始容量、最大容量和文件增长量。
3.为student数据库增加一个日志文件。
4.修改student数据库的排序规则。
5. 给student数据库添加文件组studentfgrp,再添加数据文件studentfile.ndf到文件组studentfgrp中。
6.将名为student数据库改名为STUDENTDB。
7. 删除已创建的数据库student。
8. 文件和文件组示例。
在SQL Server 2005实例上创建了一个数据库,该数据库包括一个主数据文件、一个用户定义文件组和一个日志文件。
主数据文件在主文件组中,而用户定义文件组包含两个次要数据文件。
ALTER DATABASE 语句将用户定义文件组指定为默认文件组。
9. 为test01创建数据库快照。
代码:例1.例2.例3.例4.例5.例6.例8.例9.结果:例1.例3.例4.例5.例6.例7.例8.例9.第三章表和数据完整性1. 利用CREATE TABLE命令建立课程信息表course,表结构如表所示。
2. 利用CREATE TABLE命令建立学生分数表score,表结构如表所示。
该表中主键由两个列构成。
3.利用CREATE TABLE命令建立教师信息表teacher,表结构如表所示。
4.利用CREATE TABLE命令建立班级信息表结构如表所示。
5.为了完善teaching数据库的表间联系,创建表结构如所示的纽带表teach_class。
然后查看该表的有关CREATE TABLE命令脚本信息。
6.在test01数据库中创建一个新表student1,然后修改其列属性。
7. 修改test01中表student1的列column_class数据类型和名称。
数据库系统概论第四版最新答案.

数据库第四版答案(王珊萨师煊)第1章绪论1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l )数据(Data ) :描述事物的符号记录称为数据。
数据的种类有数字、文字、图形、图像、声音、正文等。
数据与其语义是不可分的。
解析在现代计算机系统中数据的概念是广义的。
早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。
现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。
数据与其语义是不可分的。
500 这个数字可以表示一件物品的价格是500 元,也可以表示一个学术会议参加的人数有500 人,还可以表示一袋奶粉重500 克。
( 2 )数据库(DataBase ,简称DB ) :数据库是长期储存在计算机内的、有组织的、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
( 3 )数据库系统(DataBas 。
Sytem ,简称DBS ) :数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。
解析数据库系统和数据库是两个概念。
数据库系统是一个人一机系统,数据库是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统简称为数据库。
希望读者能够从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引起混淆。
( 4 )数据库管理系统(DataBase Management sytem ,简称DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包括数据定义功能、数据操纵功能、数据库的运行管理功能、数据库的建立和维护功能。
解析DBMS 是一个大型的复杂的软件系统,是计算机中的基础软件。
目前,专门研制DBMS 的厂商及其研制的DBMS 产品很多。
数据库系统原理课后答案 第五章

5.1 名词解释(1)SQL模式:SQL模式是表和授权的静态定义。
一个SQL模式定义为基本表的集合。
一个由模式名和模式拥有者的用户名或账号来确定,并包含模式中每一个元素(基本表、视图、索引等)的定义。
(2)SQL数据库:SQL(Structured Query Language),即‘结构式查询语言’,采用英语单词表示和结构式的语法规则。
一个SQL数据库是表的汇集,它用一个或多个SQL模式定义。
(3)基本表:在SQL中,把传统的关系模型中的关系模式称为基本表(Base Table)。
基本表是实际存储在数据库中的表,对应一个关系。
(4)存储文件:在SQL中,把传统的关系模型中的存储模式称为存储文件(Stored File)。
每个存储文件与外部存储器上一个物理文件对应。
(5)视图:在SQL中,把传统的关系模型中的子模式称为视图(View),视图是从若干基本表和(或)其他视图构造出来的表。
(6)行:在SQL中,把传统的关系模型中的元组称为行(row)。
(7)列:在SQL中,把传统的关系模型中的属性称为列(coloumn)。
(8)实表:基本表被称为“实表”,它是实际存放在数据库中的表。
(9)虚表:视图被称为“虚表”,创建一个视图时,只把视图的定义存储在数据词典中,而不存储视图所对应的数据。
(10)相关子查询:在嵌套查询中出现的符合以下特征的子查询:子查询中查询条件依赖于外层查询中的某个值,所以子查询的处理不只一次,要反复求值,以供外层查询使用。
(11)联接查询:查询时先对表进行笛卡尔积操作,然后再做等值联接、选择、投影等操作。
联接查询的效率比嵌套查询低。
(12)交互式SQL:在终端交互方式下使用的SQL语言称为交互式SQL。
(13)嵌入式SQL:嵌入在高级语言的程序中使用的SQL语言称为嵌入式SQL。
(14)共享变量:SQL和宿主语言的接口。
共享变量有宿主语言程序定义,再用SQL 的DECLARE语句说明, SQL语句就可引用这些变量传递数据库信息。
数据库第五章课后习题答案

关系规范化理论题目4.20 设关系模式R(ABC),F是R上成立的FD集,F={B→A,C→A },ρ={AB,BC }是R上的一个分解,那么分解ρ是否保持FD集F?并说明理由。
答:已知F={ B→A,C→A },而πAB(F)={ B→A },πBC(F)=φ,显然,分解ρ丢失了FD C→A。
4.21 设关系模式R(ABC),F是R上成立的FD集,F={B→C,C→A },那么分解ρ={AB,AC }相对于F,是否无损分解和保持FD?并说明理由。
答:①已知F={ B→C,C→A },而πAB(F)=φ,πAC(F)={ C→A }显然,这个分解丢失了FD B→C②用测试过程可以知道,ρ相对于F是损失分解。
4.22 设关系模式R(ABCD),F是R上成立的FD集,F={A→B,B→C,A→D,D→C },ρ={AB,AC,BD }是R的一个分解。
①相对于F,ρ是无损分解吗?为什么?②试求F在ρ的每个模式上的投影。
③ρ保持F吗?为什么?答:①用测试过程可以知道,ρ相对于F是损失分解。
②πAB(F)={ A→B },πAC(F)={ A→C },πBD(F)=φ。
③显然,分解ρ不保持FD集F,丢失了B→C、A→D和D→C等三个FD。
4.23 设关系模式R(ABCD),R上的FD集F={A→C,D→C,BD→A},试说明ρ={AB,ACD,BCD }相对于F是损失分解的理由。
答:据已知的F集,不可能把初始表格修改为有一个全a行的表格,因此ρ相对于F是损失分解。
4.24 设关系模式R(ABCD)上FD集为F,并且F={A→B,B→C,D→B}。
①R分解成ρ={ACD,BD},试求F在ACD和BD上的投影。
②ACD和BD是BCNF吗?如不是,望分解成BCNF。
解:①F在模式ACD上的投影为{A→C,D→C},F在模式BD上的投影为{D→B}。
②由于模式ACD的关键码是AD,因此显然模式ACD不是BCNF。
《快速念咒:MySQL入门指南与进阶实战》笔记

《快速念咒:MySQL入门指南与进阶实战》阅读记录1. 第一章数据库基础在开始学习MySQL之前,了解一些数据库的基础知识是非常重要的。
数据库是一个用于存储和管理数据的计算机软件系统,它允许用户通过关键字或特定的查询语言来检索、更新和管理数据。
在数据库中,数据是以表格的形式进行组织的,每个表格都包含了一组相关的数据项,这些数据项被称为记录。
表(Table):表是数据库中存储数据的基本单位。
每个表都有一个唯一的名称,并由行(Row)和列(Column)组成。
每一行代表一个数据记录,每一列代表一个特定的数据属性。
字段(Field):字段是表中的一列,代表了数据的一种属性。
每个字段都有一个唯一的名称和一个数据类型,用于定义该字段可以存储的数据种类。
主键(Primary Key):主键是表中的一个特殊字段,用于唯一标识表中的每一行记录。
主键的值必须是唯一的,且不能为NULL。
外键(Foreign Key):外键是一个表中的字段,它的值引用了另一个表的主键值。
外键用于建立两个表之间的联系,确保引用完整性。
索引(Index):索引是一种数据库优化技术,用于提高查询性能。
通过创建索引,数据库可以更快地定位到表中的特定记录,而不必扫描整个表。
SQL(Structured Query Language):SQL是用于与数据库进行交互的编程语言。
它包括用于数据查询、插入、更新和删除的操作符和语法结构。
理解这些基本概念是学习MySQL的前提。
通过掌握SQL语言的基本语法和操作,你将能够有效地管理和操作数据库中的数据。
在接下来的章节中,我们将深入探讨MySQL的具体应用,包括如何创建和管理数据库、表、以及如何执行复杂的查询操作。
2. 第二章数据库设计《快速念咒:MySQL入门指南与进阶实战》是一本全面介绍MySQL 数据库的书籍,其中第二章详细阐述了数据库设计的基础知识和实践技巧。
在这一章节中,作者首先介绍了数据库设计的基本概念和目标,包括数据模型、实体关系模型(ER模型)等,并解释了如何通过这些模型来描述现实世界中的数据和业务逻辑。
数据库系统概论(第四版)课后习题解答
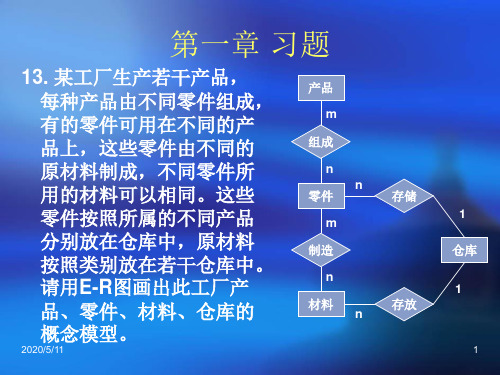
第二章 习题(续)
7.关系代数的基本运算有哪些?如何用这些基本运 算来表示其他运算? 答:在8种关系代数的基本运算中,并、差、笛卡儿 积、投影和选择5种运算为基本的运算。其他3种运 算,即交、连接和除,均可以用5种基本运算来表 达。 交运算:R∩S=R-(R-S) 连接运算:R S AB ( R S )
2012-12-5 11
ALPHA语言: RANGE SPJ SPJX P PX S SX GET W(J.JNO):SPJX(SPJX.JNO=J.JNO∧ SX(SX.SNO=SPJ.SNO∧SX.CITY=‘天津’∧ PX(PX.PNO=SPJX.PNO∧PX.COLOR=‘红’)) 解析: ① S、P、SPJ表上各设一个元组变量。 ② 解题思路:所要找的是满足给定条件的工程项目代码JNO。因此,对工程项目表J中 的每一个JNO进行判断: 看SPJ中是否存在这样的元组,其JNO=J.JNO,并且所用的零件是红色的,该零件 的供应商是天津的。 如果SPJ中不存在这样的元组,则该工程项目代码JNO满足条件,放入结果集中。 如果SPJ中存在这样的元组,则该工程项目代码JNO不满足条件,不能放入结果集 中,再对工程表J中的下一个JNO进行同样的判断。 直到所有JNO都检查完。 结果集中是所有未使用天津供应商生产的红色零件的工程项目代码,包括未使用任 何零件的工程项目代码。
第二章 习题(续)
(5) 求至少用了供应商S1所供应的全部零件的工程项目代码JNO。 答: 关系代数: /*第一部分是所有工程及该工程所用的零件,第二部分是供应商S1所供 应的全部零件号*/ 对于SPJ表中的某个JNO,如果该工程使用的所有零件的集合包含供应 商S1所供应的全部零件号,则该JNO符合本题条件,它在除法运算的结 果集中。 ALPHA语言:(类似于教材第2.5节例14) RANGE SPJ SPJX SPJ SPJY P PX GET W(J.JNO):PX(SPJX(SPJX.PNO=PX.PNO∧SPJX.SNO=‘S1’) →SPJY(SPJY.JNO=J.JNO∧SPJY.PNO= PX.PNO))
数据库系统概论(第四版)课本答案

第1章绪论1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l 〕数据〔Data ) :描述事物的符号记录称为数据。
数据的种类有数字、文字、图形、图像、声音、正文等。
数据与其语义是不可分的。
解析在现代计算机系统中数据的概念是广义的。
早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。
现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。
数据与其语义是不可分的。
500 这个数字可以表示一件物品的价格是500 元,也可以表示一个学术会议参加的人数有500 人,还可以表示一袋奶粉重500 克。
( 2 〕数据库〔DataBase ,简称DB ) :数据库是长期储存在计算机内的、有组织的、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
( 3 〕数据库系统〔DataBas 。
Sytem ,简称DBS ) :数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统〔及其开发工具〕、应用系统、数据库管理员构成。
解析数据库系统和数据库是两个概念。
数据库系统是一个人一机系统,数据库是数据库系统的一个组成局部。
但是在日常工作中人们常常把数据库系统简称为数据库。
希望读者能够从人们讲话或文章的上下文中区分“数据库系统〞和“数据库〞,不要引起混淆。
( 4 〕数据库管理系统〔DataBase Management sytem ,简称DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包括数据定义功能、数据操纵功能、数据库的运行管理功能、数据库的建立和维护功能。
解析DBMS 是一个大型的复杂的软件系统,是计算机中的根底软件。
目前,专门研制DBMS 的厂商及其研制的DBMS 产品很多。
database 用法

database用法一、简介Database(数据库)是一种用于存储、管理和检索数据的工具。
它是一种强大的技术,可以大大提高数据处理的效率和精度。
在许多领域,如商业、科研、教育等,数据库都发挥着至关重要的作用。
二、基本概念1.数据库管理系统(DBMS):DBMS是用于管理数据库的软件,它负责存储、检索、更新数据,以及执行其他与数据库相关的操作。
2.表:表是数据库的基本组成单位,它是一种数据结构,用于存储相关数据项。
3.列:列是表中的数据类型列表,如数字、文本、日期等。
4.记录:记录是表中的数据单元,用于存储具体信息。
5.查询:查询是用于检索数据库中数据的方法,可以通过指定条件、排序等来获取所需数据。
6.更新:更新是指对数据库中数据进行修改的操作。
7.删除:删除是指从数据库中移除数据的过程。
三、安装与配置1.下载和安装DBMS软件:根据所使用的数据库类型(如MySQL、Oracle、SQLServer等),下载并安装相应的DBMS软件。
2.配置数据库连接:根据所使用的编程语言和框架,配置数据库连接,以便于与数据库进行通信。
3.创建数据库和表:使用DBMS的管理工具或编程接口,创建所需的数据库和表。
四、基本操作1.插入数据:将数据插入到表中。
2.查询数据:检索符合特定条件的数据。
3.更新数据:修改表中的数据。
4.删除数据:从表中移除数据。
5.执行SQL语句:SQL(结构化查询语言)是用于操作数据库的标准语言。
它可以用于执行各种数据库操作,如查询、插入、更新和删除数据。
6.使用编程语言访问数据库:许多编程语言提供了访问数据库的接口和库,如Python的MySQLConnector、Java的JDBC等。
通过这些接口和库,可以更方便地与数据库进行交互。
五、常见问题及解决方案1.连接问题:检查网络连接、防火墙设置、数据库服务是否启动等,以确保能够正常连接到数据库服务器。
2.数据插入错误:检查数据类型是否匹配、是否有语法错误等。
最新Oracle11g数据库基础教程课后习题答案

Oracle11g数据库基础教程参考答案第5章数据库存储设置与管理P70.实训题(8)为USERS表空间添加一个数据文件,文件名为USERS05.DBF,大小为5 0MB。
ALTER TABLESPACE USERS ADD DATAFILE‘D:\ORACLE\ORADATA\ORCL\%users05.dbf’ SIZE 50M;(9)为EXAMPLE表空间添加一个数据文件,文件名为example05.dbf,大小为20MB。
ALTER TABLESPACE EXAMPLEADD DATAFILE ‘D:\ORACLE\ORADATA\ORCL\example05.dbf’ SIZE 20M;(10)修改USERS表空间中的userdata05.dbf为自动扩展方式,每次扩展5MB,最大为100MB。
ALTER DATABASE DATAFILE‘D:\ORACLE\ORADATA\ORCL\%userdata05.dbf’ AUTOEXTEND ON NEXT 5M MAXSIZE 100M;(14)为数据库添加一个重做日志文件组,组内包含两个成员文件,分别为redo5a.log和redo5b.log,大小分别为5MB。
ALTER DATABASE ADD LOGFILE GROUP 5(‘D:\ORACLE\ORADATA\ORCL\redo5a.log’,‘D:\ORACLE\ORADATA\ORCL\redo5b.log’)SIZE 5M;(15)为新建的重做日志文件组添加一个成员文件,名称为redo5c.log。
ALTER DATABASE ADD LOGFILE MEMBER‘D:\ORACLE\ORADATA\ORCL\redo5c.log’ TO GROUP 5;(16)将数据库设置为归档模式,并采用自动归档方式。
SHUTDOWN IMMEDIATE STARTUP MOUNTALTER DATABASE ARCHIVELOG;ALTER DATABASE OPEN;ALTER SYSTEM ARCHIVE LOG START(8)ALTER TABLESPACE USERSADD DATAFILE ‘D:\ORACLE\ORADATA\ORCL\userdata05.dbf’ SIZE 50M’;(9)ALTER TABLESPACE EXAMPLEADD DATAFILE ‘D:\ORACLE\ORADATA\ORCL\example05.dbf’ SIZE 20M’;(10)ALTER DATABASE DATAFILE ‘D:\ORACLE\ORADATA\ORCL\userdata05.dbf’ AUTOEXTEND ON NEXT 5M MAXSIZE 100M;(14)ALTER DATABASE ADD LOGFILE GROUP 5(‘D:\ORACLE\ORADATA\ORCL\redo05a.log’,’D:\ORACLE\ORADATA\ORCL\redo05b.log’)SIZE 5M;(15)ALTER DATABASE ADD LOGFILE MEMBER‘D:\ORACLE\ORADATA\ORCL\redo05c.log’ TO GROUP 5;(16)SHUTDOWN IMMEDIATESTARTUP MOUNTALTER DATABASE ARCHIVELOG;ALTER DATABASE OPEN;ALTER SYSTEM ARCHIVE LOG START第6章数据库对象的创建与管理2.实训题(2)Create table exer_class(CNO number(2) primary key,CNAME varchar2(20),NUM number(3))Create table exer_student(SNO number(4) primary key,SNAME varchar2(10) unique,SAGE number,SEX char(2),CNO number(2))(3)Alter table exer_student add constraint ck_sage check (sage>0 and sage<=100);(4)alter table exer_student add constraint ck_stu check(sex='M' or sex='F')modify sex default 'M'(5)Create unique index ind_cname on exer_class(cname);(6)Create view s_c asSelect sno,sname,sage,sex,o,cname,numFrom exer_class c join exer_student sOn o=o;(7)Create sequence sequ1 start with 100000001;(8)create table exer_student_range(sno number(4) primary key,sname varchar2(10),sage number,sex char(2),cno number(2))partition by range(sage)(partition part1 values less than(20) tablespace example,partition part2 values less than(30) tablespace orcltbs1,partition part3 values less than(maxvalue) tablespace orcltbs2)(9)create table exer_student_list(sno number(4) primary key,sname varchar2(10),sage number,sex char(2),cno number(2))partition by list(sex)(partition man values('M') tablespace orcltbs1,partition woman values('F') tablespace orcltbs2)(10)Create index ind on exer_student_range(sno) local;第9章PL/SQL语言基础1.实训题(1)declarecursor c_emp is select * from employees;beginfor v_emp in c_emp loopdbms_output.put_line(v_emp.first_name||' '||v_st_name||' '|| v_emp.employee_id||' '||v_emp.salary||' '||v_emp.department_id); end loop;end;(2)declarev_avgsal employees.salary%type;beginfor v_emp in (select * from employees) loopselect avg(salary) into v_avgsal from employeeswhere department_id=v_emp.department_id;if v_emp.salary>v_avgsal thendbms_output.put_line(v_emp.first_name||' '||v_st_name||' '|| v_emp.employee_id||' '||v_emp.salary||' '||v_emp.department_id);end if;end loop;end;(3)declarecursor c_emp isselect e.employee_id eid,st_name ename,e.department_id edid,m.employee_id mid,st_name mnamefrom employees e join employees mon e.manager_id=m.employee_id;v_emp c_emp%rowtype;beginopen c_emp;loopfetch c_emp into v_emp;exit when c_emp%notfound;dbms_output.put_line(v_emp.eid||' '||v_emp.ename||' '||v_emp.edid||' '||v_emp.mid||' '||v_emp.mname);end loop;close c_emp;end;(4)declarev_emp employees%rowtype;beginselect * into v_emp from employees where last_name='Smith';dbms_output.put_line(v_emp.employee_id||' '||v_emp.first_name||' '||v_st_name||' '||v_emp.salary||' '||v_emp.department_id); exceptionwhen no_data_found theninsert into employees(employee_id,last_name,salary,email,hire_date, job_id,department_id)values(2010,'Smith',7500,'*****************.cn',to_date('2000-10-5','yyyy-mm-dd'),'AD_VP',50);when too_many_rows thenfor v_emp in(select * from employees where last_name='Smith')loopdbms_output.put_line(v_emp.employee_id||' '||v_emp.first_name||' '||v_st_name||' '||v_emp.salary||' '||v_emp.department_id);end loop;end;第10章PL/SQL程序设计(1)创建一个存储过程,以员工号为参数,输出该员工的工资。
数据库系统原理课后答案第一章

数据库系统原理课后答案第⼀章1.1 名词解释(1) DB:即数据库(Database),是统⼀管理的相关数据的集合。
DB能为各种⽤户共享,具有最⼩冗余度,数据间联系密切,⽽⼜有较⾼的数据独⽴性。
(2) DBMS:即数据库管理系统(Database Management System),是位于⽤户与操作系统之间的⼀层数据管理软件,为⽤户或应⽤程序提供访问DB的⽅法,包括DB的建⽴、查询、更新及各种数据控制。
DBMS总是基于某种数据模型,可以分为层次型、⽹状型、关系型、⾯向对象型DBMS。
(3) DBS:即数据库系统(Database System),是实现有组织地、动态地存储⼤量关联数据,⽅便多⽤户访问的计算机软件、硬件和数据资源组成的系统,即采⽤了数据库技术的计算机系统。
(4) 1:1联系:如果实体集E1中的每个实体最多只能和实体集E2中的⼀个实体有联系,反之亦然,那么实体集E1对E2的联系称为“⼀对⼀联系”,记为“1:1”。
(5) 1:N联系:如果实体集E1中每个实体与实体集E2中任意个(零个或多个)实体有联系,⽽E2中每个实体⾄多和E1中的⼀个实体有联系,那么E1对E2的联系是“⼀对多联系”,记为“1:N”。
(6) M:N联系:如果实体集E1中每个实体与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么E1对E2的联系是“多对多联系”,记为“M:N”。
(7) 数据模型:模型是对现实世界的抽象。
在数据库技术中,表⽰实体类型及实体类型间联系的模型称为“数据模型”。
它可分为两种类型:概念数据模型和结构数据模型。
(6) 概念数据模型:是独门于计算机系统的模型,完全不涉及信息在系统中的表⽰,只是⽤来描述某个特定组织所关⼼的信息结构。
(9) 结构数据模型:是直接⾯向数据库的逻辑结构,是现实世界的第⼆层抽象。
这类模型涉及到计算机系统和数据库管理系统,所以称为“结构数据模型”。
结构数据模型应包含:数据结构、数据操作、数据完整性约束三部分。
(完整版)database习题参考答案第2、3章

第2章习题参考答案三简答题(1)查询T1老师所授课程的课程号和课程名。
ΠCNO,CN(σTNO=’T1’(TC)*ΠCNO,CN(C))ΠCNO(σTNO=’T1’(TC))*ΠCNO,CN(C)(2)查询年龄大于18岁男同学的学号、姓名、系别。
ΠSNO, SN, Dept(σAge>18∧Sex=’男’(S))(3)查询“李力”老师所授课程的课程号、课程名和课时。
ΠCNO (ΠTNO(σTN=’李力’(T))*TC)* CΠCNO,CN, CT(σTN=’李力’(T)*TC* C)(4)查询学号为S1的同学所选修课程的课程号、课程名和成绩。
ΠCNO,CN,Score(σSNO=’S1’(SC)*ΠCNO,CN(C))ΠCNO, Score(σSNO=’S1’(SC))*ΠCNO,CN(C)(5)查询“钱尔”同学所选修课程的课程号、课程名和成绩。
ΠCNO,CN,Score(ΠSNO(σSN=’钱尔’(S))* SC*ΠCNO,CN(C))ΠCNO,Score(ΠSNO(σSN=’钱尔’(S))* SC)*ΠCNO,CN(C)(6)查询至少选修“刘伟”老师所授全部课程的学生姓名。
ΠSN(ΠSNO, CNO(SC)÷ΠCNO(σTN=’刘伟’(T*TC))* S)(7)查询“李思”同学未选修的课程的课程号和课程名。
ΠCNO, CN((ΠCNO(C)-ΠCNO(σSN=’李思’(S)*SC))*C)ΠCNO, CN (C)-ΠCNO, CN (σSN=’李思’(S)*SC*C)ΠCNO, CN (C)-Π CNO(σSN=’李思’(S)*SC)*ΠCNO, CN(C)(8)查询全部学生都选修了的课程的课程号和课程名。
ΠSNO, CNO(SC)÷ΠSNO(S)*ΠCNO, CN(C)(9)查询选修了课程号为C1和C2的学生的学号和姓名。
ΠSNo,CNo(SC)÷ΠCNo(σCNo =’C1’∨ CNo =’C2’(C))*ΠSNo,SN(S)(10)查询选修全部课程的学生的学号和姓名。
unix下oracle命令

;
=====================================================================================================================================
create tablespace mqc datafile '/opt/ora10/oradata/gnnt/qc.dbf' size 20000m
批量删除
find /users/demo1 -name *.log.* -exec rm -r {} \;
find /users/demo1 -name *.log* -exec rm -r {} \;
find /users/demo1 -name *_log.* -exec rm -r {} \;
startup pfile=/opt/ora10/product/10.2/dbs/abc123.ora
=====================================================================================================================================
因为你用的是自动内存管理~
pga_aggregate_target big integer 1G
sga_target big integer 9G
=====================================================================================================================================
数据库第二版课后习题答案

数据库第二版课后习题答案数据库第二版课后习题答案数据库是计算机科学中重要的概念之一,它提供了一种有效地存储和管理数据的方式。
数据库系统的设计与实现是数据库课程的重要内容之一。
在学习数据库课程时,课后习题是巩固知识和提高能力的重要途径。
本文将为大家提供数据库第二版课后习题的答案,希望对大家的学习有所帮助。
第一章数据库系统概述1. 数据库是什么?答:数据库是一个有组织的、可共享的、可维护的数据集合,它以一定的数据模型为基础,描述了现实世界中某个特定领域的数据和关系。
2. 数据库系统的特点有哪些?答:数据库系统具有以下特点:- 数据的独立性:数据库系统将数据与程序相分离,使得数据的修改不会影响到程序的运行。
- 数据的共享性:多个用户可以同时访问数据库,并且可以共享数据。
- 数据的冗余性小:通过数据库系统的数据一致性和完整性约束,可以减少数据的冗余性。
- 数据的易扩展性:数据库系统可以方便地进行扩展和修改,以满足不同需求。
- 数据的安全性:数据库系统提供了权限管理和数据加密等机制,保证数据的安全性。
第二章关系数据库与SQL1. 什么是关系数据库?答:关系数据库是一种基于关系模型的数据库,它使用表格(关系)来表示和存储数据。
关系数据库中的数据以行和列的形式组织,每个表格代表一个实体集,每一行代表一个实体,每一列代表一个属性。
2. 什么是SQL?答:SQL(Structured Query Language)是一种用于管理关系数据库的语言。
它包含了数据定义语言(DDL)、数据操纵语言(DML)和数据控制语言(DCL)等部分。
通过SQL,用户可以对数据库进行创建、查询、更新和删除等操作。
第三章数据库设计1. 数据库设计的步骤有哪些?答:数据库设计的步骤包括:- 需求分析:确定数据库的需求和目标,了解用户的需求。
- 概念设计:根据需求分析的结果,设计数据库的概念模型,包括实体、属性和关系等。
- 逻辑设计:将概念模型转换为逻辑模型,包括表格的设计、关系的建立和约束的定义等。
Oracle Database数据库高级功能练习题参考答案

Oracle Database数据库高级功能练习题参考答案Oracle Database是一个功能强大的关系型数据库管理系统,拥有许多高级功能,可以满足各种复杂的数据管理和分析需求。
下面是一些Oracle Database高级功能练习题的参考答案,供大家参考和学习。
练习题一:子查询1.查询所有在员工表(Employees)中的非经理员工的信息。
```sqlSELECT *FROM EmployeesWHERE employee_id NOT IN (SELECT manager_id FROM Employees);```练习题二:分区表1.创建一个以年为分区键的分区表(OrderTable),包含订单号(order_id)、订单日期(order_date)和订单金额(order_amount)。
```sqlCREATE TABLE OrderTable(order_id NUMBER,order_date DATE,order_amount NUMBER)PARTITION BY RANGE (TO_CHAR(order_date,'YYYY'))(PARTITION p2018 VALUES LESS THAN ('2019'),PARTITION p2019 VALUES LESS THAN ('2020'),PARTITION p2020 VALUES LESS THAN ('2021'),...);```练习题三:索引1.为员工表(Employees)的姓氏(last_name)列创建一个B树索引。
```sqlCREATE INDEX idx_last_nameON Employees (last_name);```练习题四:触发器1.创建一个触发器,当向订单表(Orders)插入一条新的订单时,在订单历史表(OrderHistory)中插入一条记录。
数据库系统基础教程第五章答案

Exercise 5。
1。
1 As a set:Average = 2.37 As a bag:Average = 2。
48 Exercise 5。
1。
2Average = 218 As a bag:Average = 215 Exercise 5.1.3a As a set:18As a bag:bore1516141615151418Exercise 5。
1。
3bπbore(Ships Classes)Exercise 5.1。
4aFor bags:On the left-hand side:Given bags R and S where a tuple t appears n and m times respectively, the union ofbags R and S will have tuple t appear n + m times。
The further union of bag T with the tuple t appearing o times will have tuple t appear n + m + o times in the final result.On the right—hand side:Given bags S and T where a tuple t appears m and o times respectively, the union of bags R and S will have tuple t appear m + o times. The further union of bag R with the tuple t appearing n times will have tuple t appear m + o + n times in the final result。
For sets:This is a similar case when dealing with bags except the tuple t can only appear at most once in each set. The tuple t only appears in the result if all the sets have the tuple t. Otherwise, the tuple t will not appear in the result。
数据库系统基础教程第五章答案
数据库系统基础教程第五章答案Exercise 5.1.1 As a set:Average = 2.37 As a bag:Average = 2.48 Exercise 5.1.2Average = 218 As a bag:Average = 215 Exercise 5.1.3a As a set:18As a bag:bore1516141615151418Exercise 5.1.3bπ(Ships Classes)boreExercise 5.1.4aFor bags:On the left-hand side:Given bags R and S where a tuple t appears n and m times respectively, the union of bags R and S will have tuple t appear n + m times. The further union of bag T with the tuple t appearing o times will havetuple t appear n + m + o times in the final result.On the right-hand side:Given bags S and T where a tuple t appears m and o times respectively,the union of bags R and S will have tuple t appear m + o times. Thefurther union of bag R with the tuple t appearing n times will havetuple t appear m + o + n times in the final result.For sets:This is a similar case when dealing with bags except the tuple t can only appear at most once in each set. The tuple t only appears in the result if all the sets have the tuple t. Otherwise, the tuple t will not appear in the result. Since we cannot have duplicates, the result only has at most one copy of the tuple t.Exercise 5.1.4bFor bags:On the left-hand side:Given bags R and S where a tuple t appears n and m times respectively,the intersection of bags R and S will have tuple t appear min( n, m )times. The further intersection of bag T with the tuple t appearing otimes will produce tuple t min( o, min( n, m ) ) times in the finalresult.On the right-hand side:Given bags S and T where a tuple t appears m and o times respectively,the intersection of bags R and S will have tuple t appear min( m, o )times. The further intersection of bag R with the tuple t appearing ntimes will produce tuple t min( n, min( m, o ) ) times in the finalresult.The intersection of bags R,S and T will yield a result where tuple t appears min( n,m,o ) times.For sets:This is a similar case when dealing with bags except the tuple t can only appear at most once in each set. The tuple t only appears in the result if all the sets have the tuple t. Otherwise, the tuple t will not appear in the result.Exercise 5.1.4cFor bags:On the left-hand side:Given that tuple r in R, which appears m times, can successfully joinwith tuple s in S, which appears n times, we expect the result tocontain mn copies. Also given that tuple t in T, which appears o times, can successfully join with the joined tuples of r and s, we expect thefinal result to have mno copies.On the right-hand side:Given that tuple s in S, which appears n times, can successfully joinwith tuple t in T, which appears o times, we expect the result tocontain no copies. Also given that tuple r in R, which appears m times,can successfully join with the joined tuples of s and t, we expect thefinal result to have nom copies.The order in which we perform the natural join does not matter for bags.For sets:This is a similar case when dealing with bags except the joined tuples can only appear at most once in each result. If there are tuples r,s,t inrelations R,S,T that can successfully join, then the result will contain a tuple with the schema of their joined attributes. Exercise 5.1.4dFor bags:Suppose a tuple t occurs n and m times in bags R and S respectively. In the union of these two bags R S, tuple t would appear n + m times. Likewise, in the union of these two bags S R, tuple t would appear m + n times. Both sides of the relation yield the same result.For sets:A tuple t can only appear at most one time. Tuple t might appear each in sets R and S one or zero times. The combinations of number of occurrences for tuple t in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple t appears in both sets R and S will the union R S have the tuple t. The same reasoning holds when we take the union S R.Therefore the commutative law for union holds.Exercise 5.1.4eFor bags:Suppose a tuple t occurs n and m times in bags R and S respectively. In the intersection of these two bags R ∩ S, tuple t would appear min( n,m ) times. Likewise in the intersection of these two bags S ∩ R, tuple t would appear min( m,n ) times. Both sides of the relation yield the same result.For sets:A tuple t can only appear at most one time. Tuple t might appear each in sets R and S one or zero times. The combinations of number of occurrences for tuplet in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple t appears in at least one of the sets R and S will the intersection R ∩ S have the tuple t. The same reasoning holds when we take the intersection S ∩ R.Therefore the commutative law for intersection holds.Exercise 5.1.4fFor bags:Suppose a tuple t occurs n times in bag R and tuple u occurs m times in bag S. Suppose also that the two tuples t,u can successfully join. Then in thenatural join of these two bags R S, the joined tuple would appear nm times. Likewise in the natural join of these two bags S R, the joined tuple would appear mn times. Both sides of the relation yield the same result.For sets:An arbitrary tuple t can only appear at most one time in any set. Tuples u,v might appear respectively in sets R and S one or zero times. The combinations of number of occurrences for tuples u,v in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple u exists in R and tuple v exists in S will the natural join R S have the joined tuple. The same reasoning holds when we take the natural join S R.Therefore the commutative law for natural join holds.Exercise 5.1.4gFor bags:Suppose tuple t appears m times in R and n times in S. If we take the union of R and S first, we will get a relation where tuple t appears m + n times. Taking the projection of a list of attributes L will yield a resultingrelation where the projected attributes from tuple t appear m + n times. If we take the projection of the attributes in list L first, then the projected attributes from tuple t would appear m times from R and n times from S. The union of these resulting relations would have the projected attributes oftuple t appear m + n times.For sets:An arbitrary tuple t can only appear at most one time in any set. Tuple tmight appear in sets R and S one or zero times. The combinations of number of occurrences for tuple t in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple t exists in R or S (or both R and S) will the projected attributes of tuple t appear in the result.Therefore the law holds.Exercise 5.1.4hFor bags:Suppose tuple t appears u times in R, v times in S and w times in T. On theleft hand side, the intersection of S and T would produce a result where tuple t would appear min(v , w) times. With the addition of the union of R, the overall result would have u + min(v , w) copies of tuple t. On the right hand side, we would get a result of min(u + v, u + w) copies of tuple t. The expressions on both the left and right sides are equivalent.For sets:An arbitrary tuple t can only appear at most one time in any set. Tuple tmight appear in sets R,S and T one or zero times. The combinations of numberof occurrences for tuple t in R, S and T respectively are (0,0,0), (0,0,1), (0,1,0), (0,1,1), (1,0,0), (1,0,1), (1,1,0) and (1,1,1). Only when tuple t appears in R or in both S and T will the result have tuple t.Therefore the distributive law of union over intersection holds.Exercise 5.1.4iSuppose that in relation R, u tuples satisfy condition C and v tuples satisfy condition D. Suppose also that w tuples satisfy both conditions C and D where w≤ min(v , w). Then the left hand side will return those w tuples. On the(R) produces u tuples and σD(R) produces v tuples. However, right hand side, σCwe know the intersection will produce the same w tuples in the result.。
数据库应用01 数据库系统概述

1.3 关系数据库
关系模型 关系完整性约束
2021/8/5
1.3.1 关系模型
关系的基本特点 关系的操作 关系模型的优点
2021/8/5
1. 关系模型的基本概念(1)
关系数据库系统是支持关系数据模型的数据 库系统。
免费的关系数据库系统
MySQL / SQLite /
学习Access理由:
简单、易学习。 具备关系数据库系统的基本概念。 缺点:商业版权的桌面级数据库
2021/8/5
1. 关系模型的基本概念(2)
学(号1)关姓系名
性 别
出生 日期
成 绩
民族
籍贯
班号
贷 款 否
简照 历片
S0102590一刘个嘉关美 系女就是199一1-8张-10二6维70 表汉族,通北京常将会计一学个101没有Yes
2021/8/5
4)实体型(Entity Type)
具有相同属性的实体具有共同的特征和性质。 用实体名及其属性名集合来抽象同类实体,
称答为:实概体念型的。范畴不同 事实物体的是若干个属体性;值的集合可表征为一个实体 若实干体个集属性是型集所合组成;的集合可表征一个实体的类
型实,体简型称为是“相实同体型实”体。的抽象 例 同如类:型学的实生体是集实合体组成型实,体而集。王滨是一 问个题具:体上的述学三生个(概为念的实同体异)的地方?
信息与数据 数据处理 数据库系统
2021/8/5
1.1.1 信息与数据
数据:记录现实世界中各种信息并可以识别 的物理符号,是信息的载体,是信息的具体 表现形式。
数据含义的广义性:字符(文字和符号)、图表 (图形、图像和表格)及声音等。
2021/8/5
数据库系统概论第五版课后习题答案

数据库系统概论第五版课后习题答案第1章绪论1 ?试述数据、数据库、数据库系统、数据库管理系统的概念。
答:(l )数据(Data ):描述事物的符号记录称为数据。
数据的种类有数字、文字、图形、图像、声音、正文等。
数据与其语义是不可分的。
解析在现代计算机系统中数据的概念是广义的。
早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。
现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。
数据与其语义是不可分的。
500这个数字可以表示一件物品的价格是500 元,也可以表示一个学术会议参加的人数有500 人,还可以表示一袋奶粉重500克。
(2 )数据库(DataBase ,简称DB ):数据库是长期储存在计算机内的、有组织的、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
(3 )数据库系统(DataBas 。
Sytem ,简称DBS ):数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其苑⒐ぞ撸、应用系统、数据库管理员构成。
解析数据库系统和数据库是两个概念。
数据库系统是一个人一机系统,数据库是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统简称为数据库。
希望读者能够从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引起混淆。
(4 )数据库管理系统(DataBase Management sytem ,简称DBMs ):数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS的主要功能包括数据定义功能、数据操纵功能、数据库的运行管理功能、数据库的建立和维护功能。
解析DBMS是一个大型的复杂的软件系统,是计算机中的基础软件。
目前,专门研制DBMS的厂商及其研制的DBMS产品很多。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
功能分析 功能模型 功能说明
事务设计 程序说明 应用程序设计 程序编码调试
数据库原理及应用
5.1 数据库设计概述
5.1.1 数据库和信息系统 5.1.2 数据库设计的特点 5.1.3 数据库设计方法简述
5.1.4 数据库设计的基本步骤
数据库原理及应用
5.1.3 数据库设计方法简述
• 手工试凑法
– 设计质量与设计人员的经验和水平有直接关系 – 缺乏科学理论和工程方法的支持,工程的质量 难以保证 – 数据库运行一段时间后常常又不同程度地发现 各种问题,增加了维护代价
数据库设计的基本步骤(续)
– 逻辑设计阶段 • 首先将E-R图转换成具体的数据库产品支持 的数据模型,如关系模型,形成数据库逻辑 模式
• 然后根据用户处理的要求、安全性的考虑, 在基本表的基础上再建立必要的视图(View), 形成数据的外模式
数据库原理及应用
数据库设计的基本步骤(续)
– 物理设计阶段 • 根据DBMS特点和处理的需要,进行物理存 储安排,建立索引,形成数据库内模式
数据库原理及应用
数据库设计人员应该具备的技术和知识
• 数据库的基本知识和数据库设计技术 • 计算机科学的基础知识和程序设计的方法和 技巧
• 软件工程的原理和方法
• 应用领域的知识
数据库原理及应用
5.1 数据库设计概述
5.1.1 数据库和信息系统 5.1.2 数据库设计的特点 5.1.3 数据库设计方法简述
数据库原理及应用
数据库设计的基本步骤(续)
⒉概念结构设计阶段
– 是整个数据库设计的关键 – 通过对用户需求进行综合、归纳与抽象,形成 一个独立于具体DBMS的概念模型
数据库原理及应用
数据库设计的基本步骤(续)
⒊逻辑结构设计阶段
– 将概念结构转换为某个DBMS所支持的数据模 型
– 对其进行优化
数据库原理及应用
数据库原理及应用
数据库设计方法简述(续)
• 计算机辅助设计
– ORACLE Designer 2000 – CA ERWin – SYBASE PowerDesigner – Rational Rose
数据库原理及应用
5.1 数据库设计概述
5.1.1 数据库和信息系统 5.1.2 数据库设计的特点 5.1.3 数据库设计方法简述
数据库原理及应用
一、 调查与初步分析用户需求
⑴ 调查组织机构情况 – 组织部门的组成情况 – 各部门的职责等
数据库原理及应用
调查与初步分析用户需求(续)
⑵ 调查各部门的业务活动情况。调查重点之一。
– 各个部门输入和使用什么数据 – 如何加工处理这些数据
– 输出什么信息
– 输出到什么部门 – 输出结果的格式是什么
数据库原理及应用
需求分析(续)
• 需求分析就是分析用户的需要与要求
– 需求分析是设计数据库的起点 – 需求分析的结果是否准确地反映了用户的实 际要求,将直接影响到后面各个阶段的设计, 并影响到设计结果是否合理和实用
数据库原理及应用
5.2 需求分析
5.2.1 需求分析的任务 5.2.2 需求分析的方法 5.2.3 数据字典
IPO表…… 输入: 输出: 处理:
物理 设计 实施 阶段
存储安排 方法选择 存取路径建立
Creat…… Load……
模块设计 IPO表 程序编码、 编译联结、 测试
编写模式 装入数据 数据库试运行
分区1 分区2
Main( ) …… if…… then …… end
运行、 维护
性能监测、转储/恢复 数据库重组和重构
须充分考虑今后可能的扩充和改变,不能仅 仅按当前应用需求来设计数据库
数据库原理及应用
二、需求分析的重点
• 需求分析的重点是调查、收集与分析用户在数据 管理中的信息要求、处理要求、安全性与完整性 要求。 • 信息要求 – 用户需要从数据库中获得信息的内容与性质 – 由用户的信息要求可以导出数据要求,即在数 据库中需要存储哪些数据
数据库原理及应用
数据库设计的基本步骤(续)
⒍数据库运行和维护阶段
– 数据库应用系统经过试运行后即可投入正式运 行。 – 在数据库系统运行过程中必须不断地对其进行 评价、调整与修改。
数据库原理及应用
数据库设计的基本步骤(续)
设计一个完善的数据库应用系统往往是上 述六个阶段的不断反复。
P202图7.2
⑴跟班作业 – 通过亲身参加业务工作了解业务活动的情况 – 能比较准确地理解用户的需求,但比较耗时 ⑵开调查会 – 通过与用户座谈来了解业务活动情况及用户需 求 ⑶请专人介绍
数据库原理及应用
数据库设计的基本步骤(续)
3. 程序员 – 在系统实施阶段参与进来,负责编制程序 4. 操作员
– 在系统实施阶段参与进来,准备软硬件环 境
数据库原理及应用
数据库设计的基本步骤(续)
二、数据库设计的过程(六个阶段) ⒈需求分析阶段
– 准确了解与分析用户需求(包括数据与处理) – 是整个设计过程的基础,是最困难、最耗费时 间的一步
数据库原理及应用
数据库设计的特点(续)
• 结构和行为分离的设计
– 传统的软件工程忽视对应用中数据语义的分析 和抽象,只要有可能就尽量推迟数据结构设计 的决策 – 早期的数据库设计致力于数据模型和建模方法 研究,忽视了对行为的设计
数据库原理及应用
数据库设计的特点(续)
现实世界
数据分析 概念模型设计 逻辑数据库设计 物理数据库设计 子模式设计 建立数据库
数据库原理及应用
数据库设计方法简述(续)
• 规范设计法
– 手工设计方法 – 基本思想 • 过程迭代和逐步求精
数据库原理及应用
数据库设计方法简述(续)
• 规范设计法(续)
– 典型方法 • 新奥尔良(New Orleans)方法 – 将数据库设计分为四个阶段 • S.B.Yao方法 – 将数据库设计分为五个步骤 • I.R.Palmer方法 – 把数据库设计当成一步接一步的过程
数据库原理及应用
调查与初步分析用户需(续)
⑶ 在熟悉业务活动的基础上,协助用户明确对新系 统的各种要求。调查重点之二。
– 信息要求
– 处理要求
– 完全性与完整性要求
数据库原理及应用
调查与初步分析用户需求(续)
⑷ 对前面调查的结果进行初步分析 – 确定新系统的边界
• 确定哪些功能由计算机完成或将来准备让计算 机完成 • 确定哪些活动由人工完成 由计算机完成的功能就是新系统应该实现的功能。
需 求 分析
数据字典、全系统中数据项、 数据流、数据存储的描述
数据流图和判定表(判定树)、数 据字典中处理过程的描述
系统说明书包括: ①新系统要求、 方案和概图 ②反映新系统信息 流的数据流图
概念模型(E-R图)
逻辑 结构 设计
数据字典 某种数据模型 关系 非关系
概念结 构设计
系统结构图 (模块结构)
5.1.4 数据库设计的基本步骤
数据库原理及应用
数据库设计概述(续)
• 什么是数据库设计
– 数据库设计是指对于一个给定的应用环境,构 造最优的数据库模式,建立数据库及其应用系 统,使之能够有效地存储数据,满足各种用户 的应用需求(信息要求和处理要求) – 在数据库领域内,常常把使用数据库的各类系 统统称为数据库应用系统。
……
新旧系统转换、运行、维护(修正性、 适应性、改善性维护)
数据库原理及应用
数据库设计的基本步骤(续)
• 数据库各级模式的形成过程(P205图7.4)
– 需求分析阶段 • 综合各个用户的应用需求 – 概念设计阶段 • 形成独立于机器特点,独立于各个DBMS产 品的概念模式(E-R图)
数据库原理及应用
数据库原理及应用
需求分析的难点(续)
• 解决方法
– 设计人员必须采用有效的方法,与用户不断深 入地进行交流,才能逐步得以确定用户的实际
需求
数据库原理及应用
5.2 需求分析
5.2.1 需求分析的任务 5.2.2 需求分析的方法 5.2.3 数据字典
数据库原理及应用
5.2.2 需求分析的方法
• 调查清楚用户的实际需求并进行初步分析 • 与用户达成共识 • 进一步分析与表达这些需求
数据库原理及应用
设计特点
• 在设计过程中把数据库的设计和对数据 库中数据处理的设计紧密结合起来 • 将这两个方面的需求分析、抽象、设计、 实现在各个阶段同时进行,相互参照, 相互补充,以完善两方面的设计 • 设计过程各个阶段的设计描述:P204图 7.3
数据库原理及应用 设计 阶 段
设 计 描 述 数 据 处 理
5.1.4 数据库设计的基本步骤
数据库原理及应用
5.1.4 数据库设计的基本步骤
一、数据库设计的准备工作 选定参加设计的人员 1. 数据库分析设计人员
– 数据库设计的核心人员
– 自始至终参与数据库设计 – 其水平决定了数据库系统的质量
数据库原理及应用
5.1.4 数据库设计的基本步骤
2. 用户 – 在数据库设计中也是举足轻重的 – 主要参加需求分析和数据库的运行维护 – 用户积极参与带来的好处 • 加速数据库设计 • 提高数据库设计的质量
数据库设计的基本步骤(续)
⒋数据库物理设计阶段
– 为逻辑数据模型选取一个最适合应用环境的物
理结构(包括存储结构和存取方法)
数据库原理及应用
数据库设计的基本步骤(续)
⒌数据库实施阶段
– 运用DBMS提供的数据语言、工具及宿主语言, 根据逻辑设计和物理设计的结果 • 建立数据库 • 编制与调试应用程序 • 组织数据入库 • 并进行试运行
数据库原理及应用