我国完成31个大豆基因组重测序
全基因组重测序数据分析详细说明

全基因组重测序数据分析详细说明全基因组重测序(whole genome sequencing, WGS)是一种高通量测序技术,用于获取个体的整个基因组信息。
全基因组重测序数据分析是指对这些数据进行处理、分析和解读,以获得有关个体的遗传变异、基因型、表达和功能等信息。
下面详细说明全基因组重测序数据分析的过程和方法。
首先,全基因组重测序数据的质量控制是必不可少的。
这一步骤包括对测序数据进行质量评估、剔除低质量序列,并进行去除接头序列和过滤序列等预处理操作,以确保后续分析的准确性和可靠性。
接下来,需要对全基因组重测序数据进行序列比对,将读取序列与参考基因组进行比对,以确定每个读取序列在参考基因组上的位置。
常用的比对工具包括Bowtie、BWA、BLAST等。
比对的结果将提供每个读取序列的基因组位置信息。
在序列比对完成后,就可以进行个体的变异检测。
变异检测的目的是识别个体的单核苷酸多态性(single nucleotide polymorphisms, SNPs)、插入缺失变异(insertions/deletions, indels)和结构变异(structural variations, SVs)等基因组变异。
通常,变异检测分为两个步骤:变异发现和变异筛选。
变异发现即根据比对结果,通过一定的算法和统计学原理,找到潜在的变异位点。
然后,利用临床数据库、已知变异数据库和基因功能注释数据库等,进行变异筛选,剔除假阳性和无功能变异,筛选出最有可能的致病变异。
接着,对筛选出的变异位点进行基因型確定。
基因型的确定可以通过直接从比对结果中读取碱基信息,或者通过再次测序来获取高度精确的基因型,以获得更可靠的变异信息。
随后,对变异位点进行注释和功能预测。
注释是指对变异位点进行功能和可能影响的基因、基因组区域和调控元件等进行注释。
常用的注释工具包括ANNOVAR、SnpEff、VEP等。
功能预测则是根据变异位点的位置和可能影响的功能进行预测,如是否影响蛋白质功能、是否在编码序列、是否在启动子或增强子区域等。
已完成基因组测序的生物(植物部分)

水稻、玉米、大豆、甘蓝、白菜、高粱、黄瓜、西瓜、马铃薯、番茄、拟南芥、杨树、麻风树、苹果、桃、葡萄、花生拟南芥籼稻粳稻葡萄番木瓜高粱黄瓜玉米栽培大豆苹果蓖麻野草莓马铃薯白菜野生番茄番茄梨甜瓜香蕉亚麻大麦普通小麦西瓜甜橙陆地棉梅毛竹桃芝麻杨树麻风树卷柏狗尾草属花生甘蓝物种基因组大小和开放阅读框文献Sesamum indicum L. Sesame 芝麻(2n = 26)293.7 Mb, 10,656 orfs 1Oryza brachyantha短药野生稻261 Mb, 32,038 orfs 2Chondrus crispus Red seaweed爱尔兰海藻105 Mb, 9,606 orfs 3Pyropia yezoensis susabi-nori海苔43 Mb, 10,327 orfs 4Prunus persica Peach 桃226.6 of 265 Mb 27,852 orfs 5Aegilops tauschii 山羊草(DD)4.23 Gb (97% of the 4.36), 43,150 orfs 6 Triticum urartu 乌拉尔图小麦(AA)4.66 Gb (94.3 % of 4.94 Gb, 34,879 orfs 7 moso bamboo (Phyllostachys heterocycla) 毛竹2.05 Gb (95%) 31,987 orfs 8Cicer arietinum Chickpea鹰嘴豆~738-Mb,28,269 orfs 9 520 Mb (70% of 740 Mb), 27,571 orfs 10Prunus mume 梅280 Mb, 31,390 orfs 11Gossypium hirsutum L.陆地棉2.425 Gb 12Gossypium hirsutum L. 雷蒙德氏棉761.8 Mb 13Citrus sinensis甜橙87.3% of ~367 Mb, 29,445 orfs 14甜橙367 Mb 15Citrullus lanatus watermelon 西瓜353.5 of ~425 Mb (83.2%) 23,440 orfs 16 Betula nana dwarf birch,矮桦450 Mb 17Nannochloropsis oceanica CCMP1779微绿球藻(产油藻类之一)28.7 Mb,11,973 orfs 18Triticum aestivum bread wheat普通小麦17 Gb, 94,000 and 96,000 orfs 19 Hordeum vulgare L. barley 大麦1.13 Gb of 5.1 Gb,26,159 high confidence orfs,53,000 low confidence orfs 20Gossypium raimondii cotton 雷蒙德氏棉D subgenome,88% of 880 Mb 40,976 orfs 21Linum usitatissimum flax 亚麻302 mb (81%), 43,384 orfs 22Musa acuminata banana 香蕉472.2 of 523 Mb, 36,542 orfs 23Cucumis melo L. melon 甜瓜375 Mb(83.3%)27,427 orfs 24Pyrus bretschneideri Rehd. cv. Dangshansuli 梨(砀山酥梨)512.0 Mb (97.1%), 42,812 orfs 25,26Solanum lycopersicum 番茄760/900 Mb,34727 orfs 27S. pimpinellifolium LA1589野生番茄739 MbSetaria 狗尾草属(谷子、青狗尾草)400 Mb,25000-29000 orfs 28,29 Cajanus cajan pigeonpea木豆833 Mb,48,680 orfs 30Nannochloropis gaditana 一种海藻~29 Mb, 9,052 orfs 31Medicago truncatula蒺藜苜蓿350.2 Mb, 62,388 orfs 32Brassica rapa 白菜485 Mb 33Solanum tuberosum 马铃薯0.73 Mb,39031 orfs 34Thellungiella parvula条叶蓝芥13.08 Mb 29,338 orfs 35Arabidopsis lyrata lyrata 玉山筷子芥? 183.7 Mb, 32670 orfs 36Fragaria vesca 野草莓240 Mb,34,809 orfs 37Theobroma cacao 可可76% of 430 Mb, 28,798 orfs 38Aureococcus anophagefferens褐潮藻32 Mb, 11501 orfs 39Selaginella moellendorfii江南卷柏208.5 Mb, 34782 orfs 40Jatropha curcas Palawan麻疯树285.9 Mb, 40929 orfs 41Oryza glaberrima 光稃稻(非洲栽培稻)206.3 Mb (0.6x), 10 080 orfs (>70% coverage) 42Phoenix dactylifera 棕枣380 Mb of 658 Mb, 25,059 orfs 43Chlorella sp. NC64A小球藻属40000 Kb, 9791 orfs 44Ricinus communis蓖麻325 Mb, 31,237 orfs 45Malus domestica (Malus x domestica)苹果742.3 Mb 46Volvox carteri f. nagariensis 69-1b一种团藻120 Mb, 14437 orfs 47 Brachypodium distachyon 短柄草272 Mb,25,532 orfs 48Glycine max cultivar Williams 82栽培大豆1.1 Gb, 46430 orfs 49Zea mays ssp. Mays Zea mays ssp. Parviglumis Zea mays ssp. Mexicana Tripsacum dactyloides var. meridionale 无法下载附表50Zea mays mays cv. B73玉米2.06 Gb, 106046 orfs 51Cucumis sativus 9930 黄瓜243.5 Mb, 63312 orfs 52Micromonas pusilla金藻21.7 Mb, 10248 orfs 53Sorghum bicolor 高粱697.6 Mb, 32886 orfs 54Phaeodactylum tricornutum 三角褐指藻24.6 Mb, 9479 orfs 55Carica papaya L. papaya 番木瓜271 Mb (75%), 28,629 orfs 56 Physcomitrella patens patens小立碗藓454 Mb, 35805 orfs 57Vitis vinifera L. Pinot Noir, clone ENTAV 115葡萄504.6 Mb, 29585 orfs 58 Vitis vinifera PN40024葡萄475 Mb 59Ostreococcus lucimarinus绿色鞭毛藻13.2 Mb, 7640 orfs 60 Chlamydomonas reinhardtii 莱茵衣藻100 Mb, 15256 orfs 61Populus trichocarpa黑三角叶杨550 Mb, 45000 orfs 62Ostreococcus tauri 绿藻12.6 Mb, 7892 orfs 63Oryza sativa ssp. japonica 粳稻360.8 Mb, 37544 orfs 64Thalassiosira pseudonana 硅藻25 Mb, 11242 orfs 65Cyanidioschyzon merolae 10D红藻16.5 Mb, 5331 orfs 66Oryza sativa ssp. japonica粳稻420 Mb, 50000 orfs 67Oryza sativa L. ssp. Indica籼稻420 Mb, 59855 orfs 68Guillardia theta -蓝隐藻,551 Kb, 553 orfs 69Arabidopsis thaliana Columbia拟南芥119.7 Mb, 31392 orfs 70参考文献1 Zhang, H. et al. Genome sequencing of the important oilseed crop Sesamum indicum L. Genome Biology 14, 401 (2013).2 Chen, J. et al. Whole-genome sequencing of Oryza brachyantha reveals mechanisms underlying Oryza genome evolution. Nat Commun 4, 1595 (2013).3 Collén, J. et al. Genome structure and metabolic features in the red seaweed Chondrus crispus shed light on evolution of the Archaeplastida. Proceedings of the National Academy of Sciences 110, 5247-5252 (2013).4 Nakamura, Y. et al. The first symbiont-free genome sequence of marine red alga, susabi-nori Pyropia yezoensis. PLoS ONE 8, e57122 (2013).5 Verde, I. et al. The high-quality draft genome of peach (Prunus persica) identifies unique patterns of genetic diversity, domestication and genome evolution. Nature Genetics advance online publication (2013).6 Jia, J. et al. Aegilops tauschii draft genome sequence reveals a gene repertoire for wheat adaptation. Nature 496, 91-95 (2013).7 Ling, H.-Q. et al. Draft genome of the wheat A-genome progenitor Triticum urartu. Nature 496, 87-90 (2013).8 Peng, Z. et al. The draft genome of the fast-growing non-timber forest species moso bamboo (Phyllostachys heterocycla). Nature Genetics 45, 456-461 (2013).9 Jain, M. et al. A draft genome sequence of the pulse crop chickpea (Cicer arietinum L.). Plant Journal, DOI: 10.1111/tpj.12173 (2013).10 Varshney, R. K. et al. Draft genome sequence of chickpea (Cicer arietinum) provides a resource for trait improvement. Nat Biotech 31, 240-246 (2013).11 Zhang, Q. et al. The genome of Prunus mume. Nat Commun 3, 1318 (2012).12 Lee, M.-K. et al. Construction of a plant-transformation-competent BIBAC library and genome sequence analysis of polyploid Upland cotton (Gossypium hirsutum L.). BMC Genomics 14, 208 (2013).13 Paterson, A. H. et al. Repeated polyploidization of Gossypium genomes and the evolution of spinnable cotton fibres. Nature 492, 423-427 (2012).14 Xu, Q. et al. The draft genome of sweet orange (Citrus sinensis). Nat Genet 45,59–66 (2013).15 Belknap, W. R. et al. Characterizing the citrus cultivar Carrizo genome through 454 shotgun sequencing. Genome 54, 1005-1015 (2011).16 Guo, S. et al. The draft genome of watermelon (Citrullus lanatus) and resequencing of 20 diverse accessions. Nat Genet 45, 51–58 (2013).17 Wang, N. et al. Genome sequence of dwarf birch (Betula nana) and cross-species RAD markers. Mol Ecol Article first published online: 21 NOV 2012 DOI:10.1111/mec.12131 (2012).18 Vieler, A. et al. Genome, functional gene annotation, and nuclear transformation of the heterokont oleaginous alga Nannochloropsis oceanica CCMP1779. PLoS Genet 8, e1003064 (2012).19 Brenchley, R. et al. Analysis of the bread wheat genome using whole-genome shotgun sequencing. Nature 491, 705-710 (2012).20 Consortium, T. I. B. G. S. A physical, genetic and functional sequence assembly of the barley genome. Nature 491, 711–716 (2012).21 Wang, K. et al. The draft genome of a diploid cotton Gossypium raimondii. Nature Genetics 44, 1098–1103 (2012).22 Wang, Z. et al. The genome of flax (Linum usitatissimum) assembled de novo from short shotgun sequence reads. The Plant Journal 72, 461-473 (2012).23 D'Hont, A. et al. The banana (Musa acuminata) genome and the evolution of monocotyledonous plants. Nature 488, 213–217 (2012).24 Garcia-Mas, J. et al. The genome of melon (Cucumis melo L.). PNAS 109, 11872-11877 (2012).25 reporter, A. G. s. Consortium releases pear genome data. GenomeWeb Daily News (2012).26 Wu, J. et al. The genome of pear (Pyrus bretschneideri Rehd.). GenomeRes.Published in Advance November 13, 2012, doi:10.1101/gr.144311.112 (2012).27 Consortium, T. T. G. The tomato genome sequence provides insights into fleshy fruit evolution. Nature 485, 635–641 (2012).28 Bennetzen, J. L. et al. Reference genome sequence of the model plant Setaria. Nat Biotech 30, 555-561 (2012).29 Zhang, G. et al. Genome sequence of foxtail millet (Setaria italica) provides insights into grass evolution and biofuel potential. Nat Biotech 30, 549-554 (2012).30 Varshney, R. K. et al. Draft genome sequence of pigeonpea (Cajanus cajan), an orphan legume crop of resource-poor farmers. Nat Biotech 30, 83-89 (2012).31 Radakovits, R. et al. Draft genome sequence and genetic transformation of the oleaginous alga Nannochloropis gaditana. Nat Commun 3, 686 (2012).32 Young, N. D. et al. The Medicago genome provides insight into the evolution of rhizobial symbioses. Nature 480, 520–524 (2011).33 Wang, X. et al. The genome of the mesopolyploid crop species Brassica rapa. Nat. Genet. 43, 1035-1039 (2011).34 Consortium, T. P. G. S. Genome sequence and analysis of the tuber crop potato. Nature 475, 189-195 (2011).35 Dassanayake, M. et al. The genome of the extremophile crucifer Thellungiella parvula. Nat. Genet. 43, 913-918 (2011).36 Hu, T. T. et al. The Arabidopsis lyrata genome sequence and the basis of rapid genome size change. Nat. Genet. 43, 476-481 (2011).37 Shulaev, V. et al. The genome of woodland strawberry (Fragaria vesca). Nat. Genet. 43, 109-116 (2011).38 Argout, X. et al. The genome of Theobroma cacao. Nat. Genet. 43, 101-108 (2011).39 Gobler, C. J. et al. Niche of harmful alga Aureococcus anophagefferens revealed through ecogenomics. PNAS 108, 4352-4357 (2011).40 Banks, J. A. et al. The selaginella genome identifies genetic changes associated with the evolution of vascular plants. Science 332, 960-963 (2011).41 Sato, S. et al. Sequence analysis of the genome of an oil-bearing tree, Jatropha curcas L. DNA Res. 18, 65-76 (2011).42 Sakai, H. et al. Distinct evolutionary patterns of Oryza glaberrima deciphered by genome sequencing and comparative analysis. Plant Journal 66, 796-805 (2011).43 Al-Dous, E. K. et al. De novo genome sequencing and comparative genomics of date palm (Phoenix dactylifera). Nat Biotech 29, 521-527 (2011).44 Blanc, G. et al. The Chlorella variabilis NC64A genome reveals adaptation to photosymbiosis, coevolution with viruses, and cryptic sex. Plant Cell 22, 2943-2955 (2010).45 Chan, A. P. et al. Draft genome sequence of the oilseed species Ricinus communis. Nat Biotech 28(951-956 (2010).46 Velasco, R. et al. The genome of the domesticated apple (Malus x domestica Borkh.). Nat. Genet. 42, 833-839 (2010).47 Prochnik, S. E. et al. Genomic analysis of organismal complexity in the multicellular green alga Volvox carteri. Science 329, 223-226 (2010).48 Initiative, T. I. B. Genome sequencing and analysis of the model grass Brachypodium distachyon. Nature 463, 763-768 (2010).49 Schmutz, J. et al. Genome sequence of the palaeopolyploid soybean. Nature 463, 178-183 (2010).50 Hufford, M. B. et al. Comparative population genomics of maize domestication and improvement. Nat Genet 44, 808-811 (2012).51 Wei, F. et al. The physical and genetic framework of the maize B73 genome. PLoS Genet 5, e1000715 (2009).52 Huang, S. et al. The genome of the cucumber, Cucumis sativus L. Nat. Genet. 41, 1275-1281 (2009).53 Worden, A. Z. et al. Green evolution and dynamic adaptations revealed by genomes of the marine picoeukaryotes Micromonas. Science 324, 268-272 (2009).54 Paterson, A. H. et al. The Sorghum bicolor genome and the diversification of grasses. Nature 457, 551-556 (2009).55 Bowler, C. et al. The Phaeodactylum genome reveals the evolutionary history of diatom genomes. Nature 456, 239-244 (2008).56 Ming, R. et al. The draft genome of the transgenic tropical fruit tree papaya (Carica papaya Linnaeus). Nature 452, 991-996 (2008).57 Rensing, S. A. et al. The Physcomitrella genome reveals evolutionary insights into the conquest of land by plants. Science 319, 64-69 (2008).58 Velasco, R. et al. A high quality draft consensus sequence of the genome of a heterozygous grapevine variety. PLoS One 2, e1326 (2007).59 Jaillon, O. et al. The grapevine genome sequence suggests ancestral hexaploidization in major angiosperm phyla. Nature 449, 463-467 (2007).60 Palenik, B. et al. The tiny eukaryote Ostreococcus provides genomic insights into the paradox of plankton speciation. PNAS 104, 7705-7710 (2007).61 Merchant, S. S. et al. The Chlamydomonas genome reveals the evolution of key animal and plant functions. Science 318, 245-250 (2007).62 Tuskan, G. A. et al. The genome of black cottonwood, Populus trichocarpa (Torr. & Gray). Science 313, 1596-1604 (2006).63 Derelle, E. et al. Genome analysis of the smallest free-living eukaryote Ostreococcus tauri unveils many unique features. PNAS 103, 11647-11652 (2006). 64 Project, I. R. G. S. The map-based sequence of the rice genome. Nature 436,793-800 (2005).65 Armbrust, E. V. et al. The genome of the diatom Thalassiosira Pseudonana: ecology, evolution, and metabolism. Science 306, 79-86 (2004).66 Matsuzaki, M. et al. Genome sequence of the ultrasmall unicellular red alga Cyanidioschyzon merolae 10D. Nature 428, 653-657 (2004).67 Goff, S. A. et al. A draft sequence of the rice genome (Oryza sativa L. ssp. japonica). Science 296, 92-100 (2002).68 Yu, J. et al. A draft sequence of the rice genome (Oryza sativa L. ssp. indica). Science 296, 79-92 (2002).69 Douglas, S. et al. The highly reduced genome of an enslaved algal nucleus. Nature 410, 1091-1096 (2001).70 Kaul, S. et al. Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature 408, 796-815 (2000).。
我国大豆基因组学研究获重大突破

江苏 省农 科院 园艺所 专家利 用“ 江苏 省农业 科技 自主创 新资 金 ” 项 , 展抗病 优质 立 开 新 品种选 育 , 育 出草莓 新品种“ 玉 ” 品质优 , 选 宁 , 抗炭疽 病 能力强 , 耐贮运 , 望解 决草莓 有 种 苗供应 紧缺难 题 。
据 《 明 日报》 光 报道 , 港 中文大 学 、 香 华大基 因研究 院 、 农业 部 、 中国科 学 院等 单位 合 作 的“ 豆 回家 对 野生 大豆 和栽 培 该
大 豆全基 因组进 行 了大规模 遗传 多态性 分析 , 为全 球大 豆的遗 传学研 究提 供 了非常 有价 值 的资源 , 为大豆种 质资源 保护和 分子育 种带来 新的科 学启示 。 研究 人员 运用 新一 代测序 技 术对 1株 野生 大 豆和 l株栽 培 大豆 进行 了全 基 因组 重 7 4 测序, 总共发 现 了60 3 多万个 单 核苷 酸多态 性位 点 , 建立 了高密度 的 分子标 记 图谱 。 同时 分别 对野 生大豆 和栽培 大豆 进行组 装 , 从而鉴 定 出了 l万 多个 两种大 豆 中获得和 缺 失变 8
目I
据 《 技 日报》 道 , 科 报 国家 林业 局新 批准 国 际竹 藤网络 中心 成立 绿色 经济 研 究 中心 、 竹 藤资源 与环 境研 究中心 、 竹藤 生物 质新材 料研 究中心 、 竹藤 资源 化学利 用研 究 中心 、 基 因科学 与基 因产业 化研究 中心 和热 带森林 植物种 质 资源实 验 中心 。该6 研究 机构将 加强
大豆与野生大豆部分同源基因间基因置换分析
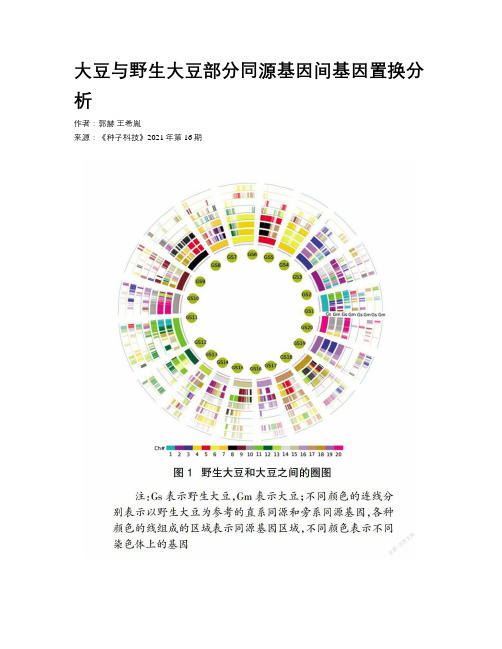
大豆与野生大豆部分同源基因间基因置换分析作者:郭赫王希胤来源:《种子科技》2021年第16期摘要:以大豆和野生大豆为研究对象,利用系统发育分析比较推断其最近一次加倍事件所产生的同源基因间发生基因置换的规模。
结果表明,大豆中有37对同源基因间发生了基因置换,野生大豆中有33对同源基因发生了基因置换。
通过对基因置换与基因在染色体上的位置关系研究发现,靠近染色体两端的基因更容易发生基因置换。
关键词:大豆;野生大豆;基因置换文章编号: 1005-2690(2021)16-0002-03 中国图书分类号: S565.1 文献标志码: B大豆(Glycine max)是重要的经济作物和油料作物。
大豆经历过豆科共有的四倍体事件(Legume-common tetraploid,LCT)后又经历过一次大豆独有的四倍体事件(Soybean-specific tetraploid,SST)[1],是同源四倍体。
目前,大豆与野生大豆(Glycine soja)的全基因組测序工作已经完成[2-3]。
对大豆与野生大豆于最近一次全基因组加倍事件产生的同源基因间进行比较研究,有利于理解其基因组的进化。
全基因组加倍(whole genome duplication,WGD)即多倍化是基因复制的主要方式之一,植物的进化过程中多倍化是反复发生的,多倍化产生的大量重复基因为新功能的进化提供了原材料[4]。
全基因组加倍后发生的染色体重组、基因丢失等现象对基因组结构及功能都造成很大影响[5]。
遗传重组(genetic recomnnation)作为生物进化的主要推动力之一,对DNA序列损伤的修复和同源序列间信息的传递有着重要意义[6]。
很多物种多倍化后产生的同源序列之间的同源重组与经典的同源片段间重组不同,称为非正常遗传重组[7]。
单向的一个基因替换其同源基因的过程称为基因置换(gene conversion)[8-9]。
1 材料和方法1.1 物种基因组数据豆科植物大豆和野生大豆的全基因序列由公共数据库NCBI(https:///)下载获得,包括其全基因组DNA(cds)序列、蛋白质序列(pep)以及其基因注释文件(gff3)。
斯茹林Quantum Neo 中文操作手册V1.6

Rockingham Drive, Linford Wood East, Milton Keynes MK14 6LY, England Tele 电话 +44 (0) 1908 233 833 传真: +44 (0) 1908 235 333
CERULEAN
版本控制
版次
时间
所做变更
程序设计者
打开仪器,给它 30 分钟使其稳定到环境条件。
电脑里的本地日期和时间必须设置正确。Quantum Neo 使用此信息作为结果。
规格说明
Quantum Neo 的仪器规格和各种测量参数,请参阅来自当地斯茹林销售经理、斯茹林办公室的数据表,或通过斯茹林官方网站 。
P 新增自动取样器和重复模式的改变
BSW
手册范围 用户手册就是为如何配置仪器、校准、加载并运行样本,以及获得仪器结果提供相关信息。 更多帮助 斯茹林可以提供更深入的技术知识、故障查找、诊断以及维护和仪器上的培训课程。对于这些选项,请联系您所在地区的斯茹林 销售或服务经理。
斯茹林还提供全面的安装、备件、修理、故障维修、年度维护以及合约服务。对于这些选项,请联系您所在地区的斯茹林销售或 服务经理。
如需仪器的进一步技术支持,请联系 technical.support@ 或您所在地区的斯茹林办公室。 调试 客户必须在第一次使用前对 Quantum Neo 进行风险评估。
按钮使用的图标 .................................................................................................................................................................. 5 启动......................................................................................................................................................................................... 6
全基因组重测序原理

全基因组重测序原理
全基因组重测序是一种通过高通量测序技术对一个个体的整个
基因组进行全面测序的方法。
它是基因组学研究中的重要工具,可
以帮助科学家们识别个体基因组中的变异,从而揭示与疾病相关的
遗传变化,推动个性化医学的发展。
全基因组重测序的原理基本上可以分为几个步骤。
首先,需要
提取待测序个体的DNA样本,然后将其打断成较小的片段。
接下来,这些DNA片段会被连接到测序芯片或流式细胞仪上,然后进行测序。
现代的高通量测序技术可以同时测序成千上万个DNA片段,从而大
大提高了测序的效率。
在测序完成后,科学家们会利用计算机软件将这些测序数据进
行比对和分析。
通过将测序数据与已知的参考基因组进行比对,可
以识别出个体基因组中的单核苷酸多态性(SNP)、插入缺失变异(Indels)以及结构变异等。
这些变异的发现对于研究人类疾病的
遗传基础、进行疾病风险评估以及个性化医学的实践具有重要意义。
总的来说,全基因组重测序技术的发展为我们提供了一个全面
了解个体遗传信息的途径,有助于揭示疾病的发病机制,推动个性
化医学的发展,为预防和治疗疾病提供了更精准的方法。
随着技术的不断进步和成本的不断降低,相信全基因组重测序技术将在医学研究和临床实践中发挥越来越重要的作用。
已完成基因组测序的生物(植物部分)

水稻、玉米、大豆、甘蓝、白菜、高粱、黄瓜、西瓜、马铃薯、番茄、拟南芥、杨树、麻风树、苹果、桃、葡萄、花生拟南芥籼稻粳稻葡萄番木瓜高粱黄瓜玉米栽培大豆苹果蓖麻野草莓马铃薯白菜野生番茄番茄梨甜瓜香蕉亚麻大麦普通小麦西瓜甜橙陆地棉梅毛竹桃芝麻杨树麻风树卷柏狗尾草属花生甘蓝物种基因组大小和开放阅读框文献Sesamum indicum L. Sesame 芝麻(2n = 26)293.7 Mb, 10,656 orfs 1Oryza brachyantha短药野生稻261 Mb, 32,038 orfs 2Chondrus crispus Red seaweed爱尔兰海藻105 Mb, 9,606 orfs 3Pyropia yezoensis susabi-nori海苔43 Mb, 10,327 orfs 4Prunus persica Peach 桃226.6 of 265 Mb 27,852 orfs 5Aegilops tauschii 山羊草(DD)4.23 Gb (97% of the 4.36), 43,150 orfs 6 Triticum urartu 乌拉尔图小麦(AA)4.66 Gb (94.3 % of 4.94 Gb, 34,879 orfs 7 moso bamboo (Phyllostachys heterocycla) 毛竹2.05 Gb (95%) 31,987 orfs 8Cicer arietinum Chickpea鹰嘴豆~738-Mb,28,269 orfs 9 520 Mb (70% of 740 Mb), 27,571 orfs 10Prunus mume 梅280 Mb, 31,390 orfs 11Gossypium hirsutum L.陆地棉2.425 Gb 12Gossypium hirsutum L. 雷蒙德氏棉761.8 Mb 13Citrus sinensis甜橙87.3% of ~367 Mb, 29,445 orfs 14甜橙367 Mb 15Citrullus lanatus watermelon 西瓜353.5 of ~425 Mb (83.2%) 23,440 orfs 16 Betula nana dwarf birch,矮桦450 Mb 17Nannochloropsis oceanica CCMP1779微绿球藻(产油藻类之一)28.7 Mb,11,973 orfs 18Triticum aestivum bread wheat普通小麦17 Gb, 94,000 and 96,000 orfs 19 Hordeum vulgare L. barley 大麦1.13 Gb of 5.1 Gb,26,159 high confidence orfs,53,000 low confidence orfs 20Gossypium raimondii cotton 雷蒙德氏棉D subgenome,88% of 880 Mb 40,976 orfs 21Linum usitatissimum flax 亚麻302 mb (81%), 43,384 orfs 22Musa acuminata banana 香蕉472.2 of 523 Mb, 36,542 orfs 23Cucumis melo L. melon 甜瓜375 Mb(83.3%)27,427 orfs 24Pyrus bretschneideri Rehd. cv. Dangshansuli 梨(砀山酥梨)512.0 Mb (97.1%), 42,812 orfs 25,26Solanum lycopersicum 番茄760/900 Mb,34727 orfs 27S. pimpinellifolium LA1589野生番茄739 MbSetaria 狗尾草属(谷子、青狗尾草)400 Mb,25000-29000 orfs 28,29 Cajanus cajan pigeonpea木豆833 Mb,48,680 orfs 30Nannochloropis gaditana 一种海藻~29 Mb, 9,052 orfs 31Medicago truncatula蒺藜苜蓿350.2 Mb, 62,388 orfs 32Brassica rapa 白菜485 Mb 33Solanum tuberosum 马铃薯0.73 Mb,39031 orfs 34Thellungiella parvula条叶蓝芥13.08 Mb 29,338 orfs 35Arabidopsis lyrata lyrata 玉山筷子芥? 183.7 Mb, 32670 orfs 36Fragaria vesca 野草莓240 Mb,34,809 orfs 37Theobroma cacao 可可76% of 430 Mb, 28,798 orfs 38Aureococcus anophagefferens褐潮藻32 Mb, 11501 orfs 39Selaginella moellendorfii江南卷柏208.5 Mb, 34782 orfs 40Jatropha curcas Palawan麻疯树285.9 Mb, 40929 orfs 41Oryza glaberrima 光稃稻(非洲栽培稻)206.3 Mb (0.6x), 10 080 orfs (>70% coverage) 42Phoenix dactylifera 棕枣380 Mb of 658 Mb, 25,059 orfs 43Chlorella sp. NC64A小球藻属40000 Kb, 9791 orfs 44Ricinus communis蓖麻325 Mb, 31,237 orfs 45Malus domestica (Malus x domestica)苹果742.3 Mb 46Volvox carteri f. nagariensis 69-1b一种团藻120 Mb, 14437 orfs 47 Brachypodium distachyon 短柄草272 Mb,25,532 orfs 48Glycine max cultivar Williams 82栽培大豆1.1 Gb, 46430 orfs 49Zea mays ssp. Mays Zea mays ssp. Parviglumis Zea mays ssp. Mexicana Tripsacum dactyloides var. meridionale 无法下载附表50Zea mays mays cv. B73玉米2.06 Gb, 106046 orfs 51Cucumis sativus 9930 黄瓜243.5 Mb, 63312 orfs 52Micromonas pusilla金藻21.7 Mb, 10248 orfs 53Sorghum bicolor 高粱697.6 Mb, 32886 orfs 54Phaeodactylum tricornutum 三角褐指藻24.6 Mb, 9479 orfs 55Carica papaya L. papaya 番木瓜271 Mb (75%), 28,629 orfs 56 Physcomitrella patens patens小立碗藓454 Mb, 35805 orfs 57Vitis vinifera L. Pinot Noir, clone ENTAV 115葡萄504.6 Mb, 29585 orfs 58 Vitis vinifera PN40024葡萄475 Mb 59Ostreococcus lucimarinus绿色鞭毛藻13.2 Mb, 7640 orfs 60 Chlamydomonas reinhardtii 莱茵衣藻100 Mb, 15256 orfs 61Populus trichocarpa黑三角叶杨550 Mb, 45000 orfs 62Ostreococcus tauri 绿藻12.6 Mb, 7892 orfs 63Oryza sativa ssp. japonica 粳稻360.8 Mb, 37544 orfs 64Thalassiosira pseudonana 硅藻25 Mb, 11242 orfs 65Cyanidioschyzon merolae 10D红藻16.5 Mb, 5331 orfs 66Oryza sativa ssp. japonica粳稻420 Mb, 50000 orfs 67Oryza sativa L. ssp. Indica籼稻420 Mb, 59855 orfs 68Guillardia theta -蓝隐藻,551 Kb, 553 orfs 69Arabidopsis thaliana Columbia拟南芥119.7 Mb, 31392 orfs 70参考文献1 Zhang, H. et al. Genome sequencing of the important oilseed crop Sesamum indicum L. Genome Biology 14, 401 (2013).2 Chen, J. et al. Whole-genome sequencing of Oryza brachyantha reveals mechanisms underlying Oryza genome evolution. Nat Commun 4, 1595 (2013).3 Collén, J. et al. Genome structure and metabolic features in the red seaweed Chondrus crispus shed light on evolution of the Archaeplastida. Proceedings of the National Academy of Sciences 110, 5247-5252 (2013).4 Nakamura, Y. et al. The first symbiont-free genome sequence of marine red alga, susabi-nori Pyropia yezoensis. PLoS ONE 8, e57122 (2013).5 Verde, I. et al. The high-quality draft genome of peach (Prunus persica) identifies unique patterns of genetic diversity, domestication and genome evolution. Nature Genetics advance online publication (2013).6 Jia, J. et al. Aegilops tauschii draft genome sequence reveals a gene repertoire for wheat adaptation. Nature 496, 91-95 (2013).7 Ling, H.-Q. et al. Draft genome of the wheat A-genome progenitor Triticum urartu. Nature 496, 87-90 (2013).8 Peng, Z. et al. The draft genome of the fast-growing non-timber forest species moso bamboo (Phyllostachys heterocycla). Nature Genetics 45, 456-461 (2013).9 Jain, M. et al. A draft genome sequence of the pulse crop chickpea (Cicer arietinum L.). Plant Journal, DOI: 10.1111/tpj.12173 (2013).10 Varshney, R. K. et al. Draft genome sequence of chickpea (Cicer arietinum) provides a resource for trait improvement. Nat Biotech 31, 240-246 (2013).11 Zhang, Q. et al. The genome of Prunus mume. Nat Commun 3, 1318 (2012).12 Lee, M.-K. et al. Construction of a plant-transformation-competent BIBAC library and genome sequence analysis of polyploid Upland cotton (Gossypium hirsutum L.). BMC Genomics 14, 208 (2013).13 Paterson, A. H. et al. Repeated polyploidization of Gossypium genomes and the evolution of spinnable cotton fibres. Nature 492, 423-427 (2012).14 Xu, Q. et al. The draft genome of sweet orange (Citrus sinensis). Nat Genet 45,59–66 (2013).15 Belknap, W. R. et al. Characterizing the citrus cultivar Carrizo genome through 454 shotgun sequencing. Genome 54, 1005-1015 (2011).16 Guo, S. et al. The draft genome of watermelon (Citrullus lanatus) and resequencing of 20 diverse accessions. Nat Genet 45, 51–58 (2013).17 Wang, N. et al. Genome sequence of dwarf birch (Betula nana) and cross-species RAD markers. Mol Ecol Article first published online: 21 NOV 2012 DOI:10.1111/mec.12131 (2012).18 Vieler, A. et al. Genome, functional gene annotation, and nuclear transformation of the heterokont oleaginous alga Nannochloropsis oceanica CCMP1779. PLoS Genet 8, e1003064 (2012).19 Brenchley, R. et al. Analysis of the bread wheat genome using whole-genome shotgun sequencing. Nature 491, 705-710 (2012).20 Consortium, T. I. B. G. S. A physical, genetic and functional sequence assembly of the barley genome. Nature 491, 711–716 (2012).21 Wang, K. et al. The draft genome of a diploid cotton Gossypium raimondii. Nature Genetics 44, 1098–1103 (2012).22 Wang, Z. et al. The genome of flax (Linum usitatissimum) assembled de novo from short shotgun sequence reads. The Plant Journal 72, 461-473 (2012).23 D'Hont, A. et al. The banana (Musa acuminata) genome and the evolution of monocotyledonous plants. Nature 488, 213–217 (2012).24 Garcia-Mas, J. et al. The genome of melon (Cucumis melo L.). PNAS 109, 11872-11877 (2012).25 reporter, A. G. s. Consortium releases pear genome data. GenomeWeb Daily News (2012).26 Wu, J. et al. The genome of pear (Pyrus bretschneideri Rehd.). GenomeRes.Published in Advance November 13, 2012, doi:10.1101/gr.144311.112 (2012).27 Consortium, T. T. G. The tomato genome sequence provides insights into fleshy fruit evolution. Nature 485, 635–641 (2012).28 Bennetzen, J. L. et al. Reference genome sequence of the model plant Setaria. Nat Biotech 30, 555-561 (2012).29 Zhang, G. et al. Genome sequence of foxtail millet (Setaria italica) provides insights into grass evolution and biofuel potential. Nat Biotech 30, 549-554 (2012).30 Varshney, R. K. et al. Draft genome sequence of pigeonpea (Cajanus cajan), an orphan legume crop of resource-poor farmers. Nat Biotech 30, 83-89 (2012).31 Radakovits, R. et al. Draft genome sequence and genetic transformation of the oleaginous alga Nannochloropis gaditana. Nat Commun 3, 686 (2012).32 Young, N. D. et al. The Medicago genome provides insight into the evolution of rhizobial symbioses. Nature 480, 520–524 (2011).33 Wang, X. et al. The genome of the mesopolyploid crop species Brassica rapa. Nat. Genet. 43, 1035-1039 (2011).34 Consortium, T. P. G. S. Genome sequence and analysis of the tuber crop potato. Nature 475, 189-195 (2011).35 Dassanayake, M. et al. The genome of the extremophile crucifer Thellungiella parvula. Nat. Genet. 43, 913-918 (2011).36 Hu, T. T. et al. The Arabidopsis lyrata genome sequence and the basis of rapid genome size change. Nat. Genet. 43, 476-481 (2011).37 Shulaev, V. et al. The genome of woodland strawberry (Fragaria vesca). Nat. Genet. 43, 109-116 (2011).38 Argout, X. et al. The genome of Theobroma cacao. Nat. Genet. 43, 101-108 (2011).39 Gobler, C. J. et al. Niche of harmful alga Aureococcus anophagefferens revealed through ecogenomics. PNAS 108, 4352-4357 (2011).40 Banks, J. A. et al. The selaginella genome identifies genetic changes associated with the evolution of vascular plants. Science 332, 960-963 (2011).41 Sato, S. et al. Sequence analysis of the genome of an oil-bearing tree, Jatropha curcas L. DNA Res. 18, 65-76 (2011).42 Sakai, H. et al. Distinct evolutionary patterns of Oryza glaberrima deciphered by genome sequencing and comparative analysis. Plant Journal 66, 796-805 (2011).43 Al-Dous, E. K. et al. De novo genome sequencing and comparative genomics of date palm (Phoenix dactylifera). Nat Biotech 29, 521-527 (2011).44 Blanc, G. et al. The Chlorella variabilis NC64A genome reveals adaptation to photosymbiosis, coevolution with viruses, and cryptic sex. Plant Cell 22, 2943-2955 (2010).45 Chan, A. P. et al. Draft genome sequence of the oilseed species Ricinus communis. Nat Biotech 28(951-956 (2010).46 Velasco, R. et al. The genome of the domesticated apple (Malus x domestica Borkh.). Nat. Genet. 42, 833-839 (2010).47 Prochnik, S. E. et al. Genomic analysis of organismal complexity in the multicellular green alga Volvox carteri. Science 329, 223-226 (2010).48 Initiative, T. I. B. Genome sequencing and analysis of the model grass Brachypodium distachyon. Nature 463, 763-768 (2010).49 Schmutz, J. et al. Genome sequence of the palaeopolyploid soybean. Nature 463, 178-183 (2010).50 Hufford, M. B. et al. Comparative population genomics of maize domestication and improvement. Nat Genet 44, 808-811 (2012).51 Wei, F. et al. The physical and genetic framework of the maize B73 genome. PLoS Genet 5, e1000715 (2009).52 Huang, S. et al. The genome of the cucumber, Cucumis sativus L. Nat. Genet. 41, 1275-1281 (2009).53 Worden, A. Z. et al. Green evolution and dynamic adaptations revealed by genomes of the marine picoeukaryotes Micromonas. Science 324, 268-272 (2009).54 Paterson, A. H. et al. The Sorghum bicolor genome and the diversification of grasses. Nature 457, 551-556 (2009).55 Bowler, C. et al. The Phaeodactylum genome reveals the evolutionary history of diatom genomes. Nature 456, 239-244 (2008).56 Ming, R. et al. The draft genome of the transgenic tropical fruit tree papaya (Carica papaya Linnaeus). Nature 452, 991-996 (2008).57 Rensing, S. A. et al. The Physcomitrella genome reveals evolutionary insights into the conquest of land by plants. Science 319, 64-69 (2008).58 Velasco, R. et al. A high quality draft consensus sequence of the genome of a heterozygous grapevine variety. PLoS One 2, e1326 (2007).59 Jaillon, O. et al. The grapevine genome sequence suggests ancestral hexaploidization in major angiosperm phyla. Nature 449, 463-467 (2007).60 Palenik, B. et al. The tiny eukaryote Ostreococcus provides genomic insights into the paradox of plankton speciation. PNAS 104, 7705-7710 (2007).61 Merchant, S. S. et al. The Chlamydomonas genome reveals the evolution of key animal and plant functions. Science 318, 245-250 (2007).62 Tuskan, G. A. et al. The genome of black cottonwood, Populus trichocarpa (Torr. & Gray). Science 313, 1596-1604 (2006).63 Derelle, E. et al. Genome analysis of the smallest free-living eukaryote Ostreococcus tauri unveils many unique features. PNAS 103, 11647-11652 (2006). 64 Project, I. R. G. S. The map-based sequence of the rice genome. Nature 436,793-800 (2005).65 Armbrust, E. V. et al. The genome of the diatom Thalassiosira Pseudonana: ecology, evolution, and metabolism. Science 306, 79-86 (2004).66 Matsuzaki, M. et al. Genome sequence of the ultrasmall unicellular red alga Cyanidioschyzon merolae 10D. Nature 428, 653-657 (2004).67 Goff, S. A. et al. A draft sequence of the rice genome (Oryza sativa L. ssp. japonica). Science 296, 92-100 (2002).68 Yu, J. et al. A draft sequence of the rice genome (Oryza sativa L. ssp. indica). Science 296, 79-92 (2002).69 Douglas, S. et al. The highly reduced genome of an enslaved algal nucleus. Nature 410, 1091-1096 (2001).70 Kaul, S. et al. Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature 408, 796-815 (2000).。
重测序

全基因组重测序项目简介全基因组重测序是对已有参考序列(Reference Sequence)的物种的不同个体进行基因组测序,并以此为基础进行个体或群体水平的差异性分析。
通过这种方法,可以寻找出大量的单核苷酸多态性位点(SNP),插入缺失位点(InDel,Insertion Deletion),结构变异位点(SV,Structure Variation),拷贝数变异(Copy Number Variation,CNV)等变异信息,从而获得生物群体的遗传特征。
这对在群体水平上研究物种的进化历史、环境适应性、自然选择等方面具有重大意义。
利用全基因组重测序有助于快速发现与动植物重要性状相关的遗传变异,缩短分子育种的实验周期;有助于发现人类疾病相关的重要变异基因,加快生物医药研发的速度等,这对人类疾病及动植物育种研究等方面具有重大的指导意义。
技术流程提取基因组DNA后,采用物理方法随机打断,选择性回收所需长度的DNA片段(0.2~5Kb),并在两端连接接头以构建测序文库,进行桥式PCR(Bridge Amplification)制备Cluster,最后利用Paired-End的方法对插入片段进行重测序。
生物信息分析1.数据量产出总碱基数量、Totally mapped reads、Uniquely mapped reads统计,测序深度分析。
2.一致性序列组装与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。
3.SNP检测及在基因组中的分布提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。
并根据参考基因组序列对检测到的变异进行注释。
4.InDel检测及在基因组的分布在进行mapping的过程中,进行容Gap的比对并检测可信的Short InDel。
加强大豆种质资源创新与利用,提升大豆新品种科技水平

加强大豆种质资源创新与利用,提升大豆新品种科技水平加强大豆种质资源创新与利用,提升大豆新品种科技水平大豆作为我国重要的粮油作物之一,对农业生产和国民经济发展起着举足轻重的作用。
如何加强大豆种质资源创新与利用,提升大豆新品种的科技水平,对于保障国家粮食安全、促进农业可持续发展具有重要意义。
本文将从大豆种质资源的创新与利用以及大豆新品种的科技提升两个方面进行探讨。
一、加强大豆种质资源创新与利用大豆种质资源创新与利用是培育高产、优质、抗逆品种的基础。
针对我国大豆种质资源性状单一、遗传背景较窄的问题,应加强大豆种质资源的收集、评估和利用。
1. 种质资源收集与保护通过系统的采集、整理和保存工作,获取大量丰富的大豆种质资源样本。
建立大豆种质资源库,开展大豆种质资源的鉴定、鉴定和鉴定工作,为后续的科研和新品种培育工作奠定基础。
2. 种质资源评估与筛选对收集到的大豆种质资源进行系统评估,分析其形态特征、遗传背景和农艺性状等。
通过筛选和鉴定出具有高产、优质、抗逆性状的优良种质,为后续的杂交育种工作提供优质材料。
3. 种质资源利用与创新利用鉴定出的优良品种进行杂交育种工作,通过优势互补、遗传改良等手段,培育出适应我国不同气候、土壤条件的优质大豆新品种。
同时,利用生物技术手段对种质资源进行基因改造,提高大豆的抗病虫害和抗逆能力,进一步提升大豆产量和品质。
二、提升大豆新品种科技水平提升大豆新品种的科技水平,是实现大豆高效生产的关键。
在育种技术、遗传改良和栽培管理等方面进行创新,推动大豆新品种的发展。
1. 培育技术创新加强对大豆育种的技术创新研究,包括基因工程、分子标记辅助育种、杂交育种等。
通过精准选育和高效筛选的手段,缩短育种周期,提高育种效率,加速新品种的推广应用。
2. 遗传改良研究利用现代生物技术手段对大豆基因组进行深入研究,揭示与大豆品质相关的关键基因和调控网络。
通过基因改造、转基因技术等手段,培育出具有高抗病虫害、高产和高品质的新品种。
大豆基因组的DNA测序和基因编辑

大豆基因组的DNA测序和基因编辑大豆是一种重要的粮食和油料作物,其主要生产地在北美洲、南美洲和东亚。
在过去的数十年里,大豆在农业、食品、生物科学等领域发挥着重要作用。
为深入了解大豆基因组结构和遗传规律,以及实现对大豆基因的编辑和改良,DNA测序和基因编辑技术成为了必要方法。
一、大豆基因组测序DNA测序是研究生物基因组结构和功能的基础技术之一,它将DNA序列通过高通量测序技术快速获取并分析。
大豆基因组在2010年被完成测序,其基因组大小为975 Mb,共有46,430个基因,同时也揭示了大豆的基因组结构和生命活动机制。
通过基因组测序,可以揭示大豆中包括新华小蜜蜂素、异黄酮和花青素等重要的生物活性物质合成途径和基因调控网络,这将有助于开发和应用大豆资源。
二、大豆基因编辑基因编辑技术是指通过特定的酶切剪切、添加、删除基因,从而实现对基因组进行准确而有效的改造。
对于大豆这样的复杂植物,基因编辑技术在实现其高效定向改造的问题上具有重要意义。
利用基因编辑技术,可以增强大豆对病虫害的抵抗力,提高大豆的产量和质量,进而促进农业可持续发展。
需要注意的是,基因编辑技术在改造生物基因组方面存在伦理和安全等问题,必须遵循科学伦理和相关安全管理规定。
实施基因编辑技术需要精准识别目标基因,利用CRISPR/Cas9系统或其他酶切系统进行编辑。
此外,需要对编辑后的基因进行合理评估和选择,确保其不会对人类健康和生态环境产生潜在的风险。
结语大豆基因组的DNA测序和基因编辑对于提高大豆品质、抗病抗虫和缩短育种时间等方面的优化,都有着很大的帮助。
随着技术的不断发展,相信大豆基因编辑技术会发挥更大的作用,真正实现大豆生产的可持续发展。
同时,需要我们在实践中逐渐发展出更加完善的伦理规定和管理措施,确保基因编辑技术在带来发展的同时,不会产生损害。
我国科学家在人类基因组计划中的贡献

我国科学家在人类基因组计划中的贡献大家好,今天我要给大家讲一个非常有趣的话题,那就是我国科学家在人类基因组计划中的贡献。
你知道人类基因组计划是什么吗?简单来说,就是要把人类所有的基因都测序出来,这样我们就能了解人类的基因结构,从而更好地研究疾病、治疗疾病。
这个计划可不是一蹴而就的,需要很多国家的科学家共同努力。
而我国科学家在其中发挥了非常重要的作用,他们的贡献可以说是举足轻重的。
让我们来看看我国科学家在人类基因组计划中的具体贡献。
在2003年,我国科学家成功地完成了中国第一个人类基因组的工作,这是一个非常重要的里程碑。
这个成果不仅展示了我国科学家的实力,也为我国的生物技术发展奠定了基础。
此后,我国科学家还参与了国际人类基因组计划的多个关键项目,为整个计划的成功做出了巨大贡献。
那么,我国科学家是如何完成这些任务的呢?其实,这背后有很多不为人知的故事。
比如说,有一位名叫陈新家的科学家,他在研究过程中发现了一种新的基因突变现象,这个发现对于理解疾病的发生机制具有重要意义。
但是,这个发现并没有得到广泛的认可,陈新家一度感到很沮丧。
幸运的是,他遇到了一位热心的老师,这位老师鼓励他坚持下去,最终陈新家的发现得到了认可,并为人类基因组计划带来了重要的突破。
除了陈新家之外,还有很多其他优秀的我国科学家在人类基因组计划中发挥了重要作用。
他们用自己的智慧和汗水,为人类的健康事业做出了巨大贡献。
可以说,没有他们的努力,我们可能还无法享受到现代医学带来的种种便利。
那么,我国科学家在人类基因组计划中的贡献到底有多大呢?我们可以用一个例子来说明。
在人类基因组计划中,有一项任务是要测定所有人类的基因序列。
这项任务非常庞大,需要处理的数据量相当于现在互联网上的所有信息。
而我国科学家在这个任务中发挥了关键作用,他们成功地完成了这项任务,并且比预定的时间提前了很多。
这个成绩在全球范围内都是非常惊人的,充分展示了我国科学家的实力。
我国科学家在人类基因组计划中的贡献是不可忽视的。
利用转录组测序分析大豆矮小突变体中差异表达基因

利用转录组测序分析大豆矮小突变体中差异表达基因近年来,随着测序技术的发展,转录组测序成为研究生物体内基因表达的重要手段之一。
通过转录组测序,可以得知特定生物体在某个生长阶段或环境适应中的基因表达情况。
在大豆研究中,通过转录组测序研究矮小突变体的差异表达基因,可以帮助我们深入了解大豆生长发育中的分子机制。
矮小突变体是指生长期较同个物种的正常个体矮小的一类突变体。
在大豆中,矮小突变体的发现对于提高大豆的产量和抗病能力具有重要意义。
通过转录组测序研究矮小突变体中的差异表达基因,可以揭示矮小突变体生长发育的分子机制,从而为大豆育种提供理论依据。
在利用转录组测序研究大豆矮小突变体中的差异表达基因时,首先需要选择合适的实验材料和对照材料。
一般情况下,可以选择与突变体具有相似生长发育阶段的野生型作为对照材料。
然后,通过高通量测序技术对突变体和对照样品进行测序,获取大量的转录组测序数据。
接下来,对测序数据进行质量控制和过滤,去除低质量的数据和接头序列。
然后使用比对算法将测序数据比对到参考基因组上,得到每个基因的表达情况。
通过比较突变体和对照样品之间的差异表达基因进行筛选,并对其进行功能注释和富集分析。
差异表达基因分析的结果通常可以揭示突变体和对照样品在基因表达水平上的差异,可以给出候选基因的列表。
我们可以进一步对这些候选基因进行生物学实验验证,以了解这些基因在大豆生长发育中的具体功能。
通过转录组测序研究矮小突变体中的差异表达基因,可以明确突变体生长发育过程中哪些基因发生了变化,从而了解突变体的生长发育机制。
此外,通过功能注释和富集分析,我们还可以了解突变体中差异表达基因所参与的生物学过程和通路。
转录组测序研究在大豆育种中的应用前景广阔。
通过研究矮小突变体中差异表达基因,可以为大豆产量和抗病能力的提高提供重要的理论基础。
同时,转录组测序还可以帮助我们发现更多的潜在基因,用于大豆的遗传改良和功能研究。
总之,利用转录组测序研究大豆矮小突变体中的差异表达基因有助于我们了解大豆生长发育过程中的分子机制。
大豆基因组学及基因功能研究

大豆基因组学及基因功能研究大豆(Glycine max)是世界上最重要的粮食作物之一,在全球范围内享有很高的贡献和重要性。
大豆基因组学及基因功能研究是目前学者们关注的热点研究方向之一,以期为大豆育种提供更多精准的科学依据。
一、大豆基因组学研究随着DNA测序技术和计算化生物学的发展,大豆基因组学已经取得了重大的进展。
2010年,大豆基因组正式完整测序,为后续的基因功能研究奠定了坚实的基础。
由于大豆基因组相对比较大,拥有近1.1亿个碱基对,是近年来被测序的大型作物之一。
在基因组的完整测序之后,学者们开始对大豆基因的结构、分布和功能进行研究。
根据已有的研究,大豆基因组包含约4万个基因,从而为育种和改良大豆提供了广阔的空间。
育种者和种植者可通过对大豆基因组信息的掌握,获取对大豆品质、产量、适应性、耐病性等方面的深入了解,并为后续的育种工作奠定基础。
二、大豆基因功能研究大豆基因功能研究是目前大豆研究的前沿领域之一。
这个研究领域是基于下一代测序基因组的快速开发和基于多向通路和异位组的全基因表观分析的精确基因功能探索和研究。
其中,大豆转录组学研究是基因功能研究的核心内容之一。
通过对大豆的转录组数据的分析和比较,我们可以轻松地掌握大豆在不同地理环境、不同生长阶段以及不同病虫害侵袭下的响应机制,对大豆基因功能进行深入了解,并打开一扇深入了解大豆分子机制的大门。
另外,基因编辑技术的引入也为大豆基因功能研究提供了新的契机。
通过CRISPR/Cas9、ZFNs (zinc finger nucleases)、TALENS (transcription activator-likeeffector nucleases)等先进的基因编辑技术,研究人员可以对目标基因进行精准定点变异,以此验证该基因的特定功能和生物学过程的相关性。
三、大豆基因组学及基因功能研究应用前景大豆基因组学及基因功能研究的广泛应用前景,主要体现在以下几个方面:1. 大豆育种的改良在对大豆基因组学和基因功能的深入了解基础上,可利用基因工程等现代生命科学技术,进一步为大豆育种提供高效精准的科学依据,大幅度提高大豆的产量和品质,深度塑造豆类作物的未来。
大豆基因组

大豆基因组大豆是世界上最重要的植物之一,因其高蛋白质、脂肪和其他营养成分而受到欢迎。
大豆在农业、食品和工业方面都起着重要作用,并成为未来全球可持续农业发展的关键作物。
研究人员花了大量的时间,致力于深入了解大豆的基因组。
整理和分析大豆基因组的重点是为了提高大豆的可持续农业发展,这可以通过改良遗传材料来实现。
2008年,研究人员宣布完成了大豆基因组的完整测序。
大豆基因组的特点是,它的数据量小,但比同类植物的其他基因组拥有更多的基因。
它有820万个碱基对,其中只有460万个碱基对被标记为可能有用的基因。
大豆基因组具有各种蛋白质、酶、生物活性物质、抗病物质和其他营养成分,分别由各自的基因编码。
研究发现,大豆基因组中所有这些基因都存在显著的联系,这表明它们之间存在着某种机制,可以调节大豆的生长、发育和生产的性能。
研究人员基于大豆基因组的数据,建立了大豆基因功能分类,将大豆基因组中的基因进行分类。
该分类通过研究分类在拟南芥基因组和拟南芥转录组中的对应关系,进一步明确了大豆基因组的结构和功能。
研究人员还基于大豆基因组的信息,设计了一种新的生物技术,可以直接通过DNA来识别和调节大豆微量元素的分布,从而改善大豆植株的品质和产量。
此外,研究人员也基于大豆基因组的信息,构建了大豆基因组网络,以了解其中不同基因之间的相互作用。
此外,还有一些研究可以基于大豆基因组信息,改进大豆抗逆性和抗病性,增加大豆饲料和食品的营养价值。
大豆基因组研究为科学家提供了重要的信息,可以改善大豆品种,提高其营养价值和农作物产量。
研究人员将继续进行大豆基因组的深入研究,以开发新的基因改造技术,期望在未来可以更好地应用大豆基因组来实现更有效的农业发展。
本文分析了大豆基因组的特点,概述了研究人员对大豆基因的研究,关注的重点是改善大豆的可持续农业发展。
研究人员通过对大豆基因组的整理和分析,建立了大豆基因功能分类,设计了一种生物技术,可以改善大豆植株的品质和产量。
基因组重测序 样本杂合率计算

基因组重测序样本杂合率计算基因组重测序是一种先进的技术,可以对生物体的全部基因组进行全面测序,并获取大量的遗传信息。
其中一个重要的指标是样本的杂合率,它反映了样本中存在的杂合位点的比例。
本文将介绍样本杂合率计算的相关方法和意义。
样本杂合率是指在基因组重测序中,对于每个位点上的两个基因拷贝,有多少比例是不同的。
在人类基因组中,每个位点上的两个拷贝可以来自于父母的遗传信息,一种是来自父亲,一种是来自母亲。
如果两个拷贝相同,则称该位点为纯合位点;如果两个拷贝不同,则称该位点为杂合位点。
为了计算样本的杂合率,首先需要进行基因组重测序。
这个过程包括将DNA样本提取、文库构建、DNA片段测序、数据分析等多个步骤。
在数据分析阶段,需要对测序得到的DNA片段进行比对,将其与参考基因组进行比对,找到每个位点上的碱基信息。
通过比对信息,可以确定每个位点上的两个拷贝是否相同,从而计算杂合率。
样本杂合率的计算可以使用多种方法。
一种常用的方法是通过比对信息中的碱基质量值来判断两个拷贝是否相同。
碱基质量值是指测序过程中对每个碱基的测量质量,通常用Phred质量分数表示。
如果两个拷贝的碱基质量值相同或接近,则可以认为它们是相同的;如果碱基质量值差异较大,则可以认为它们是不同的。
通过设定一个阈值,可以将杂合位点与纯合位点进行区分,并计算杂合率。
另一种常用的方法是使用单核苷酸多态性(Single Nucleotide Polymorphism, SNP)信息。
SNP是指在基因组中,不同个体之间存在的单个碱基差异。
通过对比样本与参考基因组的SNP信息,可以确定每个位点上的两个拷贝是否相同。
如果两个拷贝的SNP信息相同,则可以认为它们是相同的;如果SNP信息不同,则可以认为它们是不同的。
通过统计杂合位点的数量,可以计算样本的杂合率。
样本杂合率的计算对于遗传研究和疾病研究具有重要意义。
在遗传研究中,杂合率可以用来评估一个种群或个体的遗传多样性。
大豆遗传育种中的最新技术

大豆遗传育种中的最新技术大豆作为世界上最主要的油料和蛋白原料之一,一直是农业科技研究的热门领域。
随着基因测序技术等生物学技术的发展,研究人员已经开始探索大豆遗传育种的最新技术,以改良品种、提高产量和质量,从而支持世界各地的人们更好地满足他们对大豆及其各种产品的需求。
一、分子标记辅助选择分子标记辅助选择是一种新兴的遗传育种技术,它基于对特定大豆基因序列的了解,将大豆基因组进行分级和类别划分,并通过对多个行为数据进行分析,快速筛选出大豆种类中最符合种植者需求和期望的潜在品种。
在很大程度上,这项技术已经取代了过去依靠单独植物品质的方法进行繁殖的方式。
二、全基因组重测序全基因组重测序是一种先进的遗传育种技术,它使用基因测序技术来厘清大豆基因组的各个细节和机理。
大豆基因组还是一个相当复杂和巨大的系统,因为这些基因不仅仅决定了大豆的基础性状如形态、生长和发育,还直接影响了大豆产量和品质等多种属性。
通过全基因组重测序技术,研究人员可以更好地了解各种大豆品种之间的细微差别,并从中找出适合特定种植条件和目的的最佳品种。
三、基因组编辑基因组编辑是另一种先进的遗传育种技术,它需要利用基因編輯工具来创造新变异和次薄弱种植品种,特别是那些不容易实现的遗传改进或传统育种无法解决的问题。
基因组编辑技术可以做到精准的基因编辑、代替或删除,从而创造出具有更高生产力、适应力和适宜性的新品种。
四、高通量鉴定技术高通量鉴定技术是一种定制的遗传育种技术,它利用基因芯片和DNA测序等技术高度监测植物基因组的表达、药物反应、代谢作用和抗病性等多种事项,比如大豆的叶面积、温度容限和固氮能力等,从而为选育新品种提供必要的科学基础和支持。
综上所述,大豆遗传育种中的最新技术已经在很长一段时间里得到了各界的大力推崇。
它不仅能帮助生产者解决一些特定的育种方面要求,而且可以创造出对环境和社会层面有利的新品种。
大豆科技的发展不仅影响农业部门,也对工业、医疗、食品和生物医学研究等各个领域的科技发展产生重要影响。
【高考真题】2022年新高考生物真题试卷(福建卷)

1 / 23【高考真题】2022年新高考生物真题试卷(福建卷)姓名:__________ 班级:__________考号:__________1.下列关于黑藻生命活动的叙述,错误的是( )A .叶片细胞吸水时,细胞液的渗透压降低B .光合作用时,在类囊体薄膜上合成A TPC .有氧呼吸时,在细胞质基质中产生CO 2D .细胞分裂时,会发生核膜的消失和重建2.科研人员在2003年完成了大部分的人类基因组测序工作,2022年宣布测完剩余的8%序列。
这些序列富含高度重复序列,且多位于端粒区和着丝点区。
下列叙述错误的是( )A .通过人类基因组可以确定基因的位置和表达量B .人类基因组中一定含有可转录但不翻译的基因C .着丝点区的突变可能影响姐妹染色单体的正常分离D .人类基因组测序全部完成有助于细胞衰老分子机制的研究3.我国科研人员在航天器微重力环境下对多能干细胞的分化进行了研究,发现与正常重力相比,多能干细胞在微重力环境下加速分化为功能健全的心肌细胞。
下列叙述错误的是( )A .微重力环境下多能干细胞和心肌细胞具有相同的细胞周期B .微重力环境下进行人体细胞的体外培养需定期更换培养液C .多能干细胞在分化过程中蛋白质种类和数量发生了改变D .该研究有助于了解微重力对细胞生命活动的影响4.新冠病毒通过S 蛋白与细胞膜上的ACE2蛋白结合后侵染人体细胞。
病毒的S 基因易发生突变,而ORF1a/b 和N 基因相对保守。
奥秘克戎变异株S 基因多个位点发生突变,传染性增强,加强免疫接种可以降低重症发生率。
下列叙述错误的是( )2 / 23○…………订……○…………订……※装※※订※※线※※内※※答※A .用ORF1a/b 和N 基因同时作为核酸检测靶标,比仅用S 基因作靶标检测的准确率更高B .灭活疫苗可诱导产生的抗体种类,比根据S 蛋白设计的mRNA 疫苗产生的抗体种类多C .变异株突变若发生在抗体特异性结合位点,可导致相应抗体药物对变异株效力的下降D .变异株S 基因的突变减弱了S 蛋白与ACE2蛋白的结合能力,有利于病毒感染细胞5.高浓度NH 4NO 3会毒害野生型拟南芥幼苗,诱导幼苗根毛畸形分叉。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
土耕地 (. ) 0 4 m层草甸土荒地(.)黑土 O 3 ;2 —0c 3 1 > 0
荒 地 (.1> 土 耕 地 (. ) 草 甸 土 耕 地 (. ) 05 ) 黑 04 > 4 O3 ; 6
f 】 刘述强, 长利, 2 张 高君峰, 土壤水分 空间变异性 的研究叨. 等. 东
是 因为 多年 的耕 种使 降 。黑 土是 公认 的优质 耕地 土壤 ,目前 应该注 重黑 土耕 地的保 护 ,减 少水 土流 失 的 ,同时
土荒地 (. ) 05 草甸 土 耕地 (.6 。可 以看 出在 0 2 4 03 ) ~O c m层 ,两 种土 壤 荒地 的人 渗性 能 都优 于耕 地 ,这
一
【 】 高鹏, 4 穆兴 民. 黄土丘陵 区不 同土地利用方式下土壤水分人渗
的对 比试验[. J 中国水土保持科学, 0 5 1 ()2 — 1 ] 2 0 ,24: 7 3 .
技,0 82 ()4 — 4 20 , 33:7 5 . [ 7] 于同艳 , 张兴义. 耕作措施对黑土耕层水分 的影响叨. 西南大学 学报,0 7 2 ()1 1 14 20 , 93:2 — 2 . [ 8] 王伟, 张洪江, 李猛, 重庆 四面山林 地土壤水分人渗特性研 等. 究及评价【 . J 水土保 持学报 ,0 8 2 ()9 - 8 1 2 0 , 24: 5 9 . [ 9] G a . ryRE 土壤物理性 质测定法【 . M]翁德衡译. 北京: 科学 出版
方 面是 因为 试 验在 秋 季耕 地 上 的作 物 收 获 后 进
行 ,土壤出现板结 ,另一方面由于常年的耕作对耕
地 土壤 产 生 了一 定 的影 响 ,这 一 点 可 以从 4 — 0 0 6
[ ] 陆永玲, 5 魏永霞, 张忠学, . 于运 动波方程的坡面降雨径流 等 基 模型的应用研究 【. J 东北农业大学学报, 09 4 ( :8 5 . 】 20 ,o4 4 — 1 ) [ 】 刘志远. 同外 界条件对土壤人渗性 能影 响的研究【. 6 不 J 林业科 】
北农业大学学报,0 8 3 ()12 16 2 0 , 98: 2 — 2 .
[ 3] Hl l .nrdeintsip yis . e okA ae i rs, ieD It ut l hs [ N wY r: cd metes l o o oo c M]
18 . 9 2
4 ~ 0c O 6 m层黑土耕地 (. )黑土荒地(. )草甸 0 2> 8 0 4> 7
・
5 8・
东
北
农
业
大
学
学
报
第 4 卷 l
稳定 入渗 速率 与土壤 容重 呈负相 关 ,与非 毛管孔 隙 度和土 壤初始 含水量 呈正相 关 。 采 用 H r n水 分 人 渗模 型对 四类 土 壤 的 人 渗 ot o 过程 进 行拟 合 ,结 果相 关 系数 R都 大于 09 .,可 见 H r n 型对 四类土壤 都有较 好 的适 用性 。 ot 模 o
通过秸秆还 田和施有机肥的方法补充更新有机质保 持 与提 高黑 土肥力 。
[ 参 考 文 献 】
灰色关联评价表明;在 0 2 m层关联度草甸 ~0c
土荒地 ( )黑 土荒 地 (. )草 甸 土耕地 (.2 >黑 1> 06 > 8 05 )
【 】 赵西宁, 1 吴发启 . 土壤水分入渗的研究进 展和评述咖. 西北林学
社 .9 8 16 19 1 7 :4 —4 .
c m层 次 两种 耕 地 土壤 的相对 人 渗性 能 有 所增 加 得 到证 实 。 2~ 0c 0 4 m层 的耕 地较 差 的人 渗性 能 还 可 能来 自犁底层 的影 响 ,犁底层 土壤 结构致 密孑 隙度 L 较 小致 使水 分人 渗不 畅 。0 2 m 层黑 土耕 地 的相 ~ 0c 对 入渗 性能最 差 ,随着 深度 的增加 逐渐好 转 ,可能