纵向数据单指标模型中参数的经验似然置信域
删失数据下单指标模型的经验似然推断

其 中 e =ZG—E( ̄l i i Zaxd. 利用 Z u和 Xu 1 的 思想可 以构 造一个经 验对数 似然 比函数 . h e[ 1 J 注 意 到 约束 l= 1意 味着 真 实参 数 是一 个 单位 球上 的 边界 点 ,在这 些边 界 点 上 l 9 Xi可能 不存在 导数 .因此 ,我 们采用 “ 一个分 量 ”的方 法.令 = ( , , ), I ’ ) ( 去 … T 而 ( =( , , 一, +, , ) ) … … 是删 去第 r个分 量 所形成 的 ( p一1 维 向量 .不 失一般 ) 性 ,我 们假定 真实参 数 具 有正 的分 量 , 否则 ,可 以考虑 = 一( 一 ( /. 么, 1 r ) 2那 我 们可 以将 表示 为
摘要 : 考虑删失数据下单指标模型 ,研究了模型 中参数的经验似 然推断,证明了所提 出的调整 的经验对数似然比渐近于卡方分布,由此构造相应兴趣参数的置信域.进一步,由于模型 中参
数 向量的范数等于 1 利用该约束条件来 降低参数 的维 数,从而增加置信域的精度 .模拟研究 , 比较 了经验似然方法和正 态逼近 方法的有限样本性 质,从置信域 的面积和 覆盖概率 两方面进 行了 比较 ,模拟结果表明经验似然方法优于正态逼近方法. 关键词:删失数据 ;单指标模型;经验似然 ; ) ( 。分布.
调整因子,使得调整后的经验对数似然比函数渐近于 ) 分布,由此构造 的置信域 . ( 在第 3节 中,通过 数值 模拟研 究 比较 了经验似 然方法 和正 态逼近 方法 的有 限样本性 质 .在 第 4节 中,给 出本 文所 有渐近 结果 的详 细证 明过程 .
2 参数的经验似然
令 ZG = ZSl1一G(i ) i ii( Z一), 1… ,, 中 G 是 删失变 量 的分 布 函数 ,显然 , i= , n 其 E(iI ) ZGXi =E(d . Y Xd 因此 ,我们有
纵向结构方程模型

纵向结构方程模型纵向结构方程模型(Longitudinal Structural Equation Modeling,简称LSEM)是一种统计分析方法,用于研究随时间变化的数据。
它结合了纵向数据分析和结构方程模型的优势,可以探索变量之间的因果关系,并对这些关系进行长期跟踪和预测。
本文将介绍纵向结构方程模型的基本概念和应用。
我们来了解一下纵向数据。
纵向数据是指在不同时间点上对同一组个体进行观测的数据。
比如,我们可以通过跟踪一组人员在不同年龄阶段的学习成绩,来研究年龄对学习成绩的影响。
纵向数据具有时间顺序性和个体间的相关性,因此分析纵向数据需要考虑这些特点。
而结构方程模型(Structural Equation Modeling,简称SEM)是一种多变量分析方法,用于研究变量之间的因果关系。
它可以将观测到的变量与潜在的变量联系起来,从而揭示出背后的结构。
结构方程模型通过建立测量模型和结构模型,可以量化变量之间的关系,并进行模型拟合和参数估计。
纵向结构方程模型则将纵向数据和结构方程模型相结合,可以对变量在时间上的变化进行建模和分析。
它可以探索变量之间的因果关系是否随时间发生变化,以及这些关系对个体或群体的长期影响。
纵向结构方程模型可以用于各种研究领域,例如教育、心理学、社会科学等。
在应用纵向结构方程模型时,首先需要收集纵向数据,并确定研究的目的和研究问题。
然后,需要选择适当的变量,建立测量模型和结构模型,并进行模型拟合和参数估计。
模型拟合的指标包括χ²值、RMSEA、CFI等,用于评估模型的拟合程度和模型的解释力。
纵向结构方程模型的应用非常广泛。
例如,在教育研究中,可以使用纵向结构方程模型来研究学生的学习动机、学习策略和学习成绩之间的关系,并探索这些关系是否随时间发生变化。
在心理学研究中,可以使用纵向结构方程模型来研究个体的心理健康状态、社交支持和生活满意度之间的关系,并预测这些关系对个体的长期影响。
【国家自然科学基金】_右删失_基金支持热词逐年推荐_【万方软件创新助手】_20140730
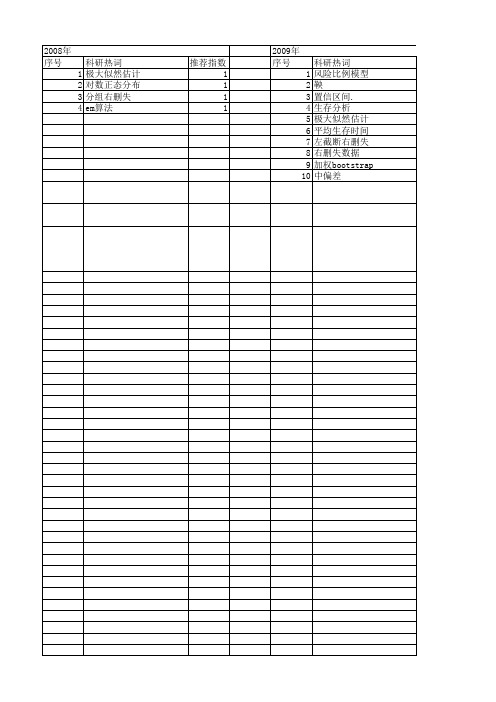
科研热词 极大似然估计 对数正态分布 分组右删失 em算法
推荐指数 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10
科研热词 风险比例模型 鞅 置信区间. 生存分析 极大似然估计 平均生存时间 左截断右删失 右删失数据1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2014年 科研热词 推荐指数 非线性回归 1 经验分布函数 1 满条件分布 1 影响函数 1 广义 m估计 1 完全数据似然函数 1 右删失数据 1 右删失 1 单一插补法 1 区间删失数据 1 sc(self-consistent)算法 1 metropolis-hastings 算法 1 mcmc 方法 1 kaplan-meier权 1 gibbs 抽样 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13
科研热词 推荐指数 零膨胀poisson回归 1 随机效应 1 经验似然估计 1 线性 1 混合物 1 极限分布 1 有限样本性质 1 最大边际似然估计 1 指标模型 1 应用程序 1 右删失数据 1 删失数据 1 censored data, regression model, 1 empirical likeli
推荐指数 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4
科研热词 非线性模型 调整的经验似然 置信域 删失数据
推荐指数 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9
2011年 科研热词 随机删失 经验bayes检验 线性模型 纵向数据 相合性 渐进最优性 无偏转换 收敛速度 删失 推荐指数 1 1 1 1 1 1 1 1 1
数据分析怎么做-数据分析的六种基本分析方法

数据分析怎么做?数据分析的六种基本分析方法随着互联网的进展和普及,数据分析已经成为了各行各业的必备技能。
数据分析可以关心企业更好地了解市场和客户需求,优化产品和服务,提高效率和竞争力。
但是,数据分析并不是一件简洁的事情,需要把握肯定的分析方法和技巧。
本文将介绍数据分析的六种基本分析方法,关心读者更好地进行数据分析。
描述性统计分析描述性统计分析是数据分析的基础,它可以关心我们了解数据的基本状况。
描述性统计分析包括以下几个方面:1.中心趋势:平均数、中位数、众数等。
2.离散程度:标准差、方差、极差等。
3.分布形态:偏度、峰度等。
通过描述性统计分析,我们可以了解数据的分布状况,推断数据是否符合正态分布,是否存在特别值等。
相关性分析相关性分析可以关心我们了解两个或多个变量之间的关系。
相关性分析包括以下几个方面:1.相关系数:皮尔逊相关系数、斯皮尔曼等级相关系数等。
2.散点图:通过散点图可以直观地看出两个变量之间的关系。
3.回归分析:通过回归分析可以建立两个变量之间的数学模型,猜测一个变量的值。
通过相关性分析,我们可以了解变量之间的关系,找出影响因素,为后续的猜测和决策供应依据。
假设检验假设检验可以关心我们推断样本数据是否代表总体数据。
假设检验包括以下几个方面:1.假设:提出一个假设,例如“这个样本的平均值等于总体的平均值”。
2.显著性水平:设定一个显著性水平,例如0.05。
3.检验统计量:计算一个检验统计量,例如t值。
4.拒绝域:依据显著性水平和自由度确定拒绝域。
5.推断结论:依据检验统计量是否在拒绝域内,推断是否拒绝原假设。
通过假设检验,我们可以推断样本数据是否代表总体数据,从而对数据进行更加精确的分析和猜测。
因子分析因子分析可以关心我们找出数据中的潜在因素,从而简化数据分析。
因子分析包括以下几个方面:1.提取因子:通过主成分分析或因子分析提取潜在因子。
2.旋转因子:通过旋转因子,使得因子之间的相关性最小。
2-纵向数据分析-ARIMA

持续下降)。
Xt
Xt
t
t
(a)
(b)
图 9.1 平稳时间序列与非平稳时间序列图
西安交大管理学院 2011-春
11
然而,对X取一阶差分(first difference): Xt=Xt-Xt-1=t
由于t是一个白噪声,则序列{Xt}是平稳的。
后面将会看到:如果一个时间序列是非平稳的,它常常可通过取差分的方法而形 成平稳序列。
• 因此 P lim ˆ P lim xiui / n 0
n
P lim xi2 / n
Q
• 如果X是非平稳数据(如表现出向上的趋势),则(2)不成立,回 归估计量不满足“一致性”,基于大样本的统计推断也就遇到麻烦。
西安交大管理学院 2011-春
6
时间序列数据的平稳性
1999
82673.1
2000
89112.5
西安交大管理学院 2011-春
14
平稳性的单位根检验 (unit root test)
1、DF检验
随机游走序列: Xt=Xt-1+t 是非平稳的,其中t是白噪声。而该序列可看成是随机模型:
Xt=Xt-1+t 中参数=1时的情形。
对式: Xt=Xt-1+t (*) 进行回归,如果确实发现=1,就说随机变量Xt 有一个单位根。
西安交大管理学院 2011-春
3
内容
1 序列自相关及检验(ARMA) 2 平稳时间序列模型 3 非平稳时间序列模型 4 协整和误差修正模型 5 条件异方差模型
–自回归条件异方差模型(ARCH) –非对称ARCH –成分ARCH 6 向量自回归和误差修正模型 –向量自回归VAR –误差修正模型VEC
【国家自然科学基金】_纠偏_基金支持热词逐年推荐_【万方软件创新助手】_20140802
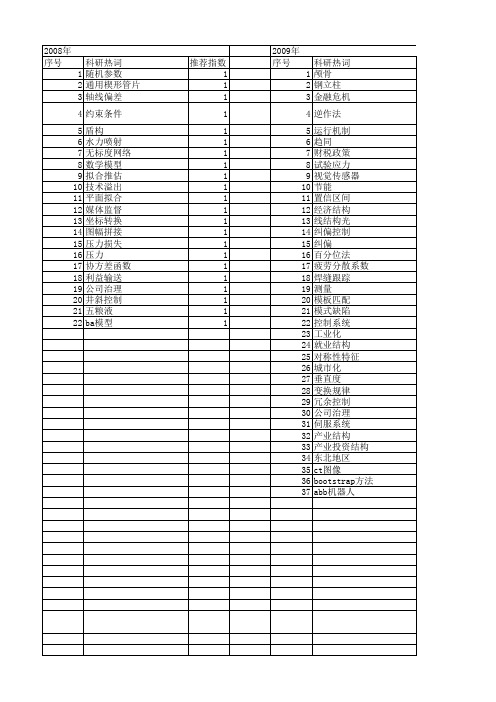
科研热词 颅骨 钢立柱 金融危机 逆作法 运行机制 趋同 财税政策 试验应力 视觉传感器 节能 置信区间 经济结构 线结构光 纠偏控制 纠偏 百分位法 疲劳分散系数 焊缝跟踪 测量 模板匹配 模式缺陷 控制系统 工业化 就业结构 对称性特征 城市化 垂直度 变换规律 冗余控制 公司治理 伺服系统 产业结构 产业投资结构 东北地区 ct图像 bootstrap方法 abb机器人
2008年 序号 1 2 3 4 5 6 18 19 20 21 22
科研热词 随机参数 通用楔形管片 轴线偏差 约束条件 盾构 水力喷射 无标度网络 数学模型 拟合推估 技术溢出 平面拟合 媒体监督 坐标转换 图幅拼接 压力损失 压力 协方差函数 利益输送 公司治理 井斜控制 五粮液 ba模型
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
"基准"成本
1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
纵向数据研究进展

纵向数据半参数建模研究计划一、研究回顾纵向数据是指对一组个体按时间顺序或空间顺序追踪重复测得的数据,对每一个体在不同时间或不同实验条件下多次测量,所得的数据兼有时间序列和截面数据的特点。
这种数据的特点是所研究的反应变量的观测值随时间变化,相关的协变量也随时间变化有一系列的观察,具有上述特点的数据在医学、生物学、社会学、经济学、心理学等领域极为常见。
由于在纵向数据中对同一个个体的多次重复观察之间往往具有相关性,如何处理这种个体内的相关性便成为纵向分析中不可回避的问题。
此外,在纵向数据分析中还要较好地研究协变量对反应变量的影响,同一个体重复测量值内部的相关结构的信息在统计分析中应得到充分的利用。
作为对重复测量数据的相关性的刻画,早期主要采用参数的方法。
比如误差项为时间序列的多元线性模型、生长曲线模型等,由于随机误差项的结构很复杂,经常会不可避免的遇到维数灾祸。
以后又发展到非线性形式、离散的泛函形式的纵向数据模型,形成了比较成熟的非参数模型和半参数模型。
由于在纵向数据中经常遇到缺失或测量误差,这些都会增加统计分析的难度。
纵向数据的参数回归分析方法是早期研究的主要方法。
一般线性模型往往假定误差项为多元正态分布,零均值向量,协方差阵为分块对角阵。
进一步按协方差阵可细分均匀相关,指数相关,一步相关等。
可用极大似然法或加权最小二乘法以及广义估计方程的方法进行估计或统计推断。
广义线性模型可将连续型反应变量的研究推广至离散型,如Logistic边缘模型、泊松回归模型等,还可解决反应变量是分类数据的情形。
混合效应模型是研究纵向数据的强有力的工具。
对于具有不同类的个体(heterogeneous individuals)的研究,引入随机效应来反映个体的异质性,从而反映同一个体的观测的内相关性,这是纵向数据研究的十分重要的方法。
参数模型直观且易于进行统计分析,当假设的模型成立时,其推断的精度也较高。
然而如果假设的模型与实际不符,参数模型就会带来很大偏差。
部分线性反映变量含误差模型的经验似然置信区域

收 稿 日期 :0 50 —0 20 -51
检验 卢是否为参数的真实值与检验 ( 是否为 0 z) 等价 。 由文 献 [ ] 这 可 由经 验 似 然 比来 检 验 。 P 3 , 令
J 1
cv删 。(
t2 2 i r1
Hale Waihona Puke , …,=. 『 '
Z j=
jY 一 (i
一g t ) (i 。 )
O
若 为参 数 的真 实值 , E( 则 z )=00≤ i , 要 , ≤n 故
模型 是 变量 含误 差 模 型 中 的一 种 , 量 含 误差 变
模型已被应用到很多领域 , 如经济、 生物等。 一些作
词: 经验似 然 ; 映 变量含误 差 ; 反 渐近 置信 区域 文 献标 识码 : A 文章 编 号 :0 0 4 2 0 ) 10 0 4 1 0 7 X( 0 7 0 - 9 3 0 4 中图分 类号 : 2 2 1 0 1 .
经验 似然 是 O e 完 全样 本 下 提 出 的一 种 非 w n在 参 数统计 方法 。它有 类 似于 B o—rp的抽样 特 性 , ot t sa
线性反 映 变量 含误 差模 型 。结果
得 到 了 Wi s定理 的 非 参数 形 式 , 理 用 来构 造 参数 向量 的 渐 l k 定
近置信 区域 。结论
关 键
参 数 的 置信 区域 也 可 由其他 方 法来 构 建 , 与 正 态逼近 或 自助 法 相 比 , 但 经
验 似 然方 法在 实践 中更 直接 和 简单 。
纵向数据模型分析

所以,= 2f D为等效最低点, v √ g, 绳的拉力最大。
设小球到 D点的速 度为 , 由动 能定理得 :
×2 =2 l mg×2 = 2my - l
2
F
() 2 等效 ( 力) : 重 法 将重力 与电场力进行合成 , 合力 F 等 效 于 “ 力” a 鱼 等效于 “ 重 , =二 重力加速度” F☆ , 的方 向等效于
摘要 : 纵向研 究方法是心理 学研 究领域 的一种 重要 方法 , 近年来 , 国外在 纵向研 究数据 分析 方法上取得 了一 系列理论和
应 用上 的进展 。文章 对此方法进行 了简要的回顾 , 重点阐述 了最近发展起 来的纵向研 究的方法—— 多层线性模型和 并 潜 变量增 长曲线模 型 , 并在此基础上对 几种 常用的方法进 行 了比较。
我们应 该注 意到这些边 界期望函数模 型通 过反复测量 , 结果是独立 的,因为它们是协变量和固定参数模型。这是我 们通常不能确定 的, 因此我们需要更复杂的模型。
3 过渡模 型
’
其销售量和营业额 的状况是 否有变化 。纵 向 据就是通 过重 数
复上述调查过程而得到 的,它对研 究各个领域 的行 为动态提 供 非常有用的信息 。下面我们列举几个 纵 向数据模 型。
lgf =x p o( l
截 面数据 联 合起 来,这种 合并 的数据 我们 称之 为纵 向数据
( o gtdnl t)纵 向数据广泛地存在于 自然界 、 L n i iaDa , u a 社会界 , 其 分析方法广泛 应用 于各个领域 .例如房产公司在不 同时期 的 销 售 数 据 ,在 一 定 时 间 内对 公 司 销 售 量 的 调 查 。在 每 一 时期 的调查中, 同一家房产公司被抽样, 以观察 自上一次调查以来 ,
【国家自然科学基金】_单指标模型_基金支持热词逐年推荐_【万方软件创新助手】_20140731
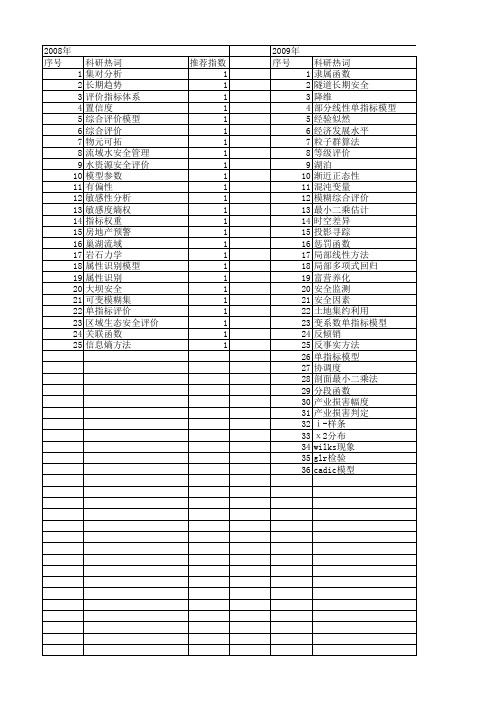
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
科研热词 经验似然 单指标模型 模型检验 变量选择 参数估计 删失数据 隶属函数 陆源有机质 逼近理想解的排序法 边缘海 自适应 线性回归模型 粗糙集理论 符号数据分析 突出危险性 短文本 相似权 用户行为 模糊聚类 木质素 支链和类异戊二烯四醚 底层指标 工程岩体 岩体质量评价 属性综合评价 属性测度 属性数学 垃圾评论者检测 垃圾评论 区间数据 区分权 化学生物标志物 分级标准 典型样本 产品评论 χ ~2分布 x2分布
1 1 1 1
2014年 科研热词 预警 视觉变量 统计制图符号 生态安全评价 灰色预测 湿地 建造模型 布局 图元 图们江流域 推荐指数 1 1 1 1 1 1 1 1 1 1
科研热词 经验似然 预测 韦伯-费希纳定律 限制正交性 降维 逆回归 距离判别分析 置信域 纵向数据 稀疏性 现状诊断 混合蛙跳算法 水环境 核实数据 损伤 指数公式 广东省东江流域 岩体爆破 层次分析法 安全判据 地下水评价 发散维数 单指标模型 单指标ev模型 农村饮用水安全 充分降维 云理论 ㏑-正则化
推荐指数 5 5 3 3 3 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
随机设计下部分线性模型经验欧氏似然比置信域

妻P ( ( ) ) 。 y一g 一x 一0
记 一X ( , ( f 一X ) y 一g T ) 卢。
(.) 22
利 用 拉 格 朗 日乘子 法 求 出可 求 出 L() 表 达 式 为 卢的
L 卢一一÷ ∑(P一1 ( ) n )
一 一
1 主 要 结 果
随机 设计下部 分线性模 型 经验
欧 氏似 然 比 置 信 域
齐化 富 王 炜
( 岛港 湾职 业技 术 学 院数 力 教 研 室 山 东 青 岛 2 60 ) 青 64 4
摘 要
在随机设 计下本文构造 了部分线性模型的经验欧 氏似然 比统计量 , 由它的极限分布构造 了部分线形模 型参 并
由 非参 数 回归 估 计 的相 合 性 及 假 定 可 知
gl 一 ∑ W () , 2() ∑ W () j () X g 一 Y.
E , e 一 > 0未 知 , { X , ) e=OE ; 且 ( l ) 互独立. 相
为 g () g () 1 、 2 的相 合 估 计 。 从 而 [ ] 义 欧 氏 似 然 比 统 计 量 : p 6定 L( )一
÷ c ̄, n i 耋P -}
其 中 P . . 满 足 … P
P > 0 l … . ∑ P 一 l 。— , . ,
它 有 诸 多优 点 , 此 方 法 研 究 模 型 ( _ ) 见 文 献 [ ] 用 11可 4。
(w n 1 9 ) 出可 用 欧 氏距 离 代 替 似 然 距 离 , 献 E ] ) e (9 1 提 文 6 在 固定 设 计 点列 的情 况 下 给 出了 回归 参 数 卢的经 验 欧 氏 似 然 置 信 域 。众所 周 知 。 定 设 计 点 列 和 随 机 点 列 是 不 一 样 的 固 模 型 , 文在 随 机 设 计 点 列 下 给 出 模 型 (. ) 回 归 参 数 卢 本 11中 的经 验 欧 氏经 验 似 然 置 信 区域 。
纵向数据研究进展

纵向数据半参数建模研究计划一、研究回顾纵向数据是指对一组个体按时间顺序或空间顺序追踪重复测得的数据,对每一个体在不同时间或不同实验条件下多次测量,所得的数据兼有时间序列和截面数据的特点。
这种数据的特点是所研究的反应变量的观测值随时间变化,相关的协变量也随时间变化有一系列的观察,具有上述特点的数据在医学、生物学、社会学、经济学、心理学等领域极为常见。
由于在纵向数据中对同一个个体的多次重复观察之间往往具有相关性,如何处理这种个体内的相关性便成为纵向分析中不可回避的问题。
此外,在纵向数据分析中还要较好地研究协变量对反应变量的影响,同一个体重复测量值内部的相关结构的信息在统计分析中应得到充分的利用。
作为对重复测量数据的相关性的刻画,早期主要采用参数的方法。
比如误差项为时间序列的多元线性模型、生长曲线模型等,由于随机误差项的结构很复杂,经常会不可避免的遇到维数灾祸。
以后又发展到非线性形式、离散的泛函形式的纵向数据模型,形成了比较成熟的非参数模型和半参数模型。
由于在纵向数据中经常遇到缺失或测量误差,这些都会增加统计分析的难度。
纵向数据的参数回归分析方法是早期研究的主要方法。
一般线性模型往往假定误差项为多元正态分布,零均值向量,协方差阵为分块对角阵。
进一步按协方差阵可细分均匀相关,指数相关,一步相关等。
可用极大似然法或加权最小二乘法以及广义估计方程的方法进行估计或统计推断。
广义线性模型可将连续型反应变量的研究推广至离散型,如Logistic边缘模型、泊松回归模型等,还可解决反应变量是分类数据的情形。
混合效应模型是研究纵向数据的强有力的工具。
对于具有不同类的个体(heterogeneous individuals)的研究,引入随机效应来反映个体的异质性,从而反映同一个体的观测的内相关性,这是纵向数据研究的十分重要的方法。
参数模型直观且易于进行统计分析,当假设的模型成立时,其推断的精度也较高。
然而如果假设的模型与实际不符,参数模型就会带来很大偏差。
纵向数据分析中的经验似然方法和分位数回归方法

n
n
n
L(θ ) = sup
wi : wi 0, wi = 1, wi g(Zi ; θ ) = 0 .
2. MAIN RESULTS
Let Yi j and Xi j be the jth response and covariate for the ith subject (i = 1, . . . , n; j = 1, . . . , ni ),
where the subjects are assumed to be independent and the responses for the same subject are corre-
1. INTRODUCTION
Quantile regression (Koenker & Basset, 1978) provides a complement to the mean regression model, and allows a systematic examination of the conditional distribution of the response given the covariate at different quantile levels; see Koenker (2005), He & Shao (1996), Knight (1998), Mu & He (2007) and references therein for overview and discussions. Koenker (2004) studied quantile regression for longitudinal data; see also Reich et al. (2010) and Dunson et al. (2003) for Bayesian approaches. Incorporating the correlations in longitudinal data is essential for efficient inferences, as demonstrated by Liang & Zeger (1986), Lin & Carroll (2006), and Fan et al. (2007), among others. Nonetheless, incorporating the withinsubject correlations is more difficult yet less studied for quantile regression in longitudinal data analysis. He et al. (2003) discussed estimating the covariances by sample versions. However, their method is limited to balanced data and covariance estimation may be difficult when the number of repeated measurements is large.
1纵向数据分析-文超

线性随机效应模型randomeffectsmodels是经典的线性模型的一种推广就是把原来固定的回归系数看作是随机变量一般都是假设是来自正态分布
纵向数据
2014 6
张 文 年超 月
目 录
1、什么是纵向数据?
2、介绍这类数据的分析方法
重点内容
(1)方差分析※ (2)多层统计分析模型:针对纵向数据的发展模型(线性随机效应混合模型)※ (3)广义线性随机效应混合模型※ (4)广义线性方程GEE(GEE简介.ppt、刘静老师的pdf) (5)潜变量增长曲线模型(参考.ppt) (6)决策树及随机效应模型(了解)
一元方差分析
方差分析
多元方差分析
随机截距发展模型
随机截距斜率发展模型
发展 模型
治疗效应的评估模型 多层线性模型 (线性发展模型)
纵向数据分析方 法
在模型中控制个体背景协变量
时间尺度编码
设定残差协方差结构
广义线性 混合模型
在模型中纳入时间变化协变量
多项式曲线发展模型
潜变量增长曲线 模型
高次方程多项式发展模型中共 线性问题的处理
注:预计占用时间:2~3次课;
什么是纵向数据?
纵向数据是指一个被试群体在一个或多个变量上,多个时间点的测量 结果。例如,一组纵向数据中有N个个体,所关心的变量有M个,测量 时间点为T个。与横向数据相比,纵向数据有多个时间点,即T>1.而横 断数据T=1.纵向数据的第i个个体在第j个变量上的第t次测量结果可以 表示为Yijt ,其中(i=1,2,„,N; j=1,2,„M;t=1,2,„T),纵向 数据比横断数据多了一个时间维度。
解释名词:转移模型、混合效应模型
几种常用分布的总体均值方差的经验似然比置信区间估计

J e 0
3
d :
^ J
.
。
=
0
^ 3 1 J (e 0~ 、 0
) = ) =
1 几 种 常 见 分布 的 总体 均值 方差 的经 验似 然
对几种 常见 分布 的总体 我们 可 以在更 一般 条件下 , 得到它们 参数 的经验 似然估计 , 主要 结果如下 :
定 理 1 设 随机 变 量 X ~ E( , P( , n P , , ) ( n P a p 均 未 知 ,X , ) ( ) B( , ) r( ) , ; , ; , ) , i~
收 稿 日期 :2 1-11 0 1 .6 0
作 者 简介 :崔 恩华 (94) 男 , 苏 连 云 港 人 , 士 研 究 生 , 究 方 向 为数 理 统计 18一 , 江 硕 研
第 2期
崔恩华等 : 几种常用分布 的总体 均值 方差 的经验似然 比置信区间估计
17 0
2 主要 结 果 的证 明
第 1 第2 O卷 期
2 1 年 4月 01
淮 阴师 范 学 院 学 报 ( 自然 科 学 )
J U N L O U II E C E SC L E E ( a rl cec) O R A FH AYN T A H R O L G N t a Si e u n
Vo. 0 No. 11 2 Ap .2 1 r 01
估计, 又利 用均 值 的无偏估 计量 代 替均值 的情 况 下, 出 了其方差 的经验似 然置信 区间. 给
关键词 :总体 ;均 值 ;方差 ;经验 似 然 中图分 类号 : 2 27 0 1 . 文献标 识码 : A 文章 编号 :6 1 86 2 1)20 0 . 17 . 7 (0 10 .160 6 4
部分线性单指标EV模型中参数的经验似然置信域

部分线性单指标EV模型中参数的经验似然置信域
裴丽芳;王永刚
【期刊名称】《应用数学》
【年(卷),期】2011(24)3
【摘要】考虑部分线性单指标EV模型,利用纠偏方法构造了模型中未知参数的经验对数似然比统计量.在适当条件下,证明了所提出的统计量依分布收敛于标准χ2分布,所得结果可以构造未知参数的置信域.通过模拟研究在置信域精度及其覆盖概率大小方面进行了说明.
【总页数】9页(P593-601)
【关键词】部分线性单指标EV模型;经验似然;x^2分布;置信域
【作者】裴丽芳;王永刚
【作者单位】洛阳理工学院数理部;郑州大学数学系
【正文语种】中文
【中图分类】O212.7
【相关文献】
1.部分线性EV模型中参数的经验似然置信域 [J], 刘常胜;张晓果
2.缺失数据下非线性EV模型参数的经验似然置信域 [J], 刘强;薛留根
3.部分线性模型参数的经验欧氏似然置信域 [J], 颜贵兴
4.非线性半参数EV模型的经验似然置信域 [J], 冯三营; 李高荣; 薛留根; 陈放
5.非线性EV回归模型中参数的经验似然置信域 [J], 冯三营;薛留根;李高荣
因版权原因,仅展示原文概要,查看原文内容请购买。
2-纵向数据分析-ARCH

第一部分:纵向数据(时间序列)分析
1 2 3 4 5 序列自相关及检验(ARMA) 平稳时间序列模型 非平稳时间序列模型 协整和误差修正模型 条件异方差模型 –自回归条件异方差模型(ARCH) –非对称ARCH –成分ARCH 6 向量自回归和误差修正模型 –向量自回归 –误差修正模型
西安交大管理学院 2011-春 2
yt xt γ t2 ut
标准差:
(1.14)
returet 1 2 t t2 ut
t2 1ut21 p ut2 p 1 t21 q t2 q
这种类型的模型(其中期望风险用条件方差表示)就称为 GARCH-M模型。
如果扰动项方差中没有自相关,就会有 H0 : var(ut ) 2 这时
(1.3)
并假设在时刻 ( t1 ) 所有信息已知的条件下,扰动项 ut 的
ut
~ N 0 , ( 0 1ut21 )
0
(1.2)
1 2 p 0
也就是,ut 遵循以0为均值,(0+ 1u2t-1 )为方差的正态分布。 由于(6.1.2)中ut的方差依赖于前期的平方扰动项,我们称它 为ARCH(1)过程:
ARCH-M模型的另一种不同形式是将条件方差换成条件
yt xt γ t ut yt xt γ ln( t2 ) ut
2 在EViews中估计ARCH模型
或取对数
估计GARCH和 ARCH模型,首先 选择Quick/Estimate Equation或Object/ New Object/ Equation,然后在 Method的下拉菜单 中选择ARCH,得 到如下的对话框。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
研究的热点 问题. 考虑来 自 个个体的数据, n 其第i 个个体具有mi 次观测( =1… , ) 总的 , n,
n
观测数为Ⅳ = ∑ mi 本文假 定mt 界的, . 是有 该假定意味着 总的样本容量Ⅳ与个 体数凡 同 是
=
l
价的量. 设 J 和 J 分别是第 ∈ 个个体的第 次观测 = 1… , 的响应变量和协变 , m)
应用 概 率 统 t 第 _六 卷 { 卜 第二 期 2 1 年4 0 0 月
Ch n s o na f Ap i d Pr ab l y i e e J ur lo ple ob ii t a a it c 12 nd St t s i s Vo . 6 No. 2 Apr 0 0 .2 1
人学 博士启动基金和河南省 自然科学研究(08 l00 ) 20 B 109资助.
本 文2 0 q 9 8 0 8 -月 日收 到 , 0 8 l 月3 日收 到 修改 稿 . = 20 年 0 0
第 = 期 :
李 高 荣 冯 一 营 薛 留根 : 向 数据 单 指标 模 型 中参 数 的经 验 似 然 置 信 域 纵
平 均 导 数 估 计 方 法 : ea d Z u8构造 了模 型 中 指标 参数 向 量 的经 验 似 然 置 信 域 . 于 纵 Xu n h [ 】 对 向数 据 情 形 , ho n ie[在 研 究 响 应 变 量 和 协 变 量 j 间关 系 的 统 计 推 断 时 , C iua dMilr】 l 9 之
介绍 了一种边缘 建模方法 并提 出了估 计 的估计方 程( E ) 法, 一步研 究 了广义线 性 E E方 进
混合模型.
本 文 采 用 Ow n1,1 出 的 经 验 似 然 方 法 构 造 了纵 向数 据 单 指 标 模 型 f.) 兴 趣 指 e [】l】 【 提 11中 标 参 数 的三 种 经 验 对 数 似 然 比统 计 量 , 明 了所 提 出 的统 计 量 具 有 渐 近 x 分 布 , 得 结 果 证 所 可 以构 造 参 数 的 置 信 域 . 验 似 然 方 法 在 构 造 置信 域 方 面 有 许 多优 点 , 先 无 需 对 渐 近 方 经 首 差 进 行 估 计 : 次 所 得 到 的置 信 域 的形 状 由数 据 自行 决 定 等 .Koaz k 哿经验 似 然 方 法 其 lcy [ 应 用 到广 义 线 性 模 型 .S i n a []H a ga dJn [] 用 经 验 似 然 方 法 研 究 了具 有 h dL u1  ̄ W n n ig1 利 a 3 4 固定 设 计 的部 分 线 性 模 型 中 参 数 的 置 信 域 . 近 , ea dZ u1]D h n e 6 究 最 Xu n h [ S Z ua dXu [J 5 1研 了部 分 线性 单指 标 模 型 中参 数 的经验 似 然 置信 域 .
11 9
中参 数 的 最 小 二 乘 估 计 的渐 近 性 质 , 且 讨 论 了联 系 函 数 的 非 参 数 估 计 的 窗 宽 选 择 问题 : 并
So e[ I i l [提 出了平均 导数方法, tkr lJ r e 4 3 H/d 等 ]  ̄ 相关文献还 有『, 1P w l7 5 6; o e [描述 了密度加 权 l】
模.
模 型f.) 1 是一个重要 的统计模 型, 1 它可 以减少在 拟合 多元 非参数 回归函数时所 谓的 “ 维数祸根” 问题. 关于 模型f. 在独 立数据 情形下, 11 ) 许多作 者在不 同的假 设条件 下对其
做 了 一 定 研 究 , 提 出 了一 些 研 究 方 法 .例 如 , ci r[ ̄Hgde 【分 别 研 究 了模 型 并 Ihmua1 f rl等 2 ]l J
摘 要
考虑 纵 向数 据 单指 标 模 型 , 针对 纵 向数 据 组 问 独 立 的 特 点 , 出 了模 型 中未 知 参 数 的 三 种经 验 对 提 数 似 然 比统 计 量 . 适 当条 件 下 , 明 了所 提 出 的统 计 量 依 分 布 收 敛 于) 分 布 , 得 结 果 可 以构造 未 知 在 证 ( 。 所 参 数 的 置 信 域 . 一步证 明 了 所提 出 的 纠 偏 的 经 验 对 数 似 然 比有 许 多 优 良 的性 质 .通 过 模 拟 研 究 对 所 进
中国博士后科 学基金(0 8 4 0 3 ) 海市博士后科研 资助计划(8 1 1 1 、 2 0 O 3 6 3 、上 0 R2 4 2 ) 国家 自 然科学 ̄ - 0 7 0 3 、 ( 8 1 1 ) 北京 1 市自 然科学基 金( 1 2 O ) 国家教育 部博士点专项 基金(0 7 0 5 O ) 北京 市属 市管高等 学校 人才强校 计划 、 10 o 8 、 200 003、 北京工业
纵 向数据单指标模型 中参数 的经验似然置信域 木
李 高荣 , 冯三营。 薛 留根
(北京J业大学应用数理学院, - 北京, 0 1 4 华东师范大学金 融与统计学院, 102 ; 上海, 0 2 1 204 ) (洛阳师 范学 院数学科 学学 院, 。 洛阳, 70 2 412)
量 , 们具 有 下面 的关 系形 式 : 它
=9 T ) i ( +e , j
i 1… , ,J:1 … ,t = , n , /i g,
(. 1) 1
其中 是P×1 的未知参数 向量, ( 是一个未知的一元联系函数, t 随机误差, _. g) e是 记第i 个个
体的随机误差 向量为 = ( ,l, ,iir {i = 1… , } 1e … e ) , e, 2 ‘ i , n 相互独立, ̄ ( l ) , ] Ee Xi =0 i V re = ∑ ( a (i ) i正定阵) 考虑到模型的可识别性 , . 我们要求 I 1 这里l 1 I , 一 JJ .表示E cd a ul en i
捉方 法 进 行 了说 明 .
关 键 词: 纵 向数据, 单指标模型, 经验似然, 置信域 .
学 科 分 类 号 : O2 27 1 ..
§. 引 1
言
纵 向数 据 广 泛 存 在 于 医学 、流 行 病 学 、经 济 学 和 社 会 科 学 等 领 域 中,已经 成 为统 计 学