统计学数据的描述性分析习题
《统计分析与SPSS的应用(第五版)》课后练习答案(第3章)

《统计分析与SPSS的应用(第五版)》课后练习答案(第3章)第三章:统计分析与SPSS的应用(第五版) 课后练习答案第一节:描述性统计在本章的课后习题中,我们将通过SPSS软件进行一系列的统计分析。
本节将提供第三章的课后习题答案,通过展示实际的数据和分析结果,帮助读者更好地理解统计分析的应用和SPSS软件的操作。
1. 描述性统计分析题目:使用某城市2019年1月至12月的气温数据,计算月平均气温、最高气温和最低气温的描述性统计指标。
答案:通过SPSS导入数据,选择变量"月份"和"气温",并进行描述性统计分析。
结果显示,2019年1月至12月的气温数据的月平均气温、最高气温和最低气温的描述性统计指标如下:月平均气温:- 平均值:20°C- 标准差:2°C- 最小值:15°C- 最大值:25°C最高气温:- 平均值:28°C- 标准差:3°C- 最小值:22°C- 最大值:35°C最低气温:- 平均值:12°C- 标准差:2°C- 最小值:8°C- 最大值:18°C根据以上结果,我们可以得出结论:2019年该城市的月平均气温在20°C左右,最高气温在28°C左右,最低气温在12°C左右。
气温的变化范围相对较小,波动性较小。
这些结果可以帮助我们对该城市的气候情况进行初步了解。
2. 相关性分析题目:使用某企业2018年1月至12月的销售额和广告投入数据,计算销售额和广告投入之间的相关性。
答案:通过SPSS导入数据,选择变量"销售额"和"广告投入",并进行相关性分析。
结果显示,2018年1月至12月的销售额和广告投入之间的Pearson 相关系数为0.85,表明二者呈现强正相关关系。
统计学各章节练习题

计量资料的统计描述练习题选择题:1、描述一组偏态分布资料的变异度,以()指标较好。
A、全距B、标准差C、变异系数D、四分位数间距E、方差2、用均数和标准差可以全面描述()资料的特征。
A、正偏态分布B、负偏态分布C、正态分布D、对称分布E、对数正态分布3、各观察值均加(或减)同一数后()。
A、均数不变B、几何均数不变C、中位数不变D、标准差不变E、变异系数不变4、比较某地1~2岁和5~6岁儿童身高的变异程度,宜用()。
A、极差B、四分位数间距C、方差D、变异系数E、标准差5、偏态分布宜用()描述其分布的集中趋势。
A、均数B、标准差C、中位数D、四分位数间距E、方差6、各观察值同乘以一个不等于0的常数后,()不变。
A、算术均数B、标准差C、几何均数D、中位数E、变异系数7、()分布的资料,均数等于中位数。
A、对数正态B、正偏态C、负偏态D、偏态E、正态9、横轴上,标准正态曲线下从0到2.58的面积为()。
A、99%B、45%C、99.5%D、47.5%E、49.5%10、当各观察值呈倍数变化(等比关系)时,平均数宜用()。
A、均数B、几何均数C、中位数D、相对数E、四分位数1、算术均数和中位数相比,算数均数()A、抽样误差更大B、不易受极端值的影响C、更充分利用数据信息D、更适用于偏态分布资料E、更适用于分布不明确资料2、计算几何均数时,采用以e为底的自然对数ln(X)和采用以10为底的常用对数lg(X),所得的计算结果()A、相同B、不相同C、有时相同,有时不同D、只能采用ln(X)E、只能采用lg(X)3、在服从正态分布条件下,样本标准差S的值()A、与算术均数无关B、与个体的变异程度有关C、与样本量无关D、与集中趋势有关E、与量纲无关4、比较身高和体重两组数据的变异大小,宜采用()A、方差B、标准差C、全距D、四分位数间距E、变异系数5、变异系数CV的数值()A、一定大于等于1B、一定小于等于1C、一定比标准差小D、一定等于1E、可以大于1,也可以小于1概率分布1、正态分布曲线下方横轴上方,从μ到μ+2.58σ的面积占曲线下总面积的()A、99%B、95%C、47.5%D、49.5%E、90%2、在X轴上方,标准正态曲线下中间95%的面积所对应X的取值范围是()A、-∞~+1.96B、-1.96~+1.96C、-∞~+2.58D、-2.58~+2.58E、-1.64~+1.643、正态曲线上的拐点的横坐标为()A 、μ±2σB 、μ±σC 、μ±3σD 、μ±1.96σE 、μ±2.58σ 4、计算医学参考值范围最好是()A 、百分位数法B 、正态分布法C 、对数正态分布法D 、标准化法E 、结合原始数据分布选择计算公式5、根据200个人的发铅值(分布为偏态分布),计算正常人发铅值95%参考值范围应选择()A 、双侧正态分布法B 、双侧百分位数法C 、单上侧正态分布法D 、单下侧百分位数法E 、单上侧百分位数法 6、正态分布中,当μ恒定时,σ越大A 、曲线沿横轴向左移动B 、曲线沿横轴向右移动C 、观察值变异程度越大,曲线越扁平D 、观察值变异程度越小,曲线越细高E 、曲线位置和形状不变7、均数的标准误反映了()A 、个体变异程度的大小B 、个体集中趋势的位置C 、指标的分布特征D 、频数的分布特征E 、样本均数与总体均数的差异参数估计1、当样本含量增大时,以下说法正确的是()A 、标准差会变小B 、标准差会变大C 、样本均数标准误会变大D 、样本均数标准误会变小E 、以上都不对 2、区间x S x 58.2±的含义是()A 、99%总体观察值在此范围内B 、99%样本观察值在此范围内C 、总体均数99%置信区间D 、样本均数99%置信区间E 、以上都不对 3、通常可采用以下哪种方法来减小抽样误差()A 、减小样本标准差B 、增大样本标准差C 、减小样本量D 、增大样本量E 、以上都不对4、均数的标准误反映了()A 、个体变异程度的大小B 、个体集中趋势的位置C 、指标的分布特征D 、频数的分布特征E 、样本均数的与总体均数的差异假设检验1、两样本均数比较的t 检验,差别有统计学意义时,P 值越小,说明() A 、两样本均数差别越大B 、两总体均数差别越大C 、越有理由认为两总体均数不同D 、越有理由认为两样本均数不同E 、越有理由认为两总体均数不相同2、在参数未知的正态总体中随机抽样,≥-||μx ()的概率为5%。
应用统计学(第三章 数据的描述性分析)

累积频率 Cumulative P
0.02 0.09 0.28 0.63
0.84 0.95 1.00
a.自然值进行分组,最大值17,最小值11 b.数据主要集中在14,向两侧分布逐渐减少
(3)计量数据
100例健康男子血清总胆固醇(mol/L)测定结果
4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.71 5.69 4.12 4.56 4.37 5.39 6.30 5.21 7.22 5.54 3.93 5.21 6.51 5.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.69 4.38 4.89 6.25 5.32 4.50 4.63 3.61 4.44 4.43 4.25 4.03 5.85 4.09 3.35 4.08 4.49 5.30 4.97 3.18 3.97 5.16 5.10 5.85 4.79 5.34 4.24 4.32 4.77 6.36 6.38 4.88 5.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.09 4.52 4.38 4.31 4.58 5.72 6.55 4.76 4.61 4.17 4.03 4.47 3.40 3.91 2.70 4.60 4.09 5.96 5.48 4.40 4.55 5.38 3.89 4.60 4.47 3.64 4.34 5.18 6.14 3.24 4.90
15
21
0.21
0.84
16
11
0.11
0.95
17
5
0.05
1.00
表 2-2 100只梅花鸡每月产蛋数次数分布表
每月产蛋数
11 12 13 14 15 16 17
医学统计学定性资料统计描述思考与练习带答案

第五章定性资料的统计描述【思考与练习】一、思考题1.应用相对数时需要注意哪些问题?2. 为什么不能以构成比代替率?3. 标准化率计算的直接法和间接法的应用有何区别?4. 常用动态数列分析指标有哪几种?各有何用途?5. 率的标准化需要注意哪些问题?二、案例辨析题某医生对98例女性生殖器溃疡患者的血清进行检测,发现杜克雷氏链杆菌、梅毒螺旋体和人类单纯疱疹病毒2型病原体感染患者分别是30、51、17例,于是该医生得出结论:女性生殖器溃疡患者3种病原体的感染率分别为30.6%(30/98)、52.0%(51/98)和17.4%(17/98)。
该结论是否正确?为什么?三、最佳选择题1. 某地2006年肝炎发病人数占当年传染病发病人数的10.1%,该指标为BA. 率B. 构成比C. 发病率D. 相对比E. 时点患病率2. 标准化死亡比SMR是指AA. 实际死亡数/预期死亡数B. 预期死亡数/实际死亡数C. 实际发病数/预期发病数D. 预期发病数/实际发病数E. 预期发病数/预期死亡数3. 某地人口数:男性13,697,600人,女性13,194,142人;五种心血管疾病的死亡人数:男性16774人,女性23334人;其中肺心病死亡人数:男性13952人,女性19369人。
可计算出这样一些相对数:11395283.18%16774p ==, 2139521936983.08%1677423334p +==+,313952101.86/1013697600p ==万, 416774122.46/1013697600p ==万,523334176.85/1013194142p ==万, 645p p p =+71395219369123.91/101369760013194142p +==+万81677423334149.15/101369760013194142p +==+万该地男性居民五种心血管疾病的死亡率为D A. 1p B. 2p C. 3pD. 4pE. 5p4. 根据第3题资料,该地居民五种心血管病的总死亡率为E A. 1p B. 2p C. 5pD. 6pE. 8p5. 根据第3题资料,该地男、女性居民肺心病的合计死亡率为D A. 2p B. 5pC. 6pD. 7pE. 8p6. 某地区2000~2005年结核病的发病人数为015,,,a a a ⋯,则该地区结核病在此期间的平均增长速度是DA .0156a a a ⋯+++B.C.D.1-E.7. 经调查得知甲、乙两地的恶性肿瘤的粗死亡率均为89.94/10万,但经过标准化后甲地恶性肿瘤的死亡率为82.74/10万,而乙地为93.52/10万,发生此现象最有可能的原因是C A. 甲地的诊断技术水平更高B. 乙地的恶性肿瘤防治工作做得比甲地更好C. 甲地的老年人口在总人口中所占比例比乙地多D. 乙地的老年人口在总人口中所占比例比甲地多E. 甲地的男性人口在总人口中所占比例比乙地多 8. 下列不属于相对比的指标是 C A. 相对危险度RR B. 比值比ORC. 病死率D. 变异系数CVE. 性别比9. 计算标准化率时,宜采用间接法的情况是BA.已知被标准化组的年龄别死亡率与年龄别人口数B.已知被标准化组的死亡总数与年龄别人口数C.已知标准组年龄构成与死亡总数D.已知标准组的人口总数与年龄别人口数E.被标化组各年龄段人口基数较大四、综合分析题1. 为研究经常吸烟与慢性阻塞性肺病(COPD)的关系,1998~2000年间,某医生收集了356例COPD患者的吸烟史,经常吸烟(日平均1支以上,30年)的COPD 患者有231例;而同时期同年龄段的479名非COPD患者中,经常吸烟的有183例。
统计学习题1

第2章统计数据的描述练习:2.1为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:700 716 728 719 685 709 691 684 705 718706 715 712 722 691 708 690 692 707 701708 729 694 681 695 685 706 661 735 665668 710 693 697 674 658 698 666 696 698706 692 691 747 699 682 698 700 710 722694 690 736 689 696 651 673 749 708 727688 689 683 685 702 741 698 713 676 702701 671 718 707 683 717 733 712 683 692693 697 664 681 721 720 677 679 695 691713 699 725 726 704 729 703 696 717 688(1)利用计算机对上面的数据进行排序;(2)以组距为10进行等距分组,整理成频数分布表,并绘制直方图;(3)绘制茎叶图,并与直方图作比较。
2.2某百货公司6月份各天的销售额数据如下(单位:万元):257 276 297 252 238 310 240 236 265 278271 292 261 281 301 274 267 280 291 258272 284 268 303 273 263 322 249 269 295(1)计算该百货公司日销售额的均值、中位数和四分位数;(2)计算日销售额的标准差。
2.3在某地区抽取的120家企业按利润额进行分组,结果如下:按利润额分组(万元)企业数(个)200~300 19300~400 30400~500 42500~600 18600以上11合计120计算120家企业利润额的均值和标准差。
统计学各章习题及答案

统计学习题目录第一章绪论 _________________________________________________ 2第二章数据的收集与整理 _____________________________________ 4第三章统计表与统计图 _______________________________________ 6第四章数据的描述性分析 _____________________________________ 8第五章参数估计 ____________________________________________ 12第六章假设检验 ____________________________________________ 16第七章方差分析 ____________________________________________ 20第八章非参数检验 __________________________________________ 23第九章相关与回归分析 ______________________________________ 26第十章多元统计分析 ________________________________________ 30第十一章时间序列分析 ______________________________________ 34第十二章指数 ______________________________________________ 37第十三章统计决策 __________________________________________ 41第十四章统计质量管理 ______________________________________ 44第一章绪论习题一、单项选择题1。
推断统计学研究(D)。
A.统计数据收集的方法B.数据加工处理的方法C.统计数据显示的方法D.如何根据样本数据去推断总体数量特征的方法2。
统计学习题第四章数据分布特征的描述习题答案

第四章 静态指标分析法(一)一、填空题1、数据分布集中趋势的测度值(指标)主要有、和。
其中和用于测度品质数据集中趋势的分布特征,用于测度数值型数据集中趋势的分布特征。
2、标准差是反映的最主要指标(测度值)。
3、几何平均数是计算和的比较适用的一种方法。
4、当两组数据的平均数不等时,要比较其数据的差异程度大小,需要计算。
5、在测定数据分布特征时,如果M M e X 0==,则认为数据呈分布。
6、当一组工人的月平均工资悬殊较大时,用他们工资的比其算术平均数更能代表全部工人工资的总体水平。
二.选择题单选题:1.反映的时间状况不同,总量指标可分为( )A 总量指标和时点总量指标B 时点总量指标和时期总量指标C 时期总量指标和时间指标D 实物量指标和价值量指标2、某厂1999年完成产值200万元,2000年计划增长10%,实际完成了231万元,超额完成( )A 5.5%B 5%C 115.5%D 15.5%3、在同一变量数列中,当标志值(变量值)比较大的次数较多时,计算出来的平均数( )A 接近标志值小的一方B 接近标志值大的一方C 接近次数少的一方D 接近哪一方无法判断4、在计算平均数时,权数的意义和作用是不变的,而权数的具体表现( )A 可变的B 总是各组单位数C 总是各组标志总量D 总是各组标志值 5、1998年某厂甲车间工人的月平均工资为520元,乙车间工人的月平均工资为540元,1999年各车间的工资水平不变,但甲车间的工人占全部工人的比重由原来的40%提高到了60%,则1999年两车间工人的总平均工资比1998年( )A 提高B 不变C 降低D 不能做结论 6、在变异指标(离散程度测度值)中,其数值越小,则( )A 说明变量值越分散,平均数代表性越低B 说明变量值越集中,平均数代表性越高C 说明变量值越分散,平均数代表性越高D 说明变量值越集中,平均数代表性越低7、有甲、乙两数列,已知甲数列:07.7,70==甲甲σX ;乙数列:41.3,7==乙乙σX 根据以上资料可直接判断( )A 甲数列的平均数代表性大B 乙数列的平均数代表性大C 两数列的平均数代表性相同D 不能直接判别8、杭州地区每百人手机拥有量为90部,这个指标是 ( )A 、比例相对指标B 、比较相对指标C 、结构相对指标D 、强度相对指标 9、某组数据呈正态分布,计算出算术平均数为5,中位数为7,则该数据分布为 ( ) A 、左偏分布 B 、右偏分布 C 、对称分布 D 、无法判断10、加权算术平均数的大小 ( )A 主要受各组标志值大小的影响,与各组次数多少无关;B 主要受各组次数多少的影响,与各组标志值大小无关;C 既与各组标志值大小无关,也与各组次数多少无关;D 既与各组标志值大小有关,也受各组次数多少的影响11、已知一分配数列,最小组限为30元,最大组限为200元,不可能是平均数的为 ( ) A 、50元 B 、80元 C 、120元 D 、210元12、比较两个单位的资料,甲的标准差小于乙的标准差,则 ( ) A 两个单位的平均数代表性相同 B 甲单位平均数代表性大于乙单位C 乙单位平均数代表性大于甲单位D 不能确定哪个单位的平均数代表性大 13、若单项数列的所有标志值都增加常数9,而次数都减少三分之一,则其算术平均数 ( ) A 、增加9 B 、增加6C 、减少三分之一 D 、增加三分之二 14、如果数据分布很不均匀,则应编制( )A 开口组B 闭口组C 等距数列D 异距数列 15、计算总量指标的基本原则是:( ) A 总体性B 全面性C 同质性D 可比性16、某企业的职工工资分为四组:800元以下;800-1000元;1000—1500元;1500以上,则1500元以上这组组中值应近似为()A1500元 B 1600元 C 1750元D 2000元 17、统计分组的首要问题是( )A 选择分组变量和确定组限B 按品质标志分组C 运用多个标志进行分组,形成一个分组体系D 善于运用复合分组18、某连续变量数列,其末组为开口组,下限为200,又知其邻组的组中值为170,则末组组中值为( )A 230B 260C 185D 215 19、分配数列中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是( )A 钟型分布B U 型分布C J 型分布D 倒J 型分布 20、要了解上海市居民家庭的开支情况,最合适的调查方式是:() A 普查B 抽样调查C 典型调查D 重点调查21、已知两个同类企业的职工平均工资的标准差分别为5元和6元,而平均工资分别为3000元,3500元则两企业的工资离散程度为 ( )A 甲大于乙B 乙大于甲C 一样的D 无法判断 22、加权算术平均数的大小取决于( )A 变量值B 频数C 变量值和频数D 频率23、如果所有标志值的频数都减少为原来的1/5,而标志值仍然不变.那么算术平均数( ) A 不变 B 扩大到5倍 C 减少为原来的1/5 D 不能预测其变化 24、 计算平均比率最好用 ( )A 算术平均数B 调和平均数C 几何平均数D 中位数25、若两数列的标准差相等而平均数不同,在比较两数列的离散程度大小时,应采用() A 全距 B 平均差 C 标准差 D 标准差系数26、若n=20,∑∑==2080,2002x x ,标准差为( )A 2B 4C 1.5D 327、已知某总体3215,3256==eMM,则数据的分布形态为( )A左偏分布B正态分布 C 右偏分布DU型分布28、一次小型出口商品洽谈会,所有厂商的平均成交额的方差为156.25万元,标准差系数为14.2%,则平均成交额为( )万元A11 B 177.5 C 22.19 D 8826、欲粗略了解我国钢铁生产的基本情况,调查了上钢、鞍钢等十几个大型的钢铁企业,这是()A普查B重点调查C典型调查D抽样调查多选题:1.某企业计划2000年成本降低率为8%,实际降低了10%。
统计学习题

第一章绪论(一)判断题1、统计数字的具体性是统计学区别于数学的根本标志。
()2、社会经济统计是在质与量的联系中,观察和研究社会经济现象的数量方面。
()3、离散变量的数值包括整数和小数。
()4、总体和总体单位的概念不是固定不变的,任何一对总体和总体单位都可以互相变换。
()5、统计指标系是对许多指标的总称。
()(二)单项选择题1、统计研究的数量必须是()抽象的量具体的量连续不断的量可直接相加的量2、统计总体最基本的特征是()数量性同质性综合性差异性3、统计总体的同质性是指()总体单位各标志值不应有差异总体的各项指标都是同类性质的指标总体全部单位在所有标志上具有同类性质总体全部单位在所有某一个或几个标志上具有同类性质4、一个统计总体()只能有一个标志只能有一个指标可以有多个标志可以有多个指标5、总体和总体单位不是固定不变的,由于研究目的不同()总体单位有可能变换为总体,总体也有可能变换为总体单位总体只能变换为总体单位,总体单位不能变换为总体总体单位只能变换为总体,总体不能变换为总体单位任何一对总体和总体单位都可以互相变换6、某小组学生数学考试分别为60分、68分、75分和85分。
这四个数字是()标志指标标志值变量五)简答题1、为什么说社会经济统计是认识社会的有力武器?2、什么是总体和总体单位?试举例说明它们之间的关系。
3、什么是标志?它有哪些分类?4、指标和标志有何区别和联系?Answer1:(一)判断题1.(√)2.(√)3.(×)4.(×)5.(×)(二)单项选择题1.②2.②3.④4.④5.①6.③(五)简答题1.社会经济统计是认识社会的有力武器,其理由有二。
第一,因为任何事物都是质与量的对立统一,任何事物的量都依存于一定的质,而任何事物的质都可以在一定的条件下,通过一定的形式表现为一定的量。
第二,社会经济统计量最基本的特点就是以数字为语言,研究事物的量。
主观和客观两方面的原因,使统计能够成为认识社会的有力武器。
统计学-数据的描述性分析

92801.20 10
80 70 1.43 7
计算结果表明,第二次考试成绩更好些.
② 对称分布中的 3 法则
4、如要分别反映甲、乙、丙三个班的考试情况,你会 选择用哪些指标来衡量?
5、如要比较甲、乙、丙三个班的考试情况的优劣,你 又会选择什么样的指标来衡量? 6、甲乙丙三个班的考试成绩分别服从对称分布、左 偏分布、右偏分布中的哪种分布?为什么?
由组距数列确定中位数
n
先计算各组的累计次数,再按公式
i
1
fi
xnfn
fi
i1
fi
xi
例3.1.1 一位投资者持有一种股票,2019,2019,2019,2000年 收益率分别为4.5% ,2.0% ,3.5% ,5.4% .计算该投资者在这四 年内的平均收益率.
例3.1.2 某企业四个车间流水作业生产某产品, 一车间产 品合格率99%,二车间为95%,三车间为92%,四车间为90%,
适用范围
众数主要用于分类数据,也可用于顺序数据和数值型数据, 对于未分组数据和单项式分组数据,众数位置确定之后便 找到了众数.
例:分类数据的众数
例:顺序数据的众数
②.中位数(Median)
中位数是一组数据按一定顺序排列后,处于中间位置 上的变量
负偏 注: (1)中位数总是介于众数和平均数之间.
注:(1)
(2) 数值平均数主要适用于定量数据,而不适用于定性数据. (3) 简单数值平均数适用于未分组的资料,加权数值平均数 适用于分组的资料.
3.1.2 位置平均数
①.众数(Mode)
一组数据中出现次数最多的变量值.
主要特点: ●不受极端值的影响. ●有的数据无众数或有多个众数.
数据的描述性统计练习题

1数据的描述性统计练习题一、填空题1. 一组数据向某以中心值靠拢的倾向反映了数据的(集中趋势)。
2. (众数)是一组数据中出现次数最多的变量值。
3. 一组数据排序后处于中间位置的变量值称为(中位数)。
4. 不受极端值影响的集中趋势度量指标有(四分位数)(众数)(中位数)。
5. 一组数据的最大值与最小值之差称为(极差)。
6. (离散系数)一组数据的标准差与其相应的均值之比。
7. 数据分布的不对称性是(偏度)。
8. 数据分布的尖峰程度称为(峰度)。
9. 计算比率的平均数一般用(几何平均法),它实际上是各变量值对数的(算术平均数)。
二、单项选择题1. 对于对称分布的数据,众数、中位数和平均数的关系是(B)A. 众数>中位数>平均数B. 众数=中位数=平均数C. 平均数>中位数>众数D. 中位数>众数>平均数2. 可以计算平均数的数据类型是(C)A.分类数据B.顺序型数据C.数值型数据D.所有数据3. 顺序数据的集中趋势测度的指标(B)A.中位数B.平均数C.极差D.标准差4. 数值型数据的离散程度测度方法中,受极端变量值影响最大的是(A)A.极差B.方差C.均方差D.平均差5. 当偏态系数为正数是,说明数据的分布是(C)A.正态分布B.左偏分布C.右偏分布D.U型分布三、多项选择题1. 数据的分布特征可以从以下哪几个方面测度和描述(ABCD)A.集中趋势B.分布的偏态C.分布的峰态D.离散程度E.长期趋势2. 受极端变量值影响的集中趋势的度量指标是(CDE)A.众数B.分位数C.算数平均数D.调和平均数E.几何平均数3. 加权算术平均数的大小的影响因素有(AC)A.变量值B.样本容量C.权数D.分组的组数E.数据的类型4. 数值型数据离散程度的测度指标有(ABCDE)A.变异系数B.极差C.标准差D.异众比率E.四分位数5. 离散系数的主要作用是(BD)A.说明数据的集中趋势B.比较不同计量单位数据的离散程度C.说明数据的偏态程度D.比较不同变量值水平数据的离散程度E.说明数据的峰态程度四、简答题1. 什么是数据的集中趋势反映数据集中趋势的指标有哪些数据的集中趋势指一组数据向某一中心值靠拢的倾向。
统计学练习题及答案
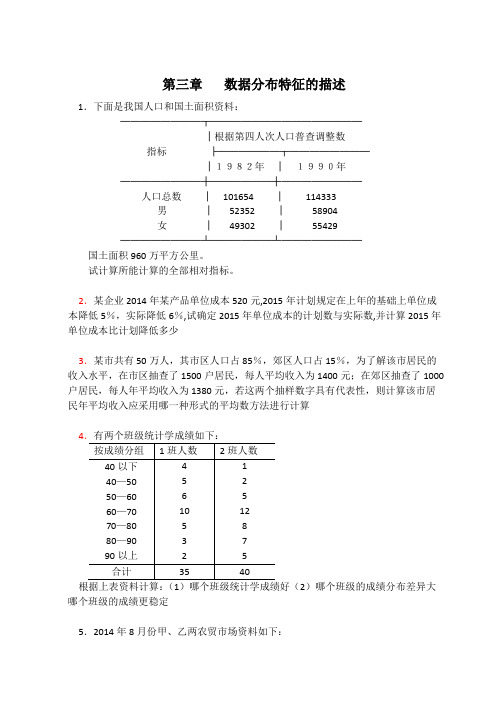
第三章数据分布特征的描述1.下面是我国人口和国土面积资料:────────┬───────────────│根据第四人次人口普查调整数指标├──────┬────────│1982年│1990年────────┼──────┼────────人口总数│101654 │114333男│52352 │58904女│49302 │55429────────┴──────┴────────国土面积960万平方公里。
试计算所能计算的全部相对指标。
2.某企业2014年某产品单位成本520元,2015年计划规定在上年的基础上单位成本降低5%,实际降低6%,试确定2015年单位成本的计划数与实际数,并计算2015年单位成本比计划降低多少3.某市共有50万人,其市区人口占85%,郊区人口占15%,为了解该市居民的收入水平,在市区抽查了1500户居民,每人平均收入为1400元;在郊区抽查了1000户居民,每人年平均收入为1380元,若这两个抽样数字具有代表性,则计算该市居民年平均收入应采用哪一种形式的平均数方法进行计算4根据上表资料计算:(1)哪个班级统计学成绩好(2)哪个班级的成绩分布差异大哪个班级的成绩更稳定5.2014年8月份甲、乙两农贸市场资料如下:────┬──────┬─────────┬─────────品种│价格(元/斤)│甲市场成交额(万元)│乙市场成交量(万斤)────┼──────┼─────────┼─────────甲│││2乙│││1丙│││1────┼──────┼─────────┼─────────合计│──││4────┴──────┴─────────┴─────────试问哪一个市场农产品的平均价格较高并说明原因。
6.某车间有甲、乙两个生产组,甲组平均每个工人的日产量36件,标准差件。
乙组工人资料如下:要求:(1)计算乙组平均每个工人的日产量和标准差。
(2)比较甲、乙两个生产小组哪个组的平均日产量更有代表性比较哪组的产量更稳定比较哪组的产量差异大第四章抽样调查检验结果如下:1.某进出口公司出口茶叶,为检查其每包规格的重量,抽取样本100包,(1)确定每包平均重量的抽样平均误差和极限误差;(2)估计这批茶叶每包平均重量的范围,确定是否达到规格要求。
统计学简答题35734

1、解释描述统计和推断统计(练习卷答案)(1)描述统计是研究数据收集、处理、汇总、图表描述、概括与分析等统计方法,内容有收集数据、整理数据、展示数据、描述性分析。
(2)推断统计是研究如何利用样本数据来推断总体特征的统计学方法、包含参数估计、假设检验。
2、统计数据可分为哪几种类型?不同类型的数据各有什么特点?按照所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据特点:分类数据是只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,是用文字来表述的。
顺序数据是只能归于某一有序类别的非数字型数据。
顺序数据虽然也是类别,但这些类别是有序的。
数值型数据是按数字尺度测量的观察值,其结果表现为具体的数值。
现实中所处理的大多数是数值型数据。
按照统计数据的收集方法,可以将其分为观测数据和实验数据。
特点:观测数据是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制条件下得到的,有关社会经济现象的统计数据几乎都是观测数据。
实验数据则是在实验中控制实验对象而收集到的数据。
自然科学领域的大多数数据都为实验数据。
按照被描述的现象与时间关系,可以将其分为截面数据和时间序列数据。
特点:截面数据是在相同或近似相同的时间点上收集的数据,这类数据通常是在不同空间上获得的,用来描述现象在某一时刻的变化情况。
时间序列数据是在不同时间收集到的数据,这列数据是按时间顺序收集得到的,用于所描述现象随时间变化的情况。
3、解释分类数据、顺序数据和数值型数据的含义。
分类数据是只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,是用文字来表述的。
顺序数据是只能归于某一有序类别的非数字型数据。
顺序数据虽然也是类别,但这些类别是有序的。
数值型数据是按数字尺度测量的观察值,其结果表现为具体的数值。
现实中所处理的大多数是数值型数据。
4、变量可分为哪几类?分类变量(是说明事物类别的一个名称,其取值是分类数据)顺序变量(是说明事物有序类别的一个名称,其取值是顺序数据)数值型变量(是说明事物数字特征的一个名称,其取值是数值型数据)可分为离散型变量(只能取可数值的变量,它只能取有限个值而且其取值都以整位数断开,可以一一列举)、连续型变量(可以在一个或多个区间中取任何值的变量,它的取值是连续不断的,不能一一列举)第二章:数据的搜集1、比较概率抽样和非概率抽样的特点。
统计学习题(抽样分布、参数估计)

统计学习题(抽样分布、参数估计)练习题第1章绪论(略)第2章统计数据的描述2.1某家商场为了解前来该商场购物的顾客的学历分布情况,随机抽取了100名顾客。
其学历表示为:1.初中;2.高中/中专;3.大专;4.本科及以上学历。
调查结果如下:4222434414 2244432422 3121441424 2332134344 3312424324 2322212244 2123333334 2343313232 4313434214 2242334121(1)制作一张频数分布表。
(2)绘制一张条形图,反映学历分布。
2.2为了解某电信客户对该电信公司的服务的满意度情况,某调查公司分别对两个地区的电信用户在以下五个方面对受访用户的满意情况进行了问卷调查得到的数据如下(表中数据为平均满意度打分,从1分到10分满意度依次递增):地区企业形象客户期望质量感知价值感知客户总体满意度A 8.269504 7.51773 9.2624117.9148948.411348B 7.447368 8.3684218.9736848.1052637.394737试用条形图反映将两地区的满意度情况。
2.3下面是一个班50个学生的经济学考试成绩:88569179699088718279 988534744810075956092 83646569996445766369 6874948167818453912484628183698429667594(1)对这50名学生的经济学考试成绩进行分组并将其整理成频数分布表,绘制直方图。
(2)用茎叶图将原始数据表现出来。
2.4如下数据反映的是某大学近视度数的情况,共120名受访同学,男女同学各60名。
男149 161761821310 80 951081414 0 144145151515161681882121 0 21211052121211116817521 0 356462121212121312121 0 2121212121375375383838 8 45566065120 30120 7521女120 3334537437538700 90700 60141516212121211517170 0 0 0 0 0 0 0 5 521 0 1752121214043451217517 8 181818518519195196202021 0 21212121212121333335 0 3636363840474865055(1)按近视度数分别对男女学生进行分组。
第三章 统计学习题

第三章统计数据的描述(1)一、填空题2、动态相对指标有_______和_______两种基本形式。
3、某现象的某一指标在同一时间不同空间上的指标值对比的结果是_______,在同一空间不同时间上的指标值对比的结果是_______。
4、同质总体中部分数值与总体全部数值对比的结果是_______,各部分数值相互对比的结果是_______。
7、相对指标一般都采用______的形式来表现,有些特殊的相对数,则采用_______的形式来表现。
9、强度相对指标的分子、分母一般可以互换,因而有_______和_______之分。
10、长期计划执行结果的检查方法有两种,一种是_______,另一种是_______。
11、计算和应用计划完成程度相对指标时,当计划任务是按最低限额规定时,则计划完成百分数以_______100%为好,当计划任务是按最高限额规定时,则计划完成百分数以_______100%为好。
12、结构相对数的取值介于_______之间,各组结构相对数的和恒等于_______。
15、比例相对数是一种_______性比例,而比较相对数则是一种_______性比例。
二、单选题3、某厂劳动生产率计划比上年提高8%,实际仅提高4%,则其计划完成百分数为()。
A.4% B.50% C.96.30% D.103.85%4、某厂某产品的单位产品成本计划规定比去年降低5%,实际降低了7%,则其计划完成百分数为():、A.97.9% B.140.0% C.102.2% D.71.4%5、联合国粮农组织依据恩格尔系数的高低,提出的富裕标准是恩格尔系数为()。
A.30%以下B.30%—40%C.40%—50%D.50%—59%7、总体各部分结构相对数的和应()。
A.等于100% B.小于100% C.大于100% D.小于或等于100%10、将相对指标与总量指标结合应用,通常是计算()。
A.平均增长水平B.平均发展速度C.平均增长速度D.增长1%的绝对值11、反映总体各部分之间数量联系程度和比例关系协调平衡状况的综合指标是()。
统计学习题和答案解析[完整]
![统计学习题和答案解析[完整]](https://img.taocdn.com/s3/m/51a359cd0242a8956bece4c6.png)
第一部分计量资料的统计描述一、最佳选择题1、描述一组偏态分布资料的变异度,以()指标较好。
A、全距B、标准差C、变异系数D、四分位数间距E、方差2.用均数和标准差可以全面描述()资料的特征。
A.正偏态分布 B.负偏态分布 C.正态分布D.对称分布 E.对数正态分布3.各观察值均加(或减)同一数后()。
A.均数不变,标准差改变 B.均数改变,标准差不变C.两者均不变 D.两者均改变 E.以上都不对4.比较身高和体重两组数据变异度大小宜采用()。
A.变异系数 B.方差 C.极差 D.标准差 E.四分位数间距5.偏态分布宜用()描述其分布的集中趋势。
A.算术均数 B.标准差 C.中位数 D.四分位数间距 E.方差6.各观察值同乘以一个不等于0的常数后,()不变。
A.算术均数 B.标准差 C.几何均数 D.中位数 E.变异系数7.()分布的资料,均数等于中位数。
A.对数正态 B.正偏态 C.负偏态 D.偏态 E.正态8.对数正态分布是一种()分布。
(说明:设X变量经Y=lgX变换后服从正态分布,问X变量属何种分布?)A.正态 B.近似正态 C.左偏态 D.右偏态 E.对称9.最小组段无下限或最大组段无上限的频数分布资料,可用()描述其集中趋势。
A.均数 B.标准差 C.中位数 D.四分位数间距 E.几何均数10.血清学滴度资料最常用来表示其平均水平的指标是()。
A.算术平均数 B.中位数 C.几何均数 D.变异系数 E.标准差二、简答题1、对于一组近似正态分布的资料,除样本含量n外,还可计算,S和,问各说明什么?2、试述正态分布、标准正态分布及对数正态分布的某单位1999年正常成年女子血清联系和区别。
甘油三酯(mmol/L)测量结果3、说明频数分布表的用途。
4、变异系数的用途是什么?组段频数5、试述正态分布的面积分布规律。
0.6~ 10.7~ 3三、计算分析题0.8~ 91、根据1999年某地某单位的体检资料,116名正常 0.9~ 13成年女子的血清甘油三酯(mmol/L)测量结果如右表, 1.0~ 19请据此资料: 1.1~ 25(1)描述集中趋势应选择何指标?并计算之。
统计学基础练习题库及参考答案

第一章 定量资料的统计描述 1第一部分一、单选题1、甲乙丙三位研究者评价人们对四种方便面的喜好程度。
甲让评定者先挑选出最喜欢的品 牌,然后挑出剩余三种最喜欢的, 最后挑出剩余两种比较喜欢的。
研究者乙让评定者把四种 品牌分别给予 1~5 的等级评定 (1 表示最不 , 5 表示最喜欢 ),研究者丙只是让评定者挑出 自己最喜欢的品牌。
三位研究者所使用的数据类型是: BA .称名数据 -顺序数据 -计数数据B .顺序数据 -等距数据 -称名数据C .顺序数据 -等距数据 -顺序数据D .顺序数据 -等比数据 -计数数据2、调查 200 名不同年龄组的被试对手表的偏好程度如下:表 1 200该题自变量和因变量的数据类型是: A .称名数据 -顺序数据 C .顺序数据 -等距数据3、 157.5 的实上限是: CA . 157.75B . 157.65 4、随机现象的数量化表示称为 :B A .自变量 B .随机变量 5、实验或研究对象的全体称为: AA .总体B .样本点 6、下列数据中,哪个数据是顺序变量: A .父亲月收入 2400 元C .约翰 100 米短跑得第 2 名 二、概念题 数据类型、变量、观测值、随机变量、总体、样本、个体、次数、比率、概率、参数、统计 量、 μ、ρ、r 、 σ、 S 、 β、 n 。
第一章 定量资料的统计描述 2一、单选题1、一批数据中各个不同数据值出现的次数情况是: AA .次数分布B .概率密度C .累积概率密度D .概率2、以下各种图形中,表示连续数据频次分布的是: CA .条图B .圆图C .直方图D .散点图3、特别适用于描述具有百分比结构的分类数据的统计图 :BC .157.55D .158.5 C .因变量 D. 相关变量 C .个体 D .元素 C B .迈克的语文成绩是 80 分 D .玛丽某项技能测试得了 5 分。
DB .计数数据 -等比数据A.散点图B.圆图C.条图 D .线图5、以下各种统计图中,表示离散数据频次分布的:AA.圆图B.直方图C.散点图 D .线形图6、相关变量的统计图是: AA.散点图B.圆图C.条图 D .线图7、适用于描述某种事物在时间上的变化趋势,以及一事物随另外一事物的发展变化的趋势,还适用于比较不同人物群体在心理或教育现象上的变化特征以及相互联系的统计图是: DA散点图B圆图C条图D.线图二、多选题1、频次分布可以为:ABCDA .简单次数分布B.分组次数分布C.相对次数分布D.累积次数分布2、以下各种图形中,表示连续数据频次分布的是:BDA .圆图B.直方图C.条图D.线图3、累加曲线的形状大约有:ABDA .正偏态B.负偏态C.F 分布D.正态分布4、统计图按照形状划分为:ABCDA直方图B曲线图C圆图D.散点图三简答题1、简述条图、直方图、圆图、线图、散点图的用途。
描述统计作业及参考答案

第一章练习题1.1统计一词有哪几种含义?1.2什么是统计学?怎样理解统计学与统计数据的关系?1.3怎样理解描述统计和推断统计在统计方法探索数量规律性中的地位和作用?1.4统计学与数学有何区别与联系?1.5怎样理解统计学与其他学科的关系?第二章练习题2.1某家用电器生产厂家想通过市场调查了解以下问题:a.企业产品的知名度;b.产品的市场占有率;c.用户对产品质量的评价及满意程度。
要求:(1) 请你设计出一份调查方案;(2 ) 你认为这项调查采取哪种调查方法比较合适?(3 ) 设计出一份调查问卷。
2.2根据上面的数据进行适当的分组,编制频数分布表,并绘制频数分布的直方图和茎叶图。
2.3要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累计频数和累计频率;(2)如果按企业成绩规定:销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、—般企业、落后企业进行分组。
2.4已知1991—1997年我国的国内生产总值数据如下表:其中:在1997年的国内生产总值中,第一产业为13969亿元,第二产业为36770亿元,第三产业为24033亿元。
(1)根据1991—1997年的国内生总值数据,绘制折线图、条形图;(2)根据1997年的国内生产总值及其构成数据,绘制圆形图(饼图)2.5某贸易公司销售额计划比去年增长3%,实际比去年增长5%,试问该公司计划完成情况是多少?又知该公司经营的产品每台成本应在去年699元的基础上降低12元,实际今年成本672元,试确定降低成本的计划完成情况指标。
2.6选择题:1.相对指标值的大小()。
(1)随总体范围扩大而增大(2)随总体范围扩大而减小(3)随总体范围缩小而减小(4)与总体范围大小无关(5)可用于不同总体的比较2. 以最髙限度为任务提出的计划指标,计划完成程度()。
(1)以<100%为完成好计划(2)以>100%为完成好计划(3)以<或=100%为完成好计划(4)以>或=100%为完成好计划(5)以=100%为完成好计划3. 时点指标数值()。
统计数据的分析经典题题型

统计数据的分析经典题题型统计数据的分析是一个重要的领域,对于许多行业和决策过程都起着至关重要的作用。
在这篇文档中,我们将介绍一些统计数据分析的经典题题型。
1. 描述性统计题型描述性统计是对数据进行统计分析的基础。
以下是一些常见的描述性统计题型:- 平均数问题:计算一组数据的算术平均值,即将所有数值相加后除以数据的个数。
- 中位数问题:计算一组数据的中位数,即将数据按照数值大小排列后,位于中间位置的数值。
- 众数问题:计算一组数据的众数,即出现频率最高的数值。
- 极差问题:计算一组数据的极差,即最大值与最小值之间的差距。
- 标准差问题:计算一组数据的标准差,用于衡量数据的离散程度。
2. 假设检验题型假设检验是用来验证某个假设是否成立的统计方法。
以下是一些常见的假设检验题型:- 单样本 t 检验问题:用于检验一个样本的均值是否与指定的均值有显著差异。
- 双样本 t 检验问题:用于检验两个样本的均值是否有显著差异。
- 卡方检验问题:用于检验两个或多个分类变量之间的关联性。
- 方差分析问题:用于比较两个或多个样本均值之间的差异是否显著。
3. 回归分析题型回归分析是用来研究变量之间关系的统计方法。
以下是一些常见的回归分析题型:- 线性回归问题:建立一个线性模型,用于预测因变量与一个或多个自变量之间的关系。
- 多项式回归问题:建立一个多项式模型,用于预测因变量与一个或多个自变量之间的关系。
- 逻辑回归问题:用于预测二分类结果的概率。
4. 抽样调查题型抽样调查是收集数据的常用方法之一。
以下是一些常见的抽样调查题型:- 简单随机抽样问题:从总体中随机选择样本。
- 系统抽样问题:按照一定的系统规则选择样本。
- 分层抽样问题:将总体划分为若干层,然后从各层中分别抽取样本。
- 整群抽样问题:将总体划分为若干群,然后从部分群中抽取样本。
统计数据的分析经典题题型是统计学中常用的问题类型,掌握这些题型将有助于我们更好地理解和应用统计数据分析方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、判断题(把正确的符号“√”或错误的符号“×”填写在题后的括号中。
) 1、众数是总体中出现最多的次数。
( )
2、权数对算术平均数的影响作用只表现为各组出现次数的多少,与各组次数占总数的比重无关。
( )
二、单项选择题 1、对于不同水平的总体不能直接用标准差比较其标志变动度,这时需分别计算各自的( )来比较。
A.标准差系数
B.平均差
C.全距
D.均方差
2、某车间7位工人的日产零件数为16、20、25、2
3、12、35、27件,则它的全距为( )
A 、 25
B 、17、
C 、23
D 、10
3、某10位举重运动员体重分别为:101斤、102斤、103斤、108斤、102斤、105斤、102斤、110斤、105斤、102斤,据此计算平均数,结果满足( )。
A 、算术平均数=中位数=众数 B 、众数>中位数>算术平均数 C 、中位数>算术平均数>众数 D 、算术平均数>中位数>众数
4、对于一个右偏的频数分布,一般情况下( )的值最大。
A 、中位数
B 、众数
C 、算术平均数
D 、调和平均数
6.甲乙两数列,甲数列的标准差甲σ大于乙数列的标准差乙σ,则两个数列的平均数的代表性为( ).
A 、甲大于乙
B 、乙大于甲
C 、相同
D 、无法判断 7、权数对算术平均数的影响作用,实质上取决于( ) A 、作为权数的各组单位数占总体单位数比重的大小 B 、各组标志值占总体标志总量比重的大小 C 、标志值本身的大小 D 、标志值数量的多少
8.某变量数列如下:53,55,54,57,56,55,54,55,则其中位数为( ). A 、54 B 、55 C 、56.5 D 、57 9.如果某个分布是极度右偏,则其偏度系数为( ).
A 、-0.3
B 、0.3
C 、-2.9
D 、2.9 三、多项选择题
1、平均数的种类有( )。
A 、算术平均数
B 、众数
C 、中位数
D 、调和平均数
E 、几何平均数
2、在什么条件下,加权算术平均数等于简单算术平均数()。
A、各组次数相等
B、各组变量值不等
C、变量数列为组距数列
D、各组次数都为1
E、各组次数占总次数的比重相等
四、计算题
1.某企业产品的有关资料如下:
品种单位成本1998年总成本1999年总产量
甲乙丙15
20
30
2100
3000
1500
215
75
50
试指出哪一年的总平均成本高,为什么?
2.有甲乙两个品种的粮食作物,经播种实验后得知甲品种的平均亩产量为998斤,标准差为
亩产量(斤/亩)播种面积(亩)
1000 950 1100 900 1050 0.8
0.9
1.0 1.1 1.2
试研究两个品种的平均亩产量,以确定哪一种具有较大稳定性,更有推广价值。
3. 为了了解大学生每月伙食费的支出情况,在北京某高校随机抽取了250名学生进行调查,得到样本数据如下:
月伙食费用支出额(元)人数(户)
150以下10
150~200 20
200~250 110
250~300 90
300~350 15
350以上 5
合计250
根据表中的样本数据:
(1)每月伙食支出在200~300之间的人数占总人数的百分比是多少?
(2)计算大学生每月伙食费的算术平均数;
(3)计算大学生每月伙食的样本标准差.
4、某厂甲、乙两个工人班组,每班组有8名工人,每个班组每个工人的月生产量记录如下:
甲班组:20、40、60、70、80、100、120、70
乙班组:67、68、69、70、71、72、73、70
计算甲、乙两组工人平均每人产量;
计算全距,平均差、标准差,标准差系数;比较甲、乙两组的平均每人产量的代表性。
一、判断题 1、× 2、× 二、单项选择题
1、A
2、C
3、D
4、C 6、D 7、A 8、B 9、D 三、多项选择题
1、ABCDE
2、ADE 四、计算题
1、解:1998年平均单位产品成本:
1999年平均单位产品成本:
所以由以上结果可知1998年的总成本高。
2.
解:甲组:16.0998
7
.162x
V ==
=甲
甲δ
乙组:1.847f
xf
x =∑∑=公斤/亩
170.1f
f
x x 2
=∑-∑=
)(乙δ
2.0847.1
1
.170x V ==
=
乙
乙
乙δ
乙V > 甲V 所以甲组更有代表性,更稳定、更值得推广
3、解:(1)每月伙食费支出在200~300元之间的人数占总人数的百分比:11090
80%250
+=
(2)算术平均数:
125101752022511027590325153755
244250
i i
i x f x f
⨯+⨯+⨯+⨯+⨯+⨯=
=
=∑∑
(3)样本标准差:
222()(125244)10(375244)546.881
249
i
i
i
x x f s f --⨯++-⨯=
==-∑∑
4、解 元
3.18340
1500
15003225507521530*5020*7515*215=++=++++=
=
∑∑f
xf x 元41.19340
6600
30
1500203000152100150030002100x m m ==
++++==
∑∑x
甲班组:平均每人产量 件70=∑=n
x x 全距 件10020120min max =-=-=x x R
平均差 AD 件5.228180
==-∑=
n
x x 标准差 ()件6.298
7000
2
==-∑=n x x σ 标准差系数 %29.4270
6.29===x V σσ 乙班组:平均每人产量 件70=∑=n
x x 全距 件66773min max =-=-=x x R 平均差 AD=
件5.18
12==-∑n
x x
标准差 ()件5.38
28
2
==
-∑=
n
x x σ 标准差系数 %00.5705.3==
=x V σσ 分析说明:从甲、乙两组计算结果看出,尽管两组的平均每人产量相同,但乙班组的标
志变异指标值均小于甲班组,所以,乙班组的人均产量的代表性较好。